

Abstract
Background
Joint modelling of longitudinal and time-to-event outcomes has received considerable attention over recent years. Commensurate with this has been a rise in statistical software options for fitting these models. However, these tools have generally been limited to a single longitudinal outcome. Here, we describe the classical joint model to the case of multiple longitudinal outcomes, propose a practical algorithm for fitting the models, and demonstrate how to fit the models using a new package for the statistical software platform R, joineRML.
Results
A multivariate linear mixed sub-model is specified for the longitudinal outcomes, and a Cox proportional hazards regression model with time-varying covariates is specified for the event time sub-model. The association between models is captured through a zero-mean multivariate latent Gaussian process. The models are fitted using a Monte Carlo Expectation-Maximisation algorithm, and inferences are based on approximate standard errors from the empirical profile information matrix, which are contrasted to an alternative bootstrap estimation approach. We illustrate the model and software on a real data example for patients with primary biliary cirrhosis with three repeatedly measured biomarkers.
Conclusions
An open-source software package capable of fitting multivariate joint models is available. The underlying algorithm and source code makes use of several methods to increase computational speed.
Electronic supplementary material
The online version of this article (10.1186/s12874-018-0502-1) contains supplementary material, which is available to authorized users.
Keywords: Joint modelling, Longitudinal data, Multivariate data, Time-to-event data, Software
Background
In many clinical studies, subjects are followed-up repeatedly and response data collected. For example, routine blood tests might be performed at each follow-up clinic appointment for patients enrolled in a randomized drug trial, and biomarker measurements recorded. An event time is also usually of interest, for example time of death or study drop-out. It has been repeatedly shown elsewhere that if the longitudinal and event-time outcomes are correlated, then modelling the two outcome processes separately, for example using linear mixed models and Cox regression models, can lead to biased effect size estimates [1]. The same criticism has also been levelled at the application of so-called two-stage models [2]. The motivation for using joint models can be broadly separated into interest in drawing inference about (1) the time-to-event process whilst adjusting for the intermittently measured (and potentially error-prone) longitudinal outcomes, and (2) the longitudinal data process whilst adjusting for a potentially informative drop-out mechanism [3]. The literature on joint modelling is extensive, with excellent reviews given by Tsiatis and Davidian [4], Gould et al. [5], and the book by Rizopoulos [6].
Joint modelling has until recently been predominated by modelling a single longitudinal outcome together with a solitary event time outcome; herein referred to as univariate joint modelling. Commensurate with methodological research has been an increase in wide-ranging clinical applications (e.g. [7]). Recent innovations in the field of joint models have included the incorporation of multivariate longitudinal data [8], competing risks data [9, 10], recurrent events data [11], multivariate time-to-event data [12, 13], non-continuous repeated measurements (e.g. count, binary, ordinal, and censored data) [14], non-normally and non-parametrically distributed random effects [15], alternative estimation methodologies (e.g. Bayesian fitting and conditional estimating equations) [16, 17], and different association structures [18]. In this article, we specifically focus on the first innovation: multivariate longitudinal data. In this situation, we assume that multiple longitudinal outcomes are measured on each subject, which can be unbalanced and measured at different times for each subject.
Despite the inherently obvious benefits of harnessing all data in a single model or the published research on the topic of joint models for multivariate longitudinal data, a recent literature review by Hickey et al. [19] identified that publicly available software for fitting such models was lacking, which has translated into limited uptake by biomedical researchers. In this article we present the classical joint model described by Henderson et al. [3] extended to the case of multiple longitudinal outcomes. An algorithm proposed by Lin et al. [20] is used to fit the model, augmented by techniques to reduce the computational fitting time, including a quasi-Newton update approach, variance reduction method, and dynamic Monte Carlo updates. This algorithm is encoded into a R sofware package–joineRML. A simulation analysis and real-world data example are used to demonstrate the accuracy of the algorithm and the software, respectively.
Implementation
As a prelude to the introduction and demonstration of the newly introduced software package, in the following section we describe the underlying model formulation and model fitting methodology.
Model
For each subject i=1,…,n, is the K-variate continuous outcome vector, where each yik denotes an (nik×1)-vector of observed longitudinal measurements for the k-th outcome type: . Each outcome is measured at observed (possibly pre-specified) times tijk for j=1,…,nik, which can differ between subjects and outcomes. Additionally, for each subject there is an event time , which is subject to right censoring. Therefore, we observe , where Ci corresponds to a potential censoring time, and the failure indicator δi, which is equal to 1 if the failure is observed and 0 otherwise. We assume that both censoring and measurement times are non-informative.
The model we describe is the natural extension of the model proposed by Henderson et al. [3] to the case of multivariate longitudinal data. The model posits an unobserved or latent zero-mean (K+1)-variate Gaussian process that is realised independently for each subject, . This latent process subsequently links the separate sub-models via association parameters.
The k-th longitudinal data sub-model is given by
| 1 |
where μik(t) is the mean response, and εik(t) is the model error term, which we assume to be independent and identically distributed normal with mean 0 and variance . The mean response is specified as a linear model
| 2 |
where xik(t) is a pk-vector of (possibly) time-varying covariates with corresponding fixed effect terms βk. is specified as
| 3 |
where zik(t) is an rk-vector of (possibly) time-varying covariates with corresponding subject-and-outcome random effect terms bik, which follow a zero-mean multivariate normal distribution with (rk×rk)-variance-covariance matrix Dkk. To account for dependence between the different longitudinal outcome outcomes, we let cov(bik,bil)=Dkl for k≠l. Furthermore, we assume εik(t) and bik are uncorrelated, and that the censoring times are independent of the random effects. These distributional assumptions together with the model given by (1)–(3) are equivalent to the multivariate extension of the Laird and Ware [21] linear mixed effects model. More flexible specifications of can be used [3], including for example, stationary Gaussian processes. However, we do not consider these cases here owing to the increased computational burden it carries, even for the univariate case.
The sub-model for the time-to-event outcome is given by the hazard model
where λ0(·) is an unspecified baseline hazard, and vi(t) is a q-vector of (possibly) time-varying covariates with corresponding fixed effect terms γv. Conditional on Wi(t) and the observed covariate data, the longitudinal and time-to-event data generating processes are conditionally independent. To establish a latent association, we specify W2i(t) as a linear combination of :
where γy=(γy1,…,γyK) are the corresponding association parameters. To emphasise the dependence of W2i(t) on the random effects, we explicitly write it as W2i(t,bi) from here onwards. As per , W2i(t,bi) can also be flexibly extended, for example to include subject-specific frailty effects [3].
Estimation
Likelihood
For each subject i, let and be block-diagonal matrices, where is an (nik×pk)-design matrix, with the j-th row corresponding to the pk-vector of covariates measured at time tijk, and denotes the direct matrix sum. The notation similarly follows for the random effects design matrices, Zik. We denote the error terms by a diagonal matrix and write the overall variance-covariance matrix for the random effects as
where In denotes an n×n identity matrix. We further define and . Hence, we can then rewrite the longitudinal outcome sub-model as
For the estimation, we will assume that the covariates in the time-to-event sub-model are time-independent and known at baseline, i.e. vi≡vi(0). Extensions of the estimation procedure for time-varying covariates are outlined elsewhere [6, p. 115]. The observed data likelihood for the joint outcome is given by
| 4 |
where is the collection of unknown parameters that we want to estimate, with vech(D) denoting the half-vectorisation operator that returns the vector of lower-triangular elements of matrix D.
