

Abstract
Everyday speech perception is challenged by external acoustic interferences that hinder verbal communication. Here, we directly compared how different levels of the auditory system (brainstem vs. cortex) code speech and how their neural representations are affected by two acoustic stressors: noise and reverberation. We recorded multichannel (64 ch) brainstem frequency-following responses (FFRs) and cortical event-related potentials (ERPs) simultaneously in normal hearing individuals to speech sounds presented in mild and moderate levels of noise and reverb. We matched signal-to-noise and direct-to- reverberant ratios to equate the severity between classes of interference. Electrode recordings were parsed into source waveforms to assess the relative contribution of region-specific brain areas [i.e., brainstem (BS), primary auditory cortex (A1), inferior frontal gyrus (IFG)]. Results showed that reverberation was less detrimental to (and in some cases facilitated) the neural encoding of speech compared to additive noise. Inter-regional correlations revealed associations between BS and A1 responses, suggesting subcortical speech representations influence higher auditory-cortical areas. Functional connectivity analyses further showed that directed signaling toward A1 in both feedforward cortico-collicular (BS→A1) and feedback cortico-cortical (IFG→A1) pathways were strong predictors of degraded speech perception and differentiated “good” vs. “poor” perceivers. Our findings demonstrate a functional interplay within the brain’s speech network that depends on the form and severity of acoustic interference. We infer that in addition to the quality of neural representations within individual brain regions, listeners’ success at the “cocktail party” is modulated based on how information is transferred among subcortical and cortical hubs of the auditory-linguistic network.
Keywords: Auditory scene analysis, distributed source analysis, event-related potentials (ERPs), frequency-following response (FFR), speech processing, functional connectivity
INTRODUCTION
In natural listening environments, noise and reverberation hinder the successful extraction of speech information (for review, see White-Schwoch and Kraus, 2017). Although both are acoustic interferences, each has a distinct effect on speech signals (for review, see Bidelman, 2017; Helfer and Wilber, 1990; Nabelek and Dagenais, 1986). Noise is caused by the addition of external competing sound(s) that masks target speech. Contrastively, reverberation is the persistence of reflected acoustic energy in the sound field caused by internal room acoustics (Kinsler et al., 2000). Reverberation produces an overlap between direct and indirect sounds that “smears” a signal’s spectrum. Natural reverberation also acts to low-pass filter speech compared to the overall flattening of modulations produced by noise. Conveniently, the degree of noise and reverberation superimposed on a target signal can be quantified by similar metrics. For noise, the relative contribution of “noise” and “signal” are quantified via the signal-to- noise ratio (SNR). Similarly, the proportions of acoustic energy attributable to signal and reverberant energy are characterized (in dB) by the direct-to-reverberant energy ratio (D/R), or less commonly, “wet- to-dry” ratio (von Békésy, 1938; Zahorik, 2002).
While both acoustic stressors hinder intelligibility, behavioral studies reveal that human listeners show a differential sensitivity when perceiving signals in noise vs. reverberation (Larsen et al., 2008; McShefferty et al., 2015; Zahorik, 2002). That is, even when the relative intensities between signal and interference are matched in severity (i.e., SNR≈D/R), noise and reverberation can impact speech perception in different manners. While each interference reduces speech understanding by ~15–20%, vowel confusion patterns can differ under these two acoustic backdrops (Nabelek and Dagenais, 1986). Interestingly, reverb also induces less listening effort than noise during speech comprehension, even at similar levels of behavioral performance (Picou et al., 2016). This suggests that while there is a comparable tax on speech intelligibility, noise and reverberation might uniquely impact the underlying neural representations for speech (cf. White-Schwoch and Kraus, 2017). To our knowledge, this possibility has not been formally tested.
It is now well-established that speech-in-noise (SIN) understanding is determined by more than audibility or peripheral hearing status (Middelweerd et al., 1990; Song et al., 2011) (but see Humes and Roberts, 1990). The fact that SIN performance is not reliably predicted from the audiogram (Killion and Niquette, 2000) and varies among even normal-hearing listeners (Song et al., 2011) has led to the notion that central brain mechanisms play a critical role in supporting successful cocktail listening (e.g., Alain et al., 2014; Bidelman and Howell, 2016; Billings et al., 2009; Billings et al., 2010; Billings et al., 2013; Parbery-Clark et al., 2011; Song et al., 2011). In this regard, electrophysiological studies have been important in elucidating these central factors of speech sound processing.
The brain’s neuroelectric response to speech reflects an aggregate of activity generated from both brainstem and cortical structures. By exploiting properties of each response (e.g., spectral bandwidth), one can isolate their contributions within the scalp EEG and examine sound encoding within various structures of the auditory hierarchy (Bidelman et al., 2013). The cortical ERPs are composed of several “waves” (e.g., P1-N1-P2), reflecting activation of auditory thalamus, cortex, and associative areas (Picton et al., 1999). ERPs are sensitive to the acoustic features of speech (Agung et al., 2006; Chang et al., 2010; Kraus and Cheour, 2000; Sharma and Dorman, 1999) and correlate with listeners’ perceptual skills (Bidelman et al., 2014b; Ross and Tremblay, 2009; Tremblay et al., 2001). The subcortical component, or frequency-following response (FFR), is a sustained potential emitted dominantly from the upper brainstem that closely mirrors acoustic stimuli with high fidelity (Bidelman, 2018; Krishnan, 2007; Skoe and Kraus, 2010). FFR activity similarly correlates with listeners’ SIN perception (Anderson et al., 2010; Parbery-Clark et al., 2009a; Song et al., 2011). Yet, few studies have examined FFRs to reverberant speech (Bidelman and Krishnan, 2010; Fujihira and Shiraishi, 2015), and we unaware of any directly contrasting the effects of noise and reverb on speech FFRs. Moreover, while a number of studies have investigated the independent contributions of brainstem (e.g., Bidelman, 2016; Bidelman and Krishnan, 2010; Billings et al., 2013; Krishnan et al., 2010; Parbery-Clark et al., 2009a; Song et al., 2011) and cortical neurophysiology (e.g., Alain et al., 2014; Bidelman and Howell, 2016; Billings et al., 2010; Billings et al., 2013; Shtyrov et al., 1998) to degraded speech processing, examining these functional levels simultaneously (within individual listeners) would offer a more comprehensive, systems-level characterization of the biological mechanisms underlying cocktail party listening in different acoustic scenarios and possible interplay between stages of the neuroaxis.
To this end, our recent studies have championed the use of concurrent FFR-ERPs recordings to examine hierarchical auditory processing (e.g., Bidelman, 2015; Bidelman and Alain, 2015b; Bidelman et al., 2013; Bidelman et al., 2014b) (see also Bellier et al., 2015; Slugocki et al., 2017). Dual FFR-ERP paradigms have provided important insight into how lower vs. higher tiers of the neuroaxis code complex sounds and interact during early perception when object-based representations of speech are still in their nascent stages (e.g., Bidelman et al., 2013). Translational applications have further shown how brainstem vs. cortical function is uniquely strengthened by plasticity (Bidelman and Alain, 2015a; Bidelman et al., 2014a; Musacchia et al., 2008), are differentially compromised by hearing loss (Bidelman et al., 2014b), and are altered in neurocognitive disorders (Bidelman et al., 2017). This approach emphasizes a growing body of work that advocates speech processing as an integrative and dynamic network (Kraus and White-Schwoch, 2015; Obleser et al., 2007; Scott et al., 2009) which includes possible interactions and/or signal transformations between brainstem-cortex (Gao and Suga, 1998; Suga et al., 2002) and auditory-linguistic brain areas downstream (Du et al., 2014). Given that early brainstem-cortical and later auditory-linguistic interplay can presumably vary on an individual basis, we hypothesized these individual differences might modulate cocktail party perception. Here, we exploited dual FFR-ERPs to further investigate the neural encoding of impoverished (noisy and reverberant) speech and better define the functional connectivity between subcortical and cortical hubs of the auditory system.
The aims of the present study were thus twofold. First, we directly compared how subcortical and cortical levels of the auditory system encode different forms of degraded speech information. While previous reports have investigated relations between brainstem and cortical auditory processing (e.g., Bidelman et al., 2013; Bidelman et al., 2017; Krishnan et al., 2012; Musacchia et al., 2008; Slugocki et al., 2017), studies have focused exclusively on scalp (electrode-level) recordings and therefore, can only infer contributions of sub- and neo-cortex from volume conducted mixtures of EEG signals. Here, source analysis of brainstem FFRs and cortical ERPs allowed us to parse region-specific activity with higher granularity and more definitively reveal how neural processing within each tier of the neuroaxis coordinate during speech processing. Functional connectivity analysis evaluated the directed, causal signaling between brainstem and cortical regions and how inter-regional neural communication might predict listeners’ speech perception skills. We also measured source FFR/ERPs elicited by noisy and reverberant speech. This allowed us to directly assess how neural speech representations are affected by different acoustic stressors common to the auditory scene. To anticipate, our data reveal that degraded speech perception is governed by intra- and inter- regional brainstem-cortical activity including important cortico-collicular (brainstem-cortical) and cortico- cortical (frontotemporal) signaling.
METHODS
Participants
Eleven adults (age: 24.7 ± 2.7 years) participated in the experiment. All had obtained a similar level of formal education (at least an undergraduate degree), and were monolingual speakers of American English. Musical training is known to enhance auditory evoked responses (e.g., Bidelman et al., 2011; Musacchia et al., 2008; Zendel and Alain, 2009) and improve degraded speech-listening skills (Bidelman and Krishnan, 2010; Parbery-Clark et al., 2009a; Parbery-Clark et al., 2009b). Hence, all participants were required to have minimal formal musical training (1.3 ± 1.8 years) and none within the past 5 years. Audiometric screening confirmed normal hearing (i.e., thresholds < 25 dB HL) at octave frequencies (250–8000 Hz). All participants reported no history of neuropsychiatric disorders. Participants gave written informed consent in compliance with a protocol approved by the University of Memphis Institutional Review Board and were compensated monetarily for their time.
Stimuli
Brainstem and cortical auditory ERPs were elicited by a 300 ms/vCv/speech token/ama/(Bidelman and Howell, 2016) (Figure 1). The pitch prosody fell gradually over the token’s duration (F0= 120 Hz to 88 Hz). Vowel formant frequencies (F1–F3) were 830, 1200, and 2760 Hz, respectively.
