

Summary
In this paper, our interest is in the perturbation analysis of level‐dependent quasi‐birth‐and‐death (LD‐QBD) processes, which constitute a wide class of structured Markov chains. An LD‐QBD process has the special feature that its space of states can be structured by levels (groups of states), so that a tridiagonal‐by‐blocks structure is obtained for its infinitesimal generator. For these processes, a number of algorithmic procedures exist in the literature in order to compute several performance measures while exploiting the underlying matrix structure; among others, these measures are related to first‐passage times to a certain level L(0) and hitting probabilities at this level, the maximum level visited by the process before reaching states of level L(0), and the stationary distribution. For the case of a finite number of states, our aim here is to develop analogous algorithms to the ones analyzing these measures, for their perturbation analysis. This approach uses matrix calculus and exploits the specific structure of the infinitesimal generator, which allows us to obtain additional information during the perturbation analysis of the LD‐QBD process by dealing with specific matrices carrying probabilistic insights of the dynamics of the process. We illustrate the approach by means of applying multitype versions of the susceptible‐infective (SI) and susceptible‐infective‐susceptible (SIS) epidemic models to the spread of antibiotic‐sensitive and antibiotic‐resistant bacterial strains in a hospital ward.
Keywords: epidemic model, hitting time, matrix calculus, perturbation analysis, QBD process
1. INTRODUCTION
Recently, Caswell1 used matrix calculus to provide the sensitivities and elasticities (i.e., dimensionless sensitivities) of the dynamics of absorbing continuous‐time Markov chains (CTMCs) to arbitrary parameters, which may correspond to either the transition rates themselves or functions of these rates that have substantive meaning. More concretely, Caswell1 derived formulas for the sensitivity and elasticity of the moments of the time until absorption, the time spent in each transient state, and the number of visits to each transient state before absorption, being the resulting expressions applied to a model for the progress of colorectal cancer. The results in the work of Caswell1 are closely related to the investigation of absorbing Markov chains in discrete time, with applications to demographic and ecological problems in the work of Caswell.2
The reader is alerted to the fact that, although perturbation analysis of Markov chains is a long‐standing problem (see, for example, the survey by Avrachenkov et al.3), the approach suggested by Caswell1, 2 is not aligned with the classical treatment of the sensitivity analysis for perturbed Markov chains; see other works.4, 5, 6, 7, 8 In the classical framework, the problem is essentially based on bounding the distance between stationary distributions in a suitable functional space when the one‐step transition probability matrix P of a discrete‐time Markov chain is replaced by another one‐step transition probability matrix P′; see, for example, the papers by Li et al.6 and Seneta.8 For CTMCs, the impact on the steady‐state distribution is usually measured when the infinitesimal generator Q is perturbed to Q′(ϵ) = Q + ϵQ∗, where ϵ is a sufficiently small positive number and the perturbation matrix Q ∗ satisfies certain weak conditions; see, for example, section 3 in the work of Altman et al.9 The papers by Altman et al.,9 and Heidergott et al.10 are two representative contributions to the perturbation analysis for denumerable and finite Markov chains with applications to queueing models. In the epidemiological setting, Hautphenne et al.11 presented an analytical sensitivity treatment for a continuous‐time Markovian branching process and showed its applications to the early spread of an influenza‐like epidemic on a network of cities in the United States. Chitnis et al.12 computed sensitivity indices of the reproductive number and the endemic equilibrium point to the parameters on a deterministic model of malaria transmission. The interest of these authors11, 12 is in sensitivities/elasticities, instead of perturbations, with respect to a single parameter, whence the mathematical modelling in the works11, 12 may be seen as the scalar version of that in the works of Caswell.1, 2
In this paper, the aim is to complement the general treatment of Caswell1, 2 by taking advantage of the sparsity of the underlying matrices arising when analyzing a class of structured CTMCs. Specifically, the interest is in level‐dependent quasi‐birth‐and‐death (LD‐QBD) processes (see, e.g., section 7.2 in the work of Artalejo and Gómez‐Corral13), which are CTMCs in two dimensions, the level and the phase, such that the process only jumps across either adjacent levels or the same level in one transition. In analyzing LD‐QBD processes, matrix‐analytic methods14, 15 are popular as modeling tools that allow us to construct and study, under a unified and algorithmic tractable framework, a variety of stochastic models, such as epidemic models,16, 17, 18 inventory problems,19 reliability systems,20, 21 retrial queues,22, 23 and two‐species competition processes,24, 25, 26 among others. The starting point in our analysis is the paper by Gaver et al.,27 where the emphasis is upon obtaining numerical methods for evaluating stationary distributions and moments of first‐passage times in finite LD‐QBD processes. In the setting of perturbed QBD processes analyzed under the classical perspective, the paper by Li and Liu28 is an excellent work where censoring techniques and stochastic integral functionals are used to discuss infinitesimal sensitivity analysis, even in the case of perturbed structured Markov chains and Markovian arrival streams; for a related work, see the work of Dendievel et al.,29 where properties of the perturbed stationary distribution of a QBD process are derived by restricting the process to the first two levels of states.
The results to be presented here deal with perturbation analysis of finite LD‐QBD processes as an important tool for understanding how certain parameters—inherently linked to the dynamics of the model—determine the properties of the process, as well as for predicting how small changes in the environmental conditions will modify the outcome. We present an efficient computational approach to the perturbation analysis of finite LD‐QBD processes in terms of first‐passage times to a certain level L(0) and related hitting probabilities (Section 2.1), the maximum level visited by the process before reaching states in level L(0)(Section 2.2) and the stationary distribution (Section 2.3). Our results are motivated by, but not restricted to, epidemic models, whence we include two examples (Sections 3.1 and 3.2) describing the spread of two infectious agents among a finite population of individuals, under the assumption that each infectious agent confers immunity against the second agent. In the context of nosocomial pathogens, these epidemic models allow us to construct (Section 3.3) simple mathematical models of bacterial transmission within a hospital ward, in such a way that first‐passage times permit us to study the length of an outbreak; the stationary distribution is a long‐run description of the epidemic; and the maximum level visited by the LD‐QBD process is seen as an important measure in studying infectious peaks during an outbreak.
2. FINITE LD‐QBD PROCESSES
First, we introduce some terminology and notation for CTMCs and LD‐QBD processes. The interest is in a CTMC on the two‐dimensional state space, as follows:
where the first coordinate i represents the level, and the second one j is termed the phase of the state (i,j). We analyze the case of a potentially different but finite number M i+1 of phases per level, and we partition as with L(i)={(i,j):0≤j≤M i} and 0≤i≤K. The CTMC is then called an LD‐QBD process if transitions from a state are only permitted to either states in the same level or states in adjacent levels, and the infinitesimal rates are assumed to be potentially level dependent. By using a row‐to‐column orientation, this assumption yields a block‐tridiagonal infinitesimal generator
| (1) |
where entries of are linked to transitions from the state (i,j)∈L(i) to the state (i′, j′) ∈ L(i′), with i′ ∈ {i − 1, i, i + 1}; in writing Equation (1), we may assume a lexicographical ordering of states in , which means that states in level L(i) precede those in L(i+1), and within level L(i) with 0≤i≤K, the state (i,j) precedes state (i,j+1) for phases 0≤j≤M i−1, so that . Note that, in the conservative case (i.e., , for any 0≤i≤K and 0≤j≤M i, with , and L(i′) is the empty set if i′ ∈ {−1, K + 1}), states of are all positive recurrent as is irreducible.
We shall consider here the general case where the entries of Q depend on some parameters in a column vector θ=(θ 1,θ 2,…,θ s)T, in such a way that matrix Q remains the infinitesimal generator of a suitably defined conservative LD‐QBD process—on an irreducible class of states—for sufficiently small perturbations of θ. In Sections 2.1‐2.3, we present, in a unified way and algorithmically tractable manner, the perturbation analysis of three properties of the LD‐QBD process with respect to θ, and similar to the paper by Caswell,1 we use matrix calculus to differentiate matrices and vectors arising from the underlying algorithmic treatment of these properties. For the glossary of matrix notation and a summary of those matrix calculus properties used in Sections 2.1‐2.3, we refer the reader to Appendix A.
2.1. First‐passage times and hitting probabilities
Let T (i, j) be the first‐passage time to level L(0), provided that the initial state of is (i,j), and p (i, j)(n) be the probability, starting from (i,j), of reaching L(0) by visiting state (0,n), for phases 0≤n≤M 0 and states . It is clear that, in the case i=0, first‐passage times verify T (0, j)=0 almost surely, and hitting probabilities are given by p (0, j)(n)=δ j,n, for phases 0≤j,n≤M 0, where δ a,b denotes Kronecker's delta.
In this section, we quantify the effects of changes in some entries of θ on the behavior of in terms of T (i, j) and p (i, j)(n) for states , which are closely related to an outbreak in epidemics (Section 3). The discussion that follows is based on the derivatives of the expectations and probabilities p (i, j)(n) with respect to the parameter θ r, for integers l≥1 and 1≤r≤s. To this end, we first focus on first‐passage times T (i, j) for states and proceed in two steps; specifically, we present in the first step an algorithmic solution (Algorithm 1.A) for computing the moments , for integers l≥1, which is useful in deriving a second solution (Algorithm 1.B) for the partial derivatives , for integers l≥1 and 1≤r≤s.
