

Abstract
This paper reports the construction of a multi-modal annotated database of spoken discourse and co-verbal gestures by native healthy speakers of Cantonese and individuals with language impairment, Cantonese AphasiaBank. This corpus was established as a foundation for aphasiologists and clinicians to design and conduct research investigations into theoretical and clinical issues related to acquired language disorders in Chinese. Details in terms of the purpose, structure, and levels of annotation of the database (containing part-of-speech annotated orthographic transcripts with Romanization and corresponding videos) were described. The discussion presents the challenges of building a spoken database of a language that is not linguistically well-researched and without a proper written form for many of its lexical items, as well as how these issues are addressed. More importantly, the paper highlights the potential of Cantonese AphasiaBank as a powerful research tool to linguists and psycholinguists.
Keywords: language database, Cantonese, Chinese, aphasia, discourse, gestures, stroke
Introduction
The value of language databases to linguistic and especially psycholinguistic studies has been well-recognized and demonstrated by researchers in these fields. This paper introduces a newly developed spoken language database, the Cantonese AphasiaBank (Kong & Law, 2010–2014), that has been made available in the public domain since 2016. The database, containing discourse samples from unimpaired native Cantonese speakers and right-handed people with aphasia (PWA) living in Hong Kong of different ages and education levels, is first of its kind in Asian languages for studying spoken narratives. The PWA in the database include different aphasia types caused by stroke. Significantly, it encompasses not only information on distinctive linguistic properties in discourse production, but also non-verbal behaviors (i.e. co-verbal gestures) produced by healthy speakers and PWA. The elicitation protocol follows the English AphasiaBank protocol (MacWhinney, Fromm, Forbes, & Holland, 2011), but with careful adaptation to the local Chinese culture. This corpus was established with the premise that it would provide the necessary foundation for aphasiologists and clinicians to design and conduct research investigations of theoretical and clinical issues related to acquired language disorders in Chinese. The overarching goal of constructing this database is to improve the planning of assessment and remediation procedures for Chinese-speaking PWA worldwide, including those living in North America, through actively sharing this multimedia database with any clinicians and researchers who work with Chinese speakers with acquired language deficits. However, as Cantonese AphasiaBank contains both normal and disordered language data, we will demonstrate that it constitutes a rich resource for addressing various issues of language behaviors that are of interest to linguists, neurolinguists, and psycholinguists.
Generally speaking, corpora drawn from written texts outnumber those based on the spoken language. This is also the case for Chinese as revealed in a survey of Chinese language corpora for research (Yang, 2006), in which about 70% of the listed corpora were constructed using a written source. The Cantonese AphasiaBank was designed to distinguish from these databases in several ways. Not only was its scale larger than most corpora in terms of the number of speakers, but also its scope of content that included both unimpaired language and aphasic discourse production. In addition, information on verbal language performance ranging from the lexical, clausal/sentential, to discoursal levels were systematically captured and presented, along with performance of co-verbal gestures that are synchronized with discourse language production. Finally, unlike most previous databases that were based on open-ended conversations, the participants in this database performed an identical set of discourse tasks with target contents controlled. As a result of these unique features, the Cantonese AphasiaBank allowed investigations by linguists, neurolinguists, and psycholinguists. Apart from the above, the database has also supported education of student-clinicians of speech-language pathologists1.
In order to better appreciate how the Cantonese AphasiaBank is advantageous for research applications and, therefore, a new contribution to current resources, a brief introduction of stroke-induced aphasia and a review of existing spoken Chinese databases is in order. Stroke has been listed as one of the target diseases on the global agenda for prevention and control by the World Health Organization. The burden of stroke is particularly serious in Asian countries (Kim, 2014) because of their rapidly aging population. The prevalence of post-stroke aphasia in the Indo-European populations is about 40% (Salter, Teasell, Foley, & Allen, 2014; Wade, Hewer, David, & Menderby, 1986). Applying this prevalence rate to Chinese speakers (due to the lack of comparable figures available for Asian countries), one can see a huge demand for language rehabilitation from these individuals. However, compared to the rigorous research agenda of investigating and evidence-based protocols for managing aphasia in English, there is a great paucity of resources reported for use in Chinese-speaking PWA (Kong, 2017). Chinese PWA is one of the underrepresented minority groups as listed by National Institutes of Health. Traditionally, aphasiology research has employed methods of single case studies, case series, or participants in groups of small sizes (Martin & Kalinyak-Fliszar, 2014; Willmes, 2007). Using big data to predict epidemics, address pathological deficits, and improve quality of life has become an upcoming trend in the healthcare industry, including the field of speech therapy or communication sciences and disorders (Faroqi-Shah, 2016). Many clinical as well as research questions can only be answered with data from substantial numbers of patients, their performances across different language tasks, and responses to individual test items. The Cantonese AphasiaBank project (Kong & Law, 2010–2014) was initiated to go beyond the conventional narrow-sampling approach of investigation.
The Chinese language family consists of seven major dialects including Mandarin, Min, Hakka, Wu, Cantonese, Xiang, and Gan. According to a number of reviews of spoken Chinese databases (Chui & Lai, 2008; Leung & Law, 2001; Wang, 2001; Yang 2006), there are currently a total of 13 in Mandarin, and ten in spoken Cantonese. Noted that Cantonese is the second most widely spoken dialect with over 52 million speakers distributed over southern China and overseas Chinese communities; it also differs from Mandarin in that it has both the spoken and corresponding written form. Similar to corpora in other languages, Chinese spoken databases serve different purposes and may represent different registers or genres from different sources. Some consist of recordings of read single words, utterances and passages from printed materials in Mandarin (e.g., Chou & Tseng, 1999) or in Cantonese (e.g., Lee, Lo, Ching, & Meng, 2002) for developing speech recognition and synthesis technology; some contain pre-planned dialogues from television dramas in Mandarin (e.g., Lee, 2011) or in Cantonese (e.g., Xu & Lee, 1998), while others contain speech of a more spontaneous nature from telephone conversations in Mandarin (e.g., Zhou, Li, Yin, & Zong, 2010), Cantonese radio programs (e.g., Leung & Law, 2001), and monologues such as storytelling in Mandarin (e.g., Chafe, 1980) or in Cantonese (e.g., Chui & Lai, 2008). The above-mentioned databases were constructed solely with language samples of unimpaired speakers. Moreover, videos files capturing speakers’ performance during time of speech sample collection were absent since the majority of language materials in these databases were based on audio recordings2. Furthermore, only two of these Cantonese adult corpora, namely the Hong Kong Cantonese Adult Language Corpus (HKCAC; Leung & Law, 2001; Leung, Law, & Fung, 2004) and the Hong Kong University Cantonese Corpus (HKUCC; Luke & Nancarrow, 1997; Wong, 2006a) have part-of-speech (POS) tagging3.
In the rest of this paper, we describe the background of building Cantonese AphasiaBank. Specific search functions of this database, its multi-modal display features, as well as specific challenges of and solutions to annotation of database contents will also be illustrated. We will also demonstrate how Cantonese AphasiaBank can be used by researchers of different language disciplines as a research tool that can subsequently facilitate the management of Chinese-speaking PWA.
Cantonese AphasiaBank
There are two corpora in Cantonese AphasiaBank, CANtonese corpus of Oral Narratives (CANON) and Database of Speech and GEsture (DoSaGE). They can be accessed at http://www.speech.hku.hk/caphbank/search/. After registration, users can utilize all database contents they wish to analyze (see Figure 1 for the ‘About us’ and ‘Log in’ screen).
Figure 1.

