

Abstract
Providing medical trainees with effective feedback is critical to the successful development of their diagnostic reasoning skills. We present the design of DrKnow, a web-based learning application that utilises a clinical decision support system (CDSS) and virtual cases to support the development of problem-solving and decision-making skills in medical students. Based on the clinical information they request and prioritise, DrKnow provides personalised feedback to help students develop differential and provisional diagnoses at key decision points as they work through the virtual cases. Once students make a final diagnosis, DrKnow presents students with information about their overall diagnostic performance as well as recommendations for diagnosing similar cases. This paper argues that designing DrKnow around a task-sensitive CDSS provides a suitable approach enabling positive student learning outcomes, while simultaneously overcoming the resource challenges of expert clinician-supported bedside teaching.
Introduction
Well developed diagnostic reasoning skills are fundamental to the clinical diagnostic process, ensuring accurate diagnosis from patient presentations and appropriate management of their conditions. Bedside teaching practice is an accepted and effective method for developing medical trainees diagnostic reasoning, in which students are observed by clinical experts while they are interviewing patients1. A contemporary bedside teaching encounter would involve a senior doctor with a small group of students. The students would take turns interviewing and examining the patient, under senior doctor observation and guidance, with the aim of establishing an appropriate diagnosis and management plan. A typical bedside teaching encounter involves 4 key steps: 1) the doctor describes the age, sex and presenting complaint of the patient on the way to their bedside so that students can begin to consider the diagnostic possibilities; 2) At the patients bedside, a student takes the medical history (i.e. asking relevant questions to help prioritise likely diagnoses) and the senior doctor may suggest additional questions in order to help guide the student; 3) The student then examines the patient with a particular focus on examining organ systems related to the diagnoses they consider likely; and 4) The students are then asked which investigations they would request in order to further clarify their likely differential diagnoses. At the conclusion of the bedside encounter the doctor and students typically move to a separate room and then debrief and the correct diagnosis is revealed.
The bedside teaching model can be described as adopting a hypothetico-deductive approach to diagnosis2, in which the expert provides feedback to inform the student’s decision-making processes3,4. The senior doctor (or expert) assesses a student’s competency by considering their differential diagnoses at each of the four steps. The questions they ask the patient, the examinations they prioritise and the investigations they order, all provide the expert with clear indications of the diagnoses the student is considering (or omitting). The role of the expert is to confirm whether the student’s decisions are correct and to identify and help the student work through any errors or misconceptions at the end of each step. The feedback provided by the expert will ideally be tailored to the students’ knowledge and experience level and will take into account how they interact with the patient, elicit and utilise any available patient information. Good expert feedback will also guide the student’s diagnostic reasoning process rather than simply confirming or rejecting a particular diagnosis. The diagnostic skills are developed though the serial-clue approach5 in bedside teaching by practising the appropriate use of non-analytical and analytical modes of reasoning6 to solve a problem. Non-analytical reasoning is a process of mapping factual knowledge to a decision. The mapping process is simple, fast and works for solving general problems. Analytical reasoning is a process of making a decision based on multiple facts and rules. Analytical process is a slow, conscious process that requires rational thinking, logic, deductive reasoning, cognitive effort, and critical thinking to formulate a conclusion. By default, non-analytical reasoning is attempted for problem solving; those with good diagnostic skills have the awareness to switch to an analytical process when required.
Although bedside teaching remains a key teaching and learning activity for developing medical students’ diagnostic skills, it is staff, time and resource intensive to deliver, with a senior doctor typically taking time away from patient care to work alongside a small group of students. As a result, it is a costly and often difficult activity to support, particularly when large cohorts of students are involved. Some of the limitations of practice also create challenges in the supervision of junior doctors, and it is within this context in particular that the Clinical Decision Support Systems (CDSS) in health professional training have been developed for enhancing the development of diagnostic skills though a virtual learning environment such as SimDeCS7 and AMPLIA8. The use of a CDSS to simulate bedside teaching encounters could provide a number of benefits, including the ability to allow students to practice diagnostic reasoning without having to rely on the availability of senior doctors and suitable patients. The key advantage of using CDSS is their capacity to assess an individual’s decision-making performance. However, the scalability of such systems is limited because the expert model needs to be developed by human experts.
In this paper, we present a new method to generalise the concept of feedback generation by automating an expert model directly from clinical data and use the model to directly transform the knowledge into a feasible and flexible form of feedback. For example, when working through a series of virtual cases, this provides an opportunity – by analysing the student’s decisions, when they were made, and the order in which they were made – to inform the delivery of personalised feedback on performance and for direction of learning. If appropriately structured and scaffolded, and provided in real time, this feedback has the potential to model at least some of the elements of the sort of feedback that would normally be provided by expert clinical observers during the bedside teaching process.
