

Abstract
Many studies in reading have shown the enhancing effect of context on the processing of a word before it is directly fixated (parafoveal processing of words). Here, we examined whether scene context influences the parafoveal processing of objects and enhances the extraction of object information. Using a modified boundary paradigm called the Dot-Boundary paradigm, participants fixated on a suddenly onsetting cue before the preview object would onset 4° away. The preview object could be identical to the target, visually similar, visually dissimilar or a control (black rectangle). The preview changed to the target object once a saccade toward the object was made. Critically, the objects were presented on either a consistent or an inconsistent scene background. Results revealed that there was a greater processing benefit for consistent than inconsistent scene backgrounds and that identical and visually similar previews produced greater processing benefits than other previews. In the second experiment, we added an additional context condition in which the target location was inconsistent, but the scene semantics remained consistent. We found that changing the location of the target object disrupted the processing benefit derived from the consistent context. Most importantly, across both experiments, the effect of preview was not enhanced by scene context. Thus, preview information and scene context appear to independently boost the parafoveal processing of objects without any interaction from object–scene congruency.
Keywords: Object recognition, eye movements, scene context, parafoveal processing
For decades, researchers have used eye movements to investigate how we process visual information (Henderson, 2003; Rayner, 1998, 2009), and a central question in this research is how visual information is integrated over successive fixations. Studies have shown that information obtained parafoveally (~4°-5° from fixation) can be seamlessly integrated with information obtained at fixation once a new fixation is made (Rayner, 1998; Rayner, McConkie, & Ehrlich, 1978). Although many studies have examined how object information is integrated across fixations (Breitmeyer, Kropfl, & Julesz, 1982; Henderson, 1997; Henderson, Pollatsek, & Rayner, 1989; Pollatsek, Rayner, & Collins, 1984), none to our knowledge have manipulated parafoveal object information and scene context to look at the possible enhancing effects of context on parafoveal extraction of information. In this study, we investigate whether scene context has an impact on the parafoveal processing of objects.
Parafoveal processing has been investigated extensively in reading and word processing. In a seminal study, Rayner (1975) introduced the boundary paradigm, in which an invisible boundary is placed just to the left of the target word. Before the observer fixates the target, a preview is presented. Once a saccade crosses the boundary, the target word replaces the preview. In a series of studies, Rayner and colleagues (Blanchard, Pollatsek, & Rayner, 1989; Inhoff & Rayner, 1986; Rayner & Bertera, 1979; Rayner et al., 1978) demonstrated that while orthographic and phonological codes are integrated across fixations, semantic codes are not (for review, see Rayner, 2009; cf. Schotter, 2013).
In contrast to parafoveal word processing, fewer studies have examined parafoveal processing of objects (Henderson, 1992; Henderson, Pollatsek, & Rayner, 1987; Henderson et al., 1989; Henderson & Siefert, 1999, 2001; Morgan & Meyer, 2005; Sanocki, 1993). Pollatsek and colleagues (1984) found that more information was integrated from visually similar previews than semantically similar previews. Furthermore, using flanker objects that were either semantically consistent or inconsistent with a target object, Henderson (1992) demonstrated that context provided by the semantically consistent flankers increased parafoveal processing of the target object. In addition, studies have shown that the degree to which parafoveal information is processed also depends on the difficulty of processing the fixated object, such that parafoveal processing is limited when information at fixation is difficult to process (Henderson et al., 1987; Morgan & Meyer, 2005), similar to reading (Henderson & Ferreira, 1990). Thus, there is reason to believe that the parafoveal processing of words and objects shares common perceptual and semantic processing constraints.
At a higher contextual level, studies have shown that sentence context plays an important role in parafoveal processing of words. As the predictability of a word in a sentence increases, there is an increased acquisition of parafoveal information (Balota, Pollatsek, & Rayner, 1985; McClelland & O’Regan, 1981; McConkie & Zola, 1979). Context has also been connected to how words are identified. For example, if the word is short and constrained by context, it is often identified prior to fixation and skipped during reading (Drieghe, Rayner, & Pollatsek, 2005; Juhasz, White, Liversedge, & Rayner, 2008; Rayner & Well, 1996). Based on this research, similar contextual constraints could affect parafoveal processing of objects in scenes.
In this regard, extensive research has examined the influence of scene context on object recognition. Early studies demonstrated that objects appearing in semantically consistent backgrounds were processed faster than in inconsistent scenes (Biederman, Glass, & Stacy, 1973; Biederman, Mezzanotte, & Rabinowitz, 1982; Boyce & Pollatsek, 1992; Boyce, Pollatsek, & Rayner, 1989; Loftus & Mackworth, 1978). While there is some debate as to whether these effects occur early or later in processing (Biederman et al., 1982; Davenport & Potter, 2004; De Graef, De Troy, & D’Ydewalle, 1992; Friedman, 1979; Hollingworth, 1998; Oliva & Torralba, 2007; Palmer, 1975), researchers agree that semantically consistent scenes do increase the predictability of objects contained within them (Bar, 2004; Demiral, Malcolm, & Henderson, 2012; Ganis & Kutas, 2003; Hollingworth, 1998; Oliva & Torralba, 2007; Võ & Wolfe, 2013; Võ, Zwickel, & Schneider, 2010).
In the present study, we examined the effect of scene context on the parafoveal processing of objects with a modified boundary paradigm (akin to Rayner, 1975; see Figure 1): the Dot-Boundary paradigm. On each trial, participants were asked to identify a suddenly onsetting object. At the start of each trial, a target object name was specified and participants viewed a preview scene (Consistent or Inconsistent). Following scene onset, a red dot would appear, and once fixated, an object would onset 4° from that location. Prior to object fixation, a preview object was shown to manipulate the object information available from the parafovea. The preview object was identical to the target (Identical), had a similar shape (Visually Similar), had a different shape (Visually Dissimilar) or was a control preview consisting of a black rectangle (Control—indicating target’s location with no visual information). As participants saccaded toward the object, an invisible boundary around the preview object triggered it to change to the target object. This manipulation allowed us to examine whether scene context influences the parafoveal processing of objects and whether it has an enhancing effect on the extraction of parafoveal object information. Additionally, we examined whether parafoveal object information could modulate the effect of context.
Figure 1.

Example trial sequence for Consistent context Visually Dissimilar preview condition. The target object is highlighted by an orange oval.
Interestingly, researchers have also demonstrated that the location of an object within a scene has a strong influence on its predictability (Castelhano & Heaven, 2011; Malcolm & Henderson, 2010; Oliva & Torralba, 2007; Võ & Henderson, 2009; Võ et al., 2010). In Experiment 2, we added a condition in which the target’s location was inconsistent within a semantically consistent scene. If scene semantics drives predictability of the target, then changing the target location should not affect parafoveal processing. However, if scene context drives target predictability based on both semantic and location information, then the preview benefit should be reduced when the location is inconsistent.
For each experiment, we analyzed the effects of context and preview more generally and then directly examined whether scene context had an enhancing effect on parafoveal processing of objects. If scene context does enhance object processing in the parafovea, then we would expect that semantic constraints of a consistent versus inconsistent context will produce a processing advantage for objects, and we would expect this advantage to be greatest in the Identical preview condition compared to all others.
