

Abstract
We introduce a class of covariate-adjusted skewed functional models (cSFM) designed for functional data exhibiting location-dependent marginal distributions. We propose a semi-parametric copula model for the pointwise marginal distributions, which are allowed to depend on covariates, and the functional dependence, which is assumed covariate invariant. The proposed cSFM framework provides a unifying platform for pointwise quantile estimation and trajectory prediction. We consider a computationally feasible procedure that handles densely as well as sparsely observed functional data. The methods are examined numerically using simulations and is applied to a new tractography study of multiple sclerosis. Furthermore, the methodology is implemented in the R package cSFM, which is publicly available on CRAN.
Keywords: Covariate modeling, Diffusion tensor imaging, Functional principal component analysis, Gaussian copula, Quantile estimation, Skewed function
1. Introduction
Development in technology and computation has facilitated the recording of repeated measures with high frequency, allowing the data to be viewed as a function. Functional data analysis (FDA) has developed rapidly due to the increasing applications in many areas such as medical fields, environmental science, image analysis, and traffic modeling (Ramsay and Silverman, 2002, 2005; Ferraty and Vieu, 2006; Serban and others, 2013; Gertheiss and others, 2013, to name a few). Most approaches in FDA are based on the first two order moments—mean and covariance functions. An example is the functional principal component analysis (FPCA), which has become a standard tool to achieve dimension reduction in FDA. Limited investigation has been done to incorporate covariates in the framework of FPCA (Cardot, 2007; Jiang and Wang, 2010). However, there are important cases where both higher order moments and covariate information are of interest. For example, in our brain tractography application it is of interest to study how the parallel diffusivity recorded at many locations along the main white matter tract of the brain—corpus callosum (CCA)—varies with the tract location, while accounting for additional covariate information provided by the parallel diffusivity mean summary along a neighboring tract—left corticospinal tract. Furthermore, we want to study how this dependence is different for multiple sclerosis (MS) diseased and healthy subjects; see Figure 1 for visual display. At a quick look, it appears that the skewness of the parallel diffusivity along the CCA varies across the tract location, and this dependence is different for MS and healthy subjects. Thus, accounting for higher-order moments of the pointwise distribution, as well as for the additional available covariate in the modeling of the parallel diffusivity profiles has the potential to provide a more complete description of the observed data, which could lead to generating new scientific hypotheses. In this paper, we introduce a novel semiparametric approach to model functional data in the presence of skewed distributions, while accounting for additional covariates, and propose a practically feasible estimation algorithm.
Fig. 1.

Observed parallel diffusivity (LO) along the CCA tract locations and the covariate lCST-mLO, for 160 MS and 42 healthy subjects. (a) MS subjects and (b) healthy subjects.
The approach we propose is fundamentally different from the standard FPCA because: (i) it targets the entire distribution of the functional data; (ii) it uses copula to account for functional dependence; (iii) it allows for non-symmetric location-varying distribution of the data, and (iv) it accommodates additional covariate information in a parsimonious manner. Staicu and others (2012) introduced a copula-based approach and proposed models for functional data exhibiting skewness that vary with temporal location. Copula approaches (Sklar, 1959) have been under intense methodological development and allow to separate the modeling into the pointwise distributions and the dependence structure. While the pointwise distributions capture the higher order moments, the copula describes the dependence. One advantage of this approach is that it provides an unifying platform for both pointwise quantile estimation and prediction of trajectories by incorporating functional dependence. Our paper considers this direction; the proposed model framework extends Staicu and others (2012) to incorporate additional covariates in a parsimonious way. Recently, Soiaporn and others (unpublished data) proposed an extension of the copula-based approach to model jointly multiple functional responses.
When covariate information is available, Cardot (2007) proposed conditional FPCA, by conditioning on the covariate, and discussed estimation of the conditional mean and covariances through nonparametric kernel estimators. Jiang and Wang (2010) provided a covariate-adjusted FPCA, by assuming covariates effect either in the mean and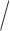 or covariance functions. Both approaches rely on the first two moments to either estimate the mean and covariance functions or reconstruct the trajectories, and do not account for functional data that are pointwise skewed. The methods introduced in Staicu and others (2012), which account for such features are not directly applicable, as they require multiple responses to be observed for each time point and covariate value, which is almost never the case when the covariate is continuous—the case of interest in this paper.
or covariance functions. Both approaches rely on the first two moments to either estimate the mean and covariance functions or reconstruct the trajectories, and do not account for functional data that are pointwise skewed. The methods introduced in Staicu and others (2012), which account for such features are not directly applicable, as they require multiple responses to be observed for each time point and covariate value, which is almost never the case when the covariate is continuous—the case of interest in this paper.
We consider flexible parametric families to describe the pointwise distributions and assume that the corresponding mean, variance, and additional parameters describing the shape of the distribution vary smoothly with both the time and the additional covariate. To ensure a parsimonious model, we assume that the dependence—as accounted for, via copula—is covariate-invariant. Nevertheless, our modeling strategy allows for the (Pearson) covariance of the functional responses to vary with the additional covariate (Cardot, 2007; Jiang and Wang, 2010). Our estimation approach is based on modeling the smooth parameter functions using bi-variate regression splines and employing computationally feasible simultaneous optimization for the unknown basis coefficients; the knots selection is carried using information criterion. Once the parameter functions are estimated, pointwise quantile estimates can be obtained directly, at no additional cost, for any level of quantile. Prediction of the trajectories is based on the calibration of the process’ dependence, which allows to borrow strength from the existing FPCA techniques. The methods are implemented in the R package cSFM, which is publicly available.
The remaining of this paper is organized as follows. Section 2 introduces the proposed covariate-adjusted skewed functional model. Section 3 discusses an estimation technique using regression splines, as well as the model selection. Section 4 describes the prediction procedure. The finite sample performance of the proposed method is evaluated through simulation studies in Section 5. Section 6 demonstrates an application of the proposed method to the tractography data.
2. Modeling methodology
Let 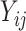 be the response for subject
be the response for subject 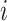 measured at time point
measured at time point 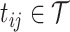 for
for  and let
and let 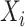 be a
be a 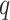 -dimensional vector of additional covariate information associated with the subject, for
-dimensional vector of additional covariate information associated with the subject, for 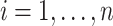 . With slight abuse of notation let
. With slight abuse of notation let 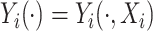 be the underlying function associated with the
be the underlying function associated with the 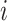 th subject such that
th subject such that 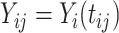 ; here the notation
; here the notation 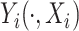 is used to emphasize the dependence of the response on the covariate
is used to emphasize the dependence of the response on the covariate  . It is assumed that
. It is assumed that 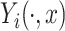 is a square integrable function for all
is a square integrable function for all 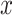 and that
and that 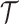 is closed interval. We introduce a semiparametric modeling framework to describe covariate-dependent functional data as
is closed interval. We introduce a semiparametric modeling framework to describe covariate-dependent functional data as
 |
(2.1) |
where 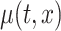 and
and 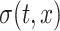 denote the mean and standard deviation of
denote the mean and standard deviation of 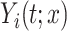 ,
, 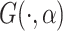 is a cumulative (CDF) with zero-mean, unit-variance and which is parameterized by parameter, scalar or vector,
is a cumulative (CDF) with zero-mean, unit-variance and which is parameterized by parameter, scalar or vector,  , and
, and  is its inverse function. Because
is its inverse function. Because 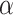 does not affect the mean nor the variance of the distribution, but instead is related to higher order moments—such as skewness and kurtosis—it is referred to as the “shape parameter”. For example,
does not affect the mean nor the variance of the distribution, but instead is related to higher order moments—such as skewness and kurtosis—it is referred to as the “shape parameter”. For example, 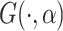 could be the CDF of a standard skewed normal distribution (Azzalini, 1985) parameterized by a scalar parameter or the skew-
could be the CDF of a standard skewed normal distribution (Azzalini, 1985) parameterized by a scalar parameter or the skew- distribution (Azzalini, 2013), parameterized by a two-dimensional shape parameter. Model (2.1) assumes that the shape parameter
distribution (Azzalini, 2013), parameterized by a two-dimensional shape parameter. Model (2.1) assumes that the shape parameter 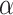 varies over
varies over 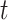 and in addition depends on the covariate
and in addition depends on the covariate  . For each
. For each  , the random variable
, the random variable  is assumed to follow
is assumed to follow 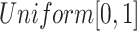 . The dependence of
. The dependence of 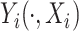 is modeled implicitly through the correlated latent process
is modeled implicitly through the correlated latent process 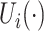 ; thus (2.1) assumes that the covariate influences the pointwise distributions, but not the dependence, as captured by
; thus (2.1) assumes that the covariate influences the pointwise distributions, but not the dependence, as captured by  . The dependence will be modeled using copulas, such as Gaussian copula (Ruppert, 2010), which allow modularity, by separating pointwise distributions and the mutual stochastic dependence. Although model (2.1) is parsimonious, remark that it allows the covariate
. The dependence will be modeled using copulas, such as Gaussian copula (Ruppert, 2010), which allow modularity, by separating pointwise distributions and the mutual stochastic dependence. Although model (2.1) is parsimonious, remark that it allows the covariate 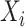 to influence both the mean and the Pearson covariance of the process
to influence both the mean and the Pearson covariance of the process 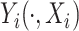 .
