

Abstract
In order to successfully interact with objects, we must maintain stable representations of their locations in the world. However, their images on our retina may be displaced several times per second by large, rapid eye movements. A number of studies have demonstrated that visual processing is heavily influenced by gaze-centered (retinotopic) information, including a recent finding that memory for an object’s location is more accurate and precise in gaze-centered (retinotopic) than world-centered (spatiotopic) coordinates (Golomb & Kanwisher, 2012b). This effect is somewhat surprising, given our intuition that behavior is successfully guided by spatiotopic representations. In the present experiment, we asked whether the visual system may rely on a more spatiotopic memory store depending on the mode of responding. Specifically, we tested whether reaching toward and tapping directly on an object’s location could improve memory for its spatiotopic location. Participants performed a spatial working memory task under four conditions: retinotopic vs. spatiotopic task, and computer mouse click vs. touchscreen reaching response. When participants responded by clicking with a mouse on the screen, we replicated Golomb & Kanwisher’s original results, finding that memory was more accurate in retinotopic than spatiotopic coordinates, and that the accuracy of spatiotopic memory deteriorated substantially more than retinotopic memory with additional eye movements during the memory delay. Critically, we found the same pattern of results when participants responded by using their finger to reach and tap the remembered location on the monitor. These results further support the hypothesis that spatial memory is natively retinotopic; we found no evidence that engaging the motor system improves spatiotopic memory across saccades.
Introduction
The input to our visual system shifts dramatically as we make eye movements several times per second, yet we are able to successfully act on the objects we encounter in the world. It seems intuitive that we must create a stable representation of their locations, especially in domains such as memory when the object of interest is not constantly visible in the scene. One way our visual system might accomplish this is by immediately transforming remembered locations from gaze-centered (retinotopic) coordinates into gaze-independent (spatiotopic) coordinates so that the remembered location would be relatively unperturbed by the large number of eye movements we make. Alternatively, our visual system may store remembered locations in retinotopic coordinates and dynamically update them after each eye movement.
A number of studies have examined retinotopic vs spatiotopic processing across a variety of domains (Afraz & Cavanagh, 2009; Golomb, Chun, & Mazer, 2008; Golomb & Kanwisher, 2012b; Hayhoe, Lachter, & Feldman, 1991; Irwin, 1991; Knapen, Rolfs, Wexler, & Cavanagh, 2010; Melcher, 2007; Melcher & Morrone, 2003; Ong, Hooshvar, Zhang, & Bisley, 2009; Pertzov, Zohary, & Avidan, 2010; Prime, Vesia, & Crawford, 2011; Rolfs, Jonikaitis, Deubel, & Cavanagh, 2011). In spatial memory, Golomb & Kanwisher (2012b) tested the two alternatives described above. They found that human participants were better able to remember retinotopic locations than spatiotopic locations across saccades, and that there was a greater accumulation of error across saccades when remembering spatiotopic than retinotopic locations. This is consistent with storage of the location in a retinotopic format, with imperfect updating of the location with each saccade (retinotopic-plus-updating account).
However, the fact that spatial memory was better in retinotopic than spatiotopic coordinates is somewhat unintuitive, since spatiotopic coordinates seem more ecologically relevant and useful for human behavior. Why, then, would memory be better preserved in retinotopic coordinates? One possibility is that this finding is a byproduct of the spatial organization of the visual system, which has been shown to be coded in primarily retinotopic coordinates (Cohen & Andersen, 2002; Gardner, Merriam, Movshon, & Heeger, 2008; Golomb & Kanwisher, 2012a; Medendorp, Goltz, Vilis, & Crawford, 2003). However, another possibility is that the retinotopic advantage in the Golomb and Kanwisher memory task was due to the method of reporting responses (mouse click), whereas a task that engages more action-based processes (e.g., reaching) might better engage the spatiotopic memory system.
Visual stability is important both for perceiving the world and for effectively acting within it. It is possible that spatial locations are represented differently when observers intend to act on them compared to when they do not. For example, in the case of peri-saccadic mislocalization, observers commonly misperceive the location of a briefly presented stimulus around the time of a saccade (Matin & Pearce, 1965), yet they are still able to accurately point at the location (Burr, Morrone, & Ross, 2001). An intriguing theory in the visual working memory literature is that the visual system is able to flexibly make use of different memory stores according to task demands (Serences, 2016). Here we test the possibility that the spatial memory task in Golomb & Kanwisher (2012b) might similarly rely on different memory stores depending on task demands; specifically, that the original task may have implicitly encouraged the use of a retinotopic memory store, whereas a task better optimized to engage the motor system might rely on a more spatiotopic memory store.
In Golomb & Kanwisher’s (2012b) experiment, participants used a mouse to place a cursor over the location where they remembered seeing the object and clicked the mouse when the cursor was in the correct position. Participants were able to adjust the mouse and move the cursor around until they found something that looked right, and it is possible that the opportunity to make use of these fine visual discriminations preferentially recruited more low-level sensory processes. The low-level nature of the task may have made it more likely to reflect retinotopic processing, since it is well-established that early visual areas have retinotopic representations(Gardner et al., 2008; Golomb & Kanwisher, 2012a).
Moreover, the use of the mouse report and fine visual discriminations could have encouraged a reliance on more perceptual rather than motor processes. From an intuitive standpoint, we might see how retinotopic (eye-centered) coordinates could dominate in the perceptual domain, but spatiotopic (e.g., head-centered, body-centered, world-centered) coordinates certainly seem more relevant for executing motor actions in the world. More generally, there may be differences between tasks that engage vision-for-perception versus vision-for-action. A classic neural dissociation is that the ventral visual stream is responsible for vision for perception, while the dorsal visual stream is responsible for vision-for-action (Goodale et al., 1994; Goodale, Milner, Jakobson, & Carey, 1991; Goodale & Milner, 1992; James, Culham, Humphrey, Milner, & Goodale, 2003; Newcombe, Ratcliff, & Damasio, 1987); patients with damage to one visual stream or the other can exhibit strikingly different visual processing abilities. There has been debate over the extent to which other aspects of visual processing may or may not be altered depending on whether participants directly interact with a target. For example, there have been reports of visual illusions affecting perception but not action (e.g., Aglioti, DeSouza, & Goodale, 1995; Gentilucci, Chieffi, Daprati, Saetti, & Toni, 1996), though these have been subsequently challenged (e.g., Franz, Gegenfurtner, Bulthoff, & Fahle, 2000). Similarly, there is also debate (Firestone 2013) over a group of studies claiming that perception is affected by actions that the observer intends to perform (e.g., Witt, 2011; Witt, Proffitt, & Epstein, 2005).
In the current experiment, we adopt a new task intended to manipulate task demands and better engage the motor system to encourage a more spatiotopic spatial memory store. Specifically, we have participants interact directly with the remembered location by reaching out and touching the location on the screen. Reaching is a simple, naturalistic movement that is commonly used in tasks of visually-guided action (Bruno, Bernardis, & Gentilucci, 2008; Cohen & Andersen, 2002; Cressman, Franks, Enns, & Chua, 2007; Culham, Gallivan, Cavina-pratesi, & Quinlan, 2008; Gallivan, Cavina-Pratesi, & Culham, 2009; Song & Nakayama, 2009), and is known to activate parietal, dorsal-stream brain regions (Andersen, Andersen, Hwang, & Hauschild, 2014; Cohen & Andersen, 2002; Johnson et al., 1996; Kertzman, Schwarz, Zeffiro, & Hallett, 1997; Snyder, Batista, & Andersen, 1997). We reasoned that while both the mouse and reaching tasks involve motor processes, the reaching task should more strongly engage the motor system, especially in this task.
