

Abstract
In recent years, the research of artificial neural networks based on fractional calculus has attracted much attention. In this paper, we proposed a fractional-order deep backpropagation (BP) neural network model with L2 regularization. The proposed network was optimized by the fractional gradient descent method with Caputo derivative. We also illustrated the necessary conditions for the convergence of the proposed network. The influence of L2 regularization on the convergence was analyzed with the fractional-order variational method. The experiments have been performed on the MNIST dataset to demonstrate that the proposed network was deterministically convergent and can effectively avoid overfitting.
1. Introduction
It is well known that artificial neural networks (ANNs) are the abstraction, simplification, and simulation of the human brains and reflect the basic characteristics of the human brains [1]. In recent years, great progress has been made in the research of deep neural networks. Due to the powerful ability of complex nonlinear mapping, many practical problems have been successfully solved by ANNs in the fields of pattern recognition, intelligent robot, automatic control, prediction, biology, medicine, economics, and other fields [2, 3]. BP neural network is one of the most basic and typical multilayer forward neural networks, which are trained by backpropagation (BP) algorithm. BP, which is an efficient way for optimization of ANNs, was firstly introduced by Werbos in 1974. Then, Rumelhart and McCelland et al. implemented the BP algorithm in detail in 1987 and applied it to the multilayer network version of Minsky [4–6].
The fractional calculus has a history as long as the integral order calculus. In the past three hundred years, the theory of fractional calculus has made great progresses [7–11]. Its basics are differentiation and integration of arbitrary fractional order. Nowadays, fractional calculus is widely used in diffusion processes [12–14], viscoelasticity theory [15], automation control [16–18], signal processing [19–21], image processing [22–25], medical imaging [26–28], neural networks [29–37], and many other fields. Due to the long-term memory, nonlocality, and weak singularity characteristics [29–37], fractional calculus has been successfully applied to ANNs. For instance, Boroomand constructed the Hopfield neural networks based on fractional calculus [37]. Kaslik analyzed the stability of Hopfield neural networks [30]. Pu proposed a fractional steepest descent approach and offered a detailed analysis of its learning conditions, stability, and convergence [38]. Wang applied the fractional steepest descent algorithm to train BP neural networks and proved the monotonicity and convergence of a three-layer example [33]. However, there are three limitations in the proposed fractional-order BP neural network models in [33]. First, the neural network in [33] just had 3 layers, which was actually a shadow network and was not proper to demonstrate its potential for deep learning. Second, the fractional order v of this model was restricted to (0,1] without reasonable analysis. Third, the loss function did not contain the regularization term, which is an efficient way to avoid overfitting, especially when the training set has small scalar. Overfitting means that the model has high prediction accuracy on training set but has the low prediction accuracy on testing set. This makes the generalization ability of the model poor, and the application value is greatly reduced.
In this paper, we proposed a deep fractional-order BP neural network with L2 regularization term, and the fractional-order v could be any positive real number. With the fractional-order variational method, the influence of L2 regularization on the convergence of the proposed model was exploited. The performance of the proposed model was evaluated on the MINST dataset.
The structure of the paper is as follows: in Section 2, the definitions and simple properties of fractional calculus are introduced. In Section 3, the proposed fractional-order multilayer BP neural networks are given in detail. In Section 4, the necessary conditions and the influence of L2 regularization for the convergence of the proposed BP algorithm are stated. In Section 5, experimental results are presented to illustrate the effectiveness of our model. Finally, the paper is concluded in Section 6.
2. Background Theory for Fractional Calculus
In this section, the basic knowledge of fractional calculus is introduced, including the definitions and several simple properties used in this paper.
Different from integer calculus, fractional derivative does not have a unified temporal definition expression up to now. The commonly used definitions of fractional derivative are Grünwald-Letnikov (G-L), Riemann-Liouville (R-L), and Caputo derivatives [7–11].
The following is the G-L definition of fractional derivative:
| (1) |
where
| (2) |
aG − LDxv denotes the fractional differential operator based on G-L definition, f(x) denotes a differintegrable function, v is the fractional order, [a, x] is the domain of f(x), Γ is the Gamma function, and [·] is the rounding function.
The R-L definition of fractional derivative is as follows:
| (3) |
where aR − LDxv denotes the fractional differential operator based on G-L definition; n = [v + 1]. Moreover, the G-L fractional derivative can be deduced from the definition of the R-L fractional derivative.
The Caputo definition of fractional derivative is as follows:
| (4) |
where aCDxv is the fractional differential operator based on Caputo definition, n = [v + 1].
