

Abstract
Many empirical networks have community structure, in which nodes are densely interconnected within each community (i.e., a group of nodes) and sparsely across different communities. Like other local and meso-scale structure of networks, communities are generally heterogeneous in various aspects such as the size, density of edges, connectivity to other communities and significance. In the present study, we propose a method to statistically test the significance of individual communities in a given network. Compared to the previous methods, the present algorithm is unique in that it accepts different community-detection algorithms and the corresponding quality function for single communities. The present method requires that a quality of each community can be quantified and that community detection is performed as optimisation of such a quality function summed over the communities. Various community detection algorithms including modularity maximisation and graph partitioning meet this criterion. Our method estimates a distribution of the quality function for randomised networks to calculate a likelihood of each community in the given network. We illustrate our algorithm by synthetic and empirical networks.
Introduction
Many biological, physical and social systems can be expressed as networks, with nodes representing individual entities within the network and edges representing pairwise relationships between nodes1,2. Among various structural properties of networks, many empirical networks have community structure such that a network is composed of communities, which are groups of nodes that are densely interconnected with each other while sparsely interconnected with those in other groups3,4. A community may correspond to the role of nodes. For example, communities may correspond to functional modules of proteins5, groups of airports serving the same geographical region6 and herds of people sharing an interest7.
Many algorithms have been proposed for finding communities in networks3,4. These algorithms are often equipped with a quality function with which to judge whether or not the detected community structure is significant overall. A much less asked fundamental question is the significance of individual communities. In fact, a network may be composed of a part where community structure is pronounced and another part where community structure is vague or absent. To discuss community structure in such a “chimera” network, one needs methods to assess statistical significance of single communities.
In the present study, we consider the significance of single communities that have been detected by a non-overlapping community-detection algorithm. An algorithm for testing significance of individual communities was previously proposed8. In that algorithm, one uses a quality function for individual communities to compare the quality of a community in question, detected in the given network, and that detected in randomised networks. The distribution of the quality function in randomised networks is analytically known. The authors then used the same significant test in OSLOM, which is an algorithm for finding various types of communities9. However, OSLOM does not optimise the same quality function as that used in the aforementioned statistical test or its aggregate over the different communities. The same discrepancy exists in a different significance test for single communities10. In an extreme case, let us suppose one detects communities by optimising a quality function that is very different from the quality function used in the statistical test. Then, the detected communities may have small values of the quality function used in the statistical test and will be judged to be insignificant. However, in terms of the quality function used in the community detection, the detected communities may be sufficiently strong.
This pitfall may be overcome if one uses the same quality function for the community detection and the statistical test. There exist such significance tests for individual communities11,12. However, these significance tests11,12 do not consider the possible dependence of the quality function value on the size of community10,13,14. This practice is problematic for the following reason. Suppose that two communities in the given network have different sizes and bear the same value of the quality function. Then, the significance level (i.e., p-value) in these statistical tests is the same for the two communities. In general, however, the quality function value may be positively correlated with the community size, which is in fact often the case (Methods section). In this case, it is easier for the larger community to attain the observed quality function value than for the smaller community under the null model. Then, the smaller community should be judged to be more significant than the larger community if they yield the same quality function value. An aforementioned statistical test does consider the dependence of the quality function value on the community size10. However, that method does not use a common quality function between community detection and statistical testing, as discussed already.
Based on these considerations, it will be useful to develop methods to test the significance of individual communities that (i) use a quality function that is consistent with the one used in community detection, and (ii) take into account the dependence of the quality function value on the community size. We will develop a new statistical test for individual communities that meets these criteria. An additional feature of our method is that it allows for general quality functions. Python code for the present significance test is available at https://github.com/skojaku/qstest/.
Methods
Correlation between quality and community size
We consider unweighted networks composed of N nodes. Denote their N × N adjacency matrix by A = (Aij), where Aij = 1 if nodes i and j are adjacent and Aij = 0 otherwise. We assume that the network is undirected (i.e., Aij = Aji for all i ≠ j) and does not contain self-loops (i.e., Aii = 0). Let M be the number of edges in the network. We denote by the degree of node i.
One may regard a community as significant if its quality value is significantly larger than that expected for randomised networks. This intuitive approach has a problem. To see this, let us consider a benchmark network generated by the Lancichinetti-Fortunato-Radicchi (LFR) model15 (Fig. 1(a)). The network has N = 103 nodes and consists of C non-overlapping communities. Each node i belongs to one of the C = 31 communities. To generate the network, we set the average node’s degree to 10, the maximum node’s degree to 100, the range of the number of nodes in a community c (denoted by nc) to [10,100] and the power-law exponent for the distributions of di and nc to 2. Let us consider a quality function given by13,14
| 1 |
Figure 1.

(a) A network with 31 non-overlapping communities generated by the LFR model. The circles represent nodes. The lines between the nodes represent edges. The colour of each node indicates the planted community to which the node belongs. (b–e) Quality of a community (i.e., , , and ) plotted against its number of nodes, nc. The circles indicate the planted communities shown in panel (a). The crosses indicate the communities detected in 500 randomised networks generated by the configuration model. To find communities in the randomised networks, we use the Louvain algorithm26 for (panel (b)) and a variant of the Kernighan–Lin algorithm27 for , and (panels (c–e)).
