

Abstract
Environmental DNA (eDNA) metabarcoding can greatly enhance our understanding of global biodiversity and our ability to detect rare or cryptic species. However, sampling effort must be considered when interpreting results from these surveys. We explored how sampling effort influenced biodiversity patterns and nonindigenous species (NIS) detection in an eDNA metabarcoding survey of four commercial ports. Overall, we captured sequences from 18 metazoan phyla with minimal differences in taxonomic coverage between 18 S and COI primer sets. While community dissimilarity patterns were consistent across primers and sampling effort, richness patterns were not, suggesting that richness estimates are extremely sensitive to primer choice and sampling effort. The survey detected 64 potential NIS, with COI identifying more known NIS from port checklists but 18 S identifying more operational taxonomic units shared between three or more ports that represent un-recorded potential NIS. Overall, we conclude that eDNA metabarcoding surveys can reveal global similarity patterns among ports across a broad array of taxa and can also detect potential NIS in these key habitats. However, richness estimates and species assignments require caution. Based on results of this study, we make several recommendations for port eDNA sampling design and suggest several areas for future research.
Subject terms: Biodiversity, Molecular ecology
Introduction
Global biodiversity surveys are crucial for understanding the impacts of changes in climate and human activity but can be logistically difficult to standardize across many taxa and sites. Port ecosystems are hotspots of harmful aquatic invasions1 and subject to changes in coastal land use and global shipping patterns influenced by trade policies, infrastructure development, and climate-driven changes in sea ice, salinity, and temperature. Currently our knowledge of patterns and processes driving invasions in these ecosystems is limited due to challenges associated with traditional survey methods (e.g., SCUBA, settlement plates, plankton tows, and benthic trawls), including difficulties in port access and low capture rates for cryptic or rare species. Thus, few comprehensive port surveys exist, and those that do are mainly limited to larger organisms1.
Environmental DNA (eDNA) metabarcoding surveys have proven useful for many ecosystems and could potentially overcome the limitations of traditional port surveys. Aquatic eDNA can be shed from feces, scales, gametes, or other extra-organismal sources of DNA suspended in water2. Sampling eDNA requires collection of water in the field, which can be used to metabarcode a broad suite of species using general primers and high-throughput sequencing. Recent studies in coastal marine ecosystems have demonstrated the efficacy of this method to describe biodiversity3. For example, Thomsen et al.4 and Yamamoto et al.5 detected higher fish richness with eDNA metabarcoding compared to traditional methods, Kelly et al.6 demonstrated a link between eel-grass metazoans and coastal urbanization with eDNA metabarcoding, Ardura et al.7 used eDNA metabarcoding to track species transport in ballast water, and Borell et al.8 used eDNA metabarcoding to identify three invasive invertebrates in Bay of Biscay ports. Clearly, eDNA metabarcoding shows great promise for understanding biodiversity and detecting species transported by shipping.
Standardized port eDNA metabarcoding surveys could greatly increase our understanding of biodiversity in these dynamic, globally-connected habitats. However, developing a standardized protocol that is applicable globally is challenging because ports vary considerably in size, complexity, hydrodynamics, physical structures, and benthic substrates. Variation in eDNA sampling collection, extraction, and sequencing methods can complicate comparison of samples from different projects9. Even when sampling methods are identical, an increase in sampling effort almost inevitably yields more species collected10. Sampling effort variation can therefore confound comparisons of species richness and community similarity even among studies using similar methods11 and, if not adequately considered, prevent accurate understanding of global biodiversity.
This study’s goal was to apply an eDNA metabarcoding survey method for metazoans (multicellular animals) to ports and determine how primer set and sampling effort influences global biodiversity patterns and nonindigenous species (NIS) detection. We sampled eDNA from surface waters in four ports with inexpensive and quick collection methods, and used two universal metazoan primer sets, 18 S and COI, to make the survey taxonomically broad. To optimize sampling effort for future port surveys, we explored how eDNA collection effort and sequencing depth influenced biodiversity metrics. Lastly, we evaluated the ability of each primer set to detect both known and un-recorded potential NIS. Our results support multiple recommendations for standardizing eDNA metabarcoding sampling effort in future port eDNA metabarcoding surveys.
Results and Discussion
A total of 146 eDNA samples were collected across four ports. The number of samples per site and the number of sites differed among ports (Fig. 1) for logistical reasons. At Chicago, USA, 20 samples were taken at one site on 20 November 2013 from a dock. In Churchill, Canada, 20 samples were taken at one site on 13 August 2015 from a beach near a dock at slack high tide. In Singapore, 40 samples were taken at two sites on 11 July 2014 from docks (n = 20 per site) during flood tide. In Adelaide, Australia, 66 samples were taken at low tide at 7 sites on 3 July 2014 from a boat, with four sites sampled within two meters of a dock and three sites sampled in the middle of the channel (n = 9 or 10 per site). Churchill eDNA samples had slightly different collection, DNA extraction, and sequencing protocols than those from other ports, but all sample sequences were trimmed, clustered, and assigned to taxa using the same bioinformatics pathway (see Supplementary Methods).
Figure 1.

