

Abstract
This paper presents a comprehensive theory for the demographic analysis of populations in which individuals are classified by both age and stage. The earliest demographic models were age classified. Ecologists adopted methods developed by human demographers and used life tables to quantify survivorship and fertility of cohorts and the growth rates and structures of populations. Later, motivated by studies of plants and insects, matrix population models structured by size or stage were developed. The theory of these models has been extended to cover all the aspects of age‐classified demography and more. It is a natural development to consider populations classified by both age and stage. A steady trickle of results has appeared since the 1960s, analyzing one or another aspect of age × stage‐classified populations, in both ecology and human demography. Here, we use the vec‐permutation formulation of multistate matrix population models to incorporate age‐ and stage‐specific vital rates into demographic analysis. We present cohort results for the life table functions (survivorship, mortality, and fertility), the dynamics of intra‐cohort selection, the statistics of longevity, the joint distribution of age and stage at death, and the statistics of life disparity. Combining transitions and fertility yields a complete set of population dynamic results, including population growth rates and structures, net reproductive rate, the statistics of lifetime reproduction, and measures of generation time. We present a complete analysis of a hypothetical model species, inspired by poecilogonous marine invertebrates that produce two kinds of larval offspring. Given the joint effects of age and stage, many familiar demographic results become multidimensional, so calculations of marginal and mixture distributions are an important tool. From an age‐classified point of view, stage structure is a form of unobserved heterogeneity. From a stage‐classified point of view, age structure is unobserved heterogeneity. In an age × stage‐classified model, variance in demographic outcomes can be partitioned into contributions from both sources. Because these models are formulated as matrices, they are amenable to a complete sensitivity analysis. As more detailed and longer longitudinal studies are developed, age × stage‐classified demography will become more common and more important.
Keywords: age‐stage classification, elasticity, generation time, heterogeneity, Markov chain models, matrix population models, mortality, net reproductive rate, sensitivity, survivorship, vec‐permutation matrix
Introduction
As demographic data become more detailed, they reveal more, and more diverse, differences among individuals. These types of heterogeneity led to the development of increasingly complicated demographic models. Demographic analysis in ecology can be divided into three periods. The first, building on the work of Lotka and many others, used age‐classified models and life table functions to compute survival, fertility, life expectancy, intrinsic rates of increase, stable age distributions, and reproductive values. It became a fully developed population theory by the mid‐20th century (e.g., Lotka 1939, Keyfitz 1968, Coale 1972). It was quickly adopted by population biologists and ecologists, from the mortality studies of Pearl and Miner (1935) and the comparative life table studies of Deevey (1947) to the use of the Euler‐Lotka equation to calculate population growth rates (e.g., Birch 1948, Leslie and Park 1949). Fisher (1930), Norton (1928), and Charlesworth (1994), among others, applied age‐classified theory to evolutionary questions, and it became the basis of evolutionary demography and life history theory (e.g., Cole 1954, Lewontin 1965, Hamilton 1966, Stearns 1992).
The second period saw the widespread adoption of stage‐classified methods based largely on matrix population models classified by stage (Lefkovitch 1965, Werner and Caswell 1977) where stage might refer to size, instar, developmental stage, physiological condition, behavioral status, etc. Plant ecologists were at the forefront of this development because the modular construction and plastic growth of plants tend to make age less suitable as a state variable in many cases. Today, age‐classified models are still more common among animal models and stage‐classified models more common among plant models (Salguero‐Gómez et al. 2015, 2016).
Stage‐classified matrix models made it possible to compute population growth rates and structures, sensitivity, and elasticity analyses, and their extensions to periodic and stochastic environments, as well as to develop sophisticated treatments of nonlinear dynamics. This led eventually to a fully developed theory of stage‐classified demography in a variety of mathematical frameworks (Nisbet and Gurney 1982, Metz and Diekmann 1986, Tuljapurkar 1990, Tuljapurkar and Caswell 1997, Easterling et al. 2000, Caswell 2001, Ellner et al. 2016).
Now, increasingly extensive and detailed individual data are being collected and it is becoming apparent that combining age‐ and stage‐classification is sometimes useful. This is accompanied, in both ecology and human demography, by an interest in incorporating more biological or social detail into the analyses.
Our goal here is to present a comprehensive methodological treatment of age × stage‐classified matrix population models. The methods will be presented in a way that can be applied to any species, with any life cycle, described by any pattern of transitions among any set of stages, with any type of reproduction of any kind(s) of offspring. We will provide a hypothetical example to suggest how a particular species might be analyzed.
Explicit and implicit age dependence
As a first step, we recognize that age dependence may be either implicit or explicit. Any stage‐classified model produces implicit age‐classified results because, even though age has no effect on the vital rates, an individual still becomes one unit older with the passage of one unit of time. Age‐specific results (e.g., life expectancy) computed from such a model are implicit in the stage structure of the life cycle. Methods based on absorbing Markov chains are widely used to extract implicit age dependence from stage‐classified models (e.g., Feichtinger 1971, Cochran and Ellner 1992, Caswell 2001, 2006, 2009, Steinsaltz and Evans 2004, Tuljapurkar and Horvitz 2006, Horvitz and Tuljapurkar 2008). These are not, however, age × stage‐classified models and the results do not reveal anything about the interaction of age‐specific and stage‐specific rates.
This paper addresses explicit age dependence, in which individuals are classified by their age and stage, and the vital rates depend on both variables. The literature on explicit age × stage demography is scattered, with fragmentary results appearing in the ecological and demographic literatures. Goodman (1969) first introduced the matrix formulation of age‐stage models. Even before that, a continuous‐time age × size model written as a partial differential equation was presented by Sinko and Streifer (1967). Csetenyi and Logofet (1989) and Logofet (2002, 2013) explored the graph‐theoretic implications of the block structure appearing in age × stage models, in relation to the irreducibility and primitivity of the resulting model. Recent papers (Caswell 2012, Caswell and Shyu 2012) have developed matrix models and their sensitivity analysis, for both cohort properties and population growth rate, for age × stage‐classified models. These were used in an evolutionary analysis of the selection gradients on senescence, as a function of age and of stage, by Caswell and Salguero‐Gómez (2013). Steiner et al. (2012) explored some aspects of longevity and later (Steiner et al. 2014) developed a powerful age × stage‐classified analysis of the relation between generation time and population growth rate, with applications to life history theory (generation time will be considered here in the section entitled Population dynamics: generation time ).
Multiregional models are an important special case of age × stage‐classified models. They classify individuals by age and spatial location, and were one of the earliest applications of matrix population models (Rogers 1968) and have been extensively developed in human demography (e.g., Rogers 1975) and ecology (Lebreton 1996, 2005, Lebreton et al. 2000). There is a rich literature in health demography of multistate models (e.g., Willekens 2014) in which individuals are classified by age and health status (see, e.g., Wu et al. 2006 for colorectal cancer, Zhou et al. (2016) for dementia, or Honeycutt et al. (2003) for diabetes). These models focus on longevity and occupancy times in various age‐stage combinations, and include only the survival and transition portion of the life cycle. Some epidemiological models have combined age and infection status in nonlinear matrix models that include the infection process (e.g., Klepac and Caswell 2011, Metcalf et al. 2012).
Perhaps the human demographic usage closest in conceptual structure to ecological practice are multistate population projections, which are used to forecast the short‐term, transient dynamics of populations under scenarios of changing mortality, fertility, and migration rates. The basic age‐specific projections are sometimes augmented by a stage classification to examine the joint age × stage dynamics. The flavor of these efforts is shown by studies on, e.g., the interaction of age with citizenship status (Sánchez Gassen 2014), disability (Van der Gaag et al. 2015), or education level (Loichinger 2015).
Ecological examples of explicit age × stage models are not common. Law (1983) considered the theoretical problem of age × stage models but presented only a hypothetical example. De Roos (2008) analyzes a continuous‐time model in which age and stage can be combined. More empirical studies can be found in, e.g., van Groenendael and Slim (1988) and Zuidema et al. (2009).
Heterogeneity
The more closely one looks at individual organisms, the more ways in which they appear to differ. The problem of heterogeneity is to figure out how those differences affect population dynamics. This is the essence of demography: accounting for differences due to age, development, sex, physiological condition, breeding status, etc. The analyses to be presented here are a way to incorporate diverse types of heterogeneity into demographic analysis.
Outline
The rest of the paper is organized as follows:
A systematic method for the construction of age × stage‐classified models.
The life table functions that define survivorship, mortality, and the age and stage at death of individuals, and quantify intra‐cohort selection.
The fertility functions that describe reproduction of individuals across the life cycle.
The statistics of longevity for cohorts, including life expectancy and also measures of variability, state occupancy times, and life disparity.
Characteristics of population dynamics, including the population growth rate, stable structure, reproductive value, net reproductive rate, and measures of generation time.
Sensitivity and elasticity analysis, showing a completely general formula for the effects of changes in any parameter[s] affecting any of the age‐specific or stage‐specific rates on any quantity calculated from the model.
Table 1 is a list of all the demographic results that will be presented, keyed to the equations in which they are derived.
Table 1.
Age × stage‐classified demographic analysis
| Notation | Equation | ||
|---|---|---|---|
| Model construction | |||
| Population vector |
|
(3) | |
| Forbidden age‐stage combinations | U i, F i | (8), (9) | |
| Block‐diagonal matrices | , , , | (10) | |
| Age × stage‐classified projection matrices | , , | (11), (12), (13) | |
| Life table functions | |||
| Survivorship vector[s] | ℓ(x), L | (17), (46) | |
| Survivorship of mixed cohort | ℓ(x | π) | (19) | |
| Mortality rate vector | μ(x) | (22) | |
| Mortality rate of mixed cohort | μ(x | π) | (23) | |
| Intra‐cohort selection | |||
| Joint age × stage |
|
(25) | |
| Marginal stage |
|
(26) | |
| Marginal age |
|
(27) | |
| Fertility | |||
| Fertility matrix | F x | ||
| Weighted fertility vector | f weighted(x) | (29) | |
| Mixed fertility vector | f mixed(x) | (30) | |
| Weighted and mixed fertility vector | f(x) | (32) | |
| Longevity statistics | |||
| Fundamental matrix |
|
(34) | |
| Moments and variance of longevity | , | (35), (36), (37) | |
| Decomposition of variance in longevity | V within, V between | (43), (45) | |
| Distribution of age and stage at death | |||
| Joint age × stage distribution |
|
(50) | |
| Marginal age distribution | B age | (51) | |
| Marginal stage distribution | B stage | (52) | |
| Life disparity, years of life lost |
|
(57) | |
| Population dynamics | |||
| Population projection |
|
(60) | |
| Stable population structure | |||
| Marginal age structure |
|
(61) | |
| Marginal stage structure |
|
(62) | |
| Reproductive value | v | (63) | |
| Net reproductive rate | R 0 | (67) | |
| Mean lifetime reproduction | |||
| Next generation matrix | R 11 | (73) | |
| Weighted lifetime reproduction | r weighted | (75) | |
| Mixed lifetime reproduction | r mixed | (76) | |
| Total lifetime reproduction | ρ | (77) | |
| Cohort generation time | Γ | (88) | |
| Sensitivity analysis | |||
| Sensitivity of output ξ to parameters θ | d ξ/d θ ⊤ | (89) | |
Results are shown for model construction, life table functions, longevity statistics, and population dynamics, with equation numbers in which the results are presented.
Notation
Matrices are denoted by uppercase boldface letters (e.g., U), and vectors by lowercase boldface letters (e.g., n). Block‐diagonal matrices are denoted by blackboard font (e.g., ). Matrices and vectors associated with the full age × stage model are denoted, e.g., , ; these matrices are block structured and contain entries for all combinations of age classes and stages. The number of age classes is ω and the number of stages is s. The notation for matrices used in model construction is tabulated for easy reference in Table 2.
Table 2.
Matrices used in constructing the age × stage‐classified projection matrix, where ω denotes the number of age classes and s the number of stages
| Symbol | Expression | Size | Description | |||
|---|---|---|---|---|---|---|
| Matrix describing the full population | ||||||
|
|
|
|
Age × stage population projection matrix | |||
| Matrices describing transitions and survival of existing individuals | ||||||
|
|
|
|
Age × stage transition and survival matrix | |||
|
|
|
|
Block diagonal age × stage transition matrix | |||
|
|
|
|
Block diagonal age transition matrix | |||
| U j | U j |
|
Stage transition matrix for age class j | |||
| D i | D i |
|
Age transition matrix for stage i | |||
| Matrices describing reproduction | ||||||
|
|
|
|
Age × stage fertility matrix | |||
|
|
|
|
Block diagonal fertility matrix | |||
|
|
|
|
Block diagonal age assignment matrix | |||
| F j | F j |
|
Fertility matrix for age class j | |||
| H i | H i |
|
Age assignment matrix for offspring of stage i |
The index i denotes stages, ; the index j denotes age classes, .