.
The class described by model (2.1) extends the class of models proposed by Staicu and others (2012) for skewed functional data, to account for additional covariate information; thus, we call it covariate-adjusted skewed functional model (cSFM). For discrete covariate 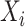 , the approach of Staicu and others (2012) can still be used, provided that the number of realizations
, the approach of Staicu and others (2012) can still be used, provided that the number of realizations 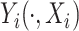 for each covariate value increases with the sample size. Nevertheless, when the covariate
for each covariate value increases with the sample size. Nevertheless, when the covariate 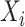 is continuous the methods discussed in Staicu and others (2012) are not applicable and new methodology is required. The extension raises many challenges and is far from straightforward. For example, accounting for covariates as proposed in model (2.1) leads to an increased dimensionality of the problem, and thus demands for computationally feasible algorithms. Models for functional data that accommodate covariate effects have been investigated recently. For example, Jiang and Wang (2011) proposed single index models to summarize the covariate effect in the mean function, and consider regular FPCA to model the residuals; Jiang and Wang (2010) introduced a modification of the existing FPCA to account for additional covariates by incorporating covariate effects in the mean and
is continuous the methods discussed in Staicu and others (2012) are not applicable and new methodology is required. The extension raises many challenges and is far from straightforward. For example, accounting for covariates as proposed in model (2.1) leads to an increased dimensionality of the problem, and thus demands for computationally feasible algorithms. Models for functional data that accommodate covariate effects have been investigated recently. For example, Jiang and Wang (2011) proposed single index models to summarize the covariate effect in the mean function, and consider regular FPCA to model the residuals; Jiang and Wang (2010) introduced a modification of the existing FPCA to account for additional covariates by incorporating covariate effects in the mean and or covariance functions. However, the current approaches are limited in that the complete pointwise distribution is implicitly assumed to be characterized by its first two moments. However, even if the covariate only affects these two moments, the higher order moments should be taken into account during estimation.
or covariance functions. However, the current approaches are limited in that the complete pointwise distribution is implicitly assumed to be characterized by its first two moments. However, even if the covariate only affects these two moments, the higher order moments should be taken into account during estimation.
A close inspection of the model (2.1) shows that if 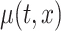 ,
, 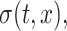 and
and 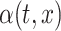 are known, then
are known, then 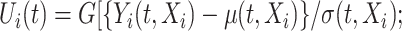
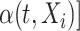 is the latent process obtained by a transformation of the observed functional data
is the latent process obtained by a transformation of the observed functional data 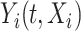 . Thus, model (2.1) serves a dual purpose: (i) to generalize standard approaches to functional data, by providing a distributional framework and (ii) to provide a class of transformations for functional data that maps correlated functional processes with complex pointwise characteristics to correlated functional processes with simple pointwise characteristics. Also (2.1) provides a unifying platform for (i) modeling the pointwise quantile functions as
. Thus, model (2.1) serves a dual purpose: (i) to generalize standard approaches to functional data, by providing a distributional framework and (ii) to provide a class of transformations for functional data that maps correlated functional processes with complex pointwise characteristics to correlated functional processes with simple pointwise characteristics. Also (2.1) provides a unifying platform for (i) modeling the pointwise quantile functions as 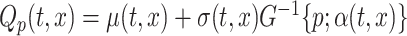 , for
, for  and (ii) reconstruction of individual profiles, using standard FPCA techniques to recover the latent process
and (ii) reconstruction of individual profiles, using standard FPCA techniques to recover the latent process  .
.
3. Estimation procedure
We estimate the population-level functions  ,
, 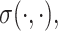 and
and 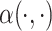 using regression splines, based on tensor product B-splines; approaches based on the other bases choices may be used following the same scheme. Since
using regression splines, based on tensor product B-splines; approaches based on the other bases choices may be used following the same scheme. Since  is uniformly distributed for each
is uniformly distributed for each 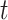 , it follows that the joint distribution of
, it follows that the joint distribution of 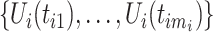 is, by definition, a copula; parametric copulas, such as Gaussian copulas, that are parameterized by correlation functions are considered. The estimation methodology contains two steps: (i) estimation of the parameters jointly by a pseudo-likelihood approach and (ii) nonparametric estimation of the latent copula correlation.
is, by definition, a copula; parametric copulas, such as Gaussian copulas, that are parameterized by correlation functions are considered. The estimation methodology contains two steps: (i) estimation of the parameters jointly by a pseudo-likelihood approach and (ii) nonparametric estimation of the latent copula correlation.
3.1. Population-level function estimation
The methodology is demonstrated via a univariate continuous covariate, while extensions to discrete and categorical covariates, and the multiple covariate case follow naturally. Let  and
and 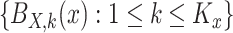 be univariate B-spline bases of degrees
be univariate B-spline bases of degrees 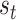 and
and  on
on  and
and  respectively, with
respectively, with 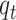 and
and 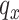 interior knots placed at equally spaced quantiles (de Boor, 2001; Ruppert and others, 2003); here
interior knots placed at equally spaced quantiles (de Boor, 2001; Ruppert and others, 2003); here 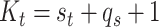 and
and 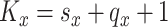 . We use a bivariate spline model representation based on tensor product B-spline bases (Durrett, 2005) for both the mean and log variance functions:
. We use a bivariate spline model representation based on tensor product B-spline bases (Durrett, 2005) for both the mean and log variance functions:
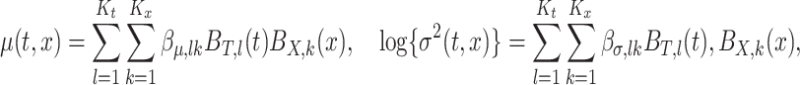 |
(3.1) |
where the numbers of univariate bases functions,  and
and 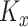 , for the mean and variance functions are assumed equal, for simplicity. Often the shape parameter function requires careful handling. In our experience modeling an appropriate one-to-one transformation improves the numerical stability (see also Staicu and others, 2012). Let
, for the mean and variance functions are assumed equal, for simplicity. Often the shape parameter function requires careful handling. In our experience modeling an appropriate one-to-one transformation improves the numerical stability (see also Staicu and others, 2012). Let  be such a transformation,
be such a transformation,
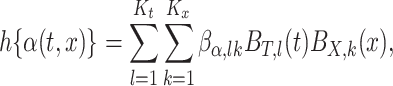 |
(3.2) |
for convenience, assume the same number of univariate basis functions, 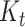 and
and  as for the mean
as for the mean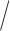 variance functions. Different bases are used in the simulation and allowed in the developed R package cSFM. If
variance functions. Different bases are used in the simulation and allowed in the developed R package cSFM. If 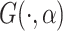 is the centered
is the centered scaled skewed normal distribution, we work with the centered parameterization, based on skewness (Arellano-Valle and Azzalini, 2008). Let
scaled skewed normal distribution, we work with the centered parameterization, based on skewness (Arellano-Valle and Azzalini, 2008). Let 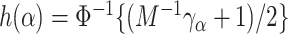 , for
, for  is the inverse CDF of the standard normal,
is the inverse CDF of the standard normal,  , and
, and 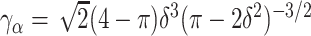 for
for  . Function
. Function 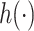 reparameterizes the shape parameter using the skewness
reparameterizes the shape parameter using the skewness 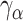 , which is bounded by
, which is bounded by 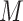 , and maps it to the real line.
