

Abstract
Background
It is common in applied epidemiological and clinical research to convert continuous variables into categorical variables by grouping values into categories. Such categorized variables are then often used as exposure variables in some regression model. There are numerous statistical arguments why this practice should be avoided, and in this paper we present yet another such argument.
Methods
We show that categorization may lead to spurious interaction in multiple regression models. We give precise analytical expressions for when this may happen in the linear regression model with normally distributed exposure variables, and we show by simulations that the analytical results are valid also for other distributions. Further, we give an interpretation of the results in terms of a measurement error problem.
Results
We show that, in the case of a linear model with two normally distributed exposure variables, both categorized at the same cut point, a spurious interaction will be induced unless the two variables are categorized at the median or they are uncorrelated. In simulations with exposure variables following other distributions, we confirm this general effect of categorization, but we also show that the effect of the choice of cut point varies over different distributions.
Conclusion
Categorization of continuous exposure variables leads to a number of problems, among them spurious interaction effects. Hence, this practice should be avoided and other methods should be considered.
Keywords: Categorization, Dichotomization, Interaction, Regression, Measurement error
Background
It is common in epidemiological and medical research to categorize exposure variables measured on a continuous scale and treat them as categorical in the statistical analysis. The continuous variables can be dichotomized or they can be divided into more than two groups, the latter alternative allowing investigation of a possible dose-response relationship. Examples of this practice include Body Mass Index (BMI) categorized according to pre-defined values and nutritional intake categorized according to observed quintiles. There may be several reasons for this practice. The most common ones being that it makes the analysis and the interpretation easier; one avoids having to model the actual relationship between the exposure variables and the response, and that it mimics clinical practice where one typically divides patients into groups (hypertensive vs. normotensive, obese vs. non-obese).
A number of papers have appeared, both in the biostatistical [1–7], epidemiological [8–13] and psychological [14–16] literature, pointing to problems with this approach and arguing against it. Among the problems are loss of information and power, but also an increased risk of type I error if continuous confounder variables are categorized. Recently, also predictive performance of models with categorized predictors is criticized [7]. We will not repeat their arguments here, but rather point to a problem that has received much less attention; that categorization of continuous exposure variables may lead to spurious interaction effects in a multiple regression model against an outcome.
This problem was observed already in 1974, by Humphreys and Fleishman [17], in a simulation study of the behavior of the ANOVA model in situations with two categorized explanatory variables. Later, the same type of problem was also noted by Paunonen and Jackson [18] in an investigation of possible effect modification of the association between personality trait measures and resulting behavior. They noted that effect modification, or interaction, was often observed if the effect modifier in question was dichotomized and a stratified analysis was performed, while if the same association was investigated in a linear regression model, keeping the effect modifier on its original scale and introducing a product term, effect modification was less often observed. This observation led Bissonnette et al. [19] to perform a simulation study investigating the same problem. They also found that when they simulated a model with no interaction, dichotomized the potential effect modifier and then performed a stratified analysis, effect modification was often observed. However, no real understanding of or explanation for the findings was provided.
Maxwell and Delaney [14] carried out a formal analytical investigation of the effects of dichotomizing the explanatory variables in a linear regression model. Specifically, they showed that in a model with two correlated explanatory variables X1 and X2, if the true relationship between one of the explanatory variables and the outcome Y was non-linear, a spurious interaction effect appeared when dichotomizing X1 and X2 at the median. This result has later been referred to by a number of other authors who have discussed the practice of categorization [2, 16], and the non-linear nature of the relationship between the explanatory variable and the outcome seems to have been taken as the explanation of the spurious interaction.
In this paper we will look into this problem in some more detail. We have two exposure variables X1 and X2 that are correlated, and where both of them are dichotomized. The situation where only one of them is dichotomized follows directly. Furthermore, they are both to be related to an outcome variable Y by some regression model. Throughout we will assume that there is no interaction between X1 and X2. In much earlier work, it has been assumed that the variables have been categorized at the median. However, in many medical and epidemiological applications, it is more relevant to consider categorization at more extreme values, and / or at several cut points. This leads to some interesting findings.
In our analytical treatment of the problem, we take the regression model to be linear, and we assume normally distributed variables X1 and X2. However, the results apply to regression models and distributions in general. We have also carried out a small simulation study in order to explore the effects for different distributions. We will first give two examples to show the relevance of the problem.