As noted by Henderson et al. [3], the observed data likelihood can be calculated by rewriting it as
where the marginal distribution f(yi | θ) is a multivariate normal density with mean Xiβ and variance-covariance matrix , and f(bi | yi,θ) is given by (6).
MCEM algorithm
We determine maximum likelihood estimates of the parameters θ using the Monte Carlo Expectation Maximisation (MCEM) algorithm [22], by treating the random effects bi as missing data. This is effectively the same as the conventional Expectation-Maximisation (EM) algorithm, as used by Wulfsohn and Tsiatis [23] and Ratcliffe et al. [24] in the context of fitting univariate data joint models, except the E-step exploits a Monte Carlo (MC) integration routine as opposed to Gaussian quadrature methods, which we expect to be beneficial when the dimension of random effects becomes large.
Starting from an initial estimate of the parameters, , the procedure involves iterating between the following two steps until convergence is achieved.
-
E-step. At the (m+1)-th iteration, we compute the expected log-likelihood of the complete data conditional on the observed data and the current estimate of the parameters,
Here, the complete-data likelihood contribution for subject i is given by the integrand of (4).
- M-step. We maximise with respect to θ. Namely, we set
The M-step estimators naturally follow from Wulfsohn and Tsiatis [23] and Lin et al. [20]. Maximizers for all parameters except γv and γy are available in closed-form; algebraic details are presented in Additional file 1. The parameters are jointly updated using a one-step Newton-Raphson algorithm as
where denotes the value of γ at the current iteration, is the corresponding score, and is the observed information matrix, which is equal to the derivative of the negative score. Further details of this update are given in Additional file 1. The M-step for γ is computationally expensive to evaluate. Therefore, we also propose a quasi-Newton one-step update by approximating by an empirical information matrix for γ, which can be considered an analogue of the Gauss-Newton method [25, p. 8]. To further compensate for this approximation, we also use a nominal step-size of 0.5 rather than 1, which is used when using the Newton-Raphson update.
The M-step involves terms of the form , for known functions h(·). The conditional expectation of a function of the random effects can be written as
| 5 |
where is given by
and is calculated from multivariate normal distribution theory as
| 6 |
with . As this becomes computationally expensive using Gaussian quadrature commensurate with increasing dimension of bi, we estimate the integrals by MC sampling such that the expectation is approximated by the ratio of the sample means for and evaluated at each MC draw. Furthermore, we use antithetic simulation for variance reduction in the MC integration. Instead of directly sampling from (6), we sample Ω∼N(0,Ir) and obtain the pairs
where Ci is the Cholesky decomposition of Ai such that . Therefore we only need to draw N/2 samples using this approach, and by virtue of the negative correlation between the pairs, it leads to a smaller variance in the sample means taken in the approximation than would be obtained from N independent simulations. The choice of N is described below.
Initial values
The EM algorithm requires that initial parameters are specified, namely . By choosing values close to the maximizer, the number of iterations required to reach convergence should be reduced.
For the time-to-event sub-model, a quasi-two-stage model is fitted when the measurement times are balanced, i.e. when tijk=tij∀k. That is, we fit separate LMMs for each longitudinal outcome as per (1), ignoring the correlation between different outcomes. This is straightforward to implement using standard software, in particular using lme() and coxph() from the R packages nlme [26] and survival [27], respectively. From the fitted models, the best linear unbiased predictions (BLUPs) of the separate model random effects are used to estimate each function. These estimates are then included as time-varying covariates in a Cox regression model, alongside any other fixed effect covariates, which can be straightforwardly fitted using standard software. In the situation that the data are not balanced, i.e. when tijk≠tij∀k, then we fit a standard Cox proportional hazards regression model to estimate γv and set γyk=0∀k.
For the longitudinal data sub-model, when K>1 we first find the maximum likelihood estimate of by running a separate EM algorithm for the multivariate linear mixed model. Both the E- and M-step updates are available in closed form, and the initial parameters for this EM algorithm are available from the separate LMM fits, with D initialized as block-diagonal. As these are estimated using an EM rather than MCEM algorithm, we can specify a stricter convergence criterion on the estimates.
Convergence and stopping rules
Two standard stopping rules for the deterministic EM algorithm used to declare convergence are the relative and absolute differences, defined as
| 7 |
| 8 |
respectively, for some appropriate choice of ε0, ε1, and ε2, where the maximum is taken over the components of θ. For reference, the R package JM [28] implements (7) (in combination with another rule based on relative change in the likelihood), whereas the R package joineR [29] implements (8). The relative difference might be unstable about parameters near zero that are subject to MC error. Therefore, the convergence criterion for each parameter might be chosen separately at each EM iteration based on whether the absolute magnitude is below or above some threshold. A similar approach is adopted in the EM algorithms employed by the software package SAS [30, p. 330].
The choice of N and the monitoring of convergence are conflated when applying a MCEM algorithm, and a dynamic approach is required. As noted by [22], it is computationally inefficient to use a large N in the early phase of the algorithm when the parameter estimates are likely to be far from the maximizer. On the flip side, as the parameter estimates approach the maximizer, the stopping rules will fail as the changes in parameter estimates will be swamped by MC error. Therefore, it has been recommended that one increase N as the estimate moves towards the maximizer. Although this might be done subjectively [31] or by pre-specified rules [32], an automated approach is preferable and necessary for a software implementation. Booth and Hobert [33] proposed an update rule based on a confidence ellipsoid for the maximizer at the (m+1)-th iteration, calculated using an approximate sandwich estimator for the maximizer, which accounts for the MC error at each iteration. This approach requires additional variance estimation at each iteration, therefore we opt for a simpler approach described by Ripatti et al. [34]. Namely, we calculate a coefficient of variation at the (m+1)-th iteration as
where is given by (7), and sd(·) and mean(·) are the sample standard deviation and mean functions, respectively. If , then N:=N+⌊N/δ⌋, for some small positive integer δ. Typically, we run the MCEM algorithm with a small N (for a fixed number of iterations—a burn-in) before implementing this update rule in order to get into the approximately correct parameter region. Appropriate values for other parameters will be application specific, however we have found δ=3, N=100K (for 100K burn-in iterations), ε1=0.001, and ε0=ε2=0.005 delivers reasonably accurate estimates in many cases, where K was earlier defined as the number of longitudinal outcomes.
As the EM monotonicity property is lost due to the MC integrations in the MCEM algorithm, convergence might be prematurely declared due to stochasticity if the ε-values are too large. To reduce the chance of this occurring, we require that the stopping rule is satisfied for 3 consecutive iterations [33, 34]. However, in any case, trace plots should be inspected to confirm convergence is appropriate.
Standard error estimation
Standard error (SE) estimation is usually based on inverting the observed information matrix. When the baseline hazard is unspecified, as is the case here, this presents several challenges. First, will generally be a high-dimensional vector, which might lead to numerical difficulties in the inversion of the observed information matrix [6]. Second, the profile likelihood estimates based on the usual observed information matrix approach are known to be underestimated [35]. The reason for this is that the profile estimates are implicit, since the posterior expectations, given by (5), depend on the parameters being estimated, including λ0(t) [6, p. 67].
