

Abstract
An individualized treatment rule (ITR) is a treatment rule which assigns treatments to individuals based on (a subset of) their measured covariates. An optimal ITR is the ITR which maximizes the population mean outcome. Previous works in this area have assumed that treatment is an unlimited resource so that the entire population can be treated if this strategy maximizes the population mean outcome. We consider optimal ITRs in settings where the treatment resource is limited so that there is a maximum proportion of the population which can be treated. We give a general closed-form expression for an optimal stochastic ITR in this resource-limited setting, and a closed-form expression for the optimal deterministic ITR under an additional assumption. We also present an estimator of the mean outcome under the optimal stochastic ITR in a large semiparametric model that at most places restrictions on the probability of treatment assignment given covariates. We give conditions under which our estimator is efficient among all regular and asymptotically linear estimators. All of our results are supported by simulations.
Keywords: asymptotic linearity, individualized treatments, efficient influence curve, influence curve, resource constraint
1. Introduction
Suppose one wishes to maximize the population mean of some outcome using some binary point treatment, where for each individual clinicians have access to (some subset of) measured baseline covariates. Such a treatment strategy is termed an individualized treatment regime (ITR), and the (counterfactual) population mean outcome under an ITR is referred to as the value of an ITR. The ITR which maximizes the value is referred to as the optimal ITR or the optimal rule. There has been much recent work on this problem in the case where treatment is an unlimited resource (see Murphy [1] and Robins [2] for early works on the topic, and Chakraborty and Moodie [3] for a recent overview). It has been shown that the optimal treatment in this context is given by checking the sign of the average treatment effect conditional on (some subset of) the baseline covariates, also known as the blip function [2].
The optimal ITR assigns treatment to people from a given strata of covariates for which treatment is on average beneficial, and does not assign treatment to this strata otherwise. If treatment is even slightly beneficial to all subsets of the population, then such a treatment strategy would suggest treating the entire population. There are many realistic situations in which such a treatment strategy, or any strategy that treats a large proportion of the population, is not feasible due to limitations on the total amount of the treatment resource. In a discussion of Murphy [1], Arjas observed that resource constraints may render optimal ITRs of little practical use when the treatment of interest is a social or educational program, though no solution to the constrained problem was given [4].
The mathematical modeling literature has considered the resource allocation problem to a greater extent. Lasry et al. [5] developed a model to allocate the annual CDC budget for HIV prevention programs to subpopulations which would benefit most from such an intervention. Tao et al. [6] consider a mathematical model to optimally allocate screening procedures for sexually tranmitted diseases subject to a cost constraint. Though Tao et al. do not frame the problem as a statistical estimation problem, they end up confronting similar optimization challenges to those that we will face. In particular, they confront the (weakly) NP-hard knapsack problem from the combinatorial optimization literature [7, 8]. We will end up avoiding most of the challenges associated with this problem by primarily focusing on stochastic treatment rules, which will reduce to the easier fractional knapsack problem [9, 8]. Stochastic ITRs allow the treatment to rely on some external stochastic mechanism for individuals in a particular strata of covariates.
We consider a resource constraint under which there is a maximum proportion of the population which can be treated. We primarily focus on evaluating the public health impact of an optimal resource-constrained (R-C) ITR via its value. The value function has been shown to be of interest in several previous works (see, e.g., Zhang et al. [10], van der Laan and Luedtke [11], Goldberg et al. [12]. Despite the general interest of this quantity, estimating this quantity is challenging for unconstrained deterministic regimes at so-called exceptional laws, i.e. probability distributions at which the blip function is zero in some positive probability strata of covariates [2]; a slightly more general assumption is given in Luedtke and van der Laan [13]. Chakraborty et al. [14] showed that one can develop confidence intervals for this parameter using m-out-of-n bootstrap, though these confidence intervals shrink at a slower than root-n rate. Luedtke and van der Laan [13] showed that root-n rate confidence intervals can be developed for this quantity under reasonable conditions in the large semiparametric model which at most places restrictions on the treatment mechanism.
We develop a root-n rate estimator for the optimal R-C value and corresponding confidence intervals in this same large semiparametric model. We show that our estimator is efficient among all regular and asymptotically linear estimators under conditions. When the baseline covariates are continuous and the resource constraint is active, i.e. when the optimal R-C value is less than the optimal unconstrained value, these conditions are far more reasonable than the non-exceptional law assumption needed for regular estimation of the optimal unconstrained value.
We now give a brief outline of the paper. Section 2 defines the statistical estimation problem of interest, gives an expression for the optimal deterministic rule under a condition, and gives a general expression for the optimal stochastic rule. Section 3 presents our estimator of the optimal R-C value. Section 4 presents conditions under which the optimal R-C value is pathwise differentiable, and gives an explicit expression for the canonical gradient under these conditions. Section 5 describes the properties of our estimator, including how to develop confidence intervals for the optimal R-C value. Section 6 presents our simulation methods. Section 7 presents our simulation results. Section 8 closes with a discussion and areas of future research. All proofs are given in the Appendix.
2. Optimal R-C rule and value
Suppose we observe n independent and identically distributed (i.i.d.) draws from a single time point data structure (W, A, Y)~P0, here the vector of covariates W has support , the treatment A has support {0,1}, and the outcome Y has support in the closed unit interval. Our statistical model is nonparametric, beyond possible knowledge of the treatment mechanism, i.e. the probability of treatment given covariates. Little generality is lost with the bound on Y, given that any continuous outcome bounded in [b, c] can be rescaled to the unit interval with the linear transformation (y – b)/(c – b). Suppose that treatment are resources are limited so that at most a κ ϵ (0,1) proportion of the population can receive the treatment A = 1. Let V be some function ofW, and denote the support of V with . A deterministic treatment rule takes as input a function of the covariates and outputs a binary treatment decision . The stochastic treatment rules considered in this work are maps from to {0,1}, where is the support of some random variable U~PU. If d is a stochastic rule and is fixed, then d(u,·) represents a deterministic treatment rule. Throughout this work we will let U be drawn independently of all draws from P0.