Map of sites sampled for this study. Maps were generated with the ggmap package version 2.6.136 in R programming language version 3.2.237 using map tiles by © Stamen Design, under CC BY 3.0. (https://creativecommons.org/licenses/by/3.0/), with data by OpenStreetMap, under CC BY SA (https://creativecommons.org/licenses/by-sa/3.0/). This figure is not covered by the CC BY license.
Taxonomic Coverage of Primer Sets
Clustering and filtering yielded 8,525 18 S and 11,872 COI molecular operational taxonomic units (MOTUs) across all samples, of which 13% of 18 S (1,117) and 39% of COI (4,605) MOTUs were assigned to a metazoan phylum (metMOTUs; see Supplementary Table S1 for sample and site sequencing summaries). No-template control filtering removed reads from 52 18 S and 245 COI metMOTUs from all field samples. Cooler blank filtering removed three reads from two COI metMOTUs from Chicago samples, six reads from one 18 S and 15 reads from 5 COI metMOTUS from Singapore samples, and 43 reads from three 18 S and 30,846 reads from 18 COI metMOTUs from Adelaide samples (the latter read count being dominated by common dust mite Dermatophagoides pteronyssinus). All 11 mock species were sequenced and correctly assigned in the COI data, while only three mock species were sequenced and none correctly assigned in the 18 S data.
COI primers produced more metMOTUs, but many of these had weak taxonomic assignments. Pooling metMOTUs across all ports and using only those with assignments with > 90% sequence coverage and identity yielded 795 18 S metMOTUs spanning 18 phyla and 600 COI metMOTUs spanning 11 phyla (Fig. 2). While COI lacked 7 minor phyla (Brachiopoda, Ctenophora, Entoprocta, Hemichordata, Nematoda, Nemertea, and Placozoa) and had relatively more Chordate metMOTUs than 18 S, both primer datasets were dominated by Arthropoda metMOTUs and had similar proportions for Annelida, Cnidaria, Mollusca, Porifera, and Rotifera.
Figure 2.
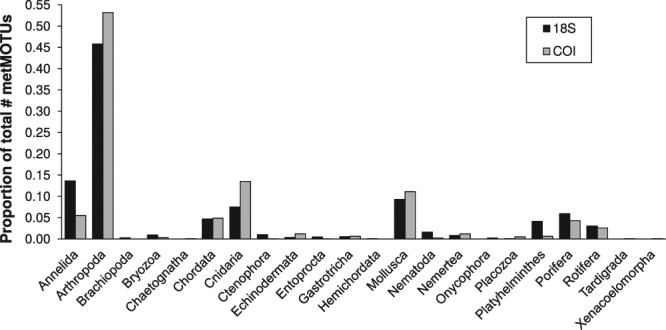
Proportion of metazoan MOTUs in each phylum for the 18 S (black) and COI (grey) datasets.
Overall, the COI primers successfully retrieved all mock fish species and yielded more metMOTUs than 18 S, which is similar to the findings of Borrell et al.8. However, many of the COI metMOTUs had low quality taxonomic assignments. After filtering metMOTUs based on assignment quality, the taxonomic coverage for the 18 S primer set was higher than that of COI, indicating a trade-off between metMOTU abundance and assignment quality in these primers. Despite the differences, relative metMOTU abundances in major metazoan phyla were similar with both primer sets.
Variation in Sequencing and eDNA Collection Effort
Sequencing effort differed among samples, but general patterns were apparent (see Supplementary Figures S1 and S2 and Tables S2 and S3 for with-sample rarefaction curves and richness estimates). Churchill, Chicago, and Singapore Woodlands were sequenced at the shallowest depth for both primers (average <50,000 reads per sample), while other sites averaged ~75,000–190,000 reads per sample. Within-sample rarefaction curves did not plateau in Churchill samples (<20,000 reads per sample) but began to plateau at ~25,000 reads in Chicago and Singapore Woodlands samples and ~100,000–150,000 reads in samples from all other sites. An average of 80.8% and 78.6% of Chao1 estimated metMOTUs were recovered per 18 S and COI sample, respectively, with Churchill samples having the lowest completeness (74% and 73% of Chao1 estimate for 18 S and COI, respectively).
Variation in eDNA collection effort existed among sites as well. 18 S sample rarefaction curves plateaued at Chicago, Churchill and both Singapore sites at 5–15 samples while COI curves plateaued at 15–20 samples at these sites (Fig. 3). Adelaide curves, which had only 9 or 10 samples each, did not plateau in either 18 S or COI curves. Aggregation of metMOTUs within samples, as indicated by sample curves falling below read curves, was apparent in Singapore Yacht 18 S, Singapore Yacht COI, Singapore Woodlands COI, and Chicago COI curves (Fig. 3). This pattern, typically attributed to spatial aggregation of species in traditional surveys, could here be due to either spatial aggregation of metazoan eDNA in port surface waters or variation in PCR reactions among samples. Further experimentation is needed to tease apart these non-exclusive factors.
Figure 3.

Rarified metMOTU accumulation curves by reads and samples for each site. Solid black line denotes COI read rarefaction, grey line denotes COI sample rarefaction, dark blue line denotes 18 S read rarefaction, and light blue line denotes 18 S sample rarefaction. Read curves were plotted on the x-axis using the average number of reads per sample. Errors bars represent 95% confidence intervals.
