

Abstract
The SNF1-related protein kinase 1 (SnRK1) is a heterotrimeric eukaryotic kinase that interacts with diverse proteins and regulates their activity in response to starvation and stress signals. Recently, the FCS-like zinc finger (FLZ) proteins were identified as a potential scaffold for SnRK1 in plants. However, the evolutionary and mechanistic aspect of this complex formation is currently unknown. Here, in silico analyses predicted that FLZ proteins possess conserved intrinsically disordered regions (IDRs) with a propensity for protein binding in the N and C termini across the plant lineage. We observed that the Arabidopsis FLZ proteins promiscuously interact with SnRK1 subunits, which formed different isoenzyme complexes. The FLZ domain was essential for mediating the interaction with SnRK1α subunits, whereas the IDRs in the N termini facilitated interactions with the β and βγ subunits of SnRK1. Furthermore, the IDRs in the N termini were important for mediating dimerization of different FLZ proteins. Of note, the interaction of FLZ with SnRK1 was confined to cytoplasmic foci, which colocalized with the endoplasmic reticulum. An evolutionary analysis revealed that in general, the IDR-rich regions are under more relaxed selection than the FLZ domain. In summary, the findings in our study reveal the structural details, origin, and evolution of a land plant–specific scaffold of SnRK1 formed by the coordinated actions of IDRs and structured regions in the FLZ proteins. We propose that the FLZ protein complex might be involved in providing flexibility, thus enhancing the binding repertoire of the SnRK1 hub in land plants.
Keywords: protein–protein interaction, protein complex, intrinsically disordered protein, scaffold protein, plant, protein evolution, zinc finger, energy signaling, FCS-like zinc finger, SnRK1
Introduction
Energy status is one of the major determinants of growth decisions and aging in all eukaryotes (1, 2). The surveillance and the growth optimization according to energy status are achieved by the action of two antagonistic kinases: SNF1-related protein kinase 1 (SnRK1) and target of rapamycin (TOR)6 in eukaryotes (3–5). During energy deficit, 5′ AMP-activated protein kinase (AMPK) and sucrose nonfermenting 1 (SNF1), the mammalian and yeast homolog of SnRK1, respectively, are activated, and through a series of phosphorylation events, they minimize the energy-consuming processes directly or indirectly by inhibiting TOR activity (3). When the cells return to the energy-rich state, AMPK activity is curtailed, and through increased TOR activity, growth acceleration is achieved (3, 4).
Although the function of SnRK1 and TOR is conserved across the eukaryotes, comparative evolutionary and functional analysis in the last 2 decades revealed that they also underwent significant lineage-specific changes that resulted in divergence in structural composition and activation mechanisms (3–5). SnRK1 is a heterotrimeric kinase with α kinase and β and βγ regulatory subunits (3). Only the TOR1 complex is identified in plants, which is composed of TOR kinase and the regulatory components, viz. regulatory-associated protein of mTOR (RAPTOR) and lethal with SEC13 protein 8 (LST8) (4). Functional analysis revealed many lineage-specific regulators of TOR–SnRK1 signaling in plants suggesting the optimization of these pathways to meet the needs of the autotrophic life (3, 4).
The FCS-like zinc finger (FLZ) proteins are recently identified terrestrial plant-specific C2–C2 zinc finger proteins (6, 7). FLZ proteins extensively interact with SnRK1 kinase subunits and share common interacting partners suggesting that FLZ proteins might be acting as adaptors to facilitate the interaction of the SnRK1 complex with effector proteins (8, 9). In plants, SnRK1 is a convergent point of many extrinsic and intrinsic signals (3). In agreement with this, FLZ proteins were found to be interacting with regulators of hormone signaling, with development and abiotic and biotic stresses supporting their role as adaptors to mediate SnRK1 signaling (8, 10). Functional analysis of FLZ genes identified their roles in the regulation of many SnRK1-regulated processes (11–13). Consistent with these studies, we recently identified that two members of Arabidopsis FLZ gene family work as negative regulators of SnRK1 signaling (14). Interestingly, many FLZ proteins also showed interaction with RAPTOR, which suggests that they may work as scaffolds by bringing both SnRK1 and TOR complexes in close proximity, which is required for the energy-dependent antagonistic interaction (8, 10).
The scaffold proteins usually possess high conformational flexibility to accommodate the interaction with diverse proteins (15). The plasticity and adaptability of scaffold proteins are usually achieved by the presence of intrinsically disordered regions (IDRs) in these proteins (16). FLZ proteins show low sequence conservation outside the FLZ domain indicating that these regions might be enriched with disordered regions (6, 7). IDRs lack fixed secondary or tertiary structures. They are particularly enriched in eukaryotic proteins and thought to be related to organismal complexity (17). The pliable nature of IDRs increases the binding repertoire of proteins. Consistent with this, hub proteins are generally found to be enriched with IDRs (17, 18). The versatile interaction property of FLZ proteins, coupled with their low sequence conservation in the N and C termini, indicates that IDRs might be contributing to the protein interactions of FLZ proteins.
In this study, we employed a large dataset of FLZ proteins from 33 sequenced plant genomes to study the origin and evolution of IDRs in the FLZ protein family. Our analyses predict that the FLZ family proteins possess evolutionarily conserved protein-binding IDRs in the N and C termini. Specific enrichment of post-translational modification (PTM) sites responsible for protein–protein interaction in the IDR-rich region indicates their role in enhancing the interaction repertoire. The protein–protein interaction assays identified that IDRs in the N termini and the structured FLZ domain mediate the interactions with specific SnRK1 subunits in Arabidopsis. The scaffold proteins provide an interaction surface for other proteins by virtue of their large size or through dimerization (19). We also found that FLZ proteins form homo- and heterodimers through the IDRs in the N termini. Interestingly, in planta interaction assays identified that the interaction of FLZ proteins with SnRK1 subunits was specific to cytoplasmic foci that colocalizes with the endoplasmic reticulum (ER). The evolutionary analysis identified that the sequence divergence in the IDR-rich N and C termini is more dynamic compared with the structured FLZ domain. Thus, this study uncovers the origin and evolution of a plant-specific complex formed by the division of labor between the structured FLZ domain and the IDRs, and this complex might be important in mediating the function of the conserved eukaryotic energy gauge, SnRK1.
Results
N and C termini of FLZ proteins are enriched with intrinsically disordered regions
The FLZ proteins from 33 sequenced plant genomes, which belong to key taxonomical positions, were identified through BLAST and HMM-based searches (Fig. S1). A nonredundant dataset of these FLZ proteins was created and used for the subsequent analysis (Table S1). To find out the disorder propensity of FLZ proteins, we employed PONDR-FIT, which is a meta-predictor of PONDR-VLXT, PONDR-VSL2, PONDR-VL3, FoldIndex, IUPred, and TopIDP predictors and displays enhanced accuracy over individual predictors (20). FLZ proteins show limited domain acquisition throughout the plant lineage, and they usually possess a solitary FLZ domain (Fig. 1A and Table S2), which is predicted to form an α–β–α topology (6, 7). Using PONDR-FIT, we first predicted the disorder propensity of FLZ proteins from the model plant Arabidopsis. Most of the FLZ proteins from Arabidopsis are predicted to have high propensity for disorder in N and C termini compared with the FLZ domain (Fig. 1B). FLZ domain–containing proteins are absent in all the green algae (Chlorophyta) species sequenced until now, and we identified an FLZ protein from Klebsormidium flaccidum, which belongs to Charophyta, suggesting that the origin of FLZ domain coincides with the terrestrialization of plants (Fig. S1) (21). The FLZ protein of K. flaccidum was also predicted to have high propensity for disorder at the N and C termini. Furthermore, the FLZ proteins from Bryophyta and Pteridophyta also showed a similar trend indicating that the disorder of N and C termini of FLZ proteins is conserved (Fig. 1C). The FLZ gene family is highly expanded in spermatophytes due to the common and lineage-specific whole-genome duplication (WGD) events (Fig. S1) (6). Analysis of the disorder propensity of FLZ proteins from 28 species belonging to Spermatophyta suggested that N and C termini of FLZ proteins possess high propensity for disorder in all species analyzed (Fig. 1D). These results collectively suggest that disordered nature of N and C termini of FLZ proteins is an evolutionarily conserved feature.
Figure 1.

Disorder in FLZ protein family across the plant lineage. A, schematic representation of domain structure of FLZ proteins. The domain structure of Arabidopsis FLZ1 is shown here as an example. B, average disorder of different regions of FLZ proteins from Arabidopsis thaliana (Ath). C, average disorder of different regions of FLZ proteins from K. flaccidum (Kfa), Marchantia polymorpha (Mpo), Physcomitrella patens (Ppa), Sphagnum fallax (Sfa), and Selaginella moellendorffii (Smo). D, average disorder of different regions of FLZ proteins from 28 Spermatophyta proteomes. Each species is shown in different background colors. E, relationship between IDR length and frequency of occurrence in FLZ protein family. The bars indicate the relationship between IDR length and frequency after categorizing IDRs into groups based on length. The IDRs with a length difference of up to five amino acids were grouped together. The red dots indicate the relationship between IDR length and frequency without any grouping. F, average distribution of short (SIDR; 10–29 residues) and long (LIDR; 30 or more residues) IDRs in different regions of FLZ protein family. The detailed table of IDRs in FLZ protein family is given in Table S3.
IDRs generally show great variation in sequence and length. We calculated the number of predicted short (10–29 residues) and long (30 or more residues) IDRs from the FLZ protein family across the plant lineage (Table S3). We found that the number of predicted short IDRs is very high compared with long IDRs in the FLZ protein family (Fig. 1E). The N termini showed high frequency of both predicted short and long IDRs followed by C termini (Fig. 1F). Interestingly, many IDRs were also predicted in the junction of the N and C termini and FLZ domain. The probability for IDRs was found to be less in the structured FLZ domain region (Fig. 1F).
Although the number of FLZ proteins is highly expanded in spermatophytes, the average size of FLZ proteins is conspicuously reduced in spermatophytes (Fig. S1). We compared the size of FLZ proteins from lower plants with Arabidopsis and rice, and it seems that the reduction in the size of IDR-rich N terminus is responsible for the reduction in the overall protein size in spermatophytes (Fig. S2).
N and C termini of FLZ proteins predicted to have high propensity for protein binding
IDRs generally facilitate versatile protein and nucleic acid binding (22). To get clues about the molecular functions of the IDRs in the N and C termini of FLZ proteins, we analyzed the nucleic acid- and protein-binding propensities using DisoRDPbind, which is an efficient multiple parameter-based predictor of protein-, DNA-, and RNA-binding residues in IDRs (23). In our analysis, both N and C termini were predicted to have consistently high propensity for protein binding in all species analyzed. In the case of the C terminus, many proteins were also predicted to have high RNA-binding propensity (Fig. 2A).
