

Abstract
Dehydrins, plant proteins that are upregulated during dehydration stress conditions, have modular sequences that can contain three conserved motifs (the Y-, S-, and K-segments). The presence and order of these motifs are used to classify dehydrins into one of five architectures: Kn, SKn, KnS, YnKn, and YnSKn, where the subscript n describes the number of copies of that motif. In this study, an architectural and phylogenetic analysis was performed on 426 dehydrin sequences that were identified in 53 angiosperm and 3 gymnosperm genomes. It was found that angiosperms contained all five architectures, while gymnosperms only contained Kn and SKn dehydrins. This suggests that the ancestral dehydrin in spermatophytes was either Kn or SKn, and the Y-segment containing dehydrins first arose in angiosperms. A high-level split between the YnSKn dehydrins from either the Kn or SKn dehydrins could not be confidently identified, however, two lower level architectural divisions appear to have occurred after different duplication events. The first likely occurred after a whole genome duplication, resulting in the duplication of a Y3SK2 dehydrin; the duplicate subsequently lost an S- and K- segment to become a Y3K1 dehydrin. The second split occurred after a tandem duplication of a Y1SK2 dehydrin, where the duplicate lost both the Y- and S- segment and gained four K-segments, resulting in a K6 dehydrin. We suggest that the newly arisen Y3K1 dehydrin is possibly on its way to pseudogenization, while the newly arisen K6 dehydrin developed a novel function in cold protection.
Introduction
Due to their sessile nature, plants have evolved various methods for responding to biotic and abiotic stresses. Contact with abiotic (environmental) stresses can cause severe damage to plants, which can result in crop loss, growth impairment, and even death [1,2]. Dehydration, itself a significant abiotic stress in plants, can take many forms, such as drought, cold, and high salinity. Under such conditions, plants face numerous problems, including mechanical impairment, alterations in turgor pressure, and loss of cell integrity [1]. A group of proteins, known as dehydration proteins (dehydrins), have their expression correlated with dehydration stress and protection [3]. Dehydrins are a member of a protein family known as the late embryogenesis abundant (LEA) proteins [3–7]. The exact in vivo biochemical function of dehydrins is currently unknown, however in vitro experiments have given clues as to how they can protect plants. Experiments have shown that dehydrins may have roles in enzyme cryoprotection [8–14], membrane protection [15–17], and protection against reactive oxygen species [18–20].
Dehydrin sequences are highly hydrophobic, with over 50% of the residues being charged or polar, and over 25% being alanine or glycine [21]. Not surprisingly, these proteins are classified as being intrinsically disordered proteins (IDPs), which has been experimentally demonstrated for dehydrins by several circular dichroism and NMR studies [22–26]. IDPs that are fully disordered, as is the case for dehydrins, have very little secondary structure and almost no tertiary structure. As such, they are described as “protein clouds” [27] or resembling “cooked spaghetti” [28]. In the case of dehydrins, their disordered nature is important in their cryoprotective function, likely related to their large hydrodynamic radius compared to ordered proteins with the same number of residues [25], and their ability to bind large quantities of water molecules and ions [29].
Since the biological function of dehydrins has not yet been fully established, and they do not have regular tertiary structure, dehydrins are technically defined by the presence of a motif known as the K-segment, which is a lysine-rich motif than can be defined by the sequence [XKXGXX(D/E)KIK(D/E)KXPG] [21,30]. Although the K-segment is used to define a dehydrin, no one position in the K-segment is completely conserved [31]. There are two other common motifs found in dehydrins: the Y-segment ([D(D/E)(Y/H/F)GNPX], where the X is mostly hydrophobic), and the S-segment ([LHR(S/T)GS4-6(S/D/E)(D/E)3]) [30]. The role of the Y-segment is unknown, however due to its similarity to the nucleotide binding site of the Escherichia coli chaperone protein GroES, it has been suggested that the Y-segment may have a similar function, although our work suggests otherwise (Boddington & Graether, unpublished results). In the case of the S-segment, it has been found that, when phosphorylated, it can transfer dehydrins to the nucleus from the cytosol [32]. In between the conserved motifs are the ϕ-segments, which are stretches of sequence with a variable length, and while not conserved, they do contain mostly small, polar and charged amino acids. The conserved segments are used to classify dehydrins into five major architectures: Kn, SKn, KnS, YnKn, and YnSKn, where the subscript n indicates a segment that may occur multiple times, and the order represents how they are arranged in the protein sequence [30].
The roles and the cellular localization of the different dehydrin architectures is not fully known and understood, but some patterns in the upregulation under abiotic stress have been identified. In a review by Graether and Boddington [31], it was found that the majority of Kn, SKn, and KnS dehydrins were upregulated during cold stress, with some also being upregulated under desiccation and salt stress. YnSKn dehydrins were only upregulated during desiccation and salt stress. Of the two YnKn they compared, one was upregulated under cold stress, and the other was upregulated by desiccation and salt stress [31]. In terms of localization, most dehydrins are found in both the nucleus and the cytoplasm, however SKn dehydrins have been found near the plasma membrane [33,34], and one KnS dehydrin has been found in the mitochondria [16]. The localization of many S-segment containing dehydrins to the nucleus supports the proposed role of the S-segment. However both Kn and YnKn dehydrins have also been found in the nucleus, suggesting the S-segment may not be the sole sequence element required for a dehydrin to be moved to the nucleus [35–37].
Plant evolution has led to diverse numbers and architectures of dehydrins in different plant species. Of the 35 angiosperm species examined by Malik et al., all of them contained at least one SKn dehydrin [21]. Thirty-three species contained at least one YnSKn dehydrin, 13 species contained at least one YnKn dehydrin, 15 species contained at least one Kn dehydrin, and 23 species contained at least one KnS dehydrin [21]. The number of each type of architecture varied, with some species having as many as nine dehydrins with the same architecture. Understanding how and when these architectures arose is important in gaining an improved knowledge of dehydrin function.
The evolution of dehydrins has been previously studied in Arabidopsis thaliana [6,38], Malus domestica [39], Solanum tuberosum [40], Brassica napus [41], Populus trichocarpa [42], Hordeum vulgare [43], and Oryza [44]. However, they focused primarily on the evolution of dehydrins in one species or genus. Studying the evolution of dehydrins as a whole can provide broader insight into their origins and role in plants. Understanding which dehydrins were retained after duplication, and how they changed, is important in understanding their function. We investigate here how different dehydrin architectures may have arisen, and been retained or lost, after various duplication events.
Materials and methods
Dehydrin sequence database
Dehydrin sequences were collected from the Phytozome 12 database using Biomart to filter for sequences with the dehydrin PFAM designation (PF00257) [45–47]. Duplicate sequences, alternative transcripts, sequences that did not start with methionine, sequences with ambiguous amino acids, or sequences from early released genomes were removed. A K-segment motif was generated using Multiple EM Motif Elicitation (MEME)[48] on the sequences collected by Malik et al. to create a K-segment search expression [21]. MEME is a tool that can be used to find ungapped motifs in a set of sequences [48]. Motif Alignment & Search Tool (MAST) was then used to search for the K-segment in the first set of sequences collected using the dehydrin PFAM description; only sequences that had the motif with a combined p-value of <10−5 were kept [49]. The retained sequences were used to search for more sequence in the Phytozome using BLASTP; matches with an E-value <1 were kept [45]. The same search for the K-segment using MEME was repeated, and the newly refined collection of sequences was used to search for more sequences in the Phytozome using BLASTP again. This process was repeated until no new sequences were collected [45]. The same search was performed in the ConGenIE database [50] to search for dehydrins in Picea abies and Pinus taeda, and in the Giga database to search for dehydrins in Ginkgo bilboa [51]. Three sequences in the Phytozome and two sequences in the ConGenIE database were detected that had the PFAM description for reticulon-like proteins; these sequences were not added to the database.
