

Abstract
The aim of this study is to assess the performance of two machine-learning technologies, namely, deep learning (DL) and support vector machine (SVM) algorithms, for detecting central retinal vein occlusion (CRVO) in ultrawide-field fundus images. Images from 125 CRVO patients (n=125 images) and 202 non-CRVO normal subjects (n=238 images) were included in this study. Training to construct the DL model using deep convolutional neural network algorithms was provided using ultrawide-field fundus images. The SVM uses scikit-learn library with a radial basis function kernel. The diagnostic abilities of DL and the SVM were compared by assessing their sensitivity, specificity, and area under the curve (AUC) of the receiver operating characteristic curve for CRVO. For diagnosing CRVO, the DL model had a sensitivity of 98.4% (95% confidence interval (CI), 94.3–99.8%) and a specificity of 97.9% (95% CI, 94.6–99.1%) with an AUC of 0.989 (95% CI, 0.980–0.999). In contrast, the SVM model had a sensitivity of 84.0% (95% CI, 76.3–89.3%) and a specificity of 87.5% (95% CI, 82.7–91.1%) with an AUC of 0.895 (95% CI, 0.859–0.931). Thus, the DL model outperformed the SVM model in all indices assessed (P < 0.001 for all). Our data suggest that a DL model derived using ultrawide-field fundus images could distinguish between normal and CRVO images with a high level of accuracy and that automatic CRVO detection in ultrawide-field fundus ophthalmoscopy is possible. This proposed DL-based model can also be used in ultrawide-field fundus ophthalmoscopy to accurately diagnose CRVO and improve medical care in remote locations where it is difficult for patients to attend an ophthalmic medical center.
1. Introduction
Central retinal vein occlusion (CRVO) is a vascular disease of the eye and a known cause of significant visual morbidity, including sudden blindness [1]. Pathogenesis of CRVO is believed to follow the principles of Virchow's triad of thrombogenesis, namely, vessel damage, stasis, and hypercoagulability [2]. In CRVO, the fundus may show retinal hemorrhages, dilated tortuous retinal veins, cotton-wool spots, optic edema, and macular edema (ME); ME is the most important cause of visual impairment in CRVO [3]. Intravitreous injections of antivascular endothelial growth factor (VEGF) agents have been shown to significantly improve visual acuity in eyes with CRVO-associated ME [4]. However, any delay in treatment with anti-VEGF agents results in poor functional improvement, and it is difficult to subsequently achieve satisfactory improvement in vision [5–7].
Thus, it is important to treat CRVO patients in an ophthalmic specialty center immediately after the onset to preserve visual function. However, establishing a large number of such centers is impractical because of rising public healthcare costs, a problem that is burdening several nations worldwide [8].
Recent remarkable advances in medical equipment include the ultrawide-field scanning laser ophthalmoscope, the Optos 200T× (Optos PLC, Dunfermline, United Kingdom). The Optos can easily and noninvasively provide wide-field fundus images (Figure 1) without mydriatic agent use, and it has been used for diagnosing or monitoring multiple conditions and for treatment evaluation in peripheral retinal and vascular pathology [9]. Importantly, if pupillary block and elevated intraocular pressure associated with dilation can be avoided, a trained nonmedical personnel can safely capture images to use them in telemedicine applications, especially in areas without ophthalmologists.
Figure 1.

Representative fundus images obtained using ultrawide-field scanning laser ophthalmoscopy. Ultrawide-field fundus images of the right eye without central retinal vein occlusion (CRVO) (A) and with CRVO (B).
Image processing approaches using two machine-learning algorithms, namely, deep learning (DL) and support vector machines (SVMs), have retained investigator attention for years because of their extremely high-performance levels; in fact, increasing number of studies have assessed their applications in medical imaging [10–14]. Nonetheless, in ophthalmology, the use of image processing technology that uses DL algorithms and SVM models to analyze medical images has been previously reported [13, 15, 16]. However, to the best of our knowledge, no study has evaluated the possibility of automated CRVO diagnosis using Optos images and machine-learning technology. Therefore, in this study, we assessed the ability of a DL model to detect CRVO using Optos images and compared the results between DL- and SVM-based algorithms.
2. Materials and Methods
2.1. Image Dataset
Optos images of patients with acute CRVO and those without fundus diseases were extracted from the clinical database of the ophthalmology departments of the Tsukazaki Hospital, Tokushima University Hospital, and Hayashi Eye Hospital. These images were reviewed by a retinal specialist and stored in an analytical database. Of the 363 fundus images selected, 125 were from CRVO patients and 238 were from non-CRVO healthy subjects.