To begin with, we condition on the first transition of the process occurring from the initial state . Starting at (i,j), the first state visited by may be any state (i′, j′) ∈ L∗(i, j) with probability , and T (i, j) can be readily decomposed into , where the random variable is exponentially distributed with parameter −q (i, j),(i, j), and and are independent by the Markovian property. This implies that, by conditioning on each possible first transition (i, j) → (i′, j′) of the process , the Laplace–Stieltjes transforms , for R e(z)≥0 and states , satisfy the equalities
| (2) |
with because and with . By multiplying Equation (2) by z−q (i, j),(i, j), we derive the matrix equality
| (3) |
for the column vector φ(z) of Laplace–Stieltjes transforms φ (i, j)(z), for R e(z)≥0 and states , where the matrix is obtained from Q by deleting rows and columns associated with states of L(0); b is given by
and is the cardinality of the subset . By taking derivatives in Equation (3) with respect to z at point z=0 and noting that , we characterize the values , for l≥1, as the solution to the system of linear equations
| (4) |
where
with , for 1≤i≤K, and the matrix A has the structured form
| (5) |
In Equation (5), the submatrix is obtained from by dividing elements of its (1+j)th row, for integers 0≤j≤M i, by the value Δ(i, j)=−q (i, j),(i, j), and the diagonal elements of A i,i are all equal to zero, for 1≤i≤K, that is, the matrix A is related to the embedded jump chain and consists of one‐step transition probabilities from states of to states in . The column vector b (l) in Equation (4) has the form
where the subvector is specified by with , for 1≤i≤K, which represents element‐by‐element vector division. Then, subvectors of moments in Equation (4) can be iteratively computed, starting with , for 1≤i≤K, from previously computed subvectors of moments of order l−1, as indicated in Algorithm 1.A. The proof of Algorithm 1.A is based on a matrix version (see, e.g., p. 144 in the work of Ciarlet30) of the well‐known forward‐elimination–backward‐substitution method for solving a system of linear equations, and it is thus omitted.
Algorithm 1.A
Computation of the expectations of first‐passage times to level L(0), for l≥1 and states .
- Step 1:
Set p=0;
for i=1,…,K, evaluate
;
;
;
for i=K−1,…,1, evaluate
.
- Step 2:
While p<l, repeat
p=p+1;
;
for i=K−1,…,1, evaluate
;
;
for i=2,…,K, evaluate
;
for i=1,…,K, evaluate
.
For every state , the random time T (i,j) may be formulated as the time until absorption into an absorbing state 0 for a finite CTMC defined on the states , with initial probability vector and infinitesimal generator
where J′ = M1 + 1 + J is the cardinality of the class of transient states, the column vector q is given by , is a column vector with J ′ entries that are all equal to zero, with the exception of a single one at the f i, jth entry, and , By section 2.3 in the work of Latouche and Ramaswami,15 this means that the first‐passage time T (i, j) follows a phase type law with representation , and consequently, moments of T (i, j) can be evaluated as
Algorithm 1.A is then an alternative algorithmic solution to the general‐purpose expression , where inverse matrices of smaller orders M i+1 are progressively evaluated instead of a single inverse matrix of order J ′.
Moreover, we stress that, because first‐passage times can be seen as absorption times, arguments by Caswell1 for sensitivity and elasticity of the moments of first‐passage times in absorbing CTMCs can be readily applied. Here, however, we suggest to adapt the matrix calculus approach of Caswell1, and by exploiting the block‐tridiagonal structure of Q in (1), we derive an analogous algorithm to Algorithm 1.A (Algorithm 1.B) allowing us to compute the partial derivatives of in an efficient and unified manner. More concretely, Algorithm 1.B is derived by using matrix calculus to differentiate matrices and vectors in Algorithm 1.A with respect to the vector θ of parameters; for example, in evaluating from the equality , for p<l and 2≤i≤K, in Algorithm 1.A (Step 2), straightforward algebra yields
as the reader may easily verify by applying properties 1–4 in Appendix A.
A particular feature of this approach is that it allows us to obtain some extra information about the effect of small perturbations in θ on the expected numbers of visits to states of L(i), before reaching states in L(i−1). To be concrete, we consider a family of CTMCs, where with 1≤i≤K is the restriction of the process , observed during those intervals of time spent at states in level L(i), before the process moves down to level L(i−1) for the first time, and the process is the restriction of observed at the lowest level L(0). This means that, for 1≤i≤K, is a transient CTMC. Then, for a fixed integer 1≤i≤K−1, the matrix is related to the embedded jump chain of the restricted process , and more particularly, its entry can be seen as the expected number of visits to the state (i,j ′), starting from the state (i,j), before the first visit of to any of the states in L(i−1) (or, equivalently, because the process is forced to pass through states in level L(i−1) when it leaves level L(i)); in the special case i=K, the restricted version amounts to the original process , and the entry records the expected number of visits to the state (K,j ′), starting from the state (K,j), before leaving level L(K). In analyzing the sensitivity of these expected numbers of visits to states in L(i), for integers 1≤i≤K, we remark here that, for integers 1≤i≤K, the derivatives of the matrix can then be derived from the identity
where matrices and are evaluated from Algorithms 1.A (Step 1) and 1.B (Step 1), respectively.
We note that, in Algorithm 1.B, matrices are evaluated as a prerequisite for computing the submatrices containing the partial derivatives , for integers l≥1 and 1≤r≤s and states .
Algorithm 1.B
Computation of the partial derivatives , for integers l≥1 and 1≤r≤s and states .
- Step 1:
Set p=0;
for i=1,…,K, evaluate
;
;
;
for i=K−1,…,1, evaluate
.
- Step 2:
While p<l, repeat
p=p+1;
;
for i=K−1,…,1, evaluate
;
for i=2,…,K, evaluate
;
for i=1,…,K, evaluate
Similar to first‐passage times, the hitting probabilities p (i, j)(n), for states and phases 0≤n≤M 0, can be analyzed by using a first‐step argument, yielding
| (6) |
Then, it is clear from Equations (2) and (6) that the hitting probabilities p (i, j)(n), for states and phases 0≤n≤M 0, can be determined as the solution to Equation (4) with the column vectors m (l) and b (l) replaced by
respectively, where and , for integers 1≤i≤K. Algorithm 2.A is then a simplified version of Algorithm 1.A, from which we may evaluate the hitting probability p (i, j)(n) as the (1+j)th entry of the column vector p i(n), for states and phases 0≤n≤M 0.
Algorithm 2.A
Computation of the hitting probabilities p (i,j)(n), for states and phases 0≤n≤M 0+1.
For i=K,…,1, evaluate
;
;
;
for i=K−1,…,1, evaluate
;
;
for i=2,…,K, evaluate
.
Regarding the perturbation of hitting probabilities, matrix calculus results (Appendix A) applied to Algorithm 2.A lead us to Algorithm 2.B with a solution for the partial derivatives ∂ p (i, j)(n)/∂ θ r for states , phases 0≤n≤M 0, and integers 1≤r≤s, which are stored in the (1+n)th row and the rth column of the Jacobian matrix , for 1≤i≤K. Algorithm 2.B makes use of matrices , previously computed in Algorithm 1.B.
Algorithm 2.B
Computation of the partial derivatives ∂ p (i, j)(n)/∂ θ r, for states , phases 0≤n≤M 0, and integers 1≤r≤s.
For i=K,…,1, evaluate
;
;
for i=K−1,…,1, evaluate
;
for i=2,…,K, evaluate
2.2. Maximum level visited before reaching level L(0)
In this section, we briefly present the perturbation analysis of the probability distribution of the maximum level visited by the LD‐QBD process before reaching states of level L(0), provided that X(0)=(i,j), for states . To this end, we first observe that the random variable is identically distributed as its counterpart in the embedded jump chain. We then suggest to compute the conditional probabilities , for integers x∈{i+1,…,K} and initial states , by noting that is equal to the probability that, starting from (i,j), the embedded jump process enters the subset of states but avoiding states of L(0). Hence, for each fixed integer x∈{i+1,…,K}, we consider an absorbing discrete‐time process defined on the state space
where 0 and x are obtained by lumping the level L(0) and the subset together to make two absorbing states. The one‐step transition probability matrix of has the structured form
where we let and be and , respectively, , J ′′′=M x−1+1+J ′′, and
In a similar manner to Equation (6), a first‐step argument allows us to observe that the conditional probabilities , for integers x∈{i+1,…,K} and initial states , can be thought of as restricted hitting probabilities verifying Equation (4) with obvious modifications in matrices and vectors. To be concrete, the one‐step transition probability matrix A in Equation (4) is replaced by , and the column vectors m (l) and b (l) are replaced, respectively, by and , with
and . This means that, for every integer x∈{i+1,…,K}, the conditional mass function of can be derived from Algorithm 2.A as
As a result, the partial derivatives , for integers 1≤r≤s, are evaluated as , whose terms are readily derived by adapting Algorithm 2.B in an appropriate manner.
