

Abstract
Background
The accuracy of microbial community surveys based on marker-gene and metagenomic sequencing (MGS) suffers from the presence of contaminants—DNA sequences not truly present in the sample. Contaminants come from various sources, including reagents. Appropriate laboratory practices can reduce contamination, but do not eliminate it. Here we introduce decontam (https://github.com/benjjneb/decontam), an open-source R package that implements a statistical classification procedure that identifies contaminants in MGS data based on two widely reproduced patterns: contaminants appear at higher frequencies in low-concentration samples and are often found in negative controls.
Results
Decontam classified amplicon sequence variants (ASVs) in a human oral dataset consistently with prior microscopic observations of the microbial taxa inhabiting that environment and previous reports of contaminant taxa. In metagenomics and marker-gene measurements of a dilution series, decontam substantially reduced technical variation arising from different sequencing protocols. The application of decontam to two recently published datasets corroborated and extended their conclusions that little evidence existed for an indigenous placenta microbiome and that some low-frequency taxa seemingly associated with preterm birth were contaminants.
Conclusions
Decontam improves the quality of metagenomic and marker-gene sequencing by identifying and removing contaminant DNA sequences. Decontam integrates easily with existing MGS workflows and allows researchers to generate more accurate profiles of microbial communities at little to no additional cost.
Electronic supplementary material
The online version of this article (10.1186/s40168-018-0605-2) contains supplementary material, which is available to authorized users.
Keywords: Microbiome, Metagenomics, Marker-gene, 16S rRNA gene, DNA contamination
Background
High-throughput sequencing of DNA from environmental samples is a powerful tool for investigating microbial and non-microbial communities. Community composition can be characterized by sequencing taxonomically informative marker genes, such as the 16S rRNA gene in bacteria [1–4]. Shotgun metagenomics, in which all DNA recovered from a sample is sequenced, can also characterize functional potential [5–7]. However, the accuracy of marker-gene and metagenomic sequencing (MGS) is limited in practice by several processes that introduce contaminants—DNA sequences not truly present in the sampled community.
Failure to account for DNA contamination can lead to inaccurate data interpretation. Contamination falsely inflates within-sample diversity [8, 9], obscures differences between samples [8, 10], and interferes with comparisons across studies [10, 11]. Contamination disproportionately affects samples from low-biomass environments with less endogenous sample DNA [10, 12–16] and can lead to controversial claims about the presence of bacteria in low microbial biomass environments like blood and body tissues [12, 13, 15–17]. In high-biomass environments, contaminants can comprise a significant fraction of low-frequency sequences in the data [18], limiting reliable resolution of low-frequency variants and contributing to false-positive associations in exploratory analyses [19].
Attempts to control DNA contamination before and after sequencing have had mixed success. One common practice is to process reagent-only [9, 14, 20] or blank sampling instrument [21] negative control samples alongside biological samples at the DNA extraction and PCR steps. Contamination is often assumed to be absent if control samples do not yield a band on an agarose gel [22, 23]. However, band-less samples can generate non-negligible numbers of sequencing reads [14, 15], suggesting that gel-based quality control is insufficient.
There are two major types of contaminants in MGS experiments that arise from different sources. External contamination is contributed from outside the samples being measured, with potential sources that include research subjects’ or investigators’ bodies [24, 25], laboratory surfaces and air [10, 21, 26], and, perhaps most importantly, sample collection instruments and laboratory reagents [9, 12, 14]. Internal or cross-contamination arises when samples mix with each other during sample processing [9] or sequencing [33]. Contamination can be reduced through laboratory techniques such as UV irradiation, “ultrapurification” and/or enzymatic treatment of reagents, and the separation of pre- and post-PCR areas [9, 12, 27, 28]. However, even optimal lab practices do not completely eliminate DNA contamination [11, 14].
In silico contaminant removal can complement existing laboratory approaches, but distinguishing contaminating microbial DNA from true microbial sequences can be difficult and is not often performed [14, 16]. Perhaps, the most common in silico decontamination method in practice is the removal of sequences below an ad hoc relative abundance threshold [21, 29–31]. However, relative abundance thresholds remove rare features truly present in the sample and do not remove abundant contaminants that are the most likely to interfere with subsequent analysis. Another approach is the removal of sequences that appear in negative controls (e.g., [10, 32, 20]). However, cross-contamination between samples often causes abundant true sequences to be detected in negative controls [9, 19, 33]. Finally, “blacklist” methods exclude sequences or taxa previously identified as contaminants, but do not identify study-specific contaminants and often remove true sequences.
Despite the widespread problem of contamination, few software tools exist that directly address MGS contaminants. SourceTracker uses Bayesian mixtures to identify the proportion of a sample consistent with origin from external contaminating sources of known composition, but does not identify specific contaminants [26]. The visualizations and summary statistics provided by the An’vio software package can be used to identify contaminant metagenome-assembled genomes (MAGs) [34], but this relies on user expertise to identify contaminant-specific patterns and does not apply to marker-gene data. Recently, a new method for identifying cross-contaminants arising from index switching during sequencing has been developed for dual-indexed MGS libraries, but this method does not apply to other types of contamination [33].
Here, we introduce and validate decontam, a simple-to-use open-source R package that identifies and removes external contaminants in MGS data. Decontam implements two simple de novo classification methods based on widely reproduced signatures of external contamination: (1) Sequences from contaminating taxa are likely to have frequencies that inversely correlate with sample DNA concentration [8, 14, 16, 30] and (2) sequences from contaminating taxa are likely to have higher prevalence in control samples than in true samples [10, 31, 32]. Frequency-based contaminant identification relies on auxiliary DNA quantitation data that is in most cases intrinsic to MGS sample preparation. Prevalence-based contaminant identification relies on sequenced negative controls [11, 14]. Decontam is not intended to detect cross-contamination, which presents with qualitatively different statistical patterns in MGS data.
We validated decontam on marker-gene and metagenomics datasets generated by our laboratory and others. In an oral 16S rRNA gene dataset, decontam classifications were consistent with curated reference databases of common contaminating microbial genera and known oral microbes. In data generated by Salter et al., decontam selectively removed contaminants, thereby reducing technical variation due to sequencing center or DNA extraction kit in marker-gene and shotgun metagenomics data, respectively. The application of decontam to 16S rRNA gene sequencing data generated from placenta biopsies corroborated the conclusion that the data did not support the existence of a placenta microbiome [15]. Decontam improved a recent exploratory analysis of associations between preterm birth and the vaginal microbiota by identifying run-specific contaminants [19]. Our results suggest that decontam distinguishes contaminants from non-contaminants across diverse studies and that removal of these contaminants improves the accuracy of biological inferences in studies that use MGS methods to investigate microbial communities.
Description of the method
Frequency-based contaminant identification
Let total sample DNA (T) be a mixture of two components (T = C + S): contaminating DNA (C) present in uniform concentration across samples and true sample DNA (S) present in varying concentration across samples. Let the frequency of a sequence, or set of sequences, be its abundance divided by the total abundance of all sequences in the sample (alternative terms used equivalently include proportion and relative abundance). In the limit S >> C, the frequency of contaminating DNA (fC) is inversely proportional to total DNA T (Fig. 1), while the frequency of sample DNA (fS) is independent of T:
Fig. 1.

