

Abstract
Many modern estimators require bootstrapping to calculate confidence intervals because either no analytic standard error is available or the distribution of the parameter of interest is non-symmetric. It remains however unclear how to obtain valid bootstrap inference when dealing with multiple imputation to address missing data. We present four methods which are intuitively appealing, easy to implement, and combine bootstrap estimation with multiple imputation. We show that three of the four approaches yield valid inference, but that the performance of the methods varies with respect to the number of imputed data sets and the extent of missingness. Simulation studies reveal the behavior of our approaches in finite samples. A topical analysis from HIV treatment research, which determines the optimal timing of antiretroviral treatment initiation in young children, demonstrates the practical implications of the four methods in a sophisticated and realistic setting. This analysis suffers from missing data and uses the g-formula for inference, a method for which no standard errors are available.
Keywords: missing data, resampling, g-methods, causal inference, HIV
1. Introduction
Multiple imputation (MI) is a popular method to address missing data. Based on assumptions about the data distribution (and the mechanism which gives rise to the missing data) missing values can be imputed by means of draws from the posterior predictive distribution of the unobserved data given the observed data. This procedure is repeated to create M imputed data sets, the analysis is then conducted on each of these data sets and the M results (M point and M variance estimates) are combined by a set of simple rules [1].
During the last 30 years a lot of progress has been made to make MI useable for different settings: implementations are available in several software packages [2, 3, 4, 5], review articles provide guidance to deal with practical challenges [6, 7, 8], non-normal –possibly categorical–variables can often successfully be imputed [9, 3, 6], useful diagnostic tools have been suggested [3, 10], and first attempts to address longitudinal data and other complicated data structures have been made [11, 4].
While both opportunities and challenges of multiple imputation are discussed in the literature, we believe an important consideration regarding the inference after imputation has been neglected so far: if there is no analytic or no ideal solution to obtain standard errors for the parameters of the analysis model, and nonparametric bootstrap estimation is used to estimate them, it is unclear how to obtain valid inference – in particular how to obtain appropriate confidence intervals. Moreover, bootstrap estimation is also often used when a parameter’s distribution is assumed to be non-normal and bootstrap inference with missing data is then not clear either. As we will explain below, many modern statistical concepts, often applied to inform policy guidelines or enhance practical developments, rely on bootstrap estimation. It is therefore necessary to have guidance for bootstrap estimation for multiply imputed data.
In general, one can distinguish between two approaches for bootstrap inference when using multiple imputation: with the first approach, M imputed datsets are created and bootstrap estimation is applied to each of them; or, alternatively, B bootstrap samples of the original data set (including missing values) are drawn and in each of these samples the data are multiply imputed. For the former approach one could use bootstrapping to estimate the standard error in each imputed data set and apply the standard MI combining rules; alternatively, the B × M estimates could be pooled and 95% confidence intervals could be calculated based on the 2.5th and 97.5th percentiles of the respective empirical distribution. For the latter approach either multiple imputation combining rules can be applied to the imputed data of each bootstrap sample to obtain B point estimates which in turn may be used to construct confidence intervals; or the B × M estimates of the pooled data are used for interval estimation.
To the best of our knowledge, the consequences of using the above approaches have not been studied in the literature before. The use of the bootstrap in the context of missing data has often been viewed as a frequentist alternative to multiple imputation [12], or an option to obtain confidence intervals after single imputation [13]. The bootstrap can also be used to create multiple imputations [14]. However, none of these studies have addressed the construction of bootstrap confidence intervals when data needs to be multiply imputed because of missing data. As emphasized above, this is however of particularly great importance when standard errors of the analysis model cannot be calculated easily, for example for causal inference estimators (e.g. the g-formula).
It is not surprising that the bootstrap has nevertheless been combined with multiple imputation for particular analyses. Multiple imputation of bootstrap samples has been implemented in [15, 16, 17, 18], whereas bootstrapping the imputed data sets was preferred by [19, 20, 21]. Other work doesn’t offer all details of the implementation [22]. All these analyses give however little justification for the chosen method and for some analyses important details on how the confidence intervals were calculated are missing; it seems that pragmatic reasons as well as computational efficiency typically guide the choice of the approach. None of the studies offer a statistical discussion of the chosen method.
The present article demonstrates the implications of different methods which combine bootstrap inference with multiple imputation. It is novel in that it introduces four different, intuitively appealing, bootstrap confidence intervals for data which require multiple imputation, illustrates their intrinsic features, and argues which of them is to be preferred.
Section 2 introduces our motivating analysis of causal inference in HIV research. The different methodological approaches are described in detail in Section 3 and are evaluated by means of both numerical investigations (Section 4) and theoretical considerations (Section 6). The implications of the different approaches are further emphasized in the data analysis of Section 5. We conclude in Section 7.
2. Motivation
During the last decade the World Health Organization (WHO) updated their recommendations on the use of antiretroviral drugs for treating and preventing HIV infection several times. In the past, antiretroviral treatment (ART) was only given to a child if his/her measurements of CD4 lymphocytes fell below a critical value or if a clinically severe event (such as tuberculosis or persistent diarrhoea) occurred. Based on both increased knowledge from trials and causal modeling studies, as well as pragmatic and programmatic considerations, these criteria have been gradually expanded to allow earlier treatment initiation in children: in 2013 it was suggested that all children who present under the age of 5 are treated immediately, while for older children CD4-based criteria still existed. By the end of 2015 WHO decided to recommend immediate treatment initiation in all children and adults. ART has shown to be effective and to reduce mortality in infants and adults [23, 24, 25], but concerns remain due to a potentially increased risk of toxicities, early development of drug resistance, and limited future options for people who fail treatment.
It remains therefore important to investigate the effect of different treatment initiation rules on mortality, morbidity and child development outcomes; however given the shift in ART guidelines towards earlier treatment initiation it is not ethically possible anymore to conduct a trial which answers this question in detail. Thus, observational data can be used to obtain the relevant estimates. Methods such as inverse probability weighting of marginal structural models, the g-computation formula, and targeted maximum likelihood estimation can be used to obtain estimates in complicated longitudinal settings where time-varying confounders affected by prior treatment are present — such as, for example, CD4 count which influences both the probability of ART initiation and outcome measures [26, 27].
In situations where treatment rules are dynamic, i.e. where they are based on a time-varying variable such as CD4 lymphocyte count, the g-computation formula [28] is the intuitive method to use. It is computationally intensive and allows the comparison of outcomes for different treatment options; confidence intervals are typically based on nonparametric bootstrap estimation. However, in resource limited settings data may be missing for administrative, logistic, and clerical reasons, as well as due to loss to follow-up and missed clinic visits. Depending on the underlying assumptions about the reasons for missing data, this problem can either be addressed by the g-formula directly or by using multiple imputation. However, it is not immediately clear how to combine multiple imputation with bootstrap estimation to obtain valid confidence intervals.
