

Abstract
Ambient mass spectrometry is an analytical approach that enables ionization of molecules under open-air conditions with no sample preparation and very fast sampling times. Rapid evaporative ionization mass spectrometry (REIMS) is a relatively new type of ambient mass spectrometry that has demonstrated applications in both human health and food science. Here, we present an evaluation of REIMS as a tool to generate molecular scale information as an objective measure for the assessment of beef quality attributes. Eight different machine learning algorithms were compared to generate predictive models using REIMS data to classify beef quality attributes based on the United States Department of Agriculture (USDA) quality grade, production background, breed type and muscle tenderness. The results revealed that the optimal machine learning algorithm, as assessed by predictive accuracy, was different depending on the classification problem, suggesting that a “one size fits all” approach to developing predictive models from REIMS data is not appropriate. The highest performing models for each classification achieved prediction accuracies between 81.5–99%, indicating the potential of the approach to complement current methods for classifying quality attributes in beef.
Introduction
In food science, chemical screening of ingredients and finished products is critical to ensure quality for food producers and consumers. Mass spectrometry (MS) is an important chemical detection platform for food analysis; however, methods typically require lengthy and complex sample preparation steps and analysis times1. Ambient mass spectrometry is a relatively new approach that enables ionization of molecules under ambient conditions with no sample preparation and very fast sampling times. Takats et al. reported the first ambient ionization approach, desorption electrospray ionization (DESI), in 20042. There are now over thirty reported ambient ionization techniques spanning application areas from pharmaceutical analysis to biological imaging to forensics and explosives detection3. The application of ambient ionization technology for the analysis of food and in particular for the detection of food fraud was recently reviewed by Black et al.1.
Rapid Evaporative Ionization Mass Spectrometry (REIMS) is an emerging ambient ionization technique that has demonstrated applications in both human medicine and food science4. For example, REIMS-based tissue analysis can be used for intraoperative analysis of histological tissue for identification of cancerous tissue margins and other prognostic and diagnostic applications5–9. While the REIMS technology was initially developed with biomedical applications in mind, it has also proven to be a valuable tool for the analysis of food. Recently, utilization of REIMS for the analysis of meat products has generated very promising results across various classification scenarios reflective of important quality attributes such as genetic differences, production background, and sensory attributes. Balog et al. (2016) used REIMS to differentiate between various mammalian meat species and beef breeds with 100% and 97% accuracy, respectively10. Similarly, Black et al. used REIMS to accurately (98.9%) classify several fish species as an approach for detecting food fraud in the seafood industry11. Guitton et al. (2018) utilized REIMS to detect lipid changes in porcine muscle tissue reflective of treatment with ractopamine, a common growth-promotant used to increase muscle mass in swine12. Verplanken et al. (2017) successfully segregated pork carcasses with and without boar taint, an important sensory attribute related to pork quality13. Importantly, these examples illustrate the potential value of using REIMS to generate molecular scale information as an objective measure for the assessment of meat quality.
To utilize molecular profiles generated by REIMS or any of the ambient ionization techniques as a means to classify samples, one must employ machine learning algorithms to generate a predictive model. Machine learning is the process of rapidly finding and characterizing patterns in complex data14. There are many different types of machine learning including, for example, decision tree learning, network analysis, linear regression, support vector machines, and similarity functions14. Each of these algorithms are based on different mathematical approaches and thus, it is expected that with variation in the types of samples, data, and phenotypes in an experiment, one algorithm can greatly outperform others in terms of prediction accuracy. The majority of REIMS applications have used linear discriminant analysis on principal component analysis (PCA-LDA) reduced data for the generation of predictive models. The PCA-LDA method performs well for classification of groups that tend to show large differences in the molecular profile of samples, such as the REIMS-meat studies described above. However, when molecular profiles of samples are not overly distinct (e.g. consumer food preference) or classification of multiple groups within a single model is desired, alternative machine learning approaches may outperform PCA-LDA15.
In this study, the predictive accuracy of eight different machine learning algorithms were compared for the generation of predictive models using REIMS data to classify attributes of beef based on USDA quality grade, production background, breed type and muscle tenderness.
Methods
Institutional Animal Care and Use Committee approval was not required for this study as samples were obtained postmortem from federally inspected harvest facilities.