The unit vector e i is a vector with a 1 in the ith entry and zeros elsewhere. The unit matrix E ij is a matrix with a 1 in the (i,j) entry and zeros elsewhere; the dimensions will be indicated if not clear from the context. The dimensions of certain matrices and vectors are denoted by subscripts; I s is an identity matrix of order s and 1 s is a s × 1 vector of ones. When convenient, MATLAB (MathWorks, Natick, MA, USA) notation will be used to refer to rows and columns of matrices; thus X(i,:) is the ith row and X(:,j) the jth column of X. The diagonal matrix with x on the diagonal and zeros elsewhere is denoted . The symbol ° denotes the Hadamard, or element‐by‐element product; the symbol ⊗ denotes the Kronecker product. The vec operator transforms a matrix to a vector by stacking the columns on top of each other. The symbol ‖x‖ denotes the 1‐norm of the vector x. The transpose of the matrix X is X ⊤. The matrix K is the vec‐permutation matrix (Henderson and Searle 1981); see Box 2. The mean and variance are denoted by E(·) and V(·) respectively.
Box 1. Creating marginals and mixtures.
The Kronecker product expressions for computing marginals (e.g., Eqs. (27) and (28)) and mixtures [e.g., equation (19)] may appear confusing at first sight. There is a simple trick to deriving them, which we will reveal here. It relies on the properties of the vec operator and on Roth's theorem that, for any matrices X, Y and Z,
(Roth 1934). In this paper, we have agreed to organize by grouping stages within age classes; that is, by applying the vec operator to the array in Eq. (1), in which stages appear as rows and ages as columns
Matrices (e.g., , ) and vectors (e.g., , ) inherit the same block structure.
Any linear combination of rows of (i.e., combinations of stages) can be written as a matrix R, and any linear combination columns of (i.e., of ages) can be written as a matrix C, and applied to as
Applying the vec operator to this gives
Thus (C ⊤ ⊗ R) operating on the rows of any age × stage block‐structured matrix or vector captures the operations implied by R and C operating on ,
e.g., adding all stages to get a marginal age structure
e.g., adding all ages to get a marginal stage distribution
e.g., a mixture, defined by a vector π s, all of age class 1
These matrices operate on arrays with the structure of ; i.e., on the rows of an object in which columns have stages arranged within ages. To operate on columns, for example on the columns of the fundamental matrix , the arrays must be transposed (the transpose of a Kronecker product is the product of the transposes). Thus the mixture in Eq. A.7 applied to the columns of would be
Constructing Age × Stage Models
The population vector
Each individual is jointly classified by its age and its stage; the population composition at any time can be written as
| (1) |
where rows correspond to stages (1, …, s) and columns to age classes (1, …, ω). The population vector is obtained from as
| (2) |
| (3) |
In , stages are grouped within age classes. The vector can be transformed so that age classes are grouped within stages,
| (4) |
where K s,ω is the vec permutation matrix (Magnus and Neudecker 1979, Henderson and Searle 1981). This transformation is essential to the analysis of the model, as will be seen below. An explicit formula for K s,ω is given in Box 2. All results can be obtained using this arrangement, by properly reformulating the relevant matrices.
Age‐ and stage‐specific demography
The influence of age and stage on the vital rates is captured in four sets of matrices:
Matrices U j, for (dimension s × s). These matrices contain stage transitions, including mortality, of living individuals in each age class. Because the entries of the U j refer to stages, and each matrix corresponds to an age class, the set includes arbitrarily complicated interactions of age and stage in determining mortality and transitions.
Matrices F j, for (dimension s × s). These matrices contain fertilities, describing the stage‐specific per capita production of new individuals by reproduction, for individuals in each age class. Because the entries of the F j refer to stages, and each matrix corresponds to an age class, the set includes arbitrarily complicated interactions of age and stage in determining fertility.
Matrices D i, for (dimension ω × ω). These matrices contain age transitions for individuals in each stage.
Matrices H i, for (dimension ω × ω). These matrices assign newly produced offspring, of parents in stage i, to an initial age class (usually the first).
The matrices U j and F j correspond to the familiar decomposition of a projection matrix A into components due to transitions and survival of extant individuals (U) and due to fertility (F)
| (5) |
Now, however, the matrices are defined for each of the ω age classes. This flexible formulation permits age to influence any of the stage‐specific vital rates, in any way, described in either parametric or nonparametric terms. Similarly, it permits stages to influence age‐specific rates in any way.
The matrix F j describes reproduction by all stages in age class j. An age × stage model must account for the possibility that multiple types of offspring may be produced (e.g. a plant may produce seedlings of different sizes). In the special case where all offspring are of the same stage, F j will have positive entries in only one row, usually chosen to be the first.
The matrices U j and F j move individuals among stages, account for survival, and create new offspring of various stages, at rates that depend on the current age. Following these processes, individuals must be allocated to their next age class. The matrices D i advance surviving individuals from one age class to the next; the simplest such model contains ones on the subdiagonal and the ω, ω corner; e.g., (for ω = 3)
| (6) |
The ω, ω entry converts the final age class into an open‐ended category. Setting it to 0 would kill all individuals at age ω.
As written in Eq. (8), advancement in age involves no deaths; all mortality is included in the U j. This need not be the case. If desired, an additional age‐specific mortality hazard, affecting stage i could be incorporated by replacing the ones in D i by survival probabilities <1. Such mortality can always be incorporated into the U j, so we will not explore its incorporation into the D i here.
The matrix H i allocates the newborn individuals, regardless of the age of their parent, into age class 1. Thus (e.g., for )
| (7) |
Impossible age × stage combinations
An operational decision is required to deal with “impossible” age‐stage combinations. For example, if stages are size classes, perhaps large individuals never occur in young age classes, and small individuals never occur in old age classes. In such cases, we set the rows and columns of the U j corresponding to these impossible combinations to 0
| (8) |
Because no offspring can be produced by a parent of an impossible age‐stage combination
| (9) |
The age × stage‐classified projection matrices
To construct the age × stage model using the vec‐permutation matrix formulation, we first construct block diagonal matrices , , , and , which contain the matrices U j, F j, D i, and H i, respectively, on the diagonal. That is
| (10) |
with similar construction for the others. The block diagonal matrices are all of dimension sω × sω.
The age × stage‐classified projection matrices are defined in terms of the block‐diagonal matrices as
| (11) |
| (12) |
| (13) |
where is the vec‐permutation matrix. From right to left in Eq. (12), the matrix first moves individuals among stages within their age classes. The vec‐permutation matrix K rearranges age classes within stages, the matrix advances individuals to the next age class, and the matrix K ⊤ returns the vector to its original arrangement. In Eq. (13), the matrix produces new offspring, then K rearranges age classes within stages, and the matrix assigns all newborn individuals to the first age class.
A little manipulation of these matrices reveals that has a block‐Leslie form (e.g., for )
| (14) |
where the 0 matrices are of dimension s × s. The formulation of in Eq. (4), in which stages are grouped within age classes, leads to this familiar structure (e.g., Goodman 1969, Feeney 1970, Lebreton 1996). The formulation of with age classes grouped within stages, where , rearranges the blocks in Eq. (15) (e.g., Rogers 1968, Cohen 1982; see Caswell 2001: Section 4.3).
The systematic construction of by the vec‐permutation matrix algorithm in Eqs. (12) and (13) is enormously beneficial. The biological content of the model, and hence the data collection and data analysis effort, comes from assembling the demographic information in the U j and F j. Of the s 2ω2 entries of , at most only 2s 2ω entries contain demographic information. The expressions for and isolate these components and make it more efficient to conduct analyses, especially sensitivity analyses.
In a later section (A model species example), we develop a hypothetical example to demonstrate the calculations, for a life cycle including two types of larvae and two types of adults.
Life Table Functions
The classical life table functions are the survivorship ℓ(x), the mortality rate μ(x), and the distribution of age at death b(x), where x represents age. Together, these functions are a time‐honored way to characterize age‐specific demography, longevity, and life histories (e.g., Pearl and Miner 1935, Dublin and Lotka 1937, Deevey 1947, Slobodkin 1961, Hutchinson 1978). As is well known, any one of them suffices to calculate any of the others.
In this section, we derive the life table functions for age × stage‐classified models. The extra dimension of stage classification adds a rich set of additional life table perspectives. In an age‐classified model, for example, survival to some age x either happens or it does not; if it does, it follows a defined pathway of ages 1, …, x. In an age × stage‐classified model, survival to a given age can take place via a potentially infinite set of developmental pathways through the combinations of ages and life history stages. Each pathway has its own probability of occurrence, and the life table functions must integrate over all those pathways and probabilities. In addition, if there are multiple types of offspring, a cohort may start off with a mixture of different stages at birth, which will affect the survival and mortality results. Fortunately, the matrix formulation makes these calculations possible.
Survivorship and mortality
Survivorship ℓ(x) is the probability that an individual survives from age 0 to age x,
| (15) |
In an age‐classified model, ℓ(x) is calculated by projecting an initial age 0 cohort of size 1; the resulting values give the proportion of the cohort surviving.
In an age × stage‐classified model, a survivorship vector is obtained by projecting a cohort using
| (16) |
The survivorship vector , of dimension , inherits the block age‐stage structure of ; its entries give the probability of survival to age x of an individual starting in every age‐stage combination. We extract the vector of survivorship starting from the first age class by
| (17) |
where e 1 is a unit vector of length ω with 1 in the first position and zeros elsewhere. The ith entry of gives the survivorship to age x of an individual starting life in stage i, accounting for the joint effects of age and stage on survival, integrating over all age‐stage developmental pathways between birth and age x.
If the cohort begins as a mixture of stages specified by a mixing distribution π, the resulting survivorship function is
| (18) |
| (19) |
Note that our convention (Eq. (9)) that transitions involving impossible age‐stage combinations are set to 0 implies that if stage i does not occur among the types of offspring.
In age‐classified models, the mortality rate, or hazard function, μ(x) is defined by the relationship
| (20) |
so that
| (21) |
That is, mortality rates are given by the slope (with the sign reversed) of the log of the survivorship function.
In the age × stage‐classified model, using the vector in Eq. (18), we obtain a vector of mortality rates as a function of birth stage as
| (22) |
where is given by Eq. (18) and the log function is applied elementwise. The mortality schedule for birth stage i, μi(x) is undefined if stage i and age class 1 is an impossible combination.
The apparent mortality schedule (i.e., what would appear to an observer ignorant of the mixed composition of the cohort) for a mixed cohort with mixing distribution π, is
| (23) |
where ℓ(x | π) is given by (19). This schedule is “apparent” because it results from the mixture of different initial stages; no individual actually experiences μ(x | π). Eqs. (23) and (24) provide mortality schedules resulting from the full age‐stage dynamics; μ(x) and μ(x | π) capture the full complexity of age‐ and stage‐specific development. We will return briefly to the survivorship function, and present an alternative method of computation, in the section entitled The fundamental matrix and longevity .
Intra‐cohort selection
In an age‐classified model, as a cohort ages, it shrinks as individuals die. In an age × stage‐classified model, a cohort shrinks and its stage composition changes. Stages with higher mortality rates and/or shorter stage durations decrease in relative frequency due to intra‐cohort selection.
To analyze intra‐cohort selection, define an initial cohort and project it forward by
| (24) |
The projected cohort vector gives the complete joint distribution of abundance by age and stage at age x, dependent on the initial cohort . Normalizing to sum to 1 gives the joint age‐stage frequency distribution,
| (25) |
from which the marginal age and stage distributions can be calculated as:
| (26) |
| (27) |
The general approach to the computation of such mixture and marginal quantities is outlined in Box 1. In general, will converge, as x increases, to the right eigenvector corresponding to the dominant eigenvalue of (Horvitz and Tuljapurkar 2008).
Box 2. Computing the vec‐permutation matrix.
