

Abstract
Background
Estimating heterogeneous treatment effect is a fundamental problem in biological and medical applications. Recently, several recursive partitioning methods have been proposed to identify the subgroups that respond differently towards a treatment, and they rely on a fitness criterion to minimize the error between the estimated treatment effects and the unobservable ground truths.
Results
In this paper, we propose that a heterogeneity criterion, which maximizes the differences of treatment effects among the subgroups, also needs to be considered. Moreover, we show that better performances can be achieved when the fitness and the heterogeneous criteria are considered simultaneously. Selecting the optimal splitting points then becomes a multi-objective problem; however, a solution that achieves optimal in both aspects are often not available. To solve this problem, we propose a multi-objective splitting procedure to balance both criteria. The proposed procedure is computationally efficient and fits naturally into the existing recursive partitioning framework. Experimental results show that the proposed multi-objective approach performs consistently better than existing ones.
Conclusion
Heterogeneity should be considered with fitness in heterogeneous treatment effect estimation, and the proposed multi-objective splitting procedure achieves the best performance by balancing both criteria.
Keywords: Heterogeneous treatment effect, Breast cancer, Radiotherapy
Background
Treatment effect estimation is a fundamental problem in scientific research. Biologists use it to study the regulatory relationships between numerous genes [1], and medical researchers rely on it to determine whether a treatment is effective for the patients [2].
Traditionally, the treatment effect is estimated as an average value for the entire population. However, understanding the heterogeneity of treatment effects are important for many applications. For example, although radiotherapy is an effective treatment for cancer patients in general, some of the patients do not benefit from it because of their different gene expression patterns [3].
It is desirable to apply principled data mining methods to inference the heterogeneity in the treatment effects [4]. Tree-based recursive partitioning methods [5], originally proposed for regression and classification, are perfect candidates for modeling treatment effect heterogeneity. Unlike methods which have strong predictive power but are difficult to interpret, tree-based methods often excel on both frontiers. Their output, tree models, can be easily interpreted by human experts, which is of an important consideration in both biological and medical applications.
A fundamental impediment must be cleared before recursive partitioning methods can be applied to estimate heterogeneous treatment effects. In regression and classification, the target variables are available in the training data. Unfortunately, such information is almost never available in treatment effect estimation because a sample can either be treated or not treated. In other words, only one of the two potential outcomes is observable but both outcomes are needed for the estimation [6].
Recently, a number of recursive partitioning methods have been proposed to solve the problem by utilizing the fitness criterion [7–9]. Specifically, these methods employ a surrogate loss function to minimize the error between the estimated treatment effects and the unobservable ground truth treatment effects.
Understanding the heterogeneity of treatment effect has important real-world implications. For example, consider two models describing the radiotherapy treatment effect for breast cancer patients (Fig. 1). The first model divides the patients into two sub-populations according to the expression level of gene1, and the second model places the split at gene2. If the errors of both models are within an acceptable level, the second model should be preferred because it shed more lights on how the treatment effects vary among different subpopulations of the patients.
Fig. 1.
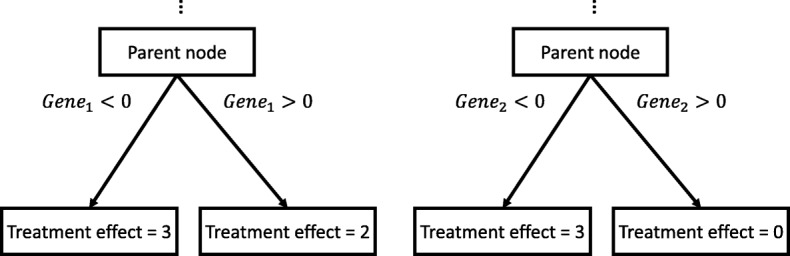
Illustration of two models for estimating heterogeneous treatment effect. The first model preferred fitness while the second one prioritized heterogeneity
Heterogeneity should be considered explicitly during the recursive partitioning process. As illustrated in Fig. 2, although the first model has slightly lower estimated error than the second one, it provides less insight on treatment effect heterogeneity than the second model. In this example, existing methods will prefer the first model and fail to revealing the heterogeneity because the heterogeneity is not considered.
Fig. 2.
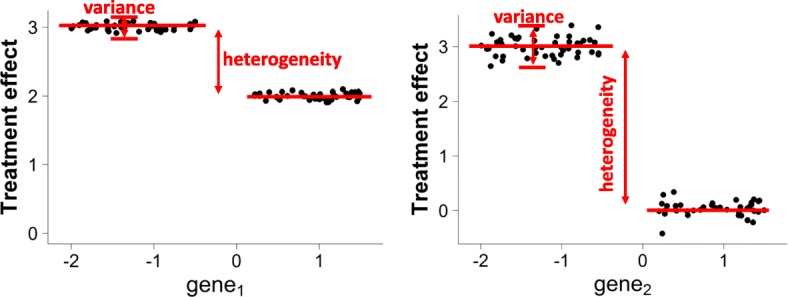
Estimated treatment effects for models in Fig. 1. When the sub-populations are split at gene2, the estimated error is slightly larger than splitting at gene1. This explains why existing methods prefer Model 1. However, the heterogeneity of treatment effects is ignored in this criterion
Without explicitly maximizing heterogeneity, a criterion may favor splits resulting in homogeneous nodes. Producing homogeneous nodes is problematic for applications where the number of samples are limited, which is almost ubiquitous in bioinformatics problems. A split with homogeneous nodes will halve the sample size without providing insight to the treatment effect heterogeneity, and the reliability of treatment effect estimation for the subsequent splits will decrease. A closely related method, namely the Causal Tree (CT) [7], does not explicitly maximize the heterogeneity and often produce split leading to homogeneous nodes.