, and maps it to the real line.
Let 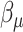 be the
be the  -dimensional column vector obtained by stacking
-dimensional column vector obtained by stacking  first over
first over 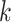 and then over
and then over 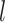 , and similarly define the vectors
, and similarly define the vectors  and
and  . As well define
. As well define 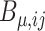 as the
as the  -dimensional column vector with elements
-dimensional column vector with elements  , so we have
, so we have 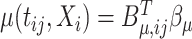 . Likewise define the
. Likewise define the  dimensional vectors
dimensional vectors 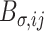 and
and 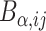 such that
such that 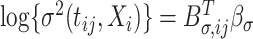 and
and 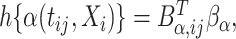 respectively. It follows that observation
respectively. It follows that observation 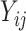 has mean equal to
has mean equal to 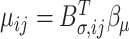 , variance equal to
, variance equal to 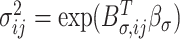 and furthermore that
and furthermore that  has distribution with the CDF specified by
has distribution with the CDF specified by 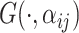 where
where  , and
, and 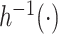 is the inverse function of
is the inverse function of 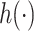 . Conditional on the bivariate basis functions, the parameters
. Conditional on the bivariate basis functions, the parameters 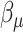 ,
, 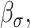 and
and 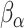 are estimated using maximum likelihood estimation and a working independence assumption. Specifically, if
are estimated using maximum likelihood estimation and a working independence assumption. Specifically, if 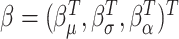 is the overall parameter vector, and denote by
is the overall parameter vector, and denote by 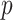 its length, then
its length, then 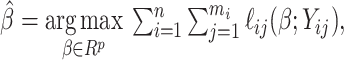 where
where 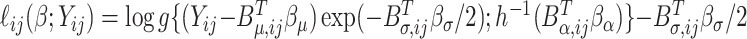 is the log-likelihood function of
is the log-likelihood function of 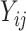 and
and 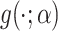 is the probability density function corresponding to the CDF
is the probability density function corresponding to the CDF  . The estimates of the parameter functions
. The estimates of the parameter functions  ,
, 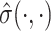 and
and 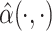 are obtained by substituting
are obtained by substituting 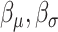 , and
, and 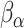 from (3.1) and (3.2) with the corresponding counterparts from
from (3.1) and (3.2) with the corresponding counterparts from 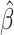 .
.
Quasi-Newton algorithm can be used for the likelihood optimization via function optim in the R package stats. However, a direct application of this function is unstable due to the large dimension of the parameters. In our developed R package and simulation experiments, the parameter estimation is carried with optim by providing closed form expressions for the gradient, leading to stable computation and faster iteration convergence rates.
The function 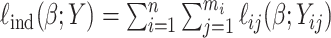 is a misspecified likelihood, based on an independence model;
is a misspecified likelihood, based on an independence model; 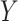 is the vector of
is the vector of 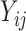 's. Using Sklar's theorem (Sklar, 1959), the full likelihood of the observed data
's. Using Sklar's theorem (Sklar, 1959), the full likelihood of the observed data 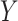 can be written as
can be written as 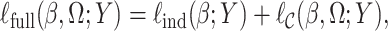 where
where 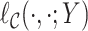 is the log-likelihood function of the copula and is fully specified by the parameters
is the log-likelihood function of the copula and is fully specified by the parameters 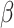 and
and 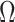 . For the Gaussian copula, the parameter
. For the Gaussian copula, the parameter 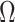 is the correlation of an appropriate latent random variable. Direct estimation of
is the correlation of an appropriate latent random variable. Direct estimation of 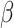 and
and  using the full likelihood involves optimization over a large dimensional space, and thus would be computationally challenging or unfeasible. Our proposed estimation—known in the literature by “pseudo likelihood” (Ruppert, 2010)—uses two steps. First, the population-level parameters are estimated using
using the full likelihood involves optimization over a large dimensional space, and thus would be computationally challenging or unfeasible. Our proposed estimation—known in the literature by “pseudo likelihood” (Ruppert, 2010)—uses two steps. First, the population-level parameters are estimated using 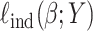 , and then the copula parameter is estimated as the correlation of an appropriate latent variable, using a method of moment approach.
, and then the copula parameter is estimated as the correlation of an appropriate latent variable, using a method of moment approach.
Once the population-level functions are estimated, the cSFM approach allows the estimation of the pointwise quantile for any quantile levels: the estimated pointwise quantile function of level 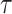 is obtained by
is obtained by 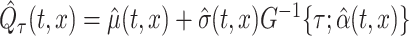 .
.
3.2. Copula calibration
Here we discuss estimation of the copula parameter 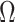 , when a Gaussian copula is assumed to describe the dependence. We begin with providing insights into the latent variable whose correlation is given by the copula parameter. Specifically, let
, when a Gaussian copula is assumed to describe the dependence. We begin with providing insights into the latent variable whose correlation is given by the copula parameter. Specifically, let 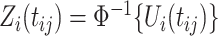 , where recall
, where recall 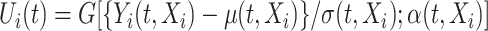 is the covariate-free underlying process. It follows that
is the covariate-free underlying process. It follows that 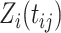 has standard normal distribution, for every
has standard normal distribution, for every 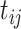 . Furthermore, let
. Furthermore, let 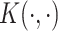 be the covariance function of the induced Gaussian process
be the covariance function of the induced Gaussian process  defined by
defined by 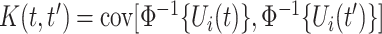 ; notice that the covariance and correlation function coincide for the induced latent process. Thus, the copula parameter,
; notice that the covariance and correlation function coincide for the induced latent process. Thus, the copula parameter, 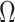 , consists of all correlation coefficients
, consists of all correlation coefficients 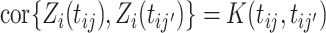 , for all
, for all  ,
,  . Due to the large dimensionality of this parameter, likelihood-based approaches would be unfeasible. Instead, moment-based methods are a common alternative in practice (Ruppert, 2010). Our approach relies on the assumption that the covariance function
. Due to the large dimensionality of this parameter, likelihood-based approaches would be unfeasible. Instead, moment-based methods are a common alternative in practice (Ruppert, 2010). Our approach relies on the assumption that the covariance function 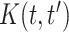 is smooth for
is smooth for 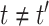 , which is commonly made in the FDA literature (Yao and others, 2005; Ramsay and Silverman, 2005). For given estimates of the population-level functions, the copula parameter can be estimated directly using either (i) the Pearson correlation of the induced latent process or (ii) the nonparametric Kendall's tau; we detail each method as follows.
, which is commonly made in the FDA literature (Yao and others, 2005; Ramsay and Silverman, 2005). For given estimates of the population-level functions, the copula parameter can be estimated directly using either (i) the Pearson correlation of the induced latent process or (ii) the nonparametric Kendall's tau; we detail each method as follows.