Experiment 1
Methods
Participants
Two groups of 20 Queen’s University undergraduates participated in the experiment for course credit or for US$10/hr. All participants had normal or corrected-to-normal vision.
Stimulus and apparatus
In total, 50 black and white photographs depicting various indoor and outdoor scenes (800 × 600 pixels; 38.1° × 28.6°) were used as stimuli and were collected from various sources (e.g., Internet, catalogues). All edits were made using Adobe Photoshop. Target objects were selected for each image (average 2.5° × 2.8°). There were two context conditions (Consistent and Inconsistent) and four preview conditions (Identical, Visually Similar, Visually Dissimilar and Control), for a total of eight images created for each target.1 Figure 2 shows example images for each condition. For semantically consistent contexts, each image was paired with an image from the same category, and a single selected object from each image was replaced with the other (i.e., a teapot in Kitchen2 was swapped with a toaster in Kitchen1).2 For semantically inconsistent contexts, each image was paired with an image from a different category, and target objects were placed in the same x–y coordinates within the new context.
Figure 2.

Example of images used in each of the context conditions in the Consistent and Inconsistent conditions. The target object is highlighted by an orange oval (upper panel). Example preview conditions for a specific example (lower panel).
The scene image with the target object served as the Target image and Identical preview. For the Visually Similar and Visually Dissimilar previews, objects with similar and different shapes, respectively, were placed in the same location as the target. For the Control preview, targets were replaced with a black square (4° × 4°). Target cues were created by placing the target’s basic-level category name (i.e., toaster, lamp, etc.) in black text at the center of a gray background.
Eye movements were tracked using an EyeLink 1000 (SR Research), sampling at 1000 Hz. Participants were seated 60 cm away from the monitor on a head and chin rest and were calibrated using a 9-point calibration screen. Calibration checks between each trial ensured that the calibration error was kept low (average spatial error < 0.4°, maximum error < 0.7°). The stimuli were displayed on 21″ cathode ray tube (CRT) monitor at a resolution of 800 × 600 pixels and 100 Hz refresh rate. The display change from the preview to the target was typically completed during the saccade (~9 ms after the trigger), while vision was suppressed. Viewing was binocular, but only the right eye was monitored.
Procedure
The context condition was run as a between-subject manipulation (two groups, Consistent and Inconsistent context conditions) and the preview conditions as a within-subject manipulation. All participants were instructed to indicate whether an object name matched the target object, with a 1:1 ratio of match to mismatch trials.
An example trial sequence for the Dot-Boundary paradigm is shown in Figure 1. For each trial, the target name cue was shown for 2 s, followed by a fixation cross for 500 ms and then by the preview scene. The preview scene did not contain the target (or preview) object. A red dot cue (2° × 2°) appeared 450 ms after scene onset, and participants were instructed to fixate on the dot when it appeared. Once fixated, a preview object appeared at a linear distance of 4° from the dot. An invisible boundary was located 2.5° from the preview’s edge, and as participants made a saccade toward the object, the preview would change to the target object. Participants then indicated via button press whether the suddenly appearing object matched the target name. Participants completed 3 practice trials followed by 50 experimental trials. The experiment lasted ~30 min.
Results and discussion
Analysis
The focus of the analyses was on the eye movement patterns that resulted from context and preview effects. However, for completeness, we also analyzed two behavioral measures (discriminability and bias). For all analysis, all trials (target match and mismatch) were included. To prevent anticipation and attention-lapse errors from biasing results, trials in which the latency of the initial saccade to the target was shorter than 80 ms or longer than 800 ms were discarded. In addition, trials in which the display change from the preview to the target object occurred too late (either at the end of a saccade or during a fixation) were excluded. Data loss, including loss of eye gaze by the tracker, totaled 16.4% (data loss rates did not differ between conditions and were equivalent to past studies with similar manipulations; e.g., Rayner, Castelhano, & Yang, 2009). For the eye movement analyses, target regions were defined as a 1° border around the target’s outermost edge.
Discrimination and bias
To look at overall behavioral performance on this task, we examined measures of discrimination (d′) and bias (c) across conditions.3 Mean values are displayed in Table 1. We analyzed each measure using a 2 × 4 (Scene Context × Preview) mixed analysis of variance (ANOVA). Although there were no differences in participants’ ability to accurately discriminate the identity of the target object across preview conditions or an interaction (all Fs ≤ 1, ps > 0.5, η2s < 0.06), we found that discriminability was higher for Inconsistent than Consistent scene context conditions (F(3, 114) = 7.37, p = 0.01, η2 = 0.67). One might assume this was because participants were simply more likely to say “yes” when the target name and scene context matched, but the bias analysis did not show such an effect. In a 2 × 4 (Scene Context × Preview) mixed ANOVA for the bias measure, we found no significant differences (all Fs = <1, ps > 0.2, η2s < 0.3). When we examined the directionality of the bias for Consistent and Inconsistent scenes (using one-sample t-tests), we found a slight marginally significant “no” bias for the Inconsistent condition (M = 0.04, standard deviation [SD] = 0.08; t(19) = 1.88, p = 0.076, d = 0.43), but no significant difference from neutral for the Consistent condition (M = 0.02, SD = 0.15; t(19) = 0.49, p > 0.6, d = 0.11) scene contexts.
Table 1.
Mean values (and standard deviations) for each Context condition across preview conditions for Experiment 1.
| Preview condition |
||||
|---|---|---|---|---|
| Control | Visually Dissimilar | Visually Similar | Identical | |
| Discriminability and bias | ||||
| Discriminability (d′) | ||||
| Consistent | 1.43 (0.68) | 1.40 (0.53) | 1.32 (0.72) | 1.46 (0.62) |
| Inconsistent | 1.64 (0.38) | 1.76 (0.45) | 1.56 (0.51) | 1.51 (0.57) |
| Response bias (c) | ||||
| Consistent | 0.08 (0.25) | 0.06 (0.30) | −0.06 (0.20) | −0.02 (0.28) |
| Inconsistent | 0.07 (0.18) | 0.03 (0.16) | 0.002 (0.21) | 0.04 (0.28) |
| Eye movement measures | ||||
| Prior fixation duration | ||||
| Consistent | 347 (93) | 337 (98) | 355 (82) | 264 (84) |
| Inconsistent | 382 (152) | 425 (148) | 383 (160) | 381 (154) |
| Proportion of objects skipped | ||||
| Consistent | 0.20 (0.29) | 0.19 (0.24) | 0.19 (0.24) | 0.20 (0.29) |
| Inconsistent | 0.09 (0.15) | 0.08 (0.16) | 0.12 (0.18) | 0.13 (0.21) |
Prior fixation duration
To examine how the preview may have affected preprocessing of the target, we examined the fixation duration immediately prior to target fixation. Mean values across preview and context condition are shown in Table 1. We found that prior to fixating the target object, fixations in an Inconsistent context (393 ms) were significantly longer than in a Consistent context (326 ms; F(1, 30) = 11.44, p = 0.002, η2 = 0.07). No other effects were significant (preview: F(3, 90) = 1.16, p > 0.3, η2 = 0.03; interaction: F < 1, p > 0.4, η2 = 0.02). This suggests that even with differences in preview, the decision to saccade toward the target was largely affected by context. However, because the target was not visible during this fixation (in the majority of conditions), we can attribute the shorter fixations to whether the target name was consistent with the scene category.