Mixture model of contaminants and non-contaminants in MGS experiments. Contaminant DNA is expected to be present in approximately equal and low concentrations across samples, while sample DNA concentrations can vary widely. As a result, the expected frequency of contaminant DNA varies inversely with total sample DNA concentration (red), while the expected frequency of non-contaminant DNA does not (blue)
For each sequence feature, two models are compared: a contaminant model, in which expected frequency varies inversely with total DNA concentration, and a non-contaminant model, in which expected frequency is independent of total DNA concentration. More precisely, two linear models are fit to the log-transformed frequencies as a function of the log-transformed total DNA, a contaminant model with slope − 1 and a non-contaminant model with slope 0. Samples in which the sequence feature is absent are omitted. The ratio R between the sums-of-squared-residuals of the contaminant and non-contaminant models is computed, and then, the score statistic P is defined as the tail probability at value R of an F distribution with degrees of freedom equal to the number of samples in which the feature was present. The score statistic P ranges from 0 to 1. Small scores indicate the contaminant model is a better fit, and high scores indicate that the non-contaminant model is a better fit.
Although inspired by the general linear F test, the frequency-based score statistic is not a p value, i.e., it is not associated with any guarantees on the type 1 error rate. The frequency-based score statistic is best thought of as a transformation that takes as input two values—the ratio of the sum-of-squared residuals, and the number of observations—and outputs a score that is a better classification statistic than the ratio of the sum-of-squared residuals alone. This transformation differentiates between otherwise identical ratios of sum-of-squared residuals that are supported by different numbers of observations, and appropriately outputs scores closer to the extremes (0/1) when non-unitary ratios are supported by more observations.
Frequency-based contaminant identification is not recommended for extremely low-biomass samples (C~S or C > S) because the simple approximations we are making for the dependence of contaminant frequency on total DNA concentration break down when contaminants comprise a large fraction of sequencing reads.
Prevalence-based contaminant identification
Once again, let total sample DNA (T) be a mixture of contaminating DNA (C) and true sample DNA (S), i.e., T = C + S. The results of MGS sequencing can be thought of as an incomplete sampling of T. Thus, in negative controls (S~0), the likelihood of detecting any given contaminant sequence feature will be higher than in true samples (S > 0). That is, the prevalence of contaminants will be higher in negative controls than in true samples due to the absence of competing DNA in the sequencing process.
For each sequence feature, a chi-square statistic on the 2 × 2 presence-absence table in true samples and negative controls is computed, and a score statistic P is defined as the tail probability of the chi-square distribution at that value. The p value from Fisher’s exact test is used as the score statistic instead if there are too few samples for the chi-square approximation. The score statistic ranges from 0 to 1. Small scores indicate the contaminant model of higher prevalence in negative control samples is a better fit.
Although the prevalence-based score statistic is set equal to a p-value from the chi-square or Fisher’s exact tests, it is used by decontam only as a score that effectively distinguishes between the contaminant and non-contaminant mixture components. This treatment is also recommended by the potential for cross-contamination to violate distributional assumptions related to independence between samples.
Prevalence-based contaminant identification remains valid in very low biomass environments where a majority of MGS sequences might derive from contaminants rather than true inhabitants of the sampled environment (i.e. C ~ S or C > S). Even in the low-biomass regime, it is still expected that non-contaminants will appear in a larger fraction of true samples than in negative control samples.
Sequencing batches and composite identification
Separately processed samples may have different contaminants [12, 14, 28, 36]. Decontam allows the user to specify processing batches, in which case score statistics are generated from each batch independently and then combined in a user-selectable fashion for classification (for example, by taking the minimum score across batches). Decontam also provides simple methods to combine scores from the frequency and prevalence methods into a composite score statistic. For example, the combined method uses Fisher’s method to combine the frequency and prevalence score statistics (interpreted as tail probabilities) into a composite score statistic that is then used for classification.
Classification
A sequence feature is classified as contaminant or non-contaminant by comparing its associated score statistic P to a user-defined threshold P*, where P can be the frequency, prevalence, or composite score. If P < P*, the sequence feature is classified as a contaminant. The default classification threshold is P* = 0.1, but we highly recommend that users inspect the distribution of scores in their data and consider adjusting P* based on specific dataset characteristics (see also the “Discussion” section). The threshold P* = 0.5 has a particularly simple interpretation: In the frequency approach, sequence features would be classified as contaminants if the contaminant model is a better fit than the non-contaminant model, and in the prevalence approach, sequence features would be classified as contaminants if present in a higher fraction of negative controls than true samples.
The decontam R package
The contaminant classification methods introduced here are implemented in the open-source decontam R package available from GitHub (https://github.com/benjjneb/decontam) and the Bioconductor repository [35]. The primary function, isContaminant, implements frequency- and prevalence-based contaminant identification that can be applied to a variety of sequence features including amplicon sequence variants (ASVs), operational taxonomic units (OTUs), taxonomic groups (e.g., genera), orthologous genes, metagenome-assembled-genomes (MAGs), and any other feature with quantitative per-sample relative abundance that is derived from marker-gene or metagenomics sequencing data (see also the “Discussion” section).
The primary input to isContaminant is a feature table of the relative abundances or frequencies of sequence features in each sample (e.g., an OTU table). In addition, isContaminant requires one of two types of auxiliary data for frequency- and prevalence-based contaminant identification, respectively: (1) quantitative DNA concentrations for each sample, often obtained during amplicon or shotgun sequencing library preparation in the form of a standardized fluorescence intensity (e.g., PicoGreen), and/or (2) sequenced negative control samples, preferably DNA extraction controls to which no sample DNA was added. Contaminants identified by decontam can be removed from the feature table with basic R functions described in decontam vignettes.
The isNotContaminant function supports the alternative use case of identifying non-contaminant sequence features in very low-biomass samples (C > S). isNotContaminant implements the prevalence method, but with the standard prevalence score P replaced with 1 − P, so low scores are now those associated with non-contaminants. isNotContaminant does not implement the frequency method for reasons described above and classifies very low prevalence samples conservatively, i.e., as contaminants, as is appropriate for the low-biomass regime.
Results
Decontam discriminates likely contaminants from likely inhabitants of the human oral cavity
As part of an ongoing study of the human oral microbiome [37], we processed 33 reagent-only or blank-swab DNA extraction negative control samples alongside and in the same manner as 712 oral mucosa samples. We inspected the frequencies of amplicon sequence variants (ASVs) as a function of DNA concentration (range: undetectable to 39 ng/μL) measured by fluorescent intensity after PCR and prior to sequencing. Two clear patterns emerged (Fig. 2a): ASV frequencies that were independent of DNA concentration and ASV frequencies that were inversely proportional to DNA concentration [8, 14, 16, 30], consistent with total DNA consisting of a mixture of contaminant and non-contaminant components. Taxonomic assignments for ASVs with inverse frequency patterns were consistent with contamination. For example, Seq3 was a fungal mitochondrial DNA sequence, while Seq53 and Seq152 were assigned to the commonly contaminating genera Methylobacterium and Phyllobacterium [8, 12, 14, 15]. Taxonomic assignments of ASVs with frequencies independent of sample DNA concentration were consistent with membership in the oral microbiota, for example, Seq1, Streptococcus sp.; Seq12, Neisseria sp.; and Seq200, Treponema sp. [37–41]. The total concentration of contaminants assigned by the prevalence method was roughly constant and independent of total DNA concentration, consistent with our mixture model (Additional file 1: Figure S1).
Fig. 2.

Frequency patterns and decontam scores of microbial sequences from an oral 16S rRNA gene dataset. a Frequency patterns of six sequences from a 16S rRNA gene study of human oral mucosal microbial communities. The frequencies of sequence variants Seq3, Seq152, and Seq53 vary inversely with sample DNA, a characteristic of contaminants. The frequencies of Seq1, Seq12, and Seq200 are independent of sample DNA concentration, a characteristic of genuine sample sequences. Scores for each of the six sequences were computed by the frequency (F), prevalence (P), and combined (C) methods as implemented in the isContaminant function in the decontam R package, and are indicated in the bottom left of each panel. b Scores for each amplicon sequence variant (ASV) present in two or more samples were computed as in a. The histogram of scores is shown, with color intensity depending on the number of samples (or prevalence) in which each ASV was present
The distribution of scores assigned by decontam reflected the bimodal distribution expected from a mixture of contaminant and non-contaminant components (Fig. 2b), albeit with an additional mode near 0.5 consisting of low-prevalence taxa for which decontam has little discriminatory power. Most ASVs (Fig. 2b) and an even larger majority of total reads (Additional file 1: Figure S2) were assigned high scores suggesting non-contaminant origin. The distribution of scores from the combined method, which combines the frequency-based and prevalence-based scores into a composite score, had the cleanest bimodal distribution (Fig. 2b), suggesting it will provide the most robust classifications when both DNA concentration and negative control data are available.