Illustration 1, height and lung function
The first illustration uses data on lung function collected among Norwegian medical students. Peak expiratory flow (PEF), l/min, was measured six times for each student; three times in sitting position and three times in standing position. We will be using the mean of the six measurements in this illustration. In addition to PEF, we also measured the height of the students (cm) and we have gender information. In total we have data from 377 students, and we will model PEF as a function of gender and height (centered). Running the simple linear regression model PEF = β0 + β1 × gender + β2 × height + β3 × gender × height + ε leads to the following estimated coefficients (SE): = 556.7 l/min (9.2 l/min), = − 129.7 l/min (11.0 l/min), = 3.7 (l/min)/cm (0.9 (l/min)/cm), = − 0.8 l/min (1.1 l/min). Using the conventional 5% significance level, we have clearly significant effects of gender and height, but no interaction. Next, we categorize height according to the gender specific 90th percentiles; 189 cm for men and 175 cm for women, coding zero if the subject is below the cut-off and one if above. We will then run the same linear model as above, but with the categorized version of height. This leads to the following estimated coefficients (SE): =578.4 l/min (6.4 l/min), = − 168.8 l/min (8.1 l/min), = 64.7 l/min (17.3 l/min), = − 48.5 l/min (22.6 l/min). We notice that we have a significant interaction at the conventional 5% level (p = 0.03). This would indicate that the effect of being among the higher 10% is significantly lower among women than among men, and while being among the 10% highest males leads to an increased PEF of 64.7 l/min, the same increase is only 16.2 l/min for females.
Illustration 2, myocardial infarction
The second example is taken from a huge Norwegian health survey. During the period from 1985 until 1999 the Norwegian government conducted health surveys inviting men and women in the age of 40–42 years to participate. We will be analyzing a subset of these data, collected during the period 1985 to 1994. We have measured, among other things, Body Mass Index (BMI) and systolic blood pressure (BP) on a total of 133,139 subjects. These subjects have been followed for on average 19 years, and death of myocardial infarction is registered through a linkage to the Norwegian Cause of Death Registry. We will restrict our analysis to subjects with BMI > 20 to avoid having to deal with obvious non-linearities. This leaves us with 132,150 subjects. Among these there were 2542 (1.9%) deaths. We fit a logistic regression model for the odds of death by myocardial infarction as a linear function of BMI (kg/m2) and BP (per 10 mmHg) and the interaction between BMI and BP. The estimated coefficients (SE) are 0.20 (0.04) for BMI, 0.61 (0.08) for BP, − 0.01 (0.003) for the interaction term and a constant term of − 14.06 (1.20). Due to the large sample size, all the estimated effects are clearly significant at the conventional 5% level. However, the estimated interaction term has no practical significance. Next, we divide the sample into two BMI groups (obese vs. non-obese) by making a cut-off at 30 kg/m2, and we divide the sample into two BP groups (hypertensive vs. normotensive) by making a cut-off at 140 mmHg. Based on the two categorized variables we run the same logistic model as above (main effects of BMI and BP and the interaction BMI × BP). The estimated coefficients are 0.81 (0.09) for BMI, 1.03 (0.04) for BP, − 0.41 (0.11) for the interaction and a constant term of − 4.43 (0.03). This would indicate that the effect of being obese varies between normotensive and hypertensive so that among normotensive subjects there is an odds ratio of death equal Exp(0.81) = 2.25, while among the hypertensive the effect of being obese is reduced to an odds ratio of Exp(0.81–0.41) = 1.49, a substantial difference.
Both examples show how categorization may lead to substantial changes in the interpretation of the data in practical data analysis.
Methods
Analytical developments, categorization in the bivariate normal situation
Assume we have a linear relationship between two exposure variables X1, X2, and an outcome variable Y, satisfying the linear regression equation.
| 1 |
where we assume Notice that there is no interaction in the true model. Furthermore, assume where for simplicity we let c1 = c2 = c. Let us define . We have no interaction between and if and only if μ00 − μ10 = μ01 − μ11⇒ μ11 − μ01 − μ10 + μ00 = 0.
