

Abstract
Humans are able to identify and track a target speaker amid a cacophony of acoustic interference, an ability which is often referred to as the cocktail party phenomenon. Results from several decades of studying this phenomenon have culminated in recent years in various promising attempts to decode the attentional state of a listener in a competing-speaker environment from non-invasive neuroimaging recordings such as magnetoencephalography (MEG) and electroencephalography (EEG). To this end, most existing approaches compute correlation-based measures by either regressing the features of each speech stream to the M/EEG channels (the decoding approach) or vice versa (the encoding approach). To produce robust results, these procedures require multiple trials for training purposes. Also, their decoding accuracy drops significantly when operating at high temporal resolutions. Thus, they are not well-suited for emerging real-time applications such as smart hearing aid devices or brain-computer interface systems, where training data might be limited and high temporal resolutions are desired. In this paper, we close this gap by developing an algorithmic pipeline for real-time decoding of the attentional state. Our proposed framework consists of three main modules: (1) Real-time and robust estimation of encoding or decoding coefficients, achieved by sparse adaptive filtering, (2) Extracting reliable markers of the attentional state, and thereby generalizing the widely-used correlation-based measures thereof, and (3) Devising a near real-time state-space estimator that translates the noisy and variable attention markers to robust and statistically interpretable estimates of the attentional state with minimal delay. Our proposed algorithms integrate various techniques including forgetting factor-based adaptive filtering, ℓ1-regularization, forward-backward splitting algorithms, fixed-lag smoothing, and Expectation Maximization. We validate the performance of our proposed framework using comprehensive simulations as well as application to experimentally acquired M/EEG data. Our results reveal that the proposed real-time algorithms perform nearly as accurately as the existing state-of-the-art offline techniques, while providing a significant degree of adaptivity, statistical robustness, and computational savings.
Keywords: attention, auditory, real-time, dynamic estimation, EEG, MEG, state-space models, Bayesian filtering
1. Introduction
The ability to select a single speaker in an auditory scene, consisting of multiple competing speakers, and maintain attention to that speaker is one of the hallmarks of human brain function. This phenomenon has been referred to as the cocktail party effect (Brungart, 2001; Haykin and Chen, 2005; McDermott, 2009). The mechanisms underlying the real-time process by which the brain segregates multiple sources in a cocktail party setting, have been the topic of active research for decades (Cherry, 1953; Middlebrooks et al., 2017). Although the details of these mechanisms are for the most part unknown, various studies have pointed to the role of specific neural processes involved in this function. As the acoustic signals propagate through the auditory pathway, they are decomposed into spectrotemporal features at different stages, and a rich representation of the complex auditory environment reaches the auditory cortex. It has been hypothesized that the perception of an auditory object is the result of adaptive binding as well as discounting of these features (Bregman, 1994; Griffiths and Warren, 2004; Fishman and Steinschneider, 2010; Shamma et al., 2011).
From a computational modeling perspective, there have been several attempts at designing so-called “attention decoders,” where the goal is to reliably decode the attentional focus of a listener in a multi-speaker environment using non-invasive neuroimaging techniques like electroencephalography (EEG) (Power et al., 2012; Mirkovic et al., 2015; O'Sullivan et al., 2015; Zink et al., 2017) and magnetoencephalography (MEG) (Ding and Simon, 2012a,b; Akram et al., 2014, 2016, 2017). These methods are typically based on reverse correlation or estimating linear encoding/decoding models using off-line regression techniques, and thereby detecting specific lags in the model coefficients that are modulated by the attentional state (Kaya and Elhilali, 2017). For instance, encoding coefficients comprise salient peaks at a typical lag of ~100ms for MEG (Ding and Simon, 2012a), and envelope reconstruction performance is optimal at a lag of ~200ms for EEG (O'Sullivan et al., 2015).
Although the foregoing approaches have proven successful in reliable attention decoding, they have two major limitations that make them less appealing for emerging real-time applications such as Brain-Computer Interface (BCI) systems and smart hearing aids. First, the temporal resolution of existing approaches for reliable attention decoding is on the order of ~10s, and their decoding accuracy drops significantly when operating at temporal resolutions of ~1s, i.e., the time scale at which humans are able to switch attention from one speaker to another (Zink et al., 2016, 2017). Second, approaches based on linear regression (e.g., reverse correlation) need large training datasets, often from multiple subjects and trials, to estimate the decoder/encoder reliably. Access to such training data is only possible through repeated calibration stages, which may not always be possible in real-time applications with potential variations in recording settings. While recent results (Akram et al., 2014, 2016) address the first shortcoming by employing state-space models and thereby producing robust estimates of the attentional state from limited data at high temporal resolutions, they are not yet suitable for real-time applications as they operate in the so-called “batch-mode” regime, i.e., they require the entire data from a trial at once in order to estimate the attentional state.
In this paper, we close this gap by designing a modular framework for real-time attention decoding from non-invasive M/EEG recordings that overcomes the aforementioned limitations using techniques from Bayesian filtering. Our proposed framework includes three main modules. The first module pertains to estimating dynamic models of decoding/encoding in real-time. To this end, we use the forgetting factor mechanism of the Recursive Least Squares (RLS) algorithm together with the ℓ1 regularization penalty from Lasso to capture the dynamics in the data while preventing overfitting (Sheikhattar et al., 2015a; Akram et al., 2017). The real-time inference is then efficiently carried out using a Forward-Backward Splitting (FBS) procedure (Combettes and Pesquet, 2011). In the second module, we extract an attention-modulated feature, which we refer to as “attention marker,” as a function of the M/EEG recordings, the estimated encoding/decoding coefficients, and the auditory stimuli. For instance, the attention marker can be a correlation-based measure or the magnitude of certain peaks in the model coefficients. We carefully design the attention marker features to capture the attention modulation and thereby maximally separate the contributions of the attended and unattended speakers in the neural response in both MEG and EEG applications.
The extracted features are then passed to a novel state-space estimator in the third module, and thereby are translated into probabilistic, robust, and dynamic measures of the attentional state, which can be used for soft-decision making in real-time applications. The state-space estimator is based on Bayesian fixed-lag smoothing, and operates in near real-time with controllable delay. The fixed-lag design creates a trade-off between real-time operation and robustness to stochastic fluctuations. In addition, we modify the Expectation-Maximization algorithm and the nonlinear filtering and smoothing techniques of Akram et al. (2016) for real-time implementation. Compared to existing techniques, our algorithms require minimal supervised data for initialization and tuning, which makes them more suitable for the applications of real-time attention decoding with limited training data. In order to validate our real-time attention decoding algorithms, we apply them to both simulated and experimentally recorded EEG and MEG data in dual-speaker environments. Our results suggest that the performance of our proposed framework is comparable to the state-of-the-art results of Mirkovic et al. (2015), O'Sullivan et al. (2015), and Akram et al. (2016), while operating in near real-time with ~2s delay.
The rest of the paper is organized as follows: In section 2, we develop the three main modules in our proposed framework as well as the corresponding estimation algorithms. We present the application of our framework to both synthetic and experimentally recorded M/EEG data in section 3, followed by discussion and concluding remarks in section 4.
2. Material and methods
Figure 1 summarizes our proposed framework for real-time tracking of selective auditory attention from M/EEG. In the Dynamic Encoder/Decoder Estimation module, the encoding/decoding models are fit to neural data in real-time. The Attention Marker module uses the estimated model coefficients as well as the recorded data to compute a feature that is modulated by the instantaneous attentional state. Finally, in the State-Space Model module, the foregoing features are refined through a linear state-space model with nonlinear observations, resulting in robust and dynamic estimates of the attentional state.
Figure 1.
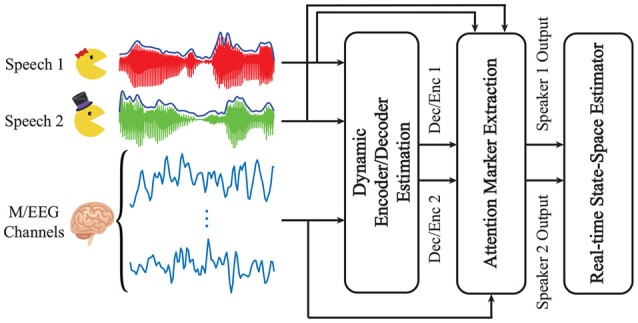
A schematic depiction of our proposed framework for real-time tracking of selective auditory attention from M/EEG.
In section 2.1, we formally define the dynamic encoding and decoding models, and develop low-complexity and real-time techniques for their estimation. This is followed by section 2.2, in which we define suitable attention markers for M/EEG inspired by existing literature. In section 2.3, we propose a state-space model that processes the extracted attention markers in order to produce near real-time estimates of the attentional state with minimal delay.
2.1. Dynamic encoding and decoding models
The role of a neural encoding model is to map the stimulus to the neural response. Inspired by existing literature on attention decoding (Ding and Simon, 2012a; O'Sullivan et al., 2015; Akram et al., 2016), we take the speech envelopes as covariates representing the stimuli. The neural response is manifested in the M/EEG recordings. Encoding models can be used to predict the neural response from the stimulus. In contrast, in a neural decoding model, the goal is to express the stimulus as a function of the neural response. Inspired by previous studies, we consider linear encoding and decoding models in this work.
The encoding and decoding models can be cast as mathematically dual formulations. In a dual-speaker environment, let and denote the speech envelopes (in logarithmic scale), corresponding to speakers 1 and 2, respectively, for t = 1, 2, …, T. Also, let denote the neural response recorded at time t and channel c, for c = 1, 2, …, C. Throughout the paper, we assume the same sampling frequency fs for both the M/EEG channels and the envelopes. Consider consecutive and non-overlapping windows of length W, and define . We consider piece-wise constant dynamics for the encoding and decoding coefficients, in which the coefficients assume to be constant over each window. Note that we define the temporal resolution in an attention decoding procedure as the duration of a data segment to which a measure of the attentional state is attributed. Therefore, determines the temporal resolution in our attention decoding framework.
In the encoding setting, we define the vector for i = 1, 2, where Le is the total lag considered in the model. Also, let Et denote a generic linear combination of with some fixed set of weights. These weights can be set to select a single channel, i.e., for some c, or they can be pre-estimated from training data so that Et represents the dominant auditory component of the neural response (de Cheveigné and Simon, 2008). The encoding coefficients then relate to Et. In the decoding setting, we define the vector and , where Ld is the total lag in the decoding model and determines the extent of future neural responses affected by the current stimuli. The decoding coefficients then relate to .
Our goal is to recursively estimate the encoding/decoding coefficients in a real-time fashion as the new data samples become available. In addtion, we aim to simultaneously induce adaptivity of the parameter estimates and capture their sparsity. To this end, we employ the following generic optimization problem:
| (1) |
where yj and Xj are respectively the vector of response variables and the matrix of covariates pertinent to window j, θ is the parameter vector, λ ∈ (0, 1] is the forgetting factor, and γ is a regularization parameter. The optimization problem of Equation 1 is a modified version of the LASSO problem (Tibshirani, 1996).