To assess the classification accuracy of decontam, we generated two databases to serve as proxies for true oral sequences and contaminants (see the “Methods” section). Decontam assigned scores less than 0.5 to most ASVs from genera present in the contamination database, including features Seq3, Seq53, and Seq152 (Fig. 2a). In contrast, most ASVs from genera present in the oral database, including Seq1, Seq12, and Seq200, were assigned scores greater than 0.5 (Fig. 2a). ASVs belonging to genera found in both databases or neither database display a range of scores (Additional file 1: Figure S3), suggesting that the reference databases constructed here incompletely separate oral and contaminating genera.
To quantitatively assess the accuracy of decontam, we examined a restricted set of genera that were clearly and unambiguously classified as contaminants or oral taxa by our reference databases (see the “Methods” section). The scores assigned by the frequency and prevalence methods to all ASVs are shown in Fig. 3a, with points colored if their genus has an unambiguous reference classification. Each panel represents a different sample prevalence threshold (e.g., whether the ASV was detected in 2, 3–5, 6-10, or 11+ samples). As expected, the power of decontam to discriminate between contaminants and non-contaminants increases with the number of samples in which each ASV was present (its prevalence). At high prevalence, the frequency-, prevalence-, and reference-based classifications are nearly identical. An interactive three-dimensional comparison of the frequency, prevalence, and combined scores is available at https://benjjneb.github.io/DecontamManuscript/Analyses/oral_contamination.html.
Fig. 3.

Classification accuracy of decontam on microbial sequences in an oral mucosa dataset. a The scores assigned by the frequency and prevalence methods are plotted for each ASV present in two or more samples in the oral mucosa dataset. Points are colored if their genus can be unambiguously classified as oral or contaminant by comparison to a compiled reference database. b ASVs with unambiguous reference-based classifications were used as the ground truth for evaluating the sensitivity and specificity of decontam. Receiver-operator-characteristic (ROC) curves are plotted for the frequency, prevalence, and combined methods at the level of ASVs and at the level of reads (i.e., weighting by ASV relative abundance). Points show the default classification threshold of P* = 0.1
We developed receiver-operator-characteristic (ROC) curves of the classifier performance of the frequency, prevalence, and combined methods on the subset of ASVs with unambiguous reference-based classifications and using the reference-based classification as the ground truth. The sensitivity of all methods to detect contaminant ASVs reaches substantial levels before significant degradation in specificity occurs (Fig. 3b). At the default threshold of 0.1 (indicated by points in Fig. 3b), the frequency method has an ASV sensitivity/specificity of 0.33/1.00, the prevalence method 0.61/ 0.95, and the combined method 0.45/0.99. Accuracy is far higher when accounting for the relative abundance of each ASV and evaluating performance on a per-read basis. At the default classification threshold of 0.1, the per-read sensitivity/specificity is 0.97/1.0000 for the frequency method, 0.77/0.9994 (prevalence), and 0.98/0.9999 (combined).
These results indicate that decontam has high classification accuracy on the abundant and prevalent sequence features that will most impact subsequent analysis. The classification accuracy of decontam may be even higher than reported here given our reliance on imperfect taxonomic assignments to set a ground truth. For example, the apparent high-prevalence false-negative (the red point in the upper-right of the 11+ panel in Fig. 3a) was assigned to the genus Peptococcus, which is known to colonize the human mouth [42, 43]. However, Peptococcus was not present in our incomplete database of cultivated oral genera, so it was treated as a ground truth contaminant in our accuracy analysis.
Application of decontam to a dilution-series test dataset
Salter et al. characterized a dilution series of a Salmonella bongori monoculture over a range of six 10-fold dilutions by 16S rRNA gene sequencing at three sequencing centers, and by shotgun metagenomics using four DNA extraction kits (one of which yielded little DNA and is excluded). Standard DNA quantitation data were not reported, so the reported 16S qPCR results (Fig. 2 from Ref. [14]) were used to quantify sample DNA concentrations.
Over 50% of the contaminant (i.e., non-S. bongori) amplicon reads and over 80% of the contaminant shotgun reads were correctly classified as contaminants by decontam’s frequency method at the default threshold P* = 0.1, and sensitivity increased with higher values of P* (Fig. 4). A smaller fraction of the unique sequence features (ASVs in the 16S rRNA gene data and genera in the shotgun data) were identified as contaminants due to the small number of samples in this dataset (six samples per batch) and the lower sensitivity of decontam on contaminants present in few samples (e.g., Fig. 3a). Identifying contaminants on a per-batch basis was more effective than pooling data across sequencing centers and DNA extraction kits, which had different contaminant spectra (Fig. 4).
Fig. 4.

Proportion of contaminants in the S. bongori dilution series identified by the decontam frequency method. The frequency method was applied to all data pooled together (solid line), and on a per-batch basis (dashed line). Batches were specified as the sequencing centers for the 16S data, and the DNA extraction kits for the shotgun data. The fraction of contaminants identified (sensitivity) was evaluated on a per-read basis and on a per-variant basis (ASVs for 16S data, genera for shotgun data) over a range of classification thresholds. Green lines show maximum possible classifier sensitivity, given that decontam cannot identify contaminants only present in a single sample
No Salmonella bongori reads were classified as contaminants under any P* threshold, and the S. bongori variants were assigned the highest scores (> 0.98) in these datasets. Negative controls were not included in the shotgun metagenomics sequencing, and only a single negative control was included in the 16S rRNA gene sequencing, so we did not evaluate the prevalence method on this dataset.
Removal of contaminants identified by decontam significantly reduced batch effects between sequencing centers and DNA extraction kits (Fig. 5). As the classification threshold increased from P* = 0.0 (no contaminants removed) to P* = 0.1 (default) to P* = 0.5 (aggressive removal), the multi-dimensional scaling ordination distance between samples from different batches decreased. This effect was most dramatic at the intermediate dilutions where both S. bongori and various contaminants comprised a significant fraction of the total sequences.
Fig. 5.

Removal of contaminants identified by decontam reduces technical variation in dilution series of S. bongori. A dilution series of 0, 1, 2, 3, 4, and 5 ten-fold dilutions of a pure culture of Salmonella bongori was subjected to a amplicon sequencing of the 16S rRNA gene at three sequencing centers and b shotgun sequencing using three different DNA extraction kits. Contaminants were identified by the decontam frequency method with a classification threshold of P* = 0.0 (no contaminants identified), P* = 0.1 (default), and P* = 0.5 (aggressive identification). After contaminant removal, pairwise between-sample Bray-Curtis dissimilarities were calculated, and an MDS ordination was performed. The two dimensions explaining the greatest variation in the data are shown
In a recent study, Karstens et al. performed an independent evaluation of the decontam frequency method on a more complex dilution series constructed from a mock community of eight bacterial strains. They report that decontam correctly classified 74–91% of contaminant reads, and made no false-positive contaminant identifications [57].
Identification of non-contaminant sequences in a low-biomass environment
Recently, evidence from marker-gene sequencing of placental samples was used to propose that the human placenta harbors an indigenous microbiota [17]. However, contamination has since been proposed as an alternative explanation of those results [15, 44]. To examine this question further, Lauder et al. performed 16S rRNA gene sequencing on placenta biopsy samples and multiple negative control samples using two different DNA extraction kits. They found that samples clustered by kit rather than by placental or negative control origin, suggesting that most sequences observed in the placenta samples derived from reagent contamination.
