

Abstract
Mutation rate and effective population size (Ne) jointly determine intraspecific genetic diversity, but the role of mutation rate is often ignored. Here we investigate genetic diversity, spontaneous mutation rate and Ne in the giant duckweed (Spirodela polyrhiza). Despite its large census population size, whole-genome sequencing of 68 globally sampled individuals reveals extremely low intraspecific genetic diversity. Assessed under natural conditions, the genome-wide spontaneous mutation rate is at least seven times lower than estimates made for other multicellular eukaryotes, whereas Ne is large. These results demonstrate that low genetic diversity can be associated with large-Ne species, where selection can reduce mutation rates to very low levels. This study also highlights that accurate estimates of mutation rate can help to explain seemingly unexpected patterns of genome-wide variation.
While the role of effective population size (Ne) in explaining variation in genetic diversity has received much attention, the role of spontaneous mutation rate is largely ignored. Here, Xu et al. show that giant duckweed has a high Ne yet low genetic diversity, likely due to its low mutation rate.
Introduction
Explaining within-species genetic diversity—measured as the level of intraspecific DNA sequence variation—is one of the major goals in evolutionary and conservation biology1,2. While intraspecific genetic diversity is known to vary widely among species, the underlying causes remain controversial3,4. According to population genetic theory, the population mutation parameter (θ) is determined by the product of the spontaneous neutral mutation rate (μ) and effective population size (Ne), and in diploid species θ = 4 × Ne × μ5. In practice, the parameter θ is often estimated by the average pairwise nucleotide diversity (π) at putatively neutral sites6. While the role of Ne in explaining variation in genetic diversity among taxa has received much theoretical and empirical attention, the influence of variation in mutation rate remains largely ignored3,4,7.
As most spontaneous mutations are deleterious, selection should favor lower mutation rates, but in small populations the efficacy of selection to lower the mutation rate is limited (s ≪ 1/Ne, where s is the selection coefficient against the increase of mutation rate) as genetic drift overrides the effect of natural selection. This ‘drift-barrier’ hypothesis can explain variation in mutation rates and the observed logarithmic-scaled negative relationship between Ne and μ among species8. An important prediction of this model is that a large effective population size could result in the evolution of a low mutation rate. One consequence of this is that populations with very large effective population sizes may have very low genetic diversity, when selection has driven mutation rate to an extremely low level. However, to our knowledge, whether this pattern is present in eukaryotes is unknown, largely due to the paucity of studies quantifying both genome-wide diversity and spontaneous mutation rates.
To better understand the relationship between genetic diversity, mutation rate, and Ne, we independently obtained genome-wide and range-wide estimates of genetic diversity and mutation rate in the diploid freshwater plant Spirodela polyrhiza L. (Schleid.) (“giant duckweed”). This species is one of the fastest growing angiosperms; under suitable growth conditions, it reproduces predominantly by asexual budding with a duplication rate of 2–3 days9,10. Consequently, S. polyrhiza often achieves extremely high census population sizes in nature as millions of individuals can be found in a single pond. However, previous studies using a limited number of genetic markers found low genetic diversity11,12, and whole genome resequencing of two genotypes revealed overall low heterozygosity13. Here, by sequencing 68 world-wide distributed genotypes and measuring spontaneous mutation rate under natural conditions, we show that low genetic variation in S. polyrhiza is associated with low mutation rate in the giant duckweed.
Results and Discussion
Genetic diversity in S. polyrhiza
To provide genome-wide and range-wide estimates of genetic diversity in S. polyrhiza, we sequenced the genomes of 68 genotypes representing the global distribution of the species, using Illumina short-read sequencing with 29× average coverage (Supplementary Data 1). All sequence reads were aligned to the S. polyrhiza reference genome14 using the BWA-MEM aligner and genetic variants were identified using GATK15. In total, we found 996,115 biallelic and 7,880 multiallelic high-quality single nucleotide polymorphisms (SNPs) as well as 214,262 small indels. This represents on average one SNP per 145 bp in the S. polyrhiza genome, which is low compared to an average of one SNP per 23 bp in Arabidopsis thaliana when a comparable number of genotypes are sequenced16. Among all biallelic SNPs, 14,191 nonsynonymous and 8865 synonymous SNPs were found (Supplementary Table 1 and Supplementary Data 2). The estimated S. polyrhiza range-wide pairwise nucleotide diversity at synonymous sites (πS) was 0.00093, which is among the lowest values reported for any multicellular eukaryote for which genome-wide genetic diversity has been estimated (see Supplementary Data 3)3.
Population structure analysis based on genome-wide polymorphisms revealed four population clusters in S. polyrhiza, which are centered in four geographic regions: America, Europe, India, and Southeast (SE) Asia (Fig. 1). A few samples showed discrepancies between their geographic origin and population cluster assignment based on their genomic variation, likely due to either recent migrations of the duckweed associated with human activities or mis-labeling during long-term maintenance of the duckweed collections. The pairwise Fst, an indicator of relative differentiation between populations, ranged from 0.35 to 0.82 (Supplementary Table 2), suggesting distinct regional populations in S. polyrhiza. Between populations, the genome-wide nucleotide diversity from all sites ranged between 0.00067 (SE Asian versus European population) and 0.00013 (European versus American population). Within populations, π calculated from all sites ranged from 0.00018 (American population) to 0.00056 (SE Asian population) (Fig. 1b, Supplementary Table 3). The extent of linkage disequilibrium (LD) declined with physical distance between linked loci and this rate of decline varied between populations (Fig. 1c). The average distance between SNPs with an LD coefficient (r2) of 0.33 varied from 8.6 kb in the SE Asian population to 86.8 kb in the European population. The relatively slow decay of LD in S. polyrhiza may be attributed to its predominantly clonal reproduction. Comparing across populations, we observed much faster LD decay in the SE Asian population, suggesting more frequent (historical or ongoing) sexual reproduction in this region and/or higher Ne. Together, these results establish that genome-wide nucleotide diversity in S. polyrhiza is extremely low and sexual reproduction might be frequent in the SE Asian population.
