

SUMMARY
Modern epidemiological studies collect data on time-varying individual-specific characteristics, such as body mass index and blood pressure. Incorporation of such time-dependent covariates in time-to-event models is of great interest, but raises some challenges. Of specific concern are measurement error, and the non-synchronous updating of covariates across individuals, due for example to missing data. It is well known that in the presence of either of these issues the last observation carried forward (LOCF) approach traditionally used leads to bias. Joint models of longitudinal and time-to-event outcomes, developed recently, address these complexities by specifying a model for the joint distribution of all processes and are commonly fitted by maximum likelihood or Bayesian approaches. However, the adequate specification of the full joint distribution can be a challenging modeling task, especially with multiple longitudinal markers. In fact, most available software packages are unable to handle more than one marker and offer a restricted choice of survival models. We propose a two-stage approach, Multiple Imputation for Joint Modeling (MIJM), to incorporate multiple time-dependent continuous covariates in the semi-parametric Cox and additive hazard models. Assuming a primary focus on the time-to-event model, the MIJM approach handles the joint distribution of the markers using multiple imputation by chained equations, a computationally convenient procedure that is widely available in mainstream statistical software. We developed an R package “survtd” that allows MIJM and other approaches in this manuscript to be applied easily, with just one call to its main function. A simulation study showed that MIJM performs well across a wide range of scenarios in terms of bias and coverage probability, particularly compared with LOCF, simpler two-stage approaches, and a Bayesian joint model. The Framingham Heart Study is used to illustrate the approach.
Keywords: Additive hazard model, Cox model, Joint model, Measurement error, Missing data, Multiple imputation, Multiple overimputation, Regression calibration, Time-dependent covariates
1. Introduction
Large-scale studies in which data are collected from individuals over time are central to modern health research. Our motivating example and a pioneer of such studies in epidemiology is the Framingham Heart Study (FHS), in which a wide range of time-varying exposures have been collected regularly over a period of more than 55 years. These variables include both physical/biological characteristics [body mass index (BMI), blood pressure, etc.] and behavioral/socio-demographic characteristics (smoking, marital status, etc.). To understand the pathways by which such characteristics may affect the occurrence of health events (death, diabetes onset, etc.), it is common to incorporate them as time-dependent covariates in models for a time-to-event outcome.
Hazard models are often adopted, assuming that the hazard rate at a given time depends on the current “true” (error-free) values of the covariates. In principle, unbiased estimation of these models requires that we know, at each observed event time, the current true covariate values for the set of individuals still at risk just before that point. This requirement is rarely, if ever, fulfilled for time-dependent continuous covariates, or markers, for two main reasons. First, many markers, particularly biological markers, are measured with error due to flaws in technical procedures and biological, non-prognostic, and short-term variations. Second, these covariates are usually measured in discrete time, but changes in their values and failures both occur in continuous time. Thus, the true values of the markers at the event times can be viewed as missing data.
This missing data problem is commonly dealt with using the last observation carried forward (LOCF) approach, i.e. singly imputing a missing value at an event time with the last observation available. Andersen and Liestøl (2003) found that the bias imparted by this approach increases with the degree of measurement error and with non-synchronous updating of the covariates across individuals, for instance due to skipped follow-up visits. While missing visit-specific measurements are not those necessary to fit the model (i.e. those at the event times), this missingness exacerbates the biases arising from the discrete-time observation of continuously changing characteristics.
The caveats of LOCF have led to the development of joint modeling approaches, whereby the joint distribution of a number of time-dependent markers (usually just one) and the time-to-event outcome is modeled. Various maximum likelihood methods (e.g. De Gruttola and Tu, 1994; Wulfsohn and Tsiatis, 1997) and Bayesian approaches (e.g. Faucett and Thomas, 1996; Daniels and Hogan, 2008; Hanson and others, 2011; Rizopoulos, 2016b) have been developed to fit these models, and comprehensive reviews are available (e.g. Wu and others, 2012). Drawbacks of these methods are the reliance of their performance on the correct specification of the full joint distribution, which can be a difficult task, and their computational complexity, which limits the flexibility of joint modeling packages available in mainstream statistical software. Indeed, most packages cannot handle more than one marker and are constrained to parametric hazard functions or proportional hazards models (Gould and others, 2015; Hickey and others, 2016). Restriction to such survival models is also evident in specific models proposed for the setting with multiple time-dependent markers (e.g. Xu and Zeger, 2001; Chi and Ibrahim, 2006; Rizopoulos and Ghosh, 2011).
Two-stage joint modeling approaches are an appealing alternative to full joint modeling to tackle multiple markers and other survival models, such as the additive hazard model. Various two-stage methods have been proposed for one marker (Wu and others 2012), but the general principle of the simpler versions is as follows. In the first stage, a linear mixed model is fitted to estimate the subject-specific true marker trajectories, and the missing values at the event times are singly imputed from these. In the second stage, the hazard model is fitted using the imputed data. These simple approaches rely on approximations to the marker distribution and can be less efficient than joint-estimation methods. Notably, issues could arise: (i) when the uncertainty in the single imputations is not accounted for in the second stage; (ii) when, with multiple markers, the interrelations among these are not accounted for in the first stage; and (iii) when the informative drop-out induced by the events is ignored in the first stage, leading to an inaccurate approximation of the marker distribution (Ye and others, 2008; Albert and Shih, 2010).
We propose a new two-stage approach, Multiple Imputation for Joint Modeling (MIJM), to incorporate multiple markers in the semi-parametric Cox and additive hazard models. We draw from the literature on multiple imputation (MI) (Rubin, 1987), a missing data approach, to improve upon simple two-stage approaches. The joint distribution of the markers is treated as a nuisance, which is computationally convenient, but also reasonable when interest lies in the time-to-event model and considering that adequately specifying that multivariate distribution may be challenging. The approach is easy to implement in mainstream software. The R package  (Moreno-Betancur, 2017) facilitates its application (see Section 7 of supplementary material available at Biostatistics online).
(Moreno-Betancur, 2017) facilitates its application (see Section 7 of supplementary material available at Biostatistics online).
2. Notation and assumptions
Suppose that 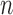 individuals in a study are followed until an event of interest occurs (e.g. death) or a censoring time (e.g. due to end of study). We assume independence across individuals and independent censoring given covariates. For
individuals in a study are followed until an event of interest occurs (e.g. death) or a censoring time (e.g. due to end of study). We assume independence across individuals and independent censoring given covariates. For 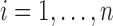 , let
, let 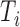 and
and 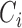 denote, respectively, the time to event and the right-censoring time, so the observed time is
denote, respectively, the time to event and the right-censoring time, so the observed time is 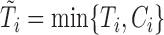 and the event indicator is
and the event indicator is 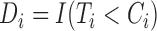 , where
, where 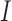 is the indicator function. Let
is the indicator function. Let 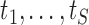 denote the set of times, indexed in increasing order, at which an event was observed (i.e. all
denote the set of times, indexed in increasing order, at which an event was observed (i.e. all 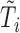 such that
such that 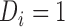 ). The aim is to model the hazard rate of the event, denoted by
). The aim is to model the hazard rate of the event, denoted by  at time
at time  , as a function of a vector
, as a function of a vector 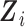 of time-fixed covariates measured at baseline, assumed to be fully-observed without error, and several, say
of time-fixed covariates measured at baseline, assumed to be fully-observed without error, and several, say 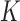 , time-varying continuous markers. Let
, time-varying continuous markers. Let  denote the “true” (error-free) value of the
denote the “true” (error-free) value of the  th marker for individual
th marker for individual 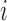 at time
at time 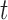 (
(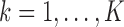 ;
; 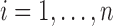 ;
; 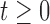 ).
).
2.1. Target hazard rate models
We consider two types of model, both assuming that the hazard rate depends on the current value of all markers and the time-fixed covariates, and leaving the baseline hazard, denoted by 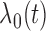 , unspecified. The two models differ in the interpretation of their respective regression coefficients, providing complementary information of interest. The Cox proportional hazards model assumes that covariates have multiplicative effects on the hazard, in the following standard form:
, unspecified. The two models differ in the interpretation of their respective regression coefficients, providing complementary information of interest. The Cox proportional hazards model assumes that covariates have multiplicative effects on the hazard, in the following standard form:
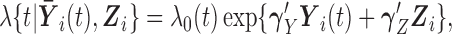 |
(2.1) |
where  and
and 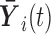 denotes the history of the markers until time
denotes the history of the markers until time 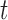 . Regression coefficients in this model provide relative measures of association (hazard ratios). The semi-parametric additive hazard model (Lin and Ying, 1994) is the additive counterpart of model (2.1), and its coefficients provide absolute measures of association (hazard differences):
. Regression coefficients in this model provide relative measures of association (hazard ratios). The semi-parametric additive hazard model (Lin and Ying, 1994) is the additive counterpart of model (2.1), and its coefficients provide absolute measures of association (hazard differences):
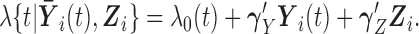 |
(2.2) |
2.2. Assumptions about the marker measurement process
In principle, unbiased estimation of models (2.1) and (2.2) requires data on the true marker values at the observed event times, but these are virtually never available. The trajectories 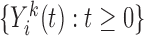 are not observed in continuous time, but are often to be measured at a set of pre-fixed visit times,
are not observed in continuous time, but are often to be measured at a set of pre-fixed visit times, 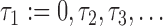 , common to all individuals, until the event or censoring occurs. The visit times will not generally coincide with the event times
, common to all individuals, until the event or censoring occurs. The visit times will not generally coincide with the event times 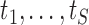 . Let
. Let 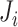 denote the number of planned visit times occurring before
denote the number of planned visit times occurring before 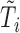 . Further, for each marker some of the
. Further, for each marker some of the  measurements can be missing (e.g. due to skipped visits). We refer to these as missing “at-risk-visit” measurements, to distinguish them both from the missing values at the event times needed to fit the hazard models and from potentially missing measurements after the event or censoring occurs. We assume that the probability of a missing at-risk-visit value does not depend on the value itself given values of that marker at other visits, values of the other
measurements can be missing (e.g. due to skipped visits). We refer to these as missing “at-risk-visit” measurements, to distinguish them both from the missing values at the event times needed to fit the hazard models and from potentially missing measurements after the event or censoring occurs. We assume that the probability of a missing at-risk-visit value does not depend on the value itself given values of that marker at other visits, values of the other  markers at that visit, the time-fixed covariates, the time-to-event outcome and visit timing. This is a more relaxed condition than the “everywhere missing at random” assumption (Seaman and others, 2013).
