

Abstract
Objective: The Patient Reported Outcomes Measurement Information System (PROMIS) initiative developed an array of patient reported outcome (PRO) measures. To reduce the number of questions administered, PROMIS utilizes unidimensional item response theory and unidimensional computer adaptive testing (UCAT), which means a separate set of questions is administered for each measured trait. Multidimensional item response theory (MIRT) and multidimensional computer adaptive testing (MCAT) simultaneously assess correlated traits. The objective was to investigate the extent to which MCAT reduces patient burden relative to UCAT in the case of PROs.
Methods: One MIRT and 3 unidimensional item response theory models were developed using the related traits anxiety, depression, and anger. Using these models, MCAT and UCAT performance was compared with simulated individuals.
Results: Surprisingly, the root mean squared error for both methods increased with the number of items. These results were driven by large errors for individuals with low trait levels. A second analysis focused on individuals aligned with item content. For these individuals, both MCAT and UCAT accuracies improved with additional items. Furthermore, MCAT reduced the test length by 50%.
Discussion: For the PROMIS Emotional Distress banks, neither UCAT nor MCAT provided accurate estimates for individuals at low trait levels. Because the items in these banks were designed to detect clinical levels of distress, there is little information for individuals with low trait values. However, trait estimates for individuals targeted by the banks were accurate and MCAT asked substantially fewer questions.
Conclusion: By reducing the number of items administered, MCAT can allow clinicians and researchers to assess a wider range of PROs with less patient burden.
Keywords: precision medicine, patient reported outcomes, item response theory, MIRT, computer adaptive testing, MCAT
BACKGROUND
Precision medicine is an approach to medical treatment that proposes customization of health care, with medical decisions and therapeutic interventions tailored to the individual characteristics of the patient.1 An important component of precision medicine is integrating the patient’s perspective into treatment decisions. Patient reported outcomes (PROs) provide information about the patient's health condition that comes directly from the patient, without a physician’s interpretation. These can include subjective reports of symptoms as well as physical and social functioning and health-related quality of life (HRQL).2
The importance of the patient perspective has been prominent for at least 20 years.3–5 Discrepancies between patient and clinician reports of HRQL and health status have been established.6,7 Physicians often report fewer symptom8–11 and lower symptom severity12,13 than patients. There is also evidence that PROs can provide more information about toxicity and symptoms than physicians or adverse event reports.14,15 Studies have shown that, for some subjective symptoms (eg, in sexual function), clinician ratings are no better than chance in predicting PROs of the symptoms.16,17
When extending precision medicine to include the patient’s perspective, an additional goal is to minimize the patient’s burden when collecting the information. In order to obtain reliable scores, PRO measures typically ask patients to respond to a dozen or more questions related to each domain. A broad assessment involving many different outcomes could be very time-consuming for the patient. In addition, efforts to shorten measures often come at the cost of measurement precision, because shorter measures typically have lower reliability.18
One approach to dealing with this issue is to use item response theory (IRT) and computer adaptive testing (CAT). A measure can be dynamically personalized by utilizing the patient’s prior answers to select subsequent items. For example, an individual who responds “very much” to an initial depression item would next be given an item known to distinguish among high levels of depression, while another individual who responds “never” to the initial item would be given an item that distinguishes well among low levels of depression. By only administering questions targeted to the subject’s ability or trait level, testing times have, on average, been cut in half while overall test reliability has improved.19 The efficiencies long noted in educational testing and credentialing are equally applicable to the measurement of PROs. Patients can typically complete a PRO CAT in an average of 5 questions with reliability similar to a typical 15-to-25-item survey measure.20 With this lower level of overall burden, it becomes much easier to administer more comprehensive assessments to patients.
While the use of CAT is still relatively new to PRO measurement, a number of PRO CATs have been developed in recent years21–24 and are starting to be used in clinical practice.25 For example, Wagner et al.26 describe the use of CAT-based screening measures completed by cancer patients either in advance of their medical visit or while in the hospital waiting room, which were integrated into electronic health records and used to generate automatic notifications when symptom levels were severe.