The Cantonese AphasiaBank ‘About us’ and ‘Log in’ screenshot
CANtonese corpus of Oral Narratives (CANON)
CANON differs importantly from HKUCC in a number of aspects. While HKUCC contains mainly conversations of a variety of topics among highly educated young and middle-aged Cantonese speakers and HKCAC contains conversations recorded from phone-in programs on the radio, data in Cantonese AphasiaBank are monologues collected from local native speakers of Cantonese residing in Hong Kong (a linguistically homogenous city of China) balanced in gender, age, and education. To be specific, the first corpus, namely CANtonese corpus of Oral Narratives (CANON), contains annotated orthographic and morphological information as well as romanized transcripts of 149 unimpaired speakers and 105 PWA. The language elicitation protocol included (1) description of a single color photo displaying the scene of rescuing someone in a flood, (2) description of a single black and white line drawing of “Cat Rescue”, (3) two sequential picture description tasks using two sets of black and white drawings – “Broken Window” and “Refused Umbrella”, (4) a procedural discourse task of describing how to prepare an “Egg and Ham Sandwich”, (5) telling of two stories – “The Boy Who Cried Wolf” and “Tortoise and Hare”, and (6) a personal monologue of an important event. For all PWA, the protocol included (7) an additional monologue task of telling their “stroke story”. Only tasks (1) to (5) were elicited using pictorial materials. If needed, task-specific probing questions were also given. Apart from the above narrative tasks, each PWA is administered language tests to assess repetition of words and phrases, noun and verb naming, and (non-)verbal semantic skills as well as the Action Research Arm Test (ARAT; Lyle, 1981) to quantify the degree of upper limb hemiplegia. The demographic information of both speaker groups is given in Tables 1 and 2. Figure 2 shows the interface displayed to users for selecting subject using the embedded filter features in this database (including “subject type”, “aphasia type”, “gender’, “age”, “education level”, and “ARAT score”).
Table 1.
Distribution of Unimpaired Participants and Persons with Aphasia (PWA) by Age and Education Subgroups
| Male | Female | ||||
|---|---|---|---|---|---|
| Unimpaired Participants | |||||
| Age (in year) | Low Education | High Education | Low Education | High Education | Sub-total |
| 18 – 39 | 12 | 12 | 10 | 13 | 47 |
| 40 – 59 | 15 | 9 | 12 | 12 | 48 |
| 60 or above | 11 | 15 | 22 | 6 | 54 |
| Sub-total | 38 | 36 | 44 | 31 | (149) |
| Persons with Aphasia | |||||
| 18 – 39 | 3 (1 Wernicke’s + 1 Broca’s + 1 Global) | 2 (1 Transcortical motor + 1 Isolation) | 2 (2 Anomic) | 1 (1 Transcortical motor) | 8 |
| 40 – 59 | 47 (26 Anomic + 4 Transcortical sensory + 11 Broca’s + 5 Transcortical motor + 1 Global) | 5 (4 Anomic + 1 Transcortical sensory) | 15 (11 Anomic + 1 Broca’s + 3 Transcortical motor) | 1 (1 Transcortical motor) | 68 |
| 60 or above | 10 (5 Anomic + 1 Transcortical sensory + 1 Broca’s + 3 Transcortical motor) | 3 (3 Anomic) | 10 (5 Anomic + 1 Wernicke’s + 2 Broca’s + 1 Transcortical motor + 1 Isolation) | 6 (4 Anomic + 1 Broca’s + 1 Global) | 29 |
| Sub-total | 60 | 10 | 27 | 8 | (105) |
Note. Higher or lower than secondary school for the two younger groups, and higher or low than primary school for the oldest group, i.e., at least 14 years as higher education for the two younger groups and at least 7 years as higher education for the elderly group. The high illiteracy rate in native Cantonese elderly speakers in Hong Kong (and in Mainland China as well as many Chinese oversea communities) limited our application of the same high-low education criterion for all participant groups. According to Hong Kong SAR Government (2003), over half of the Hong Kong population during 1970s had only attained primary school education; the percentage of was even higher prior to that. Furthermore, over the decades, many jobs now requiring tertiary education qualification previously only required secondary school education. We believe that education and working experience could associate with language abilities of our elderly group participants. This had led us to draw this equivalence (of 7 years of education for the oldest group is comparable to 14 years of education for the two younger groups, in terms of language abilities).
Table 2.
Demographic Information on Persons with Aphasia (PWA)
| Fluent | Non-fluent | ||||||
|---|---|---|---|---|---|---|---|
| Aphasia syndrome | Anomic | Wernicke’s | Transcortical sensory | Broca’s | Transcortical motor | Isolation | Global |
| Gender | 39M + 21F | 1M + 1F | 6M + 0F | 13M + 4F | 9M + 6F | 1M + 1F | 2M + 1F |
| Age (in years) | 55.00 (9.97)a | 52.92 (5.70) | 49.33 (15.91) | 55.24 (8.53) | 57.31 (14.21) | 50.92 (16.38) | 49.92 (13.75) |
| 55.00 (9.97) | 55.41 (11.58) | ||||||
| 55.15 (10.51) | |||||||
| Years of education | 9.07 (3.55) | 5.50 (7.78) | 11.00 (3.29) | 8.71 (3.04) | 10.13 (5.54) | 9.50 (4.95) | 10.00 (2.65) |
| 9.13 (3.67) | 9.43 (4.19) | ||||||
| 9.24 (3.85) | |||||||
| Aphasia Quotient (AQ)b | 89.84 (7.37) | 65.35 (11.10) | 73.83 (11.67) | 47.81 (13.33) | 69.89 (9.65) | 11.45 (0.64) | 44.47 (5.57) |
| 87.70 (9.80) | 54.52 (18.66) | ||||||
| 76.01 (20.88) | |||||||
| Post onset time (in years) | 5.18 (4.51) | 1.58 (1.30) | 2.43 (2.08) | 4.25 (5.50) | 4.09 (3.58) | 3.63 (2.89) | 2.42 (1.52) |
| 4.83 (4.38) | 4.01 (4.326) | ||||||
| 4.54 (4.37) | |||||||
Note.
values are given in “mean and (standard deviations)”.
Based on the results of the Cantonese version of the Western Aphasia Battery (Yiu, 1992) and the maximum is 100, a higher score of AQ indicates a lower severity of language impairment.
M = male; F = female.
Figure 2.

A screenshot of subject filter features and results in Cantonese AphasiaBank
As one can see, the data of CANON are not free language samples, that is, the target content of spoken output was controlled to be the same across our participants. The advantage of task specific data is to enable us to have control over the content such that one may study how language output differs as a function of age, gender, and education. The language samples were orthographically transcribed by two linguistically trained research assistants. Inter-rater reliability of orthographic transcription was computed by randomly selecting 10% of the samples and double-checked against the audio recordings by the project investigators, and was found to have an agreement of greater than 99%.
Database of Speech and GEsture (DoSaGE)
The second corpus in Cantonese AphasiaBank is the Database of Speech and GEsture (DoSaGE) that contains digitized video recordings of procedural discourse, story-telling, and personal monologue from 131 (of the 149) unimpaired speakers and 96 (of the 105) PWA in CANON. These videos are synchronized with the corresponding orthographic transcripts, using EUDICO Linguistic Annotator (Lausberg & Sloetjes, 2009), with independent annotation of the forms and functions of all co-verbal gestures (Table 3).
Table 3.
List of Gesture Annotations in Cantonese AphasiaBank
| Gesture annotation | Abbreviation |
|---|---|
| Forms | |
| Iconic | i |
| Metaphoric | meta |
| Deictic | dei |
| Emblem | em |
| Beats | be |
| Non-identifiable | non |
| Functions | |
| Providing additional information | pro |
| Enhancing language content | en |
| Alternate means of communication | alt |
| Guiding speech flow | gui |
| Reinforcing prosody of speech | rein |
| Assisting lexical retrieval | lex |
| Assisting sentence reconstruction | sent |
| No specific function | no |
Markup, search, and annotation in CANON
This section describes the characteristics, structure, and annotation of the data in CANON. Note that the morphological tagging of parts-of-speech (POS) in CANON is automatic, unlike the manual annotation in HKUCC, with specific tagging rules written for CANON to reflect morphological processes of Cantonese.
