

Abstract
Circadian rhythmicity, the 24-hour cycle responsive to light and dark, is determined by periodic oscillations in gene transcription. This phenomenon has broad ramifications in physiologic function. Recent work has disclosed more cycles in gene transcription, and to the uncovering of these we apply a novel signal processing methodology known as the pencil method and compare it to conventional parametric, nonparametric, and statistical methods. Methods: In order to assess periodicity of gene expression over time, we analyzed a database derived from livers of mice entrained to a 12-hour light/12-hour dark cycle. We also analyzed artificially generated signals to identify differences between the pencil decomposition and other alternative methods. Results: The pencil decomposition revealed hitherto-unsuspected oscillations in gene transcription with 12-hour periodicity. The pencil method was robust in detecting the 24-hour circadian cycle that was known to exist, as well as confirming the existence of shorter-period oscillations. A key consequence of this approach is that orthogonality of the different oscillatory components can be demonstrated. thus indicating a biological independence of these oscillations, that has been subsequently confirmed empirically by knocking out the gene responsible for the 24-hour clock. Conclusion: System identification techniques can be applied to biological systems and can uncover important characteristics that may elude visual inspection of the data. Significance: The pencil method provides new insights on the essence of gene expression and discloses a wide variety of oscillations in addition to the well-studied circadian pattern. This insight opens the door to the study of novel mechanisms by which oscillatory gene expression signals exert their regulatory effect on cells to influence human diseases.
Introduction
Gene transcription is the process by which the genetic code residing in DNA is transferred to RNA in the nucleus as the inauguration of protein synthesis. The latter process is called translation and occurs in the cytoplasm of the cell. Circadian rhythm, the 24-hour cycle that governs many functions of the cell, is the result of a complex interaction of transcriptional and translational processes. The importance of circadian rhythm to physiologic processes has been underscored in 2017 by the awarding of the Nobel Prize in Physiology or Medicine to the investigators who described the molecular mechanisms controlling it. However, in addition to the circadian oscillation driven by light and dark, other so-called infradian and ultradian rhythms have clear biologic import. Blood pressure, some circulating hormones, and some physiological functions appear to have 12-hour periodicity whereas other processes such as the menstrual cycle more closely follow a lunar cycle.
Accordingly, we sought to uncover novel 12-hour oscillations in gene expression. In many cases, the 12-hour gene oscillation is superimposed on the 24-hour cycle; thus it is hidden in conventional analysis. Additionally, experiments designed to elucidate the 24-hour circadian often do not have the granularity required to reveal an interval of less than 24 hours as they are constrained by the Shannon-Nyquist Sampling Theorem [1].
To reveal periodicities in gene expression other than the 24-hour circadian cycle, we applied digital signal processing methodology to this biologic phenomenon. Although this approach is, to our knowledge, less commonly used in the biological field, it is justified because the transcription of DNA to RNA is indeed a signal, packed with information for making the enormous repertoire of proteins.
To extract the fundamental oscillations (amplitude and period) present in the data, we utilized publicly available time-series microarray datasets on circadian gene expression in mouse liver (under constant darkness) [2] and analyzed over 18,000 genes spanning a variety of cellular process ranging from core clock control, metabolism, and cell cycle to the unfolded protein responses (UPR), a measure of cell stress. In addition, one set of measurements of RER (respiratory exchange ratio) from wild-type mice (generated by us) was also performed. We constructed linear, discrete-time, time-invariant models of low order, driven by initial conditions, which approximately fit the data and thus reveal the fundamental oscillations present in each data set. In addition to the 24-hour (circadian) cycle known to be present, other fundamental oscillations have been revealed using our approach.
Methods
We searched for 12-hour oscillations in several biological systems. Systems were chosen that represented not only gene transcription but also phenotype; they represent the way in which these biological systems are expressed in the whole organism. The reasoning was that if the 12-hour oscillation in transcription was biologically significant, it would be represented in some measurable function of the cell.
Initially, we analyzed a set of transcription data [2] that was collected in mouse liver obtained from animals in constant darkness after being entrained in a 12-hour light/12-hour dark environment. Mice were sacrificed at 1-hour intervals for 48 hours, thus providing enough data points to analyze the signal. The dataset thus obtained contains RNA values for all coding genes. The RNA data were generated using a standard microarray methodology. In addition, RER (respiratory exchange ratio) measurements in mice were also measured and analyzed. The novelty in our analysis consists in using the so-called matrix-pencil method [3]. This is a data-driven system-identification method. It constructs dynamical systems based on time-series data and finds the dominant oscillations present in the ultradian or infradian rhythms. Our purpose here is to compare this method with other established strategies for spectral estimation, including both parametric spectrum estimation methods like MUSIC (MUltiple Signal Classification), ESPRIT (Estimation of Signal Parameters via Rotational Invariance Techniques), and Prony’s (least squares) as well as classical nonparametric models like wavelet transforms and statistical methods like RAIN. These are compared with each other using both artificial and measured data.
Basic signal processing methods
The data. We consider finite records of data resulting as described above. Generically they are denoted by yi, i = 1, ⋯, N.
- Basic model: sum of exponentials. We seek to approximate the data by means of linear combinations of exponentials plus noise. Thus we seek k pairs of complex numbers αi, βi, i = 1, 2, ⋯, k, such that
is the noiseless part of the signal and w(t) is the noise. The requirement is: y(m) ≈ ym, m = 1, 2, ⋯, N. Existing approaches to address this problem are MUSIC, ESPRIT, Prony’s (least squares) method, wavelet transform and statistical methods described later.(1) - Second model: descriptor representation. The equivalent descriptor model uses an associated internal variable of the system. The resulting equations are:
with initial condition , where E, , .(2) - Third model: AR (Auto Regressive) representation. The above model can also be expressed as an AR model driven by an initial condition. As above we let y(t) = y*(t) + w(t), (where y*(t) is the noiseless term and w(t) the noise). It follows that (1) can be rewritten as:
with initial conditions y*(ℓ), ℓ = 0, 1, ⋯, k − 1.(3)
Goal. Discover the fundamental oscillations inherent in the gene data, using these models and reduced versions thereof.
