

Summary
Hippocampal replays are episodes of sequential place cell activity during sharp wave ripple oscillations (SWRs). Conflicting hypotheses implicate awake replay in learning from rewards, and in memory retrieval for decision-making. Further, awake replays can be forwards, in the same order as experienced, or reverse, in the opposite order. However, while the presence or absence of reward has been reported to modulate SWR rate, the effect of reward changes on replay, and on replay direction in particular, have not been examined. Here we report divergence in the response of forwards and reverse replays to changing reward. While both classes of replays were observed at reward locations, only reverse replays increased their rate at increased reward, or decreased their rate at decreased reward, while forward replays were unchanged. These data demonstrate a unique relationship between reverse replay and reward processing, and point to a functional distinction between different directions of replay.
ETOC BLURB
Ambrose, et al. describe changes in reverse-ordered, but not forward-ordered, hippocampal replay in response to changing reward contingency. This suggests that reverse replay plays a distinct role in reward-related enhancement of memory consolidation.
Introduction
Pyramidal cells in the CA1 region of the hippocampus, known as place cells, code for space by firing in a particular location in an environment called the place field (O’Keefe and Dostrovsky, 1971; O’Keefe and Nadel, 1978), determined experimentally by correlating recorded spikes with position while an animal moves around. However, when the animal is at rest, place cells can be activated in temporally compressed population bursts that depict, on a faster timescale, behavioral trajectories through extended sequences of places. These events, often referred to as “replay”, are associated with fast (150–250 Hz) oscillatory events in the local field potential (LFP) known as sharp wave ripples (SWRs; Buzsaki, 1986; Csicsvari et al., 1999).
SWR-associated replay was first reported in slow-wave sleep (Lee and Wilson, 2002), but later was found to also occur in the awake state whenever an animal pauses in an environment (Foster and Wilson, 2006). The latter study reported one further, surprising property of awake replay – it played behavioral sequences in reverse, starting with the current location of the animal, and moving backwards along the preceding, incoming trajectory. In the study, animals happened to pause mainly at rewarded locations, so that these locations were where the reverse replay occurred. While this correspondence did not imply a relationship, it suggested a solution to the so-called “temporal credit assignment problem” – the fact that an animal must make decisions about its movements when far away from a reward, and the reward by itself offers no perceptible guidance signal. In the classical place cell picture, there was no possibility of making direct associations between reward and cells whose place fields were far away, since when the animal is at the reward, these cells would be silent. Reverse replay at the reward offered a potential mechanism to associate place cells firing along the incoming route with estimates of future reward, and so was interpreted as a learning mechanism (Foster and Wilson, 2006).
Subsequently, reverse replay was replicated, but additionally it was found that forward replay also occurred during awake immobility (Csicsvari et al., 2007; Davidson et al., 2009; Diba and Buzsaki, 2007; Gupta et al., 2010; Karlsson and Frank, 2009). Although forward replay is not as theoretically attractive for temporal credit assignment as reverse, it does offer a more intuitive notion of memory recall. Thus, several recent studies have reported awake replay effects that were interpreted as forward planning of upcoming behavior (Jadhav et al., 2012; Pfeiffer and Foster, 2013; Singer et al., 2013). However, replay directionality was not directly measured in these studies. So the important question remains: do reverse and forward replay have different functions? In particular, does reverse replay have a specific relationship to reward, if it is involved in encoding recent paths to the reward? If so, is that relationship absent for forward replay, if forward replay is by contrast involved in recalling memories of how to get to other locations?
To address these questions, we designed two experiments in which we varied reward magnitude, to determine the effect on hippocampal awake replays recorded during stopping periods. Previous studies that reported effects of reward and/or goal on SWRs or on replay have tended to utilize complex behaviors dependent on rather demanding learned tasks (Dupret et al., 2010; Pfeiffer and Foster, 2013; Singer and Frank, 2009). By contrast, we used running up and down the linear track, a task chosen for its simplicity, and its relative imperviousness to changes in reward. Animals were trained to run from one end to the other, and did so regardless of whether the amount of reward was increased at one end, or even removed. Thus we could examine the effects of reward manipulation against a relatively constant behavioral background. In this classic design, in which forward and reverse replay were first reported, we hoped to uncover differences in the response of these two types of replay to increases or decreases in reward.
Results
To test the effect of changing reward magnitude on SWRs and replay, we performed two experiments in which rats encountered varying reward while running on a linear track task (Figure 1A). The experimental approach was similar for the two experiments, with the difference that Experiment One tested the effect of increased reward and Experiment Two tested the effect of decreased reward. During each day of recording, rats were exposed to the same linear track in three successive epochs, during each of which rats completed 15–20 running laps (out and back) for liquid chocolate reward available at each end of the track. However, during epoch 2, the amount of reward available on each lap was changed at one end of the track only: in Experiment One, the rewarded was 4× larger, while in Experiment Two, no reward was provided. Thus, epochs 1 and 3 tested baseline activity with equal reward available at both track ends, while epoch 2 tested the effect of a change in reward magnitude at one end of the track. Running performance was relatively impervious to the manipulation of reward, with some differences in running speed for Experiment Two, but not for Experiment One (Figure S1).
Figure 1. Experimental design and place cell decoding.

(A) Schematic of an experimental session. Reward was increased to 4× baseline at one end of the track in epoch 2 of Experiment One, and decreased to 0× in Experiment Two. See Figure S1 for running behavior. (B) Ripple (150–250Hz) filtered local field potential (top) and Bayesian decoding of the associated spike train during behavior (bottom). Actual position of rat overlaid in cyan. (C) Four example SWRs (top) with associated replay (bottom) which occurred at the ends of the track during the behavioral episode shown in B within the indicated time windows. See also Figure S1 and Table S1.
We tested five rats on both experiments for a total of 7 sessions of Experiment One and 8 sessions of Experiment Two. In order to characterize the effect of reward changes on SWR events and on replay, rats were implanted with 40 tetrode microdrives targeting the CA1 region of the hippocampus, and single unit and LFP data were recorded concurrently. 120 ± 10 simultaneously recorded units were isolated per run (Table S1). For each unit, we determined its place field on the track, and using Bayesian decoding methods on a coarse timescale (200ms), we were able to make very accurate estimates of the rat’s actual position during running behavior (Figure 1B, Table S1). Then, during stopping periods at the track ends, we identified SWRs as peaks in ripple power (150–250Hz) in the LFP, and we applied Bayesian decoding on a fine timescale (10ms; see methods) to measure trajectory replay. On average, 15–20% of SWRs were determined to contain significant trajectory replay (Figure 1C, Table S1).
