

Abstract
The real-time estimation of polar motion (PM) is needed for the navigation of Earth satellite and interplanetary spacecraft. However, it is impossible to have real-time information due to the complexity of the measurement model and data processing. Various prediction methods have been developed. However, the accuracy of PM prediction is still not satisfactory even for a few days in the future. Therefore, new techniques or a combination of the existing methods need to be investigated for improving the accuracy of the predicted PM. There is a well-introduced method called Copula, and we want to combine it with singular spectrum analysis (SSA) method for PM prediction. In this study, first, we model the predominant trend of PM time series using SSA. Then, the difference between PM time series and its SSA estimation is modeled using Copula-based analysis. Multiple sets of PM predictions which range between 1 and 365 days have been performed based on an IERS 08 C04 time series to assess the capability of our hybrid model. Our results illustrate that the proposed method can efficiently predict PM. The improvement in PM prediction accuracy up to 365 days in the future is found to be around 40% on average and up to 65 and 46% in terms of success rate for the and , respectively.
Keywords: Copula, SSA, Polar motion, EOP, Prediction
Introduction
Polar motion (PM) describes the movement of the Earth’s rotation axis w.r.t the Earth surface. The study of PM provides valuable information for studying many geophysical and meteorological phenomena (Barnes et al. 1983; Wahr 1982, 1983; Mathews et al. 1991; Gross et al. 2003; Chen and Wilson 2005; Gross 2015; Seitz and Schuh 2010; Schuh and Böhm 2011).
Since the 1960s, highly accurate PM coordinates can be obtained by different space geodesy techniques. These techniques include: Satellite Laser Ranging (SLR) (Coulot et al. 2010), Lunar Laser Ranging (LLR) (Dickey et al. 1985), Doppler Orbitography and Radiopositioning Integrated by Satellite (DORIS) (Angermann et al. 2010), Global Navigation Satellite Systems (GNSS) (Dow et al. 2009; Byram and Hackman 2012), and very-long-baseline interferometry (VLBI) (Schuh and Schmitz-Hübsch 2000; Nilsson et al. 2010, 2011, 2014).
Accurate real-time PM is needed for high-precision satellite navigation and positioning and spacecraft tracking (Kalarus et al. 2010; Stamatakos 2017). However, the PM is not provided in real time due to the complexity of the measurement model and data processing; PM coordinates are available with a delay of hours to days (Bizouard and Gambis 2009; Schuh and Behrend 2012). Therefore, it is essential to predict the PM parameters precisely.
Different methods and means have been investigated and applied for PM prediction such as least squares (LS) collocation (Włodzimierz 1990), spectral analysis and LS extrapolation method (Akulenko et al. 2002), LS extrapolation of a harmonic model and autoregressive (AR) prediction (Kosek et al. 1998, 2007; Xu et al. 2012), wavelets and fuzzy inference systems (Akyilmaz and Kutterer 2004; Akyilmaz et al. 2011) modeling and forecasting excitation functions (Chin et al. 2004), Kalman filter with atmospheric angular momentum forecasts (Freedman et al. 1994), and artificial neural network (ANN) (Schuh et al. 2002; Kalarus and Kosek 2004). The Earth orientation parameters prediction comparison campaign (EOP PCC) took place within (2005–2009), and the results demonstrate that there is no particular method superior to other for all prediction intervals (Kalarus et al. 2010). Among these methods, the combination of LS and AR process is considered to be one of the most effective for PM prediction (Kalarus et al. 2010). The mentioned combination method achieved reasonable results for short-term forecasting. However, due to the complexity of the PM excitation model, it is not able to reproduce the time variation of the periodic terms that influence the long-term predictive accuracy of PM. Consequently, a new prediction method is required that could bring us significantly closer to meeting the accuracy goals pursued by the Global Geodetic Observing System (GGOS) of the International Association of Geodesy (IAG), i.e., 1 mm accuracy and 0.1 mm/year stability on global scales in terms of the ITRF defining parameters (Plag and Pearlman 2009). Therefore new techniques or a combination of the existing methods need to be investigated for improving the efficiency of the predicted PM considering the time variation of the periodic terms and the trend. In this study, we examined the combination of singular spectrum analysis (SSA) and Copula-based analysis to predict PM. SSA is not constrained by the assumptions of using predetermined functions such as sine wave as the base; it rather exploits data-driven base functions for extracting fundamental components of the time series and applies a classification method to explore the relationship between the derived elements (Broomhead and King 1986; Vautard et al. 1992; Zotov 2005). The Copula method operates linear and nonlinear dependency between variables, and it is a potent and efficient tool for dealing with multi-dimensional data and modeling the relationship between parameters (Joe 1997). The combination of SSA and Copula-based methods will be applied for the first time as a novel stochastic tool for PM determination.
PM is the sum of two statistically independent parts: trend and undulation. This hybrid model consists of a deterministic annual and the Chandler component as well as long-term lower-frequency parts which are estimated by SSA. The difference between the deterministic solution and the PM data is then used in a Copula-based model to predict stochastic processes. Then, the final PM prediction is a combination of the deterministic prediction (derived from the SSA solution) and the stochastic prediction (obtained from the Copula solution). To this end, first, the time series of PM from EOP 08 C04 were analyzed, and the trend is modeled and separated by SSA. Then, a Copula prediction model is made based on the SSA-separated time series. Finally, the accuracy of the proposed combined method is verified through different sets of PM prediction tests.
Methodology
In this study, we developed and explored the integration of Copula-based analysis and SSA for precisely predicting PM.
Singular spectrum analysis
To maximize the prediction performance, we need a mathematical tool to retrieve all time-correlated information from the time series. As a matter of fact, the existence of excitations of PM can profoundly affect the forecasting procedure, particularly in longer intervals. Therefore, the exploitation of efficient techniques is crucial to minimize the risk of having gross errors.
SSA is a nonparametric spectral estimation method which can be used for decomposing a time series into the sum of interpretable components, e.g., trend, periodic components, and noise, without a priori assumption about the constituent components (Golyandina et al. 2001).
SSA is able to remove redundancies and groups uncorrelated information into informative empirical functions which can reveal main aspects of the time series. The mentioned functions are used as bases of a subspace in which the time series is a member of and can be exploited for modeling the time series in a desired level of details. Therefore, the model can simulate the future entries of the time series using these base functions.
The SSA method for trend extraction can be succinctly expressed as two stages:
Decomposition
First the time series is embedded in an L-dimensional vector space. The outcome of this stage will be a trajectory matrix () which consists of L rows. The matrix has been simply formed using L-element lagged vectors taken from the time series by sliding a window of size L.
| 1 |
| 2 |
| 3 |
being and .
Having the trajectory matrix formed, singular value decomposition (SVD) is applied to factorize in the form of in order to retrieve its principal components (PC).
| 4 |
where and are the left and right singular vectors, respectively, and is a diagonal matrix consisting of singular values of which reflect the importance of each corresponding pair of left–right singular vectors. The decomposition step can be performed using calculation of eigenvalues and eigenvectors of the matrix .