Note that the modularity is the sum of over the communities7. We find a strong positive correlation between and nc (circles in Fig. 1(b)). This is also true for communities in randomised networks that are generated by the configuration model, i.e., random networks that preserve the expected degree of each node (crosses in Fig. 1(b)). Crucially, large communities detected in the randomised networks have larger values than small communities in the original network do. Therefore, we can not judge the significance of communities solely by the value of . The results are qualitatively the same for other quality functions for individual communities introduced in the following section (Fig. 1(c,d and e)).
Our statistical test
On the basis of the observations made in the previous section, we construct a statistical test for individual communities as follows. Note that we do not specify the quality function qc, which may be or a different one. Moreover, we do not specify how one measures the size sc of community c. We refer to the present statistical test based on a quality function q and community size s as the (q, s)–test.
Suppose that we have a community c with quality qc and size sc. We judge community c to be significant if its qc value is larger than those for communities of the same size sc detected in randomised networks. We compute , which is the probability that a community of size sc detected in randomised networks generated by the configuration model has a quality value larger than qc. We numerically estimate as follows. First, we generate 500 randomised networks using the configuration model. Then, we detect communities in each randomised network by the algorithm that has been used to detect communities in the original network. Let be the sum of the number of communities detected in the 500 randomised networks. For each community in the randomised networks, we compute the quality and size . Then, we compute the average values, i.e., and , and the unbiased estimation of the standard deviation, i.e., and . We estimate the joint probability distribution using the kernel density estimator16 as follows:
| 2 |
where h is the width of the kernel. The function f (·, ·) is the bivariate Gaussian kernel (i.e., bivariate standard normal distribution) given by
| 3 |
where
| 4 |
is the Pearson correlation coefficient between and . The probability distribution estimated by the Gaussian kernels is close to any form of the true probability distribution as the number of samples increases17. Although there are also non-Gaussian kernels that share this property17, we used the Gaussian kernels, which is a state-of-the-art method. The width h is a free parameter that affects the speed of the convergence to the true probability distribution. Optimising the value of h requires assumptions for the true probability distributions and intensive computations18,19. Therefore, we set according to Scott’s rule-of-thumb20, which often provides a reasonable estimate in practice18–20.
The conditional probability, , is given by
| 5 |
The integration of f (x1, x2) over x1 yields
| 6 |
where Φ (·) is the cumulative distribution function of the standard normal distribution. By substituting Eq. (6) into Eq. (5), we have
| 7 |
Finally, we regard community c as significant if , where α ∈ [0, 1] is the significance level. The conditional probability obeys a uniform probability distribution over [0, 1] for a community detected in a randomised network (see Supplementary Information 1). One can estimate more accurate p-values (i.e. ) using a larger number of randomised networks, which, however, requires an additional computational time. We opt to use 500 randomised networks to obtain sufficiently accurate p-values in a reasonable time. In fact, the p-value does not change much if one increases the number of randomised networks beyond 500 or if one uses networks with different numbers of nodes and communities (Supplementary Information 2).
As the number of communities, C, increases, some insignificant communities would be significant owing to the multiple comparison problem. To avoid this, we use the Šidák correction21, i.e., α = 1 − (1 − α′)1/C, where α′ ∈ [0, 1] is the targeted significance level. We set α′ = 0.05.
Time complexity
The time complexity of the proposed statistical test is evaluated as follows. Generating one randomised network from the configuration model consumes time using an efficient algorithm22, which is implemented in some network analysis software23,24. For each generated randomised network, we detect communities. Any community-detection algorithm qualified for the present statistical test computes the quality and size of the individual communities and maximises the quality function for the entire network. We use the quality and size of the optimised communities in the statistical test. We carry out these procedures for each of the R randomised networks, consuming time in total, where Z is the time complexity of the community-detection algorithm. We compute the p-value for each of the C communities in the original network using Eq. (7) with RCconf samples on average, and , where Cconf is the average number of communities detected in a randomised network. This incurs a time complexity of . In total, the proposed statistical test requires time.
The time complexity can be mitigated using parallel computing. In other words, one runs multiple threads, each of which generates independent samples of . Once the sampling is completed in all the threads, one computes the p-value using Eq. (7). We used 16 threads on a computer with the Intel 2.6 GHz Sandy Bridge processors and 4GB of memory. For the largest network we analysed (i.e., Internet25; N = 34,761 nodes), our statistical test needed 403 seconds using the Louvain community-detection algorithm, which has a time complexity of 26. With the Kernighan-Lin community-detection algorithm having a time complexity of 27, it took 17,763 seconds (i.e. approximately 5 hours).
Community detection with different quality functions
Among various quality functions for individual communities apart from 4,13,14, we consider the following three quality functions. The internal average degree14 (i.e., normalised number of intra-community edges), denoted by , is defined by
| 8 |
The maximisation of yields a community having dense intra-community connectivity. The expansion14, denoted by , is defined by
| 9 |
The maximisation of yields a community having sparse inter-community connectivity. Finally, the conductance14, denoted by , is defined by
| 10 |
where volc is the sum of degrees of nodes (i.e., volume) in a community c. Similar to the case of , the maximisation of yields a community having sparse inter-community connectivity. One can also interpret the maximisation of as the maximisation of the number of intra-community edges28.