The Patient Reported Outcomes Measurement Information System (PROMIS) is an initiative funded by the National Institutes of Health to improve assessment of self-reported symptoms and other HRQL27 domains across many chronic diseases.18 PROMIS has developed and validated 27 adult and 9 pediatric CATs across the broad domains of physical, mental, and social health. In practical application, the PROMIS CATs have shown greater reliability, fewer ceiling and floor effects, and more responsiveness to change than gold standard instruments.27
PROMIS is a good initial step toward efficient patient-specific assessment of PROs. However, PROMIS relies on unidimensional IRT (UIRT) and unidimensional CAT (UCAT), which means that there is an independent, separate set of questions administered for each measured trait. Yet there are correlations among many of the traits assessed by PROMIS. For example, depression, anxiety, and anger are closely related,28,29 and many questions that ascertain levels of depression can also provide information about levels of anxiety and anger. Multidimensional IRT (MIRT) provides flexible models for representing the interdependencies among items reflecting several correlated traits. A multidimensional CAT (MCAT)30–32 selects items from a pool such that the items selected maximize information provided on all of the correlated traits. Such a model can significantly reduce the number of items administered in measuring PROs, thereby substantially ameliorating the patient’s burden of answering many questions. Researchers have recently realized the value of the MCAT approach in health services.22,33,34
In the current study, we investigated the extent to which MCAT can reduce test length relative to UCAT in the case of PROs. We identified 3 related traits, depression, anxiety, and anger, and we developed an MIRT model for these traits using existing PROMIS item banks. We created our own 3-dimensional MCAT software to administer questions based on this MIRT model. Then, levels of depression, anxiety, and anger were simulated for 1000 individuals. We applied both the PROMIS UCAT software and our own MCAT software to these simulated individuals. Our results indicate that MCAT substantially decreased the number of questions required to ascertain the values of these 3 traits relative to the UCATs. Before proceeding, we briefly review IRT and CAT.
Item response theory
In IRT,35,36 we estimate a subject’s trait level from the responses he or she provides. Traits are hypothetical, or latent, constructs such as knowledge or quality in some domain. As an example, a trait can be calculus knowledge and the responses answers to calculus problems. Since a trait is not directly observable, responses are used as indicators of the trait.
The probability distribution of correctly answering a dichotomous item given the level of a trait is ordinarily modeled using the 2-parameter logistic evidence model:
| (1) |
where bj measures where the item is located on the latent trait continuum (eg, whether it is easy or difficult) and aj is a discrimination parameter measuring how sensitive the item is to differences in the latent trait. Once items are developed for an IRT model, the model is calibrated (ie, the values of the bj and aj parameters are learned) using a sample of individuals for whom the model is intended.35,36
For many PROs, we have a rating scale rather than a binary correct/incorrect answer. That is, the responses range, for example, between very dissatisfied and very satisfied. So an item represents a variable on an ordinal scale. The graded response model37 provides an extension of Equation (1) to the case of ordinal response options.
UIRT estimates a single trait by itself. Traits in a given domain can be related, which means that many items that ascertain the level of one trait can also provide information about the level of other traits. These relationships can be modeled using MIRT.38 An important step in developing an MIRT model is to determine the appropriate structure for the relationships among the multiple traits.39 One might apply a full MIRT model where each item loads onto each trait; however, often a more parsimonious structure is appropriate. Because the item banks for anxiety, depression, and anger were specifically created to reflect these 3 distinct traits, we adopted a model with a simple structure, in which each item has a path to only 1 latent variable, as illustrated in Figure 1. In this model, each set of items is treated as a unidimensional indicator of a single trait, and multidimensionality is represented through correlations among the latent variables. See30 for an extension of Equation (1) to MIRT.
Figure 1.

An MIRT model with simple structure.
Computer adaptive testing
Rather than administering all questions to all individuals, CAT40 improves test measurement quality and efficiency by administering an optimal set of items to each examinee. CAT selects items sequentially to minimize uncertainty regarding the person’s trait level, as indexed by the standard error (SE) of the estimate of θ. Commonly employed item selection criteria used in CAT include maximizing Fisher’s information (FI)41 and using Kullback-Leibler information.42 Chen et al.43 reviewed proposed alternative selection methods. Multidimensional CAT (MCAT) applies CAT using an MIRT model.30–32
OBJECTIVE
A simulation was used to explore the efficiency and accuracy of MCAT using the PROMIS Emotional Distress domain (anxiety, depression, and anger). The primary research question was whether the use of MCAT could achieve a comparable or better level of measurement accuracy with a smaller number of items relative to UCAT in the domain of PRO.
METHOD
Sample generation
The models used in this study were estimated using a representative sample of the general population of the United States, collected for development of the PROMIS item banks.27 The data were randomly split into halves, with 6263 cases used to calibrate the IRT models and 6262 cases used to generate simulated responses, as described below. Because the data collection involved a large number of items across 14 domains, it was not possible to collect responses to all items from all participants. Therefore, a structured missing data strategy was used, with some participants responding to all items from 2 domains and others responding to 7 items from each of the 14 domains. Multiple imputation of missing responses was used in the analysis.
