

Abstract
We address the problem of constraint-based causal discovery with mixed data types, such as (but not limited to) continuous, binary, multinomial, and ordinal variables. We use likelihood-ratio tests based on appropriate regression models and show how to derive symmetric conditional independence tests. Such tests can then be directly used by existing constraint-based methods with mixed data, such as the PC and FCI algorithms for learning Bayesian networks and maximal ancestral graphs, respectively. In experiments on simulated Bayesian networks, we employ the PC algorithm with different conditional independence tests for mixed data and show that the proposed approach outperforms alternatives in terms of learning accuracy.
Keywords: Constraint-based learning, Bayesian networks, Maximal ancestral graphs, Mixed data, Conditional independence tests
Introduction
Typically, datasets contain different variable types, such as continuous (e.g., temperature), nominal (e.g., sex), ordinal (e.g., movie ratings), or censored time-to-event (e.g., customer churn), to name a few. Furthermore, data may be measured over time (e.g., longitudinal data) or without considering time (e.g., cross-sectional data). Such heterogeneous data are not exceptions, but the norm in many domains (e.g., biomedicine, psychology, and business). In such cases, it is important and necessary to apply causal discovery methods that are able to handle mixed data types.
Unfortunately, most current approaches do not handle heterogeneous variable types. Constraint-based methods, like the PC and FCI algorithms [37] for Bayesian network (BN) and maximal ancestral graph (MAG) learning, respectively, are general methods that use conditional independence tests to learn the causal network. Thus, in principle, they can be applied to heterogeneous variable types, as long as an appropriate conditional independence test is employed. For continuous variables, typical choices are the partial correlation test [3] or kernel-based tests [46]. Categorical variables are usually handled with the test or the G test [1]. Similarly, most score-based methods, such as the K2 [9] and GES [7] algorithms for BN learning, employ scores for categorical variables [9, 16] or for continuous variables only [14]. Although there exist both constraint-based [4, 10, 27] and score-based [4, 13, 15, 30] approaches for learning with mixed data, they are limited in the variable types they can handle and are too computationally expensive or make unrealistic assumptions.
In this work, we propose a simple and general method to handle mixed variables. We show how to deal with mixtures of continuous, binary, nominal, and ordinal variables, although the same methodology can be used to derive tests for other data types, such as count data, proportions (percentages), positive and strictly positive data, censored data, as well as robust versions for heteroscedastic data; see the R package MXM [24] for a list of available tests. Those tests can be directly plugged-in to existing constraint-based learning algorithms, such as the PC and FCI algorithms. Naturally, the proposed method is not limited to BN and MAG learning algorithms, but can be used with any algorithm that employs conditional independence tests, such as algorithms for Markov network structure discovery [6] or for feature selection [38].
We employ likelihood-ratio tests based on regression models to devise conditional independence tests for mixed data. A likelihood-ratio test for conditional independence of variables X and Y given a (possibly empty) set of variables can be performed by fitting two regression models for X, one using and one with , and comparing their goodness-of-fit. Under the null hypothesis of conditional independence, both models should fit the data equally well, as the inclusion of Y does not provide any additional information for X once is accounted for. Alternatively, one can flip X and Y and fit two regression models for Y instead. Unfortunately, those tests do not necessarily give the same results, especially for low sample scenarios, and thus are not symmetric. Symmetry is an important property, as the test decisions should not depend on the variable order.
In simulated experiments, we demonstrate that in the sample limit and by using appropriate regression models, both tests return the same p value and thus are asymptotically symmetric. To handle finite sample cases, we consider different approaches to obtain symmetry, such as performing both tests and combining them appropriately, or by performing only one test in an order-invariant fashion using predefined rules (similar to [34]). Finally, we evaluate two proposed symmetric tests (one of each category) against an alternative conditional independence test for mixtures of ordinal and continuous variables [10] on simulated BNs and show that the symmetric test based on performing two asymmetric likelihood-ratio tests, called MM, outperforms the rest.
Preliminaries
Bayesian networks and maximal ancestral graphs
A Bayesian network (BN) [31, 37] consists of a directed acyclic graph G over vertices (variables) and a joint probability distribution P. P is linked to G through the Markov condition, which states that each variable is conditionally independent of its nondescendants given its parents. The joint distribution P can then be written as
where p is the total number of variables in G and Pa() denotes the parent set of in G. If all conditional independencies in P are entailed by the Markov condition, the BN is called faithful. Furthermore, BNs assume causal sufficiency, that is, that there are no latent confounders between variables in .
A causal BN is a BN where edges are interpreted causally. Specifically, an edge exists if X is a direct cause of Y in the context of the measured variables . Typically, multiple BNs encode the same set of conditional independencies. Such BNs are called Markov equivalent, and the set of all Markov equivalent BNs forms a Markov equivalence class. This class can be represented by a completed partially directed acyclic graph (PDAG), which in addition to directed edges also contains undirected edges. Undirected edges may be oriented either way in some BN in the Markov equivalence class (although not all combinations are possible), while directed and missing edges are shared among all equivalent networks.
Two classes of algorithms for BN learning are constraint-based and score-based methods. Constraint-based learning algorithms, such as the PC algorithm [37], employ conditional independence tests to discover the structure of the network, and perform an orientation phase afterward to orient (some of) the edges, and a PDAG is returned. Score-based methods [7, 9, 16] assign a score on the whole network based on how well it fits the data and perform a search in the space of BNs or PDAGs to identify a high-scoring network.
Maximal ancestral graphs (MAG) [33] are generalizations of BNs that admit the presence of latent confounders, and thus drop the causal sufficiency assumption. In addition to directed edges, they also contain bidirected edges, which encode dependencies due to latent confounders. As for BNs, multiple Markov equivalent networks may exist, forming a Markov equivalence class, which can be represented by a graph called partial ancestral graph (PAG). The FCI algorithm [37, 45], an extension of the PC algorithm, outputs such a PAG.