Sample Collection
Beef strip loin sections (longissimus muscle) were collected to represent 7 carcass types [Select (n = 42), Low Choice (n = 42), Top Choice (n = 39), Prime (n = 42), Dark Cutter (n = 41), Grass-fed (n = 42), and Wagyu (n = 42)] in order to provide significant variation in beef flavor attributes, tenderness, fat percentages, and animal production. Product specifications for each carcass type were verified by Colorado State University (CSU) personnel using official USDA grades and personal communication with individual suppliers to verify origin16. All carcasses selected were A-maturity and had typical beef-type characteristics to avoid dairy-type and Bos indicus breed influence. With the exception of Dark Cutter carcasses, all selected carcasses were free from dark cutting lean characteristics. Select, Low Choice, Top Choice, and Prime carcasses presented marbling scores of slight (Sl), small (Sm), modest (Mt) and moderate (Md), and slighty abundant (Slab) and moderately abundant (Mab), respectively. Additional note was taken of these 4 carcass types meeting the USDA requirements for certification of Angus influence17. Grass-fed carcasses were selected from cattle fed a 100% forage-based diet the entirety of their lives and carcasses had marbling scores within Sm00-Md99 (superscripts represent the numerical marbling score). Wagyu carcasses were selected from crossbred Wagyu cattle (50% Wagyu, 50% Angus) and had marbling scores within SlAb00-Mab99. Dark Cutter carcasses were selected from those exhibiting dark cutting characteristics (dark colored lean) with marbling scores from Sm00-Md99. From each half of each carcass, a 5 cm thick strip loin section was collected from a point starting at the 13th rib. Each strip loin section was cut to yield a single 2.54 cm steak (NAMP 1180). The steak from the left side of the carcass was used for REIMS analysis and the steak from the right side of the carcass was used for shear force analysis. Steaks were individually vacuum packaged, aged (1 °C) for 14 d postmortem, and frozen (−20 °C) until analysis.
Shear Force
Slice shear force (SSF) measurements were obtained from every steak using procedures described by Shackelford et al.18. Within 5 min of recording peak internal temperature, a 1 cm × 5 cm slice was removed from the steak parallel to the muscle fibers from the lateral end and sheared perpendicular to the muscle fibers, using a slice shear force machine (Model GR-152, Tallgrass Solutions, Inc., Manhattan, KS) equipped with a flat, blunt-end blade (crosshead speed: 500 mm/min, load capacity: 100 kg), resulting in a single SSF measurement for each steak. Slice shear force values are reliable objective measurements of meat tenderness and were used to divide the observations into two classifications. According to standards, steaks were classified into 2 tenderness categories, tender or tough19. Steaks with a SSF value less than 20.0 kg were classified as tender, and steaks with a SSF value equal to or greater than 20.0 kg were classified as tough. Measured SSF values ranged from 8.20 kg to 45.57 kg with an average of 17.33 kg and a standard deviation of 5.97 kg. The distribution of the SSF values coded by tenderness classification is illustrated in Fig. 1.
Figure 1.
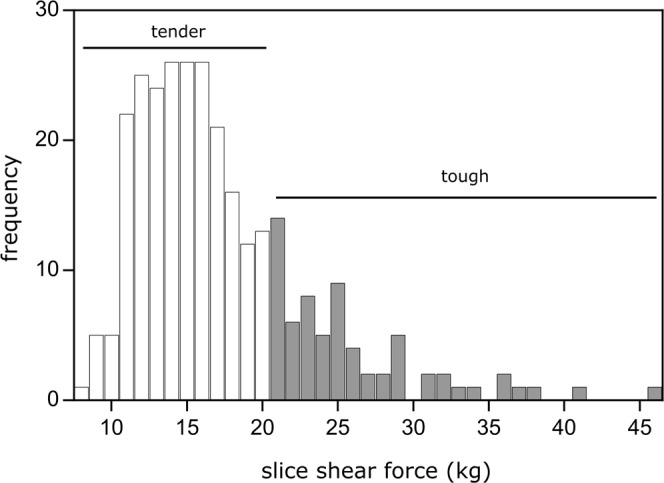
Histogram of slice shear force values and tenderness classifications as tender (<20.0 kg) and tough (≥20.0 kg).