Fractional calculus is more difficult to compute than integer calculus. Several mathematical properties used in this paper are given here. The fractional differential of a linear combination of differintegral functions is as follows:
| (5) |
where f(x) and g(x) are differintegral functions and λ and β are constants.
The fractional differential of constant function f(x) = C, (C is a constant) is different under different definitions:
For the G-L definition,
| (6) |
For the R-L definition,
| (7) |
And for the Caputo definition
| (8) |
According to (6), (7) and (8), we can know that for the G-L and R-L definition, the fractional differential of constant function is not equal to 0. Only with the Caputo definition, the fractional differential of constant function equals to 0, which is consistent to the integer-order calculus. Therefore, the Caputo definition is widely used in solving engineering problems and it was employed to calculate the fractional-order derivative in this paper. The fractional differential of function f(x) = (x − a)p, (p > −1) is as follows:
| (9) |
3. Algorithm Description
3.1. Fractional-Order Deep BP Neural Networks
In this section, we introduce the fractional-order deep BP neural network with L layers. nl, l = 1,2,…, L, is the number of neurons for the l-th layer. Wl = (wjil)nl+1×nl denotes the weight matrix connecting the l-th layer and the (l + 1)-th layer. fl denotes the corresponding activation function for the l-th layer. Xj and Oj are the input and the corresponding ideal output of the j-th sample and the training sample set is {Xj, Oj}j=1J. Zl = (z1l, z2l …, znl+1l) denotes the total inputs of l-th layer. If neurons in the l-th layer are not connected to any neurons in previous layer, these neurons are called external outputs of the l-th layer, denoted as A1l. On the contrary, if neurons in the l-th layer are connected to every neuron in previous layer, these neurons are called internal outputs of l-th layer, denoted as A2l. Al = (a1l, a2l …, anll) denotes the total outputs of l-th layer. The forward computing of the fractional-order deep BP neural networks is as follows:
| (10) |
| (11) |
| (12) |
Particularly, external outputs can exist in any layer except the last one. With the square error function, the error corresponding to j-th sample can be denoted as:
| (13) |
where ajiL denotes the i-th element of AjL, oji denotes the i-th element of Oj.
The total error of the neural networks is defined as
| (14) |
In order to minimize the total error of the fractional-order deep BP neural network, the weights are updated by the fractional gradient descent method with Caputo derivative. Let i = 1,2, ..., nl. The backpropagation of fractional-order deep BP neural networks can be derived with the following steps.
Firstly, we define that
| (15) |
According to (13), we can know that
| (16) |
Then the relationship between δil and δil+1 can be given by
| (17) |
Then, according to the chain rule and (17), we have
| (18) |
The updating formula is
| (19) |
where t ∈ N denotes the t-th iteration and η > 0 is the learning rate.
3.2. Fractional Deep BP Neural Networks with L2 Regularization
Fractional-order BP neural network can be overfitted easily when the training set has small scalar. L2 regularization is a useful way to avoid models to be overfitted without modifying the architecture of network. Therefore, by introducing the L2 regularization term into the total error, the modified error function can be presented as
| (20) |
where ‖W‖2 denotes the sum of squares of all weights and λ ≥ 0 denotes the regularization parameter.
By introducing (18), we have
| (21) |
The updating formula is
| (22) |
where t ∈ N denotes the t-th iteration and η > 0 is the learning rate.
4. Convergence Analysis
In this section, the convergence of the proposed fractional-order BP neural network is analyzed. According to previous studies [39–42], there are four necessary conditions for the convergence of BP neural networks:
(1) The activation functions fl, (l = 1,2,…, L) are bounded and infinitely differentiable on R and all of their corresponding derivatives are also continuous and bounded on R. This condition can be easily satisfied because the most common sigmoid activation functions are uniformly bounded on R and infinitely differentiable.
(2) The boundedness of the weight sequence {(wjil)t} is valid during training procedure and Ω ∈ R∑1L−1nl·nl+1 is the domain of all weights with certain boundary.
(3) The learning rate η > 0 has an upper bound.
(4) Let W denote the weights matrix that consists of all weights and ϕ = {W∣DWvEL2 = 0} be the v-order stationary point set of the error function. One necessary condition is that ϕ is a finite set.
Then, the influence of L2 regularization on the convergence is derived by using the fractional-order variational method.