Figure 1. Speech stimuli.

Example time waveforms and spectrograms for the speech stimulus/ama/presented in clean (no noise), noise-degraded (+5 dB SNR), and reverberant (+5 dB D/R) tokens.
Noise-degraded speech
In addition to this “clean” stimulus (SNR = ∞ dB), noise-degraded stimuli were created by adding four-talker babble noise (Killion et al., 2004) to the clean token at SNRs of +10 and +5 dB. SNR was manipulated by changing the level of the masker rather than the signal to ensure SNR was inversely correlated with overall sound level (Binder et al., 2004). To mimic real-world acoustic scenarios, babble was presented continuously so that it was not time-locked to the stimulus presentation (e.g., Alain et al., 2012).
Reverberant speech
Reverberant speech was simulated via convolution reverb. We used the XFX1 (v1) reverb plugin in Sound Forge 9 (Sony Inc.) with the “Rich Hall” preset to simulate acoustics of a realistic room (RT60: 500 ms; early reflection style: 16 ms; predelay: 30 ms; filter attenuation: 20– 12000 Hz; early reflection attenuation: −20 dB). We then exported the “wet” (reverberant) portion of the signal (i.e., 0% mix of the “dry” speech) to extract only the “interference” component of the reverberant signal. Effectively, this resulted in a simulation as if the speech was produced in a reverberant environment but with only indirect (reflected) energy containing no direct sound. We then mixed the original (clean) speech token with this reverberation to create reverb-degraded speech at mild and medium direct-to-reverberant ratios (D/R) of +10 and +5 dB, respectively. Importantly, this approach allowed us to precisely control and equate the overall level of severity (i.e., SNR and D/R) between noise- and reverb-degraded stimuli. This avoided potential confounds of having different degrees of acoustic “noisiness” (i.e., signal figure-ground quality) between noise and reverb conditions and allowed us to focus on differences in sound quality produced by each acoustic stressor1. Acoustic waveform and spectrograms are illustrated for the clean, +5dB SNR noise-degraded, and +5 dB D/R reverberant speech in Figure 1.
Procedure
Listeners heard 2000 trials of each condition (passive listening) presented with fixed, rarefaction polarity using a jittered interstimulus interval (400–700 ms; 20-ms steps, uniform distribution). Stimulus presentation was controlled by MATLAB® 2013b (The MathWorks) routed to a TDT RP2 interface (Tucker-Davis Technologies). Tokens were delivered binaurally at 81 dB SPL through ER-30 insert earphones (Etymotic Research). ER-30 earphones feature an extended acoustic tubing (20 ft) that allowed us to place their transducers outside the testing booth. Spatially separating the transducer from participants avoided the possibility of electromagnetic stimulus artifact from contaminating neural responses (Aiken and Picton, 2008; Campbell et al., 2012). The low-pass frequency response of the headphone apparatus was corrected with a dual channel 15 band graphical equalizer (dbx EQ Model 215s; Harman) to achieve a flat frequency response through 4 kHz. Stimulus level was calibrated using a Larson–Davis SPL meter (Model LxT) measured in a 2-cc coupler (IEC 60126). The entire experimental procedure, including electrophysiological and behavioral testing (described below) took ~2 hrs.
Behavioral speech-in-noise task
Before EEG testing, we measured listeners’ speech reception thresholds in noise using the QuickSIN test (Killion et al., 2004). Participants were presented two lists of six sentences with five key words per sentence embedded in four-talker babble noise. Sentences were presented at 70 dB SPL via insert earphones (bilaterally) using pre-recorded signal-to-noise ratios (SNRs) that decreased in 5 dB steps from 25 dB (very easy) to 0 dB (very difficult). Listeners scored one point for each key word correctly repeated. “SNR loss” (computed in dB) was determined as the SNR required to correctly identify 50% of the key words (Killion et al., 2004). We averaged SNR loss from two lists for each listener. As there is no reverb analog to the QuickSIN, this test functioned as a (normative) behavioral assay of degraded speech listening skills.
Electrophysiological recordings
EEG acquisition and preprocessing
Electrophysiological recording procedures were identical to our previous report (Bidelman and Howell, 2016). Neuroelectric activity was recorded from 64 sintered Ag/AgCl electrodes at standard 10-10 scalp locations (Oostenveld and Praamstra, 2001). EEGs were digitized at a sampling rate of 5000 Hz (SynAmps RT amplifiers; Compumedics Neuroscan) using an online passband of DC-2500 Hz. Electrodes placed on the outer canthi of the eyes and the superior and inferior orbit were used to monitor ocular activity. During online acquisition, all electrodes were referenced to an additional sensor placed ~1 cm posterior to Cz. Data were re-referenced off-line to a common average reference for subsequent analyses. Contact impedances were maintained ≤ 5 kΩ.
Subsequent pre-processing was performed in Curry 7 (Compumedics Neuroscan). Ocular artifacts (saccades and blinks) were first corrected in the continuous EEG using a principal component analysis (PCA) (Picton et al., 2000). Cleaned EEGs were then epoched (−200–550 ms), baseline-corrected to the pre-stimulus period, and averaged in the time domain to obtain compound evoked responses (containing both brainstem and cortical activity) for each stimulus condition per participant.
Source waveform derivations
Scalp potentials (sensor-level recordings) were transformed to source space using discrete inverse models. Fitting was carried out in BESA® Research v6.1 (BESA, GmbH). We used a four-shell volume conductor head model (Berg and Scherg, 1994; Sarvas, 1987) with BESA default settings, i.e., relative conductivities (1/Ωm) of 0.33, 0.33, 0.0042, and 1 for the head, scalp, skull, and cerebrospinal fluid, respectively, and sizes of 85 mm (radius), 6 mm (thickness), 7 mm (thickness), and 1 mm (thickness) (Herdman et al., 2002; Picton et al., 1999). From grand averaged responses, we seeded dipoles in prominent hubs of the speech network, including brainstem (BS), bilateral primary auditory cortex (A1), and bilateral inferior frontal gyrus (IFG). Although a simplistic speech circuit, these three regions of interest (ROIs) have been shown to predict SIN processing in several neuroimaging studies (Adank et al., 2012; Bidelman and Krishnan, 2010; Bidelman and Dexter, 2015; Bidelman and Howell, 2016; Binder et al., 2004; Coffey et al., 2017; Du et al., 2014; Scott and McGettigan, 2013; Song et al., 2011) and allowed specific hypothesis testing of the relation between auditory brainstem-cortical connectivity and degraded speech perception. Sparse source models have also been shown to better resolve subcortical sources in M/EEG than denser dipole configurations (Krishnaswamy et al., 2017), further justifying a restricted dipole count. While EEG inverse solutions are non-unique, we have confirmed the biological plausibility of this brainstem-cortical configuration (clean spatial separation, spatiotemporal dynamics) using identical modeling assumptions in our recent source imaging and computational studies (Bidelman, 2018). Overall, the model provided an excellent fit to the grand averaged data across stimuli and listeners (goodness of fit: 82 ± 4.5%). This dipole configuration was then used to guide source derivations at the single-subject level.
To extract each individual’s source waveforms within each ROI, we transformed listener’s scalp recordings into source-level responses using a virtual source montage (Scherg et al., 2002). This digital re-montaging applies a spatial filter to all electrodes (defined by the foci of our dipole configuration). Relative weights are then optimized to image activity within each brain ROI while suppressing overlapping activity stemming from other active brain regions (for details, see Scherg and Ebersole, 1994; Scherg et al., 2002). This allowed us to reduce each listener’s electrode recordings (64-channels) to 5 source channels, each of which estimated activity generated within a single ROI (i.e., left/right IFG, left/right A1, BS). For each participant, the model was held fixed and was used as a spatial filter to derive their source waveforms (Zendel and Alain, 2014), reflecting the neuronal current (in units nAm) as seen within each anatomical ROI. Source waveforms were then bandpass filtered into high- (80 – 1500 Hz) and low- (0.5 –20 Hz) frequency bands to isolate the periodic brainstem FFR vs. slower cortical ERP waves from each listeners’ compound evoked potential (Bidelman et al., 2013; Musacchia et al., 2008). Comparing FFR and ERP source waveforms allowed us to assess the relative contribution of brainstem and cortical generators to degraded speech processing. Identical model assumptions for the inverse solution (e.g., volume conductor, conductivities) were used for brainstem and cortical ROIs waveforms; only the anatomical location of the dipole differed. Importantly, EEG provides more consistent SNR for both deep (brainstem) and superficial sources (cortex) and between focal and distributed models compared to other neuroimaging modalities (e.g., MEG; Goldenholz et al., 2009).
FFR/ERP source waveform quantification
FFRs and ERP source waveforms were quantified based on their amplitude (FFR: RMS amplitude; ERP: N1 amplitude). Previous studies have shown correspondence between these measures and degraded speech perception (Bidelman and Howell, 2016; Billings et al., 2013; Parbery-Clark et al., 2011). The cortical N1 was taken as the negative-going deflection between 100 and 150 ms based on the expected noise-related delay in the ERPs (Bidelman and Howell, 2016; Billings et al., 2009) after factoring in the acoustic delay of the headphones based on the speed of sound in air [17.8 ms = (20 ft)/(1125 ft/s)].
Distributed source imaging (CLARA)
We used Classical Low Resolution Electromagnetic Tomography Analysis Recursively Applied (CLARA) [BESA (v6.1)] to estimate the neuronal current density underlying the sensor data recorded at the scalp. Distributed analyses were applied only to cortical activity (i.e., 0.5–20 Hz filtered data). The CLARA technique models the inverse solution as a large collection of elementary dipoles distributed over nodes on a mesh of the cortical volume. The aggregate strength of current density in each voxel can then be projected spatiotemporally onto the neuroanatomy, akin to a functional map in fMRI. CLARA estimates the total variance of the scalp-recorded data and applies a smoothness constraint to ensure current changes little between adjacent brain regions (Michel et al., 2004; Picton et al., 1999). CLARA renders highly focal source images by iteratively reducing the source space during repeated estimations. On each step (x10), a spatially smoothed LORETA solution (Pascual-Marqui et al., 2002) is recomputed and voxels below a 1% max amplitude threshold are removed. This provided a spatial weighting term for each voxel of the LORETA image on the subsequent step. Ten iterations were used with a voxel size of 5 mm in Talairach space and regularization (parameter accounting for noise) set at 0.01% singular value decomposition. The spatial resolution of CLARA is estimated at 5–10 mm (Iordanov et al., 2014; Iordanov et al., 2016), which is smaller (better) than the physical distances between PAC and IFG, and between BS and PAC (~35–40 mm) (Mazziotta et al., 1995). We have previously used this approach to image electrophysiological speech processing (e.g., Alain et al., 2017; Bidelman, 2018). Source activations were visualized on BESA’s adult brain template (Richards et al., 2016).