SWR and replay frequency increases at increased reward
In the increased reward experiment (Experiment One) SWR occurrence began to peak within seconds of the rat’s arrival at the reward well area, before tapering off for the duration of the stopping period (Figure 2A). In the equal reward epochs the numbers of SWRs appeared similar at both ends of the track, however in the unequal reward epoch there appeared to be many more SWRs at the increased reward end. Although the rats stopped for significantly longer at the 4× reward than at the × reward (20.3 ± 2.8s and 8.1 ± 1.3s respectively, p=0.031, Wilcoxon signed rank test), the increase in SWR number was not simply due to a greater amount of time stopped but reflected an overall increase in the rate of SWRs (Figure 2B). Similarly to SWRs, the rate of replays increased at the increased reward end (Figures 2D and 2E).
Figure 2. SWRs and replays are increased at 4× reward.

(A) SWR occurrence during the first 20s of each stopping period over 15 laps, summed across all sessions. Color bar indicates number of SWRs. (B) Difference in SWR rate between ends of the track over the first 20s of each stopping period (mean ± SEM, n=maximum of 467 stopping periods in the equal reward condition and 217 in the unequal reward condition. Note that this number decreases over stopping period due to variability of time spent at the reward well). (C) Percent difference in SWR rate from unchanged to increased reward end of track in the equal and unequal reward conditions (mean ± 95% confidence interval). (D) Replay occurrence, as shown in A. (E) Difference in replay rate between ends of the track, as shown in B. (F) Difference in replay rate between ends of the track, as shown in C. *** indicates p < 0.001. See also Figures S2, and S4, and Table S2.
To quantify these changes we fit a Poisson generalized linear model (GLM) to estimate the rate of events, defined as the number of events per second, at both ends of the track and under the two reward conditions (see experimental methods). The difference in SWR rate between ends of the track was much greater in the unequal reward condition (4× versus 1× reward) than when equal reward was present at both ends (Figure 2C, z=5.24, p=1.61×10−7, Table S2). Similarly, the difference in replay rate between ends of the track was greater in the unequal reward condition (Figure 2F, z=3.45, p=5.67×10−4; Table S2). Thus, both SWR rate and replay rate reflected the increase in reward during epoch 2.
Interestingly, the difference in both SWR and replay rate between ends of track in the unequal reward condition was due to both an increase in rate at the changed end, and a decrease in rate at the unchanged end (Figure S4A, black squares – SWRs/s, black circles – replays/s). This suggests that the rate of events adaptively coded relative reward magnitude rather than absolute reward. The simultaneous increase and decrease in rates at the increased and unchanged reward ends, respectively, meant that the overall rates of SWRs and replays were not sensitive to the increase in reward associated with epoch 2 (Figure S2A and S2B).
Differential behavior of forward and reverse replay at increased reward
Although we observed reward related changes in bi-directional replay rate, the contribution of forward and reverse replay remained unclear. We therefore classified the previously identified replays by their directionality, by calculating directional place fields for all units. Although some units had similar fields in both directions, the spatial representation of “up” and “down” heading trajectories were easily distinguishable (Figure 3A). Directional decoding accuracy was comparable to bi-directional decoding (Table S1). The original replays were re-decoded using directional place fields resulting in a posterior probability containing information on both position on track and heading direction (Figure 3B). Based on our criterion 79% (581/738 replays in Experiment One) and 77% (314/409 replays in Experiment Two) of replays were classified as forward or reverse and the remaining 21% (157/738) and 23% (95/409) were omitted from further analysis. Thus, forward and reverse replays were non-overlapping subsets of the total replays which occurred concurrently during the experiment.
Figure 3. Reverse but not forward replays encode increase in reward.
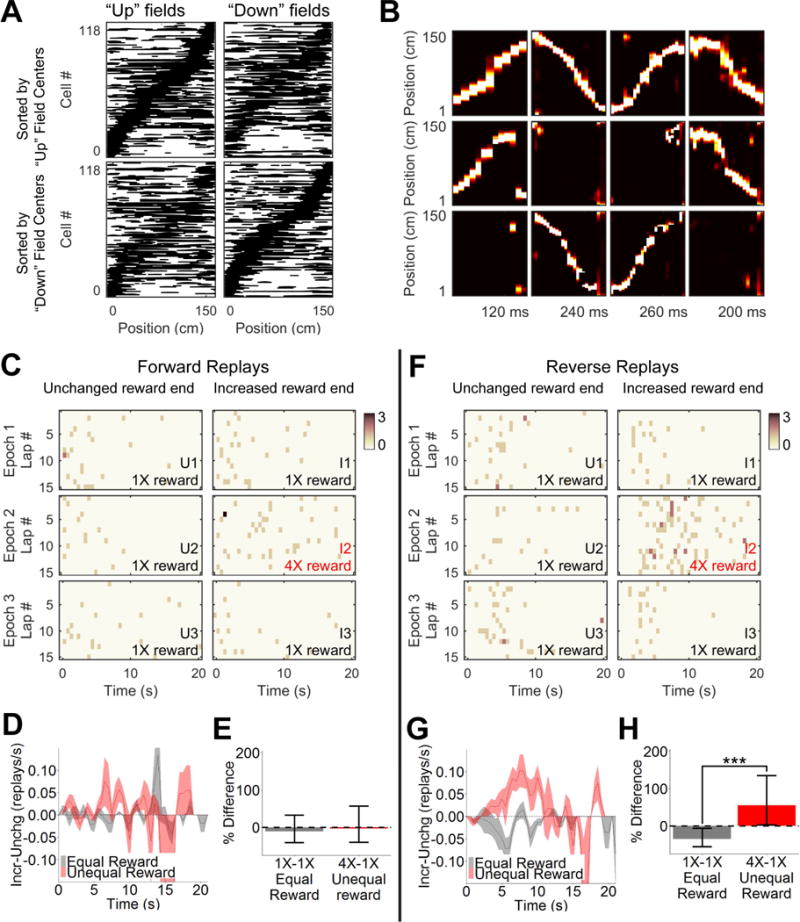
(A) Unidirectional place fields of 118 simultaneously recorded units in CA1. “Up” direction (left) and “down” direction (right) fields, sorted by “up” field centers (top) or “down” field centers (bottom). (B) Four example replays decoded using bi-directional fields (top), “up” directional fields (middle) and “down” directional fields (bottom). Replays were assigned the following identities, from left to right: forward replay moving up the track, forward replay moving down the track, reverse replay moving up the track, and reverse replay moving down the track. (C) Forward replay occurrence in the first 20s of each stopping period over 15 laps, summed across all sessions. Color bar indicates number of replays. (D) Difference in forward replay rate between ends of the track in the first 20s of each stopping period (mean ± SEM, as in Figure 2B). (E) Percent difference in forward replay rate from unchanged to increased reward end of track in the equal and unequal reward conditions (mean ± 95% confidence interval). (F) Reverse replay occurrence as shown in C. (G) Difference in reverse replay rate between ends of the track, as shown in D. (H) Difference in reverse replay rate between ends of the track, as shown in E. *** indicates p < 0.001. See also Figures S2–S5 and Table S2.