For , we adopt the Louvain algorithm to maximise the modularity (i.e., sum of over the communities, ) to find communities in the original and randomised networks. However, the Louvain algorithm is not available to , where , or . Therefore, we adopt a variant of the Kernighan–Lin algorithm29 used in a previous study27. The algorithm seeks partitioning of the network into communities that maximises Q. Suppose that each node i has a tentative label indicating the index of the community to which node i belongs. First, we assign each node to one of the C communities selected uniformly at random. Second, for each node i, we tentatively relabel it to a different label and measure the increment in Q. Third, we select the node i and its new label c that maximise the increment in Q among all nodes i (1 ≤ i ≤ N) and all possible new labels. Regardless of whether Q increases or not, we accept the proposed relabelling of node i (i.e., set ). Fourth, we determine the pair of another node j (j ≠ i) and its tentative new label c′, which maximises the increment in Q, and change the label of j to c′ (i.e., ). In this manner, we relabel nodes one by one. Here we do not relabel the nodes that have already been relabelled. After sequentially relabelling the N nodes, we select the labelling that yields the largest value of Q among the N + 1 labellings that have appeared in the course of relabelling the N nodes. If the initial labelling (before relabelling any node) yields the largest value of Q, we terminate the algorithm. Otherwise, we use the labelling that has yielded the largest Q value among the N + 1 labellings as the initial labelling in the next round of updating the labels. We repeat the aforementioned procedure to sequentially relabel N nodes and select the best labelling. We repeat rounds of updating until the initial labelling is the best labelling in the round in terms of the Q value.
To find communities in networks using , or , we need to specify the number of communities, C. Otherwise, the maximisation of the quality functions may yield trivial communities. For example, is always the largest when each connected component constitutes a community because there is no inter-community edge. In the analysis of synthetic networks, we set C to the number of planted communities. For empirical networks, we set C to the number of communities identified by the Louvain algorithm.
Other statistical tests
We compare the (q, s)–test with two statistical tests, i.e., the test proposed by Spirin and Mirny10 and the test proposed by Lancichinetti, Radicchi and Ramasco8, which we refer to as the S–test and L–test, respectively. As is the case with the (q, s)–test, both S–test and L–test adopt the configuration model as the null model. For both statistical tests, we set the significance level for a single community to α = 1 − (1 − α′)1/C, where α′ = 0.05.
The S–test regards a community as significant if it has more intra-community edges than a community composed of the same number of nodes detected in randomised networks does. Their original algorithm10 is slow for large networks. Therefore, we adopt the Kernighan–Lin algorithm29 to optimise the quality function for a community adopted in the S–test. Up to our numerical efforts, our implementation is faster and also finds better community structure than their original algorithm does in terms of their quality function.
The L–test regards a community as significant if every node in the community has more neighbours within the community than that expected for the configuration model. In the original paper8, the authors defined two significance measures, i.e., -score and -score. We adopt the –score, which is less conservative than the –score. In the original article8, the –score is claimed to be more trustworthy than the –score because the –score but not the B-score relies on an extreme value statistics.
Data
We apply the statistical test to the 12 empirical networks listed in Table 1. We ignore the directions and weights of edges in the empirical networks.
Table 1.
Properties of 12 empirical networks.
| Network | N | M | C | n c | volc | ||
|---|---|---|---|---|---|---|---|
| Min | Max | Min | Max | ||||
| Karate30 | 34 | 78 | 3 | 5 | 17 | 16 | 78 |
| Dolphin31 | 62 | 159 | 4 | 7 | 22 | 37 | 123 |
| Les Misérables32 | 77 | 254 | 10 | 2 | 16 | 3 | 147 |
| Email33 | 151 | 1527 | 6 | 16 | 50 | 258 | 1081 |
| Jazz34 | 198 | 2742 | 6 | 3 | 63 | 9 | 2029 |
| Network science7 | 379 | 914 | 11 | 6 | 65 | 27 | 290 |
| Blog35 | 1222 | 16,714 | 2 | 565 | 657 | 15,755 | 17,673 |
| Airport36,37 | 2939 | 15,677 | 20 | 2 | 712 | 2 | 12,638 |
| Protein38,39 | 3023 | 6149 | 161 | 2 | 312 | 2 | 1832 |
| Chess25 | 7115 | 55,779 | 409 | 2 | 812 | 3 | 23,034 |
| Astro-ph (co-authorship)40 | 18,771 | 198,050 | 116 | 2 | 3547 | 2 | 98,628 |
| Internet25 | 34,761 | 107,720 | 65 | 4 | 13,710 | 7 | 106,881 |
Column C indicates the number of communities detected by the Louvain algorithm. Columns nc and volc indicate the number of nodes in a community and the sum of degrees of nodes in a community, respectively.
The karate club network represents the relationships among the members of a university’s karate club30. Each node represents a member of the karate club. Two members are defined to be adjacent if they are friends outside of the club activities.
The dolphin social network represents the relationships of the dolphins living near Doubtful Sound in New Zealand31. Each node represents a dolphin. Two dolphins are defined to be adjacent if they are frequently observed in the same school.