According to (20), EL2 is defined as a fractional-order multivariable function. The proposed fractional-order BP algorithm is to minimize EL2. Let U denote the fractional-order extreme point of EL2 and ξ denotes an admissible point. In addition, U is composed of U1, U2,…, UL−1 where Ul (l = 1,2,…, L − 1) denotes the weights matrix between the l-th and (l + 1)-th layer when EL2 reaches the extreme value. ξ is composed of ξ1, ξ2,…, ξL−1 where ξl corresponds to Ul. The initial weights are random values, so the initial points of weights can be represented as U + (α − 1)ξ, where α is a vector that consists of small parameters α1, α2,…, αL−1, and αl corresponds to Ul and ξl. If α = 1, it means αl = 1(l = 1,2,…, L − 1), then U + (α − 1)ξ = U, and EL2 reaches the extreme value. Thus, the process of training the BP neural networks from a random initial weight W to U can be treated as the process of training α with a random initial value to α = 1.
The fractional-order derivative of EL2 on U + (α − 1)ξ is given as
| (23) |
where v is the fractional order, which is a positive real number.
From (23), we can see that when α = 1, if the v-order differential of E(U + (α − 1)ξ) with respect to α is existent, δ1(α) has a v-order extreme point and we have
| (24) |
In this case, the output of each layer in the neural networks is still given by (10) and (11) and the input of each layer is turned into the following:
| (25) |
When αl = 1, we have
| (26) |
Without loss of generality, according to (18), for the l-th layer of the networks, the v-order differential of E with respect to αl can be calculated as
| (27) |
where δl denotes the column vector DZl1E.
Since the value of ξ is stochastic, according to variation principle [43], to allow (24) to be set up, a necessary condition is that for every layer of the networks
| (28) |
Secondly, without loss of generality, for δ2(α) we have
| (29) |
To allow (29) to be set up, a necessary condition is
| (30) |
With (28) and (30), the Euler-Lagrange equation of DαvδEL2|α=1 can be written as
| (31) |
Equation (31) is the necessary condition for the convergence of the proposed fractional-order BP neural networks with L2 regularization. From (31), we can see that if λ > 0, then (δl+1 · (Al)T) ≠ 0. (δl+1 · (Al)T) is the first-order derivative of E in terms of U and can be calculated by U and input sample X. It means that the extreme point U of the proposed algorithm is not equal to the extreme point of integer-order BP algorithm or fractional-order BP algorithm. U changes with the different value of λ and v. In addition, it is also clear that the regularization parameter λ is bounded since the values of input samples X and weights W are bounded and v is a constant during the training process.
5. Experiments
In this section, the following simulations were carried out to evaluate the performance of the presented algorithm. The simulations have been performed on the MNIST handwritten digital dataset. Each digit in the dataset is a 28 × 28 image. Each image is associated with a label from 0 to 9. We divided each image into four parts, which were top-left, bottom-left, bottom-right, and top-right, and each part was a 14 × 14 matrix. We vectorized each part of the image as a 196 × 1 vector and each label as a 10 × 1 vector.
In order to identify the handwritten digits in MNIST dataset, a neural network with 8 layers was proposed. Figure 1 shows the topological structure of the neural networks. For the first four layers of the network, each layer has 196 external neurons and 32 internal neurons. The outputs of the external neurons are in turn four parts of an image and the outputs of the internal neurons of the first layer are 1. The last four layers have no external neurons. The fifth layer, sixth layer, and seventh layer have 64 internal nodes and the output layer has ten nodes. The activation functions of all neurons except the first layer are sigmoid functions, which can be given as follows:
| (32) |
Figure 1.

The topological structure of the neural networks.
The MNIST dataset has a total number of 60000 training samples and 10000 testing samples. The simulations demonstrate the performance of the proposed fractional-order BP neural network with L2 regularization, fractional-order BP neural network, traditional BP neural network, and traditional BP neural network with L2 regularization. To evaluate the robustness of our proposed network for a small set of training samples, we set the number of training samples to be (10000, 20000, 30000, 40000, 50000, and 60000). Different fractional v-order derivatives were employed to compute the gradient of error function, where v = 1/9, 2/9, 3/9, 4/9, 5/9, 6/9, 7/9, 8/9, 9/9, 10/9, 11/9, 12/9, 13/9, 14/9, 15/9, 16/9, 17/9, 19/9, and 20/9 separately (v = 9/9 = 1 corresponds to standard integer-order derivative for the common BP; v ≠ 2 because if v = 2 the change of weights after each iteration is 0, and the weights of the neural networks cannot be updated). The learning rate was set to be 3 and the batch size was set to be 100. The number of epochs n was 300. Two main metrics—training accuracy and testing accuracy—were used to measure the performance of the results from different networks. Each network was trained 5 times and the average values were calculated.