3. Methodological Framework
Let be a n × (p + 1) data matrix consisting of an outcome variable y = (y1, …, yn)′ and covariates Xj = (X1j, …, Xnj)′, j = 1, …, p. The 1 × p vector xi = (xi1, …, xip) contains the ith observation of each of the p covariates and X = (x1′, …, xn′)′ is the matrix of all covariates. Suppose we are interested in estimating θ = (θ1,…, θk)′, k ≥ 1, which may be a regression coefficient, an odds ratio, a factor loading, or a counterfactual outcome. If some data are missing, making the data matrix to consist of both observed and missing values, , and the missingness mechanism is ignorable, valid inference for θ can be obtained using multiple imputation. Following Rubin [1] we regard valid inference to mean that the point estimate for θ is approximately unbiased and that interval estimates are randomization valid in the sense that actual interval coverage equals the nominal interval coverage.
Under multiple imputation M augmented sets of data are generated, and the imputations (which replace the missing values) are based on draws from the predictive posterior distribution of the missing data given the observed data , or an approximation thereof. The point estimate for θ is
| (1) |
where refers to the estimate of θ in the mth imputed set of data , m = 1, …, M. Variance estimates can be obtained using the between imputation covariance and the average within imputation covariance :
| (2) |
For the scalar case this equates to
To construct confidence intervals for in the scalar case, it may be assumed that follows a tR-distribution with approximately degrees of freedom [29], though there are alternative approximations, especially for small samples [30]. Note that for reliable variance estimation M should not be too small; see White et al. [6] for some rules of thumb.
Consider the situation where there is no analytic or no ideal solution to estimate , for example when estimating the treatment effect in the presence of time-varying confounders affected by prior treatment using g-methods [31, 26]. If there are no missing data, bootstrap percentile confidence intervals may offer a solution: based on B bootstrap samples , b = 1, …, B, we obtain B point estimates . Consider the ordered set of estimates , where ; the bootstrap 1 − 2α% confidence interval for θ is then defined as
where denotes the α-percentile of the ordered bootstrap estimates . However, in the presence of missing data the construction of confidence intervals is not immediately clear as corresponds to M estimates , i.e. is the point estimate calculated from the mth imputed data set. It seems intuitive to consider the following four approaches:
- Method 1, MI Boot (pooled sample [PS]): Multiple imputation is utilized for the data set . For each of the M imputed data sets , B bootstrap samples are drawn which yields M × B data sets ; b = 1, …, B; m = 1, …, M. In each of these data sets the quantity of interest is estimated, that is . The pooled sample of ordered estimates is used to construct the 1 − 2α% confidence interval for θ:
where is the α-percentile of the ordered bootstrap estimates .(3) Method 2, MI Boot: Multiple imputation is utilized for the data set . For each of the M imputed data sets , B bootstrap samples are drawn which yields M × B data sets ; b = 1, …, B; m = 1, …, M. The bootstrap samples are used to estimate the standard error of (each scalar component of) in each imputed data set respectively, i.e. with . This results in M point estimates (calculated from the imputed, but not yet bootstrapped data), and M standard errors (calculated from the respective bootstrap samples). One can thus calculate standard multiple imputation confidence intervals, possibly based on a tR-distribution, as explained above.
- Method 3, Boot MI (pooled sample [PS]): B bootstrap samples (including missing data) are drawn and multiple imputation is utilized in each bootstrap sample. Therefore, there are B × M imputed data sets which can be used to obtain the corresponding point estimates . The set of the pooled ordered estimates can then be used to construct the 1 − 2α% confidence interval for θ:
where is the α-percentile of the ordered bootstrap estimates .(4) - Method 4, Boot MI: B bootstrap samples (including missing data) are drawn, and each of them is imputed M times. Therefore, there are M imputed data sets, , which are associated with each bootstrap sample . They can be used to obtain the corresponding point estimates . Thus, applying (1) to the estimates of each bootstrap sample yields B point estimates for θ. The set of ordered estimates can then be used to construct the 1 − 2Pα% confidence interval for θ:
where is the α-percentile of the ordered bootstrap estimates .(5)
While all of the methods described above are straightforward to implement it is unclear if they yield valid inference, i.e. if the actual interval coverage level equals the nominal coverage level. Before we delve into some theoretical and practical considerations we expose some of the intrinsic features of the different interval estimates using Monte Carlo simulations.
4. Simulation Studies
To study the performance of the methods introduced above we consider four simulation settings: a simple one, to ensure that these comparisons are not complicated by the simulation setup; a more complicated one, to study the four methods under a more sophisticated variable dependence structure; a survival analysis setting to allow comparisons beyond a linear regression setup; and a complex longitudinal setting where time-dependent confounding (affected by prior treatment) is present, to allow comparisons to our data analysis in Section 5.
Setting 1
We simulate a normally distributed variable X1 with mean 0 and variance 1. We then define μy = 0 + 0.4X1 and θ = βtrue = (0, 0.4)′. The outcome is generated from N(μy, 2) and the analysis model of interest is the linear model. Values of X1 are defined to be missing with probability
With this, about 16% of values of X1 were missing (at random).
Setting 2
The observations for 6 variables are generated using the following normal and Bernoulli distributions: X1 ~ N(0, 1), X2 ~ N(0, 1), X3 ~ N(0, 1), X4 ~ B(0.5), X5 ~ B(0.7), and X6 ~ B(0.3). To model the dependency between the covariates we use a Clayton Copula [32] with a copula parameter of 1 which indicates moderate correlations among the covariates. We then define μy = 3 − 2X1 + 3X3 − 4X5 and θ = βtrue = (3, −2, 0, 3, 0, −4, 0)′. The outcome is generated from N(μy, 2) and the analysis model of interest is the linear model. Values of X1 and X3 are defined to be missing (at random) with probabilities
where a and b equate to 0.75 and 0.25 in a low missingness setting (and to 0.4 and 2.5 in a high missingness setting). This yields about 6% and 14% (45% and 38%) of missing values for X1 and X3 respectively.
Setting 3
This setting is inspired by the analysis and data in Schomaker et al. [33]. We simulate X1 ~ logN(4.286, 1.086) and X2 ~ logN(10.76, 1.8086). Again, the dependency of the variables is modeled with a Clayton copula with a copula parameter of 1. Survival times y are simulated from − log(U)/h0{exp(Xβ)} where U is drawn from a distribution that is uniform on the interval [0, 1], h0 = 0.1, and the linear predictor Xβ is defined as −0.3 ln X1 + 0.3 log10 X2. Therefore, βtrue = (−0.3, 0.3)′. Censoring times are simulated as − log(U)/0.2. The observed survival time T is thus min(y, C). Values of X1 are defined to be missing based on the following function:
This yields about 8% of missing values.
Setting 4
This setting is inspired by our data analysis from Section 5. We generate longitudinal data (t = 0, 1, …, 12) for 3 time-dependent confounders , an outcome (Yt), an intervention (At), as well as baseline data for 7 variables, using structural equation models [34]. The data generating mechanism and the motivation thereof is described in Appendix B. In this simulation we are interested in a counterfactual outcome Yt which would have been observed under 2 different intervention rules , j = 1, 2, which assign treatment (At) always or never. We denote these target quantities as ψ1 and ψ2 and their true values are −1.03 and −2.45 respectively. They can be estimated using the sequential g-formula, with bootstrap confidence intervals, see Appendix A for more details.