Moreover, heterogeneity and fitness need to be considered simultaneously during the splitting procedure. If the splitting is based solely on the heterogeneity criterion, the algorithm will be prone to favor models with spuriously high treatment effect differences but unacceptably estimation errors. Finding the optimal splits should be considered as a multiple-objective problem: the first objective is to maximize the fitness (minimize the estimated errors of treatment effect) and the second objective is to maximize the heterogeneity.
In this paper, we first propose the Maximizing Heterogeneity (MH) splitting criterion for heterogeneous treatment effect estimation under the recursive partitioning framework. Then we propose the multi-objective (MO) splitting procedure to consider both the heterogeneities and the fitnesses when building a recursive partitioning model. When solutions which maximize heterogeneity and fitness simultaneously are not achievable, MO aims to strike a balance between both criteria by allowing a certain degree of slack into their dominance relationships.
We compare the proposed methods with existing methods using both simulated and real-world datasets. Experiment results demonstrate that while MH performs better than existing ones in many cases, it is prone to error when the differences in treatment effects become small among subgroups. When fitness and heterogeneity are balanced, MO performs consistently better than all compared methods.
Methods
Preliminaries
In this section, we introduce necessary definitions and results for heterogeneous treatment effect estimation.
Let Wi∈{0,1} denote the treatment assignment, Yi denote the observed outcome, and xi={xi1,…,xip} denote the pre-treatment covariates. The data consists of i.i.d. samples (Yi,Wi,xi), for i=1,…,N. For the sake of simplicity, the subscript i will be omitted when the context is clear.
Let Y(W) denote the potential outcome if an individual has received the treatment W, then the observed outcome Y can be described as Y=WY(1)+(1−W)Y(0). Although each sample is associated with two potential outcomes Y(1) and Y(0), only one of them can be realized as the observed outcome Y.
The average treatment effect (ATE) is defined as the expected outcome if the entire population were treated minus the outcome if they were not treated [6]:
| 1 |
Since only one of the two potential outcomes can be observed, Equation 1 is counterfactual and cannot be estimated straightforwardly. When the treatment assignment is completely random, i.e., 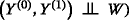 , the average treatment effect can be estimated as .
, the average treatment effect can be estimated as .
However, the treatment assignment is often not randomized. In such cases, the unconfoundedness assumption [6] is needed in order to estimate treatment effect in these circumstances:
Assumption 1
![]()
With the assumption, an unbiased ATE estimation can be achieved with the help of propensity score [10]. The propensity score is defined as e(x)=Pr(W=1|x), the probability of treatment assignment conditioning on the covariates.
The propensity score can then be estimated with a variety of methods. Some popular choices include logistic regression, random forests, and boosting [11].
When treatment effects are heterogeneous across the population, estimating the conditional average treatment effect (CATE) [6] in various subpopulations defined by the possible values of the covariates x often provides more insight than estimating the ATE on the entire population. Specifically, CATE is defined as:
Recursive partitioning provides an ideal way for estimating CATE. Starting from the root node containing the entire population, a tree model is constructed by recursively splitting the node into two disjoint child nodes. By the end of the procedure, the subpopulations with heterogeneous treatment effects are naturally presented in the leaves of the model. For each leaf node, τ(x) can be estimated by calculating the ATE using only the samples within the node as follows:
| 2 |
where the treatment propensity e(xi) is either known from experimental design or estimated from observational data.
The core component of a recursive partitioning model is the splitting criterion. At each split, the splitting criterion relies on a scoring function to evaluate the qualities of all potential splitting points. The recursive partitioning model then makes the split at the splitting point with the highest score.
The fitness criterion, one of the most widely adopted splitting criteria, aims to maximize the fitness of the model by minimizing the mean squared error(MSE). However, since the true treatment effects are not observable, the MSE cannot be estimated straightforwardly. In [7, 9], the authors observed that under Assumption 1, it can be obtained that
| 3 |
Relying on Eq. 3, [7] has proposed to utilize an alternative scoring function to estimate the error as:
| 4 |
where τL and τR are the estimated treatment effects, nL and nR are the numbers of samples in the left and right child node.
The proposed multi-objective splitting criterion
A problem of the fitness criterion is that the expectation equation in 3 is only valid when the sample size is sufficiently large. Unfortunately, in recursive partitioning the sample size of a node becomes more and more smaller than the sample size of the original dataset N as the tree grows. To make things worse, this problem is amplified in biological and medical researches, where N is already small relative to the number of variables.
From the examples in Figs. 1 and 2, it is conceivable that explicitly considering heterogeneity is beneficial for recursive partitioning model construction.