Rapid Evaporative Ionization Mass Spectrometry (REIMS)
Chemical fingerprints of strip loin sections were acquired using rapid evaporative ionization mass spectrometry (REIMS). Prior to analysis, samples were thawed at 0–4 °C for 16–24 h. Samples were analyzed using a Synapt G2 Si Q-ToF, fitted with a REIMS ionization source coupled with a monopolar electrosurgical hand piece (“iKnife”, Waters Corporation, Milford, MA) powered by an Erbotom ICC 300 electrosurgical generator (Erbe Elektromedizin GmbH, Tubingen, Germany) using in the “dry cut” mode at a power of 40 W. A continual flow (200 μL/min) of 2 ng/mL leucine-enkephalin was introduced directly to the REIMS source during sampling. The cone voltage was set to 40 V, and the heater bias to 80 V. At least five “burns” were collected for each sample within a 2.54 × 2.54 cm square from the center of the steak (Supplementary Fig. 1), with each burn lasting approximately 1 sec. Spectra were collected in negative mode ionization from 100–1,000 m/z. Preprocessing was performed using the LiveID software (Waters Corporation) and includes lock mass correction (leucine-enkephalin), background subtraction using standard Masslynx preprocessing algorithms, and normalization to total ion current. Peak binning was performed at intervals of 0.5 m/z resulting in a total of 1,800 bins. The bins from the five burns were summed to create a single value for each sample. Mass bins in the range of 550–600 were excluded from the data matrix to remove the internal standard signal (leucine-enkephalin, m/z 554.632) resulting in a final data matrix containing 1,700 variables (m/z bins) and 290 observations (samples).
Data Analysis
All data reduction, machine learning, and evaluation of predictive models was performed within the R statistical environment20.
Data were grouped together to create the desired classifications for each model set. The classification groups and four model sets are described in Table 1 and include “Main”, “Specialized”, “Breed”, and “Tenderness”. Due to similarities in sensory performance (data not shown), Select and Low Choice, as well as, Top Choice and Prime samples were combined to create two new classification groups: Low Choice/Select and Top Choice/Prime. The Main model set used the five classification categories: Low Choice/Select, Top Choice/Prime, Dark Cutter, Grass-fed, and Wagyu. The Specialized model set exclusively used the Wagyu, Grass-Fed, and Dark Cutter classifications. The Breed model set was based on classification of Angus or non-Angus as determined from the carcass meeting the USDA requirements for certification of Angus influence or not17. Additionally, only data from Select, Low Choice, Top Choice, and Prime carcasses were used in the Breed model set. Lastly, the Tenderness model set was defined by the slice shear force measurement as described above.
Table 1.
Summary of classification groupings and number of observations used for each of the four model sets.
| Classifications (# of observations) | Model Sets | |||
|---|---|---|---|---|
| Main | Specialized | Breed | Tenderness | |
| Dark Cutter (41) | × | × | ||
| Top Choice/Prime* (81) | × | |||
| Low Choice/Select* (84) | × | |||
| Wagyu (42) | × | × | ||
| Grass fed (42) | × | × | ||
| Tender (215) | × | |||
| Tough (74) | × | |||
| Angus (159) | × | |||
| Not Angus (46) | × | |||
Data Pre-processing With Dimension Reduction
Dimension reduction was performed using (i) principal component analysis (PCA), (ii) feature selection (FS), or (iii) PCA followed by FS (PCA-FS). PCA dimension reduction was performed using the PCA function in the package FactoMineR with unit variance scaling21. FS is a supervised method of data reduction where the predictors chosen are specific to the separation of the given classes. FS was performed separately for each model set in the study (i.e., Main, Specialized, Breed, and Tenderness) using the caret R package22,23. Data was pre-processed by removing highly correlated m/z bins (Pearson’s |r| > 0.90; findCorrelation function) followed by the rfe function and finally assessed with five-fold cross validation. During the feature selection process, all 1,700 m/z bins were considered to account for all possible selected variables. PCA-FS consisted of performing a similar feature selection process on the principal components, rather than the 1,700 mass bins. PCA-FS was performed using 10-fold cross validation because it was significantly more computationally efficient to conduct FS on the principal components than on the entire set of 1700 m/z bins. For all model assessment performed in this study, X-fold cross validation refers to removal of (100/X)% of the data as a validation set where the remaining (100-(100/X))% is used as the training set. This procedure was repeated X times and the average of the prediction accuracy is recorded.
Machine Learning Algorithms To Predict Beef Quality
A total of eight machine learning algorithms were compared for predictive accuracy of each model set. These include: (1) support vector machine with a linear kernel (SVM-L), radial kernel (SVM-R), and polynomial kernel (SVM-P), (2) random forest (RF), (3) K-nearest neighbor (Knn), (4) linear discriminant analysis (LDA), (5) penalized discriminant analysis (PDA), (6) extreme gradient boosting (XGBoost), (7) logistic boosting (LogitBoost), and (8) partial least squares discriminant analysis (PLSDA). An initial screening of all the machine learning algorithms except PLSDA was performed using the train function in the caret package. PLSDA is not supported in the train function and thus PLSDA models were constructed using the plsDA function24 built into the DiscriMiner package. Visualization plots of the PLSDA model based on the PCA-FS reduced data were generated using the ggpubr package. Ellipses were drawn using a 90% probability region. 10-fold cross validation was used to evaluate the prediction accuracy (correct predictions/total predictions × 100) of all eight machine learning algorithms. For PLSDA, a manual 10-fold cross-fold validation was conducted using the predict function.