To overcome these challenges, Hsieh et al. [35] recommended to use bootstrap methods to calculate the SEs. However, this approach is computationally expensive. Moreover, despite the purported theoretical advantages, we also note that recently it has been suggested that bootstrap estimators might actually overestimate the SEs; e.g. [36, p. 740] and [35, p. 1041]. At the model development stage, it is often of interest to gauge the strength of association of model covariates, which is not feasible with repeated bootstrap implementations. Hence, an approximate SE estimator is desirable. In either case, the theoretical properties will be contaminated by the addition of MC error from the MCEM algorithm, and it is not yet fully understood what the ramifications of this are. Hence, any standard errors must be interpreted with a degree of caution. We consider two estimators below.
1. Bootstrap method. These are estimated by sampling n subjects with replacement and re-labelling the subjects with indices i′=1,…,n. We then re-fit the model to the bootstrap-sampled dataset. It is important to note that we re-sample subjects, not individual data points. This is repeated B-times, for a sufficiently large integer B. Since we already have the MLEs from the fitted model, we can use these as initial values for each bootstrap model fit, thus reducing initial computational overheads in calculating approximate initial parameters. For each iteration, we extract the model parameter estimates for . Note that we do not estimate SEs for λ0(t) using this approach. However, they are generally not of inferential interest. When B is sufficiently large, the SEs can be estimated from the estimated coefficients of the bootstrap samples. Alternatively, 100(1−α)%-confidence intervals can be estimated from the the 100α/2-th and 100(1−α/2)-th percentiles.
2. Empirical information matrix method. Using the Breslow estimator for , the profile score vector for is calculated (see Additional file 1). We approximate the profile information for θ−λ by , where is the observed empirical information [25] given by
| 9 |
si(θ−λ) is the conditional expectation of the complete-data profile score for subject i, S(θ−λ) is the score defined by , and a⊗2=aa⊤ is outer product for a vector a. At the maximizer, , meaning that the right hand-side of (9) is zero. Due to the MC error in the MCEM algorithm, this will not be exactly zero, and therefore we include it in the calculations. As per the bootstrap approach, SEs for the baseline hazard are again not calculated. We note that this SE estimator will be subject to the exact same theoretical limitation of underestimation described by Hsieh et al. [35], since the profiling was implicit; that is, because the posterior expectations involve the parameters θ.
Software
The model described here is implemented in the R package joineRML, which is available on the The Comprehensive R Archive Network (CRAN) (https://CRAN.R-project.org/package=joineRML). The principal function in joineRML is mjoint(). The primary arguments for implementing mjoint() are summarised in Table 1. To achieve computationally efficiency, parts of the MCEM algorithm in joineRML are coded in C++ using the Armadillo linear algebra library and integrated using the R package RcppArmadillo [37].
Table 1.
The primary argumentsa with descriptions for the mjoint() function in the R package joineRML
| Argument | Description |
|---|---|
| formLongFixed | a list of formulae for the fixed effects component of each longitudinal outcome. The left hand-hand side defines the response, and the right-hand side specifies the fixed effect terms. |
| formLongRandom | a list of one-sided formulae specifying the model for the random effects effects of each longitudinal outcome. |
| formSurv | a formula specifying the proportional hazards regression model (not including the latent association structure). |
| data | a list of data.frame objects for each longitudinal outcome in which to interpret the variables named in the formLongFixed and formLongRandom. The list structure enables one to include multiple longitudinal outcomes with different measurement protocols. If the multiple longitudinal outcomes are measured at the same time points for each patient (i.e. tijk=tij∀k), then a single data.frame object can be given instead of a list. It is assumed that each data frame is in long format. |
| survData | (optional) a data.frame in which to interpret the variables named in the formSurv. If survData is not given, then mjoint() looks for the time-to-event data in data. |
| timeVar | a character string indicating the time variable in the linear mixed effects model. |
| inits | (optional) a list of initial values for some or all of the parameters estimated in the model. |
| control | (optional) a list of control parameters. These allow for the control of ε0, ε1, and ε2 in (7) and (8); the choice of N, δ, and convergence criteria; the maximum number of MCEM iterations, and the minimum number of MCEM iterations during burn-in. Additionally, the control argument gammaOpt can be used to specify whether a one-step Newton-Raphson (=~NR~) or Gauss-Newton-like (=~GN~) update should be used for the M-step update of γ. |
amjoint() also takes the optional additional arguments verbose, which if TRUE allows for monitoring updates at each MCEM algorithm iteration, and pfs, which if FALSE can force the function not to calculate post-fit statistics such as the BLUPs and associated standard errors of the random effects and approximate standard errors of the model parameters. In general, these arguments are not required
A model fitted using the mjoint() function returns an object of class mjoint. By default, approximate SE estimates are calculated using the empirical information matrix. If one wishes to use bootstrap standard error estimates, then the user can pass the model object to the bootSE() function. Several generic functions (or rather, S3 methods) can also be applied to mjoint objects, as described in Table 2. These generic functions include common methods, for example coef(), which extracts the model coefficients; ranef(), which extracts the BLUPs (and optional standard errors); and resid(), which extracts the residuals from the linear mixed sub-model. The intention of these functions is to have a common syntax with standard R packages for linear mixed models [26] and survival analysis [27]. Additionally, plotting capabilities are included in joineRML. These include trace plots for assessment of convergence of the MCEM algorithm, and caterpillar plots for subject-specific random effects (Table 2).
Table 2.
Additional functions with descriptions that can be applied to objects of class mjointa
| Function(s) | Returns |
|---|---|
| logLik, AIC, BIC | the log-likelihood, Akaike information criterion and Bayesian information criterion statistics, respectively |
| coef, fixef | the fixed effects parameter estimates |
| ranef | the BLUPs (and optional standard errors) |
| printa, summaryc | short and long model summary outputs, respectively |
| fitted, resid | the fitted values and raw residuals from the multivariate LMM sub-model, respectively |
| plot b | the MCEM algorithm convergence trace plots |
| sigma | the residual standard errors from the LMM sub-model |
| vcov | the variance-covariance matrix of the main parameters of the fitted model (except the baseline hazard) |
| getVarCov | the random effects variance-covariance matrix |
| confint | the confidence intervals based on asymptotic normality |
| update | specific parts of a fitted model can be updated, e.g. by adding or removing terms from a sub-model, and then re-fitted |
| sampleData | sample data (with or without replacement) from a joint model |
aprint() also applies to objects of class summary.mjoint and bootSE inheriting from the summary() and bootSE() functions, respectively
bplot() also accepts objects of class ranef.mjoint inheriting from the ranef() function, which displays a caterpillar plot (with 95% prediction intervals) for each random effect
csummary() can also take the optional argument of an object of class bootSE inheriting from the function bootSE(), which overrides the approximate SEs and CIs with those from a bootstrap estimation routine
The package also provides several datasets, and a function simData() that allows for simulation of data from joint models with multiple longitudinal outcomes. joineRML can also fit univariate joint models, however in this case we would currently recommend that the R packages joineR [29], JM [28], or frailtypack [38] are used, which are optimized for the univariate case and exploits Gaussian quadrature. In addition, these packages allow for extensions to more complex cases; for example, competing risks [28, 29] and recurrent events [38].
