

Abstract
Recent advances in machine learning (ML) have led to enthusiasm about its use throughout the biopharmaceutical industry. The ML methods can be applied to a wide range of problems and have the potential to revolutionize aspects of drug development. The incorporation of ML in modeling and simulation (M&S) has been eagerly anticipated, and in this perspective, we highlight examples in which ML and M&S approaches can be integrated as complementary parts of a clinical pharmacology workflow.
Recent advances in machine learning (ML) have led to, for example, intelligent algorithms based on deep learning that enable accurate face and voice recognition on mobile phones. Consequently, these demonstrations have generated excitement about potential applications of ML in the biopharmaceutical industry, particularly toward research and development and personalized health care.1 Many ML algorithms evolved over recent decades from a combination of computer science, engineering, and statistical methods,2, 3 and in the last few years advances in data storage and computational power have enabled ML to become a daily reality. Applications of ML in the context of pharmaceutical research typically showcase algorithms trained on huge data sets that identify correlations between features predictive of a given outcome.4 A few highlights from the drug discovery and development pipeline in which ML methods have added value are predictions of ligand‐protein binding from chemical properties,5 automatic classification of biopsy images,6 and prediction of medical events from electronic health records.7
We define ML as “a set of methods that can automatically detect patterns in data, and then use the uncovered patterns to predict future data, or to perform other kinds of decision making under uncertainty.”2 These algorithms span from classical regression and support vector machines to deep convolutional neural networks. In particular, we consider deep and/or convolutional neural networks and ensemble tree‐based methods, which have demonstrated excellent performance in automatically detecting and learning the most appropriate data representation to build predictive models.3, 8
Quantitative modelers in clinical pharmacology streamline clinical drug development using mathematical approaches, such as nonlinear mixed‐effects modeling, Bayesian approaches, stochastic and deterministic ordinary differential equations, and computational rule‐based methods. We hereafter refer to this approach as modeling and simulation (M&S). The M&S models are usually interpretable and transparent, influencing translation from animal to human, explaining response variability across patients, informing dose selection and treatment regimens, and predicting efficacious combinations of therapies. In contrast to M&S workflows, “black box” ML techniques require fewer assumptions about the interactions but automatically identify correlations between features in a data set that improve the model's ability to predict a certain output.
In this perspective, we discuss examples of how ML can add value to M&S workflows and where M&S methods can be used to improve interpretability of ML methods in the context of clinical pharmacology. We assert that M&S and ML are complementary and that there is great potential to join forces of the two approaches, exploiting their relative merits. ML is a promising future avenue for M&S that will increasingly be incorporated to improve performance of, and confidence in, clinical pharmacological models. Below, we outline two illustrative examples of scenarios in which we anticipate a strong benefit in model performance and/or predictivity by combining the strengths of M&S and ML. Thereby, we hope to stimulate discussion and promote wider application of ML within the M&S community.
1. Machine learning for improving complex model performance
Many M&S models, such as quantitative systems pharmacology or pathophysiology models, can be computationally intensive to evaluate, which often limits the opportunity for full exploration of parameter sensitivity, model identifiability, and model behavior. Models that are prone to high computational costs are typically cell signaling models consisting of numerous ordinary differential equations, agent‐based models, and models comprising stochastic or partial differential equations. Traditional methods to analyze these complex and typically nonlinear mathematical systems, including global sensitivity and identifiability analyses, can be prohibitively intensive to run. Alden and colleagues9 proposed a combined approach to tackle this challenge.
Several ML algorithms lend themselves to such problems, improving the efficiency and performance of model analysis. Here, we describe an example of how ML can supplement M&S model analysis and/or computation and lead to a deeper understanding of the M&S model and its properties.
In order to conduct a global parameter sensitivity analysis to investigate the contributions of each of the M&S model parameters to the resulting model behavior, it is necessary to perform simulations of the model on a comprehensive random sample of a potentially high dimensional parameter space. For small‐medium scale models with 10 parameters, prohibitively many simulations (on the order of 1010) are required for a full exploration of the parameter space.