For the encoding problem, we define and , for k = 1, 2, …, K and i = 1, 2. Therefore, the full encoding covariate matrix at the kth window is defined as , where the all-ones vector 𝟙W×1 corresponds to the regression intercept. In the decoding problem, we define , where i ∈ {1, 2}. Also, the full decoding covariate matrix at the kth window is , for k = 1, 2, …, K.
The optimization problem of Equation (1) has a useful Bayesian interpretation: if the observation noise were i.i.d. Gaussian, and the parameters were exponentially distributed, it is akin to the maximum a posteriori (MAP) estimate of the parameters. The quadratic terms correspond to the exponentially-weighted log-likelihood of the observations up to window k, and the ℓ1-norm corresponds to the log-density of an independent exponential prior on the elements of θ. The exponential prior serves as an effective regularization to promote sparsity of the estimate . Note that we have for the encoding model and for the decoding model in (1).
Remark 1. The hyperparameter λ provides a tradeoff between the adaptivity and the robustness of estimated coefficients, and it can be determined based on the inherent dynamics in the data. The case of λ = 1 corresponds to the natural data log-likelihood, i.e., the batch-mode parameter estimates. It has been shown that can serve as the effective number of recent samples used to calculate in (1) (Sheikhattar et al., 2015b). The parameter can also be viewed as the dynamic integration time: it needs to be chosen long enough so that the estimation is stable, but also short enough to be able to capture the dynamics of neural process involved in switching attention. The hyperparameter γ controls the tradeoff between the Maximum Likelihood (ML) fit and the sparsity of estimated coefficients, and it is usually determined through cross-validation.
Remark 2. In the decoding problem, Equation (1) is solved separately at each window for each speech envelope, resulting in a set of decoding coefficients per speaker. In the encoding setting, we combine the stimuli as explained and solve Equation (1) once at each window to obtain both of the encoder estimates. If the encoding/decoding coefficients are expected to be sparse in a basis represented by the columns of a matrix G, such as the Haar or Gabor bases, we can replace Xj in (1) by XjG, for j = 1, 2, …, k, and solve for as before. Then, the final encoding/decoding coefficients are given by . In the context of encoding models, the coefficients are referred to as the Temporal Response Function (TRF) (Ding and Simon, 2012a; Akram et al., 2017). The TRFs are known to exhibit some degree of sparsity on a basis consisting of shifted Gaussian kernels (see Akram et al., 2017 for details).
Remark 3. It is worth discussing the rationale behind the dynamic updating of the encoding/decoding models, as opposed to considering fixed canonical encoding/decoding models common in existing work. First, estimation of the canonical encoding/decoding models in existing literature requires large training datasets. In emerging real-time applications of attention decoding, access to such large supervised training datasets may not be feasible. In addition, slight changes to the electrode placement may require recalibration of the canonical encoders/decoders. Thus, by dynamic updating of the encoding/decoding models we aim at minimizing the amount of supervised training data, which can be a bottleneck in emerging real-time applications.
Second, recent results have shown that dynamics of the encoding/decoding models indeed carry important information regarding the underlying attention process (Ding and Simon, 2012a,b; Power et al., 2012; Zion Golumbic et al., 2013; Akram et al., 2017). Therefore, dynamic estimates of these models can be beneficial in attention decoding. In order to mitigate the variability of our dynamic estimates of the encoding/decoding models, we have employed the ℓ1-regularized least squares estimation framework with a forgetting factor.
In summary, we argue that the dynamic framework used here is more preferable for real-time applications with limited training data and in the presence of attention dynamics. It is worth noting that our modular framework can still be used if the encoder/decoder models are pre-estimated and fixed. We refer the reader to section 2.3 and Remark 6 for more details.
Remark 4. Throughout the paper, we assume that the envelopes of the clean speech are available. Given that this assumption does not hold in practical scenarios, recent algorithms on the extraction of speech envelopes from acoustic mixtures (Biesmans et al., 2015, 2017; Aroudi et al., 2016; O'Sullivan et al., 2017; Van Eyndhoven et al., 2017) can be added as a pre-processing module to our framework.
Among the many existing algorithms for solving the modified LASSO problem of Equation (1), we choose the Forward-Backward Splitting (FBS) algorithm (Combettes and Pesquet, 2011), also known as the proximal gradient method. When coupled with proper step-size adjustment methods, FBS is well-suited for real-time and low-complexity updates of at each window. In this work, we have used the FASTA software package (Goldstein et al., 2014) available online (Goldstein et al., 2015), which has built-in features for all the FBS stepsize adjustment methods. A detailed overview of the FBS algorithm and its properties is given in section 1 of the Supplementary Material.
2.2. Attention markers
We define the attention marker as a mapping function from the estimated encoding/decoding coefficients for each speaker as well as the data in each window to positive real numbers. To be more precise, at window k and for speaker i, in the context of encoding models, the attention marker takes the speaker's estimated encoding coefficients , the speaker's covariate matrix , and the M/EEG responses yk as inputs; similarly, in the context of decoding models, the attention marker takes the speaker's estimated decoding coefficients , the M/EEG covariate matrix Xk, and the speaker's speech envelope vector as inputs. In both cases, the attention marker outputs a positive real number, which we denote by henceforth, for i = 1, 2 and k = 1, 2, …, K. Thus, in the modular design of Figure 1, at each window k, the two outputs and are passed from the Attention Marker module to the State-Space Model module as measures of the attentional state at window k.
In O'Sullivan et al. (2015), a correlation-based measure has been adopted in the decoding model to classify the attended and the unattended speeches in a dual-speaker environment. The approach in O'Sullivan et al. (2015) is based on estimating an attended (resp. unattended) decoder from the training data to reconstruct the attended (resp. unattended) speech envelope from EEG for each trial. Then, the correlation of this reconstructed envelope with each of the two speech envelopes is computed, and the speaker with the larger correlation coefficient is deemed as the attended (resp. unattended) speaker. This method cannot be directly applied to the real-time setting, since the lack of abundant training data hinders reliable estimation of these decoders. However, assuming that the auditory M/EEG response is more influenced by the attended speaker than the unattended one, we can expect that the decoder corresponding to the attended speaker exhibits a higher performance in reconstructing the speech envelope it has been trained on. This can be inferred from the findings in O'Sullivan et al. (2015), where a trained attended decoder results in 10% more attention decoding accuracy than a trained unattended decoder, as well as the findings in Ding and Simon (2012a). Inspired by these results, we can define the attention marker in the decoding scenario as the correlation magnitude between the speech envelope and its reconstruction by the corresponding decoder, i.e., for i = 1, 2 and k = 1, 2, …, K. As we will demonstrate later in section 3, this attention marker is suitable for the analysis of EEG recordings.
In the context of cocktail party studies using MEG, it has been shown that the magnitude of the negative peak in the TRF of the attended speaker around a lag of 100ms, referred to as the M100 component, is larger than that of the unattended speaker (Ding and Simon, 2012a; Akram et al., 2016, 2017). Inspired by these findings, in the encoding scenario applied to MEG data, we can define the attention marker to be the magnitude of the coefficients corresponding to the M100 component, for i = 1, 2 and k = 1, 2, …, K.
Due to the inherent uncertainties in the M/EEG recordings, the limitations of non-invasive neuroimaging in isolating the relevant neural processes, and the unknown and likely nonlinear processes involved in auditory attention, the foregoing attention markers derived from linear models are not readily reliable indicators of the attentional state. Given ample training data, nevertheless, these attention markers have been validated using batch-mode analysis. However, their usage in a real-time setting at high temporal resolution requires more care, as the limited data in real-time applications and computation over small windows add more sources of uncertainty to the foregoing list. To address this issue, a state-space model is required in the real-time setting to correct for the uncertainties and stochastic fluctuations of the attention markers caused by the limited integration time in real-time application. We will discuss in detail the formulation and advantages of such a state-space model in the following subsection.
2.3. State-space model
In order to translate the attention markers and , for k = 1, 2, …, K, into a robust and statistically interpretable measure of the attentional state, we employ state-space models. Inspired by the models used in Akram et al. (2016), we design a new state-space model and a corresponding estimator that operates in a fixed-lag smoothing fashion, and thereby admits real-time processing while maintaining the benefits of batch-mode state-space models. Recall that the index k corresponds to a window in time ranging from t = (k − 1)W + 1 to t = kW; however, we refer to each index k as an instance when talking about the state-space model, so as not to conflate it with the sliding window in the forthcoming treatment.
Figure 2 displays the fixed-lag smoothing design of the state-space estimator. Suppose that we are at the instance k = k0. We consider an active sliding window of length KA: = KB + KF + 1 as shown in Figure 2, where KF and KB are respectively called the forward-lag and the backward-lag. In order to carry out the computations in real-time, we assume all of the attentional state estimates to be fixed prior to this window and only update our estimates for the instances within, based on 's and 's inside the window. In a fixed-lag framework, at k = k0, the goal is to provide an estimate of the attentional state at instance k = k*, where . Thus, when using a decoding (resp. encoding) model, the built-in attention decoding delay of our framework is (Ld + KFW)/fs (resp. KFW/fs) seconds. It is worth noting that in addition to the built-in delay, our attention decoding results are affected by another source of delay, which we refer to as the transition delay. The transition delay is due to the forgetting factor mechanism as well as the smoothing effect in the state-space estimation, which we will discuss further in section 3.1. The parameter KF creates a tradeoff between real-time and robust estimation of the attentional state. For KF = 0, the estimation is carried out fully in real-time; however, the estimates lack robustness to the fluctuations of the outputs of the attention marker block. The backward-lag KB determines the attention marker samples prior to k* that are used in the inference procedure, and it controls the computational cost of the state-space model for fixed values of KF. Throughout the rest of the paper, we use the expression real-time for referring to algorithms that operate with a fixed forward-lag of KF. We will discuss specific choices of KF and KB and their implications in section 3.
Figure 2.
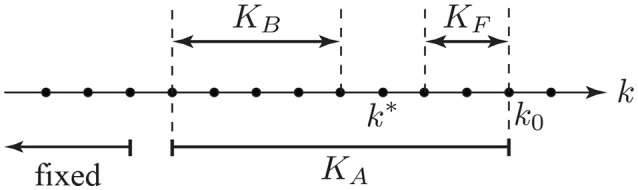
The parameters involved in state-space fixed-lag smoothing.
Suppose we have a sliding window of length KA where the instances are indexed by k = 1, 2, …, KA. Inspired by Akram et al. (2016), we assume a linear state-space model on the logit-probability of attending to speaker 1. We define the binary random variable nk = 1 when speaker 1 is attended and nk = 2 when speaker 2 is attended, at instance k. The goal is to obtain estimates of pk: = P (nk = 1) together with its confidence intervals for 1 ≤ k ≤ KA. The state dynamics are given by:
| (2) |
The dynamics of the main latent variable zk are controlled by its transition scale c0 and state variance ηk. The hyperparameter 0 ≤ c0 ≤ 1 ensures the stability of the updates for zk. The state variance ηk is modeled using an Inverse-Gamma conjugate prior with hyper-parameters a0 and b0. The log-prior of the Inverse-Gamma density takes the form for ηk > 0, where C is a normalization constant. By choosing a0 greater than and sufficiently close to 2, the variance of the Inverse-Gamma distribution takes large values and therefore can serve as a non-informative conjugate prior. Considering the fact that we do not expect the attentional state to have high fluctuations within a small window of time, we can further tune the hyperparameters a0 and b0 for the prior to promote smaller values of ηk's. This way, we can avoid large consecutive fluctuations of the zk's, and consequently the pk's.