For a distribution P, let . For notational convenience, we let . Let be a deterministic treatment regime. For a distribution P, let represent the value of . Under causal assumptions, this quantity is equal to the counterfactual mean outcome if, possibly contrary to fact, the rule d̃ were implemented in the population [15, 16]. The optimal R-C deterministic regime at P is defined as the deterministic regime d̃ which solves the optimization problem
| (1) |
For a stochastic regime d, let represent the value of d. Under causal assumptions, this quantity is equal to the counterfactual mean outcome if, possibly contrary to fact, the stochastic rule d were implemented in the population (see Ref. [17] for a similar identification result). The optimal R-C stochastic regime at P is defined as the stochastic treatment regime dwhich solves the optimization problem
| (2) |
We call the optimal value under a R-C stochastic regime Ψ(P). Because any deterministic regime can be written as a stochastic regime which does not rely on the stochastic mechanism U, we have that . The constraint above is primarily meant to represent a clinical setting where each patient arrives at the clinic with covariate summary measure V, a value of U is drawn from PUfor this patient, and treatment is then assigned according to d(U, V). By Fubini’s theorem, this is like rewriting the above constraint as . Nonetheless, this constraint also represents the case where a single value of U = u is drawn for the entire population, and each individual is treated according to the deterministic regime d(u, ·), i.e. . This case appears less interesting because, for a fixed u, there is no guarantee that EP[d(u, V)] ≤ κ.
For a distribution P, define the blip function as
Let SP represent the survival function of , i.e. . Let
| (3) |
For notational convenience we let , , , and .
Define the deterministic treatment rule as , and for notational convenience let . We have the following result.
Theorem 1
If , then the is an optimal deterministic rule satisfying the resource constraint, i.e. attains the maximum described in eq. (1).
One can in fact show that is the P almost surely unique optimal deterministic regime under the stated condition. We do not treat the case where for deterministic regimes, since in this case (1) is a more challenging problem: for discrete V with positive treatment effect in all strata, eq. (1) is a special case of the 0–1 knapsack problem, which is NP-hard, though is considered one of the easier problems in this class [7, 8]. In the knapsack problem, one has a collection of items, each with a value and a weight. Given a knapsack which can only carry a limited weight, the objective is to choose which items to bring so as to maximize the value of the items in the knapsack while respecting the weight restriction. Considering the optimization problem over stochastic rather than deterministic regimes yields a fractional knapsack problem, which is known to be solvable in polynomial time [9, 8]. The fractional knapsack problem differs from the 0–1 knapsack problem in that one can pack partial items, with the value of the partial items proportional to the fraction of the item packed.
Define the stochastic treatment rule dP by its distribution with respect to a random variable drawn from PU:
We will let . Note that and dP(U, V) are PU × P almost surely equal if or if τP ≤ 0, and thus have the same value in these settings. It is easy to show that
| (4) |
The following theorem establishes the optimality of the stochastic rule dP in a resource-limited setting.
Theorem 2
The maximum in eq. (2) is attained at d = dP, i.e. dP is an optimal stochastic rule.
Note that the above theorem does not claim that dP is the unique optimal stochastic regime. For discrete V, the above theorem is an immediate consequence of the discussion of the knapsack problem in Dantzig [9].
In this paper we focus on the value of the optimal stochastic rule. Nonetheless, the techniques that we present in this paper will only yield valid inference in the case where the data are generated according to a distribution P0 for which . This is analogous to assuming a non-exceptional law in settings where resources are not limited [13, 2], though we note that for continuous covariates V this assumption is much more likely if τ0 > 0. It seems unlikely that the treatment effect in some positive probability strata of covariates will concentrate on some arbitrary (determined by the constraint κ) value τ0. Nonetheless, one could deal with situations where using similar martingale-based online estimation techniques to those presented in Luedtke and van der Laan [13].
3. Estimating the optimal optimal R-C value
We now present an estimation strategy for the optimal R-C rule. The upcoming sections justify this strategy and suggest that it will perform well for a wide variety of data generating distributions. The estimation strategy proceeds as follows:
Obtain estimates , , and gn of , , and g0 using any desired estimation strategy which respects the fact that Y is bounded in the unit interval.
Estimate the marginal distributions of W and V with the corresponding empirical distributions.
Estimate S0 with the plug-in estimator Sn given by .
Estimate η0 with the plug-in estimator .
Estimate τ0 with the plug-in estimator given by .
- Estimate d0 with the plug-in estimator dn with distribution
- Run a TMLE for the parameter :
-
(a)For , define . Run a univariate logistic regression using:
- Outcome : (yi : i = 1,..., n)
- Offset :
- Covariate : (H(ai, wi) : i = 1,..., n).
-
(a)
Let εn represent the estimate of the coefficient for the covariate, i.e.
where .
-
(b)
Define .
-
(c)Estimate using the plug-in estimator given by
We use as our estimate of Ψ(Ρ0). We will denote this estimator , where we have defined so that . Note that we have used a TMLE for the data dependent parameter , which represents the value under a stochastic intervention dn. Nonetheless, we assume that for many of the results pertaining to our estimator , i.e. we assume that the optimal R-C rule is deterministic. We view estimating the value under a stochastic rather than deterministic intervention as worthwhile because one can give conditions under which the above estimator is (root-n) consistent for Ψ(P0) at all laws P0, even if non-negligible bias invalidates standard Wald-type confidence intervals for the parameter of interest at laws P0 for which .
We will use to denote any distribution for which , and has the marginal empirical distribution of W for the marginal distribution of W. We note that such a distribution exists provided that and gn fall in the parameter spaces of and P⟼gP, respectively.
In practice we recommend estimating and using an ensemble method such as super-learning to make an optimal bias-variance trade-off (or, more generally, minimize cross-validated risk) between a mix of parametric models and data adaptive regression algorithms [18, 19]. If the treatment mechanism g0 is unknown then we recommend using similar data adaptive approaches to obtain the estimate gn. If g0 is known (as in a randomized controlled trial without missingness), then one can either take gn = g0 or estimate g0 using a correctly specified parametric model, which we expect to increase the efficiency of estimators when the part of the likelihood is misspecified [20, 21].
There is typically little downside to using data adaptive approaches to estimate the needed portions of the likelihood, though we do give a formal empirical process condition in Section 5.1 which describes exactly how data adaptive these estimators can be. If one is concerned about the data adaptivity of the estimators of the needed portions of the likelihood, then one can consider a cross-validated TMLE approach such as that presented in van der Laan and Luedtke [20] or an online one-step estimator as that presented in Luedtke and van der Laan [13]. These two approaches make no restrictions on the data adaptivity of the estimators of , , or g0.