Proportion of objects skipped
We examined how often participants skipped fixating the target, which corresponded to the number of times participants responded without directly fixating the target. Mean values across conditions are shown in Table 1. We found that objects in a Consistent context (20%) were significantly more likely to be skipped than in an Inconsistent context (11%; F(1, 38) = 5.29, p = 0.027, η2 = 0.04). In the framework of this paradigm, skipping rates could be driven by a response bias based on the consistency between the named target and the scene context (Castelhano & Henderson, 2008; Hollingworth & Henderson, 1998), or based on the information extracted from the parafoveal preview, or a combination of both. In this experiment, the higher skipping rates correspond to lower discriminability scores. As there was no effect of bias, we surmise that participants were basing their decision on parafoveal information.
Target processing
In order to examine the effects of scene context on parafoveal processing of objects, we looked at a number of standard target processing measures. We measured First Gaze Duration (sum of all fixation durations on the target within the first viewing period) and Total Time (sum of all fixation durations on the target object).4 The mean values of the target processing measures are shown in Figure 3. First, we analyzed the processing measures using a 2 × 4 (Scene Context × Preview Conditions) mixed ANOVA. First Gaze Duration and Total Time revealed main effects of scene context (F(1, 68) = 14.21, p = 0.001, η2 = 0.19; F(1, 68) = 13.44, p = 0.001, η2 = 0.16, respectively) and preview (F(3, 114) = 3.31, p = 0.02, η2 = 0.05; F(3, 114) = 3.49, p = 0.018, η2 = 0.04, respectively), but no interaction (F < 1, p > 0.25, η2 < 0.01).
Figure 3.
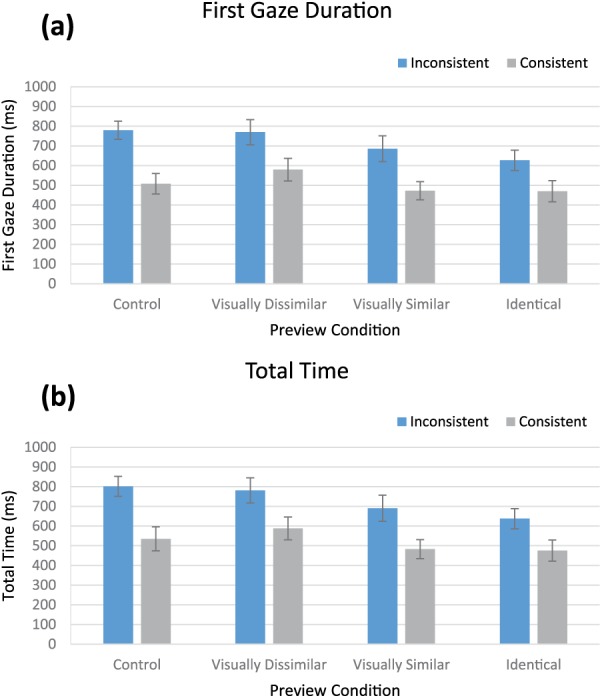
Target processing mean values for (a) First Gaze Duration and (b) Total Time for each Context condition across preview conditions for Experiment 1. Error bars: ±1 SE.
First, similar to past reading studies (Balota et al., 1985; Balota & Rayner, 1983), we conducted preplanned comparisons of all preview conditions contrasted with the Identical preview to examine the effects of visual previews on parafoveal processing. For First Gaze Duration and Total Time, we found that compared to the Identical preview, the Control preview (t(39) = 1.88, p = 0.068, d = 0.38; t(39) = 2.1, p = 0.042, d = 0.42) and Visually Dissimilar preview (t(39) = 2.65, p = 0.012, d = 0.47; t(39) = 2.72, p = 0.01, d = 0.48) produced marginally or significantly longer fixation times, while the Visually Similar preview did not (t(39) = 0.83, p > 0.4, d = 0.12; t(39) = 0.78, p > 0.4, d = 0.12).
Second, we examined whether the object preview could be combined with scene context information to lead to greater extraction of object identity information. To address this question, we conducted planned comparisons contrasting the Identical preview (the strongest cue of object information) to the Control preview (no object information) when presented in a Consistent and Inconsistent scene context in a 2 × 2 mixed ANOVA for each eye movement measure (see Figure 3). This is similar to analyses in the reading literature that found synergistic effects of context on the extraction of word identity (Balota et al., 1985; Balota & Rayner, 1983; Ehrlich & Rayner, 1981). The logic is that if scene context can enhance the extraction of object identity information, we would expect an interaction between these two conditions, with the Identical preview producing a greater preview benefit when presented in a Consistent context than in an Inconsistent context or when the Control preview is shown in either a Consistent or Inconsistent context. However, we found no such pattern. For both First Gaze Duration and Total Time, we found that while scene context (F(1, 38) = 17.35, p < 0.001, η2 = 0.70; F(1, 38) = 15.00, p < 0.001, η2 = 0.68, respectively) and preview (F(1, 38) = 5.07, p = 0.032, η2 = 0.05; F(1, 38) = 4.42, p = 0.042, η2 = 0.04, respectively) contributed significantly to object identification processing, we found no evidence that scene context served to further enhance object processing based on preview information (F(1, 38) = 1.29, p = 0.26, η2 < 0.001; F(1, 38) = 0.97, p = 0.33, η2 < 0.01, respectively).
The results from Experiment 1 point to scene context as an independent contributor to object processing. This is in line with many other studies that have examined how scene context contributes to object processing (Castelhano & Heaven, 2010; Davenport & Potter, 2004; De Graef et al., 1990; Hollingworth & Henderson, 1998; Malcolm & Henderson, 2010). One explanation is the “bag of words” approach (Greene, 2013), which posits that the semantic associations between object and scene may be sufficient to enhance processing, such that objects are easier to process because the scene provides a semantic boost (rather than a perceptual boost). However, research has also shown that objects placed in unexpected locations of a semantically consistent context result in reduced accuracy and longer processing times (Castelhano & Heaven, 2011; Malcolm & Henderson, 2009; Võ & Henderson, 2009; Võ et al., 2010) and that this effect is independent of the semantic boost offered by the scene context (Castelhano & Heaven, 2011). In order to examine this question more closely, we conducted a second experiment to examine whether scene context’s contribution to the preview benefit was linked to the location of the object within the scene.
In Experiment 2, the same paradigm was used as in Experiment 1, but the targets were moved to an incongruent location in the scene. If scene context offers a boost to object processing solely at the semantic level of processing, then we expect the preview benefit from scene context to be similar to that found in Experiment 1. If the scene context boost arises from both the semantic and placement information of the object within the scene, then we would expect that scene context would no longer have an effect. If the scene context boost is partially explained by the combination of scene context and location, and partially explained by semantic information, then we would expect the effect to remain but be reduced in size when the object is placed in an inconsistent location.