Figure 2.

Binding propensity and post-translational modification sites of FLZ proteins. A, average RNA, DNA, and protein-binding propensity of N and C termini of FLZ proteins. B, predicted phosphorylation sites in different regions of FLZ proteins. C, predicted arginine methylation sites in different regions of FLZ proteins. D, predicted lysine acetylation sites in different regions of FLZ proteins. The detailed table of PTM sites in the FLZ protein family is given in Table S4. The p value obtained in the paired t test indicating the statistically significant difference in the number of PTM sites between N or C termini and FLZ domain is given in the graphs.
The IDRs are generally enriched with sites for PTMs such as phosphorylation, acetylation, and methylation (24–28). These modifications alter the target-binding properties of IDRs and increase the repertoire of protein states in the cell (17, 29). Phosphorylation, arginine methylation, and lysine acetylation are known to modulate protein–protein interactions (22, 27, 28, 30). Because the N and C termini of FLZ proteins are predicted to have high propensity for protein binding, we analyzed the extent of enrichment of putative phosphorylation-, acetylation-, and methylation-prone residues in these regions as compared with the structured FLZ domain. Indeed, we found a significant increase in the number of potent serine and threonine phosphorylation sites in N terminus followed by the C terminus as compared with the FLZ domain (Fig. 2B; Table S4). However, we did not find any major increase in the putative tyrosine phosphorylation sites in the N terminus. A significant decrease in the tyrosine sites was observed in C terminus as compared with the FLZ domain region (Fig. 2B; Table S4). Furthermore, we observed significant increases in the putative arginine methylation and lysine acetylation sites in the N termini compared with FLZ domain (Fig. 2, C, and D; Table S4).
Prediction of disorder-to-order transition regions and low complexity regions in the FLZ proteins
IDRs may or may not undergo disorder-to-order transition upon binding with targets (17, 31). To understand the evolutionary perspective of disorder-to-order transition in FLZ proteins, we predicted the regions that can undergo disorder-to-order transition upon binding to globular protein partners in the IDRs of FLZ proteins from lower plants and Amborella trichopoda, a basal species from the sister lineage of angiosperms using ANCHOR (32, 33). The IDRs in the N terminus of FLZ proteins from lower plants were predicted to be highly enriched with such binding regions, whereas a general reduction in their number and restricted distribution of binding regions was predicted in A. trichopoda (Fig. S3A). Other spermatophytes also showed the same scenario (Fig. S3B). Molecular recognition features (MoRFs) are short motifs (typically 10–70 residues long) in the IDRs that undergo disorder-to-order transition upon binding with their targets, and they are generally involved in facilitating protein–protein interactions (22, 34). The fMoRFpred prediction revealed low enrichment of MoRFs in the FLZ proteins in both lower plants and spermatophytes (Fig. S3, C and D) (35, 36).
The low complexity regions (LCRs) in the proteins are formed due to limited diversity and repetition of certain amino acid types. They are highly abundant in eukaryotic proteins in their IDRs and often enhance the binding promiscuity (37–39). In our analysis using SEG algorithm (40), LCRs were predominantly predicted in the IDRs of the N terminus of lower plants, whereas reduction in their number and restricted distribution was observed in spermatophytes (Fig. S3, E and F).
Arabidopsis FLZ proteins interact with all subunits of SnRK1
The in silico analysis suggested that FLZ proteins possess IDRs, which are potentially involved in protein–protein interaction. It is already reported that many FLZ proteins promiscuously interact with α kinase subunits of SnRK1 in Arabidopsis (8, 9). To experimentally validate the role of IDRs in protein–protein interaction, we selected the interaction of FLZ proteins with SnRK1. SnRK1 is an obligate heterotrimeric enzyme, and FLZ proteins are proposed to be an adaptor of SnRK1; therefore, we hypothesized that the interaction might not be restricted to kinase subunits. To test this, we cloned all 18 Arabidopsis FLZs in the BD vector for the Y2H experiment with SnRK1 subunits. Prior to the Y2H experiment, BD–FLZ clones were transformed in yeast, and their auto-activation and toxicity were checked. In this assay, all 18 Arabidopsis FLZ proteins showed no auto-activation and toxicity in yeast (Fig. S4). Next, we cloned SnRK1α1, -α2, -β1, -β2, -β3, -βγ, and -γ1 subunits in the AD vector. The BD and AD constructs were cotransformed in yeast, and interaction was analyzed. As reported previously, FLZ proteins showed promiscuous interaction with SnRK1α subunits in yeast (Fig. 3). In a previous study, no interaction of SnRK1α subunits with FLZ14 and FLZ17/18 in yeast was observed (9). Interestingly, in our analysis, we found that all 18 Arabidopsis FLZ proteins, including FLZ14 and FLZ17/18, can interact strongly with both α subunits in yeast. The β subunits showed interaction with many FLZ proteins in variable strengths. Among the β subunits, SnRK1β3 interacted with most numbers of the FLZ protein family. SnRK1βγ showed strong interaction with FLZ2 and FLZ13 and weak interaction with FLZ8. Earlier, based on the sequence similarity, a cystathionine β-synthase protein was annotated as a γ subunit in Arabidopsis; however, protein–protein interaction and complementation studies found that it can neither complement the yeast snf4 mutant nor interact with α and β subunits (41, 42). Later, this protein was found to have sequence similarity with SDS23, which works as an alternative energy sensor in fungi (5). None of the 18 FLZ proteins showed interaction with this SnRK1γ1/SDS23 LIKE (SDS23L) protein suggesting that FLZ proteins specifically interact with SnRK1 subunits that were found to be forming an enzyme complex in the earlier study (Fig. 3) (42). SNF1-related-kinase 1 activating kinase 1 and 2 (SnAK1 and SnAK2) are redundant upstream kinases of SnRK1 that are essential for SnRK1 activity (43). Because these kinases physically interact with the SnRK1 complex, we investigated whether FLZ proteins can also interact with SnAK1 and SnAK2. In the Y2H assay, none of the 18 FLZ proteins showed interaction with SnAK1 or SnAK2 confirming that the interaction of FLZ proteins is restricted to the SnRK1 complex (Fig. S5).
Figure 3.

Interaction of FLZ proteins with SnRK1 subunits. The CDS of SnRK1 and FLZ genes were cloned in AD and BD vectors respectively. The constructs were cotransformed, and interaction was screened on DDO (upper row in each group) and QDO plates supplemented with X-α-Gal and AbA (lower row in each group). Simultaneously, a negative control experiment with BD vector and AD construct was carried out to identify false interactions.
FLZ domain mediates the interaction with SnRK1α subunits
The FLZ domain of FLZ1 is sufficient to mediate its interaction with PFA–DSP3 and STH2 suggesting that FLZ domain is the canonical protein–protein interaction module in the FLZ proteins (6). Consistent with this, the FLZ domain of FLZ12 alone was found to be sufficient to mediate interaction with SnRK1α subunits (9). Our in silico analysis identified that the N and C termini of FLZ proteins are highly enriched with IDRs with protein-binding propensities, and FLZ domain is the least disordered region in FLZ proteins. To find out which part of the FLZ protein is responsible for the interaction with SnRK1α subunits, we first cloned the FLZ domain region from five diverse FLZ proteins (Fig. 4A) and checked their ability to interact with SnRK1α1 and -α2. Interestingly, all five FLZ domains showed strong interaction with SnRK1α2, whereas the FLZ domain of FLZ1, -2, and -8 showed strong interaction with SnRK1α1 (Fig. 4B). However, the FLZ domain of FLZ3 showed a weak interaction, and the FLZ domain of FLZ15 did not show any interaction at all (Fig. 4B). Consistent with the previous report (9), these results suggest that the FLZ domain is majorly responsible for facilitating interaction with SnRK1α subunits. Furthermore, we checked whether the IDR-rich N and C termini of FLZ1 and FLZ2 can establish interaction with SnRK1α subunits. In the Y2H assay, neither N nor C termini showed interaction with SnRK1α (Fig. 4C). To confirm the role of the FLZ domain in mediating interaction with SnRK1α subunits, we replaced conserved cysteine residues with serine in the FLZ domain of FLZ8 (Fig. 4D). In the interaction assay with FLZ8Δ1, the strength of interaction with SnRK1α1 was reduced compared with the intact FLZ domain, whereas FLZ8Δ2 and FLZ8Δ1-Δ2 showed a more pronounced reduction in the interaction (Fig. 4E). The interaction property of FLZ8Δ1 was dramatically reduced when we also replaced the adjacent cysteine (Cys-225 and Cys-227, FLZ8Δ1-Δ3 construct) residues with serine residues (Fig. 4E). This result suggests that the ability of the nonconserved cysteine residues (Cys-225 and Cys-227) to partially replace the function of conserved cysteine residues (Cys-226 and Cys-229) could be the reason for the retention of interaction in the FLZ8Δ1 construct. Taken together, mapping and site-directed mutagenesis (SDM) analysis confirmed that the FLZ domain is the canonical SnRK1α-interacting module in FLZ proteins.
Figure 4.

Role of FLZ domain in mediating the interaction of FLZ proteins with SnRK1 subunits. A, composition of FLZ proteins. The FLZ domain is represented by red box. Number indicates the position of the FLZ domain and other regions in the protein. B, interaction of FLZ domain of FLZ1, FLZ2, FLZ3, FLZ8, and FLZ15 with SnRK1α subunits. C, interaction of N and C termini of FLZ1 with SnRK1α subunits. D, FLZ domain of FLZ8 indicating the position of Δ1, Δ2, and Δ3 mutations. The cysteine residues that form the CX2CX18FCSX2C signature zinc finger motif are indicated by red, and the nonconserved cysteine residues are indicated by blue. E, interaction of FLZ8 and mutated FLZ8 (Δ1, Δ2, Δ1-Δ2, and Δ1-Δ3) with SnRK1α2 subunit. F, interaction of FLZ domain of FLZ1, FLZ2, and FLZ8 with SnRK1β1 subunit. G, interaction of FLZ domain of FLZ1, FLZ2, and FLZ8 with SnRK1β2 subunit. H, interaction of FLZ domain of FLZ1, FLZ2, FLZ3, FLZ8, and FLZ15 with SnRK1β3 subunit. I, interaction of FLZ domain of FLZ2 with SnRK1βγ subunit. The SnRK1 and FLZ constructs were prepared in AD and BD vectors, respectively. The cotransformed colonies of Y2H Gold were screened on DDO (upper row in each group) and QDO plates supplemented with X-α-Gal and AbA (lower row in each group).
