

Abstract
As an effective modeling, analysis and computational tool, graph theory is widely used in biological mathematics to deal with various biology problems. In the field of microbiology, graph can express the molecular structure, where cell, gene or protein can be denoted as a vertex, and the connect element can be regarded as an edge. In this way, the biological activity characteristic can be measured via topological index computing in the corresponding graphs. In our article, we mainly study the biology features of biological networks in terms of eccentric topological indices computation. By means of graph structure analysis and distance calculating, the exact expression of several important eccentric related indices of hypertree network and X-tree are determined. The conclusions we get in this paper illustrate that the bioengineering has the promising application prospects.
Keywords: Biological mathematics, DNA sequence, Biological networks, Topological index
1. Introduction
In mathematical biology, mathematical methods are applied to biology to deal with various modeling and calculation problems. In the microscopic field of biology, DNA and other protein molecular structure can be represented as a graph, and thus as a mathematical tool, graph theory is introduced to the analysis and calculation of molecular topology.
1.1. Example 1. DNA graphs
The study of DNA sequence is the most important issue in biology science, and there are lots of contributions on DNA analysis and computation from mathematical and algorithmic point of view (Rastgou et al., 2017, Shoaib et al., 2017) pointed out that Hartree-Fock exchange percentage of density functional has a key factor in getting the structure electronic properties. The notable features sequencing platform based on a mathematical framework and it working mechanism has some characteristics, such as: optimizing cost, implement, and sensitivity analysis to different parameters (O'Reilly et al., 2016). The demography and reproductive success and by means of coalescent theory to compute mitochondrial DNA sequences from the Japanese sardine (Niwa et al., 2016, F.J. Khan et al., 2017, H.U. Khan et al., 2017, Samina and Khan, 2017). The DNA storage channel and modeled the read process considering profile vectors. They raised new asymmetric coding tricks to combat the effects of sequencing noise and synthesis, and an asymptotic analysis of the number of profile vectors was also presented. At last, two families of codes for this channel model were constructed. To effectively store FASTQ files raised by big DNA sequencers, Chlopkowski et al. (2016) determined a specialized compressor designing. The ionization potential with single and double excitations was estimated by means of equation of motion coupled cluster trick, and VIEs is estimated in terms of density functional theory with dispersion corrected omega B97x-D (Chakraborty and Ghosh, 2016). A studied on how to build independent spanning trees on hypercubes and how to use them to predict mitochondrial DNA sequence parts through paths on the hypercube (da Silva and Pedrini, 2016). An alignment-free technology for DNA sequence similarity analysis based on graph theory concepts and genetic codes (Jafarzadeh and Iranmanesh, 2016a, Jafarzadeh and Iranmanesh, 2016b). The new approach to test the DNA sequences using optical joint Fourier transform (Alqallaf and Cherri, 2016). Theoretically studied the transverse electron transport through all four DNA nucleotide bases by electron propagator theory (Kletsov et al., 2015).
Let be an integer. The DNA graph is defined by Wang et al. (2008), and it said that a directed graph is DNA graph whether it can assign a label of length k to each vertex as follows:
-
(1)
where ;
-
(2)
if ;
-
(3)
if an only if .
For a multiset consists of oligonucleotides with length k, a DNA graph can be constructed as follows: set each oligonucleotide with length k from the multiset as a vertex; add an arc between two vertices if the rightmost nucleotides of first vertex overlap with the leftmost nucleotides of the second one. Several contributions on DNA graph and DNA mathematical expression (Aram and Iranmanesh, 2012, Pesek and Zerovnik, 2008, Jafarzadeh and Iranmanesh, 2012, Bokhari and Sauer, 2005, Blazewicz et al., 1999, Sa-Ardyen et al., 2003, Pendavingh et al., 2003, Blazewicz et al., 2009, Pevzner et al., 2001, Jafarzadeh and Iranmanesh, 2013, F.J. Khan et al., 2017, H.U. Khan et al., 2017, Shah and Bushnaq, 2017).