Next, we develop an observation model relating the state dynamics of Equation (2) to the observations and for k = 1, 2, …, KA. To this end, we use the latent variable nk as the link between the states and observations:
| (3) |
When speaker i = 1, 2 is attended to, we use a Log-Normal distribution on 's, with log-density given by , where μ(a) ∈ ℝ, , and C(i) is a normalization constant, for i = 1, 2, and k = 1, 2, …, KA. Similarly, when speaker i = 1, 2 is not attended to, we use a Log-Normal distribution on with parameters ρ(u) and μ(u). As mentioned before, choosing an appropriate attention marker results in a statistical separation between and , if only one speaker is attended. The Log-Normal distribution is a unimodal distribution on ℝ>0 which lets us capture this concentration in the values of 's. In contrast to Akram et al. (2016), this distribution also leads to closed form update rules, which significantly reduces computational costs. We have also imposed conjugate priors on the joint distribution of (ρ, μ)'s, which factorizes as ln P(ρ, μ) = lnP(ρ) + lnP(μ | ρ). The hyperparameters α0, β0, and μ0 serve to tune the attended and the unattended Log-Normal distributions to create separation between the attended and unattended cases. These hyperparameters can be determined based on the mean and variance information of 's in a supervised manner, in which the attended speaker labels are known, while enforcing large enough variances for the priors not to be too restrictive in estimating the Log-Normal distribution parameters. As will be discussed in our simulation and real-data analysis, this tuning step can be performed using a minimal amount of labeled data, which is significantly less than those required for reliable pre-estimation of encoder/decoder coefficients in existing approaches.
The parameters of the state-space model are therefore , which have to be inferred from and . As mentioned before, our goal in the fixed-lag smoothing approach is to estimate as well as its confidence intervals in each window, where . However, in order to do so in our model, we perform the inference step over all the parameters in Ω and output the estimate of and its confidence intervals. The calculation of confidence intervals is discussed in detail at the end of section 2 of the Supplementary Material. In short, the density of each zk given the set of observed attention markers, estimated variances, and estimated Log-Normal distribution parameters is recursively approximated by a Gaussian density. Then, the mean of this Gaussian approximation is reported as the estimated zk and its confidence intervals are determined based on the corresponding variance. The estimated Ω would then serve as the initialization for parameter estimation in the next window. The parameters in Ω can be inferred through two nested EM algorithms as in Akram et al. (2016). In section 2 of the Supplementary Material, we have given a detailed derivation of the EM framework and update rules in the real-time setting, as well as solutions to further reduce the computational costs thereof. From here on, we refer to the output of the introduced framework, which operates with the discussed built-in delay, as the real-time (state-space) estimator. In section 3.1, we compare the performance of the real-time estimator against that of the batch-mode (state-space) estimator. We define the batch-mode estimator as applying the state-space model in Equations (2) and (3) on all the computed attention markers in a trial at once, i.e., KA = K, rather than in a fixed-lag sliding window fashion. In other words, the batch-mode estimator observes all the attention marker samples in a trial, i.e., for i = 1, 2 and k = 1, …, K, and then infers the attention probabilities. In this sense, it is similar to the state-space estimator used in Akram et al. (2016). The batch-mode estimator provides a robust estimate of the attentional state at any instance by having access to all the future and past attention markers. Thus, it can serve as a performance benchmark for tuning the fixed-lag sliding window hyperparameters in the real-time estimator. We will further discuss this point in section 3.1.4.
Remark 5. The state-space models given in Equations (2) and (3) have two major differences with the one used in Akram et al. (2016). First, in Akram et al. (2016), the distribution over the correlative measure for the unattended speaker is assumed to be uniform. However, this assumption may not hold for other attention markers in general. For instance, the M100 magnitude of the TRF estimated from MEG data is a positive random variable, which is concentrated on higher values for the attended speaker compared to the unattended speaker. In order to address this issue, we consider a parametric distribution in Equation (3) over the attention marker corresponding to the unattended speaker and infer its parameters from the data. If this distribution is indeed uniform and non-informative, the variance of the unattended distribution, which is estimated from the data, would be large enough to capture the flatness of the distribution. Second, the parametrization of the observations using Log-Normal densities and their corresponding priors factorized using Gamma and Gaussian priors, admits fast and closed-form update equations in the real-time setting. As we have shown in section 2 of the Supplementary Material, these models also have the advantage of incorporating low-complexity updates by simplifying the EM procedure. In addition, the Log-Normal distribution as a generic unimodal distribution allows us to model a larger class of attention markers.
Remark 6. As mentioned in section 1, one limitation of existing approaches based on reverse-correlation is that their decoding accuracy drops significantly when operating at high temporal resolutions. The major source for this performance deterioration is the stochastic fluctuations and uncertainties in correlation values when computed over small windows of length ~1s. Therefore, when enough training data is available for reliable pre-estimation of decoders/encoders, our real-time state-space module can be added as a complementary final step to the foregoing approaches in order to correct for the stochastic fluctuations in the calculated correlation values.
2.4. EEG recording and experiment specifications
Sixty four-channel EEG was recorded using the actiCHamp system (Brain Vision LLC, Morrisville, NC, US) and active EEG electrodes with Cz channel being the reference. The data was digitized at a 10kHz sampling frequency. Insert earphones ER-2 (Etymotic Research Inc., Elk Grove Village, IL, US) were used to deliver sound to the subjects while sitting in a sound-attenuated booth. The earphones were driven by the clinical audiometer Piano (Inventis SRL, Padova, Italy), and the volume was adjusted for every subject's right and left ears separately until the loudness in both ears was matched at a comfortably loud listening level. Three normal-hearing adults participated in the study. The mean age of subjects was 49.5 years with the standard deviation of 7.18 years. The study included a constant-attention experiment, where the subjects were asked to sit in front of a computer screen and restrict motion while any audio was playing. The data used in this paper corresponds to 3 subjects, 24 trials each.
The stimulus set contained eight story segments, each approximately 10 min long. Four segments were narrated by male speaker 1 (M1) and the other four by male speaker 2 (M2). The stimuli were presented to the subjects in a dichotic fashion, where the stories read by M1 were played in the left ear, and stories read by M2 were played in the right ear for all the subjects. Each subject listened to 24 trials of the dichotic stimulus. Each trial had a duration of approximately 1 min, and for each subject, no storyline was repeated in more than one trial. During each trial, the participants were instructed to look at an arrow at the center of the screen, which determined whether to attend to the right-ear story or to the left one. The arrow remained fixed for the duration of each trial, making it a constant-attention experiment. At the end of each trial, two multiple choice semantic questions about the attended story were displayed on the screen to keep the subjects alert. The responses of the subjects as well as their reaction time were recorded as a behavioral measure of the subjects' level of attention, and above eighty percent of the questions were answered correctly by each subject. Breaks and snacks were given between stories if requested. All the audio recordings, corresponding questions, and transcripts were obtained from a collection of stories recorded at Hafter Auditory Perception Lab at UC Berkeley.
2.5. MEG recording and experiment specifications
MEG signals were recorded with a sampling rate of 1kHz using a 160-channel whole-head system (Kanazawa Institute of Technology, Kanazawa, Japan) in a dimly lit magnetically shielded room (Vacuumschmelze GmbH & Co. KG, Hanau, Germany). Detection coils were arranged in a uniform array on a helmet-shaped surface on the bottom of the dewar with 25mm between the centers of two adjacent 15.5mm diameter coils. The sensors are first-order axial gradiometers with a baseline of 50mm, resulting in field sensitivities of or better in the white noise region.
The two speech signals were presented at 65dB SPL using the software package Presentation (Neurobehavioral Systems Inc., Berkeley, CA, US). The stimuli were delivered to the subjects' ears with 50Ω sound tubing (E-A-RTONE 3A; Etymotic Research), attached to E-A-RLINK foam plugs inserted into the ear canal. Also, the whole acoustic delivery system was equalized to give an approximately flat transfer function from 40 to 3, 000Hz. A 200Hz low-pass filter and a notch filter at 60Hz were applied to the magnetic signal in an online fashion for noise removal. Three of the 160 channels are magnetometers separated from the others and used as reference channels. Finally, to quantify the head movement, five electromagnetic coils were used to measure each subject's head position inside the MEG machine once before and once after the experiment.
Nine normal-hearing, right-handed young adults (ages between 20 and 31) participated in this study. The study includes two sets of experiments: the constant-attention experiment and the attention-switch experiment, in each of which six subjects participated. Three subjects took part in both of the experiments. The experimental procedure were approved by the University of Maryland Institutional Review Board (IRB), and written informed consent was obtained from each subject before the experiment.
The stimuli included four non-overlapping segments from the book A Child's History of England by Charles Dickens. Two of the segments were narrated by a man and the other two by a woman. Three different mixtures, each 60s long, were generated and used in the experiments to prevent reduction in the attentional focus of the subjects. Each mixture included a segment narrated by the male speaker and one narrated the the female speaker. In all trials, the stimuli were delivered diotically to both ears using tube phones inserted into the ear canals at a level of approximately 65dB SPL. The constant-attention experiment consisted of two conditions: (1) attending to the male speaker in the first mixture, (2) attending to the female speaker in the second mixture. In the attention-switch experiment, subjects were instructed to focus on the female speaker in the first 28s of the trial, switch their attention to the male speaker after hearing a 2s pause (28th to 30th s), and maintain their focus on the latter speaker through the end of the trial. Each mixture was repeated three times in the experiments, resulting in six trials per speaker for the constant-attention experiment and three trials per speaker for the attention-switch experiment. After the presentation of each mixture, subjects answered comprehensive questions related to the segment they were instructed to focus on, as a way to keep them motivated to attend to the target speaker. Eighty percent of the questions were answered correctly on average. Furthermore, a preliminary experiment for each of the nine participating subjects was performed prior to the main experiments. In this study, the subjects listened to a single speech stream, first segment in the stimuli set narrated by the male speaker, for three trials each 60s long. The MEG recordings from the preliminary experiment were used to calculate the subject-specific linear combination of MEG channels which forms the auditory component of the response, as will be explained next. Note that for each subject, all the recordings were performed in a single session resulting in a minimal change of the subject's head position with respect to the MEG sensors.
3. Results
In this section, we apply our real-time attention decoding framework to synthetic data as well as M/EEG recordings. Section 3.1 includes the simulation results, and Sections 3.2 and 3.3 demonstrate the results for the analysis of EEG and MEG recordings, respectively.
3.1. Simulations
In order to validate our proposed framework, we perform two sets of simulations. The first simulation pertains to our EEG analysis and employs a decoding model, which we describe below in full detail. The second simulation, for our MEG analysis using an encoding model, is deferred to the Supplementary Material section 4, in the interest of space.