Results
Simulation analysis
A simulation study was conducted assuming two longitudinal outcomes and n=200 subjects. Longitudinal data were simulated according to a follow-up schedule of 6 time points (at times 0,1,…,5), with each model including subject-and-outcome-specific random-intercepts and random-slopes: bi=(b0i1,b1i1,b0i2,b1i2)⊤, Correlation was induced between the 2 outcomes by assuming correlation of − 0.5 between the random intercepts for each outcome. Event times were simulated from a Gompertz distribution with shape θ1=−3.5 and scale exp(θ0)= exp(0.25)≈1.28, following the methodology described by Austin [39]. Independent censoring times were drawn from an exponential distribution with rate 0.05. Any subject where the event and censoring time exceeded 5 was administratively censored at the truncation time C=5.1. For all sub-models, we included a pair of covariates Xi=(xi1,xi2)⊤, where xi1 is a continuous covariate independently drawn from N(0,1) and xi2 is a binary covariate independently drawn from Bin(1,0.5). The sub-models are given as
where D is specified unstructured (4×4)-covariance matrix with 10 unique parameters. Simulating datasets is straightforward using the joineRML package by means of the simData() function. The true parameter values and results from 500 simulations are shown in Table 3. In particular, we display the mean estimate, the bias, the empirical SE (= the standard deviation of the the parameter estimates); the mean SE (= the mean SE of each parameter calculated for each fitted model); the mean square error (MSE), and the coverage. The results confirm that the model fitting algorithm generally performs well.
Table 3.
Results of simulation study
| Parameter | True value | Mean estimated value | Empirical SE | Mean SE | Bias | MSE | Coverage |
|---|---|---|---|---|---|---|---|
| D 11 | 0.2500 | 0.2411 | 0.0435 | — | −0.0089 | 0.0020 | — |
| D 21 | 0.0000 | 0.0010 | 0.0136 | — | 0.0010 | 0.0002 | — |
| D 31 | −0.1250 | −0.1212 | 0.0295 | — | 0.0038 | 0.0009 | — |
| D 41 | 0.0000 | −0.0006 | 0.0127 | — | −0.0006 | 0.0002 | — |
| D 22 | 0.0400 | 0.0396 | 0.0072 | — | −0.0004 | 0.0001 | — |
| D 32 | 0.0000 | −0.0002 | 0.0138 | — | −0.0002 | 0.0002 | — |
| D 42 | 0.0000 | −0.0001 | 0.0055 | — | −0.0001 | 0.0000 | — |
| D 33 | 0.2500 | 0.2420 | 0.0400 | — | −0.0080 | 0.0017 | — |
| D 43 | 0.0000 | 0.0007 | 0.0134 | — | 0.0007 | 0.0002 | — |
| D 44 | 0.0400 | 0.0399 | 0.0075 | — | −0.0001 | 0.0001 | — |
| β 0,1 | 0.0000 | 0.0028 | 0.0612 | 0.0660 | 0.0028 | 0.0038 | 0.9660 |
| β 1,1 | 1.0000 | 1.0012 | 0.0218 | 0.0229 | 0.0012 | 0.0005 | 0.9500 |
| β 2,1 | 1.0000 | 1.0010 | 0.0449 | 0.0470 | 0.0010 | 0.0020 | 0.9540 |
| β 3,1 | 1.0000 | 0.9932 | 0.0897 | 0.0925 | −0.0068 | 0.0081 | 0.9440 |
| 0.2500 | 0.2506 | 0.0165 | 0.0171 | 0.0006 | 0.0003 | 0.9560 | |
| β 0,2 | 0.0000 | −0.0026 | 0.0637 | 0.0655 | −0.0026 | 0.0041 | 0.9660 |
| β 1,2 | −1.0000 | −1.0011 | 0.0229 | 0.0223 | −0.0011 | 0.0005 | 0.9480 |
| β 2,2 | 0.0000 | 0.0008 | 0.0399 | 0.0472 | 0.0008 | 0.0016 | 0.9700 |
| β 3,2 | 0.5000 | 0.5061 | 0.0894 | 0.0923 | 0.0061 | 0.0080 | 0.9540 |
| 0.2500 | 0.2501 | 0.0162 | 0.0171 | 0.0001 | 0.0003 | 0.9540 | |
| γ v1 | 0.0000 | 0.0011 | 0.1243 | 0.1392 | 0.0011 | 0.0155 | 0.9720 |
| γ v2 | 1.0000 | 1.0487 | 0.2837 | 0.2750 | 0.0487 | 0.0829 | 0.9340 |
| γ y1 | −0.5000 | −0.5121 | 0.1936 | 0.2084 | −0.0121 | 0.0376 | 0.9560 |
| γ y2 | 1.0000 | 1.0311 | 0.2220 | 0.2145 | 0.0311 | 0.0502 | 0.9400 |
A second simulation analysis was conducted using the parameters above (with n=100 subjects per dataset). However, in this case we used a heavier-tailed distribution for the random effects: a multivariate t5 distribution [40]. The bias for the fixed effect coefficients was comparable to the multivariate normal random effects simulation study (above). The empirical standard error was consistently smaller than the mean standard error, resulting in coverage between 95% and 99% for the coefficient parameters. Rizopoulos et al. [41] noted that the misspecification of the random effects distributions was minimised as the number of longitudinal measurements per subject increased, but that the standard errors are generally affected. These findings are broadly in agreement with the simulation study conducted here, and other studies [42, 43]. Choi et al. [44] provide a review of existing research on the misspecification of random effects in joint modelling.
Example
We consider the primary biliary cirrhosis (PBC) data collected at the Mayo Clinic between 1974 to 1984 [45]. This dataset has been widely analyzed using joint modelling methods [18, 46, 47]. PBC is a long-term liver disease in which the bile ducts in the liver become damaged. Progressively, this leads to a build-up of bile in the liver, which can damage it and eventually lead to cirrhosis. If PBC is not treated or reaches an advanced stage, it can lead to several major complications, including mortality. In this study, 312 patients were randomised to receive D-penicillamine (n=158) or placebo (n=154). In this example we analyse the subset of patients randomized to placebo.
Patients with PBC typically have abnormalities in several blood tests; hence, during follow-up several biomarkers associated with liver function were serially recorded for these patients. We consider three biomarkers: serum bilirunbin (denoted serBilir in the model and data; measured in units of mg/dl), serum albumin (albumin; mg/dl), and prothrombin time (prothrombin; seconds). Patients had a mean 6.3 (SD = 3.7) visits (including baseline). The data can be accessed from the joineRML package via the command data(pbc2). Profile plots for each biomarker are shown in Fig. 1, indicating distinct differences in trajectories between the those who died during follow-up and those who did not (right-censored cases). A Kaplan-Meier curve for overall survival is shown in Fig. 2. There were a total of 69 (44.8%) deaths during follow-up in the placebo subset.
Fig. 1.

Longitudinal trajectory plots. The black lines show individual subject trajectories, and the coloured lines show smoothed (LOESS) curves stratified by whether the patient experienced the endpoint (blue) or not (red)
Fig. 2.