The vec‐permutation matrix (Magnus and Neudecker 1979, Henderson and Searle 1981) connects the vec operator and the matrix transpose. If X is a matrix, then
The matrix can be calculated as
where E ij is a matrix, of dimension , with a 1 in the (i,j) entry and zeros elsewhere.
The choice of depends on the question of interest. By definition, a cohort consists of individuals of the same age, which we can take as age class 1. Define π 0 as the distribution of stages within this age class. Then
| (28) |
where e 1 is a vector of length ω with a 1 in the first entry and zeros elsewhere. If the goal is to analyze a cohort all members of which start in stage j, then π 0 is a unit vector of length s with a 1 in the jth location and zeros elsewhere.
The fertility function
In an age‐classified model, the (scalar) fertility function f(x) gives the mean number of offspring produced, per unit time, by a parent aged x. In an age × stage‐classified model the fertility matrices F x, for , are the multivariate analogue of f(x). The (i,j) entry of F x is the expected number of offspring of type i produced, per unit time, by a parent of type j and age class x.
The fertility matrix F x can be simplified to obtain three different age‐specific fertility measures.
Weighted offspring production. Multiple offspring types, when they exist, are combined into a weighted sum, with weights defined by, e.g., body size, parental investment, reproductive value, etc. Let c be such a vector of weights (s × 1). The vector of weighted fertility at age x is
| (29) |
The jth entry of f weighted(x) is the weighted mean number of offspring produced by a parent of stage j at age x.
Mixed offspring production. The vector giving the offspring, of all types, produced at age x by a mixture of stages given by a mixing distribution π(x), is
| (30) |
One source for π(x) is the stage structure of a cohort of individuals of age x. Given an initial cohort composition containing only individuals in age class 1, the appropriate mixture is
| (31) |
given by Eq. (27). The jth entry of f mixed(x) is the number of type j offspring produced per individual in a mixed cohort at age x, with a specified composition.
Mixed and weighted offspring production. The scalar fertility function, giving the weighted number of offspring produced by a mixed cohort at age x, is
| (32) |
If only one type of offspring exists, and if stages do not differ in their fertility, f(x) reduces to the familiar age‐specific fertility function.
The functions F x, f weighted(x), f mixed(x), and f(x) capture different aspects of the (possibly complicated) age‐ and stage‐dependence of reproduction.
Cohort Dynamics: Longevity Statistics
Longevity is the age at death of an individual. Statistics of longevity are frequently used to summarize mortality schedules. The most familiar such statistic is the life expectancy, or mean age at death. Measures of variation (the variance, standard deviation, coefficient of variation, and life discrepancy) provide information on stochastic variation in longevity among individuals. For example, many human populations have recently exhibited declines in variance in longevity, accompanying increases in life expectancy (e.g., Edwards and Tuljapurkar 2005, Tuljapurkar and Edwards 2011, Vaupel et al. 2011, Van Raalte and Caswell 2013, Engelman et al. 2014).
In age × stage‐classified models, longevity depends on how mortality varies over age and among stages, and we now turn to the calculation of these statistics.
The fundamental matrix and longevity
Longevity statistics are obtained by treating as the transient matrix of an age × stage‐classified absorbing Markov chain (Feichtinger 1971, Caswell 2001, 2006, 2009, 2013). If the states are numbered so that the transient (alive) states precede the absorbing (dead) states, the transition matrix for such a chain can be written
| (33) |
where is a matrix of transition probabilities from transient to absorbing states. We will consider in detail in the section entitled Age and stage at death .
The fundamental matrix for the chain is
| (34) |
The matrix inherits the block structure of , with stages arranged within age classes. The (i,j) element of is the expected time spent in transient state i by an individual starting in transient state j (see Caswell 2006, 2009, 2013 for the higher moments and variances), where i and j range over all combinations of age and stage.
Longevity is measured by the time to eventual absorption in one of the states representing death. Well known results from Markov chain theory (Iosifescu 1980: Theorem 3.2) give the vectors of the mean and the second moments of time to absorption, which satisfy
| (35) |
| (36) |
The entries of , of dimension sω × 1, give the life expectancy of individuals of each age‐stage combination. The entries are arranged as in , with stages within age classes. The vector contains the second moments of longevity, so the vector of variances of longevity is
| (37) |
This vector contains the variances in remaining longevity among individuals of every possible age‐stage combination, reflecting stochasticity in advancement through age classes and transitions among stages. This variance can be decomposed into contributions within and between stages (cf. Hartemink et al. 2017), as we show in the next section.
Partitioning the variance in longevity
In a cohort at age x, individuals will vary in longevity for two reasons: the stochasticity inherent in aging and transitions, and the heterogeneity inherent in the stage distribution at age x. To analyze the variance in remaining longevity at age x, define the vector η(x), of dimension , whose ith entry gives the remaining longevity of individuals of stage i at age x, and the scalar η(x) that gives the remaining longevity of an individual of age x in a mixed cohort. Extract the mean and variance of remaining longevity in age class x as
| (38) |
| (39) |
where e x(ω) is a unit vector of length ω with 1 in the xth position and zeros elsewhere, E( · ) is the mean and V( · ) is the variance.
Let π(x), of dimension s × 1 be the mixing distribution of stages at age x. This could be obtained as the vector m stage(x) in Eq. (27). Then the mean longevity of age class x, treated as a mixture of stages, is
| (40) |
and the variance is partitioned into a component due to stochasticity within a given stage and a component due to heterogeneity among the stages,
| (41) |
where the within‐group variance is the expectation over π(x) of the variances,
| (42) |
| (43) |
The between‐group variance is the variance over π(x) of the means,
| (44) |
| (45) |
This variance decomposition is well‐known in probability theory (Rényi 1970: Chapter 5.6, Theorem 1), forms the basis of the analysis of variance in statistics (e.g. Kempthorne 1957), and is a familiar tool in the analysis of mixture models (Frühwirth‐Schnatter 2006). It is a valuable tool in quantifying the relative contributions of heterogeneity and individual stochasticity to the variance in demographic outcomes (e.g. Caswell 2009, Edwards 2011, Hartemink et al. 2017, Jenouvrier et al. 2018, Hartemink and Caswell 2018). It is a natural tool for the analysis of age × stage‐classified models, because the incorporation of stage‐dependence is a natural way to include the effects of heterogeneity in age‐specific parameters.
1. Beyond longevity
The Expressions 43 and 45 require only the expressions for the mean and the variance of η, for each stage at each age of interest. Although we have described it in terms of variance in longevity, it can be applied to any quantity for which those quantities are available. For example, a stage‐classified calculation has applied the analysis to age at first reproduction and lifetime reproductive output (Jenouvrier et al. 2018). The extension to age × stage‐classified models will, in some cases, require an extension of occupancy time theory (Roth and Caswell 2018), in other cases the variance terms are directly available.
2. Survivorship revisited
The fundamental matrix provides an alternative way to compute survivorship, dependent on the stage of the individual at birth (Keyfitz and Caswell 2005). Starting with , we first aggregate the rows by summing stages within age classes; the result gives the mean number of visits to each age class. But an age class can be visited at most once, so the mean number of visits equals the probability of ever visiting that age class, which is the survivorship. The column block corresponding to starting age class 1 contains the survivorship of each stage at that initial age; this is
| (46) |
The matrix L, of dimension , contains as columns the survivorship functions for each stage. The survivorship for a mixture of initial stages, specified by a mixing distribution vector π s, is given by
| (47) |
Age and stage at death
In classical age‐structured life tables, the probability distribution of age at death is . In age × stage‐classified analysis, there is a joint distribution of age and stage at death, for an individual of any initial age‐stage combination. To obtain this joint distribution, we construct a mortality matrix in the absorbing Markov chain (Eq. (35)) such that the absorbing states are defined by the combination of age and stage at death. To do so, define q i as the vector of stage‐specific mortality probabilities for age class i, obtained from U i as
| (48) |
Then the mortality matrix is
| (49) |
inheriting the block structure of .
As a simple extension of the result for age‐ or stage‐classified models (Caswell 2001, 2009, 2012) all the joint distributions of age and stage at death are contained in the matrix
| (50) |
Each column of contains the joint distribution of age and stage at death for an individual in one of the possible age‐stage categories.
Marginalizing by summing stages within age classes, or age classes within stages, gives the marginal age and stage distributions as the columns of the matrices
| (51) |
| (52) |
The distributions resulting from a mixed cohort, with mixture distribution π sω are
| (53) |
| (54) |
| (55) |
As this collection of results makes clear, the combination of age and stage dependence of all the vital rates creates rich opportunities to examine the distributions of age and stage at death.
Life disparity: years of life lost
An important application of is to the calculation of the life disparity, or the mean number of life years lost to mortality, an index introduced by Vaupel and Canudas Romo (2003). In an age‐classified model, an individual that dies at age x, which happens with probability b(x), loses some remaining years of life that would have been available had the individual not, in fact, died. The lost years of life are unknown, but their expectation is the remaining life expectancy at age x. Thus the expectation of the life lost due to mortality is obtained by integrating over all ages at death
| (56) |
where e(x) is remaining life expectancy at age x.
The mean life lost plays another role: it is a measure of the variation in age at death called life disparity. If all individuals were to die at the same age, say x*, then b(x) would be a delta function at x* and e(x*) would be 0, and (Eq. (57)) would give . As a measure of variability in longevity, e † is highly correlated with the standard deviation of longevity and other measures of variation. Vaupel et al. (2011) analyzed patterns of e † across countries in relation to life expectancy as a way to analyze premature death.
In an age × stage‐classified model, we define a vector
| (57) |
The vector contains the expected remaining longevity of every age‐stage combination; the columns of contain the probabilities of death at each age‐stage combination. Thus the vector contains the expected life lost due to mortality, for individuals of every age and stage combination. These age × stage‐specific expectations can be combined according to a mixing distribution π (dimension ) as
| (58) |
The result is a scalar, the mean life lost due to mortality in a cohort composed of age‐stage combinations in proportions given by .
Population Dynamics: Growth and Structure
We turn now from probabilistic outcomes for individuals within cohorts to the dynamics of populations. Population dynamics are the outcome of survival, development, and fertility throughout the life cycle. The first two are accounted for by ; the third is accounted for by . The basic projection of population dynamics is
| (59) |
| (60) |
with specified initial population .
Stable population theory and demographic ergodicity
If is time‐invariant, we expect the population to converge, from any non‐negative and non‐zero initial population, to exponential growth at a rate λ given by the dominant eigenvalue of , and a structure proportional to the corresponding right eigenvector . The reproductive value vector will be given by the corresponding left eigenvector of .
When normalized to sum to 1, the vector gives the joint age × stage distribution in the stable population. The marginal stable age and stage distributions are given by
| (61) |
| (62) |
The reproductive value vector is not a probability distribution; instead, the entries of give the asymptotic relative sizes of populations initialized with a single individual of the corresponding age‐stage combination. The reproductive value of a mixture of ages and stages is
| (63) |
where π is the mixing distribution.
Ergodicity
Our expectation of ergodic behavior (the convergence to exponential growth and a stable structure from any initial condition) may be disappointed, because may not be irreducible (a matrix is irreducible if there exists a pathway from every state to every other state). The Perron‐Frobenius theorem guarantees that the state space of a reducible matrix can be decomposed into subspaces, each of which leads to different asymptotic behavior (see Csetenyi and Logofet 1989, Caswell 2001: Section 4.5, Stott et al. 2010, Caswell 2012: Appendix B). For example, life cycles with post‐reproductive age classes are reducible and the behavior of such a population depends on whether the initial population contains only post‐reproductive individuals (eventual extinction) or contains some reproductive individuals (potential population growth).
The i‐state space of an age × stage‐classified model will certainly be reducible if it contains some impossible combinations, which appear as rows and columns of zeros in (see Eqs. (9) and (10)). These states cannot be reached from, nor do they lead to, any other states; hence is reducible. However, if we make the eminently reasonable decision not to start with a population composed solely of impossible individuals, these states will have no effect on eventual dynamics.
It is more challenging to deal with reducibility generated by the complicated pathways through the life cycle produced by the interaction of age‐specific and stage‐specific processes. Stochastic ergodic theorems may provide some guidance (Cohen 1982). Ergodicity can, in any specific case, be determined using the patterns of zero and non‐zero entries of the reproductive value vector (Caswell 2012). If has positive entries for all non‐impossible states, then population dynamics converge to λ and from any initial condition not restricted to impossible states. If has zero entries for some non‐impossible states, then an initial condition restricted to those states would not converge to , but rather to the distribution given by a different eigenvector. This possibility can easily be checked for any specified matrix.