Machine learning prediction to support bedside teaching
Learning tools that provide personalised support (i.e. feedback) to learners based on their use of the tool have been shown to enhance the learning process across a range of learning contexts4,9,10. While delivering effective automated personalised feedback can be difficult, particularly when done in real time, improvements in machine learning approaches and their increasing application within computer-based learning tools have led to a number of advances on this front11. Our aim was to utilise machine learning, within the context of a CDSS-based learning tool, to inform the delivery of personalised feedback on a medical student’s diagnostic decision-making. The tool simulates some of the key elements (for example type and timing) of feedback delivered during face-to-face bedside teaching activities.
To explore this possibility, we developed “DrKnow”12, a web-based learning and teaching tool, designed to support the development of problem-solving and decision-making skills in medical students during their clinical years. Students use DrKnow to explore scenarios involving a virtual patient. Students acquire information from the virtual patient in four progressive steps: considering the chief complaint, assessing patient histories, performing a (simulated) physical examination, selecting and evaluating appropriate investigations, and integrating these findings to arrive at a diagnosis. The student is prompted to provide and prioritise three differential diagnoses (from the available five options) at the end of each step. In our case study, each scenario starts with a presentation of abdominal pain but is accompanied by a different set of clinical features and targets one of five final diagnoses, namely appendicitis (AP), gastroenteritis (GE), urinary tract infection (UTI), ectopic pregnancy (EP), and pelvic inflammatory disease (PID).
As students work through a scenario, a machine learning model embedded within DrKnow monitors and analyses their decision path and formulates feedback accordingly. It does this by finding associations between the selected information and target diagnoses; these associations are presented via a combination of simple infographics and text. The feedback is designed to highlight to students which information supports or rejects their interim differential diagnoses. On completion of the case, it summarises their overall diagnostic performance and presents recommendations for diagnosing similar or related cases. DrKnow feedback was derived from a model trained from known clinical cases extracted from electronic health records of Austin Hospital.* The model generates a probabilistic prediction for a case based on available patient information, which is incorporated into the feedback provided at key points within each case. The Naive Bayes classifier was selected to use in the learning tool based on the consideration of clinically appropriate predictions and classification performance (see Khumrin et al (2017)12 for details of model selection).
Feedback modules
DrKnow feedback is coordinated through three feedback modules as described below. Feedback is delivered at four interim points, each corresponding to one of the four steps of bedside teaching. A final piece of feedback, which includes a summary of their performance, is delivered once the student submits their overall diagnostic decision.
Virtual patient module: The virtual patient module stores learning content (clinical scenarios) and coordinates with the analytical module to present scenarios with feedback appropriate to and based on the students decision path. The virtual patient module processes and represents each scenario as a virtual patient with which the student interacts. Apart from the chief complaint, no additional information can be viewed or selected during the first stage of case. However, the student is able to select from a range of available information during the three subsequent stages patient history, physical examination, and investigation. During these three stages, DrKnow generates question-answer pairs that are asked and answered in relation to the virtual patient. The student’s selections are then passed to the analytical module which returns a list of supporting information and potential diagnoses with probabilities. After completing the investigations stage of the case, students make a final diagnostic decision. The virtual patient module then assesses all diagnostic decisions within the case and summarises the student’s decision-making process, presenting information that includes measures of their overall performance as well as general and/or specific learning recommendations.
Monitoring module: The monitoring module monitors and records actions as students select information and formulate their hypotheses in the virtual patient module. The monitoring module transfers information including selected patient information and student diagnostic hypotheses to the analytical module for analysis.
Analytical module: The analytical module stores and analyses knowledge and expertise about teaching and diagnosing patients with abdominal pain. The analytical module also assesses a student’s learning (using data captured by the monitoring module) and interprets predictions based on these data to highlight associations between the patient information selected by the student and their diagnostic hypotheses. The analytical module also acts as a clinical expert by using the available data to generate individualised feedback to inform the student’s learning path, delivered via the virtual patient module.
