

Abstract
We present our process mining system for analyzing the trauma resuscitation process to improve medical team performance and patient outcomes. Our system has four main parts: trauma resuscitation process model discovery, process model enhancement (or repair), process deviation analysis, and process recommendation. We developed novel algorithms to address the technical challenges for each problem. We validated our system on real-world trauma resuscitation data from the Children’s National Medical Center (CNMC), a level 1 trauma center. Our results show our system’s capability of supporting complex medical processes. Our approaches were also implemented in an interactive visual analytic tool.
Keywords: Process Mining, Trauma Resuscitation, Medical Process Diagnosis
I. Introduction
TRAUMA is the leading cause of death and acquired disability among children and young adults. Because early trauma evaluation and management strongly impact the injury’s outcome, it is critical that severely injured patients receive efficient and error-free treatment in the first several hours of injury. During the trauma resuscitation, multidisciplinary teams rapidly identify and treat potential life-threatening injuries, then develop and execute a short-term management plan. The Advanced Trauma Life Support (ATLS) [1] protocol has been widely adopted as the initial evaluation and management strategy for injured patients worldwide. Although its implementation has been associated with improved outcomes, the application of this protocol has been shown to vary considerably, even with experienced teams. Many deviations from the ATLS protocol, e.g. the omission or delaying of steps, may have minimal impact on the outcome, but have been shown to increase the likelihood of a major uncorrected error that may lead to an adverse outcome.
The objective of this project is to develop a computerized decision support system that can automatically identify deviations during trauma resuscitations and provide real-time alerts of risk conditions to the medical team. We are approaching this goal using four process mining techniques [2] (Figure 1). (1) Process model discovery, extracting workflow models from data. (2) Process model enhancement, repairing the workflow model to mitigate the divergence between data-driven workflow models and expert hand-made models. (3) Process deviation analysis, discovering and analyzing the medical team errors. (4) Process recommendation, building a recommender system that can give treatment suggestions to medical teams.
Figure 1.
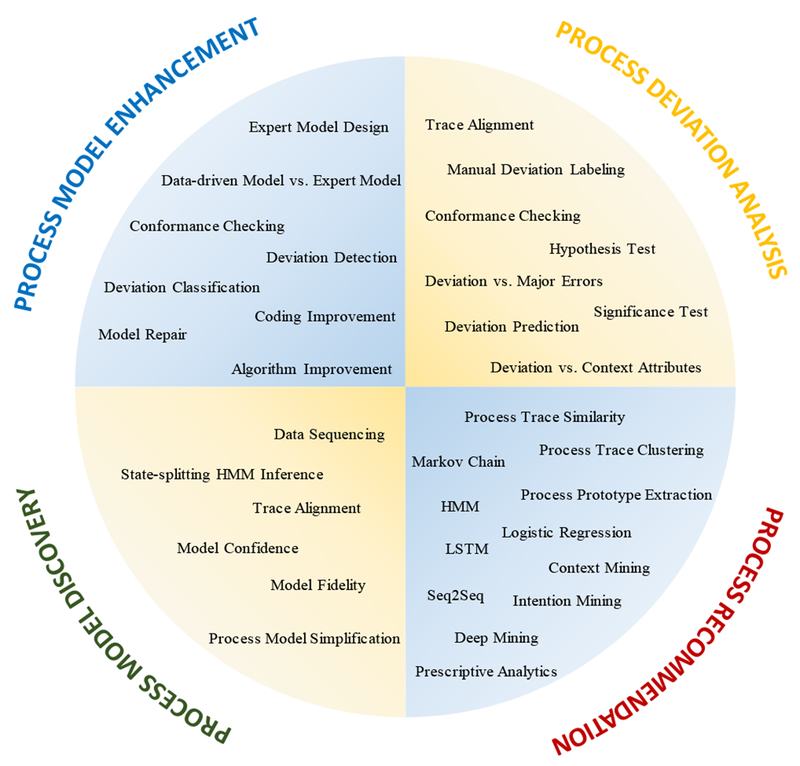
Process mining framework with related techniques we used in trauma resuscitation process analysis.
Key challenges for this study include limited data size, permissible deviations, variable patients, and concurrent teamwork. (1) Limited data: the trauma resuscitation workflow data needs to be coded manually in a labor-intensive way. To our best knowledge, there is no reliable system that can automatically capture trauma resuscitation workflow data. (2) Permissible deviations: it is necessary to distinguish the acceptable deviations (false alarms) from unexpected deviations (true alarms). (3) Variable patients: patients come to the trauma bay with different injuries that need different treatment plans. (4) Concurrent teamwork: trauma resuscitations need concurrent collaborative work within a medical team comprised of examining providers (surveying physicians), bedside nurses (left nurse, right nurse and charge nurse), and other team roles (e.g., surgical coordinator, anesthetist).
