

Abstract
In recent years, driven by scientific and clinical concerns, there has been an increased interest in the analysis of functional brain networks. The goal of these analyses is to better understand how brain regions interact, how this depends upon experimental conditions and behavioral measures and how anomalies (disease) can be recognized. In this work we provide, firstly, a brief review of some of the main existing methods of functional brain network analysis. But rather than compare them, as a traditional review would do, instead, we draw attention to their significant limitations and blind spots. Then, secondly, relevant experts, sketch a number of emerging methods, which can break through these limitations. In particular we discuss five such methods. The first two, stochastic block models and exponential random graph models, provide an inferential basis for network analysis lacking in the exploratory graph analysis methods. The other three address: network comparison via persistent homology, time-varying connectivity that distinguishes sample fluctuations from neural fluctuations and, network system identification that draws inferential strength from temporal autocorrelation.
Keywords: fMRI, causality, time-varying, graph, ERGM, small world network, topological data analysis, system identification
I. Introduction
In the last two decades, interest has surged in network (NW) analysis across a wide range of disciplines. In fact modern network studies have a long history, stretching back at least 5 decades 1 in a number of disciplines, with the best known being perhaps, Physics [1] and Sociology [2]; but others include: Economics (diffusion of innovations), Epidemiology (disease transmission), Electrical Engineering (power grids), Civil Engineering (transport), and still others.
Several factors have led to the recent widespread interest. The most obvious is that network data has become readily available to almost all disciplines due to advances in sensing and measurement technologies and storage. This has led to a demand for deeper understanding of NWs which in turn has led to advances such as: graphical analysis of network architecture e.g. small world NWs [3], methods of study of network dynamics [4]; and ultimately to the emergence of a network science [5] aimed at understanding network structure and function.
In neuroimaging, brain network study has been dominated by resting-state functional magnetic resonance imaging (rs-fMRI), where blood oxygen level dependent (BOLD) signals are measured in subjects at rest. A number of such rs-studies have found spontaneous activity that is highly correlated between multiple brain regions (e.g. [102], [103]). Because of this, the study of functional connectivity, or the undirected association between two or more fMRI time series, has come to the forefront of research efforts in the field. Here the time series can be obtained from individual voxels, [104], [105], [106], averaged over pre-specified regions of interest [107], or estimated using independent component analysis [108].
Thus network literature is then, in the midst of a classic exponential explosion in volume and it is not possible for any scholar or lab or even subdiscipline of scholars to keep up with it. How then to proceed? The classic leakage (‘diffusion of innovations [6]’) 2 mechanism between disciplines ensures that significant new approaches will slowly make their way to other knowledge territories [8]. This paper is meant to be an example of, as well as to hopefully hasten, that process.
This short review paper has two major objectives. Firstly to briefly review some of the major current approaches in brain connectivity with the aim of highlighting significant blind spots; issues that are holding up development but being ignored. And secondly to sketch some emerging techniques that can break through these blind spots.
A. What is a Functional Network?
But before we get to this we must address the fundamental question of definition. This is necessary because unfortunately some current language is misleading if not confused. What then is a NW? What is the difference between a system and a NW? What is network structure? What is network function? What is network dynamics? What is the difference between ‘time-varying’, ‘dynamic’ and fluctuating?
We follow a terminology, more than half a century old, developed in areas such as Mathematical System Theory, Control Engineering, Statistical Signal Processing and Physics. We are also informed by the long running concern in the neurosciences with structure versus function.
A network consists of nodes connected by links 3. For simplicity, in a brain activity network, we take a node to be an anatomical parcel carrying a scalar or vector time series (see [9] for a more detailed discussion). This definition implies an underlying architecture showing how the nodes are connected. But it says nothing about interactions between nodes. Now let us now recall the following definition: a system is a set of interacting components forming a complex whole. Joining these two we get what we will call a functional network (fNW): a set of interacting nodes. A particular task may involve only a subset of connected nodes so a single network will be capable of performing many different functions.
There are then two aspects to a fNW: the ‘map’ or architecture showing how nodes are connected and the dynamics (time-lagged interaction) between the nodes, which shows how the fNW is used, namely its function. We prefer to use ‘structure’ solely for anatomical NWs. So anatomical NWs only have architecture while fNWs have both architecture and dynamics. The architecture of the fNW will vary with the task and in general be a subset of the architecture of the whole NW.
To understand the function of a fNW (carrying out a particular task) we thus need to understand the architecture and the dynamics. Clearly the architecture will constrain the dynamics in various ways, but just knowing the architecture is not enough to understand the function. This is why graph analysis methods, which only deal with architecture, cannot provide a complete understanding of fNW function.
Three pairs of words are used to distinguish between constancy versus change with time: time-invariant versus time-varying (TV); static versus dynamic; stationary versus non-stationary. In everyday language the first of each pair are used interchangeably as are the second of each pair and this has led to more than just semantic confusion because their technical uses are not interchangeable.
We need to describe time change for: nodal signals, network architecture, network function. The following mutually exclusive terminology is standard in the disciplines referred to above. For general discussion we say that nodal signals, architecture, and dynamics, may fluctuate over time. Specific terminology is as follows: nodal signals may be statistically stationary 4 or statistically non-stationary; architecture may be time-invariant or time-varying; network function can be static or dynamic and the dynamics may be statistically stationary or statistically non-stationary. Again note that ‘dynamics’ refers to the time-lagged interaction between nodal signals.
Unfortunately, it seems that in incorrectly using the term ‘dynamic’ connectivity for TV connectivity, the research community thinks it is treating dynamics whereas it has been ignoring it, i.e. failing to deal with time-lagged nodal interaction.
B. Constructing Functional Networks
To provide some context for the paper we sketch a standard approach to constructing a network model from rs-fMRI data, which broadly involves four steps:
Define the network nodes: Divide the brain into regions of interest (parcels representing network nodes) and collate the data within to give a single representative time series at each node.
Construct the network: Estimate whether the link between each pair of nodes is active (architecture), and the strength of link if it is active (dynamics).
Network Interpretation: Analyze the network architecture and dynamics within each individual network.
Network Comparison: Assess similarity and differences in architecture and dynamics between individual networks.
We note the crucial need in steps 1, 2, to deal comprehensively with potential artefacts [16],[17].
As explained below, Sections II,III deal with step 3. Sections IV,VI deal with step 2. Section V deals with step 4.
C. Omissions
Omitted areas include those already well surveyed or those whose blind spots have not been tackled. Graph analysis5 methods are well surveyed e.g. see [12]. Those badly in need of (whole paper) reviews include: Granger causality, see [10] and the critique in [11]; multi-modal methods, see [15]; software, a starting point is the recent controversy over major fMRI software ‘bugs’ as discussed in [14].
D. Blind Spots and Breakthroughs
The remainder of the paper splits naturally into two parts. In part I, consisting of section II,III, it is assumed that link strengths are given. In part II, consisting of sections IV,V,VI link strengths are estimated from the nodal time series data. We now introduce each section briefly.
While graph analysis methods have received intense attention in fNW modeling they are only exploratory, whereas for scientific and clinical use one needs to do inference, a problem that has been poorly addressed. Both stochastic block models (section II) and statistical network models (section III) provide an inferential basis for structural modeling.
Although time-varying connectivity has rapidly gained attention, early warnings of the need to find ways to distinguish sampling fluctuation from neural fluctuation [107] have been ignored. This can only be done from a principled inferential basis. Such methods are surveyed in section IV. Network comparison is fundamental for distinguishing abnormal from normal. Graph analysis methods may be able to do that if the networks have the same number of nodes and links. But what has been ignored, is that in practice, the networks to be compared have differing numbers of nodes and links as well as spatial and temporal resolutions. Standard graph analysis methods cannot handle this. But Persistent Homology (section V) can. As discussed above, function is intimately concerned with inter-nodal interaction and hence with nodal memory i.e. dynamics. But the current linear correlation-based connectivity analysis cannot deal with this. To do so one must take autocorrelation into account and until recently it has been ignored. Emerging approaches that include it, are discussed in section VI. Section VII contains conclusions.
II. Stochastic Block Models
A. A Short History
Stochastic block models (SBMs) originate from the social science objects called "sociograms" [18]. These social networks were later modeled by adjacency matrices. The representation of block models came with the idea that within a network, nodes could be grouped in communities, or clusters or blocks, and the nodes belonging to the same group would have similar structure or pattern of connections with the nodes of another community. [19] defined a block as a set of nodes which share a common "equivalence structure" with nodes in another block. In stochastic block models randomness is introduced, and this pattern of connections or equivalence structure is "stochastic", therefore providing a more flexible definition. The pattern of connections is represented by a probability of connections with other groups: given that two nodes e.g. i and j are from blocks A and B, the presence of a link between the nodes is governed by the probability : pAB. SBMs initially proposed by Snijders and Nowicki [20] are today ubiquitous in many network characteristics estimation and analysis tasks, including community detection (see section II-C). The classical model generates simple non weighted networks and only allows a node to be assigned to a single block, but extensions have been developed (see below).
B. Definitions and Overview
The SBM is a generative model for graphs that takes as inputs n nodes, a partition of the nodes into B non overlapping blocks (or communities) C = C1, C2, ⋯,CB, and a B × B matrix of probability Pkl specifying the probability of connection between nodes in Ck and Cl.
This model has the advantages of a link generative model, making assumptions explicit, clarifying interpretation of the parameters, and permitting the use of statistical techniques such as likelihood scores for model comparison: given a SBM M and some observed graph G, one can compute P(G∣M). However, estimation of the model from data can be costly.
Note that if Pkl = p for all k, l, the graphs generated are Erdös-Rényi random graphs. If Pkk ≥ Pkl for k ≠ l, then the model generates assortative communities, otherwise the communities are dissortative.
Figure 1 illustrates the type of graph obtained from a SBM model with five blocks.
Figure 1.