DrKnow feedback generation
Through the cooperation of the three modules, the system provides simple yet helpful feedback, derived from the relationship between student selections and the predictions of a machine learning model. Specifically, DrKnow mimics the feedback available in traditional bedside teaching, through four core components of feedback: 1) relevance of information selected to support or reject a provisional diagnosis, 2) meaningfulness of the differential diagnosis given supporting information, 3) student overall performance, and 4) recommendations for subsequent cases. For each patient scenario attempted, students receive feedback at the four interim steps in the diagnostic process, and final feedback on submission of their final decision. The feedback presents at each of the interim stages consists of which selected clinical features support the proposed diagnoses (component 1), plus the three most likely diagnoses (component 2) based on the requested information. Students can use this feedback to inform what features to select (and diagnoses to consider) during subsequent steps. The final feedback provides students the correct diagnosis and an assessment of their overall diagnostic performance (component 3). It also identifies which patient information is key to the correct diagnosis this includes features that were selected by the student as well as those that they ignored but should have considered (component 4).
Interim feedback
In bedside teaching, expert feedback is typically provided at four interim steps leading up to the student’s final diagnostic decision. The purpose of this feedback is to help students to review and reflect on their diagnostic rationale, and to inform the next steps in their decision-making process (e.g. what additional case information is most relevant to the case). The feedback produced by DrKnow seeks to model this approach by comparing the student’s current decision status to DrKnow’s predictions and by highlighting which selected patient features support and do not support the proposed diagnoses. This information should be sufficient to support both review and reflection (how am I doing; am I considering the right diagnoses; how useful has the patient information I have selected been?) as well as providing some direction for what they should do at the next stage of the case (should I prioritise a different diagnosis; what patient information will best support my decision-making?). DrKnow’s first step in generating this feedback is to determine what information supports the interim diagnoses. The analytical module uses the NB machine learning model to identify the value of a feature by comparing the diagnostic probability of a condition with and without the feature included. The model measures the contribution of the feature using the posterior probability13, and we can use this effect to determine how a selected piece of information associates with a diagnosis. For example, the presence of diarrhoea is strongly associated with GE (posterior probability 0.7) but not at all for the other four diagnoses (<0.04). As a result, if the presence of diarrhoea is not indicated (or included among the selected features), then the probability of GE being among the preferred diagnoses is considerably reduced. One way of visualising the real time effect of feature inclusion or removal on probability is through the use of nomograms14,15.
Selecting features (patient information) from a case instance that are targeted to AP demonstrates how DrKnow utilises this approach. The analytical module tests the informativeness of a feature by removing one feature value at a time and observing the effect of the missing information. For example, the analytical module duplicates the default instance and replaces the first value of the feature with “?”. The analytical module removes the target class of both instances and passes them to the DrKnow decision support system. DrKnow uses the NB model to make a prediction for each instance, returning a probabilistic prediction for each of five diagnoses. The prediction for the target class (in this case AP) is compared between the two instances. If the presence of a feature increases the probability of prediction, the analytical module interprets the feature as a positive factor. Otherwise, the decrease is interpreted as a negative factor. In the example, the presence of the first feature helps the NB model to predict AP because the prediction increases. The analytical module applies this testing to all available features and presents the respective information as DrKnow feedback, in a summary table of features with the informative direction (see Figure 1). The positive and negative signs represent positive and negative factors, respectively. The feedback shows that both the age of the virtual patient, 27 years old, and the gender value of female support PID whereas only age supports AP and gender supports UTI. The analytical module uses supporting information in the table to find the three most likely diagnoses. The most likely diagnoses are determined by a simple counting approach (without considering probabilities). Figure 1 shows an example of how DrKnow uses the support features to arrive at the most likely diagnoses. The analytical module counts the number of positive factors to rank the five diagnoses; PID has the highest number of positive factors (two factors) and is ranked first, followed by EP and AP which each have one positive factor. The analytical module displays the three most likely diagnoses on the right side of student diagnoses. Overall, the feedback indicates to students what information supports which diagnosis and presents the three most likely diagnoses based on the selected information.
Figure 1.