N terminus mediates the interaction with SnRK1β and βγ subunits
We further investigated the role of different parts of FLZ proteins in mediating interaction with SnRK1β and βγ subunits. Strikingly, except for a few weak interactions, the FLZ domain failed to establish interaction with SnRK1β1–3 and βγ subunits (Fig. 4, F–I). This result suggested that other regions in the FLZ proteins might be responsible for mediating interaction with SnRK1β and βγ subunits. To test this, we checked the interaction of the N and C termini of FLZ1 with the SnRK1β subunits and the N and C termini of FLZ2 with the SnRK1β and βγ subunits. We found that the N terminus alone is sufficient to mediate interaction with SnRK1β and βγ subunits (Fig. 5, A and B). Apart from α subunits, FLZ8 interacts strongly with all three β subunits in yeast (Fig. 3). Because the N termini of FLZ1 and FLZ2 are responsible for interaction with SnRK1β subunits, we hypothesized that the mutation of cysteine residues in the FLZ domain should not hamper the interaction of FLZ8 with β subunits. In our assay, we found that FLZ8Δ1, FLZ8Δ2, and FLZ8Δ1-Δ2 constructs produced strong interaction with all three β subunits indicating that the IDR-rich N terminus is responsible for establishing interaction with SnRK1β and βγ subunits (Fig. 5, C–E).
Figure 5.

Role of N terminus in mediating the interaction of FLZ proteins with SnRK1β and βγ subunits. A, full-length and partial construct of FLZ1 and their interaction with SnRK1β subunits with negative control experiment. B, full-length and partial construct of FLZ2 and their interaction with SnRK1β and βγ subunits with negative control experiment. C, interaction of FLZ8 and mutated FLZ8 (Δ1, Δ2, and Δ1-Δ2) with SnRK1β1. D, interaction of FLZ8 and mutated FLZ8 (Δ1, Δ2, and Δ1-Δ2) with SnRK1β2. E, interaction of FLZ8 and mutated FLZ8 (Δ1, Δ2, and Δ1-Δ2) with SnRK1β3. The SnRK1 and FLZ1 constructs were prepared in AD and BD vector, respectively. The cotransformed colonies of Y2H Gold were screened on DDO (1st column in each group) and QDO plates supplemented with X-α-Gal and AbA (2nd column in each group).
FLZ–SnRK1 interaction site colocalizes with endoplasmic reticulum
To confirm the Y2H results and to identify the in planta interaction site of FLZ–SnRK1, we performed BiFC assay of SnRK1 subunits with different FLZ proteins. In the BiFC assay, all FLZ proteins were found to be interacting with SnRK1α subunits in cytoplasmic foci as sinuous bodies (Fig. 6A; Fig. S6). These bodies were predominantly found to be closely associated with the nucleus. These results prompted us to investigate whether they are ER-associated with the nucleus. To investigate this possibility, we employed a widely used ER-marker, which was constructed by the fusion of ER-signal peptide of WALL-ASSOCIATED KINASE 2 and an ER retention peptide to mCherry (44). Indeed, we found a strong colocalization of BiFC signal with the ER-marker signal (Fig. 6A; Fig. S6). To further confirm this, we used ER–Tracker Red dye. The interaction of FLZ15 with SnRK1α1 was found to colocalize with the signal of ER–Tracker dye (Fig. 6B). These results collectively confirm the colocalization of the SnRK1–FLZ interaction with ER. The interaction of FLZ4 with SnRK1β3 was also found to be localized to cytoplasmic sinuous bodies (Fig. S7A). Furthermore, staining with ER–Tracker Red dye identified that this interaction also colocalizes with ER (Fig. S7B). The BiFC signal of FLZ–SnRK1 interaction was found to be specific because removal of SnRK1 subunits or FLZ proteins resulted in the abolition of the fluorescent signal (Fig. S8). Intriguingly, subcellular localization analysis found that only FLZ9 and FLZ15 are predominantly localized to cytoplasmic bodies, whereas most of the FLZ proteins were found to be localized uniformly in both nucleus and cytoplasm (Fig. S9).
Figure 6.

In planta interaction of FLZ proteins with SnRK1α kinase subunits. A, BiFC analysis of the interaction of FLZ proteins with SnRK1α1 and -α2. The whole cell representation is given in Fig. S6. FLZ proteins were fused to (YFP(1–174)) N terminus of YFP, and SnRK1α1 and -α2 were fused with (YFP(175-end)) C terminus of YFP. The interactions were co-localized with ER marker construct fused with mCherry. B, colocalization of FLZ15–SnRK1α1 interaction with ER–Tracker Red. Wavelengths used for activation/detection (absorption/emission) of the fluorophores: YFP(514/530 nm); DAPI (351/450 nm); mCherry (575/610 nm); ER–Tracker Red (587/615 nm).
FLZ proteins undergo homo- and heterodimerization
The in planta BiFC assay identified that FLZ proteins interact with SnRK1 subunits in the same cytoplasmic foci. This result suggested that either different FLZ proteins might be recruited to the SnRK1 complex on the basis of specific cues or that SnRK1 might be forming a complex with multiple FLZ proteins simultaneously. The promiscuous interaction of FLZ proteins with SnRK1α subunits led us to propose their role as adaptor proteins of SnRK1, which help in the recruitment of SnRK1 targets to the complex (9). In this investigation, we also observed that multiple FLZ proteins interact with not only SnRK1α but also with the β and βγ subunits. These results led us to speculate that various FLZ proteins might be forming a complex with SnRK1, and the FLZ proteins might be physically interacting among themselves to facilitate the formation of this complex.
To test this hypothesis, we cloned 10 FLZs in the AD vector, and their interaction with 16 FLZ proteins in the BD vector was screened through the Y2H assay. Indeed, we found homo- and heterodimerization of FLZ proteins with varying strengths (Fig. 7). Among the combinations we analyzed, FLZ7, FLZ10, FLZ12, and FLZ15 showed homodimerization. Interestingly, these proteins also showed a high degree of heterodimerization with other proteins, whereas members such as FLZ1, FLZ6, and FLZ11 interacted specifically with one or two FLZ proteins (Fig. 7).
Figure 7.

Homo- and heterodimerization of FLZ proteins. The FLZ genes were cloned in AD and BD vectors; constructs were cotransformed; and interaction was screened on DDO (upper row in each group) and QDO plates supplemented with X-α-Gal and AbA (lower row in each group). Simultaneously, a negative control experiment with BD vector and AD construct was carried out to identify false interactions.
N terminus is involved in the interaction among FLZ proteins
To identify which part of the protein is responsible for mediating interaction among the members of FLZ family, we first analyzed which part of FLZ2 can mediate the interaction with the other FLZ proteins. Mapping of interacting regions identified that among the different parts of FLZ2, only the N terminus could recapitulate the interaction with full-length proteins (Fig. 8A). To confirm the role of the N terminus in mediating the interaction with other FLZ proteins, we mapped the FLZ-interaction region of FLZ1, which interacted with FLZ7 and FLZ15 in the previous assay. In the interaction site mapping, FLZ7 and FLZ15 were found to be strongly interacting with the N terminus of FLZ1. FLZ15 showed a weak interaction with the FLZ domain as well (Fig. 8B). The Y2H assay with the N terminus of both interacting FLZ proteins identified strong interaction confirming that the N terminus alone is sufficient for mediating interaction among these FLZ proteins (Fig. 8, C and D).
Figure 8.

Role of N terminus in mediating the heterodimerization of FLZ proteins. A, interaction of FLZ7 and FLZ15 with full-length and partial constructs of FLZ1. B, interaction of FLZ7, FLZ10, FLZ11, FLZ12, and FLZ15 with full-length and partial constructs of FLZ2. C, composition of FLZ7 and FLZ15. D, interaction analysis of N terminus of FLZ1 and FLZ2 with the N terminus of FLZ7 and FLZ15. The constructs prepared in AD and BD were cotransformed in Y2H Gold strain and screened on DDO (1st column in each group) and QDO plates supplemented with X-α-Gal and AbA (2nd column in each group).
IDRs in the N terminus are involved in mediating interaction with FLZ proteins and SnRK1 subunits
The in silico analyses predict that the N terminus of FLZ proteins is enriched with protein-binding IDRs. In agreement with this, protein–protein interaction analysis identified that the IDR-rich N terminus of FLZ proteins is responsible for mediating interaction with other FLZ proteins and SnRK1β and βγ subunits. To decipher the specific role of IDRs in mediating interactions, we first selected FLZ1 and FLZ2, a paralogous pair, which showed extensive interaction with other FLZ proteins and SnRK1 subunits in the Y2H assays. FLZ1 is a comparatively large protein due to the longer N terminus harboring a long IDR of 79 residues, which covers most of the N terminus (hereinafter referred as FLZ1NIDR1) (Fig. 9A). In FLZ2, the middle region of FLZ1NIDR1 is lost during evolution, which resulted in the formation of two separate IDR-rich regions (hereafter referred to as FLZ2NIDR1 and FLZ2NIDR2). The second IDR-rich region in the FLZ2 was found to be only 9 amino acids long on the cutoff parameters we employed; however, because these regions show similarity with the long FLZ1NIDR1, we considered it as a short IDR (Fig. 9A). We first cloned the short IDRs of FLZ2 separately, and their interaction property was analyzed with FLZ7 and FLZ10, which was found to be interacting with FLZ2 through the N terminus in the earlier experiment (Fig. 8C). Intriguingly, only FLZ2NIDR2 could recapitulate the interaction of FLZ2 with FLZ7 and FLZ10 (Fig. 9B). This result suggested that specific IDRs in the N terminus might be involved in mediating interaction among FLZ proteins. Furthermore, we analyzed which of the IDRs is involved in mediating the interaction of FLZ2 with SnRK1β and βγ subunits. SnRK1β and βγ subunits were found to be interacting with both IDRs in yeast (Fig. 9C). Collectively, these results suggest that IDRs specifically or collectively are involved in mediating interactions of FLZ proteins with other proteins. To identify whether this specificity of IDR is conserved, we checked the interaction capacity of the long IDR of FLZ1. We divided the FLZ1NIDR1 into two parts, where FLZ1NIDR1 (1–48) harbors the region that shows similarity with FLZ2NIDR1 and FLZ1NIDR1 (49–81) shows similarity with FLZ2NIDR2 (Fig. 9A). In the interaction assay with both parts of FLZ1NIDR1, only FLZ1NIDR1 (49–81), which shows sequence similarity with FLZ2NIDR2, could recapitulate the interaction of FLZ1 with FLZ7 and FLZ15 (Fig. 9D). FLZ1 interacts with all three SnRK1β subunits through the N terminus. In the Y2H assay with FLZ2NIDR1 and FLZ2NIDR2, we found that both these IDRs are cooperatively involved in facilitating the interaction with SnRK1β subunits (Fig. 9C). To find whether this property is conserved in FLZ1 also, we tested the interaction of FLZ1NIDR1 (1–48) and FLZ1NIDR1 (49–81) with SnRK1β subunits. As observed in FLZ2, both regions were found to be interacting with SnRK1β subunits (Fig. 9E). These results suggest that specific IDR regions might be involved in mediating different interaction in FLZ proteins, and this specificity might be conserved among paralogs.