In addition, there is another reason we might predict the reaching task would engage more spatiotopic motor processing. In Golomb & Kanwisher’s (2012b) task, the mouse movement was always initiated from the final fixation location, which was not known at the time of encoding; thus this task might have implicitly encouraged a retinotopic (fixation-relative) memory store, because the spatiotopic motor plan could not be stored in advance. In the new reaching task, subjects execute a reaching movement from a known start position on every trial (finger resting on spacebar), which could allow for the spatiotopic motor plan to be formed and preserved at the time of encoding. If what is remembered across the delay is the motor plan and not the visual representation – or if the visual representation is influenced by the intention to act – then we might expect stronger spatiotopic task performance in the reaching task because the spatiotopic motor plan may not have to be updated with each eye movement.
Motor and reaching plans are thought to be encoded in parietal and frontal areas, and the evidence for different reference frame representations in these areas is mixed. Some findings advocate for head-centered (e.g. Duhamel, Bremmer, BenHamed, & Graf, 1997), hand-centered (e.g. Graziano, Yap, & Gross, 1994), or hybrid (e.g. Mullette-Gillman, Cohen, & Groh, 2009) reference frame representations in these areas, supporting the idea that that parietal cortex encodes movement in multiple coordinate systems depending on the task (Colby, 1998; Graziano, 2001; Mullette-Gillman et al., 2009; Pertzov, Avidan, & Zohary, 2011). However, other reports have found primarily eye-centered representations (Batista, Buneo, Snyder, & Andersen, 1999; Medendorp et al., 2003), arguing for a common eye-centered reference frame for movement plans (Cohen & Andersen, 2002). Behavioral studies of reaching have also found mixed evidence for hand-centered versus eye-centered representations (Graziano, 2001; Henriques, Klier, Smith, Lowy, & Crawford, 1998; Pouget, Ducom, Torri, & Bavelier, 2002; Soechting & Flanders, 1989; Thomas, 2017; Tipper, Howard, & Houghton, 1998; Tipper, Lortie, & Baylis, 1992), although none have directly tested accuracy as we do here, comparing an eye-centered task to a world-, head-, or body-centered task (here all grouped together as “spatiotopic”).
In the present experiment, we tested whether the benefit for retinotopic vs spatiotopic memory found by Golomb & Kanwisher (2012b) was modulated or reversed when participants directly interacted with remembered locations. To do this, we tested participants’ memory for retinotopic vs. spatiotopic locations across a variable number of saccades (0 to 2), for two response types: reaching to tap the remembered locations on a touchscreen vs. using a mouse to click on the screen location. We predicted that if the intention to act on a remembered location influenced the native reference frame used to store memories for spatial locations, both the overall lower performance and the larger accumulation of errors in the spatiotopic task would be modulated or reversed.
Methods
Participants
Twelve participants were included in the study, which consisted of four sessions each. One additional participant was run but did not meet our predetermined accuracy requirement (see below), so was not included in data analyses. All subjects reported normal or corrected-to-normal vision and gave informed consent, and study protocols were approved by the Ohio State University Behavioral and Social Sciences Institutional Review Board. Participants were compensated with payment.
Experimental setup and stimuli
Participants were seated with their chin in a chinrest, with their eyes approximately 29cm away from a touchscreen monitor. Screen resolution was 1280 × 1024. The screen was cleaned before each session and calibrated before each touchscreen response session. An Eyelink tower-mount eye-tracking camera was mounted above the chinrest, allowing eye-tracking data to be collected throughout each session without occlusion of the camera due to reaching movements. The room was darkened aside from the stimulus computer, and an opaque mask with a circular aperture was placed over the screen to minimize strategic use of the corners or edges of the screen as screen-centered landmarks.
There were four possible fixation locations (upper left, upper right, lower left, lower right; forming the corners of an invisible square 11 degrees VA in width, centered with respect to the screen). Memory cues indicating locations to be remembered were black-outlined squares sized 0.8 × 0.8 degrees VA. The memory cue location on each trial was a randomly chosen location within the central portion of the screen (in an invisible square measuring 5.2 × 5.2 degrees VA between the possible fixation locations). This was done so that, on average, correct answers were an equal distance from the final fixation in the retinotopic and spatiotopic tasks (see Figures 1b, 3).
Figure 1.
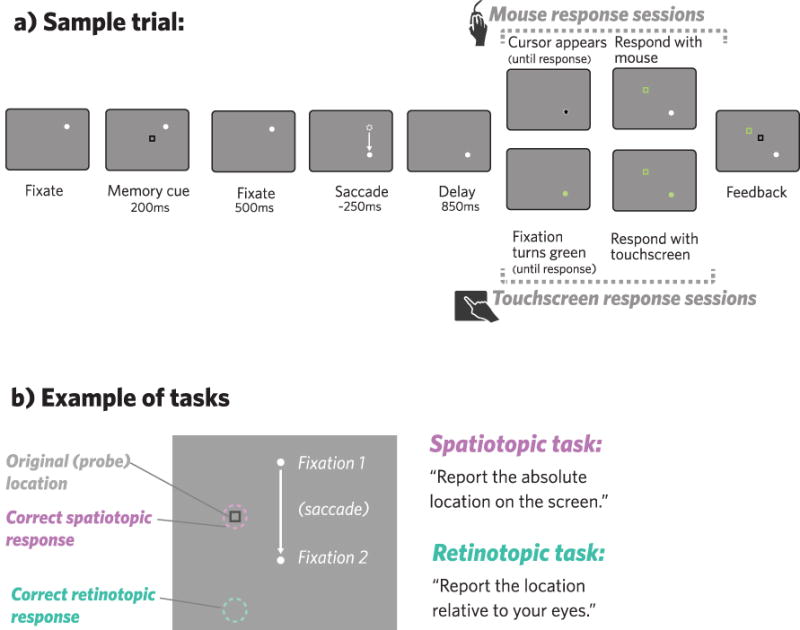
a) Each trial began with a white fixation dot; participants were instructed to keep their eyes on the white dot whenever it was on the screen. After participants were fixating, a black square (memory cue) appeared on the screen for participants to remember the location of, either in retinotopic coordinates or spatiotopic coordinates, depending on the session. After the cue disappeared, participants fixated for another 500 seconds. Depending on the saccade condition, the fixation point moved to a new location between 0–2 times, waiting until the eye-tracker had picked up the participants’ correct fixation before moving to the next location. After an 850ms delay at the final fixation location, participants were signaled to respond, either by a cursor that appeared at the fixation (mouse response sessions), or by a color change in the fixation dot (touchscreen response sessions). After participants responded, a square appeared at their responded location (green), followed by another at the correct location (black) to give participants feedback. b) Examples of correct responses in the spatiotopic task (pink) and the retinotopic task (green).