Therefore, we propose that a heterogeneity criterion, which maximizes the differences in treatment effects of the child nodes, also needs to be considered for recursive partitioning. Specifically, the proposed heterogeneity criterion favors the split with the largest treatment effect heterogeneity in the subpopulations of the child nodes:
| 5 |
In Fig. 2, a recursive partitioning method utilizing will choose gene2 over gene1. Because when splitting at gene2, since it results in larger heterogeneity in treatment effects than splitting at gene1. In the following sections, we will refer the criterion in Eq. 5 as Maximizing Heterogeneity (MH).
As will be demonstrated in the next section, relying only on the MH criterion achieves better performances than using the fitness criterion in many cases. But still, there are circumstances where the MH criterion would achieve worse performances than the fitness criterion.
This is caused by the fact that the MH criterion does not place any consideration on the fitness of the model. In other words, the MH criterion would select a splitting point with high heterogeneity even if it also has high mean squared error.
Consider the example in Fig. 2, suppose there exists another covariate gene3 and splitting at gene3 achieves higher heterogeneity than splitting at gene2, but also has higher mean squared error, then an algorithm relying only on the MH criterion will split at gene3 despite the unacceptably high MSE.
Therefore, an ideal splitting point should achieve the highest quality in terms of both the fitness criterion and the heterogeneity criterion . Unfortunately, such solutions are often not available in real-world applications.
To solve this problem, we further propose splitting criterion based on multi-objective optimization to search for the most suitable splitting point. Specifically, the multi-objective criterion does not seek splitting points with the highest heterogeneity or fitness, but prefers one with a balanced fitness and heterogeneity scores.
Let denote a fitness and heterogeneity scores pair for the i-th possible splitting point, and let be the set containing the score corresponding to all the potential split points. The goal then becomes finding the optimal si from . To achieve this, a dominance relationship over the set needs to be defined.
Pareto dominance is a popular choice when it comes to multi-objective optimization [12]. A score vector is said to Pareto-dominate another one if and only if all its components are not smaller than the others, and at least one of its component is larger than that of the others. Then the Pareto set is an unique set which contains all the vectors that are not Pareto-dominated by any other vectors.
Despite its popularity, the original Pareto dominance concept is not suitable for our problem for two reasons. Firstly, Pareto set often contains substantial size of elements; therefore, not only are they often prohibitive to optimize, but also creates difficulties for how to choose from. Secondly, the definition of Pareto dominance does not allow the “trade-off between” among scores.
We propose an extension of the Pareto dominance relationship to achieve our objective, the ε-dominance relationship [13].
Definition 1
(ε-dominance) Score pair is said to ε-dominate for some ε=(ε1,ε2), denoted as si>εsj, if and only if:
The ε-dominance enables the capability of specifying a magnitude of difference for the different criteria (Fig. 3). Intuitively, in order for score pair si to not be ε-dominated by sj, both of si’s components must be at least larger than sj by a margin specified by ε.
Fig. 3.
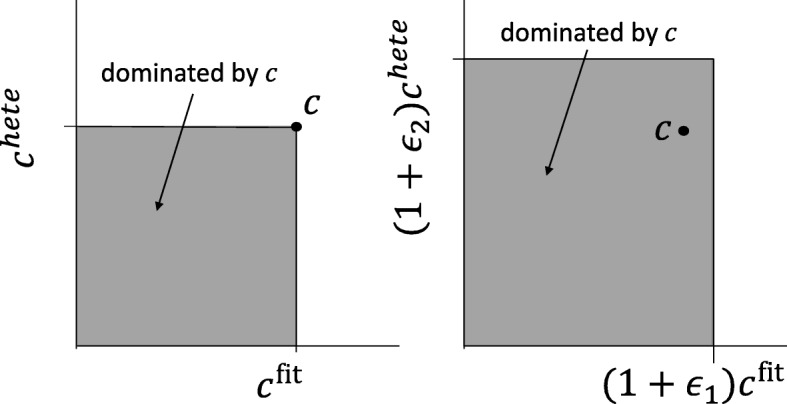
Comparison of Pareto-dominance and ε-dominance
With Definition 1, the ε-optimal set of is defined as the subset where all elements in S is ε-dominated by at least one element of , and all elements in are in the Pareto-set of :
Definition 2
(ε-optimal set) Let be a set of score vectors. Then the ε-splitting set S⋆ is defined as follows:
- Any score s∈S is ε-dominated by at least one score s⋆∈S⋆, i.e.
- Every score s⋆∈S⋆ are not Pareto-dominated by any score s∈S, i.e.
Comparison of Pareto-set and ε-optimal set are illustrated in Fig. 4, the top left panel depicts the elements in and its corresponding Pareto-set, and other panels describe the ε-optimal set with various ε. Compared to the Pareto-set, ε-optimal set contains significantly smaller number of elements. When ε is sufficiently small, the ε-optimal set is equivalent to the Pareto-optimal set [14].
Fig. 4.
