

Abstract
Protein-directed dynamic combinatorial chemistry is an emerging technique for efficient discovery of novel chemical structures for binding to a target protein. Typically, this method relies on a library of small molecules that react reversibly with each other to generate a combinatorial library. The components in the combinatorial library are at equilibrium with each other under thermodynamic control. When a protein is added to the equilibrium mixture, and if the protein interacts with any components of the combinatorial library, the position of the equilibrium will shift and those components that interact with the protein will be amplified, which can then be identified by a suitable biophysical technique. Such information is useful as a starting point to guide further organic synthesis of novel protein ligands and enzyme inhibitors. This review uses literature examples to discuss the practicalities of applying this method to inhibitor discovery, in particular, the set-up of the combinatorial library, the reversible reactions that may be employed, and the choice of detection methods to screen protein ligands from a mixture of reversibly forming molecules.
Keywords: dynamic combinatorial chemistry, enzyme inhibition, ligand screening, drug discovery, ligand binding, reversible reaction, biophysical techniques
1. Introduction
The development of novel chemical agents to inhibit the catalytic activity of disease-causing enzymes is a major theme of medicinal chemistry research and drug discovery programmes. Currently, high-throughput screening (HTS) is one of the most utilised methods—particularly in the pharmaceutical industry—to identify chemical structures that are important for binding and inhibiting target enzymes, and act as a starting point for subsequent organic synthesis and structural-activity relationship studies [1,2,3,4]. Whilst HTS has proven to be an invaluable tool in inhibitor and drug discovery, it can be expensive, time consuming and—depending on the composition of the screening library—the screen may only cover a limited chemical space, thus potentially limiting the number of unique chemical scaffolds that can be identified from HTS [5,6,7,8].
There is a paradigm shift in the drug discovery community to move away from screening large libraries (e.g., hundreds of thousands of compounds) to the use of alternative screening approaches and focus on much smaller chemical libraries (e.g., a few thousand compounds maximum) [9]. The protein-directed dynamic combinatorial chemistry (DCC) method [10,11,12,13,14,15,16,17,18] and the related fragment-based screening method [19,20,21,22,23] are two examples of these alternative screening approaches, which, when compared to HTS, are relatively inexpensive and allow the exploration of large chemical space in a more efficient manner.
The concept of protein-directed DCC was coined in the late 1990s by the supramolecular chemistry community [24], and since then, there have been rapid developments in the field. Protein-directed DCC relies on a library of small molecules that can react reversibly with each other to generate chemical diversity [10,11,12,13,14,15,16,17,18]. Early publications have focussed on proof-of-principle studies, which included investigating the types of reversible chemical reactions that are compatible with protein-directed DCC, and the range of biophysical techniques that are suitable for the detection of protein binders from a dynamic and complex mixture. The technology has matured over the last decade, and there are now numerous examples of successful applications of protein-directed DCC to discover novel enzyme inhibitors that are of medicinal interest, in particular from academic research laboratories. A review article published last year has made an excellent summary of these examples [18].
The aim of this review is to use literature examples to discuss the practical application of protein-directed DCC to discover protein ligands and enzyme inhibitors. It begins with a brief introduction about the concept of protein-directed DCC, which is then followed by a more in-depth discussion about the factors that one should consider when setting up a protein-directed DCC screening project.
2. The Protein-Directed DCC Method
2.1. General Concept
The basic make-up of a protein-compatible combinatorial library typically involves a mixture of small and simple molecules that can react reversibly with each other in aqueous solution and at physiologically-relevant pH. These molecules are often referred to as ‘building blocks’. All of these small molecule building blocks and their reaction products are at equilibrium with each other in the mixture under thermodynamic control, and their relative distribution in the mixture reflects their respective thermodynamic stability within the equilibrium (Figure 1a).
Figure 1.

(a) The principle of protein-directed dynamic combinatorial (DCC). • and ▪ denote functional groups for reversible reactions; (b) If a component of the dynamic combinatorial library (DCL) interacts with the protein (e.g., component B:C), its concentration will increase and the concentration of the other components will decrease. Such changes can be monitored by an appropriate biophysical technique such as high performance liquid chromatography (HPLC; e.g., schematic illustration of HPLC traces is shown above).
Such a combinatorial library can be highly dynamic in nature. For instance, when an ‘external influence’, such as a protein, is added to the combinatorial library, and if the protein interacts with (i.e., binds) some components of the mixture, according to Le Chatelier’s principle, the equilibrium position will shift and those components that interact with the protein will be amplified (Figure 1b). These hits can then be used to guide organic synthesis to obtain ‘stable analogue’ inhibitors for further testing. The equilibrium mixture of the reversibly reacting building blocks is called a ‘dynamic combinatorial library (DCL)’, and the external influence (protein) is often referred to as a ‘template’.
Practically, the design of any protein-directed DCC experiments should include four components: (1) a protein template; (2) a library of building blocks; (3) a reversible reaction; and (4) analytical method(s).
2.2. Composition of a Dynamic Combinatorial Library
Library design is of utmost importance in protein-directed DCC. Unlike HTS, whose libraries contain a large number of structurally diverse compounds, DCLs tend to be more focussed and are usually guided by protein structural information. Typically, the design of a DCL may begin with a so-called ‘scaffold molecule’. A scaffold ligand is a ligand that is designed to bind the target protein, and at the same time contains a functional group for reversible reaction with other components of the DCL. The design of the scaffold molecule may be based on an existing binder, by analyses of the target protein structure, or by molecular modelling. The reversible reaction functional group can be placed in a way that it is pointing out towards a secondary binding pocket where additional interactions are desired.
The reason that protein-directed DCC is rarely applied in a completely random manner is likely due to practicality. As each building block in a DCL should contain at least one functional group for the reversible reaction, it is expensive and impractical to synthesise thousands of custom-made building blocks to generate a truly random DCL. The use of a scaffold ligand ensures that at least one molecule in the DCL will bind the target protein. In order to generate chemical diversity within the DCL, the scaffold ligand is complemented with a library of small molecules, each of them containing a functional group to react reversibly with the scaffold ligand, and different structures to cover different geometrical and functional spaces.
The concept of using a scaffold ligand to explore a secondary binding pocket was demonstrated by Demetriades et al. in 2012 [25]. Prolyl hydroxylase domain 2 (PHD2) is a Fe(II) metalloenzyme that contains two neighbouring binding pockets: one binds the co-substrate 2-oxoglutarate (2OG) via the metal ion Fe(II), and the other binds its protein substrate hypoxia inducible factor (HIF). Many PHD2 inhibitors are designed to compete against 2OG for binding to the ferrous iron in the co-substrate binding site, and it is postulated that selectivity and enhanced inhibition potency may be achieved by extending such inhibitors into the substrate binding pocket. The reversible boronate ester formation reaction, which involves boronic acids and diols, was used to generate the DCL.
