

Abstract
The research literature has revealed mixed outcomes on various procedures for increasing vocalizations and echoic responding in persons with disabilities (Miguel, Carr, & Michael The Analysis of Verbal Behavior, 18, 3–13, 2002; Stock, Schulze, & Mirenda The Analysis of Verbal Behavior, 24, 123–133, 2008). We examined the efficacy of an assessment procedure for identifying the most effective echoic teaching procedure to six students diagnosed autism spectrum disorder (ASD) and other developmental delays. The assessment procedure included a within-participant comparison of vocal imitation training (VIT), stimulus–stimulus pairing (SSP), and a mand-model procedure (MM). A functional analysis of the responses was conducted to determine whether responding was functionally an echoic or a mand. The results indicated that the assessment was effective in identifying a teaching procedure for five out of the six participants and that responding was established under echoic control. These outcomes support the efficacy of this assessment procedure for identifying effective echoic teaching procedures.
Keywords: Echoic, Functional analysis, Mand-model, Stimulus–stimulus pairing, Vocal imitation
An echoic is defined as verbal behavior under the influence of a verbal stimulus with which it is formally similar and has point-to-point correspondence (Skinner, 1957). The echoic is fundamental to teaching other forms of verbal behavior and communication (Lovaas, 2003; Sundberg & Partington, 1998). For example, teachers, therapists, and other caregivers commonly use echoic prompts to teach mands (e.g., “What do you want? Juice”). Echoic responding has been demonstrated to facilitate the acquisition of more complex vocal verbal responses for individuals with limited communication skills. For example, Kodak and Clements (2009) demonstrated that echoic training, conducted concurrently with mand and tact training, facilitated the acquisition of both mands and tacts in a child who had failed to acquire these repertoires during mand-only and tact-only training. Echoic prompts have also been employed in a number of studies evaluating the acquisition of intraverbal responding and asking questions (Watkins, Pack-Teixeira, & Howard, 1989; Williams, Donley, & Keller, 2000, respectively). It has also been suggested that an echoic repertoire is integral for listener responding and joint control. Listening involves actively responding to the verbal stimuli emitted by the speaker (Schlinger, 2008). Accordingly, when a person is listening, he is covertly echoing the verbal stimuli. Joint control consists of “a discrete event, a change in stimulus control that occurs when a response topography evoked by one stimulus … and preserved by rehearsal, is emitted under the additional (and thus joint) control of a second stimulus” (Lowenkron, 1998, p. 332). For example, if a child has learned to tact colors and is then presented with an array of colored cards and instructed to point to the named color, she will scan the various cards and tact each of them, perhaps covertly, while also rehearsing (covertly or overtly echoing) the named color. She then points to the correct card because that card occasioned a tact that is topographically identical to the response she was rehearsing as a self-echoic response (Sidener, 2006). The research literature has revealed that establishing an echoic repertoire in persons lacking vocal verbal behavior can be a challenging task (e.g., Drash, High, & Tudor, 1999; Koegel, O’Dell, & Dunlap, 1988). Given the potential challenging nature of teaching the echoic, and the aforementioned points regarding the importance of the echoic repertoire, it is critical to identify effective procedures for teaching echoic responding.
A number of teaching procedures are used to increase vocalizations and/or establish echoic responding. With vocal imitation training (VIT), reinforcers are delivered contingent on imitation of a modeled sound or upon successive approximations of a target sound (i.e., shaping). Establishing verbal responses through the use of differential reinforcement of imitation, with or without shaping, has been demonstrated to be effective in several studies (Baer, Peterson, & Sherman, 1967; Brigham & Sherman, 1968; Carroll & Klatt, 2008; Lovaas, Berberich, Perloff, & Schaeffer, 1966). Another procedure is stimulus–stimulus pairing (SSP) which consists of pairing sounds with a conditioned or unconditioned reinforcer in an attempt to condition the target sound as a reinforcer. This procedure is usually employed to increase rates of vocalizations, which are then brought under echoic control through the use of differential reinforcement. Previous research has evaluated the effects of SSP on frequency of vocalizations, and these studies have found that the SSP procedure was occasionally effective for some participants (Carroll & Klatt, 2008; Miguel et al., 2002) but it did not result in an increase in vocalizations for all participants (Esch, Carr, & Michael, 2005). Few studies have investigated whether the SSP procedure may facilitate the acquisition of responding under echoic control (Carroll & Klatt, 2008; Esch et al., 2005) and although both of these studies combined the SSP procedure with direct reinforcement of imitation, only one participant acquired echoic responding (Carroll and Klat). It is however plausible that SSP without the use of direct reinforcement could facilitate the acquisition of echoic responding if the echoic response achieves parity with the model. Parity is achieved when vocalizations emitted by the speaker conform to those emitted by members of the verbal community resulting in automatic reinforcement (Palmer, 1996). Thus, echoic responding may be automatically reinforced. Finally, although limited studies exist, a mand-model (MM) procedure has also been employed for increasing communicative responses (see LeBlanc, Esch, Sidener, & Firth, 2006, for a review). Although variations exist, usually the MM procedure involves the identification of preferred items that are then available during the teaching sessions. Once a session begins, if the child attempts to access one of these items, the therapist provides a prompt (a mand) for the target response (e.g., “What do you want?”). Access to the item is contingent on emission of the target response. If the child does not emit the correct response, a model (echoic prompt) may be presented. Thus, the procedure may be helpful in establishing a number of responses. For instance, Nigam, Schlosser, and Lloyd (2006) employed matrix training and a MM procedure to teach children graphic symbol combinations and found that the procedure was effective for two out of the three participants.
No single echoic teaching procedure has been found to be effective for all learners. For instance, although there is research support for the VIT procedure (Carroll & Klatt, 2008; Lovaas et al., 1966), this procedure is limited to those learners who emit vocalizations, thus precluding those learners who do not emit vocalizations from benefitting from this procedure. The SSP procedure is used to establish vocal responding in a learner. Studies evaluating the effects of SSP on the frequency of target vocalizations and echoic responding have produced mixed results (Carroll & Klatt, 2008; Normand & Knoll, 2006). It is important to consider that there are many methodological variations across studies on the SSP procedure (see Shillingsburg, Hollander, Yosick, Bowen, & Muskat, 2015 for a review of SSP) making it difficult to draw conclusions about its efficacy. A few studies that have evaluated the MM procedure have also demonstrated it to be effective for some, but not all, participants (e.g., Nigam et al., 2006).
In consideration of the points described above regarding the mixed outcomes in the research literature of echoic teaching procedures, and of the importance of individualizing behavioral intervention programs, developing an assessment protocol to identify the most effective procedure to teach echoic responding is warranted. Therefore, the purpose of the current investigation was to assess an assessment protocol to identify the most effective of three echoic teaching procedures in individuals with limited communication skills. The three teaching procedures included (1) VIT, (2) SSP, and (3) MM. Although limited research has evaluated the effects of SSP on the acquisition of specific verbal operants (Esch et al., 2005; Yoon, 1998; Yoon & Feliciano, 2007), SSP was included in this evaluation because there is evidence suggesting it may facilitate the acquisition of verbal operants (Yoon, 1998), and it may be more effective than VIT for increasing vocalizations (Yoon & Bennett, 2000).