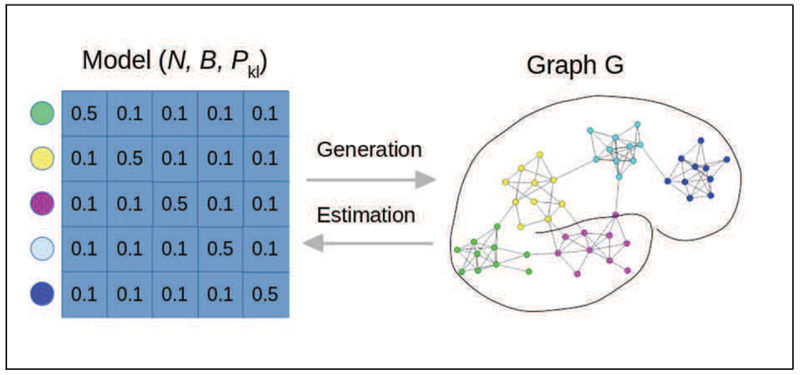
Stochastic Block Model: the model allows the generation of assortative communities, for example here the probability of connection is 0.5 within communities (i.e. blocks), and 0.1 across communities. The model consists of the number of nodes N, the partition of the nodes B, and the matrix of connection probability Pkl. normalsize
C. Use of SBMs for Community Detection
There are many deterministic algorithms to detect communities (or equivalently clusters) of the nodes of the graph (minimum cut, hierarchical clustering, Girvan-Newman algorithm [21], modularity maximization). Loosely speaking most algorithms attempt to maximize the number of connections within clusters and minimize it across clusters. Modularity (such as Newman and Girvan’s [21]) measures quantify the quality of the separation of the communities and are used as objective functions to estimate the clustering. The choice of the number of clusters (communities) is a critical element of any community detection attempt and algorithms often require this number to be fixed. The Spectral [22] and Fast Louvain [23] are two widely used examples of estimating this number.
Because SBMs can generate a wide range of networks, they are useful statistical models for community detection when the parameters of the model can be sufficiently accurately estimated. The estimation generally relies on maximum likelihood techniques [20], optimized with variational Bayes in the work of [24]. The number of blocks can be estimated with a number of techniques such as AIC and BIC, but the Integrated Classification Likelihood is well adapted in this context [24].
While these techniques have already shown their usefulness, it is worth noting the limitations of SBMs for the recovery of graph structure. Because SBMs are simple they may not necessarily provide a good and/or insightful model of actual fMRI data, and technically may not be able to recover fully or partially the true nodal partition [25]. We discuss below whether these models can be useful specifically for fMRI network detection given the characteristics of these signals.
D. Current use in fMRI Studies
The use of SBMs is only emerging in fMRI, and only a few studies have so far used this aproach for estimation of communities and of graph characteristics, despite the fact that SBMs are a widespread fundamental graph statistical tool. The reasons for this limited use are likely due to:
the difficulty of estimation in particular for a large number of nodes and communities, and the competition of established deterministic approaches,
the lack of well-documented libraries adapted for estimation on fMRI data,
the limitations of the original model to unweighted graphs and non-overlapping communities, making this tool better adapted to anatomical connectivity [26]
Nevertheless SBMs are now being investigated by some authors for brain functional data. For instance, Pavlovic’s work extends the original SBM from Snijders and Nowicki [20] and from Daudin and colleagues [24], to multi-subject and repeated measure analyses where a common group level network is estimated while allowing inter-subject variations, as well as providing statistical tests for inference between populations. In a recent study, Rajapakse and colleagues [27] used the Human Connectome Project resting state data and show that SBM and degree corrected SBM (dc-SBM) have higher likelihood measures compared to power law and exponential networks. It should be noted that these works may need to be further pursue and replicated to better assess the usefulness of SBMs. These techniques are unlikely to be widely used until the methods are included into well maintained and well tested libraries (see for instance [28]. In addition, it is unclear how these methods will be able to scale if the number of region of interests is larger than the few hundreds tested for instance in [27], or to adapt to more complex temporal structure that may be needed for instance in longitudinal studies.
E. Future use in fMRI
Because SBMs are being extended in several ways, in particular to weighted graphs, degree corrected, and overlapping communities, its usefulness for fMRI data is likely to grow in the future. In the long term, the benefit of a formal statistical link generative model will outweigh the cost of additional computation implied by the use of these models. This however will only take place if well-documented, well-tested and efficient software libraries are developed and released, and if the theoretical limitations are clearly communicated to and understood by the brain imaging community. Finally, as with other models, there is a critical need to develop the validation frameworks for SBM and extensions, both with simulated data and more importantly with the convergence of biological results in specific neuroscience questions. Further use of SBMs also needs much tighter collaborations with cognitive neuroscientists, demonstrating their usefulness in providing answers to neuroscience or cognitive neuroscience questions that current methods cannot.
III. Statistical Network Models
Following the discussion in the introduction brain NW analysis necessitates a holistic multivariate modeling framework that allows assessing the effects of multiple variables of interest and topological NW features on the overall NW structure. That is, if we have
we want the ability to model the probability density function of the network given the covariates P (Yi∣Xi, θi), where θi are the parameters that relate the covariates to the NW structure. Strides in developing such a framework have been made both with exponential random graph models (ERGMs) [29],[30],[31],[32] and mixed models [33], but more work is needed on refining these approaches, and developing new ones.
We briefly delineate these two analytical approaches for brain NW analysis in sections III.A and III.B.
A. Exponential Random Graph Models (ERGMs)
ERGMs have the form of the regular exponential family given below:
| (1) |
Here Y is an n × n (n nodes) random symmetric adjacency matrix representing a brain network from a particular class of NWs, with Yij = 1 if a link exists between nodes i and j and Yij = 0 otherwise. The probability mass function (pmf) (Pθ (Y = y∣X)) of this class of NWs is a function of the prespecified network features defined by g(y, X). This vector of prespecified explanatory metrics can consist of covariates that are functions of the network y (e.g., number of paths of length two) and nodal covariates (X) (e.g., brain location of the node). The parameter vector θ, associated with g(y, X), quantifies the relative significance of the network features in explaining the structure of the network after accounting for the contribution of all other network features in the model. More specifically, θ indicates the change in the log odds of a link existing for each unit increase in the corresponding explanatory metric. If the θ value corresponding to a given metric is large and positive, then that metric plays a considerable role in explaining the network architecture and is more prevalent than in the null model (random network with the probability of a link existing (p)= 0.5). Conversely, if the θ value is large and negative, then that metric still plays a considerable role in explaining the network architecture but is less prevalent than in the null model. Consequently, inferences can be made about whether certain local features/substructures are observed in the network more than would be expected by chance [34], enabling hypothesis development regarding the biological processes that produce these structural properties. The normalizing constant κ (θ) ensures that the probabilities sum to one. This approach allows representing the global brain NW structure by locally specified explanatory metrics, thus providing a means to examine the nature of NWs that are likely to emerge from these effects.
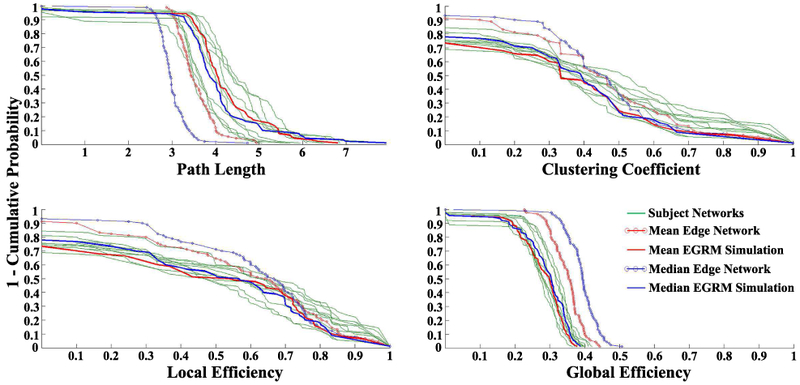
ERGMs provide a powerful approach for modeling, analyzing and simulating functional [29],[30] and structural [32] brain NWs while controlling for confounding that arises from NW metric dependencies. For example, as a proof of concept, [29] applied them to (task-free) fMRI connectivity NWs from 10 normal participants aged 20-35 and found they provided a good fit to the data as evidenced by the goodness-of-fit (GOF) plots and simulations. Additionally, the analysis found NW level difference between the five younger (aged 20-26) and five slightly older (aged 29-35) participants. Namely, that if two brain regions are not functionally connected, they are more likely to have shared connections with other regions in the brain NWs of the older group. Though speculative, this could be the result of older brains maintaining indirect connections between areas that have lost their direct connections. ERGMs also show utility in producing group-based "representative" NWs [30]. Simply averaging the connectivity matrices, and thresholding the resulting matrix, fails to produce an accurate “summary” brain NW [30],[35]. The need for these representative NWs is well documented [36],[37],[38],[39],[40],[41],[42],[43]. Using the same fMRI connectivity data discussed above, [30] simulated representative NWs from the pmf employing the average (mean and median) parameter estimates from the ERGM fits to each participant. Figure 3 exhibits the nodal distributions for path length, clustering coefficient, global efficiency, and local efficiency for the 10 participants’ NWs, mean and median correlation NWs (from averaging the connectivity matrices), and the most representative (mean and median) simulated ERGM NWs. The ERGM-based NWs more accurately capture both the average of the NW properties across the participants and distributions of those properties than the mean and median correlation NWs.
Figure 3.

Cartoon model of important differences found between the NWs of farmworkers and non-farmworkers. Each network node represents a brain region and the lines represent functional connections. The node color indicates the module membership and the edge thickness represents connection strength. The average connection probability (density) and strength are the same between farmworkers and non-farmworkers. However, brain NWs of farmworkers are more modularly organized and have higher functional specificity and lower inter-modular integrity when compared to non-farmworkers (stronger connections are shown with thicker edges). Reproduced from [56]. normalsize
Despite the utility of the ERGM framework for brain Networks, important limitations remain. Multiple-participant comparisons can pose problems given that these models were originally developed for the modelling of one NW at a time [29]. Additionally, the programming work load increases linearly with the number of participants since ERGMs must be fitted and assessed for each participant individually [30]. Incorporating novel metrics (perhaps more rooted in brain biology) may be difficult due to degeneracy issues that may arise [44],[45]. MCMC MLE fits of ERGMs can be computationally intensive and may fail to converge with more spatially resolved NWs than the 90 ROI ones used in previous analyses. Model fits with this approach have been shown to handle NWs of several thousand nodes [55]; however, convergence properties are more dependent on the number and topological structure of the edges than the node count [55]. Further work is needed to more precisely assess the scalability of ERGMs in the brain NW context. While well-suited for substructural assessments, link-level examinations remain difficult with these models. Moreover, most ERGM developments have been for binary NWs; approaches for weighted NWs have been developed [46],[47], but have yet to be ported into the brain NW context.