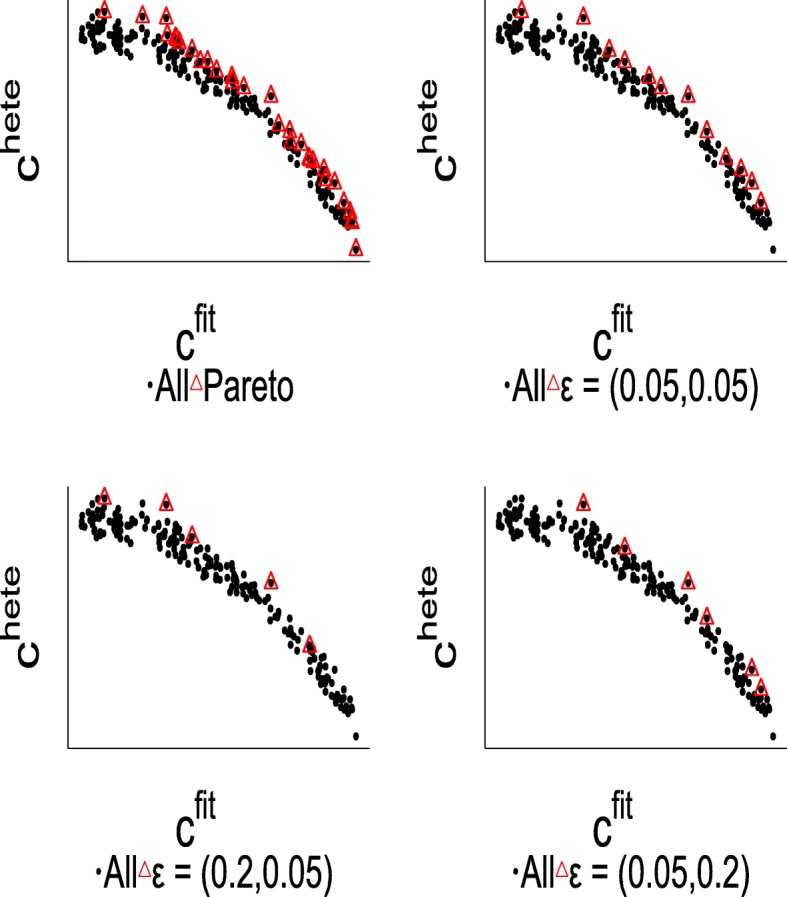
Comparison of Pareto-set and the ε-optimal set with various ε values
With Definitions 1 and 2, we now discuss how to maintain the ε-optimal set while scanning through all the potential split points without too much extra computational costs. This is achieved by dividing the two dimension search space into squares of size , and only keeps one element which are not ε-dominated by others within the box. We present the details in Algorithm 1.
Algorithm 1 has two important properties. Firstly it is guaranteed to converge to the ε-optimal set. Secondly, it is guaranteed that the algorithm only needs to deal with a small number of score pairs. Formally, we summarize these properties in the following theorem.

Theorem
Let S be the set of all score pairs for all possible splitting points. Then the output of Algorithm 1, S⋆ is an ε-optimal set of S with bounded size:
Proof Sketch
On the coarse level, the search space is discretized into two-dimensional squares of size , where each vector uniquely belongs to one of the squares. Applying the ε dominance relation on these spaces, the algorithm always maintains a set of non-dominated squares, thus guaranteeing the ε-optimal property. On the fine level at most one element is kept as a representative vector in each square. Within a square, the representative vector can only be replaced another one if it is ε-dominated, thus guaranteeing convergence. □
An important benefit of this result is that the size of set S⋆ is small and irrelevant of the total number of score pairs. For example, if ε1 and ε2 are set to be 0.2, then the upper bound of S⋆ is 75. Since Algorithm 2 needs to run at each splitting point, its time complexity is crucial to the overall running time of the MO. Fortunately, since the size of the candidate set is bounded, the time complexity of the search procedure is not affected by the number of possible split points.
Although the ε-optimal set is guaranteed to be of a small size, we still need to select one splitting point from its elements. According to our experiment, choosing the one with maximum achieves the best performance. Because the true treatment effect is unobservable, the cross-validation procedure also cannot be conducted straightforwardly as standard regression methods. In this work, we follow the method proposed in [7] for cross-validation.
Finally, we summarize the multi-objective tree construction procedure in Algorithm 2. The structure of splitting procedure remains similar to the CART [5] method. However, instead of only evaluate the fitness, the multi-objective criterion computes both the score and the proposed score at the same time. Then it updates the ε-optimal set and continues the usual splitting routine.

Results
In this section we compare the performances of different splitting criteria in the recursive partitioning treatment effect estimation methods: Regression Tree (RT) [5], Transformed Outcome Tree (TOT) [6], Causal Tree (CT) [7], T-Statistic Tree (TS) [8], the proposed Maximizing Heterogeneity criterion (MH) and Multi-Objective criterion (MO).
Synthetic data
Because the underlying treatment effects are generally inaccessible in most real-world data, we first evaluate the performance using synthetic data with the known ground truth.
We generate a group of 4 synthetic datasets to compare the performance of the proposed MH and MO criteria against existing algorithms. To ensure a fair comparison, the simulations are designed in a similar way of those used in [7, 8].