Values of , , , Yt are set to be missing based on a MAR process as described in Appendix B. This yields about 10%, 31%, 22% and 44% of missing baseline values, and 10%, 1%, 1%, and 2% of missing follow-up values.
In all 4 settings multiple imputation is utilized with Amelia II under a joint modeling approach, see Honaker et al. [3] and Section 6 for details. In settings 1-3 the probability of a missing observation depends on the outcome. One would therefore expect parameter estimates in a regression model of a complete case analysis to be biased, but estimates following multiple imputation to be approximately unbiased [35, 36].
We estimate the confidence intervals for the parameters of interest using the aforementioned four approaches, as well as using the analytic standard errors obtained from the linear model and the Cox proportional hazards model (method “no bootstrap”) for the first three settings. The “no bootstrap” method serves therefore as a gold standard and reference for the other methods. We generate n = 1000 observations, B = 200 bootstrap samples, and M = 10 imputations. Based on ℛ = 1000 simulation runs we evaluate the coverage probability and median width of the respective confidence intervals.
Results
The computation time for Boot MI was always greater than for MI Boot, for example by a factor of 13 in the first simulation setting and by a factor of 1.3 in the fourth setting.
In all settings the point estimates for β were approximately unbiased.
Table 1 summarizes the main results of the simulations. Using no bootstrapping yields estimated coverage probabilities of about 95%, for all parameters and settings, as one would expect.
Table 1.
Results of the simulation studies: estimated coverage probability (top), median confidence intervals width (middle), and standard errors for different methods (bottom). The bottom panel lists standard errors estimated from the 1000 point estimates of the simulation (“simulated”) and the mean estimated standard error across the simulated data sets, for both the analytical standard error (“no bootstrap”) and the bootstrap standard error (“MI Boot”). All results are based on 200 bootstrap samples and 10 imputations.
| Method | Setting 1 | Setting 2 (low missingness) | Setting 3 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| β1 | β1 | β2 | β3 | β4 | β5 | β6 | β1 | β2 | ||
| Coverage Probability | 1) MI Boot (PS) | 93% | 95% | 95% | 94% | 94% | 95% | 95% | 95% | 95% |
| 2) MI Boot | 95% | 95% | 95% | 95% | 94% | 95% | 95% | 95% | 95% | |
| 3) Boot MI (PS) | 97% | 96% | 95% | 96% | 95% | 96% | 96% | 96% | 96% | |
| 4) Boot MI | 94% | 94% | 94% | 94% | 94% | 94% | 94% | 94% | 94% | |
| 5) no bootstrap | 95% | 95% | 95% | 95% | 95% | 95% | 96% | 95% | 95% | |
|
| ||||||||||
| Median CI Width | 1) MI Boot (PS) | 0.30 | 0.33 | 0.33 | 0.33 | 0.60 | 0.68 | 0.62 | 0.25 | 0.31 |
| 2) MI Boot | 0.31 | 0.34 | 0.34 | 0.34 | 0.61 | 0.69 | 0.63 | 0.26 | 0.31 | |
| 3) Boot MI (PS) | 0.35 | 0.36 | 0.35 | 0.35 | 0.64 | 0.72 | 0.66 | 0.26 | 0.31 | |
| 4) Boot MI | 0.30 | 0.33 | 0.33 | 0.33 | 0.60 | 0.67 | 0.62 | 0.24 | 0.30 | |
| 5) no bootstrap | 0.31 | 0.34 | 0.34 | 0.34 | 0.61 | 0.69 | 0.63 | 0.25 | 0.31 | |
|
| ||||||||||
| Std. Error | simulated | 0.08 | 0.09 | 0.09 | 0.09 | 0.16 | 0.18 | 0.16 | 0.06 | 0.08 |
| no bootstrap | 0.08 | 0.09 | 0.09 | 0.09 | 0.16 | 0.18 | 0.16 | 0.06 | 0.08 | |
| MI Boot | 0.08 | 0.09 | 0.09 | 0.09 | 0.16 | 0.18 | 0.16 | 0.07 | 0.08 | |
|
| ||||||||||
| Method | Setting 2 (high missingness) | Setting 4 | ||||||||
|
| ||||||||||
| β1 | β2 | β3 | β4 | β5 | β6 | ψ1 | ψ2 | |||
|
| ||||||||||
| Coverage Probability | 1) MI Boot (PS) | 89% | 91% | 92% | 91% | 92% | 92% | 94% | 94% | |
| 2) MI Boot | 91% | 93% | 94% | 94% | 94% | 94% | 94% | 94% | ||
| 3) Boot MI (PS) | 96% | 97% | 98% | 98% | 97% | 98% | 94% | 94% | ||
| 4) Boot MI | 90% | 93% | 93% | 95% | 94% | 94% | 94% | 92% | ||
| 5) no bootstrap | 91% | 93% | 94% | 94% | 94% | 94% | – | – | ||
|
| ||||||||||
| Median CI Width | 1) MI Boot (PS) | 0.44 | 0.40 | 0.44 | 0.79 | 0.87 | 0.78 | 0.20 | 0.21 | |
| 2) MI Boot | 0.48 | 0.44 | 0.49 | 0.87 | 0.95 | 0.86 | 0.20 | 0.22 | ||
| 3) Boot MI (PS) | 0.58 | 0.51 | 0.59 | 1.03 | 1.12 | 1.01 | 0.21 | 0.23 | ||
| 4) Boot MI | 0.47 | 0.43 | 0.47 | 0.84 | 0.92 | 0.82 | 0.20 | 0.22 | ||
| 5) no bootstrap | 0.48 | 0.44 | 0.49 | 0.87 | 0.95 | 0.86 | – | – | ||
|
| ||||||||||
| Std. Error | simulated | 0.12 | 0.11 | 0.12 | 0.22 | 0.24 | 0.21 | – | – | |
| no bootstrap | 0.12 | 0.12 | 0.12 | 0.22 | 0.24 | 0.22 | – | – | ||
| MI Boot | 0.12 | 0.11 | 0.12 | 0.22 | 0.24 | 0.21 | – | – | ||
Bootstrapping the imputed data (MI Boot, MI Boot [PS]) yields estimated coverage probabilities of about 95% and confidence interval widths which are similar to each other, except for the high missingness setting of simulation 2. The standard errors for each component of β as simulated in the 1000 simulation runs were almost identical to the mean estimated standard errors under MI Boot, which suggests good standard error estimation of the latter approach. In the first simulation setting the coverage of MI Boot pooled is a bit too low for M = 10 (93%), but is closer to 95% if M is large (M = 20, Figure 1).
Figure 1.
