

Abstract
Evidence-based personalized medicine formalizes treatment selection as an individualized treatment regime that maps up-to-date patient information into the space of possible treatments. Available patient information may include static features such race, gender, family history, genetic and genomic information, as well as longitudinal information including the emergence of comorbidities, waxing and waning of symptoms, side-effect burden, and adherence. Dynamic information measured at multiple time points before treatment assignment should be included as input to the treatment regime. However, subject longitudinal measurements are typically sparse, irregularly spaced, noisy, and vary in number across subjects. Existing estimators for treatment regimes require equal information be measured on each subject and thus standard practice is to summarize longitudinal subject information into a scalar, ad hoc summary during data pre-processing. This reduction of the longitudinal information to a scalar feature precedes estimation of a treatment regime and is therefore not informed by subject outcomes, treatments, or covariates. Furthermore, we show that this reduction requires more stringent causal assumptions for consistent estimation than are necessary. We propose a data-driven method for constructing maximally prescriptive yet interpretable features that can be used with standard methods for estimating optimal treatment regimes. In our proposed framework, we treat the subject longitudinal information as a realization of a stochastic process observed with error at discrete time points. Functionals of this latent process are then combined with outcome models to estimate an optimal treatment regime. The proposed methodology requires weaker causal assumptions than Q-learning with an ad hoc scalar summary and is consistent for the optimal treatment regime.
1 Introduction
It is widely recognized by clinical and intervention scientists that the best possible care requires personalized treatment based on individual patient characteristics (Piquette-Miller et al., 2007; Insel, 2009; Hamburg and Collins, 2010; Lauer and Collins, 2010; Topol, 2012). Individualized treatment regimes (ITRs) formalize personalized treatment selection as a function from current patient information to a recommended treatment. An optimal ITR maximizes the expectation of a desirable outcome when applied to an entire population of interest. There has been a recent surge of research on developing estimators for optimal ITRs including regression-based estimators (Lu et al., 2011; Qian and Murphy, 2011a; McKeague and Qian, 2011), and direct-search estimators (Zhao et al., 2012; Zhang et al., 2012a,b; Orellana et al., 2010). ITRs are the atoms of dynamic treatment regimes (Murphy, 2003; Robins, 1986, 1989, 1997, 2004) which are currently a subject of intense research including both estimation (Henderson et al., 2010a; Zhao et al., 2011; Goldberg and Kosorok, 2012; Zhang et al., 2013; Moodie et al., 2013; Laber et al., 2014) and inference (Chakraborty et al., 2010; Moodie and Richardson, 2010; Chakraborty et al., 2013; Laber et al., 2013b); recent surveys include Schulte et al. (2014); Chakraborty and Moodie (2013); Chakraborty and Murphy (2014).
Despite this influx of research, most existing methods for estimating optimal ITRs from observational or randomized study data assume that each patient is measured at the same, fixed time points and that patient measurements are made without error. This is unrealistic in many clinical settings where noisy patient measurements are taken at clinic visits which are sparsely observed and irregularly spaced. Thus, to apply existing estimation methods, a standard approach is to reduce patient longitudinal information into an ad hoc scalar summary which is assumed to be measured perfectly. However, this potentially obfuscates important scientific information contained the patient longitudinal process, ignores measurement error, requires strong causal assumptions, and may lead to an ITR of poor quality.
We model the pre-treatment patient longitudinal information as a noisy proxy of a smooth latent process and employ methods from functional data analysis to form a regression-based estimator of the optimal ITR. We assume that the effect of the true latent process is represented either as: (i) an inner product of the latent process and an unknown, nonparametrically modeled, coefficient function; or (ii) a non-linear parametric functional of the latent process. Under mild regularity conditions, we prove that the proposed estimator is consistent if the true optimal decision rule is linear in the static patient information and depends on the true latent process as described above. The proposed estimator applies to both randomized and observational studies with sparsely observed, irregularly spaced, and noisy longitudinal measurements. While we focus on a single binary treatment decision, the proposed work provides a foundation for several extensions including multiple treatments and treatment decision points.
There are several recently proposed methods that use functional data to inform construction of optimal ITRs. McKeague and Qian (2014), Ciarleglio et al. (2015), and Ciarleglio et al. (2016) developed estimators for optimal ITRs that allow for pre-treatment functional predictors that are densely sampled without noise. In contrast, as mentioned previously, our focus is on sparse, noisy, and irregularly spaced data.
Our approach uses non-parametric estimators of the mean and covariance functions of the latent process. An alternative approach would be to posit parametric models for the mean and/or covariance functions using, e.g., mixed-effects models (Laird and Ware, 1982; Diggle et al., 2002; Fitzmaurice et al., 2012); this approach is especially appealing in contexts where scientific theory can be used to inform the choice of parametric model. Our proposed approach can also be used with such models, however, in our motivating biomedical applications there is not sufficient theory to inform the choice of these models so we will not discuss this approach further.
In Section 2, we review regression-based estimators of the optimal ITR and conditions needed to identify the optimal ITR using randomized or observational data. In Section 3, we describe our proposed estimator and state conditions under which it consistently estimates the optimal ITR. The finite sample performance of the proposed estimator is illustrated using simulation experiments in Section 4 and application to a study of major depressive disorder in Section 5. Extensions and open problems are discussed in Section 6.
2 Regression-based methods for estimating optimal ITRs
Assume that data available to estimate an ITR are of the form which comprise n i.i.d. copies of a trajectory {X, W(T), A, Y} where: denotes pre-treatment subject covariate information; W(T) = {W(T1), …, W(TM)} denotes M pretreatment proxy measurements taken at times T = (T1, …, TM); A ∈ {−1, 1} denotes treatment assigned; and denotes an outcome coded so that higher values are better. Capital letters, like X, denote random variables and lowercase letters, like x, denote instances of these random variables. Both M and T are treated as random variables as the number and timing of observations varies across subjects. Observation times T are allowed to vary in number, be sparse, and irregularly spaced. For example, in the STAR*D study of major depressive disorder, W(T) might denote patient-reported Quick Inventory of Depressive Symptomatology (QIDS-SR, Rush et al., 2003), recorded at each clinic visit.