Conditional independence tests
Let X and Y be two random variables, and be a (possibly empty) set of random variables. X and Y are conditionally independent given , if holds for all values of X, Y, and . Equivalently, conditional independence of X and Y given implies and . Such statements can be tested using conditional independence tests. Examples of commonly employed conditional independence tests are the partial correlation test [3] for continuous multivariate Gaussian variables, and the G test and the (asymptotically equivalent) test [1, 37] for categorical variables. All aforementioned tests are either likelihood-ratio tests or approximations of them; see [8] for the relation of partial correlation test and F test, and [1] for the connections of the G test to log-linear models and likelihood-ratio tests.
Likelihood-ratio tests, or asymptotically equivalent approximations thereof such as score tests or Wald tests, can be used to compare the goodness-of-fit of nested statistical models. Examples of statistical models are linear regression, binary logistic regression, multinomial regression, and ordinal regression. Two models are called nested, if one model is a special case of the other. Let (reduced model) be a model for X using , and (full model) be a model for X using . is nested within , as can be transformed into by simply setting the coefficients of Y to zero. We proceed with a brief description of the likelihood-ratio test; implementation details are considered in Sect. 2.3. Let be the log-likelihood of a model M, and let be the number of parameters in M. The test statistic T of a nested likelihood-ratio test between and equals and follows asymptotically a distribution with degrees of freedom [42]. It is important to note that this result assumes that the larger hypothesis is correctly specified, that is, that its assumptions are met (such as functional form and distribution assumption) and that all necessary variables are included. In case of model misspecification, the likelihood-ratio test statistic follows a different distribution [12] and should be handled appropriately [40, 41]. This topic is out of the scope of the current paper and will not be further considered hereafter.
Note that if the models and fit the data equally well and thus are equivalent, it implies that X and Y are conditionally independent given (assuming again, correct model specification), as Y does not provide any additional information for X once is given. We will use this property to show how to implement conditional independence tests for mixed variable types in Sect. 4.
Implementing likelihood-ratio tests with mixed data
Without loss of generality, we assume hereafter that Y is the outcome variable, and likelihood-ratio tests are performed using regressions on Y. In order to fit a regression model M for variable Y using mixed continuous, nominal, and ordinal variables, the nominal and ordinal variables have to be first transformed appropriately. Let X be a categorical (nominal or ordinal) variable, taking distinct values. X can be used in M by transforming X into dummy binary variables (also called indicator variables). Note that variables are used instead of one for each value of X, as the excluded one can be determined given the others. The degrees of freedom of variable X is denoted as and equals 1 for continuous variables and for categorical variables. Similarly, the degrees of freedom for a set of variables is defined as . We note that we only consider linear models with intercept terms and no interaction terms, but everything stated can be directly applied to models with interaction or nonlinear terms.
Linear regression
Linear regression models can be used if Y is continuous. The number of parameters of the reduced model equals , whereas for , . Typically, F tests are used for linear regression. The F statistic is computed as
where and are the residual sum of squares of models and , respectively, and n is the sample size. The F statistic, under the null hypothesis (the reduced model is the correct one), follows an F distribution with () degrees of freedom, which is asymptotically equivalent to a distribution with degrees of freedom. Alternatively, if X is also continuous, only the full model is required and a t test on the coefficient of X can be performed.1
Logistic regression
In case Y is nominal, a binary or multinomial logistic regression model can be used, while for ordinal Y, ordinal logistic regression is more appropriate. Typically, ordinal logistic regression makes the proportional odds assumption (also known as ordered logit regression): All levels of the ordinal variable must have the same slope, and the estimated constants are nondecreasing. The proportional odds model that Y has a value larger than j given a set of predictors is
Notice that the values of are the same for each category of Y (i.e., the log-odds functions for each class of Y are parallel). In practice, the proportional odds assumption does not necessarily hold [2]. Because of that, we consider the generalized ordered logit model [43] hereafter, which does not make the proportional odds assumption. The generalized ordered logit model is
where is the coefficient of the i-th variable for the j-the category of Y. Williams [43] described a simple way to fit this model. This is done by fitting a series of binary logistic regressions, where the categories of Y are combined. If there are categories for example, then for , category 1 is contrasted with categories 2, 3, and 4; for , the contrast is between categories 1 and 2 versus 3 and 4; and for , it is categories 1, 2, and 3 versus category 4.
Finally, for both multinomial regression and ordinal regression (using the generalized ordered logit model), the number of parameters is and , and the likelihood-ratio test has degrees of freedom.
Limitations
We note that we implicitly assume that the assumptions of the respective models hold. For instance, linear regression assumes (among others) independent and Gaussian residuals, homoscedasticity and that the outcome is a linear function of the model variables. The latter also applies to logistic regression models, and specifically that the log-odds ratio is a linear function of the variables. If the model assumptions do not hold, the tests do not follow the same asymptotic distribution, and thus may lead to different results. However, we note that linear regression models are robust to deviations from the assumption of normality of residuals, and to a smaller degree to deviations of the homoscedasticity assumption [26]. The latter could also be handled by using tests based on robust regression.