Pearson correlation. Let 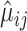 ,
, 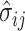 , and
, and 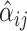 be the estimates of the mean, standard deviation and shape based on the fixed bases and the parameter estimate
be the estimates of the mean, standard deviation and shape based on the fixed bases and the parameter estimate 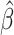 . The induced latent Gaussian process evaluated at time
. The induced latent Gaussian process evaluated at time 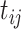 can be approximated by
can be approximated by 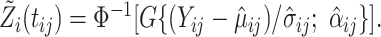 To account for all sources of errors, it is assumed that
To account for all sources of errors, it is assumed that  is a realization of a Gaussian latent process at time
is a realization of a Gaussian latent process at time 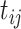 which is contaminated with measurement error. Standard FPCA techniques can be used to estimate the correlation of the latent process, via a reduced rank approximation of the covariance and bivariate smoothing techniques. Let
which is contaminated with measurement error. Standard FPCA techniques can be used to estimate the correlation of the latent process, via a reduced rank approximation of the covariance and bivariate smoothing techniques. Let 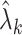 and
and 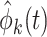 be the estimated
be the estimated  th eigenvalue and eigenfunction and
th eigenvalue and eigenfunction and  be the estimated noise variance. The underlying covariance
be the estimated noise variance. The underlying covariance 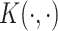 is estimated by
is estimated by  , where
, where  is a finite truncation determined by the percentage of explained variance criterion; see Staicu and others (2012) for more details.
is a finite truncation determined by the percentage of explained variance criterion; see Staicu and others (2012) for more details.
Kendall's tau. The correlation function 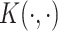 can also be estimated by the Kendall's tau correlation of the latent process. Using (5.32) of McNeil and others (2010), let
can also be estimated by the Kendall's tau correlation of the latent process. Using (5.32) of McNeil and others (2010), let 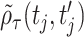 be the sample Kendall's tau between
be the sample Kendall's tau between 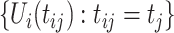 and
and 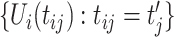 ;
; 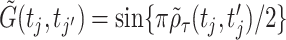 can be viewed as an undersmooth estimator of the Pearson correlation of the latent Gaussian process contaminated with error. Reduced rank approximation is again used to ensure positive definiteness of the estimated correlation function. The use of Kendall's tau is more appealing because of the invariance property of Kendall's tau to increasing functions.
can be viewed as an undersmooth estimator of the Pearson correlation of the latent Gaussian process contaminated with error. Reduced rank approximation is again used to ensure positive definiteness of the estimated correlation function. The use of Kendall's tau is more appealing because of the invariance property of Kendall's tau to increasing functions.
When small values of the response at points  are followed by small values at the adjacent points, then a
are followed by small values at the adjacent points, then a  -copula captures the model dependence better. Our methodology can be extended to accommodate a
-copula captures the model dependence better. Our methodology can be extended to accommodate a 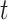 -copula. The estimation of the copula parameters follows roughly the same direction as Staicu and others (2012): the main difference is that both the Kendall's tau correlation and the degrees of freedom parameter will be estimated from the underlying process
-copula. The estimation of the copula parameters follows roughly the same direction as Staicu and others (2012): the main difference is that both the Kendall's tau correlation and the degrees of freedom parameter will be estimated from the underlying process  , where
, where 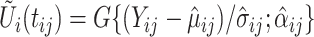 as opposed to the response
as opposed to the response 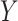 .
.
3.3. Selection of the number of knots
Our estimation algorithm is based on specified bases functions, as described by preset degrees and number of knots that are placed at equally spaced quantiles. Typically, the degree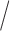 order of the basis functions is chosen to describe certain characteristics of the parameter functions—such as the number of continuous derivatives. The number of knots is a tuning parameter and controls the bias-variance trade-off. We propose to select the number of knots using the Akaike information criterion (AIC) (Akaike, 1970), by exploiting the semi-parametric modeling framework. In general,
order of the basis functions is chosen to describe certain characteristics of the parameter functions—such as the number of continuous derivatives. The number of knots is a tuning parameter and controls the bias-variance trade-off. We propose to select the number of knots using the Akaike information criterion (AIC) (Akaike, 1970), by exploiting the semi-parametric modeling framework. In general,  , and the optimal number of knots is selected by minimizing AIC. AIC does not depend on the sample size—a property which makes it more appealing when comparing with its competitors Bayesian information criterion and cross-validation methods. Also AIC is shown to be asymptotically optimal in terms of choosing the best approximating model when the underlying true model is infinite dimensional (Shibata, 1981; Li, 1987).
, and the optimal number of knots is selected by minimizing AIC. AIC does not depend on the sample size—a property which makes it more appealing when comparing with its competitors Bayesian information criterion and cross-validation methods. Also AIC is shown to be asymptotically optimal in terms of choosing the best approximating model when the underlying true model is infinite dimensional (Shibata, 1981; Li, 1987).
4. Prediction of trajectories
Reconstructing trajectories are highly important in functional data analysis. Benefiting from the copula-based modeling in (2.1), we can reconstruct trajectories by borrowing strength from the standard FPCA techniques. Specifically, let 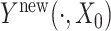 be a new response observed incompletely at few values
be a new response observed incompletely at few values 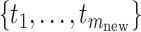 , and corresponding to the covariate value
, and corresponding to the covariate value 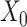 . To reconstruct the trajectory
. To reconstruct the trajectory 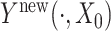 , the key step is in the prediction of the latent trajectory
, the key step is in the prediction of the latent trajectory  . Once such
. Once such 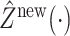 is available, let
is available, let  and calculate the predicted trajectory
and calculate the predicted trajectory 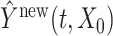 using model (2.1) with the estimated population-level functions
using model (2.1) with the estimated population-level functions 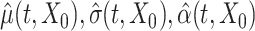 and the predicted latent trajectory
and the predicted latent trajectory 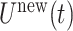 in place of
in place of 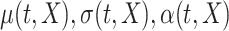 , and
, and 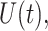 respectively;
respectively; 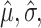 and
and 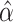 are determined as in Section 3.1.
are determined as in Section 3.1.
Next, we discuss prediction of the latent trajectory 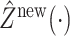 . For any
. For any 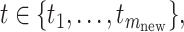 application of the previous formula gives
application of the previous formula gives 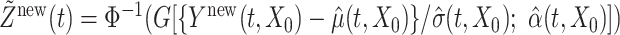 . As discussed in Section 3.2, our methodology assumes that the latent random curves
. As discussed in Section 3.2, our methodology assumes that the latent random curves 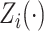 are independent and identical realizations of a process with smooth covariance function that are contaminated with measurement error. It can be decomposed using the Karhunen–Loève expansion as
are independent and identical realizations of a process with smooth covariance function that are contaminated with measurement error. It can be decomposed using the Karhunen–Loève expansion as 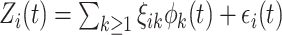 , where
, where  is zero-mean random variables, with covariance equal to
is zero-mean random variables, with covariance equal to 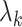 , and uncorrelated over
, and uncorrelated over  , and
, and 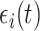 is white noise process with covariance
is white noise process with covariance 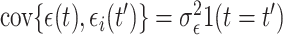 ; here
; here 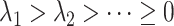 . Using the observed data
. Using the observed data  , and thus
, and thus 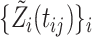 , and furthermore let
, and furthermore let 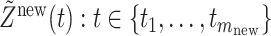 correspond to the incompletely observed
correspond to the incompletely observed 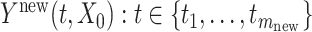 . We predict
. We predict 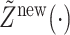 by
by 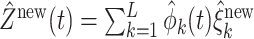 , where
, where 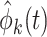 is the estimated eigenfunctions corresponding to the sample of discretely and noisy measured profiles
is the estimated eigenfunctions corresponding to the sample of discretely and noisy measured profiles  and
and  is the reduced rank truncation used in the estimation of the copula correlation, as determined in Section 3.2. Furthermore,
is the reduced rank truncation used in the estimation of the copula correlation, as determined in Section 3.2. Furthermore, 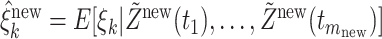 is determined using conditional expectation (Yao and others, 2005).
is determined using conditional expectation (Yao and others, 2005).
Intuitively, the proposed methodology is directly applicable to functional data observed on a sparse design; however, additional numerical investigation is necessary in order to assess the accuracy of the estimation procedure in this setting.
