

Abstract
Resolution proof systems for quantified Boolean formulas (QBFs) provide a formal model for studying the limitations of state-of-the-art search-based QBF solvers that use these systems to generate proofs. We study a combination of two proof systems supported by the solver DepQBF: Q-resolution with generalized universal reduction according to a dependency scheme and long distance Q-resolution. We show that the resulting proof system—which we call long-distance Q(D)-resolution—is sound for the reflexive resolution-path dependency scheme. In fact, we prove that it admits strategy extraction in polynomial time. This comes as an application of a general result, by which we identify a whole class of dependency schemes for which long-distance Q(D)-resolution admits polynomial-time strategy extraction. As a special case, we obtain soundness and polynomial-time strategy extraction for long distance Q(D)-resolution with the standard dependency scheme. We further show that search-based QBF solvers using a dependency scheme D and learning with long-distance Q-resolution generate long-distance Q(D)-resolution proofs. The above soundness results thus translate to partial soundness results for such solvers: they declare an input QBF to be false only if it is indeed false. Finally, we report on experiments with a configuration of DepQBF that uses the standard dependency scheme and learning based on long-distance Q-resolution.
Keywords: QBF, Q-resolution, Dependency schemes, Strategy extraction
Introduction
Quantified Boolean formulas (QBFs) offer succinct encodings for problems from domains such as formal verification, synthesis, and planning [5, 13, 16, 30, 38, 43]. Although the combination of (more verbose) propositional encodings with SAT solvers is still the state-of-the-art approach to many of these problems, QBF solvers are gaining ground. An arsenal of new techniques has been introduced over the past few years [10, 11, 14, 22, 23, 25, 26, 29, 32, 33, 35], and these advances in solver technology have been accompanied by the development of a better understanding of the underlying QBF proof systems and their limitations [4, 7–9, 12, 18, 27, 42].
Search-based solvers implementing the QCDCL algorithm [15, 46] represent one of the principal state-of-the-art approaches in QBF solving. Akin to modern SAT solvers, these solvers rely on successive variable assignments in combination with fast constraint propagation and learning. Unlike SAT solvers, however, search-based QBF solvers are constrained by the variable dependencies induced by the quantifier prefix:1 while SAT solvers can assign variables in any order, search-based QBF solvers can only assign variables from the leftmost quantifier block that contains unassigned variables, since the assignment of a variable further to the right might depend on the variable assignment to this block. In the most extreme case, this forces solvers into a fixed order of variable assignments, rendering decision variable heuristics ineffective.
The search-based solver DepQBF uses dependency schemes to partially bypass this restriction [10, 31]. Dependency schemes can sometimes identify pairs of variables as independent, allowing the solver to assign them in any order. This gives decision heuristics more freedom and results in increased performance [10].
While this provides a strong motivation to use dependency schemes, their integration with QCDCL poses challenges of its own. Soundness of the proof system underlying QCDCL with the standard dependency scheme as implemented in DepQBF was shown only recently [42], and combining other state-of-the-art techniques with dependency schemes is often highly nontrivial. In this paper, we focus on two such issues:
Long-distance Q-resolution permits the derivation of tautological clauses in certain cases [2, 45, 47]. This system can be used in constraint learning as an alternative to Q-resolution, leading to fewer backtracks during search and, sometimes, reduced runtime [19]. In addition, clause learning based on long-distance Q-resolution is substantially easier to implement. However, it is open whether QCDCL with learning based on long-distance Q-resolution is sound when combined with known dependency schemes.
For applications in verification and synthesis, it is not enough for solvers to decide whether an input QBF is true or false—they also have to generate a certificate. Such certificates can be efficiently constructed from Q-resolution [2] and even long-distance Q-resolution proofs [3]. However, it is not clear whether this is possible for proofs generated by QCDCL with the standard dependency scheme.
We define LDQ(D)-resolution as consisting of long-distance Q-resolution with a dependency scheme D, and show that a search-based QBF solver using dependency scheme D and learning based on long-distance Q-resolution generates an LDQ(D)-resolution refutation whenever it declares an input QBF to be false. This allows us to partially address (a) by showing that long-distance Q-resolution combined with the reflexive resolution-path dependency scheme [42] is sound. In fact, we prove that this proof system allows for certificate extraction in polynomial time, thus resolving (b) as well. These results also hold for long-distance Q-resolution combined with the weaker standard dependency scheme. We thus provide a partial soundness argument for QCDCL with these dependency schemes and learning based on long-distance Q-resolution to the effect that “false” answers can be trusted.
Our proof relies on a familiar interpretation of Q-resolution refutations as winning strategies for the universal player in the evaluation game [24]. We identify a natural property of dependency schemes D that not only allows for the interpretation of an LDQ(D)-refutation as a winning strategy for the universal player, but even implies polynomial-time certificate extraction from an LDQ(D)-refutation. We then show that the reflexive resolution path dependency scheme in fact has this property.
One of our motivations for studying the combination of long-distance Q-resolution and dependency schemes is that it is already supported by DepQBF. To complement our theoretical results, and to provide further motivation for resolving the question of soundness of “true” answers, we performed experiments using a configuration of DepQBF with both features activated. These experiments show that performance with learning based on LDQ(D)-resolution is on par with and—in some cases—even slightly better than the performance of DepQBF with other configurations of constraint learning.
Organization
Section 2 establishes basic notions used throughout this paper. In Sect. 3, we review dependency schemes and introduce the LDQ(D) proof system. In Sect. 4, we present a version of QCDCL which combines dependency schemes with learning based on long-distance Q-resolution and argue that this algorithm generates LDQ(D) proofs. Section 5 is split into two parts: in the first part, we define a property of dependency schemes D and prove that it is sufficient for soundness of LDQ(D); in the second part, we show that the reflexive resolution-path dependency scheme has this property. In Sect. 6, we report on experiments with a version of DepQBF that generates LDQ(D)-proofs. In Sect. 7, we briefly discuss recently published related work. We conclude in Sect. 8 with some open questions.
Preliminaries
Formulas and Assignments
A literal is a negated or unnegated variable. If x is a variable, we write and , and let . We sometimes call literals x and the positive and negative polarity of variable x. If X is a set of literals, we write for the set . A clause is a finite disjunction of literals, and a term is a finite conjunction of literals. We call a clause tautological if it contains the same variable negated as well as unnegated. A CNF formula is a finite conjunction of non-tautological clauses. Whenever convenient, we treat clauses and terms as sets of literals, and CNF formulas as sets of sets of literals. We write for the set of variables occurring (negated or unnegated) in a clause or term S, that is, . Moreover, we let denote the set of variables occurring in a CNF formula .
A truth assignment (or simply assignment) to a set X of variables is a mapping . We write [X] for the set of truth assignments to X, and extend to literals by letting for . Let be a truth assignment. The restriction of a clause (term) S by is defined as follows: if there is a literal such that ( then (). Otherwise, . The restriction of a CNF formula by the assignment is defined .
PCNF Formulas
A PCNF formula is denoted by , where is a CNF formula and is a sequence such that , for , and the are pairwise disjoint sets of variables. We call the matrix of and the (quantifier) prefix of , and refer to the as quantifier blocks. We require that and write . We define a partial order on as . We extend to a relation on literals in the obvious way and drop the subscript whenever is understood. For we let and denote the sets of variables to the right and to the left of x in , respectively. Relative to the PCNF formula , variable x is called existential (universal) if and (). The set of existential (universal) variables occurring in is denoted (). The size of a PCNF formula is defined as . If is an assignment, then denotes the PCNF formula , where is the quantifier prefix obtained from by deleting variables that do not occur in . True and false PCNF formulas are defined in the usual way.
Countermodels
Let be a PCNF formula. A countermodel of is an indexed family of functions such that for every assignment satisfying for .
Proposition 1
(Folklore) A PCNF formula is false if, and only if, it has a countermodel.
Dependency Schemes and LDQ(D)-Resolution
In this section, we introduce the proof system LDQ(D), which combines Q(D)-resolution [42] with long-distance Q-resolution [2]. Q-resolution is a generalization of propositional resolution to PCNF formulas [28]. Q-resolution is of practical interest due to its relation to search based QBF solvers that implement Quantified Conflict Driven Constraint Learning (QCDCL) [15, 46]: the traces of QCDCL solvers correspond to Q-resolution proofs [19, 21]. QCDCL—which will be described in more detail in Sect. 4—generalizes the well-known DPLL procedure [17] from SAT to QSAT. In a nutshell, DPLL searches for a satisfying assignment of an input formula by propagating unit clauses and assigning pure literals until the formula cannot be simplified any further, at which point it picks an unassigned variable and branches on the assignment of this variable. Any of the remaining variables can be chosen for assignment, but the order of assignment can have significant effects on the runtime. Modern conflict driven clause learning (CDCL) SAT solvers derived from the DPLL algorithm use sophisticated heuristics to determine what variable to assign next [34].