Net reproductive rate
The familiar net reproductive rate in age‐classified models,
| (64) |
serves three functions (Caswell 2009): it is the mean number of (usually female) offspring produced over a lifetime, it is the per‐generation growth rate of the population, and it is an indicator function that distinguishes population growth (R 0 > 1) from population decline (R 0 < 1). Cushing and Zhou (1994) generalized this concept to stage‐classified models by showing that
| (65) |
where R is the next‐generation matrix,
| (66) |
If F contains only a single type of offspring, then Eq. (66) satisfies all three functions of the net reproductive rate. But if multiple types of offspring exist, then R 0 defined by Eq. (66) satisfies the last two (per‐generation growth rate and growth indicator function), but it is not the mean lifetime number of offspring. Indeed, if multiple types of offspring exist, there is no single “number of offspring” to calculate.
The Cushing‐Zhou result (Eq. (66)) applies equally to age × stage‐classified models, so
| (67) |
where . However, taking advantage of the structure of the population vector, we can carry the analysis further. Let F ij and N ij denote the age blocks in and , respectively. For example, for ,
| (68) |
Then
| (69) |
| (70) |
The matrix is block upper‐triangular, and hence its dominant eigenvalue is
| (71) |
The matrix R 11 is of dimension ; its (i,j) entry is
| (72) |
It can be extracted easily from as
| (73) |
where
| (74) |
The remaining lifetime reproductive output at age class j is obtained by applying the following analyses to the block R 1j.
Mean lifetime reproduction
As was the case for stage‐classified models, if there exists only a single stage of offspring, then R 0 calculated from the Cushing‐Zhou theorem also gives the mean lifetime reproduction. However, when there are multiple offspring stages, the matrix R 11 contains information on the production of all these types of offspring. Just as we did for the age‐specific fertility function in Eqs. (29)–(32), we can aggregate lifetime reproductive output in several ways.
Weighted mean lifetime reproduction. Let c s be a vector of weights, of dimension . Then
| (75) |
The vector r weighted is a weighted combination of the rows of R 11, and c, a vector whose entries assign weights to the different types of offspring. The ith entry of r weighted gives the mean weighted lifetime reproduction by an individual starting life in stage i.
Lifetime reproduction of a mixed cohort. A cohort starting as a mixture specified by a mixing distribution π will have a lifetime reproductive output of
| (76) |
This vector is a weighted combination of the columns of R 11; its ith entry is the mean lifetime production of type i offspring by the mixed cohort.
Mixed and weighted lifetime reproduction. A scalar measure of mean lifetime reproduction is given by
| (77) |
In the special case where only a single type of offspring is produced, . But in general, lifetime offspring production in age‐stage models is a more diverse and nuanced concept than R 0. Note that much more information about lifetime reproductive output, including variances, higher moments, and sensitivity analysis can be obtained using Markov chains with rewards (Caswell 2011, van Daalen and Caswell 2015, 2017). The application of these methods to age × stage‐classified models will be explored elsewhere.
Population Dynamics: Generation Time
Generation time, which is defined in several ways, is an important demographic measure of the time scale on which a population operates (Gaillard et al. 2005, Lebreton 2005, Steiner et al. 2014). In conservation standards established by the International Union for the Conservation of Nature, population decline measured in units of generation time helps establish the threat level for a species.
Three measures of generation time are in common use in age‐classified demography (Coale 1972, Caswell 2001): the growth rate generation time, which is the time required to grow by a factor of R 0,
| (78) |
the cohort generation time, which is the mean age of the production of offspring by an individual,
| (79) |
and the stable age generation time, which is the mean age of the parents of the offspring produced in a population at the stable age distribution c(x),
| (80) |
Of these three, the cohort generation time is the most appropriate as a measure of the time scale on which a life history operates, because it is explicitly calculated as a property of an individual over its lifetime. The cohort generation time is denoted as μ by Coale (1972), but that symbol is also used for the mortality rate. It is not unusual for such notational conflicts to arise when discussing demographic calculations that span a variety of indices or processes.
Three complications arise in extending the familiar calculations for age‐classified demography to age × stage models: (1) Multiple kinds of offspring may be produced, following different age schedules, and thus each appearing to have a different generation time; (2) Individuals that start life in different offspring stages may survive, mature, and reproduce differently, and hence have different generation times; (3) Unlike age‐classified models, in which a cohort is always of a fixed age, a cohort may start life as a mixture of stages.
The cohort generation time for stage‐classified models was derived in (Caswell 2009: Appendix A.5). What follows is the extension to age × stage‐classified models, in which both age and stage trajectories must be taken into account.
Begin with a cohort (dimension sω × 1); being a cohort, it contains only age class 1 individuals, but may have any initial stage distribution. Normalize the cohort so that . The survivors of this cohort at age x are
| (81) |
and the offspring, in the first age class, produced by these survivors are
| (82) |
where e 1 is a unit vector of length ω. Summing this quantity over all ages gives the vector of total lifetime reproduction,
| (83) |
| (84) |
| (85) |
The mean age of the production of the offspring over the lifetime is proportional to
| (86) |
But
| (87) |
The proportionality constant is required to make the entries of ϕ life sum to 1 as probability distributions; with this normalization the vector of cohort generation times, for each starting stage of offspring, is
| (88) |
The ith entry of Γ is the mean age of production of offspring of type i by a cohort of individuals with initial stage distribution , and accounting for all stage transitions tha occur as the individuals age. Entries of Γ corresponding to stages that never appear as offspring will be undefined (0/0) in Eq. (89); they should be set equal to 0.
Sensitivity Analysis of Age × Stage‐Classified Models
In this paper, each step in the construction and analysis of the age × stage‐classified model has been written in terms of matrix operations. This is not only for notational, analytical, and computational efficiency. It also makes possible the systematic calculation of the sensitivity of any output to changes in any set of parameters, using matrix calculus. Some previous studies have applied matrix calculus to vec‐permutation models that are similar or equivalent to age × stage‐classified models, including stage‐classified epidemics (Klepac and Caswell 2011), spatial models (Strasser et al. 2012), the sensitivity of population growth rate in age‐stage models (Caswell 2012, Caswell and Shyu 2012, Caswell and Salguero‐Gómez 2013), and the effects of age and frailty (Roth and Caswell 2016). These results can be extended to a general sensitivity analysis of age × stage‐classified models; details will be presented elsewhere.
Let ξ be any output variable (see Table 1), scalar‐ or vector‐valued, calculated from , and let θ be a vector of parameters that affect any of the U i and/or F i. In matrix calculus notation, the sensitivity of ξ to θ is
| (89) |
Each of the numbered terms in (Eq. (90)) has its own function.
Term 1
Expresses the dependence of the outcome variable ξ on the matrix or its components and . this matrix is obtained by differentiating ξ with respect to and .
For example, if , then Term 1 is the familiar derivative of λ to the entries of the matrix ,
| (90) |
But suppose instead that interest focuses on the net reproductive rate, as defined by Eq. (68), and let y and x be the right and left eigenvectors of corresponding to R 0, scaled so that . Then , and Term 1 is the derivative of the net reproductive rate with respect to , which is
| (91) |
| (92) |
| (93) |
| (94) |
(extending calculations from Caswell 2009 to the age × stage case).
The point of these two examples is that Term 1 is the only part of the sensitivity calculation that depends on what the dependent variable may be (λ, R 0, or anything else).
Term 2
These are constant matrices, depending only on the vec‐permutation matrix K the age transition matrix and the age assignment matrix . Since and are given by Eqs. (11) and (12), the two derivatives in Term 2 are
| (95) |
| (96) |
Notice that these matrices are independent of the dependent variable or on the identity of the parameters θ.
Term 3
These are the derivatives of the block diagonal matrices and to their diagonal entries U i and F i. As such they depend only on the arrangement of the matrices on the diagonal. A new way to obtain these derivatives is based on Eqs. (15) and (16) of Caswell and van Daalen (2016). Define the matrices P i and Q i, of dimension and , respectively,
| (97) |
Then
| (98) |
Again, note that this term is independent of the dependent variable and the parameters being perturbed.
Terms 4 and 5
These terms contain the biologically interesting part of the calculation, because it is at this point that we find the dependence of the transition and survival matrices U i and the fertility matrices F i on the parameter vector θ. This is the point where the age‐stage specific processes of survival, growth, development, reproduction, etc. are determined.
The possibilities are limited only by imagination. As an example, suppose that interest focuses on a parameter that imposes a multiplicative perturbation on the stage‐specific survival probabilities at a specified age or ages. We can write
| (99) |
where Σ i is a diagonal matrix with a vector of survival probabilities σ on the diagonal and G i is a matrix of transition probabilities conditional on survival. From this expression, it can be shown that
| (100) |
Now incorporate the parameter vector by writing , where is the baseline vector of stage‐specific survival probabilities at age class i. Then
| (101) |
| (102) |
Because this perturbation is hypothesized to affect only survival, the derivatives of F i to θ in Eq. (90) are all zero.
This calculation is an arbitrary example. The reader can no doubt think up possible applications (e.g., θ might describe harvest or bycatch impacts that reduce the survival probability of certain stages of a threatened species, or it might reflect allocation of resources to survival, with an associated cost in fertility, …).
The causal pathways from a parameter vector θ to some demographic outcome ξ can be enormously complex in an age × stage‐classified model. The great value of the vec‐permutation formulation is that all these pathways are taken into account, and that attention can focus on the effects of parameters on the age × stage‐specific vital rates in terms 4 and 5, and on the way that the outcome is computed from the age × stage matrix in term 1. The connection between these two, for any outcome for any species described by any set of stages, is given by the series of constant, and easily computable, matrices in terms 2 and 3.
A Model Species Example
Here, we construct and analyze an age × stage‐classified matrix model for a hypothetical model species, inspired by (although not identical to) poecilogonous marine invertebrates (Levin et al. 1987, Krug 2007, Knott and McHugh 2012). These are species that produce two dramatically different types of larval offspring. One type, so‐called planktotrophic larvae, feed during the larval stage and receive only a small parental investment. The other type, lecithotrophic larvae, do not feed, and rely on a large parental investment in the form of a yolk reserve. Lecithotrophic larvae are more costly to produce and are produced in lower numbers than are planktotrophic larvae. However, lecithotrophic larvae have a higher survival probability than their planktotrophic siblings, an advantage that persists into post‐larval life (Levin et al. 1987).
Our model species has four stages: large and small juveniles, and adults that began life as either large or small juveniles. We will refer to these as large and small adults, although large‐born and small‐born might be more accurate. matlab code for the calculations is available as an Supporting information.
The age × stage‐classified model
The life cycle of our model species contains small and large juveniles and small and large adults. Stage‐specific demography is defined in terms of survival probability σ, maturation probability (conditional on survival) γ, and fertility f. Each of these parameters is a function of both stage and age. The resulting life cycle graph is shown in Fig. 1; the model parameters are described in Table 3. The life cycle graph describes the stages; age dependence enters by making the survival, maturation, and fertility parameters in the graph into functions of age as well as stage.
Figure 1.
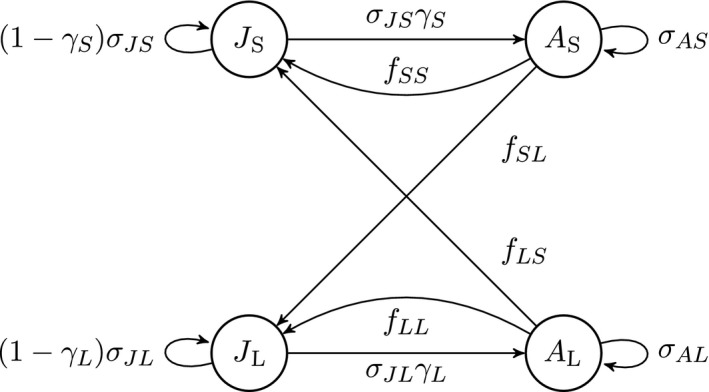
Life cycle graph for the example species. The nodes represent the four stages: small juvenile (J S), large juvenile (J L), small adult (A S) and large adult (A L). The arrows represent survival, maturation, and reproduction. The per‐time‐step probabilities of survival (σJS, σJL, σAS, σAL) and maturation (γS, γL) and the per‐time‐step production of new individuals (f SS, f SL, f LS, f LL) all depend on age, x.
Table 3.