The network of Les Misérables represents the relationships between the characters of a novel, Les Misèrables32. Each node represents a character of the book. Each edge indicates that they appear in the same chapter of the book.
The Enron email network represents the email interactions among the staff of Enron Inc33. Each node represents an email account. Each edge indicates that an email is sent from one account to the other account.
The jazz network represents the collaborations among jazz musicians34. Each node represents a jazz musician. Each edge indicates that two musicians belong to the same band.
The network of network scientists represents the collaborations between researchers in network science7. Each node represents a researcher. Two researchers are defined to be adjacent if they have published a co-authored paper cited by one of two popular review papers on network science. Then, some nodes and edges were added manually by the author of the article7. We only consider the largest connected component of the network.
The political blog network is the network of blogs on the United States presidential election in 200435. Each node represents a blog. Two blogs are defined to be adjacent if there is at least one hyperlink between the two blogs on their front page.
The airport network consists of nodes representing airports in the world36,37. Two airports are defined to be adjacent if there is a direct commercial flight between the two airports.
The protein network represents the physical interactions among human proteins38,39. Each node represents a protein. Two proteins are defined to be adjacent if they physically interact.
The Chess network represents the chess matches between players25. Each node represents a chess player. Each edge indicates that they have played at least once.
The Astro-ph network represents the collaborations among the researchers who published a joint paper in the arXiv’s astro-ph section40. Each node represents a researcher. Two researchers are defined to be adjacent if they have published a joint paper.
The Internet network represents the network of autonomous systems25. A node represents an autonomous system, which is a group of routers maintained by a network operator. Two autonomous systems are defined to be adjacent if they have a logical peering relation.
Results
We measure the size of a community in two ways: the number of nodes in a community c, nc, and the sum of degrees of nodes in a community c, volc. In the next two subsections, we consider the –test and the –test. We show the results for other quality functions in the third subsection.
Synthetic networks
In this section, we examine synthetic networks with planted communities. We generate networks using the LFR model15, which places edges such that the node’s degree, (i.e., di), and the number of nodes in a community c, (i.e., nc), follow power-law distributions. We set the power-law exponent for the distributions of di and nc to 2, the average node’s degree to 10, the maximum degree to 100 and the range of nc to [20,200]. The networks are composed of N = 103 nodes. Each node i has an average fraction 1 − μ of neighbours belonging to the same community, where μ ∈ {0, 0.025, 0.05, …, 1} is a mixing parameter controlling the “strength” of community structure. With μ = 0, all edges are placed within communities, and the community structure is the strongest. With μ = 1, all edges are between different communities. We set the extent of overlaps between different communities to zero.
We generate 30 networks using the LFR model at each μ value. For each generated network, we classify the planted communities into significant and insignificant communities by each statistical test. Then, we compute the true positive rate (i.e., the fraction of significant communities in the network). Finally, we average the true positive rate over the 30 generated networks.
Figure 2 shows the true positive rate as a function of μ. The true positive rate for the S–test is smallest for the entire range of μ, indicating that the S–test is the most conservative. The S–test does not regard all the planted communities as significant even at μ = 0 for the following reason. In the S–test, one detects the strongest community in each randomised network, where the strength of a community is measured by the number of intra-community edges. Then, a focal community in the original network is regarded as significant if it is stronger than the majority of the strongest communities detected in the randomised networks. The strongest communities in the randomised networks often contain almost the largest possible number of intra-community edges, whereas the planted communities do not always even at μ = 0. Therefore, the S–test concludes that some planted communities are insignificant. The true positive rate for the L–test is 1 when μ = 0 and ranges between 0.55 and 0.95 for 0 < μ ≤ 0.5. The true positive rate for the –test and that for the –test are comparable and close to 1 for 0 ≤ μ ≤ 0.3. In contrast, there is a visible difference between the results for the – and the – tests for 0.3 < μ ≤ 0.5. This result suggests that the definition of the size of a community may affect the significance of weak communities but not of strong communities.
Figure 2.
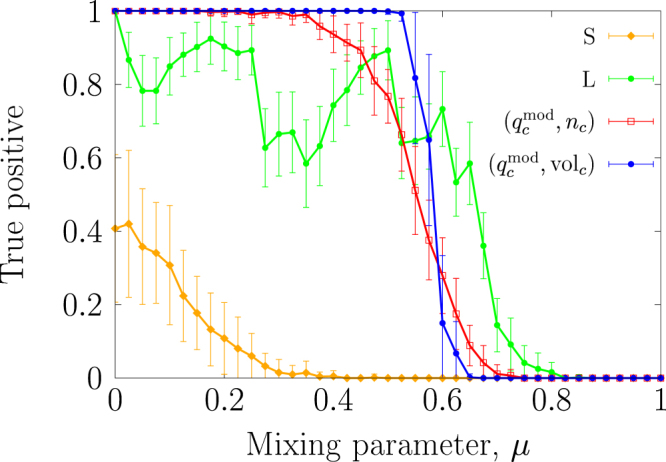
True positive rate for the statistical tests applied to the networks generated by the LFR model. Legends S, L, and indicate the S–test, the L–test, the –test and the –test, respectively. The error bars indicate the ±1 standard deviation.