Fig. 1.

Nucleotide diversity, population structure and linkage disequilibrium in S. polyrhiza. a Geographic distribution of the 68 sequenced samples, colored according to population structure. The insert at the lower left corner shows the results from the STRUCTURE analysis using genome-wide polymorphisms. Each colored line refers to an individual and the Y-axis refers to the likelihood of membership to each cluster. Genome wide πs refers to average pairwise nucleotide diversity at synonymous sites. SE: Southeast. b Principal coordinate analysis (PCA) based on genome-wide nucleotide diversity data. Average pairwise nucleotide diversity (π) calculated from all sites is shown for each population. c Decay of linkage disequilibrium (LD) with physical distance in four populations. The dashed line indicates an LD value of r2 = 0.33. Data are deposited in figshare58
Mutation rate and effective population size in S. polyrhiza
To investigate if the observed low genomic diversity in S. polyrhiza can be explained by universally low mutation rate or, alternatively, low effective population size, we estimated the spontaneous mutation rate and used our estimates of mutation rate and genomic diversity to estimate effective population size. Because environmental factors, such as ultraviolet (UV) light, which prevails in the native habitats of S. polyrhiza, can affect mutation rates17–21, mutation rates measured in the lab may not necessarily reflect mutation rates in nature. In an attempt to get an estimate of mutation rate more similar to what would be observed in nature we estimated the genomic mutation rate in indoor and outdoor mutation accumulation (MA) experiments, and manipulated UV light in the outdoor experiments to further assess the effect of environmental factors (see Supplementary Fig. 1 and Supplementary Data 4). Offspring of a single common ancestor were propagated as single descendants under these conditions for 20 generations (see Supplementary Fig. 2), after which individual plants from five replicates per treatment were collected, and their genomes sequenced and compared to the ancestral genome. We obtained genome information for 16 individuals (including the common ancestor) with an average coverage of 28× (Supplementary Table 4) and identified genetic variants in more than 79.7% of the S. polyrhiza genome (~126 Mb). Among the 15 offspring, four de novo mutations were identified and confirmed by Sanger sequencing. These mutations all originated from the outdoor MA experiments, and located in non-coding regions. One mutation (C:GT:A) was found in a UV-shielded line and the other three mutations (two C:GT:A and one C:GA:T) were found in UV-exposed lines (Table 1). Further analysis that compared the heterozygous sites of maternal and offspring individuals suggested a low false-negative rate for our mutation identification pipeline (average: 1.6%, 95% CI 0.2–3.0%). In addition, we spiked 1000 synthetic non-reference mutations to the sequence alignments and successfully recalled 945 of them using the same variant calling and filtering method. This gave a false negative rate of 5.5% (95% CI 4.1–7.2%). It is possible that we failed to detect mutations in regions of the genome not accessible using the current sequencing technology (mainly repetitive sequences). Given that the protein-coding region of the S. polyrhiza genome is 17.4 Mb, we estimate the number of mutations per generation in the entire protein-coding DNA of S. polyrhiza under natural, outdoor conditions to be 0.0041 ± 0.0038 (mean ± SD). As so few mutations were observed, we were unable to perform robust statistical analysis to test for treatment effects. However, the higher number of mutations found in outdoor samples and in the presence of UV light is consistent with the hypothesis that outdoor environmental factors increase the spontaneous mutation rate.
Table 1.
Summary of the sequencing data and detected mutations
| Sample ID | Treatment | # Mutations | Callable sites (Mb) |
|---|---|---|---|
| A | Indoor | 0 | 126.4 |
| E | Indoor | 0 | 125.7 |
| I | Indoor | 0 | 126.0 |
| J | Indoor | 0 | 126.4 |
| N | Indoor | 0 | 125.9 |
| B | Outdoor-noUV | 0 | 126.1 |
| G | Outdoor-noUV | 1 | 126.3 |
| K | Outdoor-noUV | 0 | 124.2 |
| O | Outdoor-noUV | 0 | 125.9 |
| P | Outdoor-noUV | 0 | 126.4 |
| C | Outdoor-UV | 1 | 125.6 |
| D | Outdoor-UV | 1 | 126.3 |
| L | Outdoor-UV | 1 | 126.3 |
| M | Outdoor-UV | 0 | 126.3 |
| Q | Outdoor-UV | 0 | 126.0 |
Each row shows the sample information and number of verified mutations. Effective sites are estimated as the total number of sites with sufficient coverage for finding de novo variants using our pipeline. The mutation rate is calculated as μ = (number of mutations/sum of effective sites)/number of generations. The average mutation rates (95% confidence interval) for samples grown under indoor, outdoor-noUV and outdoor-UV conditions are: <7.92 × 10−11 (NA), 7.92 × 10−11 (2.07 × 10−11 to 3.98 × 10−10), and 2.38 × 10−10 (4.76 × 10−11 to 7.30 × 10−10), respectively. The 95% confidence intervals were calculated based on the assumption that the number of mutations is Poisson distributed
The genome-wide mutation rate in S. polyrhiza is within the range of mutation rates reported for unicellular eukaryotes and Eubacteria, but is more than seven times lower than the reported rates for multicellular eukaryotes (Fig. 2). This estimated seven-fold difference between S. polyrhiza and other multicellular eukaryotes is a conservative estimate, as all MA experiments in other organisms were performed under controlled indoor conditions, under which no mutations were observed in S. polyrhiza.