2.3. Stationary regime
To determine the stationary distribution of the LD‐QBD process , many approaches may be followed, and for general purposes, most of them yield algorithmic procedures. These algorithmic procedures are usually based on the tridiagonal‐by‐blocks form (1) of the infinitesimal generator Q without any further assumption, except that the LD‐QBD process is irreducible. We focus here on the solution given by Gaver et al.,27 which proceeds in two steps: During the first step, the procedure progressively reduces the state space by removing one level at each iteration, until a CTMC defined on states of L(K) is constructed; once this CTMC on level L(K) is solved, the procedure iteratively computes the stationary vector of the process in the second step, by adding back one level at each iteration. This yields the procedure described in Algorithm 3.A, which amounts to that in algorithm A in the work of Gaver et al.,27 from which we may evaluate the stationary probabilities for states as the (1+j)th entry of the column vector π i, regardless of the initial state .
Algorithm 3.A
(Linear level reduction algorithm; see section 2 in the work of Gaver et al.27) Computation of the stationary probabilities π(i,j), for states .
Step 1: B 0=Q 0,0;
for i=1,…,K, evaluate
;
evaluate by solving
with .
Step 2: Set ;
for i=K−1,…,0, evaluate
;
;
for i=0,…,K, evaluate
.
Then, an appeal to the matrix calculus results in Appendix A allows us to differentiate matrices and vectors with respect to the vector θ of parameters on Steps 1–2 of Algorithm 3.A and, consequently, to provide the perturbation analysis of in terms of partial derivatives of the stationary probabilities ∂π(i,j)/∂ θ r, for integers 1≤r≤s, which are located at the (1+j)th row and the rth column of the matrix , for states .
Algorithm 3.B
Computation of the partial derivatives ∂π(i,j)/∂ θ r, for integers 1≤r≤s and states .
Step 1: ;
;
for i=1,…,K, evaluate
;
;
evaluate by solving
with .
Step 2: Set ;
for i=K−1,…,0, evaluate
;
;
for i=0,…,K, evaluate
.
For a fixed integer 0≤i≤K−1, the matrix B i in Algorithm 3.A (Step 1) can be thought of as the infinitesimal generator of the restriction of the LD‐QBD process , observed during those intervals of time spent at level L(i), before it enters level L(i+1) for the first time. It is clear that the state space of the restriction is given by L(i), and is a transient CTMC in the case 0≤i≤K−1, whereas the restriction of the process to states in L(K) is positive recurrent. Therefore, the entry is interpreted as recording the expected total time spent in the state (i,j ′), starting from the state (i,j), before the first visit of to any of the states in L(i+1), for integers 1≤i≤K−1. represents the expected total time spent in (0,j ′), given that the process starts from the state (0,j), before leaving level L(0). Thus, regarding the effect of small perturbations in θ on these expected total times spent at states in L(i) with 0≤i≤K−1, we point out here that, for phases 0≤j,j ′≤M i and integers 1≤r≤s, the partial derivatives can be readily derived from the matrices (Step 1 in Algorithm 3.A) and (Step 1 in Algorithm 3.B), because .
3. APPLICATIONS TO EPIDEMIC MODELS
LD‐QBD processes are natural tools for the analysis of epidemic models governed by exponential laws. In Sections 3.1 and 3.2, we briefly discuss two models with epidemics in competition; specifically, two epidemic agents are assumed to be simultaneously present in a finite population, in such a way that they interact to increase or decrease each other's effectiveness, and each agent confers immunity against the other epidemic agent. In Section 3.3, these models are linked to the work by Lipsitch et al.,31 where a mathematical model of bacterial transmission within a hospital is described in order to study the effects of measures to control nosocomial transmission of bacteria and reduce antimicrobial resistance in nosocomial pathogens.
3.1. The multitype S I epidemic model
The first example corresponds to the S I 1,I 2 epidemic model analyzed by Saunders32 (see also Billard et al.33), which describes the spread of two types of infectious diseases—termed type‐1 and type‐2—among a homogeneously mixed closed population of N individuals. Infected individuals do not recover, but suffering one type of infectious disease provides immunity against the other. By denoting by S(t), I 1(t), and I 2(t), the number of susceptible individuals, and the numbers of type‐1 and type‐2 infectives, respectively, at time t≥0, we may describe the dynamics of the S I 1,I 2 epidemic model in terms of the finite CTMC , where S(t)=N−I 1(t)−I 2(t) and J(t)=I 1(t)−I 1 with initial numbers I 1(0)=I 1 and I 2(0)=I 2 of infectives. The state space of has the form
and transitions among states are due to either a new type‐1 infection (i.e., (i,j)→(i−1,j+1)) with rate i(j+I 1)β 1 or a new type‐2 infection (i.e., (i,j)→(i−1,j)) with rate i(N−i−j−I 1)β 2, for strictly positive contact rates β 1 and β 2; see Figure 1.
Figure 1.

Multitype S I stochastic epidemic model
Let T be the time to reach the end of the epidemic spread, that is, . In order to analyze the numbers I 1(T) and I 2(T) of infectives at time T, we may decompose the state space by levels as with , whence K=N−I 1−I 2 and level L(i) consists of M i+1=N−I 1−I 2−i+1 states, according to notation in Section 2. This labeling of states leads us to an LD‐QBD process defined on , whose infinitesimal generator is specified according to Equation (1) as follows:
-
1.For integers 1≤i≤N−I 1−I 2, the (1+j,1+j ′)th entry of Q i,i−1 is given by
for 0≤j≤M i and 0≤j ′≤M i−1. -
2.
The submatrix Q 0,0 takes the form and, for integers 1≤i≤N−I 1−I 2, the submatrix Q i,i is a diagonal matrix with diagonal entries (Q i,i)1+j,1+j=−(( j+I 1)i β 1+(N−i−j−I 1)i β 2), for 0≤j≤M i.
-
3.
For integers 0≤i≤N−I 1−I 2−1, the submatrix Q i,i+1 is a null matrix, that is, .
In the terminology of Sections 2.1‐2.3, the random time T corresponds to the time instant to reach states of L(0), provided that starts from state (N−I 1−I 2,0). Thus, the joint probability distribution of the numbers (I 1(T),I 2(T)) of type‐1 and type‐2 infectives at the end of the epidemic spread amounts to the hitting probabilities , for integers I 1≤i 1≤N−I 2, because the event {I 1(T)=i 1,I 2(T)=N−i 1} is equivalent to {S(T)=0,J(T)=i 1−I 1}.
3.2. The multitype S I S epidemic model
In this section, we focus on a multitype S I S epidemic model with two strains and external sources of infection, which is shown in Figure 2. Similar to the case analyzed in Section 3.1, the resulting S I 1,I 2 S epidemic model describes the spread of two types of infection among a closed population of N homogeneous individuals, where now a susceptible individual can become a type‐k infective, for k∈{1,2}, due to either external factors (with rate λ k≥0) or an infectious contact with a type‐k infective (with rate β k>0). In the spirit of the work of Kirupaharan and Allen,34 any type‐k infective cannot be infected by any type‐k ′ infective, with k ′≠k, until his/her infectious period expires. Type‐k infectious periods are assumed to be exponentially distributed with mean , for k∈{1,2}.
Figure 2.

Multitype S I S stochastic epidemic model
The S I 1,I 2 S epidemic process is analyzed by using the random variables S(t), I 1(t), and I 2(t) at an arbitrary time t, with S(0)=N−I 1−I 2, I 1(0)=I 1, I 2(0)=I 2 representing the initial conditions. Nevertheless, the construction of the underlying LD‐QBD process in Sections 3.2.1 and 3.2.2 shall depend on the probabilistic descriptors under study, which are related to the global outbreak (Section 3.2.1), the outbreak corresponding to the kth strain (Section 3.2.2), and the stationary distribution (Section 3.2.3).
3.2.1. Descriptors of the global outbreak
Let T be the time for both strains to become extinct for the first time and be the global peak of infection during the outbreak, that is, reflects the length of a global outbreak, and records the maximum number of simultaneously infected individuals before the global outbreak expires. Because these random indexes refer to I 1(t)+I 2(t), we define here the process as
where I(t)=I 1(t)+I 2(t) and J(t)=I 2(t), so that the number of susceptible individuals, and the numbers of type‐1 and type‐2 infectives are given by S(t)=N−I(t), I 1(t)=I(t)−J(t), and I 2(t)=J(t), respectively. The process can be seen as an LD‐QBD process defined on the state space with ith level L 1(i)={(i,j):0≤j≤i}, for integers 0≤i≤N, that is, K=N and level L 1(i) contains M i+1=i+1 states, for 0≤i≤N. This means that, under the initial conditions I 1(0)=I 1 and I 2(0)=I 2, the random time T corresponds to the first‐passage time , and the probability distribution of can be determined by analyzing the distribution of the maximum level visited by the process before reaching states of level L 1(0). Therefore, moments of T are progressively computed from Algorithm 1.A, whereas their local sensitivity analysis is carried out by means of Algorithm 1.B; in a similar manner, the conditional probabilities and their corresponding derivatives are derived from an adaptation of Algorithms 2.A and 2.B (according to our comments in Section 2.2). The submatrices , for i ′∈{i−1,i,i+1}, to be used in these algorithms are specified by the following:
-
1.For 1≤i≤N, the (1+j,1+j ′)th entry of Q i,i−1 is given by
for 0≤j≤i and 0≤j ′≤i−1. -
2.