However, an ML step can streamline the analysis while enriching the results. For this approach, the model is simulated for a broad but not exhaustive number (e.g., thousands) of randomly generated parameter sets. The model parameters used for each simulation constitute the “input” data set for an ML algorithm, and the results of the simulations constitute the “output” data set. Several ML algorithms, such as deep neural networks and ensemble tree‐based methods, can be implemented to infer relationships between the “input” and “output” data set. After training the ML algorithm on the simulated data sets, the outcomes of model simulations for many more parameter sets can be predicted. An illustrative diagram is provided in Figure 1 a. The outlined approach significantly reduces the number of parameter samples for which actual simulations need to be performed. The resulting predicted outcomes are used to investigate the sensitivity of the model's outcomes to its constituent parameters.
Figure 1.
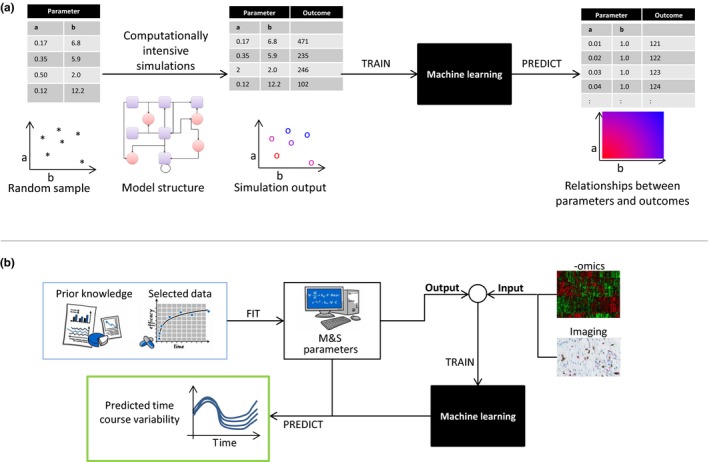
(a) A two‐parameter example illustrates the method of using machine learning (ML) to improve efficiency of global sensitivity analysis for complex mathematical models. Taking a random sample of model parameters a and b, simulations are performed and the outcomes recorded. The parameter sample and corresponding outcomes are used to train an ML algorithm, which is subsequently used to predict model outcomes for a richer range of parameter sets in order to streamline model analyses. (b) The workflow illustrates how to integrate big data into modeling and simulation. Data and prior knowledge are used for calibrating the parameters of a mathematical model, depicted by the box “M&S.” The resulting patient‐specific parameters are passed as “output” along with ‐omics and imaging data as “input” to train an ML algorithm, with the aim to establish a link between them. By predicting model parameter sets for measured “input” data, time courses and their variabilities can be analyzed by forward evaluation of the mathematical model.
By reducing the number of simulations by several orders of magnitude, model analyses are no longer prohibitively computationally intensive. The described method applies to many computationally demanding model classes involving ordinary, stochastic, or partial differential equations, or other formulations. Furthermore, similar approaches can be used to investigate identifiability, inter‐individual variability via nonlinear mixed effects modeling, steady state and linear stability analyses, and to identify regions of parameter space that generate unusual emergent properties in the temporal dynamics of the system.
2. Integrating big data into m&s
Recent advances in measurement technology have led to the generation of data at scale, including ‐omics, imaging, laboratory tests, and digital biomarkers. These taken together are known as “big data”. Typical big data sets in a clinical setting contain thousands to millions of data points for each patient, and this number is likely to increase. It is assumed that big data sets contain important information about patients and their diseases and that understanding these data is a key step toward next‐generation personalized health care. Big data sets are well suited to ML approaches, and there are many examples in which such data sets have been used to train ML models to address specific questions.5, 6, 7 However, due to their “black box” nature, pure ML models do not necessarily provide biological insight or interpretability of results. The M&S community, who traditionally focus on relatively few variables such as drug concentration, biomarkers, or clinical end points, is challenged with the need to incorporate big data sets into tractable models accounting for known biological mechanisms. There is potential for combined approaches in which ML methods supplement M&S models to make informed decisions in a timely manner using all available patient data.