Figure 3.
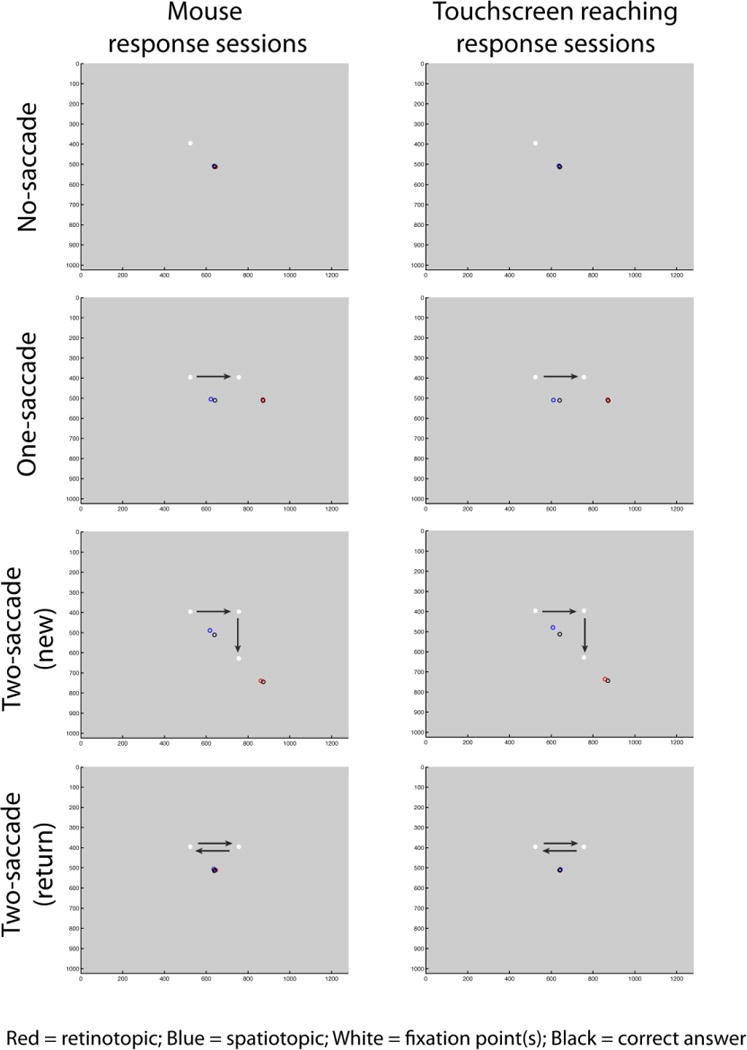
Average response locations (aligned across fixations) plotted by saccade condition (rows), memory task (retinotopic vs. spatiotopic sessions; indicated by red and blue circles), and response type (mouse vs. touchscreen response sessions; columns). All trials of a given condition were aligned to the example fixation locations and saccade directions shown. We collapsed across horizontal and vertical 1-saccade conditions in this plot and in our main analyses. Arrows indicate saccade direction and were not actually presented on the screen.
Experimental procedures
Each participant completed four sessions: spatiotopic memory task - mouse response; spatiotopic memory task - touchscreen response; retinotopic memory task - mouse response; retinotopic memory task - touchscreen response. Each session was performed on a different day; participants always did the two mouse sessions followed by the two touchscreen sessions, or vice versa. Aside from that constraint, the order of the sessions was fully counterbalanced across participants. In each session, participants were instructed to keep their eyes on a white fixation dot while remembering the location of a square that appeared on the screen, either its absolute location on the screen (spatiotopic memory task) or its location with respect to where they were looking (retinotopic memory task). Before beginning the second session (always a different memory task than the first), participants were asked to predict which memory task would be harder.
Each trial (Fig 1a) began when the white fixation dot appeared at one of the four possible fixation locations. Once participants were fixating (verified by the eye-tracker), the memory cue (black square) appeared for 200ms, followed by a fixation-only delay for 500ms. Next, participants were cued to make a variable number of saccades. The different saccade conditions were: 0 saccades, 1 horizontal saccade, 1 vertical saccade, 2 saccades (horizontal and vertical), or 2 saccades “return” (saccading away and then returning to the original fixation; this final condition was included mainly as a control for secondary analyses, since retinotopic and spatiotopic coordinates reconverged here). Each saccade condition was equally likely and counterbalanced across trials. Within these saccade conditions, fixation location and saccade direction(s) were also equally likely and randomized across trials. To cue each saccade, the fixation dot disappeared from its current location and immediately re-appeared in one of the other possible fixation locations on the screen; participants were instructed to move their eyes to the new fixation location as quickly as possible. After the saccade was completed (verified by the eye-tracker), there was a post-saccade delay of 850 ms, and then participants were cued to either make a second saccade (if the fixation dot moved elsewhere), or report the remembered location (cued as described below). In 0-saccade trials the fixation dot never moved, and the memory cue appeared after the initial delay. In mouse response sessions, the memory report cue was a cursor that appeared at the current fixation location, and participants dragged it to the remembered location and clicked on their final response. In touchscreen response sessions, the fixation dot turned green, signaling participants that they could lift their right finger off the keyboard and tap the remembered location on the touchscreen. In both response conditions, participants were required to continue fixating while they responded. To provide feedback in all sessions, a green square appeared at the location of the participants’ response, and a black square (identical to the original square) indicated the correct response. To prevent subjects from responding too early or “cheating”, the mouse cursor remained hidden until the memory report cue in mouse response sessions, and participants needed to keep their finger depressed on the spacebar until the memory report cue in touchscreen response sessions.
Participants completed 6 runs of the task in each session. Each run consisted of 40 trials1 (8 per each of the 5 saccade conditions), for a total of 48 trials per condition. Throughout each trial, gaze position was tracked, and trials were aborted and repeated later in a run if participants’ eyes deviated more than 2 degrees visual angle for more than 20ms. Before the first two sessions (the first retinotopic session and the first spatiotopic session), participants completed a sequence of 4 practice runs. The first practice run consisted of 4 no-saccade trials, the second consisted of 4 one-saccade trials, and the third consisted of 4 two-saccade trials. The 4th practice run consisted of 8 total trials, with saccade conditions intermixed as in the main experiment. The experimenter was available for questions during this time, and participants had the option to repeat the practice before moving on to the main task, or again before the 3rd and 4th sessions if they felt they needed to.
Analyses
As in Golomb & Kanwisher (2012b), we planned to discard trials with errors larger than 5.5 degrees visual angle, which corresponded to a response in the wrong quadrant of the screen. We also planned to discard a participant’s data if any of their sessions had 10% or more of trials cut, replacing them with another participant with the same counterbalance order. A total of one participant was excluded for poor performance (two sessions with >10% large errors each) and replaced, and an average of 0.7% of trials for the remaining participants were discarded.
We calculated memory accuracy on each trial as the absolute value of the difference (distance, in degrees visual angle) between the reported position and the correct position. This “error” measure was averaged across trials for each condition, task, and subject, and statistical analyses were conducted using repeated-measures ANOVAs. Effect size was reported using partial eta-squared (np2).