We used the prevalence method as implemented in the isNotContaminant function to further explore the possibility that some ASVs in the Lauder et al. dataset could be consistent with placental origin, despite being too rare to drive whole-community ordination results. The prevalence score statistic, unlike the frequency score statistic, can be interpreted as a p value, which allowed us to select candidate non-contaminant ASVs based on a false discovery rate (FDR) threshold [56]. We found that six of the 810 ASVs present in at least five samples were identified as non-contaminants at an FDR threshold of 0.5 (Table 1). Five of those six ASVs matched Homo sapiens rather than any bacterial taxa. That is, five of the six ASVs classified by the prevalence method as non-contaminants were classified correctly, as those ASVs were truly present in the placental samples. However, these non-contaminants are not evidence of a placental microbiome, and instead, the five Homo sapiens ASVs likely arose from off-target amplification of human DNA in the placenta biopsy. The other putative non-contaminant ASV was a Ruminococcaceae variant, a known member of human gut microbial communities [2], but we are unable to establish its ground truth.
Table 1.
Amplicon sequence variants from placenta samples classified by decontam as non-contaminants
| P (adjusted) | Taxa | Placenta (n = 24) | Negative (n = 27) | Saliva (n = 12) | Vagina (n = 6) | |
|---|---|---|---|---|---|---|
| 1 | 1.2 × 10−5 | Homo sapiens | 19 | 0 | 0 | 1 |
| 2 | 0.11 | Homo sapiens | 11 | 0 | 0 | 0 |
| 3 | 0.17 | Homo sapiens | 9 | 0 | 0 | 0 |
| 4 | 0.17 | Homo sapiens | 9 | 0 | 0 | 0 |
| 5 | 0.47 | Ruminococcaceae sp. | 8 | 0 | 0 | 0 |
| 6 | 0.47 | Homo sapiens | 8 | 0 | 0 | 1 |
Eight hundred ten ASVs present in at least five samples were evaluated by the prevalence method as implemented in the isNotContaminant function. The six ASVs classified as non-contaminants using an FDR threshold of 0.5 [56] are shown. Taxonomy was assigned by BLAST-ing sequences against the nt database. Prevalence is reported for each sample type included in the study
Reduction of false-positive associations between the gestational microbiota and preterm birth
A recent exploratory analysis of associations between the gestational vaginal microbiota and preterm birth (PTB) identified a number of microbial taxa seemingly associated with PTB [19]. However, the authors concluded that many of these significant associations were run-specific contaminants rather than true biological signal. We used decontam to further explore the possibility that some contaminant ASVs were significantly associated with PTB in this dataset.
We generated decontam scores using the prevalence, frequency, and combined methods, while specifying the sequencing runs as batches. The scores assigned by all methods showed the expected bimodal score distribution, and the combined method produced the clearest low-score peak (i.e., putative contaminant) (Additional file 1: Figure S4). Scores assigned by the frequency and prevalence methods were broadly consistent, especially at low values (Additional file 1: Figure S5). We generated a plot similar to the exploratory analysis presented in the original Callahan et al.’s paper, but colored ASVs by the scores assigned by the combined method (Fig. 6). Four of the ASVs most significantly associated with PTB were assigned scores less than 10−6, strongly supporting a contaminant origin. Representatives from the genera of those four ASVs have been previously observed as contaminants (Herbaspirillum: refs. [12, 14, 45]; Pseudomonas: refs. [8, 9, 12, 14, 31]; Tumebacillus: refs. [12, 46]; Yersinia: ref. [47]), corroborating decontam’s classification.
Fig. 6.
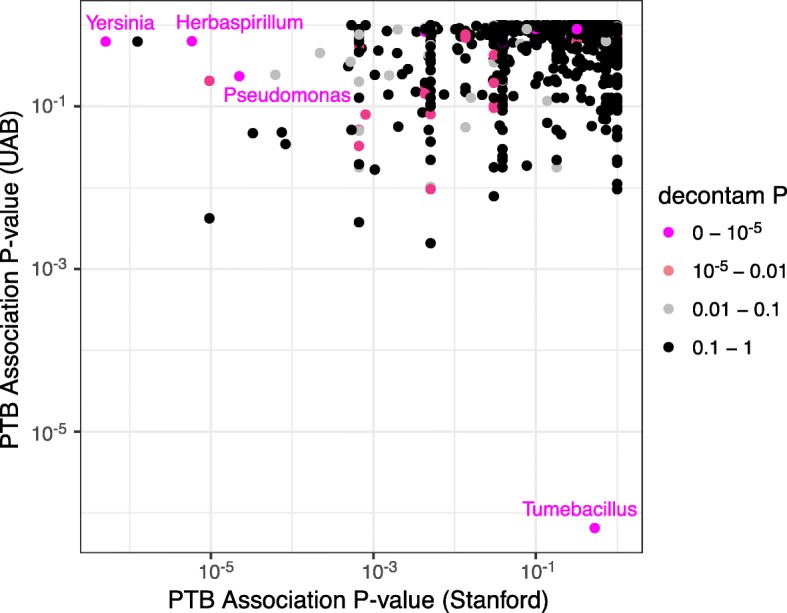
Diagnosing contamination in an exploratory analysis of the vaginal microbiota and preterm birth (PTB). The association between PTB and an increase in the average gestational frequency of various ASVs was evaluated in the two cohorts of women (Stanford and UAB) analyzed in [19]. The x- and y-axes display the P values of the association between increased gestational frequency and PTB (one-sided Wilcoxon rank-sum test) in the Stanford and UAB cohorts, respectively. Points are colored by the score assigned to them by the isContaminant function in the decontam R package, using the combined method. Several ASVs that were strongly associated with PTB in either the Stanford or UAB cohorts are clearly identified as contaminants with a decontam score of less than 10−5 (genera in magenta text)
Discussion
Previous work has established two common signatures of contaminants in MGS data: frequency inversely proportional to sample DNA concentration [8, 14, 16, 30] and presence in negative controls [10, 31, 32]. Building on that work, we developed a simple model of the mixture between contaminant and sample DNA that serves as the basis of frequency-based and prevalence-based statistical classification procedures for identifying contaminants. These methods are implemented in the open-source R package decontam and can be used to diagnose, identify, and remove contaminants in marker-gene and metagenomic sequencing datasets.
The classification of contaminants by decontam was internally and externally consistent in real datasets. The independent frequency and prevalence methods produced largely consistent results, and the distribution of scores recapitulated the bimodal distribution expected from the proposed mixture model of total DNA. Decontam classifications were consistent with literature expectations in a subset of genera that the literature unambiguously described as true inhabitants or contaminants.
The classification accuracy of decontam increased with the number of samples in which a sequence feature appeared (its prevalence). The rate of false-positive contaminant identification was low for all features, consistent with the findings of an independent benchmarking study [57]. The sensitivity of contaminant identification increased substantially with feature prevalence. As a result, while the specificity and sensitivity of decontam on a per-feature basis were sometimes moderate, accuracy evaluated on a per-read basis reached exceptional levels.
In several example datasets, the application of decontam improved biological interpretation. Removal of contaminants identified by decontam reduced variation due to sequencing center and DNA extraction kit, an oft-cited issue in high-throughput marker-gene and metagenomics studies [14, 48]. Decontam corroborated recent conclusions that little evidence of an indigenous placenta microbiome existed in a marker-gene dataset from placenta biopsies, and extended that conclusion to rare sequences [15]. Decontam identified several contaminant taxa in a recent study that a naïve exploratory analysis would have found to be significantly associated with preterm birth [19].