For each of the four model sets (Main, Specialized, Breed, Tenderness), the eight machine learning algorithms were applied on data following the four pre-processing options (no reduction, PCA, FS, or PCA-FS reduction). Prediction accuracies of each model were determined by 10-fold cross validation.
The top three performing models (in terms of prediction accuracy based on 10-fold cross validation) for each model set were further optimized via parameter tuning using the specific functions in R rather than the train function (Table 2). Following optimization, the top three models were revalidated using 100-fold cross validation for each model set (a higher fold cross validation was used to more precisely estimate the precision accuracy).
Table 2.
R packages and functions used for the development of final predictive models.
| Machine Learning Algorithm | R Function | Package |
|---|---|---|
| LDA | lda() | MASS |
| LogitBoost | LogitBoost() | caTools |
| PDA | fda () | mda |
| SVM | svm() | e1071 |
| XGBoost | xgboost() | xgboost |
| PLSDA | plsDA() | DiscriMiner |
Results and Discussion
REIMS analysis of the beef samples in this study resulted in a data matrix that included 1,700 m/z bins per sample, for a total of 290 samples in the full experiment. This type of unbalanced data, typical in omics experiments, (i.e. many more predictors than observations) can lead to issues when applying machine learning algorithms such as slow computational time and the possibility of model overfitting15. To address this challenge, three types of dimension reduction methods were compared in this study including: principal component analysis (PCA), feature selection (FS), and PCA followed by FS (PCA-FS). In PCA, the data transforms the predictor variables into a smaller number of variables (termed principal components, PCs), based on predictor co-variation (direction and magnitude) in the data, and is an unsupervised method22. When employed for data reduction, all of the PCs are retained and the output is a new dataset that represents 100% of the variation in the data using substantially fewer predictors. In FS, a supervised, recursive feature elimination method is used to remove predictor variables from the data matrix22. FS applies a backwards selection of predictors based on a ranking of predictor importance. The less important predictors are sequentially eliminated, with the goal of finding the smallest subset of predictors that can generate an accurate predictive model. The PCA-FS method is based on reducing the data into components, then performing FS on components to reduce redundancy in the data matrix.
Here, the PCA, FS-, and PCA-FS methods were applied to the data matrix of 1,700 m/z bins for each of the four model sets. The PCA, FS, and PCA-FS methods reduced the data matrix to 226 (13.3%), 240 (14.0%), and 22 (1.3%) mean predictor variables, respectively (Table 3). The number of predictors in the processed data was most variable for the FS method (coefficient of variation 92%; among the four model sets), indicating that PCA is likely to produce a more consistently sized data matrix for predictive modeling.
Table 3.
Number (percent) of predictors for each dimension reduction technique for each model set.
| Model Set | Original | PCA | FS | PCA-FS |
|---|---|---|---|---|
| Main | 1,700 (100%) | 289 (17%) | 229 (13.47%) | 24 (1.41%) |
| Specialized | 1,700 (100%) | 124 (7.29%) | 60 (3.53%) | 8 (0.47%) |
| Breed | 1,700 (100%) | 203 (11.94%) | 602 (35.41%) | 38 (2.24%) |
| Tenderness | 1,700 (100%) | 289 (17%) | 67 (3.94%) | 16 (0.94%) |
Machine learning algorithms varied in their prediction accuracy
In this study, eight machine learning algorithms were compared for the prediction of specific quality attributes in beef based on molecular profiles generated by REIMS.
Partial least squares discriminant analysis (PLSDA)
A model that transforms data into partial least squares components that can be then used to classify an observation. PLSDA is a common chemometrics method used in mass spectrometry ‘omics’ experiments to predict outcomes based on chemical signals15,25, however this algorithm can be easily misused, misinterpreted, and is prone to overfitting25. The PLSDA algorithm has many advantages including performance power when working with multivariate data along with methods of dealing with collinear variables26. PLSDA is similar to a supervised version of principal component analysis. However, in this study, the PLSDA model was used as a classification algorithm and for data visualization rather than a dimension reduction technique. The data were visualized using the first two PLS components of the PCA-FS dimensionally reduced data (Fig. 2). The Specialized model set showed clear separation between classes, with slight overlap between the dark cutter and grass-fed classes. The most overlap was observed in the Main model set where only the Wagyu class appears to separate clearly from the others. For the Breed and Tenderness model sets, there is clear separation of the classes with some overlap of the moderate values.
Figure 2.

Visualization of the PLSDA model for each of the model sets. Plots represent the first two PLS components of the PCA-FS reduced data.