1.2. Example 2. Biological networks
The main task of microorganism science is to study the viruses, protozoa, bacteria, euglena, opalinia, fungi, paramecium and amoeba et al. All living organisms consist of cells which are basic structure of life and can be expressed as vertex in the graph model. As an important biology computation model, biological networks are used to deal with biology problems in which its vertex represent cells, genes or proteins, and its edges are expressed as the potential connection between these components. For instance, the mathematical framework of protein interaction, gene expression, carrier transfer information and metabolic networks can be regarded as biological networks. The topological index defined on biological networks can be considered as a numeric function which maps the given structure to a real number, and thus measure its physical, chemical and biological characters. Some contributions on biological networks and other graph applications in biology science can refer to (Jafarzadeh and Iranmanesh, 2016a, Jafarzadeh and Iranmanesh, 2016b, Nandagopal and Elowitz, 2011, Rajan et al., 2015, Alexander, 2013, Banerjee and Jost, 2007, Ma'ayan, 2008, Mason and Verwoerd, 2006, Lesne, 2006, Eckman and Brown, 2006, Aittokallio and Schwikowski, 2006, El-Ghoul et al., 2006).
In this paper, we focus on the biochemical properties of biological networks via topological index computation. The structure of the rest of this paper is stated as follows: we first give the information about the setting of topological index defined on biological networks; then, the main results and their detailed proofs are presented in Section 3; at last, we discuss the future projects in this filed.
2. Setting
In what follows, let G = be a undirected molecular graph with vertex set and edge set , where each vertex expresses a cell, gene or protein, and each edge is presented as the connection between two components. A topological index can be a function f: which can map each molecular graph to a positive real number. Several degree-based or distance-based topological indices like Wiener index, atom-bond connectivity index, harmonic index, sum connectivity index and others are defined to test the chemical, physical, pharmaceutical and biological properties. Furthermore, there are some mention-able work on distance-based and degree-based topological indices of special structures which can be referred to Basavanagoud et al., 2017, Gao et al., 2016a, Gao et al., 2016b, Gao et al., 2016c, Gao et al., 2016d, Gao et al., 2017a, Gao et al., 2017b, Gao and Siddiqui, 2017, Gao and Wang, 2015, Gao and Wang, 2016.
The distance between two vertices u and v in a connected graph is denoted as the length of the shortest path between them. For any vertex , the eccentricity of v is defined as .
Ghorbani and Khaki (2010) introduced the eccentric version of geometric-arithmetic index as fourth geometric-arithmetic eccentricity index which is stated as
The fourth Zagreb index is defined by Farahani and Kanna (2015) as
Its multiplicative version, named as the fourth multiplicative Zagreb index, is stated by
Analogously, the sixth Zagreb index is described as
And, the multiplicative version, named as sixth multiplicative Zagreb index is defined by
Correspondingly, the fourth Zagreb polynomial and the sixth Zagreb polynomial are defined as
and
respectively.
Motivated by Kulli (2016) who introduced the multiplicative version of first atom bond connectivity index, we defined the fifth multiplicative atom bond connectivity index
The traditional tree pattern of a tree which is a connected cyclic graph, is usually a binary tree where is composed with vertices, and there are a left reference, a right reference and a data element existing in it. We name the top most vertex root. There are three fields in the vertex of the binary tree. To illustrate, the data are denoted in one field, and the information of left and right sons of the vertex is located in the other two fields. The binary tree can meet the requirements to be a complete binary tree (described in Fig. 1), if there are just two descendants in every internal vertex.
Fig. 1.
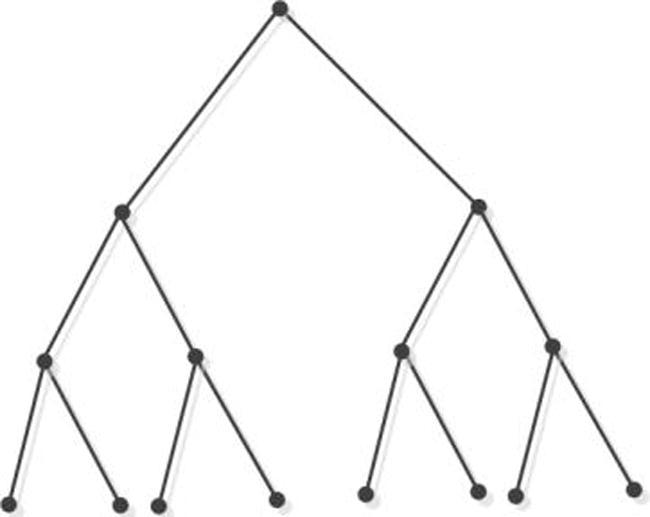
Binary tree.