For each participant in Cantonese AphasiaBank, the orthographic transcriptions of all language samples are combined into one single document with a code name. The identities, personal and demographic information of the participants, and times and dates of individual recordings are kept in a separate master file. Each narrative in the transcript begins with a line marking the name of the sample. Transcriptions are formatted using the Codes for the Human Analysis of Transcripts4 (CHAT; MacWhinney 2000). The transcripts in CANON are linked to audio and video recordings through a computerized analytic program named Child Language Analyses (CLAN; MacWhinney, 2003). CLAN allows one to carry out a variety of linguistic analyses, such as frequency count, lexical diversity, mean length of utterance (MLU), as well as searches for user-specified combinations of words, character strings, or words in context, etc.
In addition to orthographic transcription, each lexical entry or token demarcated by a space is annotated for POS, an automatically generated phonetic transcription in Cantonese romanization, and an English gloss. For each transcript, segmentation of utterances largely follows the “one verb or clause per line” principle, except when a verb subcategorizes for a clause. Specifically, a new utterance (therefore a new line in CLAN) is formed (1) when a speaker restarts, partially repeats what s/he just said, (2) when a speaker switches to a new topic or when the topic contains more than a noun phrase (i.e., a clause), (3) when there is an interjection, a connective, or a filler between clauses, or (4) whenever the adverbial
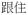 (
(
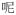 ) ‘then’ is used. Examples of two utterances are given in Figure 3, where (a) shows morphological annotation with unambiguous tagging, (b) illustrates initial POS tagging with some tokens having multiple tags separated by the symbol “^” (shown in shaded text), and POS annotation after the transcript has been manually verified. In each example, the first tier represents orthographic transcription, where tokens are divided by a space. The second tier consists of information on POS, Cantonese Romanization and an English gloss of each token, and in that order.
) ‘then’ is used. Examples of two utterances are given in Figure 3, where (a) shows morphological annotation with unambiguous tagging, (b) illustrates initial POS tagging with some tokens having multiple tags separated by the symbol “^” (shown in shaded text), and POS annotation after the transcript has been manually verified. In each example, the first tier represents orthographic transcription, where tokens are divided by a space. The second tier consists of information on POS, Cantonese Romanization and an English gloss of each token, and in that order.
Figure 3.

Format and levels of annotation
The morphological (POS) tagset in CANON has a total of 38 classes as listed in Table 4, fewer than the set of 54 tags in HKUCC, another adult Cantonese corpus mentioned earlier. While the two tagsets share many common classes as expected, the main differences lie in that (i) derivational and inflectional morphemes are distinguished in terms of their position of occurrence in HKUCC but classified under the category of “affix” in CANON; (ii) major content word classes, i.e., nouns, verbs, and adjectives, are distinguished in terms of number of constituent morphemes and furthermore in internal structure for verbs in CANON but not so in HKUCC; (iii) the classes of “short form”, “fixed expression” and “idioms” in HKUCC fall in the category of “expression” in CANON; and (iv) the classes of time, pronoun, numeral, verb, adjective and noun morphemes in HKUCC do not have counterparts in CANON. Although seven of the eight narratives from each participant are elicited using specific stimuli, the variety of lexical forms in the language samples is still evident. A total of 4,450 entries are listed in the CANON dictionary5.
Table 4.
List of Part-of-Speech Tags in Cantonese AphasiaBank
| Part-of-speech | Abbreviation | Example with explanation |
|---|---|---|
| Functional morphemes | ||
| Affix | / |
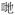 ‘plural marker’ ‘plural marker’ |
| Aspectual marker | asp |
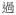 ‘experiential marker’ ‘experiential marker’ |
| Classifier | cl |
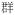 ‘group’ ‘group’ |
| Communicator | co |
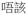 ‘thank you’ ‘thank you’ |
| Conjunction | conj |
 ‘and’ ‘and’ |
| Connective | conn |
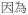 ‘because’ ‘because’ |
| Demonstrative | dem |
 ‘that’ ‘that’ |
| Determiner | det |
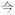 ‘this’ ‘this’ |
| Expression | exp |
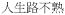 ‘feeling out of place’ ‘feeling out of place’ |
| Filler | fil | gam2aa6 |
| Interjection | int |
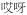 ‘ouch’ ‘ouch’ |
| Locative | loc |
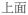 ‘above’ ‘above’ |
| Numeral | num |
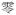 ‘zero’ ‘zero’ |
| Onomatopoeia | on |
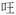 ‘a bark’ ‘a bark’ |
| Preposition | prep |
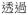 ‘through’ ‘through’ |
| Pro-word | pro |
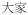 ‘each other’ ‘each other’ |
| Quantifier | quan |
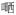 ‘all’ ‘all’ |
| Sentence final particle | sfp |
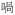 ‘reported speech’ ‘reported speech’ |
| Structural particle | stprt |
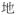 ‘-ly’ ‘-ly’ |
| Verbal particle | vprt |
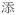 ‘also’ ‘also’ |
| wh-word | wh |
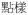 ‘how’ ‘how’ |
| Adjective | ||
| Adjective | adj |
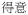 ‘funny’ ‘funny’ |
| Complex adjective | adj-com |
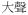 ‘loud’ ‘loud’ |
| Adverb | ||
| Adverb | adv |
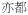 ‘also’ ‘also’ |
| Adverb of negation | adv-neg |
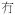 ‘have not’ ‘have not’ |
| Noun | ||
| Noun (monosyllabic) | n-mono |
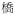 ‘bridge’ ‘bridge’ |
| Noun (multisyllabic) | n-multi |
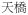 ‘overpath’ ‘overpath’ |
| Proper noun | n-prop |
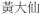
|
| Verb | ||
| Auxiliary verb | aux |
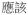 ‘should’ ‘should’ |
| Directional verb | vdirc |
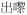 ‘come out’ ‘come out’ |
| Verb (monosyllabic) | v-mono |
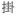 ‘hang’ ‘hang’ |
| Verb (multisyllabic) | v-multi |
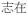 ‘care’ ‘care’ |
| Verb (adj+v) | v-adj+v |
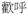 ‘cheer’ ‘cheer’ |
| Verb (n+v) | v-n+v |
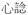 ‘think’ ‘think’ |
| Verb (v+adj) | v-v+adj |
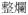 ‘break’ ‘break’ |
| Verb (v+n) | v-v+n |
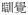 ‘sleep’ ‘sleep’ |
| Verb (v+v) | v-v+v |
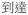 ‘arrive’ ‘arrive’ |
| Verb (v+v+n) | v-v+v+n |
 ‘awake’ ‘awake’ |
Note: adj = adjective; n = noun; v = verb.
The current study applied the MOR tagger, a computational systems for the morphosyntactic analysis of the spoken language data in the CHILDES (http://childes.psy.cmu.edu) and TalkBank (http://talkbank.org) databases, for automatic annotation of POS. This procedure generally followed those listed in the English AphasiaBank project (MacWhinney & Fromm, 2016). According to MacWhinney (2012), the MOR grammars have been built for Indo-European languages, such as English, Spanish, French, Italian, Dutch, and German, as well as three Asian languages, including Mandarin, Cantonese, and Japanese. Specifically, the Cantonese MOR tagger (http://talkbank.org/morgrams/) was designed based on statistical distribution of lexical items in Cantonese and then with contextual rules of Cantonese grammar. While the MOR tagger reaches 98% accuracy on English adult corpora (MacWhinney, 2012), the tagger in the CANON has a comparable but slightly lower tagging accuracy (based on the total token of 132,024).
Users of Cantonese AphasiaBank who want to conduct a quick and simple search of specific lexical information of the database transcripts can do so through the “Search by Word” tab. The search can be performed by specifying one or more of the following parameters: a particular Chinese character, a specific Chinese lexicon (that is made up of one or more Chinese characters), jyutping (a romanization system for Cantonese developed by the Linguistic Society of Hong Kong), part-of-speech tags of transcription, glossary in English, and narrative task(s) that contain the search item. Figure 4 displays a screenshot of the interface displayed to users for defining search criteria on this tab. The length of utterances to be displayed in the results can also be pre-set by adjusting the concordance length parameter.