Results
Saccade direction
We first verified that there were no differences between the vertical and horizontal one-saccade conditions, so that we could collapse across saccade direction to examine accumulation of error across number of saccades (per Golomb & Kanwisher 2012b). Using a three-way ANOVA with saccade direction (horizontal vs vertical one-saccade conditions), memory task (retinotopic vs. spatiotopic), and response type (mouse vs. touchscreen), we found no significant main effects or interactions involving saccade direction (all p’s > 0.57 and F’s < 0.33). The analyses that follow thus collapse across saccade direction (a break-down of results by saccade direction can be found in the supplement).
Retinotopic vs spatiotopic accumulation of error across saccades
Figure 2 shows the average error of the spatial memory report for the retinotopic and spatiotopic tasks as a function of number of saccades, for the mouse and touchscreen-reaching responses. For each response modality, we performed a 2-way repeated measures ANOVA with within-participant factors of number of saccades (0–2; collapsed across vertical and horizontal 1-saccade conditions and excluding 2-saccade return condition) and memory task (retinotopic vs. spatiotopic). Note that we did not include the 2-saccade return condition in this primary analysis, since the retinotopic and spatiotopic coordinates re-converged in this condition.
Figure 2.
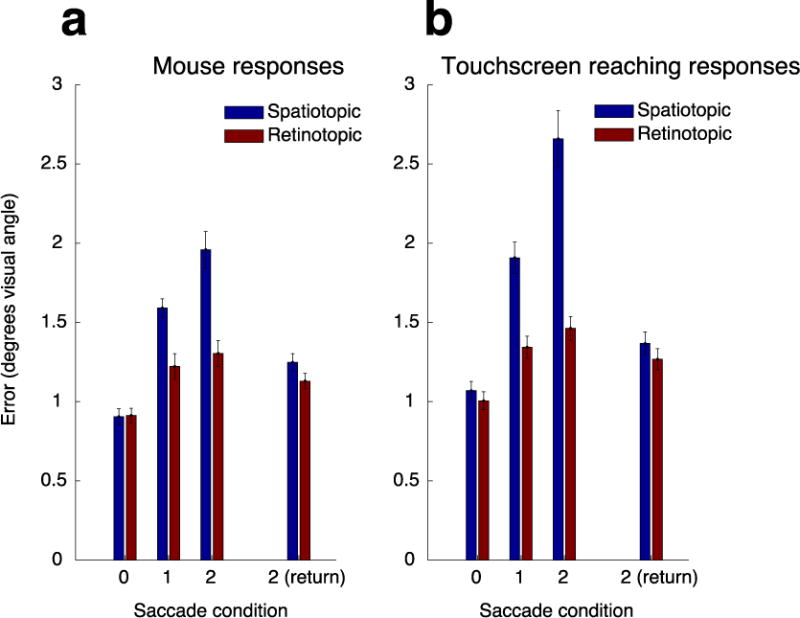
Error distances plotted by saccade condition, memory task (retinotopic vs. spatiotopic sessions), and response type (mouse response sessions in subpanel a vs. touchscreen response sessions in subpanel b). We collapsed across horizontal and vertical 1-saccade conditions in this plot and in our main analyses. Error bars are across-subject s.e.m.
Our mouse response results replicate Golomb & Kanwisher’s (2012b) findings. First, we found a main effect of number of saccades (F(1.27,13.92) = 94.98, p < 0.001, Greenhouse-Geisser-corrected, np2 = .90), indicating an increase in error with more saccades and/or increasing memory delay. Importantly, we found larger overall error in the spatiotopic condition than the retinotopic condition (main effect of memory task: F(1,11) = 17.07, p = 0.002, np2 = 0.608), as well as a greater accumulation of error in the spatiotopic compared to the retinotopic condition as number of saccades increased (task × number of saccades interaction: F(1.27,13.98) = 16.46, p = 0.001, Greenhouse-Geisser-corrected, np2 = .60).
Do we find the same pattern of memory errors when participants must directly reach toward the remembered location during report? In the touchscreen-reach task we again found a main effect of saccade number (F(1.02,11.24) = 104.69, p < 0.001, Greenhouse-Geisser-corrected, np2 = .91). Critically, we also still found greater spatiotopic error and steeper accumulation of spatiotopic error in the touchscreen task (main effect of memory task: F(1,11) = 46.00, p < 0.001, np2 = 0.81; Task × Number of Saccades interaction: F(1.24,13.66) = 38.32, p < 0.001, Greenhouse-Geisser-corrected, np2 = 0.78). Thus both for mouse and reaching responses, not only is retinotopic spatial memory better than spatiotopic spatial memory, but the errors in the spatiotopic task accumulate more with each additional saccade during the memory delay.
To investigate whether there were any differences between the response modalities in terms of these effects, we performed a 3-way repeated measures ANOVA with within-participant factors of number of saccades (0–2), memory task (retinotopic vs. spatiotopic), and response type (mouse vs. touchscreen). Contrary to our predictions, neither the worse overall performance in the spatiotopic task nor the larger spatiotopic accumulation of error was decreased in the touchscreen condition. Instead, these effects were significantly amplified (memory task by response type interaction: F(1,11) = 10.65, p = 0.008, np2 = 0.49; three-way interaction: F(1.30,14.29) = 8.48, p = 0.008, Greenhouse-Geisser-corrected, np2 = .44), indicating an even greater benefit for retinotopic memory in the reaching task.
We also found a main effect of response type (F(1,11) = 26.90, p < 0.0001, np2 = .71), with the magnitude of errors being overall larger for touchscreen responses than mouse responses. This effect is not particularly surprising, both because tapping the screen with a finger is inherently less precise than clicking with a small cursor and because the mouse response condition offered more opportunities for participants to visually fine-tune their responses. Importantly, this difference in overall accuracy cannot explain our key finding that in both tasks, memory for retinotopic locations across saccades is more precise (and accumulates less) than spatiotopic locations.
2-Saccade (Return) Condition
In the main analyses above, we compared the 0, 1, and 2-saccade (new) conditions and found that error accumulated with increasing number of saccades for all tasks, with the key finding being a greater accumulation of error for the spatiotopic tasks. What is the cause of this accumulation, and why would it be greater for spatiotopic? Memory error could have accumulated from 0 to 2 saccades due to an increase in memory delay duration, an increase in number of saccades executed during the delay, or a saccade-related memory updating process. The fact that spatiotopic and retinotopic tasks were matched for memory delays and number of saccades executed argues against these being critical factors in the steeper spatiotopic accumulation. The main difference between the tasks thus appears to lie in how spatial memory is updated across saccades; updating (remapping) appeared to occur with each additional saccade for the spatiotopic task but not the retinotopic task (as in Golomb & Kanwisher, 2012b). As a further test of this cumulative updating explanation, we performed a secondary analysis comparing trials that all had the same number of saccades (two) but ended either at a new fixation that had not been visited yet on that trial (2-saccade new condition) or returned to the original fixation (2-saccade return condition). As shown in Figure 2, only in the 2-saccade new condition did spatiotopic memory deteriorate; when the second saccade returned the eyes back to the original location, there was no need for the updated representation, and spatiotopic task accuracy was improved to retinotopic levels. This memory task by 2-saccade type interaction was significant (F(1,11) = 25.8, p < 0.001; np2 = 0.70). Consistent with the main findings above, we also found a significant three-way interaction here (F(1,11) = 11.68; p = .006; np2 = .52), showing that this pattern was similar but amplified for the touchscreen condition.