3.1.1. Simulation settings
In order to simulate EEG data under a dual-speaker condition, we use the following generative model:
| (4) |
where and are respectively the speech envelopes of speakers 1 and 2 at time t; the output et is the simulated neural response, which denotes an auditory component of the EEG or the EEG response at a given channel at time t for t = 1, 2, …, T. Motivated by the analysis of LTI systems, ht can be considered as the impulse response of the neural process resulting in et, and * represents the convolution operator; the scalar μ is an unknown constant mean, and ut denotes a zero-mean i.i.d Gaussian noise. The weight functions and are signals modulated by the attentional state which determine the contributions of speakers 1 and 2 to et, respectively. In order to simulate the attention modulation effect, we assume that when speaker 1 (resp. 2) is attended to at time t, we have (resp. ).
We have chosen two 60s-long speech segments from those used in the MEG experiment (see section 2.5) and calculated and as their envelopes for a sampling rate of fs = 200Hz. Also, we have set μ = 0.02 and in Equation (4). Figure 3A shows the location and amplitude of the lag components in the impulse response, which is then smoothed using a Gaussian kernel with standard deviation of 10ms to result in the final impulse response ht, shown in Figure 3B. The significant components of ht are chosen at 50ms and 100ms lags, with a few smaller components at higher latencies (Akram et al., 2016). It is noteworthy that existing results (Ding and Simon, 2012a; Power et al., 2012; Akram et al., 2017) suggest that this impulse response (i.e., the TRF) is not the same for the attended and unattended speakers, as discussed in section 2.2. However, we have considered the same ht for both speakers in this simulation for simplicity, given that our focus here is to model the stronger presence of the attended speaker in the neural response in terms of the extracted attention markers. In section 4 of the Supplementary Material, we indeed use an encoding model consisting of different and attention-modulated TRFs for the two speakers. The weight signals and in Equation (4) are chosen to favor speaker 1 in the (0s, 30s) interval and speaker 2 in the (30s, 60s) interval.
Figure 3.
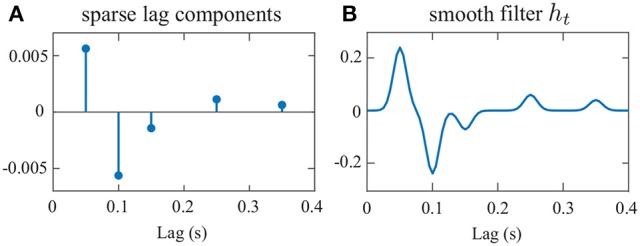
Impulse response ht used in Equation (4). (A) sparse lag components, (B) the smooth impulse response.
3.1.2. Parameter selection
We aim at estimating decoders in this simulation, which linearly map et and its lags to and . To estimate the decoders, we have considered consecutive non-overlapping windows of length 0.25s resulting in K = 240 windows of length W = 50 samples. Also, we have chosen γ = 0.001, through cross-validation, and λ = 0.95 in estimating the decoding coefficients, which results in an effective data length of 5s for decoder estimation. The forward lags of the neural response have been limited to a 0.4s window, i.e., Ld = 80 samples. Given that the decoder corresponds to the inverse of a smooth kernel ht, it may not have the same smoothness properties of ht. Hence, we do not employ a smooth basis for decoder estimation. We have used the FASTA package (Goldstein et al., 2014) with Nesterov's acceleration method to implement the forward-backward splitting algorithm for encoder/decoder estimation. As for the state-space model estimators, we have considered 20 (inner and outer) EM iterations for the batch-mode estimators, while for the real-time estimators, we use 1 inner EM iteration and 20 outer EM iterations (see section 2 of the Supplementary Material for more details).
There are three criteria for choosing the fixed-lag smoothing parameters: First, how close to the true real-time analysis the system operates is determined by KF. Second, the computational cost of the system is determined by KA. Third, how close the output of the system is to that of the batch-mode estimator is determined by both KF and KA. These three criteria form a tradeoff in tuning the parameters KA and KF. Specific choices of these parameters are given in the next subsection.
For tuning the hyperparameters of the priors on the attended and unattended distributions, we have used a separate 15s sample trial generated from the same simulation model in Equation (4) for each of the three cases. The parameters have been chosen by fitting the Log-Normal distributions to the attention marker outputs from the sample trials in a supervised manner (with known attentional state). The variance of the Gamma priors and have been chosen large enough such that the priors are non-informative. This step can be thought of as the initialization of the algorithms prior to data analysis. For the Inverse-Gamma prior on the state-space variances, we have chosen a0 = 2.008 and b0 = 0.2016, resulting in a mean of 0.2 and a variance of 5. This prior favors small values of ηk's to ensure that the state estimates are immune to large fluctuations of the attention markers, while the large variance (compared to the mean) results in a non-informative prior for smaller values of ηk's.
3.1.3. Estimation results
Figure 4 shows the results of our estimation framework for a correlation-based attention marker. Row A in Figure 4 shows three cases considered for modulating the weights and , where the weights are contaminated with Gaussian noise to model extra uncertainties in determining the contribution of each speech to the neural response, arising from irrelevant or background neural processes. In order to probe the transition delay of the state-space estimates due to abrupt changes in the attentional state, the two weight vectors undergo step-like transition at 30 s. Cases 1, 2, and 3 exhibit increasing levels of difficulty in discriminating the contributions of the two speakers to the neural response. Rows B and C in Figure 4 respectively show the decoder estimates for speakers 1 and 2. As expected, the significant components of the decoders around 50, 100, and 150ms lags, are modulated by the attentional state, and the modulation effect weakens as we move from Case 1 to 3. In Case 1, these components are less significant overall for the decoder estimates of speaker 2 in the [0s, 30s] time interval and become larger as the attention switches to speaker 2 during the rest of the trial (red boxes in row C of Case 1). On the other hand, in Case 3, the magnitude of said components does not change notably across the 30 s mark. The TRF ht in the forward generative model of Equation (4) is an FIR filter with significant components at lags which are multiples of 0.05s (see Figure 3B). Therefore, the decoder estimates in Figure 4 correspond to truncated IIR filters, which form approximate inverse filters of the TRF. Therefore, it is expected that they comprise significant components at lags which are multiples of 0.05s as well, but decay exponentially fast.
Figure 4.

Estimation results of application to simulated EEG data for the correlation-based attention marker: (A) Input weights and in Equation (4), which determine the relative effect of the two speeches on the neural response. Based on our generative model, the attention is on speaker 1 for the first half of each trial and on speaker 2 for the second half. Case 1 corresponds to a scenario where the effects of the attended and unattended speeches in the neural response are well-separated. This separation decreases as we move from Case 1 to Case 3. (B) Estimated decoder for speaker 1. (C) Estimated decoder for speaker 2. In Case 1, the significant components of the estimated decoders near the 50, 100, and 150ms lags are notably modulated by the attentional state as highlighted by the red boxes. This effect weakens in Case 2 and visually disappears in Case 3. (D) Output of the correlation-based attention marker for each speaker. (E) Output of the batch-mode state-space estimator for the correlation-based attention marker as the estimated probability of attending to speaker 1. (F) Output of the real-time state-space estimator, i.e., fixed-lag smoother, for the correlation-based attention marker as the estimated probability of attending to speaker 1. The real-time estimator is not as robust as the batch-mode estimator to the stochastic fluctuations of the attention marker in row D and is more prone to misclassifications. The red arrows in rows E and F of Case 2 show that the batch-mode estimator correctly classifies the instance as attending to speaker 2, while the real-time estimator is unable to determine the attentional state.
We have considered two different attention markers for this simulation. Row D in Figure 4 displays the output of a correlation-based attention marker for speakers 1 and 2, which is calculated as for i = 1, 2 and k = 1, 2, …, K. As discussed in section 2.2, this attention marker is a measure of how well a decoder can reconstruct its target envelope. As observed in row D of Figure 4, the attention marker is a highly variable surrogate of the attentional state at each instance, i.e., on average the attention marker output for speaker 1 is higher then that of speaker 2 in the (0s, 30s) interval and vice versa in the (30s, 60s) interval. The reliability of the attention marker significantly degrades going from Case 1 to 3. This highlights the need for state-space modeling and estimation in order to optimally exploit the attention marker.
Rows E and F in Figure 4 respectively show the batch-mode and real-time estimator outputs as the inferred attentional state probabilities pk = P(nk = 1) for k = 1, …, K, for the correlation-based attention marker, where colored hulls indicate 90% confidence intervals. Row F in Figure 4 corresponds to the fixed-lag smoother, using a window of length 15s (KA =⌊15fs/W⌋), and a forward-lag of 1.5s (KF =⌊1.5fs/W⌋). By accounting for the lag in the decoder (Ld), the built-in delay in estimating the attentional state is 1.9s. Note that all the relevant figures showing the outputs of the real-time estimator are calibrated with respect to the built-in delay for the sake of illustration. Thus, these figures must be interpreted as non-causal when KF > 0, since the estimated attentional state at each time depends on the future KF samples of the attention marker. Recall that in the batch-mode estimator, all of the attention marker outputs across the trial are available to the state-space estimator, as opposed to the fixed-lag real-time estimator which has access to a limited number of the attention markers. Therefore, the output of the batch-mode estimator (Row E) is a more robust measure of the instantaneous attentional state as compared to the real-time estimator (Row F), since it is less sensitive to the stochastic fluctuations of the attention markers in row D. For example, in the instance marked by the red arrows in rows E and F of Case 2 in Figure 4, the batch-mode estimator classifies the instance correctly as attending to speaker 2, while the real-time estimator cannot make an informed decision since pk = 0.5 falls within the 90% confidence interval of the estimate at this instance. However, the real-time estimator exhibits performance closely matching that of the batch-mode estimator for most instances, while operating in real-time with limited data access and significantly lower computational complexity. Comparing the state-space estimators with the raw attention markers in Figure 4D, we observe the smoothing effect of the state-space model which makes its output robust to the stochastic fluctuations in the attention marker at high temporal resolution. Section 3 of the Supplementary Material includes a comparison of this smoothing effect with that of a typical Gaussian smoothing kernel applied directly to the attention markers.
Row A in Figure 5 exhibits the output of another attention marker computed as the ℓ1-norm of the decoder given by for i = 1, 2 and k = 1, 2, …, K, where the first element of (the intercept parameter) is discarded in computing the ℓ1-norm. This attention marker captures the effect of the significant peaks in the decoder. The rationale behind using the ℓ1-norm based attention marker is the following: in the extreme case that the neural response is solely driven by the attended speech, we expect the unattended decoder coefficients to be small in magnitude and randomly distributed across the time lags. The attended decoder, however, is expected to have a sparse set of informative and significant components corresponding to the specific latencies involved in auditory processing. Thus, the ℓ1-norm serves to distinguish between these two cases by capturing such significant components. Rows B and C in Figure 5 show the batch-mode and real-time estimates of the attentional state probabilities for the ℓ1-based attention marker, respectively, where colored hulls indicate 90% confidence intervals. Consistent with the results of the correlation-based attention marker (Rows E and F in Figure 4), the real-time estimator exhibits performance close to that of the batch-mode estimator. Comparing Figures 4, 5 reveals the dependence of the attentional state estimation performance on the choice of the attention marker: while the correlation-based attention marker is more widely used, the ℓ1-based attention marker provides smoother estimates of the attention probabilities, and can be used as an alternative to the correlation-based attention marker. Overall, this simulation illustrates that if the attended stimulus has a stronger presence in the neural response than the unattended one, both the correlation-based and ℓ1-based attention markers can be attention modulated and can therefore potentially be used in real M/EEG analysis.