We used K-fold cross validation in this study, and it has been described in detail elsewhere [17, 18]. Briefly, image data were divided into K groups, and (K − 1) groups were used as training data, whereas one data group was used for validation. This process was repeated K times until each of the K groups became a validation dataset. The number of groups (K) was calculated using Sturges' formula (K = 1 + log2 N). Sturges' formula is used to decide the number of classes in the histogram [19, 20]. Thus, in this study, we categorized the data into nine groups.
Images in the training dataset were augmented by adjusting for brightness, gamma correction, histogram equalization, noise addition, and inversion so that the amount of training data increased by 18-fold. The deep convolutional neural network (DNN) model, as detailed below, was created and was trained using preprocessed image data.
This study was conducted in compliance with the principles of the Declaration of Helsinki and was approved by the ethics committees of Tsukazaki Hospital, Tokushima University Hospital, and Hayashi Eye Hospital.
2.2. Deep Learning Model and Training
A DNN model called the Visual Geometry Group-16 (VGG-16) [21] was used in the present study, and its schematic is shown in Figure 2. This type of DNN is configured to automatically learn local features of images and generate a classification model [22–24]. The aspect ratio of the original Optos images was 3,900 × 3,072 pixels; however, for analysis, we changed the aspect ratio of all input images and resized them to 256 × 192 pixels. As the RGB input of images had a range of 0–255, it was first normalized to a range of 0–1 by dividing it by 255.
Figure 2.

Overall architecture of Visual Geometry Group-16 model. Visual Geometry Group-16 (VGG-16) comprises five blocks and three fully connected layers. Each block includes convolutional layers followed by a max-pooling layer. Flattening of the output matrix after block 5 resulted in two fully connected layers for binary classification. The deep convolutional neural network used ImageNet parameters; the weights of blocks 1–4 were fixed, whereas the weights of block 5 and the fully connected layers were adjusted.
The VGG-16 model comprises five blocks and three fully connected layers. Each block includes convolutional layers followed by a max-pooling layer with decreasing position sensitivity but greater generic recognition [25]. Flattening of the output from block 5 results in only two fully connected layers. The first layer removes spatial information from the extracted feature vectors, and the second layer is a classification layer that uses feature vectors from target images acquired in previous layers in combination with the softmax function for binary classification. To improve generalization performance, dropout processing was performed such that masking was achieved with a probability of 25% in the first fully connected layer.
Fine tuning was used to increase the learning speed and achieve higher performance with lower quantitates of data [26, 27]. We used the following parameters from ImageNet: blocks 1 to 4 were fixed, whereas block 5 and the fully connected layers were trained.
The weights of block 5 and the fully connected layers were updated using the optimization momentum stochastic gradient descent algorithm (learning coefficient = 0.0005, inertial term = 0.9) [28, 29]. Of the 40 DL models obtained in 40 learning cycles, the one with the highest rate of correct answers for the test data was selected as the DL model to be evaluated in this study. For this purpose, Keras (https://keras.io/ja/) was run on TensorFlow (https://www.tensorflow.org/) written in Python and was used to build and evaluate the model. We trained the model using the CPU of Core (TM) i7-8700K by Intel and the GPU of GeForce GTX 1080 Ti by NVIDIA.
2.3. Support Vector Machine Model
We used the soft-margin SVM implemented in the scikit-learn library using the radial basis function kernel [30]. We reduced all images to 60 dimensions as this was the number of dimensions that was found to provide the highest correct answer rate for the test data; for this, we tested 10–70 dimensions in steps of 10. The optimal values for cost parameter “C” of the SVM algorithm and parameter “γ” of the radial basis function were determined by grid search using quadrant cross validation, and the combination with the highest average correct answer rate was selected. The parameter values tested for C were 1, 10, 100, and 1000 and those for γ were 0.0001, 0.001, 0.01, 0.1, and 1. The final learning model was generated using the optimized parameter values of C = 10 and γ = 0.0001.
2.4. Outcomes
Receiver operating characteristic (ROC) curves for CRVO were created on the basis of the ability of the DL and SVM models to distinguish between CRVO and non-CRVO images, and the models were compared using area under the curve (AUC), sensitivity, and specificity values.