Dehydrin architecture annotation
The sequences in the dehydrin database were run through the MEME software, to search for 10 different motifs; the rest of the parameters were left at the default settings [48]. The detected motifs were used to mark sequences as belonging to the Kn, SKn, YnKn, YnSKn, or KnS architectures [21]. The S-segment in some KnS dehydrin were not detected by MEME; after visual inspection of all of the sequences, those that matched the regular expression [S(SGD)SDSD] were annotated as KnS dehydrins.
Multiple sequence alignments and phylogenetic tree construction
The dehydrin protein sequences were aligned using MUSCLE on Emboss using the default parameters [52,53]. Multiple sequence alignments (MSA) were visualized using Seaview [54]. The phylogenetic tree was constructed using an MSA that included only dehydrins from spermatophytes in order to prevent very divergent dehydrins from reducing the quality of the alignment. PAL2NAL was used to convert the protein alignment into a codon alignment [55]. Next, the codon alignment was run through Model Generator to obtain parameters for use in a maximum-likelihood tree [56]. The maximum-likelihood phylogenetic tree was constructed using RAxML, with the general time reversible model for the substitution model and the GAMMA model with invariant sites for rate heterogeneity [57]. One hundred rapid bootstrap samplings were run. The resulting tree was visualized using MEGA X [58].
Dehydrin ortholog detection
To check if a dehydrin ortholog was present in another species, a reciprocal BLASTP search was performed. To perform this search, a gene of interest from the first organism is used in a BLAST search against a database of genes from the second organism. The top hit is then BLASTed against the first organism; if the top hit matches the original gene of interest, the sequences are considered to be orthologs. Dehydrins were only considered to be orthologs if the E-value was also <10−10. If an ortholog could not be found, the dehydrin DNA sequence was used in a BLASTN search against the species of interest genome for potential matches that may be located in regions considered to be non-coding sequences.
Synteny analysis
The protein sequences of the first five genes that flank both sides of the dehydrin genes were collected and used to create a sequence database. BLASTP was used to search through the database of flanking genes using all sequences in the dehydrin database. Sequences that matched with an E-value of <10−5 were considered to be similar to each other.
Results
After performing the filtering and iterative searching as described in the Material and Methods, a total of 426 dehydrin sequences were collected from 56 spermatophyte genomes. Of those dehydrins, 69 were the Kn architecture, 54 were KnS, 140 were SKn, 22 were YnKn, and 141 were YnSKn. In the three gymnosperm species, 22 Kn and 21 SKn architectures were identified. Aside from the three well-documented segments (Y-, S- and K-segments), only two other motifs were consistently detected (i.e. in at least ~100 sequences). The logo of one motif can be seen in Fig 1, and is similar to the F-segment that was previously described by Strimbeck [59], but the two segment definitions differ at the termini. The F-segment described in Fig 1 has an additional Glu at the N-terminal end, followed by two fairly variable residues, while the F-segment described by Strimbeck had an additional two Lys at the C-terminal end [59]. The F-segment was found in 121 sequences, of which 111 were SKn dehydrins and 10 were Kn dehydrins. The other motif that was detected is a string of Lys (11 residues of Lys interspersed with Arg, Asp and Glu), which was found in 94 sequences. In the 51 KnS dehydrins and 42 SKn dehydrins, the poly-Lys repeat was located between the S- and K-segments. It was also detected in one Kn dehydrin.
Fig 1. Logo representation of the F-segment discovered with MEME.

The logo representation was generated using WebLogo [60]. The first three residues of the F-segment discovered in MEME were not very conserved, and were therefore removed for this representation. Colors represent each amino acid group: Black for hydrophobic (Ala, Ile, Leu, Met, Phe, Pro, Trp, Val), green for polar (Cys, Gly, Ser, Thr, Tyr), purple for neutral (Asn, Gln), red for negatively charged (Asp, Glu), and blue for positively charged (Lys, Arg, His).
The initial phylogenetic tree (Fig 2 and S1 Fig) had all of the KnS and YnSKn dehydrins fall into their own separate subtrees. The majority of the SKn dehydrins did fall into one subtree, however, somewhat surprisingly, SKn dehydrins were spread throughout the phylogenetic tree. All of the gymnosperm SKn dehydrins fell outside of the subtree that contained the majority of the SKn dehydrins, and were located between the KnS and YnSKn dehydrin subtrees. Some SKn dehydrins were also present in the YnSKn dehydrin subtree. The YnSKn dehydrin subtree also contained all of the YnKn dehydrins, which were spread throughout the subtree. Lastly, the Kn dehydrins were present throughout the whole tree. Note that the bootstrap values identified for the large architecture splits were fairly low, with the highest being 20 for the KnS dehydrins.
Fig 2. Simplified phylogenetic tree showing the major dehydrin architecture clusters.

The phylogenetic tree in S1 Fig was reduced into clusters by visual inspection in order to minimize the number of clusters while trying to generate clusters that were enriched with just one architecture type. The colors represent the major architecture present in each cluster; red for Kn dehydrins, magenta for KnS dehydrins, blue for SKn dehydrins, and green for YnSKn dehydrins.
Our goal was to determine which architectures likely evolved from another, but the scattering of some of the dehydrins among other architectures, and the low bootstrap values, were issues that needed to be considered first. With respect to the bootstrap values, the problem with dehydrins is that the conserved Y-, S-, K-segments are interspersed with poorly conserved ϕ-segments, making an accurate MSA a challenge. When a phylogeny is guided by a multiple sequence alignment, the quality of the alignment has a substantial impact on the resulting organization. A recently developed algorithm, called bubble clustering [61], has demonstrated a very high level of stability in constructing phylogeny and so rebuilding the phylogeny in the future with bubble clustering based on non-positional data may yield higher-quality results.
The other possibility, and the one we deal with here, is that some of the protein sequences are the result of sequence annotation errors. The sequences were analyzed to determine the typical number of exons present and the location of the conserved motifs with respect to the exon boundaries. Only angiosperm sequences were used for the analysis, since the gymnosperms data set consisted of only three species. Table 1 shows that most YnSKn, YnKn, and SKn dehydrins have two exons, while KnS dehydrins mostly consist of one or two exons. In both YnSKn and SKn dehydrins with two exons, the first exon ends with the S-segment, a feature previously identified by Jiménez-Bremont et al. [62].
Table 1. Comparison of dehydrin exon numbers in different architectures.
| Dehydrin Architecture | |||||
|---|---|---|---|---|---|
| Number of Exons | YnSKn | YnKn | SKn | KnS | Kn |
| 5+ | 3* | 0 | 1 | 0 | 1 |
| 4 | 3 | 0 | 2 | 1 | 2 |
| 3 | 8 | 1 | 7 | 3 | 5 |
| 2 | 124 | 14 | 109 | 30 | 24 |
| 1 | 3 | 7 | 0 | 20 | 15 |
*See the text for an explanation.
Dehydrins with exons numbers higher than two and dehydrins with a different architecture than their neighbors in the initially generated tree (S1 Fig) were further inspected for possible sequence annotation errors. The non-coding regions flanking the dehydrin genes were investigated using JBrowser on Phytozome [45,63]. In cases where conserved motifs were detected in the putative intron of the dehydrin, or upstream or downstream of the dehydrin gene, the dehydrin sequence was reannotated to include the missing motifs. For cases where the segments were discovered in a non-coding region, but were separated from a dehydrin coding sequence by a stop codon, or if the segment was found to be out of frame, the sequence was recorded as a possible misannotation and the segment’s presence was documented. However, the protein sequence was left unchanged. The same was done for sequences where ambiguous nucleotides were present in the intron or present between a segment further upstream or downstream from the sequence of interest. Some dehydrin gene sequences were located near the ends of genome scaffold; this may have resulted in dehydrin sequences being split across two pieces of scaffold with only one part of the sequence being detected. Some sequences with more than the expected number of exons were reannotated to have two exons, but reannotation did not result in architectural changes. However, in two cases (marked with an asterisk in Table 1), the reannotation resulted in the dehydrin gene no longer being fused with a DNAJ or DNAJ-X domain containing gene.