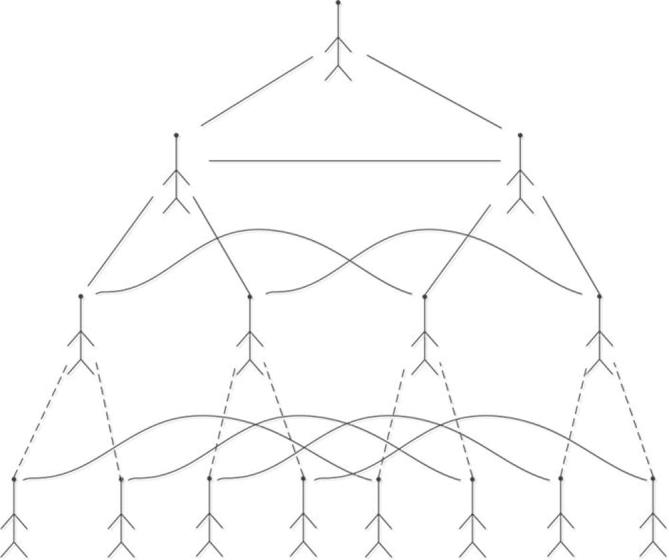
The fundamental structure of hypertree k-level is easy to be confirmed as a complete binary tree . The root vertex of the tree is marked by label 1 and its root is at level 0. If 0 and 1 are added to the labels of the parent vertex separately, we can obtain the labels of left and right children. Then we can denote the children of the vertex x into 2x and 2x + 1. Moreover, other links of hypertree are horizontal and when the label difference of the vertices is , the two vertices which share the same level of the tree are joined. As a result, if we add edges (sibling edges) between left and right children of the same parent vertex, we will get the 1-rooted sibling tree (described in Fig. 2) from the 1-rooted tree .
Fig. 2.

1-rooted sibling tree network .
We also obtain the X-tree whose structure is described in Fig. 3 from complete binary tree on vertices of height and adding paths left to right by all the vertices at level i with .
Fig. 3.

k-level X-tree network .
3. Main results and proofs
This section mainly aims to calculate a closed result of eccentric related indices. Besides, the result of two kinds of eccentric version Zagreb polynomials for hyper binary trees, and for k-level networks is also aimed to be achieved. Meanwhile, with the purpose to explore the biological properties and activities, this section will borrow the networks to biological networks. There are numerous micro livings such as bacteria, viruses and others in our everyday life, which could be a problem of our life and also a good thing for our health. In terms of the structure of bacteria, they are single celled without true nucleus. The bacteria reproduce quickly and productively by conducting binary fission. During the process, a parental cell is splited into two daughter cells. Sometimes, bacteria and viruses could be dangerous in our life, for they may cause disease or make the disease more serious. With the help of replication, the action of copying, we start the reproduction procedure of viruses. Some diseases like Tuberculosis, cholera, typhoid, influenza, HIV (AIDS), chicken pox might be fatal if they are not considered seriously in time.
In the process, it’s the infected person that serves as the media to spread diseases. For example, a person who gets cold and fever will spread the bacteria and viruses whenever they get touch with other people. They can spread by sneezing or by touching/shaking hands with others. Usually, the body fluids play a necessary role in transferring bacteria and viruses among people. We can regard the hypertree network as hypertree biological network. Hence, the parental vertex is considered as the ill person who carries bacteria and viruses, which is shown in Fig. 4. The bacteria reproduce quickly and productively by conducting binary fission, so we can suppose two persons that are infected by an ill person. Their interaction and communications will help to increase the disease level. Maybe one patient is weaker than another one for his immunological deficiency, which arouses the increase in this kind of disease. What we practice in reality to deal with the problem is to take anti-infection medicine. In the below, we obtain a closed result of eccentric related indices and polynomials for hypertree k level which is presented in Fig. 5.
Fig. 4.
Hypertree biological network.
Fig. 5.

k-level hypertree network .
Let and . The edge set E(G) and vertex set V (G) can be classed into the following subsets:
-
•
for any i with , let = {u ∈ V(G)| = i} and ;
-
•
for any i, j meet ≤ i, j ≤ Δ, let = {e = uv ∈ E(G)| = i, and = j} and .
Theorem 1
Let be the k-level hypertree network. We have
Proof of Theorem 1
We prove the result based on the structure analysis and edge dividing technology.