Let denote diagonal entries of (the eigenvalues of ) and indicate the corresponding eigenvectors of which are also called empirical orthogonal functions (EOF) of . The right singular vectors of are eigenvectors of calculated by:
| 5 |
Now, the trajectory matrix can be written as:
| 6 |
Reconstruction
This stage aims to rebuild the time series using the reconstructed version of trajectory matrix. So, a subset of can be chosen for reconstruction of the trajectory matrix. The choice of PCs of defines how smooth would be the reconstructed version of the time series and how much detail of the original time series would be captured. Having a proper selection of PCs, a representative trend is extracted by applying diagonal averaging to the reconstructed trajectory matrix (. Let , and then, the trend of the time series is:
| 7 |
Copula-based analysis
There is a well-introduced method called Copula that can be applied for polar motion modeling, estimation, and prediction. The word of Copula is a Latin noun that means a link or tie. The Copula method exploits linear and nonlinear dependency between variables. It is a potent and efficient tool for dealing with multi-dimensional data and modeling the relation between parameters based on the marginal distribution functions of the variables (Embrechts et al. 2002). Copula appeared in the context for the first time by Sklar (1959). Sklar’s theorem indicates that a Copula function C connects a given multivariate distribution function with its univariate marginal. For bivariate distribution, there is a bivariate Copula C which models the joint cumulative probability distribution function of two variables X and Y based on the marginal cumulative distribution functions and .
| 8 |
where C describes the joint distribution function .u and v are transformed of X and Y to uniform distribution, respectively. Then, Joe (1997) and Nelsen (2007) developed the idea of the Copula. For many years, the Copula method has been used for modeling the dependence structure between random variables in different types of studies, e.g., economics (Rachev and Mittnik 2000; Patton 2006, 2009), biomedicine (Wang and Wells 2000; Escarela and Carriere 2003), hydrology (Bárdossy and Li 2008; Bárdossy and Pegram 2009; Verhoest et al. 2015), meteorology (Laux et al. 2011; Vogl et al. 2012), hydro-geodesy (Modiri et al. 2015). A brief introduction to the concept of copula function is given in the next subsections.
Characteristic of Copulas
In the bivariate case, a Copula is represented as a function C from to [0, 1] so that (Genest and Rivest 1993; Jaworski et al. 2010):
| 9 |
| 10 |
Copula is an increasing function. It implies that holds
| 11 |
Copula is a continuous function:
| 12 |
The Copula density is computed by differentiating Copula cumulative distribution function.
| 13 |
Empirical Copula
The empirical Copula is an estimator for the unknown theoretical Copula distribution, and it is defined in the rank space as follows (Genest and Rivest 1993; Genest and Favre 2007; Laux et al. 2011):
| 14 |
where,
denote the pairs of ranks of the variable ,
denote the pairs of ranks of the variable ,
n is the length of the data vector,
1(...) is the indicator function. If the condition is true, the indicator function is equal to 1. Otherwise, the indicator function is equal to 0.
Archimedean Copula
A number of Copulas can be estimated directly with the simple form. They are named Archimedean Copulas. An Archimedean Copula can be presented in the following form:
| 15 |
where is the Copula parameter and the function is the generator of the Copula with the following characteristics (Nelsen 2007):
for all , is decreasing,
for all , is convex,
,
and is defined by
There are three commonly used Archimedean Copula which are explained as follows and will be investigated in this study (see Table 1).
-
Clayton Copulas
The generator of the Clayton Copula (see Fig. 1) is given by
Therefore, the cumulative distribution function (CDF) for Clayton Copula is defined as (Clayton 1978):16
where is restricted on the interval . If , it shows the independence case and when , indicate high dependency in the lower rank space.17 -
Frank Copula
The generator of the Frank Copula (see Fig. 2) is given by
The parameter is defined over . The CDF for Frank Copula is given by (Joe 1997; Lee and Long 2009)18
Frank Copula allows to model data with positive and negative dependency. The large positive and negative indicate high dependency, and implies total independence. The Frank Copula is a suitable method for two data sets with the same dynamic characteristics (Rodriguez 2007).19 -
Gumbel Copulas
Gumbel Copula (see Fig. 3) is famous for its ability to capture strong upper tail dependence and weak lower tail dependence. Gumbel Copula is used to model asymmetric relationship in the data (Jaworski et al. 2010). The Gumbel Copula generator is written as:
The CDF for Gumbel Copula is given by (Nelsen 2007)20
The Copula parameter is on the interval . If is equal 1, Copula shows independence. When , the Gumbel Copula indicates high dependence between the random variables.21
Table 1.
Three ordinary families of Archimedean Copulas (Clayton, Frank, and Gumbel Copula) and their generator, parameter space, and their formula
| Family | Generator | Parameter | Formula |
|---|---|---|---|
| Clayton | |||
| Frank | |||
| Gumbel |
is the parameter of the Copula called the dependence parameter, which measures the dependence between the marginal
Fig. 1.
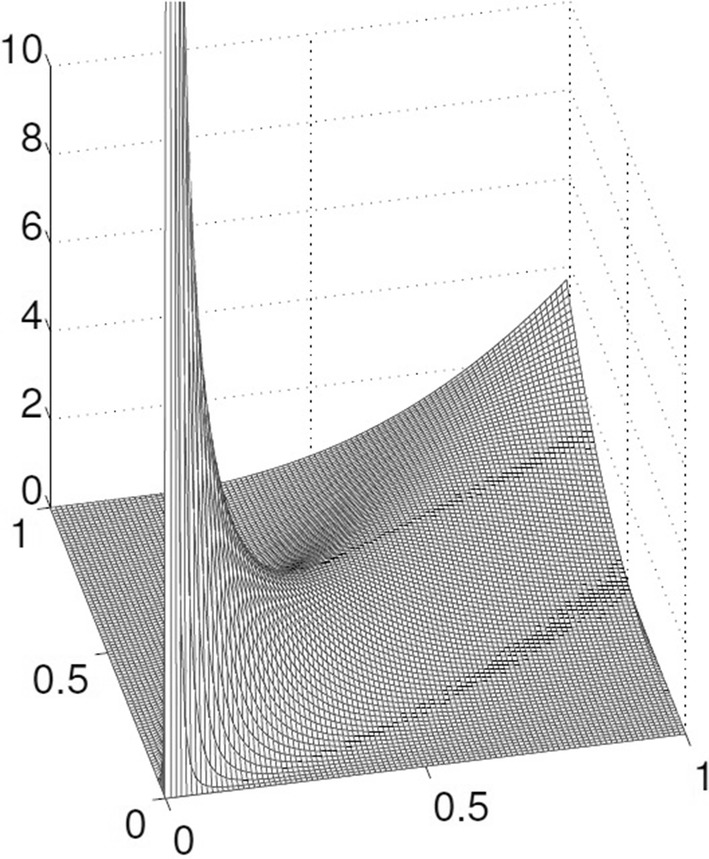
Clayton Copula with parameter . The Clayton Copula is an asymmetric Archimedean Copula; it shows greater dependence in the lower tail than in the upper tail
Fig. 2.