Model parameters used in the life cycle graph in Fig. 1
| Notation | Description |
|---|---|
| Per‐time step survival probability | |
| σJS(j) | small juvenile |
| σJL(j) | large juvenile |
| σAS(j) | small adult |
| σAL(j) | large adult |
| Per‐time step maturation probability | |
| γS(j) | small juvenile |
| γL(j) | large juvenile |
| Per‐time step production | |
| f SS(j) | of small juveniles by small adults |
| f SL(j) | of large juveniles by small adults |
| f LS(j) | of small juveniles by large adults |
| f LL(j) | of large juveniles by large adults |
The index j refers to the age class of the individual; for reproduction it refers to the age class of the parents.
Life history description
Because the two types of offspring differ in the resources allocated to them by the parent, offspring type has consequences throughout the life cycle. Both juvenile and adult survival probability are lower for small individuals (Fig. 2a and b). Small juveniles also begin to mature later than large ones and their maximum maturation probability is lower (Fig. 2c).
Figure 2.
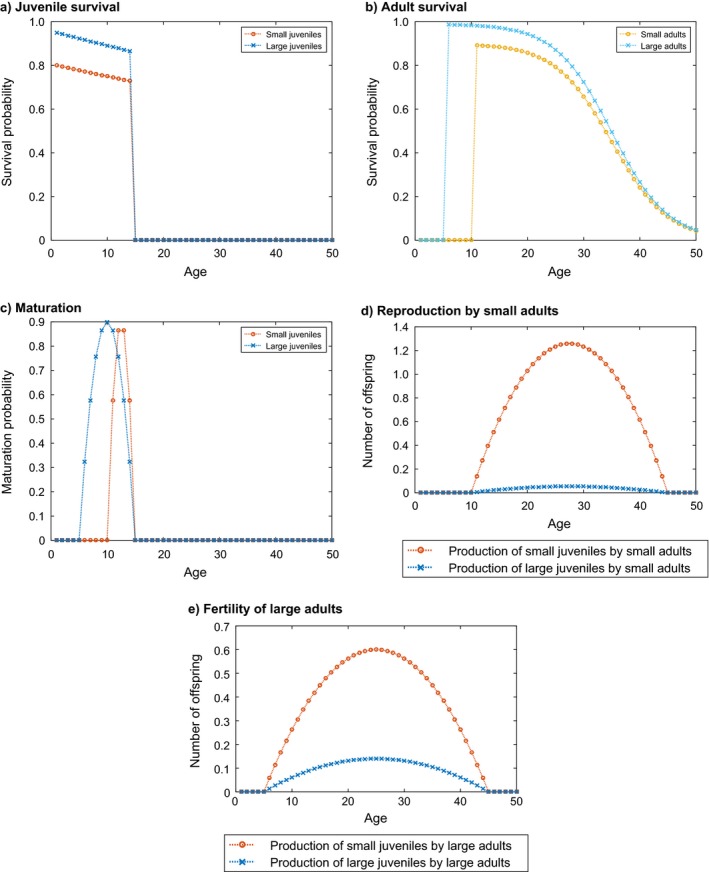
The age × stage‐specific life history parameters for the example species.
Small individuals are less costly to produce, so they are produced at a higher rate, by both small and large adults. We have incorporated a certain heritability of type, which results in large adults producing relatively more large juveniles and small adults producing relatively more small juveniles (Fig. 2d and e).
Matrix construction
We construct the age × stage model from the stage transition matrices U x, the reproduction matrices F x, the age transition matrix D and the age assignment matrix H. The life cycle contains s = 4 stages (stage 1, small juveniles; 2, large juveniles; 3, small adults; and 4, large adults), and we consider ω = 50 age classes.
The matrix U x describes the transition and survival probabilities for individuals in age class x,
| (103) |
The s × s matrices F x describe the stage‐specific per capita production of new individuals by reproduction, for individuals in age class x,
| (104) |
The first and second rows of F x describe per capita production of small and large juveniles, respectively.
The matrix D i advances the age class of surviving individuals in stage i. All of the D i are identical, given by Eq. (7). The matrices H i that assign newborn individuals to the first age class are all identical, given by Eq. (8). The matrices , , and are created by putting U i, F i, D i, and H i on the diagonals, as in Eq. (11). Each of these matrices is of dimension , which for our model is . Finally, the age × stage‐classified projection matrices , , and are constructed following Eqs. (12), (13), (14).
Population growth and structure
It is convenient to begin with analyses of population growth, because the stable population structure will provide a family of mixing distributions that will be used several times in the cohort analyses to follow.
Stable population structure
Using the parameters defined by Fig. 2, the population growth rate given by the dominant eigenvalue of is . The joint distribution of age and stage in the stable population is contained in the corresponding eigenvector , normalized to sum to 1. Fig. 3 shows the joint distribution of age and stage and the marginal age distribution w age and stage distribution w stage, calculated from Eqs. (62) and (63).
Figure 3.
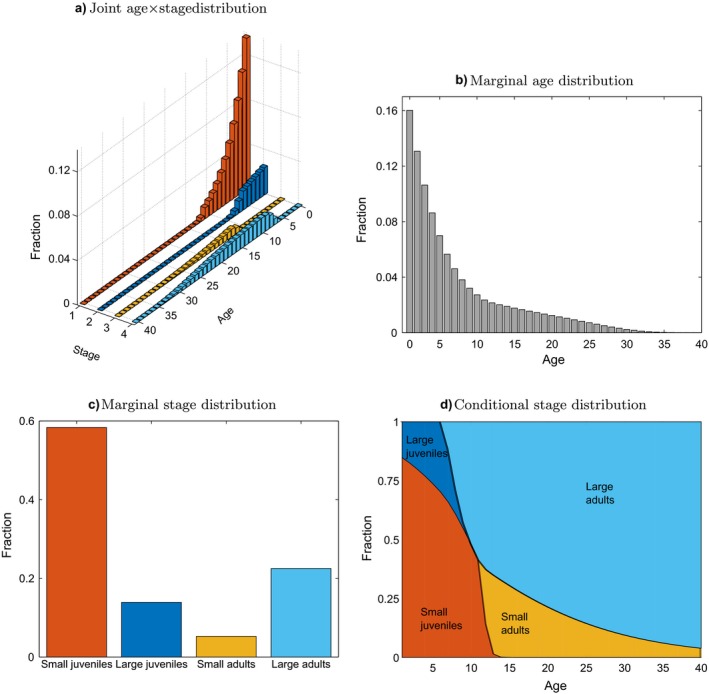
The stable population structure for the model species, showing (a) the joint distribution by age and stage, (b) the marginal stable age distribution, (c) the marginal stable stage distribution, and (d) the conditional stable stage distribution.
The joint distribution of age and stage in the stable population is dominated by young and small individuals (Fig. 3a). Adults (small and large) appear only at later ages. The marginal age distribution decays rapidly with age; most individuals are younger than 10. The marginal stage distribution is dominated by small juveniles (~60%). Large juveniles are much scarcer (~15%). Large adults, however, are more common (~20%) than small adults (~5%).
Even with only four stages, the interaction between age and stage in the stable population is complicated. The conditional stage distribution within each age class is shown in Fig. 3d. Up until an age of about 10, the population is dominated by small juveniles, but at later ages, it is dominated by large adults. The pattern results from the differences in survival probability and development time between large and small juveniles and adults.
A mixing distribution for cohort initiation
Cohort dynamics begin with a group of newborn individuals, all in the first age class, but in possibly different stages. Calculations of survivorship, longevity, reproduction, and the age and stage at death need the stage distribution of the cohort as a mixing distribution. The mixing distribution π (dimension s × 1) is obtained by extracting the entries of corresponding to age class 1 and normalizing so that the resulting vector sums to 1
| (105) |
| (106) |
where e 1 is a unit vector of length ω. Thus about 85% of the new offspring in the stable population are small.
Reproductive value
Reproductive value is given by the left eigenvector of (dimension ). It is a relative measure of contribution to future population size, customarily scaled relative to that of a newborn individual. In our model species, there are two such types, so Fig. 4 shows reproductive value scaled relative to that of a small juvenile.
Figure 4.
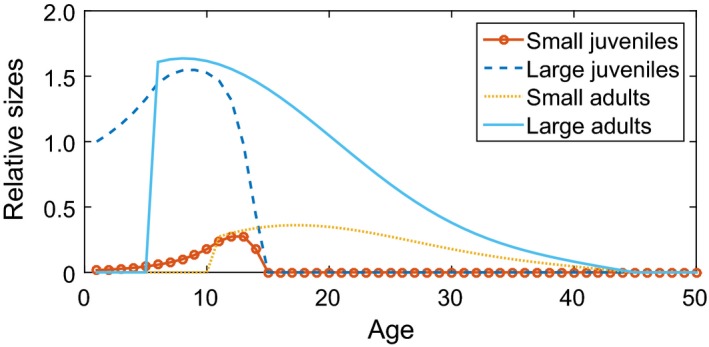
The age‐specific relative reproductive value of each stage for the example species, scaled relative to that of a large juvenile at birth.
The survival and maturation advantages of large juveniles relative to small juveniles translate into a dramatic increase in reproductive value. Juvenile reproductive value increases with age, as individuals get closer to maturation. After maturation, large adults have a reproductive advantage.
Cohort analyses
Survivorship
The stage‐specific survivorship vector is calculated by projecting a cohort with Eq. (18) and counting the proportion of survivors. Because our model species has two possible initial stages, small and large juveniles, the vector has only two non‐zero entries. Fig. 5 shows the survivorship of small and large individuals. Survivorship declines rapidly at young ages, when individuals are subject to the high mortality rates of the juvenile stages, and then declines more slowly after maturation. Large individuals have a dramatic survivorship advantage. The survivorship of a mixed cohort, starting with a mixing distribution π calculated from the stable structure in Eq. (107), lies between the survivorship curves for small and large individuals, but much closer to that of small individuals. This reflects the dominance of the mixing distribution by small juveniles.
Figure 5.
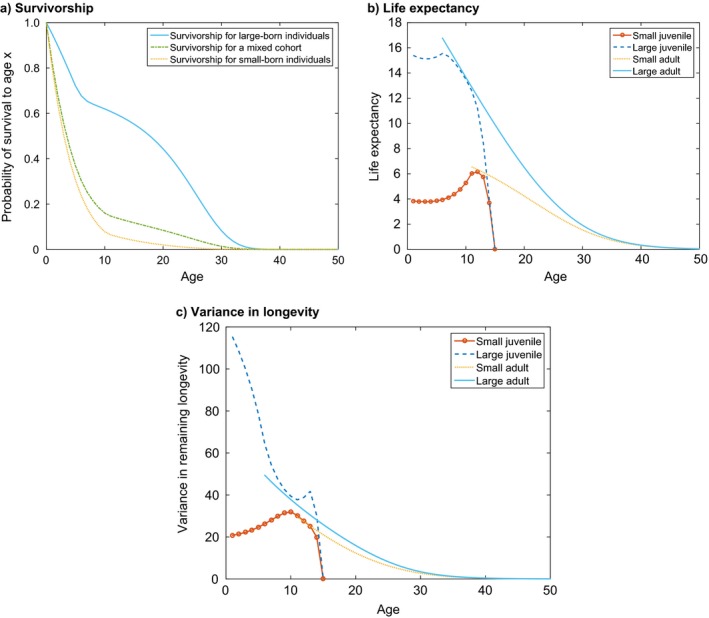
Properties of the example species. (a) Survivorship ℓ(x) for small and large individuals, and for a mixed cohort with proportions given by the mixing distribution π. (b) Remaining life expectancy as a function of age for each of the four stages. (c) Variance in remaining longevity as a function of age for each of the four stages.
Longevity
The remaining life expectancy (mean remaining longevity at a given age) of every stage is given by the vector , of dimension , calculated from the fundamental matrix using Eq. (36) (Fig. 5c). Life expectancy of juveniles increases with age as they approach maturity, after which they will experience higher survival probability. The life expectancy of the adult stages decreases smoothly with age.
The variance in longevity, calculated using Eq. (38), decreases with age for large juveniles, but shows a peak just before the end of maturation, at which point individuals either die very soon, or mature and probably survive for quite some time, hence the large variance (Fig. 5c). Small juveniles show a similar peak in variance. For adults, variance decreases steadily with age.
The mean and variance of longevity for a mixed cohort are calculated using Eqs. (41) and (42) and the mixing distribution vector π 1 given by Eq. (107). The resulting mean and variance in longevity, at birth, are shown in Table 4.