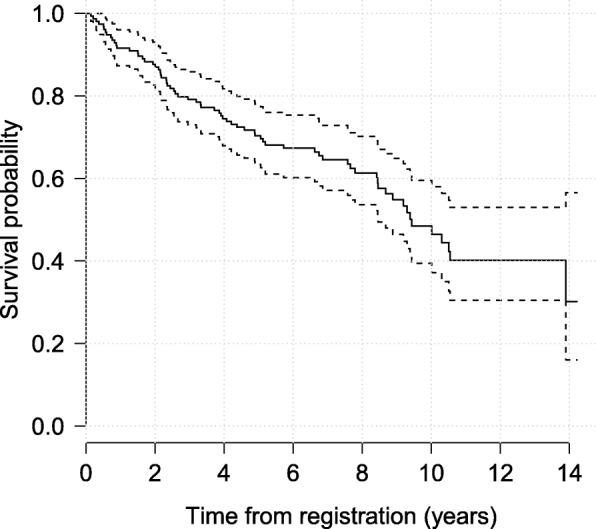
Kaplan-Meier curve for overall survival. A pointwise 95% band is shown (dashed lines). In total, 69 patients (of 154) died during follow-up
We fit a relatively simple joint model for the purposes of demonstration, which encompasses the following trivariate longitudinal data sub-model:
and a time-to-event sub-model for the study endpoint of death:
The log transformation of bilirubin is standard, and confirmed reasonable based on inspection of Q-Q plots for residuals from a separate fitted linear mixed model fitted using the lme() function from the R package nlme. Albumin did not require transformation. Residuals were grossly non-normal for prothrombin time using both untransformed and log-transformed outcomes. Therefore, a Box-Cox transformation was applied, which suggested an inverse-quartic transform might be suitable, which was confirmed by inspection of a Q-Q plot. The pairwise correlations for baseline measurements between the three transformed markers were 0.19 (prothrombin time vs. albumin), − 0.30 (bilirubin vs. prothrombin time and albumin). The model is fit using the joineRML R package (version 0.2.0) using the following code.

Here, we have specified a more stringent tolerance value for ε0 than the default setting in mjoint(). Additionally, the burn-in phase was increased to 400 iterations after inspection of convergence trace plots. The model fits in 3.1 min on a MacBook Air 1.6GHz Intel Core i5 with 8GB or RAM running R version 3.3.0, having completed 423 MCEM iterations (not including the EM algorithm iterations performed for determining the initial values of the separate multivariate linear mixed sub-model) with a final MC size of M=3528. The fitted model results are shown in Table 4.
Table 4.
Fitted multivariate and separate univariate joint models to the PBC data
| joineRML (NR) | joineRML (GN) | Bootstrap | joineR | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Estimate | SE | 95% CId | Estimate | SE | 95% CId | SE | 95% CIe | Estimate | SE | 95% CIe | |
| β 0,1 | 0.5541 | 0.0858 | (0.3859, 0.7223) | 0.5549 | 0.0846 | (0.3892, 0.7207) | 0.0800 | (0.4264, 0.7435) | 0.5545 | 0.0838 | (0.3802, 0.7031) |
| β 1,1 | 0.2009 | 0.0201 | (0.1616, 0.2402) | 0.2008 | 0.0201 | (0.1614, 0.2402) | 0.0204 | (0.1669, 0.2468) | 0.1808 | 0.0209 | (0.1430, 0.2324) |
| β 0,2 | 3.5549 | 0.0356 | (3.4850, 3.6248) | 3.5546 | 0.0357 | (3.4846, 3.6245) | 0.0255 | (3.4972, 3.5904) | 3.5437 | 0.0333 | (3.4418, 3.6095) |
| β 1,2 | −0.1245 | 0.0101 | (−0.1444, −0.1047) | −0.1246 | 0.0101 | (−0.1444, −0.1047) | 0.0120 | (−0.1489, −0.1063) | −0.0997 | 0.0113 | (−0.1256, −0.0773) |
| β 0,3 | 0.8304 | 0.0212 | (0.7888, 0.8719) | 0.8301 | 0.0210 | (0.7888, 0.8713) | 0.0196 | (0.7953, 0.8638) | 0.8233 | 0.0220 | (0.7818, 0.8677) |
| β 1,3 | −0.0577 | 0.0062 | (−0.0699, −0.0456) | −0.0577 | 0.0062 | (−0.0698, −0.0455) | 0.0057 | (−0.0698, −0.0486) | −0.0447 | 0.0052 | (−0.0555, −0.0362) |
| γ v | 0.0462 | 0.0151 | (0.0166, 0.0759) | 0.0462 | 0.0152 | (0.0165, 0.0759) | 0.0173 | (0.0198, 0.0880) | 0.0575a | 0.0123a | (0.0314, 0.0760)a |
| 0.0413b | 0.0150b | (0.0113, 0.0714)b | |||||||||
| 0.0424c | 0.0157c | (0.0146, 0.0724)c | |||||||||
| γ bil | 0.8181 | 0.2046 | (0.4171, 1.2191) | 0.8187 | 0.2036 | (0.4197, 1.2177) | 0.2153 | (0.5172, 1.4021) | 1.2182 | 0.1654 | (0.9800, 1.5331) |
| γ alb | −1.7060 | 0.6181 | (−2.9173, −0.4946) | −1.6973 | 0.6163 | (−2.9053, −0.4893) | 0.7562 | (−3.3862, −0.5188) | −3.0770 | 0.6052 | (−4.7133, −2.1987) |
| γ pro | −2.2085 | 1.6070 | (−5.3582, 0.9412) | −2.2148 | 1.6133 | (−5.3768, 0.9472) | 1.6094 | (−5.3050, 0.6723) | −7.2078 | 1.2640 | (−10.5247, −5.2616) |
Notation: SE = standard error; CI = confidence interval; NR = one-step Newton-Raphson update for γ; GN = one-step Gauss-Newton-like update for γ
aSeparate model fit for serBilir
bSeparate model fit for albumin
cSeparate model fit for prothrombin
dSEs are calculated from the inverse profile empirical information matrix, and confidence intervals are based on normal approximations of the type , where denote the estimated maximum likelihood estimates
eSEs and confidence intervals are derived from B=100 bootstrap samples, with confidence intervals based on the 2.5% and 97.5% percentiles. NB. one model failed to converge using joineRML within the maximum number of MC iterations, and so SEs and CIs are based on 99 bootstrap samples only
The fitted model indicated that an increase in the subject-specific random deviation from the population trajectory of serum bilirubin was significantly associated with increased hazard of death. A significant association was also detected for subject-specific decreases in albumin from the population mean trajectory. However, prothrombin time was not significantly associated with hazard of death, although its direction is clinically consistent with PBC disease. Albert and Shih [46] analysed the first 4-years follow-up from this dataset with the same 3 biomarkers and a discrete event time distribution using a regression calibration model. Their results were broadly consistent, although the effect of prothrombin time on the event time sub-model was strongly significant.
We also fitted 3 univariate joint models to each of the biomarkers and the event time sub-model using the R package joineR (version 1.2.0) owing to its optimization for such models. The LMM parameter estimates were similar, although the absolute magnitude of the slopes was smaller for the separate univariate models. Since 3 separate models were fitted, 3 estimates of γv were estimated, with the average comparable to the multivariate model estimate. The multivariate model estimates of γy=(γbil,γalb,γpro)⊤ were substantially attenuated relative to the separate model estimates, although the directions remained consistent. It is also interesting to note that γpro was statistically significant in the univariate model. However, the univariate models are not accounting for the correlation between different outcomes, whereas the multivariate joint model does.
