

Abstract
In spoken language, audiovisual (AV) perception occurs when the visual modality influences encoding of acoustic features (e.g., phonetic representations) at the auditory cortex. We examined how visual speech (mouth movements) transforms phonetic representations, indexed by changes to the N1 auditory evoked potential (AEP). EEG was acquired while human subjects watched and listened to videos of a speaker uttering consonant vowel (CV) syllables, /ba/ and /wa/, presented in auditory-only or AV congruent or incongruent contexts or in a context in which the consonants were replaced by white noise (noise replaced). Subjects reported whether they heard “ba” or “wa.” We hypothesized that the auditory N1 amplitude during illusory perception (caused by incongruent AV input, as in the McGurk illusion, or white noise-replaced consonants in CV utterances) should shift to reflect the auditory N1 characteristics of the phonemes conveyed visually (by mouth movements) as opposed to acoustically. Indeed, the N1 AEP became larger and occurred earlier when listeners experienced illusory “ba” (video /ba/, audio /wa/, heard as “ba”) and vice versa when they experienced illusory “wa” (video /wa/, audio /ba/, heard as “wa”), mirroring the N1 AEP characteristics for /ba/ and /wa/ observed in natural acoustic situations (e.g., auditory-only setting). This visually mediated N1 behavior was also observed for noise-replaced CVs. Taken together, the findings suggest that information relayed by the visual modality modifies phonetic representations at the auditory cortex and that similar neural mechanisms support the McGurk illusion and visually mediated phonemic restoration.
NEW & NOTEWORTHY Using a variant of the McGurk illusion experimental design (using the syllables /ba/ and /wa/), we demonstrate that lipreading influences phonetic encoding at the auditory cortex. We show that the N1 auditory evoked potential morphology shifts to resemble the N1 morphology of the syllable conveyed visually. We also show similar N1 shifts when the consonants are replaced by white noise, suggesting that the McGurk illusion and the visually mediated phonemic restoration rely on common mechanisms.
Keywords: auditory evoked potential, cross-modal encoding, McGurk illusion, phonemic restoration
INTRODUCTION
During conversational speech, especially in adverse listening situations, listeners rely on visual cues (i.e., mouth movements) to optimize their speech comprehension (Grant and Seitz 2000; Schorr et al. 2005; Sumby and Pollack 1954). Phonetic information can be deciphered from lipreading to varying degrees, with some phonemes better conveyed by mouth movements than others. Place of articulation is one factor that governs the potency of the visemes (O’Neill 1954; Walden et al. 1977), with more phonetic information being extracted from visemes with frontal places of articulation (/b/, /w/, /v/) as opposed to visemes articulated at the rear of the mouth (/g/, /k/). However, despite these characteristics, our understanding of how vision influences auditory perception is nominal. For example, even though the viseme /g/ is less evident than the viseme /b/, watching a person utter /ga/ combined with a sound of /ba/ can produce an illusory percept /da/, but no illusion is experienced when the modalities are switched (McGurk and MacDonald 1976). This suggests that visual influence on auditory perception is not dependent solely on viseme saliency but also on the characteristics of the acoustic input.
Understanding the neural mechanisms of visual and auditory interactions is central to answering questions on how the two modalities are weighted and whether audiovisual (AV) integration occurs via a common “integrator” or via one modality modifying representations of a second modality. A prevalent theory posits that the auditory and visual representations fuse in a multisensory cortex “integrator” (e.g., posterior superior temporal sulcus/gyrus, pSTS/G) to produce an optimized or modified percept (Beauchamp et al. 2004; Eskelund et al. 2011; Keil et al. 2012; Miller and D’Esposito 2005). Other theories point to a direct/indirect influence of visual networks on auditory networks (Besle et al. 2004; Kayser et al. 2008, 2010; Schorr et al. 2005; Shahin et al. 2018). In Shahin et al. (2018), individuals watched and listened to videos and audios of a speaker uttering the consonant vowel (CV) segments /ba/ and /fa/. The videos and audios were mixed and matched to produce congruent and incongruent stimulus pairs. They found that changes to the N1 auditory evoked potential (AEP) reflected changes in phonetic perception. That is, when individuals watched a video of /ba/ and listened to an audio of /fa/ but heard “ba,” the N1 increased in amplitude. When individuals watched /fa/ and listened to /ba/ but heard “fa,” the N1 decreased in amplitude. This N1 shift mirrored the N1 morphologies for /ba/ and /fa/ in auditory-only settings, since the N1 response to /ba/ is larger than the N1 to /fa/. The authors concluded that AV integration in spoken language occurs when the visual modality alters phonetic encoding at the auditory cortex. Other studies have also shown that the auditory modality alters representations at the visual cortex (Murray et al. 2016).
The goals of this study were 1) to build on Shahin et al.’s (2018) findings by generalizing the N1 results to other combinations of CVs and 2) to examine whether or not the neural mechanisms of cross-modal phonetic encoding (observed in Shahin et al. 2018) that underlie the McGurk illusion also support other visually mediated auditory illusions—in the present case, phonemic restoration (Samuel 1981; Warren 1970). Phonemic restoration is a phenomenon whereby a speech stimulus with a segment replaced by noise is perceived as continuing uninterrupted through the noise, partly because of interpolation or filling-in of missing representations from the background noise. In the case of our experiment, rather than contextual auditory speech cues, participants were given visual speech cues to aid in restoration of phonemic representations.
Our experimental design was as follows: EEG was recorded while individuals watched and listened to videos and audios of the CVs /ba/ and /wa/, mixed and matched to produce congruent and incongruent stimulus pairs. Individuals also listened to auditory-only stimuli, visual-only stimuli (silent condition), and AV /ba/ and /wa/ CVs with the consonant replaced by white noise (noise-replaced condition). Generally, in auditory-only situations, phonemic restoration is significantly less robust when the initial segment of the speech is replaced by noise compared with medial or final segments (Samuel 1981). By replacing the initial segments of the CVs, we sought to maximize the influence of visual context on phonemic restoration.
During testing, subjects responded as to whether they heard “ba” or “wa,” or in the silent condition whether they saw “ba” or “wa.” The CVs /ba/ and /wa/ were chosen because 1) they evoke distinct N1 morphologies in the auditory-only setting, with the N1 of /ba/ being larger in amplitude and occurring earlier than that of /wa/, and 2) the formant transitions of f1 and f2 for /ba/ and /wa/ only differ in the formants’ rise time, with /wa/ having slower, less abrupt formant rise times. By strengthening (exciting) and weakening (inhibiting) neural networks along the auditory cortex (Kayser et al. 2008, 2010; Shahin et al. 2018), visual networks can alter the formants’ transition representations, and in turn bias phonetic perception toward that conveyed by the visual utterance. We hypothesized that when individuals experience Illusion-ba (hear “ba” when presented with a video of /ba/ and an audio of /wa/), auditory representations to the stimulus /wa/ are reshaped to resemble those of /ba/. This in turn will cause the N1 to increase in amplitude and decrease in latency to resemble the N1 characteristics observed during auditory-only and congruent /ba/ settings. Likewise, when individuals experience Illusion-wa (hear “wa” when presented with a video of /wa/ and an audio of /ba/), the N1 should decrease in amplitude and increase in latency to resemble the N1 characteristics observed during auditory-only and congruent /wa/ settings. Similarly, in the phonemic restoration illusion, we hypothesized that cross-modal encoding will reshape the unstructured white noise representations to resemble the phonetic representations conveyed visually, shifting the N1 morphology in the same way as that observed in the above-mentioned McGurk illusions. Given that the N1 reflects neural generators originating in the auditory cortex (Scherg et al. 1989), a shift in N1 amplitude and latency toward that of the visually conveyed phonemes should be interpreted as evidence that visual input alters phonetic encoding at the auditory cortex. If the McGurk illusion and the visually mediated phonemic restoration exhibit similar N1 shifts, this would provide evidence that these illusions are supported by similar cross-modal neural mechanisms.
MATERIALS AND METHODS
This study consisted of two experiments: 1) an auditory-only experiment, which established a CV-specific reference for the N1 amplitude and latency, and 2) a main AV experiment that examined the N1 transformation as a result of the two illusion types (the McGurk illusion and the visually mediated phonemic restoration illusion). The two experiments were conducted on separate groups of subjects.
Subjects
The auditory-only experiment included 13 subjects who had a mean age of 20.1 yr (SD 1.44) (11 women, 2 men; all right handed). Nine subjects were native and four were fluent English speakers. English fluency is defined here as having spoken English continuously for at least 10 yr before participation.
The main experiment included 18 subjects. One subject withdrew from the study without completing the task. The mean age of the remaining 17 subjects was 21.1 yr (SD 2.9) (13 women, 4 men; 14 right handed). Twelve subjects were native and five were fluent English speakers.
All subjects reported normal hearing, normal and corrected vision, and no history of language deficits or neurological disorders. All subjects provided written informed consent to participation in protocols reviewed and approved by the University of California, Davis Institutional Review Board and were monetarily compensated for their participation.