In order to explore the relationship between the fractional orders and the neural network performance, the fractional-order neural networks with different orders were trained. Figure 2 shows the results of different networks with different sizes of training set. We can find that when the fractional order v exceeds 1.6, both the training and testing accuracies declined rapidly, and when the fractional order v > 2, the performances of the fractional BP neural networks were much poorer than that with 0 < v < 2. The results of v = 19/9 and 20/9 were shown in Table 1 as examples. This result is consistent with that for describing physical problems, and usually the limitation 0 < v < 2 is adopted in the fractional-order models.
Figure 2.

The relationship between the fractional order of gradient descent method and the neural network performance.
Table 1.
Performances of the algorithms when v>2.
| Size of training set | v = 19/9 | v = 20/9 | ||
|---|---|---|---|---|
| Train Accuracy | Test Accuracy | Train Accuracy | Test Accuracy | |
| 10000 | 88.65% | 83.52% | 76.31% | 72.66% |
| 20000 | 91.04% | 89.52% | 78.93% | 75.97% |
| 30000 | 93.03% | 90.65% | 82.51% | 80.79% |
| 40000 | 93.20% | 90.53% | 82.47% | 80.61% |
| 50000 | 93.02% | 91.23% | 82.53% | 81.60% |
| 60000 | 93.85% | 91.71% | 87.32% | 86.05% |
From Figure 2, it can be observed that, with the increase of the size of training set, the performances of the networks were improved visibly. Furthermore, it is also obvious that the training and testing accuracies raised gradually with increasing fractional orders and then reached the peak while v equaled 10/9 or 11/9 order. After that, the training and testing accuracies began to decline rapidly.
Table 2 shows the optimal orders under training set and testing set separately with different size of training set and it can be noticed that the optimal orders almost concentrated in 10/9 and 11/9. The only exception is that when the number of training samples was 50000, the training accuracy of order 1 was slightly higher than that in 10/9 or 11/9 order case. Generally, for the MNIST dataset the performances of fractional-order BP neural networks are better than integer order.
Table 2.
Optimal Orders and Highest Accuracies.
| Size of training set | Optimal order of training set | Optimal order of testing set | Highest training accuracy | Highest testing accuracy |
|---|---|---|---|---|
| 10000 | 10/9 | 11/9 | 98.53% | 90.31% |
| 20000 | 10/9 | 10/9 | 98.84% | 92.34% |
| 30000 | 11/9 | 11/9 | 99.05% | 93.50% |
| 40000 | 10/9 | 11/9 | 99.18% | 93.92% |
| 50000 | 1 | 10/9 | 99.20% | 94.56% |
| 60000 | 11/9 | 11/9 | 99.20% | 95.00% |
It also can be seen that, in each case, the training accuracy is much bigger than testing accuracy, which means that the BP neural networks have obvious overfitting phenomenon. To avoid overfitting, the integer-order and fractional-order BP neural networks with L2 regularization were trained. With different sizes of training set we chose the regularization parameter λ to be (2 × 10−5, 1 × 10−5, 5 × 10−6, 5 × 10−6, 5 × 10−6, and 3 × 10−6). For the fractional-order neural networks, we chose the fractional order v that had highest testing accuracy in previous simulations. When the numbers of training samples were (10000, 20000, 30000, 40000, 50000, and 60000), we separately set the fractional order v to be (11/9, 10/9, 11/9, 11/9, 10/9, 11/9).
The performance of the proposed fractional-order BP neural networks with L2 regularization and the performance comparison with integer-order BP neural networks (IOBP), integer-order BP neural networks with L2 regularization, and fractional-order BP neural networks (FOBP) in terms of training and testing accuracy are shown in Table 3 and the change of the testing accuracy with the iterations was given in Figure 3
Table 3.
Performance comparison of different type BP neural networks.
| Size of training set | Integer-order BP neural networks | Fractional-order BP neural networks | Integer-order BP neural networks with L2 regularization | Fractional-order BP neural networks with L2 regularization | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Training Accuracy | Testing Accuracy | Training Accuracy | Testing Accuracy | Training Accuracy | Testing Accuracy | Training Accuracy | Testing Accuracy | Improvement relative to IOBP | Improvement relative to FOBP | |
| 10000 | 98.41% | 89.87% | 98.48% | 90.31% | 98.45% | 93.35% | 98.43% | 93.95% | 4.54% | 4.03% |
| 20000 | 98.81% | 92.28% | 98.84% | 92.34% | 98.75% | 95.09% | 98.79% | 95.13% | 3.09% | 3.02% |
| 30000 | 98.95% | 93.38% | 99.05% | 93.50% | 98.92% | 95.15% | 98.88% | 95.62% | 2.40% | 2.27% |
| 40000 | 99.05% | 93.83% | 99.01% | 93.92% | 98.96% | 95.63% | 98.95% | 95.83% | 2.13% | 2.03% |
| 50000 | 99.20% | 94.55% | 99.17% | 94.56% | 99.11% | 96.08% | 99.15% | 96.45% | 2.01% | 2.00% |
| 60000 | 99.17% | 94.87% | 99.20% | 95.00% | 99.13% | 96.51% | 99.17% | 96.70% | 1.93% | 1.79% |
We use the following formula to calculate improvement: improvement of A compared with B = (A-B)÷B.