By analyzing the structure of and compute the distances from vertices, it’s edge set can be divided into three partitions according to the eccentricities of associated vertices:
- •
and , where i = 0 and p = k;
- •
and } and , where and ;
- •
} and
where and .
Form the definitions of eccentric version indices, we get
Thus, the desired results are obtained.
In one word, due to people’s social activity, the infected diseases could spread among people directly or indirectly. As a biological network, the X-tree is another form of binary hypertree network. We can regard the parental vertex of X-tree network as the victim, and it will spread the bacteria and viruses among people through the contact with others in in hypertree biological network. We can see that there is a strong relationship among the whole infected persons at each level X-tree in biological network, which is represented in Fig. 6. In contrast, the relevance between two infected persons and the reasons of abundant infections are dealt. As a result, the infections will increase at much higher level than hypertree biological network.
Theorem 2
Let XT(k) be the k-level X-tree with . We get
Proof of Theorem 2
Again, we prove the conclusions in light of the structure analysis and edge dividing technology.
By analyzing the structure of and compute the distances from vertices, it’s edge set can be cut into four subsets by using the eccentricities of associated vertices:
- •
= {e = uv ∈ E(G)| = ec(v) = p}: , where and ; , where and . Thus, .
- •
= {e = uv ∈ E(G)| and } and , where and ;
- •
= {e = uv ∈ E(G)| and } and , where and p = k;
- •
= {e = uv ∈ E(G)|} and where and p = k.
Fig. 6.

X-tree biological network.
Form the definitions of eccentric version indices, we get
Hence, we yield the expected conclusions.
4. Conclusions and future problems
In this paper, we discuss the theoretical topics in some biology problems, and finally determine the eccentric topological indices of biological networks in view of structure analysis, distance calculating and mathematical derivation. Since the biological networks can help the researchers better understand how infectious diseases fast increase through infected persons, the theoretical results have the wide and promising application prospects in biological, medical and pharmacy engineering.
The following topics can be considered as the future work:
-
•
How to structure a kind of graph to express the microstructure under more biology problems.
-
•
Design an algorithm with low computational complexity to express the complex DNA gene structure and apply it in gene mutation.
-
•
How to put the known theoretical results into biological reverse engineering.
Conflict of interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgements
We thank the reviewers for their constructive comments in improving the quality of this paper. This work was supported in part by the National Natural Science Foundation of China (11401519).
Footnotes
Peer review under responsibility of King Saud University.
References
- Aittokallio T., Schwikowski B. Graph-based methods for analysing networks in cell biology. Brief. Bioinform. 2006;7(3):243. doi: 10.1093/bib/bbl022. [DOI] [PubMed] [Google Scholar]
- Alexander S.A. Infinite graphs in systematic biology, with an application to the species problem. Acta. Biotheor. 2013;61(2):181–201. doi: 10.1007/s10441-012-9168-y. [DOI] [PubMed] [Google Scholar]
- Alqallaf A.K., Cherri A.K. Dna sequencing using optical joint fourier transform. Optik – Int. J. Light Electron Opt. 2016;127(4):1929–1936. [Google Scholar]
- Aram V., Iranmanesh A. 3D-dynamic representation of DNA sequences. MATCH-Commun. Math. Comput. Chemist. 2012;67:809–816. [Google Scholar]
- Banerjee A., Jost J. Graph spectra as a systematic tool in computational biology. Discrete Appl. Math. 2007;157(10):2425–2431. [Google Scholar]
- Basavanagoud B., Desai V.R., Patil S. (β, α) -Connectivity index of graphs. Appl. Math. Nonlinear Sci. 2017;2(1):369–374. [Google Scholar]
- Blazewicz J., Bryja M., Figlerowicz M., Gawron P., Kasprzak M., Kirton E. Brief communication: whole genome assembly from 454 sequencing output via modified dna graph concept. Comput. Biol. Chem. 2009;33(3):224–230. doi: 10.1016/j.compbiolchem.2009.04.005. [DOI] [PubMed] [Google Scholar]
- Blazewicz J., Hertz A., Kobler D., De Werra D. On some properties of dna graphs. Discrete Appl. Math. 1999;98(1–2):1–19. [Google Scholar]
- Bokhari S.H., Sauer J.R. A parallel graph decomposition algorithm for dna sequencing with nanopores. Bioinformatics. 2005;21(7):889–896. doi: 10.1093/bioinformatics/bti129. [DOI] [PubMed] [Google Scholar]
- Chakraborty R., Ghosh D. The effect of sequence on the ionization of guanine in dna. Phys. Chem. Chem. Phys. Pccp. 2016;18(9):6526–6533. doi: 10.1039/c5cp07804k. [DOI] [PubMed] [Google Scholar]
- Chlopkowski, M., Antczak, M., Slusarczyk, M., Wdowinski, A., Zajaczkowski, M., Kasprzak, M., 2016. High-order statistical compressor for long-term storage of dna sequencing data. RAIRO - Operations Research.