Stimuli
The stimuli (Fig. 1A) consisted of naturally spoken videos of the CVs /ba/ and /wa/. The main difference between acoustic /ba/ and acoustic /wa/ is how their formants transition to a steady state, with /wa/ having a slower formant rise time than /ba/.
Fig. 1.

A: depiction of the incongruent stimulus design giving rise to the McGurk illusion. B: spectrograms of the original and altered consonant vowel sounds used in the auditory-only experiment. Only the altered sounds were used in the main experiment.
The original visual and acoustic stimuli were obtained from a video of a female native English speaker (mean f0 = 210 Hz) uttering CV syllables. The original video was recorded with a Panasonic AG-DVX100 digital camera (30 frames/s) and Adobe Premiere Pro 2.0 (Adobe Systems). With Adobe Premiere, we extracted four 3-s video clips of the speaker uttering /ba/ and four 3-s video clips of the speaker uttering /wa/ from the original video. Each video clip contained a CV segment that began and ended with silence and a still face (no mouth movements). For each CV, the acoustic stimuli were extracted from three of the video clips whereas the visual stimulus (silent video) was extracted from the fourth video clip. The acoustic part of the CVs lasted ~370 ms (Fig. 1A). The two silent videos were chosen because the mouth movement onsets (lip closure of the /ba/ CV and lip rounding of the /wa/ CV) occurred at about the same time (same frame) relative to the beginning of the videos, but also both had corresponding acoustic onsets that occurred at about the same time relative to the beginning of the video (1,270 ms). Note that the videos began with silence and static face.
A main goal of this study was to induce the McGurk illusion from mismatched combinations of the videos and audios of these CVs. The combination of video /ba/ and audio /wa/ should be heard as “ba” (Illusion-ba), while the combination of video /wa/ and audio /ba/ should be heard as “wa” (Illusion-wa). Another goal of the present study was to demonstrate that even when the consonant is replaced by noise (noise replaced; not shown in Fig. 1), a visually mediated phonemic restoration illusion should arise, because of mechanisms similar to those that underlie the McGurk illusion. Noise-replaced audios combined with videos of /ba/ and /wa/ should be heard as “ba” and “wa,” respectively. The noise-replaced tokens were created by replacing the first 75 ms of all acoustic tokens with white noise.
Initial Testing and Further Alteration of Acoustic CVs
When tested by the principal investigator and laboratory colleagues, the incongruent combinations using the original (unaltered) naturally spoken /ba/ and /wa/ CV sounds did not induce the McGurk illusion. As a result, the acoustic parts of the original CVs were altered (Fig. 1B) in a way that made them slightly perceptually unstable, so that their neural representations could be more influenced by the visual input. To do this, using an FFT filter in Adobe Audition, we attenuated the initial (first 100 ms) formant energy of the CV /ba/ to make it a bit more like /wa/ and augmented the initial formant energy of the CV /wa/ to make it a bit more like /ba/. Furthermore, the amplitude envelopes of the /wa/ CVs were extracted, and their mean was used to amplitude modulate all CVs (including the noise-replaced CVs), so that all CVs had similar envelopes. The auditory-only experiment, however, included both the original and altered CVs. Amplitude differences of /ba/ and /wa/ CVs do not influence classification in normal-hearing adult listeners. In a study by Carpenter and Shahin (2013), the authors found that classification of /ba/ and /wa/ CVs in adult listeners remained at ceiling accuracy (>95%) even after interchanging amplitude envelopes between the two CVs, demonstrating that adult listeners rely on formant rise time rather than amplitude envelope to label these CVs (Carpenter and Shahin 2013). In addition to amplitude modulation, all acoustic CVs were normalized to the same root-mean-square value. Since acoustic features vary between utterances even by the same talker, EEG data were averaged across the three acoustic tokens for each CV type within a percept type (e.g., congruent /ba/ had all 3 /ba/ CVs). Thus differences in physical variations between the /ba/ and /wa/ utterances on AEPs were reduced.
After a retest, the experimenters deemed the new altered stimuli adequate to go forward with the study after experiencing the McGurk illusions. However, during an EEG experiment (n = 19), the altered acoustic stimuli, when combined with incongruent videos, still did not produce a robust enough McGurk illusion to yield an adequate number of trials per illusory percept. Illusion-ba was experienced 35% of the time, whereas Illusion-wa was experienced 52% of the time. Furthermore, the limited number of subjects experiencing the illusion, especially for Illusion-ba, was not adequate to conduct statistics on the EEG results. Feedback from the subjects who participated in this unsuccessful experiment informed the design of the subsequent and present main experiment. Many of the subjects conveyed to us that although they did not experience the illusion fully they did experience it partially. For example, when presented with a video of /ba/ and an audio of /wa/, several subjects heard “bwa.” When presented with a video of /wa/ and an audio of /ba/, several subjects heard “wba.” In other words, the incongruent stimuli led to activation of intermediate percepts that included both phonemes “b” and “w.” The present experimental design was then modified accordingly. Subjects were asked to report not only if they heard “ba” or “wa” but also if they heard “bwa” or “wba” (see detailed description below).
There was another minor change to the stimulus design after the original unsuccessful experiment. The videos were replaced by videos of another female speaker in which the CV utterances always started with the mouth slightly open to control for prearticulatory mouth movements. The mouth movement onsets of the two CVs occurred at the same time relative to the beginning of the videos.
Procedure
The auditory-only experiment and the main experiment had similar procedures, with a few differences. We first discuss the common procedures implemented in the two experiments and then follow with two separate paragraphs outlining the unique aspects of each experiment.
EEG was acquired while subjects sat ~90 cm in front of a 24-in. Dell monitor and watched videos of a female speaker uttering the CVs /ba/ and /wa/. EEG was recorded with a 68-channel BioSemi system (Active Two system, 10–20 Ag-AgCl electrode system, with Common Mode Sense and Driven Right Leg passive electrodes serving as grounds, A/D rate 1,024 Hz). Four of the channels were ocular electrodes. The sounds were played via one loudspeaker of a sound bar (Vizio sound bar, model S2920W-C0), which was placed directly below the monitor, at a mean intensity level of 70 dBA. The stimuli were presented with Presentation Software (v.18.1, Neurobehavioral Systems, Albany, CA). The visual presentation was limited to the lower half of the face. The face dimensions of the human speaker on the monitor were ~15 cm (ear-to-ear width) × 11.5 cm (height). To ensure consistent timing of sound onsets in EEG, the sound onset triggers were embedded with the wavefile metadata.
Subjects made judgments on whether they heard (or saw in the visual-only condition) “ba”/“bwa” or “wa”/“wba.” Except in the visual-only condition, subjects were explicitly told to make their decision based on what they heard, not what they saw. They responded by pressing a keyboard button with their left index finger for “ba”/“bwa” or by pressing a button with their left middle finger for “wa”/“wba.” They were also instructed to make their decision as soon as possible even when they were unsure of the answer. Trial duration was ~4,200 ms plus a variable jitter between 1 ms and 500 ms, plus delay due to hardware.
Auditory-only experiment.
In the auditory-only experiment, subjects listened to acoustic tokens while watching a still image of the speaker’s face. The acoustic tokens included six original (unaltered) tokens (3 /ba/ and 3 /wa/) and six altered tokens. Recall that the altered tokens of /ba/ were the ones in which the formant transitions were shifted toward those of /wa/ and vice versa for the altered tokens of /wa/. There were no noise-replaced tokens in the auditory-only experiment. All stimuli were randomized within two blocks of presentation. Each block lasted ~14.5 min and contained 182 trials. The purpose of the auditory-only experiment was to establish CV-specific amplitude and latency references for the N1 AEP, so that N1 shifts observed in the main experiment could be evaluated with respect to the auditory-only references. Also, by measuring the evoked potentials for the original and altered sounds, any effects of stimulus alteration could be factored into our interpretation.
Main experiment.
In the main experiment, the six altered acoustic tokens and the two silent videos (with mouth movements) were mixed and matched to create congruent and incongruent pairs of AV stimuli, in addition to visual-only (silent video) stimuli and noise-replaced stimuli. All CV sounds, except for the visual-only condition, were paired with the two silent videos by aligning their onsets to the 1,270 ms time point relative to the beginning of either of the two videos. Note that in the phonemic restoration condition all six noise-replaced tokens were paired with each of the /ba/ and /wa/ silent videos. All stimuli were randomized and presented in six blocks. Each block lasted ~12.5 min and had 158 trials. There were eight stimulus conditions and two possible responses (“ba”/“bwa” or “wa”/“wba”) for each stimulus condition, resulting in 16 percept types. The eight stimulus conditions were as follows: the visual-only stimuli consisted of silent video /ba/ and silent video /wa/; the congruent stimuli consisted of video /ba/ combined with audio /ba/ and video /wa/ combined with audio /wa/; the incongruent stimuli consisted of video /ba/ combined with audio /wa/ and video /wa/ combined with audio /ba/; and the noise-replaced stimuli consisted of video /ba/ combined with noise-replaced audios (either /ba/ or /wa/) or video /wa/ combined with noise-replaced audios.