For 0≤i≤N, the submatrix Q i,i has diagonal form and its diagonal entries are given by (Q i,i)1+j,1+j=−((N−i)(λ 1+λ 2+(i−j)β 1+j β 2)+(i−j)γ 1+j γ 2), for 0≤j≤i.
-
3.For 0≤i≤N−1, the (1+j,1+j ′)th entry of Q i,i+1 is given by
for 0≤j≤i and 0≤j ′≤i+1.
3.2.2. Descriptors of the outbreak for the type‐k strain
For k∈{1,2}, we let T(k) denote the time before extinction of type‐k infectives for the first time (i.e., ), be the number of type‐k ′ infectives (with k ′≠k) when this occurs, and represent the peak of infection for strain k during the time interval [0,T(k)) (i.e., ). Without any loss of generality, we focus on the case k=1 and define the CTMC on the states of . By decomposing the state space by levels with L 2(i)={(i,j):0≤j≤N−i} (i.e., K=N and L 2(i) contains M i+1=N−i+1 states), we may formulate as an LD‐QBD process with the following submatrices , for i ′∈{i−1,i,i+1}:
-
1.
For 1≤i≤N, the non‐null entries of Q i,i−1 are given by (Q i,i−1)1+j,1+j=i γ 1, for 0≤j≤N−i.
-
2.For 0≤i≤N, the entries of Q i,i are given by
for 0≤j≤N−i and 0≤j ′≤N−i. -
3.
For 0≤i≤N−1, the non‐null entries of Q i,i+1 are given by (Q i,i+1)1+j,1+j=(N−i−j)(λ 1+i β 1), for 0≤j≤N−i−1.
3.2.3. Stationary measures
Unlike the descriptors in Sections 3.2.1 and 3.2.2, which can be analyzed for nonnegative external infection rates λ 1,λ 2≥0, the analysis of the stationary distribution needs the assumption of at least an external infection stream (i.e., λ 1>0 and /or λ 2>0), so that the CTMC under analysis is positive recurrent. Then, the stationary distribution and its perturbation analysis can be readily evaluated by applying Algorithms 3.A and 3.B to either the process or the process , because they only differ in the underlying labeling of states. Once the stationary distribution is in hand, it is possible to compute the mean and standard deviation of the numbers I 1(∞) and I 2(∞) of type‐1 and type‐2 infectives, respectively, in the long term.
3.3. A mathematical model of bacterial transmission
We link the S I 1,I 2, and S I 1,I 2 S epidemic models to the deterministic model in figure A in the work of Lipsitch et al.31 for the spread of two bacterial strains in a hospital ward. Lipsitch et al.31 considered an antibiotic‐sensitive (AS) bacterial strain and an antibiotic‐resistant (AR) bacterial strain, termed strain 1 and strain 2, respectively, spreading among patients, such that the infection by one bacterial strain provides immunity against the other. Because antibiotics are commonly used in hospitals to prevent a wide range of conditions, Lipsitch et al.31 assumed that patients in the ward are routinely provided antibiotics 1 and 2, regardless of these patients being infected or not by bacteria; more concretely, antibiotic 1 is only effective against the AS bacterial strain, whereas antibiotic 2 is effective against both strains of bacteria. The acquisition of resistance by bacteria can lead to some fitness cost, amounting to a reduction of the bacterial strain infectiousness due to the corresponding mutation; to represent this fact, Lipsitch et al.31 considered a common infection rate β=1.0 days−1 and set β 1=β and β 2=(1−c)β with c∈(0,1). Spontaneous clearance of sensitive and resistant bacteria occurs at a rate γ, and contributions of antibiotics 1 and 2 to this recovery are represented by rates τ 1 and τ 2. Patients are assumed to be admitted by and discharged from the hospital ward at a common rate μ.
In our numerical experiments (Tables 1, 2, 3, 4), we consider a hospital ward with N=20 patients, initial numbers (I 1,I 2)=(1,1) of infectives, and values c∈{0.05,0.1,0.25} of fitness cost. It should be pointed out that, unlike the paper of Lipsitch et al.,31 where the deterministic model is related to frequencies, we shall consider from now on rates β 1=N −1 β and β 2=N −1(1−c)β, because the random variables in the underlying LD‐QBD processes (Section 3.1), and and (Section 3.2) amount to numbers of infectives.
Table 1.
Means and standard deviations of the time T until the end of the epidemic spread and of the numbers I 1(T) and I 2(T) of type‐1 and type‐2 infectives when this occurs in the S I 1,I 2 epidemic model
| Descriptor | c = 0.05 | c = 0.1 | c = 0.25 |
|---|---|---|---|
| E[T] | 6.19405 | 6.34476 | 6.77960 |
| σ(T) | 1.71320 | 1.75954 | 1.91860 |
| E[I 1(T)] | 10.43524 | 10.89166 | 12.38137 |
| σ(I 1(T)) | 5.46754 | 5.43652 | 5.18336 |
| E[I 2(T)] | 9.56475 | 9.10833 | 7.61862 |
| σ(I 2(T)) | 5.46754 | 5.43652 | 5.18336 |
Note. (Strain 1: antibiotic sensitive; strain 2: antibiotic resistant.)
Table 2.
Elasticities of the descriptors in Table 1 with respect to various parameters in the S I 1,I 2 epidemic model
| c | Elasticities | θ = β1 | θ = β2 | θ = c | θ = β | |
|---|---|---|---|---|---|---|
| 0.05 |
|
−0.53632 | −0.46367 | −0.00227 | −1 | |
|
|
−0.50385 | −0.49614 | +0.02611 | −1 | ||
|
|
+0.81180 | −0.81180 | +0.04272 | 0 | ||
|
|
−0.06897 | +0.06897 | −0.00363 | 0 | ||
|
|
−0.88569 | +0.88569 | −0.04661 | 0 | ||
|
|
−0.06897 | +0.06897 | −0.00363 | 0 | ||
| 0.10 |
|
−0.57432 | −0.42567 | −0.00411 | −1 | |
|
|
−0.50908 | −0.49091 | +0.05454 | −1 | ||
|
|
+0.77161 | −0.77161 | +0.08573 | 0 | ||
|
|
−0.14139 | +0.14139 | −0.01571 | 0 | ||
|
|
−0.92268 | +0.92268 | −0.10252 | 0 | ||
|
|
−0.14139 | +0.14139 | −0.01571 | 0 | ||
| 0.25 |
|
−0.69652 | −0.30348 | −0.00726 | −1 | |
|
|
−0.54844 | −0.45155 | +0.15051 | −1 | ||
|
|
+0.63487 | −0.63487 | +0.21162 | 0 | ||
|
|
−0.37968 | +0.37968 | −0.12656 | 0 | ||
|
|
−1.03176 | +1.03176 | −0.34392 | 0 | ||
|
|
−0.37968 | +0.37968 | −0.12656 | 0 |
Note. (Strain 1: antibiotic sensitive; strain 2: antibiotic resistant.)
Table 3.
Mean and standard deviation of various descriptors in the S I 1,I 2 S epidemic model with c=0.25
| Descriptor D | Expected value E[D] | Standard deviation σ(D) | |
|---|---|---|---|
| T | 2,481.58612 | 3,092.40947 | |
|
|
16.62473 | 6.47966 | |
| T(1) | 24.64084 | 44.53220 | |
| I 2(T(1)) | 4.90746 | 4.58200 | |
|
|
6.76017 | 6.38924 | |
| T(2) | 676.64801 | 1,105.89870 | |
| I 1(T(2)) | 4.51942 | 4.22930 | |
|
|
11.38508 | 8.79249 | |
| I 1(∞) | 0.81095 | 2.31470 | |
| I 2(∞) | 11.05264 | 3.90887 |
Note. (Strain 1: antibiotic sensitive; strain 2: antibiotic resistant.)
Table 4.