Mechanistic systems pharmacology models integrate prior knowledge about drug–target interactions and biological mechanisms of interest through the structure of the underlying equations, and clinical or preclinical data are used to calibrate model parameters. One of the goals of M&S in this context is to better understand and characterize response variability within patient populations. However, the driving factors for response variability often remain unclear. ML approaches can establish a link between big data and mechanistic models, and, as such, a correspondence between heterogeneity in big data sets and inter‐individual variability in response.
Potentially relevant big data, including ‐omics and imaging, can be used as an “input” to an ML algorithm, whereas the patient‐specific parameters estimated using the mechanistic model are considered as the “output”. The link between input and output is established using (deep) neural networks, which provide an automatic approach to discover meaningful data representations (in particular, through dimensionality reduction) to build a predictive model.3, 10
After training with these data, the ML algorithm is capable of predicting parameter sets from measured input data obtained from additional patients. These ML‐derived individual parameters can be implemented in the mechanistic model to predict time courses and their variability. Furthermore, the method enables the generation of virtual patient populations or determination of individual dosing regimens. A schematic for this approach is shown in Figure 1 b.
The outlined approach is a generic recipe for integrating large data sets and model‐based approaches. Different combinations of models may be favorable in certain situations, for example, a combination or “stacking” of multiple ML models to preprocess the input data.
Conclusion
We have described two conceptual and illustrative examples wherein M&S and ML join forces to improve model performance, personalization, and predictivity compared with either approach in isolation. In the first example, model performance is enhanced by including an ML step to predict unobserved model behaviors and, in the second example, the ML step identifies relationships among large ‐omics, imaging, or other complex data sets and interpretable model parameters.
We envision myriad combinations of M&S and ML in a clinical pharmacology context in the near future. One can foresee further examples, such as the virtual enhancement of data sets, to be used in ML approaches via mechanistic model simulations to address the challenge of small sample size and/or sparse temporal granularity. Another example is the incorporation of mechanistic pathophysiology models in predictive algorithms for real‐time clinical decision support in indications such as diabetes, vision loss, or epilepsy.
Overall, we believe that M&S and ML are complementary approaches within the biopharmaceutical industry. Although certainly not applicable to every scenario, the arrival of ML marks a new horizon that we are excited to explore. M&S and ML are not antagonistic approaches, and scientists are not required to choose between them for any given problem; on the contrary, modelers have the opportunity to combine elements from both to establish reliable models, improve drug development, and ultimately take steps toward personalized health care.
Funding
No funding was received for this work.
Conflict of Interest
The authors declared no competing interests for this work.
References
- 1. Baker, R.E. , Peña, J.‐M. , Jayamohan, J. & Jérusalem, A. Mechanistic models versus machine learning, a fight worth fighting for the biological community? Biol. Lett. 14, 20170660 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Murphy, K.P. Machine Learning: A Probabilistic Perspective. (MIT Press, Cambridge, MA, 2012). [Google Scholar]
- 3. LeCun, Y. , Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015). [DOI] [PubMed] [Google Scholar]
- 4. Jagga, Z. & Gupta, D. Machine learning for biomarker identification in cancer research – developments toward its clinical application. Per. Med. 12, 371–387 (2015). [DOI] [PubMed] [Google Scholar]
- 5. Chen, H. , Engkvist, O. , Wang, Y. , Olivecrona, M. & Blaschke, T. The rise of deep learning in drug discovery. Drug Discov. Today 23, 1241–1250 (2018). [DOI] [PubMed] [Google Scholar]
- 6. Litjens, G. et al Deep learning as a tool for increased accuracy and efficiency of histopathological diagnosis. Nat. Sci. Rep. 6, 26286 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Rajkomar, A. et al Scalable and accurate deep learning with electronic health records. NPJ Digit. Med. 1, 1–10 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Friedman, J. , Hastie, T. & Tibshirani, R. The elements of statistical learning. Vol. 1. No. 10. New York, NY, USA, Springer series in statistics; (2001). [Google Scholar]
- 9. Alden, K. et al Spartan: a comprehensive tool for understanding uncertainty in simulations of biological systems. PLoS Comput. Biol. 9, e1002916 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Shao, H. , Kumar, A. & Fletcher, P.T. The Riemannian geometry of deep generative models. arXiv, 1711.08014 (2017).