Support vector machine (SVM)
A discriminative classifier that separates clusters of observations with the use of a hyperplane. In particular, the SVM method determines the optimal hyperplane to differentiate between the classes within the data. Here, this study evaluated how the “kernel” parameter of SVM (linear, radial, or polynomial) can result in varying prediction accuracy.
Random Forest (RF)
A type of decision tree. Although individual classification trees tend to lack in performance compared to other machine learning algorithms, aggregating many decision trees together with methods such as bagging, random forests, and boosting can greatly increase the predictive accuracy of the model27. The RF algorithms can increase model performance compared to other classification tree methods by decorrelating the trees27. Similar to bagging, random forest methods construct n number of decision trees on bootstrapped training samples. However, the unique component of the random forest model is that for each decision split within a given tree, the model is only able to use m predictors. The parameter m can be set as any value less than or equal to the number of predictors (note that if m equals the number of original predictors it would be performing a bagging classification method). Typically, m is chosen to be approximately equal to the square root of the number of predictors. By only using m predictors at each split, the trees are decorrelated due to the same predictors not being selected for each of the trees.
K-nearest neighbor (Knn)
A nonparametric approach with no underlying assumption about the distribution of the data. This algorithm classifies observations based on the similarities in features between individuals. The model determines feature similarity by calculating the Euclidian distance between the features of different observations and assigns a distance value to each observations and their neighboring observations27. Deciding the best K value for a given data set is an optimization problem. A loop can be used to input various K values into the algorithm to find the value of K that minimizes the error rate of class prediction.
Linear discriminant analysis (LDA)
A parametric approach that assumes the predictors X1, …, Xk are drawn from a multivariate Gaussian distribution. LDA is a mathematically simple and robust method of classification. LDA uses linear decision boundaries for the classification of observations, and this method calculates a linear combination of predictor to separate the model’s classes27.
Penalized discriminant analysis (PDA)
An expansion of the linear discriminant analysis model. The PDA algorithm uses nonlinear spline basis functions and includes a penalty term that adds smoothness to the coefficients of the model to reduce the problem of multi-collinearity in the predictors28. Therefore, this penalized algorithm typically performs well when there are many highly correlated variables. When there are a large number of correlated variables within a dataset, many times, the covariance data matrix is non-invertible27. Including a penalization parameter in the model reduces the likelihood of singular (non-invertible) covariance matrices and results in improved classification accuracy.
XGBoost:
A supervised learning algorithm designed for fast computational time, especially on very large data sets. XGBoost is a form of gradient-boosted decision trees that is faster than comparable implementations of gradient boosting. Gradient boosting can generate new models based on the prediction of the residuals errors of prior models29. The term “gradient boosting” refers to the utilization of a gradient descent to minimize the loss when adding additional models (Brownlee, 2016).
LogitBoost:
A boosting logistic classification algorithm that performs as an additive logistic regression model. The Logit Boost model is similar to a generalized additive model, but rather than minimizing the exponential loss, the algorithm minimizes the logistic loss of the function. Additionally, the Logit Boost algorithm in R is trained using one node decision trees as weak learners30.
The performance of each machine learning algorithm and data reduction combination was assessed in the initial screening step (Supplementary Figs 1–6). Performance was evaluated in terms of prediction accuracy using a 10-fold cross validation. The best performing machine learning algorithm and data reduction combinations for each model set are summarized in Fig. 3 and Supplementary Table 1. For the two binary model sets, Breed and Tenderness, the prediction accuracies among the highest performing machine learning algorithm data reduction approach combinations to the lowest span only 4.5% and 9.4%, respectively (Breed range: 0.78–0.825; Tenderness range: 0.814–0.908). This result supports that all of the approaches generated a consistently accurate model. More variation was observed in the prediction accuracies for the complex Main and Specialized model sets with predictions accuracies spanning 22.7% and 24%, respectively (Main range: 0.536–0.763; Specialized range: 0.728–0.968).
Figure 3.

Prediction accuracies (based on 10-fold cross validation) for the top performing machine learning algorithm and data reduction approach combinations for each model set.
Parameter tuning and optimization was performed for the top three machine learning algorithms for each model set. The overall highest performing machine learning algorithm and data reduction approach combination for each model set was selected based on prediction accuracy (100-fold cross validation) using the optimized algorithms. Prediction accuracies for the highest performing models are reported in Table 4. Interestingly, the most accurate machine learning algorithms were different for each model set, specifically LDA, XGBoost, and SVM (both linear and radial), although in many cases prediction accuracies of the top ranked algorithms differed by less than 1% (Fig. 3). Additionally, dimension reduction using either FS or PCA-FS was optimal for all of the top performing algorithms.