Figure 5.

Estimation results of application to simulated EEG data for the ℓ1-based attention marker: (A) Output of the ℓ1-based attention marker for each speaker, corresponding to the three cases in Figure 4. (B) Output of the batch-mode state-space estimator for the ℓ1-based attention marker as the estimated probability of attending to speaker 1. (C) Output of the real-time state-space estimator for the ℓ1-based attention marker as the estimated probability of attending to speaker 1. Similar to the preceding correlation-based attention marker, the classification performance degrades when moving from Case 1 (strong attention modulation) to Case 3 (weak attention modulation).
3.1.4. Discussion and further analysis
Going from Case 1 to Case 3 in Figures 4, 5, we observe that the performance of all estimators degrades, causing a drop in the classification accuracy and confidence. This performance degradation is due to the declining power of the attention markers in separating the contributions of the attended and unattended speakers. However, comparing the outputs of the real-time and batch-mode estimators with their corresponding attention marker outputs in row D of Figure 4 and row A of Figure 5, highlights the role of the state-space model in suppressing the stochastic fluctuations of the attention markers and thereby providing a robust and smooth measure of the attentional state.
In response to abrupt step-like changes in the attentional state, we define the transition delay as the time it takes for the output of the real-time estimator to reach the pk = 0.5 level, which marks the point at which the classification label of the attended speaker changes. We calculate the transition delay after calibrating for the built-in delay, for all the real-time estimator outputs. Thus, the overall delay of the system in detecting abrupt attentional state changes is equal to the sum of the built-in and transition delays. The red intervals in Case 1 of row F in Figure 4 and row C of Figure 5 mark the transition delay of the real-time estimator corresponding to the correlation-based and ℓ1-based attention markers, respectively. From the deflection point at 30s, this delay is given by ~2.3s. The transition delay is due to the forgetting factor mechanism and the smoothing effect of the state-space estimation given the backward- and forward-lags, which have been set in place to increase the robustness of the decoding framework to stochastic fluctuations of the extracted attention markers. As a result, such classification delays in response to a sudden attention switches are expected by design. Specifically, the sole contribution of the forgetting factor mechanism to this delay can be observed as the red interval in Case 1 of row A in Figure 5, which precedes the application of the state-space estimation.
Comparing the batch-mode and the real-time estimators in Figures 4, 5, we observe that the real-time estimators closely follow the output of the batch-mode estimators, while having access to data in an online fashion. A significant deviation between the batch-mode and real-time performance is observed in rows B and C (Cases 1 and 2) of Figure 5 in the form of sharp drops in the real-time estimates of the attentional state probability. Given that the real-time estimator has only access to the attention marker within KF samples in the future, the confidence intervals significantly narrow down within the first half of the trial, as all the past and near-future observations are consistent with attention to speaker 1. However, shortly after the 30s mark, the estimator detects the change and the confidence bounds widen accordingly (see red arrows in row C of Case 2 in Figure 5).
In order to further quantify the performance gap between the batch-mode and real-time estimators, we define their relative Mean Squared Error (MSE) as:
| (5) |
where and denote the real-time and batch-mode state estimates over a given trial, respectively. We have considered the logistic transformation of and , which gives the probability of attending to speaker 1. The rationale behind this MSE metric is to measure the performance and robustness of the real-time estimator with respect to the batch-mode estimator, since they both operate on the same computed attention markers, but in different algorithmic fashions.
Figure 6 shows the effect of varying the forward-lag KF from 0s (i.e., fully real-time) to 5s with 0.5s increments for the two attention markers in Case 2 of Figures 4, 5, as an example. All of the other parameters in the simulation have been fixed as before. The left panels in Figure 6 show the MSE for different values of KF in the real-time setting. As expected, for both attention markers, the MSE decreases as the forward-lag increases. The right panels in Figure 6 display the incremental MSE defined as the change in MSE when KF is increased by 0.5s at each value, starting from KF = 0. The incremental MSE is basically the discrete derivative of the displayed MSE plots and shows the amount of relative performance boost between two consecutive values of KF, if we allow for a larger built-in delay. Notice that even a 0.5s forward-lag significantly decreases the MSE from KF = 0. The subsequent improvements of the MSE diminish as KF is increased further. Our choice of KF corresponding to 1.5s in the foregoing analysis was made to maintain a reasonable tradeoff between the MSE improvement and the built-in delay in real-time operation. In summary, Figure 6 shows that having larger forward-lags can make our estimates more robust but it creates a larger built-in delay. Whether higher levels of delay are tolerable or not depends on the particular attention decoding application.
Figure 6.
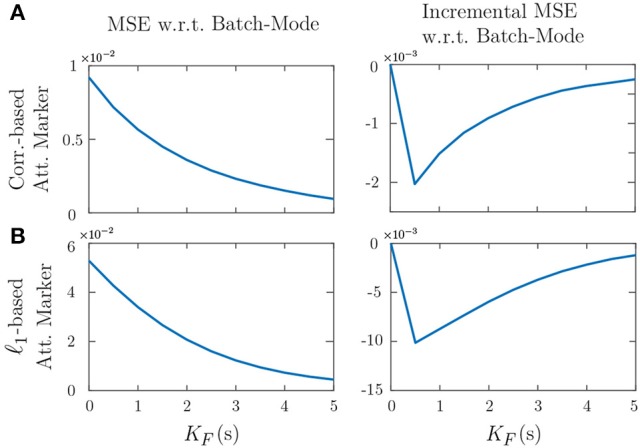
Effect of the forward-lag KF on the MSE for the two attention markers in case 2 of Figures 4, 5. (A) Correlation-based attention marker, (B) ℓ1-based attention marker. As the forward-lag increases, the MSE decreases, and the output of the real-time estimator becomes more similar to that of the batch-mode. This results in more robustness for the real-time estimator at the expense of more built-in delay in decoding the attentional state. The right panels show that the incremental improvement to the MSE decreases as KF increases.
Finally, Figure 7 shows the estimated attention probabilities and their 90% confidence intervals for the correlation-based attention marker in Case 2 of Figure 4, as an example of the output of the state-space estimator. The three curves correspond to the extreme values of KF in Figure 6 corresponding to 0s (blue) and 5s (red) forward-lags, and the batch-mode estimate (green). All the other parameters have been fixed as described above. The fixed-lag smoothing approach with KF of 5s is as robust as the batch-mode estimate. The fully real-time estimate with KF of 0s follows the same trend as the other two. However, it is susceptible to the stochastic fluctuations of the attention marker, which may lead to misclassifications (see the red arrows in Figure 7). The red interval in Figure 7 displays the difference between the transition delays corresponding to the forward-lag of 0 s and 5s. Although the built-in attention decoding delay of a 5s forward-lag is more than that of 0s by 5s, the transition delay corresponding to the former is smaller due to observing the future attention marker samples up to 5s. Therefore, the parameter KF also provides a tradeoff in the overall delay of the framework in detecting abrupt attention switches, which equals the transition delay plus the built-in delay. The choice of 1.5s for the forward-lag in our analysis was also aimed to minimize this overall delay.
Figure 7.
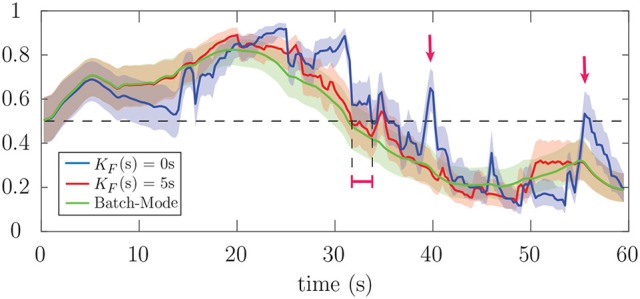
Estimated attention probabilities together with their 90% confidence intervals for the correlation-based attention marker in Case 2 of Figure 4. The blue, red and green curves correspond to KF of 0s, KF of 5s, and batch-mode estimation, respectively. The estimator for KF of 5s is nearly as robust as the batch-mode. However, the fully real-time estimator with KF of 0s is sensitive to the stochastic fluctuations of the attention markers, which results in the misclassification of the attentional state at the instances marked by red arrows.
3.2. Application to EEG
In this section, we apply our real-time attention decoding framework to EEG recordings in a dual-speaker environment. Details of the experimental procedures are given in section 2.4.
3.2.1. Preprocessing and parameter selection
Both the EEG data and the speech envelopes were downsampled to fs = 64Hz using an anti-aliasing filter. As the trials had variable lengths, we have considered the first 53s of each trial for analysis. We have considered consecutive windows of length 0.25s for decoder estimation, resulting in W = 16 samples per window and K = 212 instances for each trial. Also, we have considered lags up to 0.25s for decoder estimation, i.e., Ld = 16. The latter is motivated by the results of O'Sullivan et al. (2015) suggesting that the most relevant decoder components are within the first 0.25s lags. Prior studies have argued that the effects of auditory attention and speech perception are strongest in the frontal and close-to-ear EEG electrodes (Kähkönen et al., 2001; Power et al., 2012; Bleichner et al., 2016; Khalighinejad et al., 2017). We have only considered 28 EEG channels in the decoder estimation problem, i.e., C = 28, including the frontal channels Fz, F1-F8, FCz, FC1-FC6, FT7-FT10, C1-C6, and the T complex channels T7 and T8. This subsampling of the electrodes is inspired by the results in Mirkovic et al. (2015), which show that using an electrode subset of the same size for decoding results in nearly the same classification performance as in the case of using all the electrodes. Note that for our real-time setting, a channel selection step can considerably decrease the computational cost and the dimensionality of the decoder estimation step, given that a vector of size 1+C(Ld+1) needs to be updated within each 0.25s window.
We have determined the regularization coefficient γ = 0.4 via cross-validation and the forgetting factor λ = 0.975, which results in an effective data length of 10 s in the estimation of the decoder and is long enough for stable estimation of the decoding coefficients. It is worth noting that small values of λ, and hence small effective data lengths, may result in an under-determined inverse problem, since the dimension of the decoder is given by 1+C(Ld+1). Finally, in the FASTA package, we have used a tolerance of 0.01 together with Nesterov's accelerated gradient descent method to ensure that the processing can be done in an online fashion.
In studies involving correlation-based measures, such as O'Sullivan et al. (2015) and Akram et al. (2016), the convention is to train attended and unattended decoders/encoders using multiple trials and then use them to calculate the correlation measures over the test trials. The correlation-based attention marker, however, did not produce a statistically significant segregation of the attended and the unattended speakers in our analysis. This discrepancy seems to stem from the fact that the estimated encoders/decoders and the resulting correlations in the aforementioned studies are more informative and robust due to the use of batch-mode analysis with multiple trials for decoder estimation, as compared to our real-time framework. The ℓ1-based attention marker, however, resulted in a meaningful statistical separation between the attended and the unattended speakers. Therefore, in what follows, we present our EEG analysis results using the ℓ1-based attention marker.