Data Analyses
Analysis of the auditory-only, visual-only, and congruent stimulus type data was limited to accurate classifications, since inaccurate responses for these conditions were rare. The accurate classifications resulted in auditory-only “ba”/“bwa” and “wa”/“wba” (henceforth A-ba and A-wa); visual-only “ba”/“bwa” and “wa”/“wba” (V-ba and V-wa); and AV congruent “ba”/“bwa” and “wa”/“wba” (Cong-ba and Cong-wa). Analysis of the noise-replaced and incongruent stimulus types was limited to the illusory percept types because the illusion failure trials were too few. The noise-replaced stimulus pairs resulted in phonemically restored “ba”/“bwa” and “wa”/“wba” (PR-ba and PR-wa). Similarly, the incongruent stimulus types resulted in Illusion-ba (video /ba/, audio /wa/, heard as “ba”/“bwa”) and Illusion-wa (video /wa/, audio /ba/, heard as “wa”/“wba”) percept types.
Behavior.
In the main experiment, subjects’ percept types were converted to percentages of the total number of percept types within a stimulus type. For example, in the congruent condition, in which video /ba/ was combined with audio /ba/, accuracy was calculated as the percentage of the number of trials perceived as “ba”/“bwa” relative to the number of all trials within this condition (e.g., perceived as “ba”/“bwa” and “wa”/“wba”). A similar analysis was applied in the auditory-only experiment. In the incongruent condition, illusory percentage rather than accuracy was measured. For example, the percentage of the illusory percept Illusion-wa (video /wa/ combined with audio /ba/, heard as “wa”/“wba”) was calculated as the number of trials perceived as “wa”/“wba” divided by all incongruent trials (illusion and illusion failure, perceived as “ba”/“bwa” and “wa”/“wba”).
AEPs.
EEG data were initially analyzed with EEGLAB (Delorme and Makeig 2004), ERPLAB (Lopez-Calderon and Luck 2014), and in-house MATLAB code. Each subject’s EEG files from all blocks were concatenated into one file, downsampled to 512 Hz, and epoched from −100 to 4,000 ms around the beginning of the trial. The beginning of a trial was the instant when the trial began with silence and still frames and not the beginning of mouth movement or sounds. As a reference, the sound of /wa/ occurred 1,270 ms after the trial onset. Then the mean potential across each epoch was removed, and trials with shifts of ±150 μV in the period 1,070–1,270 ms at the ocular channels were rejected before independent component analysis (ICA) was conducted. This was done to remove ocular artifacts (i.e., blinks) occurring in this period when mouth articulation of the CVs begins, as visual perception of the mouth movement would not be possible while the eyes are closed. ICA was then performed. Bad channels were not included in the ICA. ICA components representing ocular artifacts were rejected (mean 2 per subject). After ICA correction, bad channels (max of 3 per subject) were interpolated with EEGLAB’s spherical interpolation. Ocular channels were then removed, and individual data were average-referenced and band-pass filtered between 0.1 and 30 Hz with a zero-phase (4th order) Butterworth filter. Individual data were then epoched from −100 ms before acoustic stimulus onset to 500 ms after acoustic stimulus onset to produce separate files for each percept type. Epochs for each percept type file were then baselined to the preacoustic stimulus period and linearly detrended. Epochs with amplitude shifts greater than ±100 μV at any channel were excluded from the data. Finally, for each subject, trials were averaged in the time domain to produce separate AEPs for each percept type.
Subject Inclusion
A subject had to attain a minimum of 40 artifact-free EEG trials per percept type to be included in the AEP analyses. The auditory-only experiment included data from all 13 subjects: original A-ba, 89 trials (SD 3); original A-wa, 88 trials (SD 3); altered A-ba, 88 trials (SD 4); altered A-wa, 88 trials (SD 3). In the main experiment, data from all 17 subjects were included for the control (visual only and congruent) and noise-replaced percept types: V-ba, 65 trials (SD 6); V-wa, 65 trials (SD 7); Cong-ba, 99 trials (SD 7); Cong-wa, 97 trials (SD 9); noise-replaced-ba, 134 trials (SD 11); noise-replaced-wa, 127 trials (SD 9). Data from 14 of 17 subjects were included for Illusion-ba [100 trials (SD 29)], and data from 15 of 17 subjects were included for Illusion-wa [107 trials (SD 27)].
Statistics
Behavior.
Presentation of behavioral results were limited to descriptive statistics because individuals’ responses for most measures (auditory-only, visual-only, congruent, and noise-replaced phonemic restoration conditions) were at ceiling (>90%). In the case of the McGurk illusory percepts, we present illusory percentages of individual subjects.
AEPs.
To correct for the multiple comparisons (channels) problem, we statistically analyzed the EEG data with cluster-based permutation tests (CBPTs) implemented in the FieldTrip toolbox (Maris and Oostenveld 2007; Oostenveld et al. 2011). Because we were only interested in the N1, the CBPT was confined to the 50–150 ms postacoustic onset period of the AEP waveforms. Using functions of the FieldTrip toolbox, for each contrast between two percept types (e.g., Cong-ba vs. Cong-wa; Illusion-ba vs. Illusion-wa), we conducted the CBPT to determine if, and in which channels, significant differences in N1 amplitude were found. First, two-tailed paired-samples t-tests were performed on the amplitude values of two percept types for each channel in order to assess univariate effects at the sample level. Only data samples whose t-value exceeded an α level of 0.05 (2 tailed) were considered for cluster formation, such that neighboring channels and time points with a univariate P value ≤0.05 were grouped together. Neighboring channels were clustered with FieldTrip’s triangulation method. Finally, statistics at the cluster level were calculated as the sum of all the t-values within each time-channel cluster. To assess the significance of these cluster-level statistics, a nonparametric null distribution using a Monte Carlo approximation was created by repeating the above steps for each of the 2,000 permutations of the data, in which the percept type labels of the data were randomly shuffled. The maximum of the cluster-level test statistics was recorded for each permutation to form the null distribution. Significant probabilities (P values) were computed by contrasting the real cluster-level test statistics with the null distribution of maximum cluster-level statistics. Cluster-based differences of percept type were considered significant if the cluster’s P value was <0.025. This P-value threshold was selected because most analyses involved two contrasts. In results, we report the exact cluster-based P values.
RESULTS
Behavior: Classification
In the auditory-only experiment, accurate identification of the CVs /ba/ and /wa/ was on average >95% for both the original and altered tokens. In the main experiment, accurate identification of congruent and visual-only CVs was also >95% on average. Similarly, in the noise-replaced condition individuals perceived the visually conveyed phonemes >90% of the time on average.
As for the McGurk illusory percepts, variability was high (compared with congruent or single-modality stimuli) among individuals and illusory types (Illusion-ba, Illusion-wa). Figure 2 shows the individual data (percentages) for both illusory types. The mean illusory perception percentages were 73% and 70% for Illusion-ba and Illusion-wa, respectively (medians: 83% for Illusion-ba and 88% for Illusion-wa).
Fig. 2.

Percentages of trials that each individual subject experienced the illusion percept in Illusion-ba (video /ba/, audio /wa/, heard as “ba”/“bwa”) and Illusion-wa (video /wa/, audio /ba/, heard as “wa”/“wba”).
AEPs
Auditory-only experiment.
The purpose of the auditory-only experiment was to establish CV-specific AEP morphologies (i.e., amplitude and latency AEP signatures of “ba” and “wa”). Figure 3 shows the AEP waveforms at channel Cz evoked by A-ba and A-wa of the original (Fig. 3A) and altered (Fig. 3C) CVs. Recall that the altered CVs are those in which the formant transitions of the original /ba/ and /wa/ CVs were filtered to make them more like one another and make perception of these CVs more unstable (i.e., more similar sounding). The panels below the waveforms in Fig. 3, A and C, show the topographies for A-ba and A-wa as well as the t-statistic topographical maps of the N1 period in which the waveforms of the two percept types varied significantly. Because there were no significant data points distinguishing the waveforms evoked by the altered A-ba and A-wa, we used the same N1 window of significance observed in the original A-ba and A-wa contrast to generate topographies and a t-statistic map for the altered CVs’ contrast. Figure 3, B and D, show the corresponding boxplots of the N1 amplitude averaged across time points that significantly distinguished the A-ba and A-wa AEP waveforms for the original (Fig. 3B) and altered (Fig. 3D) stimuli.
Fig. 3.

A and C, top: auditory evoked potential (AEP) waveforms evoked by the original (A) and altered (C) consonant vowel (CV) (/ba/ and /wa/) sounds of the auditory-only condition. Bottom: CV-specific topographies as well as t-statistic maps for the window in which the 2 CV-specific waveforms exhibited significance (vertical gray bar). Here and in subsequent figures, time 0 indexes voice onset. Shaded areas surrounding the waveforms indicate within-subject SE. White dots on the topographies indicate the cluster of channels with significant differences. Vertical gray bars reflect the significant time points distinguishing the waveforms of the 2 conditions. B and D: the corresponding boxplots represent the N1 amplitudes for the original (B) and altered (D) stimuli, averaged across the time points that significantly distinguished the A-ba and A-wa AEP waveforms.