Figure 3.
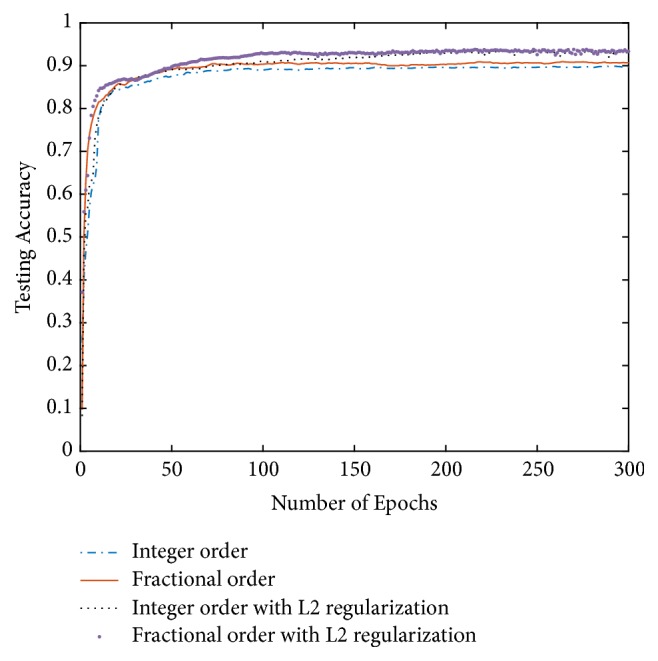
Performance comparison in terms of testing accuracy.
In Table 3 and Figure 3, it can be seen that, after the addition of L2 regularization to BP neural networks, the training accuracy is slightly decreased but the testing accuracy significantly increased, which indicated that adding L2 regularization can effectively suppress overfitting and improve the generalization of BP neural networks. Furthermore, it can be noticed that after adding L2 regularization the performance of fractional-order BP neural network is better than integer order. One important merit of the L2 regularization is that it gained more benefit while the training set is small. The most possible reason is that the network trained with the smallest number of training samples was affected most by the overfitting. With the increase of the training samples, the model gradually changed from overfitting to underfitting, so the improvement of the regularization method became faint.
Then, the stability and convergence of the proposed fractional-order BP neural networks with L2 regularization are demonstrated in Figures 4 and 5. We used the network with optimal order, which means that the size of training set was 60000, fractional-order v was 11/9, and the regularization parameter λ was 3 × 10−6. Figure 4 shows the change of the total error EL2 during the training process. Without loss of generality, the change of Dw20,205vEL2 was randomly selected and Figure 5 shows the change of it during the training process. It is clear to see that EL2 and DwvEL2 converged fast and stably and were finally close to zero. These observations effectively verify the proposed algorithm is deterministically convergent.
Figure 4.
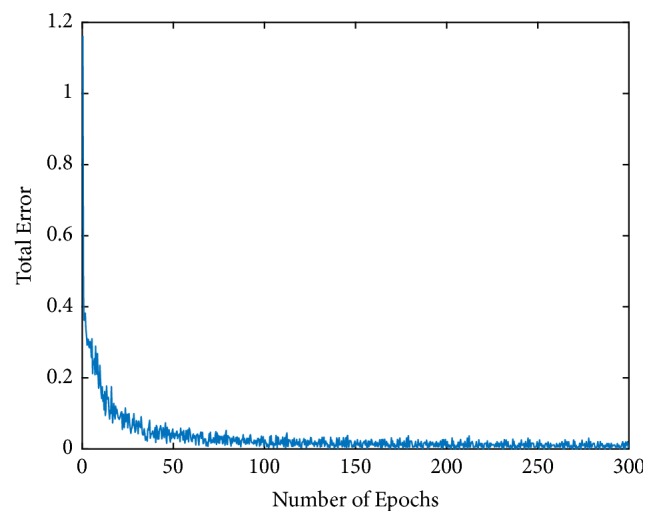
Changes of total error EL2 during the training process.