Critically, in order to evaluate the rate of forwards and reverse replay, it was necessary to observe both kinds of replay during the same stopping periods and independently of specific behaviors. It was previously reported on the linear track task that reverse replays occurred preferentially while rats faced away from the track at the end of the run, and forwards replays occurred preferentially after rats had turned around prior to running the next lap (Diba and Buzsaki, 2007). However, in neither orientation was the relationship exclusive. We analyzed times when the rat was at the well location, defined as a 10cm radius around the well (Singer and Frank, 2009) during which time the rat’s head direction was facing the well or within 90 degrees to the left or right for 83±1% of the time (mean±SEM). In our data, replays occurred in an interspersed manner relative to the beginning of each stopping period and to the beginning of each lap (Figure S3). Unlike Diba and Buzsaki, we did not observe a tendency of forward replays to occur in greater frequency before the next lap. We found no difference between forward and reverse replays in either the first or second half of the stopping periods (Wilcoxon rank sum test, first half/after lap: p=0.56, second half/before lap: p=0.59). Therefore, forward and reverse replay could be compared in our experiments independently during the same behavior.
Forward replay rate was not affected by reward condition (Figure 3E, z=0.305, p=0.76; Table S2). The rate of forward replays was very similar on both ends of the track regardless of reward magnitude (Figures 3C and 3D). Reverse replays, on the other hand, showed a robust response to increased reward (Figure 3F). The difference between ends in the unequal reward condition was significantly greater than in the equal reward condition (Figures 3G and 3H, z=3.57, p=3.60×10−4; Table S2). These data suggested that reverse replays are sensitive to the magnitude of reward, while forward replays are not. Further, reverse replay rates decreased at the unchanged end in epoch 2, thus matching the relative reward effect observed in replays and SWRs (Figure S4A, green circles; Figure S2D). This adaptive coding was not evident in the rate of forward replay (Figure S4A, purple circles; Figure S2C).
As in previous studies, the majority of forward and reverse replays were locally initiated, that is, the replayed trajectory began at the rat’s actual location (Davidson et al., 2009; Pfeiffer and Foster, 2013). Local replays comprised 86% of all replays (497/581) in Experiment One and 78% of all replays (246/314) in Experiment Two. Our results held when considering only locally initiated forward and reverse replays (Figure S5; Table S2). Remote replays were too infrequent for conclusive analysis, averaging less than five forward or reverse replays per run.
SWRs and replays are decreased when reward is removed
In Experiment Two, reward was removed at one end of the track, to test the effect of a decrease in reward magnitude on replay. SWRs were dramatically decreased in the absence of reward (Figures 4A and 4B), and the difference between reward conditions was significant (Figure 4C, z=−6.66, p=2.67×10−11, Table S3). Replays followed a similar pattern to SWRs (Figures 4D and 4E), with a significant difference between reward conditions (Figure 4F, z=−3.16, p=0.0016; Table S3).
Figure 4. SWRs and replays are diminished in absence of reward.

(A) SWR occurrence in the first 20s of each stopping period over 15 laps, summed across all sessions. Color bar indicates number of SWRs. (B) Difference in SWR rate between ends of the track in the first 20s of each stopping period (mean ± SEM, n=a maximum of 580 stopping periods in the equal reward condition and 230 in the unequal reward condition). (C) Percent difference in SWR rate from unchanged to decreased reward end of track in the equal and unequal reward conditions (mean ± 95% confidence interval). (D) Occurrence of replays as shown in A. (E) Difference in replay rate between ends of the track, as shown in B. (F) Difference in replay rate between ends of the track, as shown in C. ** indicates p < 0.01. *** indicates p < 0.001. See also Figures S2 and S4, and Table S3.
An important caveat in this experiment is that removal of reward elicited a shift in the rats’ behavior. Instead of stopping to eat, the rats paused to scan and sniff the reward area for the missing reward. Overall, the rats spent less time stopped on the unrewarded end of the track (3.3 ± 0.5 seconds versus 8.5 ± 1.3 seconds at the rewarded end, p=0.0078, Wilcoxon signed rank test), although they continued to enter the unrewarded well area as required by the task. Due to these behavioral changes, very few forward and reverse replays occurred at the changed end in epoch 2 (Figures 5A and 5D). Nevertheless, our comparison of reward conditions, which is sensitive to the relative difference between track ends, again revealed a divergence between forward and reverse replay. There was no significant difference between reward conditions for forward replays (Figures 5B and 5C, z=−1.83, p=.068; Table S3), while there was a significant difference in reverse replays (Figures 5E and 5F, z=−2.05, p=.041; Table S3). These results were replicated by analysis of local replays only (Figure S6; Table S3). Thus, the sensitivity of replay to the relative rather than absolute magnitude of reward revealed an effect of reward removal on reverse replay, driven principally by increases in the rate of replay at the opposite end of the track, at which reward magnitude had not been changed but for which the reward magnitude was now relatively greater (Figure S4). The relative reward effect results in stable overall rates of SWRs and replays across epochs (Figure S2).
Figure 5. Forward and reverse replays at decreased reward.

(A) Forward replay occurrence in the first 20s of each stopping period over 15 laps, summed across all sessions. Color bar indicates number of replays. (B) Difference in forward replay rate between ends of the track in the first 20s of each stopping periods (mean ± SEM, as in Figure 4C). (C) Percent difference in forward rate from unchanged to decreased reward end of track in the equal and unequal reward conditions (mean ± 95% confidence interval). (D) Occurrence of reverse replays as shown in A. (E) Difference in reverse replay rate between ends of the track, as shown in B. (F) Difference in reverse replay rate between ends of the track, as shown in C. * indicates p < 0.05. See also Figures S2–S4 and S6, and Table S3.