Response bias
Finally, to investigate whether participants’ responses were systematically biased relative to the true location, we plotted the average reported locations aligned to saccade direction (Figure 3) and found similar patterns to those in Golomb & Kanwisher (2012b). For the no-saccade condition and the two-saccade (return) condition, there did not appear to be a bias. For the one-saccade and two-saccade (new) conditions, subjects tended to report locations as closer to the initial fixation (i.e., foveal bias, Sheth & Shimojo, 2001) and/or over-estimated relative to the final fixation (Bock, 1986; Henriques et al., 1998). Critically, the bias was larger in magnitude for the spatiotopic than the retinotopic task, and for 2-saccade-new than 1-saccade condition, similar to the overall accuracy pattern. In other words, as the number of saccades increased in the spatiotopic task, participants responded with decreased accuracy and increased bias. As above, the pattern was similar but amplified in the touchscreen version.
Discussion
Our goal in this experiment was to investigate the underlying mechanisms of visuospatial memory—specifically, what is the native reference frame of spatial representations that are used to act on remembered locations? We hypothesized that the intention to act on a location in the world might influence the reference frame for spatial working memory. Specifically, we predicted that if the visual system is able to flexibly make use of different memory stores according to task demands (Serences, 2016), then a task relying more on vision-for-action might better engage a spatiotopic (world- or body-centered) memory store, whereas a task emphasizing vision-for-perception might rely more on a retinotopic (eye-centered) memory store (Burr et al., 2001). In this study, we replicated a recent study by Golomb & Kanwisher (2012b) which found a benefit for remembering locations in retinotopic rather than spatiotopic coordinates using a computer mouse to report responses, and we compared this to another condition in which participants responded by reaching out and tapping a touchscreen to report the remembered location.
We predicted that reaching to tap directly on a location using a finger might increase reliance on spatiotopic systems, causing a modulation or reversal of Golomb & Kanwisher’s original pattern. Instead we found the same pattern of retinotopic dominance for both response modalities, suggesting that spatial memory is encoded in retinotopic coordinates and imperfectly updated with each eye movement – even during a reaching task – a surprising finding in light of our subjective experience that we are able to effectively remember and act on locations in real-world (spatiotopic) coordinates.
Our data suggest that not only is retinotopic spatial memory better than spatiotopic spatial memory, but the errors in the spatiotopic task accumulate more with each additional saccade during the memory delay. There was a slight accumulation of retinotopic error as well, likely due to generic effects such as increased memory delay and/or the execution of saccades themselves; what is interesting is that error accumulated far more in the spatiotopic task, and it did so for both mouse responses and reaching. This selective accumulation of spatiotopic error above and beyond that seen for the retinotopic condition – combined with the fact that the differential accumulation was found for the two-saccade-new but not two-saccade-return condition – suggests that the most challenging aspect of maintaining a spatial location in memory may be the demands associated with updating (remapping) its spatiotopic position.
It is particularly interesting, then, that we found this pattern of noisier and faster-deteriorating representations in the spatiotopic reaching sessions, given that it was actually possible to encode the spatiotopic motor plan at the beginning of the trial and theoretically maintain this gaze-independent motor plan across the delay. This suggests that participants were either still relying on the natively retinotopic visual representations to perform the task, or perhaps even that the reaching motor plans themselves are natively retinotopic as well. This could be consistent with reports of eye-centered coding of reaching in parietal cortex (Batista et al., 1999; Cohen & Andersen, 2002), as well as behavioral data patterns suggesting eye-centered reaching (Henriques et al., 1998), even for non-visual cues (Pouget et al., 2002), though other studies have reported both neural and behavioral evidence for gaze-independent representations for reaching (Colby, 1998; Graziano, 2001; Soechting & Flanders, 1989; Tipper et al., 1992). Here our spatiotopic task could have been based on any non-gaze-centered coordinate system (world-centered, head-centered, hand-centered, etc), but we found no evidence spatial memory was encoded better in any of these coordinates compared to the eye-centered (retinotopic) task, even in the visually-guided reaching task.
In fact, rather than being reduced, the patterns of larger spatiotopic errors and larger spatiotopic accumulation of errors were both amplified when participants responded with a touchscreen compared to a mouse. One potential explanation for this amplification of error is that an additional transformation may be involved in the spatiotopic reaching task. For example, it is possible that, in addition to the location being transformed from retinotopic to spatiotopic coordinates with each eye movement, it must also be transformed to hand-centered coordinates, resulting in an additional accumulation of error (Andersen, Snyder, Li, & Stricanne, 1993; Pouget et al., 2002). Another possibility is that the updating process and/or the memory representations themselves are noisier for the touchscreen-reaching than mouse-based task. This would be consistent with the main effect of modality that we also found, with touchscreen responses overall less accurate than mouse responses. While this main effect may not be surprising given the differences between the tasks (e.g. mouse task allowing more opportunity to visually fine-tune responses), it is important to emphasize that these differences cannot account for the primary retinotopic vs spatiotopic results. In other words, it is possible that providing participants the opportunity to fine-tune their touchscreen responses (e.g., by placing a marker on the screen before the final response) could conceivably eliminate the main effect of response modality and/or the 3-way interaction, but we would not expect it to eliminate the significant retinotopic vs spatiotopic difference or reference frame by saccade number interaction within each modality.
Our lack of evidence for more efficiently updated spatiotopic representations when reaching invites the question of how memory for objects’ locations is represented in a format conducive to acting on those objects in our environments. Representing both visual locations and motor plans in the same reference frame could be one way to facilitate effective acting on objects in the world (Cohen & Andersen, 2002), and retinotopic representations may simply be more computationally efficient as a common reference frame. It is possible that we tolerate a bit of error in these representations at the cost of neural efficiency, especially given that during real-world processing, a number of external factors can allow us to compensate for this imperfect updating system. For example, it has been shown that when a target is re-displayed after the saccade (Deubel, Bridgeman, & Schneider, 1998; Vaziri, 2006), or when stable visual landmarks are present (Deubel, 2004; Lin & Gorea, 2011; McConkie & Currie, 1996), visual stability is much improved. Visual stability may also benefit from top-down factors and expectations(Rao, Abzug, & Sommer, 2016), indicating that the visual system might not need to solely rely on updating (Churan, Guitton, & Pack, 2011), instead deriving benefits from the largely stable visual information present in our everyday environments. In the current task we intentionally employed an impoverished visual display devoid of external landmarks, precisely because we wanted to test the native reference frame of spatial memory representations in the absence of such facilitating cues. Thus while the current results offer new insight into the underlying mechanisms of spatial memory representations, this does not necessarily mean that “spatiotopic” memory would be worse in real-world scenarios filled with rich, spatiotopically-stable landmarks. Rather, our results suggest that these landmarks and external visual cues may be even more important for visual – and motor – stability than previously realized.