The model was refitted with the one-step Newton-Raphson update for γ replaced by a Gauss-Newton-like update in a time of 2.2 minutes for 419 MCEM iterations with a final MC size of M=6272. This is easily achieved by running the following code.
![]()
In addition, we bootstrapped this model with B=100 samples to estimate SEs and contrast them with the approximate estimates based on the inverse empirical profile information matrix. In practice, one should choose B>100, particularly if using bootstrap percentile confidence intervals; however, we used a small value to reduce the computational burden on this process. In a similar spirit, we relaxed the convergence criteria and reduced the number of burn-in iterations. This is easily implemented by running the following code, taking 1.8 h to fit.

It was observed that the choice of gradient matrix in the γ-update led to virtually indistinguishable parameter estimates, although we note the same random seed was used in both cases. The bootstrap estimated SEs were broadly consistent with the approximate SEs, with no consistent pattern in underestimation observed.
Discussion
Multivariate joint models introduce three types of correlations: (1) within-subject serial correlation for repeated measures; (2) between longitudinal outcomes correlation; and (3) correlation between the multivariate LMM and time-to-event sub-models. It is important to account for all of these types of correlations; however, some authors have reported collapsing their multivariate data to permit univariate joint models to be fitted. For example, Battes et al. [7] used an ad hoc approach of either summing or multiplying the three repeated continuous measures (standardized according to clinical upper reference limits of the biomarker assays), and then applying standard univariate joint models. Wang et al. [48] fitted separate univariate joint models to each longitudinal outcome in turn. Neither approach takes complete advantage of the correlation between the multiple longitudinal measures and the time-to-event outcome.
Here, we described a new R package joineRML that can fit the models described in this paper. This was demonstrated on a real-world dataset. Although in the fitted model we assumed linear trajectories for the biomarkers, splines could be straightforwardly employed, as have been used in other multivariate joint model applications [15], albeit at the cost of additional computational time. Despite a growing availability of software for univariate joint models, Hickey et al. [19] noted that there were very few options for fitting joint models involving multivariate longitudinal data. To the best of our knowledge, options are limited to the R packages JMbayes [49], rstanarm [50], and the Stata package stjm [47]. Moreover, none of these incorporates an unspecified baseline hazard. The first two packages use Markov chain Monte Carlo (MCMC) methods to fit the joint models. Bayesian models are potentially very useful for fitting joint models, and in particular for dynamic prediction; however, MCMC is also computationally demanding, especially in the case of multivariate models. Several other publications have made BUGS code available for use with WinBUGS and OpenBUGS (e.g. [51]), but these are not easily modifiable and post-fit computations are cumbersome.
joineRML is a new software package developed to fill a void in the joint modelling field, but is still in its infancy relative to highly developed univariate joint model packages such as the R package JM [28] and Stata package stjm [47]. Future developments of joineRML intend to cover several deficiencies. First, joineRML currently only permits an association structure of the form . As has been demonstrated by others, the association might take different forms, including random-slopes and cumulative effects or some combination of multiple structures, and these may also be different for separate longitudinal outcomes [18]. Moreover, it is conceivable that separate longitudinal outcomes may interact in the hazard sub-model. Second, the use of MC integration provides a scalable solution to the issue of increasing dimensionality in the random effects. However, for simpler cases, e.g. bivariate models with random-intercepts and random-slopes (total of 4 random effects), Gaussian quadrature might be computationally superior; this trade-off requires further investigation. Third, joineRML can currently only model a single event time. However, there is a growing interest in competing risks [9] and recurrent events data [11], which if incorporated into joineRML, would provide a flexible all-round multivariate joint modelling platform. Competing risks [28, 29] and recurrent events [38] have been incorporated into joint modelling R packages already, but are limited to the case of a solitary longitudinal outcome. Of note, the PBC trial dataset analysed in this study includes times to the competing risk of liver transplantation. Fourth, with ever-increasing volumes of data collected during routine clinical visits, the need for software to fit joint models with very many longitudinal outcomes is foreseeable [52]. This would likely require the use of approximate methods for the numerical integration or data reduction methods. Fifth, additional residual diagnostics are necessary for assessing possible violations of model assumptions. The joineRML package has a resid() function for extracting the longitudinal sub-model residuals; however, these are complex for diagnostic purposes due to the informative dropout, hence the development of multiple-imputation based residuals [53].
Conclusions
In this paper we have presented an extension of the classical joint model proposed by Henderson et al. [3] and an estimation procedure for fitting the models that builds on the foundations laid by Lin et al. [20]. In addition, we described a new R package joineRML that can fit the models described in this paper, which leverages the MCEM algorithm and which should scale well for increasing number of longitudinal outcomes. This software is timely, as it has previously been highlighted that there is a paucity of software available to fit such models [19]. The software is being regularly updated and improved.
Availability and requirements
Project name:joineRMLProject home page:https://github.com/graemeleehickey/joineRML/Operating system(s): platform independent Programming language: R Other requirements: none License: GNU GPL-3 Any restrictions to use by non-academics: none
Additional file
An appendix (appendix.pdf) is available that includes details on the score vector and M-step estimators. (PDF 220 kb)
Acknowledgements
The authors would like to thank Professor Robin Henderson (University of Newcastle) for useful discussions with regards to the MCEM algorithm, and Dr Haiqun Lin (Yale University) for helpful discussions on the likelihood specification.
Funding
Funding for the project was provided by the Medical Research Council (Grant number MR/M013227/1). The funder had no role in the design of the study and collection, analysis, and interpretation of data and in writing the manuscript.
Availability of data and materials
The R package joineRML can be installed directly using install.packages(~joineRML~) in an R console. The source code is available at https://github.com/graemeleehickey/joineRML. Archived versions are available from the Comprehensive R Archive Network (CRAN) at https://cran.r-project.org/web/packages/joineRML/. joineRML is platform independent, requiring R version ≥ 3.3.0, and is published under a GNU GPL-3 license. The dataset analysed during the current study is bundled with the R package joineRML, and can be accessed by running the command data(pbc2, package = ~joineRML~).
Abbreviations
- BLUP
Best linear unbiased prediction
- CRAN
The Comprehensive R Archive Network
- EM
Expectation maximisation
- LMM
Linear mixed models
- MC
Monte Carlo
- MCEM
Monte Carlo expectation maximisation
- MLE
Maximum likelihood estimate
- PBC
Primary biliary cirrhosis
- SD
Standard deviation
- SE
Standard error
Authors’ contributions
All authors collaborated in developing the model fitting algorithm reported. The programming and running of the analysis was carried out by GLH. GLH wrote the first draft of the manuscript, with input provided by PP, AJ, and RKD. All authors contributed to the manuscript revisions. All authors read and approved the final manuscript.
Ethics approval and consent to participate
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Footnotes
Electronic supplementary material
The online version of this article (10.1186/s12874-018-0502-1) contains supplementary material, which is available to authorized users.
Contributor Information
Graeme L. Hickey, Email: graeme.hickey@liverpool.ac.uk
Pete Philipson, Email: pete.philipson@northumbria.ac.uk.
Andrea Jorgensen, Email: a.l.jorgensen@liverpool.ac.uk.