We used cluster-based permutation tests (Maris and Oostenveld, 2007) implemented in BESA Statistics (2.0) to contrast the distributed source images and identify anatomical locations in the brain volume (and over time) that distinguished noise- vs. reverb-degraded speech. For each voxel and time point, a paired samples t-test was conducted contrasting the two mild forms of acoustic interference (i.e., +10 dB SNR noise vs. +10 D/R reverb). This allowed us to determine where and when neural activity showed significant differences (p<0.05) between interferences. Cluster values were derived based on the sum of all t-values of data points within a given cluster. Significant differences were determined by generating and comparing surrogate clusters from n=1000 resamples of the data permuting between stimulus conditions (e.g., Oostenveld et al., 2011). This identified contiguous clusters of voxels over time (i.e., statistical contrast maps) where stimulus conditions were not interchangeable (i.e., noisy speech ≠ reverberant speech; p < 0.05). Importantly, BESA corrects for multiple comparisons across the aggregate of all voxels and time points by controlling the familywise error rate through this clustering process. The same procedure was then repeated to contrast the two medium forms of interference (i.e., +5 dB SNR noise vs. +5 D/R reverb). In the present study, distributed source imaging was used to identify empirically, the most relevant cortical regions that distinguish noise and reverberant speech. Source montages, based on discrete dipole modeling, were then used to quantitatively investigate the time course of speech-evoked responses within each cortical ROI and assess their relation to brainstem activity.
Functional connectivity
We measured causal (directed) information flow between nodes of the brainstem-cortical speech network using phase transfer entropy (PTE) (Lobier et al., 2014). TE is a non-parametric, information theoretic measure of directed signal interaction. It is ideal for measuring functional connectivity between regions because it can detect nonlinear associations between signals and is robust against the volume conducted cross-talk in EEG (Hillebrand et al., 2016; Vicente et al., 2011). TE was estimated using the time series of the instantaneous phases of the signals, yielding the so-called phase transfer entropy (PTE) (Hillebrand et al., 2016; Lobier et al., 2014). PTE was computed between ROIs according to Eq. 1:
| (Eq.1) |
where X and Y are the ROI signals and the log(.) term is the conditional probabilities between signals at time t+τ for sample m and n. The probabilities were obtained by building histograms of occurrences of pairs of phase estimates in the epoch (Lobier et al., 2014). Following Hillebrand et al. (2016), the number of histogram bins was set to e0.626+0.4ln(Ns − τ − 1) (Otnes and Enochson, 1972). The prediction delay τ was set as (Ns x Nch)/N±, where Ns and Nch are the number of samples and ROI sources, respectively, and N± the number of times the phase changes sign across time and ROI signals (Hillebrand et al., 2016). PTE cannot be negative and has no upper bound. Higher values indicate stronger connectivity, whereas PTEX→Y =0 implies no directed signaling.
Intuitively, PTE can be understood as the reduction in information (units bits) necessary to encode the present of ROIY if the past of ROIX is used in addition to the past of ROIY. In this sense, it is similar to the definition of Granger Causality (Barnett et al., 2009), which states that ROIX has a causal influence on the target ROIY if knowing the past of both signals improves the prediction of the target’s future compared to knowing only its past. Yet, PTE has several important advantages over other connectivity metrics: (i) PTE is more robust to realistic amounts of noise and linear mixing in the EEG that can produce false-positive connections; (ii) PTE relaxes assumptions about data normality and is therefore model-free; (iii) PTE is asymmetric so it can be computed bi-directionally between pairs of sources (X→Y vs. Y→X) to infer causal, directional flow of information between interacting brain regions. Computing PTE in both directions between pairwise sources (e.g., BS↔A1 and A1↔IFG) allowed us to quantify the relative weighting of information flowing between subcortical and cortical ROIs in both feedforward and feedback directions.
RESULTS
Sensor-level data
Scalp-recorded cortical ERPs and brainstem FFRs (electrode data) to noise and reverberant speech are shown in Figures 2–3. Visual inspection of scalp maps suggested weaker cortical responses with decreasing SNR for noise-degraded speech (Fig. 2). Weaker N1-P2 is presumably due to the decrease in inter-trial response coherence (i.e., increased jitter) caused by noise (Koerner and Zhang, 2015). This amplitude reduction was not observed for reverberant speech where ERPs showed little apparent change with increasing severity of reverb. Similarly, scalp FFRs (Fig. 3), reflecting phase-locked brainstem activity, showed a reduction in amplitude with increasing levels of noise but an apparent enhancement for speech in reverberation. This was most apparent when directly comparing mild (+10 dB SNR noise vs. mild reverb) and moderate interferences (+5 dB SNR noise vs. med. reverb). Despite matching noise SNR and reverb D/R, reverberant speech produced larger responses, particularly at the voice fundamental frequency (F0) (Fig. 3B). The volume conducted nature of sensor recordings did not allow for the separation of underlying sources. Hence, subsequent analyses were conducted in source space.
Figure 2. Cortical ERPs (electrode data).

Grand average responses at frontal and temporal channels (T7/8, Fz) to speech as a function of noise SNR (top traces) and reverb D/R (bottom traces). Responses appear as a series of obligatory waves within the first 200 ms of speech characteristic of the auditory P1- N1-P2 signature. Topographies illustrate the distribution of activity across the scalp. Blue map colors refer to negative voltage, red colors indicate positive voltage. Reverberation is less detrimental t (and in some cases facilitates) the neural encoding of speech compared to additive noise.
Figure 3. Brainstem FFRs (electrode data).

(A) Grand average time waveforms and (B) response spectra to noise-degraded and reverberant speech. F0, voice fundamental frequency. Spectra illustrate enhancements in speech encoding (particularly at F0) with reverberation compared to speech presented in equivalent amounts of interference. Otherwise as in Fig. 2.
Source waveform data
CLARA distributed source maps contrasting cortical activity (0.5–20 Hz) to noise- and reverb- degraded speech are shown in Figure 4. Contrasts between the +10 dB SNR noise and mild reverb conditions revealed responses to these mild forms of interference were differentiated in bilateral, but especially right, auditory cortex (Fig. 4A). The maximal effect (i.e., reverb > noise) occurred 80 ms after stimulus onset. Similarly, contrasts between the +5 dB SNR noise and medium reverb conditions revealed that responses to moderate interferences were differentiated ~30 ms later (108 ms), primarily within left IFG (Fig. 4B). These data suggest a distributed cortical network for speech consisting of auditory (A1) and linguistic (IFG) brain regions that is differentially engaged, intra- and inter-hemispherically, depending on the severity of acoustic interference. While these distributed source analyses provided a whole-brain view of degraded speech processing, they do not allow specific hypothesis testing within the network. Consequently, we extracted source waveforms within cortical A1 and IFG as well as brainstem ROIs to investigate how noise and reverb modulate the subcortical-cortical encoding of speech. Following our previous report (Bidelman and Howell, 2016), left and right hemisphere responses were collapsed for subsequent analyses. This reduced the dimensionality of the data and provided increased SNR for source- level analysis. Pooling hemispheres is also motivated by the fact that even monaural stimulus presentation produces bilateral auditory cortical activity (Schonwiesner et al., 2007).
Figure 4. Statistical contrasts (t-maps) of source responses to noise and reverberant speech.
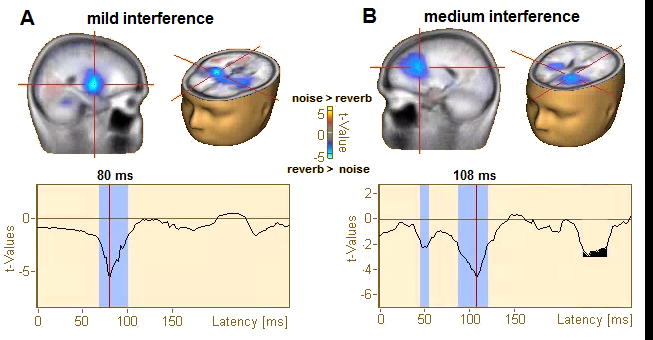
Data filtered 0.5–20 Hz (i.e., cortical activity). Functional data projected on the brain volume are displayed on the BESA brain template (Richards et al., 2016). (A) Contrast of mild forms of acoustic interference (+10 dB SNR noise vs. mild reverb). (B) Contrast of moderate forms of acoustic interference (+5 dB SNR noise vs. medium reverb). Maps are masked (p<0.05) and corrected for multiple comparisons (see text). Bottom traces show the running t-value (noise > reverb) of the cluster marker in the brain volume by crosshairs. Cool colors denote locations where reverb > noise. Degraded speech is processed in bilateral A1 and IFG. For mild acoustic interferences (A), noisy and reverberant speech are differentiable mainly in right A1. This contrasts speech in moderate interferences (B), which becomes distinguishable ~30 ms later in left IFG.
Brainstem (BS) and cortical (A1, IFG) source waveforms are shown in Figures 5A and B, respectively. BS sources illustrate the periodic frequency-following response (FFR) of the auditory midbrain (Bidelman, 2018). Response spectra (lowest panels) illustrate phase-locked activity to the voice pitch (F0≈100 Hz) and harmonic structure of speech. A1 and IFG waveforms track the time course of speech encoding in primary auditory and linguistic brain regions and modulations with noise and reverberation. We used a mixed model, 3-way ANOVA (ROI x interference type x interference level; subject=random factor) to analyze response amplitudes. Initial diagnostics revealed that amplitudes were leptokurtic (i.e., high peakedness) in their distribution. Hence, amplitudes measures were asinh(.) transformed to improve normality and homogeneity of variance assumptions necessary for parametric statistics. The ANOVA revealed significant main effects of interference type [F1,140=7.01, p=0.009] and ROI [F2,140=8.45, p=0.0003]. Planned contrasts revealed linear effects of interference level on BS [t40 =3.34, p=0.0018] and IFG [t40 =2.62, p=0.0124] amplitudes. That is, relative to clean speech, FFR amplitudes steadily increased with additional noise but were also larger for reverberant compared to noisy speech (i.e., Fig. 5C and 5E; +10 dB < +5 dB < mild < medium). This noise/reverb-related modulation was not observed in A1 [linear effect: t40 =0.64, p=0.53] (Fig. 5D). Within IFG, we also found a significant effect of interference type [F1,40=7.91, p=0.0076]. That is, despite matched level of severity, speech in mild reverb elicited larger amplitudes than speech in mild noise (p=0.0129). The facilitation effect of reverb on cortical IFG responses parallels the reverb facilitation observed in the sensor-level data (Figs. 2–3).