Figure 9.

Role of IDRs in N terminus in mediating heterodimerization of FLZ proteins and interaction with SnRK1 subunits. A, sequence alignment of the N terminus of FLZ1 and FLZ2 showing the position of IDRs. The conserved residues are marked by violet color. B, interaction analysis of FLZ2NIDR1 and FLZ2NIDR2 with FLZ7 and FLZ10. C, interaction analysis of FLZ2NIDR1 and FLZ2NIDR2 with SnRK1β and βγ subunits. D, interaction analysis of FLZ1NIDR1 (1–48) and FLZ1NIDR1 (49–81) with FLZ7 and FLZ15. E, interaction analysis of FLZ1NIDR1 (1–48) and FLZ1NIDR1 (49–81) with SnRK1β subunits. F, interaction analysis of FLZ1N and FLZ1N-FLZ2NIDR2 with FLZ10. The constructs prepared in AD and BD were cotransformed in Y2H Gold strain and screened on DDO (1st column in each group) and QDO plates supplemented with X-α-Gal and AbA (2nd column in each group).
To further confirm the role of IDRs in mediating specific interactions, we constructed a chimeric construct where the FLZ2NIDR2, which mediates the interaction with FLZ10, was fused with the N terminus of FLZ1. In the Y2H assay, the FLZ1 N terminus did not show interaction with FLZ10, whereas the chimeric construct with FLZ2NIDR2 showed interaction with FLZ10 confirming the role of IDRs in mediating specific interactions (Fig. 9F).
Different regions of FLZ proteins show different rates of sequence divergence
During evolution, protein structure tends to be more conserved than the sequence (45). Consistent with this, many studies suggest enhanced sequence divergence among IDRs (46, 47). However, later elaborative studies identified a more nuanced pattern of sequence divergence among IDRs where some IDRs and amino acids contributing to IDR formation were found to be highly conserved (17, 47–49). FLZ domain was found to be the most conserved region in FLZ proteins suggesting the existence of different rates of sequence divergence among the different regions in the FLZ proteins (6, 7). To know whether the IDR-rich N and C termini of FLZ proteins show more sequence divergence compared with the ordered FLZ domain, we estimated the Ka/Ks ratio of the N and C termini and FLZ domain region of putative orthologous genes from six closely related species each from monocot and eudicots (Fig. 10; Table S5). Interestingly, among the 112 total gene pairs we analyzed, 92 pairs showed increased Ka/Ks ratio for the N terminus compared with FLZ domain. The remaining 20 pairs showed high ratio value for FLZ domain region compared with the N terminus (Table S5). This observation suggests that different regions of FLZ proteins are evolving under different evolutionary constraint, and in general the N terminus is under a more relaxed selection than the FLZ domain. Interestingly, the C-terminal region showed great variation in the Ka/Ks ratio (Fig. 10; Table S5). In many proteins, the C-terminal region showed very high sequence divergence, and in some proteins this region was found to be under strong purifying selection. We found high variation in ratio among the orthologous genes from the same species pair. The difference in the age of duplicated genes, which occurred due to the rampant WGD events in the angiosperms, could be the major contributing factor for this variation in the ratio (50).
Figure 10.
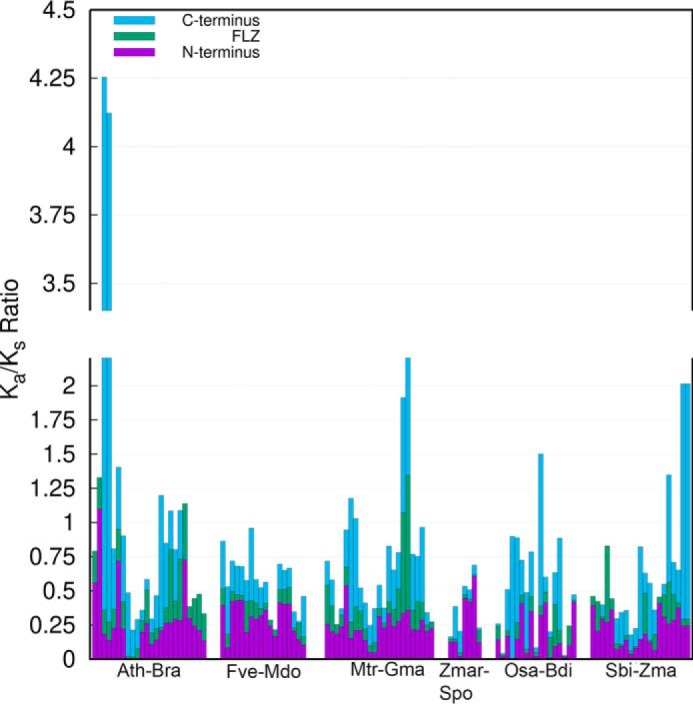
Estimation of sequence divergence rate in different regions of FLZ proteins. The Ka/Ks ratio between putative orthologous FLZ genes from 12 different angiosperms was calculated. The cumulative ratio of each orthologous gene pair is represented by single bar. The Ka/Ks ratio of each region of the gene pair is marked by different color. The detailed table of Ka/Ks estimation is given in Table S5. The species used for this analysis were abbreviated in the graph as follows: A. thaliana (Ath); Brassica rapa (Bra); Fragaria vesca (Fve); Malus domestica (Mdo); Medicago truncatula (Mdo); Glycine max (Gma); Zostera marina (Zmar); Spirodela polyrhiza (Spo); Oryza sativa (Osa); Brachypodium distachyon (Bdi); Sorghum bicolor (Sbi); and Zea mays (Zma).
Discussion
SnRK1/SNF1/AMPK1 is a conserved obligate heterotrimeric serine/threonine kinase in eukaryotes. Mounting evidence from studies using diverse eukaryotic models identified that AMPK and its homologs work as master regulators of adaptive growth in response to energy deficit (3). To achieve this, SNF1/AMPK1 interacts with a large number of proteins involved in the regulation of primary metabolism, transcription, splicing, translation, protein trafficking, autophagy, protein degradation, etc. (51–56). Many of these proteins are phosphorylation targets of SNF1/AMPK1, and through these phosphorylation events, it works as a central regulator of growth in eukaryotes (57, 58). Understandably, AMPK signaling is implicated in many diseases in humans (59). The SnRK1 subunits are also found to be interacting with diverse proteins and possess functions similar to SNF1/AMPK (8, 60). These studies suggest that SnRK1/SNF1/AMPK1 complex works as a convergent point/hub of many diverse signaling pathways. Earlier, due to promiscuous nature of the interaction of FLZ proteins with SnRK1α subunits and common interacting partners, FLZ proteins were proposed to be scaffolds of SnRK1 enzyme complex (9, 10). In this study, our in silico analysis predicts that FLZ proteins possess evolutionarily conserved IDRs. Together with the FLZ domain, they contribute to the interaction of these proteins with SnRK1 subunits and other FLZ proteins. These IDRs might be playing an important part in the proposed role of FLZ proteins as the scaffolding proteins.
The enhanced propensity for protein binding and the enrichment of PTM sites observed in the in silico analysis prompted us to investigate the role of IDRs in protein–protein interaction. Intriguingly, the FLZ domain region showed significant enrichment of potential tyrosine phosphorylation sites that could be due to the presence of two relatively conserved tyrosines in the spacer region across the plant lineage (6, 7). The conservation of these residues across the plant lineage suggests their possible roles in regulating the protein–protein interactions mediated by the FLZ domain. In our Y2H assays with all subunits of SnRK1 in Arabidopsis, we could identify previously unknown interactions of FLZ proteins with SnRK1 kinase subunits that were also verified by the BiFC assay. Furthermore, FLZ proteins also showed extensive interaction with SnRK1β and βγ subunits. It should be noted that there could be more interactions between SnRK1 subunits and FLZ proteins than what we identified in this study because the Y2H interactions are heavily dependent on the orientation of the construct and choice of AD and BD vectors (61).
The promiscuous interactions of FLZ proteins with SnRK1 subunits further reinforce their role as scaffold proteins of the SnRK1 complex. The FLZ proteins are relatively small proteins in angiosperm, and we speculated that the scaffold might be formed due to the interaction of different FLZ proteins. Indeed, we found that FLZ proteins show homo- and heterodimerization properties. Intriguingly, some proteins, such as FLZ7, FLZ12, and FLZ15, showed promiscuous dimerization property, whereas proteins such as FLZ1 and FLZ6 showed very specific interactions. It is indeed an interesting observation because, in multiprotein complexes, some core proteins can possess a promiscuous interaction property that helps in recruiting other subunits to the complex. A remarkable example for such core proteins is MED14 and MED17 subunits in the Mediator complex, which interact with a large number of other subunits (62). More functional and structural studies can uncover whether FLZ7, FLZ12, and FLZ15 possess similar functions in facilitating the formation of the FLZ protein complex.
Our results suggest that the IDRs in the N terminus are involved in the complex formation of FLZ proteins with SnRK1β and βγ subunits and FLZ proteins. The FLZ domain was found to be solely responsible for mediating interaction with SnRK1α subunits. However, in some cases the FLZ domain produced weak or no interaction. Previously, we have shown that although the FLZ domain is sufficient to mediate interaction with other proteins, the strength of the interaction is significantly diminished when the FLZ domain alone was used, suggesting that other regions in the protein facilitate stronger binding (6). Apart from this, the stringency of selection medium must have also contributed to the weak interaction; and no interaction observed in case of FLZ3 and FLZ15 with SnRK1α1. Although we predicted the enrichment of IDRs in the C terminus, in our interaction analysis with C-terminal constructs, we could not recapitulate any interactions. The C termini in FLZ proteins are usually small, and it is yet to be seen whether the IDR in this region possess any specific function or indirectly contribute to interactions facilitated by other regions.