Empirical networks
We apply the statistical tests to the 12 empirical networks listed in Table 1 (see the Data section for details). In this section, we detect communities by modularity maximisation using the Louvain algorithm26. Then, we apply the statistical tests to each detected community.
The fraction of significant communities for each statistical test is shown in Table 2. The – and the –tests identify more significant communities than the S–test and the L–test do in a majority of the 12 empirical networks. This result indicates that the – and the –tests are more generous than the S–test and L– test, which is consistent with the results for the LFR model. This is probably because the – and the – tests use to evaluate the quality of individual communities, which is consistent with the objective function of modularity maximisation, .
Table 2.
Fraction of significant communities identified by the S–test, the L–test, the (qmod, s)–test, the (qint, s)–test, the (qexp, s)–test and the (qcnd, s)–test in the 12 empirical networks.
| Network | S | L | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| n c | volc | n c | volc | n c | volc | n c | volc | |||
| Karate | 1.00 | 0.33 | 0.67 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.33 |
| Dolphin | 1.00 | 0.50 | 1.00 | 0.75 | 0.00 | 0.00 | 0.00 | 0.00 | 0.50 | 0.50 |
| Les Misérables | 0.40 | 0.40 | 0.40 | 0.60 | 0.20 | 0.40 | 0.00 | 0.00 | 0.50 | 0.40 |
| Enron | 1.00 | 0.00 | 1.00 | 1.00 | 0.33 | 0.67 | 0.00 | 0.00 | 1.00 | 1.00 |
| Jazz | 0.67 | 0.67 | 0.67 | 1.00 | 0.67 | 0.83 | 0.00 | 0.00 | 1.00 | 1.00 |
| Netscience | 1.00 | 0.64 | 1.00 | 1.00 | 0.91 | 0.82 | 0.09 | 0.09 | 0.91 | 1.00 |
| Blog | 0.00 | 1.00 | 1.00 | 1.00 | 0.50 | 0.50 | 0.00 | 0.00 | 1.00 | 1.00 |
| Airport | 0.00 | 0.60 | 0.70 | 0.80 | 0.15 | 0.55 | 0.00 | 0.00 | 0.40 | 0.20 |
| Protein | 0.00 | 0.35 | 0.14 | 0.22 | 0.03 | 0.12 | 0.01 | 0.01 | 0.00 | 0.00 |
| Chess | 0.00 | 0.25 | 0.13 | 0.15 | 0.36 | 0.58 | 0.00 | 0.00 | 0.01 | 0.03 |
| Astro-ph | — | 0.61 | 0.24 | 0.53 | 1.00 | 1.00 | 0.00 | 0.00 | 0.33 | 0.12 |
| Internet | — | 0.55 | 0.65 | 0.60 | 0.00 | 0.18 | 0.00 | 0.00 | 0.00 | 0.02 |
The hyphen indicates that the test did not terminate within 64 days on our computer (Intel 2.6 GHz Sandy Bridge processors and 4GB of memory).
To quantify the agreement between the – and the – tests, we compute the level of agreement defined by τ = (C11 + C00)/C, where C00 is the number of communities classified as insignificant by both statistical tests and C11 is the number of communities classified as significant by both tests. Note that 0 ≤ τ ≤ 1, τ = 1 if the two tests regard the same set of communities as significant, and τ = 0 if the two tests completely disagree. We compute τ between each pair of statistical tests for each empirical network and then average τ over the 12 empirical networks. The averaged τ values are shown in Table 3. We find τ = 0.42 between the S–test and the L–test, indicating that the two statistical tests disagree for a majority of communities. The L–test weakly agrees with the –test (i.e., τ = 0.58) but disagrees with the other tests for a majority of communities (i.e., τ < 0.5). The τ between the – and the –tests is large (τ = 0.84), suggesting that the significance of a majority of communities is not strongly affected by the definition of the community size.
Table 3.
Agreement between pairs of statistical tests.
| Test | S | L | ||
|---|---|---|---|---|
| S | 1.00 | 0.42 | 0.73 | 0.66 |
| L | 0.42 | 1.00 | 0.49 | 0.58 |
| 0.73 | 0.49 | 1.00 | 0.84 | |
| 0.66 | 0.58 | 0.84 | 1.00 |
Other quality functions
In this section, we examine the –, the –and the –tests, where sc is either nc or volc. For the synthetic networks, the true positive rate for the –and the –tests is small in the entire range of μ (Fig. 3). As is the case for the S–test, quality function uses the number of intra-community edges. Some planted communities are regarded as insignificant because randomised networks often contain a community having almost the largest possible number of intra-community edges (Fig. 1(c)). The quality function is the largest when the community c is disconnected from the other nodes. Randomised networks often contain many disconnected components, yielding a large value of (Fig. 1(d)). Therefore, the true positive rate for the – and the –tests is also close to zero in the entire range of μ. In contrast to – and –tests, the – and –tests yield the true positive rate close to one when μ ≤ 0.3. These results suggest that the results considerably depend on the quality function. For all the (q, s)–tests, the definition of community size (i.e., nc or volc) does not strongly influence the true positive rate.
Figure 3.