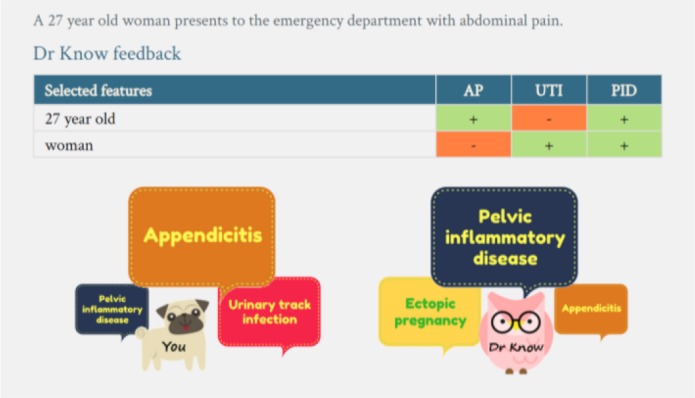
DrKnow feedback at the chief complaint stage
Final feedback
After completing the patient interview, the student must select a diagnosis. At this point, the analytical module presents a review of case performance to students (Figure 2). This final feedback includes four components: the correct diagnosis, the student’s diagnostic performance, their overall performance, plus patient information that is most relevant the correct diagnosis (as determined by the analytical module). The analytical module first matches a student’s final diagnosis to a correct diagnosis and presents the matching result. It then presents a summary of the student’s diagnostic decision path, and assesses their diagnostic performance using a range of information captured by the monitoring module. A score is determined based on both interim and final decisions, calculated through a weighted combination of number of correct diagnoses appearing in a differential diagnosis at interim stages, relevant selected information to form a correct diagnosis, and a correct final diagnosis. See Table 1 for a range of possible multipliers. The process of making a decision, and whether it is justifiable based on the available evidence, is arguably more important than whether the final decision is correct16,17. Considering this, we heuristically weight the score on the interim process relative to the final decision in a ratio of 54:46. The maximum possible score is 118; this is scaled to four performance categories: EXCELLENT (>90), GOOD (40 – 89), FAIR (20 – 39), and LIMITED (<20). A score of GOOD or better indicates that the student has demonstrated an appropriate level of decision-making expertise, which in the case of a GOOD performance may or may not include the correct diagnosis.
Figure 2.

DrKnow final feedback
Table 1.
Factors and weights for calculating a total score
| Factors | Multiplier (M) | Weight (W) | Max | % |
|---|---|---|---|---|
| Correct final diagnosis | 0-1 | 50 | 50 | 46 |
| Proper differential diagnosis | 0-4 | 10 | 40 | 37 |
| Relevant information | 0-18 | 1 | 18 | 17 |
| Total | 108 | 100 |
We analysed the scoring system in relation to four DrKnow scenarios, considering different interim and final decision performances. Scenarios A-D in Table 2 represent an example of a score where students demonstrate 1) good interim and final decisions, 2) good interim but wrong final decision, 3) poor interim but correct final decision, and 4) poor interim and final decisions, respectively. Scenario A is an example of EXCELLENT performance, where the correct diagnosis is identified during both the interim and final processes. To achieve an EXCELLENT rating, students must arrive at the correct diagnosis (50 points) and accumulate more than 40 points during the four interim stages. It is not possible to get an EXCELLENT performance by missing one process. For the interim process, students must get a correct diagnosis at least three (out of four) times in a differential diagnosis and ten (out of eighteen) pieces of relevant information. Students get at least GOOD overall performance when their final diagnosis is correct. The interim process result determines the overall performance. If the interim process is GOOD the overall performance will shift from GOOD to EXCELLENT(Scenario A), otherwise the performance stays at GOOD(Scenario C). Students can still get GOOD performance even they do not reach a correct final diagnosis (Scenario B). We set a score range and weight to cover Scenario B and C because we value the interim process as important as a final process. When a final decision is incorrect, the overall performance can be from GOOD to LIMITED depending on the interim process performance. Scenario D shows an example where a student performs poorly in both the interim and final decision.
Table 2.
Examples of student performance A (good interim and correct final decision), B (good interim and wrong final decision), C (poor interim and correct final decision), and D (poor interim and wrong final decision)
| Factors | Case A | Case B | Case C | Case D | ||||
|---|---|---|---|---|---|---|---|---|
| M x W | Score | M x W | Score | M x W | Score | M x W | Score | |
| Correct final diagnosis | 1 x 50 | 50 | 0 x 50 | 0 | 1 x 50 | 50 | 0 x 50 | 0 |
| Proper differential diagnosis | 3 x 10 | 30 | 3 x 10 | 30 | 1 x 10 | 10 | 1 x 10 | 10 |
| Relevant information | 13 x 1 | 13 | 13 x 1 | 13 | 5 x 1 | 5 | 5 x 1 | 5 |
| Total score | 93 | 43 | 65 | 15 | ||||
| Overall performance | EXCELLENT | GOOD | GOOD | LIMITED | ||||
In summary, students achieve an EXCELLENT overall performance rating when they demonstrate both GOOD interim and final decisions. They demonstrate GOOD overall performance when they demonstrate either GOOD interim performance or identify the correct final diagnosis. Failure to identify the correct diagnoses at the final stage combined with less than GOOD performance during the interim stages will result in a FAIR or LIMITED overall rating.