Figure 4.

A screenshot of “Search by Word” filter parameters in Cantonese AphasiaBank
A search for a simple Chinese keyword
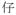 ‘son’ is illustrated here. This character, apart from acting as a noun ‘son’ in oral narratives, can also serve multiple functions such as a suffix or a constituent of a compound noun or proper noun. If a user is interested in knowing the total number of lexical items containing this character in Cantonese AphasiaBank, the frequency of occurrence in the database for each items and its part-of-speech, and/or how each lexical item was used by PWA (versus controls) across different narrative tasks, a simple “Search Keyword (Chinese)” result displayed in Figure 5 demonstrates the following: (a) there is a total of 1,303 tokens of lexical items that contains the character
, (b) there is a total of 69 different lexical types with different POS across the various narrative tasks within the database, and (c) the screenshot shows three of the 69 lexical types in the “Word” column – suffix in
‘son’ is illustrated here. This character, apart from acting as a noun ‘son’ in oral narratives, can also serve multiple functions such as a suffix or a constituent of a compound noun or proper noun. If a user is interested in knowing the total number of lexical items containing this character in Cantonese AphasiaBank, the frequency of occurrence in the database for each items and its part-of-speech, and/or how each lexical item was used by PWA (versus controls) across different narrative tasks, a simple “Search Keyword (Chinese)” result displayed in Figure 5 demonstrates the following: (a) there is a total of 1,303 tokens of lexical items that contains the character
, (b) there is a total of 69 different lexical types with different POS across the various narrative tasks within the database, and (c) the screenshot shows three of the 69 lexical types in the “Word” column – suffix in
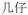 ‘small chair’, compound noun constituent in
‘small chair’, compound noun constituent in
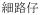 ‘child’ and
‘child’ and
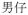 ‘boy’, and single noun in
‘son’. Note that this display of frequency of occurrence is different from the usual notion of frequency count in most databases of open-ended content, which is supposed to reflect extent of word usage. The textbox displays a list of utterances in which the keyword
appears. The tags (containing extra information pertaining to POS, jyutping, and gloss) can be removed by clicking the “Show/hide Tags” button. Each of these lines can also be clicked to further examine the language sample in which the target keyword is found. Note that there are four different matching modes, namely “Exact”, “Starts with”, “Contains”, and “Ends with” that can be selected in the “Match Mode” drop-down menu, for result filtering. In particular, the default mode of “Exact” search will only include a list of utterances where the exact same keyword appears in the database. For “Starts with”, any lexical items starting with the keyword entered will be identified. “Contains” mode will search for any lexical items that contain the keyword entered, and “Ends with” mode will identify any lexical items ending with the keyword entered. All users can then download their search results in the format of a Microsoft Excel worksheet. Importantly, these search results can be useful for linguists and/or psycholinguists who have specific research questions to address or hypotheses to test, and find our data collection methods and data presentation suitable for their purposes.
‘boy’, and single noun in
‘son’. Note that this display of frequency of occurrence is different from the usual notion of frequency count in most databases of open-ended content, which is supposed to reflect extent of word usage. The textbox displays a list of utterances in which the keyword
appears. The tags (containing extra information pertaining to POS, jyutping, and gloss) can be removed by clicking the “Show/hide Tags” button. Each of these lines can also be clicked to further examine the language sample in which the target keyword is found. Note that there are four different matching modes, namely “Exact”, “Starts with”, “Contains”, and “Ends with” that can be selected in the “Match Mode” drop-down menu, for result filtering. In particular, the default mode of “Exact” search will only include a list of utterances where the exact same keyword appears in the database. For “Starts with”, any lexical items starting with the keyword entered will be identified. “Contains” mode will search for any lexical items that contain the keyword entered, and “Ends with” mode will identify any lexical items ending with the keyword entered. All users can then download their search results in the format of a Microsoft Excel worksheet. Importantly, these search results can be useful for linguists and/or psycholinguists who have specific research questions to address or hypotheses to test, and find our data collection methods and data presentation suitable for their purposes.
Figure 5.

A screenshot of “Search by Word” results in Cantonese AphasiaBank with corresponding keywords highlighted. The code ‘BroWn’ in the text box indicates that these sentence lines were found in the sequential picture description task of the “Broken Window” drawings.
Search and display of materials in DoSaGE
The video recordings of the subjects performing all discourse production tasks can be viewed in the “Browse Videos” tab, where a simple search form (drop-down menu of “Subject type”, “Aphasia type”, and “Task”) can be found. The video will be played on the left, while a moving window of transcriptions will be displayed on the right. The current sentences spoken by the subject in the video will be highlighted in yellow. For the tasks of procedural discourse, story-telling, and personal monologue, synchronized annotation information of gestures employed by the speaker is available and highlighted in orange (see Figure 6). In other words, the video, display of language transcriptions, and gesture annotations are time-framed (with information on duration of pauses) and synchronized. The detailed multi-level and multi-modal performance of one’s discourse production is, therefore, readily available for inspection. The transcribed texts can also be clicked for the video to skip to the exact position a user desires to view. Finally, a watermark with the user’s login email address, IP address, as well as time and date of viewing is automatically generated to avoid unauthorized duplication of our database videos.
Figure 6.

A screenshot of viewing recordings of subjects in Cantonese AphasiaBank with synchronized display of video, language transcriptions, and gesture annotations
Specific challenges to building a Cantonese spoken corpus with POS annotation
There are many challenges in constructing a spoken corpus in Cantonese. We discuss below how we handle these difficulties and those that are unique to the language at every stage of the development of CANON, including challenges associated with transcribing and annotating spoken output of PWA.
Orthographic representation of colloquial morphemes
Cantonese is essentially a spoken language; therefore, the problem of orthographically transcribing colloquial morphemes in the language is obvious. While written forms for these items can be found in the popular culture, such as local magazines and comic books, there is no standardization. To deal with this problem, we consult online Cantonese dictionaries including
 (Chinese Character Database with Word Formations) at the Chinese University of Hong Kong (http://humanum.arts.cuhk.edu.hk/Lexis/lexi-can/) and CantoDict v1.4.2 (http://www.cantonese.sheik.co.uk/scripts/wordsearch.php?level=0). For morphemes not found in these sources, Cantonese Romanization would be used. As CLAN supports Unicode, colloquial characters not available in Unicode are represented either in Romanization or by an orthographically similar homophonous character; for instance, the progressive aspect marker
(Chinese Character Database with Word Formations) at the Chinese University of Hong Kong (http://humanum.arts.cuhk.edu.hk/Lexis/lexi-can/) and CantoDict v1.4.2 (http://www.cantonese.sheik.co.uk/scripts/wordsearch.php?level=0). For morphemes not found in these sources, Cantonese Romanization would be used. As CLAN supports Unicode, colloquial characters not available in Unicode are represented either in Romanization or by an orthographically similar homophonous character; for instance, the progressive aspect marker
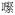 which cannot be found in Unicode is written as
which cannot be found in Unicode is written as
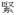 in CANON.
in CANON.
Orthographic transcription of homophonic and homographic morphemes, allomorphs, and fused syllables
Cantonese morphemes, similar to Mandarin, have a high degree of homophony, and many of which are written with the same characters, resulting in ambiguity in tagging. This is particularly problematic if the morphemes in question are highly frequent, e.g.,
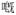 [
kE3] as a possessive marker, a relative clause marker, and a sentence final particle. Our interim solution is to distinguish the different homographic homophonous morphemes with a numeric code following the character,
1,
2,
3. Conversely, some Cantonese morphemes have alternative acceptable phonological forms, e.g. [
lIN1] and [
lIk1] for ‘carry’. In suchcases, different characters,
[
kE3] as a possessive marker, a relative clause marker, and a sentence final particle. Our interim solution is to distinguish the different homographic homophonous morphemes with a numeric code following the character,
1,
2,
3. Conversely, some Cantonese morphemes have alternative acceptable phonological forms, e.g. [
lIN1] and [
lIk1] for ‘carry’. In suchcases, different characters,
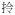 [
lIN1] and
[
lIN1] and
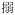 [
lIk1], would be used to represent the various forms as much as possible.