We now outline the main results of this paper, which hold under appropriate consistency and regularity conditions.
- Asymptotic linearity of :
with D0 a known function of P0.
- is an asymptotically efficient estimate of Ψ(P0).
- One can obtain a consistent estimate for the variance of D0(O). An asymptotically valid 95% confidence intervals for Ψ(P0) given by .
The upcoming sections give the consistency and regularity conditions which imply the above results.
4. Canonical gradient of the optimal R-C value
The pathwise derivative of Ψ will provide a key ingredient for analyzing the asymptotic properties of our estimator. We refer the reader to Pfanzagl [22] and Bickel et al. [23] for an overview of the crucial role that the pathwise derivative plays in semiparametric efficiency theory. We remind the reader that an estimator is an asyptotically linear estimator of a parameter Φ (P0) with influence curve provided that
If Φ is pathwise differentiable with canonical gradient then is RAL and asymptotically efficient (minimum variance) among all such RAL estimators of Φ(Ρ0) [23, 22].
For , a deterministic rule , and a real number τ, define
where . We will let . We note that is the efficient influence curve of the parameter .
Let d be some stochastic rule. The canonical gradient of Ψd is given by
Define
For ease of reference, let . The upcoming theorem makes use of the following assumptions.
C1. g0 satisfies the positivity assumption: Pr0(0 < g0(1|W) < 1) = 1.
C2. has density f0 at η0, and 0 < fο(η0) < ∞
C3. S0 is continuous in a neighborhood of η0.
C4. 0 for all τ in a neighborhood of τ0.
We now present the canonical gradient of the optimal R-C value.
Theorem 3
Suppose C1 through C4. Then Ψ is pathwise differentiable at P0 with canonical gradient D0.
Note that C3) implies that . Thus d0 is (almost surely) deterministic and the expectation over PU in the definition of D0 is superfluous. Nonetheless, this representation will prove useful when we seek to show that our estimator solves the empirical estimating equation defined by an estimate of D(d0, τ0, P0).
When the resource constraint is active, i.e. τ0 > 0, the above theorem shows that Ψ has an additional component over the optimal value parameter when no resource constraints are present [11]. The additional componentis , and is the portion ofthe derivative that relies on the fact that d0 is estimated and falls on the edge of the parameter space. We note that it is possible that the variance of D0 (O) is greater than the variance of .If τ0 = 0 then these two variances are the same, so suppose τ0 > 0. Then, provided that , we have that
For any κ ∈(0,1), it is possible to exhibit a distribution P0 which satisfies the conditions of Theorem 3 and for which . Perhaps more surprisingly, it is also possible to exhibit a distribution P0 which satisfies the conditions of Theorem 3 and for which . We omit further the discussion here because the focus of this work is on considering the estimating the value from the optimization problem (2), rather than discussing how this procedure relates to the estimation of other parameters.
5. Results about the proposed estimator
We now show that is an asymptotically linear estimator for Ψ(Ρ0) with influence curve D0 provided our estimates of the needed parts of P0 satisfy consistency and regularity conditions. Our theoretical results are presented in Section 5.1, and the conditions of our main theorem are discussed in Section 5.2.
5.1. Inference for Ψ(Ρ0)
For any distributions P and P0 satisfying positivity, stochastic intervention d, and real number τ, define the following second-order remainder terms:
Above the reliance of d and d0 on (U, V) is omitted in the notation. Let . The upcoming theorem will make use of the following assumptions.
g0 satisfies the strong positivity assumption: Pr0(δ < g0(1|W) < 1 — δ) — 1 for some δ > 0.
gn satisfies the strong positivity assumption for a fixed δ > 0 with probability approaching 1: there exists some δ > 0 such that, with probability approaching 1, Pr0(δ < gn(1|W) < 1 — δ) — 1.
.
.
belongs to a P0-Donsker class with probability approaching 1.
.
We note that the τ0 in the final condition above only enters the expression in the sum as a multiplicative constant in front of .
Theorem 4 ( is asymptotically linear)
Suppose C2) through 6. Then is a RAL estimator of Ψ(Ρ0) with influence curve D0, i.e.
Further, is efficient among all such RAL estimators of Ψ(Ρ0).
Let By the central limit theorem, converges in distribution to a distribution. Let be an estimate of . We now give the following lemma, which gives sufficient conditions for the consistency of τn for τ0.
Lemma 5(Consistency of τn)
Suppose C2) and C3). Also suppose is consistent for in L1(P0) and that the estimate belongs to a P0 Glivenko Cantelli class with probability approaching 1. Then τn → τ0 in probability.
It is easy to verify that conditions similar to those of Theorem 4, combined with the convergence of τn to τ0 as considered in the above lemma, imply that σn → σ0 in probability. Under these conditions, an asymptotically valid two-sided 1 — α confidence interval is given by
where z1—α/2 denotes the 1 — α/2 quantile of a N(0,1) random variable.
5.2. Discussion of conditions of Theorem 4
Conditions C2) and C3).
These are standard conditions used when attempting to estimate the κ-quantile η0, defined in eq. (3). Provided good estimation of , these conditions ensure that gathering a large amount of data will enable one to get a good estimate of the κ-quantile of the random variable . See Lemma 5 for an indication of what is meant by “good estimation” of . It seems reasonable to expect that these conditions will hold when V contains continuous random variables and η0 ≠ 0, since we are essentially assuming that is not degenerate at the arbirtrary (determined by κ) point η0.
Condition C4).
If τ0 > 0, then C4) is implied by C3). If τ0 = 0, then C4) is like assuming a non-exceptional law, i.e. that the probability of a there being no treatment effect in a strata of V is zero. Because τ0 is not known from the outset, we require something slightly stronger, namely that the probability of any specific small treatment effect is zero in a strata of V is zero. Note that this condition does not prohibit the treatment effect from being small, e.g. for all τ>0, but rather it prohibits there existing a sequence τm ↓ 0 with the property that infinitely often. Thus this condition does not really seem any stronger than assuming a non-exceptional law. If one is concerned about such exceptional laws then we suggest adapting the methods in [13] to the R-C setting.
Condition 1.
This condition assumes that people from each strata of covariates have a reasonable (at least a δ > 0) probability of treatment.
Condition 2.
This condition requires that our estimates of g0 respect the fact that each strata of covariates has a reasonable probability of treatment.
Condition 3.