Decontam improves on current in silico approaches to contaminant identification and removal. Decontam identifies contaminants on a per-sequence-feature basis. Decontam requires no external knowledge of the pool of potential contaminants. Decontam’s statistical classification approach avoids shortcomings of common ad hoc threshold approaches. For example, removal of all sequences detected in negative controls also removes abundant true sequences due to cross-contamination among samples [49, 50]. Removal of sequences below an ad hoc relative abundance threshold sacrifices low-frequency true sequences and fails to remove the abundant contaminants most likely to interfere with downstream analysis. In contrast, decontam readily detects abundant and prevalent contaminants, while strongly limiting false positives. Decontam can improve the quality of MGS data and subsequent analyses, at little or no cost to the investigator.
Using decontam
Experimental design
Decontam is applicable to any MGS dataset for which DNA quantitation data or sequenced negative controls are available. Simple experimental design choices can further improve the performance of decontam. Because reagents contribute significantly to contamination [8, 14–16], negative controls should contain reagents and/or sterile sample collection instruments and should be processed and sequenced alongside true samples. The sensitivity of prevalence-based classification is limited by the number of negative controls, and there is often variation among the contaminants present in each, so we recommend sequencing multiple negative controls. A simulation analysis suggests that five to six negative control samples are sufficient to identify most contaminants (assuming a significantly larger number of true samples and a prevalence patterns similar to those seen in the oral dataset; Additional file 1: Figure S6), although sensitivity continues to increase with more negative controls. We recommend investigators sequence negative controls for both amplicon and shotgun sequencing approaches and even if quality checks indicate little or no DNA is present.
In studies large enough to span multiple processing batches (e.g., sequencing runs), we recommend blocking or randomizing samples across the processing batches if possible. Contaminants are often batch-specific, and sample randomization will prevent the conflation of batch-specific contaminants with study outcomes if subsequent contaminant amelioration is not completely effective.
Method choice
The isContaminant function in decontam implements distinct frequency- and prevalence-based methods for contaminant identification and can also use both methods in combination. Choice of method should be guided first by the auxiliary data available: frequency-based identification requires DNA quantitation data and prevalence-based identification requires sequenced negative controls.
DNA concentrations measured from prepared amplicon or shotgun libraries prior to sequencing, often in the form of standardized fluorescent intensities, work effectively with the frequency method in our experience. More effort-intensive methods, such as qPCR, may improve accuracy further if those methods more accurately quantify total DNA [31]. Typically, sufficient variation in DNA concentration for the frequency method to discriminate between contaminants and non-contaminants arises naturally during sample preparation and processing. A positive control dilution series that covers a broad range of input DNA concentrations can guarantee a broad range of sample DNA concentrations [14, 57]. Evidence from Salter et al. and Karstens et al. suggests a dilution series in which the undiluted sample contains 108–109 bacteria and the most dilute sample in the series contains 103–104 bacteria may be effective.
The sensitivity of prevalence-based contaminant identification is limited if few negative controls are sequenced. In very low-biomass environments, where contaminant DNA may constitute a majority of sequencing reads, the implementation of the prevalence method in the isNotContaminant function can conveniently identify minority non-contaminants.
The score distributions generated by the combined method, which combines the frequency and prevalence scores into a composite score, showed a (slightly) cleaner bimodal distribution than the frequency or prevalence methods alone in the datasets we examine here (Fig. 2 and Additional file 1: Figure S4). Thus, we recommend generating and sequencing negative controls and using the combined approach when the necessary auxiliary data are available, although the frequency and prevalence methods are both independently effective as well.
Choice of classification threshold
Decontam classifies sequence features as contaminants by comparing the score statistic P to a classification threshold P*. We recommend that investigators inspect the distribution of scores assigned by decontam, especially when decontam is being applied to large studies spanning multiple batches such as sequencing runs, and consider non-default classification thresholds if so indicated. Typically, an appropriate classification threshold can be read directly off the score histogram. For example, the histogram of scores in Fig. 2b showed clear bimodality between very low and high scores, indicating that thresholds in the range from 0.1 to 0.5 would effectively identify the contaminants that make up the low-score mode. In the preterm birth dataset, the low-score mode in the score histogram was much narrower, indicating a threshold of 0.01 would be more appropriate (Additional file 1: Figure S4). Another useful visualization is a quantile-quantile plot of scores versus the uniform distribution.
The scores generated by decontam can also be used as quantitative diagnostics instead of as input to a binary classifier. As suggested by our re-analysis of the preterm birth dataset, the decontam scores associated with taxa found to be of interest in other analyses can inform subsequent interpretation of the results, and potentially indicate the need for additional confirmatory analyses.
Application to heterogeneous samples
Decontam uses patterns across samples to identify contaminants, but that approach can be less effective when groups of samples have systematically different contaminant patterns. One such scenario arises from separate processing batches that result in batch-specific contaminants. Decontam allows the user to specify such batches in the data, in which case scores are generated independently within each batch, with the smallest score across batches used for classification by default. Batched classification should be considered when major variation exists in sample processing steps—e.g., different sequencing runs or DNA extraction kits.
The assumptions of decontam, especially the frequency method, can be violated if bacterial biomass systematically differs between groups of samples. For example, if decontam were applied to a mixed set of stool (high biomass) and airway (low biomass) samples, real sequences in the airway samples could be classified as contaminants, because they have a higher frequency in the low-concentration samples. Therefore, we recommend applying decontam independently to samples collected from different environments. Covariation between experimental conditions-of-interest and bacterial biomass could also impinge on the accuracy of contaminant classification, especially if using the frequency method. We have included the plot_condition function in the decontam R package as a convenient way to investigate possible relationships between important experimental conditions and total DNA concentration.
Choice of sequence feature
Decontam can be applied to a variety of sequence features derived from MGS data (e.g., OTUs, ASVs, taxonomic groups, MAGs). Decontam should work most effectively on sequence features that are sufficiently resolved such that contaminants are not grouped with real strains, while also not being overly affected by MGS sequencing noise.
In marker-gene data, we expect the best performance will be achieved with post-denoising ASVs [53, 58] as ASVs are less prone than OTUs to grouping contaminants with related real strains. A general recommendation for metagenomics studies is to use finer taxonomic groups (e.g., species rather than families) and narrower functional categories (e.g., genes rather than pathways).
Limitations of decontam and complementary approaches
Decontam assumes that contaminants and true community members are distinct from one another. This basic assumption is violated by cross-contamination—contaminant sequences arising from other processed samples [33, 49, 50]. Decontam is not designed to remove cross-contamination. MGS studies would benefit from the development of methods to address cross-contamination, and some exciting progress in that area is beginning to be made [33]. In studies where cross-contamination of the negative controls is expected to predominate over external contamination, we reiterate our guidance to consider adjusting the classification threshold P* after examining the distribution of probability scores, as cross-contaminants may often be assigned intermediate scores, especially by the prevalence method.
Decontam depends on patterns across samples to identify contaminants and therefore has low sensitivity for detecting contaminants that are found in very few samples. Since very low-prevalence sequences are often uninformative in downstream analyses, it might often be appropriate to combine decontam with the removal of low-prevalence sequences that may be enriched in contaminants that decontam did not detect.
Conclusions
Contaminant removal is a critical but often overlooked step in marker-gene and metagenomics (MGS) quality control [11, 14, 15, 36, 46]. Salter et al. and Kim et al. provide excellent pre-sequencing recommendations that reduce the impact of contamination that can be complemented by in silico contaminant removal. Here we introduce a simple, flexible, open-source R package—decontam—that uses widely reproduced signatures of contaminant DNA to identify contaminants in MGS datasets. Decontam requires only data that are in most cases already generated, readily fits into existing MGS analysis workflows, and can be applied to many types of MGS data. Together, our results suggest that decontam can improve the accuracy of biological inferences across a wide variety of MGS studies at little or no additional cost.