Based on model (1) we have
| 2 |
| 3 |
| 4 |
| 5 |
In order to further investigate the relationships of interest, we need to be able to calculate the conditional expectations that enter these expressions. Define F00 = P(X1 ≤ c ∩ X2 ≤ c), F01 = P(X1 ≤ c ∩ X2 >c), F10 = P(X1 > c ∩ X2 ≤ c), F11 = P(X1 > c ∩ X2 > c),
the probabilities of belonging to each of the four combinations of . Due to symmetry,
so in the following we will focus on the conditional expectations of X1. Regier and Hamdan [20], using the Mehler identity [21], gave the following identity:
| 6 |
where φ(⋅) denotes the normal density function and Φ(⋅) denotes the corresponding cumulative distribution function.
As indicated by Regier and Hamdan [20], corresponding identities can be found by appropriate combinations of integrals and we have that
| 7 |
| 8 |
| 9 |
As mentioned, we have no interaction if μ11 − μ01 − μ10 + μ00 = 0. Using Eqs. (2), (3), (4), (5), this leads to
| 10 |
From this, it is immediately clear that we can still have a spurious interaction even in situations where one of the two exposure variables is not associated with the outcome (β1 or β2 equal zero) as the product in (10) can still be different from zero. Furthermore, no spurious interaction can take place if β1 = − β2. However, this last point is a function of our highly symmetrical situation and hence less relevant.
Using Eqs. (6), (7), (8), (9) and the fact that in our example, E(X1) = 0 and F01 = F10, formula (10) can be written
| 11 |
We have to remember that F11, F00 and F01 are also functions of c and ρ. Solving this (numerically) leads to ρ = 0 and / or c = 0, in addition to β1 = − β2 (and the degenerate solution ρ = − 1 ). That is, we have no interaction if X1 and X2 are uncorrelated (ρ = 0) or if we split at the median (c = 0). Otherwise, categorization leads to spurious interaction. By the same arguments one can show that a spurious interaction will also appear if only one of the two variables X1 and X2 are categorized, or if X1 and X2 are split into more than two categories.
One should remember that Eq. (11) is only relevant for our specific situation, with normally distributed variables and common cut point c. The important message here is that the equation is true in only very few situations, which means that with a few exceptions, categorization leads to spurious interaction. This general message is true also for other distributions.
Having established the presence of spurious interaction, it is of interest to investigate the potential size of the problem. Based on the model above, we can investigate the size of the induced interaction term relative to main effects of the categorized versions of X1, X2. Assume we fit a model where are coded 0, 1. It is easy to show that is given by μ01 − μ00 where μ00 and μ01 are given in (2) and (3), and we have already established that is given by μ11 − μ01 − μ10 + μ00 . We can use this to investigate the size of relative to for different choices of β1, β2, the cut point c and the correlation ρ. Figure 1 gives the absolute value of for varying c and ρ, for β1 = β2 = 1. We observe that with increasing cut points, the influence of the induced product term becomes substantial, even for moderate values of the correlation ρ. In this case, the ratio of to will of course be the same as to . As a bi-product we can also study the size of and as a function of the same cut point c and correlation ρ (Fig. 2), and we observe that the estimated effects increase quite rapidly with the more extreme cut points and correlations.
Fig. 1.
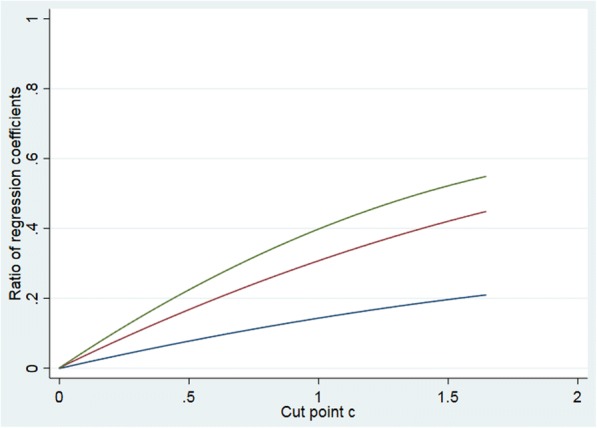
The figure gives the absolute value of the ratio between and for ρ = 0.2 (blue line), 0.5 (red line) and 0.7 (green line) as a function of the cut point c when β1 = β2 = 1
Fig. 2.