5. Simulation results
We conducted a simulation experiment to show the estimation and predictive performance of the proposed method for increasing sample sizes, and compare the results with several alternatives. Specifically, we generate data 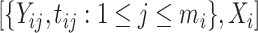 where
where  using model (2.1) with model components detailed below. For each
using model (2.1) with model components detailed below. For each 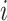 , the timepoints
, the timepoints 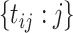 are 80 equispaced grid of values in
are 80 equispaced grid of values in  , and the covariate
, and the covariate 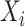 is generated from
is generated from 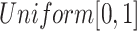 . The pointwise mean and variance functions are taken as
. The pointwise mean and variance functions are taken as 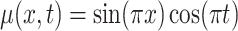 ,
, 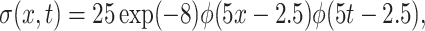 where
where  is the probability density function for a standard normal variable. We take
is the probability density function for a standard normal variable. We take 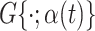 to be the CDF of the centered and scaled skewed normal distribution (Azzalini, 2013) with shape parameter
to be the CDF of the centered and scaled skewed normal distribution (Azzalini, 2013) with shape parameter 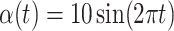 . Furthermore, the stochastic process
. Furthermore, the stochastic process 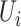 is generated from
is generated from 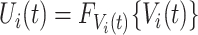 where
where 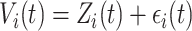 ,
, 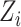 is zero-mean Gaussian process with covariance function
is zero-mean Gaussian process with covariance function  ,
, 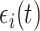 is independently generated as
is independently generated as  for all
for all 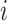 and
and 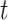 , and
, and  is the CDF of
is the CDF of 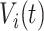 . Here
. Here  is the Fourier basis with
is the Fourier basis with 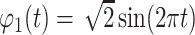 ,
, 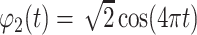 ,
,  , and so on, and
, and so on, and  for
for 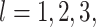 and
and 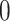 otherwise. For each scenario considered, results are based on 100 simulations.
otherwise. For each scenario considered, results are based on 100 simulations.
We measure the performance of all compared methods in three ways: (i) estimation of the population-level functions, 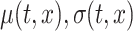 , and
, and 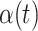 ; (ii) prediction performance; and (iii) estimation of pointwise quantile functions. To assess (i) and (ii), we compare the cSFM, by assuming that
; (ii) prediction performance; and (iii) estimation of pointwise quantile functions. To assess (i) and (ii), we compare the cSFM, by assuming that 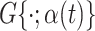 is in the family of skewed normal distributions with time-varying shape parameter
is in the family of skewed normal distributions with time-varying shape parameter  , with three alternative approaches:
, with three alternative approaches:  , which is a variant of the cSFM with the shape parameter is set to 0; two-step cSFM, which is a two-step procedure that combines penalized bivariate splines for the estimation of the mean and cFSM method for the de-meaned data; and the mean covariate adjusted FPCA method (mFPCA) introduced by Jiang and Wang (2010), which assumes the model
, which is a variant of the cSFM with the shape parameter is set to 0; two-step cSFM, which is a two-step procedure that combines penalized bivariate splines for the estimation of the mean and cFSM method for the de-meaned data; and the mean covariate adjusted FPCA method (mFPCA) introduced by Jiang and Wang (2010), which assumes the model 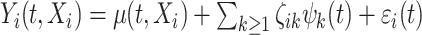 using standard FPCA notations. Here, bivariate penalized spline smoothing is used to model the mean function, and common FPCA techniques are used for the pseudo-residuals
using standard FPCA notations. Here, bivariate penalized spline smoothing is used to model the mean function, and common FPCA techniques are used for the pseudo-residuals 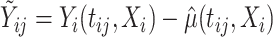 . To assess (iii), we compare the pointwise quantile functions estimated using cSFM for various quantile levels with the corresponding counterparts via
. To assess (iii), we compare the pointwise quantile functions estimated using cSFM for various quantile levels with the corresponding counterparts via  , two-step cSFM. The pointwise quantile functions with mFPCA are estimated based on Gaussian assumption of the FPC scores, which in turn imply a Gaussian distribution for the response; note that mFPCA does not necessarily assume Gaussian scores when used to make prediction. Additionally, we include the pointwise quantiles estimated using the constrained B-splines (COBS) nonparametric regression quantiles method (He and Ng, 1999).
, two-step cSFM. The pointwise quantile functions with mFPCA are estimated based on Gaussian assumption of the FPC scores, which in turn imply a Gaussian distribution for the response; note that mFPCA does not necessarily assume Gaussian scores when used to make prediction. Additionally, we include the pointwise quantiles estimated using the constrained B-splines (COBS) nonparametric regression quantiles method (He and Ng, 1999).
The model fitting is based on cubic regression splines to model the mean, variance, and shape parameter functions combined with Gaussian copula to model the process dependence, and it employs the methodology described in Section 3. For each parameter functions, 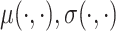 ,and
,and 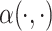 , we use the same number of knots in the
, we use the same number of knots in the  and
and 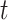 directions,
directions,  , and
, and 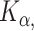 respectively; the optimal number of knots is selected via AIC using a grid search with the restriction
respectively; the optimal number of knots is selected via AIC using a grid search with the restriction 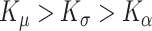 (Wang and others, 2008). For both the two-step cSFM and mFPCA, the mean function is modeled using penalized splines instead and the smoothness is controlled via two smoothing parameters; fitting is done via the R package mgcv of Wood (2011), and the smoothing parameters are selected by REML. COBS is implemented via the R package cobs (Ng and Maechler, 2011), employing quadratic splines and Schwarz-type information criterion (for the smoothing parameter).
(Wang and others, 2008). For both the two-step cSFM and mFPCA, the mean function is modeled using penalized splines instead and the smoothness is controlled via two smoothing parameters; fitting is done via the R package mgcv of Wood (2011), and the smoothing parameters are selected by REML. COBS is implemented via the R package cobs (Ng and Maechler, 2011), employing quadratic splines and Schwarz-type information criterion (for the smoothing parameter).
The performance estimation of model components is assessed through the square root of integrated mean squared error (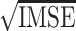 ), which, for some generic bivariate function
), which, for some generic bivariate function 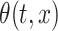 with estimator
with estimator 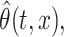 is defined as
is defined as 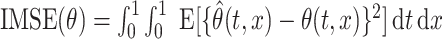 . Additionally, we consider the Kullback–Leibler divergence (KL) to evaluate the overall estimation accuracy of the pointwise distribution of
. Additionally, we consider the Kullback–Leibler divergence (KL) to evaluate the overall estimation accuracy of the pointwise distribution of 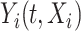 . Specifically, if
. Specifically, if 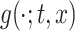 denotes the true density function of
denotes the true density function of  for time point
for time point 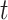 and covariate
and covariate 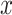 , and
, and 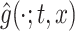 is the estimated density function obtained using the estimated mean, variance, and shape parameter functions, the integrated KL divergence (IKL) is defined as
is the estimated density function obtained using the estimated mean, variance, and shape parameter functions, the integrated KL divergence (IKL) is defined as  , where
, where 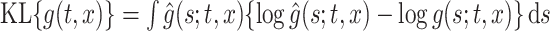 . The prediction performance is measured by the mean prediction error (MPE) calculated on a test data set with sample size 100. For the subject
. The prediction performance is measured by the mean prediction error (MPE) calculated on a test data set with sample size 100. For the subject 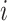 in the test data, half the locations are randomly chosen to be missing, say
in the test data, half the locations are randomly chosen to be missing, say 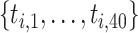 , then
, then 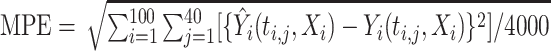 .
.