Methods
Oral and control sample processing
Sample DNA was extracted with the PowerSoil®-HTP 96 well Soil DNA Isolation Kit (MO BIO Laboratories, Carlsbad, CA, USA) and then PCR amplified in 2–4 replicate 75-μL reactions using Golay barcoded primers targeting the V4 region of the bacterial 16S rRNA gene [51]. Amplicons were purified, DNA-quantitated using the PicoGreen fluorescence-based Quant-iT dsDNA Assay Kit (ThermoFisher catalog no. Q33120), and pooled in equimolar amounts. After ethanol precipitation and size-selection, amplicons were sequenced in duplicate on two lanes of an Illumina MiSeq v3 flowcell at the W.M. Keck Center for Comparative Functional Genomics (University of Illinois, Urbana-Champaign, USA). Negative controls were processed in parallel with samples beginning at the DNA extraction step (see also Supplemental Methods in Additional file 1).
Amplicon sequence analysis
Duplicate sequencing runs from the oral dataset were concatenated and demultiplexed using QIIME’s split_libraries_fastq.py script [52]. Demultiplexed fastq files from the oral, Salter et al.’s, and placenta datasets were then processed into amplicon sequence variants (ASVs) by DADA2 version 1.8.0 [53]. The final table in the oral dataset consisted of 18,285,750 sequencing reads in 2420 unique ASVs across 767 samples. Taxonomy was assigned to each sequence using the assignTaxonomy function in the dada2 R package [59] and the non-redundant SILVA taxonomic training set (“silva_nr_v128_train_set.fa”, https://www.arb-silva.de/). Further analysis was performed using the phyloseq R package [54].
To improve taxonomic classification accuracy for oral genera, we classified oral sequences a second time using the Human Oral Microbiome Database (HOMD, ref. [42], http://www.homd.org/, “HOMD_16S_rRNA_RefSeq_V14.5.fasta”). We compared SILVA and HOMD classifications at the genus level, and we resolved assignments for the 80 sequences on which SILVA and HOMD disagreed by NCBI BLAST results.
Construction of oral and contamination databases
The oral database contains bacterial genera confirmed to inhabit the human oral plaque microbiota by microscopic visualization [39, 41, 55], and genera cultivated from the human oral cavity [42]. These genera are listed with their literature citations in the “oral_database.csv” file and the HOMD [42] as “named” or “unnamed” entries. The contamination database contains bacterial genera previously reported as contaminants in 16S rRNA gene negative controls. Contaminant genera are listed with their literature citations in the “contamination_database.csv” file. Genera were categorized into three groups by comparison to the oral and contamination databases: contaminant, if present in the contamination database and not in the oral database; oral, if present in the oral database and not in the contamination database; and ambiguous otherwise. Reference-based classification of ASVs was performed based on their assigned genus, and if no genus was assigned, then the ASV was classified as ambiguous.
Additional file
Supplementary Appendix: Supplemental Methods. Figure S1. Concentration of contaminant features across oral samples. Figure S2. Histogram of decontam scores in the oral mucosa dataset, weighted by ASV relative abundance. Figure S3. Histogram of decontam scores in the oral mucosa dataset, stratified by reference-based classification. Figure S4. Histogram of decontam scores in the preterm birth dataset. Figure S5. Density plot of scores assigned by the frequency and prevalence methods in the preterm birth dataset. (PDF 1208 kb)
Acknowledgements
We thank the study participants for specimen donation, Dr. Ava Wu and Danielle Drury at the UCSF School of Dentistry for collecting oral mucosa specimens, Dr. Mark Ryder at UCSF for managing the UCSF protocol, and Dr. Les Dethlefsen and members of the Relman Lab for helpful discussions.
Funding
This research was supported by NIH National Institute of Dental and Craniofacial Research grant R01 DE023113 (to D.A.R.), NIH R01 AI112401 (to S.P.H. and D.A.R.), the March of Dimes Prematurity Research Center at Stanford University, the Chan Zuckerburg Biohub Microbiome Initiative (D.A.R), and the Thomas C. and Joan M. Merigan Endowment at Stanford University (D.A.R.).
Availability of data and materials
The sequencing data from the human oral microbiome dataset analyzed in this article are available in the SRA repository under SRA accession number PRJNA419038. The R markdown analysis scripts and all necessary input data to reproduce the analyses in this article are available in a GitHub repository: https://github.com/benjjneb/DecontamManuscript.
Abbreviations
- ASV
Amplicon sequence variant
- MAG
Metagenome-assembled genome
- MGS
Marker-gene and metagenomic sequencing
- OTU
Operational taxonomic unit
Authors’ contributions
DAR acquired funding; NMD, DMP, SPH, DAR, and BJC designed the research; NMD, DMP, and BJC performed the research; NMD, DMP, and BJC analyzed the data; NMD and BJC wrote the manuscript; NMD, DMP, SPH, DAR, and BJC critically revised the manuscript. All authors approved the final version.
Ethics approval and consent to participate
The study was approved by the Administrative Panels on Human Subjects Research (Stanford IRB protocol #21586) and by the Human Research Protection Program at UCSF (UCSF IRB protocol ##11-06283). All research subjects provided written informed consent prior to specimen collection.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Footnotes
Nicole M. Davis and Diana M. Proctor are co-first authors.
David A. Relman and Benjamin J. Callahan are co-last-authors.
References
- 1.Fox GC, Stackebrandt E, Hespell RB, Gibson J, Maniloff J, Dyer TA, Wolfe RS, Balch WE, Tanner RS, Magrum LJ, Zablen LB. The phylogeny of prokaryotes. Science. 1980;209:457–463. doi: 10.1126/science.6771870. [DOI] [PubMed] [Google Scholar]
- 2.Eckburg PB, Bik EM, Bernstein CN, Purdom E, Dethlefsen L, Sargent M, Gill SR, Nelson KE, Relman DA. Diversity of the human intestinal microbial flora. Science. 2005;308:1635–1638. doi: 10.1126/science.1110591. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Turnbaugh PJ, Hamady M, Yatsunenko T, Cantarel BL, Duncan A, Ley RE, Sogin ML, Jones WJ, Roe BA, Affourtit JP, Egholm M. A core gut microbiome in obese and lean twins. Nature. 2009;457:480-4. [DOI] [PMC free article] [PubMed]
- 4.Ravel J, Gajer P, Abdo Z, Schneider GM, Koenig SS, McCulle SL, Karlebach S, Gorle R, Russell J, Tacket CO, Brotman RM. Vaginal microbiome of reproductive-age women. Proc Natl Acad Sci U S A. 2011;108(Suppl 1):4680–4687. doi: 10.1073/pnas.1002611107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Riesenfeld CS, Schloss PD, Handelsman J. Metagenomics: genomic analysis of microbial communities. Annu Rev Genet. 2004;38:525–552. doi: 10.1146/annurev.genet.38.072902.091216. [DOI] [PubMed] [Google Scholar]