Measure
The PROMIS item banks were developed through an extensive process, including input from subject matter experts as well as statistical item analyses.27 The domain of Emotional Distress consists of 3 traits: anxiety (29 items), depression (28 items), and anger (22 items). Respondents were asked to report the frequency of experiences during the past 7 days on a 5-point scale (1 = Never, 2 = Rarely, 3 = Sometimes, 4 = Often, 5 = Always).
CAT development
All items were calibrated for a 3-dimensional graded response MIRT model with simple structure. A preliminary analysis was conducted to confirm the structure of the MIRT model. We compared the simple structure model (Figure 2) to a full MIRT model where all items load on all traits. The 2 models produced similar fit to the data. All items loaded strongly on the intended trait, and there were no items with substantial cross-loading on nonintended traits. In the simple structure model, the 3 traits were highly correlated (anxiety-depression, r = 0.88; anxiety-anger, r = 0.78; depression-anger, r = 0.79). We also compared the 3-dimensional model to one with only a single latent trait and found substantially better fit for the 3-dimensional solution. Overall, these results support the use of the simple structure model with 3 correlated traits.
Figure 2.
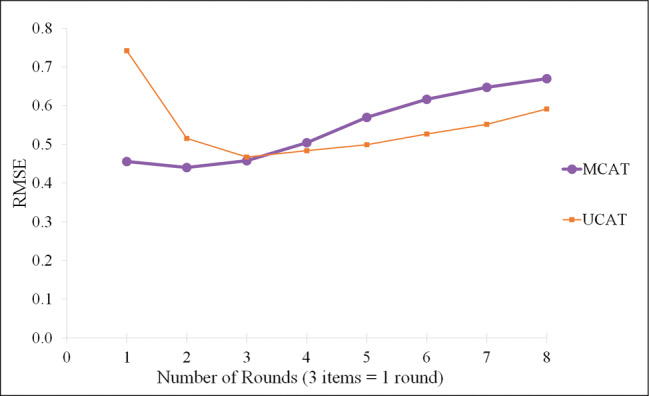
Root mean square error (RMSE) by round for all respondents.
IRT calibration was performed for the MIRT model and for a separate UIRT model for each of the 3 traits using only the items specific to each trait. All models were estimated using Markov Chain Monte Carlo estimation,44 as implemented in IRTPRO software. These 4 models were used to develop an MCAT and separate UCATs for each trait.
Software was developed to administer both unidimensional and multidimensional CATs. A Bayesian approach was used to estimate each examinee’s trait levels. Each UCAT starts with a normal prior distribution of θ, with a mean of 0 and standard deviation (SD) of 1. After each item is administered, the θ distribution is updated based on the examinee’s response. The mean of this posterior distribution is the expected a priori (EAP) estimate of θ, and the SD of the posterior distribution is the SE of θ, indicating the degree of uncertainty in that estimate.
The unidimensional CATs selected items to maximize the posterior-weighted Fisher information.45 Fisher information reflects the expected amount of information an item will provide about an estimated θ value. Posterior-weighted Fisher information is the average Fisher information taken across the individual’s posterior θ distribution.
The MCAT followed a similar procedure, adapted to deal with the multidimensional nature of the traits. The prior distribution of θ was specified as multivariate normal with mean 0 and SD 1 on each trait and correlations among the traits determined from the item calibration analysis. In the MIRT model, the Fisher information is a matrix. Segall32 recommended maximizing the determinant of the test information, which is the sum of the prior information, the information from previously administered items, and the information for the item being considered. We extended Segall’s approach by computing the posterior-weighted average of the determinant.
Simulation procedure
A second 3-dimensional MIRT model was then calibrated using the second half of the data. This model was used to simulate responses for all items for 1000 simulated respondents in the following way: 1000 trait levels were first sampled with replacement from an empirical distribution drawn from the general population (N = 6212). Then, for each sampled trait, item responses were randomly generated according to the conditional probability distribution of the responses obtained from the second 3-dimensional MIRT model.
Each simulated respondent was administered 4 CATs: MCAT for anxiety, depression, and anger; UCAT for anxiety; UCAT for depression; and UCAT for anger. All CATs followed the same basic procedure. First, an initial item was selected by the CAT algorithm. Next, a response to that item was provided using the simulated responses (discussed above). After each item, the CAT updated the posterior distribution of based on the individual’s response. This updated θ distribution was used by the CAT algorithm to select the next item.