These findings may also have implications for the debate over the extent of processing differences between the dorsal and ventral visual streams (Franz et al., 2000; Goodale et al., 1994, 1991; Goodale & Milner, 1992; James et al., 2003; Newcombe et al., 1987), as well as the extent to which vision-for-perception is separate from vision-for-action (Aglioti et al., 1995; Franz et al., 2000; Gentilucci et al., 1996). The finding of a similar pattern in our two tasks could reflect similar spatial processing in the dorsal and ventral streams—perhaps the idea of flexible memory stores (Serences, 2016) does not apply here, or even if participants were able to make use of multiple memory stores in the task, it appears that neither was very efficiently updated to spatiotopic coordinates. This is consistent with reports of retinotopic representations of spatial location throughout visual areas, including higher-level dorsal and ventral stream areas (Gardner et al., 2008; Golomb & Kanwisher, 2012a; but see Crespi et al., 2011; d’Avossa et al., 2007; McKyton & Zohary, 2007). Of course, it is also possible that there may be different processing involved in vision-for-perception versus vision-for-action, but both our mouse clicking and touchscreen reaching tasks engaged both systems. Even if this were the case, it is still notable that even the naturalistic and well-studied reaching action did not engage more efficiently updated world-centered representations.
That said, while we found no evidence here for a more efficiently spatiotopic representation for the reaching task, it is possible that other types of actions may be more conducive to finding spatiotopic representations. For example, it has been suggested that visibility of the hand during reaching, as in our experiment, may be preferable for preserving eye-centered coordinates (Batista et al., 1999). Different types of actions (e.g., eye movements vs. reaching movements) may also engage different visual processes (Lisi & Cavanagh, 2015, 2017). Indeed, there is evidence that when participants intend to make an eye movement to a location, there is some involvement of a gaze-independent coordinate system (Karn, Møller, & Hayhoe, 1997), though it is possible that this difference stems from the larger number of intervening eye movements (Sun & Goldberg, 2016). Future studies could investigate these possibilities further.
In conclusion, our results provide further evidence that visual memory for locations is maintained in retinotopic coordinates and imperfectly updated to spatiotopic coordinates with each saccade. In addition to replicating Golomb & Kanwisher’s original (2012b) findings that memory for retinotopic locations is more accurate than memory for spatiotopic locations, critically, we found no evidence that acting directly on a location via reaching and tapping led to more accurate updating, or to the storage of locations in a natively spatiotopic format. Our results may reflect (1) a visual system that is overwhelmingly coded in retinotopic coordinates, both in the dorsal and ventral streams, for perception, action, and memory, and/or (2) flexible recruitment of memory store(s) that turn out to be preferentially retinotopic across different task demands. More broadly, these results fit into a literature supporting the idea of natively retinotopic representations that must be dynamically updated (Cohen & Andersen, 2002; Duhamel, Colby, & Goldberg, 1992; Golomb et al., 2008; Golomb & Kanwisher, 2012a) – sometimes imperfectly (Golomb & Kanwisher, 2012b) – to form the basis of our ability to perceive and act effectively in the world.
Supplementary Material
Acknowledgments
This work was supported by research grants from the National Institutes of Health (R01-EY025648) and Alfred P. Sloan Foundation (BR-2014-098) to JDG. We thank Nancy Kanwisher, Emma Wu Dowd, and Tim Brady for helpful discussion.
Footnotes
One participant completed one fewer trial in one run.
References
- Afraz A, Cavanagh P. The gender-specific face aftereffect is based in retinotopic not spatiotopic coordinates across several natural image transformations. Journal of Vision. 2009;9:10.1–17. doi: 10.1167/9.10.10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Aglioti S, DeSouza JFX, Goodale MA. Size-contrast illusion deceive the eye but not the hand. Current Biology. 1995;5(6):679–685. doi: 10.1016/s0960-9822(95)00133-3. [DOI] [PubMed] [Google Scholar]
- Andersen RA, Andersen KN, Hwang E, Hauschild M. Optic ataxia: from Balint’s syndrome to the parietal reach region. Neuron. 2014;81(5):967–983. doi: 10.1007/s11103-011-9767-z.Plastid. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Andersen RA, Snyder LH, Li CS, Stricanne B. Coordinate transformations in the representation of spatial information. Current Opinion in Neurobiology. 1993;3(2):171–176. doi: 10.1016/0959-4388(93)90206-E. [DOI] [PubMed] [Google Scholar]
- Batista AP, Buneo Ca, Snyder LH, Andersen Ra. Reach plans in eye-centered coordinates. Science (New York, NY) 1999;285(5425):257–260. doi: 10.1126/science.285.5425.257. [DOI] [PubMed] [Google Scholar]
- Bock O. Contribution of retinal versus extraretinal signals towards visual localization in goal-directed movements. Experimental Brain Research. 1986;64(3):476–82. doi: 10.1007/BF00340484. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/3803485. [DOI] [PubMed] [Google Scholar]
- Bruno N, Bernardis P, Gentilucci M. Visually guided pointing, the Müller-Lyer illusion, and the functional interpretation of the dorsal-ventral split: Conclusions from 33 independent studies. Neuroscience and Biobehavioral Reviews. 2008;32(3):423–437. doi: 10.1016/j.neubiorev.2007.08.006. [DOI] [PubMed] [Google Scholar]
- Burr DC, Morrone MC, Ross J. Separate visual representations for perception and action revealed by saccadic eye movements. Current Biology. 2001;11(10):798–802. doi: 10.1016/S0960-9822(01)00183-X. [DOI] [PubMed] [Google Scholar]
- Churan J, Guitton D, Pack CC. Context dependence of receptive field remapping in superior colliculus. Journal of Neurophysiology. 2011;106:1862–1874. doi: 10.1152/jn.00288.2011. July 2011. [DOI] [PubMed] [Google Scholar]
- Cohen YE, Andersen Ra. A common reference frame for movement plans in the posterior parietal cortex. Nature Reviews Neuroscience. 2002;3(7):553–562. doi: 10.1038/nrn873. [DOI] [PubMed] [Google Scholar]
- Colby CL. Action-oriented spatial reference frames in cortex. Neuron. 1998;20(1):15–24. doi: 10.1016/S0896-6273(00)80429-8. [DOI] [PubMed] [Google Scholar]
- Crespi S, Biagi L, D’Avossa G, Burr DC, Tosetti M, Morrone MC. Spatiotopic coding of BOLD signal in human visual cortex depends on spatial attention. PLoS ONE. 2011;6(7):1–14. doi: 10.1371/journal.pone.0021661. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cressman EK, Franks IM, Enns JT, Chua R. On-line control of pointing is modified by unseen visual shapes. Consciousness and Cognition. 2007;16(2):265–275. doi: 10.1016/j.concog.2006.06.003. [DOI] [PubMed] [Google Scholar]