Processing of the data with the pencil method
The data y1, y2, ⋯, yN, are used to form the Hankel matrix:
where for simplicity it is assumed that N = 2k. Then we define the quadruple (E, A, B, C):
| (4) |
This quadruple constitutes the raw model of the data. This model is linear, time-invariant and discrete-time with a non-zero initial condition:
| (5) |
Reduced models and fundamental oscillations. The dominant part of the raw system is determined using a model reduction approach [4], [5], [6], [3]. The procedure is as follows.
Pencil procedure for obtaining dominant sub-models.
- Compute the SVDs:
- Choose the dimension r of the reduced system (e.g r = 3, r = 5, r = 7 etc.). Then
are used to project the raw system to the dominant subsystem of order r:
and .
The associated reduced model of size r is then:
Assuming (as is usually the case) that Er is invertible, the approximated data can be expressed as:
Estimating r. Important byproducts of the pencil method are the singular values s1 and s2 mentioned above. The accuracy of the approximation is determined by the first neglected singular singular value σr+1, as the resulting approximation error is proportional to this singular value. This implies the following rule.
Rule: choose r so that , where ϵ is a tolerance which depends on the data at hand. For instance ϵ = 0.01, implies roughly speaking that data contributing less than 1% to the overall result are discarded. In this regard the following remark is in order. The data considered in this paper are rather short-duration and therefore in many cases we have not truncated the data.
Partial fraction expansion of the associated transfer function. Hr(z) = Cr(z Er − Ar)−1 Br. This involves the eigenvalue decomposition (EVD) of the matrix pencil (Ar, Er), or equivalently of ; let
where the columns of Vr = [v1, ⋯, vr] are the eigenvectors, Λr = diag[λ1, ⋯, λr] are the eigenvalues of the reduced system (poles of Hr(z)), and are the rows of . The approximate data can be expressed as:
where , is the complex amplitude of the ith, oscillation; expressing this in polar form , αi is the real amplitude and θi the phase. Finally, if we express the eigenvalues as , σi is the decay (growth) rate, and ωi the frequency, of the ith oscillation.
Poles and oscillations. Often in (digital) system theory, the quantity is referred to as pole of the associated system. Oscillatory signals result when σi = 0, which it turn implies that the magnitude of the pole λi is equal to one: ∣λi∣ = 1, and the period of oscillation is .
For instance a signal with λi = 1, represents a constant (step), while signals with , (which are both on the unit circle with angles 15°, 30° degrees) represent pure oscillatory signals with periods 24, 12 hours respectively.
Angle between signals and orthogonality. In the sequel we will make use of angles between signals. Here we briefly define these concepts. Given discrete-time finite duration signals (vectors)
their inner product is defined as
where (⋅)* denotes complex conjugation and transposition; the angle between these signals is defined as
| (6) |
where ‖⋅‖ denotes the Euclidean 2-norm. Orthogonality means that the angle between the two signals is , or equivalently that their inner product is zero; this is sometimes denoted by a ⊥ b. In the sequel we also make use of the symbol 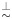 to indicate approximate orthogonality, i.e. an angle between signals close to radians or 90° degrees.
to indicate approximate orthogonality, i.e. an angle between signals close to radians or 90° degrees.
Other methods
To complete the picture, we briefly list other methods which can be used to analyze the gene data.
MUSIC
The MUSIC algorithm [7], [8], is a parametric spectral estimation method based on eigenvalue analysis of a correlation matrix. It uses the orthogonality of the signal subspace and the noise subspace to estimate the frequency of each oscillation. It assumes that a set of data can be modeled as Y = Γa + n, where , is a set of gene transcription data, Γ = [e(ω1) e(ω2) ⋯ e(ωK)] is the transpose of a Vandermonde matrix, K is the number of dominant frequencies, and , a = [a1 a2 ⋯ aK]T contains the amplitudes of the dominant K frequencies, , is white noise. The autocorrelation matrix is
where Λ = diag(λi) and M is the number of columns in the Hankel matrix. We can see that the rank of matrix ΓΛ2 ΓH equals K where the nonzero eigenvalues are . Then the sorted eigenvalues of the autocorrelation matrix Rxx can be expressed as
It follows that the noise subspace contains the eigenvectors of the autocorrelation matrix Rxx corresponding to the N − K smallest eigenvalues. Then
so ΓH G = 0, and the frequency values are the only solutions of e(ω)H GGH e(ω) = 0. The MUSIC algorithm seeks the peaks of the function 1/[e(ω)H GGH e(ω)], where ω ∈ [0, 2π]. The Root MUSIC algorithm seeks the roots of pH(z−1)GGHp(z) that is the Z-transform of e(ω)HGGHe(ω) where z = ejω ∈ C.
The MUSIC algorithm can only provide the frequency information of the signal. To obtain the amplitude of each oscillation, we need to apply least squares fitting, where the amplitudes of dominant oscillations satisfy a = (ΓH Γ)−1 ΓH x. It should mentioned that in contrast with the pencil method, MUSIC cannot provide the decay (growth) rate of the oscillations.
