

Abstract
We assessed the effects of blocking on the accuracy of arranging visual stimuli in sequences as an attempt to assess whether verbal behavior mediates nonverbal performance. Across three experiments, college students were trained to echo and tact the names of abstract images vocally (Experiments 1 and 3) and with hand signs (Experiment 2), and then, they were tested to see whether they could sequence these pictures accurately in the presence of their dictated names or signs. When participants were required to engage in a vocal blocking task, sequencing performances learned via either vocal or hand signs deteriorated (Experiments 1 and 2). In Experiment 3, vocal blocking deteriorated sequencing learned vocally, but not when participants were responding to visual samples (i.e., visual matching). Overall, only 2 out of 12 participants required joint control training to accurately sequence stimuli. Combined results suggest that vocal blocking may serve to prevent verbal behavior that could be mediating sequencing, and that joint control training is not necessary for adults to perform the sequencing task.
Keywords: Blocking, Echoic, Joint control, Tact, Verbal behavior
Conditional discrimination is commonly investigated using a matching-to-sample (MTS) procedure (Cumming & Berryman, 1961) in which reinforcement for selection of a stimulus among other comparisons is dependent upon the sample stimulus. For example, when told to match the letter “A,” only selection of the letter A from an array of letters (e.g., A, B, and C) would result in reinforcement. However, unlike the example above in which correct selection is likely to be a by-product of simple contingency shaping, when human participants display novel or untrained conditional relations, these could be mediated by verbal behavior (Horne & Lowe, 1996; Lowenkron, 2004).
There are two leading theoretical accounts of how verbal behavior may aid in solving MTS tasks: joint control (e.g., Lowenkron, 1984, 1988, 1989, 1991, 1998, 2006a; Lowenkron & Colvin, 1992, 1995; Sidener & Michael, 2006) and naming (e.g., Horne, Hughes, & Lowe, 2006; Horne & Lowe, 1996; Horne, Lowe, & Harris, 2007; Horne, Lowe, & Randle, 2004; Kobari-Wright & Miguel, 2014; Lowe, Horne, Harris, & Randle, 2002; Mahoney, Miguel, Ahearn, & Bell, 2011; Miguel & Kobari-Wright, 2013; Miguel, Petursdottir, Carr, & Michael, 2008). As the proposed study will focus on joint control, readers are referred to Horne and Lowe (1996) and Miguel (2016) for a detailed description of naming.
Lowenkron (1998) described joint control as “a discrete event, a change in stimulus control that occurs when a response topography evoked by one stimulus and preserved by rehearsal, is emitted under the additional control of a second stimulus” (p. 332). Joint control is explained as self-echoic and tact relations jointly exerting control over selection responses (Lowenkron, 1991). For example, when looking for a specific address described by a friend, a person may rehearse the dictated sequence of numbers (i.e., self-echoic) while reading the numbers of the visible addresses, and then choose an address when both the self-echoic and tact relations evoke the same response topography (i.e., same sequence of numbers). Because this selection is controlled by the events that control other verbal behavior, it is described as a descriptive autoclitic (for a description of autoclitic behavior, see Skinner, 1957).
Lowenkron (1984, 1988, 1989) initially demonstrated the role of joint control in MTS tasks by training overt self-echoics. In one such study, Lowenkron (1988) taught adolescents (ages 13–17 years) with developmental disabilities to select matching pictures (i.e., shapes) among four comparisons using an MTS procedure. Prior to training, participants could not select identical pictures following removal of the sample. They were first taught to use hand signs to tact the pictures. The experimenter then taught participants to rest their hand on a rail and maintain the sign that corresponded with the sample. Once participants consistently tacted with hand signs in the presence of samples, reinforcement was provided for holding the signs during delays after the samples were removed. Each of the participants then made accurate selections. In addition, participants used this strategy (i.e., holding the hand sign during a delay) to match exemplars during generalization tests. Thus, the author concluded that selections were likely to be dependent upon the momentary joint occurrence of the maintained hand sign and the tact evoked by the target stimulus.
In two experiments, Lowenkron (2006b) demonstrated the importance of both tact and self-echoic in accurate MTS performance. In the first experiment, the role of the tact component was examined by teaching six typically developing children (ages 5–7 years) to select a stimulus after hearing one of six different unfamiliar three-word descriptions referring to color, shape, and border features (e.g., king-bus-clip, leaf-trap-check, and pond-flag-sol). The participants were first taught to tact each of the individual features separately and were tested to see whether they could correctly select stimuli after hearing a three-word description. However, it was not until participants received additional tact training using six novel combinations of color, shape, and border features that they reliably selected pictures according to the novel three-word combinations. In the second experiment, four children (ages 6–7 years) learned to tact the individual features of familiar compound stimuli (e.g., gray-fish-dots, brown-tree-ladder, and green-chair-line). The experimenter then required the participants to vocalize names of numbers shown between the presentation of the sample stimulus and comparisons (i.e., blocking). Correct selection was less likely to occur during these blocking trials. The authors suggested that the self-echoic components of joint control might have been necessary for generalized stimulus selection because participants could not accurately select comparisons when they were prevented from emitting these self-echoics.
In a similar study, Gutierrez (2006) taught six adult females to rehearse the Chinese (Mandarin) names of four common household items (i.e., pen, cup, fork, and water) in the absence of the items and then tact their pictures in Mandarin. He then asked the participants to put the pictures in random orders as dictated in Mandarin. Two participants made no errors in sequencing, two produced chance responding, and the final two demonstrated higher than chance responding (i.e., 67 and 75 %). Next, all participants learned to rehearse aloud the sequences presented by the experimenter while arranging the pictures in the same order. After this training, all participants, including those who did not pass previous sequence tests, arranged the stimuli with at least 80 % accuracy. These results suggest that at least some of the participants could not arrange the stimuli based upon their Mandarin names without learning to rehearse dictated sequences. In the final phase, the experimenter attempted to block rehearsal by asking participants to sing a song (i.e., Happy Birthday) after dictated sequences and until the arrangement was complete. During blocking trials, performance deteriorated for all participants. Based on these findings, it was concluded that both components of joint control (i.e., echoic and tact) were necessary for generalized responding.
DeGraaf and Schlinger (2012) replicated these procedures and taught five college students to sequence different sets of pictures with either a prompting and fading procedure, or joint-control training. Participants sequenced sets learned via joint-control training in fewer trials, and could arrange sequences following longer delays than those taught using the prompting and fading procedure. In the final phase, the authors implemented blocking procedures for the sets exposed to joint control training. For 6 of the 12 trials chosen at random, participants repeated the American English alphabet or counted backwards from 100 while sequencing the pictures. Four of the five participants did not sequence accurately during blocking trials (i.e., less than 50 % of blocked trials) and the remaining participant sequenced the pictures with 80 % accuracy. Those trials without blocking resulted in 80 % or better arrangement accuracy for all participants. In a second experiment, five students were exposed to all procedures involving the arrangement of stimuli using the joint control component training only. In order to control for the possibility that the alphabet rehearsal or counting was compatible with covert rehearsal, they used the same blocking procedure as Gutierrez (i.e., singing Happy Birthday). All participants sequenced the stimuli with less than 50 % accuracy during blocking trials. Additionally, participants learned to sequence faster when directly trained to engage in the components of joint control (i.e., echoic and tact responses). Taken together, these results suggest that a history of joint control training may not only facilitate acquisition, but also improve accurate sequencing performances.