Elasticities of the descriptors in Table 3 with respect to primary parameters in the S I 1,I 2 S epidemic model with c=0.25
| Elasticities | θ = β1 | θ = β2 | θ = λ1 | θ = λ2 | θ = γ1 | θ = γ2 | |
|---|---|---|---|---|---|---|---|
|
|
+0.34677 | +9.74277 | −0.21501 | +0.68438 | −0.52104 | −11.03787 | |
|
|
+0.02910 | +9.54556 | −0.24298 | +0.61974 | −0.12515 | −10.82626 | |
|
|
+0.23125 | +0.32876 | +0.01805 | +0.03876 | −0.25994 | −0.35689 | |
|
|
−0.35035 | −0.20165 | −0.04290 | −0.04085 | +0.38545 | +0.25030 | |
|
|
+4.50387 | −2.01010 | +0.14857 | −0.49981 | −5.14178 | +1.99925 | |
|
|
+4.57286 | −2.03753 | +0.11877 | −0.64958 | −5.15409 | +2.14957 | |
|
|
+0.86287 | +1.24945 | +0.05036 | +0.13550 | −1.23667 | −1.06153 | |
|
|
+0.28166 | +0.77701 | +0.01704 | +0.01477 | −0.43910 | −0.65139 | |
|
|
+1.69079 | −0.57956 | +0.07306 | −0.08225 | −1.60528 | +0.50325 | |
|
|
+1.22316 | −0.46291 | +0.02971 | −0.08852 | −1.15905 | +0.45761 | |
|
|
−4.03536 | +9.69147 | −0.76852 | +0.33206 | +4.64273 | −10.86238 | |
|
|
−3.73132 | +9.10850 | −0.75903 | +0.27937 | +4.35939 | −10.25690 | |
|
|
+2.29215 | +0.40123 | +0.23929 | +0.03737 | −2.36991 | −0.60014 | |
|
|
+0.98563 | +0.09937 | +0.01294 | +0.01000 | −0.93989 | −0.16806 | |
|
|
−0.43243 | +1.08596 | −0.03890 | +0.07347 | +0.42559 | −1.11369 | |
|
|
−0.11834 | +0.29223 | −0.01981 | +0.00009 | +0.14455 | −0.29872 | |
|
|
+5.62035 | −6.43584 | +0.98647 | −0.55509 | −6.60683 | +6.99094 | |
|
|
+3.76640 | −3.79310 | +0.45838 | −0.37816 | −4.22478 | +4.17126 | |
|
|
−0.43187 | +1.31603 | −0.08106 | +0.06638 | +0.51294 | −1.38241 | |
|
|
+1.25353 | −1.70748 | +0.18008 | −0.19435 | −1.43362 | +1.90183 |
Note. (Strain 1: antibiotic sensitive; strain 2: antibiotic resistant.)
In Tables 1 and 2, the interest is in a preliminary scenario with τ 1=τ 2=0.0 (no usage of antibiotics), γ=0.0 (no spontaneous recovery), and μ=0.0(no arrival or departure of patients during the outbreak), which is readily translated into an S I 1,I 2 epidemic model. For practical use, it is worth noting that the derivatives of a predetermined descriptor D in Tables 1 and 2 (i.e., expected values and standard deviations of T, I 1(T) and I 2(T)) satisfy
| (7) |
| (8) |
because rates β 1 and β 2 depend on the value c of fitness cost and the rate β; note that Equations (7) and (8) are readily derived from the equalities ∂ D/∂ c=(∂ D/∂ β 2)(∂ β 2/∂ c) and ∂ D/∂ β=(∂ D/∂ β 1)(∂ β 1/∂ β)+(∂ D/∂ β 2)(∂ β 2/∂ β), respectively. This means that, in implementing Algorithms 1.B and 2.B, we may use s=2 parameters (i.e., θ=(β 1,β 2)T) instead of s=4.
In Table 1, we compute the values of the mean length E[T] of an outbreak and the mean numbers E[I 1(T)] and E[I 2(T)] of patients infected by AS and AR bacterial strains, respectively, during the outbreak, together with the corresponding standard deviations. The interest here is in analyzing the impact that small perturbations in the parameters of (β 1,β 2,c,β) have on these summary statistics, whence in Table 2 we list values of elasticities (i.e., (θ −1 D)−1 ∂ D/∂ θ) for summary statistics D and parameter θ. In terms of the sign of elasticities (which is identical to the sign of the partial derivative ∂ D/∂ θ), the main insights are as follows:
The mean length of the outbreak E[T] increases with decreasing values of β 1 and β 2, which are represented by corresponding negative partial derivatives. On the other hand, increasing values of c lead to decreasing infectiousness of the AR bacterial strain, which corresponds to longer outbreaks and thus a strictly positive partial derivative ∂ E[T]/∂ c(that is, it corresponds to longer time until all the patients become infected), whereas increasing global infectiousness β leads to decreasing values of E[T], so that ∂ E[T]/∂ β<0. These results are explained by noting that no recoveries occur in this model, so that the end of the epidemic spread occurs when all patients are infected.
The mean number E[I 1(T)] of infected patients by the AS bacterial strain increases with decreasing values of β 2(because ∂ E[I 1(T)]/∂ β 2<0) and with increasing values of β 1 and c (because ∂ E[I 1(T)]/∂ β 1>0 and ∂ E[I 1(T)]/∂ c>0), illustrating bacterial strain competition; in a similar manner, analogous comments can be made for the expected number E[I 2(T)] of patients infected by the strain of AR bacteria.
Perturbations in the common infection rate β do not affect the random variables I 1(T) and I 2(T) at all, because these perturbations lead to equal relative changes in β 1 and β 2, so that positive and negative effects on these variables are balanced out. This is directly related to the fact that the dynamics of the S I 1,I 2 epidemic model are governed by the ratio (in this case, becoming (1−c)−1), and not by the particular magnitudes of β 1 and β 2.
Stochastic uncertainty, represented by σ(T), decreases with increasing values of β 1, β 2, and β(roughly speaking, the faster infections occur, the less volatile the length of the outbreak is) and with decreasing values of c. On the other hand, uncertainty about I 1(T), represented by σ(I 1(T)), increases with β 2(because ∂ σ(I 1(T))/∂ β 2>0) and decreases with β 1 and c, for similar reasons; note that analogous comments can be made on the strain of AR bacteria in terms of σ(I 2(T)).
We stress that the comments above refer to the sign of the derivatives in Table 2 and apply regardless of the particular value of c∈{0.05,0.1,0.25}. A more detailed comparison between derivatives in absolute terms is carried out by comparing elasticities in Table 2, with the following insights:
The mean length of the outbreak is more affected by perturbations in β 1 than in β 2, and this difference is more significant with increasing values of c. This behavior is directly related to the fact that β 2<β 1, because c is strictly positive. In the special case c=0, we would expect to obtain a value for the elasticity of E[T] with respect to β 2(i.e., ) equal to its counterpart with respect to β 1(i.e., E l a s t i c i t y(E[T];β 1)). Moreover, the expected length of an outbreak is inversely proportional to β, represented by E l a s t i c i t y(E[T];β)=−1, which is to be expected because β −1=1 day, where 1 day amounts to the unit of time and thus the time unit used for E[T].
- Some symmetries can be identified; for example, it is seen that
for any value c of fitness cost. This is explained again by the fact that the dynamics in S I 1,I 2 epidemic models are governed by the ratio , so that the mean number of patients suffering infection by the AS bacterial strain can increase either by increasing the value of β 1 or decreasing the value of β 2; similar comments apply to the expected number E[I 2(T)] and standard deviations σ(I 1(T)) and σ(I 2(T)). In general, the rate β represents the most important parameter for the random index T, whereas β 1 and β 2 are equally important for the random variables I 1(T) and I 2(T), regardless of the value of c.
We now incorporate discharge and recovery of patients into the model of Lipsitch et al.31 by making use of the S I 1,I 2 S epidemic model with recovery rates γ 1=γ+τ 1+τ 2+μ and γ 2=γ+τ 2+μ, and values days and days, when discharge of patients, who are replaced by susceptible patients, occurs, on average, in 7 days (i.e., μ −1=7 days), and spontaneous recovery occurs, on average, in 30 days (i.e., γ −1=30 days). These values for τ 1, τ 2, μ, and γ correspond to realistic selections used by Lipsitch et al. (see figure 2 in the work of Lipsitch et al.31), although parameters are known to vary within concrete ranges. For instance, the average duration μ −1 of hospital stay and the average time γ −1 until the spontaneous clearance of bacterial carriage may vary between 7 and 20 days, and between 30 and 60 days, respectively; see table 1 in the work of Lipsitch et al.31 We also select rates λ 1=N −10.1 and λ 2=N −10.1 to represent infections not directly caused by infectious contacts (for example, due to environmental contamination of the hospital ward), but we should point out that these parameters are an addition not considered explicitly in the work of Lipsitch et al.31
For the sake of brevity, results in Tables 3 and 4 are related to primary parameters of θ=(β 1,β 2,λ 1,λ 2,γ 1,γ 2)T and the choice c=0.25; a further discussion on sensitivities and elasticities with respect to secondary parameters (i.e., c, β, τ 1, τ 2, μ and γ) can be found online (see Supporting information). We note that long outbreaks obtained in our numerical results (lasting for years; Table 3) are related to the fact that there is an AR bacteria in the hospital ward and that no specific control action is considered in the model. If we focus on the scenario with c=0.25, the long global outbreak represented by E[T]∼2,481 days corresponds to a random overlap of outbreaks corresponding to the AS and AR bacterial strains, until by chance the hospital ward becomes cleared of both strains of bacteria at the same time. The main contribution to this global outbreak length corresponds to long AR bacterial strain outbreaks (with expected length E[T(2)]∼676 days), overlapping with short AS bacterial strain outbreaks (with expected length E[T(1)]∼24 days). Moreover, the peak of infection in the hospital ward amounts to infected patients, with peaks of patients infected by the AS bacterial strain, and peaks of patients infected by the AR bacterial strain. Although implementing control measures within the hospital ward would contribute to decrease the values of these summary statistics (more particularly, Lipsitch et al.31 considered control strategies such as implementing barrier precautions, improving handwashing compliance levels by health‐care workers, or increasing drug dosage when bacteria are detected in the ward), considering such control actions is out of the scope of this paper, and we focus instead on the local sensitivity analysis for the parameters when no intervention is considered.