For the contrast between the waveforms of the percept types A-ba and A-wa of the original CVs (Fig. 3A), the CBPT revealed a significant amplitude difference at the central channels (Fig. 3A, bottom) in the period of 88–117 ms (P = 0.015). The period coincides with the window in which the N1 wave occurs. The significant difference is attributed to amplitude and latency differences, whereby the N1 for A-ba was larger and occurred earlier than that of A-wa. The t-statistic topography for the significant period revealed that the difference between the N1s of the two percept types is most likely auditory in nature, occurring over central sites. The same test, however, contrasting the AEP waveforms for the altered A-ba and A-wa percept types did not reveal significant differences between their waveforms. In other words, altering the acoustic properties of the two CVs to make them more similar to one another resulted in the N1s of the two CVs also becoming similar. Remember that only the altered acoustic CVs were used in the main experiment (next section), because the original CVs did not induce a robust McGurk illusion.
Main experiment.
The main experiment was conducted on a group of subjects different from the auditory-only experiment and included four conditions: visual-only (silent), congruent, noise-replaced, and incongruent conditions. The results for the percept type contrasts for these conditions are presented in four sections below.
visual only.
The purpose of the visual-only condition was to establish whether the CV-specific AEP morphologies observed in the auditory-only condition (Fig. 3) are also evoked by visual input that conveys CV type without any sound. Figure 4A, top, shows the AEP waveforms at channel Cz evoked by V-ba and V-wa. Figure 4A, bottom, shows the topographies for the two percept types as well as the t-statistic map for the period in which the waveforms of the two percept types varied significantly. Figure 4B shows a boxplot for the N1 amplitude averaged across time points that significantly distinguished V-ba and V-wa AEP waveforms.
Fig. 4.

A and C, top: auditory evoked potential (AEP) waveforms evoked by the visual-only (A) and congruent (C) percept types. Bottom: percept-specific topographies as well as t-statistic maps for the window in which each of the 2 percept types’ waveforms exhibited significant differences. B and D: the corresponding boxplots represent the N1 amplitudes for the visual-only (B) and congruent (D) stimuli, averaged across the time points that significantly distinguished the V-ba/V-wa and Cong-ba/Cong-wa AEP waveforms, respectively.
The CBPT revealed a significant difference between the waveforms of V-ba and V-wa in the period between 51 and 127 ms (P = 0.001). This period is consistent with the time window in which the N1 AEP occurs. The topographies of the two percept types showed clear indications of visual evoked activity (focused positive activity) at parieto-occipital sites but also negative activity at frontal and central sites. The frontal activity observed for V-wa likely reflects the opposite poles of the visual evoked response, but the central negative activity observed for V-ba is more consistent with auditory activity. Although we cannot rule out visual contributions, the CBPT t-statistic map emphasizes that the differences between V-ba and V-wa are more likely auditory and not visual in nature—significance was strongest at the centro-parietal sites. Although there were significant differences observed at occipital sites (O1, Oz), the significance level was weaker than that seen at centro-parietal channels and co-occurred at the edges of the centro-parietal cluster. We conclude that this activity is only an extension of the centro-parietal auditory cluster. The finding that the silent visual-only stimuli evoked auditory activity is not surprising. This cross-modal influence has been reported previously (Calvert et al. 1997; Pekkola et al. 2005).
congruent.
The purpose of the congruent condition was to establish whether the CV-specific AEP morphologies observed in the auditory-only condition are also observed in AV settings. Figure 4C, top, shows the AEP waveforms at channel Cz for Cong-ba and Cong-wa. Figure 4C, bottom, shows the topographies of the two percept types as well as the t-statistic map for the period in which the waveforms of the two percept types varied significantly. Figure 4D shows a boxplot for the N1 amplitude averaged across time points that significantly distinguished Cong-ba and Cong-wa AEP waveforms.
The CBPT revealed a significant difference between the waveforms of Cong-ba and Cong-wa in the period between 56 and 94 ms (P = 0.001), which coincides with the window in which the N1 AEP occurs. This effect was attributed to a latency and amplitude shift occurring for the N1 of Cong-ba relative to the N1 of Cong-wa (N1 of Cong-ba was larger and occurred earlier than that of Cong-wa). Just as in the visual-only condition, the topographies provide evidence that activity during this period (56–94 ms) includes visual evoked potentials, observed at the parieto-occipital sites. However, the t-statistic map distinguishing Cong-ba and Cong-wa rules out that the N1 difference is visual in nature, as significant values only occurred at centro-parietal sites, with no significant differences in this period at parieto-occipital sites. Recall that the acoustic stimuli used for the congruent (and incongruent) condition are the altered CVs, which did not evoke a difference between the waveforms of A-ba and A-wa in the auditory-only experiment. However, the original unaltered CVs did evoke an N1 for A-ba that was earlier and larger than the N1 of A-wa—the same N1 pattern we see in the AV congruent comparison. Based on this, we may conclude that visual context restores the phonetic representations along the auditory cortex that were diminished by our alteration of these CVs. The same reasoning applies to subsequent comparisons.
illusion-ba (video /ba/, audio /wa/, heard as “ba”/“bwa”).
In the Illusion-ba condition, the McGurk illusion was used to reveal that altered perception of the CV /wa/ toward hearing “ba”/“bwa”, due to visual input /ba/, coincides with an N1 morphology shift toward that of the visually conveyed CV, i.e., “ba.” We hypothesized that the N1 response to /wa/ would increase in amplitude and decrease in latency to resemble the N1 morphology of the percept type Cong-ba and become significantly larger/earlier than the N1 of Cong-wa. The results for this contrast are depicted in Fig. 5. Figure 5, A and B, top, show the AEP waveforms at channel Cz for Cong-wa vs. Illusion-ba and for Cong-ba vs. Illusion-ba, respectively. Figure 5, A and B, bottom, show the topographies for the N1s of the percept types as well as the t-statistic maps of the periods in which the waveforms of the two percept types varied significantly. Because the contrast between Illusion-ba and Cong-ba waveforms (Fig. 5B) did not yield significant differences, we used the significant period distinguishing Illusion-ba and Cong-wa (Fig. 5A) to show topographical plots for this contrast. Figure 5C shows a boxplot for the N1 amplitude evoked by Cong-ba, Illusion-ba, and Cong-wa averaged across the significant time points distinguishing the AEPs of Illusion-ba and Cong-wa.
Fig. 5.
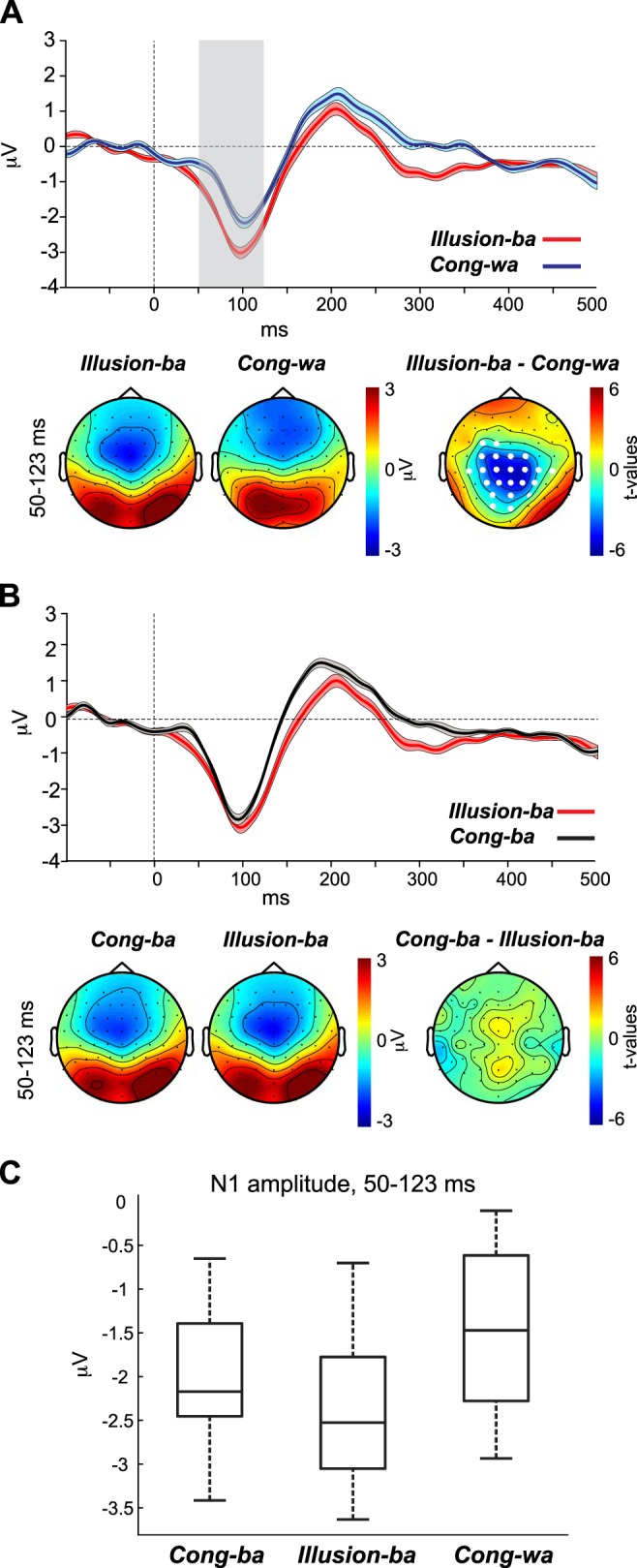
A and B, top: auditory evoked potential (AEP) waveforms evoked by the Cong-wa and Illusion-ba (A) and Cong-ba and Illusion-ba (B) percept types. Bottom: percept-specific topographies as well as t-statistic maps for the window in which each of the 2 percept types’ waveforms exhibited significant differences. C: the corresponding boxplot represents the N1 amplitude for Cong-ba, Illusion-ba, and Cong-wa, averaged across the time points that significantly distinguished the Illusion-ba and Cong-wa AEP waveforms.