The final element of the final feedback, involves the analytical module testing the potential contribution (usefulness) of all features available in a scenario (using the relative posterior probability procedure described previously) and ranking them in descending order. Those features that are most relevant to the correct diagnosis are then presented in a word cloud, with their relative size and colour reflecting and emphasising their importance18. For instance, the features “There is no pain on the left side of the abdomen”, “There is no back tenderness”, “There is no back pain”, and “The UA leukocyte is negative” are the features that most strongly support a diagnosis of AP. The word clouds are designed to effectively summarise the key features of a diagnosis at a glance, which should encourage their selection by students in subsequent cases that indicate or could support a similar diagnosis.
DrKnow feedback vs. clinical findings
In the previous section, we described the process of formulating and presenting DrKnow feedback but did not comment on whether the feedback is clinically appropriate. To test this, we selected two patient scenarios (appendicitis and ectopic pregnancy) and compared the feedback generated by DrKnow with typical clinical presentations from various literature sources for appendicitis19-22 and ectopic pregnancy23,24. Table 3 compares typical presentations found in practical clinical findings with DrKnow’s recommendations for appendicitis and ectopic pregnancy. Our clinical review showed that appendicitis most typically presents in young to middle age males with right lower abdominal pain, a history of pain migration from periumbilical area, lack of appetite, nausea, vomiting, and fever. Physical examination usually reveals abdominal guarding, positive rebound tenderness, while white blood cell counts indicate leukocytosis. Encouragingly, these same features are also highlighted within typical presentations of appendicitis by DrKnow. Ectopic pregnancy, on the other hand, typically presents in reproductive age females with either left or right lower abdominal pain, not using contraception, and have vaginal bleeding. Physical examination presents abdominal guarding, while typical laboratory findings include a positive urine pregnancy test (UPT) and elevated serum hCG levels. Again, DrKnow also identifies these features but creates additional associations between ectopic pregnancy and nausea, vomiting, and positive rebound tenderness. Then, we rank a list of possible diagnoses by counting the positive signs of features (from clinical findings and DrKnow) that match to AP and EP similar to the ranking system using in the analytical module.
Table 3.
Comparison of DrKnow feedback and typical clinical presentation in appendicitis and ectopic pregnancy
| Presentations | Appendicitis | Ectopic pregnancy | ||||
|---|---|---|---|---|---|---|
| Clinical | DrKnow | AP case | Clinical | DrKnow | AP case | |
| Young age | + | + | 27 | + | + | 20 |
| Female | Y | + | + | Y | ||
| Right lower abdominal pain | + | + | Y | Y | ||
| Pain migration from periumbilical area | + | + | N | N | ||
| Lack of appetite | + | + | Y | N | ||
| Nausea | + | + | Y | + | Y | |
| Vomiting | + | + | Y | + | Y | |
| Fever | + | + | Y | N | ||
| No contraception | Y | + | + | Y | ||
| Vaginal bleeding | N | + | + | N | ||
| Abdominal guarding | + | + | Y | + | + | N |
| Positive rebound tenderness | + | + | Y | + | N | |
| Leukocytosis | + | + | Y | Y | ||
| Urine pregnancy test (UPT) positive | N | + | + | Y | ||
| Elevate serum hCG | N | + | + | Y | ||
| Percentage of positive signs matches to AP | 90 | 90 | 50 | 50 | ||
| Percentage of positive signs matches to EP | 57 | 70 | 71 | 70 | ||
Case I: Appendicitis
Case I is a 27-year-old female presenting at an emergency department with right lower abdominal pain, no pain migration, lack of appetite, nausea, vomiting, fever, no contraceptive use, no vaginal bleeding, abdominal guarding, positive rebound tenderness, white blood cell counts show leukocytosis, negative UPT, and no elevate serum hCG. The common clinical presentations and DrKnow feedback both suggest appendicitis (90% and 90% respectively) is more likely than ectopic pregnancy (57% and 70%).
Case II: Ectopic pregnancy
Case II is a 20-year-old female presenting at an emergency department with right lower abdominal pain, pain radiating to both legs, nausea and vomiting but no lack of appetite, no fever, no contraceptive use, no vaginal bleeding, no abdominal guarding and no rebound tenderness. The patient’s white blood cell counts show leukocytosis, and they have a positive UPT, and elevated serum hCG levels. In this case, both the common clinical presentations and DrKnow feedback clearly suggest ectopic pregnancy (71% and 70%) is more likely than appendicitis (50% and 50%).
In summary, DrKnow is able to identify a proper diagnosis regarding the clinical findings in both scenarios.