The authors first designed a scaffold ligand, which contains a pyridine nitrogen and a carboxylic acid group to chelate the PHD2 active site metal ion, based on existing PHD2 inhibitors that compete against 2OG. The next step involved the introduction of the boronic acid moiety onto the scaffold ligand so that it can form boronate esters with diols in the DCL to explore the PHD2 substrate binding pocket. Two scaffold ligands with the boronic acid moiety substituted at either the 4 or 5 position of the pyridine ring were synthesised. Whilst both scaffold ligands bind to PHD2 on their own, the authors showed that only the scaffold ligand with the boronic acid moiety pointing towards the substrate binding pocket is able to form boronate esters with diols in the presence of PHD2 (Figure 2 and Table 1). Using this scaffold ligand, a series of boronate esters that contain hydrophobic aromatic ring(s) were identified with low μM or nM binding constants (KD) by mass spectrometry and nuclear magnetic resonance (NMR) spectroscopy. Based on these information, several ‘stable analogues’, in which the boronate ester bond of the boronate ester is replaced by a C-C bond, were synthesised (Table 1). Further optimisation based on protein crystallography data led to the discovery of several novel inhibitors with nanomolar KD and inhibition constant (IC50) to the enzyme (Table 1).
Figure 2.

Two scaffold ligands, both contain a boronic acid moiety, were used to explore the geometry between the co-substrate and substrate binding sites of prolyl hydroxylase domain 2 (PHD2). Whilst both boronic acids bind to PHD2 via the active site Fe(II), only the scaffold ligand with the boronic acid moiety at 5-position is able to form boronate esters with diols in the presence of PHD2, as the boronic moiety is pointing towards the substrate binding pocket (modified and reprinted with permission from [25]).
Table 1.
The application of protein-directed dynamic combinatorial chemistry has led to the discovery of novel nanomolar IC50 inhibitors for PHD2 [25]. Asterisk (*) denotes the apparent binding constant of the boronate ester species. Inhibition constant (IC50) was measured for the ‘stable analogues’ only, in which the boronate ester bond of the conjugate is replaced by a C-C bond.
| Compound(s) | KD/μM | IC50/μM |
|---|---|---|
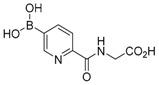
Boronic acid ‘scaffold ligand’ |
24.8 | 126 |
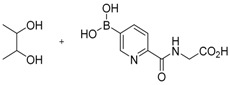
Boronate ester conjugate |
18.2 * | N/A |
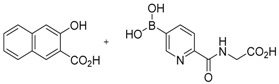
Boronate ester conjugate |
3.0 * | N/A |
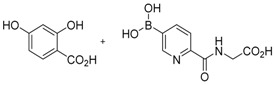
Boronate ester conjugate |
0.8 * | N/A |
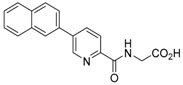
First generation stable analogue |
7.0 | >500 |
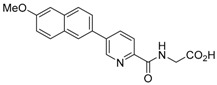
First generation stable analogue |
1.6 | 107 |
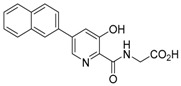
Second generation stable analogue |
0.5 | 0.017 |
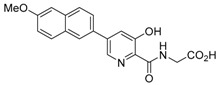
Second generation stable analogue |
0.8 | 0.013 |
Asterisk (*) denotes the apparent binding constant of the boronate ester species.
In addition to PHD2, the use of Fe(II) chelator as a scaffold ligand was also applied to a number of 2OG-dependent oxygenases including Jumonji domain 2 proteins (JMJD2) [26], which are a subfamily of histone demethylases, and AlkB [27], which is a deoxyribonucleic acid (DNA) demethylase. Similar to PHD2, the scaffold ligands were designed based on generic 2OG oxygenase inhibitors that compete against 2OG for chelation to the active site Fe(II). However, by placing the substituent that contains the functional group responsible for reversible DCC reactions at different positions on the scaffold ligand, the authors were able to obtain selectivity and potency amongst these members of the 2OG-dependent oxygenase superfamily, which share similar structural features at the 2OG co-substrate binding site but different substrate binding pocket.
In another example, Mondal et al. applied protein-directed DCC to develop inhibitors for endothiapepsin, which is a pepsin-like aspartic protease [28]. The active site of endothiapepsin contains a catalytic dyad (Asp35 and Asp219). These two amino acids cleave the peptide bond of the enzyme’s peptidyl substrate with the help of a bound water molecule. Endothiapepsin is often used as a model enzyme for mechanistic studies and for the development of other protease inhibitors such as those that target renin and β-secretase. In this example, the reversible acylhydrazone formation reaction, which involves hydrazines and aldehydes, was used.
The authors started by studying the crystal structures of endothiapepsin. They focussed on two different structures from the protein data bank. Both endothiapepsin structures contain a bound small fragment molecule. However, the binding modes of these two fragments are different. One of the fragments is bound to the protein with a crystallographically localised water molecule, whilst the other is bound directly with the catalytic dyad via hydrogen bond.
Using these two protein structures (but without considering the fragments), the authors conducted de novo in silico inhibitor design and modelled the binding of potential acylhydrazone products with and without the localised water molecule inside the binding site. The modelling studies suggest that the S1’ and S2’ pockets, which are carboxy-terminal (C-terminal) to the scissile bond, can accommodate both mono- and bicyclic aromatic moieties. The hydrophobic S2 pocket, which is amino-terminal (N-terminal) to the scissile bond, is best occupied by a mesityl substituent, whilst the S1 and S1’ pockets can host an indolyl, isobutyl, or phenyl moiety (Figure 3a). Based on these models, five hydrazines and five aldehydes (forming 50 different acylhydrazones including E/Z isomers) were screened initially by NMR spectroscopy (which cannot distinguish E/Z isomers). The active hydrazones were then crystallised with endothiapepsin and studied by protein X-ray crystallography. In agreement with the modelling studies, endothiapepsin selectively binds the E isomer from the mixture of E/Z isomers (Figure 3b). Overall, this example highlights the power of combining in silico modelling and protein-directed DCC to generate novel protein ligands or inhibitors.
Figure 3.

(a) In silico modelling of acylhydrazone has led to the identification of potential structural moieties that fit into the endothiapepsin S1, S2, S1’ and S2’ sites; (b) The application of protein-directed DCC using hydrazone formation reaction has led to the discovery of potent endothiapepsin inhibitors. The DCL was designed based on the information obtained from in silico modelling. The two most potent hits from the series in turn confirm the modelling results.
Although the most common way to generate DCL, such as the examples mentioned above, involves the use of mono-functionalised building blocks to generate dimeric molecules [29], it is also possible to use bi-functionalised linker molecules and mono-functionalised head groups for the combinatorial library (Figure 4) [30].
Figure 4.

(a) Mono-functionalised building blocks to generate dimeric molecules [29]; (b) The use of bi-functionalised linker and mono-functionalised head groups to generate trimeric molecules [30].
The use of a bi-functionalised linker molecule was demonstrated by Cancilla et al. in the quest to discover Aurora A kinase inhibitors [31]. Many kinase inhibitors to date are designed to occupy the adenosine triphosphate (ATP) binding pocket. However, such inhibitors often lack selectivity. In the case of Aurora A, it is postulated that selectivity may be achieved by targeting a second adaptive region, which is located a few angstroms away from the ATP binding site. However, targeting the adaptive site poses a different challenge as it requires the binding of ATP (or an ATP mimic) at the ATP binding site to trigger protein conformational change. In order to achieve that, the authors utilised a technique called ‘tethering’ [32], in which the scaffold molecule is covalently linked to the protein, in tandem with protein-directed DCC to probe the adaptive binding site. The reversible disulphide bond formation reaction using thiols were used as the reversible reaction.