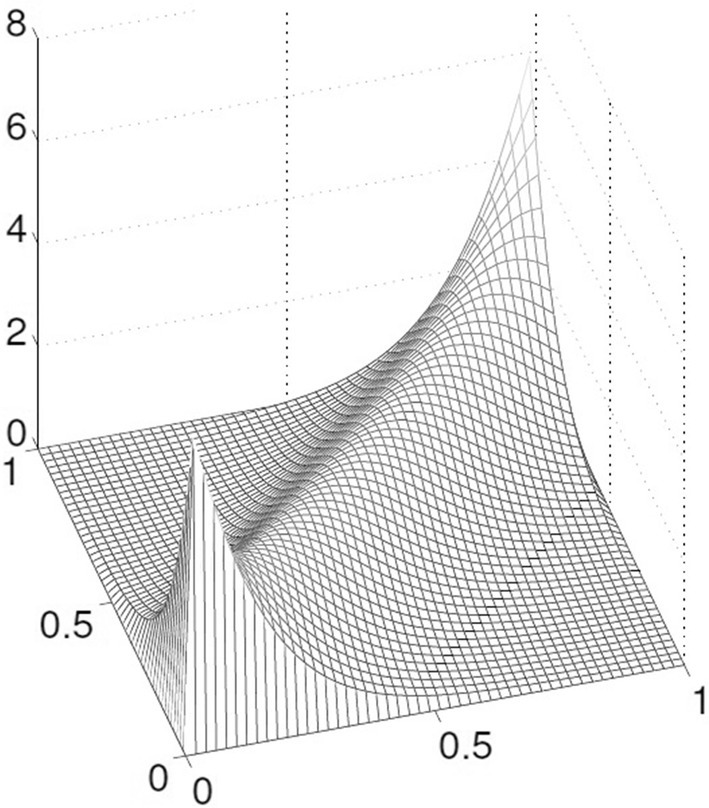
Frank Copula with parameter . The Frank Copula is a symmetric Archimedean Copula
Fig. 3.
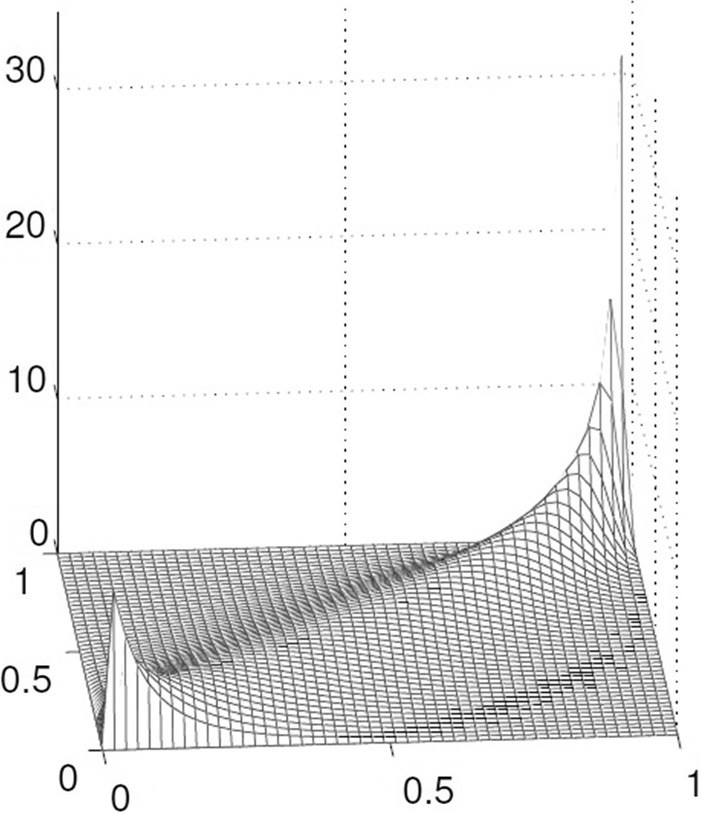
Gumbel Copula with parameter . Gumbel Copula can capture strong upper tail dependency and weak lower tail dependency
Copula parameter estimation
The widely used estimation method for the Copula parameter is the maximum likelihood (ML) estimation methodology (Joe 1997). The Copula parameters in this study are derived from ML estimation. The canonical maximum likelihood estimation (CLME) and inference for margins estimation (IFME) are two methods for estimation of the Copula parameter (Joe and Xu 1996). For both methods, the first step is marginal distribution estimation. Then, a pseudo-sample of the transformed observation is used to estimate the Copula parameter. In the IFME method, the theoretical marginal distribution parameters are estimated, and in the CMLE the univariate marginals are the empirical distribution functions (Giacomini et al. 2009). It is assumed that the sample data are n independent and identically distributed (iid) random variables. These data are transformed into uniform variates .
Let be the density function of Copula , and let be the Copula parameter which is estimated by maximizing the ML equation:
| 22 |
Computation of conditional CDF for Archimedean Copula
In this subsection, the conditional CDF of Clayton, Frank, and Gumbel Copula are computed (Yue 1999; Zhang and Singh 2007; Trivedi et al. 2007). The conditional CDF for Clayton Copula is given by (Joe 1997):
| 23 |
and for Frank Copula:
| 24 |
The conditional CDF of Gumbel Copula is:
| 25 |
Simulating from Copula-based conditional random data
This subsection provides the essential steps for data simulation using Copula-based conditional random data. The following steps are taken to fit the suitable theoretical Copula function and simulation data (Laux et al. 2011; Vogl et al. 2012).
Independent identical distribution (iid)-transformation of input time series.
Compute the marginal distribution and of the input data x and y.
Transform data to rank space using the estimated marginal distributions of data with and in rank space.
Compute the empirical Copula to the dependence structure of random variables using the rank-transformed data.
Fit a theoretical Copula function .
Compute the conditional Copula function.
Sample random data from the conditional Copula CDF.
Transfer the sample back to the data space using the inverse marginal.
Error analysis
The mean absolute error (MAE) standard is used in order to evaluate the prediction accuracy. It can be shown as follows:
| 26 |
| 27 |
where is the predicted value of the i-th prediction, is the corresponding observation value, is the error, and n is the total prediction number (Willmott and Matsuura 2005).