Discussion
While there are many differences between a student’s use of DrKnow (self-directed computer-based virtual cases) and their participation in Xa traditional expert-supported bedside teaching activity, the form and timing of feedback delivery by the DrKnow system nicely models some of the key elements of feedback provided by expert observers. This includes providing clear information on progress and performance at key stages of the activity plus guidance on what decisions (selection of features and diagnoses) should be made during subsequent steps. Through its application of machine learning, DrKnow reviews and analyses student decisions and formulates and presents content that is designed to support the development of students’ diagnostic decision-making skills within a safe, independent and hopefully engaging learning environment. In common with good bedside teaching practices, it achieves this by clearly identifying what patient and clinical information likely support potential diagnoses and which diagnoses (and features) should be prioritised. These characteristics are further enhanced through the iterative nature of the feedback and the simplicity and consistency of its presentation.
As in the case of early intervention (feedback) during expert-supported bedside teaching, the interim feedback provided by DrKnow is designed to encourage students to stop and review and reflect on their decision-making, and if necessary to adjust their thinking before making any subsequent decisions25. For example, if the interim feedback suggests AP as a likely diagnosis, but AP has not been prioritised by the students, then they can target patient or clinical features that help them to confirm or reject a diagnosis of AP during the next stage of the case. The final feedback on the other hand is designed to summarise and assess their overall performance, and to identify key supporting features for the correct diagnosis that they have and have not selected. Again, while this feedback may not provide the level of detail or the context that can be delivered by an expert clinician at the bedside, it does include a number of the key elements. In particular, it provides clear guidance on which alternative diagnoses have (and perhaps should have) been considered, and what features should be prioritised when considering future cases.
The feedback initially presents the value of information for the possible diagnoses. As presented in the process of selecting the most likely diagnoses, we counted the amount of supporting information to rank the most likely diagnosis. In the preliminary process, we tested the rank of the diagnoses using the probabilistic prediction generated by the NB model. However, we discovered that replacing a feature with a missing value (a zero-valued feature) sometimes resulted in a poor prediction, which in turn created clinical inappropriateness of the ranking in some cases. We supplied the twenty scenarios as a test set to the NB model and received model accuracy of 75%. The missing values created an extreme skew of probabilistic distribution among target classes with the result that 95% of the cases were predicted with 100% probability. Although the prediction is correct, the absolute probability (100% on a predicted diagnosis and 0% for other diagnoses) is not reasonable in a clinical approach because most of the time possible diagnoses cannot be totally excluded (except for obvious cases like ectopic pregnancy which can be excluded in a male patient). Otherwise, zero probability becomes seriously unacceptable such as when the differential diagnosis of gynaecological diseases is totally excluded in an active reproductive female patient. Regarding the skew of probabilistic distribution problem, we explored a second approach to make an assumption of the most likely diagnosis from the summation of feature association information. We take a count of positive factors where the most likely diagnosis contains the highest number of positive factors without considering the probabilistic weight of each factor because of the missing value problem. By eliminating the weight factor, the probabilistic distribution was more equally spread among target classes but the model prediction accuracy of diagnostic assumption dropped from 75% to 60% because it loses the impact of information. For example, the counting approach treats young male and female patients as having one point difference on gender whereas the weight impact on gender has a huge effect to differentiate gynaecological diseases from other diseases. Four different performance outcomes were used to demonstrate the overall performance in different diagnostic skill levels. Students are required to pass at least GOOD performance to demonstrate good diagnostic skills. GOOD or EXCELLENT scores for overall performance on a case indicate strong or developing levels of decision-making skills. Both scores are typically associated with a correct diagnosis, although it is possible to receive a GOOD score for an incorrect diagnosis if the student’s decision-making (as represented by their feature selection and interim diagnoses) is otherwise appropriate. In these cases, the assessed reasoning process performance is restricted to LIMITED, FAIR, and GOOD to clearly identify the level of their diagnostic reasoning skills.
We compared the lists of support clinical features between DrKnow and clinical findings and found that they both help to diagnose the appendicitis and ectopic pregnancy demonstration cases. However, the informativeness of features for differential diagnoses in DrKnow is less than for clinical decisions because DrKnow does not take into account the feature weight. This weight may become critical for a decision when the presentations of diseases are similar, such as for appendicitis and ectopic pregnancy. In these two cases, a final diagnosis is clinically not able to be clearly made until the result of UPT or serum hCG is available; the weight of other information is not strong enough to exclude one diagnosis for another diagnosis. In general, although the diagnostic accuracy of DrKnow as compared to other CDSSs may be below average, the overall educational value remains due to the focus on the production of effective feedback.