One way to evaluate whether joint control mediates listener responses is to use a delayed matching-to-sample (DMTS) procedure in order to observe any mediating responses after the offset of the sample and before the presentation of comparison stimuli (Sidener & Michael, 2006). Ratkos, Frider, and Poling (2016) attempted to teach overt rehearsal strategies to seven typically developing children (ages 3–6 years) during DMTS tasks. They first trained participants to tact and select each picture individually. After tact and listener training, they tested matching performance using a visual-visual delayed identity MTS (DIMTS) preparation. It was expected that participants, especially from this age group, would not perform accurately and would need additional training to use rehearsal strategies. At the beginning of each DIMTS trial, the experimenters held up the sample picture and required participants to tact it. Following an accurate tact, the sample was removed, and after a delay, the experimenters presented the same picture in an array with seven other comparisons. Results showed that after tact and listener training, only 6 out of the 7 participants could select the matching comparison at delays of up to 30 s. Only one participant needed echoic training, in which he was asked to repeat the name in the absence of the picture for 10 s. After returning to the DIMTS task, he scored above criterion (98 % at 15 s and 80 % at 30s) and did not need any further training. Because most participants scored highly after speaker and listener training alone, experimenters did not have an opportunity to train nor did they observe overt rehearsal strategies during DIMTS trials. Thus, these authors concluded that rehearsal (i.e., joint control) may have not been necessary to mediate such performances.
There were several limitations in the above-mentioned studies that render the effects of joint control training unclear. First, it is possible that different components of training led to increases in performance. For example, each participant in DeGraaf and Schlinger (2012) was exposed to prompting and fading prior to joint control training, making it impossible to evaluate whether prompting and fading or joint control training led to improvements in sequencing.
Second, in Ratkos et al. (2016), experimenters first trained participants to respond as both speakers (i.e., trained echoics and tacts) and listeners to the same pictures and then performance was tested using a visual-visual DIMTS procedure. The authors concluded that using identical sample and comparison stimuli and requiring participants’ to tact the sample at the beginning of each trial “strengthened” visual-matching responses. They suggested that rather than using verbal mediation during the delay, participants may have visualized the pictures (see Palmer, 2006; Skinner, 1957). In other words, the picture used as the sample could have evoked covert visualization, rather than echoic behavior. However, it is possible that a more complex task (i.e., sequencing cards rather than selecting one) would have required verbal mediation via joint control (i.e., self-echoic and tact).
Third, Gutierrez (2006) reported that participants could tact and respond as listeners to the experimental stimuli (common household items) in English prior to the onset of the study. Tact training in Mandarin could have established intraverbal relations between the Mandarin and English names (see Petursdottir, Ólafsdóttir, & Aradóttir, 2008). When asked to arrange stimuli in Mandarin, participants could have engaged in covert intraverbal behavior, as suggested by Horne and Lowe (1996), such as saying the English name of the dictated Mandarin name, which in turn evoked the listener response of selecting/arranging the correct stimulus. In this scenario, blocking trials interrupted intraverbal naming (see Ma, Miguel, & Jennings, 2016; Santos, Ma, & Miguel, 2015) rather than joint control. Finally, it is unclear whether the blocking procedures in the previous studies prevented mediating behavior or just interfered with task performance, rendering the joint control interpretation equivocal.
In the current study, we attempted to control for the previous limitations by only teaching arbitrary topographies (tacts and echoics/mimetics) using unfamiliar pictures, exposing participants to a more complex sequencing task, and evaluating the role of different topographies of blocking procedures. The purpose of Experiment 1 was to evaluate: (1) the role of joint control (i.e., tact and self-echoic) on sequencing random arrangements of arbitrary stimuli and (2) whether a vocal blocking task would disrupt sequencing behavior.
Experiment 1
Method
Participants and Setting
Participants were four college students (two females and two males, ages 21–25 years) recruited from a large, public university. They received course credits contingent upon completing the study. Sessions were conducted at a room on campus, which measured 3 × 5 m and contained four tables, nine chairs, three cabinets, and two computer stations. Each student participated in one session lasting between 45 min and 1.5 h.
Materials
Eight arbitrary names spoken or signed by the experimenter served as sample stimuli. Eight black and white pictures of abstract figures (7.6 cm × 12.7 cm) served as corresponding comparisons (see Fig. 1). The eight pictures were randomly divided into two sets of four pictures, and then the two sets were randomly assigned to the two-participant dyads. Each four-picture set was arranged into 24 distinct sequences. The order of the conditions is listed in Table 1. All sessions were videotaped for data collection purposes.
Fig. 1.
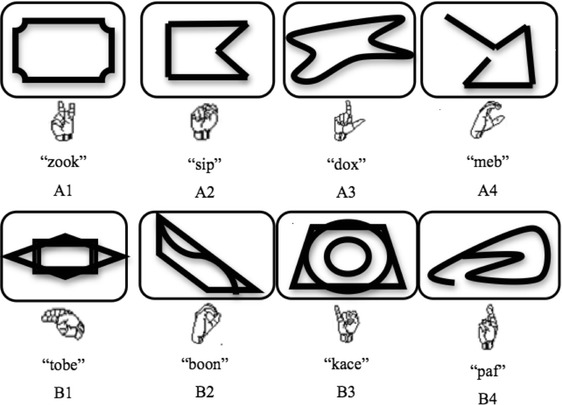
Experimental stimuli with their respective signs and vocal names spelled phonetically
Table 1.
Order and set assignment for conditions in Experiment 1
| 1. Sequencing test |
| 2. Echoic training |
| 3. Vocal tact training |
| 4. Sequencing test |
| 5. Vocal component joint control training (if needed) |
| 6. Sequencing test (if needed) |
| 7. Vocal blocking test |
| 8. Sequencing test |
| 9. Vocal blocking test |
| 10. Sequencing test |
Dependent Measures and Experimental Design
The main dependent measure was the percentage of accurate sequences (i.e., trials). A correct sequence was defined as arranging each of the four pictures from left to right, in the order dictated by the experimenter. Additional dependent measures included the percentage of independent echoics and tacts, and the number of trials to criterion during training. A correct echoic response was defined as rehearsing with point-to-point correspondence (Skinner, 1957), a vocal sample (e.g., saying “Boon” when the experimenter said “Boon”), whereas accurate tacts were defined as vocalizing the name of the visual stimulus presented (e.g., saying “Boon” when presented with the picture assigned the name “boon”).
We used a nonconcurrent multiple baseline design across participants (Watson & Workman, 1981) to show the effects of echoic and tact training, and to control for the potential confound of repeated pre-exposure to the sequencing tests. We used a reversal (ABABA) design to assess the effects of the blocking procedures (see below).
Interobserver Agreement and Treatment Integrity
A second observer independently recorded interobserver agreement (IOA) data during all sessions. For each trial, an agreement was scored if both the experimenter and the second observer scored the trial as correct, incorrect, or prompted (as defined above). IOA was calculated by dividing the number of agreements by the sum of agreements and disagreements and then converting the ratio to a percentage. Mean IOA was 100 % for P1, P3, and P4, and 99 % (range, 95.8–100 %) for P2.
A second observer also assessed treatment integrity (TI) for all sessions. Data were taken on whether each trial was correctly or incorrectly implemented. Correct implementation consisted of presenting the correct auditory samples, the timing of prompting (i.e., no delay) during the echoic, tact, and joint control training trials, correct sequences during sequencing and blocking test phases, and the outlined consequence for correct and incorrect responses during training and testing trials. If any of the aforementioned trial components were not executed correctly, TI for that trial would be scored as incorrect. TI was calculated by dividing the number of correctly implemented trials by the total number of trials conducted by the experimenter and converting the ratio to a percentage. Mean TI was 94.5 % (range, 83.3–100 %) for P1, 100 % for P2 and P3, and 98.9 % (range, 93.8–100 %) for P4.