Calculation and analysis
Data description
In this paper, the and time series (see Fig. 4) are from the International Earth Rotation and Reference Systems Service (IERS) combined earth orientation parameter (EOP) solutions 08 C04 (available at http://hpiers.obspm.fr/eop-pc/analysis/excitactive.html). The EOP 08 C04 series is derived from different geodetic techniques, and it is consistent with ITRF 2008. The EOP 08 C04 time series cover the period 1962 to the present. The sampling interval is one day.
Fig. 4.

Daily PM time series from 1990 to the present
Data processing and analysis
In this study, we defined an algorithm for PM prediction which is shown in Fig. 5. The observed PM time series can be split up into two parts. The first part is dealing with periodic effects such as Chandler wobble, annual variation, and influences of solid Earth tides and ocean tides on PM. The SSA is used to model the periodic terms of the PM. Then, the difference between the observed PM and SSA estimated data is modeled by using the Copula-based analysis method. After that, the periodic terms of PM are extrapolated using the SSA a priori model. Also, the anomaly part is predicted using the Copula-based model. Finally, the anomaly solution is added to the SSA-forecasted time series.
Fig. 5.

Scheme of the SSA+Copula model for PM prediction
Therefore, the analysis of the data is divided into two main steps:
- SSA Periodic Terms Estimation
- Selecting window parameter (L) considering the dominant periods of the time series and the prediction interval,
- Forming trajectory matrix () using L,
- Singular value decomposition of ,
- Selecting a proper group of singular values and corresponding singular vectors,
- Reconstruction of ,
- Calculation of the trend by applying diagonal averaging to .
- Copula Anomaly Modeling
- Subtract the observed PM time series by SSA-reconstructed time series,
- Forming the trajectory matrix of residual time series using window length L and time delay of 1 day,
- Compute the marginal distribution of each column of the matrix,
- Transform data to the rank space,
- Compute the empirical Copula between the column i and i+1,
- Fit the theoretical Copula model by applying appropriate goodness-of-fit tests,
- Compute the conditional Copula,
- Sample random data from the conditional Copula CDF and transfer the sample back to the data space using the inverse marginal,
- For each value of one input time series, one obtains an ensemble of possible values for other time series.
Therefore, the final PM predicted data is the sum of the results of predicted periodic terms using SSA and predicted anomaly using the Copula-based model.
SSA periodic terms estimation
Window length selection is a crucial step in SSA which has a significant impact on the decomposition of the time series. The appropriate choice for L in a periodic time series with a period T is a window length proportional to the period, meaning that the L / T is an integer. Figure 6 depicts the main periods of PM time series (Golyandina and Zhigljavsky 2013). So, the Chandler period as the main period of both time series would be a reasonable choice. Making the closest choice to the half of the length of the time series (if possible, least common multiple of the Chandler and annual periods) is recommended by Golyandina and Zhigljavsky (2013), but is avoided due to the processing time.
Fig. 6.

Spectral analysis of the (up), (down) using fast Fourier transform (FFT)
After selection of the window length, the number of singular vectors or empirical functions for reconstruction of the time series should be determined. The goal of this procedure is to find and apply a proper set of constructive components. Most significant periodicities as well as excitation mechanisms are rather low-frequency components and reveal their impact in the first few singular vectors while high-frequency components fall in later singular vectors. The singular value spectrum reflects the importance of each singular vector. Figure 7 suggests that in order to achieve an accuracy of about 1 mas in polar motion modeling, we need to utilize at least first 70 singular vectors which correspond to using all components with periods more than or equal to 14 days.
Fig. 7.
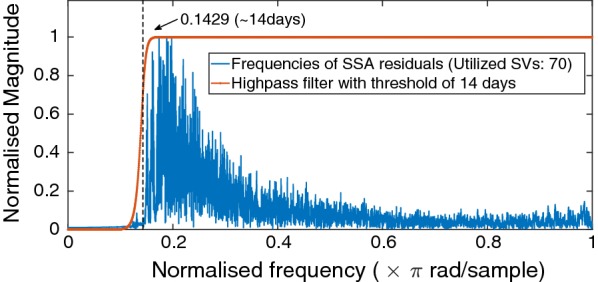
Number of singular values and vectors applied in modeling polar motion to achieve 1 mas degree of accuracy
Having the window length and the number of singular values determined, we construct the trajectory matrix. As it can be seen in Fig. 8 the data between the year of 1997 and 2003 is used as the training period. The cyan curve is the SSA-reconstructed time series. Prediction of the future entries starts by adding initial guess of future entries to the end of the time series. Then, iteration of the SSA process is done until the result of two successive iterations has a difference less than a certain threshold. This will map the initial values to the estimated periodic terms of the time series. The residual part of the difference between original time series and SSA estimated time series is named anomaly of which has a stochastic behavior. Therefore, the anomaly part will be investigated by Copula-based technique.
Fig. 8.

The original time series (upper panel), the reconstructed time series (middle panel), and the difference between original and reconstructed time series (lower panel) for
Copula anomaly modeling
The anomaly part which is shown in Fig. 8 (lower panel) with dark violet is formed into a matrix with the same window length L. Then, the dependency structure between the and is investigated for the whole dataset. Modeling the joint dependence structure with Copulas requires fitting marginal distribution to data. In this study, three univariate distribution functions are considered: extreme value, generalized extreme value, and generalized Pareto distribution (see Table 2). To identify which univariate distribution is the best suitable for both and , the root-mean-square error is estimated and the goodness of fit is examined with the Akaike and the Bayesian information criteria (AIC and BIC).
| 28 |
and
| 29 |
where k denotes the number of the free parameters in the model. n is the sample size, and B is the maximized value of the likelihood function of the estimated model. The smallest amount of AIC or BIC, respectively, suggests the best fitting model or distribution. After estimation of the parameters by maximum likelihood approach, the AIC, BIC, and RMSE values are calculated for both and distribution. As it can be seen in Fig. 9, the generalized extreme value (black) provides the best fit in comparison with the generalized Pareto distribution function (blue) and extreme value distribution function (green). Furthermore, according to Tables 3 and 4, the result of the AIC, BIC, and RMSE confirmed that the generalized extreme value provides the best fit in both and distribution. Therefore, generalized extreme value distribution was selected in this study.
Table 2.
Marginal distributions
Fig. 9.

Marginal distribution’s goodness-of-fit test for (left) and (right). Generalized extreme value distribution is the black curve, green shows the extreme value distribution, and the blue curve is generalized Pareto distribution
Table 3.
Goodness-of-fit test for marginal distribution of
| Distributions | AIC | BIC | RMSE |
|---|---|---|---|
| Extreme value | 574.60 | 582.66 | 0.04 |
| Generalized extreme value | 511.14 | 523.23 | 0.01 |
| Generalized Pareto | 758.22 | 770.31 | 0.13 |
Table 4.