Table 1 illustrates the accuracy in estimating the model components. First, it shows numerical evidence that the proposed approach for estimating the population-level functions is consistent; see the decreased IMSE for the population-level functions and decreased IKL as the sample size increases, as shown by the columns 3–5 corresponding to cSFM. The accuracy of the model dependence estimation is confirmed by the prediction error which decreases for increased sample size (see last column for 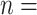 100–300). Secondly, it shows that cSFM compares favorably with the other alternatives. In particular, assuming the same semi-parametric model but not accounting for the time-varying skewness, affects slightly the estimation of the mean function, but has a pronounced negative effect on the estimation of the other components as well as on the prediction; compare the results for cSFM and
100–300). Secondly, it shows that cSFM compares favorably with the other alternatives. In particular, assuming the same semi-parametric model but not accounting for the time-varying skewness, affects slightly the estimation of the mean function, but has a pronounced negative effect on the estimation of the other components as well as on the prediction; compare the results for cSFM and 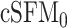 . Joint estimation of the population-level functions with regression splines (cSFM) gives more accurate estimates
. Joint estimation of the population-level functions with regression splines (cSFM) gives more accurate estimates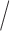 prediction than using a stepwise procedure (two-step cSFM), even the penalized splines with REML-based smoothing parameters selection is applied to estimate the mean at the first step. The main competitor is mFPCA, which uses a fully non-parametric modeling framework and accounts for the covariate solely in the mean function. The prediction performance is improved by fitting the proposed semi-parametric model with a stepwise estimation approach (two-step
prediction than using a stepwise procedure (two-step cSFM), even the penalized splines with REML-based smoothing parameters selection is applied to estimate the mean at the first step. The main competitor is mFPCA, which uses a fully non-parametric modeling framework and accounts for the covariate solely in the mean function. The prediction performance is improved by fitting the proposed semi-parametric model with a stepwise estimation approach (two-step 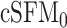 ) and even more so by using simultaneous estimation (cSFM), which accounts for the covariate dependence and time-varying skewness.
) and even more so by using simultaneous estimation (cSFM), which accounts for the covariate dependence and time-varying skewness.
Table 1.
Comparison among the proposed cSFM using regression splines and simultaneous fitting procedure, 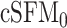 —a variant of cSFM when
—a variant of cSFM when  the two-step cSFM—a variant of cSFM using a combination of penalized splines and regression splines and stepwise fitting procedure, and mFPCA (Jiang and Wang, 2010) based on a penalized smoothing estimation procedure
the two-step cSFM—a variant of cSFM using a combination of penalized splines and regression splines and stepwise fitting procedure, and mFPCA (Jiang and Wang, 2010) based on a penalized smoothing estimation procedure
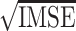 |
||||||
|---|---|---|---|---|---|---|
| Method | 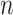 |
Mean | Log variance | Skewness | IKL | MPE |
| cSFM | 100 | 5.07 (0.17) | 453.82 (8.30) | 169.14 (5.75) | 71.07 (4.23) | 9.97 (0.10) |
 |
100 | 5.00 (0.17) | 484.81 (8.45) | 826.65 (0.00) | 356.27 (8.93) | 9.97 (0.06) |
| Two-step cSFM | 100 | 6.90 (0.15) | 545.37 (6.88) | 255.86 (7.99) | 224.3 (13.83) | 9.90 (0.06) |
| mFPCA | 100 | 6.90 (0.15) | 2769.03 (15.38) | – | – | 9.97 (0.06) |
| cSFM | 200 | 3.54 (0.11) | 287.81 (4.96) | 109.78 (3.15) | 30.54 (0.71) | 9.38 (0.05) |
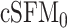 |
200 | 3.73 (0.11) | 307.21 (6.04) | 826.65 (0.00) | 313.5 (5.65) | 9.80 (0.06) |
| Two-step cSFM | 200 | 5.11 (0.11) | 439.94 (5.94) | 217.42 (6.07) | 120.78 (4.82) | 9.58 (0.06) |
| mFPCA | 200 | 5.11 (0.11) | 2792.02 (11.87) | – | – | 9.87 (0.06) |
| cSFM | 300 | 2.73 (0.09) | 224.64 (3.95) | 100.26 (2.29) | 20.31 (0.42) | 9.15 (0.06) |
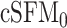 |
300 | 2.87 (0.09) | 242.81 (4.31) | 826.65 (0.00) | 318.54 (4.87) | 9.57 (0.06) |
| Two-step cSFM | 300 | 4.15 (0.09) | 384.92 (4.97) | 210.88 (5.95) | 98.48 (5.41) | 9.37 (0.06) |
| mFPCA | 300 | 4.15 (0.09) | 2782.63 (7.97) | – | – | 9.69 (0.06) |
Displayed are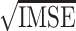 for the estimators of mean/log variance/skewness functions, integrated Kullback-Leibler (IKL) divergence of the pointwise distributions, and the mean prediction errors (MPE) for various sample sizes
for the estimators of mean/log variance/skewness functions, integrated Kullback-Leibler (IKL) divergence of the pointwise distributions, and the mean prediction errors (MPE) for various sample sizes 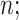 results are multiplied by
results are multiplied by  . Standard errors are reported in parenthesis.
. Standard errors are reported in parenthesis.
Table 2 assesses the performance of the cSFM with other alternatives in terms of pointwise quantile function estimation. The inappropriate normality assumption made by mFPCA leads to biased quantile estimators, especially for close-to-boundaries level of quantiles, and this is noticed by the high inaccuracy of the estimates even for large sample size (see the rows when 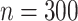 ). In contrast, by accounting for the time-varying skewness appropriately, the estimated pointwise quantile functions are very accurate, in particular for quantile levels that are close to boundaries (e.g., 95%th or 99%th quantile levels); compare the performance of cSFM and two-step cSFM with the other approaches. These findings are consistent for all the sample sizes examined. As expected, since COBS makes no parametric assumption on the underlying pointwise distribution, the accuracy of the method deteriorates greatly as the level approaches the boundaries, as fewer and fewer observations are relevant for estimation. On the other hand, the quantile estimation with cSFM relies on the estimates of population-level parameter functions, which are obtained using all data, and the accuracy of the estimates is invariant to the quantile levels. The accuracy of the quantile functions estimation with cSFM depends on the parametric assumptions. Additional numerical investigation of our procedure when the model is misspecified is included in the online Supplementary Material.
). In contrast, by accounting for the time-varying skewness appropriately, the estimated pointwise quantile functions are very accurate, in particular for quantile levels that are close to boundaries (e.g., 95%th or 99%th quantile levels); compare the performance of cSFM and two-step cSFM with the other approaches. These findings are consistent for all the sample sizes examined. As expected, since COBS makes no parametric assumption on the underlying pointwise distribution, the accuracy of the method deteriorates greatly as the level approaches the boundaries, as fewer and fewer observations are relevant for estimation. On the other hand, the quantile estimation with cSFM relies on the estimates of population-level parameter functions, which are obtained using all data, and the accuracy of the estimates is invariant to the quantile levels. The accuracy of the quantile functions estimation with cSFM depends on the parametric assumptions. Additional numerical investigation of our procedure when the model is misspecified is included in the online Supplementary Material.
Table 2.
Quantile estimation performance in terms of 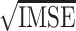
| Method | 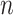 |
50% | 80% | 90% | 95% | 99% |
|---|---|---|---|---|---|---|
| cSFM | 100 | 4.81 (0.17) | 5.81 (0.18) | 6.98 (0.22) | 8.16 (0.26) | 10.83 (0.34) |
 |
100 | 6.37 (0.16) | 5.95 (0.20) | 7.54 (0.23) | 10.51 (0.26) | 18.27 (0.33) |
| Two-step cSFM | 100 | 6.71 (0.15) | 7.60 (0.15) | 8.75 (0.19) | 9.98 (0.23) | 12.78 (0.31) |
| mFPCA | 100 | 7.98 (0.15) | 14.65 (0.15) | 21.06 (0.18) | 27.07 (0.20) | 39.45 (0.25) |
| COBS | 100 | 7.28 (0.13) | 9.19 (0.17) | 11.32 (0.25) | 13.44 (0.27) | 20.89 (0.34) |
| cSFM | 200 | 3.43 (0.1) | 4.10 (0.14) | 4.92 (0.17) | 5.77 (0.19) | 7.66 (0.25) |
 |
200 | 5.5 (0.14) | 4.42 (0.14) | 5.91 (0.14) | 9.04 (0.17) | 17.03 (0.23) |
| Two-step cSFM | 200 | 4.98 (0.11) | 5.61 (0.12) | 6.44 (0.14) | 7.33 (0.16) | 9.37 (0.21) |
| mFPCA | 200 | 6.52 (0.13) | 13.98 (0.10) | 20.69 (0.11) | 26.87 (0.13) | 39.49 (0.17) |
| COBS | 200 | 4.76 (0.08) | 5.61 (0.1) | 7.12 (0.12) | 9.37 (0.15) | 17.59 (0.28) |
| cSFM | 300 | 2.67 (0.08) | 3.16 (0.10) | 3.80 (0.12) | 4.51 (0.14) | 6.18 (0.18) |
 |
300 | 4.97 (0.11) | 3.49 (0.11) | 4.93 (0.11) | 8.20 (0.13) | 16.26 (0.18) |
| Two-step cSFM | 300 | 4.09 (0.09) | 4.53 (0.10) | 5.14 (0.12) | 5.84 (0.13) | 7.55 (0.17) |
| mFPCA | 300 | 5.80 (0.11) | 13.78 (0.09) | 20.54 (0.10) | 26.73 (0.11) | 39.31 (0.14) |
| COBS | 300 | 4.04 (0.07) | 4.82 (0.08) | 6.35 (0.11) | 8.89 (0.15) | 17.13 (0.22) |
Results are displayed for quantile functions estimators at levels 50, 80, 90, 95, and 99% obtained with cSFM,  two-step cSFM, mFPCA, and COBS for various sample sizes
two-step cSFM, mFPCA, and COBS for various sample sizes 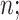 results are multiplied by
results are multiplied by  . Standard errors are reported in parenthesis.