Method
Participants and Setting
Six individuals enrolled at a school for children with autism and related disorders participated in this study. Tiffany was a 17-year-old female diagnosed with global developmental delay. Carlos was a 10-year-old male diagnosed with autism. Wade was a 14-year-old male diagnosed with pervasive developmental disorder and Landau-Kleffner syndrome (LKS) variant. Zoe was an 11-year-old male diagnosed with autism and global developmental delay. Michael was a 17-year-old male diagnosed with pervasive developmental disorder and mitochondrial cell disorder. Victor was a 7-year-old male diagnosed with autism. The Vineland Adaptive Behavior Scales, Second Edition, Expanded Interview Form (Sparrow, Cicchetti, & Balla, 2005) was used to assess the pre-training verbal behavior repertoire of five of the participants. For the sixth participant, Tiffany, the Verbal Behavior Milestones Assessment and Placement Program (VB-MAPP; Sundberg, 2008) was used in pre-training and the Vineland II was administered after this study was completed (see Table 1). In addition, participants’ imitation, listener, and tacting skills were evaluated using the New England Center for Children Core Skills Assessment (NECC-CSA; Dickson et al., 2014) ®. Participants’ scores from this assessment are displayed in Table 2. The CSA is a direct assessment of approximately 52 prerequisite skills and critical skills deemed necessary for independent living. All participants were identified through interviews with clinical staff. Tiffany and Wade’s echoic repertoires were scored as “poor correspondence” which indicated that these participants could communicate in short sentences; however, their vocalizations were unintelligible to most unfamiliar listeners. In addition, when asked to imitate words, these individuals often omitted or emitted incorrect, but similar, phonemes. Therefore, imitation of phonemes and vowel sounds was a clinical priority for Tiffany and Wade because gains in these skills could potentially improve their intelligibility.
Table 1.
Participants’ assessment scores and verbal behavior skills prior to echoic training
| Modality | Vineland II | Age equivalent | VB-Mapp | Mands | Tacts | Intraverbal | Echoic | |
|---|---|---|---|---|---|---|---|---|
| Tiffany | Vocal | 30* | 1 year, 7 months | Yes | Yes | Yes | Yes | Poor correspondence |
| Carlos | AAC | 30 | 0 year, 2 months | N/A | Yes | No | No | Limited |
| Wade | Vocal | 38 | 2 years, 2 months | N/A | Yes | Limited | Limited | Poor correspondence |
| Zoe | AAC | 26 | 1 year, 7 months | N/A | Yes | No | No | Limited |
| Michael | AAC | 24 | 0 year, 11 months | N/A | Yes | No | No | No |
| Victor | AAC | 32 | 1 year, 0 months | N/A | Yes | No | No | Limited |
Note: Tiffany’s Vinland II was completed post-echoic training. Vineland II standard scores in verbal behavior domain are reported as well as age equivalents for the speaker subdomain
Table 2.
Assessment scores and performance for echoic teaching procedures
| Participants | VIT | MM | SSP | No. of echoic acquired | Listener | Gross motor imitation | Delayed imitation | Tacting objects |
|---|---|---|---|---|---|---|---|---|
| Tiffany | Y | Y (1/2) | N | 3/6 | 5 | 5 | 2 | 5 |
| Carlos | N | Y | N | 2/6 | 1 | 5 | 5 | N/A |
| Wade | Y | Y | Y | 9/9 | 5 | 5 | 5 | 5 |
| Zoe | Y (2/3) | Y (1/3) | Y (1/3) | 4/9 | 4.33 | 5 | 5 | 1 |
| Michael | N | N | Y (2/3) | 2/9 | 2.33 | 5 | 3 | 5 |
| Victor | N | N | N | 0/6 | 1.67 | 5 | 5 | N/A |
Note: Each participant’s score in the listener repertoire consists of a mean of the scores for three different skills, indicating named body parts, named pictures, and named object. A score of “5” denotes complete mastery and a score of “1” indicates little or no independence. Acquisition of target echoic denoted by “Y″ and numbers in parenthesis indicates the number of targets mastered per teaching procedure
Sessions were conducted in a classroom, a room in the participant’s residence, or in a research room. These rooms varied in size but were at least 1.5 m by 3 m and each one contained at least one table and two chairs. The classroom also included other items commonly found in education settings such as bookshelves, toys, a trash bin, wall decorations, educational materials, and often there was a window. The rooms at the residence included common household items such as couches, cabinets, toys, wall decorations, and educational materials. Sessions were conducted three-to-five times per week depending on the participants’ availability. As often as possible, sessions were completed in a location in which other students and teachers were not present, but occasionally, other students and teachers were in the vicinity. In these cases, these students and teachers were instructed to not interact with the participant.
Preference Assessments
Preference assessments were conducted using the procedures described by Fisher et al. (1992), DeLeon and Iwata (1996), or Graff and Ciccone (2002) to identify preferred items for the participants. Items selected for the preference assessments were identified based on the information gathered in the reinforcer assessment for individuals with severe disabilities (RAISD; Fisher, Piazza, Bowman, & Amari, 1996), which was completed by one of the participant’s caregivers or teachers. Items that were selected in 80 % or more of the trials were deemed highly preferred, and these edibles were used during the echoic probes, the functional analysis (FA), and the three echoic teaching procedures. For the VIT and SSP procedures, at the start of each session (FA or teaching), preferred items were presented to the participant either in a linear array format or inside of a clear partitioned bin, depending on what was most appropriate for that participant. The participants were allowed to choose one of these items to earn during the subsequent session. This procedure was employed to address any potential fluctuating preference for these items especially since access to these items was not restricted outside of sessions. For the MM condition, the same highly preferred edible was presented across all training and FA sessions, and the participants did not have access to the item for at least 1 h prior to the sessions.
Experimental Design
A within-subjects adapted alternating-treatments design was used to compare the effects of VIT, SSP, and MM conditions (Wolery, Bailey, & Sugai, 1988). Functional analysis probes for echoic responses were completed prior to and following teaching to assess the function of participants’ vocalizations. At least two comparisons were completed with each participant to replicate findings within participants.
Response Measurement and Data Analysis
During the echoic probe and teaching sessions, data were collected on a trial-by-trial basis. Trained research assistants collected these data using paper and pen. Target vocalizations were defined as any vocalization that occurred within 5 s of the sample vocalization and matched the sample vocalization in number of phonemes as well as auditory similarity, excluding vocal stereotypy. For instance, if the target vocalization was an isolated “e,” emission of similar and/or additional phonemes (e.g., “‘yeh”; “eeeee”) was not considered a target vocalization. During echoic probe and teaching sessions, data were summarized as the percentage of trials with correct vocalizations, and during the FA probes, data were summarized as frequency per session. For the SSP teaching sessions, if the participant emitted multiple vocalizations during the same trial, the trial was scored as correct as long as at least one of the vocalizations emitted was a target vocalization. During the echoic FA probes, data were collected on the frequency of target responses during both the test and control conditions; however, vocalizations emitted within 5 s of the sample presented by the therapist were scored as correct for the test sessions only.