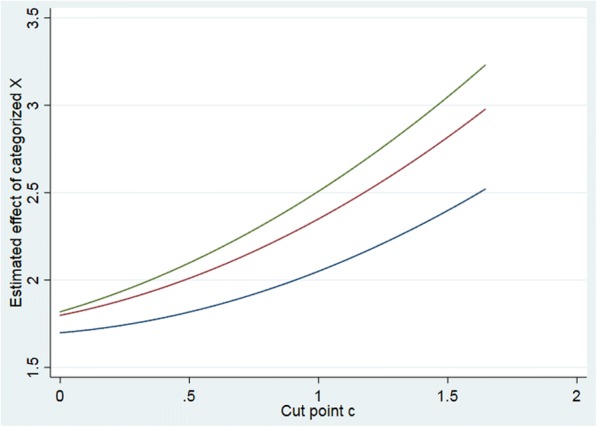
The figure gives for ρ = 0.2 (blue line), 0.5 (red line) and 0.7 (green line) as a function of the cut point c. True β2 = β1 = 1
Interpretation
Categorization of a continuous variable can be seen as an extreme form of measurement error. If there is measurement error in X1 and / or X2, and the error in X1 is differential with respect to X2 (meaning the measurement error in X1 varies with X2) or vice versa, it can be shown that this leads to an induced interaction between the observed versions of X1, X2 in a regression model [22–25]. In our case, the measurement error can be characterized by the reliability of the dichotomized variable , relative to the continuous variable Xi, i = 1, 2, as measured by the point-biserial correlation. If Xi is normally distributed, this correlation is given by , where h denotes the ordinate of the normal curve at the cut point and p and q denote the proportion of the population (or probability mass) above and below the cut point. It is easily seen that this correlation will vary with the other variable Xj, i ≠ j, as p and q will vary with Xj. Hence, the measurement error is differential and an induced interaction is to be expected.
Another way of looking at the same problem is as a problem of residual confounding. If we have a situation with a confounding variable where the effect of the confounder is not properly adjusted for, we are left with some residual confounding. This is exactly what is happening when a confounder is categorized. It is well known that this leads to biased estimates of exposure - outcome associations. In particular, Marshall and Hastrup [26] showed through simulations that such residual confounding can lead to apparent effects of variables that are strongly correlated to the confounder, but which in reality bear no association with the outcome. Marshall and Hastrup termed this effect “resonance of strong confounders”. Important for our investigation, differences in residual confounding across strata may lead to spurious interaction [27].
Simulations
To illustrate our findings and to further explore the effects of dichotomization in different situations we conducted a small simulation study. Notice that our main focus here has been to investigate the qualitative aspects of the induced interactions, and hence, we used a rather large sample size to minimize randomness.
We simulated X1, X2 according to three different distributions; standard bivariate normal, uniform [0,1], and chi-square with 2 df. We let the correlation between X1 and X2, ρ, vary over 0.2, 0.5, and 0.7, and we categorized at the 60th and the 80th percentiles, respectively. Furthermore, we simulated a response Y according to the following model, Y = β0 + β1X1 + β2X2 + ε with ε normally distributed with zero expectation and variance σ2 and independent of X1, X2. We then fit a model where is an interaction parameter. In all our simulations we let β0 = 0 and β1 = β2 = 1. Furthermore, we let the residual variance σ2 vary over the distributions in such a way that Corr(Y, Xi) = 0.3, i = 1, 2, when ρ = 0.5. The correlation ρ was then varied without changing σ2. The results of these simulations are given in Table 1. In addition, we repeated the situation with ρ = 0.7 and X1, X2 categorized at the 80th percentile, but now with βi = 2 for i = 1, 2. Further, we simulated the same situation once more with β1 = 1 and β2 = 0. The results of these simulations are given in Table 2.
Table 1.