In Table 4, we list values of the elasticities of summary statistics with respect to the parameters of (β 1,β 2,λ 1,λ 2,γ 1,γ 2), in the case c=0.25. Again, we first focus on the sign of these elasticities (equivalently, partial derivatives). As the reader may observe, the mean length of the outbreak increases with increasing values of β 1, β 2, and λ 2 and with decreasing values of γ 1 and γ 2, as one might expect. However, it is also seen that ∂ E[T]/∂ λ 1<0, which suggests that external infections of patients by the strain of AS bacteria act here as a global protection in the hospital ward, reducing the length of the global outbreak. This can be better explained by analyzing scenarios with smaller and larger values of the fitness cost c. For example, for c=0.1 (results not reported here), we find that ∂ E[T]/∂ β 1 and ∂ E[T]/∂ λ 1 are strictly negative, so that when the AR bacterial strain is infectious enough, any kind of infection by the strain of AS bacteria acts as a protection measure for the hospital ward in general terms, that is, when analyzing the global outbreak length E[T]. On the other hand, in the case c=0.5, when the fitness cost is large, and as a result, the AR bacterial strain is not so infectious, we find that ∂ E[T]/∂ β 1 and ∂ E[T]/∂ λ 1 are strictly positive, representing the fact that the protective role of the AS bacterial strain is not worth it here, given the low infectiousness of the AR bacterial strain. The scenario in Table 4 (c=0.25) should be considered as an intermediate situation, where external infections by AS bacterial strain help to protect the ward, whereas infectious contacts among patients by AS bacterial strain do not play the same protective role. These results suggest that, when considering the implementation of control strategies, special focus should be made on avoiding environmental contamination by the strain of AS bacteria, or on avoiding infectious contacts between patients by the AS bacterial strain (through health‐care workers), depending on the infectiousness of the strain of AR bacteria present in the ward. Other insights from Table 4 are as follows:
The expected peak of infection increases with increasing values of any rate representing infection and with decreasing values of the recovery rates. On the other hand, expected peaks of infection by the strain of AS bacteria increase with increasing values of β 1, λ 1, and γ 2, and with decreasing values of β 2, λ 2, and γ 1, representing the competition between both strains of bacteria. Similar comments apply not only to AR bacterial strain in terms of but also to the expected steady‐state numbers E[I 1(∞)] and E[I 2(∞)] of patients infected by AS and AR bacteria, respectively.
Derivatives of the standard deviation are difficult to interpret in the S I 1,I 2 S epidemic model. However, we may note here that, for example, the partial derivatives , , , and are strictly negative, and on the contrary, and are strictly positive. This means that the peak of the outbreak behaves in a more deterministic way with increasing values of the infection rates, whereas it behaves more stochastically when infection and recovery rates are more balanced, that is, with increasing values of recovery rates in Table 4.
In identifying the most important parameters for each descriptor, an examination of Table 4 reveals the following observations:
Symmetries identified in the S I 1,I 2 epidemic model disappear in the multitype S I S case, because incorporating the recovery of patients in the hospital ward into the S I 1,I 2 S epidemic model results in a more complex description. In particular, the specific magnitudes of β 1 and β 2 have a significant impact on the descriptors, regardless of maintaining the same value for the ratio .
When analyzing the expected length E[T] of the global outbreak, the magnitudes of β 2 and γ 2 are the most relevant ones. This fact is closely related to our comment above where the main contribution to the global outbreak length corresponds to long AR bacterial strain outbreaks. The expected length E[T(1)] of AS bacterial strain outbreaks is more affected by β 1 and γ 1, whereas β 2 and γ 2 have more impact on the expected length E[T(2)], as one would expect. However, it is interesting to note that the competition between bacterial strains has a special impact on E[T(2)], which is represented by relatively large values of E l a s t i c i t y(E[T(2)];β 1) and E l a s t i c i t y(E[T(2)];γ 1). Similar comments directly apply to and .
On the other hand, the global peak of infection, as well as the steady‐state numbers E[I 1(∞)] and E[I 2(∞)] of infected patients by strains of AS and AR bacteria, respectively, seem to be approximately equally affected by infection and recovery rates corresponding to both bacterial strains, which result in comparable absolute magnitudes for elasticities of these descriptors with respect to β 1, β 2, γ 1, and γ 2.
4. CONCLUSIONS
In this paper, we develop a comprehensive perturbation analysis of finite LD‐QBD processes by computing the partial derivatives of a number of summary statistics with respect to parameters governing the dynamics of the underlying process. This is carried out in an algorithmic fashion that adapts well‐known matrix‐analytic procedures existing in the literature for analyzing this class of Markov chains and by means of using matrix calculus techniques previously applied by Caswell1 to absorbing CTMCs. We stress here that this approach could be directly applied to any existing matrix‐analytic algorithmic solution for skip‐free Markov chains, which are more elaborated Markov chains than finite LD‐QBD processes. Furthermore, for the finite LD‐QBD process under consideration, perturbation analysis of alternative descriptors allowing for a matrix‐analytic treatment (for example, the number of visits to level L(i), for integers 1≤i≤K, before reaching level L(0), and numbers of level descents and level ascents before reaching states in L(0), among others) could also be developed in a similar manner.
Local sensitivity or perturbation analysis for LD‐QBD processes is specially relevant in epidemic modeling. This is due to the fact that not only the multitype versions of S I and S I S epidemics can be expressed in terms of LD‐QBD processes but also many other variants—including S I R, S I R S, S E I R epidemic models—can be represented in this way by conveniently labeling states; see, for example, the works by Artalejo et al.35 and Neuts and Li.36 In particular, this is possible due to the fact that events such as infections and recoveries in these processes occur one at a time in continuous time. In the special case of S I R epidemic models, the block‐tridiagonal form of Q in (1) is linked to a block‐bidiagonal form for transient states (see section 1 in the work of Neuts and Li36) when the bivariate process is defined in terms of the numbers (S(t),I(t)) of susceptibles and infectives at time t. This block‐bidiagonal form in sections 3 and 4 in the work of Neuts and Li36 permits recursive procedures for computing the final size of the epidemic and the maximum size distribution in a similar manner to that in the work of Amador et al.,37 where the joint distribution of the maximum number of infectives during an outbreak and the random time to reach this maximum number is also derived in terms of Laplace–Stieltjes transforms. For S I R epidemic models with Markov‐modulated events, we refer the reader to the work of Almaraz and Gómez‐Corral38; more concretely, LD‐QBD processes are used in the work of Almaraz and Gómez‐Corral38 to derive the probability distributions of the length of an outbreak, the final size of the epidemic, and the number of secondary cases. When these models are used for representing epidemics in reality, statistical estimation techniques, such as Bayesian approaches (for instance, approximate Bayesian computation and Monte Carlo Markov chain methods), are usually implemented in order to estimate parameters of these models from clinical data; see, for example, the work of Kypraios et al.39 In the statistical setting, it is therefore important to evaluate the impact that a small perturbation of the underlying parameters may have in the dynamics of the epidemic model, so that one can identify parameters that the model is most sensitive to, allowing for potentially devoting more computational and statistical efforts in estimating those parameter values.
When faced with sensitivities and elasticities, an obvious approach is to evaluate by direct computation the partial derivatives ∂ D/∂ θ r of any descriptor D with respect to θ r for 1≤r≤s, instead of the differentiation of D with respect to the vector θ of parameters. In the case of first‐passage times and the bacterial transmission model (Section 3.3), Figure 3 shows CPU times for Algorithms 1.B (Section 2.1) and 1.C (Appendix B), where the latter computes, starting at r=1, the partial derivatives for integers 1≤r≤s and l=1, the multitype S I epidemic model (Section 3.1) and initial state (i,j)=(I 1+I 2,I 2) with (I 1,I 2)=(1,1). In order to carry out this computational comparison while increasing the number s of parameters in θ, we consider s−2 additional external sources of type‐1 infection, so that new type‐k infections occur with respective rates if k=1, and i(N−i−j−I 1)β 2 if k=2; this means that, in Figure 3, the number of parameters equals s with s∈{2,10,25,50}, and the rate corresponds to the k ′th external source of type‐1 infection, for 0≤k ′≤s−2. It is seen that, for a large number s of parameters (s=50; Figure 3), Algorithm 1.B behaves better than Algorithm 1.C, whereas the latter performs better than the former if s is small (s∈{2,10}). This behavior can be explained by using the summary of computational complexity shown in Table 5. To be concrete, Algorithm 1.B (similar to Algorithms 2.B and 3.B) is seen to require an extra effort to construct Jacobian matrices and related matrix operations (for instance, Kronecker products and vectorization of matrices), which are not necessary in Algorithm 1.C. Because the dimension of these matrices depends on the values s and N, moderate values for the number s of parameters (s=25) are linked to intermediate situations at which Algorithm 1.B yields better results for small population sizes (N<100), but it becomes worse than Algorithm 1.C for larger sizes (N>100).