In response to the equivocal results across participants, the following rules were used to facilitate evaluation of these procedures across comparisons and participants: a procedure was deemed effective if the percentage of correct responding increased to at least 50 % during the teaching phase, independent of whether responding remained at this level; in cases where multiple procedures were found to be effective, if most data points overlapped across conditions the procedures were considered equally effective. If, however, correct responding was consistently higher for one of the echoic teaching procedures (or two in the case of Wade, comparison 1) then that procedure(s) was deemed most effective (see Table 5). In addition, for the FA probes, a sound was considered to be under echoic or mand control if the sound did not occur during the control session but was emitted at least four times during each of the test sessions that were completed post-teaching.
Table 5.
Summary of effective echoic teaching procedures for each participant
| Participants | Comparison 1 | Comparison 2 | Comparison 3 |
|---|---|---|---|
| Tiffany | VITa, MM | VIT | n/a |
| Carlos | MM | MM | n/a |
| Wade | VITa, MMa, SSP | VIT, MM, SSP | VIT, MM, SSP |
| Zoe | VITa, MM | SSP | VIT |
| Michael | SSP | None | SSP |
| Victor | None | None | n/a |
aMost effective teaching procedure
Interobserver Agreement and Procedural Integrity
Interobserver agreement data (IOA) were collected during echoic training sessions, play sessions, and the FA probes in at least 33 % of sessions across all participants and comparisons. Agreement scores were calculated by totaling the number of trials with agreement, dividing by the total number of trials, and then multiplying by 100 to obtain a percentage. Individual IOA scores are displayed in Table 3. The mean IOA across all of the participants was above 90 % (range, 80 to 100 %).
Table 3.
Mean observer agreement and treatment integrity for teaching, functional analysis, and play sessions for each of the participants
| Participants | Observer agreement | Procedural integrity | ||||
|---|---|---|---|---|---|---|
| Teach | FA | Play | Teach | FA | Play | |
| Tiffany | 98.5 (r=90–100) | 98 (r=91–100) | 100 | 99.2 (r=90–100) | 96.4 (r=88–100) | 100 |
| Carlos | 97.5 (r=85–100) | 100 | 100 | 97.7 (r=90–100) | 99.4 (r=95–100) | 98.9 (r=95–100) |
| Wade | 95.3 (r=80–100) | 96.8 (r=88–100) | 99.4 (r=96–100) | 98.8 (r=90–100) | 95.9 (r=91–100) | 100 |
| Zoe | 97.3 (r=90–100) | 97.7 (r=86–100) | 97.6 (r=90–100) | 99.5 (r=90–100) | 97 (r=90–100) | 100 |
| Michael | 97.3 (r=80–100) | 98.5 (r=89–100) | 100 | 98 (r=80–100) | 98 (r=89–100) | 100 |
| Victor | 99.2 (r=90–100) | 99.7 (r=97.7–100) | 99.7 (r=99.4–100) | 99.7 (r=95–100) | 98.9 (r=95.5–100) | 99.4 9 (r=98.9–100) |
The ranges in IOA and TI are display below each score
Procedural integrity data were collected to ensure that the experimenters were correctly implementing the procedures throughout the experiment. During the echoic training sessions, data were collected on whether the therapist presented (a) a trial approximately every 20 s, (b) the correct discriminative stimulus, and (c) the correct consequence. In addition, for the SSP condition, data were collected on the delivery of the preferred edible to ensure it was provided after the second but before the last presentation by the therapist of the target auditory stimulus. During the FA probes, data were collected on whether the therapist presented (a) a trial approximately every 20 s, (b) the correct discriminative stimulus, and (c) the correct consequence. These data were summarized by calculating the total trials with correct responses performed by the therapist during each session, dividing it by the total number of trials, then multiplying by 100 to obtain a percentage. Individual PI scores are displayed in Table 3. The mean PI across all of the participants was above 90 % (range, 80 to 100 %).
Echoic Probes
Prior to introducing the echoic teaching procedures, echoic probes were conducted by the primary therapist to identify appropriate target sounds for each participant. Sounds selected for the echoic probe were English vowels and phonemes (full list available from the first author) separated by difficulty level and based on age of acquisition of these sounds by typically developing children (Reithaug, 2002; Sander, 1972). During the probe sessions, each sound was presented across three consecutive trials and a trial was presented every 10 s. Data were collected on whether the participant correctly emitted the sound within 5 s of the model. To ensure consistent emission of these sounds by the therapists, the experimenters and a speech language pathologist recorded the emission of these vowels and phonemes, and research assistants reviewed the audio recording prior to conducting echoic probes. Sounds that were emitted correctly in 33 % or fewer trials were selected for training and performance during the echoic probes served as the baseline for evaluating the efficacy of the three echoic teaching procedures. In order to control for difficulty level across the sounds, whenever possible, sounds from the same group (e.g., long vowels) or expected age of acquisition (e.g., 1 year) were selected. However, in some cases, the participant had already acquired some of the sounds from each of these groups. In these cases, a sound from the subsequent group (e.g., short and long vowels) was selected. In one case, during a second comparison for Wade, each sound was selected from one of three subsequent groups (phonemes acquired at 3, 3.5, and 4 years of age). A set of three sounds, similar in difficulty, was identified for each teaching comparison and the sounds were then randomly assigned to one of the three echoic teaching procedures. After the sounds were assigned, attempts were made to assign the sound in the MM procedure to a highly preferred item that contained the target sound in its label (e.g., “m” and M&M® candy). Correct emission of target sound (e.g., “m”) during the MM condition resulted in the delivery of the assigned stimulus (e.g., M&M®), and hence, reinforcers delivered per target sound during this condition were consistent within and across sessions. Correct imitation of the sounds assigned to the VIT and SSP procedures resulted in the delivery of a highly preferred item; however, that item may have differed across sessions depending on participant selection at the start of the session.
Functional Analysis Probes
Procedures similar to those employed by Lerman, Parten, Addison, Vorndran, Volkert, and Kodak (2005) were used to determine the function of the responding established during echoic training. Specifically, the FA probes were conducted to determine whether the responses were established under echoic and/or mand control. The FA procedures were identical across the three teaching procedures. An FA sequence consisting of a test, control, and a second test session was conducted before and after the echoic teaching procedure comparison. During each FA session, the participant and therapist sat at a table near one another and each session lasted 5 min. Functional analysis sessions were conducted in the same room as echoic teaching sessions.
Echoic Functional Analysis
The experimenter initiated the session by establishing attending behavior (e.g., looking at the experimenter) on the part of the participant and then presenting the first model of the target sound. Verbal praise was delivered contingent on the participant’s emission of the target response (echoing the therapist) within 5 s. For the remainder of the session, the experimenter presented the target sound every 20 s. The experimenter ignored all other responses. A control session was initiated by establishing attending behavior; however, the experimenter did not initiate additional interactions with the participants throughout the remainder of the session. During control sessions, all responses emitted by the participant, including target vocalizations, were ignored. During both the testing and control conditions, an edible was delivered approximately every 90 s independent of the participant’s performance to minimize potential problem behavior. In an attempt to prevent adventitious reinforcement of vocalizations, the delivery of the edible was delayed by 10 s if the participant emitted a target vocalization. One of the participants, Tiffany, had continuous access to a moderately preferred toy (a book) across all FA sessions. This modification was made because the initial sessions were terminated due to severe challenging behavior.