In QCDCL, the quantifier prefix imposes constraints on the order of variable assignments: a variable may be assigned only if it occurs in the leftmost quantifier block with unassigned variables. Often, this is more restrictive than necessary. For instance, variables from disjoint subformulas may be assigned in any order. Intuitively, a variable can be assigned as long as it does not depend on any unassigned variable. This is the intuition underlying a generalization of QCDCL implemented in the solver DepQBF [10, 31]. DepQBF uses a dependency scheme [39] to compute an overapproximation of variable dependencies. Dependency schemes are mappings that associate every PCNF formula with a binary relation on its variables that refines the order of variables in the quantifier prefix.2
Definition 1
(Dependency Scheme) A dependency scheme is a mapping D that associates each PCNF formula with a relation called the dependency relation of with respect to D.
The mapping which simply returns the prefix ordering of an input formula can be thought of as a baseline dependency scheme:
Definition 2
(Trivial Dependency Scheme) The trivial dependency scheme associates each PCNF formula with the relation .
DepQBF uses a dependency relation to determine the order in which variables can be assigned: if y is a variable and there is no unassigned variable x such that (x, y) is in the dependency relation, then y is considered ready for assignment. DepQBF also uses the dependency relation to generalize the -reduction rule used in clause learning [10]. As a result of its use of dependency schemes, DepQBF generates proofs in a generalization of Q-resolution called Q(D)-resolution [42], a proof system that takes a dependency scheme D as a parameter.
Dependency schemes can be partially ordered based on their dependency relations: if the dependency relation computed by a dependency scheme is a subset of the dependency relation computed by a dependency scheme for each PCNF formula, then is more general than . The more general a dependency scheme, the more freedom DepQBF has in choosing decision variables. Currently, (aside from the trivial dependency scheme) DepQBF supports the so-called standard dependency scheme [39].3 We will work with the more general reflexive resolution-path dependency scheme [42], a variant of the resolution-path dependency scheme [41, 44]. This dependency scheme computes an overapproximation of variable dependencies based on whether two variables are connected by a (pair of) resolution path(s).
Definition 3
(Resolution Path) Let be a PCNF formula and let X be a set of variables. A resolution path (from to ) via X (in ) is a sequence of literals satisfying the following properties:
For all , there is a such that .
For all , .
For all , .
For all , .
If is a resolution path in via X, we say that and are connected in (with respect to X). For every we say that goes through.
One can think of a resolution path as a potential chain of implications: if each clause contains exactly two literals, then assigning to 0 requires setting to 1. If, in addition, there is such a path from to , then and have to be assigned opposite values. Accordingly, the resolution path dependency scheme identifies variables connected by a pair of resolution paths as potentially dependent on each other.
Definition 4
(Dependency Pair) Let be a PCNF formula and . We say is a resolution-path dependency pair of with respect to if at least one of the following conditions holds:
x and y, as well as and , are connected in with respect to X.
x and , as well as and y, are connected in with respect to X.
Definition 5
The reflexive resolution-path dependency scheme is the mapping that assigns to each PCNF formula the relation is a resolution-path dependency pair in with respect to .
Both Q-resolution and Q(D)-resolution only allow for the derivation of non-tautological clauses, that is, clauses that do not contain a literal negated as well as unnegated. Long-distance Q-resolution is a variant of Q-resolution that admits tautological clauses in certain cases [2]. Variants of QCDCL that allow for learned clauses to be tautological [45, 47] have been shown to generate proofs in long-distance Q-resolution [19].
In long-distance Q-resolution, when a tautological clause is created by resolution, a variable that appears in both polarities must be to the right of the pivot variable. We generalize this by requiring that the pivot be independent of a tautological variable to obtain long-distance Q(D)-resolution (LDQ(D)-resolution). The derivation rules of LDQ(D)-resolution are shown in Fig. 1.4 Here, as in the rest of the paper, D denotes an arbitrary dependency scheme.
Fig. 1.

Derivation rules of LDQ(D)-resolution for a PCNF formula
A derivation in a proof system consists of repeated applications of the derivation rules to derive a clause from the clauses of an input formula. Here, derivations will be represented by node-labeled directed acyclic graphs (DAGs). More specifically, we require these DAGs to have a unique sink (that is, a node without outgoing edges) and each of their nodes to have at most two incoming edges. We further assume an ordering on the in-neighbors (or parents) of every node with two incoming edges—that is, each node has a “first” and a “second” in-neighbor. Referring to such DAGs as proof DAGs, we define the following two operations to represent resolution and -reduction:
If is a literal and and are proof DAGs with distinct sinks and , then is the proof DAG consisting of the union of and along with a new sink v that has two incoming edges, the first one from and the second one from . Moreover, if is the label of in and is the label of in , then v is labeled with the clause .
If u is a variable and is a proof DAG with a sink w labeled with C, then denotes the proof DAG obtained from by adding an edge from w to a new node v such that v is labeled with .
Definition 6
(Derivation) An LDQ(D)-resolution derivation (LDQ(D)-derivation for short) of a clause C from a PCNF formula is a proof DAG satisfying the following properties.
Source nodes are labeled with input clauses from .
If a node with label C has parents labeled and then C can be derived from and by (long-distance) resolution.
If a node labeled with a clause C has a single parent with label then C can be derived from by -reduction with respect to the dependency scheme D.
We refer to these nodes as input nodes, resolution nodes, and -reduction nodes, respectively.
Let be an LDQ(D)-derivation from a PCNF formula . The (clause) label of the sink node is called the conclusion of , denoted . If the conclusion of is the empty clause then we refer to as an LDQ(D)-refutation of . For a node v of , the subderivation (of ) rooted at v is the proof DAG induced by v and its ancestors in . It is straightforward to verify that the resulting proof DAG is again an LDQ(D)-derivation from . For convenience, we will identify (sub)derivations with their sinks. The size of , denoted , is the total number of literal occurrences in clause labels of .
QCDCL with Dependency Schemes Generates LDQ(D)-Proofs
In this section, we present a version of the QCDCL algorithm that uses dependency schemes [10, 31] and performs constraint learning based on long-distance Q-resolution [19, 46].5 Generalizing an argument by Egly et al. [19], we will show that this algorithm produces LDQ(D)-proofs when using a dependency scheme D.
Starting from an input PCNF formula , QCDCL generates (“learns”) constraints—clauses and terms—until it produces an empty constraint, at which point it returns true (if the empty term is learned) or false (if the empty clause is learned).
One can think of QCDCL solving as proceeding in rounds. Along with a set of clauses and terms, the solver maintains an assignment (the trail, which we will represent by a sequence of literals in the order of their assignment). During each round, this assignment is extended by quantified Boolean constraint propagation (QBCP) and—possibly—branching.
Quantified Boolean constraint propagation (with dependency scheme D) consists in the exhaustive application of universal and existential reduction (relative to ) in combination with unit assignments.6 More specifically, QBCP reports a clause C as falsified if and universal reduction can be applied to to obtain the empty clause. Dually, a term T is considered satisfied if and can be reduced to the empty term. A clause C is unit under if and universal reduction yields a clause , for some existential literal such that is unassigned. Dually, a term T is unit under if and existential reduction can be applied to obtain a term containing a single universal literal . If is a unit clause, then the assignment has to be extended by in order not to falsify C, and if is a unit term, then has to be extended by in order not to satisfy T. If several clauses or terms are unit under , QBCP nondeterministically picks one and extends the assignment accordingly. This is repeated until a constraint is empty or no unit constraints remain.
If QBCP does not lead to an empty constraint, the assignment is extended by branching. That is, the solver chooses an unassigned variable y such that every variable x with is assigned, and extends the assignment by y or .
The resulting assignment can be partitioned into so-called decision levels. The decision level of an assignment is the number of literals in that were assigned by branching. The decision level of a literal in is the decision level of the prefix of that ends with . Note that each decision level greater than 0 can be associated with a unique variable assigned by branching.
Eventually, the assignment maintained by QCDCL must falsify a clause or satisfy a term. When this happens (we call this a conflict), the solver proceeds to conflict analysis to derive a learned constraint C. Initially, C is the falsified clause (satisfied term), called the conflict clause (term). The solver finds the existential (universal) literal in C that was assigned last by QBCP, and the antecedent clause (term) R responsible for this assignment. A new constraint is derived by resolving C and R and applying universal (existential) reduction (again, relative to ). This is done repeatedly until the resulting constraint C is asserting. A clause (term) S is asserting if there is a unique existential (universal) literal with maximum decision level (greater than zero) among literals in S, the corresponding decision variable is existential (universal), and every universal (existential) variable such that is assigned at a lower decision level (an asserting constraint becomes unit after backtracking). Once an asserting constraint has been found, it is added to the solver’s set of constraints. Finally, QCDCL backtracks, undoing variable assignments until reaching a decision level computed from the learned constraint.