Biodiversity Patterns
Dissimilarity ordinations consistently showed that samples grouped by port, with samples from each port forming a unique cluster in all datasets (Fig. 4). Adelaide and Singapore clusters were closer to each other than to Chicago, and the Churchill cluster, which followed different protocols, was closest to Chicago in all ordinations. Within sites, 18 S dissimilarities were larger than COI dissimilarities, but the overall pattern between sites was consistent. Samples from the two Singapore sites, located on opposite sides of the island, were distinct from each other with no overlap in any ordination. Adelaide seaward sites (Container Channel, Container Dock 1, Container Dock 2) formed a cluster unique from the four upriver sites (Fuel Channel, Fuel Dock, Marina Channel, Marina Dock) in the 18 S but not the COI ordination. Samples from sites within the two Adelaide clusters were intermixed with each other, suggesting that eDNA is well-dispersed at the scale of about 500 m-1 km. Also consistent across datasets was a significant positive correlation between Adelaide site dissimilarities and geographic distance (Fig. 5; 18 S un-rarefied r = 0.56, p = 0.02; COI un-rarefied r = 0.77, p < 0.01; 18 S rarefied r = 0.58, p = 0.02; COI rarefied r = 0.74, p < 0.01), which was expected given the estuarine gradient of this river port.
Figure 4.

Ordination of (a) 18 S un-rarefied (b) COI un-rarefied, (c) 18 S rarefied, and (d) COI rarefied datasets and using non-metric multidimensional scaling of Chao dissimilarity estimates. Samples are colored by site and ordination stress values are given on each plot.
Figure 5.
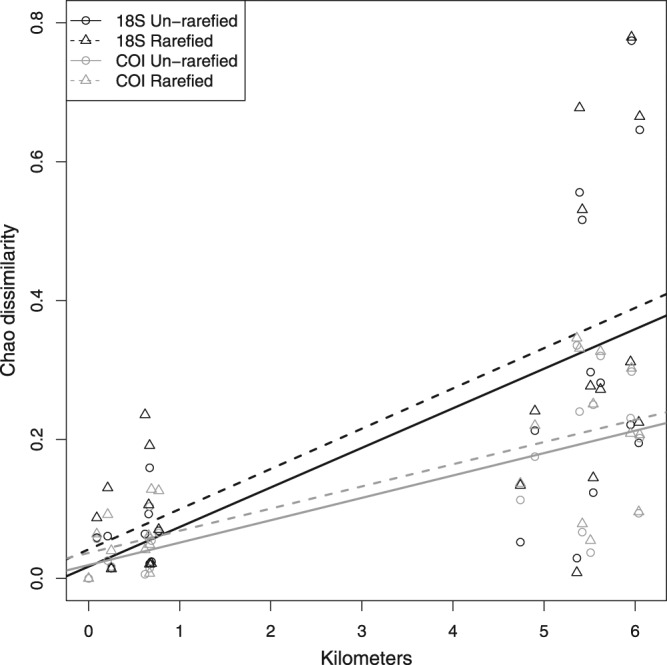
Between-site Chao dissimilarity by over-water distance for seven Adelaide sites. Linear regression lines for each primer-rarefaction combination are shown. Mantel tests were significant at the p ≤ 0.02 level for each of the four dissimilarity by distance correlations (see text).
Unlike community similarity patterns, site metMOTU richness estimates were inconsistent across barcodes and sampling effort (Fig. 6). Un-rarefied richness estimates were generally higher than those from rarefied data, except in three cases (Singapore Woodlands 18 S, Adelaide Container Dock1 18 S, and Chicago COI). Of 11 sites, un-rarefied and rarefied 95% confidence intervals overlapped at only four sites in the 18 S dataset and one site in the COI dataset, with notable differences in the COI estimates at the Singapore Yacht and all Adelaide sites. Richness rankings among the non-Churchill sites varied between barcodes and methods, but ranking correlations were significant in all cases (18 S un-rarefied and rarefied Spearman ρ = 0.83, p = 0.001; COI un-rarefied and rarefied ρ = 0.55, p = 0.05; un-rarefied 18 S and COI ρ = 0.94, p = < 0.001; rarefied 18 S and COI ρ = 0.62, p = 0.03). Churchill COI richness estimates were much higher than the other sites, perhaps due to differences in eDNA collection (e.g., the use of glass-fiber filter membranes in Churchill versus cellulose nitrate membranes in other ports), extraction (e.g. use of phenol chloroform for Churchill versus chloroform for other samples), or amplification protocols (e.g. use of a single annealing temperature for Churchill COI amplifications versus a touchdown program for other amplifications) at this site (Supplementary Methods).
Figure 6.

Site metMOTU Chao2 richness estimates at 20 samples from the (a) 18 S dataset and (b) COI dataset. Grey bars represent estimates from the un-rarefied, singleton-adjusted dataset and white bars from the rarefied dataset. Error bars represent 95% confidence intervals. *Churchill samples were collected and sequenced using a different method and so cannot be compared to the other sites.