- Da Silva E., Pedrini H. Inferring patterns in mitochondrial dna sequences through hypercube independent spanning trees. Comput. Biol. Med. 2016;70:51–57. doi: 10.1016/j.compbiomed.2016.01.004. [DOI] [PubMed] [Google Scholar]
- Eckman B.A., Brown P.G. Graph data management for molecular and cell biology. Ibm J. Res. Dev. 2006;50(6):545–560. [Google Scholar]
- El-Ghoul M., El-Ahmady A.E., Homoda T. On chaotic graphs and applications in physics and biology. Chaos, Solitons Fractals. 2006;27(1):159–173. [Google Scholar]
- Farahani M.R., Kanna R.M.R. Fourth Zagreb index of circumcoronene series of benzenoid. Leonardo Electron. J. Pract. Technol. 2015;27:155–161. [Google Scholar]
- Gao, W., Siddiqui, M.K., 2017. Molecular descriptors of nanotube, oxide, silicate, and triangulene networks. J. Chem., 2017, Article ID 6540754 (10p) doi:10.1155/2017/6540754.
- Gao W., Siddiqui M.K., Imran M., Jamil M.K., Farahani M.R. Forgotten topological index of chemical structure in drugs. Saudi Pharm. J. 2016;24(3):258–264. doi: 10.1016/j.jsps.2016.04.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gao W., Farahani M.R., Shi L. The forgotten topological index of some drug structures. Acta Med. Med. 2016;32:579–585. [Google Scholar]
- Gao, W., Wang, W.F., Farahani, M.R., 2016c. Topological indices study of molecular structure in anticancer drugs. J. Chem., 2016, Article ID 3216327 (8p). doi:10.1155/2016/3216327.
- Gao, W., Wang, W.F., Jamil, M.K., Farahani, M.R., 2016d. Electron energy studying of molecular structures via forgotten topological index computation. J. Chem., 2016, Article ID 1053183 (7p). doi:10.1155/2016/1053183.
- Gao W., Baig A.Q., Ali H., Sajjad W., Farahani M.R. Margin based ontology sparse vector learning algorithm and applied in biology science. Saudi J. Biol. Sci. 2017;24(1):132–138. doi: 10.1016/j.sjbs.2016.09.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gao W., Yan L., Shi L. Generalized Zagreb index of polyomino chains and nanotubes. Optoelectron. Adv. Mater. - Rapid Commun. 2017;11(1–2):119–124. [Google Scholar]
- Gao, W., Wang, W.F., 2015. The vertex version of weighted wiener number for bicyclic molecular structures. Comput. Math. Methods Med., 2015, Article ID 418106 (10p) doi:10.1155/2015/418106. [DOI] [PMC free article] [PubMed]
- Gao W., Wang W.F. The eccentric connectivity polynomial of two classes of nanotubes. Chaos, Solitons Fractals. 2016;89:290–294. [Google Scholar]
- Ghorbani M., Khaki A. A note on the fourth version of geometric-arithmetic index. Optoelectron. Adv. Mater. - Rapid Commun. 2010;4(12):2212–2215. [Google Scholar]
- Jafarzadeh N., Iranmanesh A. C-curve: a novel 3d graphical representation of dna sequence based on codons. Math. Biosci. 2013;241(2):217. doi: 10.1016/j.mbs.2012.11.009. [DOI] [PubMed] [Google Scholar]
- Jafarzadeh N., Iranmanesh A. A novel graphical and numerical representation for analyzing DNA sequences based on codons. MATCH-Commun. Math. Comput. Chem. 2012;68:611–620. [Google Scholar]
- Jafarzadeh N., Iranmanesh A. A new graph theoretical method for analyzing DNA sequences based on genetic codes. MATCH-Commun. Math. Comput. Chem. 2016;75(3):731–742. [Google Scholar]
- Jafarzadeh, N., Iranmanesh, A., 2016. Application of graph theory to biological problems, Studia Ubb Chemia, LXI, 9-16.