Table 4.
Summary of final prediction accuracies based on 100 fold cross validation for the top machine learning algorithm and data reduction approach combination for each model set after parameter tuning.
| Model Set | Dimension Reduction Approach | Number of predictors | Machine Learning Algorithm | Final Accuracy Rate |
|---|---|---|---|---|
| Main | PCA-FS | 24 PCs | LDA | 81.5% |
| Specialized | FS | 60 mass-bins | SVM - Linear | 99% |
| Breed | PCA-FS | 38 PCs | SVM - Radial | 85% |
| Tenderness | FS | 67 mass-bins | XGBoost | 90.5% |
Relevance of Machine Learning of REIMS data for Beef Quality Predictions
The results obtained in this study demonstrate that integrating machine learning with REIMS data can predict beef quality attributes with considerable accuracy, including quality grade, production background, breed type, and muscle tenderness. Dimension reduction improved the predictive accuracy in all cases, supporting that this is a critical step in data processing and analysis. Further, machine learning algorithms varied in their performance depending on the model set, indicating that the patterns in the chemical data (i.e. REIMS spectra) are highly complex and variable for the different facets of beef quality attributes. Thus, finding a “one size fits all” approach to generate predictive models for beef quality attributes is unlikely, and instead, evaluation of multiple algorithms should be standard practice in model development with highly complex chemical data.
Our results support the potential for REIMS analysis to be further developed to complement to the beef quality classification systems. Tenderness is a critical attribute for consumer satisfaction, which can exist independently of USDA quality grade, breed type, or production background31–33. Slice shear force can be used to verify guaranteed tender programs, but this method is laborious, costly, and destructive, and the industry has not widely adopted its use for individual carcass classification for product labeling34. Several instrument methods to classify beef tenderness have been evaluated that are less destructive than SSF and could be implemented at line speeds, but have yet to be adopted by the industry for routine use35–40. In this study, REIMS output, coupled with machine learning, correctly classified tough and tender carcasses with more than 90% accuracy (Table 1), indicating the potential value this approach for industry use.
Similarly, beef from Angus breed type cattle can receive significant premiums, as it is a requirement for several of the most desirable and highest quality branded beef programs. However, Angus influence is most commonly determined by visually assessing the predominance of black coloring of the live animal’s hide, rather than a true genetic test or physical documentation of lineage. Several machine learning algorithms evaluated in this study predicted Angus breed type with greater than 80% accuracy. It is important to note that this result does not represent a prediction of genuine Angus influence, but rather prediction of a carcass originating from an animal with a predominantly black colored hide. However, the results support the potential for prediction of true Angus genetic influence in future work, where carcasses with known genetic background could provide a more objective alternative to identifying Angus influence. Successful prediction of Grass-fed, Wagyu, and Dark Cutter carcasses with considerable accuracy in the current study suggest additional potential to utilize REIMS in determining and/or verifying various quality-related beef carcass characteristics.
Conclusions
The current study demonstrates that chemical profiles generated by REIMS and interpreted with machine learning algorithms can generate predictive models for beef quality attributes such as carcass type, production background, breed type, and muscle tenderness. The optimal machine learning algorithm, as assessed by predictive accuracy, was different depending on the classification problem, suggesting that a “one size fits all” approach to developing predictive models from REIMS data is not optimal. Furthermore, in all cases, data reduction prior to modeling improved the overall model accuracy. Taken as a whole, the results presented here lay the groundwork for future evaluation of REIMS in an on-line production setting to complement current meat classification methodologies and enable objective sorting and verification of meat products by attributes with high economic value.
Supplementary information
Acknowledgements
The authors would like to thank the Beef Checkoff for Funding. We would also like to thank Dr. Julia Balog for her input and assistance with REIMS data preprocessing.
Author Contributions
D.A.G., D.A.K., S.D.S., D.R.W., K.E.B. and T.L.W. were responsible for sampling design and sample collection; D.A.G. performed S.S.F. measurements; D.A.G., C.D.B. and J.E.P. participated in data acquisition; D.A.G., A.R.C., S-Y.K. and J.L.S. performed data analysis and statistics; J.E.P., D.A.G., A.R.S. and A.L.H. wrote manuscript text; all authors reviewed and edited the manuscript.
Data Availability
Raw mass spectrometry data files have been uploaded to the Metabolights data repository. Pre-processed mass spectrometry data and additional metadata for each sample is tabulated in Supplementary Data Table.
Competing Interests
The authors declare no competing interests.
Footnotes
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary information accompanies this paper at 10.1038/s41598-019-40927-6.