Figure 5. Brainstem FFR and cortical ERP source responses to speech in noise and reverberation.

Source waveforms (collapsed across hemispheres) extracted from cortical (IFG, A1; 0.5–20 Hz) and brainstem (BS; 80–1500 Hz) dipole sources. (A) Responses in noise, (B) Responses in reverb. Bottom traces below BS-FFR waveforms show the spectra of phase-locked activity from the brainstem source. Gray trace, stimulus waveform. (C–E) Changes in IFG, A1, and BS source amplitudes across interferences. Shading and errorbars = ±1 s.e.m.
Relations between brainstem and cortical speech responses
Pairwise Pearson’s correlations examined associations between brainstem and cortical neuroelectric responses (Fig. 6). We found that BS-FFRs were positively correlated with A1-ERP amplitudes (r=0.74, p=0.0089) such that stronger brainstem speech encoding was associated with larger auditory cortical responses (Fig. 6A). This suggests that neural activity along the ascending auditory pathway (BS→A1) might drive responses downstream. No associations were observed between BS and IFG amplitudes (Fig. 6B; r=0.37, p=0.27) nor between A1 and IFG (Fig. 6C; r=0.20, p=0.56). The lack of correlation between A1→IFG (and BS→IFG) implies that speech representations might become more independent/abstract at higher levels of the neural hierarchy.
Figure 6. Correlations between BS, A1, and IFG source activity during degraded speech processing.
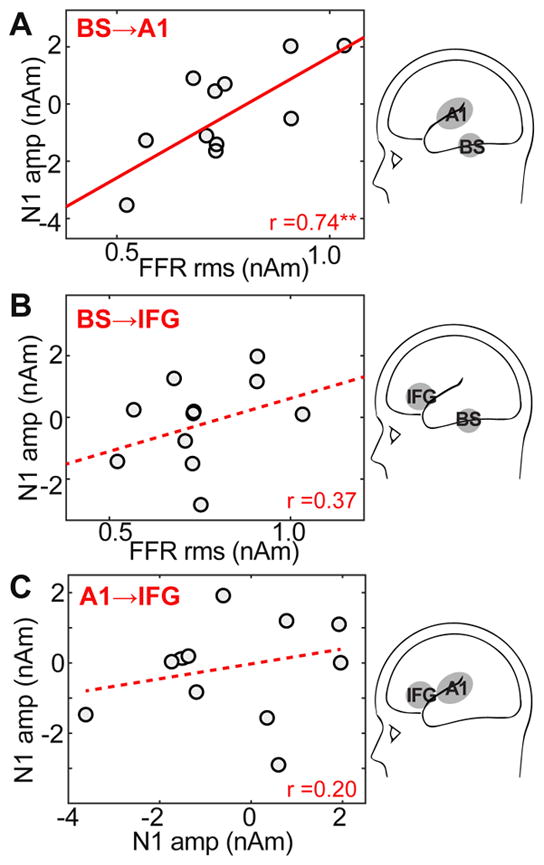
(A) BS-FFRs are positively correlated with A1-ERP amplitudes; stronger brainstem encoding of speech is associated with larger responsivity in auditory cortex. No associations were observed between BS and IFG amplitudes (B) nor between A1 and IFG (C) suggesting speech representations become more independent at higher levels of the speech hierarchy beyond lemniscal auditory regions. Solid lines, significant correlations; dotted lines, n.s. correlations. **p < 0.01
Brain-behavior relations
We used a generalized linear mixed effects model (GLME) to evaluate relationships between neural responses to acoustically-degraded speech and behavioral performance (Fig. 7A). We considered the combination of all neural amplitude measures (BSFFR, A1ERP, IFGERP; pooled across noise/reverb conditions) as well as their interactions as predictors of listeners’ QuickSIN scores. Participants were modeled as a random term [i.e., QuickSIN ~ FFR*A1*IFG + (1|subject)]. Dependent variables were mean centered to reduce multicollinearity (Afshartous and Preston, 2011). We found that the overall model was significant [F1,3=11.56, p=0.037; null hypothesis coefficients=0] accounting for 81% of the variance in QuickSIN scores (adjusted-R2= 0.81). Scrutiny of individual model terms revealed significant neural predictors in BS (p=0.0241) and IFG (p=0.011) amplitudes. In addition to these focal responses, we observed significant A1*IFG (p=0.018) and BS*IFG (p=0.011) interactions. No other terms reached significance. Collectively, these results suggest that in addition to intra-regional activity within brainstem and cortical areas (BS, IFG), cortico-collicular (BS-A1) and cortico-cortical (A1-IFG) interactions are strong predictors of degraded speech perception abilities.
Figure 7. Degraded speech perception performance is predicted by intra-regional activations and inter-regional connectivity.

(A) BS, A1, and IFG activity and their inter-regional interactions (pooled across all interference conditions) account for 81% of the variance (adj-R2) in behavioral QuickSIN scores. Cortico-collicular (BS-A1) and cortico-cortical (A1-IFG) neural interactions are also strong predictors of perception. Lines connecting ROIs show pairwise source terms that interacted in the GLME (solid lines, significant; dotted lines, n.s.) Statistical flags within ROIs reflect the main effect of that source in the GLME. (B) QuickSIN scores for “good” (n=6) vs. “poor” (n=5) SIN performers (median split of scores). Despite all having normal hearing, certain listeners obtain better (~1 dB lower) SIN thresholds indicating individual differences in SIN perception. (C) Functional connectivity in the brainstem-cortical speech network that differentiates “good” vs. “poor” SIN performers. Values represent the magnitude of connectivity computed via phase transfer entropy (Lobier et al., 2014). Statistical flags represent group contrasts at each connection. Feedforward (BS→A1) and feedback (IFG→A1) towards primary auditory cortex (A1) is stronger in “good” relative to “poor” perceivers. †p < 0.1; *p < 0.05; **p ≤ 0.01
Functional connectivity
Phase transfer entropy, quantifying the feedforward (afferent) and feedback (efferent) functional connectivity between sources, is shown in Figure 7C. To investigate the behavioral relevance of PTE connectivity measures, we divided our cohort in two groups based on a median split of listeners’ QuickSIN scores. This resulted in two subgroups, “good” (n=6) vs. “poor” (n=5) SIN performers who differed in their SIN scores (Fig. 7B). Subgroups were otherwise matched in age (t9=1.61, p=0.14), musical training (t9= 0.25, p=0.81), and gender (Fisher’s exact test: p=1). Despite all having normal hearing, good listeners obtained better (~1 dB lower) SIN thresholds [t9= -2.47, p=0.035], confirming individual differences in SIN perception (Fig. 7B) (e.g., Song et al., 2011). We then analyzed each of these group’s PTE values to assess whether or not directed, inter-regional neural connectivity (i.e., BS↔A1 and A1↔IFG) could distinguish “good” vs. “poor” SIN performers (Fig. 7C). An ANOVA conducted on PTE values revealed a significant group x region interaction in the strength of functional connectivity [F3,27=4.79, p=0.0084]. Identical results were also obtained with a Freidman non-parametric ANOVA (group x region: F3,27=4.79, p=0.0084). Tukey-Kramer contrasts revealed that this interaction was driven by stronger connectivity in “good” compared to “poorer” perceivers between IFG→A1 (p=0.0041) and marginally stronger connectivity between BS→A1 (p=0.07) (Fig. 7C). No other regional pairs showed group differences in connectivity. These results confirm both bottom up (BS→A1) and top down (IFG→A1) communication directed toward A1 is important for degraded speech perception.
DISCUSSION
By measuring source-level FFR and ERPs to noise- and reverb-degraded speech, the present study helps elucidate how central neural representations for communicative signals are affected by different acoustic stressors common to the auditory scene. Collectively, our results relate to three primary findings: (i) reverberation is less detrimental to (and in some cases facilitated) the neural encoding of speech compared to additive noise matched in acoustic severity (i.e., signal figure-ground quality); (ii) listeners’ degraded speech perception skills are predicted by intra- and inter-regional brainstem-cortical activity including cortico-collicular (brainstem-cortical) and cortico-cortical (frontotemporal) interactions; (iii) functional connectivity directed toward A1 from BS (feedforward) and IFG (feedback) differentiates “good” from “poor” perceivers on behavioral SIN tests.
Noise and reverberation differentially impact the neural encoding of speech
Direct comparisons between acoustic stressors demonstrated that reverberation causes lesser interruption to the brain’s speech representations than comparable levels of noise. These findings cannot be attributed to trivial differences in “noisiness” (i.e., acoustic figure-ground quality) as noise and reverb were matched in their severity (i.e., SNR≈D/R). At both brainstem and cortical levels, reverberant speech produced larger evoked responses compared to clean speech, a facilitation that was most apparent in BS and IFG sources. Similarly, whole-brain analyses indicated that cortical activations were stronger for mild and moderate reverberation relative to comparable noise levels in both right A1 and left IFG (Fig. 4). The lesser impact of reverb than noise we find in electrophysical responses is consistent with behavioral data that demonstrates human speech perception is remarkably resilient to reverberation (Bradley et al., 1999; Culling et al., 2003; Nielsen and Dau, 2010; Watkins, 2005) and the fact that listeners notice fewer signal changes in reverberation than in noise (Larsen et al., 2008; McShefferty et al., 2015; Zahorik, 2002).