Firstly, the authors chose diaminopyrimidine, a known structure that binds kinase ATP binding sites, as the core of the scaffold ligand. The diaminopyrimidine core was then bi-functionalised with two thiol moieties. Next, the authors introduced a cysteine residue (which contains a thiol side-chain) into the Aurora A ATP binding site by mutagenesis. This allows one of the thiol moieties of the diaminopyrimidine scaffold ligand to react with the introduced cysteine residue inside the ATP binding site once the scaffold ligand is bound to the kinase. The tethering of the scaffold ligand to the protein allows access to the adaptive site, and enables the scaffold ligand to act as a dynamic extender to explore the adaptive binding pocket by reacting reversibly with the other thiol-containing building blocks in the DCL (Figure 5). This strategy has successfully led to the discovery of new Aurora A inhibitors that bind the kinase adaptive pocket, which will otherwise be difficult to achieve.
Figure 5.

The combined use of tethering and protein-dynamic combinatorial chemistry to discover Aurora A kinase inhibitors [31]. The authors tethered the scaffold ligand onto Aurora A to access the adaptive binding pocket in order to develop selective kinase inhibitors.
The application of protein-directed DCC is not limited to enzyme inhibitors. It can also be used to design protein binders for biochemical applications. For example, posttranslational modifications of histone proteins such as lysine (de)methylation may affect chromosome structure and function and therefore play an important role in both development and disease. However, the detection of different lysine methylation states in vivo is not a trivial task, and the lack of binders that selectively recognise different lysine methylation states hinders our understanding of the histone code.
To try to solve this problem, Ingerman et al. applied thiol-disulphide exchange reaction to develop compounds that can selectively recognise histones with trimethyllsines [33]. He used eight different dithiol aromatic building blocks to construct a DCL (Figure 6). The use of aromatic compounds is to facilitate cation-π interactions with the trimethylammonium motif on trimethyllysines. These building blocks also contain carboxylic acid group(s) to promote water solubility. In the presence of a dipeptide Ac-KMe3-G-NH2 template, three (out of the eight) building blocks were identified as important for recognising the trimethyllysine moiety (Figure 6). In order to confirm the selectivity of these conjugates, the authors then conducted a second screen with dipeptides of the same amino acid sequence but this time the trimethyllysine residue was substituted by lysines of different methylation states. Finally, the binders were isolated by high performance liquid chromatography (HPLC) and their binding affinity to H3 K9 peptides were measured (Table 2). The authors showed that DCC is a promising technique to the development of protein binders for the detection of posttranslational modification on proteins in vivo.
Figure 6.

The use of dithiol aromatic building blocks to discover compounds that recognise trimethyllysine on histone peptides. rac-A2B, meso-A2B, A2C and AC3 were amplified when screened against a dipeptide containing trimethyllysine [33].
Table 2.
HPLC-purified rac-A2B, meso-A2B showed selectivity for H3 K9 Me3 peptides [33].
| Peptide | rac-A2B (KD/μM) | meso-A2B (KD/μM) |
|---|---|---|
| H3 K9Me3 | 25 ± 3 | 28 ± 4 |
| H3 K9Me2 | 58 ± 10 | 73 ± 9 |
| H3 K9 Me | 166 ± 50 | not determined |
| H3 K9 | >1200 | not determined |
Finally, although most applications of protein-directed DCC to date involve the use of small molecule building blocks, it is possible to use macromolecular (such as peptidyl) building blocks to probe protein-protein interactions. This concept is exemplified by a recent study conducted by Eisenberg et al. [34].
Repeat proteins are found in almost all cellular systems. They function as triggers and binders in diverse molecular recognition processes. For example, in eukaryotes, heat shock protein 70 (HSP70) and heat shock protein 90 (HSP90) require the help of tetratricopeptide repeat (TPR) domain-containing co-chaperones in order to perform many of their biological functions. It is postulated that synthetic repeat proteins may be used as ‘universal protein binders’ in a similar manner to antibodies for biochemical applications. However, total synthesis of large repeat proteins is difficult, and this limits the research and application of repeat proteins in biochemistry.
Although total synthesis of large proteins is not trivial, synthesis of short peptides using solid phase peptide synthesis is now a routine process. Eisenberg et al. hypothesised that it may be possible to generate novel repeat proteins by protein-directed DCC using peptides as building blocks. As a proof-of-principle study, the authors used a 34-amino acid TPR repeating peptide unit as the building block. The reversible thiol-thioester exchange reaction was used. The authors modified the peptide at the N-terminal to a thiol and at the C-terminal to a thioester. A 15-amino acid C-terminal TPR peptide was used as the C-terminal cap, which contains a fluorescein isothiocyanate (FITC)-labelled lysine to aid detection (Figure 7). The mixture was incubated at a 3:1 repeat peptide to cap peptide ratio in buffer at neutral pH, in which the mixture reached equilibrium after 1–2 days. Multiple products, including a cyclic peptide product from the TPR repeat peptide, and combinatorial proteins of up to eight repeating units were observed. When HSP90 and HSP70 peptides were added to the equilibrium mixture, those combinatorial proteins that interact best with the heat shock protein peptides were amplified, which was then quantified by mass spectrometry. This study showed that protein-directed DCC studies are not limited only to small organic molecules, and that it is possible to generate complex dynamic library of proteins, which opens up the opportunity to de novo protein design in the future.
Figure 7.

The use of thiol-thioester exchange reaction to generate dynamic combinatorial library of peptides and proteins [34].
2.3. Reversible Reactions and Reaction Conditions for Protein-Directed DCC
Various dynamic reversible reactions have been proposed and applied in protein-directed DCC, which can be divided into three main types. These include addition-elimination reactions at carbonyl groups (such as imine and hydrazone formation) [24,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49], thiol exchange reactions (such as thiol-disulphide exchange [50,51,52,53,54,55,56,57], thiol-enone reaction [58] and the hemithioacetal reaction) [59,60], and boronate ester formation reaction (Table 3) [25,61,62]. Diselenide exchange and selenenylsulphide exchange reactions have also been shown to react reversibly in water at neutral pH [63,64], although to date there are no examples of inhibitor discovery via protein-directed DCC using these reactions.
Table 3.
Common reversible reactions that are used in protein-directed DCC.
| Reaction | Scheme | Notes |
|---|---|---|
| Imine formation |  |
|
| Hydrazone formation |  |
|
| Thiol-disulphide exchange |  |
|
| Thiol-enone exchange | 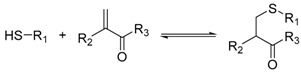 |
|
| Hemithioacetal reaction |  |
|
| Boronate ester formation |  |
|
Organic-based reactions including alkene cross metathesis and oxime formation have also been applied to protein-directed DCC via a so-called pre-equilibrated approach, in which the combinatorial library is initially generated in organic solvent or organic solvent/water mixture, which is then diluted into aqueous buffer that contains the protein target [65,66]. Although the dynamicity of such organic-based libraries is lost once the mixture is diluted in aqueous solution, the pre-equilibrated approach reduces the need for purification and therefore enables the screening of inhibitors to become a much more efficient process.