Table 4.
Mean and variance in longevity, and decomposition into contributions within and between stages at birth
| Outcome | Small‐born | Large‐born | Mixed | % |
|---|---|---|---|---|
| Mean longevity | 4.8 | 16.4 | 6.6 | |
| Variance in longevity | 20.8 | 115.4 | 52.3 | |
| Variance between | 17.2 | 32.8 | ||
| Variance within | 35.2 | 67.2 |
Mixing distribution defined by the reproductive output of the stable population.
When the variance in longevity of the mixed cohort is decomposed into that due to heterogeneity among stages and that due to stochasticity within stages, using Eqs. (44) and (46), the variance due to stochasticity was 35.2 and the variance due to heterogeneity was 17.2. Thus the percentage of the variance attributable to the heterogeneity among stages is 32.8%.
Fertility
The entries of F x in Eq. (105) give the mean production of each type of offspring by parents of each type, at each age, as shown in Fig. 2d and e. We summarize this information with the fertility indices defined in Eqs. (30), (31), (32), (33).
As an example of a weighted fertility schedule, we suppose that a large offspring is 10 times as costly as a small one, so we set
| (107) |
The resulting fertility schedule f weighted is shown in Fig. 6a. The mixed fertility schedule, given by Eq. (31) is shown in Fig. 6b. And, finally, the weighted and mixed schedule from Eq. (33) is shown in Fig. 6c.
Figure 6.
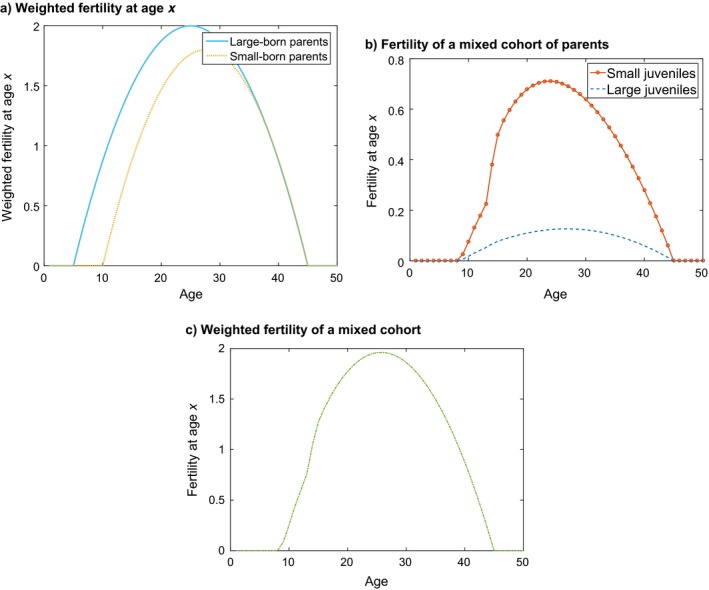
Properties of the example species. (a) Weighted age‐specific fertility f weighted(x) of small and large adults, with weights defined by the relative costs of small and large offspring (large 10 times more expensive than small). (b) The age‐specific fertility f mixed(x) of a mixed cohort of small and large parents, with the mixing distribution given by the reproduction of the stable population structure. (c) The age‐specific weighted fertility f(x) of the mixed cohort.
R0 and lifetime reproductive output
The matrix R 11 containing mean lifetime reproduction for our model species is
| (108) |
A large juvenile will, as a result of the combined age‐ and stage‐specific life history characteristics of the model species, produce many more offspring (by a 14‐fold difference for small offspring and a 78‐fold difference for large offspring). The net reproductive rate, calculated as the dominant eigenvalue of R 11, is
| (109) |
Suppose that we simply want to count total numbers of offspring produced. Then we use a weighting vector , and obtain
| (110) |
We see that, in terms of lifetime number of offspring, large individuals have a 16‐fold advantage over small individuals.
To compute the lifetime reproduction of a mixed cohort, we use the mixing distribution π calculated from the stable population in Eq. (107), to obtain
| (111) |
Combining this particular choice of weighting and mixing, we obtain the mean lifetime reproduction, by a mixed cohort, and counting total offspring of both types, as
| (112) |
The analysis of an age × stage‐classified model untangles the interacting effects of age‐ and stage‐specific parameters. Even in a simple model species, large‐born individuals have a higher survivorship than small‐born individuals, and their earlier maturation increases their survival advantage because they can escape juvenile mortality sooner. The two stages have very different lifetime reproductive output, not simply as a result of differences in production (Fig. 2d and e), but as an interacting effect of juvenile survival, adult survival, and maturation. Our model example also demonstrates how the composition of a population will influence the demographic calculations. Mixed cohorts and populations and different choices of weighting vectors determine how a mixed population will perform in terms of survival, reproduction and population growth. These mixture calculations make possible the analysis of heterogeneity in initial population structure, and in the structure that develops as cohorts age within a population.
Discussion
Our goal in this paper has been the development of a systematic methodology, of wide applicability, for the analysis of age × stage‐classified matrix population models.
Themes
Several themes have appeared repeatedly. Because the state space of an age × stage‐classified model is two‐dimensional, results that are familar as scalars in age‐classified or stage‐classified models now become vectors or matrices. The operations of marginalization and mixing thus play a critical role.
Consider any demographic quantity calculated from an age × stage‐classified model. If this quantity is a joint function of age and stage (e.g., the age and stage at death), then the marginal distributions (age at death and stage at death) are obtained as in Eqs. (52) and (53). If, on the other hand, a quantity is conditional on the age and stage of an individual (e.g., mean longevity), then the properties of this quantity for a heterogeneous cohort of individuals in different stages is calculated as a mixture, as in Eqs. (41) and (42). Using the total variance theorem, the variance in this quantity is partitioned into components due to stochasticity and to the heterogeneity created by the mixture, as in Eqs. (44) and (46). Any age × stage‐classified analysis should keep these concepts in mind.
Another theme that appears throughout our methodology is the interaction of age × stage‐dependence across three levels: the level of the individual (as in the life table functions), the level of the cohort (as in calculations of life expectancy and lifetime reproduction), and the level of the population. Although these levels are implicit in both population ecology and human demography, they appear explicitly here as a part of the methodology.
Variance is a recurring theme here. There is an increasing appreciation of the importance of variance created by stochastic differences between individuals (individual stochasticity). The inclusion of variance calculations in the approach here makes possible the decomposition of variances into components due to demographic differences (i.e., heterogeneity) among stages and ages, and to stochastic factors within stages.
Estimation and data
It is no surprise that age × stage‐classified models require an extra dimension of data: age‐specific rates at every stage, stage‐specific rates at every age. Such detailed data are rare (but see van Groenendael and Slim 1988) but we believe they will become more common as the importance of long‐term individual data is recognized (Clutton‐Brock and Sheldon 2010). The appropriate estimation procedures will, as always, depend on the properties of the species, the possibilities for monitoring, logistical difficulties, and available statistical methods. For that reason, we make no assumptions about how the stages are chosen or how the matrices U i and F i are estimated.
That being said, the generality of the method suggests some promising directions for future investigation. For example, multistate capture–recapture methods (Lebreton et al. 2009) are designed to estimate survival and transition probabilities from imperfect capture histories. In human demography and biomedical survival analysis, multistate event history methods are used to estimate age‐ and stage‐specific rates of mortality (Andersen and Keiding 2015), but the data are often less fragmentary than in capture–recapture analysis. Possible connections between these approaches might help to estimate parameters for age × stage‐classified models.
In this context, for the special case of stages defined by continuous traits, integral projection models (IPMs) are essentially statisically sophisticated tools for estimating high‐dimensional matrices. An IPM requires kernel functions for growth, survival, and fertility. If these kernels were estimated separately for age classes 1, …, ω, the resulting model would be analogous to those considered here (Ellner et al. 2016: Chapter 6). The fertility kernel are special cases of the set of F i, and the growth and survival kernels special cases of the U i, when partitioned into G i and Σ i as in Eq. (100). When discretized for analysis, the set of IPMs would provide a set of matrices to which our methods can be applied. Note, however, that stages need not be defined by discretization of continuous variables.
Data requirements
Estimating stage‐specific survival, transitions, and fertility is challenging. Obtaining these estimates as a function of age is even more so. However, we have made no assumptions about how the U i and F i vary with age, so even partial age dependence can be incorporated. Perhaps fertility varies with age but survival does not (or cannot be estimated). Or perhaps age dependence can be detected only over sets of age classes (survival and transitions described for age classes 1, 2–5, and >5, while fertility is described for age classes 1–5, 6–10, and >10). The end result in any of these cases is a set of matrices U i and F i, some of which are identical, but the analyses apply without any additional calculations.
In the limit, our method can be applied when U and F do not vary with age at all, in order to explore what would happen if age‐dependent effects were introduced (e.g., Caswell and Salguero‐Gómez 2013).
Applications
Age × stage‐classified matrix models are, in the end, matrix models. As such, they can be applied in the same way as age‐classified or stage‐classified models, to, inter alia, conservation of threatened species, control of pests, ecotoxicology, and epidemiology. These applications will require a model that specifies a management‐relevant outcome from a management‐relevant demographic structure. That might be a simple juvenile–adult model (as in our artificial species) or it might focus on the details of a particular species in a particular place at a particular time. In the latter case, one builds a model based on data from that place and time and applies the relevant methods to analyze it.
If both age and stage are significant components of the i‐state (which is the rationale for constructing an age × stage‐classified model in the first place), then applications will sometimes be well served by including the additional information. (But not necessarily. There is no reason to expect that the most complicated model is the most useful for any specific application.) Having a methodology for age × stage models that parallels that for age‐ and stage‐classified models will facilitate model selection for applications.
Heterogeneity
The role of heterogeneity in population dynamics is a problem of increasing interest (e.g. Vindenes et al. 2008, Steiner and Tuljapurkar 2012, Caswell 2014, Vindenes and Langangen 2015, Cam et al. 2016). From the perspective of an age‐classified model, stage structure is a form of unobserved heterogeneity. It distorts age‐specific outcomes because of intra‐cohort selection (Vaupel et al. 1979, Vaupel and Yashin 1983). It is an additional source of variance among individuals in demographic fate above and beyond that generated by the age schedules of fertility and mortality. From the perspective of a stage‐classified model, age is a form of unobserved heterogeneity. It distorts the dynamics of stage structures and stage durations, particularly in short‐term transient responses. It can also increase variance above that created just by the outcome of stage‐specific processes.
The age × stage‐classified methodology presented here, especially the variance decomposition analysis, can contribute to the analysis of heterogeneity, because it makes it possible to directly measure the consequences of any form of heterogeneity that can be incorporated in the model, for any outcome for which a variance is available. This includes, but is not limited to, the incorporation of latent, unobserved factors such as frailty (Caswell 2014, Hartemink et al. 2017, Jenouvrier et al. 2018, Hartemink and Caswell 2018).
Age, stage, and phenotype: incorporating heritability
The models analyzed here include stages of both parents and offspring, and so it is natural to wonder if somehow the relation of parent to offspring, and the associated concept of heritability, could be incorporating. There are three ways in which the methods could be extended to include phenotypes and heritability. Two of these correspond to the models of Coulson et al. (2010); the third is new.
Let stages represent phenotype categories. Then F i would become a map from parent phenotype to offspring phenotype, for parents of age class i, encapsulating the notion of heritability. The matrix U i would become a phenotype transition and survival matrix for age class i; its structure would depend on whether phenotype traits do or do not change over an individual lifetime. The result would be an age × phenotype model.
Replace age classes with phenotype classes. This would lead to a stage × phenotype model. The matrices U i would describe the survival and stage transitions of individuals in phenotype class i. The F i would describe the production of offspring of all stages by individuals of all stages in phenotype class i. In the age × stage model, the matrix H i is a map from parent age to offspring age. It has the trivial form of Eq. (8) because all newborn individuals start life in age class 1, regardless of the age of their parent. In the stage × phenotype model, H i would become a parent‐offspring phenotype map, encapsulating the heritability of the phenotypic trait. Perfect heritability would imply that . In the complete absence of heritability, all columns of H i would contain an identical probability vector.
In this model, the matrices D i would no longer describe age transitions, but would be replaced by phenotype transition matrices. Careful thought would be required to distinguish stages, or more generally i‐states, from phenotypic traits (e.g., body size might be a stage, while body size at birth, or the coefficients in a growth equation, would be phenotypic traits). See Chevin (2015) for related discussion.