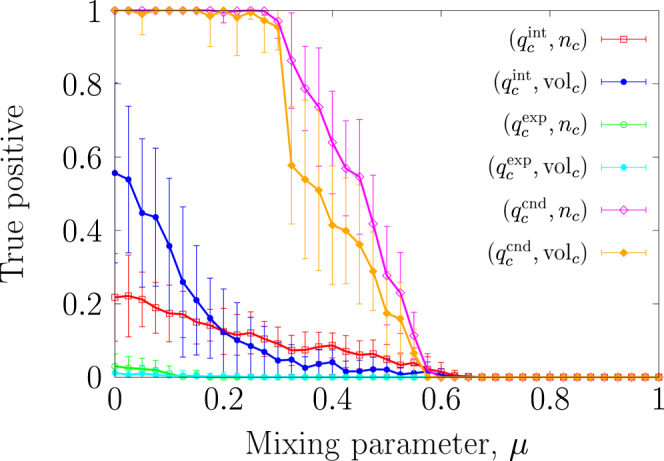
True positive rate as a function of mixing parameter, μ, for the six (q, s)–tests.
For the empirical networks, we first detect communities by maximising q, where q is either , or , using the variant of the Kernighan–Lin algorithm (see the Other statistical test sections). Then, we apply the (q,s)–test to each detected community. The results for the –, the – and the –tests applied to the 12 empirical networks are shown in Table 2. For all the networks, the –test regards more communities as significant than the – and the –tests, where sc is either nc or volc. This result is consistent with those obtained for the synthetic networks (Fig. 3). For each quality function q, the level of agreement (i.e., τ) between the different definitions of the community size (i.e., nc or volc) is shown in Table 4. For most empirical networks, the agreement τ is larger than 0.8, indicating that the results of the statistical test do not strongly depend on the definition of community size in most cases.
Table 4.
Agreement between the (qc, nc)–test and the (qc, volc)–test.
| Network | q c | ||
|---|---|---|---|
| Karate | 1.00 | 1.00 | 0.67 |
| Dolphin | 1.00 | 1.00 | 1.00 |
| Les Misérables | 0.60 | 1.00 | 0.90 |
| Enron | 0.67 | 1.00 | 1.00 |
| Jazz | 0.50 | 1.00 | 1.00 |
| Netscience | 0.73 | 1.00 | 0.91 |
| Blog | 1.00 | 1.00 | 1.00 |
| Airport | 0.60 | 1.00 | 0.60 |
| Protein | 0.90 | 0.99 | 1.00 |
| Chess | 0.77 | 1.00 | 0.98 |
| Astro-ph | 1.00 | 1.00 | 0.76 |
| Internet | 0.82 | 1.00 | 0.98 |
Discussion
We proposed a non-parametric statistical test, called the (q, s)–test, for the significance of individual communities, which accounts for the correlation between the quality and the size of single communities. We demonstrated our test with several quality functions q including the one defined as the contribution of a single community to the modularity. In fact, the (q, s)–test accepts different quality functions for individual communities such as those described in the previous literature13,14,41–43. In addition, the (q, s)–test does not demand how communities should be detected in a given network. We note that q that is consistent with the objective function for community detection should be used because the former is maximised in the (q, s)–test and the latter is maximised in community detection.
We have used two definitions of the size of a community, i.e., the number of nodes in a community (i.e., nc), and the sum of degrees of nodes in a community (i.e., volc). For degree-homogeneous networks, the choice does not matter because nc ∝ volc. However, for degree-heterogeneous networks, significant communities may considerably depend on whether we use nc or volc. If q explicitly uses its own measure of the size of a community, we should probably adopt the corresponding definition of the community size in the (q, s)–test. If a measure of community size is not explicit, we suggest that one selects a measure of community size that is more strongly correlated with q than others. If q is correlated with multiple quantities (e.g. both nc and volc) that are not perfectly correlated with each other, one can extend the (q, s)–test by adopting multivariate Gaussian kernels with three or more variables instead of bivariate Gaussian kernels. A downside of this approach is that we would need more data to reliably estimate the distribution of (q, s), where s is at least two-dimensional.
We can adopt the (q, s)–test to assess the significance of other structures of networks, such as bipartite communities44 and core-periphery structure45–47, provided that the quality function for the individual structure (e.g., a single bipartite community) is explicitly defined. In fact, we applied a variant of the (q, s)–test to core-periphery structure in our previous study47.
Robustness of community structure against random perturbations (e.g., addition, removal and rewiring of edges) is an alternative measure of the significance of communities14,48,49. With this approach, if small perturbations do not considerably change communities, then the communities are regarded as significant. Statistical tests based on quality functions including the (q, s)–test and those based on robustness may provide different results49. As is the case of quality functions, the robustness of an individual community may be correlated with the size of a community. For example, removal of a small number of intra-community edges may destroy small communities, whereas large communities may survive the removal of more intra-community edges. If this is the case, it may be worthwhile to inform a robustness–based test of individual communities by the dependence of the robustness measure on the size of a community.
Electronic supplementary material
Acknowledgements
N.M. acknowledges the support provided through JST, CREST, and JST, ERATO, Kawarabayashi Large Graph Project.
Author Contributions
N.M. conceived and designed the research; S.K. performed the computational experiments; N.M. and S.K. wrote the paper.
Competing Interests
The authors declare no competing interests.
Footnotes
Electronic supplementary material
Supplementary information accompanies this paper at 10.1038/s41598-018-25560-z.