- 6.Gill SR, Pop M, DeBoy RT, Eckburg PB, Turnbaugh PJ, Samuel BS, Gordon JI, Relman DA, Fraser-Liggett CM, Nelson KE. Metagenomic analysis of the human distal gut microbiome. Science. 2006;312:1355–1359. doi: 10.1126/science.1124234. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Anantharaman K, Brown CT, Hug LA, Sharon I, Castelle CJ, Probst AJ, Thomas BC, Singh A, Wilkins MJ, Karaoz U, Brodie EL. Thousands of microbial genomes shed light on interconnected biogeochemical processes in an aquifer system. Nat Commun. 2016;7:13219. doi: 10.1038/ncomms13219. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Jervis-Bardy J, Leong LE, Marri S, Smith RJ, Choo JM, Smith-Vaughan HC, Nosworthy E, Morris PS, O’Leary S, Rogers GB, Marsh RL. Deriving accurate microbiota profiles from human samples with low bacterial content through post-sequencing processing of Illumina MiSeq data. Microbiome. 2015;3:19. doi: 10.1186/s40168-015-0083-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Jousselin E, Clamens AL, Galan M, Bernard M, Maman S, Gschloessl B, Duport G, Meseguer AS, Calevro F, Coeur D’Acier A. Assessment of a 16S rRNA amplicon Illumina sequencing procedure for studying the microbiome of a symbiont-rich aphid genus. Mol Ecol Resour. 2016;16:628–640. doi: 10.1111/1755-0998.12478. [DOI] [PubMed] [Google Scholar]
- 10.Adams RI, Bateman AC, Bik HM, Meadow JF. Microbiota of the indoor environment: a meta-analysis. Microbiome. 2015;3:49. doi: 10.1186/s40168-015-0108-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Sinha R, Abnet CC, White O, Knight R, Huttenhower C. The microbiome quality control project: baseline study design and future directions. Genome Biol. 2015;16:276. doi: 10.1186/s13059-015-0841-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Glassing A, Dowd SE, Galandiuk S, Davis B, Chiodini RJ. Inherent bacterial DNA contamination of extraction and sequencing reagents may affect interpretation of microbiota in low bacterial biomass samples. Gut Pathog. 2016;8:24. doi: 10.1186/s13099-016-0103-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Riley DR, Sieber KB, Robinson KM, White JR, Ganesan A, Nourbakhsh S, Hotopp JC. Bacteria-human somatic cell lateral gene transfer is enriched in cancer samples. PLoS Comput Biol. 2013;9:e1003107. doi: 10.1371/journal.pcbi.1003107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Salter SJ, Cox MJ, Turek EM, Calus ST, Cookson WO, Moffatt MF, Turner P, Parkhill J, Loman NJ, Walker AW. Reagent and laboratory contamination can critically impact sequence-based microbiome analyses. BMC Biol. 2014;12:87. doi: 10.1186/s12915-014-0087-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Lauder AP, Roche AM, Sherrill-Mix S, Bailey A, Laughlin AL, Bittinger K, Leite R, Elovitz MA, Parry S, Bushman FD. Comparison of placenta samples with contamination controls does not provide evidence for a distinct placenta microbiota. Microbiome. 2016;4:29. doi: 10.1186/s40168-016-0172-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Lusk RW. Diverse and widespread contamination evident in the unmapped depths of high throughput sequencing data. PLoS One. 2014;9:e110808. doi: 10.1371/journal.pone.0110808. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Aagaard K, Ma J, Antony KM, Ganu R, Petrosino J, Versalovic J. The placenta harbors a unique microbiome. Sci Transl Med. 2014;6:237ra65. doi: 10.1126/scitranslmed.3008599. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Herbold CW, Pelikan C, Kuzyk O, Hausmann B, Angel R, Berry D, Loy A. A flexible and economical barcoding approach for highly multiplexed amplicon sequencing of diverse target genes. Front Microbiol. 2015;6:731. doi: 10.3389/fmicb.2015.00731. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Callahan BJ, DiGiulio DB, Goltsman DS, Sun CL, Costello EK, Jeganathan P, Biggio JR, Wong RJ, Druzin ML, Shaw GM, Stevenson DK. Replication and refinement of a vaginal microbial signature of preterm birth in two racially distinct cohorts of US women. Proc Natl Acad Sci. 2017;114:9966–9971. doi: 10.1073/pnas.1705899114. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Kirstahler P, Bjerrum SS, Friis-Møller A, Cour M, Aarestrup FM, Westh H, Pamp SJ. Genomics-based identification of microorganisms in human ocular body fluid. Sci Rep. 2018;8:4126. doi: 10.1038/s41598-018-22416-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Bittinger K, Charlson ES, Loy E, Shirley DJ, Haas AR, Laughlin A, Yi Y, Wu GD, Lewis JD, Frank I, Cantu E. Improved characterization of medically relevant fungi in the human respiratory tract using next-generation sequencing. Genome Biol. 2014;15:487. doi: 10.1186/s13059-014-0487-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Herrera A, Cockell CS. Exploring microbial diversity in volcanic environments: a review of methods in DNA extraction. J Microbiol Methods. 2007;70:1–12. [DOI] [PubMed]
- 23.Koren O, Spor A, Felin J, Fåk F, Stombaugh J, Tremaroli V, Behre CJ, Knight R, Fagerberg B, Ley RE, Bäckhed F. Human oral, gut, and plaque microbiota in patients with atherosclerosis. Proc Natl Acad Sci. 2011;108(Suppl 1):4592–4598. doi: 10.1073/pnas.1011383107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Kitchin PA, Szotyori Z, Fromholc C, Almond N. Avoidance of PCR false positives [corrected] Nature. 1990;344:201. doi: 10.1038/344201a0. [DOI] [PubMed] [Google Scholar]
- 25.Meadow JF, Altrichter AE, Bateman AC, Stenson J, Brown GZ, Green JL, Bohannan BJ. Humans differ in their personal microbial cloud. PeerJ. 2015;3:e1258. doi: 10.7717/peerj.1258. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Knights D, Kuczynski J, Charlson ES, Zaneveld J, Mozer MC, Collman RG, Bushman FD, Knight R, Kelley ST. Bayesian community-wide culture-independent microbial source tracking. Nat Methods. 2011;8:761-3. [DOI] [PMC free article] [PubMed]
- 27.Rand KH, Houck H. Taq polymerase contains bacterial DNA of unknown origin. Mol Cell Probes. 1990;4:445–450. doi: 10.1016/0890-8508(90)90003-I. [DOI] [PubMed] [Google Scholar]
- 28.Patel P, Garson JA, Tettmar KI, Ancliff S, McDonald C, Pitt T, Coelho J, Tedder RS. Development of an ethidium monoazide–enhanced internally controlled universal 16S rDNA real-time polymerase chain reaction assay for detection of bacterial contamination in platelet concentrates. Transfusion. 2012;52:1423–1432. doi: 10.1111/j.1537-2995.2011.03484.x. [DOI] [PubMed] [Google Scholar]
- 29.Flores GE, Henley JB, Fierer N. A direct PCR approach to accelerate analyses of human-associated microbial communities. PLoS One. 2012;7:e44563. doi: 10.1371/journal.pone.0044563. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Willner D, Daly J, Whiley D, Grimwood K, Wainwright CE, Hugenholtz P. Comparison of DNA extraction methods for microbial community profiling with an application to pediatric bronchoalveolar lavage samples. PLoS One. 2012;7:e34605. doi: 10.1371/journal.pone.0034605. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Lazarevic V, Gaïa N, Girard M, Schrenzel J. Decontamination of 16S rRNA gene amplicon sequence datasets based on bacterial load assessment by qPCR. BMC Microbiol. 2016;16:73. doi: 10.1186/s12866-016-0689-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Dunn RR, Fierer N, Henley JB, Leff JW, Menninger HL. Home life: factors structuring the bacterial diversity found within and between homes. PLoS One. 2013;8:e64133. doi: 10.1371/journal.pone.0064133. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Larsson AJ, Stanley G, Sinha R, Weissman IL, Sandberg R. Computational correction of index switching in multiplexed sequencing libraries. Nat Methods. 2018;15:305. doi: 10.1038/nmeth.4666. [DOI] [PubMed] [Google Scholar]