In normal operation, a CAT will have a stopping rule, often when the SE falls below a threshold value (eg, PROMIS currently stops asking questions when SE < 0.3). However, for the simulation, we wanted to try out a variety of stopping rules. Therefore, we let the CAT administer 8 items for each trait (UCATs) or 24 items total (MCAT). We then applied a range of stopping rules to the simulated data. For example, to simulate the stopping rule SE < 0.30, we would take as the final estimate the EAP estimate when the SE first fell below 0.30 on all 3 traits, or after 24 items if the threshold was not reached. This process was repeated for cutoffs ranging from 0.20 to 0.40 in increments of 0.025. This range is centered on the threshold of 0.3 currently implemented in the unidimensional PROMIS CATs. An SE of 0.3 corresponds to a reliability coefficient of 0.91, which is considered a desirable level of measurement precision when scores are used to make decisions about individuals.46
Outcome measures
Two criteria were used to evaluate the performance of the CATs. Root mean squared error (RMSE) was computed as a measure of accuracy. Specifically, we calculated the squared difference between the EAP estimate and the actual θ on each trait, summed these across the 3 traits, then averaged across simulated individuals, and finally took the square root of the average. The second criterion was the efficiency of each CAT, operationalized as the average number of items required to reach the stopping rule cutoff (or the maximum number of items if the stopping rule was not reached).
RESULTS
We first measured the accuracy of each CAT relative to the number of items administered. The accuracy of MCAT was compared to the combined accuracy of all 3 UCATs. We defined a round to be the administration of 3 items, either 3 MCAT items or one item from each of the 3 UCATs. For each round, RMSE was computed. Figure 2 plots RMSE vs number of rounds.
Surprisingly, RMSE increased (indicating lower accuracy) as more items were administered. The MCAT initially had a lower RMSE. However, after the third round, the UCATs began to outperform the MCAT. Further probing of the data revealed that these results were driven by large estimation errors for individuals with low trait levels (θ < 0). The items in the PROMIS Emotional Distress banks all reflect moderate to high levels of anxiety, depression, and anger. Since the item content is not aligned with low trait levels, neither the MCAT nor UCATs provide accurate estimates for individuals with θ < 0. Indeed, Choi et al.47 showed that, for the Depression item bank, there is essentially no Fisher information in all 28 items combined (test information) for individuals with low theta values.
Still, it might seem odd that the estimates actually got worse with each question. An explanation follows. The initial estimate for all individuals is 0. As individuals with negative theta values answered more questions, they were increasingly drawn to the lowest possible theta value, because they repeatedly answered “Never.” So the error increased.
A second analysis focused on individuals who were aligned with the item content; that is, only cases with θ > 0 on all 3 traits (N = 406). After removing respondents with θ below 0, the results were in line with expectations (Figure 3). For both the MCAT and UCATs, accuracy improved (RMSE decreased) with additional items. Most of the gains occurred during the first 3 rounds (9 items), and asking more than 12 items yielded little additional improvement.
Figure 3.
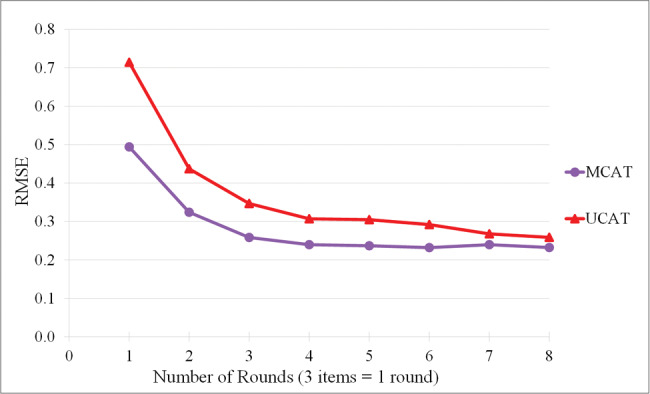
Root mean square error (RMSE) by round for respondents with θ > 0.
The MCAT consistently produced lower RMSE than the UCATs with the same number of items. In particular, the MCAT was very close to an RMSE of 0.3 (a commonly acceptable error in this domain) after just 2 rounds (6 question), whereas the UCATs did not reach that RMSE until 4 rounds (12 questions).