The parameters of the state-space models have been set similar to those used in simulations, i.e., KA =⌊15fs/W⌋, KF =⌊1.5fs/W⌋, a0 = 2.008, b0 = 0.2016. Considering the 0.25s lag in the decoder model, the built-in delay in estimating the attentional state for the real-time system is 1.75s. For estimating the prior distribution parameters for each subject, we use the first 15s of each trial. As mentioned before, considering the 15s-long sliding window, we can treat the first 15s of each trial as a tuning step in which the prior parameters are estimated in a supervised manner and the state-space model parameters are initialized with the values estimated using these initial windows. Thus, similar to the simulations, for each subject have been set according to the parameters of the two fitted Log-Normal distributions on the ℓ1-norm of the decoders in the first 15s of the trials, while choosing large variances for the priors to be non-informative.
3.2.2. Estimation results
Figure 8 shows the results of applying our proposed framework to EEG data. For graphical convenience, the data have been rearranged so that speaker 1 is always attended. The left, middle and right panels correspond to subjects 1, 2, and 3, respectively. For each subject, three example trials have been displayed in rows A, B, and C. Row A includes trials in which the attention marker clearly separates the attended and unattended speakers, while Row C contains trials in which the attention marker fails to do so. Row B displays trials in which on average the ℓ1-norm of the estimated decoder is larger for the attended speaker; however, occasionally, the attention marker fails to capture the attended speaker.
Figure 8.

Examples of the ℓ1-based attention markers (first panels), batch-mode (second panels), and real-time (third panels) state-space estimation results for nine selected EEG trials. (A) Representative trials in which the attention marker reliably separates the attended and unattended speakers. (B) Representative trials in which the attention marker separates the attended and unattended speakers on average over the trial. (C) Representative trials in which the attention marker either does not separate the two speakers or results in a larger output for the unattended speaker.
Consistent with our simulations, the real-time estimates (third graphs in rows A, B, and C) generally follow the output of the batch-mode estimates (second graphs in rows A, B, and C). However, the batch-mode estimates yield smoother transitions and larger confidence intervals in general, both of which are due to having access to future observations.
Figure 9 shows the effect of forward-lag KF on the performance of real-time estimates, similar to that shown in Figure 6 for the simulations. The forward-lag KF is increased from 0s to 5s with 0.5s increments while all the other parameters of the EEG analysis remain the same. The MSE in Figure 9 has been averaged over all trials for each subject. As we observe in the incremental MSE plot, even a 0.5s lag can significantly decrease the MSE from the case of 0s forward-lag (corresponding to the fully real-time setting). Similar to the simulations, we have chosen a KF of 1.5s for the EEG analysis, since the incremental MSE improvements are significant at this lag, and this choice results in a tolerable built-in delay for real-time applications.
Figure 9.
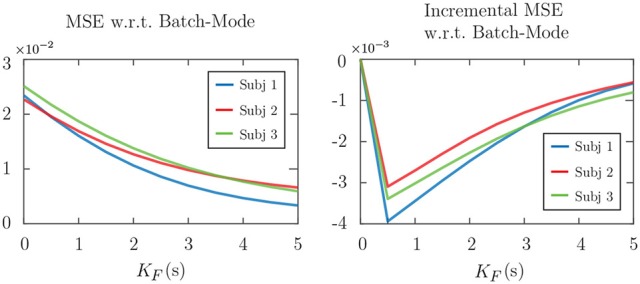
Effect of the forward-lag KF on MSE in application to real EEG data. The left panel shows the MSE with respect to the batch-mode output averaged over all the trials for each subject. The right panel displays the incremental MSE at each lag, from KF of 0s to KF of 5s with 0.5s increments.
Finally, Figure 10 summarizes the real-time classification results of our EEG analysis at the group level, in order to present subject-specific and individual trial performances. Figure 10A shows a cartoon of the estimated attention probabilities for a generic trial in order to illustrate the classification conventions. We define an instance (i.e., one of the K consecutive windows of length W samples) to be correctly (incorrectly) classified if the estimated attentional state probability together with its 90% confidence intervals lie above (below) 0.5. If the 90% confidence interval at an instance includes the 0.5 attention probability line, we do not classify it as either correct or incorrect. Figure 10B displays the correctly classified instances (y-axis) vs. those incorrectly classified (x-axis) for each trial. The subjects are color-coded and each circle corresponds to one trial. The average classification results over all trials for each subject are shown in Figure 10C. In summary, our framework provides ~80% average hit rate and ~15% average false-alarm per trial per subject. The group-level hit rate and false alarm rate are respectively given by 79.63 and 14.84%.
Figure 10.
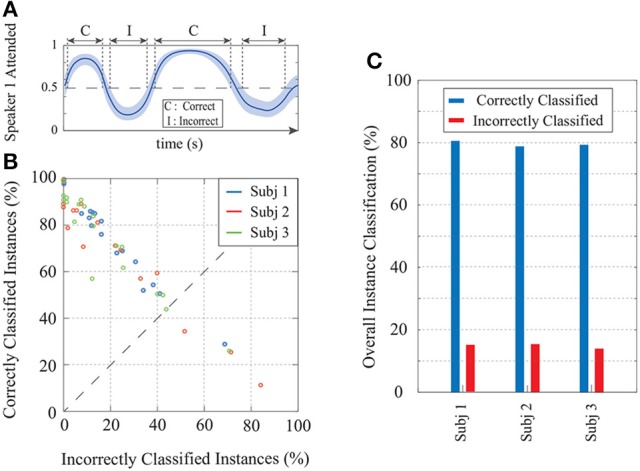
Summary of the real-time classification results in application to real EEG data. (A) A generic example of the state-space output for a trial illustrating the classification conventions. (B) Classification results per trial for all subjects; each circle corresponds to a trial and the subjects are color-coded. The trials falling below the dashed line have more incorrectly classified instances than correctly classified ones. (C) Average classification performance over all trials for the three subjects.
3.3. Application to MEG
In this section, we apply our real-time attention decoding framework to MEG recordings of multiple subjects in a dual-speaker environment. The MEG experimental procedures are discussed in section 2.5.
3.3.1. Preprocessing and parameter selection
The recorded MEG responses were band-pass filtered between 1 and 8 Hz (delta and theta bands), corresponding to the slow temporal modulations in speech (Ding and Simon, 2012a,b), and downsampled to 200 Hz. MEG recordings, like EEG, include both the stimulus-driven response as well as the background neural activity, which is irrelevant to the stimulus. For the encoding model used in our analysis, we need to extract the stimulus-driven portion of the response, namely the auditory component. In Särelä and Valpola (2005) and de Cheveigné and Simon (2008), a blind source separation algorithm called the Denoising Source Separation (DSS) is described which decomposes the data into temporally uncorrelated components ordered according to their trial-to-trial phase-locking reliability. In doing so, DSS only requires the responses in different trials and not the stimuli. Similar to Akram et al. (2016, 2017), we only use the first DSS component as the auditory component, since it tends to capture a significant amount of stimulus information and to produce a bilateral stereotypical auditory field pattern.
Since DSS is an offline algorithm operating on all the data at once, we cannot readily use it for real-time attention decoding. Instead, we apply DSS to the data from preliminary trials from each subject in order to calculate the subject-specific linear combination of the MEG channels that compose the first DSS component. We then use these channel weights to extract the MEG auditory responses during the constant-attention and attention-switch experiments in a real-time fashion. Note that the MEG sensors are not fixed with respect to the head position across subjects and are densely distributed in space. Therefore, it is not reasonable to use the same MEG channel weights for all subjects. The preliminary trials for each subject can thus serve as a training and tuning step prior to the application of our proposed attention decoding framework.
The MEG auditory component extracted using DSS is used as Et in our encoding model. Similar to our foregoing EEG analysis, we have considered consecutive windows of length 0.25s resulting in W = 50 samples per window and a total number of K = 240 instances, at a sampling frequency of 200Hz. The TRF length, or the total encoder lag, has been set to 0.4s resulting in Le = 80 in order to include the most significant TRF components (Ding and Simon, 2012a). The ℓ1-regularization parameter γ in Equation (1) has been adjusted to 1 through two-fold cross-validation, and we have chosen a forgetting factor of λ = 0.975, resulting in an effective data length of 10s, long enough to ensure estimation stability.
As for the encoder model, we have used a Gaussian dictionary G0 to enforce smoothness in the TRF estimates. The columns of G0 consist of overlapping Gaussian kernels with the standard deviation of 20 ms whose means cover the 0s to 0.4s lag range with Ts = 5 ms increments. The 20ms standard deviation is consistent with the average full width at half maximum (FWHM) of an auditory MEG evoked response (M50 or M100), empirically obtained from MEG studies (Akram et al., 2017). Thus, the overall dictionary discussed in Remark 2 takes the form G = diag (1, G0, G0). Also, similar to Akram et al. (2017), we have used the logarithm of the speech envelopes as the regression covariates. Finally, the parameters of the FASTA package in encoder estimation have been chosen similar to those in the foregoing EEG analysis.
The M100 component of the TRF has shown to be larger for the attended speaker than the unattended speaker (Ding and Simon, 2012a; Akram et al., 2017). Thus, at each instance k, we extract the magnitude of the negative peak close to the 0.1s delay in the real-time TRF estimate of each speaker as the attention markers and . For the state-space model and the fixed-lag window, we have used the same configuration as in our foregoing EEG analysis, i.e., KA =⌊15fs/W⌋, KF =⌊1.5fs/W⌋, a0 = 2.008, and b0 = 0.2016. Note that the built-in delay in estimating the attentional state is now only 1.5s, given that we use an encoding model for our MEG analysis. Furthermore, the prior distribution parameters for each subject were chosen according to the two fitted Log-Normal distributions on the extracted M100 values in the first 15s of the trials, while choosing large variances for the Gamma priors to be non-informative. Similar to the preceding cases, the first 15s of each trial can be thought of as an initialization stage.
3.3.2. Estimation results
Figure 11 shows our estimation results for four sample trials from the constant-attention (cases 1 and 2) and attention-switch (cases 3 and 4) experiments. For graphical convenience, we have rearranged the MEG data such that in the constant-attention experiment, the attention is always on speaker 1, and in the attention-switch experiment, speaker 1 is attended from 0 to 28s. Cases 1 and 3 corresponds to trials in which the extracted M100 values for the attended speaker are more significant than those of the unattended speaker during most of the trial duration. Cases 2 and 4, on the other hand, correspond to trials in which the extracted M100 values are not reliable representatives of the attentional state. Row A in Figure 11 shows the estimated TRFs for speakers 1 and 2 in time for each of the four cases. The location of the M100 peaks is shown and tracked with a narrow line (yellow) on the extracted M100 components (blue). The M50 components are also evident as positive peaks occurring around the 50ms lag. The M50 components do not strongly depend on the attentional state of the listener (Chait et al., 2004, 2010; Ding and Simon, 2012a; Akram et al., 2017), which is consistent with those shown in Figure 11A. It is worth noting that real-time estimation of the TRFs makes the estimates heavily affected by the dynamics of neural response and the background neural activity. Therefore, the estimates contain longer latency components which are typically suppressed in the offline estimates of TRFs common in the literature, which use multiple trial averaging to extract the stimulus-driven response (Ding and Simon, 2012a; Power et al., 2012). The width of the extracted components in Figure 11 is due to the usage of a Gaussian dictionary matrix to represent the TRFs.
Figure 11.