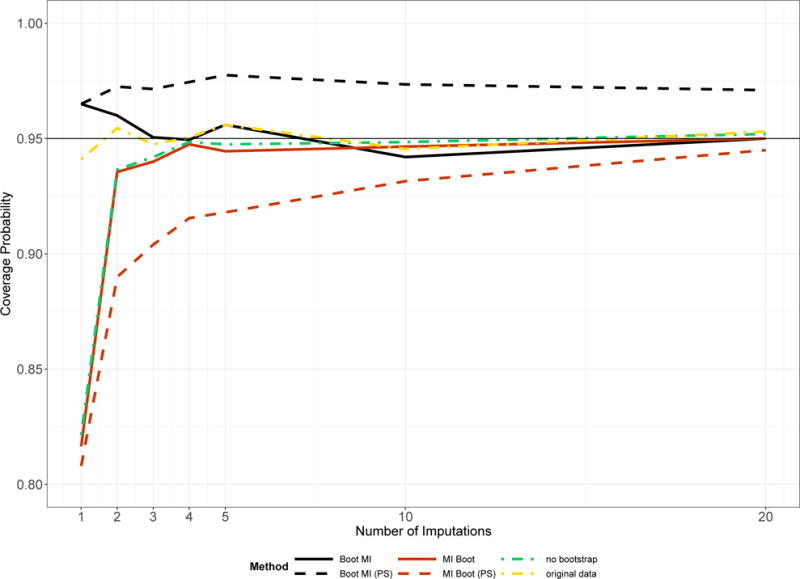
Coverage probability of the interval estimates for β1 in the first simulation setting dependent on the number of imputations. Results related to the complete simulated data, i.e. before missing data are generated, are labelled “original data”.
Imputing the bootstrapped data (Boot MI, Boot MI [PS]) led to overall good results with coverage probabilities close to the nominal level, except for the high missingness setting of simulation 2; however, using the pooled samples led to somewhat higher coverage probabilities and the interval widths were slightly different from the estimates obtained under no bootstrapping.
Figure 1 shows the coverage probability of the interval estimates for β1 in the first simulation setting given the number of imputations.
As predicted by MI theory, using multiple imputation needs generally a reasonable amount of imputed data sets to perform well – no matter whether bootstrapping is used for standard error estimation or not (MI Boot, no bootstrap). Boot MI may perform well even for M < 5, but the pooled approach has a tendency towards coverage probabilities > 95%. For M = 1 the estimated coverage probability of Boot MI is too large in the above setting.
Figure 2 offers more insight into the behaviour of ‘Boot MI (PS)’ and ‘MI Boot (PS)’ by visualizing both the bootstrap distributions in each imputed data set (method MI Boot [PS]) as well as the distribution of the estimators in each bootstrap sample (method Boot MI [PS]): one can see the slightly wider spectrum of values in the distributions related to ‘Boot MI (PS)’ explaining the somewhat larger confidence interval in the first simulation setting.
Figure 2.
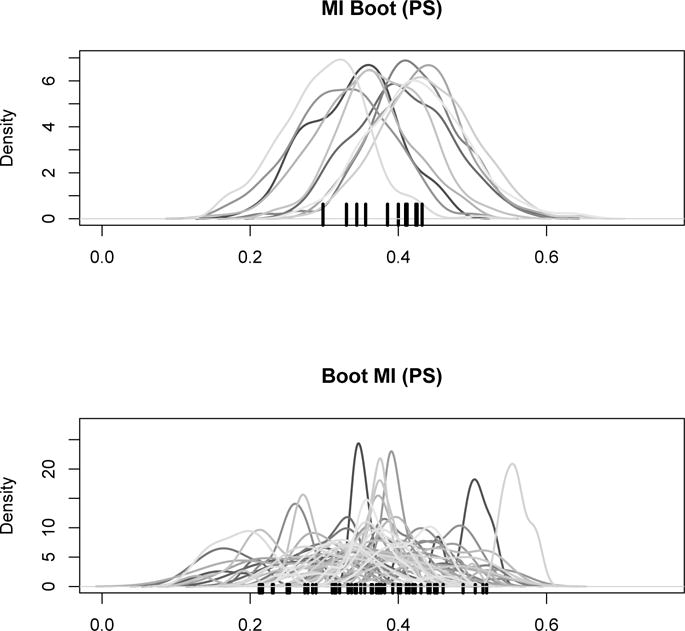
Estimate of β1 in the first simulation setting, for a random simulation run: distribution of ‘MI Boot (pooled)’ for each imputed dataset (top) and distribution of ‘Boot MI (PS)’ for 50 random bootstrap samples (PS). Point estimates are marked by the black tick marks on the x-axis.
More explanations and interpretations of the above results are given in Section 6.
5. Data Analysis
Consider the motivating question introduced in Section 2. We are interested in comparing mortality with respect to different antiretroviral treatment strategies in children between 1 and 5 years of age living with HIV. We use data from two big HIV treatment cohort collaborations (IeDEA-SA, [37]; IeDEA-WA, [38]) and evaluate mortality for 3 years of follow-up. Our analysis builds on a recently published analysis by Schomaker et al. [17].
For this analysis, we are particularly interested in the cumulative mortality difference between strategies (i) ‘immediate ART initiation’ and (ii) ‘assign ART if CD4 count < 350 cells/mm3 or CD4% < 15%’, i.e. we are comparing current practices with those in place in 2006. We can estimate these quantities using the g-formula, see Appendix A for a comprehensive summary of our implementation details and assumptions. The standard way to obtain 95% confidence intervals for this method is using bootstrapping. However, baseline data of CD4 count, CD4%, HAZ, and WAZ are missing: 18%, 28%, 40%, and 25% respectively. We use multiple imputation (using Amelia II [3]) to impute this data. We also impute follow-up data after nine months without any visit data, as from there on it is plausible that follow-up measurements that determine ART assignment (e.g. CD4 count) were taken (and are thus needed to adjust for time-dependent confounding) but were not electronically recorded, probably because of clerical and administrative errors. Under different assumptions imputation may not be needed. To combine the M = 10 imputed data sets with bootstrap estimation (B = 200) we use the four approaches introduced in Section 3: MI Boot, MI Boot (PS), Boot MI, and Boot MI (PS).
Three year mortality for immediate ART initiation was estimated as 6.08%, whereas mortality for strategy (ii) was estimated as 6.87%. This implies a mortality difference of 0.79%. The results of the respective confidence intervals are summarized in Figure 3: the estimated mortality differences are [−0.34%; 1.61%] for Boot MI (PS), [0.12%; 1.07%] for Boot MI, [−0.31%; 1.63%] for MI Boot (PS), and [−0.81%; 2.40%] for MI Boot.
Figure 3.