The learning tool has a capacity to scale to other clinical problems because the feedback (the supportiveness of clinical features, selection of diagnostic hypothesis, and final diagnostic performance) were directly generated from the expert knowledge extracted from clinical cases and independent of the type of diagnoses. The system is easily replicated by replacing the clinical case input and scenarios to retain the same functionality. The diagnoses in this study were selected because they are diagnoses sharing a similar, relatively common presentation (abdominal pain), and are frequently confused in clinical practice. This can result in detrimental clinical outcomes for patients, making them important targets for learning. We suggest that other groups of conditions with similar presentations (such as shortness of breath or chest pain) which could be confused are also good targets for the same approach.
Conclusion
Bedside teaching, in which an expert clinician observes and supports a medical student’s examination or interview and diagnosis of a patient, is a tried and tested method for supporting the development of diagnostic reasoning skills. The expert supports the student by providing feedback on their performance at key decision points, encouraging reflection and review, and if necessary guiding them towards a more appropriate decision path. Modelling this approach, we designed a learning tool (DrKnow) that employs a CDSS and machine learning to generate simple but personalised and case-dependent feedback as a student interacts with a virtual patient. This paper introduces our approach to integrating these components into a web-based learning tool that supports student learning.
As a student works through a case, DrKnow monitors their diagnostic decisions and, similar to the expert clinician role in bedside teaching, formulates and delivers interim and final feedback. The structure of the unfolding of the case, and the timing and type of feedback provided by DrKnow closely follows the natural structure of traditional bedside teaching. The feedback is derived from the relationship between the diagnoses that a student has selected, and the diagnoses that are supported by variables that a student has selected in assessing the virtual patient. Juxtaposing these two sets of diagnoses allows the student to compare their assessment with DrKnow’s prediction, encouraging reflection; common diagnoses may increase a student’s confidence, while differences may encourage a student to reconsider or revise their decisions.
While a formal evaluation of DrKnow’s use by medical students is yet to be completed, our comparative analysis of the feedback it generates and standard clinical findings suggests that the feedback is clinically appropriate. When combined with the type and timing of the feedback DrKnow provides, following closely the structure and objectives of bedside teaching, it has strong potential to supplement standard teaching practice and ultimately to improve learning outcomes.
Limitations
The current implementation of DrKnow only includes cases presenting with abdominal pain that are associated with one of five specific diseases. Its diagnostic context is therefore quite limited (e.g. compared to the variety of patients that a student might encounter during bedside teaching activities). However, our approach is relatively generic and with the inclusion of additional patient data could be extended to support additional presentations and diagnoses. The predictive accuracy of DrKnow was limited by the availability of suitable patient data for all of the target diseases. This resulted in machine learning training sets that were overly small in some cases. Missing features were also fairly common and, in some cases, further reduced DrKnow’s predictive accuracy.
Acknowledgement
PK thanks Chiang Mai University for a scholarship to support his PhD study. We also thank the Tilley family, Dr Chris Leung, and Professor Richard O’Brien of Austin Hospital Clinical School, as well as the University of Melbourne for research support.
Footnotes
Austin Hospital is in Melbourne, Australia. The data were processed and de-identified according to guidelines approved by the University of Melbourne Health Sciences Human Ethics Sub-Committee and by the Austin Hospital Human Research Ethics and Research Committee.
References