Examples from the constant-attention and attention-switch MEG experiments, using the M100 attention marker, for trials with reliable (cases 1 and 3) and unreliable (cases 2 and 4) separation of the attended and unattended speakers. (A) TRF estimates for speakers 1 and 2 over time with the extracted M100 peak positions tracked by a narrow yellow line. (B) Extracted M100 peak magnitudes over time for speakers 1 and 2 as the attention marker. In cases 1 and 3, the M100 components exhibit a strong modulation effect of the attentional state, i.e., the attended speaker has a larger M100 peak, in contrast to cases 2 and 4, where there is a weak modulation. (C) Batch-mode state-space estimates of the attentional state. (D) Real-time state-space estimates of the attentional state. The strong or weak modulation effects of attentional state in the extracted M100 components directly affects the classification accuracy and the width of the confidence intervals for both the batch-mode and real-time estimators.
Row B in Figure 11 displays the extracted M100 peak magnitudes over time for speakers 1 and 2. The attention modulation effect is more significant in cases 1 and 3. Rows C and D respectively show the batch-mode and real-time estimates of the attentional state based on the extracted M100 values. As expected, the batch-mode output is more robust to the fluctuations in the extracted M100 peak values, with smoother transitions and larger confidence intervals. Despite the poor attention modulation effect in cases 2 and 4, we observe that both the real-time and the batch-mode state-space models show reasonable performance in translating the extracted M100 peak values to a robust measure of the attentional state. This effect is notable in Rows C and D of Case 4. We performed the same analysis as in Figure 9 to assess the effect of the forward-lag parameter KF. Since the results were quite similar to those in Figures 6, 9, we have omitted them for brevity and chose the same forward-lag of 1.5s.
Finally, Figure 12 summarizes the real-time classification results for the constant-attention (left panels) and attention-switch (right panels) MEG experiments. The classification convention is similar to that used in our EEG analysis, and is illustrated in Figure 12A for the completeness. For the attention-switch experiment, the 28–30s interval is removed from the classification analysis, as it pertains to a silence period during which the subject is instructed to switch attention. Figure 12B shows the corresponding classification results, consisting of 36 trials for the constant-attention and 18 trials for the attention-switch experiments. Each circle corresponds to a single trial and the subjects in each experiment are color-coded. The average classification results per trial are shown in Figure 12C for each subject. The average hit rate and false alarm rates in the constant-attention experiments are respectively given by 71.67 and 20.81%. These quantities for the attention-switch experiment are respectively given by 64.12 and 26.16%, showing a reduction in hit rate and increase in false alarm.
Figure 12.
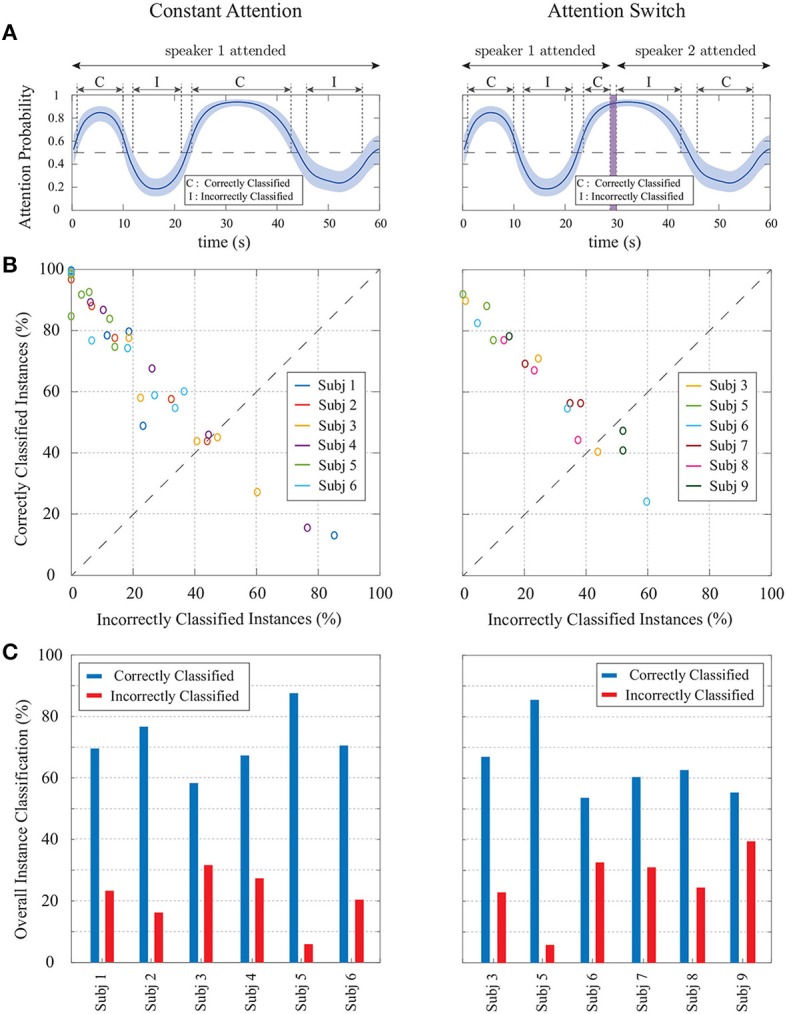
Summary of real-time classification results for the constant-attention (left panels) and attention-switch (right panels) MEG experiments. (A) a generic instance of the state-space output for a trial illustrating the classification convention. (B) Classification results per trial for all subjects; each circle corresponds to a trial and the subjects are color-coded. The trials falling below the dashed line have more incorrectly classified instances than correctly classified ones. (C) Average classification performance over all trials for the six subjects.
4. Discussion
In this work, we have proposed a framework for real-time decoding of the attentional state of a listener in a dual-speaker environment from M/EEG. This framework consists of three modules. In the first module, the encoding/decoding coefficients, relating the neural response to the envelopes of the two speech streams, are estimated in a low-complexity and real-time fashion. Existing approaches for encoder/decoder estimation operate in an offline fashion using multiple experiment trials or large training datasets (O'Sullivan et al., 2015; Akram et al., 2016; Aroudi et al., 2016; Van Eyndhoven et al., 2017), and hence are not suitable for real-time applications with limited amount of training data and potential variability in the recording setup. To address this issue, we have integrated the forgetting factor mechanism used in adaptive filtering with ℓ1-regularization, in order to capture the coefficient dynamics and mitigate overfitting.
In the second module, a function of the estimated encoding/decoding coefficients and the acoustic data, which we refer to as the attention marker, is calculated in real-time for each speaker. The role of the attention marker is to provide dynamic features that create statistical separation between the attended and the unattended speakers. Examples of such attention markers include correlation-based measures (e.g., correlation of the acoustic envelopes and their reconstruction from neural response), or measures solely based on the estimated decoding/encoding coefficients (e.g., the ℓ1-norm of the decoder coefficients or the M100 peak of the encoder).
Finally, the attention marker is passed to the third module consisting of a near real-time state-space estimator. To control the delay in state estimation, we adopt a fixed-lag smoothing paradigm, in which the past and near future data are used to estimate the states. The role of the state-space model is to translate the noisy and highly variable attention markers to robust measures of the attentional state with minimal delay. We have archived a publicly available MATLAB implementation of our framework on the open source repository GitHub in order to ease reproducibility (Miran, 2017).
We validated the performance of our proposed framework using simulated EEG and MEG data, in which the ground truth attentional states are known. We also applied our proposed methods to experimentally recorded MEG and EEG data. As for a comparison benchmark to study the effect of the parameter choices in our real-time estimator, we considered the offline state-space attention decoding approach of Akram et al. (2016). Our MEG analysis showed that although the proposed real-time estimator has access to significantly fewer data points, it closely matches the outcome of the offline state-space estimator in Akram et al. (2016), for which the entire data from multiple trials are used for attention decoding. In particular, our analysis of the MEG data in constant-attention conditions revealed a hit rate of ~70% and a false alarm rate of ~20% at the group level. While the performance is slightly degraded compared to the offline analysis of Akram et al. (2016), our algorithms operate in real-time with 1.5s built-in delay, over single trials, and using minimal tuning. Similarly, our analysis of EEG data provided ~80% hit rate and ~15% false alarm rate at a single trial level. These performance measures are slightly degraded compared to the results of offline approaches such as O'Sullivan et al. (2015).
Our proposed modular design admits the use of any attention-modulated statistic or feature as the attention marker, three of which have been considered in this work. While some attention markers perform better than the rest in certain applications, our goal in this work was to provide different examples of attention markers which can be used in the encoding/decoding models based on the literature, rather than comparing their performance against each other. The choice of the best attention marker that results in the highest classification accuracy is a problem-specific matter. Our modular design allows to evaluate the performance of a variety of attention markers for a given experimental setting, while fixing the encoding/decoding estimation and state-space modules, and to choose one that provides the desired classification performance. Our state-space module can also operate on the output of existing methods with encoder/decoder coefficients that are pre-estimated using training datasets (O'Sullivan et al., 2015; Zink et al., 2017) to provide a robust and statistically interpretable measure of the attentional state at high temporal resolutions.
A practical limitation of our proposed methodology in its current form is the need to have access to clean acoustic data in order to form regressors based on the speech envelopes. In a realistic scenario, the speaker envelopes have to be extracted from the noisy mixture of speeches recorded by microphone arrays. Thanks to a number of fairly recent results in attention decoding literature (Biesmans et al., 2015, 2017; Aroudi et al., 2016; O'Sullivan et al., 2017; Van Eyndhoven et al., 2017), it is possible to integrate our methodology with a pre-processing module that extracts the acoustic features of individual speech streams from their noisy mixtures. We view this extension as a future direction of research.
The proposed approach requires a minimal amount of labeled training data for tuning purposes. However, we can determine the attended speaker in an unlabeled dataset as the speaker whose speech signal best fits the EEG data or whose encoder/decoder estimates have larger peaks at certain time lags, and then train the decoders or hyperparameters with these data-driven labels. This can be done both in existing methods such as that of O'Sullivan et al. (2015) for attended decoder estimation and in our approach for capturing the statistical properties of attention markers for hyperparameter tuning. We view this extension to deal with unlabeled data as a future direction of research.
Our proposed framework has several advantages over existing methodologies. First, our algorithms require minimal amount of offline tuning or training. The subject-specific hyperparameters used by the algorithms are tuned prior to real-time application in a supervised manner. The only major offline tuning step in our framework is computing the subject-specific channel weights in the encoding model for MEG analysis in order to extract the auditory component of the neural response. This is due to the fact that the channel locations are not fixed with respect to the head position across subjects. It is worth noting that this step can be avoided if the encoding model treats the MEG channels separately in a multivariate model. Given that recent studies suggest that the M100 component of the encoder obtained from the MEG auditory response is a reliable attention marker (Ding and Simon, 2012a,b; Akram et al., 2017), we adopted the DSS algorithm for computing the channel weights that compose the auditory response in an offline fashion.