In this study, we contributed a comprehensive process mining framework with related techniques. We showed what problem each process mining technique solved and how these techniques worked together to achieve our project goals. We evaluated our process mining framework and techniques on a complex real-world medical case, the trauma resuscitation process. Our results showed the effectiveness of our techniques over existing process mining methods. Note that this paper is an overview of our previous work. The technical techniques can be found in our previous work.
II. Related Work
Many medical processes are performed based on domain knowledge and standard protocols. For trauma resuscitations, the ATLS [1] protocol suggests a medical examination flow based on treatment priorities: Airway → Breathing → Circulation → Neurological Disability. Despite the use of standardized evaluation and management protocols, deviations are observed in up to 85% of trauma resuscitations [3]. Although most deviations are variations that result from the flexibility or adaptability needed for managing patients with different injuries, other deviations represent “errors” that can contribute to significant adverse patient outcomes, including death [4][5].
To discover and analyze the process errors, previous research used two different approaches: data-driven and expert-model-based. Data-driven methods rely on process models or patterns discovered from historic data, while expert-model methods rely on process models or rules designed by domain experts. Data-driven methods work by comparing individual process enactments to the discovered average process representation, such as the average process trace [6], the data-driven model [7], or frequently occurring patterns [8], Expert-model-based approaches locate the deviations by checking the conformance between particular enactments to the expert model [9], or constraints or rules specified by medical experts [10]. In our study, we combined both methods. First, we discovered the data-driven model and designed the expert model based on medical domain knowledge. Then, we compared the data-driven and expert-model to uncover the discrepancies between practice and expectation. The discrepancies were evaluated by medical experts to determine if model enhancement is needed. Lastly, we used the enhanced expert model to discover and analyze more process deviations.
To reduce process errors, Clarke et al. [11] and Fitzgerald et al. [5] developed computer-aided decision support systems that recommend treatment steps. These systems, however, rely on hand-made rules specified by medical experts, lack generalizability, and are subject to human bias. We developed an automatic, data-driven, label-free framework for process analysis and recommendation.
III. Data Description And Definitions
Ninety-five resuscitations were coded by medical experts from video recordings collected at trauma bay of CNMC between August 2014 and October 2016. Collection and use of the data was approved by the Institutional Review Board.
The coded trauma resuscitation cases c =[c(1),…,c(l)]T is a vector of elements c(i). Each c(i) = {id(i),x(i),T(i)} denotes a resuscitation case (TABLE II), which is indexed with a unique case id, contains the resuscitation trace T(i). and has a vector x(i) of context attributes. A resuscitation trace includes k activities that are ordered based on activity occurrence time. Context attributes is a vector of g recorded patient attributes (e.g., patient age, injury type) and hospital factors (e.g., day vs. night shift, prehospital triage of injury severity)
TABLE II.
Sample trauma resuscitation data
 |
IV. Process Mining Methods And Results
Process model discovery, process model enhancement, and process deviation analysis are descriptive analytics, aiming to extract insights and knowledge from historic data. Process recommendation is predictive or prescriptive analytics, aiming to determine the best treatment procedure given observed context attributes (e.g., patient demographics). For each subsection, we discuss the methods first, followed by our achieved results.
A. Process Discovery of Resuscitation Workflow
Existing workflow discovery algorithms (e.g., heuristic miner, genetic miner, alpha miner [2]) have problems in handling duplicate activities. For example, during trauma resuscitation, the medical team checks patient’s eyes twice for different reasons. First, during the primary survey, they assess the patient’s pupillary response for neurological disability. Second, during the secondary survey, they examine patient’s eyes in more detail, looking for injuries to the cornea, sclera and eyelids. An accurate workflow model should be able to distinguish the first eye check from the second one, despite their identical labels. Existing workflow mining algorithms assume that duplicate activities in a process trace are equivalent. We solved this problem using Hidden Markov Models (HMM) to represent the workflow. To induce an HMM, we proposed a novel inference algorithm guided by trace alignment (AGSS) [12], AGSS (Figure 2 and Problem 1) first initializes a general Markov chain λ0. After initialization. AGSS determines two factors: which states to split and when to stop splitting. AGSS determines the splitting candidates from the alignment matrix and orders them by column frequency. After calculating the splitting candidates, AGSS performs iterative splitting.