Comparison of forward and reverse replays
While we have demonstrated through independent analyses that forwards and reverse replay respond differently to reward changes, a direct comparison of forward and reverse replay in each condition would allow us to establish whether or not the two types of replay diverge under varying reward. We therefore fit a Poisson GLM to estimate replay rate based on three variables: epoch, end of track, and replay directionality. This more complex design is a more rigorous test of the data, with its implicit correction for multiple comparisons. Nevertheless, statistically significant differences between forward and reverse replay were observed in three conditions (Figure 6, Table S4). The weakest effect was an unexpected difference on one end of the track during epoch 1 of Experiment Two (Figure 6B, right). This track end did not correspond to a fixed physical location since location was randomized between sessions, but it may have corresponded to a predictive relationship between the end where the animal was initially placed at the beginning of epoch 1 and the end chosen to be manipulated in epoch 2. While both initial placement end and manipulated end were randomized between sessions, the pairing of the two variables was biased in Experiment Two but not in Experiment One, matching the result. Thus the unchanged reward end in Experiment Two frequently corresponded to the location where the rat encountered the first reward of the experiment session and was located opposite to the end where he was set down after a potentially stressful experience of being transferred on to the track. It is important to note that absolute levels of forwards or reverse replay are difficult to relate to absolute reward levels, because of behavioral biases and because of the more general issue that animals may find places rewarding for a number of reasons in addition to the location of specific rewards introduced by the experimenter.
Figure 6. Comparison of forward and reverse replay.

(A) Forward replay rate and reverse replay rate in epochs 1–3 in Experiment One (mean ± 95% confidence interval). (B) Forward replay rate and reverse replay rate in epochs 1–3 in Experiment Two (mean ± 95% confidence interval). * indicates p<0.05, ** indicates p<0.01, *** indicates p<0.001 adjusted for multiple comparisons. See also Table S4.
In contrast to these baseline effects, the experimental manipulation of reward magnitude during each experimental day was hypothesized to have specific effects on the ratio of forwards and reverse replay, and these account for the two stronger effects identified by the model. First, the rate of reverse replays was significantly greater than the rate of forward replays at the site of increased reward, in epoch 2 of Experiment One (Figure 6A, z=4.30, p=0.0001). Second, the rate of reverse replays was significantly greater than the rate of forwards replays at the site of decreased reward, not on epoch 2 but on epoch 3, when the baseline reward level was reinstated (Figure 6B, z=3.35, p=0.0049). Interestingly, the reward level in this epoch was the same at both ends of the track, but the change in reward from epoch 2 to 3 corresponded to a large increase in reward, which may have accounted for the divergence between reverse and forward replay. Thus, this analysis identified a second form of relative response, sensitive to the change of reward magnitude with time.
Changes in replays reflect relative changes in reward
We hypothesized that forward and reverse replays across both ends of the track might reflect not only the magnitude of reward present, but relative changes in reward with time. Both experiments have an increasing phase and a decreasing phase (Fig 7A). We sought to determine if the phases were related. We again used the three variable Poisson GLM, but instead of identifying significant effects, we considered the coefficients associated with different comparisons, and asked whether across the two experiments, those comparisons associated with relative reward increases produced similar coefficients. Thus for each experiment there were twelve coefficients describing changes in replay rate for the increasing and decreasing reward phases, which were adjusted for multiple comparisons. All twelve coefficients were plotted on a grid where each square represents the normalized change in replay rate from the condition on the x-coordinate to the condition on the y-coordinate (Figure 7B and 7D).
Figure 7. Changes in forward and reverse replay consistently code for relative increase or decrease in reward.

(A) Schematic of relative increasing and decreasing phases of Experiments One and Two. (B) Set of coefficients from the linear model describing differences between forward and reverse replays, ends of track, and epochs in the increasing phase of both experiments (Experiment One, epoch 1 to epoch 2, and Experiment Two, epoch 2 to epoch 3). (C) Bootstrapped distribution of SSDs of Experiments One and Two, increasing phase. Red line represents data test statistic. (D) Set of coefficients from the linear model describing differences between forward and reverse replays, ends of track, and epochs in the decreasing phase of both experiments (Experiment One, epoch 2 to epoch 3, and Experiment Two, epoch 1 to epoch 2). (E) Bootstrapped distribution of SSDs of Experiments One and Two, decreasing phase. Red line represents data test statistic. See also Figures S4 and S7.
In order to test the similarity of the two experiments’ increasing and decreasing phases, we identified hypothesized correspondences between the two experiments. For example, the coefficient describing the increase in reward from epoch 1 to epoch 2 at the changed end in Experiment One corresponded to the coefficient describing the increase in reward from epoch 2 to epoch 3 at the changed end in Experiment Two. All the other comparisons reflected similar hypothesized correspondences. Given the vector of coefficients for each experiment, aligned to reflect the hypothesized correspondences, we calculated the sum of squared differences (SSDs) between all corresponding coefficients. This value was then used as a test statistic. We performed a bootstrap analysis in which the twelve coefficients were randomly shuffled 10,000 times, generating a null distribution of the SSDs. The SSDs between the increasing phases was compared to the null distribution and was found to be smaller (i.e. coefficients were more related) than 99.5% of the shuffled data (one-sided test, p=0.005, Fig 7C). The SSDs between the decreasing phases did not reach significance (Figure 7E, one-sided test, p=0.107), in line with the general difficulty noted above of identifying robust decreases in replay rate as opposed to increases. Nevertheless, we report a robust effect of similar responses to relative increases in reward across both experiments.
In a complementary analysis, we calculated the significance of the SSDs between opposite decreasing and increasing phases (Figure S7). As all of these phases changed in opposite directions, we expected that these coefficients might be less related than chance. This would result in SSDs which is significantly greater than the mean of the null distribution. Indeed, for all four phase pairs, the SSDs were larger than the majority of the null distribution test statistics and the difference between the decreasing phase of Experiment One, and the increasing phase of Experiment Two reached significance (one-sided test, Figure S8D). Thus we found that reward changes of the same valence are similarly coded by forward and reverse replays, while the encoding of opposite valence changes appear to be anti-correlated, regardless of the absolute reward magnitudes involved.
Discussion
Reverse but not forward replays reflect changes in reward
We observed a striking difference between forward and reverse replay response to reward. Rates of reverse replay increased in response to increased reward, and decreased in response to decreased reward, while forward replays were unaffected. Moreover, reverse replays reflected relative reward amounts within an epoch, or the reward structure of the environment, as well as changes to reward between successive epochs. In Experiment One, the increase in reverse replay rate at the × reward end of the track was accompanied by a decrease on the opposite end of the track, and reverse replays were significantly more abundant than forward at the increased reward (Figures 3 and 6). Even though the rats did not spend much time at the unrewarded location in epoch 2, we were still able to observe an increase in reverse (and not forward) replay rate with the restoration of reward at the changed reward end in epoch 3 (Figures 6 and S4). Overall, we found a consistent pattern of rate changes across both experiments that reflected effects of both relative magnitude between track ends and change over time for a given track end, across multiple instances (analysis of figure 7).