In order to examine the practical application of the CATs, we simulated a stopping rule, whereby the CATs would stop when the SE fell below a threshold on all 3 traits or after 24 items. By varying the threshold, we were able to model how the choice of a stopping rule impacted both accuracy (RMSE) and efficiency (average number of items needed to reach the SE threshold). For this analysis, we focused only on respondents who were aligned with the item content (ie, only those with θ > 0).
Table 1 shows the RMSE and average number of items for each threshold. Figure 4 plots RMSE versus the average number of questions. In general, MCAT produced a lower RMSE for a given average number of items than UCATs. These results are consistent with those discussed above concerning Figure 3.
Table 1.
MCAT vs UCAT: root mean square error (RMSE) and item count
| Cutoff | RMSE |
Mean Number of Items |
||
|---|---|---|---|---|
| MCAT | UCAT | MCAT | UCAT | |
| 0.200 | 0.232 | 0.289 | 24.000 | 19.921 |
| 0.225 | 0.233 | 0.294 | 23.860 | 17.712 |
| 0.250 | 0.239 | 0.284 | 20.956 | 15.202 |
| 0.275 | 0.243 | 0.287 | 16.293 | 12.754 |
| 0.300 | 0.241 | 0.317 | 13.224 | 10.596 |
| 0.325 | 0.244 | 0.365 | 10.796 | 8.870 |
| 0.350 | 0.257 | 0.377 | 9.232 | 8.384 |
| 0.375 | 0.278 | 0.389 | 7.850 | 7.914 |
| 0.400 | 0.299 | 0.424 | 6.860 | 6.934 |
N = 406. RMSE: root mean square error; MCAT: multidimensional computer adaptive test; UCAT: unidimensional computer adaptive test.
Figure 4.
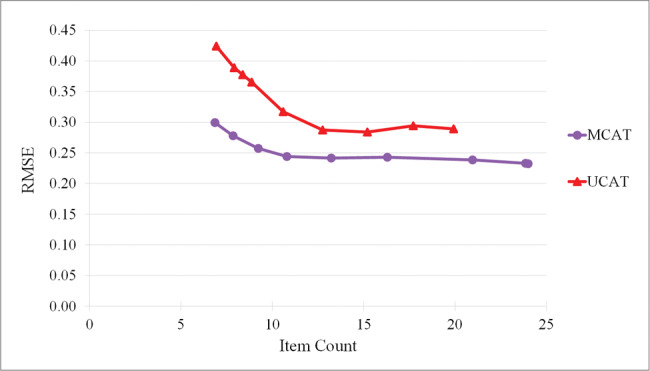
Root mean square error (RMSE) and item count at each threshold value.
The type of analysis we performed (varying the threshold) had the side benefit of informing us as to where to set the threshold to obtain a given level of accuracy. It is standard to set the threshold at 0.3 in the hope of obtaining an RMSE about equal to 0.3. However, in the case of MCAT, a threshold of 0.3 realizes a RMSE equal to 0.241, and we can set the threshold as high as 0.4 to achieve an RMSE of 0.3. This analysis informs us that, for these item banks, we can further reduce patient burden by setting the threshold at 0.4, as long as our desired RMSE is 0.3. The result is that, on average, we need to ask only 6.9 questions to ascertain the value of all 3 traits. On the other hand, if we use the UCATs with a threshold of 0.3, we will ask about 10.6 questions on average, but not achieve our goal of having RMSE < 0.3. If we interpolate, a cutoff of ∼0.29 on the UCATs would be expected to yield an RMSE < 0.3 with 11.8 items on average.
DISCUSSION
Including the patient’s perspective in medical records is essential to fully capture symptoms, level of functioning, and quality of life.2 However, a comprehensive assessment of PROs places a burden on patients to complete potentially lengthy questionnaires. CAT has been shown to effectively reduce the length of measures without sacrificing measurement precision.20
The results of the current study demonstrate that efficiency of PRO assessment can be further enhanced by simultaneously assessing several related traits. An MCAT measuring emotional distress (anxiety, depression, and anger) was found to reduce test length by 42% (ie, 7 MCAT items vs 12 UCAT items).