This condition is satisfied if and . The term takes the form of a typical double robust term that is small if either or is estimated well, and is second-order, i.e. one might hope that , if both both g0 and are estimated well. One can upper bound this remainder with a product of the L2(P0) rates of convergence of these two quantities using the Cauchy-Schwarz inequality. If g0 is known, then one can take gn = g0 and this term is zero.
Ensuring that requires a little more work but will still prove to be a reasonable condition. We will use the following margin assumption for some α > 0:
| (5) |
where “≲” denotes less than or equal to up to a multiplicative constant. This margin assumption is analogous to that used in Audibert and Tsybakov [24]. The following result relates the rate of convergence of R20(dn) to the rate at which converges to .
Theorem 6
If eq. (5) holds for some α > 0, then
The above is similar to Lemma 5.2 in Audibert and Tsybakov [24], and a similar result was proved in the context of optimal ITRs without resource constraints in Luedtke and van der Laan [13]. If S0 has a finite derivative at τ0, as is given by C2), then one can take α = 1. The above theorem then implies that if either is or is
Condition 4.
This is a mild consistency condition which is implied by the L2(P0) consistency of dn, gn, and to d0, g0, and . We note that the consistency of the intial (unfluctuated) estimate for will imply the consistency of to given 2, since in this case εn → 0 in probability, and thus in probability.
Condition 5.
This condition places restrictions on how data adaptive the estimators of d0, g0, and can be. We refer the reader to Section 2.10 of van der Vaart and Wellner [25] for conditions under which the estimates of d0, g0, and belonging to Donsker classes implies that belongs to a Donsker class. We note that this condition was avoided for estimating the value function using a cross-validated TMLE in van der Laan and Luedtke [20] and using an online estimator of the value function in Luedtke and van der Laan [13], and using either technique will allow one to avoid the condition here as well.
Condition 6.
Using the notation Pf=∫f(o)dP(o) for any distribution P and function f : , we have that
The first term is zero by the fluctuation step of the TMLE algorithm and the second term on the right is zero because uses the empirical distribution of W for the marginal distribution of W. If τ0 = 0 then clearly the third term is zero, so suppose τ0 > 0. Combining eq. (4) and the fact that dn is a substitution estimator shows that the third term is 0 with probability approaching 1 provided that τn > 0 with probability approaching 1. This will of course occur if τn → τ0 > 0 in probability, for which Lemma 5 gives sufficient conditions.
6. Simulation methods
We simulated i.i.d. draws from two data generating distributions at sample sizes 100, 200, and 1,000. For each sample size and distribution we considered resource constraints κ = 0·1 and κ = 0·9. We ran 2,000 Monte Carlo draws of each simulation setting. All simulations were run in R [26].
We first present the two data generating distributions considered, and then present the estimation strategies used.
6.1. Data generating distributions
6.1.1. Simulation 1
Our first data generating distribution is identical to the single time point simulation considered in van der Laan and Luedtke [20] and Luedtke and van der Laan [18]. The outcome is binary and the baseline covariate vector W = (W1, ..., W4) is four dimensional for this distribution, with
where H is an unobserved Bernoulli(1/2) variable independent of A, W. For this distribution .
We consider two choices for V, namely V = W3, and V = W1,..., W4. We obtained estimates of the approximate optimal R-C optimal value for this data generating distribution using 107 Monte Carlo draws. When κ = 0.1, Ψ(Ρ0) ≈ 0.493 for V = W3 and Ψ(Ρ0) ≈ 0.511 for V = W1,..., W4. When κ = 0.9, Ψ(Ρ0) ≈ 0.536 for V = W3 and Ψ(Ρ0) ≈ 0.563 for V = W1,..., W4. We note that the resource constraint is not active (τ0 = 0) when κ = 0.9 for either choice of V.
6.1.2. Simulation 2
Our second data generating distribution is very similar to one of the distributions considered in Luedtke and van der Laan [13], though has been modified so that the treatment effect is positive for all values of the covariate. The data are generated as follows:
where for we define
For this distribution and .
We use V = W. This simulation is an example of a case where almost surely, so any constraint on resources will reduce the optimal value from its unconstrained value of 0.583. In particular, we have that Ψ(Ρ0) ≈ 0.337 when κ = 0.1 and Ψ(Ρ0) ≈ 0.572 when κ = 0.9.
6.2. Estimating nuisance functions
We treated g0 as known in both simulations and let gn = g0. We estimated using the super-learner algorithm with the quasi-log-likelihood loss function (family = binomial) and a candidate library of data adaptive (SL.gam and SL.nnet) and parametric algorithms (SL.bayesglm, SL.glm, SL.glm. interaction, SL.mean, SL.step, SL.step.interaction, and SL.step.forward). We refer the reader to table 2 in the technical report Luedtke and van der Laan [18] for a brief description of these algorithms. We estimated by running a super-learner using the squared error loss function and the same candidate algorithms and used W to predict the outcome , where represents the sample mean of Y from the n observations. See Luedtke and van der Laan [18] for a justification of this estimation scheme.
Once we had our estimates , and gn we proceeded with the estimation strategy described in Section 3.
6.3. Evaluating performance
We used three methods to evaluate our proposed approach. First, we looked at the coverage of two-sided 95% confidence intervals for the optimal R-C value. Second, we report the average confidence interval widths. Finally, we looked at the power of the α = 0.025 level test H0 : Ψ(Ρ0) = μ0 against H1 : Ψ(Ρ0) > μ0, where is treated as a known quantity. Under causal assumptions, μ0 can be identified with the counterfactual quantity representing the population mean outcome if, possibly contrary to fact, no one receives treatment. If treatment is not currently being given in the population, one could substitute the population mean outcome (if known) for μ0. Our test of significance consisted of checking of the lower bound in the two-sided 95% confidence interval is greater than μ0. If an estimator of Ψ(Ρ0) is low-powered in testing H0 against H1 then clearly the estimator will have little practical value.