In all simulations, we satisfy Assumption 1 and the propensity score is set as P=0.5. The data generation mechanism is specified by the following functions:
m(x) is responsible for the mean effect which is not affected by the treatment, and τ(x) is responsible for the treatment effect. Then, the data is described as Y=m(x)+α·(2w−1)·τ(x)+σ where α is a parameter which controls the magnitude of the treatment effect, and σ is the random noise from a normal distribution.
In the first design, α1 is set to 0.5, m(x) and τ(x) include interactions among two variables:
In the second design, there are 20 variables where 12 of them are noise variables which are not related to the outcome. Specifically, α2=1 and the functions are defined as:
where 1{x>0} is the indicator function.
In the third design, the main and treatment functions are as similar as the second design except that the number of noise variables is increased to 50, and the value of α3 is set to 1.
The last design simulates non-linear treatment effect. The total number of variables is 20, and the main and treatment effect functions are defined as:
Two performance measurements are used to evaluate the compared methods. The first one is the root mean square error (RMSE) defined as:
The second criterion is the weighted root mean square error (wRMSE), where the weight is 0.1 if the estimated and the true treatment effects are of the same signs and 1 if they are of the opposite signs. Specifically,
where ω = 1 if , and ω = 0.1 for .
The wRMSE measurement is particularly important in human-related studies. For example, although the cost of predicting cats as dogs is similar as the opposite in image classification tasks, the fault of predicting a potential malign tumor as benign cost significantly more than the opposite.
To ensure that different splitting criteria are the only factors that affect the performances, all methods are compared at the same number of splits instead of using cross-validation for choosing the optimal tree depth. Because the compared methods begin to over-fit the data after their depths grow too deep, we only show the results up to the depth of 15 for each method. All results reported are the average value calculated over 100 simulation runs.
Figure 5 shows the experimental results in terms of RMSE scores. The columns of the figure correspond to the results of different simulation designs, and rows correspond to the results of different samples sizes (n=1000, n=5000 and n=50000).
Fig. 5.

RMSE results on simulation datasets. Row: different sample sizes. Column: different experiment designs
MH performs better than existing methods during the first few splits of the tree model. For example, in Setting 2, 3, and 4, the RMSE values of MH are lower than all existing methods at all splits. This aligns with previous observation that MH can swiftly identify the heterogeneities in treatment effects because it maximizes heterogeneity explicitly. In addition, the performance differences between MH and existing methods are larger in Setting 2 and 3 than those of Setting 1. This is possibly because that heterogeneities in treatment effects are more significant in Setting 2 and 3 than that of Setting 1 (α2,α3=0.5 and α1=1).
However, the performances of MH decrease as the tree grows deep. This is because that the heterogeneities in treatment effects become smaller as the tree grows, and MH can In Setting 1 with n=1000, although performs well during the first 5 splits, its RMSE values increase quickly as the tree grows deep. After the 7th split, it performs worse than TOT.
With heterogeneity and fitness both taken into consideration, MO performs consistently better than all compared methods. As can be seen from the figure, MO has the lowest RMSE values in all of the different combinations of simulation settings and sample sizes. When the sample sizes are small, the advantages of MO is the most evident. When n=1000, it is clear that MO is the most resistant to over-fitting.
The differences in performances become less significant as the sample sizes grow. With sufficient amount of samples, the expectation equation used in RT becomes reliable, and the chance that spurious heterogeneities mislead the MH criterion decreases. As the sample size increases, the differences between compared methods becomes smaller. At n=5000, TOT,TS, and CT choose exactly the same splits on all 4 settings. In the last row of the figure, the RMSE curves overlap with each other.
In most cases, the performances of existing CATE estimations methods (CT, TS, TOT) are better than the standard regression tree (RT). However, the performances of TS are worse than RT when the number of variables is large and the sample size is not sufficient, i.e., in Setting 3 when n=1000 and n=5000. This is because TS utilizes statistical tests to decide the split, which suffer from loss of power when the dimensionality grows large. In addition, the situation worsens as the sample size decreases along the tree growth.
Figure 6 shows the wRMSE results of each method. Although the trends of performances are similar to those of RMSE, it does reveal interesting insights.
Fig. 6.

wRMSE results on simulation datasets. Row: different sample sizes. Column: different experiment designs
Looking at the wRMSE results with n=1000, the Achilles’ hell of MH is more exposed. MH performs better than existing methods during the first few splits, but its performances degenerate rapidly as the trees grow deeper. After more than 10 splits, the wRMSE measurements of MH are worse than those of TOT, CT and even RT. Again, these results confirm with the observation that MH is adept at identifying heterogeneities, but it is also prone to error caused by spuriously treatment effects.
It is also worth noticing that in some cases, existing methods have slightly lower wRMSE values than MH and MO during the first few splits. This is related to the strategy of selecting a split point from the ε-optimal set. As discussed in the “Methods” section, when there are multiple elements in the ε-optimal set, the split with the highest score is chosen from the set. However, if the splitting point with the highest score is selected, the performances of MO will improve in these circumstances, but it will perform worse in other situations. This indicates an adaptive strategy for selecting splitting point from the ε-optimal set can further improve the performance.