Addressing the ERGM limitations directly provides an avenue for further inquiry; however, a mixed modeling approach may provide a more flexible, complementary method [48]. As with ERGMs, mixed modeling approaches for NW data have mostly been developed for analyzing an individual NW [48],[49],[50]. Simpson and Laurienti [33] provided the first attempt to adapt this framework to the multi-NW neuroimaging context, addressing many of the ERGM drawbacks: mixed models are well-suited for link-level examinations and multiple participant comparisons; novel metrics can be easily incorporated; and they are easily adaptable to weighted and longitudinal NWs.
B. Mixed-Effects Models
Mixed models have served as a complementary approach to ERGMs in the social NW literature [48],[49],[50],[51] and were recently ported into the brain NW context [33],[56]. Given the standard convention of having positively weighted NWs, with negative weights removed (i.e., set to 0 indicating no connection) due to the lack of metrics defined for negative values [52],[53], Simpson et al. [33] define the following two-part mixed-effects modeling framework to model both the probability of a connection (presence/absence) and the strength of a connection if it exists. Let Yijk represent the strength of the connection (quantified as the correlation in our case) and Rijk indicate whether a connection is present (presence variable) between node j and node k for the ith participant. Thus, Rijk = 0 if Yijk = 0, and Rijk = 1 if Yijk > 0 with conditional probabilities
| (2) |
where βr is a vector of population parameters (fixed effects) that relate the probability of a connection to a set of covariates (Xijk) for each participant and nodal pair (dyad), and bri is a vector of participant- and node-specific parameters (random effects) that capture how this relationship varies about the population average (βr) by participant and node (Zijk). Here Zijk is the design matrix for participant i that contains the covariate values corresponding to the respective random effects bri (i.e., it is analogous to Xijk for the fixed effects βr). Hence, pijk (βr; bri) is the probability of a connection between nodes j and k for participant i, and the logistic mixed model (part I model) for the probability of this connection follows:
| (3) |
For the part II model, which aims to model the strength of a connection given that there is one, let Sijk = [Yijk∣Rijk = 1] and FZT denote Fisher’s Z-transform. In this case, the Sijk will be the values of the correlation coefficients between nodes j and k for participant i. The mixed model for the strength of a connection (part II model) is
| (4) |
where βs is a vector of population parameters that relate the strength of a connection to the same set of covariates (Xijk) for each participant and nodal pair (dyad), bsi is a vector of participant- and node-specific parameters that capture how this relationship varies about the population average (βs) by participant and node (Zijk), and eijk accounts for the random noise in the connection strength of nodes j and k for participant i. Again Zijk is the design matrix for participant i that contains the covariate values corresponding to the respective random effects bsi. This framework enables quantifying the relationship between phenotype and brain connectivity patterns while reducing spurious correlations through inclusion of confounders, predicting phenotype based on connectivity structure, simulating NWs to establish normal ranges of topological variability, and thresholding individual NWs leveraging group information. Further details of the approach can be found in [33]. This approach was recently applied to examine the impacts of pesticide and nicotine exposures on the (task-free) functional brain NWs of Latino immigrant farmworkers [56]. Figure 4 (from [56]) presents a cartoon model of important differences found between the NWs of farmworkers (n = 48) and non-farmworkers (n = 26). Farmworkers tended to have more modularly organized brain NWs with higher functional segregation and lower inter-modular integrity. This suggests that farmworkers may have more segregated neural processing and less global integration of information.
Figure 4.

Graph filtration of: (a) attention-deficit hyperactivity disorder (ADHD); (b) autism spectrum disorder (ASD); (c) pediatric controls (Ped-Con). As the filtration value on the horizontal axis increases the NW connections in each panel increase. Reprinted from [72]. normalsize
While mixed modeling frameworks such as this one show promise, they remain in their infancy for the brain NW context. Additionally, while they can handle NWs on the order of a hundred nodes, scaling to larger NWs will require dimension reduction methods.
IV. Network Comparison using Persistent Homology
A. Why we need Persistent Homology?
There are many statistical methods of comparing NWs [57] including matrix norms of the difference between connectivity matrices [57], [58], [59]. However, the element-wise differences simply ignore the topology of the NWs failing to capture higher order similarity such as relations between pairs of columns or rows [58]. Further, matrix norms are sensitive to outliers. Since links are equally weighted a few extreme weights may severely affect the norms. Additionally norms may fail to recognize topological structures such as the connected components or cycles in the NW.
Thus it is necessary to develop comparison methods that recognize topology.
In graph analysis approaches, NW comparisons are based on features such as assortativity, betweenness centrality, smallworldness and NW homogeneity [60], [61], [62]. Comparison of such features appears to reveal changes of structural connectivity associated with different clinical populations [61]. Since weighted brain NWs are difficult to interpret and visualize, they are often turned into binary NWs by thresholding link weights [63]. The choice of threshold will impact the NW topology. To deal with this issue, a multiple comparison correction over every possible link has been proposed [64]. But now the underlying p–value impacts the topology. Another approach is to control the sparsity of links [65], [66], [63], [67]. But now one must threshold sparse parameters. Thus existing methods for binarizing weighted NWs have not escaped the threshold choice problem. Since it seems clear that the threshold must depend on cognitive conditions and clinical populations [68], a different approach is called for. A new multiscale hierarchical NW modeling framework based on persistent homology provides such an approach [69], [70], [71], [72].
B. What is Persistent Homology?
Persistent homology, a technique of computational topology [73], [74], provides a more coherent mathematical framework for comparing NWs. Instead of looking at NWs at a fixed scale, persistent homology charts the changes in topological network features over multiple resolutions and scales [74], [75], [76]. In doing so, it reveals the most ‘persistent’ topological features i.e. those that are robust to noise. This scale robustness is crucial since most NW distances are parameter and scale dependent.
Homology is an algebraic formalism to associate a sequence of objects with a topological space [74]. In persistent homology, homology usually refers to homology groups which are often built on top of a simplical complex for point cloud and NW data [77]. A simplical complex is a collection of points (0-simplex), lines (1-simplex), triangles (2-simplex) and higher dimensional counter parts. We build a vector space Ck using the set of k-simplices as a basis. The vector spaces Ck, Ck−1, Ck−2, ⋯ are then sequentially nested by boundary operator ∂k [74]:
Let Bk be a collection of boundaries obtained as the image of ∂k. Let Zk be a collection of cycles obtained as the kernel of ∂k. We have Bk ⊂ Zk and quotient space Hk = Zk∣Bk, which is called the k-th homology group. The rank of Hk is the k-th Betti number.
In persistent homological NW analysis as established in [71], [72], instead of analyzing NWs at one fixed threshold, we build the collection of nested NWs over every possible threshold using a graph filtration, a persistent homological construct [69], [72]. The graph filtration is a threshold-free framework for analyzing a family of graphs but requires hierarchically building specific nested subgraph structures. The proposed method shares some similarities to existing multithresholding or multi-resolution NW models that use many different arbitrary thresholds or scales [78], [63], [79], [72]. However such approaches are exploratory, being mainly used to visualize graph feature changes over different thresholds without quantification. Persistent homology, on the other hand, quantifies such feature changes in a coherent way.
C. What is Graph Filtration?
In persistent homology, NWs are modeled as a metric space χ = (V, ρ) consisting of a node set V and link weight function ρ which satisfies the metric properties of: nonnegativity, identity, symmetry and the triangle inequality
The most common such metric is . Using inter-nodal distances that are true metrics makes the comparison of brain NWs vastly easier due to the triangle inequality. Many NW distances are in fact metric or ultrametric [72].
Persistent homological NW analysis begins with the construction of the graph filtration. We threshold the weighted network χ = (V, ρ) at level ϵ to obtain a binary network denoted as . Then any graph X = (V, ρ) with up to r distinct link weights 0 < ρu(1) < ρu(2) < ⋯ < ρu(r) can be uniquely decomposed as a sequence of nested multiscale graph structures called the graph filtration [71], [72], [70]:
| (5) |
For any ϵ ≥ 0, is in one of the binary NWs of the filtration (5). In this sense, the representation (5) is unique.
D. What Persistent Homological Features are Used?
As the threshold level in a graph filtration increases, homologies in the homology group appear (are ’born’) and disappear (’die’). The NW topology can then be represented by the ’birth’ and ’death’ of homologies in the persistent homology. The zeroth and first homologies are a set of connected components and cycles, respectively. If a homology appears at the threshold ξ and disappears at τ, it can be encoded into a point, (ξ, τ) (0 ≤ ξ ≤ τ < ∞) in . If m homologies appear during the filtration of a NW χ = (V, ρ), the homology group can be represented by a point set . This scatter plot is called the persistence diagram [88]. The premise of persistent homology is that a homology with a longer ’duration’ is a feature of the topological space and shown as points away from the diagonal line i.e. ξ = τ in persistent diagrams while homology with a shorter ’duration’ is noise and shown as points close to the diagonal line.
Aside from the persistence diagram, various persistent homological features such as barcodes [89] and persistent landscapes [90] are available. Unfortunately, statistical inference on these nonstandard and nonlinear features turns out to be nontrivial and so mostly relies on resampling techniques such as the jackknife and permutation tests [69], [70], [91]. A simpler and possibly more effective approach is to quantify the changes in NW topology using monotonic topological features such as the number of connected components, which is called the zeroth Betti number [69], [70], [80] (Fig. 4):
| (6) |
The size of the largest cluster satisfies a similar but opposite relation of monotonic increase. Many graph theoretic features such as node degree will be also monotonic. In [80], the slope of the linear regression line is fitted in scatter plot and used to differentiate different clinical populations. In [70], integral is used as the summary statistic instead of the vector (6).