Ruwanthi Kolamunnage-Dona, Email: ruwanthi.kolamunnage-dona@liverpool.ac.uk.
References
- 1.Ibrahim JG, Chu H, Chen LM. Basic concepts and methods for joint models of longitudinal and survival data. J Clin Oncol. 2010;28(16):2796–801. doi: 10.1200/JCO.2009.25.0654. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Sweeting MJ, Thompson SG. Joint modelling of longitudinal and time-to-event data with application to predicting abdominal aortic aneurysm growth and rupture. Biom J. 2011;53(5):750–63. doi: 10.1002/bimj.201100052. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Henderson R, Diggle PJ, Dobson A. Joint modelling of longitudinal measurements and event time data. Biostatistics. 2000;1(4):465–480. doi: 10.1093/biostatistics/1.4.465. [DOI] [PubMed] [Google Scholar]
- 4.Tsiatis AA, Davidian M. Joint modeling of longitudinal and time-to-event data: an overview. Stat Sin. 2004;14:809–34. [Google Scholar]
- 5.Gould AL, Boye ME, Crowther MJ, Ibrahim JG, Quartey G, Micallef S, Bois FY. Joint modeling of survival and longitudinal non-survival data: current methods and issues. report of the DIA Bayesian joint modeling working group. Stat Med. 2015;34:2181–95. doi: 10.1002/sim.6141. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Rizopoulos D. Joint Models for Longitudinal and Time-to-Event Data, with Applications in R. Boca Raton: Chapman & Hall/CRC; 2012. [Google Scholar]
- 7.Battes LC, Caliskan K, Rizopoulos D, Constantinescu AA, Robertus JL, Akkerhuis M, Manintveld OC, Boersma E, Kardys I. Repeated measurements of NT-pro-B-type natriuretic peptide, troponin T or C-reactive protein do not predict future allograft rejection in heart transplant recipients. Transplantation. 2015;99(3):580–5. doi: 10.1097/TP.0000000000000378. [DOI] [PubMed] [Google Scholar]
- 8.Song X, Davidian M, Tsiatis AA. An estimator for the proportional hazards model with multiple longitudinal covariates measured with error. Biostatistics. 2002;3(4):511–28. doi: 10.1093/biostatistics/3.4.511. [DOI] [PubMed] [Google Scholar]
- 9.Williamson P, Kolamunnage-Dona R, Philipson P, Marson AG. Joint modelling of longitudinal and competing risks data. Stat Med. 2008;27:6426–38. doi: 10.1002/sim.3451. [DOI] [PubMed] [Google Scholar]
- 10.Hickey GL, Philipson P, Jorgensen A, Kolamunnage-Dona R. A comparison of joint models for longitudinal and competing risks data, with application to an epilepsy drug randomized controlled trial. J R Stat Soc: Ser A: Stat Soc. 2018. 10.1111/rssa.12348.
- 11.Liu L, Huang X. Joint analysis of correlated repeated measures and recurrent events processes in the presence of death, with application to a study on acquired immune deficiency syndrome. J R Stat Soc: Ser C: Appl Stat. 2009;58(1):65–81. doi: 10.1111/j.1467-9876.2008.00641.x. [DOI] [Google Scholar]
- 12.Chi YY, Ibrahim JG. Joint models for multivariate longitudinal and multivariate survival data. Biometrics. 2006;62(2):432–45. doi: 10.1111/j.1541-0420.2005.00448.x. [DOI] [PubMed] [Google Scholar]
- 13.Hickey GL, Philipson P, Jorgensen A, Kolamunnage-Dona R. Joint models of longitudinal and time-to-event data with more than one event time outcome: a review. Int J Biostat. 2018. 10.1515/ijb-2017-0047. [DOI] [PubMed]
- 14.Andrinopoulou E-R, Rizopoulos D, Takkenberg JJM, Lesaffre E. Combined dynamic predictions using joint models of two longitudinal outcomes and competing risk data. Stat Methods Med Res. 2017;26(4):1787–1801. doi: 10.1177/0962280215588340. [DOI] [PubMed] [Google Scholar]
- 15.Rizopoulos D, Ghosh P. A Bayesian semiparametric multivariate joint model for multiple longitudinal outcomes and a time-to-event. Stat Med. 2011;30(12):1366–80. doi: 10.1002/sim.4205. [DOI] [PubMed] [Google Scholar]
- 16.Faucett CL, Thomas DC. Simultaneously modelling censored survival data and repeatedly measured covariates: a Gibbs sampling approach. Stat Med. 1996;15(15):1663–85. doi: 10.1002/(SICI)1097-0258(19960815)15:15<1663::AID-SIM294>3.0.CO;2-1. [DOI] [PubMed] [Google Scholar]
- 17.Song X, Davidian M, Tsiatis AA. A semiparametric likelihood approach to joint modeling of longitudinal and time-to-event data. Biometrics. 2002;58(4):742–53. doi: 10.1111/j.0006-341X.2002.00742.x. [DOI] [PubMed] [Google Scholar]
- 18.Andrinopoulou E-R, Rizopoulos D. Bayesian shrinkage approach for a joint model of longitudinal and survival outcomes assuming different association structures. Stat Med. 2016;35(26):4813–23. doi: 10.1002/sim.7027. [DOI] [PubMed] [Google Scholar]
- 19.Hickey GL, Philipson P, Jorgensen A, Kolamunnage-Dona R. Joint modelling of time-to-event and multivariate longitudinal outcomes: recent developments and issues. BMC Med Res Methodol. 2016;16(1):1–15. doi: 10.1186/s12874-016-0212-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Lin H, McCulloch CE, Mayne ST. Maximum likelihood estimation in the joint analysis of time-to-event and multiple longitudinal variables. Stat Med. 2002;21:2369–82. doi: 10.1002/sim.1179. [DOI] [PubMed] [Google Scholar]
- 21.Laird NM, Ware JH. Random-effects models for longitudinal data. Biometrics. 1982;38(4):963–74. doi: 10.2307/2529876. [DOI] [PubMed] [Google Scholar]
- 22.Wei GC, Tanner MA. A Monte Carlo implementation of the EM algorithm and the poor man’s data augmentation algorithms. J Am Stat Assoc. 1990;85(411):699–704. doi: 10.1080/01621459.1990.10474930. [DOI] [Google Scholar]
- 23.Wulfsohn MS, Tsiatis AA. A joint model for survival and longitudinal data measured with error. Biometrics. 1997;53(1):330–9. doi: 10.2307/2533118. [DOI] [PubMed] [Google Scholar]
- 24.Ratcliffe SJ, Guo W, Ten Have TR. Joint modeling of longitudinal and survival data via a common frailty. Biometrics. 2004;60(4):892–9. doi: 10.1111/j.0006-341X.2004.00244.x. [DOI] [PubMed] [Google Scholar]
- 25.McLachlan GJ, Krishnan T. The EM Algorithm and Extensions, 2nd ed. Hoboken: Wiley-Interscience; 2008. [Google Scholar]
- 26.Pinheiro JC, Bates DM. Mixed-Effects Models in S and S-PLUS. New York: Springer; 2000. [Google Scholar]
- 27.Therneau TM, Grambsch PM. Modeling Survival Data: Extending the Cox Model. New Jersey: Springer; 2000. [Google Scholar]
- 28.Rizopoulos D. JM: an R package for the joint modelling of longitudinal and time-to-event data. Journal of Statistical Software. 2010;35(9):1–33. doi: 10.18637/jss.v035.i09. [DOI] [Google Scholar]
- 29.Philipson P, Sousa I, Diggle PJ, Williamson P, Kolamunnage-Dona R, Henderson R, Hickey GL. joineR: Joint Modelling of Repeated Measurements and Time-to-event Data. 2017. R package version 1.2.0. https://CRAN.R-project.org/package=joineR.