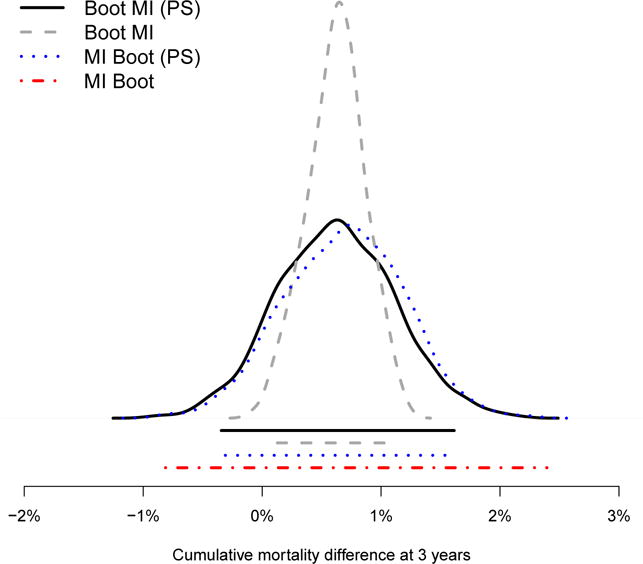
Estimated cumulative mortality difference between the interventions ‘immediate ART’ and ‘350/15’ at 3 years: distributions and confidence intervals of different estimators
Figure 3 shows that the confidence intervals vary with respect to the different approaches: the shortest interval is produced by the method Boot MI. Note that only for this method the 95% confidence interval does not contain the 0% when estimating the mortality difference, and therefore suggests a beneficial effect of immediate treatment initiation. The distributions of for Boot MI (PS) and MI Boot (PS), as well as the distribution of for Boot MI, are also visualized in the figure and are reasonably symmetric.
Figure 4 visualizes both the bootstrap distributions in each imputed data set (method MI Boot [PS]) as well as the distribution of the estimators in each bootstrap sample (method Boot MI [PS]). It is evident that the overall variation of the estimates is similar for these two approaches considered, which explains why their confidence intervals in Figure 3 are almost identical. Moreover, and of note, the top panel highlights the large variability of the point estimates used for the calculation of the MI Boot estimator. The graph indicates a large between imputation uncertainty of the point estimates, possibly due to the high missingness and complex imputation procedure. The large confidence interval of MI Boot in Figure 3, based on formula (2), reflects this uncertainty.
Figure 4.
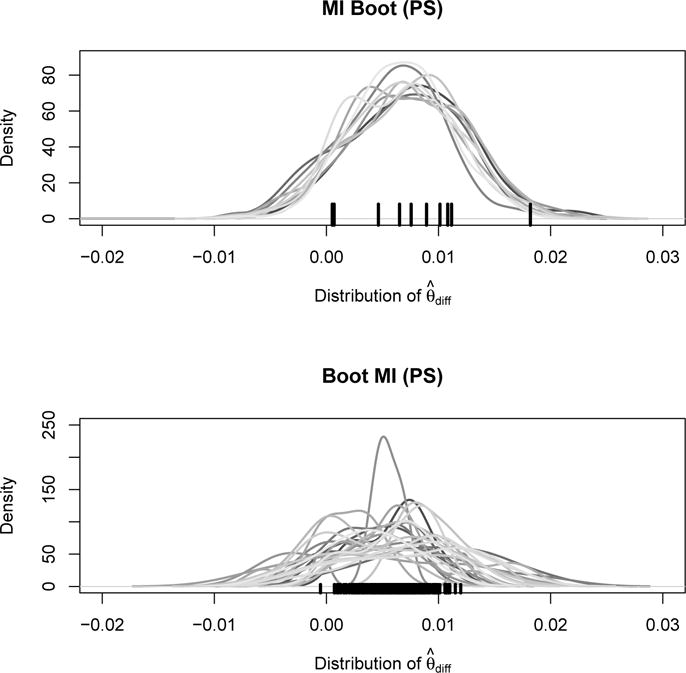
Estimated cumulative mortality difference: distribution of ‘MI Boot (PS)’ for each imputed dataset (top) and distribution of ‘Boot MI (PS)’ for 25 random bootstrap samples (bottom). Point estimates are marked by the black tick marks on the x-axis.
In summary, the above analyses suggest a beneficial effect of immediate ART initiation compared to delaying ART until CD4 count < 350 cells/mm3 or CD4% < 15% when using method 3, Boot MI. The other methods produce larger confidence intervals and do not necessarily suggest a clear mortality difference.
6. Theoretical Considerations
For the purpose of inference we are interested in the observed data posterior distribution of which is
| (6) |
Please note that ϑ refers to the parameters of the imputation model whereas θ is the quantity of interest from the analysis model. With multiple imputation we effectively approximate the integral (6) by using the average
| (7) |
where refers to draws (imputations) from the posterior predictive distribution .
MI Boot and MI Boot (PS)
The MI Boot method essentially uses rules (1) and (2) for inference, where, for a given scalar, the respective variance in each imputed data set is not calculated analytically but using bootstrapping. This approach will work if the bootstrap variance for the imputed data set is close to the analytical variance. If there is no analytical variance, it all depends on various factors such as sample size, estimator of interest, proportion of missing data, and others. The data example highlights that in complex settings with a lot of missing data the between imputation variance can be large, yielding conservative interval estimates. As well-known from MI theory M should, in many settings, be much larger than 5 for good estimates of the variance [14]. Using bootstrapping to estimate the variance does not alter these conclusions. Using MI Boot should always be complemented with a reasonably large number of imputations. This consideration also applies to MI Boot (PS), which –as seen in the simulations–, can sometimes be even more sensitive to the choice of M.
Boot MI and Boot MI (PS)
Boot MI uses for bootstrapping. Most importantly, we estimate θ, the quantity of interest, in each bootstrap sample using multiple imputation. We therefore approximate P (θ|Dobs) through (6) by using multiple imputation to obtain and bootstrapping to estimate its distribution – which is valid under the missing at random assumption.
However, if we simply pool the data and apply the method Boot MI (PS) we essentially pool all estimates : with this approach each of the B × M estimates serves then as an estimator of θ (as we do not combine/average any of them). A possible interpretation of this observation is that each estimates θ and since this is only a single draw from the posterior predictive distribution we conduct multiple imputation with M = 1, i.e. we calculate , B × M times. Such an estimator is statistically inefficient as we know from MI theory: the relative efficiency of an MI based estimator (compared to the true variance) is where γ describes the fraction of missingness (i.e. V/(W + V)) in the data. For example, if the fraction of missingness is 0.25, and M = 5, then the loss of efficiency is 5% [6]. The lower M, the lower the efficiency, and thus the higher the variance. This explains the results of the simulation studies: pooling the estimates is inefficient, does therefore overestimate the variance, and thus leads to confidence intervals with incorrect coverage.
It follows that one typically gets larger interval estimates when using Boot MI (PS) instead of Boot MI. Similarly, one can decide to use Boot MI with M = 1, which is not incorrect but often inefficient in terms of interval estimation.
Comparison
General comparisons between MI Boot and Boot MI are difficult because the within and between imputation uncertainty, as well as the within and between bootstrap sampling uncertainty, will determine the actual width of a confidence interval. If the between imputation uncertainty is large compared to between bootstrap sample uncertainty (as, for example, in the data example [Figure 4]) then MI Boot is large compared to Boot MI. However, if the between imputation uncertainty is small relative to the bootstrap sampling uncertainty, then Boot MI may give a similar confidence interval to MI Boot (as in the simulations [Figure 2]).
Another consideration is related to the application of the bootstrap. We have focused on the percentile method to create confidence intervals. However, it is also possible to create bootstrap intervals based on the t–distribution. Here, an estimator’s variance is estimated with the sample variance from the B bootstrap estimates and symmetric confidence intervals are generated based on an appropriate t-distribution. In fact, MI Boot uses this approach because in each imputed dataset we estimate the bootstrap variance , then calculate (2), followed by confidence intervals based on a tR distribution, see Section 3. A similar approach would be possible when applying Boot MI. This method produces B point estimates for θ. One could estimate the variance as , with , and then create confidence intervals based on a t-distribution. This would however require that one assumes the estimator to be approximately normally distributed.