markers at that visit, the time-fixed covariates, the time-to-event outcome and visit timing. This is a more relaxed condition than the “everywhere missing at random” assumption (Seaman and others, 2013).
Finally, when a measurement does take place, the value is measured with random error, represented as a normally distributed deviation from the true trajectory. Hence, for 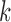 and
and 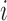 fixed, the available measurements are
fixed, the available measurements are 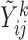 , for
, for 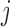 in a subset of
in a subset of 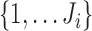 , where
, where 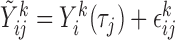 and
and 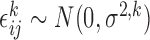 is the measurement error. The deviations
is the measurement error. The deviations 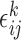 are assumed to be independent of the covariates, the markers and of each other across time-points (
are assumed to be independent of the covariates, the markers and of each other across time-points (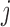 ) and markers (
) and markers (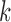 ).
).
3. Multiple Imputation for Joint Modeling (MIJM)
3.1. Overview of two-stage joint modeling approaches
The data missing to fit models (2.1) and (2.2) are the values  for
for 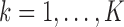 ,
, 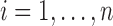 and
and 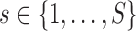 such that
such that 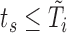 . Two-stage approaches generally seek to impute these with probable values based on fitted models (first stage), and then use these imputations to fit the hazard model (second stage). Note that there is no need to impute the missing at-risk-visit values.
. Two-stage approaches generally seek to impute these with probable values based on fitted models (first stage), and then use these imputations to fit the hazard model (second stage). Note that there is no need to impute the missing at-risk-visit values.
A simple version is to fit separately, in the first stage,  linear mixed models, one per marker, including as predictors the covariates
linear mixed models, one per marker, including as predictors the covariates  and spline or polynomial terms for functions of time (and possibly interaction terms). This yields smoothed estimates of the subject-specific true marker trajectories from which the missing values are singly imputed. The performance of this approach (henceforth “simple2S”) can be suboptimal due to issues (i)–(iii) mentioned in the introduction.
and spline or polynomial terms for functions of time (and possibly interaction terms). This yields smoothed estimates of the subject-specific true marker trajectories from which the missing values are singly imputed. The performance of this approach (henceforth “simple2S”) can be suboptimal due to issues (i)–(iii) mentioned in the introduction.
The proposed MIJM approach, described in the following sections, is a refined version using MI, under which multiple, say 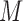 , imputations of the missing values are drawn from interdependent imputation models (in this case one model for each marker) to produce
, imputations of the missing values are drawn from interdependent imputation models (in this case one model for each marker) to produce 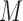 completed data sets. The analysis model (in this case the hazard model) is fitted to each completed data set and the
completed data sets. The analysis model (in this case the hazard model) is fitted to each completed data set and the 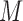 estimates obtained from these are then combined using the formulas of Rubin (1987). The benefit of multiple over single imputation is that MI standard errors appropriately reflect the uncertainty regarding the imputed values, addressing the aforementioned issue (i) of simple two-stage approaches (Bycott and Taylor, 1998; Ye and others, 2008; Albert and Shih, 2010). Further, by carefully building the
estimates obtained from these are then combined using the formulas of Rubin (1987). The benefit of multiple over single imputation is that MI standard errors appropriately reflect the uncertainty regarding the imputed values, addressing the aforementioned issue (i) of simple two-stage approaches (Bycott and Taylor, 1998; Ye and others, 2008; Albert and Shih, 2010). Further, by carefully building the 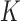 interdependent imputation models, and drawing values from these using an iterative algorithm called multiple imputation by chained equations (MICE) (van Buuren and Groothuis-Oudshoorn, 2011), our MI approach also addresses issues (ii) and (iii).
interdependent imputation models, and drawing values from these using an iterative algorithm called multiple imputation by chained equations (MICE) (van Buuren and Groothuis-Oudshoorn, 2011), our MI approach also addresses issues (ii) and (iii).
3.2. Stage 1: multiple imputation of time-dependent covariates
3.2.1. Imputation models for the longitudinal markers.
For each marker 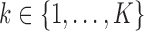 , an imputation model is built by fitting a linear mixed model to the observed values of the marker across visits and individuals (
, an imputation model is built by fitting a linear mixed model to the observed values of the marker across visits and individuals (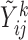 ,
, 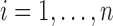 and
and  in a subset of
in a subset of 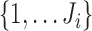 ). Specifically, expected subject-specific trajectories are modeled as:
). Specifically, expected subject-specific trajectories are modeled as:
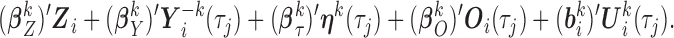 |
(3.1) |
Components of this mixed model are now described in detail. The fixed-effects vector is  and the random-effects vectors are
and the random-effects vectors are 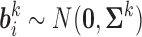 ,
, 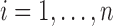 . The vector
. The vector 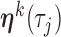 may contain spline or polynomial terms for
may contain spline or polynomial terms for 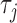 to model time-trends in the fixed-effects part of the model, which also includes the time-fixed covariates
to model time-trends in the fixed-effects part of the model, which also includes the time-fixed covariates 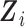 . A subset of the variables in
. A subset of the variables in 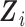 and
and  , collected in the vector
, collected in the vector 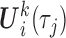 , are allowed to have subject-specific random effects. Such flexibility may be needed for markers with complex-shaped trajectories. In our simulation study and example, we considered random intercepts and slopes. Another two key sets of variables are included as predictors with fixed effects in (3.1), as described next.
, are allowed to have subject-specific random effects. Such flexibility may be needed for markers with complex-shaped trajectories. In our simulation study and example, we considered random intercepts and slopes. Another two key sets of variables are included as predictors with fixed effects in (3.1), as described next.
First, the full vector of current values of the other  markers,
markers, 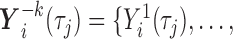
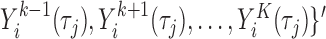 , is included. All these variables are in the target hazard model and could also be predictive of missingness, and recommendations in the MI literature suggest including all variables in any of these two categories in the imputation model (van Buuren and Groothuis-Oudshoorn, 2011). This can also be seen as an approximate way to deal with issue (ii) of simple two-stage approaches, i.e. the interrelations among the markers are accounted for.
, is included. All these variables are in the target hazard model and could also be predictive of missingness, and recommendations in the MI literature suggest including all variables in any of these two categories in the imputation model (van Buuren and Groothuis-Oudshoorn, 2011). This can also be seen as an approximate way to deal with issue (ii) of simple two-stage approaches, i.e. the interrelations among the markers are accounted for.
Second, information on the time-to-event outcome is included following recommendations for MI in the context of incomplete covariates (van Buuren and others, 1999). This addresses issue (iii) in that it provides an approximation of the marker distribution that can be sufficiently accurate for the purpose of imputation and subsequent estimation of the target time-to-event model. Specifically, we include: the Nelson–Aalen estimator of cumulative hazard at time 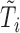 ,
, 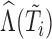 ; interactions of
; interactions of 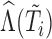 with the time-fixed covariates (succinctly,
with the time-fixed covariates (succinctly, 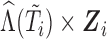 ); and a modified event indicator, defined by
); and a modified event indicator, defined by  if
if  and
and 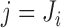 , and
, and 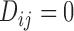 otherwise, i.e.
otherwise, i.e. 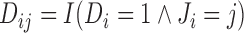 . Thus, in (3.1),
. Thus, in (3.1), 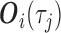 is the vector containing
is the vector containing 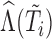 ,
, 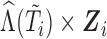 and
and 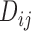 . The justification for this strategy, used by the MIJM approach, is provided in the Supplementary material available at Biostatistics online (Section 1) and extends results of White and Royston (2009). Briefly, it is based on an approximation to the conditional distribution of each marker given the time-to-event outcome.
. The justification for this strategy, used by the MIJM approach, is provided in the Supplementary material available at Biostatistics online (Section 1) and extends results of White and Royston (2009). Briefly, it is based on an approximation to the conditional distribution of each marker given the time-to-event outcome.