Figure 2.

Our Alignment-guided State-splitting algorithm for discovering a more representative data-driven workflow model [12]. (a) Trace alignment algorithm to find splitting candidates. (b)(c)(d) State-splitting HMM inference.
Problem 1: AGSS Medical Process Model Discovery:
Given: A set of resuscitation traces T = [T(1),…,T(n)].
Objective: Successively splitting state sj ∈ S to find an HMM topology λs that maximizes probability P(T|λ):
| (1) |
where P(T(i)|λ) is observation sequence probability, solved with the Forward algorithm [13]. S, the set of states to be split, is calculated using the trace alignment algorithm [14].
We tested AGSS on trauma resuscitation workflow data and compared it to existing state-splitting HMM inference algorithms (e.g., ML-SSS, STACT) [12], The performance was measured based on (1) model’s quality and (2) the algorithm’s computational efficiency. The model quality is measured by model fidelity and model confidence. Model fidelity (or accuracy) measures the agreement between a given workflow model and the observed process traces (i.e., the log likelihood of generating the observed traces using the given model). Model confidence measures how well a workflow model represents the underlying process that generates the observed process traces. High model confidence means the model describes not only the observed traces, but also the unobserved realizations of the underlying process. Our results show that AGSS is not only more computationally efficient (by a factor of , where n is the number of hidden states), but also produces HMMs of higher model fidelity (Mf) and model confidence (Mc) (TABLE I). Our results also show the workflow model discovered by AGSS is more readable and more representative than models discovered by existing HMM inference and process mining algorithms [12].
TABLE I.
Comparison of agss with existing state-splitting algorithms on primary survey and secondary survey in trauma resuscitation processes. model fidelity (Mf) and model confidence (Mc) are scaled by the number of process traces in each process.
| Primary Surrey | Secondary Survey | |||
|---|---|---|---|---|
| Mf | Mc | Mf | Mc | |
| Markov Chain | −10.00 | −10.38 | −47.59 | −44.09 |
| AGSS | −9.98 | −10.16 | −45.22 | −44.13 |
| ML-SSS (0.01) | −9.05 | −10.66 | −48.79 | −60.52 |
| Heuristic | −8.50 | −10.95 | −47.59 | −44.10 |
| MDL | −12.37 | −12.97 | −64.44 | −65.37 |
| STACT | −9.32 | −10.19 | −49.22 | −58.08 |
B. Process Model Enhancement of Resuscitation Workflow
As required for process deviation analysis, an initial expert model was developed by medical experts. The initial model underwent several revisions until the domain experts reached a consensus about which medical activities to include and in which order. We used two different approaches to enhance the expert model. First, we compared expert model to the data-driven model discovered using our AGSS algorithm. The model induced by AGSS helped discover three discrepancies between the initial expert model and actual practice. These discrepancies were analyzed for repairing the expert model [12]. Afterwards, we performed a more detailed and comprehensive model diagnosis using conformance checking [15] with twenty-four trauma resuscitation cases (Problem 2). We discovered more discrepancies between the model and practice, and came to the conclusion that our initial model could not fully represent the resuscitation process. In our preliminary analysis, we identified 57.3% (630 out of 1099) activities as deviations based on the initial expert model, of which only 24.6% (155 out of 630) were true deviations (i.e., process errors), while the remaining 75.4% deviations were false alarms due to process model incompleteness, coding errors, or inadequate algorithms. We then applied different strategies to address the false alarms, e.g., repairing the expert model, improving the coding procedure, and updating the algorithm. We tested the repaired model on ten unseen resuscitations, achieving 93.1% deviation discovery accuracy.
Problem 2: Process Enhancement:
Given: Historic resuscitation traces T = [T(1),…,T(n)] and a hand-made expert model λe.
Objective #1: Discover process deviations ε from T:
| (2) |
Where is the conformance checking algorithm [15], taking process traces and expert model as input and outputting the process deviations.
Objective #2: Classify ε as true alarms (i.e., process errors) and acceptable variations (i.e., false alarms ε′). Repair the expert model λe to eliminate ε′.
C. Process Deviation Analysis of Resuscitation Workflow
The main goal of process deviation analysis is to test our hypotheses, proving the adverse effects of accumulated deviations on trauma patient outcomes and team’s ability to compensate for major errors. The goal can be achieved in two steps. First, identify the process deviations (manually or based on conformance checking). Second, contact statistical analysis to test the association between the process deviations and patient outcomes (or patient attributes).