Procedures
All training conditions (i.e., echoic, tact, and joint control training) consisted of 8-trial blocks in which each sample (i.e., individual picture) was presented two times in a randomized fashion, with no two samples presented consecutively. During sequencing tests, randomly chosen sequences for each set were used as samples in 5-trial blocks, which were delivered vocally (e.g., “tobe, boon, kace, paf”). Overall, there were 24 possible sequences. The presentation of sequences was randomized across all phases, and sequences were not repeated for a minimum of 6 trials regardless of the condition. This ensured that each testing block of 5 trials/sequences would contain a different combination, and that participants were exposed to each possible sequence evenly throughout the course of the study (See Table 1).
Sequencing Tests
During these conditions, the experimenter said, “Please attempt to put the pictures described in left to right order, and put your hands on your lap when you are finished.” The experimenter then vocally stated a prearranged sample sequence from the assigned set (i.e., A or B), waited 4 s, and then placed the corresponding picture set upside down in a randomly arranged pile in front of the participant. The participants flipped the picture set over, arranged them in left to right order, and put their hands in their laps when finished. Nonspecific feedback from the experimenter (i.e., “Thank you”) was delivered to indicate the completion of the sequencing trial, regardless of performance. Each test consisted of five sequencing trials (i.e., a 5-trial block indicates that the participant attempted to sequence the cards five times). P1 and P3 completed one sequence pretest block, whereas P2 and P4 received an additional sequencing pretest block to ensure that exposure to testing conditions would not improve performance before component training (see below). Participants were required to sequence pictures at or below chance level during pretests to proceed to component (echoic and tact) training. After component training, participants were given two attempts to sequence cards with 80 % accuracy in a 5-trial block. If they did not pass, participants moved onto joint control training (see below).
It should be noted that once joint control training was completed and participants passed the initial sequencing test, they only were given one attempt to pass all remaining sequencing tests (i.e., sequencing during blocking and reversal phases). The purpose of this was to avoid unnecessary exposure to sequencing trials throughout the course of the study. Passing criterion for sequencing tests was one 5-trial block at or above 80 %.
Component Training
During echoic training, the participants were told, “For this portion of the experiment, you need to repeat back what I say.” The experimenter then vocally stated the names of the samples individually in the absence of any visual stimuli, and waited 5 s for the participant to respond. Correct responses (i.e., identically repeated vocal names) were followed with praise (e.g., “That’s right!”). Incorrect responses were followed with a “No,” and the repetition of the instruction. The criterion for completion of echoic training was one training block of 8 out of 8 trials without errors.
During tact training the experimenter first said to the participant, “You will now learn to say the names of the pictures.” The experimenter then held up 1 of the 4 pictures from the assigned set, one at a time, for the participant to tact. Correct responses were vocally prompted upon the presentation of a stimulus (i.e., 0-s delay) for one block. After participants correctly responded in 8 out of 8 trials without errors, they were given 5 s to respond. If an incorrect response occurred, or if the participant did not respond after 5 s, an error-correction procedure was implemented in which the experimenter would say, “No,” and repeat the trial with an immediate vocal prompt requiring the participant to repeat the name. Correct responses were followed by praise (e.g., “correct,” “that’s right”). The criterion for completion of tact training was one block of 8 out of 8 trials without errors.
Joint Control Training
During this condition, the experimenter told the participant, “Please repeat back what I say three times, then touch the picture on the table and say its name.” The experimenter then placed one picture on the table, and prompted the participant to repeat its name three times (e.g., the experimenter said “Tobe” and the participant said “Tobe, tobe, tobe”). Next the experimenter modeled touching and tacting the picture at a 0-s delay. For example, the experimenter would place a picture face-up on the table and immediately point to it. The participant imitated the point, and the experimenter then said, “Tobe” after which the participant was to echo, “Tobe.” After one 8-trial block with no errors, the 0-s delay was increased to 5 s for the point and tact portions of the response. For example, during the 5-s delay, the experimenter still presented the sample and said the name of the stimulus once (e.g., “Paf”) but did not provide any prompts to echo, point, or tact. Echoing three times, touching, and stating the name of the stimulus were all required to be considered a correct response. Correct responses were followed by praise. If the participant did not repeat the name three times, point to the stimulus, tact the stimulus correctly, or did not respond within 5 s, the error correction was initiated. Any errors resulted in the experimenter saying “No,” rehearsing the instructions, and providing the immediate prompts as described above. The criterion for termination of joint control training was one 8-trial block with independent and accurate rehearsal, touching, and vocal tact responses. At the conclusion of this training, a sequencing test block was given, and participants then had one opportunity to pass. If participants did not pass, joint-control training for entire sequences (rather than individual images) would have been initiated. However, no participants required such training.
Vocal Blocking Tests
The purpose of this phase was to attempt to prevent verbal behavior in the form of self-echoics and tacts that could account for the occurrence of joint control. All steps of the sequencing test were repeated with one exception: The experimenter first said to the participant, “When I point to you, immediately begin singing, ‘Happy Birthday.’ I will then hand you a pile of cards to arrange in the order stated. Please sing continuously while you are arranging the pictures, and place both your hands in your lap when you are finished.” Following 4 s of continuous singing, the experimenter put the picture sets in front of the participant as in sequencing tests. If the participants did not sing or paused for longer than 1 s, the experimenter removed the stimuli, reinstated the instruction and repeated the trial with a different sequence. Participants passed if they scored 80 % or higher (i.e., sequenced 4 out of 5 trials) in a single 5-trial block. Experimenters presented vocal blocking tests once and progressed to the next phase regardless of their performance.
Post-experimental Interview
The experimenter asked the participants the following questions: (1) Did you use any kind of strategies to learn the individual images? Please describe the method you used. (2) Did you use any kind of strategies to sequence the images? Please describe the method you used. (3) Did you talk to yourself about any of the images? This could include stating the relationships of the images to one another, stating a rule related to how you responded to the images, or repeating the sequences spoken to you. (4) Please describe any methods or specific strategies you used.
Results and Discussion
Figure 2 depicts data on percentage of accurate arrangements during sequencing and vocal blocking tests across participants. All participants performed between 0 and 20 % accuracy during the initial sequencing tests. Three of the four participants (P1, P2, and P4) met mastery criterion for echoic responding in one trial block, while the fourth (P3) required one additional trial block. Accurate tacts were acquired in two blocks for P1 and P3, four blocks for P4, and six blocks for P2. Following component training, 3 of the 4 participants (P1, P3, and P4) accurately sequenced the pictures in at least 4 out of 5 sequences, while P2 arranged the stimuli accurately in only 3 out of 5 sequences (60 %) in two consecutive attempts. Participant 2 required two blocks of joint-control training, after which he accurately arranged sequences in 4 out of 5 sequencing test trials 80 %. All participants scored 20 % (i.e., accurately arranged one sequence out of five opportunities) at least once during the two vocal blocking tests. During reversals (no blocking), all participants scored at least 80 % by arranging sequences correctly in 4 out of 5 trials.
Fig. 2.