Throughout the manuscript, we also consider an alternative approach, identical to MIJM in all aspects except that it includes the actual event indicator 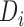 as predictor in the imputation model instead of the modified indicator, i.e.
as predictor in the imputation model instead of the modified indicator, i.e. 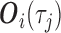 contains
contains 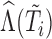 ,
,  , and
, and 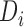 . This is the approach recommended to impute incomplete time-fixed covariates for the Cox model (White and Royston, 2009), and we assessed its comparative performance here due to its simplicity. Nonetheless, we expect that approximation to be less accurate as it is unadapted to the time-dependent covariate setting, and we thus refer to it as “unMIJM”. For unMIJM,
. This is the approach recommended to impute incomplete time-fixed covariates for the Cox model (White and Royston, 2009), and we assessed its comparative performance here due to its simplicity. Nonetheless, we expect that approximation to be less accurate as it is unadapted to the time-dependent covariate setting, and we thus refer to it as “unMIJM”. For unMIJM, 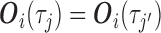 for all
for all 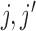 , i.e. the vector is time-fixed, but we keep the same notation throughout for simplicity.
, i.e. the vector is time-fixed, but we keep the same notation throughout for simplicity.
As usual with MI, the resulting 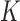 imputation models are not assumed necessarily to represent the true data generating mechanism (because of the difficulty of specifying a joint distribution that is compatible with these conditional models) but are working models for imputation purposes.
imputation models are not assumed necessarily to represent the true data generating mechanism (because of the difficulty of specifying a joint distribution that is compatible with these conditional models) but are working models for imputation purposes.
3.2.2. Multiple imputation by chained equations (MICE).
The drawing of imputations for the missing marker values at the event times (i.e. 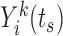 for
for  such that
such that 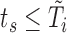 ) from the trajectories determined by (3.1) requires an iterative procedure due to the dependence of each marker model on the true values of other markers, which need to be imputed as well. We use MICE, a procedure that draws iteratively from these
) from the trajectories determined by (3.1) requires an iterative procedure due to the dependence of each marker model on the true values of other markers, which need to be imputed as well. We use MICE, a procedure that draws iteratively from these 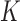 models until convergence to yield one set of imputations.
models until convergence to yield one set of imputations.
For 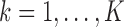 , let
, let 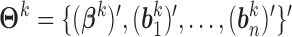 , and let
, and let 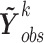 denote the vector of all the available measurements of marker
denote the vector of all the available measurements of marker 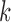 across individuals. Let
across individuals. Let 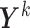 collect the true values of this marker across all individuals at their respective relevant planned visit and event times (for individual
collect the true values of this marker across all individuals at their respective relevant planned visit and event times (for individual 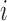 , the values for each
, the values for each 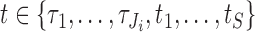 such that
such that 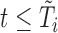 ). Let
). Let 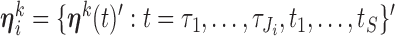 and
and 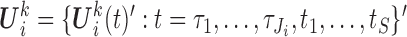 . For the MIJM method, we extend the definition of
. For the MIJM method, we extend the definition of 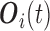 to any time-point
to any time-point 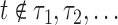 by considering the natural definition of the modified indicator at time
by considering the natural definition of the modified indicator at time 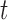 :
:  (see Section 1 of supplementary material available at Biostatistics online) and define
(see Section 1 of supplementary material available at Biostatistics online) and define  . For unMIJM, we let
. For unMIJM, we let 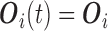 denote the corresponding time-constant vector. The vectors
denote the corresponding time-constant vector. The vectors 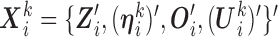 ,
, 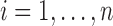 , are collected in
, are collected in 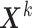 .
.
For imputation 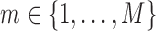 , the iterative procedure is initialized by imputations based on simple random draws
, the iterative procedure is initialized by imputations based on simple random draws 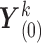 ,
, 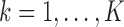 , from the data. If
, from the data. If  iterations are to be carried out, then at iteration
iterations are to be carried out, then at iteration 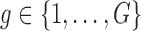 , draws
, draws 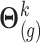 and
and  of
of 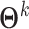 and
and  are performed sequentially for
are performed sequentially for 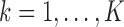 as follows, based on the current values of the remaining markers:
as follows, based on the current values of the remaining markers:
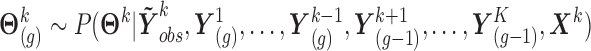 and
and
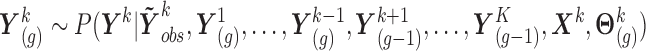 ,
where the formulations for
,
where the formulations for 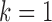 and
and 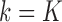 make the obvious modification. These draws are performed following (I) and (II) below, which are based on the procedure of Moreno-Betancur and Chavance (2016) but incorporating measurement error correction.
make the obvious modification. These draws are performed following (I) and (II) below, which are based on the procedure of Moreno-Betancur and Chavance (2016) but incorporating measurement error correction.
(I) Performing draws of the parameters 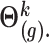
Using standard asymptotic results, the conditional (posterior) distribution of 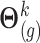 above is approximated by a normal distribution with mean and variance equal to the estimates of fixed and random effects and of their variance–covariance, respectively, given restricted maximum likelihood (REML) estimates of the variance components. Specifically, the imputation model for marker
above is approximated by a normal distribution with mean and variance equal to the estimates of fixed and random effects and of their variance–covariance, respectively, given restricted maximum likelihood (REML) estimates of the variance components. Specifically, the imputation model for marker  is fitted based on the current values of the other markers using the profiled REML criterion of Bates and others (2015). This yields maximum likelihood estimates and best linear unbiased predictors of the fixed and random effects vectors, respectively, denoted by
is fitted based on the current values of the other markers using the profiled REML criterion of Bates and others (2015). This yields maximum likelihood estimates and best linear unbiased predictors of the fixed and random effects vectors, respectively, denoted by 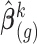 and
and 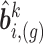 ,
, 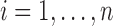 , and estimates of their variance–covariance matrices, denoted by
, and estimates of their variance–covariance matrices, denoted by 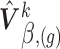 and
and 
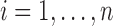 . We thus draw
. We thus draw 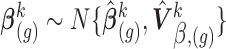 and
and 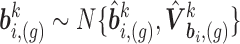 for
for 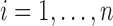 , and set
, and set  .
.
(II) Performing draws of  from the posited trajectory.
from the posited trajectory.
Draws of marker 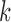 for individual
for individual 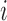 are required for all times
are required for all times 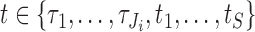 such that
such that 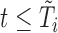 . Given
. Given 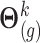 , a draw at time
, a draw at time  is obtained using the linear predictor (3.1), setting
is obtained using the linear predictor (3.1), setting 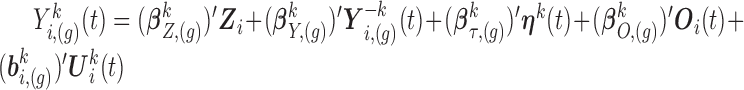 , where
, where 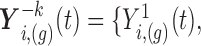
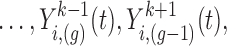
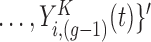 is the vector of current values of the other markers at time
is the vector of current values of the other markers at time  for individual
for individual 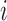 .
.
At convergence, often achieved after a small number of iterations, the algorithm yields the 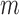 th set of imputations. In practice, the number of iterations should be based on graphical assessments of convergence (van Buuren and Groothuis-Oudshoorn, 2011), while the number of imputations may be based on relative efficiency calculations (Rubin, 1987). Note that, in addition to imputing the missing values at the observed event times
th set of imputations. In practice, the number of iterations should be based on graphical assessments of convergence (van Buuren and Groothuis-Oudshoorn, 2011), while the number of imputations may be based on relative efficiency calculations (Rubin, 1987). Note that, in addition to imputing the missing values at the observed event times 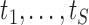 at which the individual is at risk, imputations are also performed at each iteration for all planned visit times
at which the individual is at risk, imputations are also performed at each iteration for all planned visit times  even though these values are not needed to fit the hazard model. The reason is that the imputation model (3.1) is estimated at each iteration from the values occurring at planned visit times. In practical terms, this requires stacking two distinct data sets for the imputation procedure.
even though these values are not needed to fit the hazard model. The reason is that the imputation model (3.1) is estimated at each iteration from the values occurring at planned visit times. In practical terms, this requires stacking two distinct data sets for the imputation procedure.