ESPRIT
This is another parametric spectral estimation algorithm [7], [8]. It analyzes the subspaces of the correlation matrix. It estimates the poles relying on rotational transformation. As in MUSIC: , j = 1, ⋯, K, i = 1, ⋯, N, where zj are the poles. We can construct Γ1 = Γ(1: N − 1,:), and Γ2 = Γ(2: N,:). The relationship between these two quantities is Γ2 = Γ1 Φ, where Φ = diag [z1, z2, ⋯, zK], is the phase shift matrix that represents a rotation. Now we construct a similar structure applying on signal subspace S that contains the eigenvectors of the autocorrelation matrix Rxx corresponding to the K largest eigenvalues. Let
Note that the relationship between S1 and S2 is S2 = S1 Ψ. Because Γ and S have the same column space (see [7, 8]), we have that Γ = ST, where T is an invertible subspace rotation matrix. So we have Ψ = T-1 ΦT. Therefore the poles are the eigenvalues of Ψ. Finally least square (LS) to obtain The eigenvalues of Ψ, are the poles . Thus ESPRIT can estimate both the frequency and the decay (growth) rate of the oscillations. However, as with MUSIC, we need to use LS to obtain the amplitude of each oscillation.
Wavelet transform
Wavelet transforms can be divided into two categories, the continuous (CWT) and the discrete (DWT) versions. CWT is more suitable for analyzing biologic rhythms because of the associated heat maps are two-dimensional.
In CWT a time signal x(t) is convolved with a wavelet function. This leads to a time-frequency representation which provides spectrum information in a local time window. This transform can be expressed as , where s is the frequency scale, ψ*(t) is the wavelet function. Since the signal data is obtained by sampling, we can approximately rewrite the equation as . It follows that the integral or sum is applied on the range −∞ to ∞ that means the domain of signal x(t) or x(n) should be the range from −∞ to ∞. But the signals considered have finite length, in which case the edge effects become obvious, especially in the low-frequencies.
In practice, there are many wavelet functions that can be chosen, both real- and complex-valued. Real-valued wavelets are useful for treating peaks and discontinuities of signals while complex-valued wavelets yield the information of amplitude and phase simultaneously [9].
Statistical methods
In this section three statistical methods, namely ARSER, JTK_CYCLE and RAIN, will be investigated and their ability to detect biological rhythms evaluated. Those methods focus on the (one) most dominant oscillation in the data, especial JTK_CYCLE and RAIN. These constitute statistical tests that calculate the p-value to determine whether a certain rhythm exists in the data [10–12].
ARSER
ARSER uses the autoregressive (AR) model to obtain the period of oscillation. It then uses linear regression (harmonic) to determine the amplitude and the phase of the oscillation. Finally applying the F-test to pre-processed data and regressive data determines whether an oscillation exists.
Pre-processing the data. Because the data may not be stable, ARSER applies linear detrending to the raw data. It then uses linear regression to fit the data as a straight line. Subsequently ARSER uses a fourth-order Savizky-Golay algorithm to smooth the data. This low-pass filter removes the pseudo-peaks in the spectrum.
Finding the period. ARSER uses an autoregressive model to get the period of the oscillation. Given a pre-processed dataset with period interval Δ.
where ϵt is white noise, αi are AR coefficients, n is the order of model (we choose n = length-of-data/Δ). To calculate the coefficients, ARSER uses the Yule-Walker method, maximum likelihood estimation and the Burg algorithm. After AR modeling, ARSER can calculate the spectrum:
where is the variance of white noise. ARSER finds the peaks in time window t ∈ [20, 28] as the periods {Ti} the oscillation (the optimal periods are determined by Akaike’s information criterion).
Harmonic Regression. Now we can express the pre-processed data as:
where βi1 and βi2 are the amplitudes. ARSER calculates those amplitude through linear regression.
F-test. Using the F-test compares the approximation data and pre-processed data {xt}. The null and the alternative hypotheses are respectively
where Ai are the amplitudes which are calculated using linear regression, and r is the number of coefficients obtained by linear regression. We can calculate the F coefficient by:
Then we can calculate the p value using the F-distribution p = P(F, r − 1, N − r), where P(⋅) is the probability function used to calculate the p value based on F-distribution.
JTK_CYCLE and RAIN
JTK_CYCLE and RAIN use statistical method to detect the trend in data. The former can find the increasing or decreasing trend in data and RAIN is a development of JTK_CYCLE which can combine these two.
A periodic waveform should start from the trough and increase to the peak following a decreasing part to a new trough. Because our data is sampling from the waveform, we can regard every time sampling data point as a variable. Thus we can get n variables for the waveform such that T = nΔ (T is the period of the waveform, Δ is the time interval of sampling point). We assume the variances of those variables are the same. And they have the same mean value only when the data only have noise without periodic oscillation. So the null and the alternative hypotheses are
The alternative hypotheses for RAIN is
Calculating the statistical coefficient of trend. Every variable Fi, corresponds to a sampling dataset , where mi is the number of sampling data point of the ith variable (). Let if Xik ≤ Xjl, and 0 otherwise; and , which is the Mann-Whitney U-statistic for comparison of two variables. For JTK_CYCLE, the statistical coefficient of trend is
For RAIN, the statistical coefficient of trend is
Calculating the p-value. For the test, the p-value . In order to calculate the p-value, we should make clear the distribution f(i) of statistical coefficient s when the null hypotheses H0 is true. Furthermore the distribution f(i) is computed, using a generating function . For JTK_CYCLE and RAIN we have respectively:
Thus G(z) for JTK_CYCLE and RAIN are both polynomials. We can get the distribution f(i) by calculating the coefficients of G(z), which can be used in the p-value equation.