We also found a general reduction in the size of FLZ proteins in most of the angiosperms with limited novel domain acquisition. This reduction in the overall protein size seems to have occurred due to the contraction of N termini. Although the number of FLZ proteins is limited in algae and bryophytes, they showed a relatively long N terminus with more disordered regions. In angiosperms, due to the contraction of N termini, the number and length of IDRs are generally reduced. The protein–protein interaction analysis in Arabidopsis suggests that FLZ proteins interact among themselves, and these interactions might be important in scaffold formation. Many regulatory pathways, which are essential for the survival in terrestrial environment, originated as simpler pathways with few proteins and regulatory modules in algae and bryophytes, and their complexity is gradually increased with the addition of more genes and regulatory interactions in higher plants (21, 63, 64). A classic example is the evolution of the auxin perception signaling pathway where successive additions of different modules resulted in the formation of a multilayered and complex regulatory pathway in higher plants (65). Interestingly, the expansion of FLZ gene family is also implicated in the evolution of body plan complexity in angiosperms (66). One possibility is that the solitary or limited number of FLZ proteins in the Charophyta and Bryophyta with its long N terminus enriched with IDRs can harbor SnRK1 and its limited number of binding partners in lower plants. The rampant gene duplication events in higher plants and the gradual increase of biological complexity might also have increased the complexity of SnRK1 signaling. The concurrent duplication and divergence of FLZ genes in higher plants might have resulted in functional specialization and facilitated the scaffold formation by the interaction of multiple FLZ proteins. Supporting this hypothesis, comparison of the distribution of ANCHOR-based disorder-to-order transition regions and LC regions in lower plants and spermatophytes identified a restricted distribution where some proteins in a species showed an enhanced number of such regions in spermatophytes. Taken together, these results suggest a gradual increase in the complexity of SnRK1–FLZ signaling pathway in higher plants. Interestingly, even after keeping very low stringency (five tandem amino acid residues with a propensity score of ≥0.5) for MoRF prediction, a very low number of MoRFs was predicted in the FLZ proteins, especially at the N-terminal region. In fact, proteome level analysis identified that only about 21% of the IDRs in eukaryotes contain MoRFs. This percentage is slightly increased to 29% in bacteria and archaea (36). These results indicate that a large majority of IDRs do not undergo disorder-to-order transition upon binding to the targets. These IDRs with increased conformational plasticity are often involved in the formation of fuzzy complexes (17). ANCHOR predicted more disorder-to-order transition regions in FLZ proteins compared with fMORFPred. This difference could be due to the difference in the prediction methods where MoRFPred uses more elaborative prediction strategy and displayed significantly better performance (33, 35, 67). The reduced frequency of MoRFs in the IDRs of FLZ proteins suggests that they might be involved in the formation of complexes with more conformational freedom such as fuzzy complexes, and this feature might help in recruiting diverse targets of SnRK1. The increased sequence divergence observed in the IDR-rich regions of FLZ proteins might have accelerated the adaptability and enhanced the binding repertoire of IDRs.
The in planta analysis identified that FLZ proteins interact with SnRK1 subunits in the common cytoplasmic foci indicating the formation of a complex. The colocalization analysis with a marker protein and stain in this study and a previous study identified that SnRK1–FLZ interaction colocalizes with ER, which provides clues about the biological significance of this complex (14). In most cases, these interactions were found to be located in the proximity of the nucleus suggesting that it might be the regions in ER where ribosomes are studded and mRNA translation is undergoing. Studies in various eukaryotes, including plants, suggest a pivotal role of SNF1/AMPK/SnRK1 signaling in negatively regulating the protein synthesis during energy starvation (3, 4, 68). Upon activation by starvation signals, AMPK inhibits TOR activity through phosphorylating RAPTOR, which promotes its dissociation from the TOR complex (69). This phosphorylation and the negative regulation are found to be conserved in plants as well (70). The multisubunit eukaryotic initiation factor 3 (eIF3), which is involved in the translation initiation, also works as a scaffold for TOR and its immediate target, ribosomal S6 kinases 1 and 2 (S6K1/2). Upon activation, the mTOR complex phosphorylates S6K1/2, which results in its dissociation from the eIF3 complex and further phosphorylation and activation by PDK1. The activated S6K1/2 phosphorylates eukaryotic translation initiation factor 4B (eIF4B) and ribosomal protein S6 (RPS6), a subunit of the 40S ribosome (71). mTOR, through the phosphorylation events detailed above and other phosphorylations, promotes translation in response to activation signals (68). In plants, this mechanism is found to be conserved where auxin was identified as one of the potent activators of TOR (72). TOR complex can also directly associate with ribosome (72, 73). Taken together, these results indicate that the TOR and S6K shuttle from the inactive to active pool depending on signals and that they are linked with ribosomes. Although the role of AMPK as a potent inhibitor of mTOR-mediated activation of translation is known, how the AMPK is recruited to this complex is still elusive. The interaction of cell death-inducing DNA fragmentation factor 45-like effector A (CIDEA) with AMPKβ subunit colocalizes with ER in brown adipose tissue suggesting that AMPK also exists in close proximity with ribosomes (74). In the subcellular localization assays, SnRK1 kinase subunits were found to be predominantly localized in the nucleus and cytoplasm (3, 9, 75). We found that most of the FLZ proteins also show a similar localization pattern. However, the specific localization of the SnRK1–FLZ interaction to the bodies colocalizing with ER indicates that FLZ proteins might be responsible for the recruitment of SnRK1 to the translation-regulating complex. This hypothesis is supported by the fact that FLZ proteins also show promiscuous interaction with RAPTOR (8). The expression of FLZ genes is highly regulated by cellular energy levels (76). Indeed, functional analysis with individual FLZ genes identified that they not only work as inert scaffolding proteins but also regulate the level of SnRK1α1 and hence SnRK1 and TOR activity (14). Energy status and SnRK1 signaling regulate the transcription of FLZ genes (76). These results indicate that this complex formation might be regulated by energy status and might be involved in the regulation of SnRK1 signaling in plants. Taken together, this study identified that the FLZ domain and IDRs in the FLZ proteins coordinate in the formation of a complex with SnRK1. Because SnRK1 is a highly structured complex, the surface provided by the interaction of multiple FLZ proteins may help in the recruitment of upstream and downstream factors to the SnRK1 complex.
Experimental procedures
Identification of FLZ proteins from different plant genomes
In the previous studies, we identified FLZ proteins from more than 40 plant genomes through BLASTP and PFAM and InterPro Id (PF04570 and IPR007650)–based searches (6, 7). We used this dataset to create a hidden Markov model profile of the FLZ domain. Using this HMM profile, proteins containing the FLZ domain were identified from 33 genomes, which represent important taxonomical positions in the plant lineage (Fig. S1) using Hmmsearch available in the HMMER web server version 2.15.0 with the given parameters (significance e-value: 0.01 for sequence and 0.03 for hits). Simultaneously, three rounds of iterative-BLAST searches were performed in the reference proteomes using aligned FLZ domain sequences using jackhmmer available in the HMMER web server version 2.15.0 with the given parameters (significance e-value: 0.01 for sequence and 0.03 for hits). The hits obtained from the profile HMM–based search and iterative BLAST searches were combined with the previous dataset and outliers and repeats were removed. Finally, the nonredundant dataset was screened with Batch Web CD-search Tool (77) for the presence of FLZ and other protein domains (Table S2). The final set of protein sequences used for the analysis is given in Table S1. The species tree of the 33 genomes of interest was retrieved from NCBI Taxonomy Common Tree Tool and edited and visualized in FigTree version 1.4.3 (http://tree.bio.ed.ac.uk/software/figtree/).7 The reported common and lineage-specific WGD events (50, 79) in these species were also annotated in the species tree. The average size of FLZ proteins in a species is calculated as the mean size of all FLZ proteins in the given species.
Disorder prediction
The disorder of FLZ proteins was predicted by the meta-predictor PONDR-FIT (20) using protein sequences as input. The average disorder score and standard deviation of each protein residue were obtained in the tabular form which is used for subsequent analysis (deposited in Figshare; https://figshare.com/s/0372c02ce2ed1173d93e).7 We classified IDRs into two groups. Amino acid stretches ranging from 10 to 29 residues with average disorder score for each residue of ≥0.5 are classified as short IDRs. Amino acid stretches of ≥30 residues long with average disorder score for each residue of ≥0.5 are categorized as long IDRs. As used in the earlier studies (80, 81), a maximum three tandem amino acids with less than a 0.5 average disorder score is set as the tolerance limit. The boundaries of the N terminus, the FLZ domain, and the C terminus were determined by Batch Web CD-search Tool (77), and the average disorder score of each part was calculated from the disorder score of all amino acid residues in the region. An IDR is categorized as junction-IDR if at least five disordered residues (disorder score for each residue ≥0.5) are located in the other region. The IDRs identified from different regions of FLZ proteins are given in Table S3. Statistical sampling and data sorting was performed by employing in-house C++ scripts, and figures were generated in gnuplot version 5.2.
Binding propensity, disorder-to-order transition, and low complexity region predictions
The propensity of protein and nucleic acid binding of the N and C termini were calculated by DisoRDPbind (23) using protein sequences as input. The protein, DNA, and RNA binding scores of each protein residue were obtained in tabular form. The average binding propensity of N and C termini was calculated from the binding score of all amino acid residues in the particular region (deposited in Figshare; https://figshare.com/s/0372c02ce2ed1173d93e).
The protein-binding disordered regions of FLZ proteins, which undergo disorder-to-order transition upon binding with globular proteins, were predicted by ANCHOR (33) using protein sequences as input. The results obtained were presented in tabular form (Table S6). The MoRFs were predicted by fMoRFpred (36). At least five amino acids in tandem with the propensity score of ≥0.5 for MoRF was considered as a potential MoRF. The final results obtained were presented in tabular form (Table S7).
The LCRs in the FLZ proteins were identified by SEG algorithm (40), and the results obtained were presented in tabular form (Table S8). The average protein and nucleic acid binding propensity, frequency of ANCHOR-based binding regions, MoRF, and LCR were converted to heat maps using MultiExperiment Viewer (MeV, version 4.8) (82).
Post-translational modification site prediction
The putative serine, threonine, and tyrosine phosphorylation sites with a prediction score of ≥0.5 in the N and C termini and FLZ domain regions of FLZ proteins were identified by Netphos3.1 (26). The putative arginine and lysine methylation sites with support vector machine score of ≥0.5 in different regions of FLZ proteins were identified by PMeS (83). The acetylation residues in the N and C termini and FLZ domain was predicted with PAIL (84) with medium stringency. The PTM site data obtained from this analysis was presented in Table S4. Paired t test was used to identify the difference in the distribution of PTM sites in N and C termini compared with FLZ domain.