Mand Functional Analysis
Prior to conducting mand FA probes for the sounds targeted in the VIT and SSP echoic teaching procedures, the participant was allowed to choose a highly preferred item. Highly preferred edibles were presented to the participant either in a linear array format or in a clear partitioned bin, depending on what was most appropriate for that participant. The item selected was delivered to the participant during the subsequent mand FA probes. The participant did not select a preferred item before the FA probes associated with the MM procedure because the item delivered during the FA probes was the same item used during the MM teaching condition. Prior to the start of a test session, the therapist showed the item to the participant and modeled the target response, “This is X.” For example, if the target sound was “a,” then the therapist presented the item to the participant and stated “This is ‘a’.” During these probes, target responses resulted in access to a preferred item and all other responses were ignored. For example, if the child said “a,” the therapist immediately delivered the selected edible (VIT and SSP conditions) or the associated edible (MM condition). During control sessions, the experimenter provided the participant with continuous access to the preferred item by placing small pieces of the edible on the table in front of them. As soon as the participant placed the edible on his or her mouth, another piece was placed on the table. No consequences were provided for vocalizations.
Echoic Training
The details of the three teaching procedures are summarized in Table 4. The procedures employed for the VIT and SSP conditions were based on the methods described by Stock et al. (2008), and the procedures used for the MM condition were based on the methods described by Nigam et al. (2006). These studies were selected because their procedures resulted in acquisition of the target responses by at least some of the participants in their studies, and the published studies included sufficient procedural detail to allow replication.
Table 4.
Procedural Summary
| Edible | MO manipulation | Visual of edible | Edible for target vocalizations | Model frequency | Additional prompts | |
|---|---|---|---|---|---|---|
| VIT | Varied | No | No | Yes | 1 | No |
| MM | Same | Yes | Yes | Yes | 1 | Yes |
| SSP | Varied | No | No | No | 5 | No |
General Procedures
The order of sessions was determined in a semi-random manner. Therapists were instructed to either review the session log and conduct a teaching session of the procedure with the fewest number of sessions or flip a coin. No more than two sessions of the same teaching condition were conducted consecutively. During all teaching sessions, the therapist and participant sat at a table facing one another. The therapist waited for the participant to orient towards her and engage in an attending response (e.g., placed folded hands on the table). If necessary, least-to-most prompting was used to establish an attending response. For each of the three teaching conditions, a session consisted of 20 trials presented approximately every 20 s. The mastery criterion was three consecutive sessions with 90 % or greater correct responses. A minimum of five training sessions per condition was required to ensure that data on the participant’s performance during play sessions was measured at least twice (pre- and post-training sessions 1 and 5) to allow comparison. A maximum of 10 teaching sessions were completed with most of the participants unless modifications were made to the MM teaching procedure due to lack of progress. For instance, during the MM condition if the participant emitted the target response in 5 % or fewer of the trials, then the prompting procedure was modified starting on session 6 (or 11) in an attempt to facilitate acquisition.
Vocal Imitation Training
Prior to initiating each VIT session, the participant was allowed to choose a highly preferred item. Highly preferred edibles were presented to the participant either in a linear array format or in a clear partitioned bin, depending on what was most appropriate for that participant. During the teaching session, the therapist presented the target sound one time per trial (e.g., “e”) and waited up to 5 s for the participant to echo the response. A correct response resulted in the delivery of the edible. There were no programmed consequences for no or incorrect responses. A new trial was presented approximately every 20 s.
Mand-Model
During the MM teaching condition, the same preferred edible was provided contingent on correct responses across all sessions because whenever possible the edible selected contained the target vocalization in its label. For instance, if the target sound was “p,” the preferred edible was peppermint patties for some of the participants. The participant did not have access to the item for 1 h prior to the teaching sessions. The therapist started the session by reviewing the target sound assigned to that target edible (e.g., “This is e”). Then, the therapist held the preferred item in front of the participant while presenting the vocal prompt, “What do you want?” If the participant emitted the target sound within 4 s, the experimenter delivered the edible. If the participant did not respond, a verbal prompt was presented “Tell me what you want.” If the participant failed to respond again within 4 s, another verbal prompt was presented, “Say e.” If at any point the participant emitted an incorrect response, there were no programmed consequences and the therapist presented another trial after 20 s. Some participants emitted an incorrect response following the first prompt thereby precluding the presentation of the additional prompts by the therapist. If correct responding during the fifth training session was at or below 5 % of the opportunities, the prompting procedure was modified. In these cases, the vocal prompt “Say ‘X’” was also presented following trials with an incorrect response. For instance, if the target sound was “e” and the child stated “m,” then a model prompt, “Say e” was presented. For Michael, this modification was made starting with session 11.
Stimulus–Stimulus Pairing
The participant was allowed to choose a preferred item prior to the start of each SSP training session. During each trial, the therapist presented the target sound five times (e.g., “e, e, e, e, e”) with a 1-s interval between each presentation of the sound. The preferred item was delivered between the second and fifth presentation of the target sound. If the participant emitted the target vocalization while the target sound was presented, the preferred item was not delivered during that trial to prevent direct reinforcement of the vocalization; however, it should be noted that in some cases, the participant emitted the correct sound after the edible was delivered but before it was consumed.
Play Sessions
Previous research evaluating the SSP procedure measured rates of vocalizations during observation sessions that were completed pre- and post-pairing sessions (e.g., Stock et al., 2008). These observation sessions were conducted because conditioning of the target vocalization as a reinforcer may have led to an increase in target vocalizations if responding was automatically reinforced. Inspired by this research, we presented play sessions before and after sessions 1, 5, and 10 to determine whether the free-operant level of the target response increased with continued pairing. Play sessions lasted for 5 min and participants had access to a moderately preferred toy. The sessions were completed in the same room as the teaching sessions. There were no programmed consequences for emission of the target sounds.
Results
The results of this study demonstrated that the assessment protocol was successful in identifying an effective echoic teaching procedure for five out of six children diagnosed with ASD and other developmental delays. Table 5 displays a summary of the echoic teaching procedures identified as most effective for each participant. Results demonstrated that no single procedure was most effective and that the efficacy of the three procedures varied across participants.
Individual results of the echoic teaching procedure comparisons and functional analysis probes are displayed in Figs. 1, 2, 3, 4, 5, 6, and 7. Figure 1 depicts the data from the teaching and functional analysis sequences for Tiffany. The VIT procedure led to an immediate increase in correct responding during the first comparison. In addition, correct responding increased in the MM condition once the prompt procedure was modified during session 6. Both procedures were effective; however, VIT produced consistently higher levels of correct responding. Tiffany emitted the sounds from the VIT and MM conditions at least four times during the test conditions of the echoic FA probes suggesting that both sounds were emitted under echoic control. During the second teaching comparison, correct responding increased in the VIT condition although responding was on a decreasing trend toward the end of the comparison. Correct responding also increased in the MM condition after the prompt was modified. The results of the first comparison were replicated in the second comparison; however, results of the FA probes suggested that during the post-teaching probes, only the sound from the SSP condition was emitted under echoic control. It should also be noted that during the second comparison, correct imitation of the sound assigned to the SSP condition decreased during teaching as compared to the initial functional analysis sequences. This decrease in correct responding is likely due to the contingencies in effect during the SSP teaching sessions as her therapist withheld reinforcer delivery following target vocalizations.