Experimental results: Artificial data
In this section we test the performance of different methods using artificially generated signals. For the continuous wavelet transform, we chose the complex morlet wavelet because it allows changes to the resolution in frequency and time domain. For simulation data, we assume the data has the form
where w is white noise with zero mean and variance σ2 and fi is the ith oscillation, where:
| (7) |
where Ai is the amplitude, σi is the decay (growth) rate, θi is the phase and Ti is the period. At first we assume that the samples are collected in unit time intervals. The parameters are defined in the table below; the first oscillation is almost constant with small decay; the other three oscillations have a period of approximately 24- 12- and 8-hours (see Table 1).
Table 1. Parameters used for the simulation.
| i | A | σ | θ | T |
|---|---|---|---|---|
| 1 | 1 | 0.005 | 0 | ∞ |
| 2 | 1 | 0.004 | 24.8 | |
| 3 | 0.3 | −0.002 | 11.8 | |
| 4 | 0.1 | 0.005 | 7.5 |
The experiment has the following parts. First, the sensitivity to noise is investigated. Here, the variance of noise is changed and the performance of each of the different methods is examined. Second, the impact of the length of the data is investigated. Finally, the frequency of data collection (can be referred to as sampling frequency) will be examined.
Recall that the Nyquist sampling theorem provides the lower bound for the sampling frequency in order to prevent aliasing. This can be used to determine appropriate sampling frequencies for continuous-time signals.
Sensitivity to noise
To test the sensitivity of these various methods to noise, we set the standard deviation of w as σ = [0, 0.03, 0.1, 0.3].
Fig 1 shows curves of different methods and simulation data (length 50) with σ as stated. The red points are simulation data, blue, green and magenta are the curves of the pencil, ESPRIT and MUSIC methods respectively. This figure shows that the pencil and ESPRIT methods yield a perfect fit in all situations. The MUSIC algorithm gives a good fit only for small amounts of noise. In Table 2, we display the poles obtained by using each method.
Fig 1. Curves for simulation data.

Table 2. Poles determined by different methods.
| σ = 0.01 | σ = 0.1 | ||||||
| orig. poles | Pencil | ESPRIT | MUSIC | orig. poles | Pencil | ESPRIT | MUSIC |
| 0.990 | 0.990 | 0.990 | 1.000 | 0.990 | 0.989 | 0.989 | 1.000 |
| 0.958 ± 0.248i | 0.958 ± 0.248i | 0.958 ± 0.248i | 0.970 ± 0.239i | 0.958 ± 0.248i | 0.960 ± 0.248i | 0.960 ± 0.249i | 0.974 ± 0.225i |
| 0.870 ± 0.502i | 0.870 ± 0.512i | 0.870 ± 0.512i | 0.867 ± 0.497i | 0.870 ± 0.502i | 0.867 ± 0.511i | 0.867 ± 0.512i | 0.834 ± 0.551i |
| 0.662 ± 0.735i | 0.662 ± 0.735i | 0.662 ± 0.735i | 0.693 ± 0.721i | 0.662 ± 0.735i | 0.669 − 0.772i | 0.662 ± 0.751i | -0.974 ± 0.2235i |
| σ = 0.03 | σ = 0.3 | ||||||
| orig. poles | Pencil | ESPRIT | MUSIC | orig. poles | Pencil | ESPRIT | MUSIC |
| 0.990 | 0.990 | 0.990 | 1.000 | 0.990 | 0.987 | 0.988 | 1.000 |
| 0.958 ± 0.248i | 0.958 ± 0.248i | 0.958 ± 0.248i | 0.970 ± 0.239i | 0.958 ± 0.248i | 0.965 ± 0.236i | 0.964 ± 0.239i | 0.975 ± 0.221i |
| 0.870 ± 0.502i | 0.870 ± 0.512i | 0.871 ± 0.512i | 0.861 ± 0.507i | 0.870 ± 0.502i | 0.863 ± 0.511i | 0.862 ± 0.513i | 0.880 ± 0.474i |
| 0.662 ± 0.735i | 0.660 ± 0.737i | 0.659 ± 0.736i | 0.712 ± 0.701i | 0.662 ± 0.735i | 0.007 ± 1.021i | -0.001 ± 1.012i | -0.034 ± 0.999i |
In Fig 2, the heat map of the wavelet transform is shown. It follows that yellow region is such that we cannot distinguish two oscillations with close periods. We can recognize 12h and 8h oscillations when the noise is weak. However when the noise is strong (σ = 0.3), only the strongest oscillation can be determined. The edge effect is obvious and there are ghost lines e.g. around 15h, that may lead to false estimation.
Fig 2. Heat maps of the wavelet transform.

From these considerations, we conclude that the pencil and ESPRIT methods are robust to noise. This is not the case for MUSIC and CWT.
Impact of data length
The left-hand side plot of Fig 3 shows fit curves using different methods and simulation data (noise standard deviation 0.05) with duration L = [30, 50, 100, 200]. The time interval for data collection is 1. Red points indicate simulation data, blue, green and magenta are the fit curves of pencil, ESPRIT and MUSIC algorithms, respectively.
Fig 3. Curves for simulation data.

The right-hand side plot shows poles of oscillations estimated with different methods (noise standard deviation 0.05) with duration L = [30, 50, 100, 200]. The time interval for data collection is 1. Black * indicates the original poles of the simulation data, blue, green and magenta are the estimated poles using the pencil, ESPRIT and MUSIC algorithm, respectively. For more accuracy, the poles are also listed in Table 3.