Integration of PROs into medical decision-making can be achieved only if patients are willing and able to complete the measures. A comprehensive assessment of PROs with traditional measures (typically 12–25 items per outcome) will require considerable time and effort. In contrast, Gershon and Cook20 estimated that unidimensional CATs could assess 5–10 distinct PROs in 5–10 min. Our results suggest that by using MCAT, this time could be cut down by about 40%, requiring only 3–6 min. This reduction in assessment time would substantially lessen the burden on patients and is likely to improve response rates.48
PRO assessments that can be completed in just a few minutes also open up the possibility for innovative assessment strategies, such as experience sampling or diary methods, that gather dynamic information about fluctuations in outcomes over time.49 For example, PRO measures that are administered at regular intervals following treatment can provide valuable information regarding the trajectory of patient recovery.50
An important area for future research is to develop strategies for improving CAT efficiency for individuals whose trait levels are not aligned with the item banks. For the PROMIS Emotional Distress bank (depression, anxiety, anger), neither UCAT nor MCAT provided accurate trait estimates for individuals at low trait levels. Like most existing measures in this domain, the content of the items reflects indicators of moderate to severe distress,23 and therefore the bank provides less information about individuals with low distress. Importantly, in many clinical settings where these measures would be used, the primary goal is to identify individuals in need of intervention, therefore making fine distinctions among those with low distress is not a concern.
Currently, the PROMIS implementation of the UCAT stops when either the SE falls below 0.3 or 12 items have been administered for each trait. Since the SE threshold is never reached for individuals with low trait levels, these individual must answer 36 questions when assessing all 3 traits. The use of MCAT would not ameliorate this problem, since the threshold would still not be reached. Item banks for other PROs may suffer from this same difficulty, in that they strive to learn the degree of presence of a condition. If the system could learn early that further item administration is unlikely to reduce SE, it could stop before administering unnecessary items. Choi et al.47 developed a strategy that checks the expected value of the reduction in SE for each item. If the maximum value of this reduction is sufficiently small, the CAT stops. Future research could combine this strategy with MCAT to further reduce patient burden in the case of PROs.
Creating an MCAT involves a number of design choices that should be further examined in order to determine the optimal configuration for enhancing accuracy and reducing patient burden. For the Emotional Distress bank, the data were fit well by a simple structure model, where subsets of items each loaded on a single unidimensional trait. In other domains, the structure of relationships might be more complex. For example, physical functioning might be better represented by a bifactor model, which provides a global trait score while also accounting for multiple subdomains (eg, upper-, central-, and lower-extremity function).51 The need to balance content across such subdomains when selecting items may need to be incorporated into future MCAT work.52
Funding
This work was supported by National Library of Medicine grants R01LM011962 and R01LM011663.
Competing interest
The authors have no competing interests to declare.
Contributors
Conceived the experiments: SM, MB, RN. Designed the simulations: SM. Wrote the CAT programs: MB. Ran the simulations: MB, ML. Designed and conducted the evaluation: SM, RN. Wrote the paper: RN, SM, ML. All authors read and approved the final manuscript.
REFERENCES
- 1. National Research Council (US) Committee on a Framework for Developing a New Taxonomy of Disease. Toward Precision Medicine: Building a Knowledge Network for Biomedical Research and a New Taxonomy of Disease. Washington, DC: National Academies Press; 2011. http://www.ncbi.nlm.nih.gov/books/NBK91503/. Accessed June 23, 2016. [PubMed] [Google Scholar]
- 2. Snyder CF, Jensen RE, Segal JB et al. Patient-reported outcomes (PROs): putting the patient perspective in patient-centered outcomes research. Med Care. 2013;51:S73–79. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3. Cella DF. Quality of life: the concept. J Palliat Care. 1992;8:8–13. [PubMed] [Google Scholar]