The selection of an appropriate reversible reaction for protein-directed DCC is not trivial. Ideally the reaction must occur in aqueous solution at a biologically relevant pH and temperature. The reaction must be compatible with proteins (i.e., it does not denature or react with the protein). The equilibrium should be able to establish (and re-establish) within a reasonably short timescale to allow efficient screening.
Imine formation is one of the first reversible reactions demonstrated for protein-directed DCC. The reaction can occur at neutral pH and the equilibrium can establish within 12 and 24 h. Imine formation DCL is well established and most literature examples couple imine DCL with HPLC for detection, in which imines are reduced chemically by the use of sodium cyanoborohydride to form a stable analogue before analyses by HPLC (Figure 8).
Figure 8.

The reduction of imine DCL for HPLC analyses.
Similar to imine formation, thiol-disulphide exchange reaction is also amongst some of the first reversible reactions demonstrated for protein-directed DCC, as they typically occur at neutral pH. However, such libraries often require long incubation time to reach equilibrium, as evident by earlier work conducted by Ramström and Lehn [50] and Milanesi et al. [51], in which their DCLs were left for two weeks and four days for equilibration, respectively. An improvement to the applicability of thiol-disulphide exchange in protein-directed DCC was demonstrated by Scott et al. [53]. In this work, 5′-deoxy-5′-thioadenosine was used as a scaffold ligand together with a small library of thiols to discover Mycobacterium tuberculosis pantothenate synthetase inhibitors using thiol-disulphide exchange. The thiols were present at equimolar concentrations using a glutathione redox buffer at pH 8.5 under inert atmosphere. The glutathione redox buffer promoted disulphide exchange and the DCL reached equilibrium in less than 24 h (both in the presence and absence of the protein). The reaction was then quenched (and if applicable, the protein precipitated) by the addition of strong acids. Finally, the quenched mixture was analysed by HPLC and the amplified binders were identified by HPLC peak height. This protocol by Scott et al. speeded up the equilibration time and enhanced the practicality of using thiol-disulphide exchange to discover protein inhibitors. In additional to using a glutathione redox buffer, selenols and diselenides may also be used to speed up disulphide exchange reactions [67,68]. For example, Rasmussen et al. found that 3,5-dimercaptobenzoic acids, which may react with each other via disulphide formation (to form macrocycles) in water, took seven days to reach equilibrium at pH 7.0. This was reduced to three days by the use of 1 mol % diselenide, and to two days by the use of 10 mol % diselenide [64]. Although the use of diselenides as catalysts has not been applied in protein-directed DCC, the study opened up new potentials to thiol-disulphide DCC in a high-throughput manner.
Another common reversible reaction in protein-directed DCC is the addition-elimination reaction at carbonyl groups such as the hydrazone formation reaction. For example, Ramström et al. applied reversible hydrazone formation to probe the binding site of plant lectin Concanavalin A [45]. Hydrazone exchange reaction typically takes place at acidic pH (pH 3–7), which gets slower as pH increases. The dynamicity of the reaction is essentially stopped at basic pH (above 7.5). In order to generate the combinatorial library, the authors pre-equilibrated the building blocks at pH 4 overnight, which was then diluted to pH 7 for enzymatic assays as a pseudostatic library.
This variability in the dynamicity of hydrazone formation with pH may be advantageous for screening in certain circumstances as the pseudostatic library is less complex than a dynamic library. Sindelar et al. applied hydrazone formation reaction to screen for γ-aminobutyric acid (GABA) transporter 1 (GAT1) inhibitor [46,47]. They have previously designed a liquid chromatography-mass spectrometry (LC-MS)-based competition assay to monitor the percentage displacement of a known binder (reporter) from GAT1 to screen for GAT1 binders. As a dynamic library may complicate LC-MS observations through changes in component concentrations within the equilibrium mixture, the authors used the pseudostatic hydrazone library as an advantage to aid LC-MS detection. Sets of aldehyde compounds with varying structures were reacted with an excess of the hydrazine compound for four hours at 37 °C at neutral or slightly acidic pH. Using this approach, the authors discovered a hydrazone that binds to GAT1 with low nanomolar affinity. Using this information, the authors successfully synthesised a stable analogue inhibitor by replacing the hydrozone moiety with an alkene whilst retaining similar affinity. This example illustrates the importance of choosing the right reversible reaction that is compatible to the detection technique.
In contrast, boronate ester formation reaction, another commonly used reversible reactions, is at its most dynamic when the pH of the solution is similar to the pKa of the boronic acid. In such cases, the equilibrium can re-establish within minutes after it has been perturbed [25,62]. Typically, pKa values of arylboronic acids are around 8. This property makes arylboronic acids suitable for reversible reactions at neutral pH. However, the pKa values for alkylboronic acids are higher (~10–12). Alkylboronic acids are therefore not suitable for reversible reactions at neutral pH. This is illustrated by Leung et al. in a proof-of-principle study using boronate ester formation to enhance the inhibition of serine protease α-chymotrypsin. The authors showed that at pH 5.8, ethylboronic acid does not form boronate ester with d-fructose (a sugar diol) even at 6x molar excess. They also showed that, unlike other arylboronic acids, 4-hydroxylphenylboronic acid, which contains an electron donating hydroxyl group at the 4-position of the aromatic ring, does not form boronate ester with d-fructose at pH 5.8. Measurement of pKa showed that 4-hydroxylphenylboronic acid has a pKa of 8.9, presumably due to the electron donating hydroxyl group and resonance effect onto the boron atom. When using boronate ester formation reaction, it is therefore important to measure the pKa of the boronic acid and choose a pH that is suitable for both the reversible reaction and compatible with the target protein system.
Finally, Kern and Wanner demonstrated the application of the pre-equilibrated oxime formation approach to screen for neuronal GABA transporter GAT1 inhibitors [66]. Oximes were generated by stirring aldehyde and hydroxylamine in a mixture of DMSO and water in phosphate buffer at 37 °C for 20 h, which was then diluted into aqueous buffer for testing (so that the final DMSO concentration did not exceed 10 μM). Oxime is much more stable against hydrolysis than hydrazone so effectively they remain static and stable in aqueous solution. In such cases, a deconvolution approach can be applied to ensure that the strong binders can be identified.
2.4. Protein Template
The role of the protein in protein-directed DCC is to select the best binder from the DCL by changing the equilibrium position of the mixture so that the component(s) that bind best with the protein will increase in concentration. An important criteria to consider is the amount of protein that is required to change the equilibrium of the DCL. For example, Zameo et al. applied imine formation using aldehydes and amines to discover inhibitors for hen egg-white lysozyme (HEWL) [38]. Five hundred micromolar of HEWL (1 equivalent to aldehyde and amine concentrations) was required to stabilise and amplify the best binders, which was then detected by HPLC. In another example, Leung et al. applied boronate ester formation with boronic acids and diols to probe the binding to α-chymotrypsin [62]. Two millimolar of α-chymotrypsin (1 equivalent to the boronic acid concentration) was required as the detection technique (11B-NMR) was relatively insensitive. The concentration of proteins required for protein-directed DCC is therefore significantly higher than those conditions that are commonly used in fragment-based drug discovery (low μM to nM concentrations) and this could be a limiting factor if the target enzyme is difficult or expensive to produce.