Our results relate to several earlier studies. Diba and Buzsaki first reported that both forwards and reverse replays occurred during stopping periods in a linear track running task (Diba and Buzsaki, 2007). They reported a tendency for reverse replays to occur while the animal was consuming reward with his back to the track, while forward replays were more common close to the onset of a new lap, presumably when the animal faced towards the center of the track. Mindful of this, we restricted our analysis to times when the rat’s head was within a 10 cm radius of the food well, which corresponded to the rat’s facing in the direction of the reward well over 80% of the time. Thus most of the detected replays occurred while the rat was facing towards the well in the consistent behavioral state of eating or preparing to eat and both forward and reverse replays occurred. This can be seen in Figures 3C and 3F, and Figures 5A and 5D in which replay occurrences are plotted on the same time axis. Furthermore, even under a less conservatively defined well area (30 cm around well), which included times in which the rat was facing towards the track and preparing to run, we found that significant numbers of both types of replays occurred throughout the stopping periods and were not clearly localized to the beginning or end of stopping periods (Figure S3). Therefore, our findings do not reflect a trivial behavioral change but rather the rebalancing of forward and reverse sequences during a period when both are a priori equally possible.
A pioneering study by Singer and Frank demonstrated that the presence of reward can lead to increased rates of SWRs, and showed an increase in coordinated re-activation of place cells during SWRs at reward compared to when reward is absent (Singer and Frank, 2009). We have extended these results by establishing that both increases and decreases in reward are reflected by increases and decreases in SWR rate, respectively. Further, we have examined replay directly, to reveal the surprising finding that these changes are specific to reverse replay. SWRs are highly behaviorally dependent (Buzsaki, 1986), and it is arguably difficult to rule out subtle behavioral differences underlying the expression of different rates of SWRs, as opposed to neural circuit mechanisms. Indeed, the same argument applies to the overall rates of detected replays. By contrast, observed forward and reverse replays rely on detection of similar spiking events, with only the temporal order reversed, so that they act as controls for each other, and behavioral differences should be expected to impact them both equally (given the considerations discussed in the preceding paragraph). Thus, our finding of a change in the relative rates of reverse and forward replays provides strong evidence for the role of reward in modulating hippocampal processing during SWRs. We note that in our experiments only 15–20% of SWRs were identified as replays. The remaining SWRs may have contained remote replays of other environments (Karlsson and Frank, 2009) or replays of the current environment beyond our ability to detect from only a fraction of the cell population. However, we would not expect our random sampling of cells to favor one direction of replay over another so we expect that simultaneously recording from unlimited cells would yield similar results.
Reverse reactivation has also been shown to be stronger in the open field following high speed running periods (Csicsvari et al., 2007). In our experiments we observed running speeds which would be classified as high speed running on every lap, but faster running speeds leading up to larger reward did not explain our results. Although we observed faster speeds on laps towards the increased reward in Experiment One, consistent with known effects of increasing reward (Crespi, 1942), this effect was abolished when we considered only behavior outside of reward well areas. This indicates that rats were not actually reaching higher velocities on laps towards the larger reward but rather taking more time to leave the increased reward well area after they finished eating. We observed lower running speed towards the 0× reward in epoch 2 of Experiment Two which also carried over into epoch 3, where reverse replays were increased in the opposite direction.
Implications for the functional role of reverse replay
Replay is implicated in hippocampal memory consolidation as well as the retrieval of memories to inform decision making (Carr et al., 2011; Girardeau et al., 2009; Jadhav et al., 2012) but whether replay directionality specifically contributes to these functions is unknown. Reverse replay enhancement in novel environments has been interpreted as evidence for its contribution to learning (Foster and Wilson, 2006). Unlike forward replays, the trajectory represented in a reverse replay is counterintuitive since rats do not run backwards down the track under normal circumstances. In nature, an animal may spend a large amount of time foraging for food and when food is found, the path that preceded its discovery becomes valuable. Locally initiated reverse replay may constitute a mechanism by which the representation of spatial experience preceding arrival at the current location can be mentally revisited and retroactively assigned value (Sutton and Barto, 1998). Foster and Wilson proposed that the value assignment would be accomplished by pairing reverse replay with a reward triggered phasic dopamine signal (Foster and Wilson, 2006), with the result that downstream areas might represent a value gradient during reward approach (eg van der Meer and Redish, 2011). A second functional mechanism can be envisaged given recent reports that hippocampal dopamine can transform reverse order cell firing which normally results in LTD into LTP at short delays consistent with the interspike intervals observed in replay (Zhang et al., 2009; Brzosko et al., 2015). Indeed, the Brzosko study, performed at the CA3-CA1 synapse, suggests that under certain conditions reverse replay could actually strengthen forward associations. While reverse replays are increased in novel environments, increased SWRs have also been observed at novel goal locations relative to familiar locations, and the SWR frequency at these newly learned locations was predictive of future performance (Dupret et al., 2010). This indicates a functional significance of SWRs and presumably reverse replay in consolidation of reward related memory. Since most of our replays were locally initiated, the specific trajectory that was increased in abundance at the relatively larger reward was the reverse sequence representing the most recent trajectory the rat had taken. Thus, reverse replays may serve to strengthen valuable memories and contribute to consolidation.
A potential awkwardness with interpreting reverse replay as memory consolidation follows from our finding that removing reward leads to a decreased incidence of reverse replay: one might rather expect to consolidate the memory of a reward being removed, so as not to expend energy visiting the unrewarded location. While this is a concern common to other studies of the effect of reward removal (e.g. on SWRs; Singer and Frank, 2009), our results suggest one mechanism by which appropriate memory consolidation could nevertheless result. The adaptive coding aspect of reverse replay is reflected in an increase in reverse replay at the unchanged end of the track opposite where the reward has been removed. Thus the relatively better option may be consolidated to facilitate the avoidance of lesser rewards while not explicitly encoding lack of reward.