Weaker cortical responses in noise could reflect neural desynchronization caused by lower inter- trial phase coherence (i.e., increased jitter) of responses in the presence of acoustic interference (Koerner and Zhang, 2015). But why is a similar desynchronization to speech not observed in reverberation? Animal recordings (Sayles and Winter, 2008) and previous human FFR studies (Al Osman et al., 2017; Bidelman and Krishnan, 2010) show that speech cues are more easily maintained at the neural level in 15 reverb compared to noise (for review, see Bidelman, 2017). Some investigators have also postulated that neurons in the brainstem inferior colliculus—the putative generator of scalp FFRs (Bidelman, 2018; Smith et al., 1975)—might perform a neural compensation that mitigates the negative effects of reverb and target signal representations (Slama and Delgutte, 2015). For a subset of collicular neurons, Slama and Delgutte (2015) found that the temporal coding of amplitude envelope was better for reverberant than for anechoic stimuli having the same modulation depth at the ear, indicating a robustness in auditory signal processing to reverb. The strong resilience of speech coding we find across brain levels may reflect population-level dynamics of these early neural compensatory mechanisms (Slama and Delgutte, 2015) that ultimately increase the tolerance of auditory processing in reverberation (Bradley et al., 1999; Culling et al., 2003; Nielsen and Dau, 2010; Watkins, 2005).
Alternatively, the resilience of neural responses to reverberation could reflect a refinement of auditory signal processing aided by corticofugal (cortico-collicular) efferent pathways. Cortical neurons can enhance the SNR of their own thalamo-collicular inputs via corticofugal gain but only when their receptive fields can accurately estimate task-relevant stimulus features—termed “egocentric selection” (Suga et al., 2000). However, why corticofugal effects would be specific (and/or larger) for reverberant compared to noise-degraded speech is unclear. Whether such top-down modulations can occur under strictly passive listening tasks (as used here) also remains speculative. That said, efferent modulations from the lower brainstem to the cochlea (olivocochlear bundle) that provide an “antimasking” function (Winslow and Sachs, 1987) are observed under passive scenarios and are highly predictive of SIN skills at the behavioral level (Bidelman and Bhagat, 2015; Mishra and Lutman, 2014). However, our data show that afferent (BS→A1) rather than efferent (A1→BS) brainstem-cortical signaling differentiated “good” from “poor” listeners on the QuickSIN (Fig. 7C).
Remarkably, these brain-behavior associations were observed between passive neural encoding of relatively simple speech sounds (i.e., vCv in noise) and more complex speech recognition (i.e., QuickSIN), corroborating findings of recent brainstem and cortical ERP studies (Bidelman and Dexter, 2015; Song et al., 2011). Still, most real-world “cocktail party” scenarios require more than mere passive figure-ground (cf. target-noise) analysis as assessed here. Indeed, listeners must often parse multiple streams of competing speech information in a multi-talker environment, a process itself enhanced by attention (Alain, 2007; Ding and Simon, 2012; Hill and Miller, 2010; Puvvada and Simon, 2017; Xiang et al., 2010). Future studies are needed to clarify the role of afferent/efferent interplay during speech processing and the impact of active vs. passive listening paradigms. Furthermore, while we find acoustically matched noise SNR and reverb D/R are processed differentially by the auditory system, it is still possible these interferences differ in their perceptual equivalency. Thus, an interesting extension to the present study would be to examine speech coding and brainstem-cortical connectivity for noise and reverb stimuli first titrated for perceptual difficulty. On this point, Picou et al. (2016) have recently shown that reverb induces less listening effort than noise during speech comprehension, which is consistent with our neurophysiological findings.
Hierarchical neural encoding of degraded speech
Cross-level comparisons between functional tiers revealed that noise- and reverb-related changes in neural responses were generally larger in brainstem compared to cortex. While FFRs exhibited systematic amplitude increases with increasing noise/reverb, A1 responses showed more muted changes. This suggests acoustic interferences have a differential effect on subcortical vs. cortical tiers of the auditory hierarchy during speech processing (i.e., BS > A1). To our knowledge this has not been previously reported and is only made apparent by the dual FFR-ERP paradigm used here.
The lesser effect of noise/reverb at the cortical compared to brainstem level might be accounted for by differences in how non-auditory, compensatory brain regions are marshalled during degraded speech processing. In cortex for instance, top-down control of auditory A1 responses from frontal regions can occur pre-attentively and independent of attention (Doeller et al., 2003). Top-down influences are also generally stronger at cortical relative to subcortical levels (Galbraith and Kane, 1993; Hillyard and Picton, 1979; Okamoto et al., 2011; Woods and Hillyard, 1978). Thus, the smaller interference-induced changes we find in A1 relative to brainstem (midbrain) could be due to stronger “top-down” influences from higher-order, non-auditory brain areas (e.g., IFG) to primary auditory cortex than those from corticofugal modulations between brainstem and A1. This notion is consistent with recent studies showing strong engagement of IFG (linguistic areas) in addition to A1 (primary auditory areas) during passive (Bidelman and Dexter, 2015; Bidelman and Howell, 2016) and active (Binder et al., 2004; Du et al., 2014; Scott and McGettigan, 2013) SIN processing. Indeed, our data here demonstrate that IFG is actively involved during speech processing in both distinguishing noise from reverberant speech (Fig. 4) and in predicting behavioral QuickSIN scores (Fig. 7). Our results corroborate the notion that neural activity in frontal brain regions outside conventional auditory system are robust predictors of SIN perception (Adank et al., 2012; Bidelman and Dexter, 2015; Bidelman and Howell, 2016; Binder et al., 2004; Wong et al., 2008). Nevertheless, the strong interactions we find between BS and A1 do indicate that degraded speech processing also depends on the functional interplay between subcortical and cortical hubs of the auditory hierarchy—perhaps in maintaining a veridical depiction of the speech signal during its neural ascent.
Feedforward/feedback to A1 from BS and IFG is critical to degraded speech perception
In this regard, our GLME and PTE results help reveal important patterns of functional connectivity during degraded speech processing. We found intra-regional activity within auditory BS and IFG were themselves strong predictors of listeners’ QuickSIN performance, in agreement with previous neuroimaging studies (cf. Bidelman and Howell, 2016; Binder et al., 2004; Coffey et al., 2017; Du et al., 2014). Similarly, BS and A1 activity was strongly correlated, suggesting that neural representations in lower auditory relays (which dominate FFRs) might feed-forward to influence sound encoding at the cortical level. These results corroborate findings of Coffey et al. (2017) who suggested that superior feed532 forward (brainstem-cortical) neural encoding during noise-degraded speech processing provides better information to A1. We replicate and extend these results by showing brainstem-cortical reciprocity is also critical for speech processing in other acoustic stressors (i.e., reverb) but that behavior also depends on links between auditory and linguistic cortical regions. In addition to cortico-collicular (BS-A1) associations (Bidelman and Alain, 2015a; Coffey et al., 2017), we found that cortico-cortical (A1-IFG) interactions were a strong predictor of degraded speech perception abilities (cf. Adank et al., 2012; Binder et al., 2004). The observation that BS and IFG responses were largely independent (Figs. 6 and 7A) further suggests speech undergoes several neural transformations from brainstem, through the auditory cortices, in route to linguistic brain regions during the analysis of speech.
Functional connectivity corroborated these regression results by demonstrating the direction of inter-regional signaling that drives degraded speech perception. In particular, we found that bottom up (BS→A1) and top down (IFG→A1) directed communication towards primary auditory cortex (A1) is critical in determining successful degraded speech perception and differentiating “good” vs. “poorer” listeners (Fig. 7). Our connectivity findings broadly agree with notions that speech is processed in a dynamic, and distributed fronto-temporal network (Bidelman and Dexter, 2015; Bidelman and Howell, 2016; Du et al., 2014; Obleser et al., 2007; Scott and McGettigan, 2013; Scott et al., 2009) whose engagement is differentially recruited depending on signal clarity, intelligibility, and linguistic experience (Adank et al., 2012; Bidelman and Dexter, 2015; Scott and McGettigan, 2013).
Our results reveal that a series of hierarchical computations are involved in degraded auditory processing, whereby neural correlates for speech are maintained in successively more abstract forms as the signal traverses the auditory system. This parallels similar hierarchical processing observed for non- speech sounds (Bidelman and Alain, 2015b). It is thought that information relayed from lower levels of the pathway are successively pruned so as to allow easier readout of signal identity in higher brain areas responsible for generating percepts (Chechik et al., 2006). Indeed, multi-unit (Perez et al., 2013) and ERP studies (e.g., Bidelman and Alain, 2015b; Bidelman et al., 2013; Bidelman et al., 2014b) directly comparing responses in brainstem and early sensory cortex help bolster the notion of a continued abstraction in the neural code (see also Sinex et al., 2005; Sinex et al., 2003). It is possible that the current data reflect a similar pruning operation where speech cues coded in lower structures (brainstem) are faithfully carried forward into cortex (A1) but are then recast upon arrival in IFG into more abstract, invariant representations that are more robust to surface-level stimulus manipulations like noise (Adank et al., 2012; Bidelman and Howell, 2016; Binder et al., 2004; Du et al., 2014).
Collectively, findings of the present study point to fundamental differences in how noise and reverberation affect the subcortical-cortical neural encoding of speech. A differential neural coding between interferences may help account for the challenges observed by hearing impaired listeners in certain acoustic environments (but not others) as well as the unique types of perceptual confusions listeners experience in noise compared to reverberation (Nabelek and Dagenais, 1986).
Highlights.
Examined source-level brainstem/cortical ERPs to speech in noise an reverb
Reverb less detrimental than severity-matched noise to neural encoding
BS→A1 and IFG→A1 functional connectivity predicted speech-in-noise perception
“Cocktail party” success driven by bottom-up and top-down communication toward A1
Acknowledgments
This work was supported by grants from the American Hearing Research Foundation (AHRF), American Academy of Audiology (AAA) Foundation, University of Memphis Research Investment Fund (UMRIF), and NIH/NIDCD R01DC016267 awarded to G.M.B.
Footnotes
While figure-ground quality was equated between noisy and reverberant speech (i.e., SNR = D/R), we did not attempt to control for inherent spectrotemporal difference between interferences classes. For example, unlike additive noise, reverb distorts the target itself as reflect portions of the speech signal overlap with itself and lead to a blurring or “temporal smearing” of the waveform’s fine structure (Nabelek et al., 1989; Wang & Brown, 2006). Thus, while we control the overall level of interference, we retain intrinsic differences characteristic of noise vs. reverberation (e.g., timbral flux, dynamic temporal effects, lowpass filtering in reverb vs. overall flattening of modulation in noise).