An ITR π maps available patient information to a recommended treatment so that π : dom X × dom W(T) → dom A. Under π, a patient presenting with X = x and W(T) = w(t) would be recommended treatment π{x, w(t)}. To define an optimal ITR, we use potential outcomes (Rubin, 1978; Splawa-Neyman et al., 1990). Let Y∗(a) denote the potential outcome under treatment a ∈ {−1, 1} and define Y∗(π) = Σa∈{−1, 1} Y*(a)1π{X,W(T)}=a to be the potential outcome under ITR π. The optimal ITR, say πopt, satisfies for all π. To define the optimal ITR in terms of the data-generating model we use assume: (C1) consistency, Y = Y*(A); (C2) positivity, there exists ε > 0 so that ε < P {A = a|X, W(T)} for each a ∈ {−1, 1} with probability one; and (C3) ignorability, {Y*(−1), Y*(1)} ⫫ A|X W(T). Assumption (C3) is true by construction in a randomized study, but unverifiable with data from an observational study (Robins et al., 2000). A common justification for (C3) in the analysis of an observational study is that patient covariates, i.e., {X, W(T)}, are sufficiently rich so as to capture all information used in the treatment decision process. However, current analysis methods implicitly require the stronger causal assumption (C3’) {Y*(−1), Y*(1)} ⫫ A|X, s {W(T)}, where s{w(t)} is a pre-specified, ad hoc, summary of w(t). The proposed method incorporates w(t) directly into the model and is thereby more consistent with (C3).
Define . Under (C1)–(C3), it can be shown that πopt{x, w(t)} = arg maxa∈{−1, 1} Q{x, w(t), a}. Regression-based estimators postulate a working model for Q{x, w(t), a} which is fit using the data, say , and then used to infer the optimal ITR through . Postulating a working model for Q{x, w(t), a} that fully incorporates w(t) is difficult because this information is often sparsely observed and irregularly spaced. Thus, a common strategy is to assume Q{x, w(t), a} = Q[x, s {w(t)}, a] for some scalar summary s{w(t)}. In this case, one can use standard regression methods, e.g., linear regression, to estimate Q{x, w(t), a}, by regressing Y on X, s{W(T)}, and A. For example, Chakraborty et al. (2013), Chakraborty and Moodie (2013), Laber et al. (2013a), and Schulte et al. (2014), use the slope of QIDS-SR, s{w(t)} = {w(tm) − w(t1)}/(tm − t1) in their analyses of STAR*D; while this quantity is informed by clinical expertise, it is not informed by the response Y, the treatment A, nor does it account for potential measurement error in QIDS-SR as a proxy for depression severity. Another common ad hoc summary is the most recent pre-treatment measured score s{w(t)} = tm (e.g., Shortreed et al., 2011; Nahum-Shani et al., 2012; Laber et al., 2014, 2013b); again, this summary may be informed by expert judgment but is not data-driven. In the context of an observational study, allowing w(t) to enter regression model only through s{w(T)} is implicitly assuming that the stronger causal assumption (C3’) holds.
For clarity, we describe a simple version of regression-based estimation of the optimal ITR using a linear working model for Q{x, w(t), a} of the form Q{x, w(t), a; θ} = x⊺α + βs{w(t)} + a[x⊺δ + γs{w(t)}], where θ = (α⊺, β, δ⊺, γ)⊺ and s{w(t)} is a fixed and known scalar summary of w(t). Let Pn denote the empirical measure and define . A regression-based estimator of the optimal ITR is . Regression-based estimators are convenient, intuitive, and benefit from standard regression o diagnostics and model-building techniques. For these reasons, we use the foregoing regression-based estimator as the basis for the estimators described in Section 3. However, in some settings, direct-search estimators (Zhao et al., 2012; Zhang et al., 2012a,b, 2013) may be more appropriate; see Remark 3.4 in Section 3 for a description of direct-search estimation.
3 Functional Q-learning for estimating optimal ITRs
Treating patient longitudinal information as sparse functional data we derive estimators of the optimal ITR, πopt {x, w(t)}, that do not require ad hoc summary of w(t). Without loss of generality suppose that 0 ≤ T1 < … < TM ≤ 1. We assume that W(t) = Z(t) + (t) for all t ∈ [0, 1], where Z(·) is a square integrable latent process with smooth mean and covariance functions, and ε(·) is mean-zero white noise process. Thus, we assume that the subject longitudinal measurements W(T) are noisy realizations of the true latent process Z(·) at time points T. We introduce two general models for : (i) a linear model in X, A, and Z(T); and (ii) a hybrid model that combines linear effects for X and A and a linear effect of f{Z(·); η} for a parametric functional f(·; η) indexed by unknown parameters η. These two classes of models serve as building blocks for more complex classes of models which could be obtained by adding polynomial terms or other nonlinear basis functions.
3.1 Linear working model for
We assume a linear model of the form
(A1)
where α* and β*(·) are the main effects associated with X and Z(·) and δ* and γ*(·) are interaction effects. If the coefficient functions β*(·) and γ*(·) were known and the latent process Z(·) were observed, then (A1) would correspond to a linear model. However, the coefficient functions are unknown and Z(·) is not observed. Model (A1) was studied by McKeague and Qian (2014) and Ciarleglio et al. (2015) in the setting where Z(·) is observed on a fine grid of points for each subject.
The idea behind our estimation procedure is to use orthogonal basis function expansions for both the latent process and the unknown coefficient functions, and then reduce the infinite summation by an appropriate finite truncation. Let the spectral decomposition of the covariance function, G(t, t′) = Cov{Z(t), Z(t′)}, be G(t, t′) = Σk≥1 λkϕk(t)ϕk(t′), where {λk, ϕk(·)}k≥1 are the pairs of eigenvalues/eigenfunctions with λ1 > λ2 > … ≥ 0, and {ϕk(·)}k≥1 form and orthonormal basis in L2[0, 1]. Then Z(·) can be represented using the Karhunen–Loéve expansion as Z(t) = μ(t) + Σk≥1 ξkϕk(t), where are functional principal component scores, which have mean zero, variance λk, and are mutually uncorrelated. Using the eigenfunctions {ϕk(·)}k≥1, the coefficient functions β*(·) and γ*(·) can be represented as and , where and are unknown basis coefficients. We assume that X has an intercept term. Thus, the model (A1) can be equivalently written as , where we have absorbed ∫ μ(t)β*(t)dt and ∫ μ(t)γ*(t)dt into the intercept and main effect of treatment.