The adaptive coding of relative reward by reverse replay requires information about relative reward to be transmitted to the hippocampus. Interestingly, dopamine neurons of the ventral tegmental area display the same dynamical adaptation of neural output to the current range of reward magnitude as we observed in reverse replay (Tobler et al., 2005). Moreover, these neurons classically signal reward prediction error (Schultz et al., 1997) and this is consistent with our finding of rate changes associated with changing reward across runs, such as above-baseline rates after reinstatement of reward in Experiment Two. Ventral tegmental area projections may directly drive the adaptive coding response in the hippocampus by interaction with reverse replay representing ensembles. The latter possibility is consistent with recent reports that dopamine neurons are activated during hippocampal SWRs and replay (Gomperts et al., 2015) and that activation of dopamine neurons during experience can promote later hippocampal reactivation during rest and memory consolidation (McNamara et al., 2014).
Implications for the functional role of forward replay
If reverse replay serves as a learning mechanism (Diba and Buzsaki, 2007; Foster and Wilson, 2006), forward replay is a likely candidate for memory retrieval and planning future paths. Planning is arguably simple or even unnecessary in our linear track task, and in particular, the planning requirement was not affected by the experimental changes to reward, since the required future path was always the same. For example, even when reward was removed in Experiment Two, the rat was required to visit the opposite end of the track before the remaining reward was refilled. However, the task design did not preclude the possibility of superfluous memory or planning. Interestingly, we observed an overall decreasing rate of forward replays over the course of Experiment One which reached significance in epoch 3 (Figure S2C), a pattern that might have been due to the task becoming increasingly perfunctory. By contrast, reverse replays did not decrease overall in epoch 3, presumably because they were sensitive to reward, which changed in each epoch.
Consistent with a role in planning or decision-making, in tasks involving decision making, replays (Karlsson and Frank, 2009; Singer et al., 2013) and replay-like “forward sweeps” (Johnson and Redish, 2007) are observed at choice points in conjunction with reward expectation signals in the ventral striatum (van der Meer and Redish, 2009). In a spatial memory task, replays can reflect the location of a remembered goal, and predict the behavioral trajectory an animal will take to get there (Pfeiffer and Foster, 2013). Blocking SWRs impairs working memory performance in a spatial task without affecting reference memory (Jadhav et al., 2012). However, our evidence of functional differences between forward and reverse replays, warns of the inadequacy of generalizing replay function. Replay detection and even more so accurate decoding of content requires a large number of simultaneously recorded cells, and many studies have used SWRs as a proxy for replay to bypass this technological hurdle. SWRs do not distinguish replay of the current environment from that of other environments, and do not distinguish direction. The interpretation of several previous studies would be complicated if a substantial number of the replays occurring at the time of experimental manipulation were reverse replays depicting incoming behaviors, rather than forwards replays depicting planned outgoing behaviors, as presumed.
The meaning of replay rate changes
An interesting issue in the interpretation of our results concerns the fact that reward information is apparently conveyed by the increase or decrease in rate of reverse replay. A very strong interpretation of our results would be to state that reverse replay “encodes” reward magnitude and/or reward prediction error. While possible, this interpretation sits uneasily with other considerations. For example, if reverse replay in the hippocampus is an input signal to downstream circuits that learn to predict rewards (e.g. learn a spatial value function), then increasing replay rate might be expected over time to increase the weights of place cell inputs to value-representing neurons, thereby increasing the magnitude signal conveyed by these neurons. But this is a rather unwieldy mechanism, since the number of learning events will increase without limit for as long as the rat stops in place. Alternatively, downstream circuits might be sensitive specifically to the rate of events – but it is not clear how such a replay-rate-sensitive scheme could be implemented, since the timescale involved is long (seconds). It would be computationally simpler to use separate mechanisms to encode reward magnitude and the spatial trajectory with which the reward is to be associated – for example, by pairing reverse replay sequences with larger or smaller dopamine signals, according to the model proposed in (Foster and Wilson, 2006).
We prefer a more conservative interpretation of our results: that replay rate changes arise out of coordination of reverse replay with dopaminergic or other reward-related signals, and thus the rate changes themselves are merely a necessary by-product of this coordination. Such a mechanism could facilitate synaptic strengthening within the replaying cell ensembles as well as their downstream targets and could lead to increased consolidation via later reactivation. This scheme would, however, necessitate the controlled initiation of reverse replays by an external signal, for which there is already suggestive evidence (McNamara et al., 2014). Hence, we expect that the importance of our results lies in the notion of selective triggering of reverse replay, the demonstration that reverse replay has a unique relationship to the processing of reward, and the implication that replay is a heterogeneous phenomenon with forward and reverse events having quite different functions.
Experimental Procedures
Data Acquisition and Behavior
All experimental and surgical procedures were compliant with the National Institutes of Health guidelines for animal use and approved by the JHU Animal Care and Use Committee.
Three to six month old male Long-Evans rats were food restricted to 85–90% of their free-feeding weight and trained for one week to run laps on a 1.5 or 1.8m linear track for liquid chocolate reward. Training occurred in a different environment from the recording area. Trained rats were surgically implanted with a 40 tetrode microdrive targeting area CA1 of the hippocampus as described by Pfieffer and Foster, 2013. After surgery rats underwent three training sessions on the experimental track of the same dimensions as training track but in a new location. This allowed the rats to acclimate to running with the microdrive and to become familiar with the track.
Data collection was performed using a Neuralynx data acquisition system with Cheetah software. Local field potential (LFP) was digitally filtered between 0.1 and 500Hz and recorded at 3,255Hz. Spike recording was triggered by threshold crossing events (>50uV) and recorded at 32,556Hz. The rat’s position and head direction were monitored by an overhead camera operating at 30 frames/s. Stopping periods were defined as times in which the rat’s velocity was less than 5cm/s and his position was within 10cm of the well location. All analysis was restricted to stopping periods.
Sharp wave ripple detection
One channel was selected from each of 4–7 tetrodes for LFP analysis. LFP was band-pass filtered between 150 and 250Hz and the smoothed (Gaussian kernel, s.d. = 12.5ms) Hilbert envelope of this signal was averaged across all channels. Peaks in the envelope exceeding 3s.d. above the mean, were identified as SWRs. The start and end time of each SWR event is defined as the time at which the signal crossed the mean. SWRs were used as candidate replay events.
Spike Analysis
Individual units were separated using custom clustering software (xclust2, M. A. Wilson). Only well isolated units with complex spike index (CSI) > 5 were used in analysis. The CSI considers interspike interval violations and the complex structure of spike bursts of a given unit (Quirk and Wilson, 1999). Place fields were calculated using the times when velocity exceeded 5cm/s. For bi-directional place fields, total firing activity was binned into 1.8cm position bins along the track and divided by time spent in each position. For uni-directional fields, only activity during traversals in a single direction were used. Raw fields were smoothed using a Gaussian kernel with s.d. of 3cm.