In the first contrast, the CBPT revealed a significant difference between the waveforms of Illusion-ba and Cong-wa in the period of 50–123 ms (P = 0.002), which coincides with the N1 wave. This effect was attributed to a morphology shift occurring for the N1 of Illusion-ba compared with the N1 of Cong-wa, manifested in a decrease in latency and an increase in amplitude for Illusion-ba vs. Cong-wa. The t-statistic map revealed that differences were strongest at centro-parietal, but not parieto-occipital, sites, consistent with auditory activity. In the second contrast, the CBPT did not yield significant effects between the waveforms of Cong-ba and Illusion-ba. Taken together, these results support our hypothesis that experiencing the illusion coincides with a shift in N1 AEP morphology toward the visually conveyed phonetic N1 morphology.
A caveat for comparing the results of the significant contrast (Illusion-ba > Cong-wa) with those of the nonsignificant contrast (Illusion-ba = Cong-ba) is that such a comparison is not necessarily statistically significant (Gelman and Stern 2012). To further assess the viability of this comparison we implemented a post hoc contrast test. The test evaluated whether N1 of Cong-ba + N1 of Cong-wa – 2 × N1 of Illusion-ba was statistically different from zero at channels of the significant cluster. Using the exact individual N1 amplitude values (averaged across the significant time points of each channel) of the CBPT, the test showed that the contrast was significantly different from zero at some channels [e.g., channel Cz, t(14) = 2.9, P = 0.01] but not others of the cluster. Cumulatively, the results provide evidence of a shift in the N1 with illusory perception, despite a lack of significance of the post hoc test at some channels.
illusion-wa (video /wa/, audio /ba/, heard as “wa”/“wba”).
In the Illusion-wa condition, the McGurk illusion was used to validate the idea that altered perception of the CV /ba/ toward hearing “wa”/“wba”, due to visual input /wa/, coincides with an N1 AEP morphology shift toward that of the visually conveyed CV. We hypothesized that during illusory perception the N1 in response to /ba/ would decrease in amplitude and increase in latency to resemble the N1 morphology of Cong-wa and become significantly smaller/later than the N1 of Cong-ba. The results for this contrast are depicted in Fig. 6. Figure 6, A and B, top, show the AEP waveforms at channel Cz for Cong-ba vs. Illusion-wa and for Cong-wa vs. Illusion-wa, respectively. Figure 6, A and B, bottom, show the topographies for the N1s of each percept type as well as the t-statistic maps of the periods in which the waveforms of the two percepts types varied significantly. Because the contrast between Illusion-wa and Cong-wa waveforms (Fig. 6B) did not yield significant differences, we used the significant period distinguishing Illusion-wa and Cong-ba (Fig. 6A) to show topographical plots for this contrast. Figure 6C shows a boxplot for the N1 amplitudes evoked by Cong-ba, Illusion-wa, and Cong-wa averaged across the significant time points distinguishing the AEPs of Illusion-wa and Cong-ba.
Fig. 6.
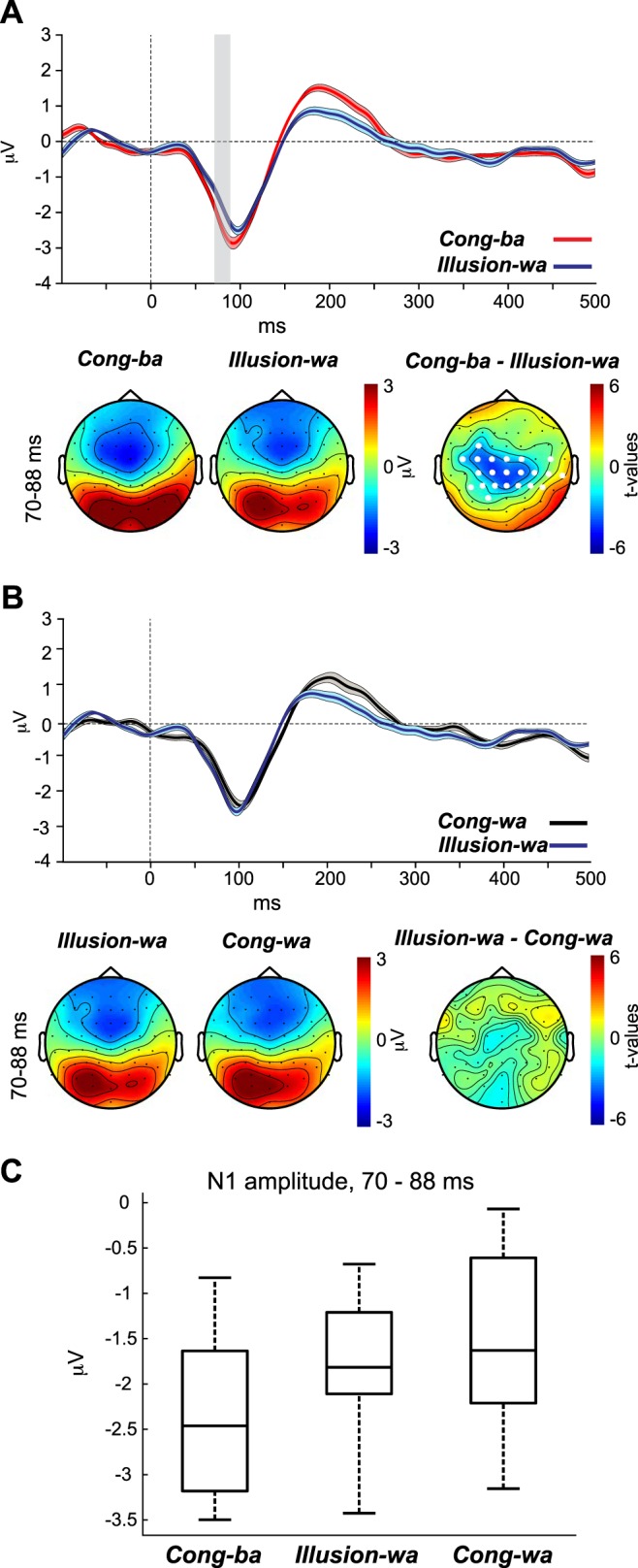
A and B, top: auditory evoked potential (AEP) waveforms evoked by the Cong-ba and Illusion-wa (A) and Cong-wa and Illusion-wa (B) percept types. Bottom: percept-specific topographies as well as t-statistic maps for the window in which each of the 2 percept types’ waveforms exhibited significant differences. C: the corresponding boxplot represents the N1 amplitude for Cong-ba, Illusion-wa, and Cong-wa, averaged across the time points that significantly distinguished the Illusion-wa and Cong-ba AEP waveforms.
In the first contrast, the CBPT revealed a significant difference between the waveforms of Illusion-wa and Cong-ba in the period between 70 and 88 ms (P = 0.004), which coincides with period of the N1 wave. This effect was attributed to a morphology shift occurring for the N1 of Illusion-wa compared with the N1 of Cong-ba, manifested as an increase in latency and a decrease in amplitude for Illusion-wa vs. Cong-ba. The t-statistic map revealed differences at centro-parietal locations, but not parieto-occipital sites, consistent with auditory activity. In the second contrast, the CBPT did not yield significant effects between the waveforms of Cong-wa and Illusion-wa. Again, these results support our hypothesis that experiencing the illusion coincides with a shift in N1 AEP morphology toward the visually conveyed phonetic N1 morphology.
Similar to the previous analysis, we also implemented the contrast test in this section. We evaluated whether N1 of Cong-ba + N1 of Cong-wa – 2 × N1 of Illusion-wa is statistically different from zero. The test showed that the contrast was significantly different from zero at some channels [e.g., channel C1, t(14) = 2.47, P = 0.03] but not others of the cluster. Again, cumulatively the results provide evidence of an N1 with illusory perception, despite a lack of significance of the post hoc test at some channels.
phonemic restoration (noise-replaced cvs, heard as the visually conveyed cvs).