Figure 5.
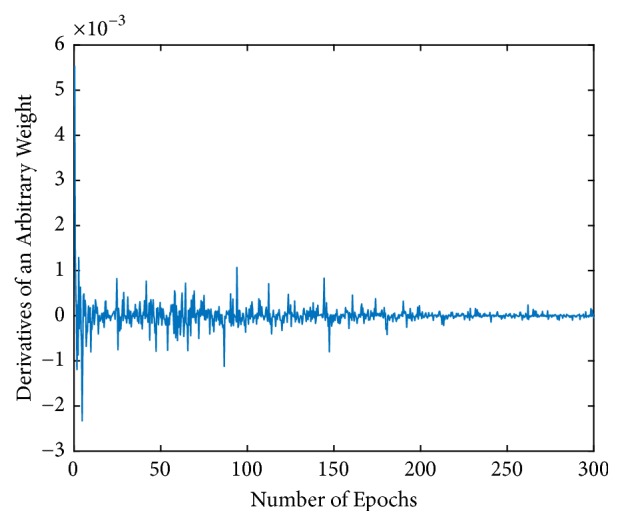
Changes of Dw20,205vEL2 during the training process.
6. Conclusion
In this paper, we applied fractional calculus and regularization method to deep BP neural networks. Different from previous studies, the proposed model had no limitations on the number of layers and the fractional-order was extended to arbitrary real number bigger than 0. L2 regularization was also imposed into the errorless function. Meanwhile, we analyzed the profits introduced by the L2 regularization on the convergence of this proposed fractional-order BP network. The numerical results support that the fractional-order BP neural networks with L2 regularization are deterministically convergent and can effectively avoid the overfitting phenomenon. Then, how to apply fractional calculus to other more complex artificial neural networks is an attracted topic in our future work.
Acknowledgments
This work was supported in part by the National Key R&D Program of China under Grant 2017YFB0802300, the National Natural Science Foundation of China under Grant 61671312, the Science and Technology Project of Sichuan Province of China under Grant 2018HH0070, and the Strategic Cooperation Project of Sichuan University and Luzhou City under Grant 2015CDLZ-G22.
Data Availability
The code of this work can be downloaded at https://github.com/BaoChunhui/Deep-fractional-BP-neural-networks.
Conflicts of Interest
The authors declare that they have no conflicts of interest.
References
- 1.Kubat M. Neural networks: a comprehensive foundation by Simon Haykin, Macmillan, 1994, ISBN 0-02-352781-7. The Knowledge Engineering Review. 13(4):409–412. doi: 10.1017/S0269888998214044. [DOI] [Google Scholar]
- 2.Kalogirou S. A. Applications of artificial neural networks in energy systems: a review. Energy Conversion and Management. 1999;40(10):1073–1087. doi: 10.1016/s0196-8904(99)00012-6. [DOI] [Google Scholar]
- 3.Demuth H. B., Beale M. H., De Jess O., Hagan M. T. Neural network design: Martin Hagan. 2014. [Google Scholar]
- 4.Rumelhart D. E., McClelland J. L., Group P. R. Parallel Distributed Processing. Vol. 1. Cambridge, MA, USA: MIT press; 1987. [Google Scholar]
- 5.Jia J., Duan H. Automatic target recognition system for unmanned aerial vehicle via backpropagation artificial neural network. Aircraft Engineering and Aerospace Technology. 2017;89(1):145–154. doi: 10.1108/AEAT-07-2015-0171. [DOI] [Google Scholar]
- 6.Wu Z., Wang H. Super-resolution Reconstruction of SAR Image based on Non-Local Means Denoising Combined with BP Neural Network. 2016. arXiv preprint arXiv:1612.04755. [Google Scholar]
- 7.Love E. R. Fractional derivatives of imaginary order. Journal Of The London Mathematical Society-Second Series. 1971;3:241–259. doi: 10.1112/jlms/s2-3.2.241. [DOI] [Google Scholar]
- 8.Povstenko Y. Linear Fractional Diffusion-Wave Equation for Scientists and Engineers. New York: Birkhäuser; 2015. [Google Scholar]
- 9.McBride A., Roach G. Fractional Calculus (Pitman Research Notes in Mathematics, No 138) Longman Science & Technology; 1986. [Google Scholar]
- 10.Nishimoto K. Fractional Calculus: Integrations and Differentiations of Arbitrary Order. New Haven, Conn, USA: University of New Haven Press; 1989. [Google Scholar]
- 11.Podlubny I. Fractional differential equations: an introduction to fractional derivatives, fractional differential equations, to methods of their solution and some of their applications. Vol. 198. Academic press; 1998. [Google Scholar]
- 12.Özdemir N., Karadeniz D. Fractional diffusion-wave problem in cylindrical coordinates. Physics Letters A. 2008;372(38):5968–5972. doi: 10.1016/j.physleta.2008.07.054. [DOI] [Google Scholar]