3.3. Stage 2: fitting the hazard model
The procedure above yields 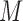 imputations of each missing value. To fit model (2.1) or (2.2) based on the
imputations of each missing value. To fit model (2.1) or (2.2) based on the 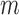 th set of imputations (
th set of imputations ( ), we require a data set with multiple rows per individual, one for each event-time
), we require a data set with multiple rows per individual, one for each event-time 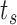 such that
such that 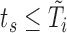 . The data set has a column for each of the
. The data set has a column for each of the 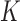 markers, including its
markers, including its 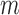 th imputed value for the corresponding individual and event time. Additional columns include the time-fixed covariates
th imputed value for the corresponding individual and event time. Additional columns include the time-fixed covariates  , which are constant across rows corresponding to the same individual. Columns defining the entry and exit times, as in the usual data set-up when dealing with time-dependent covariates, are also required (Therneau and Grambsch, 2000). Thus, for the row corresponding to individual
, which are constant across rows corresponding to the same individual. Columns defining the entry and exit times, as in the usual data set-up when dealing with time-dependent covariates, are also required (Therneau and Grambsch, 2000). Thus, for the row corresponding to individual  and event time
and event time 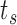 , the “entry” time is the previous event-time
, the “entry” time is the previous event-time 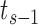 (where we define
(where we define 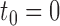 ) and the “exit” time is
) and the “exit” time is  . The data set prepared in this way can then be used in a function that fits the hazard model using a start/stop or entry/exit formulation. The
. The data set prepared in this way can then be used in a function that fits the hazard model using a start/stop or entry/exit formulation. The  results obtained are then combined using Rubin’s formulas. The main function of the R
results obtained are then combined using Rubin’s formulas. The main function of the R 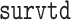 package (Moreno-Betancur, 2017) performs all the steps: data manipulation pre- and post-MI, MI procedure, model fitting, and pooling of results, so that one call to this function suffices to apply our approach (see Section 7 of supplementary material available at Biostatistics online).
package (Moreno-Betancur, 2017) performs all the steps: data manipulation pre- and post-MI, MI procedure, model fitting, and pooling of results, so that one call to this function suffices to apply our approach (see Section 7 of supplementary material available at Biostatistics online).
4. Simulation study
We aimed to compare the performance across various scenarios of the following approaches: LOCF, simple2S, unMIJM, and MIJM. We also considered a Bayesian full joint modeling method (“JMbayes”), available in a development version of the R package 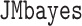 (Rizopoulos, 2016a), but only for the Cox model in a subset of scenarios. This method assumes a multivariate mixed model for the markers and a hazard model similar to (2.1) but the baseline hazard is modeled using B-splines (Rizopoulos, 2016b).
(Rizopoulos, 2016a), but only for the Cox model in a subset of scenarios. This method assumes a multivariate mixed model for the markers and a hazard model similar to (2.1) but the baseline hazard is modeled using B-splines (Rizopoulos, 2016b).
4.1. Data generation
The simulation models closely followed aspects of the FHS, but we considered a reduced sample size (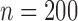 , except when assessing impact of sample size) and a less intensive and shorter schedule of planned visit times relative to the median survival time as not many studies have the luxury of such a long and intensive follow-up. For each individual
, except when assessing impact of sample size) and a less intensive and shorter schedule of planned visit times relative to the median survival time as not many studies have the luxury of such a long and intensive follow-up. For each individual 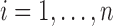 , we generated two time-fixed covariates:
, we generated two time-fixed covariates:  and
and 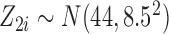 , following the distribution of gender and baseline age, respectively, in the FHS. Parameters of the models used to generate the time-dependent markers, missing data, and the time-to-event outcome, described next, were determined from the FHS by fitting analogous models to, respectively, systolic blood pressure (SBP) measurements, the probability of missing at-risk-visit SBP measurements, and mortality. Some parameters were fixed while others were varied across simulation scenarios (see next section). All parameter values and related details are provided in the Supplementary material available at Biostatistics online (Section 2).
, following the distribution of gender and baseline age, respectively, in the FHS. Parameters of the models used to generate the time-dependent markers, missing data, and the time-to-event outcome, described next, were determined from the FHS by fitting analogous models to, respectively, systolic blood pressure (SBP) measurements, the probability of missing at-risk-visit SBP measurements, and mortality. Some parameters were fixed while others were varied across simulation scenarios (see next section). All parameter values and related details are provided in the Supplementary material available at Biostatistics online (Section 2).
Repeated measures of three markers ( ) were generated for the
) were generated for the 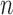 subjects at common times
subjects at common times 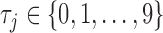 such that
such that 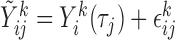 , where
, where 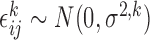 were independent across
were independent across 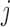 and
and  . We considered two types of model, detailed next, for the joint distribution of the multiple markers to determine the true underlying trajectories. Fixed intercept parameters were chosen in both cases so that the marginal mean of the error-polluted measurements was around 140 in all scenarios, as is the case for SBP (in mmHg) in the FHS. The marginal standard deviation varied between 30 and 50 according to the measurement error scenario (see below).
. We considered two types of model, detailed next, for the joint distribution of the multiple markers to determine the true underlying trajectories. Fixed intercept parameters were chosen in both cases so that the marginal mean of the error-polluted measurements was around 140 in all scenarios, as is the case for SBP (in mmHg) in the FHS. The marginal standard deviation varied between 30 and 50 according to the measurement error scenario (see below).
The first was a correlated random effects model, which is a multivariate mixed model, parametrizing the marginal mean of the marker vector (Fieuws and Verbeke, 2004). We drew from trajectories given by 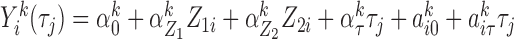 , for
, for 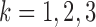 , where
, where  and
and 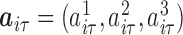 were both zero-mean multivariate normal vectors, for
were both zero-mean multivariate normal vectors, for 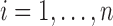 , such that
, such that 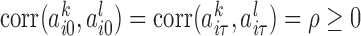 , for all
, for all 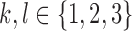 . Hence, the random intercepts across markers could be correlated, and so could the random slopes, and this correlation
. Hence, the random intercepts across markers could be correlated, and so could the random slopes, and this correlation 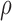 modulated the correlation between markers. The random intercepts and slopes were independent of each other, i.e.
modulated the correlation between markers. The random intercepts and slopes were independent of each other, i.e.  , for all
, for all 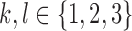 . Hence
. Hence 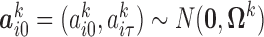 where
where 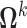 was a diagonal matrix with diagonal
was a diagonal matrix with diagonal  .
.
The second was the so-called “product-normal” model, which is based on conditional models (Spiegelhalter, 1998; Cooper and others, 2007). Here, the trajectory of marker 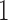 did not depend on any of the other markers and the trajectory of marker
did not depend on any of the other markers and the trajectory of marker  depended on the current values of markers 1 through
depended on the current values of markers 1 through 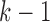 . Thus the markers were generated sequentially from a chain of conditional models, assuming that the trajectory of marker
. Thus the markers were generated sequentially from a chain of conditional models, assuming that the trajectory of marker 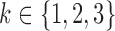 followed
followed 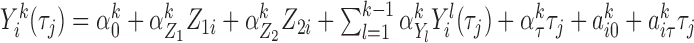 , where the fourth term was null for
, where the fourth term was null for 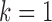 and
and 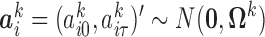 ,
, 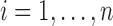 , were vectors of subject-specific random intercepts and slopes independent of each other (i.e. with
, were vectors of subject-specific random intercepts and slopes independent of each other (i.e. with 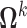 diagonal as for the correlated random effects model) and independent of the random effects for other markers. Here the interdependence among markers was controlled through the regression coefficients
diagonal as for the correlated random effects model) and independent of the random effects for other markers. Here the interdependence among markers was controlled through the regression coefficients  .
.
For both the Cox and additive hazard models, a time to event 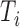 was generated for each individual using the cumulative hazard inversion method, assuming a Weibull baseline hazard with shape parameter
was generated for each individual using the cumulative hazard inversion method, assuming a Weibull baseline hazard with shape parameter  and scale parameter
and scale parameter 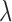 . For the Cox model, the hazard function was given by:
. For the Cox model, the hazard function was given by:  , and for the additive hazard model by
, and for the additive hazard model by 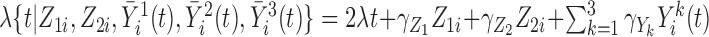 . In both cases around 20% independent censoring was superimposed by drawing censoring times
. In both cases around 20% independent censoring was superimposed by drawing censoring times 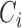 from a uniform distribution. The repeated measures of the
from a uniform distribution. The repeated measures of the 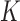 markers were then truncated at the follow-up time
markers were then truncated at the follow-up time 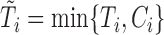 , so only
, so only 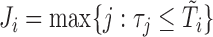 measurements were available for individual
measurements were available for individual 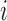 at this stage. Then measurement
at this stage. Then measurement  ,
, 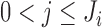 , was set to missing if
, was set to missing if  where
where  was drawn from a Bernoulli distribution with success probability following
was drawn from a Bernoulli distribution with success probability following 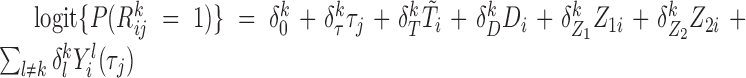 .
.
4.2. Simulation plan
In preliminary simulations, we assessed the procedure in the case of one marker (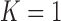 ). With
). With  markers, we performed a main set of simulations for each combination of multiple marker model and hazard rate model, altering the following aspects for each marker
markers, we performed a main set of simulations for each combination of multiple marker model and hazard rate model, altering the following aspects for each marker  to ranges observed in the FHS example. First, we varied
to ranges observed in the FHS example. First, we varied 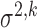 to alter the degree of measurement error, using the following intra-cluster correlation (ICC)-type measure as an indicator of the scale of error relative to total variation:
to alter the degree of measurement error, using the following intra-cluster correlation (ICC)-type measure as an indicator of the scale of error relative to total variation: 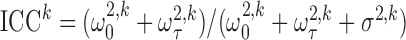 . The lower the measurement error, the higher
. The lower the measurement error, the higher 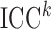 . We considered scenarios with low (
. We considered scenarios with low ( ), moderate (
), moderate (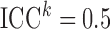 ) and high (
) and high (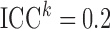 ) error. Second, we varied
) error. Second, we varied 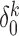 to alter the proportion
to alter the proportion 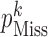 of missing at-risk-visit values to no (
of missing at-risk-visit values to no (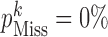 ), low (
), low (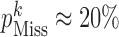 ), and high (
), and high (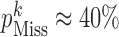 ) missingness.