[
lIk1], would be used to represent the various forms as much as possible.
A related issue is the occurrence of fused syllables, which is considered a unique feature of Chinese phonology (Wong, 2006b). Different extent of fusion from reduction to a single syllable to deletion of coda or onset can occur for different syllable strings. A single character would be used if available, e.g.
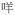 [
mE15] in Figure 1(b) for
[
mE15] in Figure 1(b) for
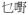 [
mAt1 jE5] ‘what’, where the rime of the first and onset of the second syllable are deleted.
[
mAt1 jE5] ‘what’, where the rime of the first and onset of the second syllable are deleted.
Line segmentation and tokenization
Partly due to the lack of word boundaries in Chinese text, the definition of a word in Chinese is far from straightforward. As characters represent morphosyllables, our guiding principle is to treat each character as a separate token, except for affixation and compounds which may appear in the categories of nouns, verbs, and adverbs. We consult the online dictionary of HKUCC for compounds in the language. After tokenization, the discourse is segmented into units for further analysis. While some spoken corpora would define an utterance in terms of prosodic boundaries (e.g., Zhou et al., 2010), our segmentation is syntactically based in anticipation for building a syntactic parser. A language sample is divided into separate lines in the transcript with each one corresponding to a clause as much as possible.
POS of grammatical morphemes
One major difficulty in grammatically annotating a Cantonese corpus is POS classification, since less systematic and theoretical research has been conducted on the Cantonese grammar, compared with Mandarin. As known among Chinese linguists, determining the POS of grammatical morphemes is particularly challenging for the so-called verbal particles and affixes because many of them (e.g. prepositions or coverbs) originate from content words. We adhere to two principles when classifying candidates for the two classes. The content word status of a morpheme is maintained unless it is a bound morpheme, e.g.,
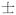 [
si6] ‘scholar’ (somewhat equivalent to the English suffixes ‘ –ist’ in ‘psychologist’, ‘–er’ in ‘philosopher’) in
[
si6] ‘scholar’ (somewhat equivalent to the English suffixes ‘ –ist’ in ‘psychologist’, ‘–er’ in ‘philosopher’) in
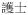 ‘nurse’,
‘nurse’,
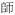 [
si1] ‘professional people’ in
[
si1] ‘professional people’ in
 ‘accountant’, and/or it is semantically empty or detached from its origin, e.g.,
[
tsAI2] (‘son’ when standalone) as an affix meaning ‘diminutive’ in
‘accountant’, and/or it is semantically empty or detached from its origin, e.g.,
[
tsAI2] (‘son’ when standalone) as an affix meaning ‘diminutive’ in
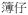 ‘a little notebook’,
‘a little notebook’,
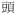 [
tHAU4] (‘head’ when standalone) ‘suffix without meaning’ in
[
tHAU4] (‘head’ when standalone) ‘suffix without meaning’ in
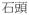 ‘rock-suffix’. As such,
‘rock-suffix’. As such,
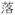 [
lOk6] ‘down’ in
[
lOk6] ‘down’ in
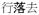 ‘walk-down-go’,
‘walk-down-go’,
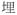 [
maI4] ‘approach’ in
[
maI4] ‘approach’ in
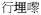 ‘walk-approach-come’ are treated as directional verbs, and
‘walk-approach-come’ are treated as directional verbs, and
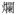 [
lan6] ‘broken’ in
[
lan6] ‘broken’ in
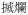 ‘tear-broken’ as the resultative component of a verbal compound, rather than verbal particles.
‘tear-broken’ as the resultative component of a verbal compound, rather than verbal particles.
Capturing morphological processes in Cantonese
Of particular interest to Chinese linguists is that much effort and resources in developing CANON have been put into automatic annotation of morphological processes. In addition to prefixation (
 ‘one’ →
‘one’ →
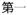 ‘first’) and suffixation (
‘first’) and suffixation (
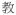 ‘teach’ →
‘teach’ →
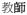 ‘teacher’), there are infixation (
‘teacher’), there are infixation (
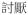 ‘annoying’ →
‘annoying’ →
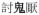 ‘really annoying’) and insertion of aspect marker (ASP), quantifier or verbal particle in a verbal compound (
‘sleep’ →
‘really annoying’) and insertion of aspect marker (ASP), quantifier or verbal particle in a verbal compound (
‘sleep’ →
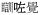 ‘fallen asleep’,
‘fallen asleep’,
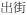 ‘go out’ →
‘go out’ →
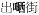 ‘all gone out’,
‘all gone out’,
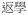 ‘go to school’ →
‘go to school’ →
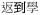 ‘able to go to school’). The cases of infixation and insertion are particularly challenging, and automatic parsing of these processes has not been dealt with previously in a Chinese corpus, as far as we know. To illustrate, while
‘able to go to school’). The cases of infixation and insertion are particularly challenging, and automatic parsing of these processes has not been dealt with previously in a Chinese corpus, as far as we know. To illustrate, while
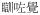 ‘fallen asleep’ is treated as an insertion of the perfective ASP
‘fallen asleep’ is treated as an insertion of the perfective ASP
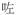 in the verb compound
in CANON, it would be marked as verb + ASP + (verb) morpheme in Wong (2006b). The latter method seems to be ad hoc and inconsistent between the verbal compound with and without ASP insertion.
in the verb compound
in CANON, it would be marked as verb + ASP + (verb) morpheme in Wong (2006b). The latter method seems to be ad hoc and inconsistent between the verbal compound with and without ASP insertion.
Besides affixation, reduplication is a prominent morphological process in Cantonese, which may involve yes/no question formation (or A-not-A question,
 ‘proud’ →
‘proud’ →
 ‘proud or not proud’), intensifying the meaning of an adjective (
‘proud or not proud’), intensifying the meaning of an adjective (
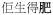 ‘he is fat’ →
‘he is fat’ →
 ‘he is very fat’, or
‘he is very fat’, or
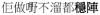 ‘he is always a reliable worker’ →
‘he is always a reliable worker’ →
 → ‘he is always a very reliable worker’, examples adapted from Gao (1984; pp. 60–63), adding a tentative aspect to a verb (
→ ‘he is always a very reliable worker’, examples adapted from Gao (1984; pp. 60–63), adding a tentative aspect to a verb (
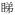 ‘to look’ →
‘to look’ →
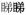 ‘have a look’), a progressive aspect to a verb (
‘to sleep’ →
‘have a look’), a progressive aspect to a verb (
‘to sleep’ →
 ‘in the middle of the sleep’), or a distributive property to a classifier (
‘in the middle of the sleep’), or a distributive property to a classifier (
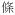 ‘classifier for long and flexible object’ →
‘classifier for long and flexible object’ →
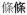 ‘every-classifier’). These surface forms can be parsed in CANON. The morphological tags contain the underlying lexical item and the added meaning (see Table 5 for illustration). In addition, the tagger can handle situations where two morphological processes have taken place, for instance, prefixation and suffixation:
‘every-classifier’). These surface forms can be parsed in CANON. The morphological tags contain the underlying lexical item and the added meaning (see Table 5 for illustration). In addition, the tagger can handle situations where two morphological processes have taken place, for instance, prefixation and suffixation:
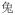 ‘rabbit’ →
‘rabbit’ →
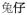 ‘rabbit + diminutive’ →
‘rabbit + diminutive’ →
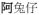 ‘endearing + rabbit + diminutive’, prefixation and reduplication:
‘endearing + rabbit + diminutive’, prefixation and reduplication:
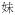 →
→
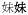 ‘sister’ →
‘sister’ →
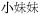 ‘little + sister’,
‘little + sister’,
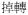 ‘turn around’ →
‘turn around’ →
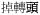 ‘turn around + suffix’ →
‘turn around + suffix’ →
 ‘turn around + aspect marker insertion + suffix’.
‘turn around + aspect marker insertion + suffix’.