. Standard errors are reported in parenthesis.
6. Analysis of the tractography data
Our motivating application is a brain tractography study for MS disease. Diffusion tensor imaging (DTI) is a magnetic resonance imaging technique that allows to visualize the white matter tracts of the brain and has been used extensively in the study of MS (Greven and others, 2010). In this paper, we consider two adjacent tracts: CCA, which connects the two hemispheres of the brain, and the left right cortico-spinal tracts (lCST
right cortico-spinal tracts (lCST rCST) which connects the left
rCST) which connects the left right part of the brain with the spinal cord and focus on the DTI modality that describes the amount of water diffusivity along the direction of the tract, parallel diffusivity (LO). Our goal to describe how the parallel diffusivity varies along the CCA tract, while accounting for the mean summary of the parallel diffusivity along the nearby tract, lCST (mean lCST-LO). Because the two tracts are in close proximity to one another it is expected that the behavior of the parallel diffusivity profile along CCA is affected by the mean lCST-LO.
right part of the brain with the spinal cord and focus on the DTI modality that describes the amount of water diffusivity along the direction of the tract, parallel diffusivity (LO). Our goal to describe how the parallel diffusivity varies along the CCA tract, while accounting for the mean summary of the parallel diffusivity along the nearby tract, lCST (mean lCST-LO). Because the two tracts are in close proximity to one another it is expected that the behavior of the parallel diffusivity profile along CCA is affected by the mean lCST-LO.
The study consists of DTI measurements for 160 MS subjects and 42 healthy individuals taken at the baseline visit. For each subject, the following variables are recorded: LO measurements at 93 equidistant locations along the CCA tract, and the mean summary of the LO along the lCST. Part of the data is available in the R-package refund (Crainiceanu and others, 2012). Figure 1 displays parallel diffusivity profiles along CCA, for the corresponding covariate mean lCST-LO - plotted separately for the MS group and the healthy subjects group (controls).
We take LO along CCA as the profile of interest and the mean summary of the lCST-LO as the available continuous covariate. Separately for MS and controls, consider the proposed cSFM using Gaussian copula to model the dependence. It is assumed that the mean lCST-LO affects both the mean and the variance at each location, and that 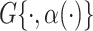 is the centered and scaled skewed normal distribution with shape parameter
is the centered and scaled skewed normal distribution with shape parameter 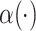 , that depends on the tract location solely. Tensor product of cubic B-splines with equal number of knots in each direction is used to model the population-level functions; let
, that depends on the tract location solely. Tensor product of cubic B-splines with equal number of knots in each direction is used to model the population-level functions; let 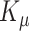 and
and  , and
, and 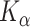 be the number of knots used in the modeling of
be the number of knots used in the modeling of 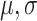 , and
, and 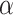 . The optimal number of knots for (
. The optimal number of knots for (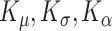 ) as selected by AIC is (9,5,4) for the MS group, and (6,3,2) for the control group. We use bootstrap by re-sampling the pairs of the subject's LO profile along the CCA plus its mean summary of the lCST-LO, to assess the variability of the estimators in each group. The results are presented for 1000 bootstraps samples.
) as selected by AIC is (9,5,4) for the MS group, and (6,3,2) for the control group. We use bootstrap by re-sampling the pairs of the subject's LO profile along the CCA plus its mean summary of the lCST-LO, to assess the variability of the estimators in each group. The results are presented for 1000 bootstraps samples.
Figure 2 shows the estimated mean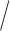 log-variance
log-variance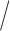 skewness functions separately for the MS and control group. The first two plots reflect different range of values for the mean summary of lCST-LO for MS patients and healthy controls. Our findings confirm prior results of Staicu and others (2012) that the overall LO exhibits a surge at the beginning of the CCA tract, followed by a slight decline and then a gradual increase towards the end of the tract, and in addition it characterizes how this behavior changes with the mean summary of the lCST-LO. The overall LO at some fixed location along the CCA tract exhibits a wavy dependence on the mean lCST-LO with multiple local moderate peak values for both groups. For MS subjects, the overall LO is decreased for values of the mean summary of the lCST-LO that are in the middle of the observed range compared with the counterparts corresponding to more extreme values of the mean summary of the lCST-LO; this is different for the control group. The rightmost plots show the estimated skewness in the two groups: using 90% pointwise bootstrap confidence intervals, we find evidence of significant pointwise skewness in the parallel diffusivity towards the end of the CCA tract, for MS patients.
skewness functions separately for the MS and control group. The first two plots reflect different range of values for the mean summary of lCST-LO for MS patients and healthy controls. Our findings confirm prior results of Staicu and others (2012) that the overall LO exhibits a surge at the beginning of the CCA tract, followed by a slight decline and then a gradual increase towards the end of the tract, and in addition it characterizes how this behavior changes with the mean summary of the lCST-LO. The overall LO at some fixed location along the CCA tract exhibits a wavy dependence on the mean lCST-LO with multiple local moderate peak values for both groups. For MS subjects, the overall LO is decreased for values of the mean summary of the lCST-LO that are in the middle of the observed range compared with the counterparts corresponding to more extreme values of the mean summary of the lCST-LO; this is different for the control group. The rightmost plots show the estimated skewness in the two groups: using 90% pointwise bootstrap confidence intervals, we find evidence of significant pointwise skewness in the parallel diffusivity towards the end of the CCA tract, for MS patients.
Fig. 2.

Estimated mean log-variance surfaces and skewness functions for MS (top panels) and control group (bottom). Pointwise 90% confidence intervals (dotted line) from 1000 bootstrap replicates are constructed for the estimated skewness function in the two groups. (a) Mean (MS), (b) log-variance (MS), (c) skewness (MS), (d) mean (control), (e) log-variance (control), and (f) skewness (control).
log-variance surfaces and skewness functions for MS (top panels) and control group (bottom). Pointwise 90% confidence intervals (dotted line) from 1000 bootstrap replicates are constructed for the estimated skewness function in the two groups. (a) Mean (MS), (b) log-variance (MS), (c) skewness (MS), (d) mean (control), (e) log-variance (control), and (f) skewness (control).