- 34.Delmont TO, Eren AM. Identifying contamination with advanced visualization and analysis practices: metagenomic approaches for eukaryotic genome assemblies. PeerJ. 2016;4:e1839. doi: 10.7717/peerj.1839. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Gentleman RC, Carey VJ, Bates DM, Bolstad B, Dettling M, Dudoit S, Ellis B, Gautier L, Ge Y, Gentry J, Hornik K. Bioconductor: open software development for computational biology and bioinformatics. Genome Biol. 2004;5:R80. doi: 10.1186/gb-2004-5-10-r80. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Goodrich JK, Di Rienzi SC, Poole AC, Koren O, Walters WA, Caporaso JG, Knight R, Ley RE. Conducting a microbiome study. Cell. 2014;158:250–262. doi: 10.1016/j.cell.2014.06.037. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Proctor DM, Fukuyama JA, Loomer PM, Armitage GC, Lee SA, Davis NM, Ryder MI, Holmes SP, Relman DA. A spatial gradient of bacterial diversity in the human oral cavity shaped by salivary flow. Nat Commun. 2018;9:681. doi: 10.1038/s41467-018-02900-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Bik EM, Long CD, Armitage GC, Loomer P, Emerson J, Mongodin EF, Nelson KE, Gill SR, Fraser-Liggett CM, Relman DA. Bacterial diversity in the oral cavity of 10 healthy individuals. ISME J. 2010;4:962-74. [DOI] [PMC free article] [PubMed]
- 39.Valm AM, Welch JL, Rieken CW, Hasegawa Y, Sogin ML, Oldenbourg R, Dewhirst FE, Borisy GG. Systems-level analysis of microbial community organization through combinatorial labeling and spectral imaging. Proc Natl Acad Sci U S A. 2011;108:4152–4157. doi: 10.1073/pnas.1101134108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Eren AM, Borisy GG, Huse SM, Welch JL. Oligotyping analysis of the human oral microbiome. Proc Natl Acad Sci U S A. 2014;111:E2875-2884. [DOI] [PMC free article] [PubMed]
- 41.Welch JL, Rossetti BJ, Rieken CW, Dewhirst FE, Borisy GG. Biogeography of a human oral microbiome at the micron scale. Proc Natl Acad Sci. 2016;113:E791–E800. doi: 10.1073/pnas.1522149113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Chen T, Yu WH, Izard J, Baranova OV, Lakshmanan A, Dewhirst FE. The human oral microbiome database: a web accessible resource for investigating oral microbe taxonomic and genomic information. Database. 2010;2010:baq013. doi: 10.1093/database/baq013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Yoshida M, Fukushima H, Yamamoto K, Ogawa K, Toda T, Sagawa H. Correlation between clinical symptoms and microorganisms isolated from root canals of teeth with periapical pathosis. J Endod. 1987;13:24–28. doi: 10.1016/S0099-2399(87)80088-2. [DOI] [PubMed] [Google Scholar]
- 44.Perez-Muñoz ME, Arrieta MC, Ramer-Tait AE, Walter J. A critical assessment of the “sterile womb” and “in utero colonization” hypotheses: implications for research on the pioneer infant microbiome. Microbiome. 2017;5:48. doi: 10.1186/s40168-017-0268-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Barton HA, Taylor NM, Lubbers BR, Pemberton AC. DNA extraction from low-biomass carbonate rock: an improved method with reduced contamination and the low-biomass contaminant database. J Microbiol Methods. 2006;66:21–31. doi: 10.1016/j.mimet.2005.10.005. [DOI] [PubMed] [Google Scholar]
- 46.Kim D, Hofstaedter CE, Zhao C, Mattei L, Tanes C, Clarke E, Lauder A, Sherrill-Mix S, Chehoud C, Kelsen J, Conrad M. Optimizing methods and dodging pitfalls in microbiome research. Microbiome. 2017;5:52. doi: 10.1186/s40168-017-0267-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Afshinnekoo E, Meydan C, Chowdhury S, Jaroudi D, Boyer C, Bernstein N, Maritz JM, Reeves D, Gandara J, Chhangawala S, Ahsanuddin S. Geospatial resolution of human and bacterial diversity with city-scale metagenomics. Cell Syst. 2015;1:72–87. doi: 10.1016/j.cels.2015.01.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Kennedy NA, Walker AW, Berry SH, Duncan SH, Farquarson FM, Louis P, Thomson JM. The impact of different DNA extraction kits and laboratories upon the assessment of human gut microbiota composition by 16S rRNA gene sequencing. PLoS One. 2014;9:e88982. doi: 10.1371/journal.pone.0088982. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Wright ES, Vetsigian KH. Quality filtering of Illumina index reads mitigates sample cross-talk. BMC Genomics. 2016;17:876. doi: 10.1186/s12864-016-3217-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Edgar RC. UNCROSS: filtering of high-frequency cross-talk in 16S amplicon reads: bioRxiv; 2016. p. 088666.
- 51.Walters W, Hyde ER, Berg-Lyons D, Ackermann G, Humphrey G, Parada A, Gilbert JA, Jansson JK, Caporaso JG, Fuhrman JA, Apprill A. Improved bacterial 16S rRNA gene (V4 and V4-5) and fungal internal transcribed spacer marker gene primers for microbial community surveys. mSystems. 2016;1:e00009–e00015. doi: 10.1128/mSystems.00009-15. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Caporaso JG, Kuczynski J, Stombaugh J, Bittinger K, Bushman FD, Costello EK, Fierer N, Pena AG, Goodrich JK, Gordon JI, Huttley GA. QIIME allows analysis of high-throughput community sequencing data. Nat Methods. 2010;7:335-6. [DOI] [PMC free article] [PubMed]
- 53.Callahan BJ, McMurdie PJ, Rosen MJ, Han AW, Johnson AJ, Holmes SP. DADA2: high-resolution sample inference from Illumina amplicon data. Nat Methods. 2016;13:581-3. [DOI] [PMC free article] [PubMed]
- 54.McMurdie PJ, Holmes S. phyloseq: an R package for reproducible interactive analysis and graphics of microbiome census data. PLoS One. 2013;8:e61217. doi: 10.1371/journal.pone.0061217. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Brinig MM, Lepp PW, Ouverney CC, Armitage GC, Relman DA. Prevalence of bacteria of division TM7 in human subgingival plaque and their association with disease. Appl Environ Microbiol. 2003;69:1687–1694. doi: 10.1128/AEM.69.3.1687-1694.2003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Benjamini Y, Hochberg Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J R Stat Soc Ser B Methodol. 1995;57:289–300.
- 57.Karstens L, Asquith M, Davin S, Fair D, Gregory WT, Wolfe AJ, Braun J, McWeeney S. Controlling for contaminants in low biomass 16S rRNA gene sequencing experiments. bioRxiv. 2018:329854. [DOI] [PMC free article] [PubMed]
- 58.Callahan BJ, McMurdie PJ, Holmes SP. Exact sequence variants should replace operational taxonomic units in marker-gene data analysis. ISME J. 2017;11:2639. doi: 10.1038/ismej.2017.119. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Wang Q, Garrity GM, Tiedje JM, Cole JR. Naive Bayesian classifier for rapid assignment of rRNA sequences into the new bacterial taxonomy. Appl Environ Microbiol. 2007;73:5261–5267. doi: 10.1128/AEM.00062-07. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary Appendix: Supplemental Methods. Figure S1. Concentration of contaminant features across oral samples. Figure S2. Histogram of decontam scores in the oral mucosa dataset, weighted by ASV relative abundance. Figure S3. Histogram of decontam scores in the oral mucosa dataset, stratified by reference-based classification. Figure S4. Histogram of decontam scores in the preterm birth dataset. Figure S5. Density plot of scores assigned by the frequency and prevalence methods in the preterm birth dataset. (PDF 1208 kb)
Data Availability Statement
The sequencing data from the human oral microbiome dataset analyzed in this article are available in the SRA repository under SRA accession number PRJNA419038. The R markdown analysis scripts and all necessary input data to reproduce the analyses in this article are available in a GitHub repository: https://github.com/benjjneb/DecontamManuscript.