Table 5.
Tagging of Morphological Rules
| Surface form | Morphological annotation |
|---|---|
| Affixation | |
Prefixation:
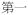 ‘number one’ ‘number one’ |
ORD#num|jat1=one |
Suffixation:
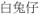 ‘little rabbit’ ‘little rabbit’ |
n|+n|baak6to3-DIM=rabbit |
Infixation:
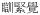 ‘sleeping’ ‘sleeping’ |
v|+v|fan3+n|gaau3&asp:gan2=sleep |
| Reduplication | |
A-not-A question:
 ‘Are you proud?’ ‘Are you proud?’ |
adj|giu1ngou6&NEG=proud |
Intensifying:
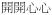 ‘very happy’ ‘very happy’ |
adj|hoi1sam1&INT=happy |
Tentative:
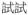 ‘give it a try’ ‘give it a try’ |
v|si3&TEN=try |
Distributive:
 ‘everyday’ ‘everyday’ |
n|jat6&EVERY=day |
| Two morphological processes | |
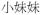 ‘little sister’ ‘little sister’ |
DMP#n|mui6&redup=sister |
Annotating spoken output of PWA
One of the greatest challenges in annotating aphasic speech output corpora is the potential disagreement of parsing POS in non-fluent or grammatically ill-formed sentences of PWA. As detailed in Kong (2016), unifying linguistic information, paralinguistic aspects of oral production, and non-verbal skills co-occurring in spoken narratives can be a daunting task due to the complexity of this phenomenon, this is especially the case when an output is produced by language-impaired people. The availability of audio and video files that are corresponding to the spoken content of PWA greatly enhanced the inter- and/or intra-rater consistency of disambiguation process of annotation.
Potential contribution to research in linguistic, psycholinguistic and neurolinguistics
The rich linguistic and prosodic data as well as videos with information on non-verbal behaviors extracted from Cantonese AphasiaBank have been proven to be extremely valuable for conducting linguistic, psycholinguistic, and neurolinguistics research in Chinese. MacWhinney and Fromm (2016) in a recent review article summarized how the AphasiaBank in English facilitated 45 research investigations in various areas of aphasic productions: (1) lexical, grammatical, and discourse output, (2) fluency and syndrome classification of aphasia, and (3) gesture employment. In addition, effects of social factors of aphasia, such as PWA’s educational background, age, gender, and occupational status, as well as intervention effects on spoken language have been explored. Here we illustrate how the Cantonese AphasiaBank may benefit researchers of different interests:
Psycholinguists in recent years have been concerned with the neural mechanisms underlying language processing and representation. Compared with the corpus that only contain natural conversational speech output of four Mandarin speakers with aphasia (Packard, 1993), our database is of a much larger scale in terms of sample size and includes a wide range of PWA with different syndromes (or types). Each participant also produced samples spanning several discourse genres arguably with different processing demands. How linguistic performance and non-verbal behaviors would vary as a function of variables such as Cantonese-speaking PWA’s age, gender, education level, or aphasia severity can be systematically analyzed. The fact that Cantonese AphasiaBank features unimpaired language dataset would allow users to compare performance between PWA and controls. For example, when contrasting the gestures of PWA and those of individuals without aphasia, videos and corresponding language samples with gesture annotations of age- and education-matched pairs of PWA and control participants can first be extracted from the database. Subsequent analyses in terms of the quantity of gestures and how their forms and functions are affected by aphasia can be conducted; this would allow a better understanding of whether and how speakers may employ gestures to enrich spoken discourse. A recent study utilizing a subset of the data bank to answer the above questions has been reported (Kong, Law, Wat, & Lai, 2015).
Neurolinguists, on the other hand, may be interested in examining how neural substrates are associated with performance in language production and comprehension. The various properties of Cantonese AphasiaBank as described above, such as lesion data of PWA, co-verbal gestures, as well as discoursal dysfluencies of repetitions, false starts, fillers, or self-corrections, constitute a rich source of information for studying theoretical processes of language production. Examples of possible questions include the impact of planning time on online language performance or effects of task demand on discourse performance (e.g., Lai, Law, & Kong, 2017).
Linguists have traditionally examined issues addressing language behaviors at specific linguistic levels, such as phonology, morphology, syntax, semantic, or discourse. Recent years have promoted an approach of language quantification that analyzes performances across linguistic levels within an individual and how they may relate to one another, namely multi-level analyses (e.g., Marini, Andreetta, Del Tin, & Carlomagno, 2011; Milman, Vega-Mendoza, & Clendenen, 2014) and multi-modal production (Linnik, Bastiaanse, & Höhle, 2016) of healthy and PWA speakers. Cantonese AphasiaBank has been utilized in a series of studies looking at issues specific to Cantonese aphasia from word to discourse levels. The major findings are summarized in Table 6. The application of multi-level analyses to data in Cantonese AphasiaBank is currently under way.
Table 6.
Current Major Findings of Investigations Using Cantonese AphasiaBank
| Aspects of verbal and non-verbal communication | Materials used | Major findings |
|---|---|---|
| Lexical processing | Connected speech (3 tasks), noun and verb naming of 19 anomic PWA and controls | With balanced age-of-acquisition, familiarity and imageability, word retrieval accuracy was higher in picture naming than connected speech, but PWA did not retrieve nouns better than verbs (Law, Kong, Lai, & Lai, 2015). |
| Connected speech (1 task) of 65 fluent PWA and controls | Analyses of vocabulary use in terms of part-of-speech, word frequency, lexical semantics, and diversity were conducted. It was found that the vocabulary size was larger for controls than that of PWA, but the distribution across parts-of-speech, frequency of occurrence, and the ratio of concrete to abstract items in major open word classes was similar for both speaker groups. In addition, the two groups proportionately used more different verbs than nouns. (Law, Kong, Lai, & Lai, 2017). | |
| Micro-linguistic performance | Connected speech (3 tasks) of 144 unimpaired speakers | Genre types (i.e., structure and style) and planning load influenced the rate of occurrence of right dislocation, a focus marking device that carried an affective function motivated by limited planning time in conversation (Lai, Law, & Kong, 2017). |
| Connected speech (3 tasks) of 131 unimpaired speakers and 48 PWA | PWA were impaired in various aspects of micro-linguistic skills, including reduced type-token ratio, lower percentage of simple or complete sentences, higher percentage of regulators and dysfluency (Kong, Law, Kwan, Lai, & Lam, 2015; Kong, Law, Wat, & Lai, 2015). | |
| Co-verbal gestures | PWA employed significantly more gestures than controls. Gesture use was influenced by aphasia severity, semantic integrity, and linguistic competence (Kong, Law, Wat, & Lai, 2015). | |
| Connected speech (3 tasks) of 23 fluent PWA, 21 non-fluent PWA, and 23 controls | Different patterns of using non-verbal behaviors were observed between the two PWA groups (Kong, Law, & Chak, 2015, 2017). | |
| Non-verbal behaviors | Connected speech (2 tasks) of 2 fluent PWA, 2 non-fluent PWA, and controls | Frequency of employing referent-related gestures, functional gestures, facial expressions, and adaptors in PWA was over double than controls. Fluent and non-fluent PWA differed qualitatively in using these non-verbal behaviors (Kong, Law, & Lee, 2010). |
| Macro-linguistic performance | Connected speech (2 tasks) of 15 anomic PWA and controls | PWA were reduced in information content and elaboration with simplified/impaired discourse structures. Their macro-linguistic deficits were evidenced by impaired cohesion and coherence (Kong, Linnik, Law, & Shum, 2014, 2017). |
| Connected speech (1 task) of 65 fluent PWA and controls | When engaged in a monologue of telling an important event of the life, there was a significant overlap in the topics between the two speaker groups (Law, Kong, Lai, & Lai, 2017). | |
| Speech prosody | All narrative tasks from 17 fluent PWA and controls | PWA were impaired in prosody that contained significantly more sentences with rising intonation (more noticeable for shorter sentences) (Lee, Lam, Kong, & Law, 2015). PWA’s syllable duration was significantly longer with more inappropriate speech pauses (Lee, Kong, Chan, & Wang, 2013). The durations of content versus function words in oral discourse were also different (Lee, Kong, & Wang, 2014). |
Note: PWA = Persons with aphasia.