Results of the simulation study
| Normal | Uniform | Chi-square | ||
|---|---|---|---|---|
| 60th percentile ρ = 0.2 |
1.74 (0.11) | 0.54 (0.04) | 2.99 (0.25) | |
| 1.73 (0.11) | 0.54 (0.04) | 3.00 (0.26) | ||
| −0.06 (0.20) | − 0.03 (0.06) | 0.63 (0.40) | ||
| 60th percentile ρ = 0.5 |
1.89 (0.14) | 0.59 (0.04) | 2.81 (0.28) | |
| 1.88 (0.14) | 0.59 (0.04) | 2.83 (0.29) | ||
| −0.16 (0.21) | − 0.08 (0.06) | 1.38 (0.43) | ||
| 60th percentile ρ = 0.7 |
1.95 (0.15) | 0.62 (0.04) | 2.60 (0.31) | |
| 1.94 (0.15) | 0.61 (0.04) | 2.63 (0.32) | ||
| −0.24 (0.22) | − 0.12 (0.07) | 1.82 (0.48) | ||
| 80th percentile ρ = 0.2 |
1.96 (0.14) | 0.57 (0.04) | 4.22 (0.27) | |
| 1.96 (0.14) | 0.57 (0.04) | 4.23 (0.28) | ||
| −0.23 (0.26) | − 0.11 (0.07) | 0.25 (0.55) | ||
| 80th percentile ρ = 0.5 |
2.22 (0.15) | 0.67 (0.04) | 4.35 (0.31) | |
| 2.22 (0.16) | 0.67 (0.05) | 4.35 (0.32) | ||
| −0.58 (0.25) | − 0.27 (0.07) | 0.50 (0.54) | ||
| 80th percentile ρ = 0.7 |
2.35 (0.16) | 0.74 (0.05) | 4.35 (0.35) | |
| 2.36 (0.18) | 0.74 (0.05) | 4.34 (0.35) | ||
| −0.81 (0.26) | − 0.40 (0.08) | 0.58 (0.56) |
The true regression coefficients βi = 1, i = 1, 2. The table gives estimated regression coefficients with corresponding empirical standard errors in parentheses
Table 2.
Results of the simulation study
| Normal | Uniform | Chi-square | ||
|---|---|---|---|---|
| 80th percentile ρ = 0.7 β1 = 1, β2 = 0 |
1.65 (0.16) | 0.50 (0.05) | 3.35 (0.35) | |
| 0.70 (0.18) | 0.24 (0.05) | 0.99 (0.35) | ||
| −0.40 (0.26) | − 0.20 (0.08) | 0.29 (0.55) | ||
| 80th percentile ρ = 0.7 βi = 2, i = 1, 2 |
4.72 (0.17) | 1.48 (0.05) | 8.69 (0.36) | |
| 4.72 (0.18) | 1.48 (0.05) | 8.68 (0.37) | ||
| −1.63 (0.27) | − 0.79 (0.08) | 1.16 (0.61) | ||
The table gives estimated regression coefficients with corresponding empirical standard errors in parentheses
In order to generate correlated variates from the three distributions, we generated bivariate normal variates with a specified correlation structure in the standard way. Furthermore, we generated uniform marginals by applying the standard normal cumulative distribution function to each of the normal variates. Finally, on the basis of a uniform variate Vj, we can generate Xj ∼ chi-square with 2 df. by Xj = − 2 ln(Vj) [28]. It is an easy task to adjust the pre-specified correlation structure so that the observed correlations are as one wish. This is done empirically, by running preliminary simulations. For each setting we ran 1000 simulations with a sample size of 10,000.
Results
Tables 1 and 2 give the results of these simulations. There are some common trends, but also some interesting differences between the distributions. First, the interaction effect becomes stronger with increasing correlation for all the distributions. We also observe that, naturally, the interaction effect becomes stronger with increasing main effects (the difference between Table 1 and the second situation in Table 2). In general, the normal distribution and the uniform distribution behave very similar. We see a stronger interaction effect with the more extreme cut-off (80th percentile vs. 60th percentile). In the skewed chi-square distribution, we observe the opposite; the stronger interaction effects appear with a cut-off at the 60th percentile. Furthermore, for the normal- and uniform distributions, the estimated interaction parameter has a negative sign, while for the chi-square distribution it has a positive sign. Finally, we confirm the result from the theoretical calculations, that even in the situation with β2 = 0, a spurious interaction appear.
If we look to the estimated standard errors, the interaction parameter becomes significant with a cut-off at the 60th percentile for the chi-square distribution in both Table 1 and Table 2, with an exception of the situation with the weaker correlation ρ = 0.2 in Table 1. For the other two distributions, we need in general to go to the more extreme cut-off (80th percentile) to find significant effects. Here, however, there are few significant effects for the chi-square distribution. It should be mentioned that categorization in general will lead to efficiency loss and the power to detect interaction effects will be low. For a general treatment of this topic, see [29].