It is worth noting that the protein concentration required in pre-equilibrated DCL is often low (μM to nM) [35,37,42,48,58,65]. This is because the combinatorial library is no longer dynamic once it is diluted with proteins. Whilst this may be advantageous if the target protein is a limiting factor, such an approach may bias towards detecting the major components that are formed in the pre-equilibrated library rather than the best binder.
2.5. Analytical Techniques
Although multiple biophysical techniques have been applied to detect the binders from a DCL, it is still a challenge to choose and apply the right analytical technique due to the dynamic nature of protein-directed DCC. Not only does the technique need to be able to detect protein ligands from a mixture of reversibly reacting molecules, it also needs to be sensitive enough to detect changes in equilibrium and concentrations. Three main types of analytical techniques have been used, including HPLC [24,36,37,38,39,40,41,42,46,47,50,51,52,53,58], native non-denaturing mass spectrometry [26,27,48,56,57], and ligand-observe NMR spectroscopy [53,59,60,61,62]. HPLC and mass spectrometry are particularly useful in protein-directed DCC because they allow the screening of the best binders and the quantification of their relative concentrations from the dynamic mixture. Ligand-observed NMR spectroscopy has also been applied, in particular with the pre-equilibrated approach [53,59,60]. However, such an approach is often complicated by ligand exchange dynamics, as observed by Caraballo et al., who applied a reversible hemithioacetal system with thiol and aldehyde to discover β-galactosidase inhibitors [59,60]. The exchange of thiol and aldehyde at neutral pH is fast on the NMR timescale and as a result their resonances are broadened, which makes them difficult to observe. It is also worth noting that nuclear Overhauser effect (NOE)-based ligand-observe NMR techniques such as saturation transfer difference (STD) and water ligand-observed via gradient spectroscopy (waterLOGSY) are often tuned to detect weak binders with KD in the range between μM and mM, so strong binders may not be detected thus leading to false negative results. In addition, false positive results due to non-specific binding are also possible, in particular with a library rich in aromatic and heterocyclic compounds, and in such cases, a complementary assay or technique is needed to confirm the NMR results [59,60]. X-ray crystallography [43] and biological assays have also been applied [35,42,45,60], although the former depends on experimental conditions for crystallisation, and for the latter a deconvoluted approach is required to identify the active compound from the mixture.
Whilst traditional biophysical approaches are well-adapted to screen small to medium size DCL, the identification of the amplified compounds for large DCL remains one of the biggest challenges. In a recent example, Reddavide et al. conducted a proof-of-principle study to combine protein-directed DCC that generates chemical diversity with DNA-encoding technology [69], which allows efficient screening of potentially hundreds of thousands of compounds [70,71]. The authors used streptavidin, which is a homotetrameric bacterial protein that binds iminobiotin, as the model protein system. Due to its homotetrameric structure, streptavidin may bind more than one iminobiotin molecules, thus making it a suitable system to illustrate the DCC principle. The authors used DNA-coupled iminobiotin with streptavidin as binder together with unmodified DNA strands as non-binders. Different numbers of hybridisation base pairs ranging from 4 to 21 were investigated. The authors found that if the number of hybridisation base pairs was too large (e.g., 21), the system formed stable DNA and as a result the system became static and no enhancement could be observed in the presence of the protein. Similarly, no enhancements were observed if the number of hybridisation base pairs was too small (e.g., 4 or 5), presumably because the DNA is unstable as there are not enough hydrogen bond interactions. The authors found that if the monomer has high affinity to the protein, the optimal length of base pairs should be 6 to 8, whilst if the monomer has low affinity to the protein, a longer DNA should be used. Although this technology is still in its infancy, it opens up the possibility to screen large DCLs in the future with further method development.
3. Summary and Outlook
Protein-directed DCC allows one to access molecular diversity for inhibitor discovery and to conduct structural-activity relationship studies without the need of comprehensive organic synthesis of different structural analogues. To date, most applications of protein-directed DCC can be classified as ‘hit-to-lead’-type projects as they always begin with a scaffold ligand which is designed to bind the target protein, and the method is applied to improve the binding affinity, inhibition potency, and/or selectivity of the ligand towards the target protein. However, the potential of protein-directed DCC is not limited to enzyme inhibitors, and there are interesting recent developments of using protein-directed DCC to design structures that recognise protein posttranslational modifications and peptidyl-based protein ligands. The dynamic nature of this method also possess many challenges for its applications, and attention must be paid to select a suitable reversible reaction that is compatible with the target protein whilst balancing the different factors affecting the dynamicity of the system including pH, incubation time, reactivity of the reversible reaction, and the concentrations of the small molecule building blocks and proteins. Several biophysical techniques have been applied to identify protein ligands from a DCL, and HPLC and mass spectrometry have emerged as the method-of-choice for many protein-directed DCC studies. In addition, novel technologies such as those that couple DCC with DNA encoded library are in development, which may allow the screening of much larger DCL in the future.
Over the last 15 years or so the protein-directed DCC technique has gone from the method development stage and the method has now led to the discovery of numerous novel protein ligands and enzyme inhibitors for many different protein systems. Although successful projects so far have been conducted mainly by academic laboratories, we believe the technology is now mature and we envisage the method will carry on to be refined and applied to discover more enzyme inhibitors by both the academia and industrial communities.
Acknowledgments
We gratefully acknowledge the financial support of the Biochemical Society, the Neurological Foundation of New Zealand, and the University of Auckland Faculty Research Development Fund.