Experiment 2
Methods
Participants
Three separate groups of 24 Queen’s University undergraduates participated in the experiment for course credit or for US$10/hr. All participants had normal or corrected-to-normal vision. None participated in Experiment 1.
Stimulus and apparatus
The stimuli were similar to those used in Experiment 1. The same four preview conditions were used, and one additional condition was added to the context condition. The new condition was an Inconsistent-Location context condition, in which the target was moved to an inconsistent location within a semantically consistent context (objects were placed in inappropriate but physically plausible locations). The location of the corresponding dot was also changed so that it remained 4° from the target object.
Procedure
As in Experiment 1, the context condition was run as a between-subject manipulation (three groups) and the preview conditions as a within-subject manipulation. The same Dot-Boundary paradigm was used, and the procedure was identical to Experiment 1.
Results and discussion
Analysis
As with Experiment 1, we eliminated trials with preemptive and delayed fixations to the target (<80 or >800 ms). In addition, trials in which the display change from the preview to the target object occurred too late (either at the end of a saccade or during a fixation) were excluded. Data loss, including tracking losses, totaled 17.7%, and the amount of data loss did not differ between conditions.
Discrimination and bias
Again, we examined measures of discrimination (d′) and bias (c) across conditions to examine overall behavioral performance. Mean values are presented in Table 2. We analyzed each measure using a 3 × 4 (Scene Context × Preview) mixed ANOVA. For both discriminability and bias, we found no differences across context (F(2, 69) = 1.61, p = 0.21, η2 = 0.02; F(2, 69) = 1.75, p = 0.18, η2 = 0.02, respectively) and preview conditions (F(3, 207) = 1.30, p = 0.28, η2 = 0.01; F(3, 207) = 1.96, p = 0.12, η2 = 0.02, respectively) nor was there an interaction (F(3, 207) = 0.13, p = 0.99, η2 < 0.01; F(3, 207) = 0.91, p = 0.49, η2 < 0.01, respectively).
Table 2.
Mean values (and standard deviations) for each Context condition across preview conditions for Experiment 2.
| Preview conditions |
||||
|---|---|---|---|---|
| Control | Visually Dissimilar | Visually Similar | Identical | |
| Discriminability and bias | ||||
| Discriminability (d′) | ||||
| Consistent | 1.77 (0.75) | 1.61 (0.49) | 1.82 (0.66) | 1.83 (0.81) |
| Inconsistent-Location | 1.72 (0.62) | 1.69 (0.88) | 1.85 (0.50) | 1.84 (0.56) |
| Inconsistent | 1.90 (0.68) | 1.90 (0.64) | 1.97 (0.58) | 2.05 (0.62) |
| Response bias (c) | ||||
| Consistent | 0.08 (0.37) | −0.004 (0.42) | 0.09 (0.34) | −0.05 (0.24) |
| Inconsistent-Location | 0.22 (0.30) | 0.19 (0.35) | 0.06 (0.32) | 0.06 (0.35) |
| Inconsistent | 0.15 (0.30) | 0.06 (0.21) | 0.07 (0.26) | 0.09 (0.25) |
| Eye movement measures | ||||
| Prior fixation duration | ||||
| Consistent | 329 (81) | 321 (72) | 342 (84) | 330 (83) |
| Inconsistent-Location | 363 (114) | 369 (113) | 380 (116) | 345 (86) |
| Inconsistent | 399 (161) | 397 (126) | 430 (127) | 459 (184) |
| Proportion of objects skipped | ||||
| Consistent | 0.24 (0.18) | 0.28 (0.21) | 0.25 (0.19) | 0.26 (0.20) |
| Inconsistent-Location | 0.08 (0.13) | 0.12 (0.18) | 0.09 (0.12) | 0.11 (0.14) |
| Inconsistent | 0.08 (0.09) | 0.10 (0.16) | 0.14 (0.18) | 0.08 (0.13) |
In preplanned comparisons, we contrasted the Identical preview condition to the other preview conditions using paired-sample two-way t-tests for both measures and found that there was a significantly higher “no” bias for the Control preview, t(71) = 2.50, p = 0.015, d = 0.37. There were no other significant differences. When we looked at the directionality of the bias across context conditions (using one-sample t-tests), we found a significant “no” bias for the Inconsistent (t(23) = 3.60, p < 0.01, d = 0.73) and Inconsistent-Location (t(23) = 3.43, p = 0.01, d = 0.70) context conditions, but no significant bias in either direction for the Consistent context condition (t(23) = 0.53, p = 0.6, d = 0.11).
Prior fixation duration
As in Experiment 1, we explored how the preview may have affected preprocessing of the target by examining the fixation immediately prior to target fixation. Mean values across context and preview conditions are shown in Table 2. We found that prior to fixating the target object, there was a significant effect of context (F(2, 69) = 5.32, p = 0.007, η2 = 0.09). No other effects were significant (preview: F(3, 207) = 1.47, p > 0.2, η2 < 0.01; interaction: F(3, 207) = 1.73, p > 0.1, η2 < 0.02). This pattern is consistent with Experiment 1. Further analyses of the context effect revealed that the Consistent context had shorter fixations (331 ms) than the Inconsistent (421 ms; t(46) = −3.16, p < 0.01, d = 0.91) but not from Inconsistent-Location conditions (364 ms; t(46) = 1.48, p > 0.1, d = 0.43). This pattern of results is consistent with a decision to saccade to the target based on how well the scene context and target category matched, rather than the properties of the preview object.
Proportion of objects skipped
We examined how often target objects were skipped using a 3 × 4 (Scene Context × Preview) mixed ANOVA (see Table 2). We found no effect of the preview condition nor an interaction between context and preview (all Fs < 1, ps > 0.5, η2s < 0.1). However, there was a significant effect of context condition (F(2, 69) = 13.17, p < 0.001, η2 = 0.17), and further analyses showed that participants were more likely to skip targets in the Consistent context condition than in either the Inconsistent (t(46) = −4.37, p < 0.001, d = 1.26) or Inconsistent-Location (t(46) = −4.10, p < 0.001, d = 1.18) context condition. This pattern replicates Experiment 1; however, in this case, the higher skipping rates were not associated with lower discriminability scores. We previously postulated that in the context of this paradigm, skipping could arise from an increased bias to respond “yes” or “no” based on whether the named target is consistent with the scene context or based on the parafoveal information, if the participant feels it is sufficient to make a decision. In this experiment, we find that there were no effects on the bias measure, although there was a significant “no” bias for the Inconsistent and Inconsistent-Location conditions. Although it is not clear from this paradigm how these two sources of influence on discrimination and skipping rates relate, the question is outside the scope of this study and will not be discussed further.
Target processing
As in Experiment 1, we examined two target processing measures (First Gaze Duration and Total Time). Figure 4 shows mean eye movement measures across conditions. A 3 × 4 (Scene Context × Preview Conditions) mixed ANOVA for each measure revealed that for First Gaze Duration and Total Time, respectively, there was a significant context (F(2, 69) = 13.71, p < 0.001, η2 = 0.22; F(2, 69) = 12.97, p < 0.001, η2 = 0.21) and preview effect (F(3, 207) = 13.33, p < 0.001, η2 = 0.04; F(3, 207) = 14.39, p < 0.001, η2 = 0.04), but no interaction (F(3, 207) = 1.40, p > 0.2, η2 < 0.01; F(3, 207) = 1.37, p > 0.2, η2 < 0.01).