Table 3. Poles for different methods.
| L = 30 | L = 100 | ||||||
| orig. poles | Pencil | ESPRIT | MUSIC | orig. poles | Pencil | ESPRIT | MUSIC |
| 0.995 | 0.896 | -1.043 | 1.000 | 0.995 | 0.994 | 0.994 | 1.000 |
| 0.964 ± 0.249i | 0.778 ± 0.661i | 0.305 ± 0.000i | 0.977 ± 0.213i | 0.964 ± 0.249i | 0.964 ± 0.249i | 0.964 ± 0.249i | 0.969 ± 0.246i |
| 0.863 ± 0.505i | 0.447 ± 0.000i | 0.772 − 0.653i | 0.806 ± 0.591i | 0.863 ± 0.505i | 0.863 ± 0.508i | 0.863 ± 0.508i | 0.857 ± 0.514i |
| 0.665 ± 0.739i | 1.093 − 0.329i | 1.085 ± 0.324i | 0.456 ± 0.889i | 0.665 ± 0.739i | 0.661 ± 0.734i | 0.659 ± 0.733i | 0.648 ± 0.761i |
| L = 50 | L = 200 | ||||||
| orig. poles | Pencil | ESPRIT | MUSIC | orig. poles | Pencil | ESPRIT | MUSIC |
| 0.995 | 0.995 | 0.995 | 1.000 | 0.995 | 0.995 | 0.995 | 1.000 |
| 0.964 ± 0.249i | 0.964 ± 0.250i | 0.964 ± 0.250i | 0.970 ± 0.239i | 0.964 ± 0.249i | 0.964 ± 0.249i | 0.964 ± 0.249i | 0.972 ± 0.234i |
| 0.863 ± 0.505i | 0.864 ± 0.511i | 0.863 ± 0.510i | 0.824 ± 0.566i | 0.863 ± 0.505i | 0.863 ± 0.508i | 0.863 ± 0.508i | 0.857 ± 0.514i |
| 0.665 ± 0.739i | 0.655 ± 0.727i | 0.652 ± 0.731i | -0.336 ± 0.941i | 0.665 ± 0.739i | 0.663 ± 0.737i | 0.663 ± 0.737i | -0.336 ± 0.941i |
Rate of data collection (sampling frequency)
To investigate the impact of sampling of the underlying continuous-time signal, we generate artificial data with L = 50. Then we apply all methods to the original dataset, the half-data set (time collection interval I = 2) and third-data set (that is 1, 4, 7, 10 ⋯ with time collection interval I = 3). In Fig 4, the left-hand side plot below shows heat maps (Y-axis is frequency domain, X-axis is time domain) of simulation data (noise standard deviation 0.05) with duration L = [30, 50, 100, 200]. The right-hand side plot shows data fit for the various methods.
Fig 4. Heat maps (left) and fit curves (right).

Conclusion. From the above considerations it follows that decreasing the sampling frequency does not affect the estimation significantly. This means that the data rate collection (sampling frequency) is not an important factor. In contrast, the data length is a crucial factor for all methods.
Experimental results: The pencil method applied to gene data
In this section we analyze a small part of the measured data in order to validata some of the aspects of the pencil method and its comparison with the other methods.
Batch consisting of 171 measurements every 40min The results in this case are summarized in Table 4 and Fig 5 (S1 File. DATA 171 is a 10 x 171 matrix; the first row contains time; the remaining rows contain the measurements taken from 9 mice.)
Table 4. Data averaged over all mice.
| A | P | T |
|---|---|---|
| 0.1594 | 0.9022 | – |
| 0.0010 | 1.0050 | 1.4483 |
| 0.0017 | 0.9985 | 1.8434 |
| 0.0034 | 0.9956 | 9.8050 |
| 0.0164 | 1.0013 | 23.9361 |
| 0.9239 | 0.9986 | dc |
Fig 5. Plots for averaged data.

Batch consisting of RER for restrictively fed mice (218 meas. every 40min) (see Table 5 and S2 File. DATA 218 is a 10 x 218 matrix; the first row contains time; the remaining rows the measurements taken from 9 mice.).
Table 5. Model parameters for mouse # 1.
| Mouse #1 | ||
|---|---|---|
| A | P | T |
| 0.0037 | 1.0005 | 4.8275 |
| 0.0116 | 0.9961 | 7.4236 |
| 0.0256 | 0.9993 | 7.9961 |
| 0.0010 | 1.0043 | 20.2774 |
| 0.0817 | 1.0001 | 23.9264 |
| 0.8843 | 1.0001 | dc |
Fig 6 shows the approximation by 1, 2 and 3 oscillations (upper pane) and the first four fundamental oscillations (lower pane). Table 6 shows the error and the angles (S3 File. DATA 15 is a 15 x 48 matrix; each row corresponds to a different gene; time runs from 1 to 48 hours).
Fig 6. Plots for mouse #1.

Table 6. Errors and angles.