E. Measuring Topological Distance Between NWs
Instead of using topological features that summarize each NW, one can directly compare NWs by computing a distance between NWs. The bottleneck distance is perhaps the most widely used distance measure in persistent homology [88], [74]. It is defined through the distance between corresponding persistence diagrams (PDs). Points in different PDs do not naturally correspond as a bijection. Thus, the computation of the distances between PDs is not straightforward and often requires bipartite graph matching algorithms [88] [92].
[93] bypassed the problem of comparing PDs by comparing the density of points in a square grid via kernel smoothing. Motivated by [93], later methods have used kernel distances [94], [95], [96]. Thus [95] introduced the persistent scale space (PSS) kernel, which is the inner product between heat diffusions with the PD-points as the initial heat sources. PSS was extended to multiple PSS kernels in determining the changes in brain NW distances in aging [96].
Gromov-Hausdorff (GH) distance is a popular NW distance, which measures the distance between the respective dendrograms of the NWs [73], [97]. Single linkage distance between two nodes is the shortest distance between two connected components that contain the nodes. GH-distance is the maximum of the single linkage distance differences [72]. It was applied to brain NWs in [71], [72]. It has been shown that the computation of GH-distance can be reduced to computing differences in single linkage matrices thus making a connection with hierarchical clustering [73], [72].
F. Computational Complexity
Persistent homology does not scale well with NW size. The computational complexity of the k-th Betti number depends on the number m of k-simplices [98]. For n nodes, m ≤ O(nk+1). The homology computation requires Gaussian elimination, which often runs in O(m3). Thus, the overall worst case computational complexity is O(n3k+3). As n increases, the computational bottleneck can be severe.
So resampling based statistical inference may not be feasible for very large-scale NWs. We need faster inference procedures that do not rely on resampling techniques [81].
G. Statistical Inference in network Distances
Given two NWs χ1 = (V, ρ1) and χ2 = (V, ρ2), we are interested in testing the null hypothesis H0 of equivalence: H0 : χ1 = χ2. In persistent homology, this inference problem is mainly addressed by comparing a topological feature between NWs or computing a distance between NWs. Unfortunately, all the standard topological features or between NW distances do not have known probability distributions, which makes statistical inference difficult. Unless we are dealing with a ‘large’ number of observed NWs and so can appeal to the central limit theorem [90], statistical inference has to be done using resampling techniques such as jackknife, bootstrap or permutation methods [72], [91], [70], which causes computational bottlenecks for large scale NWs.
To bypass the computational bottleneck, the Kolmogorov-Smirnov (KS) distance was proposed in [69], [70], [91], [81]. KS-distance is motivated by the two-sample Kolmogorov-Smirnov (KS) test [99], [69], [100], which is a nonparametric test for determining the equivalence of two cumulative distribution functions (CDFs). The curve looks exactly like a CDF if it is properly normalized. KS-distance is the maximum differences between the two curves. The number of connected components and the size of the largest connected component can be used as monotonic features f.
The advantage of the KS-distance is its simple interpretation compared to other distances. It is possible to enumerate the sample space combinatorially and determine its probability distribution exactly [81]. Simulation based comparisons between different network distances are given in [101].
V. Time-varying Functional Connectivity
Recently, focus in the brain connectivity has begun to shift from evaluating static functional connectivity over the length of a scanning session, to analyzing time-varying (TV) functional connectivity ([105]). Here the goal is to study changes in functional connectivity on the time-scale of seconds to minutes, and classify the brain into distinct connectivity patterns (i.e. ‘brain states’) to which subjects tend to move between during the course of the scan. This is illustrated in Fig.5.
Figure 5.

Figure legend: (A) Resting-state fMRI time series from 21 regions of the brain from a single subject. (B) The results of a change point analysis ([109]) show a connectivity change point roughly half way through the scanning session. The two correlation matrices represent the brain state before and after the change point. Edges between visual components (color-coded as pink) and both cognitive control (olive green) and default mode (grey) components appear to be particularly variable. normalsize
Results have demonstrated that while the patterns of connectivity describing each state are reliable across groups and individuals [110], other characteristics such as the amount of time spent in specific states and the number of transitions between states can vary as a function of individual differences such as age [111] or disease status [112], [113].
A. Sliding Windows
To date, the most widely used strategy for detecting TV functional connectivity has been the so-called sliding window technique, where a linear (aka Pearson) correlation matrix is computed over a fixed-length time window of the fMRI time series. The window is thereafter moved step-wise across time, providing a TV measure of the linear correlation between brain regions. Observations within the fixed-length window can be given equal weight, or allowed to gradually enter and exit the window as it is shifted across time [108]. Potential pitfalls of the family of sliding-window methods include using arbitrarily fixed-length windows, ignoring all values outside of the windows, and an inability to handle abrupt changes in connectivity patterns.
B. Beyond Sliding Windows
To circumvent some of these shortcomings, we now point to a number of more advanced methods.
Multivariate time series methods (e.g., Dynamic Conditional Correlations [114]) that directly model the conditional correlation between fMRI time courses have recently been introduced to the neuroimaging field [115]. These techniques have been shown to be less susceptible to noise-induced temporal variability in correlations compared to the sliding-window based approaches. However, compared to sliding-window techniques there are increased computational costs involved with using these methods, which can become substantial as the number of regions of interest increases.
Another alternative is to use time-frequency analysis (e.g., wavelet transform coherence) to examine temporal variability in the relationship between time series from different regions [107]. This allows for the estimation of the coherence and phase lag between two time series as a function of both time and frequency. This technique has provided evidence of considerable modulation of coherence across the time-frequency plane, and that significant coherence is focal in time. However, a shortcoming of this type of analysis is that it tends to produce large amounts of information, presenting particular computational challenges when analyzing multiple subjects and brain regions.
Analysis is further complicated by the fact that, in contrast to many other statistical methods that reduce the dimensionality of the data, TV functional connectivity methods tend to substantially increase the number of data points. For example, a T × d (time-by-region) input matrix becomes a d × d × T array after application of sliding-window methods. Therefore, the ability to find meaningful measures that reliably summarize TV functional connectivity is of utmost importance. One approach is to compute basic summary statistics, such as the mean and variance of the TV functional connectivity across time. Another involves the estimation of “brain states", which are defined as recurring whole-brain connectivity profiles that are reliable across subjects throughout the course of the resting state scan [116]. A common approach to determining the presence of such coherent states across subjects is to perform k-means clustering on the set of correlation matrices measured across time. States can then be defined as the patterns of connectivity at each centroid, and additional summary metrics such as the amount of time each subject spends in a given state (i.e., dwell time) and the number of transitions between states can be computed.
A crucial observation here, is that the traditional k-means clustering procedures are time-invariant, since permutation of the correlation matrices (across time) give rise to equivalent results. Hence, alternative methods that incorporate lagged temporal information will almost certainly provide better results. One such alternative uses techniques from change point analysis (e.g., [117], [118], [109]). Here time courses from multiple regions are partitioned into distinct segments, within which the data follow a multivariate Gaussian distribution with a different covariance (or inverse covariance) matrix from its neighboring segments; see Fig.5 for an illustration. A number of different algorithms have been proposed that primarily differ in the manner in which change points are determined, and the network structures are identified. Yet another promising approach is the application of Hidden Markov Models [123],[124]. Here it is assumed that the time series data can be described using a sequence of a finite number of latent states, with each state characterized by a unique covariance matrix.
As the number of regions/components included in the analysis increases, the scalability of the different methods becomes critical. Here the sliding-window approaches tend to scale better than model based approaches. The latter can becomes particularly cumbersome if a separate model is fit to each bivariate connection. Of the model based approaches the DCD approach [109] was specifically designed with scalability in mind and thus tends to work better at high-dimensions than its counterparts.
C. Comments and controversies
The problem of estimating TV connectivity is difficult in practice. A major issue is related to the relatively few degrees of freedom availabale in the data, which in turn increases the statistical difficulty in estimating the correlation matrices. This is due to a number of factors, including: (i) the use of narrow window sizes when using sliding window approaches; (ii) the inherent autocorrelation present in the data; and (iii) the fact that a number of ‘nuisance’ effects (e.g., motion, low-frequency drift, and physiological measurements) are removed from the signal prior to analysis. Together this loss in degrees of freedom will contribute to increased variation (across time) in the TV correlation, which could lead to noise being interpreted as important signal. These problems are amplified if one seeks to study TV changes in partial-correlation. Here the resulting covariance matrices risk being ill-conditioned necessitating the inclusion of potentially severe penalization terms.
In addition, it should be noted that the existence of TV functional connectivity has not been without controversy [119], [120]. For example, a recent paper by [120] made the case that much of the observed ‘dynamics’ during rest is actually attributable to sampling variability, head motion, and fluctuating sleep state. Thus, they argue a single correlation matrix is sufficient to describe the resting state as measured by BOLD fMRI.
Clearly much work remains to gain a proper understanding of TV brain architecture. To achieve this goal it is critical that proper statistics and signal processing play an important role, as there remain multiple methodological shortcomings in the regularly applied approaches (e.g. there is a pressing need for confidence intervals on ‘curves’ to measure the significance of TV fluctuations [107]; see [121] for some initial work), making it difficult to determine whether observed fluctuations in connectivity should be attributed to neuronal activity, non-neural biological signals, or noise [104], [122].
VI. Functional Network System Identification
Our point of takeoff from the introduction is problems relating to step 2 in the NW construction.
Most rs-fMRI functional connectivity studies construct the NW (Step 2) using linear correlation (LC) as a measure of functional association between brain regions [125], [126]. But LC ignores various important issues in NW construction. Chiefly it only measures indirect association between nodal or regional time series whereas neuroscientific theories can only be built from measures of direct association [127]. Thus many of the common interpretations of functional connectivity networks (Steps 3 and 4) are implicitly invalidated if the NWs are constructed using indirect measures such as LC. Instead, we describe recent advances in NW system identification using concepts from statistical signal processing, to estimate the direct (i.e. conditional or partial) relationships between brain regions from rs-fMRI data thus defining fNW architecture and dynamics.
A. Conditional Independence
Partialling (out all other nodes) or conditioning (on all other nodes) is the basic method used to compute direct measures of association between nodes from indirect ones. This underlies the construction of conditional independence graphical models (CI-GMs), where a missing link between a particular pair of nodes implies those nodes are conditionally independent given the other nodes [128], [129], [130]. Then graph analysis concepts such as path length and node degree have a clearly defined and interpretable meaning being now applied to direct association measures.