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Newman, M. E. J. Networks: An Introduction (Oxford University Press, Oxford, 2010).
- 2.Barabási, A. L. Network Science (Cambridge University Press, Cambridge, 2016).
- 3.Fortunato S. Community detection in graphs. Phys. Rep. 2010;486:75–174. doi: 10.1016/j.physrep.2009.11.002. [DOI] [Google Scholar]
- 4.Fortunato S, Hric D. Community detection in networks: A user guide. Phys. Rep. 2016;659:1–44. doi: 10.1016/j.physrep.2016.09.002. [DOI] [Google Scholar]
- 5.Jonsson PF, Cavanna T, Zicha D, Bates PA. Cluster analysis of networks generated through homology: automatic identification of important protein communities involved in cancer metastasis. BMC Bioinf. 2006;7:2. doi: 10.1186/1471-2105-7-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Guimerà R, Mossa S, Turtschi A, Amaral LAN. The worldwide air transportation network: anomalous centrality, community structure, and cities’ global roles. Proc. Natl. Acad. Sci. USA. 2005;102:7794–7799. doi: 10.1073/pnas.0407994102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Newman MEJ. Finding community structure in networks using the eigenvectors of matrices. Phys. Rev. E. 2006;74:036104. doi: 10.1103/PhysRevE.74.036104. [DOI] [PubMed] [Google Scholar]
- 8.Lancichinetti A, Radicchi F, Ramasco JJ. Statistical significance of communities in networks. Phys. Rev. E. 2010;81:046110. doi: 10.1103/PhysRevE.81.046110. [DOI] [PubMed] [Google Scholar]
- 9.Lancichinetti A, Radicchi F, Ramasco JJ, Fortunato S. Finding statistically significant communities in networks. PLOS ONE. 2011;6:e18961. doi: 10.1371/journal.pone.0018961. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Spirin V, Mirny LA. Protein complexes and functional modules in molecular networks. Proc. Natl. Acad. Sci. USA. 2003;100:12123–12128. doi: 10.1073/pnas.2032324100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Wang, B. et al. Spatial scan statistics for graph clustering. In Proc. 2008 SIAM Int. Conf. Data Mining, 727–738 (SIAM, Philadelphia, 2008).
- 12.Zhao Y, Levina E, Zhu J. Community extraction for social networks. Proc. Natl. Acad. Sci. USA. 2011;108:7321–7326. doi: 10.1073/pnas.1006642108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Leskovec, J., Lang, K. J. & Mahoney, M. W. Empirical comparison of algorithms for network community detection. In Proc. 19th Int. Conf. World Wide Web, 631–640 (ACM, New York, 2010).
- 14.Yang J, Leskovec J. Defining and evaluating network communities based on ground-truth. Know. Inf. Syst. 2015;42:181–213. doi: 10.1007/s10115-013-0693-z. [DOI] [Google Scholar]
- 15.Lancichinetti A, Fortunato S, Radicchi F. Benchmark graphs for testing community detection algorithms. Phys. Rev. E. 2008;78:046110. doi: 10.1103/PhysRevE.78.046110. [DOI] [PubMed] [Google Scholar]
- 16.Wand MP, Jones MC. Comparison of smoothing parameterizations in bivariate kernel density estimation. J. Am. Stat. Assoc. 1993;88:520–528. doi: 10.1080/01621459.1993.10476303. [DOI] [Google Scholar]
- 17.Parzen E. On estimation of a probability density function and mode. Annal. Math. Stat. 1962;33:1065–1076. doi: 10.1214/aoms/1177704472. [DOI] [Google Scholar]
- 18.Park BU, Marron JS. Comparison of data-driven bandwidth selectors. J. Am. Stat. Assoc. 1990;85:66–72. doi: 10.1080/01621459.1990.10475307. [DOI] [Google Scholar]
- 19.Jones MC, Marron JS, Sheather SJ. A brief survey of bandwidth selection for density estimation. J. Am. Stat. Assoc. 1996;91:401–407. doi: 10.1080/01621459.1996.10476701. [DOI] [Google Scholar]
- 20.Scott, D. W. Multivariate density estimation and visualization (Springer, Berlin, 2012).
- 21.Šidák Z. Rectangular confidence regions for the means of multivariate normal distributions. J. Am. Stat. Assoc. 1967;62:626–633. [Google Scholar]
- 22.Miller, J. C. & Hagberg, A. Efficient generation of networks with given expected degrees. In Frieze, A., Horn, P. & Prałat, P. (eds) Algorithms and Models for the Web Graph, vol. 6732 LNCS, 115–126 (Springer Berlin Heidelberg, Berlin, Heidelberg, 2011).
- 23.Staudt CL, Sazonovs A, Meyerhenke H. Networkit: A tool suite for large-scale complex network analysis. Network Science. 2016;4:508–530. doi: 10.1017/nws.2016.20. [DOI] [Google Scholar]
- 24.Hagberg, A. A., Schult, D. A. & Swart, P. J. Exploring network structure, dynamics, and function using networkx. In Varoquaux, G., Vaught, T. & Millman, J. (eds) Proc. 7th Python in Sci. Conf., 11–15 (Pasadena, CA USA, 2008).