Abbreviations
The following abbreviations are used in this manuscript:
| 2OG | 2-Oxoglutarate |
| ATP | Adenosine triphosphate |
| DCC | Dynamic combinatorial chemistry |
| DCL | Dynamic combinatorial library |
| DNA | Deoxyribonucleic acid |
| FITC | Fluorescein isothiocyanate |
| GABA | γ-Animobytyric acid |
| GAT1 | γ-Animobytyric acid transporter 1 |
| HEWL | Hen egg-white lysozyme |
| HIF | Hypoxia inducible factor |
| HPLC | High-performance liquid chromatography |
| HSP | Heat shock protein |
| HTS | High-throughput screening |
| JMJD2 | Jumonji domain 2 |
| LC-MS | Liquid chromatography-mass spectrometry |
| NMR | Nuclear magnetic resonance |
| NOE | Nuclear Overhauser effect |
| PHD2 | Prolyl hydroxylase domain 2 |
| STD | Saturation transfer difference |
| TPR | Tetratricopeptide repeat |
| WaterLOGSY | Water ligand-observed via gradient spectroscopy |
Author Contributions
R.H. and I.K.H.L. conceived and wrote the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- 1.Drews J. Drug discovery: A historical perspective. Science. 2000;287:1960–1964. doi: 10.1126/science.287.5460.1960. [DOI] [PubMed] [Google Scholar]
- 2.Fox S., Farr-Jones S., Sopchak L., Boggs A., Wang Nicely H., Khoury R., Biros M. High-throughput screening: Update on practices and success. J. Biomol. Screen. 2006;11:864–869. doi: 10.1177/1087057106292473. [DOI] [PubMed] [Google Scholar]
- 3.Dove A. Screening for content—The evolution of high throughput. Nat. Biotechnol. 2003;21:859–864. doi: 10.1038/nbt0803-859. [DOI] [PubMed] [Google Scholar]
- 4.Swinney D.C., Anthony J. How were new medicines discovered? Nat. Rev. Drug Discov. 2011;10:507–519. doi: 10.1038/nrd3480. [DOI] [PubMed] [Google Scholar]
- 5.Gribbon P., Andreas S. High-throughput drug discovery: What can we expect from HTS? Drug Discov. Today. 2005;10:17–22. doi: 10.1016/S1359-6446(04)03275-1. [DOI] [PubMed] [Google Scholar]
- 6.Mayr L.M., Fuerst P. The future of high-throughput screening. J. Biomol. Screen. 2008;13:443–448. doi: 10.1177/1087057108319644. [DOI] [PubMed] [Google Scholar]
- 7.Mayr L.M., Bojanic D. Novel trends in high-throughput screening. Curr. Opin. Pharmacol. 2009;9:580–588. doi: 10.1016/j.coph.2009.08.004. [DOI] [PubMed] [Google Scholar]
- 8.Macarron R., Banks M.N., Bojanic D., Burns D.J., Cirovic D.A., Garyantes T., Green D.V.S., Hertzberg R.P., Janzen W.P., Paslay J.W., et al. Impact of high-throughput screening in biomedical research. Nat. Rev. Drug Discov. 2011;10:188–195. doi: 10.1038/nrd3368. [DOI] [PubMed] [Google Scholar]
- 9.Bleicher K.H., Böhm H.-J., Müller K., Alanine A.I. A guide to drug discovery: Hit and lead generation: Beyond high-throughput screening. Nat. Rev. Drug Discov. 2003;2:369–378. doi: 10.1038/nrd1086. [DOI] [PubMed] [Google Scholar]
- 10.Lehn J.-M. Dynamic combinatorial chemistry and virtual combinatorial libraries. Chem. Eur. J. 1999;5:2455–2463. doi: 10.1002/(SICI)1521-3765(19990903)5:9<2455::AID-CHEM2455>3.0.CO;2-H. [DOI] [Google Scholar]
- 11.Klekota B., Miller B.L. Dynamic diversity and small-molecule evolution: A new paradigm for ligand identification. Trends Biotechnol. 1999;17:205–209. doi: 10.1016/S0167-7799(99)01305-0. [DOI] [PubMed] [Google Scholar]
- 12.Karan C., Miller B.L. Dynamic diversity in drug discovery: Putting small-molecule evolution to work. Drug Discov. Today. 2000;5:67–75. doi: 10.1016/S1359-6446(99)01431-2. [DOI] [PubMed] [Google Scholar]
- 13.Lehn J.-M., Eliseev A.V. Dynamic combinatorial chemistry. Science. 2001;291:2331–2332. doi: 10.1126/science.1060066. [DOI] [PubMed] [Google Scholar]
- 14.Ramström O., Lehn J.-M. Drug discovery by dynamic combinatorial libraries. Nat. Rev. Drug Discov. 2002;1:26–36. doi: 10.1038/nrd704. [DOI] [PubMed] [Google Scholar]
- 15.Rowan S.J., Cantrill S.J., Cousins G.R.L., Sanders J.K.M., Stoddart J.F. Dynamic covalent chemistry. Angew. Chem. Int. Ed. 2002;41:898–952. doi: 10.1002/1521-3773(20020315)41:6<898::AID-ANIE898>3.0.CO;2-E. [DOI] [PubMed] [Google Scholar]
- 16.Hochgürtel M., Lehn J.-M. Dynamic combinatorial diversity in drug discovery. In: Jahnke W., Erlanson D.A., editors. Fragment-Based Approaches in Drug Discovery. Wiley-VCH Verlag GmbH & Co. KGaA; Weinheim, German: 2006. pp. 341–364. Chapter 16. [Google Scholar]
- 17.Greaney M.F., Bhat V.T. Protein-directed dynamic combinatorial chemistry. In: Miller B.L., editor. Dynamic Combinatorial Chemistry: In Drug Discovery, Bioinorganic Chemistry, and Materials Sciences. John Wiley & Sons, Inc.; Hoboken, NJ, USA: 2010. pp. 43–82. Chapter 2. [Google Scholar]
- 18.Mondal M., Hirsch A.K.H. Dynamic combinatorial chemistry: A tool to facilitate the identification of inhibitors for protein targets. Chem. Soc. Rev. 2015;44:2455–2488. doi: 10.1039/C4CS00493K. [DOI] [PubMed] [Google Scholar]
- 19.Rees D.C., Congreve M., Murray C.W., Carr R. Fragment-based lead discovery. Nat. Rev. Drug Discov. 2004;3:660–672. doi: 10.1038/nrd1467. [DOI] [PubMed] [Google Scholar]
- 20.Hajduk P.J., Greer J. A decade of fragment-based drug design: Strategic advances and lessons learned. Nat. Rev. Drug Discov. 2007;6:211–219. doi: 10.1038/nrd2220. [DOI] [PubMed] [Google Scholar]
- 21.Congreve M., Chessari G., Tisi D., Woodhead A.J. Recent developments in fragment-based drug discovery. J. Med. Chem. 2008;51:3661–3680. doi: 10.1021/jm8000373. [DOI] [PubMed] [Google Scholar]
- 22.Murray C.W., Rees D.C. The rise of fragment-based drug discovery. Nat. Chem. 2009;1:187–192. doi: 10.1038/nchem.217. [DOI] [PubMed] [Google Scholar]
- 23.Scott D.E., Coyne A.G., Hudson S.A., Abell C. Fragment-based approaches in drug discovery and chemical biology. Biochemistry. 2012;51:4990–5003. doi: 10.1021/bi3005126. [DOI] [PubMed] [Google Scholar]
- 24.Huc I., Lehn J.-M. Virtual combinatorial libraries: Dynamic generation of molecular and supramolecular diversity by self-assembly. Proc. Natl. Acad. Sci. USA. 1997;94:2106–2110. doi: 10.1073/pnas.94.6.2106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Demetriades M., Leung I.K.H., Chowdhury R., Chan M.C., McDonough M.A., Yeoh K.K., Tian Y.-M., Claridge T.D.W., Ratcliffe P.J., Woon E.C.Y., et al. Dynamic combinatorial chemistry employing boronic acids/boronate esters leads to potent oxygenase inhibitors. Angew. Chem. Int. Ed. 2012;51:6672–6675. doi: 10.1002/anie.201202000. [DOI] [PubMed] [Google Scholar]