CI (i.e. direct) interactions are difficult to estimate [131], especially for a large network as for fMRI [132]. In contrast, marginal (indirect) interactions are computationally easier to obtain, e.g. via a pairwise LC, but are uninterpretable because they are dominated by indirect relations. One further benefit which emerges during the construction of a CI graph is the implicit removal of NW-wide confounding signals from the estimation of each link strength. When estimating functional brain NWs, common physiological or scanner-induced noise, uncorrected motion artifact, or other uninteresting signal present among the set of nodal signals will be accounted for during the estimation of CI links. One approach to obtain CI NW link strengths in the Gaussian setting is to replace marginal LC with partial correlation [143], [144], [145], which can be computed via the regularized inverse of the data covariance matrix.
But partial correlation is not sufficient to deal with real time series such as from rs-fMRI data, as we also need to: i) overcome the ‘curse of dimensionality’, especially when there is an equal or greater number of parameters to estimate than the number of samples within the data, and ii) account for serial temporal autocorrelations within and between nodal time series.
B. Data Dimensionality Effects
The data dimensionality issue concerns both the relatively large number of spatial links to estimate from fewer temporal data points, and particularly for fMRI, the strong collinearity between many of the voxel signals. The problem is compounded for rs-fMRI data since brain activity can only be assumed to be stationary over a relatively short time interval, typically a few minutes at best; also it is not necessarily practical to collect more temporal data over a longer scanning session. If not dealt with, these problems cause estimated NWs to be so noisy that artefacts are consistently mistaken for structure. The problem is not confined to rs-fMRI data, as spurious structure emerges even from empirical covariance matrices constructed from white noise processes (i.e. null NWs) as studied in Random Matrix Theory (RMT) [133], [134]. Spurious structure emerging from null correlation NWs has been described previously in the rs-fMRI literature [135], but the link to data dimensionality and RMT has not yet been widely explored [127], [136]. The dimensionality problem can be dealt with in part by massive parameter dimension reduction, e.g. by collating local spatial collections of voxel time series into regions to represent NW nodes and summarizing these regions by a single representative time series at each node, collating data across subjects [144], and also by sparsity regularization [137]
C. Serial Correlations
Dealing with serial or lagged temporal correlations within data is crucial, as hemodynamics induce a strong spatially-varying temporal autocorrelation profile within the data. Fig. 6 demonstrates the increase in rs-fMRI data complexity caused by temporal correlations as the temporal sampling rate is increased. These serial correlations can be dealt with by using partial coherences instead of partial correlations [138], [139] to quantify the association between each pair of nodes. The link strength is then expressed as a function of frequency, giving a separate NW at each frequency. However, attempting to analyze NWs at each frequency is challenging and would still leave unanswered the question of producing a single summary NW; to do that one needs an overall measure of link strength. That issue was addressed in [127] by using sparse conditional trajectory (frequency domain) Mutual Information (SCoTMI).
Figure 6.

Univariate autoregressive model order estimated at each voxel of example rs-fMRI datasets; Human Connectome Project data having TR=0.72s (left), temporally down-sampled and anti-aliased HCP data with TR≈2.2s (centre), and standard quality data with TR=2s (right). normalsize
D. Sparse Conditional Trajectory Mutual Information
Let xt = [x(d),t], be a jointly stationary network time series at nodes d = 1, …, D and time points t = 1, …, T. Partitioning the data as [x(a),t, x(b),t, x(z),t] where a and b are two nodes of interest, then as T → ∞ the frequency domain conditional Mutual Information is
where ρab∣z (ω) is the partial coherence at frequency ω between nodes a and b given other nodes z. For SCoTMI the partial coherence is estimated parametrically via the conditional spectra F(ω) of a vector ℓ0-sparse penalized vector autoregression model as . Estimating ρab∣z (ω) alternatively using a non-parametric estimate directly from the DFT of the data as done by [140], [141] leads to extremely noisy estimates when applied to real rs-fMRI time series [127].
The VAR model of order p is separable at each node, and the model to fit at node d is ; where , X(d),t = [y(d),t−1, …,y(d),t−p]T. The model is penalized to be sparse within each node by minimizing the cost function
and h is a tuning parameter determining the degree of sparsity. An empirical significance threshold is estimated using null (unconnected) NW simulations; NW links above the threshold are kept and links below the threshold are discarded. Implementation and details to compute F(ω) from the VAR parameters are in [127].
The SCoTMI model fitting is trivially parallelized due to the separability per node, and can easily handle NWs of hundreds or thousands of nodes if there are sufficiently many samples in the time series.
E. Example Results
We show an example of SCoTMI NWs [127] using rs-fMRI data from the Human Connectome Project. Fig. 7 shows the repeatability of detecting SCoTMI NW links across 80 individual datasets (20 subjects with 4 scanning runs each). We see here the NW architecture is qualitatively similar between SCoTMI, sparse partial correlation and partial correlation; the quantitative superiority of SCoTMI over those approaches is documented in [127].
Figure 7.

Circos diagram of the repeated link detection from 80 SCoTMI NWs (A), using an 87 node Freesurfer parcellation of grey matter regions. Line width is proportional to the number of subjects with repeated detection of a particular link. Cortical links are green, subcortical links are orange. Comparison methods include sparse partial correlation (B), partial correlation (C), and linear correlation (D). normalsize
VII. Conclusions
In the introduction we cleared up confusion surrounding definitions including possible blind spots that had been thus generated. In the reviews we pointed to significant blind spots of some of the major current methods of studying fNWs and then sketched five emerging methods drawn from other disciplines that have already proved able to address various of these blind spots.
Stochastic block models treat the nodal links stochastically. This provides a powerful framework not just for for modeling/pruning the fNW, but also for inferring the (overlapping) clustering of functional regions. This promises a rich description of the functional subnetworks which current methods provide only in a very crude way.
While graph analysis has been very useful it has not proceeded beyond the exploratory stage. ERGMs (and mixed modeling approaches) provide a modeling framework in which to embed the graph analysis methods and so provide a means of confirmatory analysis.
For TV connectivity simple exploratory sliding window methodology has reached its limits having lead to overinterpretation of the estimated fluctuations and much more sophisticated confirmatory methods, particularly involving modeling autocorrelation are needed to dig out the true time-varying fluctuations if any.
In practical neuroimaging one needs to compare NWs with differing number of nodes and links and differing spatial and temporal resolutions. Graph analysis methods cannot do this but the emrging technique of persistent homology can.
Linear correlation has dominated fNW modeling. But it only measures indirect interactions and to get at direct interaction one needs to use measures such as partial correlation. The neuroimaging community has struggled to understand this fundamental issue. Further real dynamics requires analysis of serial correlation which has been ignored. NW system identification techniques being developed in the statistical signal processing and control engineering comunities can address this kind of issue and their preliminary extension and application to neuroimaging is already providing superior results.
Certainly each of these methods has a long way to go. They each address some blind spots but not all. Thus SBMs and ERGMs so far have not addressed the issue of autocorrelation. TV connectivity has not addressed the serial correaltion problem while the ScoTMI technique has not addressed the TV connectivity problem. And persistent homology needs to be embedded in a confirmatory framework to handle multisubject inference properly.
To sum up, fNW analysis has reached a cross-roads wherein current methods have reached their limits and some new tools are needed. In fact there are an array of powerful new methods beginning to be applied to neuroimaging connectivity, that are capable of answering practical fNW questions arising in clinical and scientific application.
Figure 2.
Nodal distributions of path length, clustering coefficient, global efficiency, and local efficiency for the 10 participants NWs, mean and median correlation NWs, and most representative (mean and median) ERGM-based NWs. Reproduced from [30]. normalsize
Acknowledgments
This work was partially supported as follows: Victor Solo by NIH grant P41EB015896; Jean-Baptiste Poline by NIH-NIBIB P41 EB019936 (ReproNim) ;NIH-NIMH R01 MH083320 (CANDIShare) and NIH 5U24 DA039832 (NIF); Martin A. Lindquist by NIH grant R01-EB016061; Sean L. Simpson by NIH grant K25-EB012236 and Wake Forest Clinical and Translational Science Institute (WF CTSI) (UL1TR001420); F. DuBois Bowman and Ben Cassidy by NIH/NINDS grant U18 NS082143; Moo K. Chung by NIH grant R01-EB022856.
To several reviewers for comments that improved the paper.
Footnotes
Or even earlier? Perhaps back to the French ’Encycloepdia’s’ of the 17th Century?
A compelling contemporary documenting of this in several cases can be found in [7].
We prefer the more concrete computer science language here than the abstract mathematical one of vertex and edge.
this is the technical version of stationarity and it means that statistical properties depend only on time differences not on absolute time
Also inaccurately called graph theory
Contributor Information
Victor Solo, School of Electrical Engineering, University of New South Wales, Sydney, Australia; MGH/MIT-Martinos Center for Biomedical Imaging, Harvard Medical School, Charlestown, MA, USA..
Jean-Baptiste Poline, Helen Wills Neuroscience Institute, U.C. Berkeley, CA, USA..
Martin A. Lindquist, Department of Biostatistics, Johns Hopkins University, Baltimore, MD, USA.
Sean L. Simpson, Department of Biostatistical Sciences, Wake Forest School of Medicine, Winston-Salem, NC, USA.
F. DuBois Bowman, Department of Biostatistics, Columbia University, New York, NY, USA..
Moo K. Chung, Department of Biostatistics and Medical Informatics, University of Wisconsin-Madison, Madison, WI, USA.
Ben Cassidy, Department of Biostatistics, Columbia University, New York, NY, USA..