The computational efficiency of MH is the same as existing methods. During the searching procedure, MH simply replaces the computation of fitness criterion by the heterogeneity criterion. For MO, the multi-objective search procedure introduces additional computation cost; however, because the Theorem guarantees that the upper bound of the cardinality of S∗ is a small constant, the running time of MO is within the same magnitude of other methods. Figure 7 shows the running time of all compared methods using Setting 3 with two sample sizes n=5000 and n=50000. The results here are the average execution time of 100 runs using a PC with a 3.4GHz single core CPU and 16GB of RAM. The time complexity of MH is similar to those of CT and TOT.
Fig. 7.
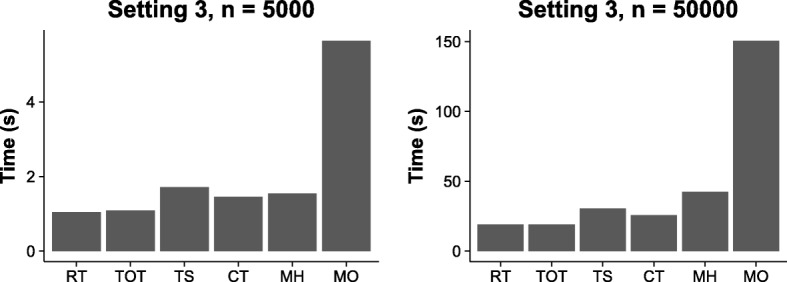
Running time comparison
Different choices of ε1 and ε2 values have influence on the performance of MO. It is worth noting that although the possible range of ε is from 0 to 1, small ε values should almost always be chosen since the effect of ε is proportional to the amount of slack in the ε-dominance relationship. Figure 8 illustrates how the parameter affects the performances in Setting 2 at sample size n=5000. In the left panel of Fig. 8, the value of ε2 is fixed at 0.05 and the value of ε1 varies; in the right panel the value of ε1 is fixed and the value of ε2 varies. The experimental results indicate that the algorithm generally achieves good performance when the ε ranges from 0.05 to 0.2.
Fig. 8.
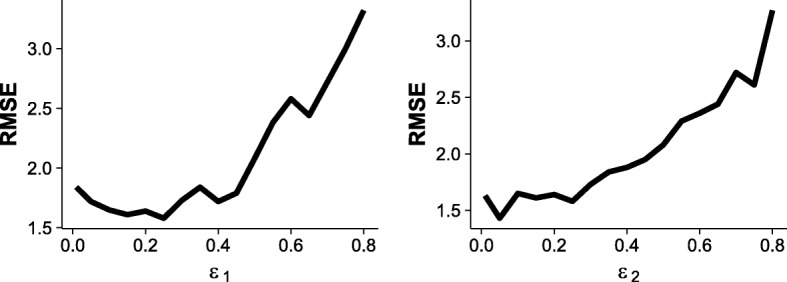
Influence of the parameters ε1 and ε2
Heterogeneous treatment effects of radiotherapy in breast cancer patient
Understanding treatment effect heterogeneity has an important impact on the life quality of cancer patients. More than 50% of the breast cancer patients have received the radiotherapy treatment, equating to over half a million patients worldwide each year. Although radiotherapy is effective for many patients, not all of them benefit from the treatment [15].
We apply previously mentioned methods to study the treatment effect heterogeneity of radiotherapy on breast cancer patients. The data is obtained from the Cancer Genome Atlas (TCGA) [16]. The radiotherapy status is used the as the treatment indicator, the gene expression profiles are used as covariates, and the relapse-free survival status is used as the outcome.
Comparison of CATE estimation algorithms on real-world data is not straightforward because the ground truth treatment effects are not observable and the sample sizes are not large enough to divide the original data into training and testing sets.
An independent collection of 3951 breast cancer patients [17] is used for performance evaluation by examining how well the genes selected by each method can differentiate the survival probability between the radiotherapy treated and the untreated patients.
In Table 1 we compare the methods using the p-values calculated with log-rank test [18] and the combined p-values calculated with the Fisher’s method [19]. Smaller p-values indicates that the selected genes are more closely related to the survival probability of breast cancer patient. Considering the limited sample size, we restrict the maximum tree size to 4 terminal nodes for each method.
Table 1.
p-values comparison on an independent breast cancer cohort
| Method | 1st Split | 2nd Split | 3rd Split | Combined |
|---|---|---|---|---|
| RT | 7 ×10−09 | 3 ×10−4 | 0.007 | 7 ×10−12 |
| CT | 1 ×10−16 | 5 ×10−4 | 0.017 | 1 ×10−18 |
| TSTATS | 1 ×10−16 | 5.4 ×10−4 | 0.017 | 1.1 ×10−18 |
| TOT | 6.7 ×10−06 | 2.5 ×10−4 | 0.017 | 9.1 ×10−09 |
| MH | 1 ×10−16 | 1.9 ×10−7 | 0.003 | 9.0 ×10−23 |
| MO | 1 ×10−16 | 1.4 ×10−10 | 0.001 | 3.5 ×10−26 |
The columns correspond to the p-values calculated using the gene selected at the first, second, the third splitting point and finally all the genes in the tree model
Overall all genes selected by the compared methods are related to the heterogeneity of radiotherapy treatment effects since all the p-values are smaller than the significance threshold (p=0.05) in every case. However, as shown in the table, every gene selected by MO achieves the smallest p-value in all compared methods. It is clear that the genes chosen by MO are clearly the most significantly related to the survival outcomes of breast cancer patients.