- 4. Donovan K, Sanson-Fisher RQ, Redman S. Measuring quality of life in cancer patients. J Clin Oncol. 1989;7:959–68. [DOI] [PubMed] [Google Scholar]
- 5. Cella DF, Tulsky DS. Quality of life in cancer: definition, purpose, and method of measurement. Cancer Invest. 1993;11:327–36. [DOI] [PubMed] [Google Scholar]
- 6. Cella D, Wagner L, Cashy J et al. Should health-related quality of life be measured in cancer symptom management clinical trials? Lessons learned using the functional assessment of cancer therapy. J Natl Cancer Inst Monogr. 2007;37:53–60. [DOI] [PubMed] [Google Scholar]
- 7. Sneeuw KCA, Sprangers MAG, Aaronson NK. The role of health care providers and significant others in evaluating the quality of life of patients with chronic disease. J Clin Epidemiol. 2002;55:1130–43. [DOI] [PubMed] [Google Scholar]
- 8. Fromme EK, Eilers KM, Mori M et al. How accurate is clinician reporting of chemotherapy adverse effects? A comparison with patient-reported symptoms from the Quality-of-Life Questionnaire C30. J Clin Oncol Off J Am Soc Clin Oncol. 2004;22:3485–90. [DOI] [PubMed] [Google Scholar]
- 9. Grossman SA, Sheidler VR, Swedeen K et al. Correlation of patient and caregiver ratings of cancer pain. J Pain Symptom Manage. 1991;6:53–57. [DOI] [PubMed] [Google Scholar]
- 10. Litwin MS, Lubeck DP, Henning JM et al. Differences in urologist and patient assessments of health related quality of life in men with prostate cancer: Results of the CaPSURE database. J Urol. 1998;159:1988–92. [DOI] [PubMed] [Google Scholar]
- 11. Vogelzang NJ, Breitbart W, Cella D et al. Patient, caregiver, and oncologist perceptions of cancer-related fatigue: results of a tripart assessment survey. The Fatigue Coalition. Semin Hematol. 1997;34:4–12. [PubMed] [Google Scholar]
- 12. Huschka M, Burger K. Does QOL provide the same information as toxicity data? Curr Probl Cancer. 2006;30:244–54. [DOI] [PubMed] [Google Scholar]
- 13. Patrick DL, Curtis JR, Engelberg RA et al. Measuring and improving the quality of dying and death. Ann Intern Med. 2003;139:410–15. [DOI] [PubMed] [Google Scholar]
- 14. Parliament MB, Danjoux CE, Clayton T. Is cancer treatment toxicity accurately reported? Int J Radiat Oncol Biol Phys. 1985;11:603–08. [DOI] [PubMed] [Google Scholar]
- 15. Varricchio CG, Sloan JA. The need for and characteristics of randomized phase III trials to evaluate symptom management in patients with cancer. J Natl Cancer Inst. 2002;94:1184–85. [DOI] [PubMed] [Google Scholar]
- 16. Bruner DW, Scott C, McGowan D et al. Factors influencing sexual outcomes in prostate cancer (PC) patients enrolled on radiation therapy oncology group (RTOG) studies 90–20 and 94–08. Qual Life Res. 1998;7:575–76. [Google Scholar]
- 17. Watkins-Bruner D, Scott C, Lawton C et al. RTOG’s first quality of life study: RTOG 90–20: a phase II trial of external beam radiation with etanidazole for locally advanced prostate cancer. Int J Radiat Oncol Biol Phys. 1995;33:901–06. [DOI] [PubMed] [Google Scholar]
- 18. Crocker L, Algina J. Introduction to Classical and Modern Test Theory. Orlando, FL: Holt, Rinehart and Winston; 1986. http://eric.ed.gov/?id=ED312281. [Google Scholar]
- 19. Sands WA, Waters BK. Introduction to ASVAB and CAT. In: Sands WA, Waters BK, McBride JR, eds. Computerized Adaptive Testing: From Inquiry to Operation. Washington, DC: American Psychological Association; 1997:3–9. [Google Scholar]
- 20. Gershon RC, Cook K. Use of computer adaptive testing in the development of machine learning algorithms. Pain Med Malden Mass. 2011;12:1450–52. [DOI] [PubMed] [Google Scholar]
- 21. Gibbons RD, Weiss DJ, Pilkonis PA et al. Development of a Computerized Adaptive Test for Depression. Arch Gen Psychiatry. 2012;69:1104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Haley SM, Ni P, Dumas HM et al. Measuring global physical health in children with cerebral palsy: illustration of a multidimensional bi-factor model and computerized adaptive testing. Qual Life Res. 2009;18:359–70. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Gibbons C, Bower P, Lovell K et al. Electronic Quality of Life Assessment Using Computer-Adaptive Testing. J Med Internet Res. 2016;18:e240. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Amtmann D, Cook KF, Jensen MP et al. Development of a PROMIS item bank to measure pain interference. PAIN. 2010;150:173–82. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25. Rose M, Bezjak A. Logistics of collecting patient-reported outcomes (PROs) in clinical practice: an overview and practical examples. Qual Life Res. 2009;18:125–36. [DOI] [PubMed] [Google Scholar]