A Bayesian decoding algorithm was used to estimate the rat’s position during each epoch as described in Pfieffer and Foster, 2013. Non-overlapping 200ms windows were used to estimate the rat’s position on a timescale of seconds. Time windows of 20ms, overlapping by 10ms were used to estimate the rat’s position during candidate replay events. Candidate events whose posterior probability’s weighted correlation (Wu and Foster, 2014) exceeded 0.6 were identified as replay events.
We verified our results with two additional replay detection criteria, increasing the weighted correlation threshold, or requiring candidate replays to pass a Monte Carlo shuffle. The Monte Carlo p-value was calculated as the number of shuffles of the posterior probability which passed threshold plus one divided by the total number of shuffles (1,500) plus one. Candidate replays with p-value less than 0.05 were confirmed as replays. Both analyses produced very similar results to our original analysis (Tables S2 and S3) although under the increased criteria we observed zero reverse replays at the removed reward which introduced a large amount of uncertainty to the linear model in Experiment Two.
To determine a threshold for identifying directional replays we calculated the percent of the Bayesian posterior probability in the decoding from the “downward” fields:
| (Equation 1) |
The distribution of downward probability has peaks close to 0% (strongly upward decoding) and 100% (strongly downward decoding) while the center of the distribution is roughly flat. The distribution from 33.5–66.5% significantly deviated from the uniform distribution (Kruskal-Wallis, p=0.044) while the 34–66% region was not significantly different from uniform (p=0.080). Therefore, we classified all replays with downward probability greater than 66.5% as downward replays and forward probability greater than 66.5% as forward replays.
Generalized linear models
Generalized linear models (GLMs) with mixed effects were used to analyze SWR and replay data. Since the data is in the form of rate, defined as number of events (SWRs or replays) per second the rat was at the reward well, the appropriate GLM is the Poisson family model with count as the outcome and an offset term for time. This model accounts for random effects of subject, in this case “rat”, and allows nesting of a second random effect, “experiment day”, with the resulting sample size number of rats (5) rather than experiment days (7). Unique intercepts are allowed for each of the nested random effects while a single slope is estimated for the data set on the whole. This means that the uncertainties associated with the estimated mean rates, which are plotted as 95% confidence intervals in all figures, are not equivalent to the uncertainty of the difference between two conditions. This explains why the differences between some conditions are highly significant, even if their 95% confidence intervals are overlapping.
Our general model was used with different outcomes (SWR, replay, forward replays, and reverse replays) and with fixed effects based on the questions being asked. GLMs were fit using the glmer() function with family=”poisson” from the lme4 package in R (freely available at http://cran.r-project.org). Multiple comparisons were corrected for using the default single-step method from the glht() function from the multcomp package in R. Model fits were assessed by visual inspection of residuals. Significance of coefficients was tested using Wald’s z-test (asymptotic t-test) which is appropriate for Poisson distributed count data. Confidence intervals were calculated using the Wald method with similar results to those obtained from the profile likelihood method.
In the first main analysis (Figures 2–5, Figures S5 and S6), we used the dummy coded categorical predictors of reward condition (unequal or equal) and end of track (unchanged or changed reward) to estimate changes in rates of event (SWRs, replays, forward replays, and reverse replays) in both experiments. We calculated the difference between reward conditions and end of track relative to a reference condition, for example, the number of events per second that occurred in the equal reward condition and on the unchanged reward end of the track. The output of this model is summarized by:
| (Equation 2) |
The coefficient b0 in a Poisson GLM is the log conditional mean event rate of the reference condition. By changing the reference conditions we were able to calculate the mean events per second under every condition. The coefficients b1 and b2 represent the log multiplicative change from the reference mean to the corresponding conditions. Thus, b1 is the change from equal to unequal reward condition, holding end of track constant while b2 is the change from unchanged reward to changed reward end of the track, holding reward condition constant. For interpretability, these coefficients were reported (in Tables S2 and S3) and plotted with their 95% confidence intervals as the percent change in events/s between ends of the track:
| (Equation 3) |
The means and confidence intervals plotted in Figures 2C, 2F, 3E, 3H, 4C, 4F, 5C, 5F, S5C, S5F, S6C, and S6F come from the coefficient b2. Meanwhile, the significance plotted in these figures comes from the interaction term, b3, which is the difference between reward conditions of the difference in rate between ends of the track.
In later analyses we used categorical variables epoch, end of track, and replay directionality as fixed effects with the outcome variable replay. For the direct comparison of forward and reverse replays we extracted the forward to reverse difference for all epoch and end of track conditions, adjusting for multiple comparisons (Figure 6, Table S4). In the full comparison of increasing and decreasing phases we used all contrasts which differed by a single variable, adjusting for multiple comparisons (Figures 7B and 7D).
In the supplemental analysis in Figure S4, we used epoch and end of track as fixed effects with the outcome variable SWR, replay, forward replay, or reverse replay rate.
| (Equation 4) |
This allowed us to estimate conditional mean rates of each outcome variable at each epoch and end of track combination (Figures S4A and S4C). We could also extract all contrasts of interest from the model, adjusting for multiple comparisons (Figures S4B and S4D). We estimated overall rates of SWRs and replays across runs by omitting end of track from the same model (Figure S2).
Additional analysis of running speed was performed (Figure S1). We analyzed this data using a linear mixed effect model which assumed normal distributions of running speed but was otherwise equivalent to the models discussed above.
Supplementary Material
Highlights.
-
-
Reverse but not forward replays are sensitive to reward context
-
-
SWR and replay rates adaptively code the given range of reward magnitudes
-
-
Reverse replay rates are altered by changes in reward from previous experience
-
-
Reverse replay rates reflect relative reward magnitudes in the same experience
Acknowledgments
The authors thank the Johns Hopkins Bloomberg School of Public Health Statistics Consulting Center for help with generalized linear mixed models. This work was supported by The McKnight Endowment Fund for Neuroscience (DF) and National Institute of Mental Health grant R01MH085823 (DF).
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
Author Contributions
Conceptualization, D.J.F.; Data collection, R.E.A. and B.E.P.; Analysis, R.E.A. and D.J.F.; Writing, R.E.A. and D.J.F.