References
- 1.Black C, Chevallier OP, Elliott CT. The current and potential applications of Ambient Mass Spectrometry in detecting food fraud. TrAC Trends in Analytical Chemistry. 2016;82:268–278. doi: 10.1016/j.trac.2016.06.005. [DOI] [Google Scholar]
- 2.Takats Z, Wiseman JM, Gologan B, Cooks RG. Mass spectrometry sampling under ambient conditions with desorption electrospray ionization. Science. 2004;306:471–473. doi: 10.1126/science.1104404. [DOI] [PubMed] [Google Scholar]
- 3.Weston DJ. Ambient ionization mass spectrometry: current understanding of mechanistic theory; analytical performance and application areas. The Analyst. 2010;135:661–668. doi: 10.1039/b925579f. [DOI] [PubMed] [Google Scholar]
- 4.Schafer KC, et al. In vivo, in situ tissue analysis using rapid evaporative ionization mass spectrometry. Angewandte Chemie (International ed. in English) 2009;48:8240–8242. doi: 10.1002/anie.200902546. [DOI] [PubMed] [Google Scholar]
- 5.Balog J, et al. Intraoperative tissue identification using rapid evaporative ionization mass spectrometry. Sci Transl Med. 2013;5:194ra193. doi: 10.1126/scitranslmed.3005623. [DOI] [PubMed] [Google Scholar]
- 6.Vaqas B, et al. Intraoperative molecular diagnosis and surgical guidance using iknife real-time mass spectrometry. Neuro-Oncology. 2016;18:197–197. doi: 10.1093/neuonc/now212.831. [DOI] [Google Scholar]
- 7.Kinross, J. M. et al. iKnife: Rapid evaporative ionization mass spectrometry (REIMS) enables real-time chemical analysis of the mucosal lipidome for diagnostic and prognostic use in colorectal cancer. Cancer Res76 (2016).
- 8.St John, E. R. et al. Rapid evaporative ionisation mass spectrometry towards real time intraoperative oncological margin status determination in breast conserving surgery. Cancer Res76 (2016).
- 9.Phelps D, et al. Diagnosis of borderline ovarian tumours by rapid evaporative ionisation mass spectrometry (REIMS) using the surgical intelligent knife (iKnife) Bjog-Int J Obstet Gy. 2016;123:E4–E4. doi: 10.1111/1471-0528.14447. [DOI] [Google Scholar]
- 10.Balog J, et al. Identification of the Species of Origin for Meat Products by Rapid Evaporative Ionization Mass Spectrometry. J Agr Food Chem. 2016;64:4793–4800. doi: 10.1021/acs.jafc.6b01041. [DOI] [PubMed] [Google Scholar]
- 11.Black C, et al. A real time metabolomic profiling approach to detecting fish fraud using rapid evaporative ionisation mass spectrometry. Metabolomics. 2017;13:153. doi: 10.1007/s11306-017-1291-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Guitton, Y. et al. Rapid evaporative ionisation mass spectrometry and chemometrics for high-throughput screening of growth promoters in meat producing animals. Food additives & contaminants. Part A, Chemistry, analysis, control, exposure & risk assessment35, Epub 2018 Jan 17 (2017). [DOI] [PubMed]
- 13.Verplanken, K. et al. Rapid evaporative ionization mass spectrometry for high-throughput screening in food analysis: The case of boar taint. Talanta169, 30–36, Epub 2017 Mar 21 (2017). [DOI] [PubMed]
- 14.Smith, T. C. & Frank, E. In Statistical Genomics: Methods and Protocols (eds Ewy Mathé & Sean Davis) 353–378 (Springer New York, 2016).
- 15.Gromski, P. S. et al. A tutorial review: Metabolomics and partial least squares-discriminant analysis–a marriage of convenience or a shotgun wedding. Anal Chim Acta879, Epub 2015 Feb 11 (2015). [DOI] [PubMed]
- 16.United States Department of Agricutlure, A. M. S. United States Standards for Grades of Carcass Beef. (2017).
- 17.United States Department of Agricutlure, A. M. S. Specification for Characteristics of Cattle Eligible for Approved Beef Programs Claiming Angus Influence. (2016).
- 18.Shackelford SD, Wheeler TL, Koohmaraie M. Evaluation of slice shear force as an objective method of assessing beef longissimus tenderness. Journal of animal science. 1999;77:2693–2699. doi: 10.2527/1999.77102693x. [DOI] [PubMed] [Google Scholar]
- 19.ASTM. Standard Specification for Tenderness Marketing Claims Associated with Meat Cuts Derived from Beef. (West Conshohocken, PA, 2018).
- 20.Team, R. C. R: A language and environment for statistical computing, http://www.R-project.org/ (2013).