As a result of the annotation error search, 30 sequences were reannotated and 28 sequences were detected as possible misannotations. Of the 30 reannotated sequences, 4 Kn dehydrins became SKn dehydrins, 3 SKn dehydrins became YnSKn dehydrins, and 1 Kn dehydrin became a KnS dehydrin, with the remaining 22 sequences not resulting in an architectural change. Within the 28 sequences that were possible misannotations (i.e. are not likely to be coding sequences), motifs were found that would make 4 Kn dehydrins become SKn dehydrins, 2 SKn dehydrins become YnSKn dehydrins, 1 Kn dehydrin become a KnS dehydrin, and 1 YnKn dehydrin become a YnSKn dehydrin. These changes brought the new total of each architecture to 59 Kn, 56 KnS, 143 SKn, 21 YnKn, and 147 YnSKn. The F-segment was now found in 115 SKn dehydrins and 6 Kn dehydrins. Of these 6 Kn dehydrins, 5 were in gymnosperms, the remaining one was in Salix purpurea.
A phylogenetic tree was then reconstructed including the 30 reannotated sequences. The newly constructed phylogenetic tree (Fig 3 and S2 Fig) has a more consistent separation of the different architectures, and could be divided into three major subtrees. The first major subtree contained all of the YnSKn dehydrins, as well as 6 Kn, 16 SKn, and 11 YnKn dehydrins. None of the SKn or Kn dehydrins in this subtree contained an F-segment. The second major subtree contained all of the KnS dehydrins, as well as 8 Kn dehydrins. The last major subtree contained all SKn dehydrins with the exception of those in the YnSKn subtree, as well as 14 Kn dehydrins. Additionally, two smaller subtrees were present, both of which contained mainly Kn dehydrins with several YnKn dehydrins. However, the larger of these subtrees had a bootstrap value of 1, which suggests that this division is more than likely meaningless. The overall bootstrap values were again fairly low for the large architecture splits, however compared to the simplified tree in Fig 2 there is an improvement in the bootstrap values for the KnS and YnSKn dehydrin containing subtrees.
Fig 3. Simplified phylogenetic tree using reannotated sequences showing major dehydrin architecture clusters.

The phylogenetic tree in S2 Fig was reduced into clusters by visual inspection in order to minimize the number of clusters while simultaneously trying to generate clusters that were enriched with just one architecture type. The colors represent the major architecture present in each cluster; red for Kn dehydrins, magenta for KnS dehydrins, blue for SKn dehydrins, and green for YnSKn dehydrins.
We subsequently examined whether the different architecture clusters had different levels of disorder using the FoldIndex tool [64]. The results (S3 Fig) are similar to those we previously observed for dehydrins when we clustered based on architecture [21]. Most of the architecture clusters have a similar amount of disorder, with the KnS dehydrin cluster appearing to be somewhat more disordered. It is not yet clear whether these differences have functional significance, or are more a reflection of the similar sequence composition of each of the different architectures.
The subtrees with bootstrap values >75 from both phylogenetic trees (S1 and S2 Figs) were inspected for large architecture divisions in order to detect possible evolutionary relationships between the dehydrins. Two subtrees of particular interest were further examined. The first subtree (Fig 4) contained all the YnKn dehydrins, as well as 9 YnSKn dehydrins, all from the family Brassicaceae. The YnKn dehydrins had three Y-segments and one K-segment; these dehydrins will from now on be referred to as the Y3K1 dehydrins. In comparison, the YnSKn dehydrins had three Y-segments and two K-segments, and will be referred to as the Y3SK2 dehydrins. One of the YnSKn dehydrins from Eutrema salsugineum, with the transcript ID Thhalv10026916m, had only one K-segment and a rather weak match to the S-segment (LRWFGISSANST). In the tree it was in the same clade as the Y3K1 dehydrins, so it was considered to be a Y3K1 dehydrin, with the assumption that the S-segment is in the process of being lost. The Y3K1 and Y3SK2 dehydrins were both present in Arabidopsis thaliana, Arabidopsis lyrata, Capsella rubella, Boechera stricta, Brassica oleracea capitata, and Eutrema salsugineum. Only the Y3K1 dehydrin was detected in Capsella grandiflora, however. The coding sequence for the Y3SK2 from C. rubella was used in a BLAST search against the C. grandiflora genome, and a fragment of 88 bp was found to be an excellent match with an E-value of 1.2 x 10−19. This sequence fragment was followed by an ambiguous nucleotide sequence, and therefore the whole sequence could not be established. Brassica rapa only contained the Y3SK2 dehydrin, so the coding sequence for the Y3K1 from B. oleracea capitata was used in a BLAST search against the entire B. rapa genome. There were no new dehydrin matches found in the non-coding sequences.
Fig 4. Subtrees with dehydrin architecture splits after gene duplication.

A) Subtree of Y3K1 and Y3SK2 dehydrins with B) surrounding gene conservation diagram. This subtree was cut from the tree in S2 Fig. C) Subtree of K6 and Y1SK2 dehydrins with D) surrounding gene conservation diagram. This subtree was cut from the tree in S1 Fig. In the gene conservation diagram, black polygons represent the dehydrins, while polygons of the same color represent genes that were matched to each other by a BLAST search (E-value < 10−5). White polygons represent genes that did not have any matches. The direction the polygon points represents on which strand the gene is located. Polygons pointing right are on the forward strand while polygons pointing left are on the reverse strand.
The genomes of species most closely related to Brassicaceae in the Phytozome (i.e. Caprica papaya, Theobroma cacao, Gossypium raimondii, Citrus clementina, and Citrus sinensis) were searched for orthologs to the Y3SK2 and Y3K1 dehydrins. Every species searched had one YnSKn dehydrin that was orthologous to either a Y3SK2 or a Y3K1 dehydrin from the subtree, however none of the species had an ortholog to both dehydrins. The sequences of all of the Y3SK2 and Y3K1 dehydrins were searched using BLAST against the genome of all the species of interest; however, no evidence of either dehydrin was found in coding or non-coding regions.
The second subtree of interest (Fig 4) was only observed in the tree in Fig 2 and S1 Fig. The subtree contained all but one of the Kn dehydrins in Brassicaceae, as well as six YnSKn and one SKn architecture dehydrin. The Kn dehydrins all consisted of six K-segments with the exception of A. lyrate, which contained two Kn dehydrins (with five and six K-segments). These dehydrins will be referred to as the K6 architecture dehydrins. The YnSKn dehydrins all contained only one Y-segment and two K-segments; the SKn dehydrins had a weak match to the Y-segment (DQFGIP) and had two K-segments. All of these dehydrins will be referred to as Y1SK2. Lastly, there was a Kn dehydrin with just two K-segments, however this A. halleri dehydrin gene was located near the end of a sequence fragment, so that the first exon may be present on a different fragment that could not be detected.
An important feature of this subtree is that all of the K6 dehydrins were found adjacent to the Y1SK2 dehydrins in the genome. In A. thaliana, A. lyrata, C. rubella, C. grandiflora, and B. stricta, both the K6 and Y1SK2 were present within ~600–1100 bp of each other. An additional K5 dehydrin was present in A. lyrata at the 5’ end of the K6 dehydrin (within ~3800 bp). B. rapa and E. salsugineum contained Y1SK2 dehydrins, but no orthologs to the K6 dehydrins were found and no matches were detected in the non-coding region of their genomes.
Although the exact subtree was not present in the phylogenetic tree in S2 Fig, there was a subtree that contained the same K6 dehydrins, and a subtree that contained the same Y1SK2 dehydrins.
The genes surrounding each of these dehydrins (Fig 4) were compared in order to investigate how the dehydrins are related to each other and to support the validity of the subtrees. In Fig 4B, it can be seen that genes surrounding the Y3K1 dehydrins are highly conserved, as well as the genes surrounding the Y3SK2 dehydrins. This would suggest that these dehydrins may have arisen after a large duplication event. The comparison of the genes surrounding the dehydrins from the Kn/YnSKn tree shows that they are highly conserved (Fig 4D). The fact that the K6 and Y1SK2 dehydrins are adjacent to each other implies that these dehydrins most likely arose through a tandem duplication event.