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- Adank P, Davis MH, Hagoort P. Neural dissociation in processing noise and accent in spoken language comprehension. Neuropsychologia. 2012;50:77–84. doi: 10.1016/j.neuropsychologia.2011.10.024. [DOI] [PubMed] [Google Scholar]
- Afshartous D, Preston RA. Key results of interaction models with centering. Journal of Statistics Education. 2011;19:1–24. [Google Scholar]
- Agung K, Purdy SC, McMahon CM, Newall P. The use of cortical auditory evoked potentials to evaluate neural encoding of speech sounds in adults. J Am Acad Audiol. 2006;17:559–72. doi: 10.3766/jaaa.17.8.3. [DOI] [PubMed] [Google Scholar]
- Aiken SJ, Picton TW. Envelope and spectral frequency-following responses to vowel sounds. Hear Res. 2008;245:35–47. doi: 10.1016/j.heares.2008.08.004. [DOI] [PubMed] [Google Scholar]
- Al Osman R, Dajani HR, Giguère C. Self-masking and overlap-masking from reverberation using the speech-evoked auditory brainstem response. J Acoust Soc Am. 2017;142:EL555–EL560. doi: 10.1121/1.5017522. [DOI] [PubMed] [Google Scholar]
- Alain C. Breaking the wave: Effects of attention and learning on concurrent sound perception. Hear Res. 2007;229:225–36. doi: 10.1016/j.heares.2007.01.011. [DOI] [PubMed] [Google Scholar]
- Alain C, McDonald K, Van Roon P. Effects of age and background noise on processing a mistuned harmonic in an otherwise periodic complex sound. Hear Res. 2012;283:126–135. doi: 10.1016/j.heares.2011.10.007. [DOI] [PubMed] [Google Scholar]
- Alain C, Roye A, Salloum C. Effects of age-related hearing loss and background noise on neuromagnetic activity from auditory cortex. Front Sys Neurosci. 2014;8:8. doi: 10.3389/fnsys.2014.00008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Alain C, Arsenault JS, Garami L, Bidelman GM, Snyder JS. Neural correlates of speech segregation based on formant frequencies of adjacent vowels. Scientific Reports. 2017;7:1–11. doi: 10.1038/srep40790. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson S, Skoe E, Chandrasekaran B, Kraus N. Neural timing is linked to speech perception in noise. J Neurosci. 2010;30:4922–4926. doi: 10.1523/JNEUROSCI.0107-10.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Barnett L, Barrett AB, Seth AK. Granger causality and transfer entropy are equivalent for Gaussian variables. Phys Rev Lett. 2009;103:238701. doi: 10.1103/PhysRevLett.103.238701. [DOI] [PubMed] [Google Scholar]
- Bellier L, Bouchet P, Jeanvoine A, Valentin O, Thai-Van H, Caclin A. Topographic recordings of auditory evoked potentials to speech: Subcortical and cortical responses. Psychophysiology. 2015;52:594–9. doi: 10.1111/psyp.12369. [DOI] [PubMed] [Google Scholar]
- Berg P, Scherg M. A fast method for forward computation of multiple-shell spherical head models. Electroencephalogr Clin Neurophysiol. 1994;90:58–64. doi: 10.1016/0013-4694(94)90113-9. [DOI] [PubMed] [Google Scholar]
- Bidelman GM. Towards an optimal paradigm for simultaneously recording cortical and brainstem auditory evoked potentials. J Neurosci Meth. 2015;241:94–100. doi: 10.1016/j.jneumeth.2014.12.019. [DOI] [PubMed] [Google Scholar]
- Bidelman GM. Relative contribution of envelope and fine structure to the subcortical encoding of noise-degraded speech. J Acoust Soc Am. 2016;140:EL358–363. doi: 10.1121/1.4965248. [DOI] [PubMed] [Google Scholar]
- Bidelman GM. Communicating in challenging environments: Noise and reverberation. In: Kraus N, Anderson S, White-Schwoch T, Fay RR, Popper AN, editors. Springer Handbook of Auditory Research: The frequency-following response: A window into human communication. Springer Nature; New York, N.Y: 2017. [Google Scholar]
- Bidelman GM. Subcortical sources dominate the neuroelectric auditory frequency-following response to speech. Neuroimage. 2018;175:56–69. doi: 10.1016/j.neuroimage.2018.03.060. [DOI] [PubMed] [Google Scholar]
- Bidelman GM, Krishnan A. Effects of reverberation on brainstem representation of speech in musicians and non-musicians. Brain Res. 2010;1355:112–125. doi: 10.1016/j.brainres.2010.07.100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bidelman GM, Bhagat SP. Right ear advantage drives the link between olivocochlear efferent “antimasking” and speech-in-noise listening benefits. NeuroReport. 2015;26:483–487. doi: 10.1097/WNR.0000000000000376. [DOI] [PubMed] [Google Scholar]
- Bidelman GM, Alain C. Musical training orchestrates coordinated neuroplasticity in auditory brainstem and cortex to counteract age-related declines in categorical vowel perception. J Neurosci. 2015a;35:1240–1249. doi: 10.1523/JNEUROSCI.3292-14.2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bidelman GM, Dexter L. Bilinguals at the “cocktail party”: Dissociable neural activity in auditory-linguistic brain regions reveals neurobiological basis for nonnative listeners’ speech-in- noise recognition deficits. Brain Lang. 2015;143:32–41. doi: 10.1016/j.bandl.2015.02.002. [DOI] [PubMed] [Google Scholar]
- Bidelman GM, Alain C. Hierarchical neurocomputations underlying concurrent sound segregation: Connecting periphery to percept. Neuropsychologia. 2015b;68:38–50. doi: 10.1016/j.neuropsychologia.2014.12.020. [DOI] [PubMed] [Google Scholar]
- Bidelman GM, Howell M. Functional changes in inter- and intra-hemispheric auditory cortical processing underlying degraded speech perception. Neuroimage. 2016;124:581–590. doi: 10.1016/j.neuroimage.2015.09.020. [DOI] [PubMed] [Google Scholar]
- Bidelman GM, Gandour JT, Krishnan A. Cross-domain effects of music and language experience on the representation of pitch in the human auditory brainstem. J Cogn Neurosci. 2011;23:425–34. doi: 10.1162/jocn.2009.21362. [DOI] [PubMed] [Google Scholar]
- Bidelman GM, Moreno S, Alain C. Tracing the emergence of categorical speech perception in the human auditory system. Neuroimage. 2013;79:201–212. doi: 10.1016/j.neuroimage.2013.04.093. [DOI] [PubMed] [Google Scholar]
- Bidelman GM, Weiss MW, Moreno S, Alain C. Coordinated plasticity in brainstem and auditory cortex contributes to enhanced categorical speech perception in musicians. Eur J Neurosci. 2014a;40:2662–2673. doi: 10.1111/ejn.12627. [DOI] [PubMed] [Google Scholar]
- Bidelman GM, Villafuerte JW, Moreno S, Alain C. Age-related changes in the subcortical- cortical encoding and categorical perception of speech. Neurobiol Aging. 2014b;35:2526–2540. doi: 10.1016/j.neurobiolaging.2014.05.006. [DOI] [PubMed] [Google Scholar]
- Bidelman GM, Lowther JE, Tak SH, Alain C. Mild cognitive impairment is characterized by deficient hierarchical speech coding between auditory brainstem and cortex. J Neurosci. 2017;37:3610–3620. doi: 10.1523/JNEUROSCI.3700-16.2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Billings CJ, Tremblay KL, Stecker GC, Tolin WM. Human evoked cortical activity to signal-to-noise ratio and absolute signal level. Hear Res. 2009;254:15–24. doi: 10.1016/j.heares.2009.04.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Billings CJ, Bennett KO, Molis MR, Leek MR. Cortical encoding of signals in noise: Effects of stimulus type and recording paradigm. Ear Hear. 2010;32:53–60. doi: 10.1097/AUD.0b013e3181ec5c46. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Billings CJ, McMillan GP, Penman TM, Gille SM. Predicting perception in noise using cortical auditory evoked potentials. J Assoc Res Oto. 2013;14:891–903. doi: 10.1007/s10162-013-0415-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Binder JR, Liebenthal E, Possing ET, Medler DA, Ward BD. Neural correlates of sensory and decision processes in auditory object identification. Nat Neurosci. 2004;7:295–301. doi: 10.1038/nn1198. [DOI] [PubMed] [Google Scholar]
- Bradley JS, Reich RD, Norcross SG. On the combined effects of signal-to-noise ratio and room acoustics on speech intelligibility. J Acoust Soc Am. 1999;106:1820–1828. doi: 10.1121/1.427932. [DOI] [PubMed] [Google Scholar]
- Campbell T, Kerlin JR, Bishop CW, Miller LM. Methods to eliminate stimulus transduction artifact from insert earphones during electroencephalography. Ear Hear. 2012;33:144–150. doi: 10.1097/AUD.0b013e3182280353. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chang EF, Rieger JW, Johnson K, Berger MS, Barbaro NM, Knight RT. Categorical speech representation in human superior temporal gyrus. Nat Neurosci. 2010;13:1428–32. doi: 10.1038/nn.2641. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chechik G, Anderson MJ, Bar-Yosef O, Young ED, Tishby N, Nelken I. Reduction of information redundancy in the ascending auditory pathway. Neuron. 2006;51:359–68. doi: 10.1016/j.neuron.2006.06.030. [DOI] [PubMed] [Google Scholar]
- Coffey EBJ, Chepesiuk AMP, Herholz SC, Baillet S, Zatorre RJ. Neural correlates of early sound encoding and their relationship to speech-in-noise perception. Front Neurosci. 2017:11. doi: 10.3389/fnins.2017.00479. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Culling JF, Hodder KI, Toh CY. Effects of reverberation on perceptual segregation of competing voices. J Acoust Soc Am. 2003;114:2871–6. doi: 10.1121/1.1616922. [DOI] [PubMed] [Google Scholar]