Furthermore, we also note that even if the data come from a BN whose functional relations are linear models as the ones considered above, there are cases where tests fail to identify certain dependencies. Consider, for example, a simple network consisting of three variables, X, Y, and Z, where Y is nominal with three levels, X and Z are continuous and Y is a parent of X and Z. Let Y be uniformly distributed, denote the binary variable corresponding to the i-th dummy variable of Y, , and , where . Thus, the conditional distribution of X and Z given Y is Gaussian, although their marginal distribution is non-Gaussian. An example of the joint distribution of X and Z with 1000 random samples is shown in Fig. 1. Notice that Y induces a nonlinear relation between X and Z, even though all functions are linear. Therefore, any test based on linear regression models on X and Z (or equivalently Pearson correlation) will not identify the dependence between them, despite them being unconditionally dependent. One approach to this problem is to use kernel-based tests (or other, nonlinear tests), which would be able to identify such a dependency asymptotically. We note that although indirect dependencies may be missed by the proposed tests, direct dependencies (edges) would still be identified. Thus, algorithms such as the conservative PC algorithm [32] that only rely on the adjacency faithfulness assumption (i.e., two adjacent variables are dependent given any set of variables) could be used in conjunction with those tests, and the results would be correct, although possibly less informative.
Fig. 1.

An example where the proposed tests fail to identify the unconditional dependency between X and Z is shown. The correlation between X and Z is 0.008, and the p value of the test equals 0.795, suggesting independence
Related work
Mixed data have been considered in the context of Markov network learning; see [44] for a review of such methods. Heckerman et al. [16] were the first to propose a Bayesian method to score BNs with mixed categorical and Gaussian variables. The score is derived under the assumption that continuous variables with discrete parents follow a conditional Gaussian distribution, similar to the graphical models considered by Lauritzen and Wermuth [25]. An important drawback of this approach is that it does not allow discrete variables to have continuous parents, limiting its use in practice. A different approach is followed by Friedman et al. [13, 30], who consider methods of discretization of continuous variables given a specific BNs structure. Such techniques can then be used to search over both, a BN structure and a discretization strategy. Margaritis and Thrun [28] propose a method for testing unconditional independence for continuous variables, which is also directly applicable to ordinal and nominal variables. The method has also been extended to the conditional case, with a single variable in the conditioning set [27]. We are not aware of any extension to the general case that considers larger conditioning sets. Bach and Jordan [4] propose a kernel-based method for graphical model learning with mixed discrete and continuous variables and show how both scores and conditional independence tests can be derived from it. Its main drawbacks are that (a) it has two hyper-parameters, which may be hard to tune and (b) that it is computationally demanding, having a time complexity of , where n is the sample size, although approximations can be used that scale linearly with sample size.
Cui et al. [10] suggested a copula-based method for performing conditional independence tests with mixed continuous and ordinal variables. The idea is to estimate the correlation matrix of all variables in the latent space (containing latent variables which are mapped to the observed variables), which can then be directly used to compute partial correlations and perform independence tests. To this end, they employ Hoff’s Gibbs sampling scheme for generating covariance matrices using copula [17]. The main disadvantage is that the correlation matrix is estimated using Gibbs sampling and thus may be computationally demanding and hard to estimate accurately. Karra and Mili [23] build upon the work of [11] and propose hybrid copula BNs, which can model both discrete and continuous variables, as well as a method for scoring such networks.
Recently, [34] proposed to use likelihood-ratio tests based on linear and logistic regression models to derive conditional independence tests for mixed continuous and nominal variables. They suggest to use linear regression instead of logistic regression whenever applicable, as it is more accurate. This work is most closely related to our approach. The main differences are: (a) They only consider continuous and nominal variables, whereas our proposed approach is more general and is able to deal with other variable types such as ordinal variables and (b) they do not address the asymmetry between both directional tests, while we propose and evaluate methods that handle it.
Symmetric conditional independence tests for mixed data
We consider conditional independence tests based on nested likelihood-ratio tests, using linear, logistic, multinomial, and ordinal regression to handle continuous, binary, nominal, and ordinal variables, respectively. For all cases, we only consider models with linear terms, without any interactions, although this is not a limitation of the proposed approach and additional terms can be included.
Let : = (X and Y are conditionally independent given ) be the null hypothesis of conditional independence. Since we do not have a direct way to test this hypothesis, we consider the null hypotheses : and : . can be tested using a nested likelihood-ratio test by regressing on X, while can be tested by flipping X and Y and regressing on Y. For instance, if X is continuous and Y is nominal, one can either fit two linear regression models for X to test , one using (full model) and one using only Y (reduced model) and perform an F test, or to fit two multinomial logistic regression models for Y in a similar fashion to test and perform a likelihood-ratio test. Ideally, both tests should give identical results and thus be symmetric.
There are special cases, such as when X and Y are continuous and linear regression models are used, where symmetry holds. Unfortunately, this does not necessarily hold in the general case. To the best of our knowledge, it is not known under which conditions such tests are symmetric. Empirical evidence (see Sect. 5) suggests that tests using the aforementioned models give the same results asymptotically (this was also mentioned in [34]). Therefore, given sufficiently many samples, any one of the two tests can be used. For small sample settings, however, the test results often differ, which motivated us to consider methods for deriving symmetric tests.
Symmetric tests by combining dependent p values
One approach is to perform both tests and to combine them appropriately. Let and be the p values of the tests for and , respectively. As both hypothesis tests essentially test the same hypothesis, one can expect the p values to be positively dependent. We use a method presented in [5] for combining dependent p values (which we call MM hereafter), an extension of a previous method [35]. The resulting p value is computed as
| 1 |
This p value can be used to assess whether at least one of the two asymmetric null hypotheses can be rejected. Moreover, it can be demonstrated that is theoretically correct even in the presence of specific types of correlations among the two p values, as in the case of one-sided p values based on Gaussian test statistics that are positively correlated [5]; whether this also holds for combining p values stemming from tests considered here is not clear and needs further investigation, but it is nevertheless a useful heuristic. In addition to that, we considered two simple approaches, by taking the minimum or the maximum between the two p values
| 2 |
| 3 |
The latter is identical to testing whether both hypotheses can be rejected and is an instance of the method by Benjamini and Heller [5] for combining dependent p values. Although taking the minimum p value should be avoided for independent p values, as it does not account for multiple testing, it may be a reasonable choice if the p values have a high positive correlation.