A multiple sequence alignment of Y3SK2 and Y3K1 was created to compare the conserved motifs (Fig 5). The first of the three Y-segments is nearly completely conserved among all of these dehydrins, with the exception of the third position, which was usually Arg and occasionally Lys. The second Y-segment had the largest variability between the Y3SK2 and Y3K1 dehydrins, since the fifth position in the Y3SK2 dehydrins was always Asn and in the Y3K1 dehydrin was nearly always Lys. The third Y-segment is well conserved between the two architectures, with the exception of the sixth position, where Y3SK2 dehydrins contained a Pro and the Y3K1 dehydrins typically contained an Ala. The region of the Y3K1 dehydrins that aligns with the S-segment of the Y3SK2 dehydrins contained very few Ser residues, although it did end in several Asp/Glu residues, which is typical for this motif. However, the S-segment in Y3SK2 and the region of Y3K1 that aligns with the S-segment are both found at the end of the first exon of their respective genes, followed by the E/D sequence at the start of the second exon. The first K-segment from the Y3SK2 dehydrins aligns poorly with the Y3K1 dehydrins. In contrast, the second K-segment from the Y3SK2 dehydrin aligns well with the K-segment of the Y3K1 dehydrins, but does show a few differences. Positions 5–7 have the largest difference between the two; in the Y3SK2 dehydrins, the fifth position is usually occupied by an Ile, the sixth position is usually occupied by Leu, and seventh is usually occupied by Asp. In the same positions in the Y3K1 dehydrins, the K-segment has Phe in position five and six, and a Lys in position seven.
Fig 5. Multiple sequence alignment of Y3K1 and Y3SK2 dehydrins comparing their conserved segments.

The multiple sequence alignment was generated by running MUSCLE with the default parameters, and was visualized using Seaview [52,54]. The conserved segments are shown bound by colored boxes. Black box, Y-segments; blue box, S-segments; orange box, K-segments. Colors represent the amino acid grouped by their chemical properties. Yellow, hydrophobic (Ala, Ile, Leu, Met, Phe, Pro, Trp, Val); green, polar (Cys, Gly, Ser, Thr, Tyr); purple, neutral (Asn, Gln); red, negatively charged (Asp, Glu); blue, positively charged (Lys, Arg, His).
We observed that the K-segments from the K6 dehydrins were highly similar in sequence. In Fig 6A, the K6 sequences were divided up such that the sequences were split after each K-segment, so that the K-segments and their preceding ϕ-segments could be aligned to each other. The last K-segment in the Y1SK2 dehydrins of their respective species was also included in the alignment along with the ϕ-segment up to the N-terminal K-segment. Fig 6B shows conservation of each position using character height. It shows that the K- and ϕ-segments are highly conserved, with the exception of gaps in the ϕ-segments.
Fig 6. Multiple sequence alignment (MSA) of the K-segments with preceding ϕ-segments in the K6 dehydrin and the C-terminal K-segment with preceding ϕ-segment in the Y1SK2 dehydrin.
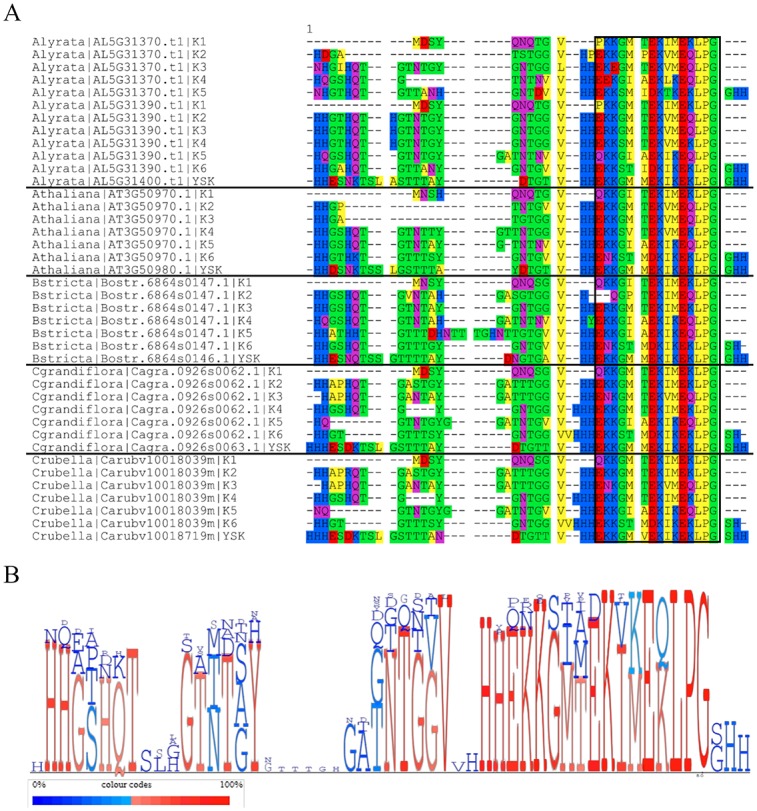
A) MSA generated running MUSCLE with the default parameters, and visualized using Seaview [52,54]. The K-segment is shown bound by a black box. Amino acid colors are as described in Fig 5. B) Character height diagram generated using MulitDisp [65]. Red letters indicate residues that are conserved in more than 50% of the sequences while blue letters indicate residues that are conserved in less than 50% of the sequences.
Expression data for the dehydrins in Arabidopsis thaliana from the subtrees in Fig 4A and 4C were compared to help gain an understanding for what roles dehydrin duplicates might play in plant biology. Tissues with the highest expression fold changes from the development map and the abiotic stress map were selected from the Arabidopsis eFP Browser [66,67]. When comparing the expression fold change of the Y3SK2 and Y3K1 dehydrins (Fig 7 and S1 Table), it was found that both architectures share similar expression patterns. The highest expression fold change for both dehydrins was during late seed stages, however the expression level and the fold change were much higher for Y3SK2 (Fig 7 and S1 Table). Conversely, the Y1SK2 and K6 dehydrins showed very different expression patterns (Fig 7 and S1 Table). Under abiotic stress conditions, particularly under cold conditions, the K6 dehydrin experienced the most upregulation, while Y1SK2 dehydrin had the most upregulation during late seed stages.
Fig 7. Bar graph comparing the fold-expression change of dehydrins from Arabidopsis thaliana shoots under abiotic stress and during seed development.

Expression fold change values were collected from Arabidopsis eFP Browser at bar.utoronto.ca [66,67]. These values are the average of duplicate measurements.
Discussion
Gene duplication is a major contributor to plant evolution. The average number of genes in plants found to be paralogous is 64.5%, ranging from 45.5% in Physcomitrella patens to 84.4% in Malus domestica [68]. There are five main mechanisms that result in gene duplication: whole genome duplication (WGD), tandem duplication, transposon-mediated duplication, segmental duplication, and retroduplication [68,69]. After duplication, a gene is either lost or retained; a gene can be lost if it undergoes pseudogenization or if it is deleted from the genome [68,69]. This can occur for various reasons, for example, if the duplicated gene is redundant and its loss results in no decrease in fitness [68,69]. A duplicated gene is retained if it results in improved fitness, such as from a change in function [68,69]. The presence of multiple dehydrins in different plant species [21] suggests that the different copies most likely arose through duplication events. The different dehydrin architectures that arose also suggest that dehydrins may be gaining new functions or variations of their original function. The only dehydrin architectures that were found across all spermatophytes we studied were the Kn and SKn dehydrins. A lack of dehydrins containing the Y-segment in gymnosperms was previously described [70]. Expression data of Y-segment containing dehydrins was compared to SKn in A. thaliana, Populus trichocarpa, Oryza sativa, Zea mays, and Brachypodium distachyon [66,71–74]. We observed that during seed germination, Y-segment containing dehydrins were always upregulated to very high levels, whereas SKn dehydrins were not upregulated or only to a lower level (S2, S3, S4, S5 and S6 Tables). The absence of Y-segments in gymnosperms and the upregulation of Y-segment containing dehydrins in angiosperm seeds suggests the Y-segment has some role in coated seeds. Note that the F-segment was found in both angiosperm and gymnosperm SKn dehydrins [59]. These findings give rise to the possibility that the architecture of the ancestral dehydrins in spermatophytes is either a Kn or SKn dehydrin containing an F-segment, and that the YnSKn dehydrins arose after the angiosperms and gymnosperms division.