Yeast two-hybrid assays
The full-length CDS of FLZ genes and SnRK1 subunits were amplified by CDS-specific primers (Table S9) and cloned into the pCR8/GW/TOPO vector using the pCR8/GW/TOPO cloning kit (Invitrogen). Subsequently, positive clones were mobilized to pGBKT7g (BD) and pGADT7g (AD) (61) vectors using Gateway cloning strategy (Invitrogen). All partial clones of FLZ genes were prepared using specific primers (Table S9) using the same strategy. The chimeric FLZ1N–FLZ2NIDR2 was constructed in pJET1.2 vector (ThermoFisher Scientific) and mobilized to pCR8/GW/TOPO vector. Subsequently, the construct was mobilized to pGBKT7g vector. All Y2H experiments were conducted in Y2H gold yeast strain according to the manufacturer's protocol (Clontech). Before the Y2H experiment, all the BD constructs were subjected to auto-activation and toxicity test as per the manufacturer's protocol (Clontech). For Y2H assays, respective AD and BD constructs were cotransformed in Y2H gold strain using EZ-Yeast transformation kit (MP Biomedicals), and transformed colonies were selected on Double Dropout medium (DDO; Trp−/Leu−). The transformed colonies were cultured, and equal amounts of cells were spotted on interaction screening Quadruple Dropout medium (QDO) supplemented with X-α-Gal and aureobasidin A (Trp−/Leu−/His−/Ade−/XαGal+/AbA+). Simultaneously, a negative control experiment with BD vector and AD construct was carried out to identify false interactions. The experiments were repeated three times.
Site-directed mutagenesis
The SDM of FLZ domain of FLZ8 (C225S, C226S, C227S, C229S, C249S, and C252S) was performed in the pCR8/GW/TOPO-FLZ8 construct by QuikChange site-directed mutagenesis kit using the specific primers (Table S9) according to the manufacturer's protocol (Agilent). All mutations were verified by sequencing. Subsequently, the mutated constructs were mobilized to pGBKT7g using Gateway cloning (Invitrogen).
Bimolecular fluorescent complementation
The FLZ and SnRK1 subunits cloned in pCR8/GW/TOPO vector were mobilized to pSAT4-DEST-N(1–174) EYFP-C1 and pSAT5-DEST-C(175-END) EYFP-C1 vectors (85) using Gateway cloning strategy (Invitrogen). The BiFC assays were performed in onion epidermal peel system by bombarding both constructs by PDS-1000 Helios Gene Gun (Bio-Rad). A negative control experiment was conducted with vector alone along with the other construct to find out false-positive results. The ER-marker construct (44) was obtained from ABRC and transformed with BiFC constructs for colocalization. After bombardment, samples were incubated at 22 °C for at least 16 h in the dark. DAPI staining was performed as described previously (6). For staining with ER–Tracker Red dye (Invitrogen), the samples were washed three times in Hanks' balanced salt solution (HBSS) without phenol red. Subsequently, samples were stained with 1 μm ER–Tracker Red dye prepared in HBSS at 30 °C for 30 min in dark. The samples were subjected to a quick wash in HBSS before visualization. All visualization and photography were performed in TCS SP2 (AOBS) laser confocal-scanning microscope (Leica Microsystems) or AxioImager M2 Imaging System (Zeiss).
Subcellular localization assays
Subcellular localization assays were performed in onion epidermis and Arabidopsis mesophyll protoplasts. The FLZ genes cloned in pCR8/GW/TOPO vector were mobilized to pEG104 vector (86) using Gateway cloning strategy (Invitrogen). The constructs and vector alone were transfected individually to onion epidermis through PDS-1000 Helios Gene Gun (Bio-Rad) and incubated at 22 °C for at least 16 h in the dark. Arabidopsis mesophyll protoplasts were prepared and transfected with vector and constructs as described previously (87). After the transfection, mesophyll protoplasts were incubated at 22 °C for 16 h in the light. All visualization and photography were performed in TCS SP2 (AOBS) laser confocal-scanning microscope (Leica Microsystems).
Analysis of selection pressure on FLZ proteins
The putative orthologs from six closely related species each from monocots and eudicots were recovered through Bayesian phylogenetic reconstruction in TOPALI version 2.5 (88). The protein and CDS sequences were split to N and C termini and FLZ domain based on Batch Web CD-search Tool (77). The nonsynonymous (Ka) and synonymous (Ks) substitution rates and Ka/Ks ratio of each orthologous pair were estimated in the codeml program in PAML (78) package (Table S5). Protein regions with a minimum of 15 amino acid residues were considered for Ka and Ks estimation. The data sorting was performed by in-house C++ scripts, and the graph was generated in gnuplot version 5.2.
Author contributions
M. J. K. and A. L. conceptualization; M. J. K. resources; M. J. K. and A. L. data curation; M. J. K. and N. G. software; M. J. K., B. N. S., S. J., N. G., and C. T. M. formal analysis; M. J. K. and A. L. supervision; M. J. K., B. N. S., S. J., and C. T. M. investigation; M. J. K. and N. G. visualization; M. J. K., S. J., and N. G. methodology; M. J. K. writing-original draft; M. J. K. and A. L. project administration; S. J. and A. L. writing-review and editing; A. L. funding acquisition.
Supplementary Material
Acknowledgment
We acknowledge NIPGR Confocal Facility for their assistance in microscopy.
This work was supported in part by Project Grant BT/PR8001/BRB/10/1211/2013 from the Department of Biotechnology, Government of India, and a Core Grant from the National Institute of Plant Genome Research. The authors declare that they have no conflicts of interest with the contents of this article.
This article contains Figs. S1–S9 and Tables S1–S9.
Please note that the JBC is not responsible for the long-term archiving and maintenance of this site or any other third party hosted site.
- TOR
- target of rapamycin
- AMPK
- AMP-activated protein kinase
- FLZ
- FCS-like zinc finger
- IDR
- intrinsically disordered region
- PTM
- post-translational modification
- DAPI
- 4,6-diamidino-2-phenylindole
- WGD
- whole-genome duplication
- BiFC
- bimolecular fluorescent complementation
- ER
- endoplasmic reticulum
- HBSS
- Hank's balanced salt solution
- Y2H
- yeast two-hybrid
- QDO
- Quadruple Dropout medium
- DDO
- Double Dropout medium
- LCR
- low complexity region
- MoRF
- molecular recognition feature
- SDM
- site-directed mutagenesis
- BD
- DNA-binding domain
- AD
- activating domain
- CDS
- coding sequence.
References
- 1. Heilbronn L. K., and Ravussin E. (2005) Calorie restriction extends life span—but which calories? PLoS Med. 2, e231 10.1371/journal.pmed.0020231 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Minina E. A., Sanchez-Vera V., Moschou P. N., Suarez M. F., Sundberg E., Weih M., and Bozhkov P. V. (2013) Autophagy mediates caloric restriction-induced lifespan extension in Arabidopsis. Aging Cell 12, 327–329 10.1111/acel.12048 [DOI] [PubMed] [Google Scholar]
- 3. Broeckx T., Hulsmans S., and Rolland F. (2016) The plant energy sensor: evolutionary conservation and divergence of SnRK1 structure, regulation, and function. J. Exp. Bot. 67, 6215–6252 10.1093/jxb/erw416 [DOI] [PubMed] [Google Scholar]
- 4. Dobrenel T., Caldana C., Hanson J., Robaglia C., Vincentz M., Veit B., and Meyer C. (2016) TOR signaling and nutrient sensing. Annu. Rev. Plant Biol. 67, 261–285 10.1146/annurev-arplant-043014-114648 [DOI] [PubMed] [Google Scholar]
- 5. Roustan V., Jain A., Teige M., Ebersberger I., and Weckwerth W. (2016) An evolutionary perspective of AMPK–TOR signaling in the three domains of life. J. Exp. Bot. 67, 3897–3907 10.1093/jxb/erw211 [DOI] [PubMed] [Google Scholar]
- 6. Jamsheer K. M., and Laxmi A. (2014) DUF581 is plant specific FCS-like zinc finger involved in protein–protein interaction. PLoS ONE 9, e99074 10.1371/journal.pone.0099074 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Jamsheer K. M., Mannully C. T., Gopan N., and Laxmi A. (2015) Comprehensive evolutionary and expression analysis of FCS-like zinc finger gene family yields insights into their origin, expansion and divergence. PLoS ONE 10, e0134328 10.1371/journal.pone.0134328 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Arabidopsis Interactome Mapping Consortium. (2011) Evidence for network evolution in an Arabidopsis interactome map. Science 333, 601–607 10.1126/science.1203877 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Nietzsche M., Schiessl I., and Börnke F. (2014) The complex becomes more complex: protein–protein interactions of SnRK1 with DUF581 family proteins provide a framework for cell- and stimulus type-specific SnRK1 signaling in plants. Front. Plant Sci. 5, 54 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Nietzsche M., Landgraf R., Tohge T., and Börnke F. (2016) A protein–protein interaction network linking the energy-sensor kinase SnRK1 to multiple signaling pathways in Arabidopsis thaliana. Curr. Plant Biol. 5, 36–44 10.1016/j.cpb.2015.10.004 [DOI] [Google Scholar]
- 11. He Y., and Gan S. (2004) A novel zinc-finger protein with a proline-rich domain mediates ABA-regulated seed dormancy in Arabidopsis. Plant Mol. Biol. 54, 1–9 10.1023/B:PLAN.0000028730.10834.e3 [DOI] [PubMed] [Google Scholar]
- 12. Chen X., Zhang Z., Visser R. G., Broekgaarden C., and Vosman B. (2013) Overexpression of IRM1 enhances resistance to aphids in Arabidopsis thaliana. PLoS ONE 8, e70914 10.1371/journal.pone.0070914 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Hou X., Liang Y., He X., Shen Y., and Huang Z. (2013) A novel ABA-responsive TaSRHP gene from wheat contributes to enhanced resistance to salt stress in Arabidopsis thaliana. Plant Mol. Biol. Rep. 31, 791–801 10.1007/s11105-012-0549-9 [DOI] [Google Scholar]
- 14. Jamsheer K. M., Sharma M., Singh D., Mannully C. T., Jindal S., Shukla B. N., and Laxmi A. (2018) FCS-like zinc finger 6 and 10 repress SnRK1 signalling in Arabidopsis. Plant J. 94, 232–245 10.1111/tpj.13854 [DOI] [PubMed] [Google Scholar]