2.5. Heat Map
A heat map of the DNN focus site was created and classified using gradient-weighted class activation mapping [21]. Next, composite images were created by overlaying heat maps of the DNN focus site on the corresponding CRVO and non-CRVO images. The third convolution layer in block 3 was defined as the target layer, and the rectified linear unit was used as the backprop modifier. This process was performed using Python Keras-vis (https://raghakot.github.io/keras-vis/).
2.6. Statistical Analysis
Patient demographic data such as age were compared using Student's t-test, whereas Fisher's exact test was used for comparing the gender ratio and the ratio of the right to left eye images.
The 95% confidence interval (CI) of AUC was obtained as follows. Images judged to exceed a threshold were defined as positive for CRVO, and the ROC curve was created. We created nine such models and nine ROC curves. For determining AUC, the 95% CI was obtained by assuming normal distribution and using the average and standard deviation of the nine ROC curves. For estimating sensitivity and specificity, optimal cutoff values, which are the points closest to the point at which both sensitivity and specificity are 100% in each ROC curve, were used [26]. The sensitivity and specificity at the optimal cutoff value were calculated using the Youden index [31]. The ROC curve was calculated using scikit-learn, and CIs for sensitivity and specificity were determined using SciPy. The paired t-test was used to compare AUCs between the DL and the SVM models.
3. Results
We used 125 CRVO images from 125 patients (mean age, 67.8 ± 13.9 years; 67 men and 58 women; 61 left fundus and 64 right fundus images) and 238 non-CRVO images from 202 subjects (mean age, 68.6 ± 7.9 years; 104 men and 98 women; 122 left fundus and 116 right fundus images) in this analysis. No significant differences were detected between these two groups with respect to age, gender ratio, and left-right eye image ratio (Table 1).
Table 1.
Patient demographics.
| CRVO | Non-CRVO | p value | |
|---|---|---|---|
| Number of images (patients) | 125 (125) | 238 (202) | — |
| Age (yrs) | 67.8 ± 13.9 | 68.6 ± 7.9 | 0.489 (Student's t-test) |
| Sex, female | 58 (46.4%) | 98 (48.5%) | 0.734 (Fisher's exact test) |
| Left fundus | 61 (48.8%) | 122 (51.3%) | 0.660 (Fisher's exact test) |
The DL model's sensitivity for diagnosing CRVO was 98.4% (95% CI, 94.3–99.8%), its specificity was 97.9% (95% CI, 94.6–99.1%), and the AUC was 0.989 (95% CI, 0.980–0.999); in contrast, sensitivity of the SVM model was 84.0% (95% CI, 76.3–89.3%), its specificity was 87.5% (95% CI, 82.7–91.1%), and the AUC was 0.895 (95% CI, 0.859–0.931). In ROC curves, AUC of the DL model was significantly higher than that of the SVM model (P < 0.001) (Figure 3).
Figure 3.
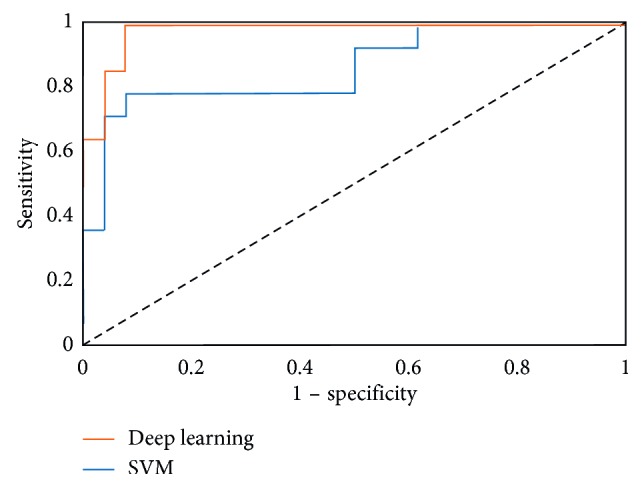
Receiver operating characteristic (ROC) curve for central retinal vein occlusion.
A composite image, comprising the fundal image superimposed with its corresponding heat map, was created by the DNN, and these images showed that DNNs could accurately identify crucial areas in the fundal images; a representative composite image is presented in Figure 4. Blue was used to indicate the strength of DNN-based identification, and an increase in color intensity was observed in areas with retinal hemorrhage and at the focus points. Thus, in non-CRVO images, the heat map showed that focal points accumulated around the optic disc, whereas in CRVO images, focal points accumulated around the optic disc and around retinal hemorrhages. These results imply that DNNs may be able to distinguish between CRVO eyes and normal eyes by identifying and highlighting retinal hemorrhages.