Pseudocode for the main QCDCL loop is shown as Algorithm 1, and pseudocode for conflict analysis is shown as Algorithm 2. We now formally state and prove a correspondence between clauses learned by QCDCL and LDQ(D)-resolution.
Proposition 2
Every clause learned by Algorithm 1 given an input PCNF can be derived from by LDQ(D)-resolution.
Proof
We will show that each learned clause constructed during conflict analysis can be derived by LDQ(D)-resolution from input clauses or previously learned clauses. In addition, we prove an invariant saying that each such clause C can be reduced to the empty clause under the trail assignment restricted to variables up to and including the existential variable assigned last among those in C. Formally, if is the trail and , then the restricted trail is . If such an i does not exist—which can happen only if C contains no existential variable—the restricted trail is empty. Let denotes the assignment corresponding to the restricted trail. We want to show that simplifies to the empty clause by -reduction. The proof is by induction on the number of resolution operations performed by Algorithm 2.
The base case with C being the conflict clause is trivial. For the inductive step, suppose that C can be reduced to the empty clause under the restricted trail assignment . Thus is the existential literal falsified last among literals in C and conflict analysis would resolve C with the antecedent R of next. We have to show the resolvent satisfies the above invariant and that this resolution operation is permissible in LDQ(D)-resolution. Let denote the trail at the time when was propagated. Clause R is unit under , that is, reduces to . In particular, we have for every existential literal and every universal literal assigned by . Since reduces to the empty clause by assumption, we further must have for every existential literal and every assigned universal literal of C. We conclude that for every existential literal and every assigned universal literal in the resolvent . This property is clearly not affected by unassigning universal variables or unassigning existential variables not occurring in , so reduces to the empty clause under its corresponding restricted trail assignment, proving that the invariant is preserved. Furthermore, it entails that any literal such that must be universal and unassigned by . Since can be reduced to by -reduction, we must have for each such literal , so can be derived from C and R in LDQ(D)-resolution.


As in the case of QCDCL without dependency schemes [19, 21] an analogue of this result can be proved for learned terms and a dual proof system (“Q-consensus”) that operates on terms instead of clauses.
The proof of Proposition 2 uses the fact that two clauses and can be resolved on variable e even if as long as . The following example illustrates that this generalization of the resolution rule is necessary for LDQ(D)-resolution to trace QCDCL with dependency schemes and long-distance Q-resolution.
Example 1
Consider the formula , where
and consists of auxiliary clauses
The clauses in are there simply to enforce that a and b are set to true and (in conjunction with ) that . It is straightforward to check that the set of dependencies computed by the reflexive resolution-path dependency scheme is
That is, the dependency scheme identifies the syntactic dependencies , and as spurious.
We now construct a possible trace of QCDCL on with and learning based on long-distance Q-resolution. At decision level 0 the unit clauses in are propagated, setting and . This does not lead to further propagation and QCDCL proceeds with the decision . Note that y can be assigned before x because . This assignment does not lead to any literals being propagated, so the algorithm makes another decision . Now clause simplifies to the unit clause and is propagated. Clause only contains x under the resulting assignment and we have a conflict. Conflict analysis first resolves clauses and to obtain the clause . Variable a depends on x, so -reduction cannot be applied. Since is the only variable from the second decision level in clause and does not depend on x, is asserting and the clause is learned by QCDCL. Backtracking undoes the decision involving and propagates instead. As a result, simplifies to , unit propagation assigns , and clause is falsified. Conflict analysis resolves and to derive the learned (unit) clause , which causes QCDCL to backtrack to decision level 0 and propagate . Now clause simplifies to . Since y is independent of x we can apply -reduction to obtain the unit clause (y) which propagates the assignment . Clause in turn becomes unit and propagates . As a result, clause simplifies to and reduces to the empty clause by -reduction. Conflict analysis resolves and so as to obtain the clause . Variable b depends on x, so -reduction cannot be applied. Next, clause is resolved with to derive . Note that this resolution step is permissible since . Further resolution steps involving unit clauses yield the clause , which can be reduced to the empty clause, so that QCDCL terminates with return value FALSE.
Soundness of and Strategy Extraction for LDQ(D)
Polynomial-Time Strategy Extraction from LDQ(D)-Refutations
A PCNF formula can be associated with an evaluation game played between an existential and a universal player. These players take turns assigning quantifier blocks in the order of the prefix. The existential player wins if the matrix evaluates to 1 under the resulting variable assignment, while the universal player wins if the matrix evaluates to 0. One can show that the formula is true (false) if and only if the existential (universal) player has a winning strategy in this game, and this winning strategy is a (counter)model.
Goultiaeva et al. [24] proved that a Q-resolution refutation can be used to compute winning moves for the universal player in the evaluation game. The idea is that universal maintains a “restriction” of the refutation by the assignment constructed in the evaluation game, which is a refutation of the restricted formula.
For assignments made by the existential player, the universal player only needs to consider each instance of resolution whose pivot variable is assigned: one of the premises is not satisfied and can be used to (re)construct a refutation.
When it is universal’s turn, the quantifier block for which she needs to pick an assignment is leftmost in the restricted formula. This means that -reduction of these variables is blocked by any of the remaining existential variables and can only be applied to a purely universal clause. In a Q-resolution refutation, these variables must therefore be reduced at the very end, and because Q-resolution does not permit tautological clauses, only one polarity of each universal variable from the leftmost block can appear in a refutation. It follows that universal can maintain a Q-resolution refutation by assigning variables from the leftmost block in such a way as to map the associated literals to 0, effectively deleting them from the remaining Q-resolution refutation.
In this manner, the universal player can maintain a refutation until the end of the game, when all variables have been assigned. At that point, a refutation consists only of the empty clause, which means that the assignment chosen by the two players falsifies a clause of the original matrix and universal has won the game.
Egly et al. [19] observed that this argument goes through even in the case of long-distance Q-resolution, since a clause containing both u and for a universal variable u can only be derived by resolving on an existential variable to the left of u, but no such existential variable exists if u is from the leftmost block.
In this section, we will prove that this argument can be generalized to LDQ(D)-refutations. We illustrate this correspondence with an example:
Example 2
Consider the PCNF formula
Figure 2 shows an LDQ(D)-refutation of . The only universal variable is u, so a strategy for the universal player in the evaluation game associated with has to determine an assignment to u given an assignment to x, the only (existential) variable preceding u. The figure illustrates how to compute the assignment to u for the two possible assignments from the restriction of the refutation by . In both cases, only one polarity of u occurs in the restricted refutation and therefore it is easy for universal to determine the correct assignment. Notice that in one of the cases, a generalized -reduction node remains present in the restriction—this shows that we cannot limit ourselves to looking at the final reduction step in the proof when looking for the variables to assign (as is the case with ordinary Q-resolution refutations, cf. [24]).
Fig. 2.

An LDQ(D)-refutation of the formula from Example 2 (above) and two restrictions (below)
The key property that allows universal to maintain a refutation in the above example is that universal variables from the leftmost quantifier block may appear in at most one polarity. We now show that this property is in fact sufficient for soundness of LDQ(D) when combined with a natural monotonicity property of dependency schemes.
Definition 7
A dependency scheme D is monotone if for every PCNF formula and every assignment to a subset of . We say that D is simple if, for every PCNF formula , every LDQ(D)-derivation from , and every universal variable , u or does not appear in . A dependency scheme D is normal if it is both monotone and simple.
As in the case of Q-resolution, universal’s move for a particular quantifier block can be computed from the assignment corresponding to the previous moves and the refutation in polynomial time. Since every polynomial-time algorithm can be implemented by a family of polynomially-sized circuits, and because these circuits can even be computed in polynomial time [1, p. 109], it follows that LDQ(D) admits polynomial-time strategy extraction when D is normal (in “Appendix Appendix:”, we present an explicit construction with a more specific bound on the runtime).
Theorem 1
Let D be a normal dependency scheme. There is a polynomial-time algorithm that, given a PCNF formula and an LDQ(D)-refutation of , computes a countermodel of .
As an application of this general result, we will prove that the reflexive resolution-path dependency scheme is normal in Sect. 5.2 below.
Theorem 2
is normal.
Corollary 1
There is a polynomial-time algorithm that, given a PCNF formula and an LDQ(D)-refutation of , computes a countermodel of .
This result immediately carries over to the less general standard dependency scheme.