An interesting observation is that four of the six methods have chosen FOXF1 as the first gene to split, indicating that FOXF1 is closely related to breast cancer and the effectiveness of radiotherapy. In biology research, FOXF1 has been recently identified as important cancer-related gene [20]. Our findings could suggest a new direction for exploring its genetic function and contribution in cancer development.
Overall, the above results suggest that heterogeneous treatment effect estimation methods can be quite helpful in identifying the responsible genes for the differentiated response to a cancer treatment. The genes discovered by the proposed MO criterion has higher consistency in the independent test data than those discovered by other methods.
The treatment effect heterogeneities discovered by MO is illustrated in Fig. 9, where each panel shows the survival curves comparison between patients with radiotherapy treatment and those without the treatment for each of the terminal nodes. For those patients that are categorized into the first and the second subgroups, their estimated treatment effects of radiotherapy are 0.22 and 0.20, respectively. As evidenced by the p-values, the survival probability of the treated patients is significantly higher than the untreated ones. In other words, patients with low FOXF1 gene expression, and those with high FOXF1 and SOHLH2 expression but low KCNN2 expression, have benefited significantly from radiotherapy treatment. However, those patients in the third and the last subgroups do not benefit from radiotherapy. Interestingly, according to their negative estimated treatment effects, the prognosis of their disease are likely to worsen following the radiotherapy treatment.
Fig. 9.

Heterogeneous treatment effects of radiotherapy on breast cancer patients
Related works
RT [5]. Standard regression tree can be modified to estimate heterogeneous treatment effects [7]. Specifically, the tree is constructed using the CART algorithm, and the treatment effect is estimated according to Eq. 2 using the samples within the same leaf.
Transformed outcome tree [6]. Transformed Outcome Tree (TOT) is based on the insight that existing regression tree methods can be used to estimate treatment effect by utilizing a transformed version of the outcome variable as the regression target. Because , standard regression tree can be applied to the transformed outcome where the estimation of the sample average of within each leaf can be interpreted as the estimation of the treatment effects.
Causal tree [7]. Causal Tree (CT) seeks the splitting point using the fitness criterion, but it does not consider the heterogeneity. In addition, they propose to divide the training samples into two disjoint parts to avoid bias in the treatment effect estimation, where the first part is used for selecting split and the second part is used to estimate the treatment effects in the model.
Squared t-Statistic tree [8]. squared T-Statistic tree (TS) seeks the split with the largest value for the square of the t-statistic for testing the null hypothesis that the average treatment effect is the same in the two potential leaves. The criterion is defined as:
where σ2 is the variance of treated and untreated samples within a node.
criterion is different from the TS criterion. Because the sample size grows smaller as the tree grows, the statistical test used in [8] suffers from loss of power. Unless the subgroup treatment effects are quite large, this method often fails to detect the effects in subgroups [21]. In the experiments it has been demonstrated that the performance of TS degenerates significantly as the number of variables increases, whereas the performances of MH remain unaffected.
Conclusion
In this paper, we demonstrate that the heterogeneity of treatment effects should be explicitly considered in the splitting procedure.
We proposed two splitting criteria, MH and MO. MH explicitly considers the heterogeneity of treatment effects, and MO is a multi-objective criterion which balances heterogeneity and fitness at the same time.
Experiment results indicate that MH achieves better performances than existing methods when the differences between treatment effects in underlying subgroups are large, but is prone to error when the differences grow small. When fitness and heterogeneity are both taken consideration, the MO criterion performs consistently better than all studied methods.
Acknowledgements
The authors would like to thank the reviewers in advance for their time and effort in improving this manuscript.
Funding
This work is supported by Australian Research Council Discovery Project (DP170101306). Thuc Duy Le is supported by NHMRC Grant (ID 1123042). Publication costs are funded by Australian Research Council Discovery Project (DP170101306).
Availability of data and materials
The datasets generated and/or analysed during the current study are available in the GitHub repository: https://github.com/WeijiaZhang24/Multi-objective
About this supplement
This article has been published as part of BMC Bioinformatics Volume 19 Supplement 19, 2018: Proceedings of the 29th International Conference on Genome Informatics (GIW 2018): bioinformatics. The full contents of the supplement are available online at https://bmcbioinformatics.biomedcentral.com/articles/supplements/volume-19-supplement-19.
Authors’ contributions
WZ implemented the method and performed all experiments. WZ, TDL, LL and JL designed the algorithm and experiments. WZ drafted the manuscript. WZ, TDL, LL and JL revised the manuscript. All authors read and approved the final manuscript.
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Weijia Zhang, Email: weijia.zhang@mymail.unisa.edu.au.
Thuc Duy Le, Email: thuc.le@unisa.edu.au.
Lin Liu, Email: lin.liu@unisa.edu.au.
Jiuyong Li, Email: jiuyong.li@unisa.edu.au.