Overall, we found that community dissimilarity patterns and dissimilarity-distance correlations were robust to barcode and sampling effort (Figs 4, 5), while site metMOTU Chao2 richness estimates were not (Fig. 6). The latter finding is consistent with Haegeman et al.12. who found that reliable bacterial MOTU richness estimates are challenging due to spurious singletons, unknown underlying MOTU abundance distributions, and the reliance of non-parametric estimators on singleton frequencies. Although we attempted to correct for spurious singletons, site metMOTU richness estimates were still variable among our datasets, indicating that they are not robust to the sequencing and collection effort variation in this study.
NIS Detections
This survey detected several known and un-recorded potential NIS, but some assignment similarity metrics were weak, particularly in the COI dataset (see Supplementary Tables S4 and S5). In Chicago, seven known NIS were detected: two with 18 S (quagga mussel Dreissena rostriformis and copepod Eurytemora affinis) and five with COI (white perch Morone Americana, common carp Cyprinus carpio, Asian clam Corbicula fluminea, copepod Eurytemora carolleeae, and European earthworm Lumbricus rubellus), all with high sequence similarity (coverage = 100%, identity >97%) except D. rostriformis (coverage = 100%, identity = 89%). In Adelaide, 11 known NIS or cryptogenic species were detected: five with both primer sets (ascidian Styela plicata, green crab Carcinus maenus, hydrozoans Plumularia setacea and Coryne eximia, Senhouse mussel Musculista senhousia, and polychaete Hydroides “elegans”), one with only 18 S (ascidian Ciona inestinalis), and four with only COI (bryozoans Tricellaria occidentalis and Watersipora arcuata, Chameleon Goby Tridentiger trigonocephalus, Mediterranean mussel Mytilus galloprovincialis). All Adelaide 18 S and six COI NIS assignments were strong (>99% coverage and identity) while four COI assignments were weak ( < 95% coverage or identity).
Un-recorded potential NIS included eight 18 S metMOTUs found in all ports, and 25 18 S and 13 COI metMOTUs found in three ports. All-port 18 S metMOTUs consisted mostly of plausible NIS, including five rotifers (two of which, Synchaeta pectinata and Cephalodella forficula are cosmopolitan), a cosmopolitan hydroid (Bougainvilla muscus), a cosmopolitan flatworm (Microstomum lineare), and human. The 25 three-port 18 S metMOTUs spanned 9 phyla and many had cosmopolitan distributions. Except for one sponge assignment with low similarity (Spongionella cf. foliascens) all of the three-port 18 S assignments had coverages >98.5% and identities > 95%. In the COI dataset, the 13 three-port metMOTUs spanned five phyla and generally had weak assignments (coverage <90% or identity <90%), with three exceptions: the feral pig Sus scrofa (coverage and identity = 100%), cladoceran Macrothrix sp. HE-364 (coverage = 100%, identity = 99%), and sponge Haliclona aculata (coverage = 100%, identity = 99%). All three of these taxa have cosmopolitan distributions; however, S. scrofa is also a common laboratory contaminant13.
Overall, many plausible NIS were identified by comparing assignments to port NIS checklists or by investigating assignments found in three or more ports. More recorded NIS were detected with COI (14) than with 18 S (8), but more metMOTUs shared between three or more ports, which represent potential but currently un-recorded NIS, were found with 18 S (33 with 18 S versus 13 with COI). However, several assignments were likely erroneous with low sequence coverages or identities, particularly in the COI dataset. Further, 18 S is well known to be more conserved among many metazoan clades14, indicating that metMOTUs shared between three or more ports may truly be different species. Further testing of universal metazoan barcodes against well-curated sequence databases and port species checklists is sorely needed to better determine the benefits and drawbacks of each barcode.
Summary and Recommendations
In summary, we detected eDNA from at least 18 metazoan phyla in ports and our analyses give us confidence that the methods used here can reliably estimate community dissimilarity patterns and identify plausible NIS without the extensive fieldwork and taxonomic expertise required by traditional surveys. Although richness estimates and some taxonomic assignments are unreliable, we conclude that eDNA metabarcoding can potentially transform our understanding of port biodiversity in the face of global change. For example, applying this survey to more ports over time could reveal changes in port species composition dissimilarities, allowing us to tease apart the effects of climate and shipping on biodiversity in these key hotspots of invasion and other anthropogenic change.
Based on our results, we make the following recommendations for future port eDNA metabarcoding surveys and research:
Protocols: Standardize eDNA collection, extraction, and sequencing protocols to maximize biodiversity pattern inference across sites. Here we used two sets of protocols, one for Churchill and one for the other three ports (see Supplementary Methods), which prevented direct comparison of biodiversity metrics between Churchill and the other ports. Further research and conversation among practitioners is needed to determine the optimal set of protocols for port eDNA surveys. We suggest that both sets of protocols used here provide a good starting point for these efforts.
Primer Choice: For biodiversity estimation, both the COI and 18 S primer sets yielded similar taxonomic breadth and dissimilarity patterns (Figs 2, 4 and 5), so either or both could be effective for this aim. To optimize NIS detection, we recommend using multiple primers, as the two primers in this survey detected different NIS (Supplementary Dataset S3). For eDNA surveys targeted at specific NIS that are known beforehand (which was not the case in this study), species-specific quantitative or digital droplet PCR assays will be more sensitive than metabarcoding15.