) missingness.
Third, we considered null, weak and strong effects of the markers on the hazard by taking 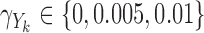 in the Cox model and
in the Cox model and 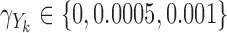 in the additive model, respectively. Estimates of these parameters were expressed as effects per 100 units for the Cox model and per 1000 units for the additive model. Fourth, we varied the strength of the pairwise marginal correlations between the three markers to low (around 0.05), moderate (around 0.15), or high (around 0.3), by setting, respectively,
in the additive model, respectively. Estimates of these parameters were expressed as effects per 100 units for the Cox model and per 1000 units for the additive model. Fourth, we varied the strength of the pairwise marginal correlations between the three markers to low (around 0.05), moderate (around 0.15), or high (around 0.3), by setting, respectively, 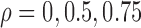 in the correlated random effects model, and
in the correlated random effects model, and 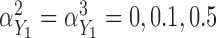 and
and 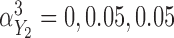 in the product-normal model. In the main set of simulations, all three markers were identical with regards to the aspects being studied. In additional simulations, we varied these aspects across the markers (details in Section 5 of supplementary material available at Biostatistics online) and also assessed the impact of increasing sample size to
in the product-normal model. In the main set of simulations, all three markers were identical with regards to the aspects being studied. In additional simulations, we varied these aspects across the markers (details in Section 5 of supplementary material available at Biostatistics online) and also assessed the impact of increasing sample size to 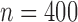 .
.
4.3. Analysis of each generated data set and performance indicators
In each scenario, 1000 data sets were generated. The target parameters,  , and
, and  , were estimated from each data set by fitting the Cox or additive model with various approaches: using the true values of the markers at the event times according to the simulation model, which shows what one would obtain if perfect data were available (“True” analysis); the LOCF approach; the simple2S approach in the main set of simulations with low and high correlation; and the two MI strategies described, MIJM and unMIJM, performing
, were estimated from each data set by fitting the Cox or additive model with various approaches: using the true values of the markers at the event times according to the simulation model, which shows what one would obtain if perfect data were available (“True” analysis); the LOCF approach; the simple2S approach in the main set of simulations with low and high correlation; and the two MI strategies described, MIJM and unMIJM, performing 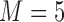 imputations and
imputations and 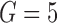 iterations. In selected scenarios, we assessed the impact of excluding the interaction term
iterations. In selected scenarios, we assessed the impact of excluding the interaction term 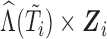 from the imputation model, and of increasing the number of imputations to
from the imputation model, and of increasing the number of imputations to 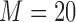 . For the Cox model only, in selected scenarios, we considered the JMbayes approach.
. For the Cox model only, in selected scenarios, we considered the JMbayes approach.
In each scenario, for each parameter 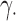 , each estimator
, each estimator 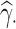 and its standard error estimator
and its standard error estimator 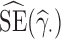 , we calculated the following indicators, where all means are taken across the 1000 generated data sets: the mean bias (MB) given by MB
, we calculated the following indicators, where all means are taken across the 1000 generated data sets: the mean bias (MB) given by MB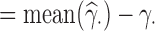 ; the mean relative bias (MRB), given by MRB
; the mean relative bias (MRB), given by MRB ; the observed (empirical) standard error (ObsSE), given by the standard deviation of
; the observed (empirical) standard error (ObsSE), given by the standard deviation of 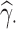 across the 1000 data sets; the standardized bias (StdBias), given by StdBias=
across the 1000 data sets; the standardized bias (StdBias), given by StdBias=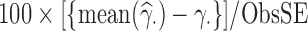 ; the mean estimated standard error (EstSE), EstSE
; the mean estimated standard error (EstSE), EstSE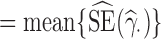 ; and the coverage probability (CP), given by the percentage of the 1000 data sets for which the 95% confidence interval (CI) contained the true value
; and the coverage probability (CP), given by the percentage of the 1000 data sets for which the 95% confidence interval (CI) contained the true value  .
.
4.4. Results
Figures 1 and 2 show the standardized bias for  with five approaches across the main set of scenarios, for the additive hazard model and
with five approaches across the main set of scenarios, for the additive hazard model and  markers generated from a correlated random effects model with low and high correlation, respectively. Table 1 shows detailed results for the additive model and both multiple marker models in selected scenarios. Next we summarize the results from the main set of simulations regarding estimation of
markers generated from a correlated random effects model with low and high correlation, respectively. Table 1 shows detailed results for the additive model and both multiple marker models in selected scenarios. Next we summarize the results from the main set of simulations regarding estimation of  ,
,  and
and 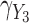 with
with 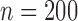 and in the settings with low and high correlation for the additive model (a total of 108 scenarios), and further below for the Cox model. In the Supplementary material available at Biostatistics online we provide results for the case
and in the settings with low and high correlation for the additive model (a total of 108 scenarios), and further below for the Cox model. In the Supplementary material available at Biostatistics online we provide results for the case 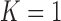 (Section 3), further results for the main simulations (Section 4) and results for the additional simulations (Section 5), which led to similar conclusions.
(Section 3), further results for the main simulations (Section 4) and results for the additional simulations (Section 5), which led to similar conclusions.
Fig. 1.

Simulation study results: Standardized bias for the regression coefficient of marker 1, 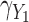 , expressed in effect per 1000 units, in the additive model with low-correlated multiple markers generated from a correlated random effects model.
, expressed in effect per 1000 units, in the additive model with low-correlated multiple markers generated from a correlated random effects model.
Fig. 2.

Simulation study results: Standardized bias for the regression coefficient of marker 1, 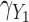 , expressed in effect per 1000 units, in the additive model with highly correlated multiple markers generated from a correlated random effects model.
, expressed in effect per 1000 units, in the additive model with highly correlated multiple markers generated from a correlated random effects model.
Table 1.
Simulation study results: Performance of estimators for additive model parameters in the scenario with moderate measurement error, low proportion of missing at-risk-visit measurements and strong effects of the markers on the hazard. Results for low and high correlations and each multiple marker model are shown. Effect sizes and standard errors are expressed per 1000 units
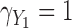
|
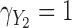
|
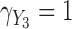
|
||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Analysis | Correlation | MRB | StdBias | ObsSE | EstSE | CP | MRB | StdBias | ObsSE | EstSE | CP | MRB | StdBias | ObsSE | EstSE | CP |
| Correlated random effects model | ||||||||||||||||
| True | Low | 4.3 | 8.8 | 0.5 | 0.5 | 96.0 | 3.1 | 6.2 | 0.5 | 0.5 | 94.2 |
 0.0 0.0 |
 0.0 0.0 |
0.5 | 0.5 | 94.7 |
| LOCF |
 54.8 54.8 |
 152.6 152.6 |
0.4 | 0.4 | 71.0 |
 55.4 55.4 |
 149.7 149.7 |
0.4 | 0.4 | 68.9 |
 57.3 57.3 |
 150.8 150.8 |
0.4 | 0.4 | 65.0 | |
| simple2S |
 14.2 14.2 |
 28.4 28.4 |
0.5 | 0.5 | 94.6 |
 15.2 15.2 |
 29.4 29.4 |
0.5 | 0.5 | 93.1 |
 16.8 16.8 |
 31.5 31.5 |
0.5 | 0.5 | 92.6 | |
| MIJM | 3.2 | 3.8 | 0.9 | 1.0 | 97.4 | 3.0 | 3.5 | 0.9 | 1.0 | 97.3 |
 1.5 1.5 |
 1.7 1.7 |
0.9 | 1.0 | 95.3 | |
| unMIJM |
 15.0 15.0 |
 28.8 28.8 |
0.5 | 0.7 | 98.9 |
 17.0 17.0 |
 31.8 31.8 |
0.5 | 0.7 | 98.9 |
 18.1 18.1 |
 32.9 32.9 |
0.5 | 0.7 | 97.9 | |
| True | High | 0.4 | 0.5 | 0.8 | 0.8 | 94.1 | 0.3 | 0.4 | 0.8 | 0.8 | 94.4 | 1.1 | 1.4 | 0.8 | 0.8 | 95.6 |
| LOCF |
 29.3 29.3 |
 71.1 71.1 |
0.4 | 0.4 | 88.5 |
 26.9 26.9 |
 65.5 65.5 |
0.4 | 0.4 | 88.4 |
 29.8 29.8 |
 74.2 74.2 |
0.4 | 0.4 | 89.6 | |
| simple2S |
 9.0 9.0 |
 12.0 12.0 |
0.8 | 0.7 | 95.1 |
 9.1 9.1 |
 12.1 12.1 |
0.8 | 0.7 | 94.8 |
 12.2 12.2 |
 16.7 16.7 |
0.7 | 0.7 | 95.6 | |
| MIJM | 27.8 | 16.6 | 1.7 | 1.8 | 96.5 | 29.2 | 17.6 | 1.7 | 1.8 | 95.6 | 25.3 | 15.6 | 1.6 | 1.7 | 96.7 | |