Age × stage × phenotype. The third possibility would be to incorporate phenotype as a third istate dimension, creating a fully age × stage × phenotype‐classified model. The projection matrix for such a model, of dimension wsp (where p is the number of phenotype classes) is obtained from a three‐dimensional array of matrices by a multigenerational generalization of the vec operator. Such models are called hyperstate matrix models; their construction and analysis is presented in Roth and Caswell (2016).
The development of age × phenotype, phenotype × stage, and especially age × stage × phenotype models is an open research problem.
Extensions of age × stage‐classified demography
The approach outlined here suggests extensions of the models; here we mention a few of these.
The construction of from the array yields a population vector in which stages are grouped within age classes. This gives a sort of priority to stage‐specific processes, treating age as a secondary characteristic. The alternative, treating age as primary and stage as a secondary kind of heterogeneity, would be obtained by transposing and creating a population vector, call it , given by
| (113) |
The dynamics of are given by a projection matrix
| (114) |
Then all the results in this paper can be extended to this alternative arrangement by transforming the matrices as in Eq. (114). In doing so, the block‐Leslie structure of in Eq. (15), in which stage matrices are arranged in the pattern of an age‐classified matrix is replaced by a structure with age‐classified matrices arranged in the pattern of the stage transitions.
Yet another intersting extension is to models structured by stage and age within a stage. Stage‐classified models lead to geometrically distributed occupancy times. But if some time must elapse before an individual can advance to the next stage, some internal structure must be imposed to keep track of how long the individual has been in the stage; see Birt et al. (2009) for a recent presentation. These models are related to the age × stage‐classified models considered here, and it will be valuable to connect the two approaches.
We have presented methods here for linear, time‐invariant models, but one value of our approach is that it permits direct extension to more sophisticated models. The population dynamics in Eq. (61) are an ordinary matrix population model, with the projection matrix written as the sum of and . Incorporating density dependence would result in a nonlinear model in which would be a function of . The possible combinations of age‐ and stage‐specific density effects make it a daunting prospect to constuct such models.
However, the methodology here builds the projection matrices from the block‐diagonal matrices like Eq. (11), each of which incorporates one of the sets of processes determining the dynamics (stage development, age transitions, fertility, and age assignment for newborn individuals). Even more, the block‐diagonal matrices in turn are composed of well‐defined matrices U i and F i describing the processes operating on each age‐stage combination. It is at the level of these component matrices that the density effects or time variation actually operate, and the formulation presented here makes those matrices directly accessible for analysis. Something like this has been approached for a stage‐classified epidemic model by Klepac and Caswell (2011).
Stability analysis, reactivity analysis, and sensitivity analysis of nonlinear age × stage‐classified models will then be approachable via extensions, similar to those in Eq. (90), of the matrix calculus approaches developed for nonlinear age‐ and stage‐classified models (Caswell 2008, Verdy and Caswell 2008).
Our methodology invites similar extensions to time‐varying and stochastic environments, by making it easily possible to explore the effects of stochasticity in age‐ and stage‐specific survival, transitions, and fertility. The same applies to spatial structure. However, adding location to the model will require increasing the dimensionality of the i‐state space (just as did the addition of phenotype discussed above). The population vector for an age × stage‐classified model is obtained by applying the vec operator to the two‐dimensional matrix in Eq. (1). The population vector for the age × stage × location model is obtained by applying a multidimensional version of the vec operator to the three‐dimensional analogue of Eq. (1). Such arrays are called hypermatices, and the higher‐dimensional models referred to as hyperstate matrix models; their construction and analysis are detailed in Roth and Caswell (2016). It should come as absolutely no surprise that adding additional dimensions to the i‐state space requires increasing amounts of additional data, but the framework presented here makes it possible, in principle, to do so. This list can be extended. We invite the reader to do so.
Supporting information
Acknowledgments
This research was supported by the European Research Council under the European Union's Seventh Framework Programme (FP7/2007‐2013), ERC Advanced Grant 322989, and also by NSF Grant DEB‐1257545, and NWO‐ALW Project ALWOP.2015.100. We thank Roberto Salguero‐Gomez and three anonymous reviewers for comments on an earlier version of the paper. Discussions in the Theoretical and Computational Ecology Department at the University of Amsterdam provided the environment for the development of this paper.
Corresponding Editor: Aimée T. Classen.
Literature Cited
- Andersen, P. K. , and Keiding N.. 2015. Event history analysis in continuous time Pages 310–319 in Wright J., editor. International encyclopedia of the social and behavioral sciences. Volume 8. Second edition Elsevier, Amsterdam, The Netherlands. [Google Scholar]
- Birch, L. C. 1948. The intrinsic rate of natural increase of an insect population. Journal of Animal Ecology 17:15–26. [Google Scholar]
- Birt, A. , Feldman R. M., Cairns D. M., Coulson R. N., Tchakerian M., Xi W., and Guldin J. M.. 2009. Stage‐structured matrix models for organisms with non‐geometric development times. Ecology 90:57–68. [DOI] [PubMed] [Google Scholar]
- Cam, E. , Aubry L. M., and Authier M.. 2016. The conundrum of heterogeneities in life history studies. Trends in Ecology & Evolution 31:872–886. [DOI] [PubMed] [Google Scholar]
- Caswell, H. 2001. Matrix population models: construction, analysis, and interpretation. Second edition Sinauer Associates, Sunderland, Massachusetts, USA. [Google Scholar]
- Caswell, H. 2006. Applications of Markov chains in demography Pages 319–334 in Langville A. N., and Stewart W. J., editors. MAM2006: Markov anniversary meeting. Boson Books, Raleigh, North Carolina, USA. [Google Scholar]
- Caswell, H. 2008. Perturbation analysis of nonlinear matrix population models. Demographic Research 18:59–116. [Google Scholar]
- Caswell, H. 2009. Stage, age and individual stochasticity in demography. Oikos 118:1763–1782. [Google Scholar]
- Caswell, H. 2011. Beyond R0: demographic models for variability of lifetime reproductive output. PLoS ONE 6:e20809. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Caswell, H. 2012. Matrix models and sensitivity analysis of populations classified by age and stage: a vec‐permutation matrix approach. Theoretical Ecology 5:403–417. [Google Scholar]
- Caswell, H. 2013. Sensitivity analysis of discrete Markov chains via matrix calculus. Linear Algebra and its Applications 438:1727–1745. [Google Scholar]
- Caswell, H. 2014. A matrix approach to the statistics of longevity in heterogeneous frailty models. Demographic Research 31:553–592. [Google Scholar]
- Caswell, H. , and Salguero-Gómez R.. 2013. Age, stage and senescence in plants. Journal of Ecology 101:585–595. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Caswell, H. , and Shyu E.. 2012. Sensitivity analysis of periodic matrix population models. Theoretical Population Biology 82:329–339. [DOI] [PubMed] [Google Scholar]
- Caswell, H. , and van Daalen S. F.. 2016. A note on the vec operator applied to unbalanced block‐structured matrices. Journal of Applied Mathematics 2016:1–3. [Google Scholar]
- Charlesworth, B. 1994. Evolution in age-structured populations. Second edition Cambridge University Press, Cambridge, UK. [Google Scholar]
- Chevin, L.-M. 2015. Evolution of adult size depends on genetic variance in growth trajectories: a comment on analyses of evolutionary dynamics using integral projection models. Methods in Ecology and Evolution 6:981–986. [Google Scholar]
- Clutton-Brock, T. , and Sheldon B. C.. 2010. Individuals and populations: the role of long‐term, individual‐based studies of animals in ecology and evolutionary biology. Trends in Ecology and Evolution 25:562–573. [DOI] [PubMed] [Google Scholar]
- Coale, A. J. 1972. The growth and structure of human populations: a mathematical approach. Princeton University Press, Princeton, New Jersey, USA. [Google Scholar]
- Cochran, M. E. , and Ellner S.. 1992. Simple methods for calculating age‐based life history parameters for stage‐structured populations. Ecological Monographs 62:345–364. [Google Scholar]
- Cohen, J. E. 1982. Multiregional age-structured populations with changing vital rates: weak and stochastic ergodic theorems Pages 477–503 in Land K. C., and Rogers A., editors. Multidimensional mathematical demography. Academic Press, New York, New York, USA. [Google Scholar]
- Cole, L. C. 1954. The population consequences of life history phenomena. Quarterly Review of Biology 29:103–137. [DOI] [PubMed] [Google Scholar]
- Coulson, T. , Tuljapurkar S., and Childs D. Z.. 2010. Using evolutionary demography to link life history theory, quantitative genetics and population ecology. Journal of Animal Ecology 79:1226–1240. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Csetenyi, A. I. , and Logofet D. O.. 1989. Leslie model revisited: some generalizations to block structures. Ecological Modelling 48:277–290. [Google Scholar]
- Cushing, J. M. , and Zhou Y.. 1994. The net reproductive value and stability in matrix population models. Natural Resources Modeling 8:297–333. [Google Scholar]
- De Roos, A. M. 2008. Demographic analysis of continuous‐time life‐history models. Ecology Letters 11:1–15. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Deevey, E. S. 1947. Life tables for natural populations of animals. Quarterly Review of Biology 22:283–314. [DOI] [PubMed] [Google Scholar]
- Dublin, L. I. , and Lotka A. J.. 1937. Uses of the life table in vital statistics. American Journal of Public Health 27:481–491. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Easterling, M. R. , Ellner S. P., and Dixon P. M.. 2000. Size‐specific sensitivity: applying a new structured population model. Ecology 81:694–708. [Google Scholar]
- Edwards, R. D. 2011. Changes in world inequality in length of life: 1970‐2000. Population and Development Review 37:499–528. [DOI] [PubMed] [Google Scholar]
- Edwards, R. D. , and Tuljapurkar S.. 2005. Inequality in life spans and a new perspective on mortality convergence across industrialized countries. Population and Development Review 31:645–674. [Google Scholar]
- Ellner, S. P. , Childs D. Z., and Rees M.. 2016. Data-driven modelling of structured populations. Springer, New York, New York, USA. [Google Scholar]
- Engelman, M. , Caswell H., and Agree E. M.. 2014. Why do lifespan variability trends for the young and old diverge? Demographic Research 30:1367–1396. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Feeney, G. M. 1970. Stable age by region distributions. Demography 7:341–348. [PubMed] [Google Scholar]
- Feichtinger, G. 1971. Stochastische modelle demographischer prozesse. Lecture Notes in Economics and Mathematical Systems. Springer-Verlag, Berlin, Germany. [Google Scholar]
- Fisher, R. A. 1930. The genetical theory of natural selection. Oxford University Press, Oxford, UK. [Google Scholar]
- Frühwirth-Schnatter, S. 2006. Finite mixture and Markov switching models. Springer-Verlag, New York, New York, USA. [Google Scholar]
- Gaillard, J.-M. , Yoccoz N. G., Lebreton J.-D., Bonenfant C., Devillard S., Loison A., Pontier D., and Allaine D.. 2005. Generation time: a reliable metric to measure life‐history variation among mammalian populations. American Naturalist 166:119–123. [DOI] [PubMed] [Google Scholar]
- Goodman, L. A. 1969. The analysis of population growth when the birth and death rates depend on several factors. Biometrics 25:659–681. [PubMed] [Google Scholar]
- Hamilton, W. D. 1966. The moulding of senescence by natural selection. Journal of Theoretical Biology 12:12–45. [DOI] [PubMed] [Google Scholar]
- Hartemink, N. , and Caswell H.. 2018. Variance in animal longevity: contributions of heterogeneity and stochasticity. Population Ecology. 10.1007/s10144-018-0616-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hartemink, N. , Missov T. I., and Caswell H.. 2017. Stochasticity, heterogeneity, and variance in longevity in human populations. Theoretical Population Biology 114:107–117. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Henderson, H. V. , and Searle S. R.. 1981. The vec‐permutation matrix, the vec operator and Kronecker products: a review. Linear and Multilinear Algebra 9:271–288. [Google Scholar]