Fig. 2.
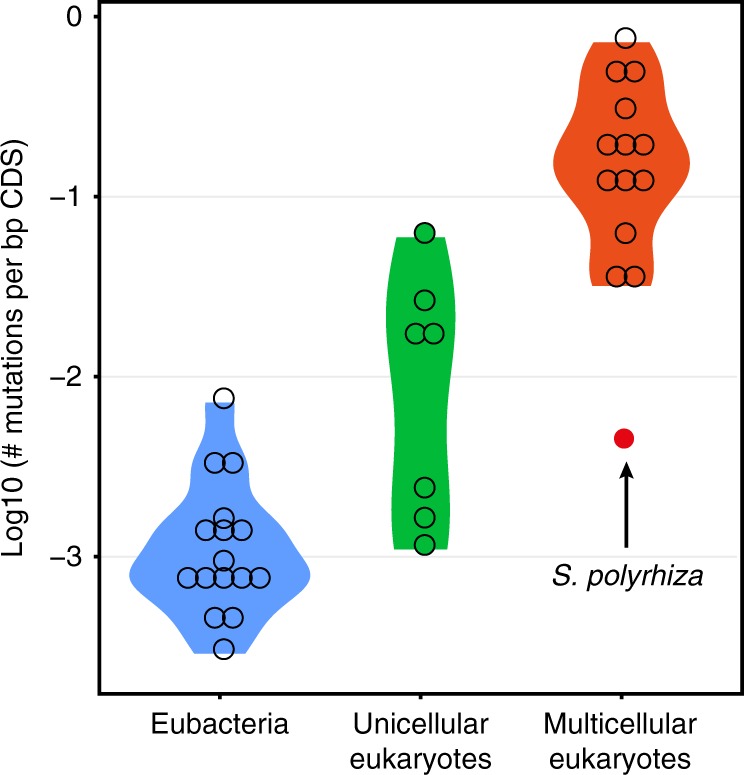
Estimated mutation rates in protein-coding regions among different organisms. The violin plots of log10-transformed numbers of mutations per base pair of protein-coding genome sequences (CDS) per generation for eubacteria, unicellular eukaryotes and multicellular eukaryotes, respectively. The kernel probability density is shown. Each circle indicates the estimate for one species. The arrow highlights the mutation rate in S. polyrhiza. Except for the mutation rate in S. polyrhiza, the plotted data were extracted from previous studies (Supplementary Data 3)
Based on these independent estimates of genetic diversity and mutation rate, we can estimate Ne in S. polyrhiza. Assuming that mutation rates during the clonal and sexual reproduction phases of S. polyrhiza are equal, the estimated effective population size of S. polyrhiza is 9.8 × 105, which is among the highest estimates for multicellular eukaryotes, where Ne was estimated using a similar approach (Supplementary Data 3). This method to estimate Ne, which is widely used, assumes populations are at their genetic equilibrium. Although there was little evidence from this study to suggest that the populations deviated dramatically from equilibrium conditions, as genome-wide Tajima’s D estimates for three out of the four populations (Indian, European, and SE Asian) were close to 0 (in the American population Tajima’s D was 0.59. Supplementary Table 3), more data is required to accurately evaluate the demographic history of S. polyrhiza.
The relatively large Ne may have contributed to the evolution of a low mutation rate in S. polyrhiza, as selection can effectively drive down the mutation rate in populations with large Ne8. In addition to large Ne, the infrequent sexual reproduction in S. polyrhiza might have enhanced the efficiency of selection to minimize the mutation rate. The relatively slow decay of genome-wide LD and the observation that S. polyrhiza rarely flowers in nature suggest that sexual reproduction and recombination in S. polyrhiza, at least in some populations, is infrequent relative to clonal reproduction. Such relatively infrequent recombination can increase linkage between a mutator allele and deleterious mutations, which as a consequence will enhance the strength of selection against mutator alleles22. Therefore, for species such as S. polyrhiza that reproduce both clonally and sexually, the frequency of asexual reproduction may be negatively correlated with the mutation rate. As ~80% of all angiosperms23, including many crop species24, can reproduce clonally, variation in the frequency of sex may have large effects on the evolution of mutation rates in plants and contribute to variation in intraspecific genetic diversity among species.
In addition to low mutation rate, linked selection can also reduce neutral nucleotide diversity by strong selection against deleterious alleles (background selection) or by substitutions of beneficial alleles at linked loci (genetic hitchhiking)25, especially in species with relatively large LD26,27. However, to precisely estimate the effect of linked selection on reducing neutral diversity in S. polyrhiza, it is essential to characterize the factors that affect linked selection, such as the frequency of sweeps, the recombination rate, the strength of selection, the age of the beneficial allele, and population demography28–31. Future studies that sequence larger natural populations of S. polyrhiza, perform long-term outdoor selection experiments and simulate different demographic models will further shed light on the extent to which linked selection might have additionally contributed to the observed low genetic diversity in S. polyrhiza.
In this study, we show that the unexpected pattern of low genetic diversity in a species with large Ne can be explained by extremely low mutation rate in S. polyrhiza. Linked selection may have further reduced the genome-wide genetic diversity. The role of mutation rate in driving variation in genetic diversity has been largely ignored, because obtaining accurate estimates of genome-wide genetic diversity and spontaneous mutation rate in a range of organisms has been difficult in the past. Our study emphasizes that accurate estimates of mutation rates are important for explaining patterns of genetic diversity within species.