To explain our findings, it will again be instructional to look at the problem as a measurement error problem. For the normal distribution, it is easy to show that the correlation between the continuous variable and the categorized version of the same variable is at its maximum with a cut-off at the median value, and it is then decreased with more extreme cut-off values. This means that there is more measurement error with the more extreme cut-off values. Based on the simulations, one can show that this is also true for the uniform distribution. However, also based on the simulations, for the chi-square distribution there is more measurement error with a cut-off at the 60th percentile than with a cut-off at the 80th percentile, as measured by the point-biserial correlation. This explains why we find the stronger interaction effects with a cut-off at the 60th percentile for the chi-square distribution, and with a cut-off at the 80th percentile for the two other distributions, as there will be more residual confounding, and hence more room for “resonance” in situations with more measurement error.
Furthermore, let us look into the differentiality of the measurement error. Thinking to the standard measurement error situation, with β1 and β2 > 0 we will have a positive interaction when there is less attenuation in the effect of X1 for higher values of X2 (and opposite), meaning the measurement error decreases with increasing X2. Again based on the simulated data, we can look at the measurement error (the point-biserial correlation) of X1 for vs. . For the normal- and the Uniform distribution, we find more measurement error in X1 for the lower category of , while for the chi-square distribution, there is more measurement error in X1 for the higher category of . This explains why the sign of the interaction term differs between the distributions.
Collapsing categorical covariates
We will briefly mention another consequence of this type of induced interaction. It is well known that tests of interaction usually have rather low power. When modelling an interaction between categorical exposure variables that takes more than two categories, a number of extra parameters have to be introduced. A common advice is then to combine exposure groups in order to decrease the number of extra parameters and hence, increase power (see e.g. Kirkwood & Sterne, Ch. 29.5) [30]. However, by doing this we will again run the risk of introducing a spurious interaction, which can be easily realized by the following illustration.
Assume we have one binary exposure variable X1 (e.g. gender) and one categorical exposure variable X2 with four categories. These two exposure variables are to be related to a binary outcome (diseased / not diseased). Assume the data look as in Table 3.
Table 3.
Illustration of the effect of collapsing exposure categories
| X1=1 | X1=2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| X 2 | Diseased | Not diseased | Total | RR | X 2 | Diseased | Not diseased | Total | RR |
| 1 | 20 | 380 | 400 | 1.0 | 1 | 5 | 95 | 100 | 1.0 |
| 2 | 30 | 270 | 300 | 2.0 | 2 | 20 | 180 | 200 | 2.0 |
| 3 | 30 | 170 | 200 | 3.0 | 3 | 45 | 255 | 300 | 3.0 |
| 4 | 20 | 80 | 100 | 4.0 | 4 | 80 | 320 | 400 | 4.0 |
The table gives the true situation
As seen from the table, there is no interaction between X1 and X2, as the association between X2 and the outcome as measured by the relative risk (RR) is constant across the two levels of X1. Next, we will combine categories 1 and 2, and 3 and 4 of X2, producing a new variable taking only two categories. This leads to Table 4.
Table 4.
Illustration of the effect of collapsing exposure categories
| X1=1 | X1=2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Diseased | Not diseased | Total | RR | Diseased | Not diseased | Total | RR | ||
| 1 | 50 | 650 | 700 | 1.00 | 1 | 25 | 275 | 300 | 1.00 |
| 2 | 50 | 250 | 300 | 2.33 | 2 | 125 | 575 | 700 | 2.14 |
The table gives the observed situation after collapsing
As observed, the association between and the outcome now differs between the two levels of X1 and a spurious interaction is introduced. Although the effect is not particularly strong in this example, an apparent increase in power may partially be due to such an induced interaction.
Discussion
We have given yet another argument to why continuous explanatory variables should not be categorized when entered into a regression model. If we have correlated exposure variables and categorize, this may lead to spurious interactions in the regression model. Furthermore, we have given an interpretation of this as a measurement error problem.
Statistical interaction is scale dependent, both with regard to model and measurement. An additive effect on a linear scale may appear as multiplicative on a transformed scale, like the logit. In the same way, any monotone transformation of the measurement scales of X1, X2 may lead to interactions. Hence, statistical interactions need to be interpreted relative to the scales on which they appear. As such, the main problem with the type of interaction discussed in the present work is not its existence but the fact that it is typically interpreted relative to its original measurement scale.
Our formal development has been within the framework of the linear regression model. However, based on the considerations above, it is easy to realize that this holds also for other regression models. Indeed, we have shown the appearance of such an interaction effect in logistic models through an example.