Bootstrapping as part of the imputation procedure
For each of the estimators introduced in Section 3, M proper multiply imputed data sets are needed. “Proper” means that the application of formulae (1) and (2) yield 1) approximately unbiased point estimates and 2) interval estimates which are randomization valid in the sense that actual interval coverage equals the nominal interval coverage. Some imputation algorithms use bootstrapping to create proper imputations, and this may not be confused with the bootstrapping step after multiple imputation which we focus on in this paper.
To follow this argument in more detail it is important to understand that proper imputations are created by means of random draws from the posterior predictive distribution of the missing data given the observed data (or an approximation thereof). These draws can (i) either be generated by specifying a multivariate distribution of the data (joint modeling) and simulate the posterior predictive distribution with a suitable algorithm; or (ii) by specifying individual conditional distributions for each variable Xj given the other variables (fully conditional modeling) and iteratively drawing and updating imputed values from these distributions which will then (ideally) converge to draws of the theoretical joint distribution; or (iii) by the use of alternative algorithms.
An example for (i) is the EMB algorithm from the R-package Amelia II which assumes a multivariate normal distribution for the data, (possibly after suitable transformations beforehand). Then, B bootstrap samples of the data (including missing values) are drawn and in each bootstrap sample the EM algorithm [39] is applied to obtain estimates of μ and Σ which can then be used to generate proper multiple imputations by means of the sweep-operator [40, 11]. Of note, the algorithm can handle highly skewed variables by imposing transformations on variables (log, square root). Categorical variables are recoded into dummy variables based on the knowledge that for binary variables the multivariate normal assumption can yield good results [9].
An example for (ii) is imputation by chained equations (ICE, mice). Here, (a) one first specifies individual conditional distributions (i.e. regression models) p(Xj|X−j, θj) for each variable. Then, (b) one iteratively fits all regression models and generates random draws of the coefficients, e.g. . Values are (c) imputed as random draws from the distribution of the regression predictions. Then, (b) and (c) are repeated k times until convergence. The process of iteratively drawing and updating the imputed values from the conditional distributions can be viewed as a Gibbs sampler that converges to draws from the (theoretical) joint distribution. This method is among the most popular ones in practice and has been implemented in many software packages [4, 5]. However, there remain theoretical concerns as a joint distribution may not always exist for a given specifications of the conditional distributions [41]. A variation of (c) is a fully Bayesian approach where the posterior predictive distribution is used to draw imputations. Here, the bootstrap is used to model the imputation uncertainty and to draw the M imputations needed for the M imputed data sets. This variation yields approximate proper imputations and is implemented in the R library Hmisc [42].
An example for (iii) is the Approximate Bayesian Bootstrap [29]. Here, the (cross-sectional) data is stratified into several strata, possibly by means of the covariates of the analysis model. Then, within each stratum (a) one draws a bootstrap sample among the complete data (with respect to the variable to be imputed). Secondly, (b) one uses the original data set (with missing values) and imputes the missing data based on units from the data set created in (a), with equal selection probability and with replacement. The multiply imputed data are obtained by repeating (a) and (b) M times.
It is evident from the above examples that many imputation methods use bootstrap methodology as part of the imputation model, that this does not replace the additional bootstrap step needed for the inference in the analysis model, and that – if they are combined – the resampling steps are nested.
7. Conclusion
The current statistical literature is not clear on how to combine bootstrap with multiple imputation inference. We have proposed that a number of approaches are intuitively appealing and three of them are correct: Boot MI, MI Boot, MI Boot (PS). Using Boot MI (PS) can lead to too large and invalid confidence intervals and is therefore not recommended.
Both Boot MI and MI Boot are probably the best options to calculate randomization valid confidence intervals when combining bootstrapping with multiple imputation. As a rule of thumb, our analyses suggest that the former may be preferred for small M or large imputation uncertainty and the latter for normal M and little/normal imputation uncertainty.
There are however other considerations when deciding between MI Boot and Boot MI. The latter is computationally much more intensive. This matters particularly when estimating the analysis model is simple in relation to creating the imputations. In fact, in our first simulation this affected the computation time by a factor of 13. However, MI Boot naturally provides symmetrical confidence intervals. These intervals may not be wanted if an estimator’s distribution is suspected to be non-normal.
Acknowledgments
We thank Jonathan Bartlett for his very valuable feedback on an earlier version of this paper. We gratefully acknowledge Mary-Ann Davies and Valeriane Leroy who contributed to the analysis and study design of the data analysis. We further thank Lorna Renner, Shobna Sawry, Sylvie N’Gbeche, Karl-Günter Technau, Francois Eboua, Frank Tanser, Haby Sygnate-Sy, Sam Phiri, Madeleine Amorissani-Folquet, Vivian Cox, Fla Koueta, Cleophas Chimbete, Annette Lawson-Evi, Janet Giddy, Clarisse Amani-Bosse, and Robin Wood for sharing their data with us. We would also like to highlight the support of the Pediatric West African Group and the Paediatric Working Group Southern Africa. The NIH has supported the above individuals, grant numbers 5U01AI069924-05 and U01AI069919.
A. Details of the G-formula Implementation
We consider n children studied at baseline (t = 0) and during discrete follow-up times (t = 1, …, T). The data consists of the outcome Yt, an intervention variable At, q time-dependent covariates , and a censoring indicator Ct. The covariates may also include baseline variables . The treatment and covariate history of an individual i up to and including time t is represented as Āt,i = (A0,i, …, At,i) and respectively. Ct equals 1 if a subject gets censored in the interval (t − 1, t], and 0 otherwise. Therefore, is the event that an individual remains uncensored until time t.
The counterfactual outcome refers to the hypothetical outcome that would have been observed at time t if subject i had received, possibly contrary to the fact, the treatment history Āt,i = āt. Similarly, are the counterfactual covariates related to the intervention Āt,i = āt. The above notation refers to static treatment rules; a treatment rule may, however, depend on covariates, and in this case it is called dynamic. A dynamic rule assigns treatment At,i ∈ {0, 1} as a function of the covariate history . The vector of decisions dt, t = 0, …, T, is denoted as . The notation refers to the treatment history up to time t according to the rule . The counterfactual outcome related to a dynamic rule is , and the counterfactual covariates are .
In our setting we study n = 5826 children for t = 0, 1, 3, 6, 9, … where the follow-up time points refer to the intervals (0, 1.5), [1.5, 4.5), [4.5, 7.5), …, [28.5, 31.5), [31.5, 36) months respectively. Follow-up measurements, if available, refer to measurements closest to the middle of the interval. In our data Yt refers to death at time t (i.e. occurring during the interval (t − 1, t]). At refers to antiretroviral treatment (ART) taken at time t. are CD4 count, CD4%, and weight for age z-score (WAZ, which serves as a proxy for WHO stage, see [43] for more details) as well as three indicator variables whether these variables have been measured at time t or not. refer to baseline values of CD4 count, CD4%, WAZ, height for age z-score (HAZ) as well as sex, age, and region. The two treatment rules of interest are:
The quantity of interest is cumulative mortality after T = 36 months, under (the intervention of) no censoring, regular 3 monthly follow-up and for treatment assignment according to , that is .