Methods
Mutation accumulation (MA) experiments with S. polyrhiza
We performed a MA experiment with S. polyrhiza for 20 generations. Spirodela polyrhiza plants were propagated under three conditions: (i) indoors in the absence of UV light, (ii) outdoors in the absence of natural UV light, and (iii) outdoors in the presence of natural UV light. Spirodela polyrhiza genotype 7498 was pre-cultivated for three weeks in N-medium—which supports optimal growth (N-medium: 0.15 mM KH2PO4, 1 mM Ca(NO3)2 × 4 H2O, 8 mM KNO3, 5 µM H3BO3, 13 µM MnCl2 × 4 H2O, 0.4 µM Na2MoO4 × 2 H2O, 1 mM MgSO4 × 7 H2O, 25 µM FeNaEDTA)—in a climate chamber operating under the following conditions: 16 h light, 8 h dark; light supplied by vertically arranged neon tubes (OSRAM, Lumilux, cool white L36W/840) on each side; light intensity at plant height: 186 ± 3 µmol s−1 m−2 outside polystyrene tubes and 142 ± 3 µmol s−1 m−2 inside polystyrene tube; temperature: 28 °C constant; humidity: 41%. The genotype 7498 originating from North Carolina (USA) was selected based on the existence of a clone-specific reference genome14. A single frond (S1) was transferred to a transparent 50 ml polystyrene tube (28.5 × 95 mm, Kisker) containing 30 ml N-medium, covered with foam cap and incubated in a climate chamber under the above specified conditions. To obtain 6 MA lineages per treatment, the S1 ancestor was propagated according to the propagation scheme (see Supplementary Fig. 2) every two to three days when daughter fronds had fully emerged from the mother frond. For the indoor MA lines, 6 lineages were consequently propagated as single descendants for 20 generations under the same conditions as described above over a period of six weeks. For the outdoor MA lines, plants were moved at the end of June 2016 into a sun-exposed field site in Jena, Germany (50°53′06.7″N 11°40′53.1″E). The fronds were propagated in plastic beakers containing 180 ml N-medium that were fitted into the cavities of white polyvinyl chloride inserts (3 mm thickness) floating inside water-filled 10 l buckets. The buckets were surrounded with a 20 cm isolation layer of soil to avoid extreme temperature fluctuations and refilled with water to compensate for evaporating water whenever needed. To manipulate UV light, the buckets were covered with either UV transmitting (GS 2458, Sandrock, Germany) or UV blocking (UV Gallery100, Sandrock, Germany) Plexiglas plates with 1–3 cm distance between the bucket edge and the plates to allow air circulation. Each MA lineage was propagated in a separate bucket. After transplanting the fronds into the field, the buckets were shaded with two layers of green clear film for the first two days to allow plants to acclimate to outdoor conditions. The first green clear film layer was removed after two days, the second layer after four days. Plants were then propagated every 2–4 days for the following 2 months as single descendants for 20 generations. The MA lineages were randomized between the buckets every two weeks. The 20th generation of the outdoor plants was moved back to the original growth chamber. To obtain genomic DNA for whole genome re-sequencing (WGS), a single frond of the 20th generation of each of the indoor and outdoor MA lines and the ancestor, of which the roots and reproductive pockets were removed, was frozen in liquid nitrogen. All samples were stored at −80 °C until DNA extraction.
DNA isolation and whole genome resequencing
The plant tissue was ground by vigorously shaking the Eppendorf tubes with three metal beads for 1 min in a paint shaker (Skandex S-7, Fluid Management, Sassenheim Holland) at 50 Hz. All DNA samples were isolated using the CTAB method32 and their quantity and quality was analyzed on Qubit. The DNA samples from the MA experiments were sequenced on Illumina HiSeq 4000 at the Genomics Center of the Max Planck Institute for Plant Breeding Research in Cologne (Germany) with 150 bp paired-end reads. For the 68 S. polyrhiza genotypes, all genotypes of S. polyrhiza (see Supplementary Data 1) were taken from the stock collection of the Matthias Schleiden Institute – Plant Physiology, University of Jena, Germany. Plants were then grown in N-medium (see details above) under a constant temperature of 28 °C and 41% humidity. Detailed information and origin of the 68 S. polyrhiza genotypes is listed in Supplementary Data 1. The genomes of the 68 genotypes of S. polyrhiza were sequenced on Illumina HiSeq X Ten at BGI (Shenzhen, China) with 150 bp paired-end reads. On average, 48.2 million reads per genotype were generated.
Short-read trimming, mapping, and variant calling
For all sequenced short reads, low-quality reads and adapter sequences were trimmed with AdapterRemoval v2.033 with the parameters: –collapse –trimns –trimqualities –minlength 36. All of the trimmed reads were then mapped to the S. polyrhiza reference genome14 using BWA-MEM34 with default parameters. All reads with multiple mapping positions in the genome were removed and only the mapped reads were kept. PCR duplicates were removed using the “rmdup” function from SAMtools35. The aligned reads were then used for variant (SNPs and small indels) calling using GATK v3.515 following the suggestions on best practices36,37. In brief, the aligned reads around indels were re-aligned using “IndelRealigner”, and variants were called using the UnifiedGenotyper function with the option -stand_call_conf 30 -stand_emit_conf 10. The variants were then filtered with the option MQ0 ≥ 4 && ((MQ0/(1.0 × DP)) > 0.1) & QUAL < 30.0 & QD < 5.0, which removes all variants that either have more than four samples with MappingQualityZero (MQ0, low mapping quality) and 10% of the mapped reads (DP) with low mapping quality, or have low Phred-scaled probability that a polymorphism exists at the site (QUAL), or low qual score normalized by allele depth (QD). The variant clusters were further annotated as more than three variants within 50 bp using the GATK VariantFiltration function. Only biallelic loci were kept for downstream analysis. The synonymous and non-synonymous variants were annotated using snpEFF (version 4.3 m)38. Due to low sequencing coverage, three individuals from the MA experiments were removed from downstream analysis (see Supplementary Fig. 2).
Population genomic analysis
To analyze genetic diversity and population genomics of the 68 genotypes, additional filtering steps were performed using vcffilter ([https://github.com/vcflib/vcflib], with parameters: -s -f DP > 510 & DP < 10,200). Variants from mitochondrial and chloroplast regions and clustered variants were removed using vcftools39. The population structure among the sequenced 68 genotypes was analyzed using fastSTRUCTURE v1.040. To this end, the loci that were not in Hardy-Weinberg equilibrium (P < 0.01) and tightly linked loci (r2 > 0.33) were removed using vcftools and bcftools41, respectively. Multiple K values (refers to number of populations) ranging from 1 to 10 were analyzed and the value K = 4 was selected using the chooseK.py function from the fastSTRUCTURE package. The genome-wide intraspecific diversity was analyzed using Popgenome v2.2.042 using a data set with no missing genotypes (61,281 SNPs, ~5% of total SNPs, were removed), and diversity at synonymous and non-synonymous sites was analyzed using SNPGenie43 using all variants. Overall, more than 88.0% of the genome and ~92.8% of the coding region had sufficient coverage for variant calling. The estimated population genomic summary statistics were then corrected based on the callable sites. Plink44 was used to calculate pairwise linkage disequilibrium (LD) from the dataset, for which related individuals were removed and only SNPs with MAF greater than 0.05 were kept. To model the decline of LD with physical distance, pairwise r2 between sites was used as the use of D′ is sensitive to small sample sizes45,46, and the decline of LD was modeled using Sved’s equation: E(r2) = (1−/(1 + 4 βd)) + 1/n, where β is the decline in LD with distance d47 and 1/n accounts for small sample size48. The extent of useful LD for mapping can be defined as r2 = 0.3349. In this study we use mean r2 for non-overlapping 100-bp bins to fit Sved’s equation.
Mutation rate estimation and false-negative calculations
Accurately estimating mutation rate requires a step-wise filtering and quality checking process. The SNP filtering pipeline for the MA experiments was developed based on previous studies50,51 and iterative manual inspections of the BAM files using Integrative Genomics Viewer (IGV)52,53. (1) To reduce false positives, we only considered the mapped and properly paired reads with insertion size greater than 100 bp and less than 600 bp using bamtools54. (2) We also excluded all genomic regions that were supported by fewer than nine or greater than 75 reads per sample from both variant counting and genome size calculation, as the variants from the regions that have low or high coverage are likely due to mapping errors (such as repetitive or duplicated regions). On average, 79.7% of the genomic region was kept. (3) Because spontaneous mutations should be only found in the offspring samples but not the ancestor, and the likelihood of a mutation occurring at the exact same position in multiple samples is extremely low (un, where u is the mutation rate, and n refers to number of samples that have a mutation at the same position), any variants that appeared in more than two samples were removed. (4) Only the heterozygous variants that were supported by at least three reads for both alleles were kept. After these filtering steps, 86 variants were found (Supplementary Data 5). Among these, 56 were annotated as variant clusters, likely due to mapping errors. To confirm this, we re-sequenced 28 of these variants that were located in clusters using a Sanger sequencing approach and found none of them confirmed to be true mutations. Therefore, all the variants that were classified as variant clusters were removed.
After removing all variant clusters, nine SNPs and 21 indels remained. Among the 21 indels, all of them were loss of heterozygosity in either the ancestral or the offspring samples. Inspecting the alignment using the IGV showed that 19 of them were located in regions of simple sequence repeats or transposable elements, which were likely false positives. To confirm this, we selected 11 indels for Sanger sequencing and found that all of them were indeed false positives. As a result, all 21 indels were removed from the downstream analysis. Among the nine SNPs, six were point mutations (due to spontaneous mutations) and three were loss-of-heterozygosity (LOH) mutations (potentially due to gene conversion events). We further validated these SNPs using a Sanger-sequencing approach. Two LOH loci were very close to the gap of the genome assembly and the PCR primers could thus not be designed. We validated the remaining seven loci (six point-mutations and one LOH). In total, four out of the six point-mutations were confirmed, and the loss of heterozygosity mutation turned out to be a false positive. The confirmed point-mutations are listed in Table 1 and were used for calculating the spontaneous mutation rate.
The relatively stringent parameters in the variant filtering process theoretically could result in a high rate of false negatives. To control this, we further estimated the false negative rate using the sequence data. We first identified all high-quality heterozygous SNP loci (30,392) from the ancestor using the same filtering parameters (coverage between 9 and 75, and at least three reads to support each of the reference and the alternative allele) and compared them with the heterozygous SNPs in the offspring using a custom script. In theory, all these variants should be found in the clonally produced offspring. Thus, the number of SNPs that could not be identified from the offspring was used to estimate the highest boundary of the false negative rate from our sequencing and variant calling/filtering pipeline, as some of these cases could be a true loss of heterozygosity.
In addition, we also estimated the false negative rate by simulating synthetic mutations to the sequence alignments, an approach that has been used previously55,56. We introduced 1000 non-reference mutations to the callable regions using BAMsurgeon57 (with parameter: –mindepth 9 –maxdepth 75 -d 0 –aligner mem –insane –force), with a frequency of 0.5 (standard deviation = 0.1). Using the same variant calling and filtering pipeline, we identified 94.5% (945 out of 1000) of the synthetic mutations that were successfully introduced to the BAM files, yielding an average false negative rate of 5.5% (95% CI 4.1–7.2%).