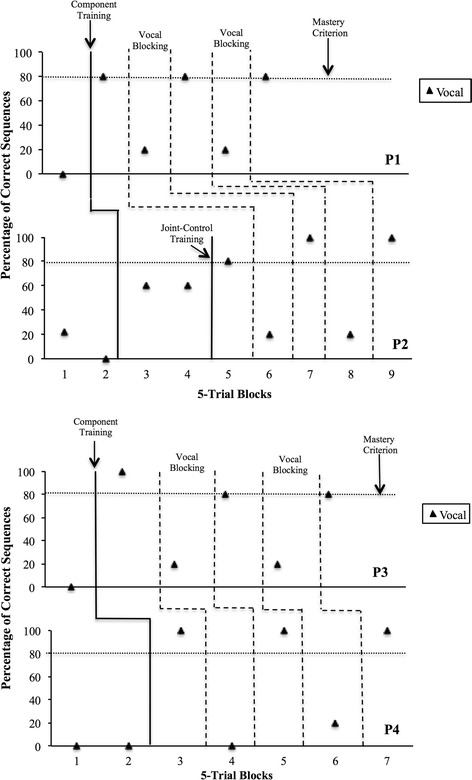
Percentage of correct sequences (closed triangles) for participants 1, 2, 3, and 4 across each sequencing and blocking conditions during Experiment 1
In the post-experimental interview, all participants (P1–P4) reported repeating the names of the sequences dictated by the experimenter and having difficulty using this strategy while singing Happy Birthday. For example, P3 said, “I had a hard time repeating the sequence when I was singing,” while P4 said, “I forgot the order when I was singing.”
Results from Experiment 1 showed that P1, P3, and P4 consistently made accurate arrangements of four unfamiliar pictures after component (echoic and tact) training. Because these participants met criterion for the sequencing post-test (80 %), joint control training was not necessary. P2 only arranged stimuli with 60 % accuracy after echoic and tact training for two consecutive 5-trial blocks. After joint-control training (i.e., rehearsing individual names and then vocally tacting pictures), he accurately sequenced 4 out of 5 trials (80 %). This suggests that for P2, training all components of joint control was necessary to accurately sequence the pictures. However, it is possible that additional tact training, or repeated exposure to sequencing tasks, could have produced similar results. After training, all participants passed all sequencing tests in the two reversal phases without vocal blocking, but could not sequence during the two vocal blocking test phases. Deteriorated performance during vocal blocking tasks as well as participants’ reports of covert rehearsal are consistent with the notion that some form of verbal behavior was necessary for engaging in these novel sequences (Lowenkron, 2004).
One limitation of Experiment 1 was that we only assessed sequencing in response to vocal instructions. Although previous studies have investigated the role of joint control using hand signs (Lowenkron, 1988; Tu, 2006), none of them have tested sequencing stimuli using signed instructions after participants learned to imitate and tact pictures using hand signs. Also, previous research (Causin, Albert, Carbone, & Sweeney-Kerwin, 2013; Lowenkron, 1988; Tu) did not attempt to block the emission of hand signs as a form of mediation. In addition, it has not been determined whether these blocking procedures prevented mediating behavior or just interfered with task performance (Palmer, 2006).
Hence, the purpose of Experiment 2 was to determine if topography-specific (i.e., vocal and hand-sign) blocking procedures would differentially influence sequencing of stimuli trained using vocal and hand signs. In other words, we evaluated whether (1) hand tapping would only prevent hand-sign rehearsal, and thus, disrupt sequencing taught with hand signs and (2) singing would only prevent vocal rehearsal, and thus, disrupt sequencing taught via vocal behavior. To test for these effects, two sets of stimuli were assigned to different training conditions for each participant. One set was taught and tested using the previously used vocal procedures, while another set was taught and tested using hand signs. Lastly, vocal and hand-sign blocking procedures were conducted for both sets. If these were in fact topography-specific blocking procedures, then vocal blocking would disrupt sequencing taught using vocal behavior, while hand-sign blocking would disrupt sequencing taught using hand signs.
Experiment 2
Method
Participants and Setting
Participants were four female college students (P5–P8), between the ages of 21 and 33 years, recruited based on their unfamiliarity with any form of sign language. Sessions were conducted in the same room as Experiment 1. Each student participated in one session lasting between one and two hours.
Materials
Materials were identical to those used in Experiment 1. Each set was randomly assigned to either vocal or hand-sign procedures. The order of procedures was randomly assigned and counterbalanced across the two pairs of participants, with each training condition alternating after the completion of its counterpart. These alterations occurred in a fixed order to ensure that no training type would have additional trials or more recent training (i.e., immediate history effects) when sequencing tests occurred (Coon & Miguel, 2012). The order of the conditions is listed in Table 2.
Table 2.
Order and set assignment for experimental conditions in Experiment 2
| Participant 5 and 6 Set A—vocal and set B—hand sign |
Participants 7 and 8 Set A—hand sign and set B—vocal |
|---|---|
| 1. Sequencing test—vocal | 1. Sequencing test—hand sign |
| 2. Sequencing test—hand sign | 2. Sequencing test—vocal |
| 3. Echoic training | 3. Mimetic training |
| 4. Mimetic training | 4. Echoic training |
| 5. Vocal tact training | 5. Hand sign tact training |
| 6. Hand sign tact training | 6. Vocal tact training |
| 7. Sequencing test—vocal | 7. Sequencing test—hand sign |
| 8. Sequencing test—hand sign | 8. Sequencing test—vocal |
| 9. Vocal component joint control training (if needed) | 9. Hand sign component joint control training (if needed) |
| 10. Hand sign component joint control training (if needed) | 10. Vocal component joint control training (if needed) |
| 11. Sequencing test—vocal (if needed) | 11. Sequencing test—hand sign (if needed) |
| 12. Sequencing test—hand sign (if needed) | 12. Sequencing test—vocal (if needed) |
| 13. Vocal blocking test—vocal | 13. Hand sign blocking test—hand sign |
| 14. Vocal blocking test—hand sign | 14. Hand sign blocking test—vocal |
| 15. Sequencing test—vocal | 15. Sequencing test—hand sign |
| 16. Sequencing test—hand sign | 16. Sequencing test—vocal |
| 17. Hand sign blocking test—vocal | 17. Vocal blocking test—hand sign |
| 18. Hand sign blocking—hand sign | 18. Vocal blocking test—vocal |
| 19. Sequencing test—vocal | 19. Sequencing test—hand sign |
| 20. Sequencing test—hand sign | 20. Sequencing test—vocal |
Dependent Measures and Experimental Design
A nonconcurrent multiple baseline design across participants was used as in Experiment 1. We also used an adapted alternating treatments design to teach the specific topographies (i.e., vocal or hand sign) assigned to each set during training (Sindelar, Rosenberg, & Wilson, 1985). Lastly, we implemented a reversal (ABACA or ACABA) after training in which A was sequencing with no blocking, B was sequencing with vocal blocking, and C was sequencing with hand-sign blocking, to demonstrate the influence of topography-specific blocking procedures (see below).
Interobserver agreement and treatment integrity TI data were also collected as described in Experiment 1. Mean IOA was 100 % for P5, P6, and P7, and 97.8 % (range, 80–100 %) for P8. Mean TI was 99.4 % (range, 87.5–100 %) for P5, 98.6 % (range, 80–100 %) for P6, 99.2 % (range, 87.5–100 %) for P7, and 99.3 % (range, 80–100 %) for P8.
Procedures
We exposed participants to the conditions as summarized in Table 2. All training and testing conditions for sets taught with vocal procedures were identical to those used in Experiment 1. Training and testing conditions for sets taught using hand signs are described below. Training blocks for each set were alternated until participants met mastery criteria for echoic or mimetic and vocal or signed tacting (see below). Next, we presented sequencing test blocks for each set. We then presented 1 of 2 types of topography blocking procedures, vocal blocking or hand-sign blocking, followed by a return to sequencing tests. Lastly, we required the participants to engage in a second blocking test (i.e., vocal if the hand-sign condition was conducted previously, or hand signs if the vocal condition was not conducted), and then an additional sequencing test. The order of blocking test types was counterbalanced across pairs of participants. The experimenter conducted a post-experimental interview as described in Experiment 1.
Hand Sign Sequencing Tests
The experimenter first told the participant, “Please attempt to put the pictures described in left to right order, and put your hands on your lap when you are finished.” The experimenter then signed a prearranged sample sequence from the assigned set (i.e., A or B), waited 4 s, and then placed the corresponding picture set upside down in a randomly arranged pile in front of the participant. The participants then flipped the picture set over, arranged them in left to right order, and put their hands in their laps when finished. Correct or incorrect sequencing was followed by nonspecific feedback to indicate the completion of the trial. Like Experiment 1, after component training, participants were given two attempts to sequence cards with 80 % accuracy in a 5-trial block. If they did not pass, participants moved onto hand sign joint control training (see below).
As in Experiment 1, the passing criterion for the remaining hand-sign sequencing tests was 80 % for one 5-trial block. Participants moved to the next phase regardless of their performance.
Hand Sign Component Training
We taught participants to engage in mimetic and hand-sign tact responses that corresponded to the assigned sets. During mimetic training, participants were instructed to imitate the hand signs in the absence of any pictures. Correct responses were followed with praise. Incorrect responses were followed with a “No,” and the instruction. The criterion for completion of mimetic training was one training block of 8 out of 8 trials without errors.
During hand sign tact training, the experimenter first told the participant, “You will now learn to sign the names of the pictures.” The experimenter then held up one of the four pictures from the assigned set at a time for the participant to hand-sign tact. Initially, the experimenter modeled correct responses upon the presentation of the stimulus (i.e., 0 s delay). After participants correctly responded (i.e., imitated) in 8 out 8 trials without errors, the experimenter showed the picture and waited 5 s. If an incorrect response occurred or the participant did not respond, the experimenter said “No,” and repeated the trial with an immediate model prompt for the participant to imitate the sign. Correct responses were praised (e.g., “correct,” “that’s right”). The criterion for completion of hand-sign tact training was one block of 8 out of 8 trials without errors.
Hand Sign Joint Control Training
This training condition was identical to the vocal joint control training described in Experiment 1; however, hand signs were trained rather than vocal responses. During this condition, the experimenter told the participant, “Please repeat back what I sign three times, then touch the picture on the table and sign its name.” The experimenter then placed the stimulus on the table facing up, modeled the corresponding hand sign once, after which the participant imitated the sign three times. After the participant signed three times, the experimenter pointed to the picture, and modeled the sign at a 0-s delay. A correct response was scored when each step in this sequence (i.e., signing three times, pointing to the stimulus, and tacting with the hand-sign) was performed correctly, and was followed by praise. After one 8-trial block in with no errors, we increased the 0-s delay to 5 s for the point and tact portion of the response. For example, during the 5-s delay, the experimenter still presented the sample and tacted the picture with a hand sign once (i.e., presented a model prompt), but did not prompt the participant to rehearse the sign (i.e., sign three times), point at, or tact it. Any errors resulted in the experimenter providing the immediate prompts as described above. The criterion for termination of this training was one block of 8 out of 8 trials with independent and accurate rehearsal, touching, and hand-sign tact responses.
Hand Sign Blocking Tests
This condition was identical to vocal blocking tests; however instead of singing, we asked participants to constantly tap one hand on the table while arranging the pictures. The experimenter first told the participant, “When I point to you, immediately begin tapping one hand on the table. I will then hand you a pile of cards to arrange in the order stated. Please tap continuously while you are arranging the pictures, and place both your hands in your lap when you are finished.” The experimenter presented the instruction by emitting four signs or stating four names, depending on the set being tested, and then immediately pointed to the participant as a prompt for them to begin tapping. Following 4 s of continuous tapping, the experimenter put the pictures in front of the participant as done in previous sequencing tests. If the participants did not tap or paused for longer than one second before the arrangement was complete, the experimenter removed the stimuli and repeated the trial with a different sequence. Hand-sign blocking tests were presented once, and participants moved through to the next phase whether or not they met passing criterion (80 % in a 5-trial block).
Post-experimental Interview
The experimenter asked the participants the same questions as in Experiment 1, but questions referred to both hand signs and vocal responses.
Results and Discussion
Figure 3 depicts data on percentage of accurate arrangements during vocal and hand-sign sequencing and blocking tests across participants. P5, P6, P7, and P8 performed scored 0 % accuracy during the initial sequencing tests for both sets. All participants (P5–P8) met mastery criterion (i.e., 100 % in one 8-trial block) for echoic and mimetic responding on the first trial block and vocal tacts in three blocks. Hand-sign tacts were learned in three blocks for three participants (P5, P7, and P8), and two blocks for P6.
Fig. 3.
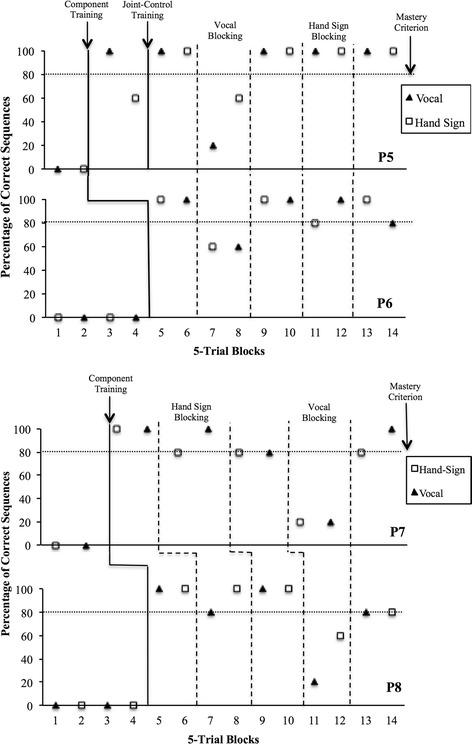
Percentage of correct sequences for sets using vocal (closed triangles) and signing procedures (open squares) for participants 5, 6, 7, and 8 across each sequencing test and blocking (hand-sign blocking and vocal blocking) conditions during Experiment 2
All participants (P5-P8) accurately arranged the set taught using vocal procedures in 5 out of 5 trials during the subsequent sequencing test and three of the participants (P6, P7, and P8) met passing criterion for hand-sign sequencing test in one trial block (see Fig. 3). P5 arranged the set using hand-sign procedures in 3 out of 5 trials (60 %), and thus moved on to hand-sign joint control training. P5 met mastery criterion for hand-sign joint control training in two blocks, and then passed the hand-sign sequencing test with 100 % accuracy. All participants (P5-P8) then passed all remaining sequencing tests for both sets of stimuli. In other words, all participants (P5-P8) passed all sequencing tests when blocking procedures were not in effect.
Interestingly, vocal blocking (i.e., singing “Happy Birthday” while sequencing) disrupted performances across both sets for all participants. For the set taught vocally, P5, P7, and P8 all scored 20 % during vocal-blocking tests, and P6 scored 60 %. For the set taught with hand signs, P5, P6, and P8 scored 60 % during vocal-blocking tests, while P7 scored 20 %. Across all participants (P5-P8), hand-sign blocking procedures did not disrupt any performances for either set. P5 passed hand-sign blocking tests with 100 % accuracy for both the vocal and hand-sign sets. P6 and P7 scored 80 % for the set taught with hand signs, and 100 % for the set taught vocally, while P8 scored 80 % for the set taught vocally, and 100% for the set taught with hand signs.
In summary, 4 out of 5 participants could sequence accurately after component training regardless of the topography (vocal or signed) of the instruction. Only one participant required joint control training to correctly sequence the set taught with signs. Vocal blocking produced consistently poor performance as seen in Gutierrez (2006) and DeGraaf and Schlinger (2012), while hand-sign blocking did not result in deteriorated sequencing performance for any of the participants. These results are also consistent with those in Experiment 1, as vocal blocking procedures disrupted all sequencing performances for P1-P4.
In the post-experimental interview, all participants reported repeating the names of the sequences presented, and to have difficulty sequencing during vocal-blocking tests. For example, P5 called B1 “pinky,” B2 “ball,” B3 “peace,” and B4 “vagina.” Upon seeing the signs for these stimuli in this order during sequencing testing, this participant would say to herself “two, fist, L, c,” while arranging the stimuli. Each participant also reported having difficulty rehearsing sequences spoken during blocking procedures and assigning vocal names to signs. For example, P5 said that during vocal-blocking tests, she could only remember the first name of the picture in each sequence trial. Participants’ performance corresponded to verbal reports because they reported using names while rehearsing during all sequencing tasks, rather than using hand signs to mediate correct sequencing. This would explain why vocal blocking also disrupted performance for the set taught with hand signs. This suggests that participants used subvocal rather than hand-sign rehearsal strategies during all sequencing tests regardless of the trained topography.
Although these findings suggest the role of verbal behavior, they did not provide unequivocal evidence that arranging sequences following verbal instructions requires verbal mediation. Since vocal-blocking interfered with sequencing tasks presented using vocal, as well as hand signs, it is possible that singing Happy Birthday was simply a distractor rather than an effective verbal-blocking procedure. However, it is important to note that all participants were verbally sophisticated adults, reported naming all stimuli, including the ones taught using hand signs, and using these names to sequence them. Therefore, it is still quite possible that vocal blocking interfered with covert verbal mediation. In order to test whether vocal blocking actually prevented verbal behavior or served merely as a distractor, we designed a control condition consisting of a sequencing test that could be completed without the use of any verbal behavior (i.e., visual matching). Thus, in Experiment 3, one set of stimuli was assigned to visual matching procedures, while the other set was assigned to vocal procedures as in Experiments 1 and 2. If vocal blocking served solely as a distractor interfering with task performance, then performance should deteriorate for both sets.
Experiment 3
Method
Participants and Setting
Participants were four college students (two females and two males, ages 21–29 years). Sessions occurred in the same location as in Experiments 1 and 2, and each student participated in one session lasting between 1 and 1.5 h.
Materials
Materials were identical to those used in Experiments 1 and 2. Each stimulus set was randomly assigned to either vocal or matching conditions. The order of conditions was randomly assigned and counterbalanced across two pairs of participants. The order is listed in Table 3.
Table 3.
Order and set assignment for experimental conditions in Experiment 3
| Participant 9 and 10 Set A—visual matching and set B—vocal |
Participants 11 and 12 Set A—vocal and set B—visual matching |
|---|---|
| 1. Sequencing test—vocal | 1. Sequencing test—matching |
| 2. Sequencing test—matching | 2. Sequencing test—vocal |
| 3. Echoic training | 3. Echoic training |
| 4. Vocal tact training | 4. Vocal tact training |
| 5. Sequencing test—vocal | 5. Sequencing test—matching |
| 6. Sequencing test—matching | 6. Sequencing test—vocal |
| 7. Vocal component joint control training (if needed) | 7. Vocal component joint control training (if needed) |
| 8. Sequencing test—vocal (if needed) | 8. Sequencing test—matching (if needed) |
| 9. Sequencing test—matching (if needed) | 9. Sequencing test—vocal (if needed) |
| 10. Vocal blocking test—vocal | 10. Vocal blocking test – matching |
| 11. Vocal blocking test—matching | 11. Vocal blocking test – vocal |
| 12. Sequencing test—vocal | 12. Sequencing test—matching |
| 13. Sequencing test—matching | 13. Sequencing test—vocal |
| 14. Vocal blocking test—vocal | 14. Vocal blocking test—matching |
| 15. Vocal blocking test—matching | 15. Vocal blocking test—vocal |
| 16. Sequencing test—vocal | 16. Sequencing test—matching |
| 17. Sequencing test—matching | 17. Sequencing test—vocal |
Dependent Measures and Experimental Design
We used a nonconcurrent multiple baseline design across participants, an adapted alternating-treatments design, and a reversal (ABABA) design as in Experiment 2. Interobserver agreement and TI data were also collected as described in Experiment 1. Mean IOA was 100 % for P9, P10, P11, and P12. Mean TI was 100 % for P9, P11, and P12, and 96.5 % (range, 87.5–100 %) for P10.
Procedures
All training and testing conditions for sets taught with vocal procedures were identical to those used in Experiments 1 and 2. Testing conditions for sets assigned to visual matching procedures are described below. Sequencing tests were evaluated for each set following component training. Each set was then exposed to vocal blocking procedures followed by a return to sequencing tests (i.e., first reversal phase), an additional vocal blocking phase, and one final sequencing test. The experimenter conducted a post-experimental interview as described in Experiment 1.
Visual Matching Sequencing Tests
All procedures used for matching sequencing tests were identical to those used for vocal sequencing tests except that the sequences were visually displayed in front of the participant during each trial. We first told the participant, “Please attempt to put the pictures in the order you see, from left to right and put your hands on your lap when you are finished.” The experimenter then put each picture in a random sequence, from left to right, using prearranged sample sequences from Experiments 1 and 2. An identical corresponding picture set was then placed upside down in a randomly arranged pile so the participant could sequence it.
Vocal Blocking Tests
We conducted vocal blocking tests across both vocal- and visual-matching sequence tests. We did not include hand-sign blocking tests because they did not show decrements in performance in Experiment 2. Conditions for these blocking tests are exactly as described in Experiment 1, however for blocking tests in the visual matching conditions, the sample sequences were placed face-up in front of the participant. Participants were read the following instructions: “When I point to you, immediately begin singing, Happy Birthday. I will then hand you a pile of cards to arrange in the order you see. Please sing continuously while you are arranging the pictures, and place both your hands in your lap when you are finished.” Participants passed if they scored 80 % or higher (i.e., sequenced 4 out of 5 trials) in a single 5-trial block. Experimenters presented vocal blocking tests once, and progressed to the next phase regardless of participants' performance.
Results and Discussion
Figure 4 depicts data on percentage of accurate arrangements during sequencing and vocal blocking tests for P9, P10, P11, and P12. All participants performed between 0 and 20 % during the initial sequencing tests for the set assigned to vocal procedures, but as expected did not make any errors for the sets whose sample sequences were displayed (i.e., visual matching sequences). For the set taught vocally, 3 out of 4 participants (P9, P10, and P11) met the mastery criterion for echoic responding in one trial block, while P12 required two blocks. Accurate vocal tacts were acquired in two blocks for P10 and P12, and three blocks for P9 and P10. Following component training for the set taught vocally, all participants sequenced with at least 80 % accuracy, and joint control training was not necessary.
Fig. 4.
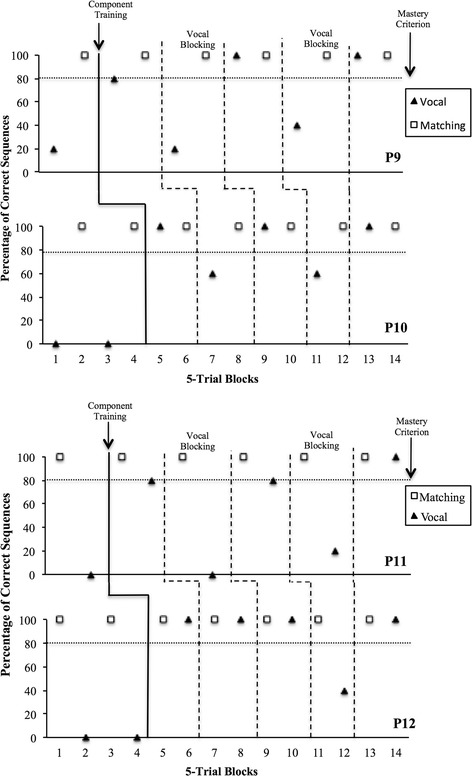
Percentage of correct sequences for sets using vocal procedures (closed triangles) and visual matching (open squares) for participants 9, 10, 11, and 12 across each sequencing and vocal blocking conditions during Experiment 3
All participants continued performing with 100 % accuracy during both visual-matching sequence and blocking tests. During the first vocal blocking test, 3 out of 4 participants did not meet the 80 % passing criterion for the set instructed using vocal procedures. In the subsequent test, all participants scored at or above the passing criterion. A return to vocal blocking procedures resulted in only one accurate sequences for P11, two for P9 and P12, and three for P10 for the set taught with vocal procedures. No errors were made by any of the participants for either set in the final sequencing test.
As in Experiment 1 and 2, all participants reported repeating the names spoken by the experimenters to themselves during sequencing. In addition, participants reported having difficulty in using this strategy during vocal blocking tests. Participants did not report having any difficulty sequencing stimuli during the visual matching task, nor did they report naming the stimuli.
The results from Experiment 3 showed that joint-control training was not necessary for any of the participants to accurately arrange sequences spoken by the experimenter during sequencing tests. This finding replicated results of Experiment 1 and 2 suggesting that self-echoic and tact rehearsal was either unnecessary or that the participants engaged in covert rehearsal without having to be trained to do so. According to the participants’ self-reports, sequences spoken were rehearsed covertly.
In order to determine whether vocal blocking was actually interfering with verbal mediation or simply disrupting all relevant performance, Experiment 3 included a control condition, namely a sequencing task that could be solved without the need of mediating verbal behavior. Data indicated that vocal-blocking procedures did not disrupt sequencing that relied on visual matching (i.e., non-mediated), but did disrupt sequencing that relied on vocal responses. This suggests that the blocking procedure may indeed interfere with covert verbal behavior used to solve the task.
General Discussion
The current study evaluated the effects of topography-specific and topography-nonspecific blocking procedures on sequencing random arrangements of arbitrary stimuli, and assessed the necessity for joint-control training with typically developing adults. Previous studies have found that novel sequencing performances improved after training participants to rehearse dictated sequences while arranging stimuli (DeGraaf & Schlinger, 2012), and joint tact-echoic stimulus control was important for accurate sequencing (Gutierrez, 2006). Our results indicate that only two participants (P2 and P5) across Experiment 1, 2, and 3 required joint-control training to make accurate arrangements of sequences after echoic and vocal tact training. These results are consistent with findings from Ratkos et al. (2016), in that participants were only trained to tact the stimuli individually, but could respond accurately to tests without the need of joint-control training. This seems to indicate that either rehearsal was not needed for most of the participants to accurately arrange the random sequences of stimuli, or that joint control as a form of mediation, occurred in the absence of training. According to post-experimental interviews, participants reported to have covertly rehearsed the sequences spoken by the experimenter or covertly tacted hand signs with vocal names when arranging stimuli in sequences. These verbal reports suggest that covert rehearsal was crucial to maintain accurate sequencing. In addition, it suggests that participants with a vocal-verbal repertoire are likely to use vocal-verbal strategies, rather than hand signs.
In Experiments 1, 2, and 3, all participants failed to reach criterion during sequencing tests when required to sing (i.e., vocal-blocking procedures) for sets taught using vocal procedures. However, vocal-blocking procedures also appeared to interfere with sequencing performance for those sets learned via hand signs (Experiment 2). As suggested above, participants assigned vocal names to all stimuli, including the ones taught using hand signs, and reported having rehearsed these names covertly. This suggests that vocal verbal mediation occurred during sequencing across sets assigned to vocal and hand-sign procedures and that vocal blocking interfered with verbal mediation necessary to sequence both of them. Future research should evaluate the effects of hand-sign blocking on sequencing established by hand signs with participants whose verbal repertoires consist of signing only.
Even though vocal blocking deteriorated sequencing performance, it rarely eliminated it for any of the participants. For example, P12 sequenced with 100 % accuracy during the first vocal blocking test. P4 was the only participant to score 0 % in any vocal blocking test. It is possible either that the vocal blocking procedure did not completely suppress verbal mediation, or that participants relied on nonverbal visualization strategies as speculated by Ratkos et al. (2016). Participants who found the names of the stimuli “difficult to remember,” still sequenced them accurately for at least one vocal-blocking trial, suggesting that vocal blocking does not always suppress performance. Future research should lengthen the exposure to blocking procedures to evaluate whether performance would improve over time.
In Experiment 3, one stimulus set was assigned to a visual-matching sequencing condition that clearly did not require mediation by verbal behavior, and another set was assigned to the same vocal procedures used in Experiments 1 and 2. During visual-matching sequencing tests, participants arranged pictures according to the sequences displayed on the table. As expected, accuracy for the matched-sequencing set remained perfect across all conditions, while sequencing performances for sets assigned to vocal procedures deteriorated during vocal blocking tests. These results further suggest that vocal blocking may have served to prevent covert verbal behavior because only the set assigned to vocal procedures was affected by vocal blocking. However, it may be possible that a more complex task that might not require verbal mediation (e.g., visual matching with a delay between sample and comparison stimuli) would have been also affected by vocal blocking as a general distractor.
There were some methodological limitations that merit consideration. First, due to an error, P5 was only given one attempt to pass the sequencing test after component training, rather than two per the protocol. It is possible that if given another opportunity, she would have sequenced at criterion (80 %) without joint control training. Also, due to potential confounds of maturation and exposure to sequencing and blocking tests, a limited number of testing trials were presented, resulting in minimal differences between pass (80 % or 4 out of 5 sequences) and fail criteria (60 %, 3 out of 5 sequences, or less). In addition, the experiment also included a low number of stimuli (four) for participants to arrange. Although the stimuli were unfamiliar to the participants, the disparity between performance during sequencing and blocking tasks may have been clearer with additional trials utilizing more complex sequences. Thus, future studies should require participants to engage in more complex sequencing tasks across additional trials, during which participants arrange a larger number of stimuli. This could reduce the likelihood that participants would guess sequences accurately or be able to arrange them while engaging in other verbal behavior.
Second, although this study investigated the role of verbal behavior as a form of mediation, it is not clear which verbal components (i.e., echoic, tact, and listener behavior) were actually required, and how these components may facilitate sequencing. However, despite the uncertainty about specific behavioral mechanisms at play, this study adds to the growing literature on verbal mediation (e.g., Ma et al., 2016; Santos et al., 2015) by suggesting that participants’ nonverbal performance (sequencing) was facilitated by their verbal behavior.
Conflict of Interest
The authors declare that they have no conflict of interest.
Ethical Approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the Human Subjects Institutional Review Board at California State University, Sacramento and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
Informed Consent
Informed consent was obtained for all individual participants included in the study. Participants could leave the study at any time, and assent was obtained at each session with participants who could leave at any time.
Footnotes
This study is based on a thesis submitted by the first author under the supervision of the third author to the Department of Psychology at California State University, Sacramento in partial fulfillment of the requirements for an M.A. degree in Psychology: Applied Behavior Analysis. We would like to thank Stephanie Cran and Timothy Fechter for their assistance with data collection, as well as Joyce Tu for her comments on a previous version of this manuscript.