Sequencing Depth: Sequencing depth recommendations vary depending on the purpose of the survey. For community dissimilarity estimation, read depths of 10,000 and 40,000 reads per sample are needed for the 18 S and COI primers used in this study, respectively. For species richness estimates or NIS detection, sequencing each sample at a depth of 150,000 reads will yield ~80% of estimated richness in most samples for both primer sets (Supplementary Dataset S2). The depth needed for less diverse sites or more specific primers is probably lower, but this should be evaluated beforehand by over-sequencing a few samples.
eDNA Sample Collection Effort: Given the observed heterogeneity of metMOTUs across samples within some sites (Fig. 3), we recommend collecting at least 9 × 250 mL samples per site to estimate community dissimilarity and 15 samplers for metMOTU richness estimation, with samples taken about every 2–4 meters in a site. Further research is needed to determine how much of this heterogeneity is due to PCR variation versus spatial aggregation of eDNA.
Number of Sites within a Port: Multiple sites will need to be sampled to capture the full biodiversity of a port (Fig. 4). Based on a dissimilarity by distance analysis for seven Adelaide sites (Fig. 5), we recommend that sites be located about 0.5–1 km apart.
Species Assignment Accuracy: Species assignments can be informative but should be treated with caution (see Supplementary Dataset S3) given known errors and omissions in sequencing and reference libraries. Any potential NIS detected with eDNA metabarcoding should therefore be confirmed with traditional surveys or species-specific qPCR or ddPCR surveys. Additional species lists for ports (and many other coastal habitats) and more complete and accurate sequence databases would enable better evaluation of eDNA metabarcoding survey accuracies.
Methods
eDNA Collection, Extraction and Amplicon Sequencing
eDNA collection, extraction and amplicon sequencing protocols differed between Churchill and the other ports (Supplementary Methods). For all ports, a sample consisted of 250 mL of surface water. Samples from Chicago, Adelaide, and Singapore were stored on ice immediately after collection and eDNA was captured in the lab by filtering through cellulose nitrate membranes (47 mm diameter, 0.45 µm pore-size) within 8 hours of collection. Churchill samples were filtered immediately in the field with a syringe and glass-fiber membranes (25 mm diameter, 0.7 µm pore-size). After filtration, all membranes were stored in a sterile microtube with 700 µl of Longmire’s buffer16.
DNA was extracted from the Chicago, Singapore, and Adelaide samples using a chloroform protocol. Amplicon sequencing included an initial 50 μL PCR using primers with 5′ tail sequences corresponding to part of the Nextera® adaptors and a second PCR to attach library specific indices and remaining Nextera® sequences. DNA was extracted from the Churchill samples using a QIAshredder (Qiagen) and phenol-chloroform protocol. Churchill amplicon sequencing involved one PCR with three 24 μL replicates per sample using barcode primers tailed on the 5′ end with the entire Nextera® adaptors.
Both protocols amplified the same two barcode sequences [a 313 bp COI fragment using the MlCOIintF17 and jgHCO219818 primers and a ribosomal 18 S gene fragment (~ 378 bp) using the 18S_574F and 18S_952R primers19] and sequenced on an Illumina MiSeq platform (Illumina, San Diego) using a paired-end MiSeq Reagent Kit V3 (sequence length = 300 bp) following manufacturer’s instructions.
Bioinformatics and Contamination Controls
Raw sequence reads were filtered based on their quality, merged, and clustered into molecular operational taxonomic units (MOTUs) at 97% similarity20 (Supplementary Methods). MOTUs were assigned to taxa in the NCBI NR database with two different approaches: SAP v1.9.321 and the BLAST function in Geneious v9.1.522. For all analyses we used only MOTUs that were assigned to the metazoan phylum (metMOTUs) by either assignment method, using the SAP assignment when the two methods disagreed.
Following recommended eDNA control protocols23, we used cooler blanks as field controls; for laboratory controls, we used mock communities and no-template controls at each step of extraction and PCR (Supplementary Methods). To remove contaminate MOTUs from the data, we subtracted contaminant reads from field samples24 as follows: mock MOTU read counts were subtracted from each field sample in the same sequencing run, cooler blank MOTU read counts were subtracted from each field sample transported in the same cooler, and no-template MOTU read counts were subtracted from all field samples.
Variation in eDNA Collection and Sampling Effort
Differences in eDNA sampling effort can occur at several stages25. We explored two types of effort that could differ among samples taken with the same protocol: sequencing effort, which is the number of reads generated per sample, and eDNA collection effort, which depends on the volume of water collected, metMOTU diversity, and spatial distribution of eDNA in the site26. To investigate variation in sequencing effort, we generated read rarefaction curves for each sample to determine if and when curves plateaued; the latter indicating all metMOTUs in the sample were sequenced. To estimate the sequencing completeness of each sample, we divided the number of observed metMOTUs by the Chao1 richness estimate27 for metMOTUs for that sample. We explored variation in eDNA collection effort among sites by plotting site-specific rarefied sample curves for each site to observe if and when curve plateaued. To investigate spatial aggregation of metMOTUs within a site, we plotted rarefied pooled read curves for each site along with the rarefied sample curves. Sample curves will increase more slowly than read curves when metMOTUs are aggregated within samples, with greater aggregation yielding a relatively slower increase in sample curves28. Sample rarefaction curves, sample Chao1 estimates, site sample rarefaction curves, and site read rarefaction curves were calculated with the R package vegan29, using the rarecurve, estimateR, specaccum (method = “random”), and specaccum (method = ”rarefaction”) functions respectively.