- Culham JC, Gallivan JP, Cavina-pratesi C, Quinlan DJ. fMRI Investigations of Reaching and Ego Space in Human Superior Parieto-Occipital Cortex. Embodiment, Ego-Space and Action, Embodiment. 2008:247–274. doi: 10.4324/9780203809891. February 2015. [DOI]
- d’Avossa G, Tosetti M, Crespi S, Biagi L, Burr DC, Morrone MC. Spatiotopic selectivity of BOLD responses to visual motion in human area MT. Nature Neuroscience. 2007;10(2):249–255. doi: 10.1038/nn1824. [DOI] [PubMed] [Google Scholar]
- Deubel H. Localization of targets across saccades: Role of landmark objects. Visual Cognition. 2004;11(2–3):173–202. doi: 10.1080/13506280344000284. [DOI] [Google Scholar]
- Deubel H, Bridgeman B, Schneider WX. Immediate post-saccadic information mediates space constancy. Vision Research. 1998;38(20):3147–59. doi: 10.1016/S0042-6989(98)00048-0. [DOI] [PubMed] [Google Scholar]
- Duhamel JR, Bremmer F, BenHamed S, Graf W. Spatial invariance of visual receptive fields in parietal cortex neurons. Nature. 1997;389(6653):845–848. doi: 10.1038/39865. [DOI] [PubMed] [Google Scholar]
- Duhamel JR, Colby CL, Goldberg ME. The updating of the representation of visual space in parietal cortex by intended eye movements. Science. 1992;255(5040):90–92. doi: 10.1126/science.1553535. Retrieved from http://visionlab.harvard.edu/members/Patrick/SpatiotopyRefs/Duhamel1992.pdf. [DOI] [PubMed] [Google Scholar]
- Firestone C. How “Paternalistic” Is Spatial Perception? Why Wearing a Heavy Backpack Doesn’t–and Couldn’t–Make Hills Look Steeper. Perspectives on Psychological Science. 2013;8(4):455–473. doi: 10.1177/1745691613489835. [DOI] [PubMed] [Google Scholar]
- Franz VH, Gegenfurtner K, Bulthoff H, Fahle M. Grasping visual illusions: No evidence for a dissociation between perception and action. Psychological Science. 2000;11(1):20–25. doi: 10.1111/1467-9280.00209. [DOI] [PubMed] [Google Scholar]
- Gallivan JP, Cavina-Pratesi C, Culham JC. Is That within Reach? fMRI Reveals That the Human Superior Parieto-Occipital Cortex Encodes Objects Reachable by the Hand. Journal of Neuroscience. 2009;29(14):4381–4391. doi: 10.1523/JNEUROSCI.0377-09.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gardner JL, Merriam EP, Movshon JA, Heeger DJ. Maps of visual space in human occipital cortex are retinotopic, not spatiotopic. The Journal of Neuroscience. 2008;28(15):3988–3999. doi: 10.1523/JNEUROSCI.5476-07.2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gentilucci M, Chieffi S, Daprati E, Saetti MC, Toni I. Visual illusion and action. Neuropsychologia. 1996;34(5):369–376. doi: 10.1016/0028-3932(95)00128-X. [DOI] [PubMed] [Google Scholar]
- Golomb JD, Chun MM, Mazer Ja. The native coordinate system of spatial attention is retinotopic. The Journal of Neuroscience. 2008;28(42):10654–10662. doi: 10.1523/JNEUROSCI.2525-08.2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Golomb JD, Kanwisher N. Higher level visual cortex represents retinotopic, not spatiotopic, object location. Cerebral Cortex. 2012a;22(12):2794–2810. doi: 10.1093/cercor/bhr357. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Golomb JD, Kanwisher N. Retinotopic memory is more precise than spatiotopic memory. Proceedings of the National Academy of Sciences of the United States of America. 2012b;109(5):1796–801. doi: 10.1073/pnas.1113168109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Goodale MA, Meenan JP, Bülthoff HH, Nicolle DA, Murphy KJ, Racicot CI. Separate neural pathways for the visual analysis of object shape in perception and prehension. Current Biology. 1994;4(7):604–610. doi: 10.1016/S0960-9822(00)00132-9. [DOI] [PubMed] [Google Scholar]
- Goodale MA, Milner AD. Separate visual pathways for perception and action. Trends in Neurosciences. 1992;15(1):20–5. doi: 10.1016/0166-2236(92)90344-8. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/1374953. [DOI] [PubMed] [Google Scholar]
- Goodale MA, Milner AD, Jakobson LS, Carey DP. A neurological dissociation between perceiving objects and grasping them. Nature. 1991 doi: 10.1038/349154a0. [DOI] [PubMed]
- Graziano MS. Is reaching eye-centered, body-centered, hand-centered, or a combination? Reviews in the Neurosciences. 2001 doi: 10.1515/REVNEURO.2001.12.2.175. [DOI] [PubMed]
- Graziano M, Yap G, Gross C. Coding of visual space by premotor neurons. Science. 1994;266(5187) doi: 10.1126/science.7973661. Retrieved from http://science.sciencemag.org/content/266/5187/1054/tab-pdf. [DOI] [PubMed] [Google Scholar]
- Hayhoe M, Lachter J, Feldman J. Integration of form across saccadic eye movements. Perception. 1991;20(3):393–402. doi: 10.1068/p200393. [DOI] [PubMed] [Google Scholar]
- Henriques DY, Klier EM, Smith Ma, Lowy D, Crawford JD. Gaze-centered remapping of remembered visual space in an open-loop pointing task. The Journal of Neuroscience : The Official Journal of the Society for Neuroscience. 1998;18(4):1583–1594. doi: 10.1523/JNEUROSCI.18-04-01583.1998. Retrieved from http://www.jneurosci.org/content/18/4/1583.short%5Cnpapers3://publication/uuid/9DA319B8-9172-4686-B0AD-2F9BEAC85CD3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Irwin E. Information Integration across Saccadic Eye Movements. Cognitive Psychology. 1991;23:420–456. doi: 10.1016/0010-0285(91)90015-g. [DOI] [PubMed] [Google Scholar]
- James TW, Culham J, Humphrey GK, Milner AD, Goodale MA. Ventral occipital lesions impair object recognition but not object-directed grasping: An fMRI study. Brain. 2003;126(11):2463–2475. doi: 10.1093/brain/awg248. [DOI] [PubMed] [Google Scholar]
- Johnson PB, Ferraina S, Bianchi L, Caminiti R, Lacquaniti F, Guigon E, Caminiti R. Cortical networks for visual reaching: Physiological and anatomical organization of frontal and parietal lobe arm regions movement. Cerebral Cortex. 1996;6(2):102–119. doi: 10.1093/cercor/6.2.102. [DOI] [PubMed] [Google Scholar]
- Karn KS, Møller P, Hayhoe MM. Reference frames in saccadic targeting. Experimental Brain Research. 1997;115(2):267–282. doi: 10.1007/PL00005696. [DOI] [PubMed] [Google Scholar]
- Kertzman C, Schwarz U, Zeffiro Ta, Hallett M. The role of posterior parietal cortex in visually guided reaching movements in humans. Experimental Brain Research. 1997;114(1):170–83. doi: 10.1007/PL00005617. [DOI] [PubMed] [Google Scholar]
- Knapen T, Rolfs M, Wexler M, Cavanagh P. The reference frame of the tilt aftereffect. Journal of Vision. 2010;10(1):8.1–13. doi: 10.1167/10.1.8. [DOI] [PubMed] [Google Scholar]
- Lin IF, Gorea A. Location and identity memory of saccade targets. Vision Research. 2011;51(3):323–332. doi: 10.1016/j.visres.2010.11.010. [DOI] [PubMed] [Google Scholar]