- 1.Max Peters and Olle Ten Cate. Bedside teaching in medical education: a literature review. Perspectives on medical education. 4 2014;3(2):76–88. doi: 10.1007/s40037-013-0083-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Thierry Pelaccia, Jacques Tardif, Emmanuel Triby, Bernard Charlin. An analysis of clinical reasoning through a recent and comprehensive approach: the dual-process theory. Medical Education Online. 1 2011;16(1):5890. doi: 10.3402/meo.v16i0.5890. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.John Spencer. Learning and teaching in the clinical environment. BMJ. 3 2003;326(7389):591–4. doi: 10.1136/bmj.326.7389.591. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Nicole Heitzmann, Frank Fischer, Lisa Kuhne-Eversmann, Martin R Fischer. Enhancing diagnostic competence with self-explanation prompts and adaptable feedback. Medical education. 10 2015;49(10):993–1003. doi: 10.1111/medu.12778. [DOI] [PubMed] [Google Scholar]
- 5.Henk G Schmidt, Slvia Mamede. How to improve the teaching of clinical reasoning: a narrative review and a proposal. Medical education. 10 2015;49(10):961–73. doi: 10.1111/medu.12775. [DOI] [PubMed] [Google Scholar]
- 6.Eugne J F M Custers. Medical Education and Cognitive Continuum Theory: An Alternative Perspective on Medical Problem Solving and Clinical Reasoning. Academic Medicine. 2013;88(8) doi: 10.1097/ACM.0b013e31829a3b10. [DOI] [PubMed] [Google Scholar]
- 7.Cecilia Dias Flores, Joo Marcelo Fonseca, Marta Rosecler Bez, Ana Respicio, Helder Coelho. Method for Building a Medical Training Simulator with Bayesian Networks : SimDeCS. Innovation in Medicine and Healthcare 2014. 2014. pp. 102–114. [PubMed]
- 8.Rosa Vicari, Cecilia Dias Flores, Louise Seixas, Joo Carlos Gluz, Helder Coelho. AMPLIA: A probabilistic learning environment. International Journal of Artificial Intelligence in Education. 2008;18(4):347–373. [Google Scholar]
- 9.Vollmar H C, Schurer-Maly C-C, Frahne J, Lelgemann M, Butzlaff M. An e-learning platform for guideline implementation-evidence- and case-based knowledge translation via the Internet. Methods ofinformation in medicine. 1 2006;45(4):389–96. [PubMed] [Google Scholar]
- 10.Chih Ming Chen, Ling Jiun Duh. Personalized web-based tutoring system based on fuzzy item response theory. Expert Systems with Applications. 2008;34(4):2298–2315. [Google Scholar]
- 11.Fernando Gutierrez, John Atkinson. Adaptive feedback selection for intelligent tutoring systems. Expert Systems with Applications. 2011;38(5):6146–6152. [Google Scholar]
- 12.Khumrin P, Ryan A, Judd T, Verspoor K. Diagnostic machine learning models for acute abdominal pain: Towards an e-learning tool for medical students. 2017;volume 245 [PubMed] [Google Scholar]
- 13.Oliver Lindhiem, Lan Yu, Damion J. Grasso, David J. Kolko, Eric A. Youngstrom. Adapting the Posterior Probability of Diagnosis Index to Enhance Evidence-Based Screening. Assessment. 4 2015;22(2):198–207. doi: 10.1177/1073191114540748. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Martin Možina, Janez Demšar, Michael Kattan, Bla Zupan. Berlin, Heidelberg: Springer; 2004. Nomograms for Visualization of Naive Bayesian Classifier; pp. 337–348. [Google Scholar]
- 15.Woojae Kim, Ku Sang Kim, Rae Woong Park. Nomogram of Naive Bayesian Model for Recurrence Prediction of Breast Cancer. Healthcare informatics research. 4 2016;22(2):89–94. doi: 10.4258/hir.2016.22.2.89. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Francesca Gino. What We Miss When We Judge a Decision by the Outcome. 2016.
- 17.Bert De Reyck, Zeger Degraeve. More important than results — London Business School. 2010.
- 18.Luca Ongaro. jQuery plugin for drawing neat word clouds that actually look like clouds. 2013.
- 19.Körner H, Söndenaa K, Söreide J A, Nysted A, Vatten L. The history is important in patients with suspected acute appendicitis. Digestive surgery. 2000;17(4):364–8. doi: 10.1159/000018880. [DOI] [PubMed] [Google Scholar]
- 20.William L Ryan. Appendicitis: symptoms, diagnosis, and treatments Digestive diseasesresearch and clinical developments series. New York: Nova Science Publisher’s; c2010., 2010. [Google Scholar]
- 21.Scott D C Stern, Adam S Cifu, Diane Altkorn. Symptom to diagnosis : an evidence-based guide. New York: McGraw-Hill Education/Medical; [2015]., 2015. [Google Scholar]
- 22.Laurell H, Hansson L-E, Gunnarsson U. Manifestations of acute appendicitis: a prospective study on acute abdominal pain. Digestive surgery. 2013;30(3):198–206. doi: 10.1159/000350043. [DOI] [PubMed] [Google Scholar]
- 23.Gracia CR, Chittams J, Hummel AC, Shaunik A, Barnhart KT, Sammel MD. Risk factors for ectopic pregnancy in women with symptomatic first-trimester pregnancies. Fertility and Sterility. 7 2006;86(1):36–43. doi: 10.1016/j.fertnstert.2005.12.023. [DOI] [PubMed] [Google Scholar]
- 24.Ganitha G, Anuradha G. A study of incidence, risk factors, clinical profile and management of 50 cases of ectopic pregnancy in a tertiary care teaching hospital. Int J Reprod Contracept Obstet Gynecol. 2017;(4):1336. [Google Scholar]
- 25.Vasilyeva E, Puuronen S, Pechenizkiy M, Rasanen P. Feedback adaptation in web-based learning systems. Int J Contin Eng Educ Life Long Learn. 2007;17(4):337–357. [Google Scholar]