- Khan F.J., Sarmin N.H., Khan A., Khan H.U. New types of fuzzy interior ideals of ordered semigroups based on fuzzy points. Matriks Sains Matematik. 2017;1(1):25–33. [Google Scholar]
- Khan H.U., Khan A., Khan F.M., Li Y. Generalized Bi-ideal of Ordered Semigroup Related to Intuitionistic Fuzzy Point. Matriks Sains Matematik. 2017;1(1):09–15. [Google Scholar]
- Kletsov, A.A., Glukhovskoy, E.G., Chumakov, A.S., Ortiz, J.V., 2015. Ab initio electron propagator calculations of transverse conduction through dna nucleotide bases in 1-nm nanopore corroborate third generation sequencing. Biochim. Biophys. Acta (BBA) – General Subjects, 1860(1), 140–145. [DOI] [PubMed]
- Kulli V.R. Multiplicative connectivity indices of certain nanotubes. Ann. Pure Appl. Math. 2016;12(2):169–176. [Google Scholar]
- Lesne A. Complex networks: from graph theory to biology. Lett. Math. Phys. 2006;78(3):235–262. [Google Scholar]
- Ma'ayan A. Network integration and graph analysis in mammalian molecular systems biology. Iet Syst. Biol. 2008;2(5):206–221. doi: 10.1049/iet-syb:20070075. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mason O., Verwoerd M. Graph theory and networks in biology. Iet Syst. Biol. 2006;1(2):89–119. doi: 10.1049/iet-syb:20060038. [DOI] [PubMed] [Google Scholar]
- Nandagopal N., Elowitz M.B. Synthetic biology: integrated gene circuits. Science. 2011;333(6047):1244–1248. doi: 10.1126/science.1207084. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Niwa H.S., Nashida K., Yanagimoto T. Reproductive skew in Japanese sardine inferred from DNA sequences. ICES J. Mar. Sci. 2016;73(9):2181–2189. [Google Scholar]
- O'Reilly E., Baccelli F., De Veciana G., Vikalo H. End-to-end optimization of high-throughput DNA sequencing. J. Comput. Biol. 2016;23(10):789–800. doi: 10.1089/cmb.2015.0185. [DOI] [PubMed] [Google Scholar]
- Pendavingh R., Schuurman P., Woeginger G.J. Recognizing dna graphs is difficult. Discrete Appl. Math. 2003;127(1):85–94. [Google Scholar]
- Pesek J., Zerovnik A. Numerical characterization of modified Hamori curve representation of DNA sequences. MATCH-Commun. Math. Comput. Chem. 2008;60:301–312. [Google Scholar]
- Pevzner P.A., Tang H., Waterman M.S. An Eulerian path approach to dna fragment assembly. Proc. Nat. Acad. Sci. USA. 2001;98(17):9748. doi: 10.1073/pnas.171285098. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rajan R.S., Anitha J., Rajasingh I. 2-power domination in certain interconnection networks. Proc. Comput. Sci. 2015;57:738–744. [Google Scholar]
- Rastgou A., Soleymanabadi H., Bodaghi A. DNA sequencing by borophene nanosheet via an electronic response: a theoretical study. Microelectron. Eng. 2017;169:9–15. [Google Scholar]
- Sa-Ardyen P., Jonoska N., Seeman N.C. Self-assembling dna graphs. Nat. Comput. 2003;2(4):427–438. [Google Scholar]
- Samina Shah K., Khan R.A. Study of nonlocal boundary value problems of non-integer order hybrid differential equations. Matriks Sains Matematik. 2017;1(1):21–24. [Google Scholar]
- Shah K., Bushnaq S. Investigating at least one solution to a systems of multi-points boundary value problems. Matriks Sains Matematik. 2017;1(1):16–20. [Google Scholar]
- Shoaib M., Sarwar M., Hussain M., Ali G. Existence and uniqueness of common fixed point for mappings satisfying integral type contractive conditions in G-metric spaces. Matriks Sains Matematik. 2017;1(1):01–08. [Google Scholar]
- Wang S.Y., Yuan J., Lin S.W. Dna labelled graphs with dna computing. Sci. China Math. 2008;51(3):437–452. [Google Scholar]