To obtain an expression for Q{x, w(t), a} we assume:
(A2) Y is conditionally independent of W(·) given Z(·);
(A3) A is independent of Z(·) given X and W(T), and 0 < c1 ≤ P(A = 1|X, W(T)) ≤ c2 < 1 with probability one for fixed constants c1 and c2;
(A4) Z(·) is independent of X given W(T);
(A5) Z(·), W(·), β(·), and γ(·), belong to L2[0, 1].
The foregoing assumptions are relatively mild: (A2) states that the noise–corrupted process W(·) provides no additional information about Y given the true signal Z(·); (A3) is satisfied if treatment is assigned according to observables X and W(T) and all subjects have a positive probability of receiving each treatment; (A4) allows us to estimate Z(·) using W(T) without reference to X, this simplifies notation and calculations but is not necessary (Jiang and Wang, 2010).
Under assumptions (A1)–(A5)
| (1) |
Let and let K be the number of terms in a finite truncation of the infinite summations in the foregoing display. Under the assumption of joint normality of the functional principle components and measurement error, ℓk{w(t)} = λkϕk(t) {Φ(t)ΛΦ(t)⊺ + σ2Im}−1 Φ(t)w(t), where ϕk(t) = {ϕk(t1), …, ϕk(tm)}⊺, Φ(t) is the m × K matrix {ϕ1(t) ⋯ ϕK(t)}, Λ = diag{λ1, …, λK} is K × K diagonal matrix, Im is the m × m identity matrix, and Var {ε(t)} ≡ σ2 is the error variance.
From (1), if the functions ℓk{w(t)} k ≥ 1 were known, then the parameters α*, δ*, β*, γ* could be estimated by the regression of Y on X, ℓk{W(T)} k ≥ 1, A. However, these functions are not known because the process Z(·) is not directly observable, the basis functions {ϕk(·)}k≥1 are not known, or both. We use functional principal component analysis (Silverman and Ramsay, 2005; Yao et al., 2005; Di et al., 2009) to construct estimators of ℓk{w(t)} for k = 1, …, K. Subsequently, we regress Y on X, A, and . The complete algorithm, which we term linear functional Q-learning, is as follows.
(FQ1) Use functional principal components to construct estimators of and of ℓk{w(t)}.
- (FQ2) Let θ ≜ (α⊺, δ⊺, β1, …, βK, γ1, …, γK)⊺, define
and compute . (FQ3) The estimated optimal decision rule is .
The finite truncation K corresponds to the number of leading functional principal components and can be selected using the percentage variance explained, cross-validation, or information criteria (see Yao et al., 2005). In our simulation experiments and illustrative application we chose K using the percentage variance explained.
The following results provide convergence rates for the functional Q-learning estimator. Subsequently, we establish that is consistent for the optimal regime πopt and derive rates of convergence for the difference , commonly known as the regret of applying the estimated regime (Lai and Robbins, 1985; Henderson et al., 2010b). Recall that denotes the observed data. Proofs are given in the Supplemental Material. We use the following assumptions:
(A6) forms a dense set in [0, 1] with probability one;
(A7) ε(·) is a Gaussian white-noise process;
(A8) for some positive Δ, where is an estimator of ;
(A9) for some positive Δ, where is an estimator of G(t, t′) ≜ Cov{Z(t), Z(t′)};
(A10) for some positive Δ, where is an estimator of ;
(A11) and E[XX⊺] is non-singular;
(A12) ;
(A13) and for all k ≥ 1, some ς > 1, and some C > 0.
Assumptions (A5)–(A10) are standard in sparse functional data analysis (Yao et al., 2005; Hall and Hosseini-Nasab, 2006; Li and Hsing, 2010; Staicu et al., 2014); (A11) is a standard assumption in regression; and (A12)–(A13) are common in scalar-on-function regression models (Hall et al., 2007; Lian, 2011; Shin and Lee, 2012).
Theorem 3.1
Assume (A1)–(A13). Let Kn be an increasing sequence of integers such that Kn → ∞ and Kn/n2Δ → 0 as n → ∞, then
The sequence Kn is dictated by the rate of decay of the tail sum as m → ∞; in the extreme case in which λk = 0 for all sufficiently large k then one can set Kn to be a constant (i.e., it need not diverge to infinity, see the Supplemental Materials for additional details). As indicated by (A8)–(A10), the constant Δ is dictated by the slowest rate of convergence among the estimators , , and ; this rate depends on the sampling design as well as the smoothness of the mean and covariance functions of the latent process (Yao et al., 2005; Hall and Hosseini-Nasab, 2006; Li and Hsing, 2010). For example, with kernel-based estimators of the mean and covariance functions under a sparse sampling design it can be shown that Δ = 1/4 is sufficient under mild regularity conditions (see Yao et al., 2005). If the functional predictor is observed on a dense grid without error, then it is possible to obtain Δ = 1/2 (Zhang and Wang, 2016). It can be seen that if Δ = 1/2 and λk = 0 for all but finitely many values, so that Kn can be chosen to be a constant, then the rate in the preceding theorem is parametric; however, in the sparse and noisy design we consider here we expect Δ < 1/2 (see Zhang and Wang, 2016) in which case the resulting rates are sub-parametric.
Corollary 3.2
Assume that the conditions for Theorem 3.1 hold and furthermore that , then converges to zero in probability.
Corollary 3.3 (Qian and Murphy, 2011)
Assume that the conditions for Theorem 3.1 hold, then
The estimated coefficients , , k = 1, …, K and the estimated basis functions can be used to form estimates of the coefficient functions β(t) and γ(t) indexing the Q-function Q{x, w(t), a} via and . Plotting the estimated coefficient functions shows how the latent process is being weighted over [0, 1] in the Q-function and thus may be scientifically informative. For example, a coefficient function that is large in magnitude and of opposite in sign at the endpoints of [0, 1] but small in magnitude in the middle of [0, 1] suggests that the change in Z(t) from the beginning to the end of the observation period is important. In this way, the linear functional Q-learning algorithm can uncover important relationships between the outcome and evolving patient characteristics including how these characteristics should be used to dictate treatment. However, in some cases, existing scientific theory may suggest a particular form for which may be nonlinear. We consider this case next.