Goodness-of-fit test for marginal distribution of
| Distributions | AIC | BIC | RMSE |
|---|---|---|---|
| Extreme value | 310.99 | 319.05 | 0.03 |
| Generalized extreme value | 261.25 | 273.34 | 0.01 |
| Generalized Pareto | 523.99 | 536.09 | 0.14 |
Estimating empirical Copula
Once the univariate marginal distribution is fitted, the dependence structure between the time series has to be investigated. The first step is to calculate the empirical Copula using Eq. (14). As it can be seen in Fig. 10, there is a scatter plot of two adjacent columns, and it shows a scatter linear dependency structure with the heavy tail. This kind of dependency structure can be correctly modeled using the Archimedean Copula.
Fig. 10.

Scatter plot (left) two adjacent columns in the residual matrix. The empirical Copula (right) is estimated based on the dependency structure of two columns
Fitting a theoretical Copula function
The next step is fitting a theoretical bivariate Archimedean Copula function with its parameters estimated by maximum likelihood approach. In this study, three different theoretical Copula functions are tested (Fig. 11): Clayton, Frank, and Gumbel Copula. For the three different Copula functions, the goodness-of-fit test, which is based on the Cramer–von Mises statistics, is applied. To evaluate the performance of the Copulas, 1000 values of the test statistics are sampled, and the proportion of values larger than is estimated by calculating the corresponding p values. The results based on show that the performance of Frank Copula is slightly better than Gumbel and Clayton Copula with less error (Table 5).
Fig. 11.

Theoretical Copula is fitted to the empirical Copula. The Copula parameter is 3.82, 15, and 3.61 for the Clayton, Frank, and Gumbel Copula, respectively
Table 5.
Goodness-of-fit test for Copula model
| Copula name | Clayton | Frank | Gumbel |
|---|---|---|---|
| Mean() | 43.57 | 12.13 | 17.58 |
365-day-ahead prediction
We utilized 6 years of observed PM time series, from January 1997 to December 2002, for the 365-day-ahead prediction. To verify the reliability of this method, the results were compared with the IERS Bulletin A predictions (https://datacenter.iers.org/web/guest/bulletins/-/somos/5Rgv/version/6). The IERS Bulletin A contains the PM parameters and the predicted PM for one year into the future, and they are released every seven days by IERS Rapid Service/Prediction Center (RS/PC), hosted by the U.S. Naval Observatory (USNO) (Petit and Luzum 2010; Gambis and Luzum 2011). The predictions of PM from the IERS Bulletin A were produced by LS + AR method. In the current prediction method, the PM prediction was the sum of the LS extrapolation model (including the Chandler period, annual, semiannual, terannual, and quarter annual terms), and the AR predictions of the LS extrapolation residuals (Kosek et al. 2007).
Discussion of results
In this study, we demonstrated the PM prediction by combination of SSA and Copula-based analysis method. Our method is tested based on the hindcast experiments using data from the past. Hence, we have calculated the results of our methods yearly for seven years of the test period 2003–2009 in comparison with Bulletin A PM prediction. As the prediction solutions of Bulletin A are available weekly, we would have approximately 52 time series of prediction for each year. So, Fig. 12 shows the mean value of MAE for each year. In Fig. 12, the Bulletin A solution is shown in black and the SSA predicted data in red. Also, the results of SSA+Copula are displayed by green, blue, and pink for Clayton, Frank, and Gumbel Copula, respectively. Compared to the results from the IERS Bulletin A, the MAE of the predictions produced by the proposed method was smaller in different short-, mid-, and long-term intervals for different cases (e.g., between 1 and 5 mas progression of prediction for different time intervals in 2003). The better prediction performance of the SSA + Copula prediction may have been due to the modeling of the linear change of the Chandler and the annual oscillation amplitudes. Besides, the combination of SSA+Copula improves the SSA solution because of its ability to model the stochastic behavior of the anomaly part of the PM time series. However, the proposed method did not always perform better, especially in cases of long-term prediction where the quality of the results was not as good as we expected (see Fig. 12). This may have been caused by changes of the amplitudes of the periodic terms in this six-year time span where the SSA was not able to capture all features in order to predict more precisely we would have to increase the interval of training time. Figure 13 presents the absolute error of 365-day-ahead prediction between 2003 and 2009. Different patterns and features can be seen in our solution and Bulletin A solution. For instance, Bulletin A predicted from January to March 2003 displays errors of more than 30 mas which cannot be found in our results, and there is a clear feature in Bulletin A mean absolute error plot from August to December 2008 which does not appear in our prediction. However, our predicted PM results indicate a periodic error in mid- and long-term predictions although the results of the combination SSA + Copula show smoother errors in comparison with the SSA results. To better understand this particular periodic error of our method, we plot Fig. 14 that demonstrates the improvement in the SSA + Copula predicted solution compared to Bulletin A. For each prediction epoch, if the difference between errors of Bulletin A prediction and errors of SSA/SSA+Copula is positive, it is considered as an improvement in prediction. Yellow color shows the progress in prediction in heat maps (see Fig. 14). The red color indicates where our method shows higher errors than Bulletin A in the prediction process. Also, the orange shows where both PM prediction techniques display the same amount of error. The results illustrate that SSA+Copula can improve the accuracy of PM prediction in the different time intervals of prediction (short, mid, and long). Tables 6 and 7 indicate the success rate of PM prediction when using the SSA + Copula algorithm. The success rate of PM prediction is illustrated by the number of improvement in PM prediction (yellow) over the total number of PM prediction (yellow+ orange+ red).
| 30 |
The improvement in the prediction is approximately 40% on average. According to Malkin and Miller (2010), there is Candler Wobble phase variation in 1850, 1925, and 2005. So, probably it is the reason why the proposed prediction method losses accuracy around the year 2005. Also, as it can be seen in Tables 6 and 7 the success rate of and can be reached up to 64.99 and 46.66%, respectively.
Fig. 12.

Mean value of MAE of and prediction for 2003, 2006, and 2009 with the unit [mas]
Fig. 13.

Absolute errors of the predicted (up) and (down) using SSA, SSA+Gumbel Copula, SSA+Clayton Copula, SSA+Frank Copula compared with Bulletin A product. The unit is [mas]
Fig. 14.

Improvement of and prediction using SSA + Copula-based model compared with Bulletin A product for 2003, 2006, and 2009. The improvement in prediction is shown by yellow color
Table 6.
Success rate of prediction [%]
| Methodyear | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | Average |
|---|---|---|---|---|---|---|---|---|
| SSA | 55.29 | 33.31 | 26.52 | 40.16 | 22.90 | 45.94 | 64.70 | 41.26 |
| SSA + Clayton | 61.71 | 33.88 | 31.91 | 40.17 | 22.91 | 45.96 | 64.95 | 43.07 |
| SSA + Frank | 58.31 | 34.31 | 33.61 | 42.50 | 22.91 | 45.97 | 64.99 | 43.22 |
| SSA + Gumbel | 55.90 | 33.81 | 28.31 | 41.00 | 22.90 | 45.94 | 64.97 | 41.83 |
Table 7.