During the search for possible annotation errors in the dehydrin sequences, an apparent fusion of a dehydrin gene and a DNAJ and DNAJ-X containing gene was seen in Brachypodium distachyon and Brachypodium stacei. This fusion was also observed in Oryza sativa by Verma et al. [44]. DNAJ, also known as heat shock protein 40 (Hsp40), is a protein known to prevent the aggregation of unfolded protein and help fold proteins through its association with Hsp70 [75,76]. Heat shock proteins are synthesized during environmental stress, and overexpression of DNAJ in Arabidopsis has been shown to improve tolerance to NaCl [77]. The fact both dehydrins and DNAJ are associated with environmental stress and are in close proximity on the genome suggests the possibility there may be an association between the two. However, the sequence analysis performed here and the lack of experimental evidence to date suggests DNAJ and dehydrins are not expressed as a fusion.
The first phylogenetic tree (Fig 2 and S1 Fig) divided the KnS and YnSKn dehydrins into their own subtrees; unexpectedly the SKn dehydrins were spread throughout the tree. The bootstrap values were also too low to reliably trust the data. The second phylogenetic tree (Fig 3 and S2 Fig) divided into major branches which contained primarily one architecture better than the first phylogenetic tree; these divisions for most part had improved bootstrap values as well. Unfortunately, it did not provide much information on where a split between the YnSKn dehydrins from either the Kn or SKn dehydrins may have occurred, because, although improved, the bootstrap values were still too low to be considered reliable.
Although a high-level architecture source could not be reliably identified, two lower level architecture divisions were suggested by the data. The first is between the Y3K1 and Y3SK2 dehydrins. It was observed that nearly all the Brassicaceae species investigated contained both a Y3K1 dehydrin and Y3SK2 dehydrin that were present on different chromosomes (Fig 4A and 4B). A comparison of closely related species revealed that they all had only one ortholog to either Y3K1 dehydrin or Y3SK2 dehydrin, and none of them contained any other YnKn dehydrin. Based on these findings, it is likely that the Y3SK2 dehydrin was duplicated before the Brassicaceae lineage arose, but after the ancestor of C. papaya and the Brassicaceae family had split. Between these events, one whole genome duplication (WGD) event had occurred in the Brassicaceae lineage [68]. Known as the α WGD event, it is thought to have occurred approximately 47 million years ago [68,78]. Genes that arose from WGD events can be identified by regions of shared synteny around the duplicate genes. With the combination of the timing of the duplication and the observed conservation of the genes surrounding the Y3K1 and Y3SK2 dehydrins (Fig 4B), it is possible that the duplication of the Y3SK2 dehydrin occurred during the α WGD event.
After the duplication, one of the duplicated Y3SK2 dehydrins could have lost its S-segment and the N-terminal K-segment through mutations (Fig 5), which would result in these species gaining a dehydrin with the Y3K1 architecture. A comparison of the expression data of the Y3K1 dehydrin to the Y3SK2 dehydrin shows that they share a similar pattern of upregulation during seed development (Fig 7). However, the expression level observed in the Y3K1 dehydrins was much lower than in the Y3SK2 dehydrins (S1 Table), which can be an indicator this gene is on its way to becoming a pseudogene [79].
A second potential architecture split was identified between the K6 and Y1SK2 dehydrins within the Brassicaceae lineage (Fig 4C and 4D). The fact that these dehydrin genes are adjacent to one another in the genome is an indicator that they arose through a tandem duplication event [80]. Tandem duplications occur during unequal cross-over events [68]. Orthologs to either the K6 and Y1SK2 dehydrins were not detected in closely related species directly outside of Brassicaceae, and in B. rapa and E. salsugineum, only the Y1SK2 dehydrin was observed. This would suggest that the dehydrin present before duplication was Y1SK2, and that the tandem duplication occurred after Arabidopsis had separated from B. rapa and E. salsugineum (14 and 24 million years ago), but before the separation between Arabidopsis and Capsella lineages (between 10 and 14 million years ago) [81]. A. lyrata is the only species to contain an additional K5 dehydrin at the 5’ end of the K6 dehydrin. This K5 dehydrin may have arisen through an additional tandem duplication event.
In order for the duplicated Y1SK2 dehydrins to become K6 dehydrins, not only would the Y- and S-segment need to be lost, but also four K-segments would need to be gained. The observation that the K-segments in the K6 dehydrins were highly similar along with the ϕ-segments between them suggests they were repeated (Fig 6A). Out of 54 positions, 32 positions were conserved in 50% or more of all the sequences (Fig 6B). These K-segments and ϕ-segments were also observed to be very similar to the C-terminal region of the Y1SK2 region after the first K-segment, suggesting that it is the source of the duplication. It is possible that during DNA replication an error occurred that resulted in the C-terminal end in one of the Y1SK2 dehydrins being repeated multiple times, eventually becoming the K6 dehydrin. This was also suggested by Bies-Ethève et al. in their observations of the K6 and Y1SK2 dehydrins in A. thaliana [38]. When comparing the expression data of the K6 and the Y1SK2 dehydrins in A. thaliana, it was seen that the conditions under which the highest level of upregulation occur is different (Fig 7). The Y1SK2 was most upregulated during seed stage development, while the K6 dehydrin was most upregulated during abiotic stress, in particular cold stress. This would suggest that the duplication has led to neofunctionalization, where the Y1SK2 dehydrins are involved in the natural dehydration that occurs in seeds, while the K6 dehydrin is involved in cold stress protection in adult plants. In experiments done by Hughes et al. [25], it was found that the larger the number of K-segments, the better the cryoprotection. This suggests that the duplicated K6 gene may have been kept due to its advantage at protecting enzymes from cold damage.
Conclusion
Two potential dehydrin architectural changes appeared after gene duplication. The first was a change from a Y3SK2 to a Y3K1 dehydrin, however the observed decrease in expression levels under similar conditions may be an indicator of the Y3K1 gene being pseudogenized. The second was a change from Y1SK2 to K6. The K6 dehydrin in A. thaliana had much higher expression during cold stress, and larger dehydrin constructs with higher numbers of K-segments have been shown to have improved enzyme cryoprotection [25]. These two duplications account for all of the Kn and YnKn dehydrins in the Brassicaceae family. Further work needs to be done to investigate what the architecture of the ancestral dehydrin was. Determining if and when the YnSKn dehydrins split from SKn may be important in answering this question.
Supporting information
The tree was generated using RAxML with 100 bootstrap replicates. The architecture assignments are defined by the following coloring scheme: Kn, red; KnS, magenta; SKn, blue; YnKn, yellow; YnSKn, green.
(PDF)
The tree was generated using RAxML with 100 bootstrap replicates. The architecture assignments are defined by the following coloring scheme: Kn, red; KnS, magenta; SKn, blue; YnKn, yellow; YnSKn, green. For the annotation analysis: ■, sequences that were unchanged; ▲, sequences that were reannotated; ●, sequences that were possible misannotations, unknown sequences, or pseudogenes. Unfilled symbols indicate dehydrin architectures that were changed by reannotation, or when motifs were found near dehydrins that were possible misannotations, unknown sequences, or pseudogenes.
(PDF)
Dehydrin sequences were clustered as described for S2 Fig, and their level of disorder was predicted using the FoldIndex algorithm [64].
(PDF)
(PDF)
(PDF)
(PDF)
(PDF)
(PDF)
(PDF)
(FASTA)
(FASTA)
(NWK)
(NWK)
(FASTA)
(FASTA)
Data Availability
All relevant data are within the paper and its Supporting Information files.