Corollary 2
There is a polynomial-time algorithm that, given a PCNF formula and an LDQ(D)-refutation of , computes a countermodel of .
In combination with Proposition 1, these results imply soundness of both proof systems.
Corollary 3
The systems LDQ(D) and LDQ(D) are sound.
The Reflexive Resolution-Path Dependency Scheme is Normal
In order to prove Theorem 2 and show that is normal, we will need some insight into the relationship between resolution paths and LDQ(D)-derivations. For a formula and a universal literal u, we will denote by the set of existential literals e such that and such that e is reachable from u by a resolution path via existential variables to the right of u in .
Lemma 1
Let be a PCNF formula and let u be a universal literal with . Let be clauses such that for some existential literal x, and , and let . Then .
Proof
Let . Of course, by adding clauses to a formula, we preserve all existing resolution paths, so . We will prove that the opposite inclusion holds as well. Let and let be a resolution path in certifying this. If is also a resolution path in , we are done. If it is not, it must be because it performs a C-transition, namely it contains two consecutive literals such that , , but and . In this case, without loss of generality, we have and . Let be the prefix of up to and including and be the suffix of starting with . Let be the concatenation of , x, , and . It is clearly a valid resolution path and it uses one fewer C-transitions than . Iterating this process, we can remove all C-transitions from to obtain a resolution path in . The resulting resolution path has the same endpoints and therefore certifies that .
The previous lemma implies that when considering reachability from an outermost universal literal in a formula , we can use clauses derived from by LDQ(D)-resolution as well. Indeed, adding clauses produced by the resolution rule does not change the set of reachable literals by Lemma 1, and adding clauses produced by universal reduction clearly does not even create new resolution paths. Particularly, if two literals ever appear together in a derived clause, there is a resolution path between them. This is summarized by the following corollary.
Corollary 4
Let be an LDQ(D)-derivation from a PCNF formula and let . Then for all existential literals , there is a resolution path from u to e in .
As a first step towards proving Theorem 2, we will prove that both polarities of an outermost universal literal cannot appear together in a single clause of a derivation.
Lemma 2
Let be an LDQ(D)-derivation from a PCNF formula and let . Then or .
Proof
Towards a contradiction, suppose . Since input clauses do not contain both polarities of any literal, there must be a resolution step inside the derivation, which merges u and into one clause. Let be such a step. Then, without loss of generality, and and by Corollary 4, there is a resolution path from u to x and from to , i.e. . However, if x depends on u, opposite polarities of u cannot be merged in a resolution step with the pivot x, a contradiction.
We will further assume that the derivation considered in the proof of Theorem 2 is in the normal form given by the following lemma.
Lemma 3
Let be an LDQ(D)-derivation from a PCNF formula , let be a universal variable such that both u and appear in , and let . There exists an LDQ(D)-derivation from a PCNF formula such that contains both u and but only -reduction steps with respect to one polarity of u.
Proof
Let be the result of removing all universal variables except u from . Removing universal variables does not introduce new resolution paths, so . The derivation can be obtained from in the following way. We first delete all occurrences of universal variables other than u from , along with -reduction steps involving such variables. The result is an LDQ(D)-derivation from , and it still contains both u and . Next, we choose a subderivation containing both u and such that none of its proper subderivations contains both literals. By Lemma 2, the conclusion C of this derivation can contain at most one of u and . If we omit all -reduction steps involving u. Otherwise, we omit all -reduction steps involving . This yields the desired LDQ(D)-derivation from .
Using Lemmas 2 and 3, we can proceed to finish the proof of Theorem 2.
Proof of Theorem 2
Towards a contradiction, consider an LDQ(D)-derivation from a formula and let be such that both polarities of u occur in this derivation. Let and let denote the simplified derivation given by Lemma 3. Assume without loss of generality that is a tree (any derivation can be turned into a tree-like derivation by copying proof nodes), and that does not contain -reduction steps involving . Since occurs in but is not reduced, must occur in the conclusion of . Thus u cannot occur in the conclusion by Lemma 2. Since u is present in the derivation , this means there must be a reduction step on u somewhere in . As u is the only universal variable and we omitted all reduction steps on , all reduction steps in are on u and must have the form depicted in Fig. 3, where is a lowermost reduction step on u and the subsequent resolutions are on pivots . Let . The clauses are derived by LDQ(D)-resolution and by Lemma 1 we know that we can use them to show resolution-path connections as if they were input clauses. By the transformations we considered we know that starting from an arbitrary LDQ(D)-derivation we can obtain a valid LDQ(D)-derivation in this form, so any contradiction we derive from here means a contradiction with the assumption that an LDQ(D)-derivation contains both polarities of a universal variable from the outermost block, thus proving Theorem 2. With that, we are ready to finish the proof.
Fig. 3.

Shape of the derivation constructed in the proof of Theorem 2
We will prove that there is a resolution path from to u going through an existential literal in , which is in contradiction with the soundness of reduction of u from . Let us consider open resolution paths, i.e. resolution paths without their final literal. If an open resolution path ends in a literal of clause C, we say that the path leads to the clause C. By induction on n, we will prove that there is an open resolution path from which leads to the clause . If , we have the path . For , let be the open path leading to and let be its last literal. Then either , in which case we have an open path leading to , or , in which case we have the open path leading to . An open path that leads to also leads to , because those two clauses only differ in the presence of u and therefore can be closed by the literal u to obtain the required resolution path.
Experiments
To gauge the potential of clause learning based on LDQ(D), we ran experiments with the search-based solver DepQBF7 in version 5.0. By default, DepQBF supports proof generation only in combination with the trivial dependency scheme—in that case, it generates Q-resolution or long-distance Q-resolution proofs (depending on whether long-distance resolution is enabled). However, by uncommenting a few lines in the source code, proof generation can also be enabled with the standard dependency scheme, and this option can even be combined with long-distance resolution. This leads to the solver generating Q(D)-resolution or LDQ(D)-resolution proofs (see Sect. 4).
We compared the performance of DepQBF in four configurations,8 each using a different proof system for constraint learning:
Long-distance Q-resolution with -reduction according to D (LDQD).
Long-distance Q-resolution with ordinary -reduction (LDQ).
Q-resolution with -reduction according to D (QD).
Ordinary Q-resolution (Q).
These experiments were performed on a cluster with Intel Xeon E5649 processors at 2.53 GHz running 64-bit Linux. We set time and memory limits of 900 s and 4 GB, respectively. Instances were taken from two tracks of the QBF Gallery 2014: the applications track consisting of 6 instance families and a total of 735 formulas, and the QBFLib track consisting of 276 formulas.
For our first set of experiments, we disabled dynamic QBCE (Quantified Blocked Clause Elimination), a technique introduced with version 5.0 of DepQBF [32]. We further used bloqqer9 (version 037) with default settings as a preprocessor. Since LDQ(D) generalizes both long-distance Q-resolution and Q(D)-resolution, we were expecting a performance increase with LDQ(D)-learning compared to learning based on the other proof systems. However, all four configurations showed virtually identical performance on both the application and QBFlib benchmark sets in terms of total runtime and instances solved within the time limit (see Table 1).
Table 1.
Solved instances, solved true instances, solved false instances, and total runtime in seconds (including timeouts) with preprocessing (but without QBCE)
| Configuration | Solved | True | False | Time |
|---|---|---|---|---|
| Application track | ||||
| LDQD | 377 | 186 | 191 | 343,455 |
| LDQ | 377 | 186 | 191 | 345,459 |
| QD | 377 | 183 | 194 | 343,928 |
| Q | 376 | 182 | 194 | 345,914 |
| QBFLib track | ||||
| LDQD | 130 | 69 | 61 | 140,743 |
| LDQ | 131 | 69 | 62 | 141,646 |
| QD | 129 | 67 | 62 | 140,975 |
| Q | 127 | 65 | 62 | 142,679 |
To get a more detailed picture, we broke down the results for the application track by instance family, limiting ourselves to instances that were solved by at least one configuration. The barplot in Fig. 4 shows that there are considerable differences in performance between solver configurations for individual instances families, with each solver configuration being outperformed by another configuration on at least one family.
Fig. 4.