- 15. Good M. C., Zalatan J. G., and Lim W. A. (2011) Scaffold proteins: hubs for controlling the flow of cellular information. Science 332, 680–686 10.1126/science.1198701 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16. Cortese M. S., Uversky V. N., and Dunker A. K. (2008) Intrinsic disorder in scaffold proteins: getting more from less. Prog. Biophys. Mol. Biol. 98, 85–106 10.1016/j.pbiomolbio.2008.05.007 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. van der Lee R., Buljan M., Lang B., Weatheritt R. J., Daughdrill G. W., Dunker A. K., Fuxreiter M., Gough J., Gsponer J., Jones D. T., Kim P. M., Kriwacki R. W., Oldfield C. J., Pappu R. V., Tompa P., et al. (2014) Classification of intrinsically disordered regions and proteins. Chem. Rev. 114, 6589–6631 10.1021/cr400525m [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Haynes C., Oldfield C. J., Ji F., Klitgord N., Cusick M. E., Radivojac P., Uversky V. N., Vidal M., and Iakoucheva L. M. (2006) Intrinsic disorder is a common feature of hub proteins from four eukaryotic interactomes. PLoS Comput. Biol. 2, e100 10.1371/journal.pcbi.0020100 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Hu J., Neiswinger J., Zhang J., Zhu H., and Qian J. (2015) Systematic prediction of scaffold proteins reveals new design principles in scaffold-mediated signal transduction. PLoS Comput. Biol. 11, e1004508 10.1371/journal.pcbi.1004508 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Xue B., Dunbrack R. L., Williams R. W., Dunker A. K., and Uversky V. N. (2010) PONDR-FIT: A meta-predictor of intrinsically disordered amino acids. Biochim. Biophys. Acta 1804, 996–1010 10.1016/j.bbapap.2010.01.011 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. Hori K., Maruyama F., Fujisawa T., Togashi T., Yamamoto N., Seo M., Sato S., Yamada T., Mori H., Tajima N., Moriyama T., Ikeuchi M., Watanabe M., Wada H., Kobayashi K., et al. (2014) Klebsormidium flaccidum genome reveals primary factors for plant terrestrial adaptation. Nat. Commun. 5, 3978 10.1038/ncomms4978 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Cumberworth A., Lamour G., Babu M. M., and Gsponer J. (2013) Promiscuity as a functional trait: intrinsically disordered regions as central players of interactomes. Biochem. J. 454, 361–369 10.1042/BJ20130545 [DOI] [PubMed] [Google Scholar]
- 23. Peng Z., and Kurgan L. (2015) High-throughput prediction of RNA, DNA and protein binding regions mediated by intrinsic disorder. Nucleic Acids Res. 43, e121 10.1093/nar/gkv585 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Collins M. O., Yu L., Campuzano I., Grant S. G., and Choudhary J. S. (2008) Phosphoproteomic analysis of the mouse brain cytosol reveals a predominance of protein phosphorylation in regions of intrinsic sequence disorder. Mol. Cell. Proteomics 7, 1331–1348 10.1074/mcp.M700564-MCP200 [DOI] [PubMed] [Google Scholar]
- 25. Gao J., and Xu D. (2012) Correlation between posttranslational modification and intrinsic disorder in protein. Pac. Symp. Biocomput. 2012, 94–103 [PMC free article] [PubMed] [Google Scholar]
- 26. Blom N., Gammeltoft S., and Brunak S. (1999) Sequence and structure-based prediction of eukaryotic protein phosphorylation sites. J. Mol. Biol. 294, 1351–1362 10.1006/jmbi.1999.3310 [DOI] [PubMed] [Google Scholar]
- 27. Erce M. A., Abeygunawardena D., Low J. K., Hart-Smith G., and Wilkins M. R. (2013) Interactions affected by arginine methylation in the yeast protein–protein interaction network. Mol. Cell. Proteomics 12, 3184–3198 10.1074/mcp.M113.031500 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Winter D. L., Abeygunawardena D., Hart-Smith G., Erce M. A., and Wilkins M. R. (2015) Lysine methylation modulates the protein–protein interactions of yeast cytochrome c Cyc1p. Proteomics 15, 2166–2176 10.1002/pmic.201400521 [DOI] [PubMed] [Google Scholar]
- 29. Young N. D., Debellé F., Oldroyd G. E., Geurts R., Cannon S. B., Udvardi M. K., Benedito V. A., Mayer K. F., Gouzy J., Schoof H., Van de Peer Y., Proost S., Cook D. R., Meyers B. C., Spannagl M., et al. (2011) The Medicago genome provides insight into the evolution of rhizobial symbioses. Nature 480, 520–524 10.1038/nature10625 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30. Iakoucheva L. M., Radivojac P., Brown C. J., O'Connor T. R., Sikes J. G., Obradovic Z., and Dunker A. K. (2004) The importance of intrinsic disorder for protein phosphorylation. Nucleic Acids Res. 32, 1037–1049 10.1093/nar/gkh253 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31. Wright P. E., and Dyson H. J. (2015) Intrinsically disordered proteins in cellular signalling and regulation. Nat. Rev. Mol. Cell Biol. 16, 18–29 10.1038/nrm3920 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32. Amborella Genome Project. (2013) The Amborella genome and the evolution of flowering plants. Science 342, 1241089 10.1126/science.1241089 [DOI] [PubMed] [Google Scholar]
- 33. Dosztányi Z., Mészáros B., and Simon I. (2009) ANCHOR: web server for predicting protein binding regions in disordered proteins. Bioinformatics 25, 2745–2746 10.1093/bioinformatics/btp518 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Hsu W.-L., Oldfield C. J., Xue B., Meng J., Huang F., Romero P., Uversky V. N., and Dunker A. K. (2013) Exploring the binding diversity of intrinsically disordered proteins involved in one-to-many binding. Protein Sci. 22, 258–273 10.1002/pro.2207 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35. Disfani F. M., Hsu W.-L., Mizianty M. J., Oldfield C. J., Xue B., Dunker A. K., Uversky V. N., and Kurgan L. (2012) MoRFpred, a computational tool for sequence-based prediction and characterization of short disorder-to-order transitioning binding regions in proteins. Bioinformatics 28, i75–i83 10.1093/bioinformatics/bts209 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36. Yan J., Dunker A. K., Uversky V. N., and Kurgan L. (2016) Molecular recognition features (MoRFs) in three domains of life. Mol. BioSyst. 12, 697–710 10.1039/C5MB00640F [DOI] [PubMed] [Google Scholar]
- 37. Karlin S., Brocchieri L., Bergman A., Mrazek J., and Gentles A. J. (2002) Amino acid runs in eukaryotic proteomes and disease associations. Proc. Natl. Acad. Sci. U.S.A. 99, 333–338 10.1073/pnas.012608599 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38. Afek A., Shakhnovich E. I., and Lukatsky D. B. (2011) Multi-scale sequence correlations increase proteome structural disorder and promiscuity. J. Mol. Biol. 409, 439–449 10.1016/j.jmb.2011.03.056 [DOI] [PubMed] [Google Scholar]
- 39. Coletta A., Pinney J. W., Solís D. Y., Marsh J., Pettifer S. R., and Attwood T. K. (2010) Low-complexity regions within protein sequences have position-dependent roles. BMC Syst. Biol. 4, 43 10.1186/1752-0509-4-43 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40. Wootton J. C., and Federhen S. (1996) Analysis of compositionally biased regions in sequence databases. Methods Enzymol. 266, 554–571 10.1016/S0076-6879(96)66035-2 [DOI] [PubMed] [Google Scholar]
- 41. Ramon M., Ruelens P., Li Y., Sheen J., Geuten K., and Rolland F. (2013) The hybrid four-CBS-domain KINβγ subunit functions as the canonical γ subunit of the plant energy sensor SnRK1. Plant J. 75, 11–25 10.1111/tpj.12192 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42. Emanuelle S., Hossain M. I., Moller I. E., Pedersen H. L., van de Meene A. M., Doblin M. S., Koay A., Oakhill J. S., Scott J. W., Willats W. G., Kemp B. E., Bacic A., Gooley P. R., and Stapleton D. I. (2015) SnRK1 from Arabidopsis thaliana is an atypical AMPK. Plant J. 82, 183–192 10.1111/tpj.12813 [DOI] [PubMed] [Google Scholar]
- 43. Glab N., Oury C., Guérinier T., Domenichini S., Crozet P., Thomas M., Vidal J., and Hodges M. (2017) The impact of Arabidopsis thaliana SNF1-related-kinase 1 (SnRK1)-activating kinase 1 (SnAK1) and SnAK2 on SnRK1 phosphorylation status: characterization of a SnAK double mutant. Plant J. 89, 1031–1041 10.1111/tpj.13445 [DOI] [PubMed] [Google Scholar]
- 44. Nelson B. K., Cai X., and Nebenführ A. (2007) A multicolored set of in vivo organelle markers for co-localization studies in Arabidopsis and other plants. Plant J. 51, 1126–1136 10.1111/j.1365-313X.2007.03212.x [DOI] [PubMed] [Google Scholar]
- 45. Goldstein R. A. (2008) The structure of protein evolution and the evolution of protein structure. Curr. Opin. Struct. Biol. 18, 170–177 10.1016/j.sbi.2008.01.006 [DOI] [PubMed] [Google Scholar]
- 46. Brown C. J., Takayama S., Campen A. M., Vise P., Marshall T. W., Oldfield C. J., Williams C. J., and Dunker A. K. (2002) Evolutionary rate heterogeneity in proteins with long disordered regions. J. Mol. Evol. 55, 104–110 10.1007/s00239-001-2309-6 [DOI] [PubMed] [Google Scholar]
- 47. Ahrens J. B., Nunez-Castilla J., and Siltberg-Liberles J. (2017) Evolution of intrinsic disorder in eukaryotic proteins. Cell. Mol. Life Sci. 74, 3163–3174 10.1007/s00018-017-2559-0 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48. Ahrens J., Dos Santos H. G., and Siltberg-Liberles J. (2016) The nuanced interplay of intrinsic disorder and other structural properties driving protein evolution. Mol. Biol. Evol. 33, 2248–2256 10.1093/molbev/msw092 [DOI] [PubMed] [Google Scholar]
- 49. Schaefer C., Schlessinger A., and Rost B. (2010) Protein secondary structure appears to be robust under in silico evolution while protein disorder appears not to be. Bioinformatics 26, 625–631 10.1093/bioinformatics/btq012 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50. Panchy N., Lehti-Shiu M., and Shiu S.-H. (2016) Evolution of gene duplication in plants. Plant Physiol. 171, 2294–2316 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51. Ho Y., Gruhler A., Heilbut A., Bader G. D., Moore L., Adams S.-L., Millar A., Taylor P., Bennett K., Boutilier K., Yang L., Wolting C., Donaldson I., Schandorff S., Shewnarane J., et al. (2002) Systematic identification of protein complexes in Saccharomyces cerevisiae by mass spectrometry. Nature 415, 180–183 10.1038/415180a [DOI] [PubMed] [Google Scholar]