There has been theoretical work for deriving the true distribution of the sum or the ratio of the two test statistics, assuming their correlation is known [19, 20]. A general, permutation-based method for estimating the correlation between test statistics has been proposed by Hongying Dai and Cui [18]. This is computationally expensive, as it requires fitting a large number of models, which is prohibitive for learning graphical models. In anecdotal experiments, we found that this method and the ones considered above produce similar results, and thus it was not further considered.
A strategy for prioritizing asymmetric tests
A different approach for deriving symmetric tests is to use a strategy to prioritize tests and to only perform one of the two tests. This is especially attractive due to its lower computational cost, compared to the previously described approach. Sedgewick et al. [34] compared tests based on linear regression and multinomial logistic regression and found that linear regression is generally more accurate. This can be explained by the fact that the full linear regression model has fewer parameters to fit than the full multinomial regression model (unless the variable is binary) and thus can be estimated more accurately given the same amount of samples. Let X be a continuous variable, and Y be a categorical (nominal or ordinal) variable taking values. The number of parameters required by a full linear regression model for X using Y and equals (see Sect. 2.3). The logistic regression model for Y on the other hand requires parameters. Thus, unless Y is binary and , the logistic regression model always contains more parameters. Everything stated above also holds for the case of unconstrained generalized ordinal regression models. Using this fact, and the observation made by Sedgewick et al. [34], we propose to prioritize tests as follows.
In case of two nominal or ordinal variables, the variable with the fewer values is regressed on, while in case of ties, an arbitrary variable is picked. Note that if the latter holds, the proposed strategy is not always symmetric; we plan to address this case in future work. Recall that if both X and Y are continuous, the tests are symmetric and thus any one of them can be used. In anecdotal experiments, we observed that ordinal regression models, especially the ones considered here, are typically harder to fit than multinomial logistic models, which is the reason why we prioritize nominal over ordinal variables. Hereafter, we will refer to this approach as the Fast approach.
Finally, we note that the problem of asymmetry has been addressed before in different contexts. The MMHC algorithm [39] for BN learning performs feature selection for each variable using the MMPC algorithm to identify a set of candidate parents and children (neighbors), which may result in cases where a variable X is a neighbor of another variable Y but the opposite does not hold. If this is the case, MMPC corrects the asymmetry by removing variable X from the set of neighbors of Y. Similar, in the context of Markov networks, Meinshausen and Bühlmann [29] consider adding an edge between two variables if their neighbor sets contain each other (logical conjunction) or if at least one of the neighbor sets contains the other (logical disjunction), where neighbor sets are inferred independently for each node. The authors state that both approaches perform similarly and are asymptotically identical. Both methods use asymmetric tests to identify the neighbors of each node and then perform a symmetry correction. This approach is similar, although not exactly the same, as taking the minimum (logical disjunction) or maximum (logical conjunction) p value. Both are valid strategies, and should perform similarly (at least for large sample sizes) to the proposed ones. However, the proposed strategies are more general, thus applicable with any method that uses conditional independence tests. In Sect. 5, we also see that the MM typically performs better than strategies based on taking the minimum or maximum p value.
Limitations
For certain variable types, such as longitudinal and censored time-to-event data, it is not always possible to perform both tests. Unless both X and Y are of the same type (e.g., both longitudinal or censored time-to-event), it is not clear how to regress on the nontime-related variable. For example, if X is a censored time-to-event variable (that is, a binary variable indicating whether an event occurred, as well a continuous variable with the time of the event), and Y is a continuous variable, it is straightforward to regress Y on X using methods such as Cox regression to perform a likelihood-ratio test, while the opposite is harder to handle. We plan to investigate such variable types in the future.
Simulation studies
We conducted experiments on simulated data to investigate the properties of mixed tests based on regression models, and to evaluate the proposed symmetric tests. Afterward, we compare the MM and Fast symmetric tests to a copula-based approach (called Copula hereafter) for mixed continuous and ordinal variables [10] in the context of BN learning. The methods were compared on synthetic BNs with continuous and ordinal variables.
Data generation
We proceed with a description of the data generation procedure used throughout the experiments. We will describe the general case for data generation given a BN structure G and the type of each variable. Let X be a variable in G, and Pa(X) be the parents of X in G. For the moment, we will only consider continuous and ordinal variables; ordinal variables will be treated separately afterward. In all experiments, ordinal variables take up to four values.
In case Pa(X) is empty, X is sampled from the standard normal distribution if it is continuous, and is uniformly distributed in case it is binary/nominal. If Pa(X) is not empty, then , which is a linear or generalized linear function depending on the type of X. Although not shown above, as before all nominal variables are transformed into dummy variables, and thus a coefficient is assigned to each dummy variable. The following procedure is used to generate data for X.
Generate samples for each variable in Pa(X) recursively, until samples for each variable are available
Sample the coefficients b of f(Pa(X)) uniformly at random from
Generate
Compute X using f(Pa(X))
In order to generate ordinal variables, we first generated a continuous variable as described above and then discretized it into 2–4 categories appropriately (without damaging the ordered property). Each category contains at least 15% of the observations, while the remaining ones are randomly allocated to all categories. This is identical to having a latent continuous variable (the one generated), but observing a discretized proxy of it. Note that, as the discretization is random, any normality of the input continuous variable is not preserved. Finally, ordinal variables in the parent sets are not treated as nominal variables, but simply as continuous ones and thus only one coefficient is used for them for the purpose of data generation.