Success rate of prediction [%]
| Methodyear | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | Average |
|---|---|---|---|---|---|---|---|---|
| SSA | 35.95 | 44.99 | 25.43 | 45.28 | 39.50 | 29.21 | 39.50 | 37.12 |
| SSA + Clayton | 35.99 | 44.84 | 24.93 | 41.27 | 39.57 | 29.14 | 39.65 | 36.48 |
| SSA + Frank | 35.94 | 44.82 | 25.54 | 46.66 | 39.45 | 29.30 | 39.70 | 37.36 |
| SSA + Gumbel | 38.45 | 44.60 | 26.66 | 44.46 | 39.36 | 29.55 | 39.74 | 37.54 |
Conclusions
The improvement in the Earth rotation prediction is a relevant, timely problem, as confirmed by the fact that the International Astronomical Union (IAU) Commission A2, the International Association of Geodesy (IAG), and the IERS have at present two Joint Working Groups on Prediction (JWG-P) and on Theory of Earth rotation and validation (JWG-ThER). According to the United Nations (UN) resolution in 2015, the primary objective of these JWGs is to assess and ensure the level of consistency of earth orientation parameter (EOP) predictions derived from theories with the corresponding EOP determined from analyses of the observational data provided by the various geodetic techniques. Therefore, accurate EOP predictions are essential to avoid any systematic drifts and/or biases between the international celestial and terrestrial reference frames (ICRF and ITRF). The results illustrate that the proposed method could efficiently and precisely predict the PM parameters. As clearly demonstrated, the SSA + Copula algorithm shows better performance for prediction in comparison with the SSA prediction. The Copula-based analysis is fully successful in its aim to increase the accuracy of PM prediction by modeling the stochastic part of the PM and subtracting PM by SSA-reconstructed time series. We suspect the main error contributions come from SSA extrapolation part. So, further investigations about the SSA training time will be required to clarify this issue. Also, SSA + Copula prediction method shows periodic errors, and these errors have a significant impact on the mean absolute error. Therefore, these occasional errors should be further investigated to have a noticeable progression in the PM prediction accuracy.
Authors' contributions
SM did most of the data analysis and writing of the manuscript. MH carried out the SSA studies and wrote a part of the manuscript. SB conceived and designed the study. RH, JMF, and HS participated in the design of the study and helped to improve the manuscript. All authors read and approved the final manuscript.
Acknowledgements
We are grateful to the International Earth Rotation and Reference Systems Service (IERS) for providing the Polar motion data. We like to thank the two anonymous reviewers for their comments which helped to improve the paper.
Competing interests
The authors declare that they have no competing interests.
Funding
The corresponding author is supported by an offer of financial assistance by GFZ German Research Centre for Geosciences, Potsdam, Germany. SB and JF works were partially supported by Projects AYA2016-79775-P (AEI/FEDER, UE). Also, SB was supported by the European Research Council (ERC) under the ERC-2017-STG SENTIFLEX project (Grant Agreement 755617).
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Abbreviations
- ANN
artificial neural network
- AR
autoregressive
- CDF
cumulative distribution function
- CLME
canonical maximum likelihood estimation
- DORIS
Doppler Orbitography and Radiopositioning Integrated by Satellite
- EOP
Earth orientation parameters
- EOP PCC
Earth orientation parameters prediction comparison campaign
- GFZ
German Research Centre for Geosciences
- GGOS
Global Geodetic Observing System
- GNSS
Global Navigation Satellite Systems
- IAG
International Association of Geodesy
- ICRF
international celestial reference frame
- IERS
International Earth Rotation and Reference Systems Service
- IFME
Inference for Margins Estimation
- LLR
Lunar Laser Ranging
- LS
least squares
- MAE
mean absolute error
- RMS
root-mean-square
- PM
polar motion
- TRF
terrestrial reference frame
- VLBI
Very-long-baseline interferometry
- SLR
Satellite Laser Ranging
- SSA
singular spectrum analysis
Contributor Information
Sadegh Modiri, Email: sadegh@gfz-potsdam.de.
Santiago Belda, Email: santiago.belda@ua.es.
Robert Heinkelmann, Email: robert.heinkelmann@gfz-potsdam.de.
Mostafa Hoseini, Email: mostafa.hoseini@ntnu.no.
José M. Ferrándiz, Email: jm.ferrandiz@ua.es
Harald Schuh, Email: harald.schuh@gfz-potsdam.de.
References
- Akulenko L, Kumakshev S, Markov YG, Rykhlova L. Forecasting the polar motions of the deformable earth. Astron Rep. 2002;46(10):858–865. doi: 10.1134/1.1515097. [DOI] [Google Scholar]
- Akyilmaz O, Kutterer H. Prediction of earth rotation parameters by fuzzy inference systems. J Geodesy. 2004;78(1–2):82–93. [Google Scholar]
- Akyilmaz O, Kutterer H, Shum C, Ayan T. Fuzzy-wavelet based prediction of earth rotation parameters. Appl Soft Comput. 2011;11(1):837–841. doi: 10.1016/j.asoc.2010.01.003. [DOI] [Google Scholar]
- Angermann D, Seitz M, Drewes H. Analysis of the DORIS contributions to IRTF2008. Adv Space Res. 2010;46(12):1633–1647. doi: 10.1016/j.asr.2010.07.018. [DOI] [Google Scholar]
- Bárdossy A, Li J. Geostatistical interpolation using copulas. Water Resour Res. 2008;44(7):1–15. doi: 10.1029/2007WR006115. [DOI] [Google Scholar]
- Bárdossy A, Pegram G. Copula based multisite model for daily precipitation simulation. Hydrol Earth Syst Sci. 2009;13(12):22–99. doi: 10.5194/hess-13-2299-2009. [DOI] [Google Scholar]
- Barnes R, White A, Wilson C. Atmospheric angular momentum fluctuations, length-of-day changes and polar motion. Proc R Soc Lond A. 1983;387(1792):31–73. doi: 10.1098/rspa.1983.0050. [DOI] [Google Scholar]
- Bizouard C, Gambis D, (2009) The combined solution c04 for earth orientation parameters consistent with international terrestrial reference frame 2005. In: Geodetic reference frames, Springer, pp. 265–270