The practical implication of this is that whenever an interaction effect appears in an analysis based on categorized explanatory variables, the categorization itself should be considered as a possible explanation. However, one should also be aware that such an induced interaction may counteract any possible true interaction present in the data, and hence, mask this true interaction. It should be mentioned that in a practical data analysis, one will need a rather large sample size or strong effects for these interactions to appear as statistically significant.
Conclusion
In summary, categorization of continuous variables should be avoided. It leads to a number of problems, including biased estimates, loss of power, inflated type-I error, and spurious interaction effects. If the true effect of the exposure variable(s) in question cannot be easily modelled by classical parametric models, non-parametric regression methods should be preferred in order to avoid the above-mentioned problems and to gain insight into the underlying relationship. If one choose to categorize despite such warnings, it is generally preferable to categorize into more than two groups in order to minimize the information loss.
Acknowledgements
The author wants to thank the Department of Molecular Medicine, Division of Physiology at the University of Oslo, for providing the PEF data for the first example, and the Norwegian Institute of Public Health and the Norwegian Cause of Death Registry for providing the health survey data for the second example. The author also wants to thank PhD Ingvild Dalen for pointing him to the problem in the first place.
Funding
Not applicable.
Availability of data and materials
Data sharing is not applicable to this article as no datasets were generated or analyzed during the current study. Code for the simulations was written in the Gauss software and can be obtained from the author.
Abbreviations
- ANOVA
Analysis of variance
- Corr
Correlation
- Df
Degrees of freedom
- Exp(.)
The exponential function
- l/min
Liters per minute
- SE
Standard error
Authors’ contributions
The author read and approved the final manuscript.
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The author declares that he has no competing interest.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Austin PC, Brunner LJ. Inflation of the type I error rate when a continuous confounding variable is categorized in logistic regression analysis. Stat Med. 2004;23:1159–1178. doi: 10.1002/sim.1687. [DOI] [PubMed] [Google Scholar]
- 2.Royston P, Altman DG, Sauerbrei W. Dichotomizing continuous predictors in multiple regression: a bad idea. Stat Med. 2006;25:127–141. doi: 10.1002/sim.2331. [DOI] [PubMed] [Google Scholar]
- 3.Altman DG, Royston P. The cost of dichotomizing continuous variables. BMJ. 2006;332:1080. doi: 10.1136/bmj.332.7549.1080. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Frøslie KF, Røislien J, Laake P, et al. Categorisation of continuous exposure variables revisited. A response to the Hyperglycaemia and adverse pregnancy outcome (HAPO) study. BMC Med Res Methodol. 2010;10:103. doi: 10.1186/1471-2288-10-103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Bennette C, Vickers A. Against quantiles: categorization of continuous variables in epidemiologic research, and its discontents. BMC Med Res Methodol. 2012;12:21. doi: 10.1186/1471-2288-12-21. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Barnwell-Ménard J-L, Li Q, Cohen AA. Effects of categorization method, regression type, and variable distribution on the inflation of type-I error rate when categorizing a confounding variable. Stat Med. 2015;34:936–949. doi: 10.1002/sim.6387. [DOI] [PubMed] [Google Scholar]
- 7.Collins GS, Ogundimu EO, Cook JA, et al. Quantifying the impact of different approaches for handling continuous predictors on the performance of a prognostic model. Stat Med. 2016;35:4124–4135. doi: 10.1002/sim.6986. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Weinberg CR. How bad is categorization? Epidemiology. 1995;6:345–347. doi: 10.1097/00001648-199507000-00002. [DOI] [PubMed] [Google Scholar]
- 9.Greenland S. Dose-response and trend analysis in epidemiology: alternatives to categorical analysis. Epidemiology. 1995;6:356–365. doi: 10.1097/00001648-199507000-00005. [DOI] [PubMed] [Google Scholar]