- 30.Dmitrienko A, Molenberghs G, Chuang-Stein C, Offen W. Analysis of Clinical Trials Using SAS: A Practical Guide. Cary: SAS Institute; 2005. [Google Scholar]
- 31.Law NJ, Taylor JM, Sandler H. The joint modeling of a longitudinal disease progression marker and the failure time process in the presence of cure. Biostatistics. 2002;3(4):547–63. doi: 10.1093/biostatistics/3.4.547. [DOI] [PubMed] [Google Scholar]
- 32.McCulloch CE. Maximum likelihood algorithms for generalized linear mixed models. J Am Stat Assoc. 1997;92(437):162–70. doi: 10.1080/01621459.1997.10473613. [DOI] [Google Scholar]
- 33.Booth JG, Hobert JP. Maximizing generalized linear mixed model likelihoods with an automated Monte Carlo EM algorithm. J R Stat Soc Ser B Stat Methodol. 1999;61(1):265–85. doi: 10.1111/1467-9868.00176. [DOI] [Google Scholar]
- 34.Ripatti S, Larsen K, Palmgren J. Maximum likelihood inference for multivariate frailty models using an automated Monte Carlo EM algorithm. Lifetime Data Anal. 2002;8(2002):349–60. doi: 10.1023/A:1020566821163. [DOI] [PubMed] [Google Scholar]
- 35.Hsieh F, Tseng YK, Wang JL. Joint modeling of survival and longitudinal data: Likelihood approach revisited. Biometrics. 2006;62(4):1037–43. doi: 10.1111/j.1541-0420.2006.00570.x. [DOI] [PubMed] [Google Scholar]
- 36.Xu C, Baines PD, Wang JL. Standard error estimation using the EM algorithm for the joint modeling of survival and longitudinal data. Biostatistics. 2014;15(4):731–44. doi: 10.1093/biostatistics/kxu015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Eddelbuettel D, Sanderson C. RcppArmadillo: accelerating r with high-performance C++ linear algebra. Comput Stat Data Anal. 2014;71:1054–63. doi: 10.1016/j.csda.2013.02.005. [DOI] [Google Scholar]
- 38.Król A, Mauguen A, Mazroui Y, Laurent A, Michiels S, Rondeau V. Tutorial in joint modeling and prediction: A statistical software for correlated longitudinal outcomes, recurrent events and a terminal event. J Stat Softw. 2017;81(3):1–52. doi: 10.18637/jss.v081.i03. [DOI] [Google Scholar]
- 39.Austin PC. Generating survival times to simulate Cox proportional hazards models with time-varying covariates. Stat Med. 2012;31(29):3946–58. doi: 10.1002/sim.5452. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Genz A, Bretz F. Computation of Multivariate Normal and t Probabilities. Berlin: Springer; 2009. [Google Scholar]
- 41.Rizopoulos D, Verbeke G, Molenberghs G. Shared parameter models under random-effects misspecification. Biometrika. 2008;95(1):63–74. doi: 10.1093/biomet/asm087. [DOI] [Google Scholar]
- 42.Xu J, Zeger SL. The evaluation of multiple surrogate endpoints. Biometrics. 2001;57(1):81–7. doi: 10.1111/j.0006-341X.2001.00081.x. [DOI] [PubMed] [Google Scholar]
- 43.Pantazis N, Touloumi G. Robustness of a parametric model for informatively censored bivariate longitudinal data under misspecification of its distributional assumptions: a simulation study. Stat Med. 2007;26:5473–85. doi: 10.1002/sim.3147. [DOI] [PubMed] [Google Scholar]
- 44.Choi J, Zeng D, Olshan AF, Cai J. Joint modeling of survival time and longitudinal outcomes with flexible random effects. Lifetime Data Anal. 2018;24(1):126–52. doi: 10.1007/s10985-017-9405-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Murtaugh PA, Dickson ER, Van Dam GM, Malinchoc M, Grambsch PM, Langworthy AL, Gips CH. Primary biliary cirrhosis: prediction of short-term survival based on repeated patient visits. Hepatology. 1994;20(1):126–134. doi: 10.1002/hep.1840200120. [DOI] [PubMed] [Google Scholar]
- 46.Albert PS, Shih JH. An approach for jointly modeling multivariate longitudinal measurements and discrete time-to-event data. Ann Appl Stat. 2010;4(3):1517–32. doi: 10.1214/10-AOAS339. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Crowther MJ, Abrams KR, Lambert PC. Joint modeling of longitudinal and survival data. Stata J. 2013;13(1):165–84. [Google Scholar]
- 48.Wang P, Shen W, Boye ME. Joint modeling of longitudinal outcomes and survival using latent growth modeling approach in a mesothelioma trial. Health Serv Outcome Res Methodol. 2012;12(2–3):182–99. doi: 10.1007/s10742-012-0092-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Rizopoulos D. The R package JMbayes for fitting joint models for longitudinal and time-to-event data using mcmc. J Stat Softw. 2016;72(7):1–45. doi: 10.18637/jss.v072.i07. [DOI] [Google Scholar]
- 50.Carpenter B, Gelman A, Hoffman MD, Lee D, Goodrich B, Betancourt M, Brubaker MA, Li P, Riddell A. Stan: a probabilistic programming language. J Stat Softw. 2017;76(1):1–32. doi: 10.18637/jss.v076.i01. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Andrinopoulou E-R, Rizopoulos D, Takkenberg JJM, Lesaffre E. Joint modeling of two longitudinal outcomes and competing risk data. Stat Med. 2014;33(18):3167–78. doi: 10.1002/sim.6158. [DOI] [PubMed] [Google Scholar]
- 52.Jaffa MA, Gebregziabher M, Jaffa AA. A joint modeling approach for right censored high dimensiondal multivariate longitudinal data. J Biom Biostat. 2014;5(4):1000203. doi: 10.4172/2155-6180.1000203. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Rizopoulos D, Verbeke G, Molenberghs G. Multiple-imputation-based residuals and diagnostic plots for joint models of longitudinal and survival outcomes. Biometrics. 2010;66(1):20–9. doi: 10.1111/j.1541-0420.2009.01273.x. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
An appendix (appendix.pdf) is available that includes details on the score vector and M-step estimators. (PDF 220 kb)
Data Availability Statement
The R package joineRML can be installed directly using install.packages(~joineRML~) in an R console. The source code is available at https://github.com/graemeleehickey/joineRML. Archived versions are available from the Comprehensive R Archive Network (CRAN) at https://cran.r-project.org/web/packages/joineRML/. joineRML is platform independent, requiring R version ≥ 3.3.0, and is published under a GNU GPL-3 license. The dataset analysed during the current study is bundled with the R package joineRML, and can be accessed by running the command data(pbc2, package = ~joineRML~).