We have demonstrated how Cantonese AphasiaBank is instrumental to enhancing our knowledge of Chinese aphasia. The availability of language materials produced by healthy as well as impaired speakers will render various researchers the opportunity to perform systematic group-based comparisons that has not been possible until now. Further exploration of the data in Cantonese AphasiaBank by researchers, instructors, speech-language pathologists, related healthcare professionals, and student clinicians may facilitate the development of fundamental principles for managing Chinese aphasia now and in the future.
Conclusions
This paper has described the background and processes involved in developing Cantonese AphasiaBank. The large scale database is distinguished from other existing spoken Chinese corpora in terms of the availability of spoken discourse and co-verbal gestures by speakers with and without aphasia containing verbal and non-verbal annotations. It promotes the use of open-source web-based access corpora for studying spoken language in a variety of discourse types among native Cantonese speakers and PWA. The rich information from the database has led to a series of linguistic, psycholinguistic and neurolingusitic studies. Further contribution of the corpora towards research and educational and/or clinical use will depend on its wider usage by researchers across disciplines.
Acknowledgments
This study is supported by a grant funded by the National Institutes of Health to Anthony Pak-Hin Kong (PI) and Sam-Po Law (Co-I) (project number: NIH-R01-DC010398). Special thanks to the staff members in the following organizations (in alphabetical order) for their help in subject recruitment: Christian Family Service Center (Kwun Tong Community Rehabilitation Day Center), Community Rehabilitation Network of The Hong Kong Society for Rehabilitation, Internal Aphasia Clinic at the University of Hong Kong, Hong Kong Stroke Association, Lee Quo Wei Day Rehabilitation and Care Centre of The Hong Kong Society for Rehabilitation, and Self Help Group for the Brain Damage. The authors would also like to acknowledge the invaluable contribution of the people living with aphasia who participated in this study.
Footnotes
Since 2014, academic and clinical staff at the University of Central Florida, The University of Hong Kong, Polytechnic University of Hong Kong, The Education University of Hong Kong, and Hong Kong Institute of Vocational Education have utilized the database as part of their instructional materials for topics related to acquired language disorders. Extension to clinical training for practicing speech-language pathologists and related medical health-care professionals is also suitable. It is believed that research and clinical applications of this shared database will grow with an increasing number of users.
It is not hard to understand why there is an imbalance between written and spoken databases. Printed materials are readily available and can be easily processed for linguistic annotation. In contrast, spoken databases require acceptable to high quality of recordings, followed by a labor intensive stage of orthographic and/or phonetic transcription before further work can be done.
Whereas most of the corpora are of adult speech, some are child language databases for language acquisition studies (e.g., Tardif, 1993; Lee & Wong, 1998).
The CHAT format was first developed during 1984–1988 by a group of developmental psycholinguists led by B. MacWhinney. The system was converted to a format compatible with the XML Internet data format between 2001 and 2004 in collaboration with the Linguistic Data Consortium (1992). CHAT has been adopted by two child language corpora in Cantonese (Fletcher, Leung, Stokes, & Weizman, 2000; Lee & Wong, 1998).
Note that this dictionary is expected to increase further in size when additional data are collected and included in the future.
References
- Chafe W. The pear stories: Cognitive, cultural and linguistic aspects of narrative production. Norwood, NJ: Ablex; 1980. [Google Scholar]
- Chou FC, Tseng CY. The design of prosodically oriented Mandarin speech database. Proceedings of the 17th International Congress on Phonetic Sciences; 1999. pp. 2375–2377. [Google Scholar]
- Chui K, Lai HL. The NCUU Corpus of Spoken Chinese: Mandarin, Hakka, and Southern Min. Taiwan Journal of Linguistics. 2008;6(2):119–144. [Google Scholar]
- Faroqi-Shah Y. The rise of big data in neurorehabilitation. Seminars in Speech and Language. 2016;37:3–9. doi: 10.1055/s-0036-1572385. [DOI] [PubMed] [Google Scholar]
- Fletcher P, Leung C-SS, Stokes S, Weizman Z. Research project entitled “Milestones in the learning of spoken Cantonese by pre-school Children” funded by the Language Fund of Hong Kong. 2000. Cantonese pre-school language development: A guide. [Google Scholar]
- Gāo NH. Investigations of Cantonese dialects. Hong Kong: Hong Kong Commercial Press; 1984. Guǎng zhōu fāng y án yán jiū. [Google Scholar]
- Hong Kong SAR Government. Report of the task force on population policy. 2003 Available at http://www.info.gov.hk/info/population/eng/
- Kim JS. Stroke in Asia: A global disaster. International Journal of Stroke. 2014;9(7):856–857. doi: 10.1111/ijs.12317. [DOI] [PubMed] [Google Scholar]
- Kong APH. Analysis of neurogenic disordered discourse production: From theory to practice. New York, NY: Routledge Psychology Press; 2016. [Google Scholar]
- Kong APH. Speech-Language services for Chinese-speaking people with aphasia (C-PWA): Considerations for assessment and intervention. SIG 2 Perspectives on Neurophysiology and Neurogenic Speech and Language Disorders. 2017;2(3):100–109. doi: 10.1044/persp2.SIG2.100. [DOI] [Google Scholar]
- Kong APH, Law S-P. Toward a multi-modal and multi-level analysis of Chinese aphasic discourse. National Institutes of Health; 2010–2014. [1-R01-DC010398]. https://projectreporter.nih.gov/project_info_description.cfm?aid=8469747. [Google Scholar]
- Kong APH, Law S-P, Chak G. An investigation of the use of co-verbal gestures in oral discourse among Chinese speakers with fluent versus non-fluent aphasia and healthy adults. Frontiers in Psychology. 2015 doi: 10.3389/conf.fpsyg.2015.65.00079. [DOI] [Google Scholar]
- Kong APH, Law SP, Chak GWC. A comparison of co-verbal gesture use in oral discourse among speakers with fluent and non-fluent aphasia. Journal of Speech, Language, and Hearing Research. 2017;60:2031–2046. doi: 10.1044/2017_JSLHR-L-16-0093. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kong APH, Law SP, Kwan CCY, Lai C, Lam V. A coding system with independent annotations of gesture forms and functions during verbal communication: Development of a Database of Speech and GEsture (DoSaGE) Journal of Nonverbal Behavior. 2015;39(1):93–111. doi: 10.1007/s10919-014-0200-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kong APH, Law SP, Lee ASY. An investigation of use of non-verbal behaviors among individuals with aphasia in Hong Kong: Preliminary data. Procedia Social and Behavioral Sciences. 2010;6:57–58. doi: 10.1016/j.sbspro.2010.08.029. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kong APH, Law SP, Wat WKC, Lai C. Co-verbal gestures among speakers with aphasia: Influence of aphasia severity, linguistic and semantic skills, and hemiplegia on gesture employment in oral discourse. Journal of Communication Disorders. 2015;56:88–102. doi: 10.1016/j.jcomdis.2015.06.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kong APH, Linnik A, Law S, Shum W. Measuring the coherence of healthy and aphasic discourse production in Chinese using Rhetorical Structure Theory (RST) Frontiers in Psychology. 2014 doi: 10.3389/conf.fpsyg.2014.64.00028. [DOI] [Google Scholar]