References
- Causin KG, Albert KM, Carbone VJ, Sweeney-Kerwin EJ. The role of joint control in teaching listener responding to children with autism and other developmental disabilities. Research in Autism Spectrum Disorders. 2013;7:997–1011. doi: 10.1016/j.rasd.2013.04.011. [DOI] [Google Scholar]
- Coon, J. T., & Miguel, C. F. (2012). The role of increased exposure to transfer-of-stimulus-control procedures on the acquisition of intraverbal behavior. Journal of Applied Behavior Analysis, 45(4), 657–666. do: 10.1901/jaba.2012.45-657. [DOI] [PMC free article] [PubMed]
- Cumming WW, Berryman R. Some data on matching behavior in the pigeon. Journal of the Experimental Analysis of Behavior. 1961;4:281–284. doi: 10.1901/jeab.1961.4-281. [DOI] [PMC free article] [PubMed] [Google Scholar]
- DeGraaf A, Schlinger H. The effect of joint control training on the acquisition and durability of a sequencing task. The Analysis of Verbal Behavior. 2012;28:59–71. doi: 10.1007/BF03393107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gutierrez RD. The role of rehearsal in joint control. The Analysis of Verbal Behavior. 2006;22:183–190. doi: 10.1007/BF03393038. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Horne PJ, Hughes JC, Lowe CF. Naming and categorization in young children: IV: listener behavior training and transfer of function. Journal of the Experimental Analysis of Behavior. 2006;85:247–273. doi: 10.1901/jeab.2006.125-04. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Horne, P. J., & Lowe, C. F. (1996). On the origins of naming and other symbolic behavior. Journal of the Experimental Analysis of Behavior, 65, 185–241. doi:10.1901/jeab.2004.81-267. [DOI] [PMC free article] [PubMed]
- Horne PJ, Lowe CF, Harris FDA. Naming and categorization in young children: V. Manual sign training. Journal of the Experimental Analysis of Behavior. 2007;87:367–381. doi: 10.1901/jeab.2007.52-06. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Horne PJ, Lowe CF, Randle VRL. Naming and categorization in young children: II. Listener behavior training. Journal of the Experimental Analysis of Behavior. 2004;81:267–288. doi: 10.1901/jeab.2004.81-267. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kobari-Wright VV, Miguel CF. The effects of listener training on the emergence of categorization and speaker behavior in children with autism. Journal of Applied Behavior Analysis. 2014;47:431–436. doi: 10.1002/jaba.115. [DOI] [PubMed] [Google Scholar]
- Lowe CF, Horne PJ, Harris FDA, Randle VRL. Naming and categorization in young children: vocal tact training. Journal of the Experimental Analysis of Behavior. 2002;78:527–549. doi: 10.1901/jeab.2002.78-527. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lowenkron B. Coding responses and the generalization of matching to sample in children. Journal of the Experimental Analysis of Behavior. 1984;42:1–18. doi: 10.1901/jeab.1984.42-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lowenkron B. Generalization of delayed identity matching in retarded children. Journal of the Experimental Analysis of Behavior. 1988;50:163–172. doi: 10.1901/jeab.1988.50-163. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lowenkron B. Instructional control of generalized relational matching to sample in children. Journal of the Experimental Analysis of Behavior. 1989;52:293–309. doi: 10.1901/jeab.1989.52-293. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lowenkron B. Joint control and the generalization of selection-based verbal behavior. The Analysis of Verbal Behavior. 1991;9:121–126. doi: 10.1007/BF03392866. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lowenkron B. Some logical functions of joint control. Journal of the Experimental Analysis of Behavior. 1998;69:327–354. doi: 10.1901/jeab.1998.69-327. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lowenkron B. Meaning: a verbal behavior account. The Analysis of Verbal Behavior. 2004;20:77–97. doi: 10.1007/BF03392996. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lowenkron B. An introduction to joint control. The Analysis of Verbal Behavior. 2006;22:123–127. doi: 10.1007/BF03393034. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lowenkron B. Joint control and the selection of stimuli from their description. The Analysis of Verbal Behavior. 2006;22:129–151. doi: 10.1007/BF03393035. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lowenkron B, Colvin V. Joint control and generalized nonidentity matching: saying when something is not. The Analysis of Verbal Behavior. 1992;10:1–10. doi: 10.1007/BF03392870. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lowenkron B, Colvin V. ‘Generalized instructional control and the production of broadly applicable relational responding’: erratum. The Analysis of Verbal Behavior. 1995;12:13–29. doi: 10.1007/BF03392894. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ma ML, Miguel CF, Jennings AM. Training intraverbal naming to establish equivalence class performances. Journal of the Experimental Analysis of Behavior. 2016;105:409–426. doi: 10.1002/jeab.203. [DOI] [PubMed] [Google Scholar]
- Mahoney AM, Miguel CF, Ahearn WH, Bell J. The role of common motor responses in stimulus categorization by preschool children. Journal of the Experimental Analysis of Behavior. 2011;95:237–262. doi: 10.1901/jeab.2011.95-237. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Miguel, C. F. (2016). Common and intraverbal bidirectional naming. The Analysis of Verbal Behavior. doi:10.1007/s40616-016-0066-2. [DOI] [PMC free article] [PubMed]
- Miguel CF, Kobari-Wright VV. The effects of tact training on the emergence of categorization and listener behavior in children with autism. Journal of Applied Behavior Analysis. 2013;46:669–673. doi: 10.1002/jaba.62. [DOI] [PubMed] [Google Scholar]
- Miguel CF, Petursdottir AI, Carr JE, Michael J. The role of naming in stimulus categorization by preschool children. Journal of the Experimental Analysis of Behavior. 2008;89:383–405. doi: 10.1901/jeab.2008-89-383. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Palmer DC. Joint control: a discussion of recent research. The Analysis of Verbal Behavior. 2006;22:209–215. doi: 10.1007/BF03393040. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Petursdottir AI, Ólafsdóttir AR, Aradóttir B. The effects of tact and listener training on the emergence of bidirectional intraverbal relations. Journal of Applied Behavior Analysis. 2008;41:411–415. doi: 10.1901/jaba.2008.41-411. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ratkos T, Frider JE, Poling A. Accurate delayed matching-to-sample responding without rehearsal: an unintentional demonstration with children. The Analysis of Verbal Behavior. 2016;32:66–77. doi: 10.1007/s40616-016-0052-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Santos PM, Ma ML, Miguel CF. Training intraverbal naming to establish matching-to-sample performances. The Analysis of Verbal Behavior. 2015;31:162–182. doi: 10.1007/s40616-015-0040-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sidener DW, Michael J. Generalization of relational matching to sample in children: a direct replication. The Analysis of Verbal Behavior. 2006;22:171–181. doi: 10.1007/BF03393037. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sindelar P, Rosenberg M, Wilson R. An adapted alternating treatments design for instructional research. Education and Treatment of Children. 1985;8:67–76. [Google Scholar]
- Skinner BF. Verbal behavior. Acton: Copley; 1957. [Google Scholar]
- Tu JC. The role of joint control in the manded selection responses of both vocal and non-vocal children with autism. The Analysis of Verbal Behavior. 2006;22:191–207. doi: 10.1007/BF03393039. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Watson PJ, Workman EA. The nonconcurrent multiple baseline across individuals design: an extension of the traditional multiple baseline design. Journal of Behavior Therapy and Experimental Psychiatry. 1981;12:257–259. doi: 10.1016/0005-7916(81)90055-0. [DOI] [PubMed] [Google Scholar]