The purpose of the noise-replaced condition was to induce the phonemic restoration illusion and assess whether the neurophysiological response of the N1 wave shifts to reflect the visually conveyed phonemes, similar to the McGurk illusions. Recall that the video of each CV was paired with noise-replaced sounds of both CVs that had the same amplitude envelope as all other CVs. Figure 7A, top, shows the AEP waveforms at channel Cz evoked by PR-ba and PR-wa percept types. Figure 7A, bottom, shows the topographies for the N1 of the two percept types as well as the t-statistic map of the period in which the waveforms of the two percept types varied significantly. Figure 7B shows a boxplot for the N1 amplitudes averaged across the significant time points distinguishing PR-ba and PR-wa AEP waveforms.
Fig. 7.

A, top: auditory evoked potential (AEP) waveforms evoked by the PR-ba and PR-wa percept types. Bottom: percept-specific topographies as well as t-statistic maps for the window in which the 2 percept types’ waveforms exhibited significant differences. B: the corresponding boxplot represents the N1 amplitudes averaged across the time points that significantly distinguished the PR-ba and PR-wa AEP waveforms.
The CBPT revealed a significant difference between the waveforms of PR-ba and PR-wa in the period between 50 and 150 ms (P = 0.001), which coincides with the period of the N1 wave. This effect was attributed to a shorter latency and a larger amplitude occurring for the N1 of PR-ba compared with the N1 of PR-wa. Similar to the previous conditions, the t-statistic map distinguishing the waveforms of PR-ba and PR-wa rules out the possibility that the N1 differences seen between the two percept types are visual in nature, since significant values only occurred at centro-parietal sites, with no significant differences in this period at parieto-occipital sites.
Caveats and Considerations
The issues of proper baseline use and subtraction of visual-only evoked potentials from AV evoked potentials were addressed in Shahin et al. (2018) and are reconsidered here.
The first issue pertains to the effect of the chosen baseline (−100 to 0 ms), which may contain visual and/or auditory activity that differs across CV types (e.g., differences in mouth movements between /ba/ and /wa/). By baselining to this period, preacoustic differences across CVs transfer to the poststimulus activity. To address this point, we reanalyzed the data using an earlier preacoustic period spanning from −300 to −200 ms. This period precedes any CV-specific mouth movements. The results of the reanalysis of the illusory effects depicted in Fig. 5A and Fig. 6A are shown in Fig. 8, A and B, respectively. The original effects were replicated, with significant differences between the two percept types of both contrasts spanning wider windows around the N1 wave. However, when widening the window of interest in the CBPT to include the prestimulus period, the reanalysis produced significant differences between the waveforms in the preacoustic period as well, suggesting that visual modulation of auditory cortex may occur even before sound onset.
Fig. 8.
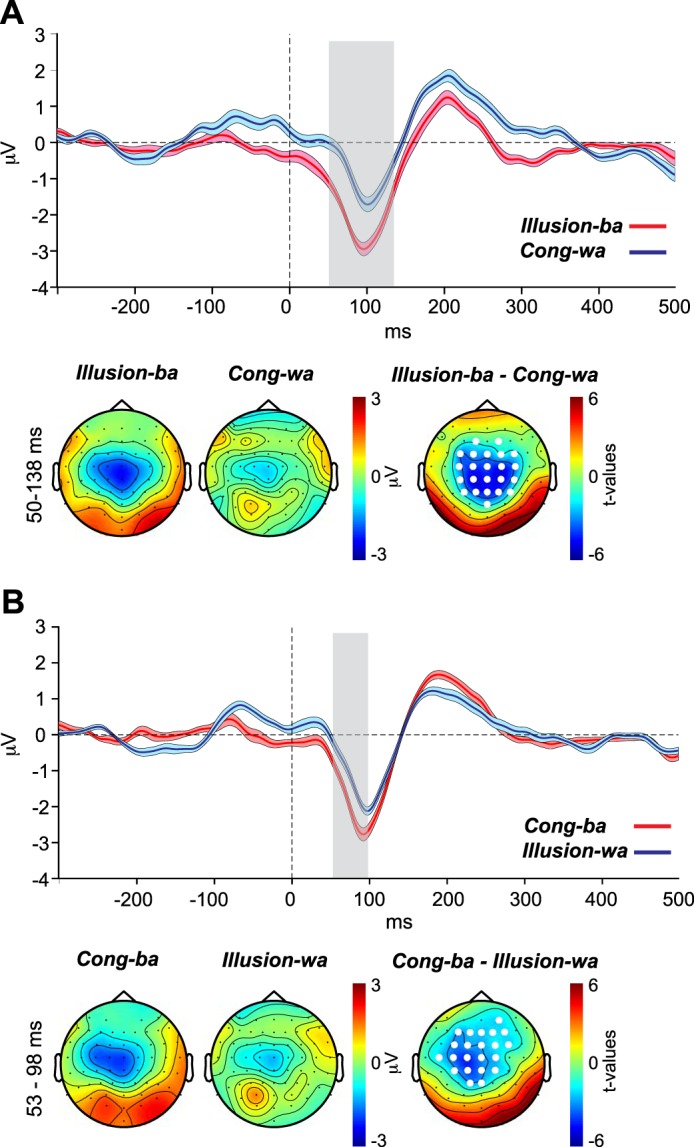
The same contrasts depicted in Fig. 5A (A) and Fig. 6A (B), with the data baselined to the −300 to −200 ms (instead of −100 to 0 ms) preacoustic period.
The second issue is the subtraction of the visual-only waveforms from the AV waveforms, to remove visually evoked effects. In Shahin et al. (2018), even though subtraction of the visual-only waveforms did not influence the results substantially, we argued against the use of the subtraction method. The main reason is that the visual-only condition likely evokes auditory activity (an important indicator of cross-modal influence) and subtraction of visual-only waveforms would remove this auditory activity. This is apparent in the present visual-only data (Fig. 4A). Although the topographies of both percept types (V-ba and V-wa) clearly showed evidence of visual evoked activity at parieto-occipital sites, the significant difference was confined to the centro-parietal sites (consistent with auditory sources), evidenced by the t-statistic map distinguishing the two percept types. Indeed, subtraction of the visual-only waveforms from the AV waveforms eliminated all significant results presented earlier.
DISCUSSION
Our results support the theory that attending to visual speech influences phonetic encoding at the auditory cortex. Electrophysiological evidence for this attribute was manifested in the dynamics of the visually altered auditory N1 AEP, when speech sounds contained different phonetic information (McGurk illusion) or lacked phonetic information (phonemic restoration). That is, regardless of the acoustic input, the N1 AEP shifted in latency and amplitude to match the N1 AEP of the visually conveyed phonemes.
Several theories have addressed the mechanisms by which vision influences phonetic perception. One theory posits that visual influence acts via a multisensory integrator, most commonly observed in the superior temporal cortex. In this integrator, visual and auditory percepts fuse and transform into an optimized or modified auditory percept (Beauchamp et al. 2010; Erickson et al. 2014; Keil et al. 2012; Miller and D’Esposito 2005). Another theory posits that visual influence on auditory perception arises at the auditory cortex (Kayser et al. 2008, 2010; Shahin et al. 2018; Smith et al. 2013). Our findings are in accordance with the latter theory, since the N1, which originates in the auditory cortex, shifted in the direction of visually conveyed auditory perception. Had the N1 dynamics reflected fusion of multisensory percepts, the N1 would have shifted in the same direction for both manipulations—that is, when the visual and auditory stimuli were /ba/ and /wa/ or /wa/ and /ba/, respectively. Notwithstanding, the present data do not rule out fusion in a multisensory network, a mechanism that may not be reflected in the N1 dynamics. In such a case, fusion or matching/mismatching processes of AV percepts at a multisensory hub may precede the N1 time window and subsequently modulate activity at the auditory cortex, giving rise to the N1 shifts observed here (Shahin et al. 2018; Venezia et al. 2017).