- 13.Özdemir N., Agrawal O. P., Karadeniz D., İskender B. B. Analysis of an axis-symmetric fractional diffusion-wave problem. Journal of Physics A: Mathematical and Theoretical. 2009;42(35):p. 355208. doi: 10.1088/1751-8113/42/35/355208. [DOI] [Google Scholar]
- 14.Povstenko Y. Solutions to the fractional diffusion-wave equation in a wedge. Fractional Calculus and Applied Analysis An International Journal for Theory and Applications. 2014;17(1):122–135. doi: 10.2478/s13540-014-0158-4. [DOI] [Google Scholar]
- 15.Bagley R. L., Torvik P. J. A theoretical basis for the application of fractional calilus to visoelasticity. Journal of Rheology. 1983;27(3):201–210. doi: 10.1122/1.549724. [DOI] [Google Scholar]
- 16.Baleanu D., Machado J. A. T., Luo A. C. J. Fractional Dynamics and Control. New York, NY, USA: Springer; 2012. [DOI] [Google Scholar]
- 17.Li C., Chen G. Chaos in the fractional order Chen system and its control. Chaos, Solitons $ Fractals. 2004;22:549–554. [Google Scholar]
- 18.Monje C. A., Vinagre B. M., Feliu V., Chen Y. Tuning and auto-tuning of fractional order controllers for industry applications. Control Engineering Practice. 2008;16(7):798–812. doi: 10.1016/j.conengprac.2007.08.006. [DOI] [Google Scholar]
- 19.Almeida L. B. Fractional fourier transform and time-frequency representations. IEEE Transactions on Signal Processing. 1994;42(11):3084–3091. doi: 10.1109/78.330368. [DOI] [Google Scholar]
- 20.Aslam M. S., Raja M. A. Z. A new adaptive strategy to improve online secondary path modeling in active noise control systems using fractional signal processing approach. Signal Processing. 2015;107:433–443. doi: 10.1016/j.sigpro.2014.04.012. [DOI] [Google Scholar]
- 21.Panda R., Dash M. Fractional generalized splines and signal processing. Signal Processing. 2006;86(9):2340–2350. doi: 10.1016/j.sigpro.2005.10.017. [DOI] [Google Scholar]
- 22.Xu M., Yang J., Zhao D., Zhao H. An image-enhancement method based on variable-order fractional differential operators. Bio-Medical Materials and Engineering. 2015;26:S1325–S1333. doi: 10.3233/BME-151430. [DOI] [PubMed] [Google Scholar]
- 23.Pu Y.-F., Zhang N., Zhang Y., Zhou J.-L. A texture image denoising approach based on fractional developmental mathematics. PAA. Pattern Analysis and Applications. 2016;19(2):427–445. doi: 10.1007/s10044-015-0477-z. [DOI] [Google Scholar]
- 24.Pu Y.-F., Zhou J.-L., Yuan X. Fractional differential mask: a fractional differential-based approach for multiscale texture enhancement. IEEE Transactions on Image Processing. 2010;19(2):491–511. doi: 10.1109/TIP.2009.2035980. [DOI] [PubMed] [Google Scholar]
- 25.Bai J., Feng X.-C. Fractional-order anisotropic diffusion for image denoising. IEEE Transactions on Image Processing. 2007;16(10):2492–2502. doi: 10.1109/TIP.2007.904971. [DOI] [PubMed] [Google Scholar]
- 26.Zhang Y., Zhang W., Lei Y., Zhou J. Few-view image reconstruction with fractional-order total variation. Journal of the Optical Society of America A: Optics, Image Science & Vision. 2014;31(5):981–995. doi: 10.1364/josaa.31.000981. [DOI] [PubMed] [Google Scholar]
- 27.Zhang Y., Wang Y., Zhang W., Lin F., Pu Y., Zhou J. Statistical iterative reconstruction using adaptive fractional order regularization. Biomedical Optics Express. 2016;7(3):1015–1029. doi: 10.1364/BOE.7.001015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Zhang Y., Pu Y.-F., Hu J.-R., Liu Y., Chen Q.-L., Zhou J.-L. Efficient CT metal artifact reduction based on fractional-order curvature diffusion. Computational and Mathematical Methods in Medicine. 2011:Art. ID 173748, 9. doi: 10.1155/2011/173748. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Pu Y.-F., Yi Z., Zhou J.-L. Defense Against Chip Cloning Attacks Based on Fractional Hopfield Neural Networks. International Journal of Neural Systems. 2017;27(4) doi: 10.1142/S0129065717500034.1750003 [DOI] [PubMed] [Google Scholar]