Variant validation using Sanger sequencing
Because the total amount of DNA from a single individual was limited, the variant validation was performed using the descendants of the ancestor and offspring individuals. Specifically, at the end of the MA experiments, one individual of each line was propagated for four more generations under indoor conditions, after which the plants were frozen in liquid nitrogen for subsequent variant validation.
To validate the candidate variants, DNA was isolated as described above. PCR primers were designed based on the 500 bp flanking sequences. The PCR reactions were performed with goTaq DNA polymerase (Promega) using 30 PCR cycles with an annealing temperature of 58 °C. The primer information is listed in Supplemental Data 6. The PCR products were checked on a 1.5% agarose gel. The PCR products were then used for sequencing reactions using BigDye v3.1, and the products from the sequencing reactions were purified and sequenced on an ABI 3130XL sequencer.
Reporting summary
Further information on experimental design is available in the Nature Research Reporting Summary linked to this article.
Supplementary information
Description of Additional Supplementary Files
Acknowledgements
We thank Claudia Michel, Beatrice Arnold and Yuanyuan Song for their help in validating the variants from the MA experiments, Stefanie Schirmer for help with the MA experiment and DNA isolation, Daniel Veit for manufacturing the facilities for outdoor duckweed growth, Thomas Städler and Martin Schäfer for constructive discussions commenting on the manuscript. We are also grateful to Tobias Neumann for providing meteorological data. This work was supported by a Marie Curie Intra-European Fellowship (No: 328935 to S. X.), the Alfred and Anneliese Sutter-Stöttner Foundation (to S. X. and M. H.), the Center for Adaptation to a Changing Environment (ACE) at ETH Zurich (to S. X., J. S. and A. W.), the Max Planck Society and the University of Münster. We acknowledge support from the Open Access Publication Fund of the University of Muenster.
Author contributions
S. G., A. W. and M. H. performed the experiments, J. S., J. B. and S. X. performed data analysis, K. J. A. and K. S. S. contributed to the giant duckweed collections, A. W. and J. G. provided resources. M. H. and S. X. conceived and supervised the project, S. X. wrote the manuscript with input from all co-authors.
Data availability
All raw DNA sequences obtained in this study are submitted to NCBI under Bioproject PRJNA476302. Data for figures are deposited in figshare at 10.6084/m9.figshare.7599767.v1 (ref. 58). The authors declare that the data supporting the findings of this study are available within the article, its Supplementary Information files, and upon request.
Competing interests
The authors declare no competing interests.
Footnotes
Journal peer review information: Nature Communications thanks the anonymous reviewers for their contribution to the peer review of this work. Peer reviewer reports are available.
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Change history
4/16/2019
The original HTML version of this Article had an incorrect Published online date of 20 March 2019; it should have been 18 March 2019. This has been corrected in the HTML version of the Article. The PDF version was correct from the time of publication.
Contributor Information
Shuqing Xu, Email: shuqing.xu@uni-muenster.de.
Meret Huber, Email: huberm@uni-muenster.de.
Supplementary information
Supplementary Information accompanies this paper at 10.1038/s41467-019-09235-5.
References
- 1.Forcada J, Hoffman JI. Climate change selects for heterozygosity in a declining fur seal population. Nature. 2014;511:462–465. doi: 10.1038/nature13542. [DOI] [PubMed] [Google Scholar]
- 2.Vander Wal E, Garant D, Festa-Bianchet M, Pelletier F. Evolutionary rescue in vertebrates: evidence, applications and uncertainty. Philos. Trans. R. Soc. Lond. B. 2013;368:20120090. doi: 10.1098/rstb.2012.0090. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Romiguier J, et al. Comparative population genomics in animals uncovers the determinants of genetic diversity. Nature. 2014;515:261–263. doi: 10.1038/nature13685. [DOI] [PubMed] [Google Scholar]
- 4.Ellegren H, Galtier N. Determinants of genetic diversity. Nat. Rev. Genet. 2016;17:422–433. doi: 10.1038/nrg.2016.58. [DOI] [PubMed] [Google Scholar]
- 5.Watterson GA. On the number of segregating sites in genetical models without recombination. Theor. Popul. Biol. 1975;7:256–276. doi: 10.1016/0040-5809(75)90020-9. [DOI] [PubMed] [Google Scholar]
- 6.Tajima F. Evolutionary relationship of DNA sequences in finite populations. Genetics. 1983;105:437–460. doi: 10.1093/genetics/105.2.437. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Corbett-Detig RB, Hartl DL, Sackton TB. Natural selection constrains neutral diversity across a wide range of species. PLoS Biol. 2015;13:e1002112. doi: 10.1371/journal.pbio.1002112. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Sung W, Ackerman MS, Miller SF, Doak TG, Lynch M. Drift-barrier hypothesis and mutation-rate evolution. Proc. Natl Acad. Sci. USA. 2012;109:18488–18492. doi: 10.1073/pnas.1216223109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Landolt, E. Physiologische und ökologische Untersuchungen an Lemnaceen. Ber. Schweiz. Bot. Ges.67, 271–401 (1957).