A remaining challenge is to understand the manner in which visual networks alter phonetic representations, represented by the N1 here, at the auditory cortex. Using a variant of the McGurk illusion design (similar to the present design), Shahin et al. (2018) proposed a putative mechanism for this phenomenon. The authors posited that in response to incongruent AV stimulus pairing phonetic networks at the auditory cortex are simultaneously activated by the different incoming visual and auditory inputs. This creates a neurophysiological state intermediate to the phonemes relayed by the two modalities. As a result, perception of the incoming sound becomes unstable; it can be perceived as the phoneme conveyed by the visual modality (visually biased) or by the auditory modality (auditorily biased). In their design (Shahin et al. 2018), individuals watched a speaker uttering visual /ba/, combined with acoustic /fa/. A subset of their subjects experienced the illusion, whereby they heard “ba.” The study demonstrated that the N1 shifted in amplitude equally when individuals experienced and failed to experience the illusion, meaning that the illusory percept created an unstable (intermediate) neurophysiological state in which the listener had to resolve the ambiguity. This intermediate-state account may explain the discrepant results observed between the preceding pilot experiment (see Initial testing and further alteration of acoustic CVs) and the present experiment. In the pilot experiment, subjects were required to respond to whether they heard “ba” or “wa,” resulting in Illusion-ba being experienced 35% of the time and Illusion-wa being experienced 52% of the time. However, when the intermediate percepts (“bwa” and “wba”) were included in the task of the present experiment, Illusion-ba was experienced 73% of the time, whereas Illusion-wa was experienced 70% of the time, albeit the experiments involved different participants. This suggests that by inclusion of an intermediary acoustic option (“bwa” and “wba”) participants were able to resolve the instability created by the competing modalities. This premise is supported by neurophysiological data. Previous functional MRI studies showed that individuals exhibited statistically equivalent activity at the pSTS when experiencing and failing to experience the McGurk illusion (Benoit et al. 2010; Nath and Beauchamp 2012). This lack of distinction in neural activity is indicative of the unstable nature of the McGurk illusion. A counter to this assertion is reflected in the present N1 results; the N1 in the present study exhibited strong shifts (not intermediate) toward the N1s of the visually conveyed CVs vs. the N1s of the acoustically conveyed CVs, suggesting that the visual input overwhelmed the acoustic influence.
Visual modulation of auditory networks as we demonstrate in this study is well established (Calvert et al. 1997; Ghazanfar et al. 2005; Kayser et al. 2008, 2010; Okada et al. 2013; but see Bernstein et al. 2002). Calvert et al. (1997) reported activation of the primary auditory cortex and association cortex via silent lipreading. However, research investigating visual influence on encoding of phonetic information at the auditory cortex has been sparse. Smith et al. (2013), using electrocorticography, showed that McGurk percepts exhibited spectrotemporal activity in the parabelt region of the auditory cortex that were more comparable in their morphologies to those of the visually conveyed phonemes than the spoken phonemes. Ghazanfar et al. (2005) reported that species-specific visual and acoustic vocalizations activate the core and lateral belt of the auditory cortex, the same regions that likely underlie the N1 generators in humans (Scherg et al. 1989; Zouridakis et al. 1998). This form of cross-modal phonetic encoding is not limited to the core and surrounding areas of the auditory cortex; rather it extends to the pSTS/G, which has been theorized to function as a multisensory hub (Beauchamp et al. 2010; Calvert et al. 2000; Keil et al. 2012). A recent functional MRI study (Zhu and Beauchamp 2017) showed that the pSTS responds to mouth movements as well as to speech sounds but not to eye movements. Although these findings can be interpreted as implicating the pSTS as a multisensory computational hub, we also argue that they are consistent with the visual and auditory modalities influencing phonetic representations, since the STG and pSTS have been linked to phonological processing (Arsenault and Buchsbaum 2015; Binder et al. 2000; Hickok and Poeppel 2007; Hocking and Price 2008; Mesgarani et al. 2014). Because with EEG it is not possible to assess with certainty the origin of the neural generators of the N1, contributions from the pSTS/G in addition to the core and parabelt regions are likely. Notwithstanding, the two interpretations (i.e., the multisensory integrator hub and visually mediated phonetic encoding) are not mutually exclusive.
One goal of this study was to consider whether a common mechanism underlies both the McGurk illusion and visually mediated phonemic restoration. We propose that because cross-modal phonetic encoding represents an inherent trait of the audiovisual system, the two above-mentioned illusions are only a manifestation of this trait. Phonemic restoration is believed to be contingent on two processes: interpolation or filling-in of missing information (e.g., phonetic representations) from background noise and suppression of noisy cues, mainly the onsets and offsets of noise segments (Riecke et al. 2009; Shahin et al. 2009, 2012). By supporting these two processes, visual input acts as a cross-modal sensory gating mechanism, optimizing the phonemic filling-in via cross-modal phonetic encoding, while minimizing the response to noisy cues (Bhat et al. 2014), by suppressing the auditory response to noisy onsets and offsets. This is consistent with the predictions of the dynamic reweighting model (Bhat et al. 2015), in which visual networks act to shift processing toward higher-level phonetic centers at the auditory cortex while inhibiting processing at lower levels (core of the auditory cortex), reducing sensitivity to acoustic onsets and offsets. In short, these mechanisms reflect the brain’s efficient wiring that allows it to apply similar processes to overcome various adverse listening situations.
In conclusion, our results provide evidence that in spoken language the visual modality acts on representations of the auditory modality, biasing the weighting of phonetic cues toward the visually conveyed phonemes. Furthermore, the present results suggest that this neural mechanism generalizes across different audiovisual situations—namely, the McGurk illusion and visually mediated phonemic restoration.
GRANTS
This work was supported by National Institute of Deafness and Other Communications Disorders Grant R01 DC-013543 (A. J. Shahin).
DISCLOSURES
No conflicts of interest, financial or otherwise, are declared by the authors.
ENDNOTE
At the request of the authors, readers are herein alerted to the fact that original EEG data related to this manuscript may be found at https://figshare.com/articles/Cross_Modal_Phonetic_Encoding_Data_files_and_Trigger_Main_and_Auditory-Only_Experiment_/7194842. These materials are not a part of this manuscript and have not undergone peer review by the American Physiological Society (APS). APS and the journal editors take no responsibility for these materials, for the website address, or for any links to or from it.
AUTHOR CONTRIBUTIONS
A.J.S. designed the experiment; N.T.A. performed experiments; N.T.A. and A.J.S. analyzed data; N.T.A. and A.J.S. interpreted results of experiments; A.J.S. prepared figures; N.T.A. and A.J.S. drafted manuscript; N.T.A. and A.J.S. edited and revised manuscript; N.T.A. and A.J.S. approved final version of manuscript.
ACKNOWLEDGMENTS
We thank Hannah Shatzer and Dr. Mark Pitt for providing the audiovisual stimuli.
REFERENCES
- Arsenault JS, Buchsbaum BR. Distributed neural representations of phonological features during speech perception. J Neurosci 35: 634–642, 2015. doi: 10.1523/JNEUROSCI.2454-14.2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Beauchamp MS, Lee KE, Argall BD, Martin A. Integration of auditory and visual information about objects in superior temporal sulcus. Neuron 41: 809–823, 2004. doi: 10.1016/S0896-6273(04)00070-4. [DOI] [PubMed] [Google Scholar]
- Beauchamp MS, Nath A, Pasalar S. fMRI-Guided transcranial magnetic stimulation reveals that the superior temporal sulcus is a cortical locus of the McGurk effect. J Neurosci 30: 2414–2417, 2010. doi: 10.1523/JNEUROSCI.4865-09.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Benoit MM, Raij T, Lin FH, Jääskeläinen IP, Stufflebeam S. Primary and multisensory cortical activity is correlated with audiovisual percepts. Hum Brain Mapp 31: 526–538, 2010. doi: 10.1002/hbm.20884. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bernstein LE, Auer ET Jr, Moore JK, Ponton CW, Don M, Singh M. Visual speech perception without primary auditory cortex activation. Neuroreport 13: 311–315, 2002. doi: 10.1097/00001756-200203040-00013. [DOI] [PubMed] [Google Scholar]
- Besle J, Fort A, Delpuech C, Giard MH. Bimodal speech: early suppressive visual effects in human auditory cortex. Eur J Neurosci 20: 2225–2234, 2004. doi: 10.1111/j.1460-9568.2004.03670.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bhat J, Miller LM, Pitt MA, Shahin AJ. Putative mechanisms mediating tolerance for audiovisual stimulus onset asynchrony. J Neurophysiol 113: 1437–1450, 2015. doi: 10.1152/jn.00200.2014. [DOI] [PubMed] [Google Scholar]