References
- 1.Zhang W, Le TD, Liu L, Zhou Z-H, Li J. Predicting miRNA targets by integrating gene regulatory knowledge with expression profiles. PLoS ONE. 2016;11(4):0152860. doi: 10.1371/journal.pone.0152860. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Zhang W, Le TD, Liu L, Zhou Z-H, Li J. Mining heterogeneous causal effects for personalized cancer treatment. Bioinformatics. 2017;33(15):2372–78. doi: 10.1093/bioinformatics/btx174. [DOI] [PubMed] [Google Scholar]
- 3.Bellon JR. Personalized radiation oncology for breast cancer: The new frontier. J Clin Oncol. 2015;33(18):1998–2000. doi: 10.1200/JCO.2015.61.2069. [DOI] [PubMed] [Google Scholar]
- 4.Atheyy S. Beyond prediction: Using big data for policy problems. Science. 2017;355(6324):483–5. doi: 10.1126/science.aal4321. [DOI] [PubMed] [Google Scholar]
- 5.Breiman L, Friedman J, Stone CJ, Olshen RA. Classification and Regression Trees.Chapman and Hall/CRC; 1984.
- 6.Imbens G, Rubin D. Causal Inference for Statistics, Social, and Biomedical Sciences.Cambridge University Press; 2015.
- 7.Athey S, Imbens G. Recursive partitionin. PNAS. 2016;113(27):7353–60. doi: 10.1073/pnas.1510489113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Su X, Tsai C-L, Wang H, Nkckerson DM, Li B. Subgroup analysis via recursive partitioning. J Mach Learn Res. 2009;10:141–58. [Google Scholar]
- 9.Wager S, Athey S. Estimation and Inference of Heterogeneous Treatment Effects using Random Forests. ArXiv. 2015. 1510.04342.
- 10.Rosenbaum PR, Rubin DB. The central role of the propensity score in observational studies for causal effects. Biometrika. 1983;70(1):41–55. doi: 10.1093/biomet/70.1.41. [DOI] [Google Scholar]
- 11.McCaffrey DF, Ridgeway G, Morral AR. Propensity score estimation with boosted regression for evaluating causal effects in observational studies. Psychol Methods. 2004;9(4):403–25. doi: 10.1037/1082-989X.9.4.403. [DOI] [PubMed] [Google Scholar]
- 12.Freitas AA. A critical review of multi-objective optimization in data mining. ACM SIGKDD Explor Newsl. 2004;6(2):77. doi: 10.1145/1046456.1046467. [DOI] [Google Scholar]
- 13.Laumanns M, Thiele L, Deb K, Zitzler E. Combining convergence and diversity in evolutionary multiobjective optimization. Evol Comput. 2002;10(3):263–82. doi: 10.1162/106365602760234108. [DOI] [PubMed] [Google Scholar]
- 14.Deb K, Mohan M, Mishra S. Evaluating the ε-domination based multi-objective evolutionary algorithm for a quick computation of pareto-optimal solutions. Evol Comput. 2005;13(4):501–25. doi: 10.1162/106365605774666895. [DOI] [PubMed] [Google Scholar]
- 15.Hayden EC. Personalized cancer therapy gets closer. Nature. 2009;458(7235):131–2. doi: 10.1038/458131a. [DOI] [PubMed] [Google Scholar]
- 16.Kandoth C, McLellan MD, Vandin F, Ye K, Niu B, Lu C, Xie M, Zhang Q, McMichael JF, Wyczalkowski MA, Leiserson MDM, Miller CA, Welch JS, Walter MJ, Wendl MC, Ley TJ, Wilson RK, Raphael BJ, Ding L. Mutational landscape and significance across 12 major cancer types. Nature. 2013;502(7471):333–9. doi: 10.1038/nature12634. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Györffy B, Lanczky A, Eklund AC, Denkert C, Budczies J, Li Q, Szallasi Z. An online survival analysis tool to rapidly assess the effect of 22,277 genes on breast cancer prognosis using microarray data of 1809 patients. Breast Cancer Res Treat. 2009;123(3):725–31. doi: 10.1007/s10549-009-0674-9. [DOI] [PubMed] [Google Scholar]
- 18.Schoenfeld D. The asymptotic properties of nonparametric tests for comparing survival distributions. Biometrika. 1981;68(1):316–9. doi: 10.1093/biomet/68.1.316. [DOI] [Google Scholar]
- 19.Whitlock MC. Combining probability from independent tests: the weighted z-method is superior to fisher's approach. J Evol Biol. 2005;18(5):1368–73. doi: 10.1111/j.1420-9101.2005.00917.x. [DOI] [PubMed] [Google Scholar]
- 20.Lo P-K, Lee JS, Liang X, Han L, Mori T, Fackler MJ, Sadik H, Argani P, Pandita TK, Sukumar S. Epigenetic inactivation of the potential tumor suppressor gene FOXF1 in breast cancer. Cancer Res. 2010;70(14):6047–58. doi: 10.1158/0008-5472.CAN-10-1576. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Pocock SJ, Assmann SE, Enos LE, Kasten LE. Subgroup analysis, covariate adjustment and baseline comparisons in clinical trial reporting: current practiceand problems. Stat Med. 2002;21(19):2917–30. doi: 10.1002/sim.1296. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The datasets generated and/or analysed during the current study are available in the GitHub repository: https://github.com/WeijiaZhang24/Multi-objective