- Ding N, Simon JZ. Emergence of neural encoding of auditory objects while listening to competing speakers. Proc Natl Acad Sci USA. 2012;109:11854–11859. doi: 10.1073/pnas.1205381109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Doeller CF, Opitz B, Mecklinger A, Krick C, Reith W, Schröger E. Prefrontal cortex involvement in preattentive auditory deviance detection:: neuroimaging and electrophysiological evidence. Neuroimage. 2003;20:1270–1282. doi: 10.1016/S1053-8119(03)00389-6. [DOI] [PubMed] [Google Scholar]
- Du Y, Buchsbaum BR, Grady CL, Alain C. Noise differentially impacts phoneme representations in the auditory and speech motor systems. Proc Natl Acad Sci USA. 2014;111:1–6. doi: 10.1073/pnas.1318738111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fujihira H, Shiraishi K. Correlations between word intelligibility under reverberation and speech auditory brainstem responses in elderly listeners. Clin Neurophysiol. 2015;126:96–102. doi: 10.1016/j.clinph.2014.05.001. [DOI] [PubMed] [Google Scholar]
- Galbraith GC, Kane JM. Brainstem frequency-following responses and cortical event-related potentials during attention. Percept Mot Skills. 1993;76:1231–1241. doi: 10.2466/pms.1993.76.3c.1231. [DOI] [PubMed] [Google Scholar]
- Gao E, Suga N. Experience-dependent corticofugal adjustment of midbrain frequency map in bat auditory system. Proc Natl Acad Sci USA. 1998;95:12663–70. doi: 10.1073/pnas.95.21.12663. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Goldenholz DM, Ahlfors SP, Hämäläinen MS, Sharon D, Ishitobi M, Vaina LM, Stufflebeam SM. Mapping the signal-to-noise-ratios of cortical sources in magnetoencephalography and electroencephalography. Hum Brain Mapp. 2009;30:1077–1086. doi: 10.1002/hbm.20571. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Helfer K, Wilber L. Hearing loss, aging, and speech perception in reverberation and in noise. J Speech Hear Res. 1990;33:149–155. doi: 10.1044/jshr.3301.149. [DOI] [PubMed] [Google Scholar]
- Herdman AT, Lins O, van Roon P, Stapells DR, Scherg M, Picton T. Intracerebral sources of human auditory steady-state responses. Brain Topogr. 2002;15:69–86. doi: 10.1023/a:1021470822922. [DOI] [PubMed] [Google Scholar]
- Hill KT, Miller LM. Auditory attentional control and selection during cocktail party listening. Cereb Cortex. 2010;20:583–590. doi: 10.1093/cercor/bhp124. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hillebrand A, Tewarie P, van Dellen E, Yu M, Carbo EWS, Douw L, Gouw AA, van Straaten ECW, Stam CJ. Direction of information flow in large-scale resting-state networks is frequency-dependent. Proc Natl Acad Sci USA. 2016;113:3867–3872. doi: 10.1073/pnas.1515657113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hillyard SA, Picton TW. Event-related brain potentials and selective information processing in man. In: Desmedt JE, editor. Progress in Clinical Neurophysiology. Karger; Basel: 1979. pp. 1–52. [Google Scholar]
- Humes LE, Roberts L. Speech-recognition difficulties of the hearing-impaired elderly: The contributions of audibility. J Speech Hear Res. 1990;33:726–35. doi: 10.1044/jshr.3304.726. [DOI] [PubMed] [Google Scholar]
- Iordanov T, Hoechstetter K, Berg P, Paul-Jordanov I, Scherg M. CLARA: classical LORETA analysis recursively applied. OHBM; 2014. [Google Scholar]
- Iordanov T, Bornfleth H, Hoechstetter K, Lanfer B, Scherg M. Performance of Cortical LORETA and Cortical CLARA Applied to MEG Data. Biomag 2016 [Google Scholar]
- Killion M, Niquette P. What can the pure-tone audiogram tell us about a patient’s snr loss? The Hearing Journal. 2000;53:46–53. [Google Scholar]
- Killion MC, Niquette PA, Gudmundsen GI, Revit LJ, Banerjee S. Development of a quick speech-in-noise test for measuring signal-to-noise ratio loss in normal-hearing and hearing- impaired listeners. J Acoust Soc Am. 2004;116:2395–405. doi: 10.1121/1.1784440. [DOI] [PubMed] [Google Scholar]
- Kinsler LE, Frey AR, Coppens AB, Sanders JV. Fundamentals of Acoustics. John Wiley & Sons, Inc; New York, NY: 2000. [Google Scholar]
- Koerner TK, Zhang Y. Effects of background noise on inter-trial phase coherence and auditory N1–P2 responses to speech stimuli. Hear Res. 2015;328:113–119. doi: 10.1016/j.heares.2015.08.002. [DOI] [PubMed] [Google Scholar]
- Kraus N, Cheour M. Speech sound representation in the brain. Audiol Neurootol. 2000;5:140–50. doi: 10.1159/000013876. [DOI] [PubMed] [Google Scholar]
- Kraus N, White-Schwoch T. Unraveling the biology of auditory learning: A cognitive- sensorimotor-reward framework. Trends Cogn Sci. 2015;19:642–54. doi: 10.1016/j.tics.2015.08.017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krishnan A. Human frequency following response. In: Burkard RF, Don M, Eggermont JJ, editors. Auditory evoked potentials: Basic principles and clinical application. Lippincott Williams & Wilkins; Baltimore: 2007. pp. 313–335. [Google Scholar]
- Krishnan A, Gandour JT, Bidelman GM. Brainstem pitch representation in native speakers of Mandarin is less susceptible to degradation of stimulus temporal regularity. Brain Res. 2010;1313:124–133. doi: 10.1016/j.brainres.2009.11.061. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krishnan A, Bidelman GM, Smalt CJ, Ananthakrishnan S, Gandour JT. Relationship between brainstem, cortical and behavioral measures relevant to pitch salience in humans. Neuropsychologia. 2012;50:2849–2859. doi: 10.1016/j.neuropsychologia.2012.08.013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krishnaswamy P, Obregon-Henao G, Ahveninen J, Khan S, Babadi B, Iglesias JE, Hamalainen MS, Purdon PL. Sparsity enables estimation of both subcortical and cortical activity from MEG and EEG. Proc Natl Acad Sci USA. 2017;114:E10465–e10474. doi: 10.1073/pnas.1705414114. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Larsen E, Iyer N, Lansing CR, Feng AS. On the minimum audible difference in direct-to770 reverberant energy ratio. J Acoust Soc Am. 2008;124:450–61. doi: 10.1121/1.2936368. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lobier M, Siebenhuhner F, Palva S, Palva JM. Phase transfer entropy: a novel phase-based measure for directed connectivity in networks coupled by oscillatory interactions. Neuroimage. 2014;85(Pt 2):853–72. doi: 10.1016/j.neuroimage.2013.08.056. [DOI] [PubMed] [Google Scholar]
- Maris E, Oostenveld R. Nonparametric statistical testing of EEG- and MEG-data. J Neurosci Meth. 2007;164:177–190. doi: 10.1016/j.jneumeth.2007.03.024. [DOI] [PubMed] [Google Scholar]
- Mazziotta JC, Toga AW, Evans A, Lancaster JL, Fox PT. A probabilistic atlas of the human brain: Theory and rationale for its development. Neuroimage. 1995;2:89–101. doi: 10.1006/nimg.1995.1012. [DOI] [PubMed] [Google Scholar]
- McShefferty D, Whitmer WM, Akeroyd MA. The just-noticeable difference in speech-to-noise ratio. Trends in Hearing. 2015;19:1–9. doi: 10.1177/2331216515572316. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Michel CM, Murray MM, Lantz G, Gonzalez S, Spinelli L, Grave de Peralta R. EEG source imaging. Clin Neurophysiol. 2004;115:2195–222. doi: 10.1016/j.clinph.2004.06.001. [DOI] [PubMed] [Google Scholar]
- Middelweerd MJ, Festen JM, Plomp R. Difficulties with speech intelligibility in noise in spite of a normal pure-tone audiogram. Audiology. 1990;29:1–7. doi: 10.3109/00206099009081640. [DOI] [PubMed] [Google Scholar]
- Mishra SK, Lutman ME. Top-down influences of the medial olivocochlear efferent system in speech perception in noise. PLoS One. 2014;9:e85756. doi: 10.1371/journal.pone.0085756. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Musacchia G, Strait D, Kraus N. Relationships between behavior, brainstem and cortical encoding of seen and heard speech in musicians and non-musicians. Hear Res. 2008;241:34–42. doi: 10.1016/j.heares.2008.04.013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nabelek AK, Dagenais PA. Vowel errors in noise and in reverberation by hearing-impaired listeners. J Acoust Soc Am. 1986;80:741–8. doi: 10.1121/1.393948. [DOI] [PubMed] [Google Scholar]
- Nabelek AK, Letowski TR, Tucker FM. Reverberant overlap- and self-masking in consonant identification. J Acoust Soc Am. 1989;86:1259–65. doi: 10.1121/1.398740. [DOI] [PubMed] [Google Scholar]
- Nielsen JB, Dau T. Revisiting perceptual compensation for effects of reverberation in speech identification. J Acoust Soc Am. 2010;128:3088–3094. doi: 10.1121/1.3494508. [DOI] [PubMed] [Google Scholar]
- Obleser J, Wise RJ, Dresner MA, Scott SK. Functional integration across brain regions improves speech perception under adverse listening conditions. J Neurosci. 2007;27:2283–9. doi: 10.1523/JNEUROSCI.4663-06.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Okamoto H, Stracke H, Bermudez P, Pantev C. Sound processing hierarchy within human auditory cortex. J Cogn Neurosci. 2011;23:1855–63. doi: 10.1162/jocn.2010.21521. [DOI] [PubMed] [Google Scholar]
- Oostenveld R, Praamstra P. The five percent electrode system for high-resolution EEG and ERP measurements. Clin Neurophysiol. 2001;112:713–719. doi: 10.1016/s1388-2457(00)00527-7. [DOI] [PubMed] [Google Scholar]
- Oostenveld R, Fries P, Maris E, Schoffelen JM. Fieldtrip: Open source software for advanced analysis of meg, eeg, and invasive electrophysiological data. Comput Intell Neurosci. 2011;2011:1–9. doi: 10.1155/2011/156869. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Otnes R, Enochson L. Digital Time Series Analysis. Wiley; 1972. [Google Scholar]