Figure 3.
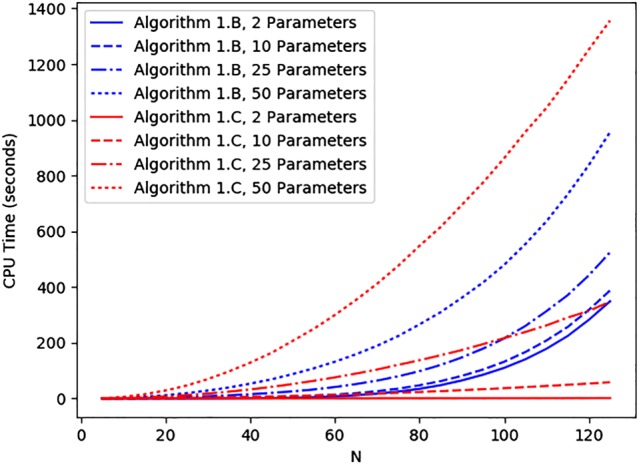
Table 5.
Computational complexity summary of Algorithms 1.A–B, 2.A–B, and 3.A–B
| Algorithm 1.A | Algorithm 1.B |
|---|---|
| • It computes the expectations of | • It computes partial derivatives , |
| first‐passage times to level L(0), for states | for 1≤r≤s, states and |
| and integers l≥1, from Equation (4). | integers l≥1, in a unified manner. |
| • It requires the computation of Jacobian matrices | |
| • It involves computing matrices H i, for | , for 1≤i≤K, involving sums, |
| 1≤i≤K, and their corresponding inverses, with | products, and Kronecker products of matrices |
| size M i+1. | and vectors, as well as vectorization of matrices, |
| with size M i+1. Inverses of matrices previously | |
| computed in Algorithm 1.A are used. | |
| • Moreover, it consists of two nested loops | • Moreover, it consists of two nested loops |
| (0≤p≤l, 1≤i≤K) involving sums and | (0≤p≤l, 1≤i≤K) involving sums, products, |
| products of matrices of size M i+1. | and Kronecker products of matrices of size |
| M i+1, as well as vectorization of these matrices. | |
| Algorithm 2.A | Algorithm 2.B |
| • It computes hitting probabilities p (i,j)(n) | • It computes partial derivatives ∂ p (i,j)(n)/∂ θ r, |
| for states and phases | for 1≤r≤s, states and phases |
| 0≤n≤M 0+1. | 0≤n≤M 0+1, in a unified manner. |
| • It consists of three iterations of a loop | |
| • Matrices H i and corresponding inverses can be | (0≤i≤K) involving sums, products, and |
| directly used here once computed in Algorithm1.A. | Kronecker products of matrices and vectors with |
| size M i+1, as well as vectorization of these | |
| matrices. Inverses computed in Algorithm 1.A are used here. | |
| • It consists of three iterations of one loop | |
| (1≤i≤K) involving sums and products of | |
| matrices with size M i+1. | |
| Algorithm 3.A | Algorithm 3.B |
| • It computes stationary probabilities π(i,j), for | • It computes partial derivatives ∂π(i,j)/∂ θ r, |
| states . | for 1≤r≤s and states , in a unified manner. |
| • A first loop (1≤i≤K) constructs Jacobian | |
| matrices , involving sums, products, | |
| • It involves computation of inverses , for | and Kronecker products of matrices and vectors |
| 0≤i≤K, with size M i+1, plus solving a | th size M i+1, as well as vectorization of |
| system of M K+1 linear equations corresponding | these matrices. It also involves solving a system |
| to level L(k). | of linear equations with (M K+1)2 equations, |
| corresponding to level L(K) after vectorizing the | |
| corresponding matrix. | |
| • Moreover, it consists of two subsequent loops | • Moreover, it consists of two subsequent |
| (0≤i≤K) involving sums and products of | loops (0≤i≤K) involving sums, products, and |
| matrices and vectors with size M i+1. | Kronecker products of matrices and vectors with |
| size M i+1, as well as vectorization of these matrices. |
Therefore, the use of Algorithms 1.B, 2.B, and 3.B is expected to be more convenient when studying more complex epidemic models, such as those incorporating population heterogeneities at the individual level (considering different individual susceptibilities, infectivities, or recovery periods), leading to LD‐QBD processes defined on networks,18, 40 these models being specially useful for analyzing epidemic processes in highly heterogeneous environments such as hospital units.40, 41 The type of local sensitivity analysis carried out here is specially interesting in this type of epidemic processes on networks because the number of parameters in these models grows combinatorially with the number N of individuals in the network. For instance, in the case of an S I R epidemic model on a directed network (see the work by López‐García 40) with external sources of infection and N individuals, the number of parameters in the model amounts to , corresponding to infectious contact rates, N external infection rates, and N recovery rates; this means that, for a population of N=10 heterogeneous individuals, the number of parameters may be as large as s=110.
In a more general setting, Table 6 shows the effect that the number of levels (K+1), the numbers of phases per level (M i+1, with 0≤i≤K), and the number of process parameters (s) has on the computational complexity of Algorithms 1.A‐1.B, 2.A‐2.B and 3.A‐3.B. It is observed that Algorithms 1.A and 2.A have computational complexities similar to the computational complexity of the linear level reduction algorithm (Algorithm 3.A) by Gaver et al.,27 because the most intensive computational effort lies in these algorithms in the inversion and product of matrices with dimensions M i+1, for 0≤i≤K. Note that the computational complexity of Algorithms 1.A‐1.B is written by considering a fixed integer l.
Table 6.
Computational complexities of Algorithms 1.A–B, 2.A–B, and 3.A–B
| Algorithm 1.A | Algorithm 1.B | ||
|---|---|---|---|
|
|
|
||
| Algorithm 2.A | Algorithm 2.B | ||
|
|
|
||
| Algorithm 3.A | Algorithm 3.B | ||
|
|
|
Supporting information
SupplementaryMaterial_NLA2160.pdf
ACKNOWLEDGEMENTS
The authors thank the editor and two anonymous referees for their constructive comments, which have improved the presentation of the paper. They also thank Peter Taylor (University of Melbourne) for his valuable comments on the sensitivity analysis of perturbed QBD processes and Markov chains and for providing them with the references.8, 9, 28, 29 This work was supported by the Ministry of Economy and Competitiveness (Government of Spain), Project MTM2014‐58091‐P, and by the Medical Research Council (UK), Project MR/N014855/1.
APPENDIX A. GLOSSARY OF NOTATION AND MATRIX CALCULUS PROPERTIES
A.1.
A.1.1.
Throughout this paper, vectors and matrices are denoted by bold lowercase and uppercase letters, respectively, with a T and A T denoting the transpose of the vector a and the matrix A. We denote the identity matrix of order h by I h, the null matrix of dimension h×l by 0 h×l, and the column vectors of zeros and ones with dimension h by 0 h and 1 h, respectively. Given a matrix A of dimension h×l and a column vector x with l entries, we let v e c A be a column vector with h l entries obtained by stacking columns within A, and D(x) denotes the diagonal matrix with x within its diagonal.
For a column vector y with h entries depending on parameters stored in a column vector x of order l, the derivative of y with respect to x amounts to the Jacobian matrix d y/d x T of dimension h×l, which is given by
As a result, derivatives of matrices can be readily derived, translating matrices into vectors by using the v e c(·) operator and by evaluating the resulting Jacobian matrices; more concretely, for a matrix A of dimension m×n with entries a ij depending on parameters stored in a column vector x of order l, the derivative of A with respect to x is related to the matrix d v e c A/d x T, which has the form
In Sections 2.1‐2.3, we obtain derivatives of certain properties of with respect to a vector w of parameter values by using four matrix calculus properties, which are as follows:
-
1.For vectors y, x, and z depending on parameters within w, and matrices W and V with identical numbers of rows, the derivative of y=W x+V z with respect to w is given by
-
2.Let A be a square matrix, whose entries depend on parameters within w. If the matrix A is nonsingular, then the derivative of A −1 with respect to w can be determined from
where ⊗ represents Kronecker's product. -
3.For a column vector x with m entries depending on parameters within w,
-
4.
For matrices A, B, and C depending on parameters within w, it is readily seen that .
For a general treatment on matrix calculus and its applications, we refer the reader to, among others, the book by Magnus and Neudecker42; more concrete results with ecological and demographic applications can be found in the works of Caswell.1, 2
APPENDIX B. A SIMPLE ALGORITHM
B.1.
B.1.1.
Starting from r=1, Algorithm 1.C allows us to derive partial derivatives of the moments of first‐passage times with respect to a single parameter θ r, for integers 1≤r≤s.
Algorithm 1.C
Computation of the partial derivatives , computed one at a time, for integers l≥1 and 1≤r≤s, and states .