Biodiversity Metrics
When sampling effort differs among samples or sites, two common approaches for comparing biodiversity metrics exist: 1) rarefy the data to the lowest effort, or 2) use non-parametric estimates that are robust to unequal sampling efforts. The rarefaction approach is compatible with many biodiversity metrics but often requires omission of a substantial amount of data. Non-parametric estimators are more robust to effort variation, but they can be biased at low effort levels and yield wide confidence intervals11. To explore how sequencing and collection effort influenced biodiversity patterns in this survey, we compared non-parametric community dissimilarity and richness estimates from un-rarefied data (where sequencing and collection effort varied among samples and sites) to those from rarefied data (where all samples had the same number of reads and all sites had the same number of samples). We rarefied by selecting 9 samples (the lowest sample number per site) with the highest read counts for each site, and then randomly selected reads without replacement from each sample up to the lowest observed read count (lowest read count 18 S = 9,081, COI = 40,401). This comparison allowed us to infer the effect of sequencing and collection effort on non-parametric biodiversity metrics and to determine if these metrics are robust across barcodes and effort levels.
We then compared three biodiversity patterns across primer and un-rarefied/rarified datasets: between-sample community dissimilarity, correlation between site dissimilarity and geographic distance, and site metMOTU richness. We estimated between-sample dissimilarities using the Chao dissimilarity index, which is similar to the Jaccard index except that it accounts for unseen metMOTUs shared between samples30, and visualized these dissimilarities with non-metric multidimensional ordination (NMDS). We evaluated the correlation between site Chao dissimilarities and over-water distance in Adelaide, a river port with 7 sites distributed along several kilometers (Fig. 1), with a Mantel test and visualized the correlation by plotting site dissimilarity by distance and adding linear regression lines for each primer set-rarefaction combination. Chao dissimilarities and NMDS ordinations were calculated using the vegan functions metaMDS and ordiplot, respectively. To calculate Adelaide site Chao dissimilarities we pooled reads from all samples in a site and used the vegan function vegdist.
To estimate metMOTU richness, we first adjusted the number of singletons (number of metMOTUs with one read per site) in each un-rarefied sample to correct for spurious sequences using the algorithm provided in Chiu and Chao31. We estimated metMOTU richness at 20 samples using the estimateD function in the R package iNEXT32,33, setting Hill number q = 0. A one-tailed Spearman rank correlation tested for concordance between site richness rankings between the different barcodes and between un-rarefied and rarefied datasets.
Because Churchill samples were filtered, extracted, and amplified differently than those from the other ports (Supplementary Methods), we did not compare its metMOTU richness with that of other ports. However, we did compare relative dissimilarity between Churchill samples and other ports.
Nonindigenous Species (NIS) Detection
In addition to revealing global biodiversity patterns, eDNA metabarcoding may also detect NIS in ports. However, errors and omissions in reference databases34 or sequences require caution for any species assignment. To assess this survey’s ability to identify NIS, we checked species assignments from Chicago and Adelaide against NIS species lists for these ports (Chicago: Great Lakes Aquatic Nonindigenous Species Information System www.glerl.noaa.gov/res/Programs/glansis; Adelaide: Wiltshire et al.35). Next, we evaluated our ability to detect unrecorded NIS by evaluating metMOTUs found in three or more ports, as species were unlikely to have dispersed naturally to at least one of any three ports in this study. For both analyses, we assessed whether an assignment was a true NIS based on percent of the metMOTU sequence that overlapped with the assignment sequence (% coverage), the extent to which the metMOTU and the assignment have the same nucleotides at the same positions (% identity), and the known global distribution of the species derived from the World Register of Marine Species (www.marinespecies.org) or the IUCN Red List (www.iucnredlist.org).
Electronic supplementary material
Acknowledgements
Many thanks to the Port of Chicago and Singapore Yacht Club for sampling access. Support for Churchill data was provided by the Churchill Northern Studies Center, Frédéric Hartog, LeeAnn Fishback, Daniel Gibson, Austin MacPherson, Heather Clark, Colin Gallagher, Phillippe Archambault, Noémie Leduc, Cecilia Hernandez and Eric Normandeau. This research was funded by the Notre Dame Environmental Research Initiative and NSF Coastal SEES grant #1427157 (to DML, EKG), ArcticNet (to LB, ALR, KH), Polar Knowledge Canada (to KH, LB, and ALR), and the Fisheries and Oceans Canada Aquatic Invasive Species Monitoring Programs (to KH).
Author Contributions
E.K.G., B.O., M.E.P., M.A.R. and D.M.L. designed the study. E.K.G., L.B., P.C., M.D., K.L.H., A.L.R., S.C.Y.L. and T.A.A.P. coordinated or performed field surveys. E.K.G., K.D., A.L.R., Y.L., B.O., M.A.R. conducted laboratory work and data analysis. E.K.G., K.D., Y.L., M.A.R. wrote the manuscript. All authors reviewed the manuscript.