Figure 4.

Representative ultrawide-field fundus images and corresponding heat maps. The ultrawide-field fundus image without central retinal vein occlusion (CRVO) (A), and its corresponding superimposed heat map (B); with CRVO (C), and its corresponding superimposed heat map (D). In the image without CRVO (A), the deep convolution neural network focused on the optic disc (blue), whereas in the image with CRVO (B), the model focused on the optic disc and on the retinal hemorrhages (blue) (D).
4. Discussion
The fundamental aim of this study was to explore the possibility of early detection of CRVO from Optos fundus photographs using DL-based algorithms. If screening for CRVO is possible noninvasively and without the use of mydriatic agents, this approach would be medically viable. Currently, it is unreasonable to expect ophthalmologists to interpret all Optos-acquired fundus images because of associated medical resource costs. Therefore, a DL model that can accurately diagnose conditions based on ultrawide-field fundus ophthalmoscopy images without the need for human input can be used to screen and diagnose a very large number of patients at a very low cost.
Here, we have used DL technology to identify Optos images that show presence of CRVO. Our results show that the DL model has higher sensitivity, specificity, and AUC values than the SVM model for detecting CRVO in Optos-derived fundus photographs.
Further, using heat maps, we show that DNN could accurately identify an area around the optic disc in the non-CRVO images, whereas in CRVO images, it focused on the area around the optic disc and could highlight retinal hemorrhages. This result implies that the proposed DNN model may be able to identify CRVO by focusing on areas with suspected retinal hemorrhages. It is known that DL algorithm-based models can automatically learn local feature values of images and generate classification models [22, 26, 29, 31]. Additionally, DL includes several layers for the identification of local features of complicated differences, which can subsequently be combined [29].
In recent years, a number of studies have addressed that CNN hugely outperforms classic ML algorithms in image classification tasks [16, 32–34]. Recently, Wang et al. have reported that the performance of the DL model was not significantly different from that of the best classical methods, including SVM and human physicians, when classifying mediastinal lymph node metastasis in nonsmall cell lung cancer using positron emission tomography/computed tomography images [35]. This could be because image information necessary for classification was lost during image convolution in DL. In contrast, we found that the performance of the DL model was better than that of the SVM model in accurately diagnosing CRVO using Optos images. As most cases of CRVO need early intervention, patients diagnosed with CRVO using this method can immediately consult retinal specialists and receive necessary advanced treatment at an ophthalmic medical center. The Optos-based telemedicine technology being proposed here could significantly help us in preserving good visual function in CRVO patients living in areas with inadequate ophthalmic care and could potentially be used to cover large areas without adequate care facilities.
Despite the above, our study has a few limitations. First, we have only compared images of normal retinas with CRVO retinas and did not include images of other retinal diseases. Based on the image examples presented in this study, it may be expected that a CNN algorithm should easily be able to classify between the two types of images. To use this model under clinical conditions, further development and testing to ensure accurate identification of multiple conditions other than CRVO would be essential. Additionally, clarity of the eye may decrease in patients with mature cataract or severe vitreous hemorrhage, and in such cases, analysis of images captured using Optos may be difficult. Thus, future studies should extensively evaluate the performance and versatility of DL using larger samples and with images of other fundus diseases.
5. Conclusions
In conclusion, the DL model performed better than the SVM model in terms of its ability to distinguish between CRVO and normal eyes using ultrawide-field fundus ophthalmoscopic images. This technology has significant potential clinical usefulness as it can be combined with telemedicine to reach large areas where no specialist care is available.
Acknowledgments
We thank Masayuki Miki and orthoptists at Tsukazaki Hospital for their support in data collection.
Data Availability
The Optos image datasets and its corresponding superimposed heat maps analyzed during the current study are available from the corresponding author on reasonable request.
Conflicts of Interest
The authors declare that there are no conflicts of interest regarding the publication of this paper.