Set r=0;
As the reader may verify, Algorithm 1.C does not use the v e c(·) operator. In Step 2, the column vector amounts to the element‐by‐element partial derivative of with respect to parameter θ r, for 1≤r≤s. Therefore, for the vector of partial derivatives of the element‐by‐element vector division , we may express
Gómez‐Corral A, López‐García M. Perturbation analysis in finite LD‐QBD processes and applications to epidemic models. Numer Linear Algebra Appl. 2018;25:e2160 10.1002/nla.2160
Footnotes
Under the assumption of a lexicographical labeling of states in , the f i,jth entry of the vector , with , amounts to the choice of (i,j) as the initial state of the process .
REFERENCES
- 1. Caswell H. Perturbation analysis of continuous‐time absorbing Markov chains. Numer Linear Algebra Appl. 2011;18(6):901–917. [Google Scholar]
- 2. Caswell H. Sensitivity analysis of discrete Markov chains via matrix calculus. Linear Algebra Appl. 2013;438(4):1727–1745. [Google Scholar]
- 3. Avrachenkov KE, Filar JA, Haviv M. Singular perturbations of Markov chains and decision processes In: Feinberg EA, Shwartz A, editors. Handbook of Markov decision processes: Methods and applications. Boston: Kluwer Academic Publishers, 2002. p. 113–150. [Google Scholar]
- 4. Dietzenbacher E. Perturbations of the Perron vector: Applications to finite Markov chains and demographic population models. Environ Plan A. 1990;22(6):747–761. [Google Scholar]
- 5. Heidergott B. Perturbation analysis of Markov chains. Paper presented at: Proceedings of the 9th International Workshop on Discrete Event Systems; 2008; Göteborg, Sweden: p. 99–104. [Google Scholar]
- 6. Li W, Jiang L, Ching W‐K, Cui L‐B. On perturbation bounds for the joint stationary distribution of multivariate Markov chain models. East Asian J Appl Math. 2013;3(1):1–17. [Google Scholar]
- 7. Rabta B, Aïssani D. Strong stability and perturbation bounds for discrete Markov chains. Linear Algebra Appl. 2008;428(8–9):1921–1927. [Google Scholar]
- 8. Seneta E. Sensitivity of finite Markov chains under perturbation. Stat Probab Lett. 1993;17(2):163–168. [Google Scholar]
- 9. Altman E, Avrachenkov KE, Núñez‐Queija R. Perturbation analysis for denumerable Markov chains with application to queueing models. Adv Appl Probab. 2004;36(3):839–853. [Google Scholar]
- 10. Heidergott B, Leahu H, Löpker A, Pflug G. Perturbation analysis of inhomogeneous finite Markov chains. Adv Appl Probab. 2016;48(1):255–273. [Google Scholar]
- 11. Hautphenne S, Krings G, Delvenne J‐C, Blondel VD. Sensitivity analysis of a branching process evolving on a network with application in epidemiology. IMA J Complex Netw. 2015;3(4):606–641. [Google Scholar]
- 12. Chitnis N, Hyman JM, Cushing JM. Determining important parameters in the spread of malaria through the sensitivity analysis of a mathematical model. Bull Math Biol. 2008;70(5):1272–1296. [DOI] [PubMed] [Google Scholar]
- 13. Artalejo JR, Gómez‐Corral A. Retrial queueing systems: A computational approach. Berlin:Springer‐Verlag; 2008. [Google Scholar]
- 14. He Q‐M. Fundamentals of matrix‐analytic methods. New York, NY:Springer; 2014. [Google Scholar]
- 15. Latouche G, Ramaswami V. Introduction to matrix analytic methods in stochastic modeling. Philadelphia: ASA‐SIAM; 1999. [Google Scholar]
- 16. Amador J. The stochastic SIRA model for computer viruses. Appl Math Comput. 2014;232:1112–1124. [Google Scholar]
- 17. Amador J. The SEIQS stochastic epidemic model with external source of infection. Appl Math Model. 2016;40(19–20):8352–8365. [Google Scholar]
- 18. Economou A, Gómez‐Corral A, López‐García M. A stochastic SIS epidemic model with heterogeneous contacts. Physica A. 2015;421:78–97. [Google Scholar]
- 19. Ching WK. Markov‐modulated Poisson processes for multi‐location inventory problems. Int J Prod Econ. 1997;53(2):217–223. [Google Scholar]
- 20. Chakravarthy SR, Gómez‐Corral A. The influence of delivery times on repairable k‐out‐of‐N systems with spares. Appl Math Model. 2009;33(5):2368–2387. [Google Scholar]
- 21. Moghaddass R, Zuo MJ, Wang W. Availability of a general k‐out‐of‐n: G system with non‐identical components considering shut‐off rules using quasi‐birth–death process. Reliab Eng Syst Saf. 2011;96(4):489–496. [Google Scholar]
- 22. Artalejo JR, Gómez‐Corral A. Modelling communication systems with phase type service and retrial times. IEEE Commun Lett. 2007;11(12):955–957. [Google Scholar]
- 23. Gómez‐Corral A, López‐García M. Maximum queue lengths during a fixed time interval in the M/M/c retrial queue. Appl Math Comput. 2014;235:124–136. [Google Scholar]
- 24. Gómez‐Corral A, López‐García M. Extinction times and size of the surviving species in a two‐species competition process. J Math Biol. 2012;64(1–2):255–289. [DOI] [PubMed] [Google Scholar]
- 25. Gómez‐Corral A, López‐García M. On the number of births and deaths during an extinction cycle, and the survival of a certain individual in a competition process. Comput Math Appl. 2012;64(3):236–259. [Google Scholar]
- 26. Gómez‐Corral A, López‐García M. Lifetime and reproduction of a marked individual in a two‐species competition process. Appl Math Comput. 2015;264:223–245. [Google Scholar]
- 27. Gaver DP, Jacobs PA, Latouche G. Finite birth‐and‐death models in randomly changing environments. Adv Appl Probab. 1984;16(4):715–731. [Google Scholar]
- 28. Li QL, Liu L. An algorithmic approach for sensitivity analysis of perturbed quasi‐birth‐and‐death processes. Queueing Syst. 2004;48(3–4):365–397. [Google Scholar]
- 29. Dendievel S, Latouche G, Remiche MA. Stationary distribution of a perturbed QBD process. ACM Sigmetrics Perform Eval Rev. 2012;39(4):40–40. [Google Scholar]
- 30. Ciarlet PG. Introduction to numerical linear algebra and optimization. Cambridge: Cambridge University Press; 1989. [Google Scholar]
- 31. Lipsitch M, Bergstrom CT, Levin BR. The epidemiology of antibiotic resistance in hospitals: Paradoxes and prescriptions. Proc Natl Acad Sci. 2000;97(4):1938–1943. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32. Saunders IW. Epidemics in competition. J Math Biol. 1981;11(3):311–318. [DOI] [PubMed] [Google Scholar]
- 33. Billard L, Lacayo H, Langberg NA. The symmetric m‐dimensional simple epidemic process. J R Stat Soc. 1979;41(2):196–202. [Google Scholar]
- 34. Kirupaharan N, Allen LJS. Coexistence of multiple pathogen strains in stochastic epidemic models with density‐dependent mortality. Bull Math Biol. 2004;66(4):841–864. [DOI] [PubMed] [Google Scholar]
- 35. Artalejo JR, Economou A, López‐Herrero MJ. The stochastic SEIR model before extinction: Computational approaches. Appl Math Comput. 2015;265:1026–1043. [Google Scholar]
- 36. Neuts MF, Li JM. An algorithmic study of SIR stochastic epidemic models In: Heyde CC, Prohorov YV, Pyke R, Rachev ST, editors. Athens conference on applied probability and time series analysis. Lecture Notes in Statistics Vol. 114. New York, NY: Springer; 1996. p. 295–306. [Google Scholar]
- 37. Amador J, Armesto D, Gómez‐Corral A. Extreme values in SIR epidemic models with two strains and cross immunity (under review); 2017. [DOI] [PubMed]
- 38. Almaraz E, Gómez‐Corral A. On SIR‐models with Markov‐modulated events: Length of an outbreak, total size of the epidemic and number of secondary cases (under review); 2017.
- 39. Kypraios T, Neal P, Prangle D. A tutorial introduction to Bayesian inference for stochastic epidemic models using Approximate Bayesian Computation. Math Biosci. 2017;287:42–53. [DOI] [PubMed] [Google Scholar]
- 40. López‐García M. Stochastic descriptors in an SIR epidemic model for heterogeneous individuals in small networks. Math Biosci. 2016;271:42–61. [DOI] [PubMed] [Google Scholar]
- 41. Worby CJ, O'Neill PD, Kypraios T, et al. Reconstructing transmission networks for communicable diseases using densely sampled genomic data: a generalized approach. Ann Appl Stat. 2016;10(1):395–417. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42. Magnus JR, Neudecker H. Matrix differential calculus with applications in statistics and econometrics. Third Edition Chichester, UK: John Wiley and Sons; 2007. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
SupplementaryMaterial_NLA2160.pdf