Figure 4.
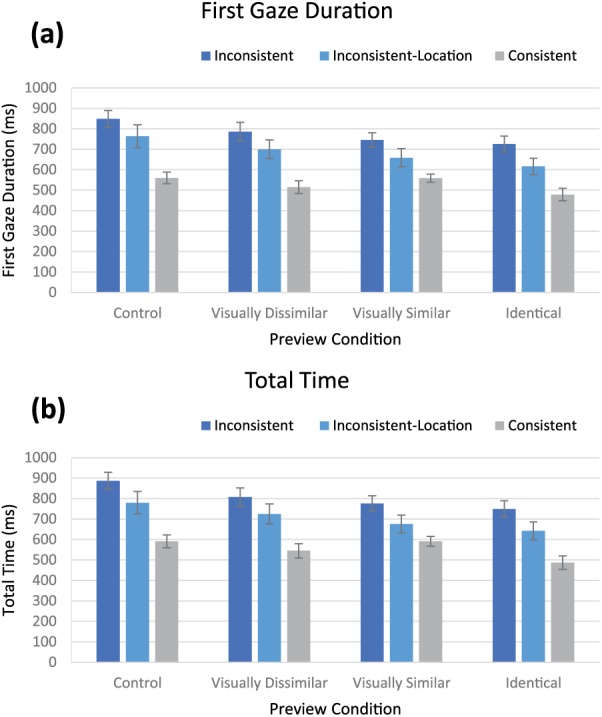
Target processing mean values for (a) First Gaze Duration and (b) Total Time for each Context condition across preview conditions for Experiment 2. Error bars: ±1 SE.
When examining the effect of context more closely, we found that Consistent context condition showed significantly shorter First Gaze Durations and Total Times than the Inconsistent-Location (t(46) = 3.27, p = 0.002, d = 0.94; t(46) = 3.07, p = 0.004, d = 0.89) and Inconsistent context conditions (t(46) = 6.19, p < 0.001, d = 1.79; t(46) = 5.84, p < 0.001, d = 1.68). This pattern of results is not only in line with previous studies examining the role of semantic consistency and location of targets on object processing more generally (Castelhano & Heaven, 2011; Malcolm & Henderson, 2009; Võ & Henderson, 2009; Võ et al., 2010) but also suggests that the benefit of scene context on object processing is partially tied to the location of the object.
Further planned comparisons of the Identical preview to other preview conditions (Balota et al., 1985; Balota & Rayner, 1983) showed an overall pattern of results similar to Experiment 1. For First Gaze Duration and Total Time, we found that compared to the Identical preview, the Control (t(71) = 6.97, p < 0.001, d = 0.53; t(71) = 6.56, p < 0.001, d = 0.60), Visually Dissimilar (t(71) = 3.38, p < 0.01, d = 0.26; t(31) = 3.53, p < 0.001, d = 0.30) and Visually Similar (t(71) = 2.45, p = 0.017, d = 0.30; t(71) = 2.93, p < 0.01, d = 0.22) previews produced significantly longer fixation times. Interestingly, processing times for the Visually Similar preview were significantly longer than the Identical preview in this experiment, but not in the previous experiment. We suspect that the difference in significant testing may have been due to the addition of the Inconsistent-Location condition, which had the effect of adding uncertainty about the object due to its placement in the scene. However, it should be noted that even though there was a difference in the statistical significance between the Visually Similar and Identical previews, there was only a modest increase in the effect size from ~0.1 to ~0.2-0.3 (both small effects according to Cohen, 1977).
As in Experiment 1, we directly examined whether there was any evidence of scene context enhancing parafoveal object processing. For each processing measure, we analyzed the contribution of the Identical and Control preview conditions when presented in the Consistent and Inconsistent scene context conditions in a 2 × 2 mixed ANOVA. We found patterns similar to Experiment 1. For First Gaze Duration and Total Time, we found an effect of preview (F(1, 46) = 25.02, p < 0.001, η2 = 0.07; F(1, 46) = 27.74, p < 0.001, η2 = 0.07) and an effect of context (F(1, 46) = 24.24, p < 0.001, η2 = 0.28; F(1, 46) = 35.82, p < 0.001, η2 = 0.36), but no significant interaction (Fs < 1, ps > 0.47, η2s < 0.01).
The second experiment suggests that the effect of context was dependent on the object’s location, as moving the target had a negative impact on performance benefits. However, the pattern of result suggests that neither the location nor the semantic link of the scene context acted to further enhance extraction of parafoveal information.
General discussion
The purpose of the present study was to address three specific questions: (1) whether scene context affects parafoveal processing of objects, (2) whether context modulates parafoveal processing depending on the preview information available and (3) whether the benefit from scene context is based on its semantic relation to the target or whether it is reliant on object location. Of primary theoretical interest was whether context and preview information would interact to enhance object processing.
In Experiment 1, we had participants identify specific objects in the scene specified by a sudden onset during fixation on a prespecified cue (red dot). In the newly introduced Dot-Boundary paradigm, a preview object was first shown, before it switched to the target object when participants made a saccade toward the target. The preview could be a control (black square), visually similar or dissimilar to the target, or could be identical to the target. We found that Identical and visually similar previews led to shorter viewing times. This effect of similar primes is akin to earlier work (Henderson, 1992; Sanocki, 1993). In particular, Sanocki (1993) found evidence that a prime shown in the parafovea preceding a target object could enhance processing, especially when it shared similar global features with the target object. However in the current study, although there was an overall benefit for semantically consistent scene contexts, there was no evidence that scene context served to enhance parafoveal processing of objects.
In Experiment 2, we further investigated the contribution of scene context by examining whether context effects were reliant on the object’s location. We added a condition in which the objects appeared in a semantically consistent context but were placed in an inconsistent location. We found that object location did influence the context effect, but again found no evidence of enhanced object recognition when presented in a semantically consistent scene context, regardless of object placement. The lack of an enhancing effect of scene context on the extraction of object information in the parafovea was contrary to previous findings in reading (Balota et al., 1985; Balota & Rayner, 1983).
The current study is not the first to show differences in how objects are processed differ from those of words (Castelhano, Mack, & Henderson, 2009). However, the context provided by a sentence for the next word may be more constrained than context provided by scenes for an object. Although there are expectations about where objects are likely to be placed in a scene (Neider & Zelinsky, 2006), there remains variance in the exact position of objects (i.e., horizontal positioning is not predicted by context; Castelhano & Heaven, 2011; Pereira & Castelhano, 2014; Torralba, Oliva, Castelhano, & Henderson, 2006). Future studies could use objects in scenes that have various levels of predictability in order to examine whether scene context could have a facilitative effect when constraints are higher.