Funding Statement
This work was funded by a SPG NSERC Discovery Grant. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1.Amara I, Zaidi I, Masmoudi K, Ludevid MD, Pagès M, Goday A, et al. Insights into Late Embryogenesis Abundant (LEA) Proteins in Plants: From Structure to the Functions. Am J Plant Sci. 2014;05: 3440–3455. 10.4236/ajps.2014.522360 [DOI] [Google Scholar]
- 2.Bhagat Kiran P., Arun Kumar R R P, Kumar Satish, Bal S.K. and A PK. Photosynthesis and Associated Aspects Under Abiotic Stresses Environment Approaches to Plant Stress and their Management. Springer, New Delhi; 2014. pp. 191–205. [Google Scholar]
- 3.Close TJ, Kortt AA, Chandler PM. A cDNA-based comparison of dehydration-induced proteins (dehydrins) in barley and corn. Plant Mol Biol. 1989;13: 95–108. 10.1007/BF00027338 [DOI] [PubMed] [Google Scholar]
- 4.Tunnacliffe A, Wise MJ. The continuing conundrum of the LEA proteins. Naturwissenschaften. 2007;94: 791–812. 10.1007/s00114-007-0254-y [DOI] [PubMed] [Google Scholar]
- 5.Battaglia M, Olvera-Carrillo Y, Garciarrubio A, Campos F, Covarrubias AA. The Enigmatic LEA Proteins and Other Hydrophilins. Plant Physiol. 2008;148: 6–24. 10.1104/pp.108.120725 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Hundertmark M, Hincha DK. LEA (Late Embryogenesis Abundant) proteins and their encoding genes in Arabidopsis thaliana. BMC Genomics. 2008;9: 1–22. 10.1186/1471-2164-9-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Hincha DK, Thalhammer A. LEA proteins: IDPs with versatile functions in cellular dehydration tolerance. Biochem Soc Trans. 2012;40: 1000–1003. 10.1042/BST20120109 [DOI] [PubMed] [Google Scholar]
- 8.Hara M, Terashima S, Kuboi T. Characterization and cryoprotective activity of cold-responsive dehydrin from Citrus unshiu. J Plant Physiol. 2001;158: 1333–1339. 10.1078/0176-1617-00600 [DOI] [Google Scholar]
- 9.Momma M, Kaneko S, Haraguchi K, Matsukura U. Peptide Mapping and Assessment of Cryoprotective Activity of 26/27-kDa Dehydrin from Soybean Seeds. Biosci Biotechnol Biochem. 2003;67: 1832–1835. 10.1271/bbb.67.1832 [DOI] [PubMed] [Google Scholar]
- 10.Goyal K, Walton LJ, Tunnacliffe A. LEA proteins prevent protein aggregation due to water stress. Biochem J. 2005;388: 151–157. 10.1042/BJ20041931 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Reyes JL, Campos F, Wei H, Arora R, Yang Y, Karlson DT, et al. Functional dissection of Hydrophilins during in vitro freeze protection. Plant, Cell Environ. 2008;31: 1781–1790. 10.1111/j.1365-3040.2008.01879.x [DOI] [PubMed] [Google Scholar]
- 12.Hughes S, Graether SP. Cryoprotective mechanism of a small intrinsically disordered dehydrin protein. Protein Sci. 2011;20: 42–50. 10.1002/pro.534 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Drira M, Saibi W, Brini F, Gargouri A, Masmoudi K, Hanin M. The K-segments of the wheat dehydrin DHN-5 are essential for the protection of lactate dehydrogenase and β-glucosidase activities in vitro. Mol Biotechnol. 2013;54: 643–650. 10.1007/s12033-012-9606-8 [DOI] [PubMed] [Google Scholar]
- 14.Rinne PLH, Kaikuranta PLM, Van Der Plas LHW, Van Der Schoot C. Dehydrins in cold-acclimated apices of birch (Betula pubescens Ehrh.): Production, localization and potential role in rescuing enzyme function during dehydration. Planta. 1999;209: 377–388. 10.1007/s004250050740 [DOI] [PubMed] [Google Scholar]
- 15.Ismail AM, Hall AE, Close TJ. Chilling tolerance during emergence of cowpea associated with a dehydrin and slow electrolyte leakage. Crop Sci. 1997;37: 1270–1277. 10.2135/cropsci1997.0011183X003700040041x [DOI] [Google Scholar]
- 16.Hara M, Terashima S, Fukaya T, Kuboi T. Enhancement of cold tolerance and inhibition of lipid peroxidation by citrus dehydrin in transgenic tobacco. Planta. 2003;217: 290–8. 10.1007/s00425-003-0986-7 [DOI] [PubMed] [Google Scholar]
- 17.Xing X, Liu Y, Kong X, Liu Y, Li D. Overexpression of a maize dehydrin gene, ZmDHN2b, in tobacco enhances tolerance to low temperature. Plant Growth Regul. 2011;65: 109–118. 10.1007/s10725-011-9580-3 [DOI] [Google Scholar]
- 18.Hara M, Fujinaga M, Kuboi T. Metal binding by citrus dehydrin with histidine-rich domains. J Exp Bot. 2005;56: 2695–2703. 10.1093/jxb/eri262 [DOI] [PubMed] [Google Scholar]
- 19.Hara M, Kondo M, Kato T. A KS-type dehydrin and its related domains reduce Cu-promoted radical generation and the histidine residues contribute to the radical-reducing activities. J Exp Bot. 2013;64: 1615–1624. 10.1093/jxb/ert016 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Xu J, Zhang YX, Wei W, Han L, Guan ZQ, Wang Z, et al. BjDHNs confer heavy-metal tolerance in plants. Mol Biotechnol. 2008;38: 91–98. 10.1007/s12033-007-9005-8 [DOI] [PubMed] [Google Scholar]
- 21.Malik AA, Veltri M, Boddington KF, Singh KK, Graether SP. Genome Analysis of Conserved Dehydrin Motifs in Vascular Plants. Front Plant Sci. 2017;8: 1–18. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Findlater EE, Graether SP. NMR assignments of the intrinsically disordered K2 and YSK2 dehydrins. Biomol NMR Assign. 2009;3: 273–5. 10.1007/s12104-009-9192-2 [DOI] [PubMed] [Google Scholar]
- 23.Koag M-C, Fenton RD, Wilkens S, Close TJ. The binding of Maize DHN1 to Lipid Vesicles. Gain of Structure and Lipid Specificity. Plant Physiol. 2003;131: 309–316. 10.1104/pp.011171 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Mouillon J-M, Eriksson SK, Harryson P. Mimicking the Plant Cell Interior under Water Stress by Macromolecular Crowding: Disordered Dehydrin Proteins Are Highly Resistant to Structural Collapse. Plant Physiol. 2008;148: 1925–1937. 10.1104/pp.108.124099 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Hughes SL, Schart V, Malcolmson J, Hogarth KA, Martynowicz DM, Tralman-Baker E, et al. The Importance of Size and Disorder in the Cryoprotective Effects of Dehydrins. Plant Physiol. 2013;163: 1376–1386. 10.1104/pp.113.226803 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Cedeño C, Żerko S, Tompa P, Koźmiński W. 1H, 15N, 13C resonance assignment of plant dehydrin early response to dehydration 10 (ERD10). Biomol NMR Assign. Springer Netherlands; 2017;11: 127–131. 10.1007/s12104-017-9732-0 [DOI] [PubMed] [Google Scholar]
- 27.Uversky VN. Dancing protein clouds: The strange biology and chaotic physics of intrinsically disordered proteins. J Biol Chem. 2016;291: 6681–6688. 10.1074/jbc.R115.685859 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Uversky VN. A decade and a half of protein intrinsic disorder: Biology still waits for physics. Protein Sci. 2013;22: 693–724. 10.1002/pro.2261 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Tompa P, Bánki P, Bokor M, Kamasa P, Kovács D, Lasanda G, et al. Protein-water and protein-buffer interactions in the aqueous solution of an intrinsically unstructured plant dehydrin: NMR intensity and DSC aspects. Biophys J. 2006;91: 2243–2249. 10.1529/biophysj.106.084723 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Close TJ. Dehydrins: Emergence of a biochemical role of a family of plant dehydration proteins. Physiol Plant. 1996;97: 795–803. [Google Scholar]