- 10.Ziegler P, Adelmann K, Zimmer S, Schmidt C, Appenroth KJ. Relative in vitro growth rates of duckweeds (Lemnaceae)—the most rapidly growing higher plants. Plant. Biol. 2015;17:33–41. doi: 10.1111/plb.12184. [DOI] [PubMed] [Google Scholar]
- 11.Xu YL, et al. Species distribution, genetic diversity and barcoding in the duckweed family (Lemnaceae) Hydrobiologia. 2015;743:75–87. doi: 10.1007/s10750-014-2014-2. [DOI] [Google Scholar]
- 12.Bog M, et al. Genetic characterization and barcoding of taxa in the genera Landoltia and Spirodela (Lemnaceae) by three plastidic markers and amplified fragment length polymorphism (AFLP) Hydrobiologia. 2015;749:169–182. doi: 10.1007/s10750-014-2163-3. [DOI] [Google Scholar]
- 13.Michael TP, et al. Comprehensive definition of genome features in Spirodela polyrhiza by high-depth physical mapping and short-read DNA sequencing strategies. Plant J. 2017;89:617–635. doi: 10.1111/tpj.13400. [DOI] [PubMed] [Google Scholar]
- 14.Wang W, et al. The Spirodela polyrhiza genome reveals insights into its neotenous reduction fast growth and aquatic lifestyle. Nat. Commun. 2014;5:3311. doi: 10.1038/ncomms4311. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.McKenna A, et al. The genome analysis toolkit: a MapReduce framework for analyzing next-generation DNA sequencing data. Genome Res. 2010;20:1297–1303. doi: 10.1101/gr.107524.110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Cao J, et al. Whole-genome sequencing of multiple Arabidopsis thaliana populations. Nat. Genet. 2011;43:956–U960. doi: 10.1038/ng.911. [DOI] [PubMed] [Google Scholar]
- 17.Jiang C, et al. Environmentally responsive genome-wide accumulation of de novo Arabidopsis thaliana mutations and epimutations. Genome Res. 2014;24:1821–1829. doi: 10.1101/gr.177659.114. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Agrawal AF, Whitlock MC. Environmental duress and epistasis: how does stress affect the strength of selection on new mutations? Trends Ecol. Evol. 2010;25:450–458. doi: 10.1016/j.tree.2010.05.003. [DOI] [PubMed] [Google Scholar]
- 19.Matsuba C, Ostrow DG, Salomon MP, Tolani A, Baer CF. Temperature, stress and spontaneous mutation in Caenorhabditis briggsae and Caenorhabditis elegans. Biol. Lett. 2013;9:20120334. doi: 10.1098/rsbl.2012.0334. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Shibai A, et al. Mutation accumulation under UV radiation in Escherichia coli. Sci. Rep. 2017;7:14531. doi: 10.1038/s41598-017-15008-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Willing EM, et al. UVR2 ensures transgenerational genome stability under simulated natural UV-B in Arabidopsis thaliana. Nat. Commun. 2016;7:13522. doi: 10.1038/ncomms13522. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.On MK. the evolutionary adjustment of spontaneous mutation rates. Genet. Res. 1966;9:23–34. [Google Scholar]
- 23.Klimes, L., Klimesov, J., Hendriks, R., van Groenendael, J. M., Kroon, Hd. In The Ecology and Evolution of Clonal Plants (eds Kroon H. & Groenendael V.) (Backhuys, Kerkwerve, 1997).
- 24.McKey D, Elias M, Pujol B, Duputie A. The evolutionary ecology of clonally propagated domesticated plants. New Phytol. 2010;186:318–332. doi: 10.1111/j.1469-8137.2010.03210.x. [DOI] [PubMed] [Google Scholar]
- 25.Stephan W. Genetic hitchhiking versus background selection: the controversy and its implications. Philos. Trans. R. Soc. Lond. B. 2010;365:1245–1253. doi: 10.1098/rstb.2009.0278. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Corbett-Detig RB, Hartl DL, Sackton TB. Natural selection constrains neutral diversity across a wide range of species. PLoS Biol. 2015;13:e1002112. doi: 10.1371/journal.pbio.1002112. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Filatov DA. Extreme Lewontin’s paradox in ubiquitous marine phytoplankton species. Mol. Biol. Evol. 2018;36:4–14. doi: 10.1093/molbev/msy195. [DOI] [PubMed] [Google Scholar]
- 28.Beissinger TM, et al. Recent demography drives changes in linked selection across the maize genome. Nat. Plants. 2016;2:16084. doi: 10.1038/nplants.2016.84. [DOI] [PubMed] [Google Scholar]
- 29.Cutter AD, Payseur BA. Genomic signatures of selection at linked sites: unifying the disparity among species. Nat. Rev. Genet. 2013;14:262. doi: 10.1038/nrg3425. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Charlesworth B. The effect of background selection against deleterious mutations on weakly selected, linked variants. Genet. Res. 1994;63:213–227. doi: 10.1017/S0016672300032365. [DOI] [PubMed] [Google Scholar]
- 31.Charlesworth B, Nordborg M, Charlesworth D. The effects of local selection, balanced polymorphism and background selection on equilibrium patterns of genetic diversity in subdivided populations. Genet. Res. 1997;70:155–174. doi: 10.1017/S0016672397002954. [DOI] [PubMed] [Google Scholar]