| Relative approximation error | Angle between approximant & error | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 3-fit | 5-fit | 7-fit | 9-fit | 3-fit | 5-fit | 7-fit | 9-fit | ||
| Gene 1 | 0.1973 | 0.1276 | 0.1122 | 0.1299 | Gene 1 | 88.72 | 88.65 | 88.66 | 90.46 |
| Gene 2 | 0.2217 | 0.2028 | 0.1669 | 0.1375 | Gene 2 | 88.00 | 89.84 | 87.27 | 86.17 |
| Gene 3 | 0.2801 | 0.3940 | 0.2038 | 0.2112 | Gene 3 | 91.92 | – | 92.25 | 91.54 |
| Gene 4 | 0.2654 | 0.2525 | – | 0.2026 | Gene 4 | 89.82 | 94.18 | – | 92.30 |
| Gene 5 | 0.4296 | 0.3780 | 0.1970 | – | Gene 5 | 84.35 | 86.36 | 89.74 | – |
| Gene 6 | 0.2493 | 0.2563 | 0.1918 | 0.1929 | Gene 6 | 86.94 | 91.78 | 88.39 | 88.78 |
| Gene 7 | 0.1971 | 0.1525 | 0.1475 | 0.1547 | Gene 7 | 89.71 | 88.23 | 88.33 | 90.17 |
| Gene 8 | 0.1914 | 0.1681 | 0.1402 | 0.1619 | Gene 8 | 87.45 | 88.19 | 87.02 | 89.11 |
| Gene 9 | 0.1832 | 0.1913 | 0.1403 | 0.1357 | Gene 9 | 86.36 | 92.63 | 86.64 | 86.68 |
| Gene 10 | 0.2016 | 0.2013 | 0.1874 | 0.2089 | Gene 10 | 86.78 | 87.81 | 86.42 | 89.90 |
| Gene 11 | 0.2637 | 0.2623 | – | 0.2083 | Gene 11 | 92.80 | 91.36 | – | 90.92 |
| Gene 12 | 0.2174 | 0.1681 | 0.2116 | 0.1484 | Gene 12 | 91.20 | 90.18 | 94.12 | 90.59 |
| Gene 13 | 0.3420 | 0.2154 | – | 0.2270 | Gene 13 | 87.25 | 88.50 | – | 91.57 |
| Gene 14 | 0.3140 | 0.2671 | 0.2452 | 0.2034 | Gene 14 | 90.36 | 94.35 | 93.30 | 91.35 |
| Gene 15 | 0.4058 | 0.3374 | 0.3052 | 0.2281 | Gene 15 | 88.15 | 84.41 | 91.66 | 90.31 |
We analyze the relationship among the decomposed oscillations, by calculating the angle among these oscillations for 10 different genes. We set r = 9, i.e. the gene signals contain four oscillations fi, i = 1, ⋯, 4. The approximant is thus . See also Table 7 (S4 File. DATA 10 is a 10 x 48 matrix; each row corresponds to a different gene; time runs from 1 to 48 hours.)
Table 7. Angle between error vector and approximates.
| Gene | r = 3 | r = 5 | r = 7 | r = 9 |
|---|---|---|---|---|
| Bmal | 89.4040 | 89.0189 | 88.7227 | 89.4645 |
| Clock | 97.5846 | 95.6007 | – | 154.5354 |
| per1 | 87.3120 | 87.0905 | – | 122.6093 |
| per2 | 84.0943 | 84.3410 | 84.2252 | 97.1281 |
| cry1 | 83.6787 | 85.7345 | 83.9466 | – |
| cry2 | 88.0607 | 85.8548 | 85.7156 | 87.9577 |
| rorc | 88.2740 | 87.0592 | 90.5345 | – |
| rora | 92.5359 | – | 90.2449 | 90.3424 |
| rev-erba | 93.4881 | 92.5612 | 91.1162 | 91.4786 |
| reb-rebb | 89.2219 | 89.2972 | 89.0471 | 90.6819 |
From the above tables, we can see that the angle between oscillations is around 90° in most situations. So oscillations are nearly orthogonal:
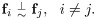 |
It has actually been shown in [13] that these oscillations are independent of each other.
Batch consisting of various measurements using mice—38 min intervals (see Table 8 (S4) and Table 9 as well as Fig 7 (S5 File. DATA 186 is a 6 x 186 matrix; the first row contains time; the rest represent: food intake, ambulatory activity, total activity, ZTOT and heat.)
Table 8. Angle between oscillations.
| Gene | f1 vs f2 | f1 vs f3 | f1 vs f4 | f2 vs f3 | f2 vs f4 | f3 vs f4 |
|---|---|---|---|---|---|---|
| Bmal | 90.9499 | 91.8664 | 87.7962 | 85.2451 | 91.2452 | 91.7038 |
| Clock | 89.4592 | 87.9364 | – | 106.0165 | – | – |
| per1 | 85.4061 | 93.9105 | 87.4712 | 74.9960 | 90.2287 | 101.0929 |
| per2 | 91.6425 | 94.1211 | 89.7681 | 88.9246 | 90.6757 | 90.4533 |
| cry1 | 83.3704 | 87.0513 | – | 89.2173 | – | – |
| cry2 | 84.0615 | 91.3131 | 90.0791 | 90.9828 | 86.2981 | 88.1623 |
| rorc | 88.6977 | 94.5739 | 87.0044 | 99.9135 | 85.2751 | 93.1401 |
| rora | 91.3788 | 89.7184 | 89.8657 | 92.8563 | 88.6223 | 90.5763 |
| rev-erba | 94.9717 | 83.6197 | 88.9055 | 98.3908 | 90.8681 | 91.7753 |
| reb-rebb | 88.4669 | 89.5753 | 90.7263 | 90.9262 | 88.9671 | 92.8038 |
Table 9. Model parameters for various activities.
| Food intake | Ambulatory activity | Total activity | ZTOT | Heat | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | P | T | A | P | T | A | P | T | A | P | T | A | P | T |
| 0.0049 | 1.0014 | 1.4798 | 34.3158 | 1.0029 | 2.1857 | 46.2589 | 0.9996 | 2.1752 | 39.9181 | 1.0055 | 6.0855 | 0.0076 | 1.0013 | - |
| 0.0143 | 0.9946 | 1.5812 | 87.9712 | 0.9997 | 8.0524 | 139.9357 | 1.0002 | 8.0445 | 86.2169 | 1.0052 | 8.1064 | 0.0225 | 0.9936 | 8.1278 |
| 0.0106 | 1.0002 | 8.5909 | 111.7862 | 1.0004 | 12.1124 | 183.2241 | 1.0009 | 12.1327 | 138.1809 | 1.0052 | 12.1725 | 0.0095 | 1.0019 | 12.3403 |
| 0.0302 | 0.9977 | 23.9810 | 185.3298 | 1.0016 | 24.4907 | 317.1999 | 1.0021 | 24.4595 | 195.7413 | 1.0071 | 24.3164 | 0.0281 | 1.0027 | 24.3605 |
| 0.1189 | 0.9992 | dc | 504.7523 | 1.0003 | dc | 1045.0577 | 1.0005 | dc | 338.0709 | 1.0062 | dc | 0.5181 | 0.9999 | dc |
Fig 7. Ambulatory activity: Approximation and oscillations.