Data Availability
Raw sequences for all samples have been deposited in NCBI’s Sequence Read Archive (SRA, http://www.ncbi.nlm.nih.gov/), with Chicago, Singapore and Adelaide sequences under BioProject PRJNA3955904 and Churchill sequences under BioProject PRJNA388333. Filtered MOTU data and R scripts for biodiversity analyses are freely available on Dryad at 10.5061/dryad.40782nd.
Competing Interests
The authors declare no competing interests.
Footnotes
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Change history
10/30/2019
A correction to this article has been published and is linked from the HTML and PDF versions of this paper. The error has been fixed in the paper.
Electronic supplementary material
Supplementary information accompanies this paper at 10.1038/s41598-018-27048-2.
References
- 1.Ruiz GM, Carlton JT, Grosholz ED, Hines AH. Global Invasions of Marine and Estuarine Habitats by Non-Indigenous Species: Mechanisms, Extent, and Consequences. Integr Comp Biol. 1997;37:621–632. [Google Scholar]
- 2.Creer S, et al. The ecologist’s field guide to sequence-based identification of biodiversity. Methods Ecol Evol. 2016;7:1008–1018. doi: 10.1111/2041-210X.12574. [DOI] [Google Scholar]
- 3.Deiner Kristy, Bik Holly M., Mächler Elvira, Seymour Mathew, Lacoursière‐Roussel Anaïs, Altermatt Florian, Creer Simon, Bista Iliana, Lodge David M., Vere Natasha, Pfrender Michael E., Bernatchez Louis. Environmental DNA metabarcoding: Transforming how we survey animal and plant communities. Molecular Ecology. 2017;26(21):5872–5895. doi: 10.1111/mec.14350. [DOI] [PubMed] [Google Scholar]
- 4.Thomsen PF, et al. Detection of a Diverse Marine Fish Fauna Using Environmental DNA from Seawater Samples. PLOS ONE. 2012;7:e41732. doi: 10.1371/journal.pone.0041732. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Yamamoto S, et al. Environmental DNA metabarcoding reveals local fish communities in a species-rich coastal sea. Scientific Reports. 2017;7:srep40368. doi: 10.1038/srep40368. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Kelly RP, et al. Genetic signatures of ecological diversity along an urbanization gradient. PeerJ. 2016;4:e2444. doi: 10.7717/peerj.2444. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Ardura A, et al. Environmental DNA evidence of transfer of North Sea molluscs across tropical waters through ballast water. J Molluscan Stud. 2015;81:495–501. doi: 10.1093/mollus/eyv022. [DOI] [Google Scholar]
- 8.Borrell YJ, Miralles L, Huu HD, Mohammed-Geba K, Garcia-Vazquez E. DNA in a bottle—Rapid metabarcoding survey for early alerts of invasive species in ports. PLOS ONE. 2017;12:e0183347. doi: 10.1371/journal.pone.0183347. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Deiner K, Walser J-C, Mächler E, Altermatt F. Choice of capture and extraction methods affect detection of freshwater biodiversity from environmental DNA. Biological Conservation. 2015;183:53–63. doi: 10.1016/j.biocon.2014.11.018. [DOI] [Google Scholar]
- 10.Evans Nathan T., Li Yiyuan, Renshaw Mark A., Olds Brett P., Deiner Kristy, Turner Cameron R., Jerde Christopher L., Lodge David M., Lamberti Gary A., Pfrender Michael E. Fish community assessment with eDNA metabarcoding: effects of sampling design and bioinformatic filtering. Canadian Journal of Fisheries and Aquatic Sciences. 2017;74(9):1362–1374. doi: 10.1139/cjfas-2016-0306. [DOI] [Google Scholar]
- 11.Gotelli NJ, Colwell RK. Quantifying biodiversity: procedures and pitfalls in the measurement and comparison of species richness. Ecology Letters. 2001;4:379–391. doi: 10.1046/j.1461-0248.2001.00230.x. [DOI] [Google Scholar]
- 12.Haegeman B, et al. Robust estimation of microbial diversity in theory and in practice. ISME J. 2013;7:1092–1101. doi: 10.1038/ismej.2013.10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Leonard JA, et al. Animal DNA in PCR reagents plagues ancient DNA research. Journal of Archaeological Science. 2007;34:1361–1366. doi: 10.1016/j.jas.2006.10.023. [DOI] [Google Scholar]
- 14.Tang CQ, et al. The widely used small subunit 18S rDNA molecule greatly underestimates true diversity in biodiversity surveys of the meiofauna. Proceedings of the National Academy of Sciences. 2012;109(40):16208–16212. doi: 10.1073/pnas.1209160109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Simmons M, et al. Active and passive environmental DNA surveillance of aquatic invasive species. Canadian Journal of Fisheries and Aquatic Sciences. 2015;73(1):76–83. doi: 10.1139/cjfas-2015-0262. [DOI] [Google Scholar]
- 16.Longmire JL, Maltbie M, Baker RJ. Use of lysis buffer in DNA isolation and its implications for museum collections. Occasional Papers of the Museum of Texas Tech University. 1997;163:1–4. [Google Scholar]
