
Figure 1:
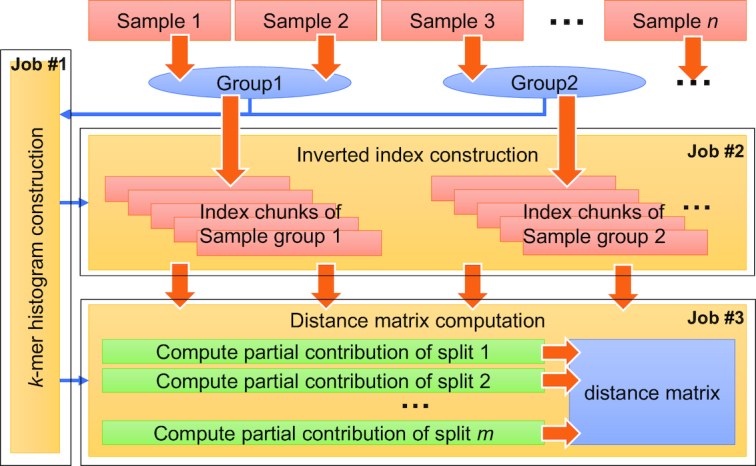
The Libra workflow. Libra consists of three MapReduce jobs (yellow boxes): (1) Libra constructs a k-mer histogram of the input samples for load-balancing. The k-mer histogram of the input samples is computed in parallel by running multiple Map tasks and a Reduce task that combines their results. (2) Libra constructs the inverted index in parallel. In the Map phase, a separate Map task is spawned for every data block in the input sample files. Each Map task generates k-mers from the sequences stored in a data block then passes them to the Reduce tasks. Each Reduce task then counts k-mers it receives and produces an index chunk. (3) In the distance matrix computation, the work is split by partitioning the k-mer space at the beginning of a MapReduce job. The k-mer histogram files for input samples are loaded, and the k-mer space is partitioned according to the k-mer distributions. A separate Map task is spawned for each partition to perform the computation in parallel and merged to produce the complete distance matrix.