- Honeycutt, A. A. , Boyle J. P., Broglio K. R., Thompson T. J., Hoerger T. J., Geiss L. S., and Narayan K. M. V.. 2003. A dynamic Markov model for forecasting diabetes prevalence in the United States through 2050. Health Care Management Science 6:155–164. [DOI] [PubMed] [Google Scholar]
- Horvitz, C. C. , and Tuljapurkar S.. 2008. Stage dynamics, period survival, and mortality plateaus. American Naturalist 172:203–215. [DOI] [PubMed] [Google Scholar]
- Hutchinson, G. E. 1978. An introduction to population ecology. Yale University Press, New Haven, Connecticut, USA. [Google Scholar]
- Iosifescu, M. 1980. Finite Markov processes and their applications. Wiley, New York, New York, USA. [Google Scholar]
- Jenouvrier, S. , Aubry L. M., Barbraud C., Weimerskirch H., and Caswell H.. 2018. Interacting effects of unobserved heterogeneity and individual stochasticity in the life cycle of the Southern fulmar. Journal of Animal Ecology 87:212–222. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kempthorne, O. 1957. An Introduction to Genetic Statistics. John Wiley & Sons, New York, New York, USA. [Google Scholar]
- Keyfitz, N. 1968. Introduction to the Mathematics of Population. Addison-Wesley, Reading, Massachusetts, USA. [Google Scholar]
- Keyfitz, N. , and Caswell H.. 2005. Applied mathematical demography. Third edition Springer, New York, New York, USA. [Google Scholar]
- Klepac, P. , and Caswell H.. 2011. The stage‐structured epidemic: linking disease and demography with a multi‐state matrix approach model. Theoretical Ecology 4:301–319. [Google Scholar]
- Knott, K. E. , and McHugh D.. 2012. Introduction to symposium: poecilogonya window on larval evolutionary transitions in marine invertebrates. Integrative and Comparative Biology 52:120–127. [DOI] [PubMed] [Google Scholar]
- Krug, P. J. 2007. Poecilogony and larval ecology in the gastropod genus Alderia*. American Malacological Bulletin 23:99–111. [Google Scholar]
- Law, R. 1983. A model for the dynamics of a plant population containing individuals classified by age and size. Ecology 64:224–230. [Google Scholar]
- Lebreton, J.-D. 1996. Demographic models for subdivided populations: the renewal equation approach. Theoretical Population Biology 49:291–313. [DOI] [PubMed] [Google Scholar]
- Lebreton, J.-D. 2005. Age, stages, and the role of generation time in matrix models. Ecological Modelling 188:22–29. [Google Scholar]
- Lebreton, J.-D. , Khaladi M., and Grosbois V.. 2000. An explicit approach to evolutionarily stable dispersal strategies: no cost of dispersal. Mathematical Biosciences 165:163–176. [DOI] [PubMed] [Google Scholar]
- Lebreton, J.-D. , Nichols J. D., Barker R. J., Pradel R., and Spendelow J. A.. 2009. Modeling individual animal histories with multistate capture‐recapture models. Advances in Ecological Research 41:87–173. [Google Scholar]
- Lefkovitch, L. 1965. The study of population growth in organisms grouped by stages. Biometrics 21:1–18. [Google Scholar]
- Leslie, P. H. , and Park T.. 1949. The intrinsic rate of natural increase of Tribolium castaneum Herbst. Ecology 30:469–477. [Google Scholar]
- Levin, L. A. , Caswell H., DePatra K. D., and Creed E. L.. 1987. Demographic consequences of larval development mode: planktotrophy vs. lecithotrophy in Streblospio benedicti . Ecology 68:1877–1886. [DOI] [PubMed] [Google Scholar]
- Lewontin, R. C. 1965. Selection for colonizing ability Pages 77–91 in Baker H. G. and Stebbins G. L., editors. The genetics of colonizing species. Academic Press, New York, New York, USA. [Google Scholar]
- Logofet, D. O. 2002. Three sources and three constituents of the formalism for a population with discrete age and stage structures (in Russian). Mathematical Modelling 14:11–22. [Google Scholar]
- Logofet, D. O. 2013. Complexity in matrix population models: polyvariant ontogeny and reproductive uncertainty. Ecological Complexity 15:43–51. [Google Scholar]
- Loichinger, E. 2015. Labor force projections up to 2053 for 26 EU countries, by age, sex, and highest level of educational attainment. Demographic Research 32:443–486. [Google Scholar]
- Lotka, A. J. 1939. Théorie analytique des associations biologiques: analyse démographique avec application particulière à l'espèce humaine. Actualitès Scientifiques et Industrielles, Hermann et Cie, Paris, France (published in translation as: Analytical theory of biological populations. Translated by D. P. Smith and H. Rossert. Plenum Press, New York, NY. 1998).
- Magnus, J. R. , and Neudecker H.. 1979. The commutation matrix: some properties and applications. Annals of Statistics 7:381–394. [Google Scholar]
- Metcalf, C. J. E. , Lessler J., Klepac P., Morice A., Grenfell B. T., and Bjørnstad O. N.. 2012. Structured models of infectious disease: inference with discrete data. Theoretical Population Biology 82:275–282. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Metz, J. A. J. , and Diekmann O.. 1986. The dynamics of physiologically structured populations. Lecture Notes in Biomathematics. Springer-Verlag, Berlin, Germany. [Google Scholar]
- Nisbet, R. M. , and Gurney W.. 1982. Modelling fluctuating populations. Wiley, Chichester, UK. [Google Scholar]
- Norton, H. T. J. 1928. Natural selection and Mendelian variation. Proceedings of the London Mathematical Society 28:1–45. [Google Scholar]
- Pearl, R. , and Miner J. R.. 1935. Experimental studies on the duration of life. XIV. The comparative mortality of certain lower organisms. Quarterly Review of Biology 10:60–79. [Google Scholar]
- Rényi, A. 1970. Probability theory. North-Holland, Amsterdam, The Netherlands. [Google Scholar]
- Rogers, A. 1968. Matrix analysis of interregional population growth and distribution. University of California Press, Berkeley, California, USA. [Google Scholar]
- Rogers, A. 1975. Introduction to multiregional mathematical demography. Wiley, New York, New York, USA. [Google Scholar]
- Roth, W. E. 1934. On direct product matrices. Bulletin of the American Mathematical Society 40:461–468. [Google Scholar]
- Roth, G. , and Caswell H.. 2016. Hyperstate matrix models: extending demographic state spaces to higher dimensions. Methods in Ecology and Evolution 7:1438–1450. [Google Scholar]
- Roth, G. , and Caswell H.. 2018. Occupancy time in sets of states for demographic models. Theoretical Population Biology 120:62–77. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Salguero-Gómez, R. , et al. 2015. The COMPADRE plant matrix database: an open online repository for plant demography. Journal of Ecology 103:202–218. [Google Scholar]
- Salguero-Gómez, R. , et al. 2016. COMADRE: a global data base of animal demography. Journal of Animal Ecology 85:371–384. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sánchez Gassen, N. E. 2014. Germany's future electors: developments of the German electorate in times of demographic change. Springer, Wiesbaden, Germany. [Google Scholar]
- Sinko, J. W. , and Streifer W.. 1967. A new model for age‐size structure of a population. Ecology 48:910–918. [Google Scholar]
- Slobodkin, L. B. 1961. Growth and regulation of animal populations. Holt, Reinhart, and Winston, New York, New York, USA. [Google Scholar]
- Stearns, S. C. 1992. The evolution of life histories. Oxford University Press, Oxford, UK. [Google Scholar]
- Steiner, U. K. , and Tuljapurkar S.. 2012. Neutral theory for life histories and individual variability in fitness components. Proceedings of the National Academy of Sciences of the United States of America 109:4684–4689. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Steiner, U. K. , Tuljapurkar S., Coulson T., and Horvitz C.. 2012. Trading stages: life expectancies in structured populations. Experimental Gerontology 47:773–781. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Steiner, U. K. , Tuljapurkar S., and Coulson T.. 2014. Generation time, net reproductive rate, and growth in stage‐age‐structured populations. American Naturalist 183:771–783. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Steinsaltz, D. , and Evans S. N.. 2004. Markov mortality models: implications of quasistationarity and varying initial distributions. Theoretical Population Biology 65:319–337. [DOI] [PubMed] [Google Scholar]
- Stott, I. , Townley S., Carslake D., and Hodgson D. J.. 2010. On reducibility and ergodicity of population projection matrix models. Methods in Ecology and Evolution 1:242–252. [Google Scholar]
- Strasser, C. A. , Neubert M. G., Caswell H., and Hunter C. M.. 2012. Contributions of high‐ and low‐quality patches to a metapopulation with stochastic disturbance. Theoretical Ecology 5:167–179. [Google Scholar]
- Tuljapurkar, S. 1990. Population dynamics in variable enviroinments. Springer-Verlag, New York, New York, USA. [Google Scholar]
- Tuljapurkar, S. , and Caswell H.. 1997. Structured-population models in marine, terrestrial, and freshwater ecosystems. Chapman and Hall, New York, New York, USA. [Google Scholar]
- Tuljapurkar, S. , and Edwards R. D.. 2011. Variance in death and its implications for modeling and forecasting mortality. Demographic Research 24:497–526. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tuljapurkar, S. , and Horvitz C. C.. 2006. From stage to age in variable environments: life expectancy and survivorship. Ecology 87:1497–1509. [DOI] [PubMed] [Google Scholar]
- van Daalen, S. , and Caswell H.. 2015. Lifetime reproduction and the second demographic transition: stochasticity and individual variation. Demographic Research 33:561–588. [Google Scholar]
- van Daalen, S. F. , and Caswell H.. 2017. Lifetime reproductive output: individual stochasticity, variance, and sensitivity analysis. Theoretical Ecology 10:355–374. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Van der Gaag, N. , Bijwaard G., de Beer J., and Bonneux L.. 2015. A multistate model to project elderly disability in case of limited data. Demographic Research 32:75. [Google Scholar]
- van Groenendael, J. M. , and Slim P.. 1988. The contrasting dynamics of two populations of Plantago lanceolata classified by age and size. Journal of Ecology 76:585–599. [Google Scholar]
- Van Raalte, A. A. , and Caswell H.. 2013. Perturbation analysis of indices of lifespan variability. Demography 50:1615–1640. [DOI] [PubMed] [Google Scholar]
- Vaupel, J. W. , and Canudas Romo V.. 2003. Decomposing change in life expectancy: a bouquet of formulas in honor of Nathan Keyfitz's 90th birthday. Demography 40:201–216. [DOI] [PubMed] [Google Scholar]
- Vaupel, J. W. , and Yashin A. I.. 1983. The deviant dynamics of death in heterogeneous populations. International Institute for Applied Systems Analysis, Laxenburg, Austria. [Google Scholar]
- Vaupel, J. W. , Manton K. G., and Stallard E.. 1979. The impact of heterogeneity in individual frailty on the dynamics of mortality. Demography 16:439–454. [PubMed] [Google Scholar]
- Vaupel, J. W. , Zhang Z., and van Raalte A. A.. 2011. Life expectancy and disparity: an international comparison of life table data. British Medical Journal Open 1:e000128. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Verdy, A. , and Caswell H.. 2008. Sensitivity analysis of reactive ecological dynamics. Bulletin of Mathematical Biology 70:1634–1659. [DOI] [PubMed] [Google Scholar]
- Vindenes, Y. , and Langangen Ø.. 2015. Individual heterogeneity in life histories and eco‐evolutionary dynamics. Ecology Letters 18:417–432. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vindenes, Y. , Engen S., and Saether B.-E.. 2008. Individual heterogeneity in vital parameters and demographic stochasticity. American Naturalist 171:455–467. [DOI] [PubMed] [Google Scholar]
- Werner, P. A. , and Caswell H.. 1977. Population growth rates and age versus stage‐distribution models for teasel (Dipsacus sylvestris Huds.). Ecology 58:1103–1111. [Google Scholar]
- Willekens, F. 2014. Multistate analysis of life histories with R. Springer, New York, New York, USA. [Google Scholar]
- Wu, G. , Wang Y.-M., Yen A., Wong J.-M., Lai H.-C., Warwick J., and Chen T.. 2006. Cost effectiveness analysis of colorectal cancer screening with stool DNA testing in intermediateincidence countries. BMC Cancer 6:136. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhou, Y. , Putter H., and Doblhammer G.. 2016. Years of life lost due to lower extremity injury in association with dementia, and care need: a 6‐year follow‐up population‐based study using a multi‐state approach among German elderly. BMC Geriatrics 16:9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zuidema, P. A. , Brienen R. J. W., During H. J., and Güneralp B.. 2009. Do persistently fast‐growing juveniles contribute disproportionately to population growth? A new analysis tool for matrix models and its application to rainforest trees. American Naturalist 174:709–719. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials