

Abstract
Midbrain dopamine neurons are thought to play a crucial role in motivating behaviors toward desired goals. While the activity of dopamine single-units is known to adhere closely to the reward prediction error signal hypothesized by learning theory, much less is known about the dynamic coordination of population-level neuronal activities in the midbrain. Local field potentials (LFPs) are thought to reflect the changes in membrane potential synchronized across a population of neurons nearby a recording electrode. These changes involve complex combinations of local spiking activity with synaptic processing that are difficult to interpret. Here we sampled LFPs from the substantia nigra pars compacta of behaving monkeys to determine if local population-level synchrony encodes specific aspects of a reward/effort instrumental task and whether dopamine single-units participate in that signal. We found that reward-correlated information is encoded in a low-frequency signal (<32-Hz; delta and beta bands) that is synchronized across a neural population that includes dopamine neurons. Conversely, high frequency power (>33-Hz; gamma band) was anticorrelated with predicted reward value and dopamine single-units were never phase-locked to those frequencies. This high-frequency signal may reflect inhibitory processes that were not otherwise observable. LFP encoding of movement-related parameters was negligible. Together, LFPs provide novel insights into the multidimensional processing of reward information subserved by dopaminergic and other components of the midbrain.
Keywords: reward, dopamine, LFP, oscillations, synchronization
INTRODUCTION
Midbrain dopamine neurons are thought to play a crucial role in reward learning and the control of incentive motivation (Berridge and Robinson, 1998; Salamone and Correa, 2002; Wise, 2004; Schultz, 2006; Bromberg-Martin et al., 2010). The spiking activity of dopamine neurons is predicted well by the reward prediction error (RPE) signal posited by classical models of instrumental behavior (Hollerman and Schultz, 1998; Schultz, 1998; Sutton and Barto, 1998; Bayer and Glimcher, 2005) in that individual dopamine neurons respond with a burst of action potentials when a reward or reward-predictive sensory cue is more valuable than expected; but little or no change from baseline firing is evoked when reality matches the prediction (Schultz et al., 1997). After an animal learns that a particular sensory cue predicts delivery of a reward, then the size of dopaminergic responses to that cue correlates with specific attributes of the predicted reward including magnitude, probability and delay to delivery (Fiorillo et al., 2003, 2008; Tobler et al., 2005; Morris et al., 2006; Roesch et al., 2007; Joshua et al., 2008; Kobayashi and Schultz, 2008; Pasquereau and Turner, 2013, 2015). In contrast, dopamine neurons rarely encode information about the physical effort required to obtain a reward (Pasquereau and Turner, 2013). In addition to this representation at the single-unit level, it is possible for task information (reflecting e.g., RPE) to be encoded at the population level by the way that spiking is synchronized or coordinated between neurons. Synchronization of spiking in a population can influence the efficacy of signal transmission to a receiving cell population (Buzsáki, 2006). And synchrony often appears as an alignment of spikes at a characteristic oscillatory frequency (Fries, 2005; Womelsdorf et al., 2007). To date, however, few studies of dopamine neuron activity have investigated possible population-level coordination in the encoding of reward attributes or other information about the task.
Local field potentials (LFPs) recorded from the brain are thought to reflect the changes in membrane potential that are shared across a population of neuronal somata located nearby a recording electrode. These changes reflect a complex combination of spike components, after-potentials, and synaptic potentials from afferent and local circuit inputs that is difficult to disentangle (Kruse and Eckhorn, 1996; Buzsáki, 2002; Liu and Newsome, 2006; Katzner et al., 2009; Rasch et al., 2009). To interpret LFP recordings with confidence, the neural source of the signal of interest must be localized, at minimum, with respect to nucleus or brain region (Lalla et al., 2017) and, preferably, with respect to neuronal subtypes (Teleńczuk et al., 2017). A well accepted approach to LFP source localization is to construct averages of LFP signals aligned to the times of local single-unit action potentials (e.g., “spike-triggered averages”) (Goldberg, 2004). The magnitude and frequency components of a spike-triggered average provide a direct link between specific aspects of the LFP signal and a single-unit’s spiking activity.
Thus, LFP sampled from the vicinity of midbrain dopamine cells may provide insights into the population-level representation of reward and other task information in that region. Indeed, reward-associated sensory stimuli have been shown to modulate the spectral power of LFPs recorded from a variety of cortical and subcortical brain regions (Paz et al., 2006; Cohen et al., 2007, 2009; Marco-Pallares et al., 2008; Pesaran et al., 2008; van der Meer and Redish, 2009; van Wingerden et al., 2010; Lima et al., 2011; Zénon et al., 2016), suggesting that reward-dependent processes can influence the dynamic coordination of activity across populations of neurons and functional networks (Fries, 2005; Kasanetz et al., 2006; Tort et al., 2008). Notably, a study of LFPs collected from the ventral tegmental area (VTA) of the rat found that power in the theta frequency-band (4-8 Hz) increased in response to a reward-predictive cue (Kim et al., 2012). This increase was coupled with an elevated synchronization in the spiking activity of VTA dopamine neurons, supporting the view that elevated spectral power reflects, at least in part, a local synchronization of neuronal spiking within the midbrain. Because the dynamic coordination of neural activity in the midbrain between dopamine and non-dopamine neurons appears critical for encoding appetitive events (Joshua et al., 2009a; Hong et al., 2011; Okada et al., 2011; Cohen et al., 2012; Kim et al., 2012; Eshel et al., 2015, 2016), we hypothesized that potentially-distinct components of the LFP signals from that region will reflect the population activity of each neuronal type. By comparing LFPs with the spiking activities of dopaminergic single-units in the vicinity of the substantia nigra pars compacta (SNc), the present study identified dissociable oscillatory signals only one of which was related to dopaminergic single-units.
To test how LFP signals, and thus local neural synchrony, reflects reward- and effort-related information, we performed recordings in the SNc while two monkeys performed an instrumental task. Distinct instruction cues predicted the size of the upcoming reward (1, 2 and 3 drops of food) and the level of upcoming force that the animal must overcome during movement execution (0, 1.8 or 3.2 N). Our results show that reward-related events influence midbrain LFP signals in a frequency-dependent manner. Power at low frequencies (<32 Hz) correlate positively with predicted reward value, similar to the way reward is encoded by dopaminergic single-units. In contrast, LFP power at higher frequencies (>33-Hz) anticorrelates with the expected reward value. Notably, dopaminergic single-unit spiking is phase-locked only to the low-frequency components of the LFP and oscillatory encoding of movement and predicted effort is virtually non-existent. Thus, as a complement to the well-described encoding of RPE by dopaminergic single-units, our findings suggest that the synchronization of local neuronal elements also carries reward information, but in ways that differ depending on oscillatory frequency and the direct spiking involvement of dopaminergic neurons.
EXPERIMENTAL PROCEDURES
Animals
Two rhesus monkeys (monkey C: 8 kg, male; monkey H: 6 kg, female) were used in this study. Procedures were approved by the Institutional Animal Care and Use Committee of the University of Pittsburgh (protocol no. 12111162) and complied with the Public Health Service Policy on the humane care and use of laboratory animals (amended 2002). The animals were housed in individual primate cages in an air-conditioned room where water was always available. Monkeys were under food restriction to increase their motivation in task performance. Throughout the study, the animals were monitored daily by an animal research technician or veterinary technician for evidence of disease or injury, and body weight was documented weekly. If a body weight <90% of baseline was observed, the food restriction was stopped.
Apparatus
Monkeys were trained to execute reaching movements with the left arm using a two-dimensional (2-D) torqueable exoskeleton (KINARM; BKIN Technologies, Kingston, ON, Canada). Visual targets and cursor feedback of hand position were presented in the horizontal plane of the task by a virtual reality system. Distinct force levels were applied at the shoulder and elbow joints by two computer-controlled torque motors so as to simulate kinetic friction loads opposing movement of the hand. The force was constant for any hand movement above a low threshold velocity (0.5 cm/s) and directly opposed the direction of movement. After six months of training (~1000 trials per day during 125 days), both monkeys performed movements with consistent trajectories and velocity profiles under all load conditions. A plastic recording chamber (custom-machined PEEK, 28×20 mm) and head holder were fixed to the skull under general anesthesia and sterile conditions. The MRI-compatible chamber was positioned in the sagittal plane with an anterior-to-posterior angle of 20°. A detailed description of the apparatus and methods can be found in Pasquereau and Turner (2013, 2015).
Effort-benefit reaching task
Monkeys were trained to perform a reaching task that manipulated movement incentive and effort independently (Fig. 1). On each behavioral trial, the animal was required to align the cursor with two visual targets (radius: 1.8 cm) displayed in succession (Fig. 1A). A trial began when a target appeared at the start position and the monkey made the appropriate joint movements to align the cursor with this target. The monkey maintained this position for a random-duration hold period during which: (a) an instruction cue was displayed at the start position (0.7–1.3 s after hold period start, 0.5 s duration), and (b) the peripheral target was displayed (0.7–1.3 s after offset of the instruction cue, at the same location for all trials, 7.5 cm distal to the start position). At the end of the start position hold period, the start position target disappeared (the go signal), thereby cueing the animal to move the cursor to the peripheral target (within <0.8 s). Movement of the arm to capture the peripheral target required coordinated flexion at the shoulder and extension at the elbow in the horizontal plane. At a random delay after successful target capture (0.7–1.3 s), food reward was delivered via a sipper tube attached to a computer-controlled peristaltic pump (each drop = ~0.5 ml, puree of fresh fruits and protein biscuits). For the instruction cues (Fig. 1B), symbols indicated the level of upcoming force that the animal would encounter (0, 1.8 or 3.2 N) and cue colors indicated the size of the upcoming reward delivery (1, 2 and 3 drops of food). The nine unique cue types (three force levels × three reward sizes) were presented in pseudo-random order across trials with equal probability. The trials were separated by 1.5-2.5 s inter-trial intervals during which the screen was black.
Figure 1.

Effort-benefit reaching task and modulation of monkeys’ performance. (A) Timeline of the standard instrumental paradigm. A visual instruction cue was presented briefly after the animal moved the hand-controlled cursor (+) to the start position. After random delays, a target was presented (second gray circle), and then the start position was extinguished (go signal), at which time the animal was required to move the cursor to the target position. At a random delay after successful target capture, reward was delivered. (B) The instruction cue presented on a single trial was selected pseudo-randomly from 9 possible visually distinct cues. The cues were associated with different levels of reward (3 quantities of food) and effort (3 different friction loads opposing movement). (C) Measures of performance were averaged (mean ± SEM) separately for each reward/effort combination across all recording sessions (81 and 26 sessions for monkeys C and H, respectively). Reaction times and movement accelerations were affected by both expected reward value (***P<0.001, two-way ANOVA) and force level (##P<0.01, ###P<0.001, two-way ANOVA). Gray lines show the reward-related effects.
Localization of the recording site
The anatomic location of the SNc and proper positioning of the recording chamber to access it were estimated from structural MRI scans (Siemens 3T Allegra Scanner, voxel size: 0.6 mm). An interactive 3-D software system (Cicerone) was used to visualize MRI images, define the target location, and predict trajectories for microelectrode penetrations (Miocinovic et al., 2007). Electrophysiological mapping was performed with penetrations spaced 1 mm apart. The boundaries of brain structures were identified on the basis of standard criteria including relative location, neuronal spike shape, firing pattern, and responsiveness to behavioral events (e.g., movement, reward). By aligning microelectrode mapping results (electrophysiologically characterized X-Y-Z locations) with structural MRI images and high-resolution 3-D templates of individual nuclei derived from an atlas (Martin and Bowden, 1996), we were able to gauge the accuracy of individual microelectrode penetrations and determine chamber coordinates for the SNc [for anatomical details, see Pasquereau and Turner (2013)].
Recording and data acquisition
During recording sessions, a glass-coated tungsten microelectrode (impedance: 0.7-1 MOhm measured at 1000 Hz) was advanced into the target nucleus using a hydraulic manipulator (MO-95, Narishige). Neuronal signals were amplified with a gain of 10K and continuously sampled at 25 KHz (RZ2, Tucker-Davis Technologies, Alachua FL). Different bandpass filters were used to analyze the spike components (single-units: 0.3-10 kHz band pass) and the lower frequency signal (LFPs: 1-200Hz). Data was stored to disk for offline analysis. Individual spikes were isolated in Offline Sorter (Plexon Inc., Dallas TX). As for LFPs, the timing of detected spikes and of relevant task events was sampled digitally at 1 kHz. Dopamine neurons were identified according to the following standard criteria: (i) location within the SNc, (ii) polyphasic extracellular waveforms, (iii) low tonic irregular spontaneous firing rates (0.5–8 spikes/s), and (iv) long duration of action potentials (>1.5 ms).
Analysis of behavioral data
We analyzed the way the animals performed the behavioral task to test whether the behavior varied according to the levels of anticipated reward and effort. Kinematic data (digitized at 1 kHz) derived from the exoskeleton were numerically filtered and combined to obtain position, and tangential velocity and acceleration. The time of movement onset was determined as the point at which tangential position crossed an empirically-derived threshold (0.12 cm). Reaction times (RT: interval between go signal and movement onset), movement durations (MD: interval between movement onset and capture of the target), peak velocity (maximum tangential velocity), and initial acceleration (determined during the first 40 ms of the movement to avoid influences of the loads) were computed for each trial. Trials with errors (3.5% of trials) or RTs defined as outliers (4.45 × median absolute deviations, equivalent to 3 × SD for a normal distribution, 3.7% of trials) were excluded from the analysis to avoid potentially confounding factors such as inattention. Two-way ANOVAs were used to test these kinematic measures for interacting effects of incentive reward and effort.
Neuronal data analysis
Neuronal recordings were accepted for analysis based on electrode location, recording quality (signal/noise ratio of ≥ 3 SD) and duration (>200 trials). Our methods used to analyze spiking activity collected during this behavioral task have been described previously in Pasquereau and Turner (2013, 2015). For different task events (i.e., instruction cue, movement onset, and reward delivery), continuous neuronal activation functions [spike density functions (SDFs)] were generated by convolving each discriminated action potential with a Gaussian kernel (20-ms variance). Mean peri-event SDFs (averaged across trials) for each of the effort and reward conditions were constructed. A neuron’s baseline firing rate was calculated as the mean of the SDFs across the 500-ms epoch immediately preceding cue instruction. A phasic response to a task event was detected by comparing SDF values relative to a cell’s baseline firing rate (P< 0.01, t-test). A neuron was judged to be task-related if it generated a significant phasic response for at least one of the task conditions. For all single-units identified as dopamine neurons, we tested whether population-averaged activities (averaged across neurons) encoded effort and/or reward levels by using a two-way ANOVA combined with a sliding window procedure (200-ms test window stepped in 50-ms). The influence of task parameters on the activity of dopamine neurons was investigated across the full trial duration: from the epoch preceding the instruction cue to the time period after the reward delivery (total duration equals to ~7 s). To continuously visualize on figures the neuronal activity across the different task events, individual SDFs (instruction, movement onset and reward delivery) were spliced together by positioning successive events following the shortest inter-event-intervals (as the delays were randomly distributed in this task).
LFPs recorded simultaneously with spiking activities were analyzed to test for any effects of task events and effort/reward levels on oscillatory activities. Possible DC offsets, linear trends, and 60 Hz line noise were first removed. Spectral analyses of LFPs were performed using routines from the Chronux software package (www.chronux.org) for Matlab (MathWorks, Natick, MA). This open-source toolbox uses the multitaper method (Bokil et al., 2010), where data were multiplied by a specified number of orthogonal tapers (we used 5 leading tapers allowing for a frequency resolution of 1 Hz), before applying a fast Fourier transform to the tapered waveforms. The transformed spectral data were then averaged over tapers as a way of reducing variance and bias. The frequency decomposition of multitapered data segments provided a set of independent spectral estimates. This method has been successfully applied to neural data in a number of cases (Mitra and Pesaran, 1999; Pesaran et al., 2002; DeCoteau et al., 2007; McCracken and Grace, 2009; Howe et al., 2011; Wood et al., 2012; Rich and Wallis, 2017). Trial-averaged LFP power was visualized and analyzed in the form of time-frequency graphics defined across a large range of frequencies calculated between 1-120 Hz. Such spectrograms were aligned on different task events (i.e., instruction cue, movement onset, and reward) and were constructed with a series of overlapping constant-width windows of 1 second advanced in 50-ms steps. The spectrograms that show multiple alignment events were spliced together from separate spectrograms for each alignment event. The delivery of multiple drops of reward induced a temporal shift of 0.5 second per drop in animal’s valuation of reward quantity (1, 2, or 3 drops). To overcome this temporal bias, we extracted segments (a period of 0.5 second with 2 drops, and 1 second with 3 drops) in spectrograms from 1 second after the onset of reward delivery. Thus, the influence of reward quantity on LFPs followed an identical time scale, independent from the duration of the reward delivery.
For each individual frequency in the spectrogram, the pre-instruction control activity (baseline) was computed as the mean power from −1100 ms to −700 ms relative to cue onset. The LFP power was expressed in z-score units relative to baseline activity. For this, the mean power computed for the baseline activity was subtracted from the power computed in each time bin, and divided by the SD of the baseline activity. The Wilcoxon signed-rank test (P<0.01 for 4 consecutive time bins) was used to select which time-frequency bins were significantly different when comparing the baseline with the task-related activity. Then, to determine whether the LFP power was influenced by reward and/or effort levels, we performed a series of Friedman’s repeated-measures ANOVA on ranks for each time-frequency bin. The threshold for significance (P<0.001) was validated by calculating the likelihood of Type 1 (false-positive) errors during the first time bin of the pre-instruction control epoch (i.e., during a time period when the animal cannot anticipate the upcoming reward and effort levels). Non-parametric tests were used because data sets were not normally distributed (Kolmogorov-Smirnov test, P>0.05). To further characterize the effect of task parameters on LFP power, we performed a series of linear regressions to determine how the LFPs were modulated (increase or decrease) in time-frequency bins where we found a significant effect. We used the equation:
where all variables for the ith trial were z-score normalized to obtain standardized regression coefficients (β). The sign of β values enabled to dissociate time-frequency bins where LFP power increased or decreased depending on the reward and effort levels.
To characterize the observed effects on oscillatory activities, different frequency bands were isolated in spectral power: delta (1– 4 Hz); theta (4–10 Hz); beta (14–32 Hz); gamma1 (33–59 Hz); and gamma2 (61–120 Hz). The power of each frequency band was calculated as the average value over the selected frequency bins. We performed the population-based analysis of frequency bands by comparing the grand average powers between task conditions (reward or effort levels) using the Kruskal-Wallis test.
To determine the relationship between spiking activity of dopamine neuron and the individual LFP trace simultaneously recorded, we tested whether spikes were phase-locked to LFP in a particular frequency band. The phase angle of the LFP oscillation at the time of spike occurrence was obtained by Hilbert-transforming the LFP signal band-pass filtered for the frequency-band of interest. For single-session-based analysis, the 0-360 degrees circular space (with local power maxima corresponding to 0) was divided into 12 bins of equal size, giving an angular resolution of 30 degrees. A LFP-neuron combination was considered phase-locked if the distribution of spike phase angles was non-uniform (Rayleigh’s test, P<0.001). Only segments of each recording session corresponding to periods of stronger LFP oscillations (20% of total duration) were used to compute phase-locking. For population-based analysis, the proportion of units phase-locked in various frequency-bands was plotted with a resolution of 10 degrees.
RESULTS
Before presenting results related to the neuronal recordings, we first establish that the two monkeys performed the effort-benefit reaching task correctly.
Animals’ performance
The nine conditioned stimuli presented during the task effectively communicated different levels of motivational value. This was evidenced by consistent effects on the task performance of both animals (Fig. 1C). Reaction times and kinematic measures were affected by both the expected reward magnitude (reaction times: F(2,107)>11.27, P<0.001; movement durations: F(2,107)>11.04, P<0.001; initial accelerations: F(2,107)>18.22, P<0.001; maximum velocities: F(2,107)>22.05, P<0.001) and the exerted physical effort (reaction times: F(2,107)>5.47, P<0.01; movement durations: F(2,107)>40.44, P<0.001; initial accelerations: F(2,107)>34.04, P<0.001; maximum velocities: F(2,107)>83.62, P<0.001). Although the specific effects of effort differed between reaction times and kinematics, overall movements were faster in trials in which large benefits and low efforts were anticipated. Details about effort/reward effects on monkeys’ behavior can be found in our previous study (Pasquereau and Turner, 2013).
Spiking activity of dopamine neurons
While the monkeys performed the behavioral task, we recorded wide-band signals (single-unit activity and LFPs) from 107 locations in the SNc at which putative dopamine neurons were encountered. Dopamine neurons were identified based on location, standard electrophysiological criteria and responsiveness to unexpected events. Data from the two monkeys were pooled for our analyses because no differences in response properties were found between the two animals. Although the task-evoked activities of these neurons have been described in detail elsewhere (Pasquereau and Turner, 2013; 2015), it is important to summarize those results here (Fig. 2) for comparisons with the LFP results. The neurons responded predominantly to conditioned reward-predicting stimuli as would be expected of dopamine neurons, as described classically (Hollerman and Schultz, 1998; Fiorillo et al., 2003; Tobler et al., 2005; Morris et al., 2006; Matsumoto and Hikosaka, 2009). Most dopamine neurons (78%, 83 of 107; P<0.01, t-test) emitted a phasic increase in discharge above the baseline firing rate following the presentation of instruction cues, whereas smaller fractions of cells showed a phasic response during the period preceding movement execution (46%, 49 of 107) or during the reward delivery (18%, 19 of 107). The presence of clear and sharp evoked responses (i.e., with a limited SEM) in the population-averaged activity confirmed that dopamine responses were well stereotyped around the reward-related events (Joshua et al., 2009a).
Figure 2.
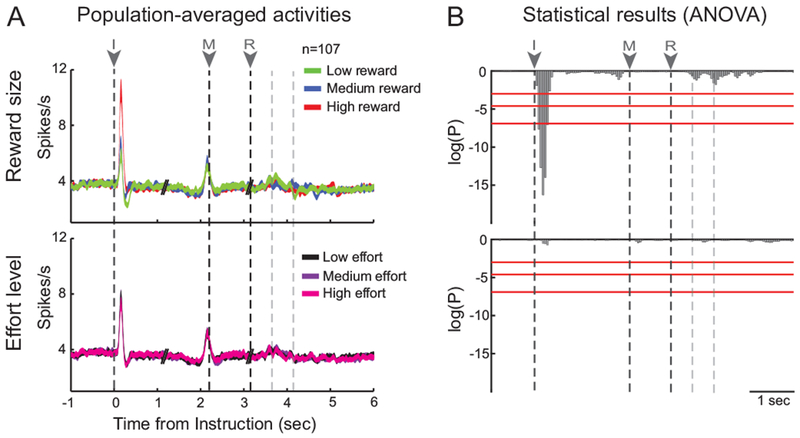
Dopamine neurons encode the expected reward quantity. (A) Population-averaged activities are shown separately across task events (I: instruction, M: movement onset, R: reward delivery) for the different types of trials related to the three reward quantities or the three effort levels. The dotted lines after reward depict the three reward drops. Spike density functions (line width = SEM) were constructed with all identified dopamine neurons (n=107). (B) The effects of reward and effort on the population activity were examined using two-way ANOVA combined with a sliding window procedure (200-ms test window stepped in 50-ms). Red lines indicate different statistical thresholds (95, 99 and 99.9%). Reward encoding was detected in response to the instruction cue (F(2,107)>7.21, P<0.001).
Consistent with the basic predictions of the RPE framework (Sutton and Barto, 1998), the magnitude of instruction-evoked single-unit responses varied with the expected reward quantity. In Figure 2A, we show population-averaged spike density functions, constructed separately across the different task events for the different types of trials related to the three reward quantities and the three effort levels. Only during the first 400-ms of the presentation of the instruction cue did the cell population firing rate encode expected reward size significantly such that the phasic cue-evoked activations scaled monotonically with the number of drops of reward (F(2,107)>7.21, P<0.001, two-way ANOVA; Fig. 2B). In other words, the bigger the future reward, the larger the phasic response evoked following presentation of the instruction cue (Tukey–Kramer post hoc comparison). None of the population responses triggered by other task events (i.e., movement and reward delivery) encoded information about reward size (F(2,107)<2.66, P>0.05, two-way ANOVA; Fig. 2B). Furthermore, no population responses were influenced by the level of effort (Fig. 2B bottom), neither around the time it was predicted by the instruction cues, nor when it was exerted by the animal during movement execution (F(2,107)<0.44, P>0.05, two-way ANOVA). Our previous cell-by-cell analysis identified a small subset of dopamine neurons (11%, n=12/107; Pasquereau and Turner, 2013) whose cue-evoked responses encoded predicted physical effort robustly and in a manner that closely matched behavioral performance. The absence of significant effort-related modulations in the population-level analysis performed here (Fig. 2B) confirms that encoding of effort-related information was rare in our population of dopamine single-units.
Phase locking between LFP and spiking activity
LFP data from the same 107 recording sessions were used to investigate any link between the encoding of task information by neural spike trains and LFP oscillatory activities. Raw LFP signals were split into frequency-bands of interest by band-pass filtering the signal. Delta, theta, beta, gamma1, and gamma2 rhythms were observed to vary across the successive events of the task. To determine whether these LFP signals could be attributed to local neuronal processes, we tested whether spikes were phase-locked to particular frequency bands of the LFP. As shown for two examples in Figures 3A-B, significant phase-locking was revealed by the non-uniform distribution of the LFP phase angles at the time of spike occurrence (Rayleigh’s test, P<0.001). We found that almost all neurons (99%, 106 of 107; Fig. 3C left) were phase locked to the delta rhythm, with preferred phases between 330 and 0 degrees, indicating that the probability of dopamine spiking was highest just before the local peak in delta oscillation. A smaller proportion of neurons (33%, 35 of 107; Fig. 3C right) showed spike-LFP phase locking in the beta frequency range. In this case, consistent with a previous primate study (Bartolo et al., 2014), the preferred phase ranged between 150 and 180 degrees, indicating that action potentials tended to occur just before the local trough in oscillation. A third minor category (7%, 8 of 107) of significant phase locking was found in the theta frequency range, although that level of incidence was not significantly greater than chance (χ2=0.54, P=0.46; χ2 test). No neurons showed spike-LFP phase relations in the gamma frequency bands. Thus, while we did not record simultaneously from pairs of neurons, the high incidence of significant phase locking to delta and beta frequencies and the narrow distribution of preferred phases for that locking (Fig. 3C) implies that the spiking activity of many individual dopamine neurons can potentially contribute to low frequency (<32-Hz) components of LFP signals recorded from the SNc. Next we tested whether these LFP low frequency signals encode reward-related information similar to the RPE encoding observed in the spiking activity of dopamine single-units.
Figure 3.

Phase locking of spike discharge of dopamine neurons. (A-B) Two exemplar neurons that were classified as phase locked to the (A) delta rhythm and (B) the beta rhythm. Each spike-triggered average and circular plot depicts the relationships between the spike occurrences and the filtered LFP signals. Significant phase-locking was revealed by the non-uniform distribution of the LFP phase angles at the time of spike occurrence (Rayleigh’s test, P<0.001). The arrow in individual circular plot shows the mean preferred angle. (C) Population results in which the number of units (in %) that were significantly phase-locked is shown as a function of the preferred angle detected (in degrees). The number of units phase-locked to LFP signals and the distributions of the preferred phases obtained with delta/beta rhythms indicate that dopamine neurons were well coordinated by these relative low-frequency oscillations.
Task-dependent LFP oscillations
We computed LFP spectrograms aligned on different task events (i.e., instruction, movement onset and reward; 1-120 Hz) for each individual recording session. In Figure 4A, we show the normalized LFP power averaged across all recording sessions (n=107) and across different task conditions (three reward quantities and three effort levels). Task-dependent changes in population-averaged LFP power were evident throughout the range of frequencies examined. For the population-averaged activity, we observed significant deviations of oscillatory power away from baseline during successive behavioral periods (threshold: P<0.01 for 4 consecutive time bins, Wilcoxon signed-rank test). The initial change in LFP power was a small decrease in anticipation of the instruction cue followed by a large increase in power immediately following presentation of the instruction cue. A second decrease in LFP power appeared immediately prior to reward delivery followed by a second large increase beginning approximately two seconds later. Notably, anticipatory decreases in LFP power preceded both reward-related events (instruction cue and reward delivery) and these decreases were deepest in the beta frequency-band (14-32 Hz).
Figure 4.

The effort-benefit task modifies the power of LFP signals. (A) Population-averaged LFP spectrogram aligned on successive task events (i.e., I - instruction, M - movement onset and R - reward). LFP powers were averaged across all recording sessions (n=107) and across different task conditions (three reward quantities and three effort levels). Power is color-coded on a normalized scale calculated from the control period (−1100 to −700 ms relative to instruction). Distinct task-dependent changes in LFP signals were detected: white and black lines delineate significant decrease and increase in power, respectively (Wilcoxon signed-rank test; P<0.01 for 4 consecutive time bins). (B) Spectral powers (mean ± SEM) of different frequency bands were compared between animals (81 versus 26 sessions for monkey C and H, respectively). (C) The inter-individual variability in the spectral powers was exanimated using the Kruskal-Wallis test. As in Fig. 2, red lines indicate different statistical thresholds.
To test whether similar task-dependent changes in LFP were observed in both monkeys, we compared spectral powers of different frequency bands between data sets from the two animals (Kruskal-Wallis test; Figs. 4B-C). Using a statistical threshold of 99.9%, no difference in LFP power was observed between animals during instruction, movement or post-reward periods. A difference between animals was found however in the beta frequency range (χ2>10.96, P<0.001; Fig. 4C) during a short period preceding the reward delivery. In subsequent analyses that combined data across animals, caution was exercised when a task-dependent effect was investigated in beta rhythm around the pre-reward period.
Influence of reward level on LFP
As described before, the spiking activity of dopamine neurons encoded the quantity of reward predicted by the instruction cue. We tested whether LFP oscillations were similarly influenced by the reward level. In Figure 5A, we show population-averaged spectrograms constructed separately for trials with small, medium, and large reward quantities. A series of Friedman’s repeated-measures ANOVAs on ranks was performed to identify individual time-frequency bins where the LFP power was correlated with reward quantity (χ2>13.82, P<0.001; Fig. 5B). Overall, we found that reward size had some influence on the LFP signal in 60% of recording session (64 of 107). Across the course of behavioral trials, these influences were most common during and immediately following appearance of the instruction cue (significant reward-dependent modulation of LFP in 30% of sessions, Fig. 5B red line) and following reward delivery (32% of sessions). For the time-frequency bins judged to be reward-dependent, we then estimated the relation between LFP power and reward size by measuring the slope of a regression line fitted to the data collected during different trial types. As shown in Figure 5C, reward-dependent changes in LFP power differed markedly depending on LFP frequency and the task period. In specific low frequency bands (<32 Hz), LFP power increased in concert with reward level, both during the instruction period, transiently, and following reward delivery. In contrast, LFP power across a wide range of high frequencies (>33 Hz) varied inversely with reward level and this relationship was present throughout most of the interval between instruction cue appearance and reward delivery and then again following reward delivery. The relative time courses of these reward-dependent variations in LFP power are illustrated in Figure 6A. Population-averaged LFP power within frequency-bands of interest was estimated separately for the three reward levels and compared using a series of Kruskal-Wallis tests (χ2>14.03, P<0.001; Fig. 6B). Following presentation of the instruction cue, the population LFP response was positively correlated with the predicted reward size first in the theta frequency range and then, ~200-ms later, in the beta band. Following this, a negative reward-dependent relationship (i.e., with a negative regression coefficient) emerged in the high frequencies of gamma2 and then attenuated before movement initiation. No significant reward-dependent modulations in LFP power were detected during motor phase of the task between movement onset and reward delivery. Approximately two seconds after reward delivery, positive reward-dependent relationships appeared in all frequency bands above theta, with the strongest relationship in the beta frequency range.
Figure 5.

Oscillatory power was modulated by reward level. (A) Population-averaged LFP spectrograms constructed separately for the different types of trials related to the three reward quantities (low, medium and high). These figures follow the conventions of Fig. 4A. The black triangle on the top indicates when a temporal segment was extracted from the data to get similar time scale between conditions after the reward delivery. (B) Influence of reward levels on LFP power was detected by a series of Friedman’s repeated-measures ANOVA (χ2>13.82, P<0.001). For each time-frequency bin, the gray scale represents the fraction of sessions significantly modulated. The red line indicates the maximum fraction of sessions modulated by the reward level across all oscillatory frequencies. (C) LFP power either increased (yellow: positive regression coefficients) or decreased (blue: negative coefficients) as a function of the reward level (linear regression).
Figure 6.

The time course of reward-dependent changes in LFPs. (A) The population-averaged signal (mean power ± SEM) was decomposed into oscillatory frequency-bands of interest for the different types of trials related to the three reward quantities. (B) Reward-dependent changes in the population averages were tested by a series of Kruskal-Wallis test. As in Fig. 2, red lines indicate different statistical thresholds. Tukey-Kramer post hoc comparisons were used to determine the type of tuning [positive (yellow) or negative (blue) slope].
Together, we found that LFP power encoded the size of an anticipated or delivered reward in a dynamic way that differed across frequency bands and task epochs. Power in the theta and beta ranges correlated positively with reward size, roughly similar to the positive relationship described for dopamine single-units (Fig. 2). Moreover, these changes appeared at short latency relative to the behavioral event (especially following instruction delivery) and lasted transiently, which is somewhat similar to the phasic responses observed in dopamine single-units. Conversely, the inverse relationship to reward size observed at higher frequency bands (> 32-Hz) appeared at a longer latency following instruction appearance and reward delivery and persisted longer, all of which contrasts sharply with the phasic positive-encoding responses of dopamine neurons. It is important to note, however, that the population activity of dopamine single-units did not encode reward size following reward delivery (Fig. 2B) as reinforcement theory predicts for such a condition in which there is no reward prediction error (Sutton and Barto, 1998). In contrast, LFP power during this period encoded reward size robustly across a wide range of frequencies above the theta frequency band. Thus, while dopamine neurons signaled a RPE (Schultz et al., 1997; Bayer and Glimcher, 2005), the LFP power varied as a function of the actual reward received. Although we cannot exclude the possibility that this relationship was secondary to some aspect of behavior that, itself, covaried with reward size, we observed no overt behaviors in our animals fit with that explanation.
Influence of effort level on LFP
In parallel, to investigate whether LFP signals were influenced by the anticipation and the exertion of physical effort during movement execution, we used the same methods as described above. In Figure 7A, the population-averaged spectrograms were constructed separately for trials that used the three levels of effort. We found that the effort level influenced only 5% of LFP recordings (5 of 107 sessions), and this mainly during movement execution when the different forces were applied (Figs. 7B-C). Because the incidence of this effort-dependent effect on LFP population was not significantly greater than chance (χ2=0.01, P=0.9; χ2 test), we considered such influence as negligible. Consistent with this result, the population-averaged analysis of frequency-bands showed that no specific rhythm of LFP oscillations was significantly modulated by the different friction loads (χ2<12.87, P>0.001, Kruskal-Wallis test; Fig. 8). Although we observed a trend to encode the effort level during the movement execution in the beta frequency range, it remained insignificant when we used the same statistical threshold as used in the analysis of reward level encoding (99.9%).
Figure 7.

Oscillatory activities were insensitive to the effort level. (A) Population-averaged LFP spectrograms constructed separately for the different types of trials related to the three effort levels (low, medium and high). These figures follow the conventions of Fig. 5. (B-C) Influence of effort levels on LFP power (Friedman’s repeated-measures ANOVA, P<0.001). Note that the effort level influenced a non-significant proportion of LFP recordings (5 of 107 sessions; χ2=0.01, P=0.9).
Figure 8.

The time course of effort-dependent changes in LFPs. (A) The population-averaged signal (mean power ± SEM) was decomposed into oscillatory frequency-bands of interest for the different types of trials related to the three effort levels. (B) Effort-dependent changes in the population averages were tested by a series of Kruskal-Wallis test. As in Fig. 2, red lines indicate different statistical thresholds.
DISCUSSION
Single-unit recordings performed in behaving non-human primate have largely shown how the midbrain dopamine neurons play a crucial role in reward learning, attention, temporal prediction, sensory processing and motivating behaviors toward desired goals (Romo and Schultz, 1990; Schultz and Romo, 1990; Ljungberg et al., 1992; Schultz, 2006; Bromberg-Martin et al., 2010; Nomoto et al., 2010; de Lafuente and Romo, 2011; Soares et al., 2016). To date, however, LFPs collected within the vicinity of these cells has remained surprisingly under-explored.
The present results reveal that LFP oscillations can be used to investigate reward-related processes within the midbrain and observe the dynamic coordination of components related and unrelated to the spiking of dopamine neurons. Despite some differences with dopamine spiking activity, in general we found that the power of LFP oscillations was tuned transiently by reward-related events during the task performance, predicting and responding to the reward delivery while disregarding processes associated with movement execution. Because a fraction of dopamine neurons were phase-locked to the delta and beta rhythms, low-frequency bands appeared as the only marker of the activity of local dopamine cells among the LFP signals. In support of this view, low-frequency bands (< 32-Hz) responded to the reward-predictive cue by scaling their power as the dopamine neurons modulate their firing rate. Indeed, consistent with the basic predictions of reinforcement theory (Sutton and Barto, 1998), the low-frequency signals encoded as well the expected reward value by gradually increasing power as a function of the quantity of the upcoming reward. The time course of those reward-dependent modulations in power correlated relatively well with the encoding of reward by dopamine single-units. For the high-frequency oscillations (> 33-Hz), instead, we found no evidence for direct relationships to dopamine spiking activity. Converse to the encoding by dopamine neurons and low-frequency LFPs, the greater power of the instruction-evoked gamma oscillations the smaller the expected reward quantity. Moreover, this reward-dependent effect began at a long latency, removing it in time from the coordinated population response of dopamine neurons. We speculate that this high-frequency LFP power may reflect synchronized activity of inhibitory inputs to the SNc (Buzsáki and Wang, 2012), while it is also quite possible that these oscillatory signals result of volume-conduction from nearby structures such as the substantia nigra pars reticulata.
One of the most notable differences that we found between LFP oscillations and dopamine neuron activity was in the encoding after reward delivery. While LFP power was modulated as a function of the actual size of reward received, the dopamine neurons as a population did not respond, consistent with their encoding of an RPE-like signal (Schultz et al., 1997; Bayer and Glimcher, 2005) (Fig. 2). This difference in encoding could reflect a local transformation of information from the afferent information received by dopamine neurons (reward size reflected in low-frequency LFPs) to that transmitted (RPE reflected in the spiking of dopamine neurons). While we did not observe any consistent behavioral factor to explain such results, we cannot exclude the possibility that LFP power varied indirectly instead as a function of different behavioral patterns (e.g., eye movements, chewing the food reward) triggered by different size of reward received.
There is considerable evidence that midbrain dopamine neurons respond consistently with a phasic burst of activity to different types of appetitive events including primary rewards and reward-predictive stimuli (Romo and Schultz, 1990; Schultz and Romo, 1990; Ljungberg et al., 1992; Wise, 2004). Those dopamine responses closely match the RPEs posited by classical models of reinforcement learning (Hollerman and Schultz, 1998; Schultz, 1998; Sutton and Barto, 1998; Bayer and Glimcher, 2005). As a facet of that prediction error signal, dopamine responses encode the reward value predicted by conditioned stimuli by combining multiple attributes of the expected reward such as the quantity, the probability and the time delay to delivery (Fiorillo et al., 2003, 2008; Tobler et al., 2005; Morris et al., 2006; Roesch et al., 2007; Joshua et al., 2008; Kobayashi and Schultz, 2008; Pasquereau and Turner, 2013, 2015). In the present study, we confirmed that midbrain dopamine neurons play a role in motivating behaviors by encoding the expected size of the upcoming reward such that the phasic cue-evoked activations scaled monotonically with the quantity of reward (Fig. 2). The strength and the sharp profile of cue-evoked activities observed in our population-averaged analysis indicated that dopamine responses were stereotyped around the reward-related event. This tight temporal linkage between spiking activities has been widely observed for dopamine neurons, which, classically, have been described as a homogenous system (Eshel et al., 2016) despite some distinctions based on gene expression, electrophysiological properties, and afferent inputs (Haber et al., 1995; Neuhoff et al., 2002; Ford et al., 2006; Margolis et al., 2008; Brown et al., 2009; Lammel et al., 2012). Considering this, we wondered if the coordination of activity across a population of dopamine neurons, as reflected in LFP recorded in their vicinity, also carries task information. Here, we found evidence consistent with that hypothesis in that dopamine encoding was accompanied by low-frequency LFP signals (i.e., theta and beta) whose power also increased as a function of the expected reward value (Figs. 5–6). Unfortunately, our approach did not permit a causal test of the rolls low-frequency rhythmic activity play within the neuronal assembly. Interestingly, increased theta power coupled with a phase synchrony of dopamine neurons has already been reported in the ventral tegmental area when a reward-predictive stimulus was presented to a rat (Kim et al., 2012). During the acquisition of cue-reward association, the proportion of these coordinated activities phase-locked to the theta rhythm correlated with the conditioned value associated to the cue (Joshua et al., 2009a; Kim et al., 2012), suggesting that low-frequency signals may be an important component of the dynamic processes related to reward conditioning. In addition to a specific role in the local processing of reward prediction, theta rhythms have been proposed to support long-range synchronization across neuronal networks to facilitate communication between brain regions (Buzsáki and Draguhn, 2004; Siapas et al., 2005; Park and Moghaddam, 2017). Thus, the tuning of low-frequency oscillations observed in our study (Figs. 5–6) may potentially serve to synchronize the local dopamine spiking activities during the period of reward anticipation and may be also reflective of inter-region processing necessary for coding value signals (van Wingerden et al., 2010). Further studies are needed to assess the exact contribution of LFP signals in the coordinated activity of both local and distal neuronal networks.
In complement, we found that high-frequency oscillations in the midbrain were modulated by reward-predictive cue such that the gamma power was inversely correlated with the associated reward value (Figs. 5–6). In other words, high-frequency oscillations preferentially responded to a low appetitive conditioned stimulus rather than to a cue associated with high reward quantity. This result contrasts with the instruction-evoked responses of dopamine neurons, which increased as a function of reward size. Although cortical studies have reported that high-frequency signals are tightly coupled to the firing of local neurons (Liu and Newsome, 2006; Belitski et al., 2008; Ray et al., 2008), here we observed no direct link with the dopamine spiking activity, suggesting that this gamma signal reflects non-dopamine components within the nearby neuronal elements. As the current dataset only contained dopamine-like single-units, no direct evidence exists as to the origin of the high-frequency oscillations. However, because gamma power was anti-correlated with reward size, it is tempting to hypothesize that the signal originated from local or inter-regional inhibitory elements. First, in addition to dopamine neurons, ~30% of neurons in the SNc are γ-aminobutyric acid (GABA)-ergic neurons (Nair-Roberts et al., 2008; Creed et al., 2014). These local GABAergic neurons strongly inhibit dopamine neurons (Tan et al., 2012), are implicated in reward prediction with increased firing in response to conditioned stimulus (Cohen et al., 2012), and contribute directly to computation of RPEs via a subtraction (Eshel et al., 2015). We speculate that these GABA neurons increase their discharge rate mainly for low-reward values as described here for high-frequency oscillations. To our knowledge, however, no study has described such a GABA response pattern in the midbrain. Second, the high-firing rate GABAergic neurons of the nearby substantia nigra pars reticulata might also contribute to this gamma LFP signal, but the predominant responses in these neurons occur when the cues predict a high reward value (Joshua et al., 2009b). Third, midbrain dopamine neurons receive massive GABA inputs from several more distant regions such as the striatum, the pallidum and the rostromedial tegmental nucleus (RMT) (Haber et al., 1990; Jhou et al., 2009). Of particular interest is that RMT activity encodes rewards in a pattern similar to that of the high-frequency LFP observed here and inverse to that of dopamine neurons (Hong et al., 2011). Further work is required to clarify which components within the neuronal network are linked directly to LFP high-frequency oscillations.
Midbrain dopamine neurons signal the RPEs posited by classical models of reinforcement learning (Hollerman and Schultz, 1998; Schultz, 1998; Sutton and Barto, 1998; Bayer and Glimcher, 2005). In our paradigm, the instruction cues informed the animal about the exact future quantity of reward to be delivered at the end of the trial. Thus, consistent with previous observations (Schultz et al., 1997), little or no dopamine single-unit response was evoked by the food reward because the reality matched to the prediction (Fig. 2). Contrary to single-unit activities, however, we found that the majority of LFP frequency-bands recorded in the SNc, and the beta band power in particular, were influenced by the trial outcome (Figs. 5–6). After reward delivery, LFP power correlated with the actual reward received rather than reflecting an RPE-like signal. This result reinforces the view that LFP power does not simply reflect the population-level activity of local dopamine single-units. If this phenomenon does not result from some unseen behavioral covariate, a credible neuronal substrate for such LFP signal could be the afferent projections from the pedunculopontine nucleus (PPN) to the SNc. PPN neurons make glutamatergic and cholinergic synaptic connections in the midbrain (Scarnati et al., 1986; Futami et al., 1995; Mena-Segovia et al., 2004) that provide one of the strongest sources of excitatory input to dopamine neurons (Matsumura, 2005; Pan and Hyland, 2005). In the primate, one category of PPN neurons has been shown to discharge phasically after reward delivery with a level of activity associated with the actual reward (Okada et al., 2011). PPN neurons exhibited stronger firing for large reward than for small one (Okada et al., 2009), thus mimicking our oscillatory signals. Taken together, LFP oscillations collected in the SNc may provide additional data dimensions along which distinct processing of predicted and actual reward values differ, both of which are necessary for the computation of RPE as represented by dopamine neurons.
In Pasquereau and Turner (2015), we have reported that even though a large fraction of our dopamine neurons changed their firing prior the time of movement onset (see Fig. 2), the timing of those responses was linked to the appearance of the visual go-signal and their magnitude did not correlate with any of a variety of measures of motor performance. Although consistent with the classical view (DeLong et al., 1983; Schultz et al., 1983), our observations were at variance with recent studies that described a direct link between the activity of midbrain dopamine neurons and motor performance (Jin and Costa, 2010; Barter et al., 2014, 2015; Varazzani et al., 2015; Dodson et al., 2016; da Silva et al., 2018). Those discrepancies raised the possibility that a select subset of dopamine neurons, one that we failed to sample from, may encode motor information. Because LFP reflects the summation of electrical fields originating from within a small (~250μm) distance of the electrode contact (Katzner et al., 2009), the present analyses offered the opportunity to overcome possible biases in the single-unit data collection (Towe and Harding, 1970). However, consistent with our initial findings, we found no evidence for a modulation of LFP power related to movement execution (Fig. 4A). None of the frequency-bands were modulated significantly by the effort level while the monkeys ‘performance varied depending on friction loads (Figs. 7–8). These results expand our previous cell-by-cell analyses (Pasquereau and Turner, 2013, 2015) in failing to find a signal in the midbrain that encoded movement or kinematics during our instrumental task.
As it is notoriously difficult to record from dopamine neurons due to their sparsity and depth, we demonstrated that LFP recordings and oscillatory activities described herein could provide an alternative tool to investigate the synchronized activities within the midbrain. We found that reward-related changes in low frequency-bands could be used to reveal a response pattern similar to dopamine spiking activity. But also, we observed that non-dopamine signals were reflected in the power of different oscillatory frequency-bands, providing a method for sampling the activity from diverse population of neurons. To determine how the midbrain processes information related to appetitive behaviors it will be essential to understand the dynamics of interactions between local and afferent signals. Novel methods using optogenetic or chemogenetic tools (i.e., the selective inhibition or stimulation of cell types) in concert with LFP recordings should be used to identify cell populations and their functions unambiguously. LFP recordings appear also relevant to future research concerning the pathophysiology of neurological and psychiatric disorders. For example, impairment of coordinated activity and joint processing of information in the midbrain may be one mechanism that produces the symptoms of disorders such as schizophrenia, for which there is no consistent dopamine marker (Moghaddam and Wood, 2014).
ACKNOWLEDGEMENTS
This work was supported by National Institute of Neurological Disorders and Stroke at the National Institutes of Health (grant numbers P01 NS044393 and R01 NS091853 to R.S.T.) and the Center for Neuroscience Research in Non-human primates (CNRN, 1P30NS076405-01A1).
REFERENCES
- Barter JW, Castro S, Sukharnikova T, Rossi MA, Yin HH (2014) The role of the substantia nigra in posture control. Eur J Neurosci 39:1465–1473. [DOI] [PubMed] [Google Scholar]
- Barter JW, Li S, Lu D, Bartholomew RA, Rossi MA, Shoemaker CT, Salas-Meza D, Gaidis E, Yin HH (2015) Beyond reward prediction errors: the role of dopamine in movement kinematics. Front Integr Neurosci 9:39. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bartolo R, Prado L, Merchant H (2014) Information processing in the primate basal ganglia during sensory-guided and internally driven rhythmic tapping. J Neurosci Off J Soc Neurosci 34:3910–3923. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bayer HM, Glimcher PW (2005) Midbrain dopamine neurons encode a quantitative reward prediction error signal. Neuron 47:129–141. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Belitski A, Gretton A, Magri C, Murayama Y, Montemurro MA, Logothetis NK, Panzeri S (2008) Low-frequency local field potentials and spikes in primary visual cortex convey independent visual information. J Neurosci Off J Soc Neurosci 28:5696–5709. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Berridge KC, Robinson TE (1998) What is the role of dopamine in reward: hedonic impact, reward learning, or incentive salience? Brain Res Brain Res Rev 28:309–369. [DOI] [PubMed] [Google Scholar]
- Bokil H, Andrews P, Kulkarni JE, Mehta S, Mitra PP (2010) Chronux: a platform for analyzing neural signals. J Neurosci Methods 192:146–151. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bromberg-Martin ES, Matsumoto M, Hikosaka O (2010) Dopamine in motivational control: rewarding, aversive, and alerting. Neuron 68:815–834. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brown MTC, Henny P, Bolam JP, Magill PJ (2009) Activity of neurochemically heterogeneous dopaminergic neurons in the substantia nigra during spontaneous and driven changes in brain state. J Neurosci Off J Soc Neurosci 29:2915–2925. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Buzsáki G (2002) Theta oscillations in the hippocampus. Neuron 33:325–340. [DOI] [PubMed] [Google Scholar]
- Buzsáki G (2006) Rhythms of the Brain. Oxford University Press; Available at: http://www.oxfordscholarship.com/view/10.1093/acprof:oso/9780195301069.001.0001/acprof-9780195301069 [Accessed April 24, 2018]. [Google Scholar]
- Buzsáki G, Draguhn A (2004) Neuronal oscillations in cortical networks. Science 304:1926–1929. [DOI] [PubMed] [Google Scholar]
- Buzsáki G, Wang X-J (2012) Mechanisms of gamma oscillations. Annu Rev Neurosci 35:203–225. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cohen JY, Haesler S, Vong L, Lowell BB, Uchida N (2012) Neuron-type-specific signals for reward and punishment in the ventral tegmental area. Nature 482:85–88. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cohen MX, Axmacher N, Lenartz D, Elger CE, Sturm V, Schlaepfer TE (2009) Neuroelectric signatures of reward learning and decision-making in the human nucleus accumbens. Neuropsychopharmacol Off Publ Am Coll Neuropsychopharmacol 34:1649–1658. [DOI] [PubMed] [Google Scholar]
- Cohen MX, Elger CE, Ranganath C (2007) Reward expectation modulates feedback-related negativity and EEG spectra. NeuroImage 35:968–978. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Creed MC, Ntamati NR, Tan KR (2014) VTA GABA neurons modulate specific learning behaviors through the control of dopamine and cholinergic systems. Front Behav Neurosci 8:8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- da Silva JA, Tecuapetla F, Paixão V, Costa RM (2018) Dopamine neuron activity before action initiation gates and invigorates future movements. Nature 554:244–248. [DOI] [PubMed] [Google Scholar]
- de Lafuente V, Romo R (2011) Dopamine neurons code subjective sensory experience and uncertainty of perceptual decisions. Proc Natl Acad Sci U S A 108:19767–19771. [DOI] [PMC free article] [PubMed] [Google Scholar]
- DeCoteau WE, Thorn C, Gibson DJ, Courtemanche R, Mitra P, Kubota Y, Graybiel AM (2007) Learning-related coordination of striatal and hippocampal theta rhythms during acquisition of a procedural maze task. Proc Natl Acad Sci U S A 104:5644–5649. [DOI] [PMC free article] [PubMed] [Google Scholar]
- DeLong MR, Crutcher MD, Georgopoulos AP (1983) Relations between movement and single cell discharge in the substantia nigra of the behaving monkey. J Neurosci Off J Soc Neurosci 3:1599–1606. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dodson PD, Dreyer JK, Jennings KA, Syed ECJ, Wade-Martins R, Cragg SJ, Bolam JP, Magill PJ (2016) Representation of spontaneous movement by dopaminergic neurons is cell-type selective and disrupted in parkinsonism. Proc Natl Acad Sci U S A 113:E2180–2188. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Eshel N, Bukwich M, Rao V, Hemmelder V, Tian J, Uchida N (2015) Arithmetic and local circuitry underlying dopamine prediction errors. Nature 525:243–246. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Eshel N, Tian J, Bukwich M, Uchida N (2016) Dopamine neurons share common response function for reward prediction error. Nat Neurosci 19:479–486. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fiorillo CD, Newsome WT, Schultz W (2008) The temporal precision of reward prediction in dopamine neurons. Nat Neurosci 11:966–973. [DOI] [PubMed] [Google Scholar]
- Fiorillo CD, Tobler PN, Schultz W (2003) Discrete coding of reward probability and uncertainty by dopamine neurons. Science 299:1898–1902. [DOI] [PubMed] [Google Scholar]
- Ford CP, Mark GP, Williams JT (2006) Properties and opioid inhibition of mesolimbic dopamine neurons vary according to target location. J Neurosci Off J Soc Neurosci 26:2788–2797. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fries P (2005) A mechanism for cognitive dynamics: neuronal communication through neuronal coherence. Trends Cogn Sci 9:474–480. [DOI] [PubMed] [Google Scholar]
- Futami T, Takakusaki K, Kitai ST (1995) Glutamatergic and cholinergic inputs from the pedunculopontine tegmental nucleus to dopamine neurons in the substantia nigra pars compacta. Neurosci Res 21:331–342. [DOI] [PubMed] [Google Scholar]
- Goldberg JA (2004) Spike Synchronization in the Cortex-Basal Ganglia Networks of Parkinsonian Primates Reflects Global Dynamics of the Local Field Potentials. J Neurosci 24:6003–6010 Available at: http://www.jneurosci.org/cgi/doi/10.1523/JNEUROSCI.4848-03.2004 [Accessed April 30, 2018]. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Haber SN, Lynd E, Klein C, Groenewegen HJ (1990) Topographic organization of the ventral striatal efferent projections in the rhesus monkey: an anterograde tracing study. J Comp Neurol 293:282–298. [DOI] [PubMed] [Google Scholar]
- Haber SN, Ryoo H, Cox C, Lu W (1995) Subsets of midbrain dopaminergic neurons in monkeys are distinguished by different levels of mRNA for the dopamine transporter: comparison with the mRNA for the D2 receptor, tyrosine hydroxylase and calbindin immunoreactivity. J Comp Neurol 362:400–410. [DOI] [PubMed] [Google Scholar]
- Hollerman JR, Schultz W (1998) Dopamine neurons report an error in the temporal prediction of reward during learning. Nat Neurosci 1:304–309. [DOI] [PubMed] [Google Scholar]
- Hong S, Jhou TC, Smith M, Saleem KS, Hikosaka O (2011) Negative reward signals from the lateral habenula to dopamine neurons are mediated by rostromedial tegmental nucleus in primates. J Neurosci Off J Soc Neurosci 31:11457–11471. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Howe MW, Atallah HE, McCool A, Gibson DJ, Graybiel AM (2011) Habit learning is associated with major shifts in frequencies of oscillatory activity and synchronized spike firing in striatum. Proc Natl Acad Sci U S A 108:16801–16806. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jhou TC, Fields HL, Baxter MG, Saper CB, Holland PC (2009) The rostromedial tegmental nucleus (RMTg), a GABAergic afferent to midbrain dopamine neurons, encodes aversive stimuli and inhibits motor responses. Neuron 61:786–800. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jin X, Costa RM (2010) Start/stop signals emerge in nigrostriatal circuits during sequence learning. Nature 466:457–462. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Joshua M, Adler A, Mitelman R, Vaadia E, Bergman H (2008) Midbrain dopaminergic neurons and striatal cholinergic interneurons encode the difference between reward and aversive events at different epochs of probabilistic classical conditioning trials. J Neurosci Off J Soc Neurosci 28:11673–11684. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Joshua M, Adler A, Prut Y, Vaadia E, Wickens JR, Bergman H (2009a) Synchronization of midbrain dopaminergic neurons is enhanced by rewarding events. Neuron 62:695–704. [DOI] [PubMed] [Google Scholar]
- Joshua M, Adler A, Rosin B, Vaadia E, Bergman H (2009b) Encoding of probabilistic rewarding and aversive events by pallidal and nigral neurons. J Neurophysiol 101:758–772. [DOI] [PubMed] [Google Scholar]
- Kasanetz F, Riquelme LA, O’Donnell P, Murer MG (2006) Turning off cortical ensembles stops striatal Up states and elicits phase perturbations in cortical and striatal slow oscillations in rat in vivo. J Physiol 577:97–113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Katzner S, Nauhaus I, Benucci A, Bonin V, Ringach DL, Carandini M (2009) Local origin of field potentials in visual cortex. Neuron 61:35–41. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kim Y, Wood J, Moghaddam B (2012) Coordinated activity of ventral tegmental neurons adapts to appetitive and aversive learning. PloS One 7:e29766. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kobayashi S, Schultz W (2008) Influence of reward delays on responses of dopamine neurons. J Neurosci Off J Soc Neurosci 28:7837–7846. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kruse W, Eckhorn R (1996) Inhibition of sustained gamma oscillations (35-80 Hz) by fast transient responses in cat visual cortex. Proc Natl Acad Sci U S A 93:6112–6117. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lalla L, Rueda Orozco PE, Jurado-Parras M-T, Brovelli A, Robbe D (2017) Local or Not Local: Investigating the Nature of Striatal Theta Oscillations in Behaving Rats. eneuro 4:ENEURO.0128-17.2017 Available at: http://eneuro.sfn.org/lookup/doi/10.1523/ENEURO.0128-17.2017 [Accessed April 24, 2018]. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lammel S, Lim BK, Ran C, Huang KW, Betley MJ, Tye KM, Deisseroth K, Malenka RC (2012) Input-specific control of reward and aversion in the ventral tegmental area. Nature 491:212–217 Available at: http://www.nature.com/doifinder/10.1038/nature11527 [Accessed November 20, 2017]. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lima B, Singer W, Neuenschwander S (2011) Gamma responses correlate with temporal expectation in monkey primary visual cortex. J Neurosci Off J Soc Neurosci 31:15919–15931. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu J, Newsome WT (2006) Local field potential in cortical area MT: stimulus tuning and behavioral correlations. J Neurosci Off J Soc Neurosci 26:7779–7790. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ljungberg T, Apicella P, Schultz W (1992) Responses of monkey dopamine neurons during learning of behavioral reactions. J Neurophysiol 67:145–163. [DOI] [PubMed] [Google Scholar]
- Marco-Pallares J, Cucurell D, Cunillera T, García R, Andrés-Pueyo A, Münte TF, Rodríguez-Fornells A (2008) Human oscillatory activity associated to reward processing in a gambling task. Neuropsychologia 46:241–248. [DOI] [PubMed] [Google Scholar]
- Margolis EB, Mitchell JM, Ishikawa J, Hjelmstad GO, Fields HL (2008) Midbrain dopamine neurons: projection target determines action potential duration and dopamine D(2) receptor inhibition. J Neurosci Off J Soc Neurosci 28:8908–8913. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Martin RF, Bowden DM (1996) A stereotaxic template atlas of the macaque brain for digital imaging and quantitative neuroanatomy. NeuroImage 4:119–150. [DOI] [PubMed] [Google Scholar]
- Matsumoto M, Hikosaka O (2009) Two types of dopamine neuron distinctly convey positive and negative motivational signals. Nature 459:837–841. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Matsumura M (2005) The pedunculopontine tegmental nucleus and experimental parkinsonism. A review. J Neurol 252 Suppl 4:IV5–IV12. [DOI] [PubMed] [Google Scholar]
- McCracken CB, Grace AA (2009) Nucleus accumbens deep brain stimulation produces region-specific alterations in local field potential oscillations and evoked responses in vivo. J Neurosci Off J Soc Neurosci 29:5354–5363. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mena-Segovia J, Bolam JP, Magill PJ (2004) Pedunculopontine nucleus and basal ganglia: distant relatives or part of the same family? Trends Neurosci 27:585–588. [DOI] [PubMed] [Google Scholar]
- Miocinovic S, Noecker AM, Maks CB, Butson CR, McIntyre CC (2007) Cicerone: stereotactic neurophysiological recording and deep brain stimulation electrode placement software system. Acta Neurochir Suppl 97:561–567. [DOI] [PubMed] [Google Scholar]
- Mitra PP, Pesaran B (1999) Analysis of dynamic brain imaging data. Biophys J 76:691–708. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moghaddam B, Wood J (2014) Teamwork matters: coordinated neuronal activity in brain systems relevant to psychiatric disorders. JAMA Psychiatry 71:197–199. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Morris G, Nevet A, Arkadir D, Vaadia E, Bergman H (2006) Midbrain dopamine neurons encode decisions for future action. Nat Neurosci 9:1057–1063. [DOI] [PubMed] [Google Scholar]
- Nair-Roberts RG, Chatelain-Badie SD, Benson E, White-Cooper H, Bolam JP, Ungless MA (2008) Stereological estimates of dopaminergic, GABAergic and glutamatergic neurons in the ventral tegmental area, substantia nigra and retrorubral field in the rat. Neuroscience 152:1024–1031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Neuhoff H, Neu A, Liss B, Roeper J (2002) I(h) channels contribute to the different functional properties of identified dopaminergic subpopulations in the midbrain. J Neurosci Off J Soc Neurosci 22:1290–1302. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nomoto K, Schultz W, Watanabe T, Sakagami M (2010) Temporally extended dopamine responses to perceptually demanding reward-predictive stimuli. J Neurosci Off J Soc Neurosci 30:10692–10702. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Okada K, Nakamura K, Kobayashi Y (2011) A neural correlate of predicted and actual reward-value information in monkey pedunculopontine tegmental and dorsal raphe nucleus during saccade tasks. Neural Plast 2011:579840. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Okada K, Toyama K, Inoue Y, Isa T, Kobayashi Y (2009) Different pedunculopontine tegmental neurons signal predicted and actual task rewards. J Neurosci Off J Soc Neurosci 29:4858–4870. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pan W-X, Hyland BI (2005) Pedunculopontine tegmental nucleus controls conditioned responses of midbrain dopamine neurons in behaving rats. J Neurosci Off J Soc Neurosci 25:4725–4732. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Park J, Moghaddam B (2017) Risk of punishment influences discrete and coordinated encoding of reward-guided actions by prefrontal cortex and VTA neurons. eLife 6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pasquereau B, Turner RS (2013) Limited encoding of effort by dopamine neurons in a cost-benefit trade-off task. J Neurosci Off J Soc Neurosci 33:8288–8300. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pasquereau B, Turner RS (2015) Dopamine neurons encode errors in predicting movement trigger occurrence. J Neurophysiol 113:1110–1123. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Paz R, Pelletier JG, Bauer EP, Paré D (2006) Emotional enhancement of memory via amygdala-driven facilitation of rhinal interactions. Nat Neurosci 9:1321–1329. [DOI] [PubMed] [Google Scholar]
- Pesaran B, Nelson MJ, Andersen RA (2008) Free choice activates a decision circuit between frontal and parietal cortex. Nature 453:406–409. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pesaran B, Pezaris JS, Sahani M, Mitra PP, Andersen RA (2002) Temporal structure in neuronal activity during working memory in macaque parietal cortex. Nat Neurosci 5:805–811. [DOI] [PubMed] [Google Scholar]
- Rasch M, Logothetis NK, Kreiman G (2009) From neurons to circuits: linear estimation of local field potentials. J Neurosci Off J Soc Neurosci 29:13785–13796. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ray S, Crone NE, Niebur E, Franaszczuk PJ, Hsiao SS (2008) Neural correlates of high-gamma oscillations (60-200 Hz) in macaque local field potentials and their potential implications in electrocorticography. J Neurosci Off J Soc Neurosci 28:11526–11536. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rich EL, Wallis JD (2017) Spatiotemporal dynamics of information encoding revealed in orbitofrontal high-gamma. Nat Commun 8:1139. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Roesch MR, Calu DJ, Schoenbaum G (2007) Dopamine neurons encode the better option in rats deciding between differently delayed or sized rewards. Nat Neurosci 10:1615–1624. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Romo R, Schultz W (1990) Dopamine neurons of the monkey midbrain: contingencies of responses to active touch during self-initiated arm movements. J Neurophysiol 63:592–606. [DOI] [PubMed] [Google Scholar]
- Salamone JD, Correa M (2002) Motivational views of reinforcement: implications for understanding the behavioral functions of nucleus accumbens dopamine. Behav Brain Res 137:3–25. [DOI] [PubMed] [Google Scholar]
- Scarnati E, Proia A, Campana E, Pacitti C (1986) A microiontophoretic study on the nature of the putative synaptic neurotransmitter involved in the pedunculopontine-substantia nigra pars compacta excitatory pathway of the rat. Exp Brain Res 62:470–478. [DOI] [PubMed] [Google Scholar]
- Schultz W (1998) Predictive reward signal of dopamine neurons. J Neurophysiol 80:1–27. [DOI] [PubMed] [Google Scholar]
- Schultz W (2006) Behavioral theories and the neurophysiology of reward. Annu Rev Psychol 57:87–115. [DOI] [PubMed] [Google Scholar]
- Schultz W, Dayan P, Montague PR (1997) A neural substrate of prediction and reward. Science 275:1593–1599. [DOI] [PubMed] [Google Scholar]
- Schultz W, Romo R (1990) Dopamine neurons of the monkey midbrain: contingencies of responses to stimuli eliciting immediate behavioral reactions. J Neurophysiol 63:607–624. [DOI] [PubMed] [Google Scholar]
- Schultz W, Ruffieux A, Aebischer P (1983) The activity of pars compacta neurons of the monkey substantia nigra in relation to motor activation. Exp Brain Res 51 Available at: http://link.springer.com/10.1007/BF00237874 [Accessed November 20, 2017]. [Google Scholar]
- Siapas AG, Lubenov EV, Wilson MA (2005) Prefrontal phase locking to hippocampal theta oscillations. Neuron 46:141–151. [DOI] [PubMed] [Google Scholar]
- Soares S, Atallah BV, Paton JJ (2016) Midbrain dopamine neurons control judgment of time. Science 354:1273–1277. [DOI] [PubMed] [Google Scholar]
- Sutton RS, Barto AG (1998) Reinforcement learning: an introduction, Nachdr. Cambridge, Mass.: MIT Press. [Google Scholar]
- Tan KR, Yvon C, Turiault M, Mirzabekov JJ, Doehner J, Labouèbe G, Deisseroth K, Tye KM, Lüscher C (2012) GABA neurons of the VTA drive conditioned place aversion. Neuron 73:1173–1183. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Teleńczuk B, Dehghani N, Le Van Quyen M, Cash SS, Halgren E, Hatsopoulos NG, Destexhe A (2017) Local field potentials primarily reflect inhibitory neuron activity in human and monkey cortex. Sci Rep 7:40211 Available at: http://www.nature.com/articles/srep40211 [Accessed April 30, 2018]. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tobler PN, Fiorillo CD, Schultz W (2005) Adaptive coding of reward value by dopamine neurons. Science 307:1642–1645. [DOI] [PubMed] [Google Scholar]
- Tort ABL, Kramer MA, Thorn C, Gibson DJ, Kubota Y, Graybiel AM, Kopell NJ (2008) Dynamic cross-frequency couplings of local field potential oscillations in rat striatum and hippocampus during performance of a T-maze task. Proc Natl Acad Sci U S A 105:20517–20522. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Towe AL, Harding GW (1970) Extracellular microelectrode sampling bias. Exp Neurol 29:366–381. [DOI] [PubMed] [Google Scholar]
- van der Meer MAA, Redish AD (2009) Low and High Gamma Oscillations in Rat Ventral Striatum have Distinct Relationships to Behavior, Reward, and Spiking Activity on a Learned Spatial Decision Task. Front Integr Neurosci 3:9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van Wingerden M, Vinck M, Lankelma J, Pennartz CMA (2010) Theta-band phase locking of orbitofrontal neurons during reward expectancy. J Neurosci Off J Soc Neurosci 30:7078–7087. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Varazzani C, San-Galli A, Gilardeau S, Bouret S (2015) Noradrenaline and dopamine neurons in the reward/effort trade-off: a direct electrophysiological comparison in behaving monkeys. J Neurosci Off J Soc Neurosci 35:7866–7877. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wise RA (2004) Dopamine, learning and motivation. Nat Rev Neurosci 5:483–494. [DOI] [PubMed] [Google Scholar]
- Womelsdorf T, Schoffelen J-M, Oostenveld R, Singer W, Desimone R, Engel AK, Fries P (2007) Modulation of Neuronal Interactions Through Neuronal Synchronization. Science 316:1609–1612 Available at: http://www.sciencemag.org/cgi/doi/10.1126/science.1139597 [Accessed April 24, 2018]. [DOI] [PubMed] [Google Scholar]
- Wood J, Kim Y, Moghaddam B (2012) Disruption of prefrontal cortex large scale neuronal activity by different classes of psychotomimetic drugs. J Neurosci Off J Soc Neurosci 32:3022–3031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zénon A, Duclos Y, Carron R, Witjas T, Baunez C, Régis J, Azulay J-P, Brown P, Eusebio A (2016) The human subthalamic nucleus encodes the subjective value of reward and the cost of effort during decision-making. Brain J Neurol 139:1830–1843. [DOI] [PMC free article] [PubMed] [Google Scholar]