Fig. 1.
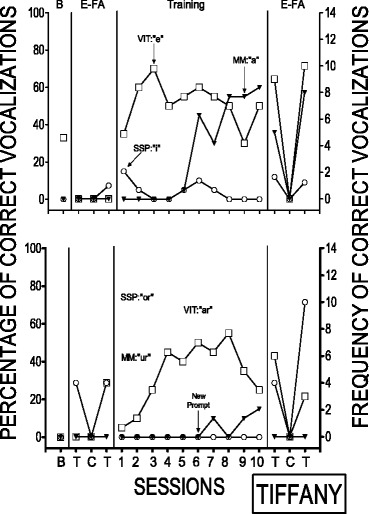
Percentage of correct vocalizations during the three training conditions and during the echoic functional analysis for Tiffany
Fig. 2.
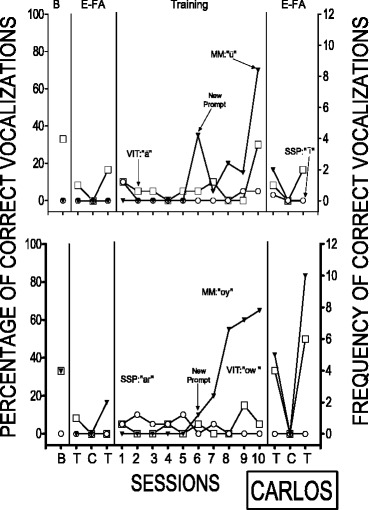
Percentage of correct vocalizations during the three training conditions and during the echoic functional analysis for Carlos
Fig. 3.
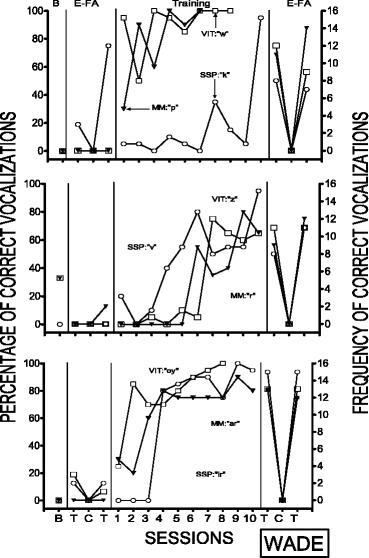
Percentage of correct vocalizations during the three training conditions and during the echoic functional analysis for Wade
Fig. 4.

Percentage of correct vocalizations during the three training conditions and during the echoic functional analysis for Zoe
Fig. 5.
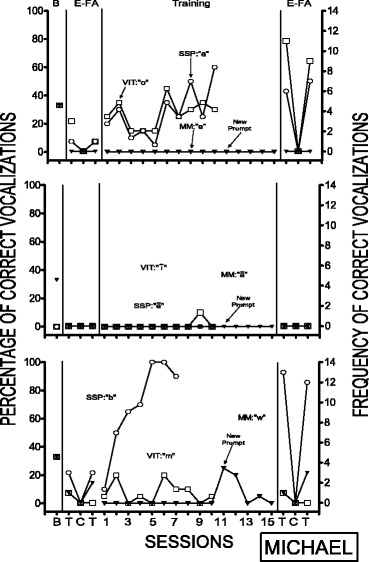
Percentage of correct vocalizations during the three training conditions and during the echoic functional analysis for Michael
Fig. 6.
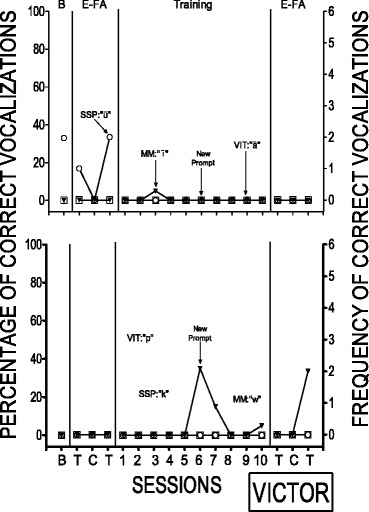
Percentage of correct vocalizations during the three training conditions and during the echoic functional analysis for Victor
Fig. 7.

Results of the mand functional analysis probes for Wade, Zoe, Michael, and Tiffany. Data from the first comparison are depicted on the top panel, data from the second comparison are on the middle panel, and data from the third comparison are on the bottom panel. Only two comparisons were completed with Tiffany
Results for Carlos are displayed in Fig. 2. During the first comparison for Carlos, target responding was initially low across all three teaching procedures; however, the change in prompt for the MM condition resulted in increases in correct responding in that condition. This was replicated across both comparisons, and so, the only effective teaching procedure for Carlos was the MM. Following training, the sounds from the VIT and MM conditions from the second comparison were emitted frequently during the test sessions of the echoic FA probes, suggesting that these sounds were under echoic control.
Figure 3 depicts the results for Wade. During the first comparison for Wade, all three procedures led to an increase in correct responding; however, the VIT and MM procedures were more effective than SSP because responding was consistently higher in these conditions in comparison to SSP. Wade acquired all three sounds during the second comparison, but the prompting procedure for the MM condition was modified so that additional prompts were provided following incorrect responding. A third comparison was completed due to the modification of the prompting procedure for the MM condition in the second comparison. Even though the prompt for MM was not modified during the third comparison, the results of the third comparison were similar to the results of the second comparison. The results of the post-teaching FA probes indicated that all three sounds, across the three comparisons, were under echoic control.
Results for Zoe are displayed in Fig. 4. During the first teaching comparison, Zoe quickly acquired the target sound in the VIT condition and responding improved in the MM condition suggesting that both procedures were effective. However, the VIT was more effective than the MM as it resulted in higher levels of echoic responding. The results of the FA probes indicated that the sound from VIT condition was under echoic control. During the second comparison, an increase in correct responding was observed only for the sound targeted in the SSP condition, although correct responding decreased as training progressed. During the FA probes, Zoe emitted the sound from the SSP condition in the test conditions suggesting that the sound was under echoic control. The results of the first teaching comparison were not replicated in the second comparison; thus, a third teaching comparison was conducted. In the last comparison, Zoe’s responding reached nearly 100 % correct for the sound in the VIT condition. His responding did not reach 50 % in any of the teaching sessions for the SSP condition. Results of the post-teaching FA indicated that only the sound from the VIT condition was under echoic control. The results of the third comparison partially replicated the findings of the first comparison.
The results for Michael are displayed in Fig. 5. During the first and third comparisons, only the SSP procedure led to an increase in correct responding above 50 %, although some correct responding was observed in the first comparison of the VIT condition. In the second comparison, none of the three procedures produced a substantial increase in echoic responding. For the first comparison, the sounds from VIT and SSP were under echoic control post-training and following the third comparison the sound from the SSP procedure was also under echoic control.
Results for Victor are displayed in Fig. 6. During the first comparison, Victor did not emit any of the sounds and therefore a second comparison was conducted. He also did not emit any sounds during the second comparison. A decrease in correct responding from baseline and the FA probes to the teaching phase was observed for the sound assigned to the SSP condition. Victor rarely emitted the target sounds; therefore, it appeared that none of the three teaching procedures were effective for establishing echoic responding.
The results of the mand FA probes for Wade, Zoe, Michael, and Tiffany are displayed in Fig. 7. Data for Carlos and Victor were not included because these participants did not emit the target vocalizations during any of the test and control sessions of the mand FA probes. During the post-training assessments completed for the first teaching comparison, Wade emitted the target sound from the VIT condition more often in the test than in the control session. In the second comparison, Wade emitted the sounds from the MM and SSP conditions more often during the test than the control sessions. Finally, Wade emitted the sound from the MM condition more often during the test than the control session of the last comparison. These data suggest that these sounds were under mand control. Following the third training comparison, Michael emitted the target sound from SSP more often during the test sessions suggesting that this sound was under mand control. Finally, neither Zoe nor Tiffany reliably emitted target vocalizations during the test conditions suggesting that neither sound was under mand control.
Discussion
This study extends the research literature on teaching echoics by examining an assessment procedure for identifying the most effective of three echoic teaching procedures: (1) VIT, (2) SSP, and (3) MM. Results indicated that the assessment procedure was efficacious for identifying the appropriate teaching procedure for five out of the six participants. Additionally, data from the functional analysis probes indicated that following teaching, most of the sounds emitted by the participants were under echoic control. The echoic teaching procedure that was identified as the most effective varied across participants suggesting that the assessment was successful with respect to identifying the most appropriate echoic teaching procedure and for contributing to the individualization of treatment planning. In situations when the assessment identifies equally effective teaching procedures, clinicians should consider other variables such as the complexity of teaching procedure and client preference. For one participant, Wade, both the VIT and MM procedures appeared to be equally effective. However, the MM procedure required withholding access to the preferred edible for at least 1 h prior to sessions and the delivery of additional prompts during training. The VIT procedure did not require withholding of preferred items and was procedurally simpler making the VIT procedure potentially preferable to the learner and result in greater treatment integrity. Previous research has evaluated relative preference for various treatments using a concurrent-chains assessment and has found that participants usually demonstrate a preference for one of the treatments evaluated (e.g., Hanley, Piazza, Fisher, Contrucci, & Maglieri, 2005; Potter, Hanley, Augustine, Clay, & Phelps, 2013). A similar preference evaluation may be conducted with echoic teaching procedures when multiple methods are found to be equally effective.
A number of variables may have influenced the differential effectiveness of the teaching procedures across participants. Their individual learning history with respect to the teaching procedures may have differed such that greater exposure to a specific teaching procedure may have increased the efficacy of said procedure. For example, previous research has shown that increased exposure to a transfer-of-stimulus control procedure is likely to increase the efficacy of that procedure (Coon & Miguel, 2012). Varying pre-training motor imitation and verbal behavior repertoires may have also influenced the results. Data displayed in Table 2 show that the participants with the lowest scores in the listener repertoire domain (Carlos, Michael, and Victor) acquired less than the 50 % of the echoic responses. These outcomes suggest a few possibilities: (1) a listener repertoire may be required to establish echoic responding, (2) a listener repertoire facilitates the acquisition of echoic responding, or (3) an echoic repertoire may facilitate the development of a listener repertoire. Future research should evaluate the relation between echoic and listener skills as well as other potential prerequisite skills such as imitation skills.
This study demonstrated that SSP without the use of socially delivered direct reinforcement may be effective in establishing echoic responding. One way to interpret these outcomes is in terms of parity. Palmer (1996) proposed that automatic reinforcement of vocalizations may occur when one’s own vocalizations conforms to those vocalizations of his verbal community. Therefore, one potential prerequisite is a well-established listener repertoire in order for the individual to determine when her vocalizations “conform or deviate” from those emitted by members of the verbal community. If the vocalizations of the speaker and her verbal community conform, then parity is achieved and this parity may reinforce echoic responding. However, if the vocalizations emitted deviate from those of the verbal community, these vocalizations should have aversive properties and therefore result in automatic punishment. Palmer (1998) described an example of behavior automatically shaped to achieve parity. In this experiment, the keys of a computer were programmed to play tones of various frequencies. The participant was then asked to play a tune that was in her listener repertoire, Mary Had a Little Lamb. As the participant pressed keys, her motor behavior produced tones that either corresponded or did not correspond to the pattern of Mary Had a Little Lamb. The feedback received through trial and error (whether the sounds produced through pressing the keys conformed or deviated from the target tune) shaped the participant’s motor behavior. In the current study, it is possible that for some participants, echoing the sample vocalization produced its own reinforcer. Limited research has investigated this potential source of automatic reinforcement and the research available has focused on the acquisition of verbal construction (i.e., passive vs. active voice) through exposure but not direct reinforcement (e.g., Ostvik, Eikeseth, & Klintwall, 2012; Silvestri, Davies-Lackey, Twyman, & Palmer, in prep; Whitehurst, Ironsmith, & Goldfein, 1974; Wright, 2006). Additional research on the role of automatic reinforcement in the establishment of echoic responding is warranted.
This study extended previous research in teaching echoic responding by including FA probes before and after training to determine whether the newly acquired responses were under mand and echoic control. The procedures for the FA probes were developed by Lerman et al. (2005) in order to assess the function of verbal behavior in an existing repertoire. The current study along with another study conducted by Normand, Machado, Hustyi, and Morley (2011) demonstrated that these FA assessment procedures may also be employed to ensure that teaching procedures are effective in establishing responses under the intended stimulus control (e.g., echoics). The results demonstrated that responding was both under echoic and mand control for some sounds. In light of these outcomes, we recommend the inclusion of FA probes in clinical practice as these will allow clinicians to assess, using a brief 15 to 20 min assessment, whether the teaching procedure produced responding under the intended stimulus control and whether the learner may also have acquired other verbal operants without additional training. This could potentially maximize instruction time by eliminating the implementation of unnecessary verbal behavior training. It should be noted that the procedures employed in the current study for the mand FA probes included a model of the target response prior to beginning a session, and it is possible that this model combined with differential reinforcement was responsible for the increase in target vocalizations during the test sessions. However, given that the procedures for the FA probes were identical pre- and post-training, the observed increases in vocalizations were likely the result of training. This study’s iteration of the procedures might have biased the MM training procedure condition because the same item was delivered across training sessions and during the mand FA, whereas for the VIT and SSP conditions, the participant was allowed to choose a preferred item at the beginning of each session. Despite this, during the post-training probes, three sounds (one sound for Wade, Zoe, and Michael) from the SSP condition and only two sounds from the MM condition (both for Wade) were under mand control. Future research on the MM procedure should also consider including tact FA probes because the target sound was emitted in the presence of the corresponding target stimulus.
Several limitations of the current research on echoic teaching procedures must be considered. Procedures for each of these teaching methods often differ across studies (e.g., frequency of sample presented per trial in SSP studies). The current study included specific iterations of each teaching procedure (VIT and SSP based on the procedures described by Stock et al., 2008; MM based on Nigam et al., 2006). Nevertheless, minor modifications were made to the original procedures in this study. For example, in this study, the sample was presented only once during each trial of the VIT condition as this is commonly done in clinical settings, yet the sample was presented five times in the study completed by Stock et al. in an attempt to control for frequency of sample presented across the VIT and SSP procedures. Also, an error-correction procedure was not included as part of the MM condition, and multiple prompts were included, instead. The presentation of additional prompts made the MM procedure similar to the VIT procedure as the last prompt involved the presentation of a model, “Say X.” Also for the MM procedure, the same stimulus was delivered across all sessions, the preferred stimulus was in view of the participant during training sessions, and access to the stimulus was restricted prior to session in an attempt to contrive the relevant motivating operations (see Table 4). It is possible that our procedures may have biased the MM procedure; however, this procedure was found to be the most effective procedure for only one participant, Carlos. Future research should evaluate whether the presentation of additional prompts for both errors of emission and commission from the onset of the training evaluation may increase the efficacy of the MM procedure. Future research may also examine the effects of employing identical guidelines for reinforcer selection across all three teaching procedures to eliminate this potential confound.
During the SSP procedure, a preferred edible was delivered between presentations of the sound by the therapist. Another potential limitation is that it may have been possible that consumption of the edible competed with vocalizations or that correct vocalizations were emitted but not within 5 s of the presentation of the target sound. Future research may address this limitation by increasing the inter-trial interval and scoring vocalizations that match the model as correct as long as they are emitted immediately after the edible is consumed. Alternatively, future research could employ a sequential pairing procedure in which the edible is delivered before the therapist presents the target sounds. This would allow the participant to consume the edible as the model sound is presented thus potentially allowing the participant to consume the item and then respond within 5 s of the last presentation of the model.
The SSP procedure is used to increase vocalizations, and it is not intended to bring vocalizations under echoic control. Although the SSP procedure resulted in acquisition of echoic responding for some of our participants, this may have been potentially due to generalization across teaching procedures. For instance, for both the VIT and MM procedures, correct imitation of the target vocalization was directly reinforced and it is possible that participants were more likely to attempt to imitate the model presented during the SSP procedure due to this novel history of reinforcement for vocal imitation. Future studies could evaluate this possibility by presenting the teaching procedures sequentially with the order counterbalanced across participants. Another option is to evaluate the SSP procedure first before the participants are exposed to differential reinforcement for imitation. In fact, the SSP procedure was the only one that did not include direct reinforcement of vocal imitation thus making this procedure distinct from VIT and MM. Future research and clinicians attempting to teach echoic responding should employ a SSP procedure that includes direct reinforcement of correct imitation. For instance, it may be fruitful to compare acquisition of echoic responding across traditional SSP and a synthesized SSP procedure that includes a direct reinforcement component.
The results of this study support the practice of employing assessments and teaching procedures that contribute to the individualization of behavioral intervention programming, a practice that is cornerstone to the field of Applied Behavior Analysis. The results of this research study have demonstrated that the assessment protocol was successful in identifying an effective echoic teaching procedure for individuals with ASD and related developmental disabilities. However, additional research is warranted to identify alternative echoic teaching procedures for those individuals for whom this assessment procedure was ineffective. It may be the case that for some learners, an alternative mode of communication should be considered if assessment measures fail to establish echoic responding. Additional research is merited to address these questions.
Conflict of Interest
The authors declare that they have no conflict of interest.
Ethical Approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
Informed Consent
Parental consent and participant assent were obtained from all individual participants included in the study.
Footnotes
This article is based on a dissertation submitted by the first author in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Behavior Analysis) degree at Western New England University. Catia Cividini-Motta is now at the University of South Florida, Tampa. Nicole Scharrer is now at ABA of Wisconsin, LLC.
References
- Baer DM, Peterson RF, Sherman JA. The development of imitation by reinforcing behavioral similarity to a model. Journal of the Experimental Analysis of Behavior. 1967;21:405–416. doi: 10.1901/jeab.1967.10-405. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brigham TA, Sherman JA. An experimental analysis of verbal imitation in preschool children. Journal of Applied Behavior Analysis. 1968;1:151–160. doi: 10.1901/jaba.1968.1-151. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Carroll RA, Klatt KP. Using stimulus-stimulus pairing and direct reinforcement to teach vocal verbal behavior to young children with autism. The Analysis of Verbal Behavior. 2008;24:135–146. doi: 10.1007/BF03393062. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Coon JT, Miguel CF. The role of increased exposure to transfer-of-stimulus-control procedures on the acquisition of intraverbal behavior. Journal of Applied Behavior Analysis. 2012;45:657–666. doi: 10.1901/jaba.2012.45-657. [DOI] [PMC free article] [PubMed] [Google Scholar]
- DeLeon IG, Iwata BA. Evaluation of a multiple-stimulus presentation format for assessing reinforcer preferences. Journal of Applied Behavior Analysis. 1996;29:513–533. doi: 10.1901/jaba.1996.29-519. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dickson CA, MacDonald RPF, Mansfield R, Guilhardi P, Johnson C, Ahearn WH. Social validation of the New England Center for Children-Core Skills Assessment. Journal of Developmental Disabilities. 2014;44:65–74. doi: 10.1007/s10803-013-1852-5. [DOI] [PubMed] [Google Scholar]
- Drash P, High RL, Tudor RM. Using mand training to establish an echoic repertoire in young children with autism. The Analysis of Verbal Behavior. 1999;16:29–44. doi: 10.1007/BF03392945. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Esch BE, Carr JE, Michael J. Evaluating stimulus-stimulus pairing and direct reinforcement in the establishment of an echoic repertoire of children diagnosed with autism. The Analysis of Verbal Behavior. 2005;21:43–58. doi: 10.1007/BF03393009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fisher WW, Piazza CC, Bowman LG, Amari A. Integrating caregiver report with systematic choice assessment to enhance reinforcer identification. American Journal of Mental Retardation. 1996;10:15–25. [PubMed] [Google Scholar]
- Fisher W, Piazza CC, Bowman LG, Hagopian LP, Owens JC, Slevin I. A comparison of two approaches for identifying reinforcers for persons with severe and profound disabilities. Journal of Applied Behavior Analysis. 1992;25:491–498. doi: 10.1901/jaba.1992.25-491. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Graff RB, Ciccone FJ. A post hoc analysis of multiple-stimulus preference assessment results. Behavioral Interventions. 2002;17:85–92. doi: 10.1002/bin.107. [DOI] [Google Scholar]
- Hanley GP, Piazza CC, Fisher WW, Contrucci SA, Maglieri KA. On the effectiveness of and preference for punishment and extinction components of function-based interventions. Journal of Applied Behavior Analysis. 2005;38:51–65. doi: 10.1901/jaba.2005.6-04. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kodak T, Clements A. Acquisition of mands and tacts with concurrent echoic training. Journal of Applied Behavior Analysis. 2009;42:839–843. doi: 10.1901/jaba.2009.42-839. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Koegel RL, O’Dell MC, Dunlap G. Producing speech use in nonverbal autistic children by reinforcing attempts. Journal of Autism and Developmental Disorders. 1988;18:525–538. doi: 10.1007/BF02211871. [DOI] [PubMed] [Google Scholar]
- LeBlanc LA, Esch JW, Sidener TM, Firth AE. Behavioral language interventions for children with autism: comparing applied verbal behavior and naturalistic teaching approaches. Analysis of Verbal Behavior. 2006;22:49–60. doi: 10.1007/BF03393026. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lerman DC, Parten M, Addison LR, Vorndran CM, Volkert VM, Kodak T. A methodology for assessing the functions of emerging speech in children with developmental disabilities. Journal of Applied Behavior Analysis. 2005;38:303–316. doi: 10.1901/jaba.2005.106-04. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lovaas OI. Teaching individuals with developmental delays: basic intervention techniques. Austin, TX: Pro-Ed; 2003. [Google Scholar]
- Lovaas OI, Berberich JP, Perloff BF, Schaeffer B. Acquisition of imitative speech in schizophrenic children. Science. 1966;151:705–707. doi: 10.1126/science.151.3711.705. [DOI] [PubMed] [Google Scholar]
- Lowenkron B. Some logical functions of joint control. Journal of the Experimental Analysis of Behavior. 1998;69:327–354. doi: 10.1901/jeab.1998.69-327. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Miguel CF, Carr JE, Michael J. The effects of a stimulus-stimulus pairing procedure on the vocal behavior of children diagnosed with autism. The Analysis of Verbal Behavior. 2002;18:3–13. doi: 10.1007/BF03392967. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nigam R, Schlosser RW, Lloyd LL. Concomitant use of the matrix strategy and the mand-model procedure in teaching graphic symbol combinations. Augmentative and Alternative Communication. 2006;22:160–177. doi: 10.1080/07434610600650052. [DOI] [PubMed] [Google Scholar]
- Normand MP, Knoll ML. The effects of a stimulus-stimulus pairing procedure on the unprompted vocalizations of a young child diagnosed with autism. The Analysis of Verbal Behavior. 2006;22:81–85. doi: 10.1007/BF03393028. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Normand MP, Machado MA, Hustyi KM, Morley AJ. Infant sign training and functional analysis. Journal of Applied Behavior Analysis. 2011;44:305–314. doi: 10.1901/jaba.2011.44-305. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ostvik L, Eikeseth S, Klintwall L. Effects of modeling and explicit reinforcement in the establishment of verbal behavior in preschool aged children. The Analysis of Verbal Behavior. 2012;28:73–82. doi: 10.1007/BF03393108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Palmer DC. Achieving parity: the role of automatic reinforcement. Journal of the Experimental Analysis of Behavior. 1996;65:289–290. doi: 10.1901/jeab.1996.65-289. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Palmer DC. The speaker as listener: the interpretation of structural regularities in verbal behavior. The Analysis of Verbal Behavior. 1998;15:3–16. doi: 10.1007/BF03392920. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Potter JN, Hanley GP, Augustine M, Clay CJ, Phelps MC. Treating stereotypy in adolescents diagnosed with autism by refining the tactic of “using stereotypy as reinforcement”. Journal of Applied Behavior Analysis. 2013;46:407–423. doi: 10.1002/jaba.52. [DOI] [PubMed] [Google Scholar]
- Reithaug D. Orchestrating success in reading. West Vancouver, BC: Stirling HeadEnterprises Inc.; 2002. [Google Scholar]
- Sander E. When are speech sounds learned? Journal of Speech and Hearing Disorders. 1972;37:55–63. doi: 10.1044/jshd.3701.55. [DOI] [PubMed] [Google Scholar]
- Schlinger HD. Listening is behaving verbally. The Behavior Analyst. 2008;31:145–161. doi: 10.1007/BF03392168. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shillingsburg MA, Hollander DL, Yosick RN, Bowen C, Muskat LR. Stimulus-stimulus pairing to increase vocalizations in children with language delays: a review. The Analysis of Verbal Behavior. 2015;31:215–235. doi: 10.1007/s40616-015-0042-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sidener DW. Joint control for dummies*: an elaboration of Lowenkron’s model of joint (stimulus) control. The Analysis of Verbal Behavior. 2006;22:199–122. doi: 10.1007/BF03393033. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Silvestri, S. M., Davies-Lackey, A. J., Twyman, J. S, & Palmer, D. C. (in preparation). The role of automatic reinforcement in the acquisition of an autoclitic frame.
- Skinner BF. Verbal behavior. Englewood Cliffs, NJ: Prentice Hall; 1957. [Google Scholar]
- Sparrow SS, Cicchetti VD, Balla AD. Vineland adaptive behavior scales. 2. Circle Pines, MN: American Guidance Service; 2005. [Google Scholar]
- Stock RA, Schulze KA, Mirenda PA. A comparison of stimulus-stimulus pairing, standard echoic training, and control procedures on the vocal behavior of children with autism. The Analysis of Verbal Behavior. 2008;24:123–133. doi: 10.1007/BF03393061. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sundberg ML. Verbal behavior milestones assessment and placement program: the VB-MAPP. Concord, CA: AVB Press; 2008. [Google Scholar]
- Sundberg ML, Partington JW. Teaching language to children with autism or other developmental disabilities. Pleasant Hill, CA: Behavior Analysts, Inc.; 1998. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Watkins CL, Pack-Teixeira L, Howard JS. Teaching intraverbal behavior to severely retarded children. The Analysis of Verbal Behavior. 1989;7:69–81. doi: 10.1007/BF03392838. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Whitehurst GJ, Ironsmith M, Goldfein M. Selective imitation of the passive construction through modeling. Journal of Experimental Child Psychology. 1974;17:288–302. doi: 10.1016/0022-0965(74)90073-3. [DOI] [Google Scholar]
- Williams G, Donley C, Keller J. Teaching children with autism to ask questions about hidden objects. Journal of Applied Behavior Analysis. 2000;33:627–630. doi: 10.1901/jaba.2000.33-627. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wolery M, Bailey DB, Sugai GM. Effective teaching: principles and procedures of applied behavior analysis with exceptional students. Boston: Allyn & Bacon; 1988. [Google Scholar]
- Wright AN. The role of modeling and automatic reinforcement in the construction of the passive voice. The Analysis of Verbal Behavior. 2006;22:153–169. doi: 10.1007/BF03393036. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yoon, S. (1998). Effects of an adult’s vocal sound paired with a reinforcing event on the subsequent acquisition of mand functions. ProQuest Dissertations Publishing, Number 9839031.
- Yoon S, Bennett GM. Effects of a stimulus-stimulus pairing procedure on conditioning vocal sounds as reinforcers. The Analysis of Verbal Behavior. 2000;17:75–88. doi: 10.1007/BF03392957. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yoon, S., & Feliciano, G. M. (2007). Stimulus-stimulus pairing and subsequent mand acquisition of children with various levels of verbal repertoires. The Analysis of Verbal Behavior, 23, 3–16. [DOI] [PMC free article] [PubMed]