- 17.Leray M, et al. A new versatile primer set targeting a short fragment of the mitochondrial COI region for metabarcoding metazoan diversity: application for characterizing coral reef fish gut contents. Frontiers in Zoology. 2013;10:34. doi: 10.1186/1742-9994-10-34. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Geller J, Meyer C, Parker M, Hawk H. Redesign of PCR primers for mitochondrial cytochrome c oxidase subunit I for marine invertebrates and application in all-taxa biotic surveys. Mol Ecol Resour. 2013;13:851–861. doi: 10.1111/1755-0998.12138. [DOI] [PubMed] [Google Scholar]
- 19.Hadziavdic K, et al. Characterization of the 18S rRNA Gene for Designing Universal Eukaryote Specific Primers. PLOS ONE. 2014;9:e87624. doi: 10.1371/journal.pone.0087624. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Edgar RC. UPARSE: highly accurate OTU sequences from microbial amplicon reads. Nat Meth. 2013;10:996–998. doi: 10.1038/nmeth.2604. [DOI] [PubMed] [Google Scholar]
- 21.Munch K, Boomsma W, Huelsenbeck JP, Willerslev E, Nielsen R. Statistical Assignment of DNA Sequences Using Bayesian Phylogenetics. Syst Biol. 2008;57:750–757. doi: 10.1080/10635150802422316. [DOI] [PubMed] [Google Scholar]
- 22.Kearse M, et al. Geneious Basic: An integrated and extendable desktop software platform for the organization and analysis of sequence data. Bioinformatics. 2012;28:1647–1649. doi: 10.1093/bioinformatics/bts199. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Goldberg CS, et al. Critical considerations for the application of environmental DNA methods to detect aquatic species. Methods Ecol Evol. 2016;7:1299–1307. doi: 10.1111/2041-210X.12595. [DOI] [Google Scholar]
- 24.Nguyen NH, Smith D, Peay K, Kennedy P. Parsing ecological signal from noise in next generation amplicon sequencing. New Phytol. 2015;205:1389–1393. doi: 10.1111/nph.12923. [DOI] [PubMed] [Google Scholar]
- 25.Shelton AO, et al. A framework for inferring biological communities from environmental DNA. Ecol Appl. 2016;26:1645–1659. doi: 10.1890/15-1733.1. [DOI] [PubMed] [Google Scholar]
- 26.Brose U, Martinez ND, Williams RJ. Estimating species richness: sensitivity to sample coverage and insensitivity to spatial patterns. Ecology. 2003;84:2364–2377. doi: 10.1890/02-0558. [DOI] [Google Scholar]
- 27.Chao A. Nonparametric estimation of the number of classes in a population. Scandinavian Journal of Statistics. 1984;11:265–270. [Google Scholar]
- 28.Crist TO, Veech JA. Additive partitioning of rarefaction curves and species–area relationships: unifying α-, β- and γ-diversity with sample size and habitat area. Ecology Letters. 2006;9:923–932. doi: 10.1111/j.1461-0248.2006.00941.x. [DOI] [PubMed] [Google Scholar]
- 29.Oksanen, J. F. et al. vegan: Community Ecology Package. (2016).
- 30.Chao A, Chazdon RL, Colwell RK, Shen T-J. A new statistical approach for assessing similarity of species composition with incidence and abundance data. Ecology Letters. 2005;8:148–159. doi: 10.1111/j.1461-0248.2004.00707.x. [DOI] [Google Scholar]
- 31.Chiu C-H, Chao A. Estimating and comparing microbial diversity in the presence of sequencing errors. PeerJ. 2016;4:e1634. doi: 10.7717/peerj.1634. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Chao A, et al. Rarefaction and extrapolation with Hill numbers: a framework for sampling and estimation in species diversity studies. Ecological Monographs. 2014;84:45–67. doi: 10.1890/13-0133.1. [DOI] [Google Scholar]
- 33.Hseih, T. C., Ma, K. H. & Chao, A. iNEXT: iNterpolation and EXTrapolation for species diversity. (2016).
- 34.Trebitz AS, Hoffman JC, Grant GW, Billehus TM, Pilgrim EM. Potential for DNA-based identification of Great Lakes fauna: match and mismatch between taxa inventories and DNA barcode libraries. Scientific Reports. 2015;5:srep12162. doi: 10.1038/srep12162. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Wiltshire K, Deveney M. Introduced marine species of South Australia: a review of records and distribution mapping. SARDI Publication No. F2010/000305-1, SARDI Research Report Series No. 2010;468:232 pages. [Google Scholar]
- 36.Kahle D, Wickham H. ggmap: Spatial Visualization withggplot2. The R Journal. 2013;5(1):144–161. doi: 10.32614/RJ-2013-014. [DOI] [Google Scholar]
- 37.R Core Team. R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. http://www.R-project.org/ (2013).
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
Raw sequences for all samples have been deposited in NCBI’s Sequence Read Archive (SRA, http://www.ncbi.nlm.nih.gov/), with Chicago, Singapore and Adelaide sequences under BioProject PRJNA3955904 and Churchill sequences under BioProject PRJNA388333. Filtered MOTU data and R scripts for biodiversity analyses are freely available on Dryad at 10.5061/dryad.40782nd.