Investigating the properties of mixed tests
We considered five combinations of variable types and corresponding regression models: (a) linear-binary (L-B), (b) linear -multinomial (L-M), (c) linear-ordinal (L-O), (d) binary-ordinal (B-O), and (e) multinomial-ordinal (M-O). For each case, we considered the following simple BN models: (a) X Y (unconditional independence), (b) and (unconditional dependence), (c) (conditional dependence of X and Y given Z), also known as collider [37], and (d) (conditional independence of X and Y given Z). In all cases, Z is continuous. We used the previously described procedure to generate data for those networks. The sample size varied in (20, 50, 100, 200, 500, 1000), and each experiment was performed 1000 times, except for case (b), which was performed 1000 times for each direction.
Figure 2 shows the correlation and decision agreements (reject or not the null hypothesis) at the 5% significance level (similar results hold true for the 0.1, 1, and 10% significance levels) between all five pairs of regression models. For the unconditional dependence case, in which both directional models were considered, we repeated the experiment twice and report averages over both cases. We did not consider the correlation of p values in dependent cases, as one is typically interested to have low enough p values to reject the null hypothesis. Overall, the correlation between both tests is very high and tends to one with increasing sample size. An exception is the multinomial-ordinal (M-O) conditional independence case, whose correlation is noticeably smaller than the rest. This can be explained by the fact that this test is the hardest one, as either test uses models with 15 parameters to be fit, requiring more samples. The proportion of decision agreements is very high for all pairs, reaching over 90% even with 200 samples. This is very encouraging, as this is the most important factor for causal discovery methods.
Fig. 2.

The correlation of the two p values and the proportion of decision agreements at the 5% significance level are shown for different pairs of regression models. The correlation of p values for (un)conditional independence increases with sample size, reaching almost perfect positive correlation in most cases. In terms of decision agreements, an agreement of over 90% is reached in all cases even with 200 samples. a Unconditional independence, b conditional independence, c unconditional dependence, and d conditional dependence
Figures 3 and 4 show the estimated type I error and power of all methods. In the unconditional cases, as well as in most conditional cases, all methods perform similarly. Whenever linear models are involved, the asymmetric linear test and the symmetric MM method outperform the rest, which can be seen mostly in the type I error on the conditional independence case. For the conditional case of binary-ordinal and multinomial-ordinal pairs, the MM method offers the best trade-off between type I error, as it very close to 5%, and power, being only slightly worse than some competitors for small samples. Asymmetric tests based on ordinal regression break down in the conditional cases for small sample sizes, and symmetric methods like MM should be preferred.
Fig. 3.
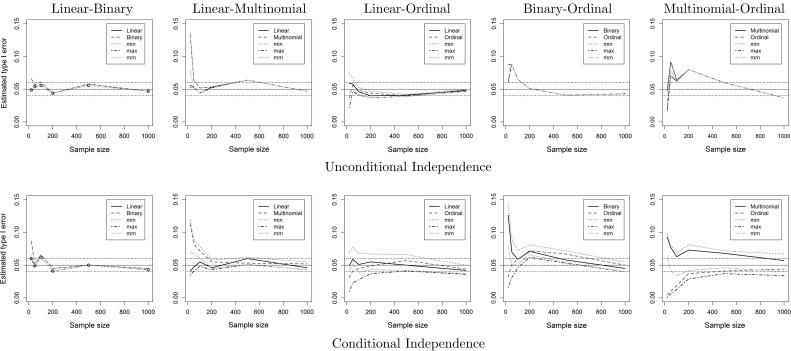
Estimated type I error on the (un)conditional independence cases for each pair of regression models, and three methods for combining dependent p values. The solid horizontal line is at the 5% level, and the two dashed lines at 4 and 6% levels. Whenever linear regression models are involved, the MM method and the linear test perform similarly. For the conditional case of binary-ordinal and multinomial-ordinal pairs, the MM method outperforms all methods
Fig. 4.

Estimated power on the (un)conditional dependence cases for each pair of regression models, and three methods for combining dependent p values. In most cases, all methods perform very similar. For the multinomial-ordinal case, ordinal regression breaks down for small samples, and MM is slightly behind the rest. This is expected, as the other methods also have a larger type I error
Evaluation on Bayesian network learning
As shown in the previous section, the best performing method is the MM method, while the proposed asymmetric approach seems to be promising if continuous variables are involved. In this section, we use those methods for BN learning. We compare them to a recent method by Cui et al. [10], which is applicable to continuous, binary, and ordinal variables. As a BN learning algorithm, we used the order-independent PC algorithm [21], as implemented in the R package pcalg [22]. The significance level was set to 0.01 for all experiments. For the Copula method, [10] used 20 burn-in samples, and 80 samples to estimate the correlation matrix using Gibbs sampling. We increased these numbers to further improve its accuracy. Specifically, we used 2p burn-in samples and 4p samples to estimate the correlation matrix, where p is the number of variables in the data.
We generated BNs with 50 and 100 variables, and with an average degree of 3 and 5. For each case, we generated 50 random BNs and sampled 200, 500, and 1000 training instances. In total, this amounts to 600 datasets. Each variable has a 50% probability of being continuous or ordinal, and ordinal variables take 2–4 values with equal probability. The sampling of the network parameters and the data generation were performed as described above.