References
- 1.Yau J. W., Lee P., Wong T. Y., Best J., Jenkins A. Retinal vein occlusion: an approach to diagnosis, systemic risk factors and management. Internal Medicine Journal. 2008;38(12):904–910. doi: 10.1111/j.1445-5994.2008.01720.x. [DOI] [PubMed] [Google Scholar]
- 2.Rogers S., McIntosh R. L., Cheung N., et al. The prevalence of retinal vein occlusion: pooled data from population studies from the United States, Europe, Asia, and Australia. Ophthalmology. 2010;117(2):313–319. doi: 10.1016/j.ophtha.2009.07.017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Hayreh S. S., Zimmerman M. B. Fundus changes in central retinal vein occlusion. Retina. 2015;35(1):29–42. doi: 10.1097/iae.0000000000000256. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Yeh S., Kim S. J., Ho A. C., et al. Therapies for macular edema associated with central retinal vein occlusion: a report by the American Academy of Ophthalmology. Ophthalmology. 2015;122(4):769–778. doi: 10.1016/j.ophtha.2014.10.013. [DOI] [PubMed] [Google Scholar]
- 5.Campochiaro P. A., Brown D. M., Awh C. C., et al. Sustained benefits from ranibizumab for macular edema following central retinal vein occlusion: twelve-month outcomes of a phase III study. Ophthalmology. 2011;118(10):2041–2049. doi: 10.1016/j.ophtha.2011.02.038. [DOI] [PubMed] [Google Scholar]
- 6.Brown D. M., Heier J. S., Clark W. L., et al. Intravitreal aflibercept injection for macular edema secondary to central retinal vein occlusion: 1-year results from the phase 3 COPERNICUS study. American Journal of Ophthalmology. 2013;155(3):429–437. doi: 10.1016/j.ajo.2012.09.026. [DOI] [PubMed] [Google Scholar]
- 7.Korobelnik J. F., Holz F. G., Roider J., et al. Intravitreal aflibercept injection for macular edema resulting from central retinal vein occlusion: one-year results of the phase 3 GALILEO study. Ophthalmology. 2014;121(1):202–208. doi: 10.1016/j.ophtha.2013.08.012. [DOI] [PubMed] [Google Scholar]
- 8.Mrsnik M. Global Aging 2013: Rising to the Challenge. Standard & Poor’s Rating Services; 2013. https://www.nact.org/resources/2013_NACT_Global_Aging.pdf. [Google Scholar]
- 9.Nagiel A., Lalane R. A., Sadda S. R., Schwarttz S. D. Ultra-wide field fundus imaging: a review of clinical applications and future trends. Retina. 2016;36(4):660–678. doi: 10.1097/iae.0000000000000937. [DOI] [PubMed] [Google Scholar]
- 10.LeCun Y., Bengio Y., Hinton G. Deep learning. Nature. 2015;521(7553):436–444. doi: 10.1038/nature14539. [DOI] [PubMed] [Google Scholar]
- 11.Liu S., Liu S., Cai W., et al. Multimodal neuroimaging feature learning for multiclass diagnosis of Alzheimer’s disease. IEEE Transactions on Biomedical Engineering. 2015;62(4):1132–1140. doi: 10.1109/tbme.2014.2372011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Litjens G., Sánchez C. I., Timofeeva N., et al. Deep learning as a tool for increased accuracy and efficiency of histopathological diagnosis. Scientific Reports. 2016;6(1) doi: 10.1038/srep26286.26286 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Gulshan V., Peng L., Coram M., et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA. 2016;316(22):2402–2410. doi: 10.1001/jama.2016.17216. [DOI] [PubMed] [Google Scholar]
- 14.Pinaya W. H., Gadelha A., Doyle O. M., et al. Using deep belief network modelling to characterize differences in brain morphometry in schizophrenia. Scientific Reports. 2016;6(1) doi: 10.1038/srep38897.38897 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Gargeya R., Leng T. Automated identification of diabetic retinopathy using deep learning. Ophthalmology. 2017;124(7):962–969. doi: 10.1016/j.ophtha.2017.02.008. [DOI] [PubMed] [Google Scholar]
- 16.Ohsugi H., Tabuchi H., Enno H., Ishitobi N. Accuracy of deep learning, a machine-learning technology, using ultra-wide-field fundus ophthalmoscopy for detecting rhegmatogenous retinal detachment. Scientific Reports. 2017;7(1):p. 9425. doi: 10.1038/s41598-017-09891-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Mosteller F., Tukey J. W. Data analysis, including statistics. In: Lindzey G., Aronson E., editors. Handbook of Social Psychology, Research Methods. Vol. 2. Reading, MA, USA: Addison-Wesley; 1968. [Google Scholar]