- 26.Rose N.R., Woon E.C.Y., Kingham G.L., King O.N.F., Mecinović J., Clifton I.J., Ng S.S., Talib-Hardy J., Oppermann U., McDonough M.A., et al. Selective inhibitors of the JMJD2 histone demethylases: Combined nondenaturing mass spectrometric screening and crystallographic approaches. J. Med. Chem. 2010;53:1810–1818. doi: 10.1021/jm901680b. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Woon E.C.Y., Demetriades M., Bagg E.A.L., Aik W., Krylova S.M., Ma J.H.Y., Chan M., Walport L.J., Wegman D.W., Dack K.N., et al. Dynamic combinatorial mass spectrometry leads to inhibitors of a 2-oxoglutarate-dependent nucleic acid demethylase. J. Med. Chem. 2012;55:2173–2184. doi: 10.1021/jm201417e. [DOI] [PubMed] [Google Scholar]
- 28.Mondal M., Radeva N., Köster H., Park A., Potamitis C., Zervou M., Klebe G., Hirsch A.K.H. Structure-based design of inhibitors of the aspartic protease endothiapepsin by exploiting dynamic combinatorial chemistry. Angew. Chem. Int. Ed. 2014;53:3259–3263. doi: 10.1002/anie.201309682. [DOI] [PubMed] [Google Scholar]
- 29.Lehn J.-M., Ramström O. Generation and Screening of a Dynamic Combinatorial Library. WO 20,010,164,605. 2001 Sep 7;
- 30.Steeneck C., Eliseev A.V., Hochguertel M., Kroth H. A Method of Forming a Dynamic Combinatorial Library Using a Scaffold. WO 2,003,034,071. 2003 Apr 24;
- 31.Cancilla M.T., He M.M., Viswanathan N., Simmons R.L., Taylor M., Fung A.D., Cao K., Erlanson D.A. Discovery of an Aurora kinase inhibitor through site-specific dynamic combinatorial chemistry. Bioorg. Med. Chem. Lett. 2008;18:3978–3981. doi: 10.1016/j.bmcl.2008.06.011. [DOI] [PubMed] [Google Scholar]
- 32.Erlanson D.A., Wells J.A., Braisted A.C. Tethering: Fragment-based drug discovery. Annu. Rev. Biophys. Biomol. Struct. 2004;33:199–223. doi: 10.1146/annurev.biophys.33.110502.140409. [DOI] [PubMed] [Google Scholar]
- 33.Ingerman L.A., Cuellar M.E., Waters M.L. A small molecule receptor that selectively recognizes trimethyl lysine in a histone peptide with native protein-like affinity. Chem. Commun. 2010;46:1839–1841. doi: 10.1039/c000255k. [DOI] [PubMed] [Google Scholar]
- 34.Eisenberg M., Shumacher I., Cohen-Luria R., Ashkenasy G. Dynamic combinatorial libraries of artificial repeat proteins. Bioorg. Med. Chem. 2013;21:3450–3457. doi: 10.1016/j.bmc.2013.03.007. [DOI] [PubMed] [Google Scholar]
- 35.Bunyapaiboonsri T., Ramström O., Lohmann S., Lehn J.-M., Peng L., Goeldner M. Dynamic deconvolution of a pre-equilibrated dynamic combinatorial library of acetylcholinesterase inhibitors. ChemBioChem. 2001;2:438–444. doi: 10.1002/1439-7633(20010601)2:6<438::AID-CBIC438>3.0.CO;2-J. [DOI] [PubMed] [Google Scholar]
- 36.Hochgürtel M., Kroth H., Piecha D., Hofmann M.W., Nicolau C., Krause S., Schaaf O., Sonnenmoser G., Eliseev A.V. Target-induced formation of neuraminidase inhibitors from in vitro virtual combinatorial libraries. Proc. Natl. Acad. Sci. USA. 2002;99:3382–3387. doi: 10.1073/pnas.052703799. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Hochgürtel M., Niesinger R., Kroth H., Piecha D., Hofmann M.W., Krause S., Schaaf O., Nicolau C., Eliseev A.V. Ketones as building blocks for dynamic combinatorial libraries: Highly active neuraminidase inhibitors generated via selective pressure of the biological target. J. Med. Chem. 2003;46:356–358. doi: 10.1021/jm025589m. [DOI] [PubMed] [Google Scholar]
- 38.Zameo S., Vauzeilles B., Beau J.-M. Dynamic combinatorial chemistry: Lysozyme selects an aromatic motif that mimics a carbohydrate residue. Angew. Chem. Int. Ed. 2005;44:965–969. doi: 10.1002/anie.200462150. [DOI] [PubMed] [Google Scholar]
- 39.Zameo S., Vauzeilles B., Beau J.-M. Direct composition analysis of a dynamic library of imines in an aqueous medium. Eur. J. Org. Chem. 2006;2006:5441–5444. doi: 10.1002/ejoc.200600859. [DOI] [Google Scholar]
- 40.Valade A., Urban D., Beau J.-M. Target-assisted selection of galatosyltransferase binders from dynamic combinatorial libraries. An unexpected solution with restricted amounts of the enzyme. ChemBioChem. 2006;7:1023–1027. doi: 10.1002/cbic.200600022. [DOI] [PubMed] [Google Scholar]
- 41.Bugaut A., Toulmé J.-J., Rayner B. SELEX and dynamic combinatorial chemistry interplay for the selection of conjugated RNA aptamers. Org. Biomol. Chem. 2006;4:4082–4088. doi: 10.1039/b610890c. [DOI] [PubMed] [Google Scholar]
- 42.Bunyapaiboonsri T., Ramström H., Ramström O., Haiech J., Lehn J.-M. Generation of bis-cationic heterocyclic inhibitors of Bacillus subtilis HPr kinase/phosphatase from a ditopic dynamic combinatorial library. J. Med. Chem. 2003;46:5803–5811. doi: 10.1021/jm030917j. [DOI] [PubMed] [Google Scholar]
- 43.Valade A., Urban D., Beau J.-M. Two galatosyltransferases’ selection of different binders from the same uridine-based dynamic combinatorial library. J. Comb. Chem. 2007;9:1–4. doi: 10.1021/cc060033w. [DOI] [PubMed] [Google Scholar]
- 44.Congreve M.S., Davis D.J., Devine L., Granata C., O’Reilly M., Wyatt P.G., Jhoti H. Detection of ligands from a dynamic combinatorial library by X-ray crystallography. Angew. Chem. Int. Ed. 2003;42:4479–4482. doi: 10.1002/anie.200351951. [DOI] [PubMed] [Google Scholar]
- 45.Ramström O., Lohmann S., Bunyapaiboonsri T., Lehn J.-M. Dynamic combinatorial carbohydrate libraries: Probing the binding site of the concanavalin A lectin. Chem. Eur. J. 2004;10:1711–1715. doi: 10.1002/chem.200305551. [DOI] [PubMed] [Google Scholar]
- 46.Sindelar M., Wanner K.T. Library screening by means of mass spectrometry (MS) binding assays-exemplarily demonstrated for a pseudostatic library addressing γ-aminobutyric acid (GABA) transporter 1 (GAT1) ChemMedChem. 2012;7:1678–1690. doi: 10.1002/cmdc.201200201. [DOI] [PubMed] [Google Scholar]
- 47.Sindelar M., Lutz T.A., Petrera M., Wanner K.T. Focused pseudostatic hydrazone libraries screened by mass spectrometry binding assay: Optimizing affinities toward γ-aminobutyric acid transporter 1. J. Med. Chem. 2013;56:1323–1340. doi: 10.1021/jm301800j. [DOI] [PubMed] [Google Scholar]