| unMIJM | 5.5 | 6.8 | 0.8 | 1.1 | 98.9 | 4.2 | 5.3 | 0.8 | 1.1 | 98.4 | 2.1 | 2.6 | 0.8 | 1.1 | 99.2 | |
| Product-normal model | ||||||||||||||||
| True | Low | 3.3 | 6.6 | 0.5 | 0.5 | 95.3 | 2.8 | 5.5 | 0.5 | 0.5 | 94.0 | 0.4 | 0.8 | 0.5 | 0.5 | 94.7 |
| LOCF |
 56.3 56.3 |
 149.9 149.9 |
0.4 | 0.4 | 66.9 |
 56.4 56.4 |
 149.1 149.1 |
0.4 | 0.4 | 66.8 |
 57.1 57.1 |
 151.5 151.5 |
0.4 | 0.4 | 66.7 | |
| simple2S |
 14.4 14.4 |
 27.7 27.7 |
0.5 | 0.5 | 94.2 |
 16.1 16.1 |
 30.5 30.5 |
0.5 | 0.5 | 93.6 |
 17.1 17.1 |
 32.4 32.4 |
0.5 | 0.5 | 93.3 | |
| MIJM | 1.3 | 1.5 | 0.9 | 1.0 | 96.4 |
 0.2 0.2 |
 0.2 0.2 |
0.9 | 1.0 | 96.6 | 0.5 | 0.5 | 0.9 | 1.0 | 96.4 | |
| unMIJM |
 15.5 15.5 |
 28.6 28.6 |
0.5 | 0.7 | 98.3 |
 16.5 16.5 |
 30.1 30.1 |
0.5 | 0.7 | 98.0 |
 19.8 19.8 |
 36.5 36.5 |
0.5 | 0.7 | 98.4 | |
| True | High | 7.5 | 12.9 | 0.6 | 0.6 | 95.2 |
 3.3 3.3 |
 6.7 6.7 |
0.5 | 0.5 | 94.8 |
 0.6 0.6 |
 1.3 1.3 |
0.5 | 0.5 | 95.1 |
| LOCF |
 30.0 30.0 |
 81.5 81.5 |
0.4 | 0.4 | 89.4 |
 42.3 42.3 |
 121.8 121.8 |
0.3 | 0.4 | 77.4 |
 38.8 38.8 |
 114.5 114.5 |
0.3 | 0.4 | 81.2 | |
| simple2S |
 11.1 11.1 |
 19.3 19.3 |
0.6 | 0.6 | 95.8 |
 13.4 13.4 |
 27.8 27.8 |
0.5 | 0.5 | 94.4 |
 8.7 8.7 |
 18.2 18.2 |
0.5 | 0.5 | 95.1 | |
| MIJM | 22.2 | 19.7 | 1.1 | 1.2 | 95.5 | 3.7 | 4.4 | 0.8 | 0.9 | 96.8 | 9.6 | 11.5 | 0.8 | 0.9 | 95.9 | |
| unMIJM | 1.1 | 1.8 | 0.6 | 0.8 | 99.1 |
 14.6 14.6 |
 29.8 29.8 |
0.5 | 0.7 | 98.3 |
 9.5 9.5 |
 19.8 19.8 |
0.5 | 0.7 | 99.2 | |
MRB, mean relative bias (%); StdBias, standardized bias (%); ObsSE, observed (empirical) standard error; EstSE, mean estimated standard error; CP, coverage probability (%).
With perfect data (“True” analysis), estimates obtained across all scenarios were approximately unbiased, standard errors were correctly estimated and CIs achieved nominal coverage (MRB between  23% and 12% and CP between 93% and 98% across all 108 scenarios; see also Table 1).
23% and 12% and CP between 93% and 98% across all 108 scenarios; see also Table 1).
The LOCF approach led to negative bias in scenarios with measurement error or missingness, and the magnitude of the bias increased as the effect size increased and as these issues were more pronounced. The bias of LOCF was worst in scenarios with low correlation between the markers (MRB between  96% and
96% and  10% across all scenarios with low correlation compared with
10% across all scenarios with low correlation compared with  89% to 2% with high correlation). Notably, with missing measurements there was a negative bias even in the scenarios with null true effects (
89% to 2% with high correlation). Notably, with missing measurements there was a negative bias even in the scenarios with null true effects ( ). The variance of the LOCF estimator decreased as the missingness and the measurement error increased, failing to reflect the increased uncertainty in these scenarios, and being even lower than what was achieved with perfect data. Together, the large biases and small standard errors translated into standardized biases of very large magnitude (Figures 1 and 2). Estimated standard errors were close to their empirical counterparts. Hence, solely as a result of the behavior of the regression coefficient estimator, this analysis yielded very poor coverage probability across most scenarios (CP as low as 3% in some scenarios).
). The variance of the LOCF estimator decreased as the missingness and the measurement error increased, failing to reflect the increased uncertainty in these scenarios, and being even lower than what was achieved with perfect data. Together, the large biases and small standard errors translated into standardized biases of very large magnitude (Figures 1 and 2). Estimated standard errors were close to their empirical counterparts. Hence, solely as a result of the behavior of the regression coefficient estimator, this analysis yielded very poor coverage probability across most scenarios (CP as low as 3% in some scenarios).
The simple2S approach had reduced bias compared with LOCF, but exhibited negative bias in scenarios with low correlation, which increased as missingness and measurement error increased (MRB between  37% and 0% across these scenarios). The approach was approximately unbiased in scenarios with high correlation (MRB between
37% and 0% across these scenarios). The approach was approximately unbiased in scenarios with high correlation (MRB between  24% and 9%). Standard errors were generally higher than for LOCF but close to those with perfect data, thus also failing to reflect the increased uncertainty due to unobserved data. Standardized biases were lower than for LOCF but still important in settings with low correlation or high missingness (Figures 1 and 2). The standard error estimator was approximately unbiased (between
24% and 9%). Standard errors were generally higher than for LOCF but close to those with perfect data, thus also failing to reflect the increased uncertainty due to unobserved data. Standardized biases were lower than for LOCF but still important in settings with low correlation or high missingness (Figures 1 and 2). The standard error estimator was approximately unbiased (between  12% and 15% difference relative to empirical standard errors). CPs were poor in settings with bias, ranging between 87% and 98% in low correlation scenarios and between 90% and 98% with high correlation.
12% and 15% difference relative to empirical standard errors). CPs were poor in settings with bias, ranging between 87% and 98% in low correlation scenarios and between 90% and 98% with high correlation.
The MIJM approach yielded approximately unbiased estimates across scenarios with low correlation (MRB between  27% and 16%). A positive bias was observed in some settings with high measurement error or strong effect size across scenarios with high correlation (MRB between
27% and 16%). A positive bias was observed in some settings with high measurement error or strong effect size across scenarios with high correlation (MRB between  13% and 80%). These biases were less pronounced for the product-normal model (MRB between
13% and 80%). These biases were less pronounced for the product-normal model (MRB between  13% and 59%) than the correlated random effects model (MRB between
13% and 59%) than the correlated random effects model (MRB between  3% and 80%), and biases in the product-normal model were highest for
3% and 80%), and biases in the product-normal model were highest for 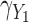 possibly because
possibly because 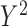 and
and 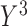 were generated with conditional models that more closely resemble the imputation model (maximal MRB 59% for
were generated with conditional models that more closely resemble the imputation model (maximal MRB 59% for 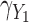 compared with 30% and 24% for
compared with 30% and 24% for 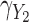 and
and  , respectively). Still, the MIJM estimator had the highest variance, which was always greater than that with perfect data and appropriately increased as missingness and measurement error increased. The variance was highest when the bias was highest, which resulted in consistently small standardized biases. Rubin’s variance formula performed well in this analysis: although it led to slightly overestimated standard errors in some cases (up to 30% higher than empirical standard error), the CIs achieved coverages close to or somewhat higher than the nominal value across all scenarios (CP between 94% and 99% across the 108 scenarios). Notably, CPs remained satisfactory even in the cases of largest bias.
, respectively). Still, the MIJM estimator had the highest variance, which was always greater than that with perfect data and appropriately increased as missingness and measurement error increased. The variance was highest when the bias was highest, which resulted in consistently small standardized biases. Rubin’s variance formula performed well in this analysis: although it led to slightly overestimated standard errors in some cases (up to 30% higher than empirical standard error), the CIs achieved coverages close to or somewhat higher than the nominal value across all scenarios (CP between 94% and 99% across the 108 scenarios). Notably, CPs remained satisfactory even in the cases of largest bias.
The unMIJM approach resulted in negative bias in scenarios with low correlation, which increased as missingness and measurement error increased (MRB between  38% and
38% and  6%). The estimator was approximately unbiased or had moderate bias across scenarios with high correlation (MRB between
6%). The estimator was approximately unbiased or had moderate bias across scenarios with high correlation (MRB between  20% and 31%). As for MIJM, in scenarios with high correlation, the bias of unMIJM was lower with the product-normal model (MRB between
20% and 31%). As for MIJM, in scenarios with high correlation, the bias of unMIJM was lower with the product-normal model (MRB between  20% and 15%) than with the correlated random effects model (MRB between
20% and 15%) than with the correlated random effects model (MRB between  15% and 31%). The standard errors of the unMIJM estimator were close to those of the True and simple2S analyses. Standardized biases were thus generally larger in magnitude or similar to those of MIJM. For this analysis, Rubin’s formula overestimated the standard error in most cases (between 10% and 73% higher than empirical standard errors), a consequence of the substantive-model-incompatibility implicit in this approach. CIs were thus over-conservative, ranging from 96% to 100% across all scenarios.