Under the assumption of consistency, i.e. if and if , sequential conditional exchangeability (or no unmeasured confounding), i.e. for , , t ∈ {0, …, T} and positivity, i.e. for ∀t, , with , the g-computation formula can estimate ψ as:
| (8) |
see [23] and [44] about more details and implications of the representation of the g-formula in this context. Note that the inner product of (8) can be written as
In the above representation of the g-formula we assume that the time ordering is .
There is no closed form solution to estimate (8), but ψ can be approximated by means of the following algorithm; Step 1: use additive linear and logistic regression models to estimate the conditional densities on the right hand side of (8), i.e. fit regression models for the outcome variables CD4 count, CD4%, WAZ, and death at t = 1, 3, .., 36 using the available covariate history and model selection. Step 2: use the models fitted in step 1 to stochastically generate Lt and Yt under a specific treatment rule. For example, for rule (ii), draw from a normal distribution related to the respective additive linear model from step 1 using the relevant covariate history data. Set A1 = 1 if the generated CD4 count at time 1 is < 350 cells/mm3 or CD4% < 15% (for rule ). Use the simulated covariate data and treatment as assigned by the rule to generate the full simulated data set forward in time and evaluate cumulative mortality after 3 years of follow-up. We refer the reader to [17], [23], and [44] to learn more about the g-formula in this context.
Note that the so-called sequential g-formula, used in the simulation study, shares the idea of standardization in the sense that one sequentially marginalizes the distribution with respect to L given the intervention rule of interest. It is just a re-expression of (8) where integration with respect L is not needed [45]:
| (9) |
B. Data Generating Process in the Simulation Study
Both baseline data (t = 0) and follow-up data (t = 1, …, 12) were created using structural equations using the R-package simcausal [34]. The below listed distributions, listed in temporal order, describe the data-generating process. Baseline data refers to region, sex, age, CD4 count, CD4%, WAZ and HAZ respectively (V1, V2, V3, , , , Y0). Follow-up data refers to CD4 count, CD4%, WAZ and HAZ ( , , , Yt), as well as an antiretroviral treatment (At) and censoring (Ct) indicator. For simplicity, no deaths are assumed. In addition to Bernoulli (B), uniform (U) and normal (N) distributions, we also use truncated normal distributions which are denoted by N[a,b] where a and b are the truncation levels. Values which are smaller a are replaced by a random draw from a U(a1, a2) distribution and values greater than b are drawn from a U(b1, b2) distribution. Values for (a1, a2, b1, b2) are (0, 50, 5000, 10000) for L1, (0.03, 0.09, 0.7, 0.8) for L2, and (−10, 3, 3, 10) for both L3 and Y. The notation means “conditional on the data that has already been measured (generated) according the the time ordering”. The distributions are as follows:
For t = 0:
For t > 0:
The data generating process leads to the following baseline values: region A = 75.5%; male sex = 51.2%; mean age = 3.0 years; mean CD4 count = 672.5; mean CD4% = 15.5%; mean WAZ = −1.5; mean HAZ = −2.5. At t = 12 the arithmetic mean of CD4 count, CD4%, WAZ and HAZ are 1092, 27.2%, −0.8, −1.5 respectively. The target quantities ψ1 and ψ2 are defined as the expected value of Y at time T, under no censoring, for a given treatment rule , where
and are −1.03 and −2.45 respectively. Missing baseline and follow-up data were created based on the following functions:
References
- 1.Rubin DB. Multiple imputation after 18+ years. Journal of the American Statistical Association. 1996;91(434):473–489. [Google Scholar]
- 2.Horton NJ, Kleinman KP. Much ado about nothing: a comparison of missing data methods and software to fit incomplete regression models. The American Statistician. 2007;61:79–90. doi: 10.1198/000313007X172556. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Honaker J, King G, Blackwell M. Amelia II: A program for missing data. Journal of Statistical Software. 2011;45(7):1–47. [Google Scholar]
- 4.van Buuren S, Groothuis-Oudshoorn K. mice: Multivariate imputation by chained equations in R. Journal of Statistical Software. 2011;45(3):1–67. [Google Scholar]
- 5.Royston P, White IR. Multiple imputation by chained equations (mice): Implementation in Stata. Journal of Statistical Software. 2011;45(4):1–20. [Google Scholar]
- 6.White IR, Royston P, Wood AM. Multiple imputation using chained equations. Statistics in medicine. 2011;30:377–399. doi: 10.1002/sim.4067. [DOI] [PubMed] [Google Scholar]
- 7.Sterne JAC, White IR, Carlin JB, Spratt M, Royston P, Kenward MG, Wood AM, Carpenter JR. Multiple imputation for missing data in epidemiological and clinical research: potential and pitfalls. British Medical Journal. 2009;339 doi: 10.1136/bmj.b2393. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Graham JW. Missing data analysis: Making it work in the real world. Annual Review of Psychology. 2009;60:549–576. doi: 10.1146/annurev.psych.58.110405.085530. [DOI] [PubMed] [Google Scholar]
- 9.Schafer J, Graham J. Missing data: our view of the state of the art. Psychological Methods. 2002;7:147–177. [PubMed] [Google Scholar]
- 10.Eddings W, Marchenko Y. Diagnostics for multiple imputation in Stata. Stata Journal. 2012;12(3):353–367. [Google Scholar]
- 11.Honaker J, King G. What to do about missing values in time-series cross-section data? American Journal of Political Science. 2010;54:561–581. [Google Scholar]
- 12.Efron B. Missing data, imputation, and the bootstrap. Journal of the American Statistical Association. 1994;89(426):463–475. [Google Scholar]
- 13.Shao J, Sitter RR. Bootstrap for imputed survey data. Journal of the American Statistical Association. 1996;91(435):1278–1288. [Google Scholar]
- 14.Little R, Rubin D. Statistical analysis with missing data. Wiley; New York: 2002. [Google Scholar]
- 15.Briggs AH, Lozano-Ortega G, Spencer S, Bale G, Spencer MD, Burge PS. Estimating the cost-effectiveness of fluticasone propionate for treating chronic obstructive pulmonary disease in the presence of missing data. Value in Health. 2006;9(4):227–235. doi: 10.1111/j.1524-4733.2006.00106.x. [DOI] [PubMed] [Google Scholar]
- 16.Schomaker M, Heumann C. Model selection and model averaging after multiple imputation. Computational Statistics & Data Analysis. 2014;71:758–770. [Google Scholar]