To evaluate the performance of the different methods, we computed the structural Hamming distance (SHD) [39], as well as the precision and recall of the network structure and orientations. Naturally, all metrics were computed on the estimated PDAG and the true PDAG. Precision and recall are proportions; hence, in order to compare their values, we used the t test applied on , where a is the precision (recall) of the MM method, and b is the corresponding precision (recall) of the competing methods.2 As for the SHD, we took the differences between the MM method and the rest. Since the values of the SHD are discrete, we used the Skellam distribution [36] and tested (via a likelihood-ratio test) whether its two parameters are equal, implying that the compared values are equal. A t test could be applied here as well, but in order to be more exact, we used a test (or distribution) designed for discrete data.
The results are summarized in Tables 1, 2, and 3. Each table contains average values over 50 random BNs. Overall, the proposed MM approach statistically significantly outperforms the other methods across all computed performance metrics. The Copula method outperforms MM in terms of both prediction metrics only in the 50-variable case with average degree 3 and 200 samples, while the Fast approach is always inferior to MM and is often comparable to Copula. Furthermore, both MM and Fast improve across all metrics with increasing sample size. Copula, however, does not always do so, and precision often declines with increasing sample size (e.g., see cases with 50 variable networks).
Table 1.
Precision and recall for the skeleton estimation
| Method | 50 variables | 100 variables | ||||
|---|---|---|---|---|---|---|
| Skeleton precision | ||||||
| 3 neighbors | ||||||
| MM | 0.783 | 0.981 | 0.988 | 0.949 | 0.971 | 0.974 |
| Fast | 0.708* | 0.971* | 0.979* | 0.936* | 0.952* | 0.951* |
| Copula | 0.898 | 0.942* | 0.975 | 0.884* | 0.896 | 0.914* |
| 5 neighbors | ||||||
| MM | 0.989 | 0.992 | 0.993 | 0.988 | 0.992 | 0.989 |
| Fast | 0.986 | 0.990 | 0.992 | 0.984 | 0.985* | 0.985* |
| Copula | 0.980* | 0.971* | 0.951* | 0.987 | 0.961* | 0.950* |
| Skeleton recall | ||||||
| 3 neighbors | ||||||
| MM | 0.172 | 0.704 | 0.808 | 0.536 | 0.707* | 0.794 |
| Fast | 0.155* | 0.639* | 0.711* | 0.507* | 0.643* | 0.684* |
| Copula | 0.152* | 0.675 | 0.796 | 0.402* | 0.669* | 0.793 |
| 5 neighbors | ||||||
| MM | 0.445 | 0.617 | 0.717 | 0.460 | 0.624 | 0.725 |
| Fast | 0.436* | 0.575* | 0.649* | 0.457 | 0.582* | 0.660* |
| Copula | 0.374* | 0.600* | 0.700 | 0.341* | 0.595* | 0.725 |
An asterisk (*) indicates that the precision or recall of the Fast or Copula approach is statistically significantly lower than that of MM at the 1% significance level. The italic font indicates that the precision of the Copula approach is statistically significantly higher than that of MM at 1% significance level
Table 2.
Precision and recall for the estimation of the orientations
| Method | 50 variables | 100 variables | ||||
|---|---|---|---|---|---|---|
| Orientation precision | ||||||
| 3 neighbors | ||||||
| MM | 0.686 | 0.979 | 0.988 | 0.943 | 0.965 | 0.974 |
| Fast | 0.608* | 0.969* | 0.978* | 0.928* | 0.942* | 0.948* |
| Copula | 0.812 | 0.940* | 0.928* | 0.976 | 0.932* | 0.913* |
| 5 neighbors | ||||||
| MM | 0.987 | 0.992 | 0.993 | 0.986 | 0.992 | 0.989 |
| Fast | 0.984 | 0.989 | 0.992 | 0.982 | 0.985* | 0.984* |
| Copula | 0.975* | 0.970* | 0.950* | 0.984 | 0.959* | 0.949* |
| Orientation recall | ||||||
| 3 neighbors | ||||||
| MM | 0.118 | 0.692 | 0.806 | 0.504 | 0.668 | 0.790 |
| Fast | 0.108* | 0.621* | 0.698* | 0.476* | 0.600* | 0.669* |
| Copula | 0.092* | 0.666 | 0.793 | 0.342* | 0.625* | 0.791 |
| 5 neighbors | ||||||
| MM | 0.413 | 0.606 | 0.711 | 0.430 | 0.613 | 0.719 |
| Fast | 0.406* | 0.561* | 0.638* | 0.428 | 0.569* | 0.649* |
| Copula | 0.327* | 0.591 | 0.696 | 0.289* | 0.583* | 0.722 |
An asterisk (*) indicates that the precision or recall of the Fast or Copula approach is statistically significantly lower than that of MM at the 1% significance level. The italic font indicates that the precision of the Copula approach is statistically significantly higher than that of MM at 1% significance level
Table 3.
Structural Hamming distance (lower is better)
| Method | 50 variables | 100 variables | ||||
|---|---|---|---|---|---|---|
| Structural Hamming distance | ||||||
| 3 neighbors | ||||||
| MM | 71.48 | 34.40 | 25.64 | 97.62 | 69.94 | 55.12 |
| Fast | 73.18* | 38.66* | 33.76* | 101.04* | 80.46* | 74.28* |
| Copula | 70.96 | 37.12* | 30.30* | 115.66* | 76.88* | 62.00* |
| 5 neighbors | ||||||
| MM | 81.46 | 57.28 | 44.54 | 158.60 | 112.35 | 87.10 |
| Fast | 82.12 | 62.62* | 53.56* | 158.50 | 123.55* | 105.30* |
| Copula | 91.60* | 60.42* | 49.84* | 191.40* | 124.95* | 93.15* |
An asterisk (*) indicates that the SHD of the Fast or Copula approach is statistically significantly higher than that of MM at the 1% significance level
Conclusions
In this paper, a general method for conditional independence testing on mixed data is proposed, such as mixtures of continuous, nominal, and ordinal variables, using likelihood-ratio tests based on regression models. Likelihood-ratio tests are not necessarily symmetric, and different approaches to derive symmetric tests are considered. In simulated experiments, it is shown that the likelihood-ratio tests considered in this paper are asymptotically symmetric. Furthermore, the proposed symmetric MM test is shown to significantly outperform competing methods in BN learning tasks. R codes to learn BNs with mixed data are available at the R package MXM [24].