Our previous deviation analyses were performed both manually by medical experts and automatically based on the conformance checking algorithms. For manual deviation analysis, we analyzed thirty-nine resuscitations and discovered the number of errors and the number of high-risk errors per resuscitation increased with the number of non-error process deviations per resuscitation (correlation-coefficient = 0.42, p = 0.01 and correlation-coefficient = 0.62, p < 0.001, respectively) [18], For automated deviation analysis, we performed conformance checking on the enhanced process model using ninety-five trauma resuscitations. We detected 1,059 process deviations in 5,659 activities of 42 commonly performed assessment activity types (11.1 deviations per case). Our results also show that the resuscitations of patients with no pre-arrival notification (p = 0.037) and blunt injury (blunt vs. non-blunt p = 0.013) were significantly correlated with more deviations.
D. Process Recommendation of Resuscitation Workflow
To help reduce medical team errors, we developed a process recommender system [16][17] (Figure 3 and Problem 3) that provides data-driven step-by-step treatment recommendations. Our system was built based on the associations between similar historic process performances and contextual information (e.g., patient demographics). We introduced a novel similarity metric (named TwS-TP [16]) that incorporates temporal information about activity performance, and handles concurrent activities. Our recommender system selects the appropriate prototype performance of the process based on user-provided context attributes. Our approach for determining the prototypes discovers the commonly performed activities and their temporal relationships.
Figure 3.

Medical process recommender framework [16]. Treatment procedures were clustered based on similarity (horizontal axis of the matrices represents time and vertical axis represents activity type). A logistic regression model is trained between context attributes and cluster membership. Treatment prototypes were calculated from each cluster. When a new patient comes to the trauma bay (bottom box), trained regression model takes context attributes as input and outputs the cluster membership (e.g., C1). A treatment prototype is recommended based on the cluster membership (e.g., Prototype of C1).
Problem 3: Process Recommendation:
Given: A new patient with context attributes x′.
Objective: Recommend a treatment plan Tx′ = [a1,…,ak]T to the medical team that maximizes:
| (3) |
where Tg is the ground-truth treatment procedure and S(Tx,Ty) is the similarity measure of two process traces [16].
We implemented our recommender system with several different similarity metrics: edit distance (ED), sequential pattern based (SP) and TwS-TP, and different clustering algorithms: hierarchical clustering (HC), density peak clustering (DPC) and affinity propagation clustering (APC). We clustered the process traces using different combinations of similarity and clustering algorithms. We used ZeroR as the baseline and selected F-score and G-means as the recommendation accuracy metrics because they are suitable for evaluating multi-class imbalance learning problem. Our results show our system on 87 trauma resuscitation cases achieved recommendation accuracy of up to 0.77 F1 score (TwS-PT + APC in TABLE III) (compared to 0.37 F1 score using ZeroR). In addition, in 55 of 87 cases (63.2%), our recommended prototype was among the 5 nearest neighbors of the actual historic procedures in a set of eighty-seven cases (Figure 4).
TABLE III.
Recommendation evaluation on trauma resuscitation process dataset. The format α (τ) represents the regression model result A and the baseline (ZeroR) result (T). Rec NC stands for recommended number of clusters.
| Trauma Resuscitation Data | ||
|---|---|---|
| Rec NC | ED(2), SP (2), Time-warping (2) | |
| Metrics | F-Score | G-means |
| ED + HC | 0.634 (0.654) | 0.448 (0.428) |
| ED + DPC | 0.692 (0.686) | 0.436 (0.413) |
| ED + APC | 0.346 (0.353) | 0.392 (0.500) |
| SP + HC | 0.637 (0.533) | 0.603 (0.471) |
| SP + DPC | 0.637 (0.533) | 0.603 (0.471) |
| SP + APC | 0.645 (0.519) | 0.591 (0.475) |
| TwS-PT + HC | 0.526 (0.392) | 0.520 (0.497) |
| TwS-PT + DPC | 0.713 (0.670) | 0.556 (0.421) |
| TwS-PT + APC | 0.767 (0.366) | 0.683 (0.499) |
Figure 4.

Number of hits of recommended process enactment within k nearest neighbors of the actual enactment.
V. Conclusion
We presented the framework and associated techniques used in our trauma resuscitation process analysis and diagnosis. Our framework includes four parts: process model discovery, process model enhancement, process deviation analysis, and process recommendation. For each part, we showed the core problems, methods, and results we achieved so far. This paper shows a substantial implementation of process mining techniques on a significant real-world problem.