- 32.Healey A, Furtado A, Cooper T, Henry RJ. Protocol: a simple method for extracting next-generation sequencing quality genomic DNA from recalcitrant plant species. Plant. Methods. 2014;10:21. doi: 10.1186/1746-4811-10-21. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Schubert M, Lindgreen S, Orlando L. AdapterRemovalv2: rapid adapter trimming, identification, and read merging. BMC Res. Notes. 2016;9:88. doi: 10.1186/s13104-016-1900-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Li H, Durbin R. Fast and accurate short read alignment with Burrows-Wheeler transform. Bioinformatics. 2009;25:1754–1760. doi: 10.1093/bioinformatics/btp324. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Li H, et al. The sequence alignment/map format and SAMtools. Bioinformatics. 2009;25:2078–2079. doi: 10.1093/bioinformatics/btp352. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.DePristo MA, et al. A framework for variation discovery and genotyping using next-generation DNA sequencing data. Nat. Genet. 2011;43:491–498. doi: 10.1038/ng.806. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Van der Auwera GA, et al. From FastQ data to high confidence variant calls: the genome analysis toolkit best practices pipeline. Curr. Protoc. Bioinform. 2013;43:11. doi: 10.1002/0471250953.bi1110s43. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Cingolani P, et al. A program for annotating and predicting the effects of single nucleotide polymorphisms, SnpEff: SNPs in the genome of Drosophila melanogaster strainw1118; iso-2; iso-3. Fly. 2012;6:80–92. doi: 10.4161/fly.19695. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Danecek P, et al. The variant call format and VCFtools. Bioinformatics. 2011;27:2156–2158. doi: 10.1093/bioinformatics/btr330. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Raj A, Stephens M, Pritchard JK. fastSTRUCTURE: variational inference of population structure in large SNP data sets. Genetics. 2014;197:573–589. doi: 10.1534/genetics.114.164350. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Li H. A statistical framework for SNP calling, mutation discovery, association mapping and population genetical parameter estimation from sequencing data. Bioinformatics. 2011;27:2987–2993. doi: 10.1093/bioinformatics/btr509. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Pfeifer B, Wittelsburger U, Ramos-Onsins SE, Lercher MJ. PopGenome: an efficient Swiss army knife for population genomic analyses in R. Mol. Biol. Evol. 2014;31:1929–1936. doi: 10.1093/molbev/msu136. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Nelson CW, Moncla LH, Hughes AL. SNPGenie: estimating evolutionary parameters to detect natural selection using pooled next-generation sequencing data. Bioinformatics. 2015;31:3709–3711. doi: 10.1093/bioinformatics/btv449. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Purcell S, et al. PLINK: a tool set for whole-genome association and population-based linkage analyses. Am. J. Hum. Genet. 2007;81:559–575. doi: 10.1086/519795. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Pritchard JK, Przeworski M. Linkage disequilibrium in humans: models and data. Am. J. Hum. Genet. 2001;69:1–14. doi: 10.1086/321275. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Weiss KM, Clark AG. Linkage disequilibrium and the mapping of complex human traits. Trends Genet. 2002;18:19–24. doi: 10.1016/S0168-9525(01)02550-1. [DOI] [PubMed] [Google Scholar]
- 47.Sved JA. Linkage disequilibrium and homozygosity of chromosome segments in finite populations. Theor. Popul. Biol. 1971;2:125–141. doi: 10.1016/0040-5809(71)90011-6. [DOI] [PubMed] [Google Scholar]
- 48.Hill WG. Estimation of effective population size from data on linkage disequilibrium. Genet. Res. 1981;38:209–216. doi: 10.1017/S0016672300020553. [DOI] [Google Scholar]
- 49.Ardlie KG, Kruglyak L, Seielstad M. Patterns of linkage disequilibrium in the human genome. Nat. Rev. Genet. 2002;3:299–309. doi: 10.1038/nrg777. [DOI] [PubMed] [Google Scholar]
- 50.Flynn JM, Chain FJ, Schoen DJ, Cristescu ME. Spontaneous mutation accumulation in Daphnia pulex in selection free vs. competitive environments. Mol. Biol. Evol. 2017;34:160–173. doi: 10.1093/molbev/msw234. [DOI] [PubMed] [Google Scholar]
- 51.Ossowski S, et al. The rate and molecular spectrum of spontaneous mutations in Arabidopsis thaliana. Science. 2010;327:92–94. doi: 10.1126/science.1180677. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Robinson JT, et al. Integrative genomics viewer. Nat. Biotechnol. 2011;29:24–26. doi: 10.1038/nbt.1754. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Thorvaldsdottir H, Robinson JT, Mesirov JP. Integrative genomics viewer (IGV): high-performance genomics data visualization and exploration. Brief. Bioinform. 2013;14:178–192. doi: 10.1093/bib/bbs017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Lopez-Maury L, Marguerat S, Bahler J. Tuning gene expression to changing environments: from rapid responses to evolutionary adaptation. Nat. Rev. Genet. 2008;9:583–593. doi: 10.1038/nrg2398. [DOI] [PubMed] [Google Scholar]
- 55.Keightley PD, Ness RW, Halligan DL, Haddrill PR. Estimation of the spontaneous mutation rate per nucleotide site in a Drosophila melanogaster full-sib family. Genetics. 2014;196:313. doi: 10.1534/genetics.113.158758. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Keightley PD, et al. Estimation of the spontaneous mutation rate in Heliconius melpomene. Mol. Biol. Evol. 2015;32:239–243. doi: 10.1093/molbev/msu302. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Ewing AD, et al. Combining tumor genome simulation with crowdsourcing to benchmark somatic single-nucleotide-variant detection. Nat. Methods. 2015;12:623. doi: 10.1038/nmeth.3407. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Xu, S. et al. SourceData.zip. 10.6084/m9.figshare.7599767.v1 (2019).
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Description of Additional Supplementary Files
Data Availability Statement
All raw DNA sequences obtained in this study are submitted to NCBI under Bioproject PRJNA476302. Data for figures are deposited in figshare at 10.6084/m9.figshare.7599767.v1 (ref. 58). The authors declare that the data supporting the findings of this study are available within the article, its Supplementary Information files, and upon request.