- 10.Greenland S. Avoiding power loss associated with categorization and ordinal scores in dose-response and trend analysis. Epidemiology. 1995;6:451–454. doi: 10.1097/00001648-199507000-00025. [DOI] [PubMed] [Google Scholar]
- 11.Brenner H, Blettner M. Controlling for continuous confounders in epidemiologic research. Epidemiology. 1997;8:429–434. doi: 10.1097/00001648-199707000-00014. [DOI] [PubMed] [Google Scholar]
- 12.Van Walraven C, Hart RG. Leave’em alone – why continuous variables should be analyzed as such. Neuroepidemiology. 2008;30:138–139. doi: 10.1159/000126908. [DOI] [PubMed] [Google Scholar]
- 13.Schellingerhout JM, Heymans MW, de Vet HCW, et al. Categorizing continuous variables resulted in different predictors in a prognostic model for nonspecific neck pain. J Clin Epidemiol. 2009;62:868–874. doi: 10.1016/j.jclinepi.2008.10.010. [DOI] [PubMed] [Google Scholar]
- 14.Maxwell SE, Delaney HD. Bivariate median splits and spurious statistical significance. Psychol Bull. 1993;113:181–190. doi: 10.1037/0033-2909.113.1.181. [DOI] [Google Scholar]
- 15.Vargha A, Rudas T, Delaney HD, et al. Dichotomization, partial correlation, and conditional independence. J Educ Behav Stat. 1993;21:264–282. doi: 10.3102/10769986021003264. [DOI] [Google Scholar]
- 16.MacCallum RC, Zhang S, Preacher KJ, et al. On the practice of dichotomization of quantitative variables. Psychol Methods. 2002;7:19–40. doi: 10.1037/1082-989X.7.1.19. [DOI] [PubMed] [Google Scholar]
- 17.Humphreys LG, Fleishman A. Pseudo-orthogonal and other analysis of variance designs involving individual-differences variables. J Educ Psychol. 1974;66:464–472. doi: 10.1037/h0036539. [DOI] [Google Scholar]
- 18.Paunonen SV, Jackson DN. Idiographic measurement strategies for personality and prediction: some unredeemed promissory notes. Psychol Rev. 1985;92:486–511. doi: 10.1037/0033-295X.92.4.486. [DOI] [Google Scholar]
- 19.Bissonnette V, Ickes W, Berstein E. Personality moderating variables: a warning about statistical artifact and a comparison of analytic techniques. J Pers. 1990;58:567–587. doi: 10.1111/j.1467-6494.1990.tb00243.x. [DOI] [Google Scholar]
- 20.Regier MH, Hamdan MA. Correlation in a bivariate normal distribution with truncation in both variables. Aust J Stat. 1971;13:77–82. doi: 10.1111/j.1467-842X.1971.tb01245.x. [DOI] [Google Scholar]
- 21.Mehler FG. Uber die Entwicklung einer Funktion von beliebig vielen Variablen nach Laplaceschen Funktionen höherer Ordnung. J Fur Mathematik. 1866;66:161–176. [Google Scholar]
- 22.Greenland S. The effect of misclassification in the presence of covariates. Am J Epi. 1980;112:564–569. doi: 10.1093/oxfordjournals.aje.a113025. [DOI] [PubMed] [Google Scholar]
- 23.Greenland S. Basic problems in interaction assessment. Environ Health Perspect. 1993;101:59–66. doi: 10.1289/ehp.93101s459. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Armstrong BG. Effect of measurement error on epidemiological studies of environmental and occupational exposures. Occup Environ Med. 1998;55:651–656. doi: 10.1136/oem.55.10.651. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Muff S, Keller LF. Reverse attenuation in interaction terms due to covariate measurement error. Biom J. 2015;57:1068–1083. doi: 10.1002/bimj.201400157. [DOI] [PubMed] [Google Scholar]
- 26.Marshall JR, Hastrup JL. Mismeasurement and the resonance of strong confounders: uncorrelated errors. Am J Epi. 1996;143:1069–1078. doi: 10.1093/oxfordjournals.aje.a008671. [DOI] [PubMed] [Google Scholar]
- 27.Pearce N, Confounding GS. Handbook of epidemiology. 2. New York: Springer; 2014. Interaction. [Google Scholar]
- 28.Johnson NL, Kotz S, Balakrishnan N. Continuous Distributions, Vol. 1, 2nd ed (p. 347) New York: Wiley; 1994. [Google Scholar]
- 29.Farewell VT, Tom BDM, Royston P. The impact of dichotomization on the efficiency of testing for an interaction effect in exponential family models. J Am Stat Assoc. 2004;99:822–831. doi: 10.1198/016214504000001169. [DOI] [Google Scholar]
- 30.Kirkwood BR, Sterne JAC. Essential medical statistics. 2. Oxford: Wiley-Blackwell; 2003. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Data sharing is not applicable to this article as no datasets were generated or analyzed during the current study. Code for the simulations was written in the Gauss software and can be obtained from the author.