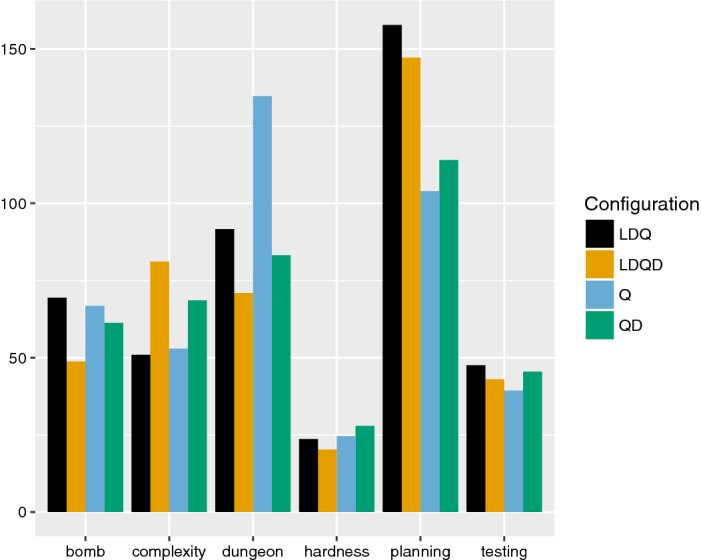
Average runtime in seconds (y-axis) for instances from the application track for each instance family (x-axis), by solver configuration (with preprocessing, but without dynamic QBCE). Here, we only considered instances that were solved by at least one configuration
For our second set of experiments, we turned on dynamic QBCE. This led to a significant performance increase both in terms of number of instances solved within the time limit and total runtime for both benchmark sets, a result that is consistent with the findings in [32]. However, as far as the performance of LDQ(D)-learning is concerned, the application and QBFlib tracks differed significantly for this experiment. While LDQ(D)-learning fared worst among the configurations both with respect to instances solved and total runtime on the application track, it was the best configuration for the QBFlib track in both respects (see Table 2). Figure 5 shows that using the standard dependency scheme was beneficial both with and without long-distance resolution for the QBFlib instances.
Table 2.
Results with preprocessing and dynamic QBCE
| Configuration | Solved | True | False | Time |
|---|---|---|---|---|
| Application track | ||||
| LDQD | 385 | 195 | 190 | 339,143 |
| LDQ | 388 | 201 | 187 | 336,739 |
| QD | 392 | 201 | 191 | 334,965 |
| Q | 389 | 198 | 191 | 337,141 |
| QBFLib track | ||||
| LDQD | 145 | 75 | 70 | 132,567 |
| LDQ | 133 | 64 | 69 | 141,682 |
| QD | 137 | 70 | 67 | 134,150 |
| Q | 129 | 62 | 67 | 142,399 |
Fig. 5.

Solved instances from the QBFLib track (x-axis) sorted by runtime (y-axis), by solver configuration (with preprocessing and dynamic QBCE)
For our final set of experiments, we left dynamic QBCE enabled but disabled preprocessing for the application track, as this was shown to lead to a performance increase in the case of learning with ordinary Q-resolution [32]. Indeed, this resulted in a performance increase across the board (see Table 3). Moreover, LDQ(D)-learning was the best configuration in terms of instances solved (on par with Q(D)-resolution) as well as in terms of overall runtime. Moreover, LDQ(D)-learning was the best configuration in terms of instances solved (on par with Q(D)-resolution) as well as in terms of overall runtime.
Table 3.
Results for the application track with QBCE (but without preprocessing)
| Configuration | Solved | True | False | Time |
|---|---|---|---|---|
| LDQD | 440 | 223 | 217 | 287,012 |
| LDQ | 435 | 223 | 212 | 291,574 |
| QD | 440 | 225 | 215 | 291,661 |
| Q | 437 | 221 | 216 | 337,141 |
Related Work
QCDCL with learning based on long-distance Q-resolution was first described by Zhang and Malik [45]. They presented an argument for the soundness of using tautological clauses (respectively, contradictory terms) within their algorithm but did not study long-distance Q-resolution as a proof system. Lacking a sound theoretical foundation, the use of tautological clauses in QCDCL was abandoned in favour of more complicated methods for constraint learning that avoid their generation [20, 21, 33].
Interest in long-distance Q-resolution was renewed when Balabanov and Jiang [2] introduced the proof system we presented in Sect. 3 (restricted to the trivial dependency scheme) and proved its soundness. Egly et al. [19] showed that a family of formulas known to be hard for Q-resolution [28] admits short long-distance Q-resolution proofs. They also demonstrated that QCDCL with learning based on long-distance resolution generates long-distance Q-resolution proofs and presented a new version of DepQBF that implements this algorithm. Finally, they showed that a long-distance Q-resolution proof can be interpreted as a winning strategy in the evaluation game associated with a QBF, generalizing a result by Goultiaeva et al. [24]. While these results established a solid theoretical framework for the use of long-distance Q-resolution within QCDCL they did not provide an intuitive account of the semantics of individual tautological clauses. Such an account was subsequently presented by Balabanov et al. [3], who showed that tautological literals can be interpreted as proxies for “phase functions” that determine whether a variable or its negation is present in clause C based on the values assigned to pivot variables appearing in the derivation of C. The authors used this interpretation to generalize the linear-time strategy extraction algorithm of Balabanov and Jiang [2] to long-distance Q-resolution proofs.
Recently and independently of this work, Beyersdorff and Blinkhorn investigated the soundness of Q-resolution proof systems parameterized by dependency schemes [6]. They define a property of dependency schemes D—full exhibition—which ensures that a certain version of long-distance Q(D)-resolution is sound, and show that the reflexive resolution-path dependency scheme has that property.
In a nutshell, a dependency scheme D is fully exhibited if every true QBF has a model such that may only depend on a universal variable u if (such models have elsewhere been referred to as D-models [40]). It is fairly straightforward to show that Q(D)-resolution is sound if D has this property, but generalizing this result to proof systems with long-distance resolution presents a challenge. Beyersdorff and Blinkhorn show that full exhibition is sufficient for soundness of a restricted version of LDQ(D)-resolution, where complementary universal literals that are “merged” by resolution must be annotated with the (existential) pivot variable, and universal reduction can be applied only if every existential variable occurring in the premise or the annotation of a universal variable is independent of the universal variable to be reduced. However, it is uncertain whether proofs generated by DepQBF with LDQ(D)-learning satisfy this additional restriction.
How full exhibition relates to our normality property is not entirely clear. Beyersdorff and Blinkhorn prove that full exhibition is not sufficient for soundness of LDQ(D)-resolution as defined here. In combination with Theorem 1, this shows that dependency schemes that are fully exhibited need not be normal. Whether there are normal dependency schemes that are not fully exhibited, on the other hand, remains open. Indeed, there is some evidence to the effect that normality entails full exhibition: consider a dependency scheme D that is not fully exhibited, and let be a true QBF that does not have a D-model. Suppose u is the only universal variable of . In this restricted case, the (non-)existence of a D-model can be expressed as a QBF by simply shifting existentials independent of u to the left. Because does not have a D-model, must be false and admit a Q-resolution refutation , which is also an LDQ(D)-refutation of . Because is true, LDQ(D)-resolution must be unsound and so D cannot be normal by Theorem 1. Obviously, the assumption that u is the only universal variable of is very restrictive, but since we can suppose that D is monotone (recall that a dependency scheme is normal if it is both simple and monotone), there is hope that the argument for an arbitrary QBF can be reduced to this case by instantiating with a suitable variable assignment.
Discussion
The results of Sects. 4 and 5 establish a partial soundness proof of QCDCL with learning based on LDQ(D): we now know that we can trust such a solver when it outputs “false”. To prove that “true” answers can be trusted as well, one has to show soundness of quantified term resolution (Q-consensus) when combined with the standard dependency scheme and long-distance resolution. The reason this does not follow from the results proved here is that they rely on a correspondence of Q-resolution derivations with dependency-inducing resolution paths that is not immediate for terms generated from an input PCNF: there is a correspondence of Q-consensus derivations with dual “resolution paths” that connect such terms, but these “resolution paths” do not induce resolution-path dependencies in the input PCNF.
The experiments in Sect. 6 indicate that we should not expect significant performance gains when switching from learning with Q(D)-resolution to LDQ(D). This is in spite of the fact that, from a purely theoretical perspective, LDQ(D) is a stronger proof system: a well-studied class of QBFs introduced by Kleine Büning, Karpinski, and Flögel requires exponentially-sized Q-resolution proofs [28] but admits short long-distance Q-resolution refutations [19], and since the standard dependency scheme does not offer any improvement over trivial dependencies on these formulas (see [12]) we obtain an exponential separation of LDQ(D)-resolution from Q(D)-resolution. From a practical point of view, the main benefit of using LDQ(D)-resolution over Q(D)-resolution is that conflict analysis is much simpler (cf. [19]). A learned constraint can be obtained from a conflict simply by resolving variables in the reverse order of their propagation (see Sect. 4). Methods that avoid the generation of tautological clauses (contradictory terms) during learning are significantly more involved [20, 21, 33].
We have shown that LDQ(D)-refutations allow for polynomial-time strategy extraction. In practice, the corresponding algorithm generates circuits that are frequently larger by an order of magnitude than the refutations provided as input. It is unclear whether this increase in size can be avoided by careful engineering alone or only by using a different approach. Faster (linear time) strategy extraction algorithms are known for “ordinary” Q-resolution and long-distance Q-resolution [2, 3]. Unfortunately, their underlying idea of setting universal variables so as to falsify the premise of some -reduction step no longer works when dependency schemes enter the mix: generalized -reduction may remove a universal variable u even in the presence (in the premise) of an existential variable e such that and the universal player can only be sure to falsify the premise if the e-literal is false, but she does not know the value of e at the time of assigning u. We believe that developing linear-time strategy extraction algorithms for Q(D)-resolution or LDQ(D)-resolution is going to require a better understanding of the power of these proof systems vis-à-vis Q-resolution and long-distance Q-resolution [12].
Acknowledgements
Open access funding provided by Austrian Science Fund (FWF). We would like to thank Florian Lonsing for helpful discussions and for pointing out how to configure DepQBF so that it generates LDQ(D) proofs. This research was partially supported by Austrian Science Fund (FWF) Grants P27721 and W1255-N23.
Proof of Theorem 1
We begin by formally defining the “restriction” of an LDQ(D)-derivation by an assignment, which is a straightforward generalization of this operation for Q-resolution derivations [24].10 The result of restricting a derivation is either a derivation or the object , which can be interpreted as representing the tautological clause containing every literal. Accordingly, we stipulate that for every literal .
Definition 8
(Restriction) Let be a PCNF formula and let be an LDQ(D)-derivation from . Further, let and let be a truth assignment. The restriction ofby, in symbols , is defined as follows.
If is an input node there are two cases. If then . Otherwise, is the proof DAG consisting of a single node labeled with .
- If , that is, if is a resolution node, we distinguish four cases:
- If then .
- If and then .
- If , , and or , we let .
- If , , , and , we define .
- If , that is, if is a -reduction node, we distinguish three cases:
- If then .
- If and then .
- If and then .
If D is a monotone dependency scheme, LDQ(D)-refutations are preserved under restriction by an existential assignment (cf. [24, Lemma 4]). This is stated in the following lemma, which can by proved by a straightforward induction on the structure of the LDQ(D)-derivation.
Lemma 4
Let D be a monotone dependency scheme, let be an LDQ(D)-derivation from a PCNF formula , let , and let be an assignment. If then . Otherwise, is an LDQ(D)-derivation from such that .
Proof
The proof is by induction on the structure of .
If is an input node then iff and otherwise, so the statement holds trivially.
- If is a resolution node we distinguish four cases:
- If , then and
where the first inclusion holds by induction hypothesis and the second inclusion follows from the definition of the resolution rule. - If and then and the statement follows via a symmetric argument.
- If , , and or then we have . Assume without loss of generality that . Then by induction hypothesis. Let be a literal such that . We distinguish two cases. If then and . Otherwise, , and we must have since . By induction hypothesis, there has to be another literal such that and . The literal is contained in as well, so .
- If , , , and , then and . By induction hypothesis, is an LDQ(D)-derivation from such that , and is an LDQ(D)-derivation from such that . Monotonicity of D ensures that after restriction, the resolution step is still sound and thus is an LDQ(D)-derivation from as well and
- If is a reduction node, we have to distinguish two cases:
- If then by definition. By induction hypothesis and since does not assign u, we get as well.
- If then by definition of the restriction operation. By induction hypothesis, is an LDQ(D)-derivation from such that . If then and the statement holds. Otherwise, if then and thus
where the last but one equality holds because does not assign u. To see that is a valid -reduction node, note that by induction hypothesis and observe that .
Above, we argued that the universal player can use an LDQ(D)-refutation for a normal dependency scheme D in order to compute winning moves in the evaluation game associated with a PCNF formula and that this can be used to compute a countermodel of the formula in polynomial time. We now prove this directly, by showing how to construct a circuit implementing a countermodel from an LDQ(D)-refutation.
We begin by describing auxiliary circuits simulating the restriction operation. Let be a PCNF formula and let be a refutation of . For each quantifier block , each subderivation of , and each literal , we will construct circuits and with inputs from such that, for every assignment ,
| 1 |
| 2 |
We first describe our construction and then prove that it satisfies the above properties in Lemma 5. Let be an input node. We let
and define for as
Moreover, for we define as
For non-input nodes, we proceed as follows. If , we define as
and if , we let
For the circuit, we distinguish two cases. Let be a literal and a derivation. If we simply let
Otherwise, if , we have to consider two cases. First, if , we let
Second, if , then
To implement the winning strategy for universal sketched above, we further construct circuits for each node of and each universal variable , such that, for each assignment ,
| 3 |
Let be a universal variable from the ith quantifier block. If is an input node, we simply define
and if is a -reduction node, we let
If , then
Lemma 5
Let be a PCNF formula and let be an LDQ(D)-derivation from . For each , each literal , every , and every truth assignment , satisfies (1), satisfies (2), and satisfies (3).
Proof
Let . As (1) and (2) are related, we will prove them first. We will use induction on the structure of , with the induction hypothesis that (1) and (2) hold. The inductive step will be carried out in two phases. In the first phase, we prove that (1) holds and in the second phase we use this additional information to prove that (2) holds as well.
Let be an input node. By Definition 8 we have if, and only if, . Since only assigns variables in X, this is the case if, and only if, , so (1) holds.
- Let such that (1) and (2) hold for and . We distinguish several cases.
- . Then . Since , it cannot be the case that and so as well. By the induction hypothesis, we have and also which means as required.
- and . Then . Since , we cannot have and thus as well. By the induction hypothesis, we have and also which means as required.
- and and or . Then and by induction hypothesis, we have as well as , and or . In any case, .
- and and and . Then . By induction hypothesis, we have and , which ensures .
Let . From the definitions, we can immediately see that and which proves (1).
We have proved that , and it can be easily checked that, by definition, for every literal . Therefore, if , (2) holds and in the following, we can restrict ourselves to the cases when . Also, we can restrict ourselves to the cases when (the literal in question) actually belongs to , because otherwise and in that case (2) clearly holds.
Let be an input node. We may assume and by the above. By definition, we can easily see that if, and only if, .
- Let such that (1) and (2) hold for and . We distinguish several cases.
- . By the induction hypothesis, we have . Also and
where the second equivalence holds by induction hypothesis. Since we have , we can write
Because and , the only disjunct in the definition of that can possibly be satisfied is the second one, so that
which establishes (2). - and . By the induction hypothesis, we have and . An argument symmetric to the one for the preceding case can be used to show (2).
- and and or . In this case which has already been taken care of (see above).
- and and and . Then and since we have restricted ourselves to the case when (see above), we have
where the final equivalence follows from the induction hypothesis. It is straightforward to verify that the last expression in turn is equivalent to the fourth disjunct in the definition of being satisfied, and since this is the only disjunct that can be satisfied in this case, we conclude that (2) holds.
Let us now turn to the proof of (3).
- If is an input node we have
by what we proved previously and the definition of for input nodes (and the fact that a literal appears in a derivation that consists of a single input node iff it occurs in the clause of associated with that node). - Let .
- . Then and by the induction hypothesis, we have
Using (2), it is readily verified that . - and . Here, (3) can be proved using an argument symmetric to one for the previous case.
- and and or . Then , so u appears in . Without loss of generality, let . By the induction hypothesis we have , which, along with the assumptions for this case and (2), implies that is satisfied by the last disjunct.
- and and and . In this case u appears in if, and only if, it appears in or in . Using the induction hypothesis and (2), one can verify that this is the case if, and only if, .
These auxiliary circuits can be efficiently constructed in a top-down manner, from the input nodes to the conclusion. By a careful analysis, we obtain the following:
Lemma 6
There is an algorithm that, given a PCNF formula and an LDQ(D)-derivation from , computes the circuits for every universal variable u in time , where .
Proof
The algorithm first sorts clauses according to a fixed order of literals. Let k be the number of quantifier blocks in the prefix of . There is at most one circuit for each node of and each . Similarly, there is at most one circuit for each node of , each , and each literal .
Once has been computed for each , the circuits can easily be constructed for each and every literal . Overall, this can be done in time
Assume that the circuits are stored in lists following the order of literals in . Then for each node , the circuits and associated with can again be computed in time , so that overall, these circuits can be computed in time for all nodes of . Having computed the circuits and , the circuits can be computed for each node and each universal variable in time .
Using Lemma 4, we can spell out the argument sketched at the beginning of this section and prove that for normal dependency schemes D, the universal player can maintain an LDQ(D)-refutation throughout the evaluation game by successively restricting an initial LDQ(D)-refutation by both players’ moves and assigning universal variables from the leftmost remaining block X so as to falsify the (unique) literals from X remaining in the refutation. Lemma 5 tells us that the circuits can be used to implement this strategy. In order to put things together, we will need the following two lemmas, which tell us that successive restriction and bulk restriction in fact yield the same result.