- Broomhead DS, King GP. Extracting qualitative dynamics from experimental data. Phys D. 1986;20(2–3):217–236. doi: 10.1016/0167-2789(86)90031-X. [DOI] [Google Scholar]
- Byram S, Hackman C (2012) High-precision GNSS orbit, clock and EOP estimation at the United States Naval Observatory. In: Position location and navigation symposium (PLANS), 2012 IEEE/ION, IEEE, pp. 659–663
- Chen J, Wilson C. Hydrological excitations of polar motion, 1993–2002. Geophys J Int. 2005;160(3):833–839. doi: 10.1111/j.1365-246X.2005.02522.x. [DOI] [Google Scholar]
- Chin TM, Gross RS, Dickey JO. Modeling and forecast of the polar motion excitation functions for short-term polar motion prediction. J Geodesy. 2004;78(6):343–353. doi: 10.1007/s00190-004-0411-4. [DOI] [Google Scholar]
- Clayton DG. A model for association in bivariate life tables and its application in epidemiological studies of familial tendency in chronic disease incidence. Biometrika. 1978;65(1):141–151. doi: 10.1093/biomet/65.1.141. [DOI] [Google Scholar]
- Coulot D, Pollet A, Collilieux X, Berio P. Global optimization of core station networks for space geodesy: application to the referencing of the STR EOP with respect to ITRF. J Geod. 2010;84(1):31. doi: 10.1007/s00190-009-0342-1. [DOI] [Google Scholar]
- Dickey J, Newhall X, Williams J. Earth orientation from Lunar Laser Ranging and an error analysis of polar motion services. J Geophys Res Solid Earth. 1985;90(B11):9353–9362. doi: 10.1029/JB090iB11p09353. [DOI] [Google Scholar]
- Dow JM, Neilan RE, Rizos C. The international GNSS service in a changing landscape of Global Navigation Satellite Systems. J Geod. 2009;83(3–4):191–198. doi: 10.1007/s00190-008-0300-3. [DOI] [Google Scholar]
- Embrechts P, McNeil A, Straumann D. Correlation and dependence in risk management: properties and pitfalls. In: Dempster MAH, editor. Risk management: value at risk and beyond. Cambridge: Cambridge University Press; 2002. pp. 176–223. [Google Scholar]
- Escarela G, Carriere JF. Fitting competing risks with an assumed Copula. Stat Methods Med Res. 2003;12(4):333–349. doi: 10.1191/0962280203sm335ra. [DOI] [PubMed] [Google Scholar]
- Freedman A, Steppe J, Dickey J, Eubanks T, Sung L-Y. The short-term prediction of universal time and length of day using atmospheric angular momentum. J Geophys Res Solid Earth. 1994;99(B4):6981–6996. doi: 10.1029/93JB02976. [DOI] [Google Scholar]
- Gambis D, Luzum B. Earth rotation monitoring, UT1 determination and prediction. Metrologia. 2011;48(4):S165. doi: 10.1088/0026-1394/48/4/S06. [DOI] [Google Scholar]
- Genest C, Favre A-C. Everything you always wanted to know about Copula modeling but were afraid to ask. J Hydrol Eng. 2007;12(4):347–368. doi: 10.1061/(ASCE)1084-0699(2007)12:4(347). [DOI] [Google Scholar]
- Genest C, Rivest L-P. Statistical inference procedures for bivariate Archimedean Copulas. J Am Stat Assoc. 1993;88(423):1034–1043. doi: 10.1080/01621459.1993.10476372. [DOI] [Google Scholar]
- Giacomini E, Härdle W, Spokoiny V. Inhomogeneous dependence modeling with time-varying Copula. J Bus Econ Stat. 2009;27(2):224–234. doi: 10.1198/jbes.2009.0016. [DOI] [Google Scholar]
- Golyandina N, Zhigljavsky A. Singular Spectrum Analysis for time series. Berlin: Springer-Verlag; 2013. [Google Scholar]
- Golyandina N, Nekrutkin V, Zhigljavsky AA. Analysis of time series structure: SSA and related techniques. New York: Chapman and Hall; 2001. [Google Scholar]
- Gross RS. Earth rotation variations—long period. Phys Geod. 2015;11:215–261. [Google Scholar]
- Gross RS, Fukumori I, Menemenlis D. Atmospheric and oceanic excitation of the earth’s wobbles during 1980–2000. J Geophys Res Solid Earth. 2003;108(B8):2370. doi: 10.1029/2002JB002143. [DOI] [Google Scholar]
- Hosking JR, Wallis JR. Parameter and quantile estimation for the generalized Pareto distribution. Technometrics. 1987;29(3):339–349. doi: 10.1080/00401706.1987.10488243. [DOI] [Google Scholar]
- Hosking JR, Wallis JR, Wood EF. Estimation of the generalized extreme-value distribution by the method of probability-weighted moments. Technometrics. 1985;27(3):251–261. doi: 10.1080/00401706.1985.10488049. [DOI] [Google Scholar]
- Jaworski P, Durante F, Härdle WK, Rychlik T (2010) Copula theory and its applications. In: proceedings of the workshop held in Warsaw, 25–26 September 2009, Vol. 198, Springer Science & Business Media
- Joe H. Multivariate models and multivariate dependence concepts. Boca Raton: CRC Press; 1997. [Google Scholar]
- Joe H, Xu JJ (1996) The estimation method of inference functions for margins for multivariate models, Technical report, Department of Statistics, University of British Columbia
- Kalarus M, Kosek W. Prediction of earth orientation parameters by artificial neural networks. Artif Satell J Planet Geod. 2004;39(2):175–184. [Google Scholar]
- Kalarus M, Schuh H, Kosek W, Akyilmaz O, Bizouard C, Gambis D, Gross R, Jovanović B, Kumakshev S, Kutterer H, et al. Achievements of the earth orientation parameters prediction comparison campaign. J Geod. 2010;84(10):587–596. doi: 10.1007/s00190-010-0387-1. [DOI] [Google Scholar]
- Kosek W, McCarthy D, Luzum B. Possible improvement of earth orientation forecast using autocovariance prediction procedures. J Geod. 1998;72(4):189–199. doi: 10.1007/s001900050160. [DOI] [Google Scholar]
- Kosek WI, Kalarus M, Niedzielski T, Capitaine N. Forecasting of the Earth orientation parameters: comparison of different algorithms. Paris: Observatoire de Paris; 2007. [Google Scholar]
- Kotz S, Nadarajah S. Extreme value distributions: theory and applications. Singapore: World Scientific; 2000. [Google Scholar]
- Laux P, Vogl S, Qiu W, Knoche H, Kunstmann H. Copula-based statistical refinement of precipitation in RCM simulations over complex terrain. Hydrol Earth Syst Sci. 2011;15(7):2401–2419. doi: 10.5194/hess-15-2401-2011. [DOI] [Google Scholar]
- Lee T-H, Long X. Copula-based multivariate GARCH model with uncorrelated dependent errors. J Econom. 2009;150(2):207–218. doi: 10.1016/j.jeconom.2008.12.008. [DOI] [Google Scholar]