These results are investigated further via bootstrap; in particular, we examine whether there is significant difference between the corresponding various model components in the MS and control group. We consider the values for the mean summary of the lCST-LO that are common to both groups. Figure 3 shows the map with significant differences between MS and control groups corresponding to the pointwise quantile functions of levels 50, 95, and 99%, using pointwise bootstrap-based confidence intervals; results for the mean, variance and skewness are included in the Supplementary Material. It appears that for higher quantile levels—95th, 99th—the parallel diffusivity is significantly different for the MS and healthy individuals for tract locations in the second half of the CCA tract, and for mean lCST-LO levels between 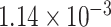 and
and 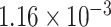 . By comparison, Staicu and others (2012) concluded that quantiles at 50th, 95th, and 99th levels are significantly different for the two groups at almost all locations along the CCA tracts. By accounting for the additional information of the mean summary of the parallel diffusivity along the lCST tract, we gain more insight into the process that describes the variation of the parallel diffusivity along the CCA, and how it is affected by the level of the mean lCST-LO. Our results indicate that when the mean lCST-LO is
. By comparison, Staicu and others (2012) concluded that quantiles at 50th, 95th, and 99th levels are significantly different for the two groups at almost all locations along the CCA tracts. By accounting for the additional information of the mean summary of the parallel diffusivity along the lCST tract, we gain more insight into the process that describes the variation of the parallel diffusivity along the CCA, and how it is affected by the level of the mean lCST-LO. Our results indicate that when the mean lCST-LO is  there is no significant difference in the overall parallel diffusivity profile along CCA between the two groups; reversed results hold for the case when the mean summary of the lCST-LO is
there is no significant difference in the overall parallel diffusivity profile along CCA between the two groups; reversed results hold for the case when the mean summary of the lCST-LO is 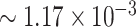 . These observations call for more formal investigations of whether the covariate has a significant effect in either the mean or the variance functions for either of the groups.
. These observations call for more formal investigations of whether the covariate has a significant effect in either the mean or the variance functions for either of the groups.
Fig. 3.

Significance maps for the difference between the MS and control based on 1000 bootstraps. Results are shown for the quantile functions at various quantile levels. The color coding is “light gray” (background) for not significant differences, “white” is for significant negative differences, and “dark” is for significant positive differences. Pointwise 90% confidence intervals from 1000 bootstrap replicates are used to measure the significance. (a) 50th quantile, (b) 95th quantile, and (c) 99th quantile.
We further conduct an out-of-sample predictive study for MS subjects, which are randomly divided into a training set (95%) and a test set (5%). The training data consist of complete and noisy subject profiles and subject covariate information, while the test data consist of incomplete and noisy profiles, with the last 10% of the tract assumed unobserved and corresponding covariate information. Prediction error is determined as in Section 5 based on 200 replications; the mean prediction error is  . By comparison, the FPCA (Yao and others, 2005) and the covariate-adjusted mFPCA (Jiang and Wang, 2010) produced higher prediction errors:
. By comparison, the FPCA (Yao and others, 2005) and the covariate-adjusted mFPCA (Jiang and Wang, 2010) produced higher prediction errors: 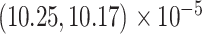 , respectively; all the three prediction errors have the maximum standard error
, respectively; all the three prediction errors have the maximum standard error 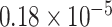 .
.
Supplementary material
Additional results on the analysis of the DTI tractgraphy data, additional numerical investigation, as well as a discussion on the validation of the model assumptions are included in the Supplementary Material which is available at http://biostatistics.oxfordjournals.org.
7. Funding
Staicu's research was supported by NSF grant DMS 1007466 and NIH grant 1R01NS085211-01. Bondell's research was supported by NSF grant DMS-1308400 and NIH grant P01-CA-142538.
Supplementary Material
Acknowledgement
The authors thank Ciprian Crainiceanu, Daniel Reich, and Peter Calabresi for the DTI dataset. The content is solely the responsibility of the authors and does not necessarily represent the social views of the National Institutes of Health. Conflict of Interest: None declared.
References
- Akaike H. (1970). Statistical predictor identification. Annals of the Institute of Statistical Mathematics 22, 203–217. [Google Scholar]
- Arellano-Valle R. B., Azzalini A. (2008). The centred parametrization for the multivariate skew-normal distribution. Journal of Multivariate Analysis 997, 1362–1382. [Google Scholar]
- Azzalini A. (1985). A class of distributions which includes the normal ones. Scandinavian Journal of Statistics 12, 171–178. [Google Scholar]
- Azzalini A. (2013). The Skew-Normal and Related Families. Cambridge: Cambridge University Press. [Google Scholar]
- Cardot H. (2007). Conditional functional principal components analysis. Scandinavian Journal of Statistics 34, 317–335. [Google Scholar]
- Crainiceanu C. M., Reiss P., Goldsmith J., Huang L., Huo L., Scheipl F. (2012). Refund: Regression with Functional Data. R package 0.1-6. http://cran.r-project.org/package=refund [Google Scholar]
- de Boor C. (2001). A Practical Guide to Splines. Applied Mathematical Sciences Springer. [Google Scholar]
- Durrett R. (2005). Probability: Theory and Examples. Duxbury Advanced Series Brooks, Cole - Thomson Learning. [Google Scholar]
- Ferraty F., Vieu P. (2006). Nonparametric Functional Data Analysis. Theory and Practice New-York: Springer. [Google Scholar]
- Gertheiss J., Maity A., Staicu A.-M. (2013). Variable selection in generalized functional linear models. Statistics. 2, 86–101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Greven S., Crainiceanu C., Caffo B., Reich D. (2010). Longitudinal functional principal component analysis. Electronic Journal of Statistics 4, 1022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- He X., Ng P. (1999). COBS: qualitatively constrained smoothing via linear programming. Computational Statistics 14, 315–338. [Google Scholar]
- Jiang C.-R., Wang J.-L. (2010). Covariate adjusted functional principal components analysis for longitudinal data. The Annals of Statistics 38, 1194–1226. [Google Scholar]
- Jiang C.-R., Wang J.-L. (2011). Functional single index models for longitudinal data. The Annals of Statistics 39, 362–388. [Google Scholar]
-
Li K. C. (1987). Asymptotic optimality for
 ,
,  , cross-validation and generalized cross-validation: discrete index set. The Annals of Statistics
15, 958–975. [Google Scholar]
, cross-validation and generalized cross-validation: discrete index set. The Annals of Statistics
15, 958–975. [Google Scholar] - McNeil A. J., Frey R., Embrechts P. (2010). Quantitative risk management: concepts, techniques, and tools. Princeton, NJ: Princeton University Press. [Google Scholar]
- Ng P. T., Maechler M. (2011). cobs: COBS – constrained B-splines (Sparse matrix based). R package version 1.2-2. http://wiki.r-project.org/rwiki/doku.php?id=packages:cran:cobs. [Google Scholar]
- Ramsay J. O., Silverman B. W. (2002). Applied Functional Data Analysis: Methods and Case Studies, vol. 77 New York: Springer. [Google Scholar]
- Ramsay J. O., Silverman B. W. (2005). Functional Data Analysis, 2nd edition New York: Springer. [Google Scholar]
- Ruppert D. (2010). Statistics and Data Analysis for Financial Engineering. Springer Texts in Statistics Springer. [Google Scholar]
- Ruppert D., Wand P., Carroll R. J. (2003). Semiparametric Regression. Cambridge Series in Statistical and Probabilistic Mathematics Cambridge University Press. [Google Scholar]
- Serban N., Staicu A.-M., Carroll J. R. (2013). Multilevel cross-dependent binary longitudinal data. Biometrics 694, 903–913. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shibata R. (1981). An optimal selection of regression variables. Biometrika 68, 45–54. [Google Scholar]
- Sklar A. (1959). Fonctions de répartition à n dimensions et leurs marges. Publications of the Institute of Statistics of the University of Paris 8, 229–231. [Google Scholar]
- Staicu A.-M., Crainiceanu C. M., Reich D. S., Ruppert D. (2012). Modeling functional data with spatially heterogeneous shape characteristics. Biometrics 68, 331–343. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang L., Brown L. D., Cai T. T., Levine M. (2008). Effect of mean on variance function estimation in nonparametric regression. The Annals of Statistics 36, 646–664. [Google Scholar]
- Wood S. N. (2011). Fast stable restricted maximum likelihood and marginal likelihood estimation of semiparametric generalized linear models. Journal of the Royal Statistical Society. B 73, 3–36. [Google Scholar]
- Yao F., Müller H.-G., Wang J.-L. (2005). Functional data analysis for sparse longitudinal data. Journal of the American Statistical Association 100, 577–590. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.