- 21.Francois, H. et al. Exploratory Multivariate Analysis by Example Using R. (Chapman and Hall/CRC 2018).
- 22.Kuhn, M. & Johnson, K. Applied Predictive Modeling 1edn, (Springer-Verlag 2013).
- 23.Kuhn, M. Building Predictive Models in R Using the caret Package. J Stat Softw (2008).
- 24.Pérez-Enciso M, Tenenhaus M. Prediction of clinical outcome with microarray data: a partial least squares discriminant analysis (PLS-DA) approach. Human Genetics. 2003;112:581–592. doi: 10.1007/s00439-003-0921-9. [DOI] [PubMed] [Google Scholar]
- 25.Gromski PS, et al. A comparative investigation of modern feature selection and classification approaches for the analysis of mass spectrometry data. Anal Chim Acta. 2014;829:1–8. doi: 10.1016/j.aca.2014.03.039. [DOI] [PubMed] [Google Scholar]
- 26.Perez, D. R. & Narasimhan, G. So you think you can PLS-DA? bioRxiv (2018).
- 27.Adler AE, et al. Comparing classification methods for diffuse reflectance spectra to improve tissue specific laser surgery. BMC Medical Research Methodology. 2014;14:91. doi: 10.1186/1471-2288-14-91. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Lenz, R. & Decker, H. J. Advances in Data Analysis. (Springer, 2018).
- 29.Chen, T. & Guestrin, C. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 785–794 (ACM, San Francisco, California, USA, 2016).
- 30.Tibshirani JF, Trevor H, Robert Additive logistic regression: a statistical view of boosting (With discussion and a rejoinder by the authors) The Annals of Statistics. 2000;28:337–407. [Google Scholar]
- 31.Boleman SJ, et al. Consumer evaluation of beef of known categories of tenderness. Journal of animal science. 1997;75:1521–1524. doi: 10.2527/1997.7561521x. [DOI] [PubMed] [Google Scholar]
- 32.Miller MF, Carr MA, Ramsey CB, Crockett KL, Hoover LC. Consumer thresholds for establishing the value of beef tenderness. Journal of animal science. 2002;79:3062–3068. doi: 10.2527/2001.79123062x. [DOI] [PubMed] [Google Scholar]
- 33.Platter WJ, et al. Effects of marbling and shear force on consumers’ willingness to pay for beef strip loin steaks. Journal of animal science. 2005;83:890–899. doi: 10.2527/2005.834890x. [DOI] [PubMed] [Google Scholar]
- 34.Wheeler TL, et al. The efficacy of three objective systems for identifying beef cuts that can be guaranteed tender. Journal of animal science. 2003;80:3315–3327. doi: 10.2527/2002.80123315x. [DOI] [PubMed] [Google Scholar]
- 35.Park B, Chen YR, Hruschka WR, Shackelford SD, Koohmaraie M. Near-infrared reflectance analysis for predicting beef longissimus tenderness. Journal of animal science. 1998;76:2115–2120. doi: 10.2527/1998.7682115x. [DOI] [PubMed] [Google Scholar]
- 36.Belk KE, et al. Evaluation of the Tendertec beef grading instrument to predict the tenderness of steaks from beef carcasses. Journal of animal science. 2001;79:688–697. doi: 10.2527/2001.793688x. [DOI] [PubMed] [Google Scholar]
- 37.Vote DJ, Belk KE, Tatum JD, Scanga JA, Smith GC. Online prediction of beef tenderness using a computer vision system equipped with a BeefCam module. Journal of animal science. 2003;81:457–465. doi: 10.2527/2003.812457x. [DOI] [PubMed] [Google Scholar]
- 38.Konda Naganathan G, et al. Partial least squares analysis of near-infrared hyperspectral images for beef tenderness prediction. Sensing and Instrumentation for Food Quality and Safety. 2008;2:178–188. doi: 10.1007/s11694-008-9051-3. [DOI] [Google Scholar]
- 39.Konda Naganathan G, et al. Three dimensional chemometric analyses of hyperspectral images for beef tenderness forecasting. Journal of Food Engineering. 2016;169:309–320. doi: 10.1016/j.jfoodeng.2015.09.001. [DOI] [Google Scholar]
- 40.Nubiato KEZ, et al. A bench-top hyperspectral imaging system to classify beef from Nellore cattle based on tenderness. Infrared Physics & Technology. 2018;89:247–254. doi: 10.1016/j.infrared.2018.01.005. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
Raw mass spectrometry data files have been uploaded to the Metabolights data repository. Pre-processed mass spectrometry data and additional metadata for each sample is tabulated in Supplementary Data Table.