- 30.Kaslik E., Sivasundaram S. Dynamics of fractional-order neural networks. Proceedings of the 2011 International Joint Conference on Neural Network, IJCNN 2011; August 2011; usa. pp. 611–618. [Google Scholar]
- 31.Pu Y.-F., Yi Z., Zhou J.-L. Fractional Hopfield neural networks: fractional dynamic associative recurrent neural networks. IEEE Transactions on Neural Networks and Learning Systems. 2017;28(10):2319–2333. doi: 10.1109/TNNLS.2016.2582512. [DOI] [PubMed] [Google Scholar]
- 32.Song C., Cao J. Dynamics in fractional-order neural networks. Neurocomputing. 2014;142:494–498. doi: 10.1016/j.neucom.2014.03.047. [DOI] [Google Scholar]
- 33.Wang J., Wen Y., Gou Y., Ye Z., Chen H. Fractional-order gradient descent learning of BP neural networks with Caputo derivative. Neural Networks. 2017;89:19–30. doi: 10.1016/j.neunet.2017.02.007. [DOI] [PubMed] [Google Scholar]
- 34.Rakkiyappan R., Sivaranjani R., Velmurugan G., Cao J. Analysis of global O (t- a) stability and global asymptotical periodicity for a class of fractional-order complex-valued neural networks with time varying delays. Neural Networks. 2016;77:51–69. doi: 10.1016/j.neunet.2016.01.007. [DOI] [PubMed] [Google Scholar]
- 35.Wang H., Yu Y., Wen G. Stability analysis of fractional-order Hopfield neural networks with time delays. Neural Networks. 2014;55:98–109. doi: 10.1016/j.neunet.2014.03.012. [DOI] [PubMed] [Google Scholar]
- 36.Wang H., Yu Y., Wen G., Zhang S., Yu J. Global stability analysis of fractional-order Hopfield neural networks with time delay. Neurocomputing. 2015;154:15–23. doi: 10.1016/j.neucom.2014.12.031. [DOI] [PubMed] [Google Scholar]
- 37.Boroomand A., Menhaj M. B. Advances in Neuro-Information Processing. Vol. 5506. Berlin, Heidelberg: Springer Berlin Heidelberg; 2009. Fractional-Order Hopfield Neural Networks; pp. 883–890. (Lecture Notes in Computer Science). [DOI] [Google Scholar]
- 38.Pu Y.-F., Zhou J.-L., Zhang Y., Zhang N., Huang G., Siarry P. Fractional extreme value adaptive training method: fractional steepest descent approach. IEEE Transactions on Neural Networks and Learning Systems. 2015;26(4):653–662. doi: 10.1109/TNNLS.2013.2286175. [DOI] [PubMed] [Google Scholar]
- 39.Shao H., Zheng G. Boundedness and convergence of online gradient method with penalty and momentum. Neurocomputing. 2011;74(5):765–770. doi: 10.1016/j.neucom.2010.10.005. [DOI] [Google Scholar]
- 40.Wu W., Feng G., Li Z., Xu Y. Deterministic convergence of an online gradient method for BP neural networks. IEEE Transactions on Neural Networks and Learning Systems. 2005;16(3):533–540. doi: 10.1109/tnn.2005.844903. [DOI] [PubMed] [Google Scholar]
- 41.Wu W., Wang J., Cheng M., Li Z. Convergence analysis of online gradient method for BP neural networks. Neural Networks. 2011;24(1):91–98. doi: 10.1016/j.neunet.2010.09.007. [DOI] [PubMed] [Google Scholar]
- 42.Zhang H., Wu W., Liu F., Yao M. Boundedness and convergence of online gadient method with penalty for feedforward neural networks. IEEE Transactions on Neural Networks and Learning Systems. 2009;20(6):1050–1054. doi: 10.1109/TNN.2009.2020848. [DOI] [PubMed] [Google Scholar]
- 43.Leitmann G. The calculus of variations and optimal control: an introduction. Vol. 24. Springer Science & Business Media; 2013. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The code of this work can be downloaded at https://github.com/BaoChunhui/Deep-fractional-BP-neural-networks.