References
- [1].Newman M, Networks: An Introduction. Oxford, UK: Oxford Univ., Press, 2010. [Google Scholar]
- [2].Wasserman S and Faust K, Social Network Analysis. Cambridge, UK: Cambridge Univ., Press, 1994. [Google Scholar]
- [3].Watts D, Small Worlds: The Dynamics of Networks Between Order and Randomness. Princeton, NJ, USA: Princeton University Press, 1999. [Google Scholar]
- [4].Cohen R and Havlin S, Complex Networks Structure, Robustness and Function. Cambridge, UK: Cambridge University Press, 2010. [Google Scholar]
- [5].Committee on Network Science for Future Army Applications, Network Science. Washington DC, USA: National Academies Press, 2005. [Google Scholar]
- [6].Rogers E, Diffusion of Innovations. New York: Free Press, 2003. [Google Scholar]
- [7].Jacobs J, In Defense of Academic Disciplines. Chicago, USA: Univ., Chicago Press, 2013. [Google Scholar]
- [8].Becher T, Academic Tribes and Territories. Buckingham, UK: Open University Press, 1989. [Google Scholar]
- [9].Stanley M, Moussa M, Paolini B, Lyday R, Burdette J, and Laurienti P, “Defining nodes in complex brain networks,” Frontiers in Computational Neuroscience, vol. 7-169, pp. 1–14, 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].Ramsay JD and Hanson SJ and Hanson C and Halchenko YO and Poldrack RA and Glymour C, “Six problems for causal inference from fMRI,” Neuroimage, vol. 49, pp. 1545–1558, 2010. [DOI] [PubMed] [Google Scholar]
- [11].Solo V, “State Space Analysis of Granger-Geweke Causality with application to fMRI,” Neural Computation, vol. 28, pp. 914–949, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Bassett D and Bullmore E, “Small-world brain networks revisited,” The Neuroscientist, vol. -, pp. 1–18, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [13].Eklund A and Nichols TE and Knutsson H, “Cluster failure: Why fMRI inferences for spatialextent have inflated false-positive rates,” PNAS, vol. 113, pp. 7900–7905, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [14].Brown E and Behrmann M, “Controversy in statistical analysis of functionalmagnetic resonance imaging data,”PNAS, vol. 114, pp. E3368–E3369, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].Calhoun VD and Sui J, “Multimodal Fusion of Brain Imaging Data:A Key to Finding the Missing Link(s) in Complex Mental Illness,”Biological Psychiatry: Cognitive Neuroscience and Neuroimaging, vol. 1, pp. 230–244, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [16].Murphy K, Birn RM and Bandettini PA, “Resting-state FMRI confounds and cleanup,” Neuroimage, vol. 80, pp. 349–359, 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [17].Power JD, Mitra A, Laumann TO, Snyder AZ, Schlaggar BL and Petersen SE, “Methods to detect, characterize, and remove motion artifact in resting state fMRI,” Neuroimage, vol. 84, pp. 320–341, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].Moreno J, “Back Matter,” Sociometry, vol. 16, no. 1, 1953. [Online]. Available: http://www.jstor.org/stable/2785959 [Google Scholar]
- [19].Lorrain F and White HC, “Structural equivalence of individuals in social networks,” Jl. Math. Sociology, vol. 1, pp. 49–80, January 1971. [Google Scholar]
- [20].Snijders TAB and Nowicki K, “Estimation and Prediction for Stochastic Blockmodels for Graphs with Latent Block Structure,” Journal of Classification, vol. 14, pp. 75–100, January 1997. [Google Scholar]
- [21].Newman MEJ and Girvan M, “Finding and evaluating community structure in networks,” Physical Review E, vol. 69, February 2004. [DOI] [PubMed] [Google Scholar]
- [22].Newman ME, “Modularity and community structure in networks,” Proc. Nat. Acad. Sciences, vol. 103, pp. 8577–8582, 2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [23].Blondel VD, Guillaume J-L, Lambiotte R, and Lefebvre E, “Fast unfolding of communities in large networks,” Jl. of Statistical Mechanics: Theory and Experiment, vol. 2008, no. 10, p. P10008, October 2008. [Google Scholar]
- [24].Daudin J-J, Picard F, and Robin S, “A mixture model for random graphs,” Statistics and Computing, vol. 18, pp. 173–183, June 2008. [Google Scholar]
- [25].Abbe E, “Community detection and stochastic block models: recent developments,” arXiv preprint arXiv: 1703.10146, 2017. [Google Scholar]
- [26].Pavlovic DM, Vertes PE, Bullmore ET, Schafer WR, and Nichols TE, “Stochastic Blockmodeling of the Modules and Core of the Caenorhabditis elegans Connectome PLoS ONE, vol. 9, p. e97584, July 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [27].Rajapakse JC, Gupta S, and Sui X, “Fitting networks models for functional brain connectivity,” in Biomedical Imaging (ISBI2017), 2017 IEEE 14th International Symposium on. IEEE, 2017, pp. 515–519. [Google Scholar]
- [28].Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, and Dubourg V, “Scikit-learn: Machine learning in Python,” Jl. of Machine Learning Research, vol. 12, pp. 2825–2830, 2011. [Google Scholar]
- [29].Simpson SL, Hayasaka S, and Laurienti PJ, Exponential random graph modeling for complex brain networks. PLoS ONE, 2011. 6(5): e20039. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [30].Simpson SL, Moussa MN, and Laurienti PJ, An ERG-modeling approach to creating group-based representative whole-brain connectivity networks. Neuroimage, 2012. 60(2): 1117–26. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [31].Simpson SL, Bowman FD, and Laurienti PJ, Analyzing complex functional brain networks: Fusing statistics and network science to understand the brain. Stat Surv, 2013. 7: 1–36. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [32].Sinke MR, et al. , Bayesian ERG-modeling of whole-brain structural networks across lifespan. NeuroImage, 2016. 135: 79–91. [DOI] [PubMed] [Google Scholar]
- [33].Simpson SL and Laurienti PJ, A two-part mixed-effects modeling framework for analyzing whole-brain network data. Neuroimage, 2015. 113: 310–319. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [34].Robins GL, Pattison PE, Kalish Y, and Lusher D,. An introduction to exponential random graph (p*) models for social networks. Social Networks, 2007. 29: 173–191. [Google Scholar]
- [35].Ginestet CE, Simmons A, Statistical parametric network analysis of functional connectivity dynamics during a working memory task. NeuroImage, 55, 688–704, 2011. [DOI] [PubMed] [Google Scholar]
- [36].Achard S, Salvador R, Whitcher B, Suckling J, Bullmore E. A resilient, low-frequency, small-world human brain functional network with highly connected association cortical hubs. Journal of Neuroscience, 26: 63–72, 2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [37].Meunier D, Achard S, Morcom A, and Bullmore E Age-related changes in modular organization of human brain functional networks. NeuroImage, 44: 715–723, 2009. [DOI] [PubMed] [Google Scholar]
- [38].Song M, Liu Y, Zhou Y, Wang K, Yu C, and Jiang T Default network and intelligence difference Conf. Proc. IEEE Eng. Med. Biol. Soc, 2212–2215, 2009. [DOI] [PubMed] [Google Scholar]
- [39].Valencia M, Pastor MA, Fernández-Seara MA, Artieda J, Martinerie J, and Chavez M Complex modular structure of large-scale brain networks. Chaos, 19: 023119, 2009. [DOI] [PubMed] [Google Scholar]
- [40].Joyce KE, Laurienti PJ, Burdette JH, and Hayasaka S A new measure of centrality for brain networks. PLoS ONE, 5: e12200, 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [41].Jirsa VK, Sporns O, Breakspear M, Deco G, and McIntosh AR Towards the virtual brain: network modeling of the intact and the damaged brain. Arch. Ital. Biol, 148: 189–205, 2010. [PubMed] [Google Scholar]
- [42].Zuo X, Ehmke R, Mennes M, Imperati D, Castellanos FX, Sporns O, and Milham MP Network centrality in the human functional connectome. Cerebral Cortex, 22: 1862–1875, 2012. [DOI] [PubMed] [Google Scholar]
- [43].Gratton C, Nomura EM, Perez F, and D’Espsito M Focal brain lesions to critical locations cause widespread disruption of the modular organization of the brain. Jl. Cogn. Neuroscience, 24: 1275–1285, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [44].Handcock MS Statistical models for social networks: Inference and degeneracy Dynamic Social Network Modelling and Analysis: Workshop Summary and Papers. eds. Breiger R, Carley K, and Pattison PE. Washington, DC: National Academy Press: 229–240, 2002. [Google Scholar]
- [45].Rinaldo A, Fienberg SE, Zhou Y On the geometry of discrete exponential families with application to exponential random graph models. Electronic Journal of Statistics, 3: 446–484, 2009. [Google Scholar]
- [46].Krivitsky PN Exponential-family random graph models for valued networks. Electronic Journal of Statistics, 6: 1100–1128, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [47].Desmarais BA, and Cranmer SJ Statistical inference for edge-valued networks: The generalized ERGM. PLoS ONE 7: e30136, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [48].Hoff PD Multiplicative latent factor models for description and prediction of social networks. Comput. Math Organ. Theory, 15: 261–272, 2009. [Google Scholar]
- [49].Hoff PD Bilinear mixed-effects models for dyadic data. Jl. Amer. Stat. Assoc, 100: 286–295, 2005. [Google Scholar]
- [50].Krivitsky PN, Handcock MS, Raftery AE, and Hoff PD Representing degree distributions, clustering, and homophily in social networks with latent cluster random effects models. Social Networks, 31: 204–213, 2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [51].Westveld AH and Hoff PD, A mixed effects model for longitudinal relational and network data, with applications to international trade and conflict. Ann. Appl. Stat, 843–872, 2011. [Google Scholar]
- [52].Telesford QK, et al. , The Brain as a Complex System: Using Network Science as a Tool for Understanding the Brain. Brain Connectivity, 2011. 1(4): 295–308. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [53].Bullmore E and Sporns O, Complex brain networks: graph theoretical analysis of structural and functional systems. Nat Rev Neurosci, 2009. 10(3): 186–98. [DOI] [PubMed] [Google Scholar]