- 31.Graether SP, Boddington KF. Disorder and function: a review of the dehydrin protein family. Front Plant Sci. 2014;5: 1–12. 10.3389/fpls.2014.00576 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Goday A, Jensen a B, Culiáñez-Macià F a, Mar Albà M, Figueras M, Serratosa J, et al. The maize abscisic acid-responsive protein Rab17 is located in the nucleus and interacts with nuclear localization signals. Plant Cell. 1994;6: 351–360. 10.1105/tpc.6.3.351 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Danyluk J., Perron A., Houde M., Limin A., Fowler B., Benhamou N., & Sarhan F. Accumulation of an Acidic Dehydrin in the Vicinity of the Plasma Membrane during Cold Acclimation of Wheat. Plant Cell Online. 1998;10: 623–638. 10.1105/tpc.10.4.623 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Yang Y, Sun X, Yang S, Li X, Yang Y. Molecular cloning and characterization of a novel SK3-type dehydrin gene from Stipa purpurea. Biochem Biophys Res Commun. 2014;448: 145–150. 10.1016/j.bbrc.2014.04.075 [DOI] [PubMed] [Google Scholar]
- 35.Houde M, Daniel C, Lachapelle M, Allard F, Laliberté S, Sarhan F. Immunolocalization of freezing-tolerance-associated proteins in the cytoplasm and nucleoplasm of wheat crown tissues. Plant J. 1995;8: 583–593. 10.1046/j.1365-313X.1995.8040583.x [DOI] [PubMed] [Google Scholar]
- 36.Wisniewski M, Webb R, Balsamo R, Close TJ, Yu XM, Griffith M. Purification, immunolocalization, cryoprotective, and antifreeze activity of PCA60: A dehydrin from peach (Prunus persica). Physiol Plant. 1999;105: 600–608. 10.1034/j.1399-3054.1999.105402.x [DOI] [Google Scholar]
- 37.Lin CH, Peng PH, Ko CY, Markhart AH, Lin TY. Characterization of a novel Y2K-type dehydrin vrdhn1 from vigna radiata. Plant Cell Physiol. 2012;53: 930–942. 10.1093/pcp/pcs040 [DOI] [PubMed] [Google Scholar]
- 38.Bies-Ethève N, Gaubier-Comella P, Debures A, Lasserre E, Jobet E, Raynal M, et al. Inventory, evolution and expression profiling diversity of the LEA (late embryogenesis abundant) protein gene family in Arabidopsis thaliana. Plant Mol Biol. 2008;67: 107–124. 10.1007/s11103-008-9304-x [DOI] [PubMed] [Google Scholar]
- 39.Liang D, Xia H, Wu S, Ma F. Genome-wide identification and expression profiling of dehydrin gene family in Malus domestica. Mol Biol Rep. 2012;39: 10759–10768. 10.1007/s11033-012-1968-2 [DOI] [PubMed] [Google Scholar]
- 40.Charfeddine S, Saïdi MN, Charfeddine M, Gargouri-Bouzid R. Genome-wide identification and expression profiling of the late embryogenesis abundant genes in potato with emphasis on dehydrins. Mol Biol Rep. 2015;42: 1163–1174. 10.1007/s11033-015-3853-2 [DOI] [PubMed] [Google Scholar]
- 41.Liang Y, Xiong Z, Zheng J, Xu D, Zhu Z, Xiang J, et al. Genome-wide identification, structural analysis and new insights into late embryogenesis abundant (LEA) gene family formation pattern in Brassica napus. Sci Rep. Nature Publishing Group; 2016;6: 1–17. 10.1038/srep24265 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Liu C-C, Li C-M, Liu B-G, Ge S-J, Dong X-M, Li W, et al. Genome-wide Identification and Characterization of a Dehydrin Gene Family in Poplar (Populus trichocarpa). Plant Mol Biol Report. 2012;30: 848–859. 10.1007/s11105-011-0395-1 [DOI] [Google Scholar]
- 43.Abedini R, GhaneGolmohammadi F, PishkamRad R, Pourabed E, Jafarnezhad A, Shobbar ZS, et al. Plant dehydrins: shedding light on structure and expression patterns of dehydrin gene family in barley. J Plant Res. Springer Japan; 2017;130: 747–763. 10.1007/s10265-017-0941-5 [DOI] [PubMed] [Google Scholar]
- 44.Verma G, Dhar YV, Srivastava D, Kidwai M, Chauhan PS, Bag SK, et al. Genome-wide analysis of rice dehydrin gene family: Its evolutionary conservedness and expression pattern in response to PEG induced dehydration stress. PLoS One. 2017;12: 1–22. 10.1371/journal.pone.0176399 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Jaume U, Munns R, Mahajan S, Tuteja N, Papi M, Sabatini S, et al. Phytozome: a comparative platform for green plant genomics. Elika. 2013;40: 1–15. 10.3389/fphys.2013.00093 [DOI] [Google Scholar]
- 46.Smedley D, Haider S, Durinck S, Pandini L, Provero P, Allen J, et al. The BioMart community portal: An innovative alternative to large, centralized data repositories. Nucleic Acids Res. 2015;43: W589–W598. 10.1093/nar/gkv350 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Finn RD, Coggill P, Eberhardt RY, Eddy SR, Mistry J, Mitchell AL, et al. The Pfam protein families database: Towards a more sustainable future. Nucleic Acids Res. 2016;44: D279–D285. 10.1093/nar/gkv1344 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Bailey TL, Elkan C. Fitting a Mixture Model by Expectation Maximization to Discover Motifs in Bipolymers. Proc Second Int Conf Intell Syst Mol Biol. 1994; 28–36. citeulike-article-id:878292 [PubMed] [Google Scholar]
- 49.Bailey TL, Gribskov M. Combining evidence using p-values: Application to sequence homology searches. Bioinformatics. 1998;14: 48–54. 10.1093/bioinformatics/14.1.48 [DOI] [PubMed] [Google Scholar]
- 50.Sundell D, Mannapperuma C, Netotea S, Delhomme N, Lin YC, Sjödin A, et al. The Plant Genome Integrative Explorer Resource: PlantGenIE.org. New Phytol. 2015;208: 1149–1156. 10.1111/nph.13557 [DOI] [PubMed] [Google Scholar]
- 51.Sneddon TP, Li P, Edmunds SC. GigaDB: Announcing the GigaScience database. Gigascience. 2012;1 10.1186/2047-217X-1-11 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Edgar RC, Tseng E, Eory L, Paton IR, Archibald AL, Burt DW. MUSCLE: multiple sequence alignment with high accuracy and high throughput. Nucleic Acids Res. 2004;32: 1792–1797. 10.1093/nar/gkh340 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Rice P, Longden L, Bleasby A. EMBOSS: The European Molecular Biology Open Software Suite. Trends Genet. 2000;16: 276–277. 10.1016/S0168-9525(00)02024-2 [DOI] [PubMed] [Google Scholar]
- 54.Gouy M, Guindon S, Gascuel O. SeaView Version 4: A Multiplatform Graphical User Interface for Sequence Alignment and Phylogenetic Tree Building. Mol Biol Evol. 2010;27: 221–224. 10.1093/molbev/msp259 [DOI] [PubMed] [Google Scholar]