Lemma 7
Let be an LDQ(D)-derivation from a PCNF formula , let , be two assignments to disjoint sets of variables. Then .
Proof
By induction on the structure of the derivation. If is an input node, we have and since both derivations consist of a single node with the same label, they are in fact equal. For derivations created by the operations, the equality is trivially preserved.
Lemma 8
Let D be a normal dependency scheme, let be a PCNF formula, let be an LDQ(D)-refutation of . Let be a universal quantifier block and let be an assignment. If is an LDQ(D)-refutation of , then is an LDQ(D)-refutation of , where is the assignment such that for each .
Proof
Assume is an LDQ(D)-refutation of . Let . Because D is simple, variable u appears in in at most one polarity. If u does not appear in at all, the restriction does not depend on . Otherwise, there is a unique literal with that appears in . By Lemma 5, iff u appears in , so if and if . It is a straightforward consequence that can be obtained from by deleting every occurrence of a variable and omitting instances of -reduction that become redundant as a result. Because D is monotone, the restriction is an LDQ(D)-refutation of , and by Lemma 7.
With that, we are ready to prove the final statement.
Lemma 9
Let D be a normal dependency scheme, let be an LDQ(D)-refutation of a PCNF formula . Then the family of functions is a countermodel of .
Proof
Let and let be a truth assignment such that for each universal variable u. Let , and let for each . We claim that is an LDQ(D)-refutation of for . The assignment is empty so and so the statement holds in that case. Suppose the claim holds for i such that . If , then is an LDQ(D)-refutation of by Lemma 4, and by Lemma 7. Otherwise, and is an LDQ(D)-refutation of by Lemma 8. This completes the proof of the claim. In particular, we now have that is an LDQ(D)-refutation of . Because does not contain any variables, the only way can have a refutation is that its matrix contains the empty clause, which means that .
Theorem 1 follows immediately from Lemmas 6 and 9. In fact, we obtain the following result.
Theorem 3
Let D be a normal dependency scheme. There is an algorithm that computes a countermodel of a PCNF formula with n variables from an LDQ(D)-refutation of in time .
Footnotes
We consider QBFs in prenex normal form.
The original definition of dependency schemes [39] is more restrictive than the one given here, but the additional requirements are irrelevant for the purposes of this paper.
Strictly speaking, it uses a refined version of the standard dependency scheme [31, p. 49].
The resolution rule as defined here is more general than the one considered in an earlier version of this paper [36], in that we admit complementary universal literals to be “merged” as long as the pivot is independent according to D (rather than ). This definition—which we is required to capture proofs generated by DepQBF (see Example 1 in Sect. 4)—was proposed in (independent) work by Beyersdorff and Blinkhorn [6].
The presentation is adapted from a recent paper on QCDCL with dependency learning [37].
For simplicity, we do not consider the pure literal rule as part of QBCP.
As a sanity check, we verified that all configurations that were able to solve a particular instance returned the same result.
Our definition slightly differs from the original for the resolution rule: if restriction removes the pivot variable from both premises, we simply pick the (restriction of the) first premise as the result (rather than the clause containing fewer literals). This simplifies the certificate extraction argument given below.
Contributor Information
Tomáš Peitl, Email: tomas.peitl@ac.tuwien.ac.at.
Friedrich Slivovsky, Phone: +43 (1) 58801 186104, Email: fslivovsky@ac.tuwien.ac.at.
Stefan Szeider, Email: stefan@ac.tuwien.ac.at.
References
- 1.Arora S, Barak B. Computational Complexity–A Modern Approach. Cambridge: Cambridge University Press; 2009. [Google Scholar]
- 2.Balabanov V, Jiang JR. Unified QBF certification and its applications. Formal Methods Syst. Des. 2012;41(1):45–65. doi: 10.1007/s10703-012-0152-6. [DOI] [Google Scholar]
- 3.Balabanov, V., Jiang, J.R., Janota, M., Widl, M.: Efficient extraction of QBF (counter) models from long-distance resolution proofs. In: Bonet, B., Koenig, S. (eds.) Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, AAAI 2015, pp. 3694–3701. AAAI Press (2015)
- 4.Balabanov, V., Widl, M., Jiang, J.R.: QBF resolution systems and their proof complexities. In: Sinz, C., Egly, U. (eds.) Theory and Applications of Satisfiability Testing–SAT 2014, Lecture Notes in Computer Science, vol. 8561, pp. 154–169. Springer, Berlin (2014)
- 5.Benedetti M, Mangassarian H. QBF-based formal verification: experience and perspectives. J. Satisf. Boolean Model. Comput. 2008;5(1–4):133–191. [Google Scholar]
- 6.Beyersdorff, O., Blinkhorn, J.: Dependency schemes in QBF calculi: semantics and soundness. In: Rueher, M. (ed.) Principles and Practice of Constraint Programming-22nd International Conference, CP 2016, Lecture Notes in Computer Science, vol. 9892, pp. 96–112. Springer, Berlin (2016)
- 7.Beyersdorff, O., Chew, L., Janota, M.: On unification of QBF resolution-based calculi. In: Csuhaj-Varjú, E., Dietzfelbinger, M. Ésik, Z. (eds.) Mathematical Foundations of Computer Science 2014–39th International Symposium, MFCS 2014, Lecture Notes in Computer Science, vol. 8635, pp. 81–93. Springer, Berlin (2014)
- 8.Beyersdorff, O., Chew, L., Janota, M.: Proof complexity of resolution-based QBF calculi. In: Mayr, E.W., Ollinger, N. (eds.) 32nd International Symposium on Theoretical Aspects of Computer Science, STACS 2015, LIPIcs, vol. 30, pp. 76–89. Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik (2015)
- 9.Beyersdorff, O., Chew, L., Mahajan, M., Shukla, A.: Feasible interpolation for QBF resolution calculi. In: Halldórsson, M.M., Iwama, K., Kobayashi, N., Speckmann, B. (eds.) Automata, Languages, and Programming–42nd International Colloquium, ICALP 2015, Lecture Notes in Computer Science, vol. 9134, pp. 180–192. Springer, Berlin (2015)
- 10.Biere, A., Lonsing, F.: Integrating dependency schemes in search-based QBF solvers. In: Strichman, O., Szeider, S. (eds.) Theory and Applications of Satisfiability Testing–SAT 2010, Lecture Notes in Computer Science, vol. 6175, pp. 158–171. Springer, Berlin (2010)
- 11.Biere, A., Lonsing, F., Seidl, M.: Blocked clause elimination for QBF. In: Bjørner, N., Sofronie-Stokkermans, V. (eds.) International Conference on Automated Deduction–CADE 23, Lecture Notes in Computer Science, vol. 6803, pp. 101–115. Springer, Berlin (2011)
- 12.Blinkhorn, J., Beyersdorff, O.: Shortening QBF proofs with dependency schemes. In: Theory and Applications of Satisfiability Testing–SAT 2017, Lecture Notes in Computer Science, vol. 10491, pp. 263–280. Springer, Berlin (2017)
- 13.Bloem, R., Könighofer, R., Seidl, M.: SAT-based synthesis methods for safety specs. In: McMillan, K.L., Rival, X. (eds.) Verification, Model Checking, and Abstract Interpretation–VMCAI 2014, Lecture Notes in Computer Science, vol. 8318, pp. 1–20. Springer, Berlin (2014)
- 14.Bubeck, U.: Model-based transformations for quantified Boolean formulas. Ph.D. thesis, University of Paderborn (2010)
- 15.Cadoli M, Schaerf M, Giovanardi A, Giovanardi M. An algorithm to evaluate Quantified Boolean Formulae and its experimental evaluation. J. Autom. Reason. 2002;28(2):101–142. doi: 10.1023/A:1015019416843. [DOI] [Google Scholar]
- 16.Cashmore, M., Fox, M., Giunchiglia, E.: Partially grounded planning as Quantified Boolean Formula. In: Borrajo, D., Kambhampati, S., Oddi, A., Fratini, S. (eds.) 23rd International Conference on Automated Planning and Scheduling, ICAPS 2013. AAAI (2013)