References
- Brzosko Z, Schultz W, Paulsen O. Retroactive modulation of spike timing-dependent plasticity by dopamine. Elife. 2015;4:e09685. doi: 10.7554/eLife.09685. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Buzsaki G. Hippocampal sharp waves: their origin and significance. Brain Res. 1986;398:242–252. doi: 10.1016/0006-8993(86)91483-6. [DOI] [PubMed] [Google Scholar]
- Carr MF, Jadhav SP, Frank LM. Hippocampal replay in the awake state: a potential substrate for memory consolidation and retrieval. Nat Neurosci. 2011;14:147–153. doi: 10.1038/nn.2732. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Crespi LP. Quantitative variation of incentive and performance in the white rat. Am J Psychol. 1942;55:467–517. [Google Scholar]
- Csicsvari J, Hirase H, Czurko A, Mamiya A, Buzsaki G. Fast network oscillations in the hippocampal CA1 region of the behaving rat. J Neurosci. 1999;19:RC20. doi: 10.1523/JNEUROSCI.19-16-j0001.1999. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Csicsvari J, O’Neill J, Allen K, Senior T. Place-selective firing contributes to the reverse-order reactivation of CA1 pyramidal cells during sharp waves in open-field exploration. Eur J Neurosci. 2007;26:704–716. doi: 10.1111/j.1460-9568.2007.05684.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Davidson TJ, Kloosterman F, Wilson MA. Hippocampal replay of extended experience. Neuron. 2009;63:497–507. doi: 10.1016/j.neuron.2009.07.027. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Diba K, Buzsaki G. Forward and reverse hippocampal place-cell sequences during ripples. Nat Neurosci. 2007;10:1241–1242. doi: 10.1038/nn1961. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dupret D, O’Neill J, Pleydell-Bouverie B, Csicsvari J. The reorganization and reactivation of hippocampal maps predict spatial memory performance. Nat Neurosci. 2010;13:995–1002. doi: 10.1038/nn.2599. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Foster DJ, Wilson MA. Reverse replay of behavioural sequences in hippocampal place cells during the awake state. Nature. 2006;440:680–683. doi: 10.1038/nature04587. [DOI] [PubMed] [Google Scholar]
- Girardeau G, Benchenane K, Wiener SI, Buzsaki G, Zugaro MB. Selective suppression of hippocampal ripples impairs spatial memory. Nat Neurosci. 2009;12:1222–1223. doi: 10.1038/nn.2384. [DOI] [PubMed] [Google Scholar]
- Gomperts SN, Kloosterman F, Wilson MA. VTA neurons coordinate with the hippocampal reactivation of spatial experience. Elife. 2015;4 doi: 10.7554/eLife.05360. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gupta AS, van der Meer MA, Touretzky DS, Redish AD. Hippocampal replay is not a simple function of experience. Neuron. 2010;65:695–705. doi: 10.1016/j.neuron.2010.01.034. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jadhav SP, Kemere C, German PW, Frank LM. Awake Hippocampal Sharp-Wave Ripples Support Spatial Memory. Science. 2012;336:1454–1458. doi: 10.1126/science.1217230. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Johnson A, Redish AD. Neural ensembles in CA3 transiently encode paths forward of the animal at a decision point. J Neurosci. 2007;27:12176–12189. doi: 10.1523/JNEUROSCI.3761-07.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Karlsson MP, Frank LM. Awake replay of remote experiences in the hippocampus. Nat Neurosci. 2009;12:913–918. doi: 10.1038/nn.2344. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee AK, Wilson MA. Memory of sequential experience in the hippocampus during slow wave sleep. Neuron. 2002;36:1183–1194. doi: 10.1016/s0896-6273(02)01096-6. [DOI] [PubMed] [Google Scholar]
- McNamara CG, Tejero-Cantero A, Trouche S, Campo-Urriza N, Dupret D. Dopaminergic neurons promote hippocampal reactivation and spatial memory persistence. Nat Neurosci. 2014;17:1658–1660. doi: 10.1038/nn.3843. [DOI] [PMC free article] [PubMed] [Google Scholar]
- O’Keefe J, Dostrovsky J. The hippocampus as a spatial map. Preliminary evidence from unit activity in the freely-moving rat. Brain Res. 1971;34:171–175. doi: 10.1016/0006-8993(71)90358-1. [DOI] [PubMed] [Google Scholar]
- O’Keefe J, Nadel L. The Hippocampus as a Cognitive Map. Oxford: Clarendon Press; 1978. [Google Scholar]
- Pfeiffer BE, Foster DJ. Hippocampal place-cell sequences depict future paths to remembered goals. Nature. 2013;497:74–79. doi: 10.1038/nature12112. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Quirk MC, Wilson MA. Interaction between spike waveform classification and temporal sequence detection. J Neurosci Methods. 1999;94:41–52. doi: 10.1016/s0165-0270(99)00124-7. [DOI] [PubMed] [Google Scholar]
- Schultz W, Dayan P, Montague PR. A neural substrate of prediction and reward. Science. 1997;275:1593–1599. doi: 10.1126/science.275.5306.1593. [DOI] [PubMed] [Google Scholar]
- Singer AC, Carr MF, Karlsson MP, Frank LM. Hippocampal SWR activity predicts correct decisions during the initial learning of an alternation task. Neuron. 2013;77:1163–1173. doi: 10.1016/j.neuron.2013.01.027. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Singer AC, Frank LM. Rewarded outcomes enhance reactivation of experience in the hippocampus. Neuron. 2009;64:910–921. doi: 10.1016/j.neuron.2009.11.016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sutton RS, Barto AG. Reinforcement learning: an introduction. MIT Press; Cambridge, MA: 1998. [Google Scholar]
- Tobler PN, Fiorillo CD, Schultz W. Adaptive coding of reward value by dopamine neurons. Science. 2005;307:1642–1645. doi: 10.1126/science.1105370. [DOI] [PubMed] [Google Scholar]
- van der Meer MA, Redish AD. Covert Expectation-of-Reward in Rat Ventral Striatum at Decision Points. Front Integr Neurosci. 2009;3:1. doi: 10.3389/neuro.07.001.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van der Meer MA, Redish AD. Theta phase precession in rat ventral striatum links place and reward information. J Neurosci. 2011;31:2843–2854. doi: 10.1523/JNEUROSCI.4869-10.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wu X, Foster DJ. Hippocampal replay captures the unique topological structure of a novel environment. J Neurosci. 2014;34:6459–6469. doi: 10.1523/JNEUROSCI.3414-13.2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang JC, Lau PM, Bi GQ. Gain in sensitivity and loss of temporal contrast of STDP by dopminergic modulation and hippocampal synapses. Proc Natl Acad Sci. 2009;106:13028–13033. doi: 10.1073/pnas.0900546106. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.