- Kong APH, Linnik A, Law S, Shum W. Measuring discourse coherence in anomic aphasia using Rhetorical Structure Theory. International Journal of Speech-Language Pathology. 2017 doi: 10.1080/17549507.2017.1293158. Epub ahead 17 Mar. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lausberg H, Sloetjes H. Coding gestural behavior with the NEUROGES-ELAN system. Behavior Research Methods. 2009;41(3):841–844. doi: 10.3758/BRM.41.3.841. [DOI] [PubMed] [Google Scholar]
- Lai CCT, Law SP, Kong APH. A quantitative study of right dislocation in Cantonese spoken discourse. Language and Speech. 2017;60(4):633–642. doi: 10.1177/0023830916688028. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Law S-P, Kong APH, Lai C. An analysis of topics and vocabulary in Chinese oral narratives by normal speakers and speakers with fluent aphasia. Clinical Linguistics and Phonetics. 2017 doi: 10.1080/02699206.2017.1334092. Epub ahead 13 Jul. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Law SP, Kong APH, Lai LWS, Lai C. Effects of context and word class on lexical retrieval in Chinese speakers with anomic aphasia. Aphasiology. 2015;29(1):81–100. doi: 10.1080/02687038.2014.951598. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee J. Toward a Parallel Corpus of Spoken Cantonese and Written Chinese. Proceedings of the 5th International Joint Conference on Natural Language Processing; 2011. pp. 1462–1466. [Google Scholar]
- Lee T, Kong APH, Chan VCF, Wang H. Analysis of auto-aligned and auto-segmented oral discourse by speakers with aphasia: A preliminary study on the acoustic parameter of duration. Procedia Social and Behavioral Sciences. 2013;94:71–72. doi: 10.1016/j.sbspro.2013.09.032. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee T, Kong APH, Wang H. Duration of content and function words in oral discourse by speakers with fluent aphasia: Preliminary data. Frontiers in Psychology. 2014 doi: 10.3389/conf.fpsyg.2014.64.00039. [DOI] [Google Scholar]
- Lee T, Lo WK, Ching PC, Meng H. Spoken language resources for Cantonese speech processing. Speech Communication. 2002;36:327–342. [Google Scholar]
- Lee T, Lam WK, Kong APH, Law S-P. Analysis of intonation patterns in Cantonese aphasia speech. Oral presentation at the 18th Oriental Chapter of International Committee for the Co-ordination and Standardization of Speech Databases and Assessment Techniques (COCOSDA)/Conference on Asian Spoken Language Research and Evaluation (CASLRE); Shanghai, China. 2015. Oct, [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee T, Wong C. CANCORP: The Hong Kong Cantonese Child Language Corpus. Cahiers de Linguistique – Asie Orientale. 1998;27(2):211–228. [Google Scholar]
- Leung MT, Law SP. HKCAC: The Hong Kong Cantonese Adult Language Corpus. International Journal of Corpus Linguistics. 2001;6(2):135–158. [Google Scholar]
- Leung MT, Law SP, Fung SY. Type and token frequencies of phonological units in Hong Kong Cantonese. Behavior Research Methods, Instruments, & Computers. 2004;36(3):500–505. doi: 10.3758/bf03195596. [DOI] [PubMed] [Google Scholar]
- Linguistic Data Consortium. 1992 http://www.ldc.upenn.edu/
- Linnik A, Bastiaanse R, Höhle B. Discourse production in aphasia: A current review of theoretical and methodological challenges. Aphasiology. 2016;30(7):765–800. doi: 10.1080/02687038.2015.1113489. [DOI] [Google Scholar]
- Luke K-K, Nancarrow O. Hong Kong University Cantonese corpus. 1997 Available at: http://www0.hku.hk/hkcancor/
- Lyle RC. A performance test for assessment of upper limb function in physical rehabilitation treatment and research. International Journal of Rehabilitation. 1981;4(4):483–492. doi: 10.1097/00004356-198112000-00001. [DOI] [PubMed] [Google Scholar]
- MacWhinney B. The CHILDES project: Tools for analyzing talk. Mahwah, NJ: Lawrence Erlbaum Associates; 2000. [Google Scholar]
- MacWhinney B. The CHILDES project: Tools for analyzing talk. Hillsdale, NJ: Lawrence Erlbaum; 2003. [Google Scholar]
- MacWhinney B. Morphosyntactic analysis of the CHILDES and TalkBank corpora. In: Calzolari N, Choukri K, editors. Proceedings of the Eight International Conference on Language Resources and Evaluation. European Language Resources Association (ELRA); 2012. pp. 2375–2380. http://www.lrec-conf.org/proceedings/lrec2012/summaries/616.html. [Google Scholar]
- MacWhinney B, Fromm D. AphasiaBank as BigData. Seminars in Speech and Language. 2016;37(1):10–22. doi: 10.1055/s-0036-1571357. [DOI] [PMC free article] [PubMed] [Google Scholar]
- MacWhinney B, Fromm D, Forbes M, Holland A. AphasiaBank: Methods for studying discourse. Aphasiology. 2011;25:1286–1307. doi: 10.1080/02687038.2011.589893. [DOI] [PMC free article] [PubMed] [Google Scholar]
- MacWhinney B, Holland A, Forbes M, Spector L, Fromm D. AphasiaBank: An international archive of aphasic language. Paper presented at Meeting of Computer-based Intervention and Diagnostic Procedure- Applications for Language Impaired Persons; Vienna, Austria. 2008. [Google Scholar]
- Marini A, Andreetta S, Del Tin S, Carlomagno S. A multi-level approach to the analysis of narrative language in aphasia. Aphasiology. 2011;25:1372–1392. [Google Scholar]
- Martin N, Kalinyak-Fliszar M. The case for single-case studies in treatment research—comments on Howard, Best and Nickels “Optimising the design of intervention studies: critiques and ways forward”. Aphasiology. 2014;29(5):570–574. doi: 10.1080/02687038.2014.987049. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Milman L, Vega-Mendoza M, Clendenen D. Integrated training for aphasia: An application of part–whole learning to treat lexical retrieval, sentence production, and discourse-level communications in three cases of nonfluent aphasia. American Journal of Speech-Language Pathology. 2014;23:105–119. doi: 10.1044/2014_AJSLP-12-0054. [DOI] [PubMed] [Google Scholar]
- Packard JL. A linguistic investigation of aphasic Chinese speech. Dordrecht: Kluwer Academic Publishers; 1993. [Google Scholar]
- Salter K, Teasell R, Foley N, Allen L. The evidence-based review of stroke rehabilitation (EBRSR) reviews current practices in stroke rehabilitation. EBRSR.com 2013 [Google Scholar]
- Tardif T. Unpublished doctoral dissertation. Yale University; 1993. Adult-to-child speech and language acquisition in Mandarin Chinese. [Google Scholar]
- Wade DT, Hewer RL, David RM, Menderby PM. Aphasia after stroke: Natural history and associated deficits. Journal of Neurology, Neurosurgery & Psychiatry. 1986;49:11–16. doi: 10.1136/jnnp.49.1.11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang J. Recent progress in corpus linguistics in China. International Journal of Corpus Linguistics. 2001;6(2):281–304. [Google Scholar]
- Willmes K. Statistical methods for a single-case study approach to aphasia therapy research. Aphasiology. 2007;4(4):415–436. doi: 10.1080/02687039008249092. [DOI] [Google Scholar]
- Wong PW. The specification of POS tagging of the Hong Kong University Cantonese Corpus. International Journal of Technology and Human Interaction. 2006a;2(1):21–38. [Google Scholar]
- Wong PW-Y. Unpublished doctoral dissertation. Ohio State University; 2006b. Syllable fusion in Hong Kong Cantonese connected speech. [Google Scholar]
- Xu L-J, Lee T. Parametric variation in three Chinese dialects, Cantonese, Shanghainese and Mandarin. Hong Kong: Research Grant Council; 1998. [Google Scholar]
- Yang X-J. Survey and prospect of China’s corpus-based research. In: Wilson A, Archer D, Rayson P, editors. Corpus linguistics around the world. New York: Rodopi; 2006. pp. 219–233. [Google Scholar]
- Zhou K, Li A, Yin Z, Zong C. CASIA-CASSIL: A Chinese telephone conversation corpus in real scenarios with multi-leveled annotation. The 7th International Conference on Language Resources and Evaluation; 2010. pp. 2407–2413. [Google Scholar]