- Lisi M, Cavanagh P. Dissociation between the perceptual and saccadic localization of moving objects. Current Biology. 2015;25(19):2535–2540. doi: 10.1016/j.cub.2015.08.021. [DOI] [PubMed] [Google Scholar]
- Lisi M, Cavanagh P. Different spatial representations guide eye and hand movements Matteo Lisi. Journal of Vision. 2017;17:1–12. doi: 10.1167/17.2.12. [DOI] [PubMed] [Google Scholar]
- Matin L, Pearce DG. Visual Perception of Direction for Stimuli Flashed During Voluntary Saccadic Eye Movements. Science (New York, NY) 1965;148(3676):1485–1488. doi: 10.1126/science.148.3676.1485. [DOI] [PubMed] [Google Scholar]
- McConkie GW, Currie CB. Visual stability across saccades while viewing complex pictures. Journal of Experimental Psychology: Human Perception and Performance. 1996;22(3):563–581. doi: 10.1037/0096-1523.22.3.563. [DOI] [PubMed] [Google Scholar]
- McKyton A, Zohary E. Beyond retinotopic mapping: The spatial representation of objects in the human lateral occipital complex. Cerebral Cortex. 2007;17(5):1164–1172. doi: 10.1093/cercor/bhl027. [DOI] [PubMed] [Google Scholar]
- Medendorp WP, Goltz HC, Vilis T, Crawford JD. Gaze-centered updating of visual space in human parietal cortex. The Journal of Neuroscience : The Official Journal of the Society for Neuroscience. 2003;23(15):6209–14. doi: 10.1167/3.9.125. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Melcher D. Predictive remapping of visual features precedes saccadic eye movements. Nature Neuroscience. 2007;10(7):903–907. doi: 10.1038/nn1917. [DOI] [PubMed] [Google Scholar]
- Melcher D, Morrone MC. Spatiotopic temporal integration of visual motion across saccadic eye movements. Nature Neuroscience. 2003;6(8):877–881. doi: 10.1038/nn1098. [DOI] [PubMed] [Google Scholar]
- Mullette-Gillman OA, Cohen YE, Groh JM. Motor-related signals in the intraparietal cortex encode locations in a hybrid, rather than eye-centered reference frame. Cerebral Cortex. 2009;19(8):1761–1775. doi: 10.1093/cercor/bhn207. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Newcombe F, Ratcliff G, Damasio H. Dissociable visual and spatial impairments following right posterior cerebral lesions: Clinical, neuropsychological and anatomical evidence. Neuropsychologia. 1987;25(1):149–161. doi: 10.1016/0028-3932(87)90127-8. [DOI] [PubMed] [Google Scholar]
- Ong WS, Hooshvar N, Zhang M, Bisley JW. Psychophysical evidence for spatiotopic processing in area MT in a short-term memory for motion task. Journal of Neurophysiology. 2009;102(4):2435–2440. doi: 10.1152/jn.00684.2009. [DOI] [PubMed] [Google Scholar]
- Pertzov Y, Avidan G, Zohary E. Multiple reference frames for saccadic planning in the human parietal cortex. The Journal of Neuroscience. 2011;31(3):1059–1068. doi: 10.1523/JNEUROSCI.3721-10.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pertzov Y, Zohary E, Avidan G. Rapid formation of spatiotopic representations as revealed by inhibition of return. The Journal of Neuroscience. 2010;30(26):8882–8887. doi: 10.1523/JNEUROSCI.3986-09.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pouget A, Ducom JC, Torri J, Bavelier D. Multisensory spatial representations in eye-centered coordinates for reaching. Cognition. 2002;83(1):1–11. doi: 10.1016/S0010-0277(01)00163-9. [DOI] [PubMed] [Google Scholar]
- Prime SL, Vesia M, Crawford JD. Cortical mechanisms for trans-saccadic memory and integration of multiple object features. Philosophical Transactions of the Royal Society B: Biological Sciences. 2011;366(1564):540–553. doi: 10.1098/rstb.2010.0184. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rao HM, Abzug ZM, Sommer MA. Visual continuity across saccades is influenced by expectations. Journal of Vision. 2016;16(5):1–18. doi: 10.1167/16.5.7. [DOI] [PubMed] [Google Scholar]
- Rolfs M, Jonikaitis D, Deubel H, Cavanagh P. Predictive remapping of attention across eye movements. Nature Neuroscience. 2011;14(2):252–6. doi: 10.1038/nn.2711. [DOI] [PubMed] [Google Scholar]
- Serences JT. Neural mechanisms of information storage in visual short-term memory. Vision Research. 2016;128:53–67. doi: 10.1016/j.visres.2016.09.010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sheth BR, Shimojo S. Compression of space in visual memory. Vision Research. 2001;41(3):329–341. doi: 10.1016/S0042-6989(00)00230-3. [DOI] [PubMed] [Google Scholar]
- Snyder LH, Batista AP, Andersen RA. Coding of intention in the posterior parietal cortex. Nature. 1997;386(6621):167–170. doi: 10.1038/386167a0. [DOI] [PubMed] [Google Scholar]
- Soechting JF, Flanders M. Sensorimotor representations for pointing to targets in three-dimensional space. Journal of Neurophysiology. 1989;62(2):582–594. doi: 10.1152/jn.1989.62.2.582. [DOI] [PubMed] [Google Scholar]
- Song JH, Nakayama K. Hidden cognitive states revealed in choice reaching tasks. Trends in Cognitive Sciences. 2009;13(8):360–366. doi: 10.1016/j.tics.2009.04.009. [DOI] [PubMed] [Google Scholar]
- Sun LD, Goldberg ME. Corollary Discharge and Oculomotor Proprioception: Cortical Mechanisms for Spatially Accurate Vision. Annual Review of Vision Science. 2016;2(1):61–84. doi: 10.1146/annurev-vision-082114-035407. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thomas LE. Action Experience Drives Visual-Processing Biases Near the Hands. Psychological Science. 2017;28(1):124–131. doi: 10.1177/0956797616678189. [DOI] [PubMed] [Google Scholar]
- Tipper SP, Howard LA, Houghton G. Action-based mechanisms of attention. Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences. 1998;353(1373):1385–1393. doi: 10.1098/rstb.1998.0292. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tipper SP, Lortie C, Baylis GC. Selective reaching: Evidence for action-centered attention. Journal of Experimental Psychology: Human Perception and Performance. 1992;18(4):891–905. doi: 10.1037/0096-1523.18.4.891. [DOI] [PubMed] [Google Scholar]
- Vaziri S. Why Does the Brain Predict Sensory Consequences of Oculomotor Commands? Optimal Integration of the Predicted and the Actual Sensory Feedback. Journal of Neuroscience. 2006;26(16):4188–4197. doi: 10.1523/JNEUROSCI.4747-05.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Witt JK. Tool use influences perceived shape and perceived parallelism, which serve as indirect measures of perceived distance. Journal of Experimental Psychology. Human Perception and Performance. 2011;37(4):1148–1156. doi: 10.1037/a0021933. [DOI] [PubMed] [Google Scholar]
- Witt JK, Proffitt DR, Epstein W. Tool use affects perceived distance, but only when you intend to use it. Journal of Experimental Psychology. Human Perception and Performance. 2005;31(5):880–888. doi: 10.1037/0096-1523.31.5.880. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.