Acknowledgements
We would like to thank the anonymous reviewers for their helpful and constructive comments. The research leading to these results has received funding from the European Research Council under the European Union’s Seventh Framework Programme (FP/2007-2013)/ERC Grant Agreement No. 617393.
Compliance with ethical standards
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Footnotes
In this case, the t test (Wald test) is equivalent to the F test (likelihood-ratio test).
The reason of this is that, these measure being proportions, the absolute difference does not reflect the same information as the ratio which is more meaningful. The difference, for example, between 0.2 and 0.1 is the same as that of 0.8 and 0.7, but their ratio is clearly not the same.
Change history
6/19/2018
The article “Constraint-based causal discovery with mixed data,” written by Michail Tsagris, Giorgos Borboudakis, Vincenzo Lagani, and Ioannis Tsamardinos, was originally published electronically on the publisher’s internet portal (currently SpringerLink) on February 2, 2018, without open access.
Contributor Information
Michail Tsagris, Phone: +30-2810-393577, Email: mtsagris@csd.uoc.gr.
Giorgos Borboudakis, Phone: +30-2810-393577, Email: borbudak@gmail.com.
Vincenzo Lagani, Phone: +30-2810-393578, Email: vlagani@csd.uoc.gr.
Ioannis Tsamardinos, Phone: +30-2810-393575, Email: tsamard.it@gmail.com.
References
- 1.Agresti A. Categorical Data Analysis, 2nd edn. Wiley Series in Probability and Statistics. 2. New York: Wiley-Interscience; 2002. [Google Scholar]
- 2.Agresti A. Analysis of Ordinal Categorical Data. Hoboken: Wiley; 2010. [Google Scholar]
- 3.Baba K, Shibata R, Sibuya M. Partial correlation and conditional correlation as measures of conditional independence. Austral. N. Z. J. Stat. 2004;46(4):657–664. doi: 10.1111/j.1467-842X.2004.00360.x. [DOI] [Google Scholar]
- 4.Bach, F.R., Jordan, M.I.: Learning graphical models with Mercer kernels. In: NIPS, vol. 15, pp. 1009–1016 (2002)
- 5.Benjamini Y, Heller R. Screening for partial conjunction hypotheses. Biometrics. 2008;64(4):1215–1222. doi: 10.1111/j.1541-0420.2007.00984.x. [DOI] [PubMed] [Google Scholar]
- 6.Bromberg F, Margaritis D, Honavar V. Efficient Markov network structure discovery using independence tests. J. Artif. Intell. Res. 2009;35:449–484. doi: 10.1613/jair.2773. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Chickering DM. Optimal structure identification with greedy search. J. Mach. Learn. Res. 2002;3(Nov):507–554. [Google Scholar]
- 8.Christensen R. Plane Answers to Complex Questions: The Theory of Linear Models. Berlin: Springer; 2011. [Google Scholar]
- 9.Cooper GF, Herskovits E. A Bayesian method for the induction of probabilistic networks from data. Mach. Learn. 1992;9(4):309–347. [Google Scholar]
- 10.Cui, R., Groot, P., Heskes, T.: Copula PC algorithm for causal discovery from mixed data. In: Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pp. 377–392. Springer (2016)
- 11.Elidan, G.: Copula Bayesian networks. In: Advances in Neural Information Processing Systems, pp. 559–567 (2010)
- 12.Foutz RV, Srivastava RC. The performance of the likelihood ratio test when the model is incorrect. Ann. Stat. 1977;5(6):1183–1194. doi: 10.1214/aos/1176344003. [DOI] [Google Scholar]
- 13.Friedman N, Goldszmidt M.: Discretizing continuous attributes while learning Bayesian networks. In: ICML, pp. 157–165 (1996)
- 14.Geiger, D., Heckerman, D.: Learning gaussian networks. In: Proceedings of the 10th International Conference on Uncertainty in Artificial Intelligence, pp. 235–243. Morgan Kaufmann Publishers Inc., (1994)
- 15.Heckerman, D., Geiger, D.: Learning Bayesian networks: a unification for discrete and Gaussian domains. In: Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence, pp. 274–284. Morgan Kaufmann Publishers Inc., (1995)
- 16.Heckerman D, Geiger D, Chickering DM. Learning Bayesian networks: the combination of knowledge and statistical data. Mach. Learn. 1995;20(3):197–243. [Google Scholar]
- 17.Hoff PD. Extending the rank likelihood for semiparametric copula estimation. Ann. Appl. Stat. 2007;1(1):265–283. doi: 10.1214/07-AOAS107. [DOI] [Google Scholar]
- 18.Hongying Dai J, Cui Y. A modified generalized Fisher method for combining probabilities from dependent tests. Front. Genet. 2014;5:32. doi: 10.3389/fgene.2014.00032. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Joarder AH. Moments of the product and ratio of two correlated chi-square variables. Stat. Pap. 2009;50(3):581–592. doi: 10.1007/s00362-007-0105-0. [DOI] [Google Scholar]
- 20.Joarder AH, Omar MH, Gupta AK. The distribution of a linear combination of two correlated chi-square variables. Revista Colombiana de Estadística. 2013;36(2):209–219. [Google Scholar]
- 21.Kalisch M, Bühlmann P. Estimating high-dimensional directed acyclic graphs with the PC-algorithm. J. Mach. Learn. Res. 2007;8(Mar):613–636. [Google Scholar]