- [54].Simpson SL and Laurienti PJ, “Disentangling brain graphs: A note on the conflation of network and connectivity analyses,” Brain Connectivity, vol. 6, no. 2, pp. 95–98, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [55].Handcock MS, Hunter DR, Butts CT, Goodreau SM, and Morris M, “statnet: Software tools for the representation, visualization, analysis and simulation of network data,” Journal of statistical software, vol. 24, no. 1, pp. 1548–1567, 2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [56].Bahrami M, Laurienti PJ, Quandt SA, Talton J, Pope CN, Summers P, Burdette JH, Chen H, Liu J, Howard TD, Arcury TA, and Simpson SL, “The impacts of pesticide and nicotine exposures on functional brain networks in latino immigrant workers,” NeuroToxicology, vol. 62, no. Supplement C, pp. 138–150, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [57].Banks D and Carley K, “Metric inference for social networks,” Journal of classification, vol. 11, pp. 121–149, 1994. [Google Scholar]
- [58].Zhu X, Suk H-I, and Shen D, “Matrix-similarity based loss function and feature selection for Alzheimer’s disease diagnosis,” in Proc. IEEE CVPR, 2014, pp. 3089–3096. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [59].Qiu A, Lee A, Tan M, and Chung M, “Manifold learning on brain functional networks in aging,” Medical image analysis, vol. 20, pp. 52–60, 2015. [DOI] [PubMed] [Google Scholar]
- [60].Bullmore E and Sporns O, “Complex brain networks: graph theoretical analysis of structural and functional systems,” Nature Review Neuroscience, vol. 10, pp. 186–98, 2009. [DOI] [PubMed] [Google Scholar]
- [61].Rubinov M and Sporns O, “Complex network measures of brain connectivity: Uses and interpretations,” NeuroImage, vol. 52, pp. 1059–1069, 2010. [DOI] [PubMed] [Google Scholar]
- [62].Uddin L, Kelly A, Biswal B, Margulies D, Shehzad Z, Shaw D, Ghaffari M, Rotrosen J, Adler L, Castellanos F, and Milham M, “Network homogeneity reveals decreased integrity of default-mode network in ADHD,” Journal of neuroscience methods, vol. 169, pp. 249–254, 2008. [DOI] [PubMed] [Google Scholar]
- [63].He Y, Chen Z, and Evans A, “Structural insights into aberrant topological patterns of large-scale cortical networks in Alzheimer’s disease,” Journal of Neuroscience, vol. 28, p. 4756, 2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [64].Rubinov M, Knock SA, Stam CJ, Micheloyannis S, Harris AW, Williams LM, and Breakspear M, “Small-world properties of nonlinear brain activity in schizophrenia.” [DOI] [PMC free article] [PubMed] [Google Scholar]
- [65].Achard S and Bullmore E, “Efficiency and cost of economical brain functional networks,” PLoS Comp. Biol, vol. 3, no. 2, p. e17, 2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [66].Bassett D, “Small-world brain networks,” The Neuroscientist, vol. 12, pp. 512–523, 2006. [DOI] [PubMed] [Google Scholar]
- [67].Meunier D, Lambiotte R, Fornito A, Ersche K, and Bullmore E, “Hierarchical modularity in human brain functional networks,” Frontiers in neuroinformatics, vol. 3:37, 2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [68].Wijk BCM, Stam CJ, and Daffertshofer A, “Comparing brain networks of different size and connectivity density using graph theory,” PloS one, vol. 5, p. e13701, 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [69].Chung M, Hanson J, Lee H, Adluru N, Alexander AL, Davidson R, and Pollak S, “Persistent homological sparse network approach to detecting white matter abnormality in maltreated children: MRI and DTI multimodal study,” MICCAI, Lecture Notes in Computer Science (LNCS), vol. 8149, pp. 300–307, 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [70].Chung M, Hanson J, Ye J, Davidson R, and Pollak S, “Persistent homology in sparse regression and its application to brain morphometry,” IEEE Trans. Med. Imaging, vol. 34, pp. 1928–1939, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [71].Lee H, Chung M, Kang H, Kim B-N, and Lee D, “Computing the shape of brain networks using graph filtration and Gromov-Hausdorff metric,” MICCAI, Lecture Notes in Computer Science, vol. 6892, pp. 302–309, 2011. [DOI] [PubMed] [Google Scholar]
- [72].Lee H, Kang H, Chung M, Kim B-N, and Lee D, “Persistent brain network homology from the perspective of dendrogram,” IEEE Trans. Med. Imaging, vol. 31, pp. 2267–2277, 2012. [DOI] [PubMed] [Google Scholar]
- [73].Carlsson G and Memoli F, “Persistent clustering and a theorem of J. Kleinberg,” arXiv preprint arXiv: 0808.2241, 2008. [Google Scholar]
- [74].Edelsbrunner H and Harer J, Computational topology: an introduction. American Mathematical Society, 2010. [Google Scholar]
- [75].Horak D, Maletić S, and Rajković M, “Persistent homology of complex networks,” Journal of Statistical Mechanics: Theory and Experiment, vol. 2009, p. P03034, 2009. [Google Scholar]
- [76].Zomorodian A and Carlsson G, “Computing persistent homology,” Discrete and Computational Geometry, vol. 33, pp. 249–274, 2005. [Google Scholar]
- [77].Lee C, H. H M.K. Kang, and Lee D, “Hole detection in metabolic connectivity of Alzheimer’s disease using k-Laplacian,” in International Conference on Medical Image Computing and Computer-Assisted Intervention, Lecture Notes in Computer Science, 2014, pp. 297–304. [PubMed] [Google Scholar]
- [78].Achard S, Salvador R, Whitcher B, Suckling J, and Bullmore E, “A resilient, low-frequency, small-world human brain functional network with highly connected association cortical hubs,” The Journal of Neuroscience, vol. 26, pp. 63–72, 2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [79].Kim W, Adluru N, Chung M, Okonkwo O, Johnson S, Bendlin B, and Singh V, “Multi-resolution statistical analysis of brain connectivity graphs in preclinical AlzheimerÕs disease,” NeuroImage, vol. 118, pp. 103–117, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [80].Lee H, Chung M, Kang H, Kim B-N, Lee D, “Discriminative persistent homology of brain networks,” in IEEE ISBI, 2011, pp. 841–844. [Google Scholar]
- [81].Chung M, Vilalta-Gil V, Lee H, Rathouz P, Lahey B, and Zald D, “Exact topological inference for paired brain networks via persistent homology,” in Information Processing in Medical Imaging (IPMI), Lecture Notes in Computer Science, vol. 10265, 2017, pp. 299–310. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [82].Petri G, Expert P, Turkheimer F, Carhart-Harris R, Nutt D, Hellyer P, and Vaccarino F, “Homological scaffolds of brain functional networks,” Journal of The Royal Society Interface, vol. 11, p. 20140873, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [83].Khalid A, Kim B, Chung M, Ye J, and Jeon D, “Tracing the evolution of multi-scale functional networks in a mouse model of depression using persistent brain network homology,” NeuroImage, vol. 101, pp. 351–363, 2014. [DOI] [PubMed] [Google Scholar]
- [84].Cassidy B, Rae C, and Solo V, “Brain activity: conditional dissimilarity and persistent homology,” in IEEE 12th ISBI, 2015, pp. 1356–1359. [Google Scholar]
- [85].Wong E, Palande S, Wang B, Zielinski B, Anderson J, and Fletcher P, “Kernel partial least squares regression for relating functional brain network topology to clinical measures of behavior,” in IEEE ISBI, 2016, pp. 1303–1306. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [86].Anirudh R, Thiagarajan J, Kim I, and Polonik W, “Autism spectrum disorder classification using graph kernels on multidimensional time series,” arXiv preprint arXiv:1611.09897, 2016. [Google Scholar]
- [87].Palande S, Jose V, Zielinski B, Anderson J, Fletcher P, and Wang B, “Revisiting abnormalities in brain network architecture underlying autism using topology-inspired statistical inference,” in International Workshop on Connectomics in Neuroimaging, 2017, pp. 98–107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [88].Cohen-Steiner D, Edelsbrunner H, and Harer J, “Stability of persistence diagrams,” Discrete and Computational Geometry, vol. 37, pp. 103–120, 2007. [Google Scholar]
- [89].Ghrist R, “Barcodes: The persistent topology of data,” Bulletin of the American Mathematical Society, vol. 45, pp. 61–75, 2008. [Google Scholar]
- [90].Bubenik P, “Statistical topological data analysis using persistence landscapes,” Jl. Mach. Learning Res, vol. 16, pp. 77–102, 2015. [Google Scholar]
- [91].Lee H, Kang H, Chung M, Lim S, Kim B-N, and Lee D, “Integrated multimodal network approach to PET and MRI based on multidimensional persistent homology,” Human Brain Mapping, vol. 38, pp. 1387–1402, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [92].Heo G, Gamble J, and Kim P, “Topological analysis of variance and the maxillary complex,” Journal of the American Statistical Association, vol. 107, pp. 477–492, 2012. [Google Scholar]
- [93].Chung M, Bubenik P, and Kim P, “Persistence diagrams of cortical surface data,” Proc. 21st IPMI, Lecture Notes in Computer Science (LNCS), vol. 5636, pp. 386–397, 2009. [DOI] [PubMed] [Google Scholar]
- [94].Pachauri D, Hinrichs C, Chung M, Johnson S, and Singh V, “Topology based kernels with application to inference problems in alzheimer’s disease,” IEEE Transactions on Medical Imaging, pp. 1760–1770, 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [95].Reininghaus J, Huber S, Bauer U, and Kwitt R, “A stable multi-scale kernel for topological machine learning,” in IEEE Conf. Comp. Vis. Pattern Recognition (CVPR), 2015, pp. 4741–4748. [Google Scholar]
- [96].Lee H, Chung M, Kang H, Kim E, Huh Y, Hahm J, Kim Y, and Lee D, “Shape variability in the dynamics of resting-state functional network and relationship with age,” in Organization for Human Brain Mapping (OHBM) Annual Meeting, 2016, p. 4583. [Google Scholar]
- [97].Chazal F, Cohen-Steiner D, Guibas L, Mémoli F, and Oudot S, “Gromov-Hausdorff stable signatures for shapes using persistence,” in Computer Graphics Forum, vol. 28, 2009, pp. 1393–1403. [Google Scholar]
- [98].Topaz C, Ziegelmeier L, and Halverson T, “Topological data analysis of biological aggregation models,” PLoS One, p. e0126383, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [99].Böhm W and Hornik K, “A Kolmogorov-Smirnov test for r samples,” Institute for Statistics and Mathematics, vol. Research Report Series, p. Report 105, 2010. [Google Scholar]