7. Simulation results
Coverage
The proposed estimation strategy performed well overall. Figure 1 demonstrates the coverage of 95% confidence intervals for the optimal R-C value. All methods performed well at all sample sizes for the highly constrained setting where κ = 0.1. The results were more mixed for the resource constraint κ = 0.9. All methods performed well at the largest sample size considered. This supports our theoretical results, which were all asymptotic in nature. For Simulation 1, in which the resource constraint was not active for either choice of V, the coverage dropped off at lower sample sizes. Coverage was approximately 90% in the two smaller sample sample sizes for V = W3, which may be expected for such an asymptotic method. For the more complex problem of estimating the optimal value when V = W1,..., W4 the coverage was somewhat lower (80% when n = 100 and 84% when n = 200). In Simulation 2, the coverage was better ( > 91%) for the smaller sample sizes. We note that the resource constraint was still active (τ0 > 0) when κ = 0.9 for this simulation, and also that the estimation problem is easier because the baseline covariate was univariate.
Figure 1:
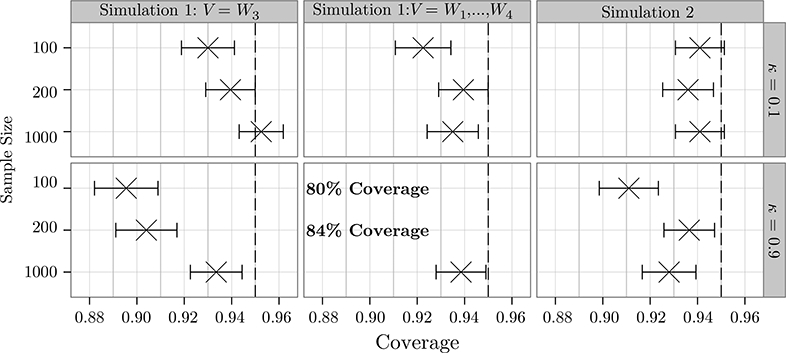
Coverage of two-sided 95% confidence intervals. As expected, coverage increases with sample size. The coverage tends to be better for κ = 0.1 than for κ = 0.9, though the estimator performed well at the largest sample size (1,000) for all simulations and choices of κ. Error bars indicate 95% confidence intervals to account for uncertainty from the finite number of Monte Carlo draws.
We report the average confidence interval widths across the 2,000 Monte Carlo draws. For n = 100, average confidence interval widths were between 0.25 and 0.26 across all simulations and choices of κ. For n = 200, all average confidence interval widths were between 0.17 and 0.18. For n = 1000, all average confidence interval widths were approximately 0.08. We note that the usefulness of such confidence intervals varies across simulations and choices of κ. When V = W3 and κ = 0.1 in Simulation 1, the optimal R-C value is approximately 0.493, versus a baseline value of approximately 0.464. Thus here the confidence interval would give the investigator little information, even at a sample size of 1,000. In Simulation 2 with κ = 0.9, on the other hand, the optimal R-C value is approximately 0.572, versus a baseline value of μ0 ≈ 0.3. Thus here all confidence intervals would likely be informative for investigators, even those made for data sets of size 100.
Figure 2 gives the power of the α = 0.025 level test H0: Ψ(Ρ0) = μ0 against the alternative H1: Ψ(Ρ0) >μ0. Overall our method appears to have reasonable power in this statistical test. We see that power increases with sample size, the key property of consistent statistical tests. We also see that power increases with κ, which is unsurprising given that Y is binary and g0(a|w) is 1/2 for all a,w. We note that power will not always increase with κ, for example if P0 is such that g0(1|w) is very small for individuals with covariate w who are treated at κ = 0.9 but not at κ = 0.1. This observation is not meant as a criticism to the estimation scheme that we have presented because we assume that κ will be chosen to reflect real resource constraints, rather than to maximize the power for a test versus for some fixed μ’.
Figure 2:
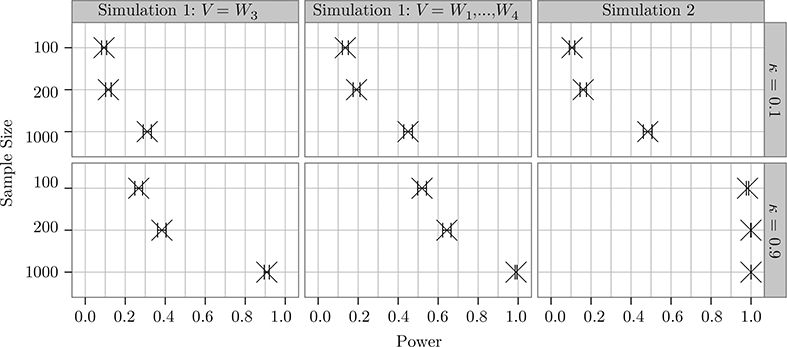
Power of the α = 0.025 level test of H0 : Ψ(Ρ0) = μ0 against H1 : Ψ(Ρ0) >μ0, where is treated as known. Power increases with sample size and κ. Error bars indicate 95% confidence intervals to account for uncertainty from the finite number of Monte Carlo draws.
We also implemented an estimating equation based estimator for the optimal R-C value and found the two methods performed similarly. We would recommend using the TMLE in practice because it has been shown to be robust to near positivity violations in a wide variety of settings [27]. We note that g0(1|w) = 1/2 for all w in both of our simulations, so no near positivity violations occurred. We do not consider the estimation equation approach any further here because the focus of this work is on considering the optimization problem (2), rather than on comparing different estimation frameworks.
8. Discussion and future work
We have considered the problem of estimating the optimal resource-constrained value. Under causal assumptions, this parameter can be identified with the maximum attainable population mean outcome under individualized treatment rules which rely on some summary of measured covariates, subject to the constraint that a maximum proportion κ of the population can be treated. We also provided an explicit expression for an optimal stochastic rule under the resource constraint.
We derived the canonical gradient of the optimal R-C value under the key assumption that the treatment effect is not exactly equal to τ0 in some strata of covariates which occurs with positive probability. The canonical gradient plays a key role in developing asymptotically linear estimators. We found that the canonical gradient of the optimal R-C value has an additional component when compared to the canonical gradient of the optimal unconstrained value when the resource constraint is active, i.e. when τ0 > 0.
We presented a targeted minimum loss-based estimator for the optimal R-C value. This estimator was designed to solve the empirical mean of an estimate of the canonical gradient. This quickly yielded conditions under which our estimator is RAL, and efficient among all such RAL estimators. All of these results rely on the condition that the treatment effect is not exactly equal to τ0 for positive probability strata of covariates. This assumption is more plausible than the typical non-exceptional law assumption when the covariates are continuous and the constraint is active because it may be unlikely that the treatment effect concentrates on an arbitrary (determined by κ) τ0 > 0. We note that this pseudo-non-exceptional law assumption has implied that the optimal stochastic rule is almost surely equal to the optimal deterministic rule. Though we have not presented formal theorems here, it is not difficult to derive conditions under which our estimator of the optimal value under a R-C stochastic rule is (root-n) consistent even when the treatment effect is equal to τ0 with positive probability, though the bias will be non-negligible (converge to zero at the same root-n rate as the variance). One could use an analogue of the variance-stabilized online estimator presented in Luedtke and van der Laan [13] to get inference for the optimal R-C value in this setting.