- 26. Wagner LI, Schink J, Bass M et al. Bringing PROMIS to practice: brief and precise symptom screening in ambulatory cancer care. Cancer. 2015;121:927–34. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27. Cella D, Riley W, Stone A et al. Initial adult health item banks and first wave testing of the Patient-Reported Outcomes Measurement Information System (PROMIS) network: 2005–2008. J Clin Epidemiol. 2010;63:1179–94. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Pilkonis PA, Choi SW, Reise SP et al. Item banks for measuring emotional distress from the Patient-Reported Outcomes Measurement Information System (PROMIS): Depression, anxiety, and anger. Assessment. 2011;18: 263–83. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. Gignac GE. Multi-factor modeling in individual differences research: some recommendations and suggestions. Personal Individ Differ. 2007;42:37–48. [Google Scholar]
- 30. Mulder J, van der Linden WJ. Multidimensional adaptive testing with optimal design criteria for item selection. Psychometrika. 2009;74:273–96. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31. Luecht RM. Multidimensional computerized adaptive testing in a certification or licensure context. Appl Psychol Meas. 1996;20:389–404. [Google Scholar]
- 32. Segall DO. Multidimensional adaptive testing. Psychometrika. 1996;61:331–54. [Google Scholar]
- 33. Gibbons RD, Weiss DJ, Kupfer DJ et al. Using computerized adaptive testing to reduce the burden of mental health assessment. Psychiatr Serv Wash DC. 2008;59:361–68. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Mulcahey MJ, Haley SM, Duffy T et al. Measuring physical functioning in children with spinal impairments with computerized adaptive testing: J Pediatr Orthop. 2008;28:330–35. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35. Embretson SE, Reise SP. Item Response Theory for Psychologists. Mahwah, NJ: Lawrence Erlbaum Associates Publishers; 2000. [Google Scholar]
- 36. Hambleton RK, Swaminathan H, Jane H. Fundamentals of Item Response Theory. Thousand Oaks, CA: Sage Publications; 1991. [Google Scholar]
- 37. Samejima F. Estimation of latent ability using a response pattern of graded scores. Psychometric Monogr. 1969;17:98. [Google Scholar]
- 38. Reckase MD. Multidimensional Item Response Theory. New York, NY: Springer; 2009. [Google Scholar]
- 39. Brunner M, Nagy G, Wilhelm O. A tutorial on hierarchically structured constructs. J Pers. 2012;80:796–846. [DOI] [PubMed] [Google Scholar]
- 40. Wainer H, Dorans NJ, Green BF et al. Computerized Adaptive Testing: A Primer. Hillsdale, NJ: Lawrence Erlbaum Associates; 1990. [Google Scholar]
- 41. Veerkamp WJJ, Berger MPF. Some New Item Selection Criteria for Adaptive Testing. J Educ Behav Stat. 1997;22:203. [Google Scholar]
- 42. Chang H-H, Ying Z. A Global Information Approach to Computerized Adaptive Testing. Appl Psychol Meas. 1996;20:213–29. [Google Scholar]
- 43. Chen S-Y, Ankenmann RD, Chang H-H. A comparison of item selection rules at the early stages of computerized adaptive testing. Appl Psychol Meas. 2000;24:241–55. [Google Scholar]
- 44. Patz RJ, Junker BW. Applications and extensions of MCMC in IRT: multiple item types, missing data, and rated responses. J Educ Behav Stat. 1999;24:342–66. [Google Scholar]
- 45. van der Linden WJ, Pashley PJ. Item selection and ability estimation in adaptive testing. In: van der Linden WJ, Glas CAW, eds. Elements of Adaptive Testing. New York, NY: Springer; 2009:3–30. [Google Scholar]
- 46. Nunnally JC, Bernstein IH. Psychometric Theory. New York, NY: McGraw-Hill; 1995. [Google Scholar]
- 47. Choi SW, Grady MW, Dodd BG. A new stopping rule for computerized adaptive testing. Educ Psychol Meas. 2010;70:1–17. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48. Rolstad S, Adler J, Rydén A. Response burden and questionnaire length: is shorter better? A review and meta-analysis. Value Health. 2011;14:1101–08. [DOI] [PubMed] [Google Scholar]
- 49. Schneider S, Stone AA. Ambulatory and diary methods can facilitate the measurement of patient-reported outcomes. Qual Life Res. 2015;25:497–506. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50. Baumhauer JF, Bozic KJ. Value-based healthcare: patient-reported outcomes in clinical decision making. Clin Orthop. 2016;474:1375–78. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51. Rose M, Bjorner JB, Gandek B et al. The PROMIS Physical Function item bank was calibrated to a standardized metric and shown to improve measurement efficiency. J Clin Epidemiol. 2014;67:516–26. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52. Veldkamp BP, van der Linden WJ. Multidimensional adaptive testing with constraints on test content. Psychometrika. 2002;67:575–88. [Google Scholar]