- Bhat J, Pitt MA, Shahin AJ. Visual context due to speech-reading suppresses the auditory response to acoustic interruptions in speech. Front Neurosci 8: 173, 2014. doi: 10.3389/fnins.2014.00173. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Binder JR, Frost JA, Hammeke TA, Bellgowan PS, Springer JA, Kaufman JN, Possing ET. Human temporal lobe activation by speech and nonspeech sounds. Cereb Cortex 10: 512–528, 2000. doi: 10.1093/cercor/10.5.512. [DOI] [PubMed] [Google Scholar]
- Calvert GA, Bullmore ET, Brammer MJ, Campbell R, Williams SC, McGuire PK, Woodruff PW, Iversen SD, David AS. Activation of auditory cortex during silent lipreading. Science 276: 593–596, 1997. doi: 10.1126/science.276.5312.593. [DOI] [PubMed] [Google Scholar]
- Calvert GA, Campbell R, Brammer MJ. Evidence from functional magnetic resonance imaging of crossmodal binding in the human heteromodal cortex. Curr Biol 10: 649–657, 2000. doi: 10.1016/S0960-9822(00)00513-3. [DOI] [PubMed] [Google Scholar]
- Carpenter AL, Shahin AJ. Development of the N1-P2 auditory evoked response to amplitude rise time and rate of formant transition of speech sounds. Neurosci Lett 544: 56–61, 2013. doi: 10.1016/j.neulet.2013.03.041. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Delorme A, Makeig S. EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J Neurosci Methods 134: 9–21, 2004. doi: 10.1016/j.jneumeth.2003.10.009. [DOI] [PubMed] [Google Scholar]
- Erickson LC, Zielinski BA, Zielinski JE, Liu G, Turkeltaub PE, Leaver AM, Rauschecker JP. Distinct cortical locations for integration of audiovisual speech and the McGurk effect. Front Psychol 5: 534, 2014. doi: 10.3389/fpsyg.2014.00534. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Eskelund K, Tuomainen J, Andersen TS. Multistage audiovisual integration of speech: dissociating identification and detection. Exp Brain Res 208: 447–457, 2011. doi: 10.1007/s00221-010-2495-9. [DOI] [PubMed] [Google Scholar]
- Gelman A, Stern H. The difference between “significant” and “not significant” is not itself statistically significant. Am Stat 60: 328–331, 2012. doi: 10.1198/000313006X152649. [DOI] [Google Scholar]
- Ghazanfar AA, Maier JX, Hoffman KL, Logothetis NK. Multisensory integration of dynamic faces and voices in rhesus monkey auditory cortex. J Neurosci 25: 5004–5012, 2005. doi: 10.1523/JNEUROSCI.0799-05.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Grant KW, Seitz PF. The use of visible speech cues for improving auditory detection of spoken sentences. J Acoust Soc Am 108: 1197–1208, 2000. doi: 10.1121/1.1288668. [DOI] [PubMed] [Google Scholar]
- Hickok G, Poeppel D. The cortical organization of speech processing. Nat Rev Neurosci 8: 393–402, 2007. doi: 10.1038/nrn2113. [DOI] [PubMed] [Google Scholar]
- Hocking J, Price CJ. The role of the posterior superior temporal sulcus in audiovisual processing. Cereb Cortex 18: 2439–2449, 2008. doi: 10.1093/cercor/bhn007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kayser C, Logothetis NK, Panzeri S. Visual enhancement of the information representation in auditory cortex. Curr Biol 20: 19–24, 2010. doi: 10.1016/j.cub.2009.10.068. [DOI] [PubMed] [Google Scholar]
- Kayser C, Petkov CI, Logothetis NK. Visual modulation of neurons in auditory cortex. Cereb Cortex 18: 1560–1574, 2008. doi: 10.1093/cercor/bhm187. [DOI] [PubMed] [Google Scholar]
- Keil J, Müller N, Ihssen N, Weisz N. On the variability of the McGurk effect: audiovisual integration depends on prestimulus brain states. Cereb Cortex 22: 221–231, 2012. doi: 10.1093/cercor/bhr125. [DOI] [PubMed] [Google Scholar]
- Lopez-Calderon J, Luck SJ. ERPLAB: an open-source toolbox for the analysis of event-related potentials. Front Hum Neurosci 8: 213, 2014. doi: 10.3389/fnhum.2014.00213. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Maris E, Oostenveld R. Nonparametric statistical testing of EEG- and MEG-data. J Neurosci Methods 164: 177–190, 2007. doi: 10.1016/j.jneumeth.2007.03.024. [DOI] [PubMed] [Google Scholar]
- McGurk H, MacDonald J. Hearing lips and seeing voices. Nature 264: 746–748, 1976. doi: 10.1038/264746a0. [DOI] [PubMed] [Google Scholar]
- Mesgarani N, Cheung C, Johnson K, Chang EF. Phonetic feature encoding in human superior temporal gyrus. Science 343: 1006–1010, 2014. doi: 10.1126/science.1245994. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Miller LM, D’Esposito M. Perceptual fusion and stimulus coincidence in the cross-modal integration of speech. J Neurosci 25: 5884–5893, 2005. doi: 10.1523/JNEUROSCI.0896-05.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Murray MM, Thelen A, Thut G, Romei V, Martuzzi R, Matusz PJ. The multisensory function of the human primary visual cortex. Neuropsychologia 83: 161–169, 2016. doi: 10.1016/j.neuropsychologia.2015.08.011. [DOI] [PubMed] [Google Scholar]
- Nath AR, Beauchamp MS. A neural basis for interindividual differences in the McGurk effect, a multisensory speech illusion. Neuroimage 59: 781–787, 2012. doi: 10.1016/j.neuroimage.2011.07.024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- O’Neill JJ. Contributions of the visual components of oral symbols to speech comprehension. J Speech Hear Disord 19: 429–439, 1954. doi: 10.1044/jshd.1904.429. [DOI] [PubMed] [Google Scholar]
- Okada K, Venezia JH, Matchin W, Saberi K, Hickok G. An fMRI study of audiovisual speech perception reveals multisensory interactions in auditory cortex. PLoS One 8: e68959, 2013. doi: 10.1371/journal.pone.0068959. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Oostenveld R, Fries P, Maris E, Schoffelen JM. FieldTrip: open source software for advanced analysis of MEG, EEG, and invasive electrophysiological data. Comput Intell Neurosci 2011: 156869, 2011. doi: 10.1155/2011/156869. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pekkola J, Ojanen V, Autti T, Jääskeläinen IP, Möttönen R, Tarkiainen A, Sams M. Primary auditory cortex activation by visual speech: an fMRI study at 3 T. Neuroreport 16: 125–128, 2005. doi: 10.1097/00001756-200502080-00010. [DOI] [PubMed] [Google Scholar]
- Riecke L, Esposito F, Bonte M, Formisano E. Hearing illusory sounds in noise: the timing of sensory-perceptual transformations in auditory cortex. Neuron 64: 550–561, 2009. doi: 10.1016/j.neuron.2009.10.016. [DOI] [PubMed] [Google Scholar]
- Samuel AG. Phonemic restoration: insights from a new methodology. J Exp Psychol Gen 110: 474–494, 1981. doi: 10.1037/0096-3445.110.4.474. [DOI] [PubMed] [Google Scholar]
- Scherg M, Vajsar J, Picton TW. A source analysis of the late human auditory evoked potentials. J Cogn Neurosci 1: 336–355, 1989. doi: 10.1162/jocn.1989.1.4.336. [DOI] [PubMed] [Google Scholar]
- Schorr EA, Fox NA, van Wassenhove V, Knudsen EI. Auditory-visual fusion in speech perception in children with cochlear implants. Proc Natl Acad Sci USA 102: 18748–18750, 2005. doi: 10.1073/pnas.0508862102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shahin AJ, Backer KC, Rosenblum LD, Kerlin JR. Neural mechanisms underlying cross-modal phonetic encoding. J Neurosci 38: 1835–1849, 2018. doi: 10.1523/JNEUROSCI.1566-17.2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shahin AJ, Bishop CW, Miller LM. Neural mechanisms for illusory filling-in of degraded speech. Neuroimage 44: 1133–1143, 2009. doi: 10.1016/j.neuroimage.2008.09.045. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shahin AJ, Kerlin JR, Bhat J, Miller LM. Neural restoration of degraded audiovisual speech. Neuroimage 60: 530–538, 2012. doi: 10.1016/j.neuroimage.2011.11.097. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith E, Duede S, Hanrahan S, Davis T, House P, Greger B. Seeing is believing: neural representations of visual stimuli in human auditory cortex correlate with illusory auditory perceptions. PLoS One 8: e73148, 2013. doi: 10.1371/journal.pone.0073148. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sumby WH, Pollack I. Visual contribution to speech intelligibility in noise. J Acoust Soc Am 26: 212–215, 1954. doi: 10.1121/1.1907309. [DOI] [Google Scholar]
- van Wassenhove V, Grant KW, Poeppel D. Visual speech speeds up the neural processing of auditory speech. Proc Natl Acad Sci USA 102: 1181–1186, 2005. doi: 10.1073/pnas.0408949102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Venezia JH, Vaden KI Jr, Rong F, Maddox D, Saberi K, Hickok G. Auditory, visual and audiovisual speech processing streams in superior temporal sulcus. Front Hum Neurosci 11: 174, 2017. doi: 10.3389/fnhum.2017.00174. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Walden BE, Prosek RA, Montgomery AA, Scherr CK, Jones CJ. Effects of training on the visual recognition of consonants. J Speech Hear Res 20: 130–145, 1977. doi: 10.1044/jshr.2001.130. [DOI] [PubMed] [Google Scholar]
- Warren RM. Perceptual restoration of missing speech sounds. Science 167: 392–393, 1970. doi: 10.1126/science.167.3917.392. [DOI] [PubMed] [Google Scholar]
- Zhu LL, Beauchamp MS. Mouth and voice: a relationship between visual and auditory preference in the human superior temporal sulcus. J Neurosci 37: 2697–2708, 2017. doi: 10.1523/JNEUROSCI.2914-16.2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zouridakis G, Simos PG, Papanicolaou AC. Multiple bilaterally asymmetric cortical sources account for the auditory N1m component. Brain Topogr 10: 183–189, 1998. doi: 10.1023/A:1022246825461. [DOI] [PubMed] [Google Scholar]