- 52. Fiedler D., Braberg H., Mehta M., Chechik G., Cagney G., Mukherjee P., Silva A. C., Shales M., Collins S. R., van Wageningen S., Kemmeren P., Holstege F. C., Weissman J. S., Keogh M.-C., Koller D., et al. (2009) Functional organization of the S. cerevisiae phosphorylation network. Cell 136, 952–963 10.1016/j.cell.2008.12.039 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53. Sharifpoor S., van Dyk D., Costanzo M., Baryshnikova A., Friesen H., Douglas A. C., Youn J.-Y., VanderSluis B., Myers C. L., Papp B., Boone C., and Andrews B. J. (2012) Functional wiring of the yeast kinome revealed by global analysis of genetic network motifs. Genome Res. 22, 791–801 10.1101/gr.129213.111 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54. Rolland T., Taan M., Charloteaux B., Pevzner S. J., Zhong Q., Sahni N., Yi S., Lemmens I., Fontanillo C., Mosca R., Kamburov A., Ghiassian S. D., Yang X., Ghamsari L., Balcha D., et al. (2014) A proteome-scale map of the human interactome network. Cell 159, 1212–1226 10.1016/j.cell.2014.10.050 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55. Huttlin E. L., Ting L., Bruckner R. J., Gebreab F., Gygi M. P., Szpyt J., Tam S., Zarraga G., Colby G., Baltier K., Dong R., Guarani V., Vaites L. P., Ordureau A., Rad R., et al. (2015) The BioPlex Network: a systematic exploration of the human interactome. Cell 162, 425–440 10.1016/j.cell.2015.06.043 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56. Hein M. Y., Hubner N. C., Poser I., Cox J., Nagaraj N., Toyoda Y., Gak I. A., Weisswange I., Mansfeld J., Buchholz F., Hyman A. A., and Mann M. (2015) A human interactome in three quantitative dimensions organized by stoichiometries and abundances. Cell 163, 712–723 10.1016/j.cell.2015.09.053 [DOI] [PubMed] [Google Scholar]
- 57. Herzig S., and Shaw R. J. (2018) AMPK: guardian of metabolism and mitochondrial homeostasis. Nat. Rev. Mol. Cell Biol. 19, 121–135 10.1038/nrm.2017.95 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58. Garcia D., and Shaw R. J. (2017) AMPK: mechanisms of cellular energy sensing and restoration of metabolic balance. Mol. Cell 66, 789–800 10.1016/j.molcel.2017.05.032 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59. Carling D. (2017) AMPK signalling in health and disease. Curr. Opin. Cell Biol. 45, 31–37 10.1016/j.ceb.2017.01.005 [DOI] [PubMed] [Google Scholar]
- 60. Baena-González E., Rolland F., Thevelein J. M., and Sheen J. (2007) A central integrator of transcription networks in plant stress and energy signalling. Nature 448, 938–942 10.1038/nature06069 [DOI] [PubMed] [Google Scholar]
- 61. Stellberger T., Häuser R., Baiker A., Pothineni V. R., Haas J., and Uetz P. (2010) Improving the yeast two-hybrid system with permutated fusions proteins: the varicella zoster virus interactome. Proteome Sci. 8, 8 10.1186/1477-5956-8-8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62. Harper T. M., and Taatjes D. J. (2017) The complex structure and function of Mediator. J. Biol. Chem. 2017 10.1074/jbc.R117.794438 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63. Shaw A. J., Szövényi P., and Shaw B. (2011) Bryophyte diversity and evolution: windows into the early evolution of land plants. Am. J. Bot. 98, 352–369 10.3732/ajb.1000316 [DOI] [PubMed] [Google Scholar]
- 64. Bowman J. L., Kohchi T., Yamato K. T., Jenkins J., Shu S., Ishizaki K., Yamaoka S., Nishihama R., Nakamura Y., Berger F., Adam C., Aki S. S., Althoff F., Araki T., Arteaga-Vazquez M. A., et al. (2017) Insights into land plant evolution garnered from the Marchantia polymorpha genome. Cell 171, 287–304 10.1016/j.cell.2017.09.030 [DOI] [PubMed] [Google Scholar]
- 65. Kato H., Nishihama R., Weijers D., and Kohchi T. (2018) Evolution of nuclear auxin signaling: lessons from genetic studies with basal land plants. J. Exp. Bot. 69, 291–301 10.1093/jxb/erx267 [DOI] [PubMed] [Google Scholar]
- 66. Kramer E. M., and Li W. (2017) A transcriptomics and comparative genomics analysis Reveals gene families with a role in body plan complexity. Front. Plant Sci. 8, 869 10.3389/fpls.2017.00869 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67. Malhis N., and Gsponer J. (2015) Computational identification of MoRFs in protein sequences. Bioinformatics 31, 1738–1744 10.1093/bioinformatics/btv060 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68. Ma X. M., and Blenis J. (2009) Molecular mechanisms of mTOR-mediated translational control. Nat. Rev. Mol. Cell Biol. 10, 307–318 10.1038/nrm2672 [DOI] [PubMed] [Google Scholar]
- 69. Gwinn D. M., Shackelford D. B., Egan D. F., Mihaylova M. M., Mery A., Vasquez D. S., Turk B. E., and Shaw R. J. (2008) AMPK phosphorylation of Raptor mediates a metabolic checkpoint. Mol. Cell 30, 214–226 10.1016/j.molcel.2008.03.003 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70. Nukarinen E., Nägele T., Pedrotti L., Wurzinger B., Mair A., Landgraf R., Börnke F., Hanson J., Teige M., Baena-Gonzalez E., Dröge-Laser W., and Weckwerth W. (2016) Quantitative phosphoproteomics reveals the role of the AMPK plant ortholog SnRK1 as a metabolic master regulator under energy deprivation. Sci. Rep. 6, 31697 10.1038/srep31697 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71. Holz M. K., Ballif B. A., Gygi S. P., and Blenis J. (2005) mTOR and S6K1 mediate assembly of the translation preinitiation complex through dynamic protein interchange and ordered phosphorylation events. Cell 123, 569–580 10.1016/j.cell.2005.10.024 [DOI] [PubMed] [Google Scholar]
- 72. Schepetilnikov M., Dimitrova M., Mancera-Martínez E., Geldreich A., Keller M., and Ryabova L. A. (2013) TOR and S6K1 promote translation reinitiation of uORF-containing mRNAs via phosphorylation of eIF3h. EMBO J. 32, 1087–1102 10.1038/emboj.2013.61 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 73. Oh W. J., Wu C. C., Kim S. J., Facchinetti V., Julien L.-A., Finlan M., Roux P. P., Su B., and Jacinto E. (2010) mTORC2 can associate with ribosomes to promote cotranslational phosphorylation and stability of nascent Akt polypeptide. EMBO J. 29, 3939–3951 10.1038/emboj.2010.271 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74. Qi J., Gong J., Zhao T., Zhao J., Lam P., Ye J., Li J. Z., Wu J., Zhou H.-M., and Li P. (2008) Downregulation of AMP-activated protein kinase by Cidea-mediated ubiquitination and degradation in brown adipose tissue. EMBO J. 27, 1537–1548 10.1038/emboj.2008.92 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75. Bitrián M., Roodbarkelari F., Horváth M., and Koncz C. (2011) BAC-recombineering for studying plant gene regulation: developmental control and cellular localization of SnRK1 kinase subunits. Plant J. 65, 829–842 10.1111/j.1365-313X.2010.04462.x [DOI] [PubMed] [Google Scholar]
- 76. Jamsheer K. M., and Laxmi A. (2015) Expression of Arabidopsis FCS-like zinc finger genes is differentially regulated by sugars, cellular energy level, and abiotic stress. Front. Plant Sci. 6, 746 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77. Marchler-Bauer A., Derbyshire M. K., Gonzales N. R., Lu S., Chitsaz F., Geer L. Y., Geer R. C., He J., Gwadz M., Hurwitz D. I., Lanczycki C. J., Lu F., Marchler G. H., Song J. S., Thanki N., et al. (2015) CDD: NCBI's conserved domain database. Nucleic Acids Res. 43, D22–D226 10.1093/nar/gku1221 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78. Suyama M., Torrents D., and Bork P. (2006) PAL2NAL: robust conversion of protein sequence alignments into the corresponding codon alignments. Nucleic Acids Res. 34, W609–W612 10.1093/nar/gkl315 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79. Lee T.-H., Tang H., Wang X., and Paterson A. H. (2013) PGDD: a database of gene and genome duplication in plants. Nucleic Acids Res. 41, D1152–D1158 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80. Tóth-Petróczy A., Oldfield C. J., Simon I., Takagi Y., Dunker A. K., Uversky V. N., and Fuxreiter M. (2008) Malleable machines in transcription regulation: the mediator complex. PLoS Comput. Biol. 4, e1000243 10.1371/journal.pcbi.1000243 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 81. Nagulapalli M., Maji S., Dwivedi N., Dahiya P., and Thakur J. K. (2016) Evolution of disorder in Mediator complex and its functional relevance. Nucleic Acids Res. 44, 1591–1612 10.1093/nar/gkv1135 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 82. Saeed A. I., Bhagabati N. K., Braisted J. C., Liang W., Sharov V., Howe E. A., Li J., Thiagarajan M., White J. A., and Quackenbush J. (2006) TM4 microarray software suite. Methods Enzymol. 411, 134–193 10.1016/S0076-6879(06)11009-5 [DOI] [PubMed] [Google Scholar]
- 83. Shi S.-P., Qiu J.-D., Sun X.-Y., Suo S.-B., Huang S.-Y., and Liang R.-P. (2012) PMeS: prediction of methylation sites based on enhanced feature encoding scheme. PLoS ONE 7, e38772 10.1371/journal.pone.0038772 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 84. Li A., Xue Y., Jin C., Wang M., and Yao X. (2006) Prediction of Nϵ-acetylation on internal lysines implemented in Bayesian discriminant method. Biochem. Biophys. Res. Commun. 350, 818–824 10.1016/j.bbrc.2006.08.199 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 85. Tzfira T., Tian G.-W., Lacroix B., Vyas S., Li J., Leitner-Dagan Y., Krichevsky A., Taylor T., Vainstein A., and Citovsky V. (2005) pSAT vectors: a modular series of plasmids for autofluorescent protein tagging and expression of multiple genes in plants. Plant Mol. Biol. 57, 503–516 10.1007/s11103-005-0340-5 [DOI] [PubMed] [Google Scholar]
- 86. Earley K. W., Haag J. R., Pontes O., Opper K., Juehne T., Song K., and Pikaard C. S. (2006) Gateway-compatible vectors for plant functional genomics and proteomics. Plant J. 45, 616–629 10.1111/j.1365-313X.2005.02617.x [DOI] [PubMed] [Google Scholar]
- 87. Wu F.-H., Shen S.-C., Lee L.-Y., Lee S.-H., Chan M.-T., and Lin C.-S. (2009) Tape-Arabidopsis Sandwich–a simpler Arabidopsis protoplast isolation method. Plant Methods 5, 16 10.1186/1746-4811-5-16 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 88. Milne I., Lindner D., Bayer M., Husmeier D., McGuire G., Marshall D. F., and Wright F. (2009) TOPALi v2: a rich graphical interface for evolutionary analyses of multiple alignments on HPC clusters and multi-core desktops. Bioinformatics 25, 126–127 10.1093/bioinformatics/btn575 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.