Our simulations confirmed our theoretical findings. We found that coverage improved with sample size, with near-nominal coverage at the largest sample size considered. This is not surprising given that most of our analytic results were asymptotic, though we note that the method also performed well at the smaller sample sizes considered. The confidence intervals were informatively tight when one considered the difference between the optimal R-C value and the value under no treatment. Further simulations are needed to fully understand the behavior of this method in practice.
Some resource constraints encountered in practice may not be of the form . For example, the cost of distributing the treatment to people may vary based on the values of the covariates. For simplicity assume V = W. If c : W → [0,∞)is a cost function, then this constraint may take the form . If τ0 = 0, then an optimal stochastic rule under such a constraint takes the form . If τ0 > 0, then an optimal stochastic rule under such a constraint takes the form for w for which or c(w) = 0, and randomly distributes the remaining resources uniformly among all remaining w. We leave further consideration of this more general resource constraint problem to future work.
In this work our primary focus has been on estimating the optimal value under a resource constraint, rather than the optimal rule under a resource constraint. Nonetheless, our estimation procedure yields an estimate dn of the optimal R-C rule. It would be interesting to further analyze dn in future work to better understand how well this estimator will perform, or if there are better estimators which more directly frame the estimation challenge as a (weighted) classification problem [28, 29]. Note that we are not guaranteed that dn satisfies the constraint, i.e. it is quite possible that , though concentration inequalities suggest that one can give conditions under which is small with probability approaching 1. One could also seek an optimal rule estimate which satisfies that, with probability at least 1 — δ for some user-defined δ > 0, .
Further work is needed to generalize this work to the multiple time point setting. Before generalizing the procedure, one must know exactly what form the multiple time point constraint takes. For example, it may be the case that only a κ proportion of the population can be treated at each time point, or it may be the case that treatment can only be administered at a κ proportion of patient-time point pairs. Regardless of which constraint one chooses, it seems that the nice recursive structure encountered in Q-learning may not hold for multiple time point R-C problems. While useful for computational considerations, being able to express the optimal rule using approximate dynamic programming is not necessary for the existence of a good optimal rule estimator, especially when the number of time points is small. If the computational complexity of the procedure is a major concern, it may be beneficial to frame the multiple time point learning problem as a single optimization problem, using smooth surrogates for indicator functions as Zhao et al. [30] do when they introduce simultaneous outcome weighted learning (SOWL). One would then need to appropriately account for the fact that the empirical resource constraint may only be approximately satisfied.
We have not considered the ethical considerations associated with allocating limiting resources to a population. The debate over the appropriate means to distribute limited treatment resources to a population is ongoing (see, e.g., Brock and Wilder [31], Macklin and Cowan [32], Singh [33], for examples in the treatment of HIV/AIDS). Clearly any investigator needs to consider the ethical issues associated with certain resource allocation schemes. Our method is optimal in a particular utilitarian sense (maximizing the expected population mean outcome with respect to an outcome of interest) and yields a treatment strategy which treats individuals who are expected to benefit most from treatment in terms of our outcome of interest. One must be careful to ensure that the outcome of interest truly captures the most important public health implications. Unlike in unconstrained individualized medicine, inappropriately prescribing treatment to a stratum will also have implications for individuals outside of that strata, namely for the individuals who do not receive treatment due to its lack of availability. We leave further ethical considerations to experts on the matter. It will be interesting to see if there are settings in which it is possible to transform the outcome or add constraints to the optimization problem so that the statistical problem considered in this paper adheres to the ethical guidelines in those settings.
We have looked to generalize previous works in estimating the value of an optimal individualized treatment regime to the case where the treatment resource is a limited resource, i.e. where it is not possible to treat the entire population. This work should allow for the application of optimal personalized treatment strategies to many new problems of interest.
Funding:
This research was supported by NIH grant R01 AI074345–06. AL was supported by the Department of Defense (DoD) through the National Defense Science & Engineering Graduate Fellowship (NDSEG) Program.
Appendix: Proofs
Proofs for Section 2
We first state a simple lemma.
Lemma 6
For a distribution P and a stochastic rule d, we have the following representation for Ψd:
Proof of Lemma 6. We have that
where the final equality holds by the law of total expectation
Proof of Theorem 1.
This result will be a consequence of Theorem 2. If , then dP (U, V ) is PU × P almost surely equal to , and thus . Thus is an optimal stochastic regime. Because the class of deterministic regimes is a subset of the class of stochastic regimes, is an optimal deterministic regime.
Proof of Theorem 2.
Let d be some stochastic treatment rule which satisfies the resource constraint. For (b, c) ∈ {0,1}2, define . Note that
| (6) |
The in the first term in 1 can be upper bounded by τΡ, and in the second term can be lower bounded by τΡ. Thus,
If τΡ = 0 then the final line is zero. Otherwise, by eq. (4). Because d satisfies the resource constraint, and thus the final line above is at least zero. Thus for all τΡ. Because d was arbitrary, dP is an optimal stochastic rule.
Proofs for Section 4
Proof of Theorem 3.
The pathwise derivative of Ψ(Q) is defined as along paths . In particular, these paths are chosen so that
The parameter Ψ is not sensitive to fluctuations of g0(a\w) = Pr0(a\w), and thus we do not need to fluctuate this portion of the likelihood. Let , , , , and . First note that
| (7) |
for an hε with
| (8) |
Note that C4) implies that d0 is (almost surely) deterministic, i.e. d0(U, ·) is almost surely a fixed function. Let represent the deterministic rule to which d(u, ·) is (almost surely) equal for all u. By Lemma 1,
| (9) |
Dividing the fourth term by ε and taking the limit as ε → 0 gives the pathwise derivative of the mean outcome under the rule that treats d0 as known. The third term can be written as , and thus the pathwise derivative of this term is . If τ0 > 0, then . The pathwise derivative of this term is zero if τ0 = 0. Thus, for all τ0,
Thus the third term in eq. (9) generates the portion of the canonical gradient, or equivalently . The remainder of this proof is used to show that the first two terms in eq. (9) are o(ε).