The current findings also contrast with other studies that have examined processing of isolated objects with surrounding objects that are either related or unrelated (Auckland, Cave, & Donnelly, 2007; Henderson, 1992). In these studies, objects that were either semantically linked or semantically distinct were placed within close proximity to the object and shown to have an effect on object processing. One difference between the context provided by related objects and those provided by a scene may stem from how closely linked an object is to a specific context (i.e., object diagnosticity; Greene, 2013). That is, with stronger ties to the context, we may find a difference or interaction in how objects are processed. However, future studies are needed to examine whether an objects’ link to a specific context would lead to enhancing effects from context. Another possible factor that could have affected context effects was that more time was needed to process the scene before it could be integrated with object information. This has been found in previous studies examining the effect of scene context on object recognition more generally (Boyce et al., 1989; Boyce & Pollatsek, 1992; De Graef et al., 1990). However, in the Dot-Boundary paradigm introduced here, participants were given an opportunity to explore the scene (for 450 ms) before the dot and preview object appeared. Future studies could explore whether greater (or lesser) amount of exposure to scene context could affect parafoveal processing of objects differently.
Furthermore, another factor that could have had an effect on potential interactions between scene context and object processing is the distance from which the preview was viewed. By examining processing of object previews from information in the parafovea, we were fairly certain that some object information was extracted (Balota et al., 1985; Balota & Rayner, 1983; Henderson, Williams, Castelhano, & Falk, 2003; Pollatsek, Rayner & Henderson, 1990). However, across both studies, we did not find evidence that information from object previews and scene context interacted in any way. This leaves open the possibility that farther distances may differ from this pattern as greater uncertainty about object information may make participants rely more on context information. This, in turn, may also affect response biases and guessing strategies for the object identity before it is directly fixated.
Additionally, we are currently exploring whether semantic information extracted from the parafovea interacts with scene context. In the current experiment, both previews manipulated were semantically distinct and varied only in their visual similarity. In previous studies on parafoveal processing of isolated objects, researchers found that there was some benefit from semantically related previews (Henderson et al., 1987, 1989). It is unclear whether such effects would translate to objects placed in scenes due to greater difficulties of parsing the object from the background (Henderson, Chanceaux, & Smith, 2009; Henderson et al., 2003; Rosenholtz, Li, & Nakano, 2007). Furthermore, there is some debate as to whether semantic information can be extracted extrafoveally (Castelhano, Pollatsek, & Cave, 2008; Nuthmann, 2013, 2014; Rayner, Balota, & Pollatsek, 1986; Võ & Henderson, 2009). Thus, future research could lead to further clarity about the role of semantics in the parafoveal processing of objects in scenes.
In conclusion, we found that both preview information and context independently influenced the parafoveal processing of objects, but there was no evidence of an interactive effect. Furthermore, the benefit of scene context was strongly tied to the location of the object within the scene. This study is a first step in investigating the effects of context on parafoveal processing of objects and suggests that effects may differ from those found for word processing in reading.
Acknowledgments
The authors wish to thank Chelsea Heaven for her help in creating the stimuli.
In the original design of this study, participants saw two other conditions that were not included in the analyses here. There was an additional manipulation of distance (10°) and the inclusion of a Semantically Similar preview condition. The data from 10° conditions were corrupted due to a programming error. The manipulation of the Semantically Similar stimuli was not processed correctly. We will, therefore, not be discussing these conditions but are currently pursuing these effects in follow-up studies.
Target objects were not native to the scenes in which they were shown in order to control for any cut-and-paste effects between consistent and inconsistent scene manipulations that may affect object processing (Castelhano & Heaven, 2011).
Discriminability (d′) and response bias (c) values were calculated using Macmillian’s (1993) formulas for yes–no tasks with a loglinear correction for zero values, which adds 0.5 to both the number of hits and false-alarms and adds 1 to both the number of signal and noise trials, prior to the calculation of the hit and false-alarm rates (Hautus, 1995; Stanislas & Todorov, 1999).
We also examined First Fixation Duration, but as there were no effects on this measure across analyses or experiments, we have decided to exclude this measure from this article.
Footnotes
Declaration of conflicting interests: The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding: The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by funding from the Natural Sciences and Engineering Research Council of Canada and the Queen Elizabeth II Graduate Scholarship in Science and Technology to E.J.P. and from the Natural Sciences and Engineering Research Council of Canada, Canadian Foundation for Innovation, Ontario Ministry of Research and Innovation and Queen’s University Advisory Research Committee to M.S.C.
References
- Auckland M. E., Cave K. R., Donnelly N. (2007). Nontarget objects can influence perceptual processes during object recognition. Psychonomic Bulletin & Review, 14, 332–337. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/17694922 [DOI] [PubMed] [Google Scholar]
- Balota D. A., Pollatsek A., Rayner K. (1985). The interaction of contextual constraints and parafoveal visual information in reading. Cognitive Psychology, 17, 364–390. doi: 10.1016/0010-0285(85)90013-1 [DOI] [PubMed] [Google Scholar]
- Balota D. A., Rayner K. (1983). Parafoveal visual information and semantic contextual constraints. Journal of Experimental Psychology: Human Perception and Performance, 9, 726–738. doi: 10.1037/0096-1523.9.5.726 [DOI] [PubMed] [Google Scholar]
- Bar M. (2004). Visual objects in context. Nature Reviews Neuroscience, 5, 617–629. doi: 10.1038/nrn1476 [DOI] [PubMed] [Google Scholar]
- Biederman I., Glass A. L., Stacy E. W. (1973). Searching for objects in real-world scenes. Journal of Experimental Psychology, 97, 22–27. doi: 10.1037/h0033776 [DOI] [PubMed] [Google Scholar]
- Biederman I., Mezzanotte R. J., Rabinowitz J. C. (1982). Scene perception: Detecting and judging objects undergoing relational violations. Cognitive Psychology, 14, 143–177. doi: 10.1016/0010-0285(82)90007-X [DOI] [PubMed] [Google Scholar]