Acknowledgment
This paper is based on research supported by National Institutes of Health under grant number 1R01LM011834-01A10
Contributor Information
Sen Yang, Department of Electrical and Computer Engineering at Rutgers University, NJ, USA. sy358@rutgers.edu.
Jingyuan Li, Department of Electrical and Computer Engineering at Rutgers University, NJ, USA. j12056@rutgers.edu.
Xiaoyi Tang, Department of Electrical and Computer Engineering at Rutgers University, NJ, USA. xt59@rutgers.edu.
Shuhong Chen, Department of Electrical and Computer Engineering at Rutgers University, NJ, USA. sc1624@rutgers.edu.
Ivan Marsic, Department of Electrical and Computer Engineering at Rutgers University, NJ, USA. marsic@jove.rutgers.edu.
Randall S. Burd, Children’s National Medical Center, Washington DC, USA. rburd@childrensnational.org
References
- [1].American College of Surgeons. Committee on Trauma Advanced trauma life support: ATLS: student course manual. American College of Surgeons, 2012. [Google Scholar]
- [2].Van Der Aalst Wil. Process mining: discovery, conformance and enhancement of business processes. Springer Science & Business Media, 2011. [Google Scholar]
- [3].Carter Elizabeth A., et al. “Adherence to ATLS primary and secondary surveys during pediatric trauma resuscitation.” Resuscitation 841 (2013): 66–71. [DOI] [PubMed] [Google Scholar]
- [4].Clarke John R., Spejewski B, Gertner AS, Webber BL, Hayward CZ, Santora TA, et al. “An objective analysis of process errors in trauma resuscitations.” Academic Emergency Medicine, 711 (2000): 1303–1310. [DOI] [PubMed] [Google Scholar]
- [5].Fitzgerald Mark, et al. “Trauma resuscitation errors and computer-assisted decision support.” Archives of Surgery 1462 (2011): 218–225. [DOI] [PubMed] [Google Scholar]
- [6].Bouarfa Loubna, and Dankelman Jenny. “Workflow mining and outlier detection from clinical activity logs.” Journal of Biomedical Informatics 456 (2012): 1185–1190. [DOI] [PubMed] [Google Scholar]
- [7].Caron Filip, et al. “Monitoring care processes in the gynecologic oncology department.” Computers in biology and medicine 44 (2014): 88–96. [DOI] [PubMed] [Google Scholar]
- [8].Christov Stefan C., Avrunin George S., and Clarke Lori A.. “Online Deviation Detection for Medical Processes” AMIA Annual Symposium Proceedings. American Medical Informatics Association, 2014. [PMC free article] [PubMed] [Google Scholar]
- [9].Kelleher Deirdre C., et al. “Effect of a checklist on advanced trauma life support workflow deviations during trauma resuscitations without pre-arrival notification.” Journal of the American College of Surgeons 2183 (2014): 459–466. [DOI] [PubMed] [Google Scholar]
- [10].Rovani Marcella, et al. “Declarative process mining in healthcare.” Expert Systems with Applications 4223 (2015): 9236–9251. [Google Scholar]
- [11].Clarke John R., et al. “Computer-generated trauma management plans: comparison with actual care.” World journal of surgery 265 (2002): 536–538. [DOI] [PubMed] [Google Scholar]
- [12].Yang Sen, et al. “Medical Workflow Modeling Using Alignment-Guided State-Splitting HMM.”, 2016. IEEE International Conference on Healthcare Informatics (ICHI), 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [13].Rabiner LR. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE, vol.77, no.2, pp. 257–286, February 1989. [Google Scholar]
- [14].Yang Sen, et al. “Duration-Aware Alignment of Process Traces” Industrial Conference on Data Mining. Springer, 2016. [Google Scholar]
- [15].Adriansyah Arya, Sidorova Natalia, and Boudewijn F. Dongen van. “Cost-based fitness in conformance checking.”, the 11th International Conference on Application of Concurrency to System Design, 2011. [Google Scholar]
- [16].Yang Sen, et al. “A Data-driven Process Recommender Framework.” Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [17].Yang Sen, et al. “VIT-PLA: Visual Interactive Tool for Process Log Analysis.” KDD 2016 Workshop on Interactive Data Exploration and Analytics. [Google Scholar]
- [18].Webman Rachel, et al. “Classification and team response to non-routine events occurring during pediatric trauma resuscitation.” The journal of trauma and acute care surgery 814 (2016): 666. [DOI] [PMC free article] [PubMed] [Google Scholar]