- 25.Kunegis, J. Available at, http://konect.uni-koblenz.de [Accessed: 2 Sep 2017].
- 26.Blondel VD, Guillaume J-L, Lambiotte R, Lefebvre E. Fast unfolding of communities in large networks. J. Stat. Mech. 2008;2008:P10008. doi: 10.1088/1742-5468/2008/10/P10008. [DOI] [Google Scholar]
- 27.Karrer B, Newman MEJ. Stochastic blockmodels and community structure in networks. Phys. Rev. E. 2011;83:016107. doi: 10.1103/PhysRevE.83.016107. [DOI] [PubMed] [Google Scholar]
- 28.von Luxburg U. A tutorial on spectral clustering. Stat. Comput. 2007;17:395–416. doi: 10.1007/s11222-007-9033-z. [DOI] [Google Scholar]
- 29.Kernighan BW, Lin S. An efficient heuristic procedure for partitioning graphs. Bell Syst. Tech. J. 1970;49:291–307. doi: 10.1002/j.1538-7305.1970.tb01770.x. [DOI] [Google Scholar]
- 30.Zachary WW. An information flow model for conflict and fission in small groups. J. Anthropol. Res. 1977;33:452–473. doi: 10.1086/jar.33.4.3629752. [DOI] [Google Scholar]
- 31.Lusseau D, et al. The bottlenose dolphin community of doubtful sound features a large proportion of long-lasting associations. Behav. Ecol. Sociobiol. 2003;54:396–405. doi: 10.1007/s00265-003-0651-y. [DOI] [Google Scholar]
- 32.Knuth, D. E. The Stanford GraphBase: A Platform for Combinatorial Computing (ACM Press, New York, 1993).
- 33.Klimt, B. & Yang, Y. The Enron corpus: A new dataset for email classification research. In Proc. 15th European Conf. Machine Learning, 217–226 (Springer, Berlin, 2004).
- 34.Gleiser PM, Danon L. Community structure in jazz. Adv. Comp. Syst. 2003;6:565–573. doi: 10.1142/S0219525903001067. [DOI] [Google Scholar]
- 35.Adamic, L. A. & Glance, N. The political blogosphere and the 2004 u.s. election: divided they blog. In Proc. 3rd Int. Workshop on Link Discovery, 36–43 (ACM, New York, 2005).
- 36.J. Patokallio. Available at, http://openflights.org [Accessed: 24 Sep 2016].
- 37.T. Opsahl. Available at, https://toreopsahl.com/2011/08/12/why-anchorage-is-not-that-important-binary-ties-and-sample-selection [Accessed: 24 Sep 2016].
- 38.Rual J, et al. Towards a proteome-scale map of the human protein-protein interaction network. Nature. 2005;437:1173–1178. doi: 10.1038/nature04209. [DOI] [PubMed] [Google Scholar]
- 39.Ma’ayan, A. Available at, http://research.mssm.edu/maayan/datasets/qualitative_networks.shtml [Accessed: 2 Sep 2017].
- 40.Leskovec J, Kleinberg J, Faloutsos C. Graph evolution: densification and shrinking diameters. ACM Trans. Knowl. Discov. Data. 2007;1:2. doi: 10.1145/1217299.1217301. [DOI] [Google Scholar]
- 41.Chen M, Kuzmin K, Szymanski BK. Community detection via maximization of modularity and its variants. IEEE Trans. Comput. Soc. Syst. 2014;1:46–65. doi: 10.1109/TCSS.2014.2307458. [DOI] [Google Scholar]
- 42.Lambiotte R, Delvenne JC, Barahona M. Random walks, markov processes and the multiscale modular organization of complex networks. IEEE Trans. Netw. Sci. Eng. 2014;1:76–90. doi: 10.1109/TNSE.2015.2391998. [DOI] [Google Scholar]
- 43.Zhang P, Moore C. Scalable detection of statistically significant communities and hierarchies, using message passing for modularity. Proc. Natl. Acad. Sci. USA. 2014;111:18144–18149. doi: 10.1073/pnas.1409770111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Newman MEJ, Leicht EA. Mixture models and exploratory analysis in networks. Proc. Natl. Acad. Sci. USA. 2007;104:9564–9569. doi: 10.1073/pnas.0610537104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Borgatti SP, Everett MG. Models of core/periphery structures. Soc. Netw. 2000;21:375–395. doi: 10.1016/S0378-8733(99)00019-2. [DOI] [Google Scholar]
- 46.Rombach MP, Porter MA, Fowler JH, Mucha PJ. Core-periphery structure in networks (revisited) SIAM Rev. 2017;59:619–646. doi: 10.1137/17M1130046. [DOI] [Google Scholar]
- 47.Kojaku, S. & Masuda, N. Core-periphery structure requires something else in the network. New J. Phys.20, 043012 (2018).
- 48.Gfeller D, Chappelier JC, De Los Rios P. Finding instabilities in the community structure of complex networks. Phys. Rev. E. 2005;72:056135. doi: 10.1103/PhysRevE.72.056135. [DOI] [PubMed] [Google Scholar]
- 49.Karrer B, Levina E, Newman MEJ. Robustness of community structure in networks. Phys. Rev. E. 2008;77:046119. doi: 10.1103/PhysRevE.77.046119. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.