- Blanchard H. E., Pollatsek A., Rayner K. (1989). The acquisition of parafoveal word information in reading. Perception & Psychophysics, 46, 85–94. doi: 10.3758/BF03208078 [DOI] [PubMed] [Google Scholar]
- Boyce S. J., Pollatsek A. (1992). Identification of objects in scenes: The role of scene background in object naming. Journal of Experimental Psychology: Learning, Memory, and Cognition, 18, 531–543. doi: 10.1037/0278-7393.18.3.531 [DOI] [PubMed] [Google Scholar]
- Boyce S. J., Pollatsek A., Rayner K. (1989). Effect of background information on object identification. Journal of Experimental Psychology: Human Perception and Performance, 15, 556–566. doi: 10.1037/0096-1523.15.3.556 [DOI] [PubMed] [Google Scholar]
- Breitmeyer B. G., Kropfl W., Julesz B. (1982). The existence and role of retinotopic and spatiotopic forms of visual persistence. Acta Psychologica, 52, 175–196. doi: 10.1016/0001-6918(82)90007-5 [DOI] [PubMed] [Google Scholar]
- Castelhano M. S., Heaven C. (2010). The relative contribution of scene context and target features to visual search in scenes. Attention, Perception & Psychophysics, 72, 1283–1297. doi: 10.3758/APP.72.5.1283 [DOI] [PubMed] [Google Scholar]
- Castelhano M. S., Heaven C. (2011). Scene context influences without scene gist: eye movements guided by spatial associations in visual search. Psychonomic Bulletin & Review, 18, 890–896. doi: 10.3758/s13423-011-0107-8 [DOI] [PubMed] [Google Scholar]
- Castelhano M. S., Henderson J. M. (2008). The influence of color on the activation of scene gist. Journal of Experimental Psychology: Human Perception and Performance, 34, 660–675. [DOI] [PubMed] [Google Scholar]
- Castelhano M. S., Mack M. L., Henderson J. M. (2009). Viewing task influences eye movement control during active scene perception. Journal of Vision, 9, 6. doi: 10.1167/9.3.6 [DOI] [PubMed] [Google Scholar]
- Castelhano M. S., Pollatsek A., Cave K. R. (2008). Typicality aids search for an unspecified target, but only in identification and not in attentional guidance. Psychonomic Bulletin & Review, 15, 795–801. doi: 10.3758/PBR.15.4.795 [DOI] [PubMed] [Google Scholar]
- Cohen J. (1977). Statistical power analysis for the behavioral sciences. New York, NY: Academic Press. [Google Scholar]
- Davenport J. L., Potter M. C. (2004). Scene consistency in object and background perception. Psychological Science, 15, 559–564. doi: 10.1111/j.0956-7976.2004.00719.x [DOI] [PubMed] [Google Scholar]
- De Graef P., Christiaens D., D’Ydewalle G. G. (1990). Perceptual effects of scene context on object identification. Psychological Research, 52, 317–329. doi: 10.1007/BF00868064 [DOI] [PubMed] [Google Scholar]
- Demiral S. B., Malcolm G. L., Henderson J. M. (2012). ERP correlates of spatially incongruent object identification during scene viewing: contextual expectancy versus simultaneous processing. Neuropsychologia, 50, 1271–1285. doi: 10.1016/j.neuropsychologia.2012.02.011 [DOI] [PubMed] [Google Scholar]
- Drieghe D., Rayner K., Pollatsek A. (2005). Eye movements and word skipping during reading revisited. Journal of Experimental Psychology: Human Perception and Performance, 31, 954–969. doi: 10.1037/0096-1523.31.5.954 [DOI] [PubMed] [Google Scholar]
- Ehrlich S. S. F., Rayner K. (1981). Contextual effects on word perception and eye movements during reading. Journal of Verbal Learning and Verbal Behavior, 20, 641–655. doi: 10.1016/S0022-5371(81)90220-6 [DOI] [Google Scholar]
- Friedman A. (1979). Framing pictures: The role of knowledge in automatized encoding and memory for gist. Journal of Experimental Psychology: General, 108, 316–355. doi: 10.1037/0096-3445.108.3.316 [DOI] [PubMed] [Google Scholar]
- Ganis G., Kutas M. (2003). An electrophysiological study of scene effects on object identification. Cognitive Brain Research, 16, 123–144. doi: 10.1016/S0926-6410(02)00244-6 [DOI] [PubMed] [Google Scholar]
- Greene M. R. (2013). Statistics of high-level scene context. Frontiers in Psychology, 4, 777. doi: 10.3389/fpsyg.2013.00777 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hautus M. J. (1995). Corrections for extreme proportions and their biasing effects on estimated values ofd′. Behavior Research Methods, 27, 46–51. [Google Scholar]
- Henderson J. M. (1992). Identifying objects across saccades: effects of extrafoveal preview and flanker object context. Journal of Experimental Psychology: Learning, Memory, and Cognition, 18, 521–530. Retrieved from http://psycnet.apa.org/journals/xlm/18/3/521/ [DOI] [PubMed] [Google Scholar]
- Henderson J. M. (1997). Transsaccadic memory and integration during real-world object perception. Psychological Science, 8, 51–55. doi: 10.1111/j.1467-9280.1997.tb00543.x [DOI] [Google Scholar]
- Henderson J. M. (2003). Human gaze control during real-world scene perception. Trends in Cognitive Sciences, 7, 498–504. [DOI] [PubMed] [Google Scholar]
- Henderson J. M., Chanceaux M., Smith T. J. (2009). The influence of clutter on real-world scene search: evidence from search efficiency and eye movements. Journal of Vision, 9, 32. doi: 10.1167/9.1.32 [DOI] [PubMed] [Google Scholar]
- Henderson J. M., Ferreira F. (1990). Effects of foveal processing difficulty on the perceptual span in reading: Implications for attention and eye movement control. Journal of Experimental Psychology: Learning, Memory, and Cognition, 16, 417–429. Retrieved from http://doi.org/2140401 [DOI] [PubMed] [Google Scholar]
- Henderson J. M., Pollatsek A., Rayner K. (1987). Effects of foveal priming and extrafoveal preview on object identification. Journal of Experimental Psychology: Human Perception and Performance, 13, 449–463. doi: 10.1037/0096-1523.13.3.449 [DOI] [PubMed] [Google Scholar]
- Henderson J. M., Pollatsek A., Rayner K. (1989). Covert visual attention and extrafoveal information use during object identification. Perception & Psychophysics, 45, 196–208. doi: 10.3758/BF03210697 [DOI] [PubMed] [Google Scholar]
- Henderson J. M., Siefert A. B. C. (1999). The influence of enantiomorphic transformation on transsaccadic object integration. Journal of Experimental Psychology: Human Perception and Performance, 25, 243–255. doi: 10.1037/0096-1523.25.1.243 [DOI] [Google Scholar]
- Henderson J. M., Siefert A. B. C. (2001). Types and tokens in transsaccadic object identification: Effects of spatial position and left-right orientation. Psychonomic Bulletin & Review, 8, 753–760. doi: 10.3758/BF03196214 [DOI] [PubMed] [Google Scholar]
- Henderson J. M., Williams C. C., Castelhano M. S., Falk R. J. (2003). Eye movements and picture processing during recognition. Perception & Psychophysics, 65, 725–734. doi: 10.3758/BF03194809 [DOI] [PubMed] [Google Scholar]
- Hollingworth A. (1998). Does consistent scene context facilitate object perception? Journal of Experimental Psychology: General, 127, 398–415. doi: 10.1037/0096-3445.127.4.398 [DOI] [PubMed] [Google Scholar]
- Hollingworth A., Henderson J. M. (1998). Does consistent scene context facilitate object perception? Journal of Experimental Psychology: General, 127, 398–415. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/9857494 [DOI] [PubMed] [Google Scholar]