- 17.Schomaker M, Davies MA, Malateste K, Renner L, Sawry S, N’Gbeche S, Technau K, Eboua FT, Tanser F, Sygnate-Sy H, et al. Growth and mortality outcomes for different antiretroviral therapy initiation criteria in children aged 1–5 years: A causal modelling analysis from West and Southern Africa. Epidemiology. 2016;27:237–246. doi: 10.1097/EDE.0000000000000412. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Worthington H, King R, Buckland ST. Analysing mark-recapture-recovery data in the presence of missing covariate data via multiple imputation. Journal of Agricultural, Biological, and Environmental Statistics. 2015;20:28. [Google Scholar]
- 19.Wu W, Jia F. A new procedure to test mediation with missing data through nonparametric bootstrapping and multiple imputation. Multivariate Behavioral Research. 2013;48(5):663–691. doi: 10.1080/00273171.2013.816235. [DOI] [PubMed] [Google Scholar]
- 20.Baneshi MR, Talei A. Assessment of internal validity of prognostic models through bootstrapping and multiple imputation of missing data. Iranian Journal of Public Health. 2012;41(5):110–115. [PMC free article] [PubMed] [Google Scholar]
- 21.Heymans MW, van Buuren S, Knol DL, van Mechelen W, de Vet HCW. Variable selection under multiple imputation using the bootstrap in a prognostic study. BMC Medical Research Methodology. 2007;7 doi: 10.1186/1471-2288-7-33. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Chaffee BW, Feldens CA, Vitolo MR. Association of long-duration breastfeeding and dental caries estimated with marginal structural models. Annals of Epidemiology. 2014;24(6):448–454. doi: 10.1016/j.annepidem.2014.01.013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Westreich D, Cole SR, Young JG, Palella F, Tien PC, Kingsley L, Gange SJ, Hernan MA. The parametric g-formula to estimate the effect of highly active antiretroviral therapy on incident AIDS or death. Statistics in medicine. 2012;31(18):2000–2009. doi: 10.1002/sim.5316. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Edmonds A, Yotebieng M, Lusiama J, Matumona Y, Kitetele F, Napravnik S, Cole SR, Van Rie A, Behets F. The effect of highly active antiretroviral therapy on the survival of HIV-infected children in a resource-deprived setting: a cohort study. PLoS Medicine. 2011;8(6):e1001 044. doi: 10.1371/journal.pmed.1001044. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Violari A, Cotton MF, Gibb DM, Babiker AG, Steyn J, Madhi SA, Jean-Philippe P, McIntyre JA. Early antiretroviral therapy and mortality among HIV-infected infants. New England Journal of Medicine. 2008;359(21):2233–2244. doi: 10.1056/NEJMoa0800971. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Daniel RM, Cousens SN, De Stavola BL, Kenward MG, Sterne JA. Methods for dealing with time-dependent confounding. Statistics in Medicine. 2013;32(9):1584–618. doi: 10.1002/sim.5686. [DOI] [PubMed] [Google Scholar]
- 27.Petersen M, Schwab J, Gruber S, Blaser N, Schomaker M, van der Laan M. Targeted maximum likelihood estimation for dynamic and static longitudinal marginal structural working models. Journal of Causal Inference. 2014;2:147–185. doi: 10.1515/jci-2013-0007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Robins J. A new approach to causal inference in mortality studies with a sustained exposure period - application to control of the healthy worker survivor effect. Mathematical Modelling. 1986;7(9–12):1393–1512. [Google Scholar]
- 29.Rubin D, Schenker N. Multiple imputation for interval estimation from simple random samples with ignorable nonresponse. Journal of the American Statistical Association. 1986;81:366–374. [Google Scholar]
- 30.Lipsitz S, Parzen M, Zhao L. A degrees-of-freedom approximation in multiple imputation. Journal of Statistical Computation and Simulation. 2002;72:309–318. [Google Scholar]
- 31.Robins J, Hernan MA. Estimation of the causal effects of time-varying exposures. CRC Press; 2009. pp. 553–599. [Google Scholar]
- 32.Yan J. Enjoy the joy of copulas: with package copula. Journal of Statistical Software. 2007;21:1–21. [Google Scholar]
- 33.Schomaker M, Hogger S, Johnson LF, Hoffmann C, Brnighausen T, Heumann C. Simultaneous treatment of missing data and measurement error in HIV research using multiple overimputation. Epidemiology. 2015;26:628–636. doi: 10.1097/EDE.0000000000000334. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Sofrygin O, van der Laan MJ, Neugebauer R. simcausal: Simulating Longitudinal Data with Causal Inference Applications. 2016 URL https://CRAN.R-project.org/package=simcausal, r package version 0.5.3.
- 35.Robins JM, Rotnitzky A, Zhao LP. Estimation of regression-coefficients when some regressors are not always observed. Journal of the American Statistical Association. 1994;89(427):846–866. [Google Scholar]
- 36.Little RJA. Regression with missing X’s - a review. Journal of the American Statistical Association. 1992;87(420):1227–1237. [Google Scholar]
- 37.Egger M, Ekouevi DK, Williams C, Lyamuya RE, Mukumbi H, Braitstein P, Hartwell T, Graber C, Chi BH, Boulle A, et al. Cohort profile: The international epidemiological databases to evaluate AIDS (IeDEA) in sub-Saharan Africa. International Journal of Epidemiology. 2012;41(5):1256–1264. doi: 10.1093/ije/dyr080. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Ekouevi DK, Azondekon A, Dicko F, Malateste K, Toure P, Eboua FT, Kouadio K, Renner L, Peterson K, Dabis F, et al. 12-month mortality and loss-to-program in antiretroviral-treated children: The iedea pediatric west african database to evaluate aids (pwada), 2000–2008. Bmc Public Health. 2011;11:519. doi: 10.1186/1471-2458-11-519. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Dempster A, Laird N, Rubin D. Maximum likelihood from incomplete data via the em algorithm. Journal of the Royal Statistical Society B. 1977;39:1–38. [Google Scholar]
- 40.Goodnight JH. Tutorial on the sweep operator. American Statistician. 1979;33(3):149–158. [Google Scholar]
- 41.Drechsler J, Rssler S. Does convergence really matter? Springer; 2008. pp. 342–355. [Google Scholar]
- 42.Harrell FE., Jr Hmisc: Harrell Miscellaneous. 2016 with contributions from Charles Dupont, many others. URL https://CRAN.R-project.org/package=Hmisc, R package version 4.0-1.
- 43.Schomaker M, Egger M, Ndirangu J, Phiri S, Moultrie H, Technau K, Cox V, Giddy J, Chimbetete C, Wood R, et al. When to start antiretroviral therapy in children aged 2–5 years: a collaborative causal modelling analysis of cohort studies from southern Africa. Plos Medicine. 2013;10(11):e1001 555. doi: 10.1371/journal.pmed.1001555. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Young JG, Cain LE, Robins JM, O’Reilly EJ, Hernan MA. Comparative effectiveness of dynamic treatment regimes: an application of the parametric g-formula. Statistics in biosciences. 2011;3(1):119–143. doi: 10.1007/s12561-011-9040-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Petersen ML. Commentary: Applying a causal road map in settings with time-dependent confounding. Epidemiology. 2014;25(6):898–901. doi: 10.1097/EDE.0000000000000178. [DOI] [PMC free article] [PubMed] [Google Scholar]