Variation of data collection rate
We compare the oscillations using all data (AD), the first half of the data (FHD), the second half of the data (SHD), odd-position data (OD), and even-position data (ED). This is done for a particular set of measurements, but the results are indicative of what happens in general.
Table 10 shows the estimated periods using different part of the data. It follows that the estimation of periods is consistent using AD, FHD, SHD.
Table 10. Periods estimated using different parts of the data.
| AD/h | FHD/h | SHD/h | OD/h | ED/h | |
|---|---|---|---|---|---|
| 1 | 24.37 | 23.01 | 24.36 | 24.37 | 24.37 |
| 2 | 12.34 | 12.41 | 12.46 | 11.90 | 12.58 |
| 3 | 8.12 | 8.42 | 7.45 | 8.25 | 8.13 |
Discussion and comments
- Orthogonality. Recall the definition of angle between signals defined by (6), and let the original vector of measurements for one gene be denoted by ; let also fi, i = 0, 1, 2, 3, 4, denote the vectors of the DC-component and of the first four fundamental oscillations obtained by means of the pencil reduction method described above. Then the corresponding approximant is . It follows that:
- a. The fundamental oscillations are approximately orthogonal among themselves:
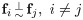 .
. - b. The associated approximant is approximately orthogonal to the error (noise):
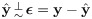 .
.
Interpretation of orthogonality. Orthogonality means that once an oscillation (e.g. the circadian or the 12h rythm) has been determined, further computations will not affect these oscillations. In other words the fundamental oscillations are independent of each other.
Manifestation of orthogonality. As we determine higher-order approximants, i.e. as we add oscillations to the model, the existing ones remain mostly unchanged. Considering the case of the para probe1 gene, we apply the ESPRIT, LS (Prony’s) and pencil methods. The statistical methods (e.g. ARSER) are not used because being non-parametric they do not allow the choice of the order of fit. ESPRIT and LS are not reliable for large orders of fit, therefore the results for the 24-fit model is not shown. The poles of these three methods are depicted in Tables 11, 12 and 13.
Connection with the Fourier transform. The above method provides an almost orthogonal decomposition of a discrete-time signal. The question arises therefore as to whether the same or improved results can be obtained using the Fourier transform and in particular the DFT. Applying the DFT to a length N sequence we obtain a decomposition in terms of the N given frequencies or periods, which are (in decreasing order) . Therefore unless the frequencies of the underlying oscillations are exactly among the ones above, the results of the DFT are not useful.
The least squares (Prony’s) method. This method is not appropriate for cases where the poles are on or close to the unit circle (pure or almost pure oscillations). Fig 8 depicts this fact in the case of the RER data. The conclusion is that while the matrix pencil method (red dots) gives oscillatory poles, this is by far not the case with the LS (prony’s) method (green dots).
Comparison of different methods (see Table 14).
Table 11. Poles for the ESPRIT method.
| ESPRIT | |||
|---|---|---|---|
| 3 − fit | 5 − fit | 7 − fit | 9 − fit |
| 0.993 | 0.993 | 0.993 | 0.993 |
| 0.939±0.273i | 0.944±0.272i | 0.943±0.274i | 0.944±0.274i |
| 0.859±0.509i | 0.866±0.505i | 0.866±0.505i | |
| 0.370±0.892i | 0.374±0.899i | ||
| −0.832±0.213i | |||
Table 12. Poles for the LS method.
| LS (Prony’s method) | |||
|---|---|---|---|
| 3 − fit | 5 − fit | 7 − fit | 9 − fit |
| 0.967 | 0.970 | 0.972 | 0.994 |
| 0.363 | 0.435±0.319i | 0.339±0.354i | 0.863±0.384i |
| −0.486±0.366i | −0.517±0.380i | 0.319±0.863i | |
| 0.363 | −0.475±0.745i | ||
| −0.806±0.299i | |||
Table 13. Poles for the pencil method.
| Pencil method | ||||
|---|---|---|---|---|
| 3-fit | 5-fit | 7-fit | 9-fit | 24-fit (all data) |
| 0.9933 | 0.9932 | 0.9931 | 0.9930 | 0.9915 |
| 0.9436 ± 0.2734i | 0.9449 ±0.2730i | 0.9446 ± 0.2742i | 0.9447 ±0.2747i | 0.9489 ± 0.2843i |
| 0.8609 ±0.5132i | 0.8659 ±0.5086i | 0.8672 ±0.5068i | 0.8729 ± 0.4812i | |
| 0.3831 ±0.9159i | 0.3902 ± 0.9121i | 0.3214 ± 1.1528i | ||
| -0.9780 ±0.3415i | -0.9368 ±0.3683i | |||
Fig 8. Comparison between pencil and LS poles.

Table 14. Strengths and weaknesses of the various methods.
| Method | Parameter Estimation | Estimation Performance | Detection of orthogonality | ||||
|---|---|---|---|---|---|---|---|
| Period | Decay Rate | Amplitude | Phase | Accuracy | Robustness | ||
| DFT | Yes | No | Yes | Yes | Low | Yes | No |
| Wavelet | Yes | Yes | Yes | No | Low | No | No |
| MUSIC | Yes | No | No | No | High | No | No |
| ESPRIT | Yes | Yes | No | No | High | Yes | No |
| Prony (LS) | Yes | Yes | No | No | No | No | No |
| Pencil | Yes | Yes | Yes | Yes | High | Yes | Yes |
Final result
We considered a dataset consisting of 18484 genes; transcription is analyzed using the pencil method [3], the ESPRIT method, Prony’s method and the three statistical methods. The distribution of the poles follow; recall that the poles of ideal oscillations have magnitude equal to 1.