Second, our framework yields robust attention decoding performance at a temporal resolution in the order of ~1 second, comparable to that at which humans switch their attention from one speaker to another. The accuracy of existing methods, however, significantly degrades when they operate at these temporal resolutions (Zink et al., 2016, 2017). Our proposed framework operates in a near real-time fashion, where the attention decoding delay can be adjusted for controlling the trade-off between robustness and adaptivity of the attentional state estimates. In addition, the probabilistic output of our attentional state decoding framework can be used for further statistical analysis and soft-decision mechanisms which are desired in smart hearing aid applications. Finally, the modular design of our framework facilitates its adaptation to more complex auditory scenes (e.g., with multiple speakers and realistic noise and reverberation conditions) and integration of other covariates relevant to real-time applications (e.g., electrooculography measurements).
Author contributions
TZ, JZS, and BB designed the research. SM and BB performed the research, with contributions to the methods by AS, SA, and TZ and experimental data supplied by TZ and JZS. All authors participated in writing the paper.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest. Author TZ is employed by Starkey Hearing Technologies. Author SA is employed by Facebook. All other authors declare no competing interests.
Acknowledgments
The authors would like to thank Dr. Tom Goldstein for helpful remarks on adapting the FASTA package options to our decoder/encoder estimation problem.
Footnotes
Funding. This material is based on work supported in part by the National Science Foundation Awards No. 1552946 and 1734892, and a research gift from the Starkey Hearing Technologies to the University of Maryland.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnins.2018.00262/full#supplementary-material
References
- Akram S., Presacco A., Simon J. Z., Shamma S. A., Babadi B. (2016). Robust decoding of selective auditory attention from MEG in a competing-speaker environment via state-space modeling. NeuroImage 124, 906–917. 10.1016/j.neuroimage.2015.09.048 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Akram S., Simon J. Z., Babadi B. (2017). Dynamic estimation of the auditory temporal response function from MEG in competing-speaker environments. IEEE Trans. Biomed. Eng. 64, 1896–1905. 10.1109/TBME.2016.2628884 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Akram S., Simon J. Z., Shamma S. A., Babadi B. (2014). A state-space model for decoding auditory attentional modulation from MEG in a competing-speaker environment, in Advances in Neural Information Processing Systems (Montreal, QC: ), 460–468. [Google Scholar]
- Aroudi A., Mirkovic B., De Vos M., Doclo S. (2016). Auditory attention decoding with EEG recordings using noisy acoustic reference signals, in Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on (Shanghai: IEEE; ), 694–698. [Google Scholar]
- Biesmans W., Das N., Francart T., Bertrand A. (2017). Auditory-inspired speech envelope extraction methods for improved EEG-based auditory attention detection in a cocktail party scenario. IEEE Trans. Neural Syst. Rehabil. Eng. 25, 402–412. 10.1109/TNSRE.2016.2571900 [DOI] [PubMed] [Google Scholar]
- Biesmans W., Vanthornhout J., Wouters J., Moonen M., Francart T., Bertrand A. (2015). Comparison of speech envelope extraction methods for EEG-based auditory attention detection in a cocktail party scenario, in Engineering in Medicine and Biology Society (EMBC), 2015 37th Annual International Conference of the IEEE (Milan: IEEE; ), 5155–5158. [DOI] [PubMed] [Google Scholar]
- Bleichner M. G., Mirkovic B., Debener S. (2016). Identifying auditory attention with ear-EEG: cEEGrid versus high-density cap-EEG comparison. J. Neural Eng. 13:066004. 10.1088/1741-2560/13/6/066004 [DOI] [PubMed] [Google Scholar]
- Bregman A. S. (1994). Auditory Scene Analysis: The Perceptual Organization of Sound. Cambridge, MA: MIT Press. [Google Scholar]
- Brungart D. S. (2001). Informational and energetic masking effects in the perception of two simultaneous talkers. J. Acoust. Soc. Am. 109, 1101–1109. 10.1121/1.1345696 [DOI] [PubMed] [Google Scholar]
- Chait M., de Cheveigné A., Poeppel D., Simon J. Z. (2010). Neural dynamics of attending and ignoring in human auditory cortex. Neuropsychologia 48, 3262–3271. 10.1016/j.neuropsychologia.2010.07.007 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chait M., Simon J. Z., Poeppel D. (2004). Auditory m50 and m100 responses to broadband noise: functional implications. Neuroreport 15, 2455–2458. 10.1097/00001756-200411150-00004 [DOI] [PubMed] [Google Scholar]
- Cherry E. C. (1953). Some experiments on the recognition of speech, with one and with two ears. J. Acoust. Soc. Am. 25, 975–979. 10.1121/1.1907229 [DOI] [Google Scholar]
- Combettes P. L., Pesquet J.-C. (eds.). (2011). Proximal splitting methods in signal processing, in Fixed-Point Algorithms for Inverse Problems in Science and Engineering (New York, NY: Springer; ), 185–212. [Google Scholar]
- de Cheveigné A., Simon J. Z. (2008). Denoising based on spatial filtering. J. Neurosci. Methods 171, 331–339. 10.1016/j.jneumeth.2008.03.015 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ding N., Simon J. Z. (2012a). Emergence of neural encoding of auditory objects while listening to competing speakers. Proc. Natl. Acad. Sci. U.S.A. 109, 11854–11859. 10.1073/pnas.1205381109 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ding N., Simon J. Z. (2012b). Neural coding of continuous speech in auditory cortex during monaural and dichotic listening. J. Neurophysiol. 107, 78–89. 10.1152/jn.00297.2011 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fishman Y. I., Steinschneider M. (2010). Neural correlates of auditory scene analysis based on inharmonicity in monkey primary auditory cortex. J. Neurosci. 30, 12480–12494. 10.1523/JNEUROSCI.1780-10.2010 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Goldstein T., Studer C., Baraniuk R. (2014). A field guide to forward-backward splitting with a FASTA implementation. arXiv:abs/1411.3406. [Google Scholar]
- Goldstein T., Studer C., Baraniuk R. (2015). FASTA: A Generalized Implementation of Forward-Backward Splitting. Available online at: http://arxiv.org/abs/1501.04979
- Griffiths T. D., Warren J. D. (2004). What is an auditory object? Nat. Rev. Neurosci. 5:887. 10.1038/nrn1538 [DOI] [PubMed] [Google Scholar]
- Haykin S., Chen Z. (2005). The cocktail party problem. Neural Comput. 17, 1875–1902. 10.1162/0899766054322964 [DOI] [PubMed] [Google Scholar]
- Kähkönen S., Ahveninen J., Jääskeläinen I. P., Kaakkola S., Näätänen R., Huttunen J., et al. (2001). Effects of haloperidol on selective attention: a combined whole-head MEG and high-resolution EEG study. Neuropsychopharmacology 25, 498–504. 10.1016/S0893-133X(01)00255-X [DOI] [PubMed] [Google Scholar]
- Kaya E. M., Elhilali M. (2017). Modelling auditory attention. Philos. Trans. R. Soc. B 372:20160101 10.1098/rstb.2016.0101 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Khalighinejad B., da Silva G. C., Mesgarani N. (2017). Dynamic encoding of acoustic features in neural responses to continuous speech. J. Neurosci. 37, 2176–2185. 10.1523/JNEUROSCI.2383-16.2017 [DOI] [PMC free article] [PubMed] [Google Scholar]
- McDermott J. H. (2009). The cocktail party problem. Curr. Biol. 19, R1024–R1027. 10.1016/j.cub.2009.09.005 [DOI] [PubMed] [Google Scholar]
- Middlebrooks J. C., Simon J. Z., Popper A. N., Fay R. R. (eds.). (2017). The auditory system at the cocktail party, in The Springer Handbook of Auditory Research Series (Springer; ), 60. [Google Scholar]
- Miran S. (2017). Real-Time Tracking of Selective Auditory Attention MATLAB Code. Available omline at: https://github.com/sinamiran/Real-Time-Tracking-of-Selective-Auditory-Attention
- Mirkovic B., Debener S., Jaeger M., De Vos M. (2015). Decoding the attended speech stream with multi-channel EEG: implications for online, daily-life applications. J. Neural Engi. 12:046007. 10.1088/1741-2560/12/4/046007 [DOI] [PubMed] [Google Scholar]
- O'Sullivan J., Chen Z., Herrero J., McKhann G. M., Sheth S. A., Mehta A. D., et al. (2017). Neural decoding of attentional selection in multi-speaker environments without access to clean sources. J. Neural Eng. 14:056001. 10.1088/1741-2552/aa7ab4 [DOI] [PMC free article] [PubMed] [Google Scholar]
- O'Sullivan J. A., Power A. J., Mesgarani N., Rajaram S., Foxe J. J., Shinn-Cunningham B. G., et al. (2015). Attentional selection in a cocktail party environment can be decoded from single-trial EEG. Cereb. Cortex 25, 1697–1706. 10.1093/cercor/bht355 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Power A. J., Foxe J. J., Forde E.-J., Reilly R. B., Lalor E. C. (2012). At what time is the cocktail party? A late locus of selective attention to natural speech. Eur. J. Neurosci. 35, 1497–1503. 10.1111/j.1460-9568.2012.08060.x [DOI] [PubMed] [Google Scholar]
- Särelä J., Valpola H. (2005). Denoising source separation. J. Mach. Learn. Res. 6, 233–272. Available online at: http://www.jmlr.org/papers/volume6/sarela05a/sarela05a.pdf [Google Scholar]
- Shamma S. A., Elhilali M., Micheyl C. (2011). Temporal coherence and attention in auditory scene analysis. Trends Neurosci. 34, 114–123. 10.1016/j.tins.2010.11.002 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sheikhattar A., Fritz J. B., Shamma S. A., Babadi B. (2015a). Adaptive sparse logistic regression with application to neuronal plasticity analysis, in Signals, Systems and Computers, 2015 49th Asilomar Conference on (Pacific Grove, CA: IEEE; ), 1551–1555. [Google Scholar]
- Sheikhattar A., Fritz J. B., Shamma S. A., Babadi B. (2015b). Recursive sparse point process regression with application to spectrotemporal receptive field plasticity analysis. IEEE Trans. Signal Process. 64, 2026–2039. 10.1109/TSP.2015.2512560 [DOI] [Google Scholar]
- Tibshirani R. (1996). Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B (Methodol.) 58, 267–288. [Google Scholar]
- Van Eyndhoven S., Francart T., Bertrand A. (2017). EEG-informed attended speaker extraction from recorded speech mixtures with application in neuro-steered hearing prostheses. IEEE Trans. Biomed. Eng. 64, 1045–1056. 10.1109/TBME.2016.2587382 [DOI] [PubMed] [Google Scholar]
- Zink R., Baptist A., Bertrand A., Van Huffel S., De Vos M. (2016). Online detection of auditory attention in a neurofeedback application, in Proceedings of the 8th International Workshop on Biosignal Interpretation (Osaka: ), 1–4. [Google Scholar]
- Zink R., Proesmans S., Bertrand A., Van Huffel S., De Vos M. (2017). Online detection of auditory attention with mobile EEG: closing the loop with neurofeedback. bioRxiv 218727. 10.1101/218727 [DOI] [Google Scholar]
- Zion Golumbic E. M., Ding N., Bickel S., Lakatos P., Schevon C. A., McKhann G. M., et al. (2013). Mechanisms underlying selective neuronal tracking of attended speech at a “cocktail party.” Neuron 77, 980–991. 10.1016/j.neuron.2012.12.037 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.