- Inhoff A. W., Rayner K. (1986). Parafoveal word processing during eye fixations in reading: Effects of word frequency. Perception & Psychophysics, 40, 431–439. doi: 10.3758/BF03208203 [DOI] [PubMed] [Google Scholar]
- Juhasz B. J., White S. J., Liversedge S. P., Rayner K. (2008). Eye movements and the use of parafoveal word length information in reading. Journal of Experimental Psychology: Human Perception and Performance, 34, 1560–1579. doi: 10.1037/a0012319 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Loftus G. R., Mackworth N. H. (1978). Cognitive determinants of fixation location during picture viewing. Journal of Experimental Psychology: Human Perception and Performance, 4, 565–572. doi: 10.1037/0096-1523.4.4.565 [DOI] [PubMed] [Google Scholar]
- Malcolm G. L., Henderson J. M. (2009). The effects of target template specificity on visual search in real-world scenes: evidence from eye movements. Journal of Vision, 9, 8. doi: 10.1167/9.11.8 [DOI] [PubMed] [Google Scholar]
- Malcolm G. L., Henderson J. M. (2010). Combining top-down processes to guide eye movements during real-world scene search. Journal of Vision, 10, 4. doi: 10.1167/10.2.4 [DOI] [PubMed] [Google Scholar]
- McClelland J. L., O’Regan J. K. (1981). Expectations increase the benefit derived from parafoveal visual information in reading words aloud. Journal of Experimental Psychology: Human Perception and Performance, 7, 634–644. doi: 10.1037/0096-1523.7.3.634 [DOI] [Google Scholar]
- McConkie G. W., Zola D. (1979). Is visual information integrated across successive fixations in reading? Perception & Psychophysics, 25, 221–224. doi: 10.3758/BF03202990 [DOI] [PubMed] [Google Scholar]
- Morgan J. L., Meyer A. S. (2005). Processing of extrafoveal objects during multiple-object naming. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31, 428–442. doi: 10.1037/0278-7393.31.3.428 [DOI] [PubMed] [Google Scholar]
- Neider M. B., Zelinsky G. J. (2006). Scene context guides eye movements during visual search. Vision Research, 46, 614–621. doi: 10.1016/j.visres.2005.08.025. [DOI] [PubMed] [Google Scholar]
- Nuthmann A. (2013). On the visual span during object search in real-world scenes. Visual Cognition, 21, 803–837. doi: 10.1080/13506285.2013.832449 [DOI] [Google Scholar]
- Nuthmann A. (2014). How do the regions of the visual field contribute to object search in real-world scenes? Evidence from eye movements. Journal of Experimental Psychology: Human Perception and Performance, 40, 342–360. doi: 10.1037/a0033854 [DOI] [PubMed] [Google Scholar]
- Oliva A., Torralba A. (2007). The role of context in object recognition. Trends in Cognitive Sciences, 11, 520–527. doi: 10.1016/j.tics.2007.09.009 [DOI] [PubMed] [Google Scholar]
- Palmer S. E. (1975). The effects of contextual scenes on the identification of objects. Memory & Cognition, 3, 519–526. doi: 10.3758/BF03197524 [DOI] [PubMed] [Google Scholar]
- Pereira E. J., Castelhano M. S. (2014). Peripheral guidance in scenes: The interaction of scene context and object content. Journal of Experimental Psychology: Human Perception and Performance, 40, 2056–2072. doi: 10.1037/a0037524 [DOI] [PubMed] [Google Scholar]
- Pollatsek A., Rayner K., Collins W. E. (1984). Integrating pictorial information across eye movements. Journal of Experimental Psychology: General, 113, 426–442. Retrieved from http://doi.org/6237171 [DOI] [PubMed] [Google Scholar]
- Pollatsek A., Rayner K., Henderson J. M. (1990). Role of spatial location in integration of pictorial information across saccades. Journal of Experimental Psychology: Human Perception and Performance, 16, 199–210. doi: 10.1037/0096-1523.16.1.199 [DOI] [PubMed] [Google Scholar]
- Rayner K. (1975). The perceptual span and peripheral cues in reading. Cognitive Psychology, 7, 65–81. [Google Scholar]
- Rayner K. (1998). Eye movements in reading and information processing: 20 years of research. Psychological Bulletin, 124, 372–422. Retrieved from http://doi.org/9849112. [DOI] [PubMed] [Google Scholar]
- Rayner K. (2009). Eye movements and attention in reading, scene perception, and visual search. The Quarterly Journal of Experimental Psychology, 62, 1457–1506. doi: 10.1080/17470210902816461 [DOI] [PubMed] [Google Scholar]
- Rayner K., Balota D. A., Pollatsek A. (1986). Against parafoveal semantic preprocessing during eye fixations in reading. Canadian Journal of Psychology/Revue Canadienne de Psychologie, 40, 473–483. doi: 10.1037/h0080111 [DOI] [PubMed] [Google Scholar]
- Rayner K., Bertera J. H. (1979). Reading without a fovea. Science (New York, N.Y.), 206, 468–469. Retrieved from http://doi.org/504987 [DOI] [PubMed] [Google Scholar]
- Rayner K., Castelhano M. S. M. S., Yang J. (2009). Eye movements and the perceptual span in older and younger readers. Psychology and Aging, 24, 755–760. doi: 10.1037/a0014300 [DOI] [PubMed] [Google Scholar]
- Rayner K., McConkie G. W., Ehrlich S. (1978). Eye movements and integrating information across fixations. Journal of Experimental Psychology: Human Perception and Performance, 4, 529–544. doi: 10.1037/0096-1523.4.4.529 [DOI] [PubMed] [Google Scholar]
- Rayner K., Well A. D. (1996). Effects of contextual constraint on eye movements in reading: A further examination. Psychonomic Bulletin & Review, 3, 504–509. doi: 10.3758/BF03214555 [DOI] [PubMed] [Google Scholar]
- Rosenholtz R., Li Y., Nakano L. (2007). Measuring visual clutter. Journal of Vision, 7, 17. doi: 10.1167/7.2.17 [DOI] [PubMed] [Google Scholar]
- Sanocki T. (1993). Time course of object identification: Evidence for a global-to-local contingency. Journal of Experimental Psychology: Human Perception and Performance, 19, 878–898. doi: 10.1037/0096-1523.19.4.878 [DOI] [PubMed] [Google Scholar]
- Schotter E. (2013). Synonyms provide semantic preview benefit in English. Journal of Memory and Language, 69, 619–633. doi: 10.1016/j.jml.2013.09.002 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stanislaw H., Todorov N. (1999). Calculation of signal detection theory measures. Behavior Research Methods, Instruments, & Computers, 31, 137–149. [DOI] [PubMed] [Google Scholar]
- Torralba A., Oliva A., Castelhano M. S., Henderson J. M. (2006). Contextual guidance of eye movements and attention in real-world scenes: The role of global features in object search. Psychological Review, 113, 766–786. doi: 10.1037/0033-295X.113.4.766 [DOI] [PubMed] [Google Scholar]
- Võ M. L.-H., Henderson J. M. (2009). Does gravity matter? Effects of semantic and syntactic inconsistencies on the allocation of attention during scene perception. Journal of Vision, 9, 24. doi: 10.1167/9.3.24 [DOI] [PubMed] [Google Scholar]
- Võ M. L.-H., Wolfe J. M. (2013). Differential electrophysiological signatures of semantic and syntactic scene processing. Psychological Science, 24, 1816–1823. doi: 10.1177/0956797613476955 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Võ M. L.-H., Zwickel J., Schneider W. X. (2010). Has someone moved my plate? The immediate and persistent effects of object location changes on gaze allocation during natural scene viewing. Attention, Perception & Psychophysics, 72, 1251–1255. doi: 10.3758/APP.72.5.1251 [DOI] [PubMed] [Google Scholar]