Furthermore the DFT and wavelet methods are also not competitive.
Fig 9 shows that the pencil method has uncovered real oscillations, since the mean of the magnitude of all poles is 1.0058 and the standard deviation is 0.0010. The ESPRIT method follows in terms of discovering oscillations, while the Prony or LS (least squares) method and the three statistical methods give weak results. As explained above the main drawback of the ESPRIT method is that it has nothing to say about the orthogonality of the oscillations, which proves to be a key outcome of the pencil method.
Fig 9. Results of analysis of 18484 genes using various methods.

Concluding remarks and outlook
The matrix pencil method allows the consistent determination of the dominant reduced-order models, thus revealing the fundamental oscillations present in the data. The essence of the matrix pencil method is that it provides a continuous-time tool for treating a discrete-time (sampled-data) problem. The DFT, in contrast, is only a discrete-time tool for treating a discrete-time problem; hence its failure in this setting.
A key consequence of the matrix-pencil approach is the demonstration of orthogonality of the different oscillatory components, in particular the 24-hour and the 12-hour cycles. This points to an independence of these oscillations. This assertion has been subsequently confirmed in the laboratory experiments reported in [13].
This analysis demonstrates the applicability of signal processing methodologies to biological systems and further shows the ability of the matrix pencil decomposition to demonstrate independence of biological rhythms.
Supporting information
(MAT)
(MAT)
(MAT)
(MAT)
(MAT)
Data Availability
All data underlying the study are within the paper and its Supporting Information files.
Funding Statement
This work was supported by National Science Foundation, CCF-1320866 to Antoulas; German Science Foundation, AN-693/1-1 to Antoulas; Max-Planck Institut für Physik Komplexer Systeme, Antoulas; NIDDK U24 DK097748 to York; NIDDK, U24 DK097748 to O’Malley; NIDDK HD07857 to O’Malley; Center for the Advancement of Science in Space, GA-2014-136, to Dacso and York; Brockman Medical Research Foundation to Dacso, O’Malley, York, Zhu; Phillip J. Carroll, Jr. Professorship to Dacso; Joyce Family Foundation to Dacso; Sonya and William Carpenter to Dacso, and National Science Foundation CISE-11703170. Bokai Zhu was supported by Junior Faculty Development award 1-18-JDF-025 from the American Diabetes Association. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1. Shannon C.E., Communication in the Presence of Noise. Proceedings OF the IRE, vol. 37, no. 1, pp. 10–21, January 1949. 10.1109/JRPROC.1949.232969 [DOI] [Google Scholar]
- 2. Hughes M. E. et al. ,Harmonics of circadian gene transcription in mammals, PLoS genetics 5, e1000442 (April, 2009). 10.1371/journal.pgen.1000442 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3. Ionita A.C. and Antoulas A.C., Matrix pencils in time and frequency domain system identification, in “Developments in Control Theory, towards Glocal Control”, edited by Qiu L., Chen J., Iwasaki T., and Fujioka H., IET Control Engineering Series, vol. 76, pages 79–88 (2012). [Google Scholar]
- 4. Antoulas A.C., Approximation of large-scale dynamical systems, Series in Design and Control, DC-6, SIAM; Philadelphia: 2005. (reprinted 2008). [Google Scholar]
- 5. Antoulas A.C., Lefteriu S., and Ionita A.C A tutorial introduction to the Loewner framework for model reduction, in Model Reduction and Approximation: Theory and Algorithms, Edited by Benner P., Cohen A., Ohlberger M., and Willcox K., SIAM, Philadelphia: (2017). [Google Scholar]
- 6. Antoulas A.C., Beattie C.A. and Gugercin S., Data-driven model reduction methods and applications, Series in Computational Science and Engineering, SIAM, Philadelphia: (2018). [Google Scholar]
- 7. Kay S., Modern Spectral Estimation: Theory and Application, Prentice-Hall, 1999. [Google Scholar]
- 8. Stoica P. and Moses R., Introduction to spectral analysis, Pretice Hall, 2005. [Google Scholar]
- 9. Leise L.T., Wavelet analysis of circadian and ultradian behavioral rhythms, Journal of circadian rhythms 111 (2013): 5 10.1186/1740-3391-11-5 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Yang Rendong and Su Zhen. “Analyzing circadian expression data by harmonic regression based on autoregressive spectral estimation.” Bioinformatics 2612 (2010): i168–i174. 10.1093/bioinformatics/btq189 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Hughes M.E., Hogenesch J.B., and Kornacker K.JTK_CYCLE: an efficient nonparametric algorithm for detecting rhythmic components in genome-scale data sets, Journal of biological rhythms, 255 (2010): 372–380. 10.1177/0748730410379711 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Thaben P.F. and Westermark P.O., Detecting rhythms in time series with RAIN, Journal of biological rhythms (2014): 0748730414553029. 10.1177/0748730414553029 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Zhu Bokai, Zhang Qiang, Pan Yinghong, Mace Emily M., York Brian, Athanasios Antoulas C., Dacso Clifford C., and O’Malley Bert W., A cell-autonomous mammalian 12-hour clock, coordinates metabolic and stress rhythms, Cell Metabolism, 25: 1305–1319, June 6, 2017. 10.1016/j.cmet.2017.05.004 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
(MAT)
(MAT)
(MAT)
(MAT)
(MAT)
Data Availability Statement
All data underlying the study are within the paper and its Supporting Information files.