Step 1: ηε→η0.
We refer the reader to eq. (3) for a definition of the quantile P→nP. This is a consequence of the continuity of S0 in a neighborhood of n0. For γ > 0,
| (10) |
For positive constants C1 and Cw,
Fix γ > 0 small enough so that S0 is continuous at n0 — γ. In this case we have that S0(η0 — γ + c1|ε|) → S0(η0 — γ) as ε → 0. By the infimum in the definition of η0, we know that S0(η0 — γ) >κ. Thus Sε(η0 — γ) >κ for all |ε| small enough.
Similarly, Sε(η0 + γ) ≤ (1 + Cw|ε|) S0(η0 + γ — C1|ε|). Fix γ > 0 small enough so that S0 is continuous at η0 + γ. Then S0(η0 + γ — C1|ε|) → S0(η0 + γ) as ε → 0. Condition C2) implies the uniqueness of the κ-quantile of , and thus that S0(η0 + γ) < κ. It follows that Sε(η0 + γ) < κ for all |ε| small enough.
Combining Sε(η0 — γ) > κ and Sε(η0 + γ) < κ for all ε close to zero with eq. (10) shows that ηε → η0 as ε → 0.
Step 2: Second term of eq. (9) is 0 eventually.
If τ0 = 0 then the result is immediate, so suppose τ0 > 0. By the previous step, ηε → η0, which implies that τε → τ0 > 0 by the continuity of the max function. It follows that τε > 0 for ε large enough. By eq. (4), for all sufficiently small |ε| and Thus the second term of eq. (9) is 0 for all |ε| small enough.
Step 3: τε - τ0 = 0(ε).
Note that κ< Sε(ηε — |ε|) ≤ (1 + Cw|ε|)S0(ηε — (1 + C1)|ε|). A Taylor expansion of S0 about η0 shows that
| (11) |
The fact that f0(η0) ε (0, ∞) shows that ηε — η0 is bounded above by some 0(ε) sequence. Similarly, κ ≥ S(ηε+|ε|) ≥ (1-CW|ε|)S0(ηε+(1+C1)|ε|)). Hence,
It follows that ηε — η0 is bounded below by some 0(ε) sequence. Combining these two bounds shows that ηε — η0 = 0(ε), which immediately implies that τε — τ0 = max{0(ε), 0} = 0(ε).
Step 4: First term of eq. (9) is ο(ε).
We know that
By C4), it follows that there exists some δ>0 such that . By the absolute continuity of Qw,ε with respect to QW,0, It follows that, for all small enough |ε| and almost all Hence,
where the penultimate inequality holds by Step 3 and eq. (7). The last line above is ο(ε) because Pr(0 < X ≤ ε) → 0 as ε → 0 for any random variable X. Thus dividing the left-hand side above byε and taking the limit as ε → 0 yields zero.
Proofs for Section 5
We give the following lemma before proving Theorem 4.
Lemma 7
Let P0 and P be distributions which satisfy the positivity assumption and for which Y is bounded in probability. Let d be some stochastic treatment rule and τ be some real number. We have that Ψd(P) - Ψ(P0)= -EP0 [D(d, τ0, P)(O)]+ R0(d, P).
Proof of Lemma 12. Note that
Standard calculations show that the first term on the right is equal to R10(d,P) [21]. If τ0> 0, then eq. (4) shows that . If τ0 = 0, then obviously τEpUxP0[d — κ] = τ0EpUxP0[d — d0] Lemma 1 shows that . Thus the second line above is equal to R20(d).
Proof of Theorem 4.
We make use of empirical process theory notation in this proof so that Pf = EP [f (O)] for a distribution P and function f. We have that
| (12) |
| (13) |
The middle term on the last line is by 1, 2, 4, and 5 [25], and the third term is by 3. This yields the asymptotic linearity result. Proposition 1 in Section 3.3 of Bickel et al. [23] yields the claim about regularity and asymptotic efficiency when conditions C2), C3), C4), and 1 hold (see Theorem 3).
Proof of Lemma 5.
We will show that ηη → η0 in probability, and then the consistency of τn follows by the continuous mapping theorem. By C3), there exists an open interval N containing η0 on which S0 is continuous. Fix η ε N. Because belongs to a Glivenko-Cantelli class with probability approaching 1, we have that
| (14) |
where we use the notation Pf = EP [f (O)] for any distribution P and function f. Let . The following display holds for all q> > 0:
| (15) |
| (16) |
Above eq. (15) holds because C3) implies that eq. (16) holds because Ζη(η) = 1 implies that and the final inequality holds by Markov’s inequality. The lemma assumes that , and thus we can choose a sequence qn ↓ 0 such that
To see that the first term on the right is o(1), note that combined with the continuity of S0 on N yield that, for n large enough,
The right-hand side is 0(1), and thus . Plugging this into eq. (14) shows that Sn(η) → S0(η) in probability. Recall that η € N was arbitrary.
Fix γ > 0. For γ small enough, η0 — γ and η0 + γ are contained in N. Thus Sn(η0 — γ) → S0(η0 + γ) and Sn(η0 + γ) → S0(η0 - γ) in probability. Further, S0(η0 - γ) > k by the definition of η0 and S0(η0 + γ) < κ by Condition C2). It follows that, with probability approaching 1, Sn(η0 — γ) >κ and Sn(η0 + γ) < κ. But |ηn — η0| > γ implies that S0(η0 - γ)— γ) ≤ κ or Sn(η0 + γ) > κ, and thus |ηn —η0| γ with probability approaching 1. Thus ηn → η0 in probability, and τn → τ0 by the continuous mapping theorem.
Proof of Theorem 6.
This proof mirrors the proof of Lemma 5.2 in Audibert and Tsybakov [24]. It is also quite similar to the proof of Theorem 7 in Luedtke and van der Laan [13], though the proof given in that working technical report is for optimal rules without any resource constraints, and also contains several typographical errors which will be corrected in the final version.