- 22.Kalisch M, Mächler M, Colombo D, Maathuis MH, Bühlmann P, et al. Causal inference using graphical models with the R package pcalg. J. Stat. Softw. 2012;47(11):1–26. doi: 10.18637/jss.v047.i11. [DOI] [Google Scholar]
- 23.Karra, K., Mili, L.: Hybrid copula Bayesian networks. In: Proceedings of the Eighth International Conference on Probabilistic Graphical Models, pp. 240–251 (2016)
- 24.Lagani V, Athineou G, Farcomeni A, Tsagris M, Tsamardinos I. Feature selection with the R package MXM: discovering statistically-equivalent feature subsets. J. Stat. Softw. 2017;80(7):1–25. doi: 10.18637/jss.v080.i07. [DOI] [Google Scholar]
- 25.Lauritzen SL, Wermuth N. Graphical models for associations between variables, some of which are qualitative and some quantitative. Ann. Stat. 1989;17(1):31–57. doi: 10.1214/aos/1176347003. [DOI] [Google Scholar]
- 26.Lumley T, Diehr P, Emerson S, Chen L. The importance of the normality assumption in large public health data sets. Annu. Rev. Public Health. 2002;23(1):151–169. doi: 10.1146/annurev.publhealth.23.100901.140546. [DOI] [PubMed] [Google Scholar]
- 27.Margaritis, D.: Distribution-free learning of Bayesian network structure in continuous domains. In: Proceedings of the Twentieth National Conference on Artificial Intelligence, pp. 825–830 (2005)
- 28.Margaritis, D., Thrun, S.: A Bayesian multiresolution independence test for continuous variables. In: Proceedings of the Seventeenth Conference on Uncertainty in Artificial Intelligence, pp. 346–353. Morgan Kaufmann Publishers Inc., (2001)
- 29.Meinshausen N, Bühlmann P. High-dimensional graphs and variable selection with the lasso. Ann. Stat. 2006;34(3):1436–1462. doi: 10.1214/009053606000000281. [DOI] [Google Scholar]
- 30.Monti, S., Cooper, G.F.: A multivariate discretization method for learning Bayesian networks from mixed data. In: Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence, pp. 404–413. Morgan Kaufmann Publishers Inc., (1998)
- 31.Pearl J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Reasoning. Los Altos: Morgan Kaufmann Publishers; 1988. [Google Scholar]
- 32.Ramsey, J., Spirtes, P., Zhang, J.: Adjacency-faithfulness and conservative causal inference. In: Proceedings of the Twenty-Second Conference on Uncertainty in Artificial Intelligence, pp. 401–408. AUAI Press (2006)
- 33.Richardson T, Spirtes P. Ancestral graph Markov models. Ann. Stat. 2002;30(4):962–1030. doi: 10.1214/aos/1031689015. [DOI] [Google Scholar]
- 34.Sedgewick, A.J., Ramsey, J.D., Spirtes, P., Glymour, C., Benos, P.V.: Mixed Graphical Models for Causal Analysis of Multi-modal Variables. arXiv:1704.02621 (2017)
- 35.Simes RJ. An improved Bonferroni procedure for multiple tests of significance. Biometrika. 1986;73(3):751–754. doi: 10.1093/biomet/73.3.751. [DOI] [Google Scholar]
- 36.Skellam JG. The frequency distribution of the difference between two Poisson variates belonging to different populations. J. R. Stat. Soc. Ser. A (General) 1946;109(Part 3):296. doi: 10.2307/2981372. [DOI] [PubMed] [Google Scholar]
- 37.Spirtes P, Glymour CN, Scheines R. Causation, Prediction, and Search. Cambridge : MIT press; 2000. [Google Scholar]
- 38.Tsamardinos, I., Aliferis, C.F., Statnikov, A.: Time and sample efficient discovery of Markov blankets and direct causal relations. In: Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 673–678. ACM (2003)
- 39.Tsamardinos I, Brown LE, Aliferis CF. The max-min hill-climbing Bayesian network structure learning algorithm. Mach. Learn. 2006;65(1):31–78. doi: 10.1007/s10994-006-6889-7. [DOI] [Google Scholar]
- 40.Vuong QH. Likelihood ratio tests for model selection and non-nested hypotheses. Econ. J. Econ. Soc. 1989;57(2):307–333. [Google Scholar]
- 41.White H. Maximum likelihood estimation of misspecified models. Econ. J. Econ. Soc. 1982;50(1):1–25. [Google Scholar]
- 42.Wilks SS. The large-sample distribution of the likelihood ratio for testing composite hypotheses. Ann. Math. Stat. 1938;9(1):60–62. doi: 10.1214/aoms/1177732360. [DOI] [Google Scholar]
- 43.Williams R. Generalized ordered logit/partial proportional odds models for ordinal dependent variables. Stata J. 2006;6(1):58. [Google Scholar]
- 44.Yang, E., Baker, Y., Ravikumar, P., Allen, G., Liu, Z.: Mixed graphical models via exponential families. In: Artificial Intelligence and Statistics, pp. 1042–1050 (2014)
- 45.Zhang J. On the completeness of orientation rules for causal discovery in the presence of latent confounders and selection bias. Artif. Intell. 2008;172(16):1873–1896. doi: 10.1016/j.artint.2008.08.001. [DOI] [Google Scholar]
- 46.Zhang, K., Peters, J., Janzing, D., Schölkopf, B.: Kernel-based conditional independence test and application in causal discovery. In: Proceedings of the 27th Conference on Uncertainty in Artificial Intelligence, pp. 804–813 (2012)