- 17.Davis M, Logemann G, Loveland D. A machine program for theorem-proving. Commun. ACM. 1962;5:394–397. doi: 10.1145/368273.368557. [DOI] [Google Scholar]
- 18.Egly, U.: On sequent systems and resolution for QBFs. In: Cimatti, A., Sebastiani, R. (eds.) Theory and Applications of Satisfiability Testing–SAT 2012, Lecture Notes in Computer Science, vol. 7317, pp. 100–113. Springer, Berlin (2012)
- 19.Egly, U., Lonsing, F., Widl, M.: Long-distance resolution: proof generation and strategy extraction in search-based QBF solving. In: McMillan, K.L., Middeldorp, A., Voronkov, A. (eds.) Logic for Programming, Artificial Intelligence, and Reasoning–LPAR 2013, Lecture Notes in Computer Science, vol. 8312, pp. 291–308. Springer, Berlin (2013)
- 20.Gelder, A.V.: Contributions to the theory of practical quantified boolean formula solving. In: Milano, M. (ed.) Principles and Practice of Constraint Programming–18th International Conference, CP 2012, Lecture Notes in Computer Science, vol. 7514, pp. 647–663. Springer, Berlin (2012)
- 21.Giunchiglia E, Narizzano M, Tacchella A. Clause/term resolution and learning in the evaluation of quantified Boolean formulas. J. Artif. Intell. Res. 2006;26:371–416. doi: 10.1613/jair.1959. [DOI] [Google Scholar]
- 22.Goultiaeva, A., Bacchus, F.: Exploiting QBF duality on a circuit representation. In: Fox, M., Poole, D. (eds.) Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2010. AAAI Press (2010)
- 23.Goultiaeva, A., Seidl, M., Biere, A.: Bridging the gap between dual propagation and CNF-based QBF solving. In: Macii, E. (ed.) Design, Automation and Test in Europe, DATE 13, pp. 811–814. EDA Consortium San Jose, CA, USA/ACM DL (2013)
- 24.Goultiaeva, A., Van Gelder, A., Bacchus, F.: A uniform approach for generating proofs and strategies for both true and false QBF formulas. In: Walsh, T. (ed.) Proceedings of IJCAI 2011, pp. 546–553. IJCAI/AAAI (2011)
- 25.Heule, M., Seidl, M., Biere, A.: A unified proof system for QBF preprocessing. In: Demri, S., Kapur, D., Weidenbach, C. (eds.) Automated Reasoning–7th International Joint Conference, IJCAR 2014, Lecture Notes in Computer Science, vol. 8562, pp. 91–106. Springer, Berlin (2014)
- 26.Janota, M., Klieber, W., Marques-Silva, J., Clarke, E.M.: Solving QBF with counterexample guided refinement. In: Cimatti, A., Sebastiani, R. (eds.) Theory and Applications of Satisfiability Testing–SAT 2012, Lecture Notes in Computer Science, vol. 7317, pp. 114–128. Springer, Berlin (2012)
- 27.Janota, M., Marques-Silva, J.: On propositional QBF expansions and Q-resolution. In: Järvisalo, M., Van Gelder, A. (eds.) Theory and Applications of Satisfiability Testing–SAT 2013, Lecture Notes in Computer Science, vol. 7962, pp. 67–82. Springer, Berlin (2013)
- 28.Kleine Büning H, Karpinski M, Flögel A. Resolution for quantified Boolean formulas. Inf. Comput. 1995;117(1):12–18. doi: 10.1006/inco.1995.1025. [DOI] [Google Scholar]
- 29.Klieber, W., Sapra, S., Gao, S., Clarke, E.M.: A non-prenex, non-clausal QBF solver with game-state learning. In: Strichman, O., Szeider, S. (eds.) Theory and Applications of Satisfiability Testing–SAT 2010, Lecture Notes in Computer Science, vol. 6175, pp. 128–142. Springer, Berlin (2010)
- 30.Kronegger, M., Pfandler, A., Pichler, R.: Conformant planning as benchmark for QBF-solvers. In: International Workshop on Quantified Boolean Formulas–QBF 2013 (2013). http://fmv.jku.at/qbf2013/
- 31.Lonsing, F.: Dependency schemes and search-based QBF solving: theory and practice. Ph.D. thesis, Johannes Kepler University, Linz, Austria (2012)
- 32.Lonsing F, Bacchus F, Biere A, Egly U, Seidl M. Enhancing search-based QBF solving by dynamic blocked clause elimination. In: Davis M, Fehnker A, McIver A, Voronkov A, editors. Logic for Programming, Artificial Intelligence, and Reasoning-20th International Conference, LPAR-20 2015. Berlin: Springer; 2015. pp. 418–433. [Google Scholar]
- 33.Lonsing, F., Egly, U., Van Gelder, A.: Efficient clause learning for quantified Boolean formulas via QBF pseudo unit propagation. In: Järvisalo, M., Van Gelder, A. (eds.) Theory and Applications of Satisfiability Testing–SAT 2013, Lecture Notes in Computer Science, vol. 7962, pp. 100–115. Springer, Berlin (2013)
- 34.Marques-Silva, J.P.: The impact of branching heuristics in propositional satisfiability algorithms. In: Barahona, P., Alferes, J.J. (eds.) Progress in Artificial Intelligence, 9th Portuguese Conference on Artificial Intelligence, EPIA ’99, Lecture Notes in Computer Science, vol. 1695, pp. 62–74. Springer, Berlin (1999)
- 35.Niemetz, A., Preiner, M., Lonsing, F., Seidl, M., Biere, A.: Resolution-based certificate extraction for QBF. In: Cimatti, A., Sebastiani, R. (eds.) Theory and Applications of Satisfiability Testing–SAT 2012, Lecture Notes in Computer Science, vol. 7317, pp. 430–435. Springer, Berlin (2012)
- 36.Peitl, T., Slivovsky, F., Szeider, S.: Long distance Q-resolution with dependency schemes. In: Creignou, N., Berre, D.L. (eds.) Theory and Applications of Satisfiability Testing–SAT 2016, Lecture Notes in Computer Science, vol. 9710, pp. 500–518. Springer, Berlin (2016)
- 37.Peitl, T., Slivovsky, F., Szeider, S.: Dependency learning for QBF. In: Gaspers, S., Walsh, T. (eds.) Theory and Applications of Satisfiability Testing–SAT 2017, Lecture Notes in Computer Science, vol. 10491, pp. 298–313. Springer, Berlin(2017)
- 38.Rintanen, J.: Asymptotically optimal encodings of conformant planning in QBF. In: 22nd AAAI Conference on Artificial Intelligence, AAAI 2007, pp. 1045–1050. AAAI (2007)
- 39.Samer M, Szeider S. Backdoor sets of quantified Boolean formulas. J. Autom. Reason. 2009;42(1):77–97. doi: 10.1007/s10817-008-9114-5. [DOI] [Google Scholar]
- 40.Slivovsky, F.: Structure in #SAT and QBF. Ph.D. thesis, TU Wien (2015)
- 41.Slivovsky, F., Szeider, S.: Computing resolution-path dependencies in linear time. In: Cimatti, A., Sebastiani, R. (eds.) Theory and Applications of Satisfiability Testing–SAT 2012, Lecture Notes in Computer Science, vol. 7317, pp. 58–71. Springer, Berlin (2012)
- 42.Slivovsky F, Szeider S. Soundness of Q-resolution with dependency schemes. Theoret. Comput. Sci. 2016;612:83–101. doi: 10.1016/j.tcs.2015.10.020. [DOI] [Google Scholar]
- 43.Staber, S., Bloem, R.: Fault localization and correction with QBF. In: Marques-Silva, J., Sakallah, K.A. (eds.) Theory and Applications of Satisfiability Testing–SAT 2007, Lecture Notes in Computer Science, vol. 4501, pp. 355–368. Springer, Berlin(2007)
- 44.Van Gelder, A.: Variable independence and resolution paths for quantified Boolean formulas. In: Lee, J. (ed.) Principles and Practice of Constraint Programming–CP 2011, Lecture Notes in Computer Science, vol. 6876, pp. 789–803. Springer, Berlin (2011)
- 45.Zhang, L., Malik, S.: Conflict driven learning in a quantified Boolean satisfiability solver. In: Pileggi, L.T. Kuehlmann, A. (eds.) Proceedings of the 2002 IEEE/ACM International Conference on Computer-aided Design, ICCAD 2002, pp. 442–449. ACM/IEEE Computer Society (2002)
- 46.Zhang, L., Malik, S.: The quest for efficient boolean satisfiability solvers. In: Brinksma, D., Larsen, K.G. (eds.) Computer Aided Verification: 14th International Conference (CAV 2002), Lecture Notes in Computer Science, vol. 2404, pp. 17–36 (2002)
- 47.Zhang, L., Malik, S.: Towards a symmetric treatment of satisfaction and conflicts in quantified Boolean formula evaluation. In: Hentenryck, P.V. (ed.) Principles and Practice of Constraint Programming–8th International Conference, CP 2002, Lecture Notes in Computer Science, vol. 2470, pp. 200–215. Springer, Berlin (2002)