15% and 31%). The standard errors of the unMIJM estimator were close to those of the True and simple2S analyses. Standardized biases were thus generally larger in magnitude or similar to those of MIJM. For this analysis, Rubin’s formula overestimated the standard error in most cases (between 10% and 73% higher than empirical standard errors), a consequence of the substantive-model-incompatibility implicit in this approach. CIs were thus over-conservative, ranging from 96% to 100% across all scenarios.
Results for the Cox model exhibited similar patterns. In the selected scenarios where it was considered, the JMbayes approach was approximately unbiased, standard errors were appropriately higher than for the True analysis, and standardized biases were small (see Table S3 of supplementary material available at Biostatistics online). This was to some extent expected for the correlated random effects model, which is the marker model assumed by JMbayes, but it is notable that this was also true for the product-normal model. On the other hand, there was a consistent underestimation of standard errors with this approach, particularly with the product-normal model. This may be due to misspecification by JMbayes of the marker model or B-splines providing a poor approximation of the baseline hazard. The biased standard error estimates led to poor CPs in some scenarios.
5. Example: Framingham Heart Study
We focused on assessing the associations between BMI, SBP and blood glucose levels, and all-cause mortality. Following Abdullah and others (2011), we fitted survival models for the time-to-death since recruitment including these time-varying markers as explanatory variables, in addition to some time-fixed baseline covariates (age, sex, country of birth, education level, smoking, alcohol use, and marital status). Analyses were restricted to the  participants who did not have diabetes or cardiovascular disease at the baseline visit, and who had all three markers non-missing on at least one of their 28 two-yearly visits. The maximum follow-up time was 59.2 years, and 4552 participants had died (93%) with the remaining being censored on December 31, 2007 (see Section 6 of supplementary material available at Biostatistics online, for Kaplan–Meier curve and statistics on baseline factors).
participants who did not have diabetes or cardiovascular disease at the baseline visit, and who had all three markers non-missing on at least one of their 28 two-yearly visits. The maximum follow-up time was 59.2 years, and 4552 participants had died (93%) with the remaining being censored on December 31, 2007 (see Section 6 of supplementary material available at Biostatistics online, for Kaplan–Meier curve and statistics on baseline factors).
Figure 3 shows the profiles of the three time-varying markers for a random subset of 10 participants. These markers span the three scenarios of measurement error explored in our simulation study, with BMI having a low degree of error (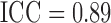 as estimated from the available data), SBP having a moderate degree of error (
as estimated from the available data), SBP having a moderate degree of error (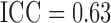 ) and blood glucose having a high degree of error (
) and blood glucose having a high degree of error ( ). The proportion of missing at-risk-visit measurements was low for BMI and SBP (21% and 24%, respectively) and high for blood glucose (41%). These characteristics suggest the need for approaches beyond LOCF. Marginal correlations estimated from the observed data were: corr(BMI,SBP) = 0.24, corr(BMI,glucose) = 0.13 and corr(SBP,glucose) = 0.14.
). The proportion of missing at-risk-visit measurements was low for BMI and SBP (21% and 24%, respectively) and high for blood glucose (41%). These characteristics suggest the need for approaches beyond LOCF. Marginal correlations estimated from the observed data were: corr(BMI,SBP) = 0.24, corr(BMI,glucose) = 0.13 and corr(SBP,glucose) = 0.14.
Fig. 3.

Trajectories based on available measurements for three time-dependent markers in the Framingham Heart Study, for all individuals (gray) and for a random sample of ten individuals (black).
We fitted Cox and additive hazard models as in (2.1) and (2.2), respectively, using LOCF, simple2S, MIJM, unMIJM, and, in the case of the Cox model, JMbayes. In the latter four approaches, time-trends for each marker were modeled using cubic polynomials of time (which provided superior or similar fit compared with natural cubic splines), and the models included random intercepts and slopes. Based on relative efficiency calculations and graphical assessments, respectively, 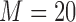 imputations and
imputations and 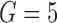 iterations were used for MIJM and unMIJM. Indeed, results with
iterations were used for MIJM and unMIJM. Indeed, results with 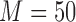 were essentially the same (not shown).
were essentially the same (not shown).
Table 2 shows the results. For BMI, all approaches suggest evidence of a protective association with each unit increase, independent of current SBP and blood glucose levels, although MIJM suggests a stronger association both in absolute and relative terms. For SBP, in relative terms all approaches suggest evidence of a weak harmful independent association with increasing SBP except MIJM, which does not show evidence of an association. In absolute terms, results are discrepant across the approaches: LOCF does not show evidence of an association, MIJM indicates a weak protective association with increasing SBP and simple2S and unMIJM display the opposite. For blood glucose, all approaches suggest evidence of a harmful independent association with increasing glucose levels in both relative and absolute terms, although MIJM suggests a much stronger relation. The results of this illustrative example are to be interpreted with caution since the fit of these simple Cox and additive hazard models could perhaps be improved by modeling U-shaped associations, particularly for SBP (see Section 6 of supplementary material available at Biostatistics online).
Table 2.
Application to the Framingham Heart Study: Estimated mortality hazard ratios (HR) and differences (HD) for an increase in one unit of each time-dependent marker, obtained by fitting multivariable Cox and additive hazard models, respectively, using various approaches to incorporate these imperfectly observed time-dependent covariates
| Cox model | Additive model | ||||||
|---|---|---|---|---|---|---|---|
| Marker | Analysis | HR | 95% CI |
 -value -value |
HDa | 95% CI |
 -value -value |
BMI (kg/m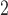 ) ) |
LOCF | 0.97 | (0.97; 0.98) |
 0.001 0.001 |
 113 113 |
( 135; 135;  91) 91) |
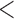 0.001 0.001 |
| simple2S | 0.98 | (0.98; 0.99) |
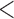 0.001 0.001 |
 110 110 |
( 134; 134;  86) 86) |
 0.001 0.001 |
|
| MIJM | 0.95 | (0.93; 0.96) |
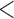 0.001 0.001 |
 200 200 |
( 233; 233;  166) 166) |
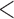 0.001 0.001 |
|
| unMIJM | 0.98 | (0.97; 0.99) |
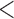 0.001 0.001 |
 106 106 |
( 133; 133;  80) 80) |
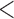 0.001 0.001 |
|
| JMbayesb | 0.98 | (0.97; 0.99) |
 0.001 0.001 |
— | — | — | |
| SBP (10 mmHg) | LOCF | 1.02 | (1.01; 1.04) |
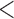 0.001 0.001 |
2 | ( 47; 50) 47; 50) |
0.95 |
| simple2S | 1.15 | (1.13; 1.17) |
 0.001 0.001 |
284 | (220; 348) |
 0.001 0.001 |
|
| MIJM | 0.97 | (0.94; 1.02) | 0.21 |
 186 186 |
( 316; 316;  56) 56) |
0.01 | |
| unMIJM | 1.13 | (1.10; 1.16) |
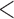 0.001 0.001 |
278 | (195; 361) |
 0.001 0.001 |
|
| JMbayesb | 1.14 | (1.12; 1.16) |
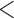 0.001 0.001 |
— | — | — | |
| Glucose (mmol/L) | LOCF | 1.05 | (1.04; 1.07) |
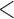 0.001 0.001 |
262 | (181; 342) |
 0.001 0.001 |
| simple2S | 1.13 | (1.11; 1.15) |
 0.001 0.001 |
719 | (584; 854) |
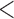 0.001 0.001 |
|
| MIJM | 1.18 | (1.14; 1.22) |
 0.001 0.001 |
971 | (721; 1221) |
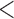 0.001 0.001 |
|
| unMIJM | 1.11 | (1.08; 1.13) |
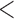 0.001 0.001 |
555 | (421; 689) |
 0.001 0.001 |
|
| JMbayesb | 1.14 | (1.12; 1.15) |
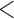 0.001 0.001 |
— | – | — | |
BMI, body mass index; SBP, systolic blood pressure; CI, confidence interval; HR, hazard ratio; HD, hazard difference.
aUnits: events per 100 000 person-years.
bThis approach was applicable only to the Cox model.
6. Concluding remarks
We developed a refined two-stage joint modeling approach, MIJM, to incorporate multiple markers in two hazard rate models. Simulation results showed that MIJM performed well with one or multiple markers, with small standardized biases and CIs that achieved nominal coverage across all scenarios studied and for all multiple-marker/survival model combinations considered. The latter shows that the absolute bias of MIJM in some extreme scenarios is of little practical significance due to the accompanying increased variability (Collins and others, 2001).