- 55.Suyama M, Torrents D, Bork P. PAL2NAL: Robust conversion of protein sequence alignments into the corresponding codon alignments. Nucleic Acids Res. 2006;34 10.1093/nar/gkl315 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Keane TM, Creevey CJ, Pentony MM, Naughton TJ, McInerney JO. Assessment of methods for amino acid matrix selection and their use on empirical data shows that ad hoc assumptions for choice of matrix are not justified. BMC Evol Biol. 2006;6 10.1186/1471-2148-6-29 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Stamatakis A. RAxML version 8: A tool for phylogenetic analysis and post-analysis of large phylogenies. Bioinformatics. 2014;30: 1312–1313. 10.1093/bioinformatics/btu033 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Kumar S, Stecher G, Li M, Knyaz C, Tamura K. MEGA X: Molecular Evolutionary Genetics Analysis across Computing Platforms. Mol Biol Evol. 2018;35: 1547–1549. 10.1093/molbev/msy096 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Strimbeck R. Hiding in plain sight: the F segment and other conserved features of seed plant SKn dehydrins. Planta. 2017;245: 1061–1066. 10.1007/s00425-017-2679-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Crooks GE, Pomthong B, Onkoksoong T, Akiyama T, Esen A, Cairns JRK, et al. WebLogo: A Sequence Logo Generator. Genome Res. 2004;14: 1188–1190. 10.1101/gr.849004 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Saunders A, Ashlock D, Houghten S. Hierarchical Clustering and Tree Stability. IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB). IEEE; 2018. pp. 1–8. 10.1109/CIBCB.2018.8404978
- 62.Jiménez-Bremont JF, Maruri-López I, Ochoa-Alfaro AE, Delgado-Sánchez P, Bravo J, Rodríguez-Kessler M. LEA Gene Introns: Is the Intron of Dehydrin Genes a Characteristic of the Serine-Segment? Plant Mol Biol Report. 2013;31: 128–140. 10.1007/s11105-012-0483-x [DOI] [Google Scholar]
- 63.Buels R, Yao E, Diesh CM, Hayes RD, Munoz-Torres M, Helt G, et al. JBrowse: A dynamic web platform for genome visualization and analysis. Genome Biol. 2016;17 10.1186/s13059-016-0924-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Prilusky J, Felder CE, Zeev-Ben-Mordehai T, Rydberg EH, Man O, Beckmann JS, et al. FoldIndex: A simple tool to predict whether a given protein sequence is intrinsically unfolded. Bioinformatics. 2005;21: 3435–3438. 10.1093/bioinformatics/bti537 [DOI] [PubMed] [Google Scholar]
- 65.Riikonen P. MultiDisp [Internet]. http://structure.bmc.lu.se/MultiDisp/
- 66.Winter D, Vinegar B, Nahal H, Ammar R, Wilson G V., Provart NJ. An “electronic fluorescent pictograph” Browser for exploring and analyzing large-scale biological data sets. PLoS One. 2007;2 10.1371/journal.pone.0000718 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Schmid M, Davison TS, Henz SR, Pape UJ, Demar M, Vingron M, et al. A gene expression map of Arabidopsis thaliana development. Nat Genet. 2005;37: 501–506. 10.1038/ng1543 [DOI] [PubMed] [Google Scholar]
- 68.Panchy N, Lehti-Shiu MD, Shiu S-H. Evolution of gene duplication in plants. Plant Physiol. 2016;171: pp.00523.2016. 10.1104/pp.16.00523 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Zhang J. Evolution by gene duplication: An update. Trends Ecol Evol. 2003;18: 292–298. 10.1016/S0169-5347(03)00033-8 [DOI] [Google Scholar]
- 70.Perdiguero P, Barbero MC, Cervera MT, Soto Á, Collada C. Novel conserved segments are associated with differential expression patterns for Pinaceae dehydrins. Planta. 2012;236: 1863–1874. 10.1007/s00425-012-1737-4 [DOI] [PubMed] [Google Scholar]
- 71.Wilkins O, Nahal H, Foong J, Provart NJ, Campbell MM. Expansion and Diversification of the Populus R2R3-MYB Family of Transcription Factors. Plant Physiol. 2008;149: 981–993. 10.1104/pp.108.132795 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72.Sekhon RS, Lin H, Childs KL, Hansey CN, Robin Buell C, De Leon N, et al. Genome-wide atlas of transcription during maize development. Plant J. 2011;66: 553–563. 10.1111/j.1365-313X.2011.04527.x [DOI] [PubMed] [Google Scholar]
- 73.Shaoul R, Mogilner J, Coran AG, Chemodanov E, Sukhotnik I. F-box proteins in rice. Genome-wide analysis, classification, temporal and spatial gene expression during panicle and seed development, and regulation by light and abiotic stress. Plant Physiol. 2007;143: 1467–1483. 10.1104/pp.106.091900 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74.Sibout R, Proost S, Hansen BO, Vaid N, Giorgi FM, Ho-Yue-Kuang S, et al. Expression atlas and comparative coexpression network analyses reveal important genes involved in the formation of lignified cell wall in Brachypodium distachyon. New Phytol. 2017;215: 1009–1025. 10.1111/nph.14635 [DOI] [PubMed] [Google Scholar]
- 75.Fan CY, Lee S, Cyr DM. Mechanisms for regulation of Hsp70 function by Hsp40. Cell Stress Chaperones. 2003;8: 309–316. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76.Hennessy F, Nicoll WS, Zimmermann R, Cheetham ME, Blatch GL. Not all J domains are created equal: Implications for the specificity of Hsp40-Hsp70 interactions. Protein Sci. 2005;14: 1697–1709. 10.1110/ps.051406805 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77.Zhao Z, Zhang W, Yan J, Zhang J, Liu ZLX, Yi Y. Over-expression of Arabidopsis DnaJ (Hsp40) contributes to NaCl-stress tolerance. African J Biotechnol. 2010;9: 972–978. 10.5897/AJB09.1450 [DOI] [Google Scholar]
- 78.Kagale S, Robinson SJ, Nixon J, Xiao R, Huebert T, Condie J, et al. Polyploid Evolution of the Brassicaceae during the Cenozoic Era. Plant Cell. 2014;26: 2777–2791. 10.1105/tpc.114.126391 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79.Yang L, Takuno S, Waters ER, Gaut BS. Lowly expressed genes in arabidopsis thaliana bear the signature of possible pseudogenization by promoter degradation. Mol Biol Evol. 2011;28: 1193–1203. 10.1093/molbev/msq298 [DOI] [PubMed] [Google Scholar]
- 80.Freeling M. Bias in Plant Gene Content Following Different Sorts of Duplication: Tandem, Whole-Genome, Segmental, or by Transposition. Annu Rev Plant Biol. 2009;60: 433–453. 10.1146/annurev.arplant.043008.092122 [DOI] [PubMed] [Google Scholar]
- 81.Koch MA, Kiefer M. Genome evolution among cruciferous plants: A lecture from the comparison of the genetic maps of three diploid species—Capsella rubella, Arabidopsis lyrata subsp. petraea, and A. thaliana. Am J Bot. 2005;92: 761–767. 10.3732/ajb.92.4.761 [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
The tree was generated using RAxML with 100 bootstrap replicates. The architecture assignments are defined by the following coloring scheme: Kn, red; KnS, magenta; SKn, blue; YnKn, yellow; YnSKn, green.
(PDF)
The tree was generated using RAxML with 100 bootstrap replicates. The architecture assignments are defined by the following coloring scheme: Kn, red; KnS, magenta; SKn, blue; YnKn, yellow; YnSKn, green. For the annotation analysis: ■, sequences that were unchanged; ▲, sequences that were reannotated; ●, sequences that were possible misannotations, unknown sequences, or pseudogenes. Unfilled symbols indicate dehydrin architectures that were changed by reannotation, or when motifs were found near dehydrins that were possible misannotations, unknown sequences, or pseudogenes.
(PDF)
Dehydrin sequences were clustered as described for S2 Fig, and their level of disorder was predicted using the FoldIndex algorithm [64].
(PDF)
(PDF)
(PDF)
(PDF)
(PDF)
(PDF)
(PDF)
(FASTA)
(FASTA)
(NWK)
(NWK)
(FASTA)
(FASTA)
Data Availability Statement
All relevant data are within the paper and its Supporting Information files.