- 48.Poulsen S.-A. Direct screening of a dynamic combinatorial library using mass spectrometry. J. Am. Soc. Mass Spectrom. 2006;17:1074–1080. doi: 10.1016/j.jasms.2006.03.017. [DOI] [PubMed] [Google Scholar]
- 49.Herrmann A. Dynamic mixtures and combinatorial libraries: Imines as probes for molecular evolution at the interface between chemistry and biology. Org. Biomol. Chem. 2009;7:3195–3204. doi: 10.1039/b908098h. [DOI] [PubMed] [Google Scholar]
- 50.Ramström O., Lehn J.-M. In situ generation and screening of a dynamic combinatorial carbohydrate library against concanavalin A. ChemBioChem. 2000;1:41–48. doi: 10.1002/1439-7633(20000703)1:1<41::AID-CBIC41>3.0.CO;2-L. [DOI] [PubMed] [Google Scholar]
- 51.Milanesi L., Hunter C.A., Sedelnikova S.E., Waltho J.P. Amplification of bifunctional ligands for calmodulin from a dynamic combinatorial library. Chem. Eur. J. 2006;12:1081–1087. doi: 10.1002/chem.200500357. [DOI] [PubMed] [Google Scholar]
- 52.Danieli B., Giardini A., Lesma G., Passarella D., Peretto B., Sacchetti A., Silvani A., Pratesi G., Zunino F. Thiocolchicine-podophyllotoxin conjugates: Dynamic libraries based on disulfide exchange reaction. J. Org. Chem. 2006;71:2848–2853. doi: 10.1021/jo052677g. [DOI] [PubMed] [Google Scholar]
- 53.Scott D.E., Dawes G.J., Ando M., Abell C., Ciulli A. A fragment-based approach to probing adenosine recognition sites by using dynamic combinatorial chemistry. ChemBioChem. 2009;10:2772–2779. doi: 10.1002/cbic.200900537. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Pei Z., Larsson R., Aastrup T., Anderson H., Lehn J.-M., Ramström O. Quartz crystal microbalance bioaffinity sensor for rapid identification of glycosyldisulfide lectin inhibitors from a dynamic combinatorial library. Biosens. Bioelectron. 2006;22:42–48. doi: 10.1016/j.bios.2005.11.024. [DOI] [PubMed] [Google Scholar]
- 55.André S., Pei Z., Siebert H.-C., Ramström O., Gabius H.-J. Glycosyldisulfides from dynamic combinatorial libraries as O-glycoside mimetics for plant and endogenous lectins: Their reactivities in solid-phase and cell assays and conformational analysis by molecular dynamics simulations. Bioorg. Med. Chem. 2006;14:6314–6326. doi: 10.1016/j.bmc.2006.05.045. [DOI] [PubMed] [Google Scholar]
- 56.Liénard B.M.R., Selevsek N., Oldham N.J., Schofield C.J. Combined mass spectrometry and dynamic chemistry approach to identify metalloenzyme inhibitors. ChemMedChem. 2007;2:175–179. doi: 10.1002/cmdc.200600250. [DOI] [PubMed] [Google Scholar]
- 57.Liénard B.M.R., Hüting R., Lassaux P., Galleni M., Frére J.-M., Schofield C.J. Dynamic combinatorial mass spectrometry leads to metallo-β-lactamase inhibitors. J. Med. Chem. 2008;51:684–688. doi: 10.1021/jm070866g. [DOI] [PubMed] [Google Scholar]
- 58.Shi B., Stevenson R., Campopiano D.J., Greaney M.F. Discovery of glutathione S-transferase inhibitors using dynamic combinatorial chemistry. J. Am. Chem. Soc. 2006;128:8459–8467. doi: 10.1021/ja058049y. [DOI] [PubMed] [Google Scholar]
- 59.Caraballo R., Dong H., Ribeiro J.P., Jiménez-Barbero J., Ramström O. Direct STD NMR identification of β-galactosidase inhibitors from a virtual dynamic hemithioacetal system. Angew. Chem. Int. Ed. 2010;49:589–539. doi: 10.1002/anie.200903920. [DOI] [PubMed] [Google Scholar]
- 60.Caraballo R., Sakulsombat M., Ramström O. Towards dynamic drug design: Identification and optimisation of β-galactosidase inhibitors from a dynamic hemithioacetal system. ChemBioChem. 2010;11:1600–1606. doi: 10.1002/cbic.201000158. [DOI] [PubMed] [Google Scholar]
- 61.Leung I.K.H., Demetriades M., Hardy A.P., Lejeune C., Smart T.J., Szöllössi A., Kawamura A., Schofield C.J., Claridge T.D.W. Reporter ligand NMR screening method for 2-oxoglutarate oxygenase inhibitors. J. Med. Chem. 2013;56:547–555. doi: 10.1021/jm301583m. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Leung I.K.H., Brown T., Jr., Schofield C.J., Claridge T.D.W. An approach to enzyme inhibition employing reversible boronate ester formation. Med. Chem. Commun. 2011;2:390–395. doi: 10.1039/c1md00011j. [DOI] [Google Scholar]
- 63.Ji S., Cao W., Yu Y., Xu H. Dynamic diselenide bonds: Exchange reaction induced by visible light without catalysis. Angew. Chem. Int. Ed. 2014;53:6781–6785. doi: 10.1002/anie.201403442. [DOI] [PubMed] [Google Scholar]
- 64.Rasmussen B., Sørensen A., Gotfredsen H., Pittelkow M. Dynamic combinatorial chemistry with diselenides and disulfides in water. Chem. Commun. 2014;50:3716–3718. doi: 10.1039/c4cc00523f. [DOI] [PubMed] [Google Scholar]
- 65.Poulsen S.-A., Bornaghi L.F. Fragment-based drug discovery of carbonic anhydrase II inhibitors by dynamic combinatorial chemistry utilizing alkene cross metathesis. Bioorg. Med. Chem. 2006;14:3275–3284. doi: 10.1016/j.bmc.2005.12.054. [DOI] [PubMed] [Google Scholar]
- 66.Kern F.T., Wanner K.T. Generation and screening of oxime libraries addressing the neuronal GABA transporter GAT1. ChemMedChem. 2015;10:396–410. doi: 10.1002/cmdc.201402376. [DOI] [PubMed] [Google Scholar]
- 67.Singh R., Whitesides G.M. Selenols catalyze the interchange reactions of dithiols and disulfides in water. J. Org. Chem. 1991;56:6931–6933. doi: 10.1021/jo00024a041. [DOI] [Google Scholar]
- 68.Caldwell K.A., Tappel A.L. Acceleration of sulfhydryl oxidations by selenocystine. Arch. Biochem. Biophys. 1965;112:196–200. doi: 10.1016/0003-9861(65)90029-9. [DOI] [PubMed] [Google Scholar]
- 69.Reddavide F.V., Lin W., Lehnert S., Zhang Y. DNA-encoded dynamic combinatorial chemical libraries. Angew. Chem. Int. Ed. 2015;54:7924–7928. doi: 10.1002/anie.201501775. [DOI] [PubMed] [Google Scholar]
- 70.Melkko S., Scheuermann J., Dumelin C.E., Neri D. Encoded self-assembling chemical libraries. Nat. Biotechnol. 2004;22:568–574. doi: 10.1038/nbt961. [DOI] [PubMed] [Google Scholar]
- 71.Clark M.A., Acharya R.A., Arico-Muendel C.C., Belyanskaya S.L., Benjamin D.R., Carlson N.R., Centrella P.A., Chiu C.H., Creaser S.P., Cuozzo J.W., et al. Design, synthesis and selection of DNA-encoded small-molecule libraries. Nat. Chem. Biol. 2009;5:647–654. doi: 10.1038/nchembio.211. [DOI] [PubMed] [Google Scholar]