The unMIJM approach, which differed from MIJM only in the way the time-to-event outcome was included in the imputation model, had a performance that was variable across scenarios and overall poorer than that of MIJM. This difference emphasizes the importance of appropriately addressing issue (iii) when using two-stage approaches. Further, the implicit less-refined approximation of unMIJM yielded overly-conservative CIs in most scenarios due to systematic bias in the MI variance estimator. The unMIJM approach may, however, have value in settings with highly correlated markers and low measurement error. The simple2S approach also showed variable performance across scenarios, although it performed well in scenarios with high correlation and low missingness.
Full joint modeling performed well in terms of bias, but standard error estimates seemed vulnerable to misspecification of the full joint distribution, which affected CPs. More generally, this approach is computationally challenging: at the time of writing we were unable to identify any readily available full joint modeling software, Bayesian or frequentist, that accommodated multiple markers and both semi-parametric hazard models considered in this paper. While it was possible to apply the approach assuming a proportional hazards model with spline-modeled baseline, we could only do this in selected scenarios due to extended running time. All approaches seemed clearly preferable to LOCF.
The MIJM approach can be easily implemented for any number of markers using mainstream software, and the R package  reduces this task to a single function call. Of note, the package can in addition be used to apply unMIJM, simple2S, and LOCF as easily. The MIJM approach is also computationally fast, demonstrating substantially lower running times than JMbayes.
reduces this task to a single function call. Of note, the package can in addition be used to apply unMIJM, simple2S, and LOCF as easily. The MIJM approach is also computationally fast, demonstrating substantially lower running times than JMbayes.
Future work could include refinements of MIJM to better accommodate strongly correlated markers or to tackle other time-to-event models. Assessment of the MIJM approach in the context of unplanned rather than planned visiting times would also be of interest. While there are no practical obstacles to applying the approach in that setting, assumptions about ignorability of the visiting process would be required, and the modified event indicator would be defined in terms of the last available measurement rather than the last planned visit before end of follow-up. Thus, the accuracy of the approximation underlying the approach could be affected, e.g. if there were high variability in the delays between visiting times.
To conclude, the proposed MIJM approach provides a pragmatic yet principled solution to a common problem in health research. Some inevitable approximations are involved in the imputation modeling, but the approach was robust in our simulations, which explored a wide range of scenarios using structures and parameter settings that mimicked many aspects of the FHS and could be expected to reflect other similar studies.
Supplementary Material
Acknowledgements
The authors would like to acknowledge the Framingham Heart Study (FHS) for access to the data sets. The FHS is conducted and supported by the National Heart, Lung, and Blood Institute (NHLBI) in collaboration with the FHS Investigators.
Funding
Centre of Research Excellence grant from the Australian National Health & Medical Research Council [ID#1035261] to the Victorian Centre for Biostatistics.
References
- Abdullah A., Wolfe R., Stoelwinder J. U., de Courten M., Stevenson C., Walls H. L. and Peeters A. (2011). The number of years lived with obesity and the risk of all-cause and cause-specific mortality. International Journal of Epidemiology 40, 985–996. [DOI] [PubMed] [Google Scholar]
- Albert P. S. and Shih J. H. (2010). On estimating the relationship between longitudinal measurements and time-to-event data using a simple two-stage procedure. Biometrics 66, 983–987. [DOI] [PubMed] [Google Scholar]
- Andersen P. K. and Liestøl K. (2003). Attenuation caused by infrequently updated covariates in survival analysis. Biostatistics 4, 633–649. [DOI] [PubMed] [Google Scholar]
- Bates D, Mächler M, Bolker B. M. and Walker S. C. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software 67, 1–48. [Google Scholar]
- Bycott P. and Taylor J. (1998). A comparison of smoothing techniques for CD4 data measured with error in a time-dependent Cox proportional hazards model. Statistics in Medicine 17, 2061–2077. [DOI] [PubMed] [Google Scholar]
- Chi Y. Y. and Ibrahim J. G. (2006). Joint models for multivariate longitudinal and multivariate survival data. Biometrics 62, 432–445. [DOI] [PubMed] [Google Scholar]
- Collins L. M., Schafer J. L. and Kam C. (2001). A comparison of inclusive and restrictive strategies in modern missing data procedures. Psychological Methods 6, 330–351. [PubMed] [Google Scholar]
- Cooper N. J., Lambert P. C., Abrams K. R. and Sutton A. J. (2007). Predicting costs over time using Bayesian Markov chain Monte Carlo methods: an application to early inflammatory polyarthritis. Health Economics 16, 97–56. [DOI] [PubMed] [Google Scholar]
- Daniels M. J. and Hogan J. W. (2008). Missing Data in Longitudinal Studies: Strategies for Bayesian Modeling and Sensitivity Analysis. Boca Raton, FL: CRC Press. [Google Scholar]
- De Gruttola Vi and Tu X. M. (1994). Modelling progression of CD4-lymphocytecount and its relationship to survival time. Biometrics 50, 1003–1014. [PubMed] [Google Scholar]
- Faucett C. L. and Thomas D. C. (1996). Simultaneously modelling censored survival data and repeatedly measured covariates: a Gibbs sampling approach. Statistics in Medicine 15, 1663–1685. [DOI] [PubMed] [Google Scholar]
- Fieuws S. and Verbeke G. (2004). Joint modelling of multivariate longitudinal profiles: pitfalls of the random-effects approach. Statistics in Medicine 23, 3093–3104. [DOI] [PubMed] [Google Scholar]
- Gould A. L., Boye M. E., Crowther M. J., Ibrahim J. G., Quartey G., Micallef S. and Bois F. Y. (2015). Joint modeling of survival and longitudinal non-survival data: current methods and issues. Report of the DIA bayesian joint modeling working group. Statistics in Medicine 34, 2181–2195. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hanson T. E., Branscum A. J. and Johnson W. O. (2011). Predictive comparison of joint longitudinal-survival modeling: a case study illustrating competing approaches. Lifetime Data Analysis 17, 3–28. [DOI] [PubMed] [Google Scholar]
- Hickey G. L., Philipson P., Jorgensen A. and Kolamunnage-dona R. (2016). Joint modelling of time-to-event and multivariate longitudinal outcomes: recent developments and issues. BMC Medical Research Methodology 16, 117. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lin D. Y. and Ying Z. L. (1994). Semiparametric analysis of the additive risk model. Biometrika 81, 61–71. [Google Scholar]
- Moreno-Betancur M. (2017). survtd: Survival Analysis with Time-Dependent Covariates. https://github.com/moreno-betancur/survtd. [Google Scholar]
- Moreno-Betancur M. and Chavance M. (2016). Sensitivity analysis of incomplete longitudinal data departing from the missing at random assumption: methodology and application in a clinical trial with drop-outs. Statistical Methods in Medical Research 25, 1471–1489. [DOI] [PubMed] [Google Scholar]
- Rizopoulos D. (2016a). Multivariate Joint Models for Multiple Longitudinal Outcomes and a Time-to-Event. https://www.r-bloggers.com/multivariate-joint-models-for-multiple-longitudinal-outcomes-and-a-time-to-event. [DOI] [PubMed] [Google Scholar]
- Rizopoulos D. (2016b). The R package JMbayes for fitting joint models for longitudinal and time-to-event data using MCMC. Journal of Statistical Software 72, 1–45. [Google Scholar]
- Rizopoulos D. and Ghosh P. (2011). A Bayesian semiparametric multivariate joint model for multiple longitudinal outcomes and a time-to-event. Statistics in Medicine 30, 1366–1380. [DOI] [PubMed] [Google Scholar]
- Rubin D. B. (1987). Multiple Imputation for Nonresponse in Surveys. New York: Wiley. [Google Scholar]
- Seaman S., Galati J., Jackson D. and Carlin J. B. (2013). What is meant by missing at random? Statistical Science 28, 257–268. [Google Scholar]
- Spiegelhalter D. J. (1998). Bayesian graphical modelling: a case-study in monitoring health outcomes. Journal of the Royal Statistical Society: Series C (Applied Statistics) 47, 115–133. [Google Scholar]
- Therneau T. and Grambsch P. (2000). Modeling Survival Data: Extending the Cox Model. New York: Springer. [Google Scholar]
- van Buuren S, Boshuizen H and Knook D. (1999). Multiple imputation of missing blood pressure covariates in survival analysis. Statistic in Medicine 18, 681–694. [DOI] [PubMed] [Google Scholar]
- van Buuren S. and Groothuis-Oudshoorn K. (2011). mice: Multivariate imputation by chained equations in R. Journal of Statistical Software 45, 1–67. [Google Scholar]
- White I. R. and Royston P. (2009). Imputing missing covariate values for the Cox model. Statistics in Medicine 28, 1982–1998. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wu L., Liu W., Yi G. Y. and Huang Y. (2012). Analysis of longitudinal and survival data: joint modeling, inference methods, and issues. Journal of Probability and Statistics 2012, 1–17. [Google Scholar]
- Wulfsohn M. S. and Tsiatis A. A. (1997). A joint model for survival and longitudinal data measured with error. Biometrics 53, 330–339. [PubMed] [Google Scholar]
- Xu J. and Zeger S. L. (2001). The evaluation of multiple surrogate endpoints. Biometrics 57, 81–87. [DOI] [PubMed] [Google Scholar]
- Ye W., Lin X. and Taylor J. M. G. (2008). Semiparametric modeling of longitudinal measurements and time-to-event data–a two-stage regression calibration approach. Biometrics 64, 1238–46. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.