- Parbery-Clark A, Skoe E, Kraus N. Musical experience limits the degradative effects of background noise on the neural processing of sound. J Neurosci. 2009a;29:14100–7. doi: 10.1523/JNEUROSCI.3256-09.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Parbery-Clark A, Skoe E, Lam C, Kraus N. Musician enhancement for speech-in-noise. Ear Hear. 2009b;30:653–61. doi: 10.1097/AUD.0b013e3181b412e9. [DOI] [PubMed] [Google Scholar]
- Parbery-Clark A, Marmel F, Bair J, Kraus N. What subcortical-cortical relationships tell us about processing speech in noise. Eur J Neurosci. 2011;33:549–57. doi: 10.1111/j.1460-9568.2010.07546.x. [DOI] [PubMed] [Google Scholar]
- Pascual-Marqui RD, Esslen M, Kochi K, Lehmann D. Functional imaging with low-resolution brain electromagnetic tomography (LORETA): a review. Methods Find Exp Clin Pharmacol. 2002;24(Suppl C):91–5. [PubMed] [Google Scholar]
- Perez CA, Engineer CT, Jakkamsetti V, Carraway RS, Perry MS, Kilgard MP. Different timescales for the neural coding of consonant and vowel sounds. Cereb Cortex. 2013;23:670–683. doi: 10.1093/cercor/bhs045. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Picou EM, Gordon J, Ricketts TA. The effects of noise and reverberation on listening effort for adults with normal hearing. Ear Hear. 2016;37:1–13. doi: 10.1097/AUD.0000000000000222. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Picton TW, van Roon P, Armilio ML, Berg P, Ille N, Scherg M. The correction of ocular artifacts: A topographic perspective. Clin Neurophysiol. 2000;111:53–65. doi: 10.1016/s1388-2457(99)00227-8. [DOI] [PubMed] [Google Scholar]
- Picton TW, Alain C, Woods DL, John MS, Scherg M, Valdes-Sosa P, Bosch-Bayard J, Trujillo NJ. Intracerebral sources of human auditory-evoked potentials. Audiol Neurootol. 1999;4:64–79. doi: 10.1159/000013823. [DOI] [PubMed] [Google Scholar]
- Puvvada KC, Simon JZ. Cortical representations of speech in a multitalker auditory scene. J Neurosci. 2017;37:9189–9196. doi: 10.1523/JNEUROSCI.0938-17.2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Richards JE, Sanchez C, Phillips-Meek M, Xie W. A database of age-appropriate average MRI templates. Neuroimage. 2016;124:1254–9. doi: 10.1016/j.neuroimage.2015.04.055. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ross B, Tremblay K. Stimulus experience modifies auditory neuromagnetic responses in young and older listeners. Hear Res. 2009;248:48–59. doi: 10.1016/j.heares.2008.11.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sarvas J. Basic mathematical and electromagnetic concepts of the biomagnetic inverse problem. Phys Med Biol. 1987;32:11–22. doi: 10.1088/0031-9155/32/1/004. [DOI] [PubMed] [Google Scholar]
- Sayles M, Winter IM. Reverberation challenges the temporal representation of the pitch of complex sounds. Neuron. 2008;58:789–801. doi: 10.1016/j.neuron.2008.03.029. [DOI] [PubMed] [Google Scholar]
- Scherg M, Ebersole JS. Brain source imaging of focal and multifocal epileptiform EEG activity. Neurophysiol Clin. 1994;24:51–60. doi: 10.1016/s0987-7053(05)80405-8. [DOI] [PubMed] [Google Scholar]
- Scherg M, Ille N, Bornfleth H, Berg P. Advanced tools for digital EEG review: virtual source montages, whole-head mapping, correlation, and phase analysis. J Clin Neurophysiol. 2002;19:91–112. doi: 10.1097/00004691-200203000-00001. [DOI] [PubMed] [Google Scholar]
- Schonwiesner M, Krumbholz K, Rubsamen R, Fink GR, von Cramon DY. Hemispheric asymmetry for auditory processing in the human auditory brain stem, thalamus, and cortex. Cereb Cortex. 2007;17:492–9. doi: 10.1093/cercor/bhj165. [DOI] [PubMed] [Google Scholar]
- Scott SK, McGettigan C. The neural processing of masked speech. Hear Res. 2013;303:58–66. doi: 10.1016/j.heares.2013.05.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Scott SK, Rosen S, Beaman CP, Davis JP, Wise RJ. The neural processing of masked speech: Evidence for different mechanisms in the left and right temporal lobes. J Acoust Soc Am. 2009;125:1737–43. doi: 10.1121/1.3050255. [DOI] [PubMed] [Google Scholar]
- Sharma A, Dorman MF. Cortical auditory evoked potential correlates of categorical perception of voice-onset time. J Acoust Soc Am. 1999;106:1078–83. doi: 10.1121/1.428048. [DOI] [PubMed] [Google Scholar]
- Shtyrov Y, Kujala T, Ahveninen J, Tervaniemi M, Alku P, Ilmoniemi RJ, Naatanen R. Background acoustic noise and the hemispheric lateralization of speech processing in the human brain: Magnetic mismatch negativity study. Neurosci Lett. 1998;251:141–144. doi: 10.1016/s0304-3940(98)00529-1. [DOI] [PubMed] [Google Scholar]
- Sinex DG, Li H, Velenovsky DS. Prevalence of stereotypical responses to mistuned complex tones in the inferior colliculus. J Neurophysiol. 2005;94:3523–3537. doi: 10.1152/jn.01194.2004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sinex DG, Guzik H, Li H, Hnderson SJ. Responses of auditory nerve fibers to harmonic and mistuned complex tones. Hear Res. 2003;182:130–139. doi: 10.1016/s0378-5955(03)00189-8. [DOI] [PubMed] [Google Scholar]
- Skoe E, Kraus N. Auditory brain stem response to complex sounds: A tutorial. Ear Hear. 2010;31:302–24. doi: 10.1097/AUD.0b013e3181cdb272. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Slama MCC, Delgutte B. Neural coding of sound envelope in reverberant environments. J Neurosci. 2015;35:4452–4468. doi: 10.1523/JNEUROSCI.3615-14.2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Slugocki C, Bosnyak D, Trainor L. Simultaneously-evoked auditory potentials (SEAP): A new method for concurrent measurement of cortical and subcortical auditory-evoked activity. Hear Res. 2017;345:30–42. doi: 10.1016/j.heares.2016.12.014. [DOI] [PubMed] [Google Scholar]
- Smith JC, Marsh JT, Brown WS. Far-field recorded frequency-following responses: Evidence for the locus of brainstem sources. Electroencephalogr Clin Neurophysiol. 1975;39:465–72. doi: 10.1016/0013-4694(75)90047-4. [DOI] [PubMed] [Google Scholar]
- Song JH, Skoe E, Banai K, Kraus N. Perception of speech in noise: Neural correlates. J Cogn Neurosci. 2011;23:2268–79. doi: 10.1162/jocn.2010.21556. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Suga N, Xiao Z, Ma X, Ji W. Plasticity and corticofugal modulation for hearing in adult animals. Neuron. 2002;36:9–18. doi: 10.1016/s0896-6273(02)00933-9. [DOI] [PubMed] [Google Scholar]
- Suga N, Gao E, Zhang Y, Ma X, Olsen JF. The corticofugal system for hearing: Recent progress. Proc Natl Acad Sci USA. 2000;97:11807–14. doi: 10.1073/pnas.97.22.11807. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tremblay K, Kraus N, McGee T, Ponton C, Otis B. Central auditory plasticity: Changes in the N1-P2 complex after speech-sound training. Ear Hear. 2001;22:79–90. doi: 10.1097/00003446-200104000-00001. [DOI] [PubMed] [Google Scholar]
- Vicente R, Wibral M, Lindner M, Pipa G. Transfer entropy--a model-free measure of effective connectivity for the neurosciences. J Comput Neurosci. 2011;30:45–67. doi: 10.1007/s10827-010-0262-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- von Békésy G. Über die Enstehung der Entfernungsempfindung beim Hören (On the origin of distance perception in hearing) Akust Z. 1938;3:21–31. [Google Scholar]
- Wang DL, Brown GJ. Computational auditory scene analysis. Wiley; Hoboken, NJ: 2006. [Google Scholar]
- Watkins AJ. Perceptual compensation for effects of reverberation in speech identification. J Acoust Soc Am. 2005;118:249–62. doi: 10.1121/1.1923369. [DOI] [PubMed] [Google Scholar]
- White-Schwoch T, Kraus N. The janus face of auditory learning: How life in sound shapes everyday communication. In: Kraus N, Anderson S, White-Schwoch T, Fay RR, Popper AN, editors. Springer Handbook of Auditory Research: The frequency-following response: A window into human communication. Springer; Nature, New York, N.Y: 2017. pp. 121–158. [Google Scholar]
- Winslow RL, Sachs MB. Effect of electrical stimulation of the crossed olivocochlear bundle on auditory nerve response to tones in noise. J Neurophysiol. 1987;57:1002–1021. doi: 10.1152/jn.1987.57.4.1002. [DOI] [PubMed] [Google Scholar]
- Wong PCM, Uppunda AK, Parrish TB, Dhar S. Cortical mechanisms of speech perception in noise. J Speech Lang Hear Res. 2008;51:1026–1041. doi: 10.1044/1092-4388(2008/075). [DOI] [PubMed] [Google Scholar]
- Woods DL, Hillyard SA. Attention at the cocktail party: Brainstem evoked responses reveal no peripheral gating. In: Otto DA, editor. Multidisciplinary Perspectives in Event-Related Brain Potential Research (EPA 600/9-77-043) U.S. Government Printing Office; Washington, DC: 1978. pp. 230–233. [Google Scholar]
- Xiang J, Simon J, Elhilali M. Competing streams at the cocktail party: exploring the mechanisms of attention and temporal integration. J Neurosci. 2010;30:12084–93. doi: 10.1523/JNEUROSCI.0827-10.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zahorik P. Direct-to-reverberant energy ratio sensitivity. J Acoust Soc Am. 2002;112:2110–7. doi: 10.1121/1.1506692. [DOI] [PubMed] [Google Scholar]
- Zendel BR, Alain C. Concurrent sound segregation is enhanced in musicians. J Cogn Neurosci. 2009;21:1488–1498. doi: 10.1162/jocn.2009.21140. [DOI] [PubMed] [Google Scholar]
- Zendel BR, Alain C. Enhanced attention-dependent activity in the auditory cortex of older musicians. Neurobiol Aging. 2014;35:55–63. doi: 10.1016/j.neurobiolaging.2013.06.022. [DOI] [PubMed] [Google Scholar]