Define Bn to be the function and B0 to be the function . Below we omit the dependence of Bn, B0 on V in the notation and of dn, d0 on U and V. For any t> 0, we have that
where the second inequality holds because dn ≠ d0 implies that |Bn — B0| > |B0| when |B0| > 0, the third inequality holds by the Cauchy-Schwarz and Markov inequalities, and the C0 on the final line is the constant implied by eq. (5). The first result follows by plugging into the upper bound above. We also have that
By eq. (5), it follows that
References
- 1.Murphy SA. Optimal dynamic treatment regimes. J Roy Stat Soc Ser B 2003;650:331–6. [Google Scholar]
- 2.Robins JM. Optimal structural nested models for optimal sequential decisions. In: Lin DYand Heagerty P, editors. Proc. Second Seattle Symp. Biostat, 179, 2004:189–326. [Google Scholar]
- 3.Chakraborty B, Moodie EE. Statistical methods for dynamic treatment regimes Berlin, Heidelberg, New York: Springer, 2013. [Google Scholar]
- 4.Arjas E, Jennison C, Dawid AP, Cox DR, Senn S, Cowell RG, et al. Optimal dynamic treatment regimes - discussion on the paper by murphy. J Roy Stat Soc Ser B 2003;65:355–66. [Google Scholar]
- 5.Lasry A, Sansom SL, Hicks KA, Uzunangelov V. A model for allocating CDCs HIV prevention resources in the United States. Health Care Manag Sci 2011;140:115–24. [DOI] [PubMed] [Google Scholar]
- 6.Tao G, Zhao K, Gift T, Qiu F, Chen G. Using a resource allocation model to guide better local sexually transmitted disease control and prevention programs. Oper Res Heal Care 2012;10:23–9. [Google Scholar]
- 7.Karp RM. Reducibility among combinatorial problems New York, Berlin, Heidelberg: Springer, 1972. [Google Scholar]
- 8.Korte B, Vygen J. Combinatorial optimization, 5th ed. Berlin, Heidelberg, New York: Springer, 2012. [Google Scholar]
- 9.Dantzig GB. Discrete-variable extremum problems. Oper Res 1957;50:266–88. [Google Scholar]
- 10.Zhang B, Tsiatis A, Davidian M, Zhang M, Laber E. A robust method for estimating optimal treatment regimes. Biometrics 2012;68:1010–18. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.van der Laan MJ, Luedtke AR. Targeted learning of an optimal dynamic treatment, and statistical inference for its mean outcome. Technical report 329 Available at: http://www.Bepress.Com/Ucbbiostat/, Division of Biostatistics, University of California, Berkeley, 2014a. [Google Scholar]
- 12.Goldberg Y, Song R, Zeng D, Kosorok MR. Comment on dynamic treatment regimes: technical challenges and applications. Electron J Stat 2014;8:1290–300. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Luedtke AR, van der Laan MJ. Statistical inference for the mean outcome under a possibly non-unique optimal treatment strategy. Technical Report 332 Available at: http://biostats.bepress.com/ucbbiostat/paper332/, Division of Biostatistics, University of California, Berkeley, submitted to Annals of Statistics, 2014b. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Chakraborty B, Laber EB, Zhao Y-Q. Inference about the expected performance of a data-driven dynamic treatment regime. Clin Trials 2014;110:408–17. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Pearl J Causality: models, reasoning and inference, 2nd ed. New York: Cambridge University Press, 2009. [Google Scholar]
- 16.Robins JM. A graphical approach to the identification and estimation of causal parameters in mortality studies with sustained exposure periods. Comput Math Appl 1987;140:139s–161s. ISSN 0097–4943. [DOI] [PubMed] [Google Scholar]
- 17.Daz I, van der Laan MJ. Population intervention causal effects based on stochastic interventions. Biometrics 2012;680: 541–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Luedtke AR, van der Laan MJ. Super-learning of an optimal dynamic treatment rule. Technical Report 326 Available at: http://www.bepress.com/ucbbiostat/, Division of Biostatistics, University of California, Berkeley, under Review at JCI, 2014a. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.van der Laan MJ, Polley E, Hubbard A. Super learner. Stat Appl Genet Mol 2007;60 Article 25.ISSN 1. [DOI] [PubMed] [Google Scholar]
- 20.van der Laan MJ, Luedtke AR. Targeted learning of the mean outcome under an optimal dynamic treatment rule. J Causal Inference 2014b. (Ahead Of print). DOI: 10.1515/jci-2013-0022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.van der laan MJ, Robins JM. Unified methods for censored longitudinal data and causality New York, Berlin, Heidelberg: Springer, 2003. [Google Scholar]
- 22.Pfanzagl J Estimation in semiparametric models Berlin, Heidelberg, New York: Springer, 1990. [Google Scholar]
- 23.Bickel PJ, Klaassen CAJ, Ritov Y, Wellner JA. Efficient and adaptive estimation for semiparametric models Baltimore: Johns Hopkins University Press, 1993. [Google Scholar]
- 24.Audibert JY, Tsybakov AB. Fast learning rates for plug-in classifiers. Ann Statist 2007;350:608–33. [Google Scholar]
- 25.van der Vaart AW, Wellner JA. Weak convergence and empirical processes Berlin, Heidelberg, New York: Springer, 1996. [Google Scholar]
- 26.R Core Team. R: a language and environment for statistical computing Vienna, Austria: R Foundation for Statistical Computing, 2014. Available at: http://www.r-project.org/. [Google Scholar]
- 27.van der Laan MJ, Rose S. Targeted learning: causal inference for observational and experimental data New York: Springer, 2011. [Google Scholar]
- 28.Rubin DB, van der laan MJ. Statistical issues and limitations in personalized medicine research with clinical trials. Int J Biostat 2012;8:article 18. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Zhao Y, Zeng D, Rush A, Kosorok M. Estimating individual treatment rules using outcome weighted learning. J Am Stat Assoc 2012;107:1106–18. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Zhao YQ, Zeng D, Laber EB, Kosorok MR. New statistical learning methods for estimating optimal dynamic treatment regimes. J Am Stat Assoc 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Brock DW, Wikler D. Ethical challenges in long-term funding for HIV/AIDS. Health Aff 2009;280:1666–76. [DOI] [PubMed] [Google Scholar]
- 32.Macklin R, Cowan E. Given financial constraints, it would be unethical to divert antiretroviral drugs from treatment to prevention. Health Aff 2012;310:1537–44. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Singh JA. Antiretroviral resource allocation for HIV prevention. AIDS 2013;270:863–5. [DOI] [PubMed] [Google Scholar]