- [100].Gibbons JD and Chakraborti S, Nonparametric Statistical Inference. Chapman & Hall/CRC Press, 2011. [Google Scholar]
- [101].Chung M, Lee H, Solo V, Davidson R, and Pollak S, “Topological distances between brain networks,” in Int. Workshop on Connectomics in Neuroimaging, Lec. Notes in Comp. Sci, 2017, pp. 161–170. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [102].Biswal B, Zerrin Yetkin F, Haughton VM, and Hyde JS, “Functional connectivity in the motor cortex of resting human brain using echo-planar mri,” Mag. Res. Med, vol. 34, pp. 537–541, 1995. [DOI] [PubMed] [Google Scholar]
- [103].Fox MD and Raichle ME, “Spontaneous fluctuations in brain activity observed with functional magnetic resonance imaging,” Nature Reviews Neuroscience, vol. 8, pp. 700–711, 2007. [DOI] [PubMed] [Google Scholar]
- [104].Handwerker DA, Roopchansingh V, Gonzalez-Castillo J, and Bandettini PA, “Periodic changes in fmri connectivity,” Neuroimage, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [105].Hutchison RM, Womelsdorf T, Allen EA, Bandettini PA, Calhoun VD, Corbetta M, Penna SD, Duyn J, Glover G, Gonzalez-Castillo J et al. , “Dynamic functional connectivity: Promises, issues, and interpretations,” NeuroImage, 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [106].Leonardi N and Van De Ville D, “On spurious and real fluctuations of dynamic functional connectivity during rest,” Neuroimage, vol. 104, pp. 430–436, 2015. [DOI] [PubMed] [Google Scholar]
- [107].Chang C and Glover GH, “Time-frequency dynamics of resting-state brain connectivity measured with fmri,” Neuroimage, vol. 50, pp. 81–98, 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [108].Allen EA, Damaraju E, Plis SM, Erhardt EB, Eichele T, and Calhoun VD, “Tracking whole-brain connectivity dynamics in the resting state,” Cerebral Cortex, 24, pp. 663–676, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [109].Xu Y and Lindquist MA, “Dynamic connectivity detection: an algorithm for determining functional connectivity change points in fmri data,” Frontiers in Neuroscience, vol. 9, art. 285, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [110].Yang Z, Craddock RC, Margulies DS, Yan C-G, and Milham MP, “Common intrinsic connectivity states among posteromedial cortex subdivisions: Insights from analysis of temporal dynamics,” Neuroimage, vol. 93, pp. 124–137, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [111].Hutchison RM and Morton JB, “Tracking the Brain’s Functional Coupling Dynamics over Development,” Jl. of Neuroscience, vol. 35, no. 17, pp. 6849–6859, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [112].Damaraju E, Allen E, Belger A, Ford J, McEwen S, Mathalon D, Mueller B, Pearlson G, Potkin S, Preda A et al. , “Dynamic functional connectivity analysis reveals transient states of dysconnectivity in schizophrenia,” NeuroImage: Clinical, vol. 5, pp. 298–308, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [113].Rashid B, Damaraju E, Pearlson GD, and Calhoun VD, “Dynamic connectivity states estimated from resting fmri identify differences among schizophrenia, bipolar disorder, and healthy control subjects,” Frontiers in Human Neuroscience, vol. 8, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [114].Engle R, “Dynamic conditional correlation: A simple class of multivariate generalized autoregressive conditional heteroskedasticity models,” Jl. Business & Economic Stat, vol. 20, pp. 339–350, 2002. [Google Scholar]
- [115].Lindquist MA, Xu Y, Nebel MB, and Caffo BS, “Evaluating dynamic bivariate correlations in resting-state fmri: A comparison study and a new approach,” NeuroImage, vol. 101, pp. 531–546, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [116].Calhoun VD, Miller R, Pearlson G, and Adali T, “The chronnectome: time-varying connectivity networks as the next frontier in fmri data discovery,” Neuron, vol. 84, pp. 262–274, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [117].Cribben I, Haraldsdottir R, Atlas LY, Wager TD, and Lindquist MA, “Dynamic connectivity regression: Determining state-related changes in brain connectivity,” NeuroImage, vol. 61, pp. 907–920, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [118].Cribben I, Wager TD, and Lindquist MA, “Detecting functional connectivity change points for single-subject fmri data,” Frontiers in computational neuroscience, vol. 7, art. 143, 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [119].Hindriks R, Adhikari MH, Murayama Y, Ganzetti M, Mantini D, Logothetis NK, and Deco G, “Can sliding-window correlations reveal dynamic functional connectivity in resting-state fmri?” Neuroimage, vol. 127, pp. 242–256, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [120].Laumann TO, Snyder AZ, Mitra A, Gordon EM, Gratton C, Adeyemo B, Gilmore AW, Nelson SM, Berg JJ, Greene DJ et al. , “On the stability of bold fmri correlations,” Cerebral Cortex, pp. 1–14, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [121].Kudela M, Harezlak J, and Lindquist MA, “Assessing uncertainty in dynamic functional connectivity,” NeuroImage, vol. 149, pp. 165–177, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [122].Hlinka J and Hadrava M, “On the danger of detecting network states in white noise,” Frontiers in Computational Neuroscience, vol. 9, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [123].Eavani H, Satterthwaite TD, Gur RE, Gur RC, Davatzikos C, “Unsupervised learning of functional network dynamicsin resting state fMRI,” International Conference on Information Processing in Medical Imaging, pp.426–437, Springer. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [124].Vidaurre D, Abeysuriya R, Becker R, Quinn AJ, Alfaro-Almagro F, Smith SM, Woolrich MW, “Discovering dynamic brain networks from big data in rest and task,” Neuroinmage, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [125].Craddock RC, Tungaraza RL, and Milham MP, “Connectomics and new approaches for analyzing human brain functional connectivity,” GigaScience, vol. 4, no. 1, p. 13, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [126].Smith SM, Vidaurre D, Beckmann CF, Glasser MF, Jenkinson M, Miller KL, Nichols TE, Robinson EC, Salimi-Khorshidi G, Woolrich MW, et al. , “Functional connectomics from resting-state fMRI,” Trends in cognitive sciences, vol. 17, no. 12, pp. 666–682, 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [127].Cassidy B, Rae C, and Solo V, “Brain activity: Connectivity, sparsity, and mutual information,” IEEE Trans. Med. Imaging, vol. 34, no. 4, pp. 846–860, 2015. [DOI] [PubMed] [Google Scholar]
- [128].Whittaker J, Graphical models in applied multivariate statistics. Wiley Publishing, 1990. [Google Scholar]
- [129].Lauritzen SL, Graphical models. Oxford University Press, 1996. [Google Scholar]
- [130].Kolaczyk ED, Statistical analysis of network data. Springer, 2009. [Google Scholar]
- [131].Hoyle DC, “Accuracy of pseudo-inverse covariance learning—a random matrix theory analysis,” Pattern Analysis and Machine Intelligence, IEEE Transactions on, vol. 33, no. 7, pp. 1470–1481, 2011. [DOI] [PubMed] [Google Scholar]
- [132].Ryali S, Chen T, Supekar K, and Menon V, “Estimation of functional connectivity in fMRI data using stability selection-based sparse partial correlation with elastic net penalty,” NeuroImage, vol. 59, no. 4, pp. 3852–3861, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [133].Marčenko VA and Pastur LA, “Distribution of eigenvalues for some sets of random matrices,” Sbornik: Mathematics, vol. 1, no. 4, pp. 457–483, 1967. [Google Scholar]
- [134].Bai Z and Silverstein JW, Spectral analysis of large dimensional random matrices, vol. 2 Springer, 2010. [Google Scholar]
- [135].Zalesky A, Fornito A, and Bullmore E, “On the use of correlation as a measure of network connectivity,” Neuroimage, vol. 60, no. 4, pp. 2096–2106, 2012. [DOI] [PubMed] [Google Scholar]
- [136].Wang R, Zhang Z-Z, Ma J, Yang Y, Lin P, and Wu Y, “Spectral properties of the temporal evolution of brain network structure,” Chaos: An Interdisciplinary Journal of Nonlinear Science, vol. 25, no. 12, p. 123112, 2015. [DOI] [PubMed] [Google Scholar]
- [137].Paul D and Aue A, “Random matrix theory in statistics: a review,” Journal of Statistical Planning and Inference, vol. 150, pp. 1–29, 2014. [Google Scholar]
- [138].Dahlhaus R, “Graphical interaction models for multivariate time series,” Metrika, vol. 51, no. 2, pp. 157–172, 2000. [Google Scholar]
- [139].Brillinger D, Time Series: Data Analysis and Theory. Holden-Day, San Francisco, 1981. [Google Scholar]
- [140].Brillinger DR, “Remarks concerning graphical models for time series and point processes,” Brazilian Review of Econometrics, vol. 16, no. 1, pp. 1–23, 1996. [Google Scholar]
- [141].Salvador R, Suckling J, Schwarzbauer C, and Bullmore E, “Undirected graphs of frequency-dependent functional connectivity in whole brain networks,” Philosophical Transactions of the Royal Society B: Biological Sciences, vol. 360, no. 1457, pp. 937–946, 2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [142].Irimia A, Chambers MC, Torgerson CM, and Van Horn JD, “Circular representation of human cortical networks for subject and population-level connectomic visualization,” Neuroimage, vol. 60, no. 2, pp. 1340–1351, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [143].Marrelec G, Krainik A, Duffau H, Pélégrini-Issac M, Lehéricy S, Doyon J, and Benali H, “Partial correlation for functional brain interactivity investigation in functional mri,” Neuroimage, vol. 32, no. 1, pp. 228–237, 2006. [DOI] [PubMed] [Google Scholar]
- [144].Varoquaux G, Gramfort A, Poline J-B, and Thirion B, “Brain covariance selection: better individual functional connectivity models using population prior,” in Advances in neural information processing systems, 2010, pp. 2334–2342. [Google Scholar]
- [145].Smith SM, Miller KL, Salimi-Khorshidi G, Webster M, Beckmann CF, Nichols TE, Ramsey JD, and Woolrich MW, “Network modelling methods for fmri,” Neuroimage, vol. 54, no. 2, pp. 875–891, 2011. [DOI] [PubMed] [Google Scholar]