3.2 Nonlinear working models for
In some settings, nonlinear features of a patient’s latent longitudinal process may be highly clinically informative. For example, in the context of depression and anxiety, an important feature of a patient’s evolving health status is the degree of waxing and waning of patient symptomatology (Wittchen et al., 2000). In this section, we develop functional Q-learning nonlinear summaries of the latent process that are known and suggested by domain experts or are unknown but assumed to belong to a parametric class of nonlinear models; the extension to non-parametric classes of functionals is discussed in Remark 3.5. In the context of major depressive disorder an important feature might be the variation in an individuals depression level as captured by , where and Z′(t) denotes the derivative of Z(t). In this section, we construct estimators of πopt under the assumption
| , | (A1’) |
where f and g are functionals from L2[0, 1] in to indexed by unknown parameters and . If Z(·) was observed, then (A1’) reduces to a parametric nonlinear regression model. Under (A1’) and (A2)–(A5)
Let G{·|w(t)} denote the conditional distribution of Z(·) given W(T) = w(t), then
| (2) |
We construct an estimator of Q{x, w(t), a} by first estimating G{·|w(T)} and then applying nonlinear least squares to estimate the remaining parameters in (2). To estimate G{·|w(t)} we assume that the loadings {ξk}k≥1 are a discrete-time, mean-zero Gaussian process with independent components and Var(ξk) = λk for all k ≥ 1. Under this assumption it can be seen that Z(·) given W(T) = w(t) follows a Gaussian process with mean function and covariance kernel
Expressions for the maximum likelihood estimators of m{w(t)}(t) and are obtained using the joint normality of {Z(t), Z(v), W(T)}, however, these estimators depend on the unknown basis functions {ϕk(·)}k≥1 and loading variances {λk}k≥1. Let {w(t)}(t) and denote the estimators obtained by replacing {ϕk(·)}k≥1 and {λk}k≥1 with the functional principal components estimators and , where K is a finite truncation. Let denote the distribution of Gaussian process with mean and covariance kernel . The nonlinear functional Q-learning algorithm is:
(NFQ1) Apply (FQ1) to construct estimators of ϕk(·), and for k = 1, …, K where K is a finite truncation.
- (NFQ2) Let ζ, ≜ (α⊺, δ⊺, η⊺, ρ⊺)⊺, define
and use nonlinear least squares to compute . -
(NFQ3) The estimated optimal decision rule is .
The above algorithm, can be implemented using existing statistical software with the requisite integrals being evaluated using Monte Carlo methods. Implementations of the algorithms using the R programming language (http://cran.r-project.org/) are available in the Supplemental Material. Under conditions on the smoothness of f and g, consistency of the non-linear functional Q-learning estimator follows from an argument similar to proof of Theorem 3.1.
Remark 3.4
One criticism of regression-based methods is that the form of the estimated optimal ITR is dictated by the form of the estimated Q-function. Thus, a parsimonious ITR requires a parsimonious Q-function, which may be prone to misspecification. On the other hand, a complex and expressive Q-function may lead to a complex ITR that is difficult to communicate to domain experts. This has led increased interest in direct–search, also known as policy–search, algorithms that model the marginal mean outcome as a function on the space of ITRs and then to use the maximizer of this fitted model to estimate the optimal ITR; the appeal of these methods is that the maximizer can be restricted to belong to a pre-specified class of ITRs that are interpretable or satisfy cost or logistical constraints. It is possible to use functional Q-learning to construct direct–search estimators with sparse longitudinal data. Let Π denote a class of ITRs of interest. It can be shown (Qian and Murphy, 2011b) that , where P{a|x, w(t)} denotes the propensity score P{A = a|X = x, W(T) = w(t)}. In a randomized clinical trial the propensity score is known, in observational studies this must be estimated from data. Let denote an estimator of the propensity score and an estimator of the Q-function constructed using functional Q-learning. An estimator of is . A policy–search estimator of the optimal ITR is . In this formulation, it is possible to increase the complexity of the Q-function without bincreasing the complexity of the estimated optimal ITR. For this reason, with policy–search estimators it is typical to use a non-parametric estimator of the Q-function. We discuss non-parametric estimators in the next remark.
Remark 3.5
The preceding estimation algorithm can be extended to handle more general classes of models for the conditional mean of the outcome given covariates and the latent functional process. For example, one might postulate an additive model of the form
where c, are unknown functions, f, , and and are (possibly infinitely dimensional) unknown classes of functions. Assuming this model, let and define as in the nonlinear functional Q-learning algorithm. The Q-function is
Hence, can be estimated using penalized least squares
where is a penalty function indexed by a vector of tuning parameters . The estimated optimal ITR
As discussed previously, nonparametric functional Q-learning can be used in the context of policy-search algorithms. In addition, one can compare the estimated policy using parametric functional Q-learning with the estimated policy using nonparametric functional Q-learning as a means of diagnosing model misspecification. However, developing a formal test of the parametric functional Q-learning model against a nonparametric alternative would require extending the asymptotic theory presented in the preceding section to handle nonparametric estimators; we leave this to future work.
4 Empirical study
In this section we examine the finite sample performance of functional Q-learning. Performance of an estimated ITR, , is measured in terms of the average marginal mean outcome . To form a baseline for comparison, we implemented standard Q-learning with linear models working models in X and a fixed summary function s{W(T)}. We consider two potential summary functions, the last observed value in the longitudinal trajectory sL{W(T)} = W(TM), and the mean . Let and denote the estimated optimal ITRs using Q-learning with sL{W(T)} and sμ{W(T)}. Reported simulation results are based on 1000 Monte Carlo replications.
4.1 Linear generative models
To evaluate functional Q-learning with a linear model for we use the following class of generative models: X ∼ Normal {0, Ωp(r)}, {Ωp(r)}i,j = r|i−j|, ς ~ Normal(0, IK), , t ∈ [0, 1], τ ∼ Normal(0, 1), , M ∼ Uniform{c, c + 1, …, c + d}, and T|M = m ~ Uniform[0, 1]m, where is a cubic B-spline basis with six equally spaced knots. Thus, this class of generative models is indexed by: the dimension p, coefficient vectors α* and δ*, number of basis functions K, autocorrelation r, sparsity parameters c and d, and the coefficient functions β*(t) and γ*(t). Throughout, we fix p = 5, α* ≡ −1, δ* = (−0.1, 0, …, 0), r = 1/2, and K = 10. We consider two sparsity settings: c = 5, d = 15 which we term sparse, and c = 15, d = 10 which we term moderate. We consider three settings for the coefficient functions: (S1) γ*(t) = β*(t) ∝ 1; (S2) γ*(t) = β*(t) ∝ 1t>0.90; and (S3) γ*(t) = β*(t) ∝ t − 1/2. Setting (S1) corresponds to a simple average of Z(t) and thus Q-learning using the summary sM{W(T)} may be expected to perform well, whereas Q-learning with the summary sL{W(T)} may be expected to perform poorly; setting (S2) corresponds to the average of Z(t) only over the last 10% of the time domain and therefore Q-learning using the summary sL{W(T)} may be expected to perform well, whereas Q-learning with the summary sM{W(T)} may be expected to perform poorly; and setting (S3) corresponds to a contrast between early and late values of Z(t) and thus neither summary sM{W(T)} nor sL{W(T)} captures salient features of the functional predictor and therefore Q-learning with either of these features may be expected to perform poorly.
In each setting, to control the effect size, we scale the coefficient functions so that . We assume that W(t) = Z(t)+ε(t) where ε(t) is a standard Gaussian white-noise process. We use training sets of size n = 250, results with larger sample sizes were qualitatively similar and are omitted.
Table 1 shows the marginal mean outcomes for functional Q-learning, Q-learning, and a random regime that assigns treatment by random guessing with P(A = 1) = P (A = −1) = 1/2. Functional Q-learning performs favorably compared with Q-learning in all examples considered. The performance of Q-learning appears to depend critically on the choice of summary; e.g., as anticipated, Q-learning with the summary sM{W(T)} performs well in (S1) but poorly in (S2) and (S3), whereas Q-learning with the summary sL{W(T)} performs well in (S3) but poorly in (S1) and (S2).
Table 1.
Estimated mean outcome under linear generative models for functional Q-learning, Q-learning with ad hoc features, and random guessing. Results are computed from 1000 datasets of size n = 250. Monte Carlo standard errors are in the second decimal place.
| Example | Sparsity |
|
|
|
|
|
|||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| (S1) | Sparse | 3.0 | 2.81 | 1.83 | 2.74 | 0.90 | |||||
| (S1) | Moderate | 3.0 | 2.86 | 1.79 | 2.86 | 0.90 | |||||
| (S2) | Sparse | 3.0 | 2.61 | 1.88 | 1.75 | 0.92 | |||||
| (S2) | Moderate | 3.0 | 2.81 | 1.88 | 1.80 | 0.92 | |||||
| (S3) | Sparse | 3.0 | 2.43 | 2.29 | 1.86 | 0.94 | |||||
| (S3) | Moderate | 3.0 | 2.58 | 2.40 | 1.87 | 0.94 |
4.2 Nonlinear generative models
To evaluate functional Q-learning with a nonlinear model for we use the same class of generative models as in Section 4.1 except that Y = X⊺α* + f{Z(·); η} + A[X⊺δ* + g{Z(·); ρ}] + τ, where f{z(·); η} and g{z(·); ρ} are functionals of z(·) indexed by unknown parameters η and ρ, and all other parameters are as in Section 4.1. In the settings we consider here f ≡ g and f{z(·); η} = ηf0{z(·)} where , and f0{z(·)} is a known functional of z(·) We consider three settings for f0: (S4) ; (S5) , where z′(t) denotes the derivative of z(·) at t; and (S6) f0{z(·)} = supt∈[0,1] z(t) − inft∈[0,1] z(t). To control the treatment effect size, the constant η is chosen so that .
Table 2 shows the marginal mean outcomes under functional Q-learning, Q-learning, and random guessing. Functional Q-learning consistently obtains a higher marginal mean outcome than competing methods in all settings. This suggests that if there is strong scientific theory to guide the form of the Q-function, then functional Q-learning may perform well. However, the poor performance of Q-learning with the last observation illustrates that misspecification of the form of f{z(·); η} could lead to poor performance of functional Q-learning, e.g., by incorrectly choosing f{z(·); η} to approximate z(tm).
Table 2.
Estimated mean outcome under nonlinear generative models for functional Q-learning, Q-learning with ad hoc features, and random guessing. Results are computed from 1000 datasets of n = 250. Monte Carlo standard errors are in the second decimal place.
| Example | Sparsity |
|
|
|
|
|
|||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| (S4) | Sparse | 3.0 | 2.98 | 2.73 | 2.58 | 2.53 | |||||
| (S4) | Moderate | 3.0 | 2.99 | 2.73 | 2.61 | 2.53 | |||||
| (S5) | Sparse | 3.0 | 2.55 | 1.99 | 1.99 | 2.05 | |||||
| (S5) | Moderate | 3.0 | 2.60 | 2.05 | 2.06 | 2.05 | |||||
| (S6) | Sparse | 3.0 | 2.86 | 2.60 | 2.59 | 2.55 | |||||
| (S6) | Moderate | 3.0 | 2.91 | 2.55 | 2.54 | 2.55 |
5 Application to STAR*D
Sequenced Treatment Alternatives to Relieve Depression (STAR*D, www.star-d.org; Fava et al. 2003; Rush et al. 2004) is a multi-stage, randomized trial of patients with major depressive disorder. We use data from the first stage of the trial to illustrate functional Q-learning (data can be obtained through www.nimh.nih.gov). For simplicity and to match the development of our methodology, we restrict attention to the first randomized stage of the trial and compare the two most prevalent treatments with complete outcome and covariate data: Citalopram augmented with Bupropion (A = 1) and Citalopram augmented with Buspirone (A = −1). Complete data is available on n = 192 subjects. Subjects were observed for up to 14 weeks before the initial treatment, visit times are recorded in days from baseline; almost all (92%) of subjects in the complete data visited the clinic six times during this period. We use the pre-randomization self-rated Quick Inventory of Depressive Symptomatology (QIDS) as our longitudinal predictor. The left panel of Figure 1 shows the raw QIDS score for 50 randomly sampled subjects, we have highlighted two subjects to emphasize heterogeneity in the observed patterns. Based on a survey of clinical papers and previous analyses on STAR*D (see Pineau et al., 2007; Fava et al., 2008; Young et al., 2009; Chakraborty et al., 2013; Schulte et al., 2014; Novick et al., 2015, and references therein) we include as covariates: mean Clinical Global Impression (CGI) score taken over pre-randomization visits, sex, number of comorbidities at baseline, education level (indicator of some college or above), and the log number of major depressive episodes per year between diagnoses and enrollment. To be consistent with our paradigm of maximizing a desirable outcome we use 27 minus the average QIDS score over the course of post-randomization follow-up in the first stage as our outcome. Fitting a linear working model, e.g., equation (1), to the observed data and using fifty-fold cross-validation yields an estimated value of 19.35. The center panel of Figure 1 shows the smoothed longitudinal trajectories recovered from the functional principal components analysis and Table 3 shows the estimated coefficients for non-functional predictors. In contrast, using Q-learning and using the QIDS at the time of randomization in place of the QIDS longitudinal trajectory yields a cross-validated value of 16.69. Because the marginal mean outcome of an estimated optimal treatment regime is a non-smooth functional of the underlying generative distribution standard methods for inference do not apply (van der Vaart, 1991; Laber and Murphy, 2011; Hirano and Porter, 2012). To provide a rough sense of the uncertainty in the difference in value between functional and standard Q-learning, we calculated a Z-statistic using fifty differences in value computed across each fold of the cross-validation; the resultant Z-value was 1.88, so that functional Q-learning is nearly two (crudely estimated) standard errors above the mean using standard Q-learning. Thus, incorporating longitudinal information shows promising results in this limited example. Furthermore, the analysis also produces an estimate of which is shown in the right panel of Figure (1); the estimated coefficient function weights recent observations most heavily and contrasts them with data in the first half of the study.
Figure 1.
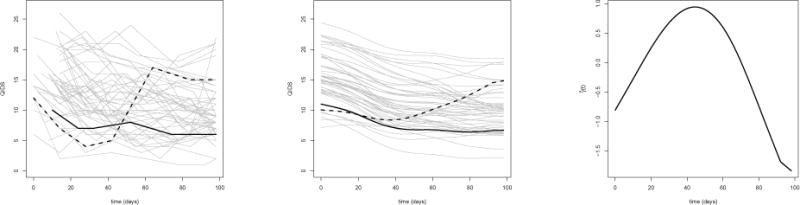
Left: Observed self-rated QIDS scores for 50 randomly selected subjects. Center: Estimated trajectories using functional principal components. Right: Estimated coefficient function .
Table 3.
Estimated coefficients and 95% nonparametric bootstrap confidence intervals for non-functional predictors.
| Term | Estimate | 95% Bootstrap CI |
|---|---|---|
| Intercept | 19.46 | (17.24, 21.95) |
| CGI | −0.50 | (−1.25, 0.26) |
| Sex | −0.52 | (−1.17, 0.18) |
| Number Comorbidities | 0.18 | (−0.39, 0.80) |
| Depressive Episodes (Log) | −0.21 | (−0.47, 0.11) |
| Education | 0.45 | (−0.22, 1.11) |
| Treatment | 0.48 | (−2.22, 2.50) |
| Treatment × CGI | −0.20 | (−0.79, 0.64) |
| Treatment × Sex | 0.23 | (−0.47, 0.94) |
| Treatment × Number Comorbidities | −0.073 | (−0.65, 0.53) |
| Treatment × Depressive Episodes (Log) | −0.031 | (−0.31, 0.26) |
| Treatment × Education | −0.050 | (−0.62, 0.72) |
6 Discussion
We proposed functional Q-learning as means of incorporating sparse, irregularly spaced, noisy longitudinal data into the estimation of optimal ITRs. We proved that under regularity conditions, including correct specification of the outcome regression models, the estimated optimal ITR is consistent for the true optimal ITR. Furthermore, the proposed method requires less stringent causal assumptions than standard Q-learning used with an ad hoc summary of longitudinal information. The proposed methodology performed favorably compared with standard methods in simulation experiments.
The proposed methodology lays the groundwork for a number of important extensions. One such extension is to incorporate the proposed estimator into each step of multiple stage Q-learning (Schulte et al., 2014) to analyze data from sequential multiple assignment randomized studies or observational longitudinal data with multiple treatments. The proposed estimators could also be extended to incorporate multivariate longitudinal processes, e.g., through additive regression models, and to discrete longitudinal processes, e.g., through latent threshold models. Finally, as noted in Remark 3.4, the proposed methodology can be used to build direct–search algorithms to estimated the optimal ITR within a pre-specified class of ITRs. We are currently pursuing a number of these extensions.
Supplementary Material
References
- Chakraborty B, Laber EB, Zhao Y. Inference for Optimal Dynamic Treatment Regimes Using an Adaptive m-Out-of-n Bootstrap Scheme. Biometrics. 2013;69(3):714–723. doi: 10.1111/biom.12052. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chakraborty B, Moodie EE. Statistical Methods for Dynamic Treatment Regimes. Springer; 2013. Statistical Reinforcement Learning; pp. 31–52. [Google Scholar]
- Chakraborty B, Murphy S, Strecher V. Inference for non-regular parameters in optimal dynamic treatment regimes. Statistical methods in medical research. 2010;19(3):317–343. doi: 10.1177/0962280209105013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chakraborty B, Murphy SA. Dynamic Treatment Regimes. Statistics. 2014;1 doi: 10.1146/annurev-statistics-022513-115553. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ciarleglio A, Petkova E, Ogden RT, Tarpey T. Treatment decisions based on scalar and functional baseline covariates. Biometrics. 2015;71(4):884–894. doi: 10.1111/biom.12346. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ciarleglio A, Petkova E, Tarpey T, Ogden RT. Flexible functional regression methods for estimating individualized treatment rules. Stat. 2016;5(1):185–199. doi: 10.1002/sta4.114. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Di CZ, Crainiceanu CM, Caffo BS, Punjabi NM. Multilevel functional principal component analysis. Annals of Applied Statistics. 2009;3(1):458–488. doi: 10.1214/08-AOAS206SUPP. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Diggle P, Heagerty P, Liang KY, Zeger S. Analysis of longitudinal data. Oxford University Press; 2002. [Google Scholar]
- Fava MA, John Rush M, Alpert JE, Balasubramani G, Wisniewski SR, Carmin CN, Biggs MM, Zisook S, Leuchter A, Howland R, et al. Difference in treatment outcome in outpatients with anxious versus nonanxious depression: a STAR* D report. American Journal of Psychiatry. 2008 doi: 10.1176/appi.ajp.2007.06111868. [DOI] [PubMed] [Google Scholar]
- Fitzmaurice GM, Laird NM, Ware JH. Applied longitudinal analysis. Vol. 998. John Wiley & Sons; 2012. [Google Scholar]
- Goldberg Y, Kosorok MR. Q-learning with censored data. Annals of statistics. 2012;40(1):529. doi: 10.1214/12-AOS968. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hall P, Horowitz JL, et al. Methodology and convergence rates for functional linear regression. The Annals of Statistics. 2007;35(1):70–91. [Google Scholar]
- Hall P, Hosseini-Nasab M. On properties of functional principal components analysis. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 2006;68(1):109–126. [Google Scholar]
- Hamburg MA, Collins FS. The path to personalized medicine. New England Journal of Medicine. 2010;363(4):301–304. doi: 10.1056/NEJMp1006304. [DOI] [PubMed] [Google Scholar]
- Henderson R, Ansell P, Alshibani D. Regret-Regression for Optimal Dynamic Treatment Regimes. Biometrics. 2010a;66(4):1192–1201. doi: 10.1111/j.1541-0420.2009.01368.x. [DOI] [PubMed] [Google Scholar]
- Henderson R, Ansell P, Alshibani D. Regret-regression for optimal dynamic treatment regimes. Biometrics. 2010b;66:1192–1201. doi: 10.1111/j.1541-0420.2009.01368.x. [DOI] [PubMed] [Google Scholar]
- Hirano K, Porter JR. Impossibility results for nondifferentiable functionals. Econometrica. 2012;80(4):1769–1790. [Google Scholar]
- Insel TR. Translating scientific opportunity into public health impact: a strategic plan for research on mental illness. Archives of General Psychiatry. 2009;66(2):128. doi: 10.1001/archgenpsychiatry.2008.540. [DOI] [PubMed] [Google Scholar]
- Jiang CR, Wang JL. Covariate adjusted functional principal components analysis for longitudinal data. The Annals of Statistics. 2010:1194–1226. [Google Scholar]
- Laber E, Linn K, Stefanski L. Interactive Q-learning. Submitted. 2013a [Google Scholar]
- Laber E, Lizotte D, Ferguson B. Set-valued dynamic treatment regimes for competing outcomes. Biometrics. 2014;70(1) doi: 10.1111/biom.12132. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Laber E, Qian M, Lizotte W, Pelham DJ, Murphy S. Dynamic treatment regimes: technical challenges and applications. Under Revision. 2013b doi: 10.1214/14-ejs920. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Laber EB, Murphy SA. Adaptive confidence intervals for the test error in classification. Journal of the American Statistical Association. 2011;106(495):904–913. doi: 10.1198/jasa.2010.tm10053. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lai TL, Robbins H. Asymptotically efficient adaptive allocation rules. Advances in applied mathematics. 1985;6(1):4–22. [Google Scholar]
- Laird NM, Ware JH. Random-effects models for longitudinal data. Biometrics. 1982:963–974. [PubMed] [Google Scholar]
- Lauer MS, Collins FS. Using Science to Improve the Nation’s Health System. JAMA: The Journal of the American Medical Association. 2010;303(21):2182–2183. doi: 10.1001/jama.2010.726. [DOI] [PubMed] [Google Scholar]
- Li Y, Hsing T. Uniform convergence rates for nonparametric regression and principal component analysis in functional/longitudinal data. The Annals of Statistics. 2010:3321–3351. [Google Scholar]
- Lian H. Functional partial linear model. Journal of Nonparametric Statistics. 2011;23(1):115–128. [Google Scholar]
- Lu W, Zhang HH, Zeng D. Variable selection for optimal treatment decision. Statistical methods in medical research. 2011 doi: 10.1177/0962280211428383. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McKeague IW, Qian M. Recent Advances in Functional Data Analysis and Related Topics. Springer; 2011. Sparse Functional Linear Regression with Applications to Personalized Medicine; pp. 213–218. [Google Scholar]
- McKeague IW, Qian M. Estimation of treatment policies based on functional predictors. Statistica Sinica. 2014;24(3):1461. doi: 10.5705/ss.2012.196. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moodie EE, Dean N, Sun YR. Q-learning: Flexible learning about useful utilities. Statistics in Biosciences. 2013:1–21. [Google Scholar]
- Moodie EE, Richardson TS. Estimating optimal dynamic regimes: Correcting bias under the null. Scandinavian Journal of Statistics. 2010;37(1):126–146. doi: 10.1111/j.1467-9469.2009.00661.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Murphy SA. Optimal dynamic treatment regimes (with discussion) Journal of the Royal Statistical Society: Series B. 2003;58:331–366. [Google Scholar]
- Nahum-Shani I, Qian M, Almirall D, Pelham WE, Gnagy B, Fabiano GA, Wax-monsky JG, Yu J, Murphy SA. Q-learning: A data analysis method for constructing adaptive interventions. Psychological methods. 2012;17(4):478. doi: 10.1037/a0029373. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Novick D, Hong J, Montgomery W, Dueñas H, Gado M, Haro JM. Predictors of remission in the treatment of major depressive disorder: real-world evidence from a 6-month prospective observational study. Neuropsychiatric disease and treatment. 2015;11:197–205. doi: 10.2147/NDT.S75498. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Orellana L, Rotnitzky A, Robins J. Dynamic regime marginal structural mean models for estimation of optimal dynamic treatment regimes, part I: Main content. Int Jrn of Biostatistics. 2010;6(2) [PubMed] [Google Scholar]
- Pineau J, Bellemare MG, Rush AJ, Ghizaru A, Murphy SA. Constructing evidence-based treatment strategies using methods from computer science. Drug and alcohol dependence. 2007;88:S52–S60. doi: 10.1016/j.drugalcdep.2007.01.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Piquette-Miller M, Grant D, et al. The art and science of personalized medicine. Clinical pharmacology and therapeutics. 2007;81(3):311–315. doi: 10.1038/sj.clpt.6100130. [DOI] [PubMed] [Google Scholar]
- Qian M, Murphy SA. Performance guarantees for individualized treatment rules. Annals of statistics. 2011a;39(2):1180. doi: 10.1214/10-AOS864. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Qian M, Murphy SA. Performance guarantees for individualized treatment rules. Annals of statistics. 2011b;39(2):1180. doi: 10.1214/10-AOS864. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Robins J. A new approach to causal inference in mortality studies with a sustained exposure periodapplication to control of the healthy worker survivor effect. Mathematical Modelling. 1986;7(9):1393–1512. [Google Scholar]
- Robins JM. The analysis of randomized and non-randomized AIDS treatment trials using a new approach to causal inference in longitudinal studies. Health service research methodology: a focus on AIDS. 1989;113:159. [Google Scholar]
- Robins JM. Latent variable modeling and applications to causality. Springer; 1997. Causal inference from complex longitudinal data; pp. 69–117. [Google Scholar]
- Robins JM. Proceedings of the second seattle Symposium in Biostatistics. Springer; 2004. Optimal structural nested models for optimal sequential decisions; pp. 189–326. [Google Scholar]
- Robins JM, Hernan MA, Brumback B. Marginal structural models and causal inference in epidemiology. Epidemiology. 2000;11(5):550–560. doi: 10.1097/00001648-200009000-00011. [DOI] [PubMed] [Google Scholar]
- Rubin D. Bayesian inference for causal effects: The role of randomization. The Annals of Statistics. 1978:34–58. [Google Scholar]
- Rush AJ, Trivedi MH, Ibrahim HM, Carmody TJ, Arnow B, Klein DN, Markowitz JC, Ninan PT, Kornstein S, Manber R, et al. The 16-Item Quick Inventory of Depressive Symptomatology (QIDS), clinician rating (QIDS-C), and self-report (QIDS-SR): a psychometric evaluation in patients with chronic major depression. Biological psychiatry. 2003;54(5):573–583. doi: 10.1016/s0006-3223(02)01866-8. [DOI] [PubMed] [Google Scholar]
- Schulte P, Tsiatis A, Laber E, Davidian M. Q- and A-learning methods for estimating optimal dynamic treatment regimes. Statistical Science. 2014;29(4) doi: 10.1214/13-STS450. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shin H, Lee MH. On prediction rate in partial functional linear regression. Journal of Multivariate Analysis. 2012;103(1):93–106. [Google Scholar]
- Shortreed SM, Laber E, Lizotte DJ, Stroup TS, Pineau J, Murphy SA. Informing sequential clinical decision-making through reinforcement learning: an empirical study. Machine learning. 2011:1–28. doi: 10.1007/s10994-010-5229-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Silverman B, Ramsay J. Functional Data Analysis. Springer; 2005. [Google Scholar]
- Splawa-Neyman J, Dabrowska D, Speed T, et al. On the application of probability theory to agricultural experiments. Essay on principles. Section 9. Statistical Science. 1990;5(4):465–472. [Google Scholar]
- Staicu AM, Li Y, Crainiceanu C, Ruppert D. Likelihood Ratio Tests for the Mean Structure of Correlated Functional Processes. Scandinavian Journal of Statistics. 2014 To appear. [Google Scholar]
- Topol EJ. The creative destruction of medicine. Basic Books; 2012. [Google Scholar]
- van der Vaart A. On differentiable functionals. The Annals of Statistics. 1991:178–204. [Google Scholar]
- Wittchen HU, Lieb R, Pfister H, Schuster P. The waxing and waning of mental disorders: evaluating the stability of syndromes of mental disorders in the population. Comprehensive Psychiatry. 2000;41(2):122–132. doi: 10.1016/s0010-440x(00)80018-8. [DOI] [PubMed] [Google Scholar]
- Yao F, Müller HG, Wang JL. Functional data analysis for sparse longitudinal data. Journal of the American Statistical Association. 2005;100(470):577–590. [Google Scholar]
- Young EA, Kornstein SG, Marcus SM, Harvey AT, Warden D, Wisniewski SR, Balasubramani G, Fava M, Trivedi MH, Rush AJ. Sex differences in response to citalopram: a STAR D report. Journal of psychiatric research. 2009;43(5):503–511. doi: 10.1016/j.jpsychires.2008.07.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang B, Tsiatis AA, Davidian M, Zhang M, Laber E. Estimating optimal treatment regimes from a classification perspective. Stat. 2012a;1(1):103–114. doi: 10.1002/sta.411. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang B, Tsiatis AA, Laber EB, Davidian M. A robust method for estimating optimal treatment regimes. Biometrics. 2012b;68(4):1010–1018. doi: 10.1111/j.1541-0420.2012.01763.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang B, Tsiatis AA, Laber EB, Davidian M. Robust estimation of optimal dynamic treatment regimes for sequential treatment decisions. Biometrika. 2013 doi: 10.1093/biomet/ast014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang X, Wang JL. From sparse to dense functional data and beyond. The Annals of Statistics. 2016;44(5):2281–2321. [Google Scholar]
- Zhao Y, Zeng D, Socinski MA, Kosorok MR. Reinforcement learning strategies for clinical trials in nonsmall cell lung cancer. Biometrics. 2011;67(4):1422–1433. doi: 10.1111/j.1541-0420.2011.01572.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao YQ, Zeng D, Rush AJ, Kosorok MR. Estimating individualized treatment rules using outcome weighted learning. Journal of the American Statistical Association. 2012;107(499):1106–1118. doi: 10.1080/01621459.2012.695674. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.