- Malkin Z, Miller N. Chandler wobble: two more large phase jumps revealed. Earth Planets Space. 2010;62(12):943–947. doi: 10.5047/eps.2010.11.002. [DOI] [Google Scholar]
- Mathews P, Buffett BA, Herring TA, Shapiro II. Forced nutations of the earth: influence of inner core dynamics: 1. Theory. J Geophys Res Solid Earth. 1991;96(B5):8219–8242. doi: 10.1029/90JB01955. [DOI] [Google Scholar]
- Modiri S, Lorenz C, Sneeuw N, Kunstmann H, (2015) Copula-based estimation of large-scale water storage changes: exploiting the dependence structure between hydrological and grace data. In: EGU general assembly conference abstracts, Vol. 17
- Nelsen RB. An introduction to copulas. Berlin: Springer Science & Business Media; 2007. [Google Scholar]
- Nilsson T, Böhm J, Schuh H. Sub-diurnal earth rotation variations observed by VLBI. Artif Satell. 2010;45(2):49–55. doi: 10.2478/v10018-010-0005-8. [DOI] [Google Scholar]
- Nilsson T, Böhm J, Schuh H. Universal time from VLBI single-baseline observations during CONT08. J Geod. 2011;85(7):415–423. doi: 10.1007/s00190-010-0436-9. [DOI] [Google Scholar]
- Nilsson T, Heinkelmann R, Karbon M, Raposo-Pulido V, Soja B, Schuh H. Earth orientation parameters estimated from VLBI during the CONT11 campaign. J Geod. 2014;88(5):491–502. doi: 10.1007/s00190-014-0700-5. [DOI] [Google Scholar]
- Patton AJ. Modelling asymmetric exchange rate dependence. Int Econ Rev. 2006;47(2):527–556. doi: 10.1111/j.1468-2354.2006.00387.x. [DOI] [Google Scholar]
- Patton AJ. Copula-based models for financial time series. In: Mikosch T, Kreiß J-P, Davis RA, Andersen TG, editors. Handbook of financial time series. Berlin: Springer; 2009. pp. 767–785. [Google Scholar]
- Petit G, Luzum B (2010) IERS conventions (2010), Technical report, Bureau International des poids et mesures sevres (France)
- Plag H-P, Pearlman M. Global geodetic observing system: meeting the requirements of a global society on a changing planet in 2020. Berlin: Springer; 2009. [Google Scholar]
- Rachev S, Mittnik S. Stable Paretian models in finance. New York: Willey; 2000. [Google Scholar]
- Rodriguez JC. Measuring financial contagion: a copula approach. J Empir Finance. 2007;14(3):401–423. doi: 10.1016/j.jempfin.2006.07.002. [DOI] [Google Scholar]
- Schuh H, Behrend D. VLBI: a fascinating technique for geodesy and astrometry. J Geodyn. 2012;61:68–80. doi: 10.1016/j.jog.2012.07.007. [DOI] [Google Scholar]
- Schuh H, Böhm S. Earth rotation. In: Gupta HK, editor. Encyclopedia of solid earth geophysics. Dordrecht: Springer; 2011. pp. 123–129. [Google Scholar]
- Schuh H, Schmitz-Hübsch H. Short period variations in earth rotation as seen by VLBI. Surv Geophys. 2000;21(5–6):499–520. doi: 10.1023/A:1006769727728. [DOI] [Google Scholar]
- Schuh H, Ulrich M, Egger D, Müller J, Schwegmann W. Prediction of earth orientation parameters by artificial neural networks. J Geod. 2002;76(5):247–258. doi: 10.1007/s00190-001-0242-5. [DOI] [Google Scholar]
- Seitz F, Schuh H. Earth rotation. In: Xu G, editor. Sciences of geodesy-I. Berlin: Springer; 2010. pp. 185–227. [Google Scholar]
- Sklar M. Fonctions de repartition an dimensions et leurs marges. Publ. Inst. Statist. Univ. Paris. 1959;8:229–231. [Google Scholar]
- Stamatakos N (2017) IERS rapid service prediction center products and services: improvement, changes, and challenges, 2012 to 2017. In: Proceedings of the Journées Systèmes de référence spatio-temporels’
- Trivedi PK, Zimmer DM, et al. Copula modeling: an introduction for practitioners. FoundTrends® Economet. 2007;1(1):1–111. [Google Scholar]
- Vautard R, Yiou P, Ghil M. Singular-Spectrum Analysis: a toolkit for short, noisy chaotic signals. Phys D. 1992;58(1–4):95–126. doi: 10.1016/0167-2789(92)90103-T. [DOI] [Google Scholar]
- Verhoest NE, van den Berg MJ, Martens B, Lievens H, Wood EF, Pan M, Kerr YH, Al Bitar A, Tomer SK, Drusch M, et al. Copula-based downscaling of coarse-scale soil moisture observations with implicit bias correction. IEEE Trans Geosci Remote Sens. 2015;53(6):3507–3521. doi: 10.1109/TGRS.2014.2378913. [DOI] [Google Scholar]
- Vogl S, Laux P, Qiu W, Mao G, Kunstmann H. Copula-based assimilation of radar and gauge information to derive bias-corrected precipitation fields. Hydrol Earth Syst Sci. 2012;16(7):2311–2328. doi: 10.5194/hess-16-2311-2012. [DOI] [Google Scholar]
- Wahr JM. The effects of the atmosphere and oceans on the earth’s wobble—I. Theory. Geophys J Int. 1982;70(2):349–372. doi: 10.1111/j.1365-246X.1982.tb04972.x. [DOI] [Google Scholar]
- Wahr JM. The effects of the atmosphere and oceans on the earth’s wobble and on the seasonal variations in the length of day—II. results. Geophys J Int. 1983;74(2):451–487. [Google Scholar]
- Wang W, Wells MT. Model selection and semiparametric inference for bivariate failure-time data. J Am Stat Assoc. 2000;95(449):62–72. doi: 10.1080/01621459.2000.10473899. [DOI] [Google Scholar]
- Willmott CJ, Matsuura K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim Res. 2005;30(1):79–82. doi: 10.3354/cr030079. [DOI] [Google Scholar]
- Włodzimierz H. Polar motion prediction by the least-squares collocation method. In: Boucher C, Wilkins GA, editors. Earth rotation and coordinate reference frames. US: Springer; 1990. pp. 50–57. [Google Scholar]
- Xu X, Zhou Y, Liao X. Short-term earth orientation parameters predictions by combination of the least-squares, AR model and Kalman filter. J Geodyn. 2012;62:83–86. doi: 10.1016/j.jog.2011.12.001. [DOI] [Google Scholar]
- Yue S. Applying bivariate normal distribution to flood frequency analysis. Water Int. 1999;24(3):248–254. doi: 10.1080/02508069908692168. [DOI] [Google Scholar]
- Zhang L, Singh VP. Bivariate rainfall frequency distributions using Archimedean Copulas. J Hydrol. 2007;332(1–2):93–109. doi: 10.1016/j.jhydrol.2006.06.033. [DOI] [Google Scholar]
- Zotov L. Regression methods of earth rotation prediction. Mosc Univ Phys Bull. 2005;5(2005):36–50. [Google Scholar]