- 18.Kohavi R. A study of cross-validation and bootstrap for accuracy estimation and model selection. Proceedings of International Joint Conference on Artificial Intelligence (IJCAI); 1995; Stanford, CA, USA. Stanford University; pp. 1137–1145. [Google Scholar]
- 19.Maslove D. M., Podchiyska T., Lowe H. J. Discretization of continuous features in clinical datasets. Journal of the American Medical Informatics Association. 2013;20(3):544–553. doi: 10.1136/amiajnl-2012-000929. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Sturges H. A. The choice of a class interval. Journal of the American Statistical Association. 1926;21(153):65–66. doi: 10.1080/01621459.1926.10502161. [DOI] [Google Scholar]
- 21.Akobeng A. K. Understanding diagnostic tests 3: receiver operating characteristic curves. Acta Paediatrica. 2007;96(5):644–647. doi: 10.1111/j.1651-2227.2006.00178.x. [DOI] [PubMed] [Google Scholar]
- 22.Deng J., Dong W., Socher R., Li L. J., Li K., Fei-Fei L. Imagenet: a large-scale hierarchical image database. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition; 2009; pp. 248–255. [Google Scholar]
- 23.Russakovsky O., Deng J., Su H., et al. Imagenet large scale visual recognition challenge. International Journal of Computer Vision. 2015;115(3):211–252. doi: 10.1007/s11263-015-0816-y. [DOI] [Google Scholar]
- 24.Lee C. Y., Xie S., Gallagher P., Zhang Z., Tu Z. Deeply-supervised nets. Proceedings of 18th International Conference on Artificial Intelligence and Statistics AISTATS; 2015; San Diego, CA, USA. p. p. 5. [Google Scholar]
- 25.Scherer D., Andreas M., Sven B. Evaluation of pooling operations in convolutional architectures for object recognition. Proceedings of 20th International Artificial Neural Networks–ICANN; 2010; Thessaloniki, Greece. pp. 92–101. [Google Scholar]
- 26.Redmon J., Divvala S., Girshick R., Farhadi F. 2015. You only look once: unified, real-time object detection. arXiv preprint arXiv; 1506.02640. [Google Scholar]
- 27.Agrawal P., Girshick R., Malik J. Analyzing the performance of multilayer neural networks for object recognition. Proceedings of European Conference on Computer Vision; 2014; Zurich, Switzerland. pp. 329–344. [DOI] [Google Scholar]
- 28.Qian N. On the momentum term in gradient descent learning algorithms. Neural Networks. 1999;12(1):145–151. doi: 10.1016/s0893-6080(98)00116-6. [DOI] [PubMed] [Google Scholar]
- 29.Nesterov Y. A method for unconstrained convex minimization problem with the rate of convergence O (1/k2) Doklady AN USSR. 1983;269:543–547. [Google Scholar]
- 30.Brereton R. G., Lloyd G. R. Support vector machines for classification and regression. Analyst. 2010;135(2):230–267. doi: 10.1039/b918972f. [DOI] [PubMed] [Google Scholar]
- 31.Schisterman E. F., Faraggi D., Reiser B., Hu J. Youden Index and the optimal threshold for markers with mass at zero. Statistics in Medicine. 2008;27(2):297–315. doi: 10.1002/sim.2993. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Quan C., Hua L., Sun X., Bai W. Multichannel convolutional neural network for biological relation extraction. BioMed Research International. 2016;2016:10. doi: 10.1155/2016/1850404.1850404 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Seong S. B., Pae C., Park H. J. Geometric convolutional neural network for analyzing surface-based neuroimaging data. Frontiers in Neuroinformatics. 2018;12:p. 42. doi: 10.3389/fninf.2018.00042. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Maruyama T., Hayashi N., Sato Y., et al. Comparison of medical image classification accuracy among three machine learning methods. Journal of X-Ray Science and Technology. 2018:1–9. doi: 10.3233/XST-18386. [DOI] [PubMed] [Google Scholar]
- 35.Wang H., Zhou Z., Li Y., et al. Comparison of machine learning methods for classifying mediastinal lymph node metastasis of non-small cell lung cancer from 18F-FDG PET/CT images. EJNMMI Research. 2017;7(1):p. 11. doi: 10.1186/s13550-017-0260-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The Optos image datasets and its corresponding superimposed heat maps analyzed during the current study are available from the corresponding author on reasonable request.