

Abstract
At least two distinct processes have been identified by which motor commands are adapted according to movement-related feedback: reward-based learning and sensory error-based learning. In sensory error-based learning, mappings between sensory targets and motor commands are recalibrated according to sensory error feedback. In reward-based learning, motor commands are associated with subjective value, such that successful actions are reinforced. We designed two tasks to isolate reward- and sensory error-based motor adaptation, and we used electroencephalography in humans to identify and dissociate the neural correlates of reward and sensory error feedback processing. We designed a visuomotor rotation task to isolate sensory error-based learning that was induced by altered visual feedback of hand position. In a reward learning task, we isolated reward-based learning induced by binary reward feedback that was decoupled from the visual target. A fronto-central event-related potential called the feedback-related negativity (FRN) was elicited specifically by binary reward feedback but not sensory error feedback. A more posterior component called the P300 was evoked by feedback in both tasks. In the visuomotor rotation task, P300 amplitude was increased by sensory error induced by perturbed visual feedback and was correlated with learning rate. In the reward learning task, P300 amplitude was increased by reward relative to nonreward and by surprise regardless of feedback valence. We propose that during motor adaptation the FRN specifically reflects a reward-based learning signal whereas the P300 reflects feedback processing that is related to adaptation more generally.
NEW & NOTEWORTHY We studied the event-related potentials evoked by feedback stimuli during motor adaptation tasks that isolate reward- and sensory error-based learning mechanisms. We found that the feedback-related negativity was specifically elicited by binary reward feedback, whereas the P300 was observed in both tasks. These results reveal neural processes associated with different learning mechanisms and elucidate which classes of errors, from a computational standpoint, elicit the feedback-related negativity and P300.
Keywords: feedback-related negativity, human, motor adaptation, P300, reward
INTRODUCTION
It is thought that at least two distinct learning processes can simultaneously contribute to sensorimotor adaptation, sensory error-based learning and reward-based learning (Galea et al. 2015; Huang et al. 2011; Izawa and Shadmehr 2011; Nikooyan and Ahmed 2015; Shmuelof et al. 2012). Electroencephalography (EEG) has been used to identify neural signatures of error processing in various motor learning and movement execution tasks, but it remains unclear how these neural responses relate to distinct reward- and sensory error-based motor learning mechanisms (Krigolson et al. 2008; MacLean et al. 2015; Torrecillos et al. 2014). Here we identified neural signatures of processing sensory error and reward feedback in separate motor adaptation paradigms that produce comparable changes in behavior.
In theories of motor adaptation, sensory error-based learning occurs when sensory feedback indicates a state of the motor system that differs from the intended or predicted consequence of a motor command. Sensory error-based learning is thought to occur in visuomotor rotation (VMR) paradigms in which visual feedback of hand position is rotated relative to the actual angle of reach. Adaptation, in which motor output is adjusted to compensate for perturbations, is thought to be driven largely by sensory prediction error in these tasks (Izawa and Shadmehr 2011; Marko et al. 2012). Sensory error feedback activates brain regions including primary sensory motor areas, posterior parietal cortex, and cerebellum (Bédard and Sanes 2014; Diedrichsen et al. 2005; Inoue et al. 2000, 2016; Krakauer et al. 2004). Tanaka et al. (2009) propose that sensory prediction errors computed by the cerebellum produce adaptation via changes in synaptic weighting between the posterior parietal cortex and motor cortex. Furthermore, strategic aiming also contributes to behavioral compensation for VMRs in a manner that is largely independent from the automatic visuomotor recalibration that is driven by cerebellar circuits (Benson et al. 2011; Mazzoni and Krakauer 2006; McDougle et al. 2016; Taylor et al. 2014).
Recent research suggests that a reinforcement- or reward-based learning process can also contribute to motor adaptation in parallel to a sensory error-based learning system and that reward feedback can drive motor learning even in the absence of sensory error feedback (Holland et al. 2018; Izawa and Shadmehr 2011; Therrien et al. 2016). Reward-based learning has been isolated experimentally by providing participants with only binary reward feedback, indicating success or failure, without visual feedback of hand position. Reward-based motor learning has been modeled as computational reinforcement learning, which maps actions to abstract representations of reward or success rather than to the sensory consequences of action. Phasic dopaminergic release in the ventral tegmental area and striatum signals reward outcomes (Glimcher 2011), and dopaminergic activity has been implicated in reward-based motor learning (Galea et al. 2013; Pekny et al. 2015).
EEG has been used to identify neural correlates of error monitoring, but few studies have employed motor adaptation tasks. An event-related potential (ERP) known as the feedback-related negativity (FRN) occurs in response to task-related feedback. The reinforcement learning (RL) theory of the FRN states that subjectively favorable or rewarding outcomes elicit a positive voltage potential generated by medial frontal areas whereas unfavorable outcomes elicit a negative potential (Heydari and Holroyd 2016; Holroyd and Coles 2002; Nieuwenhuis et al. 2004; Walsh and Anderson 2012). This voltage difference is proposed to reflect a process of reinforcing successful actions and/or deterring unrewarding actions. Alternative accounts of the FRN state that it is not specifically tied to the rewarding quality of outcomes but is generated when predictions are violated generally (Alexander and Brown 2011; Hauser et al. 2014). Another framework attributes the FRN to response conflict elicited by performance feedback (Cockburn and Frank 2011; Yeung et al. 2004).
Our goal was to test the RL theory of the FRN in the context of motor adaptation by determining whether the FRN is elicited specifically by reinforcement outcomes but not sensory error. Counterfactually, if the FRN simply reflects violation of expectations or conflict due to updated response activation, then sensory error should also elicit an FRN. Previous studies have reported FRN-like neural responses to sensory error feedback (Krigolson et al. 2008; MacLean et al. 2015; Reuter et al. 2018; Savoie et al. 2018; Torrecillos et al. 2014). However, perturbation of sensory outcomes typically coincides with a failure to meet the goals of the task, making it difficult to differentiate reinforcement-related error processing from sensory error processing. Furthermore, previous research has introduced perturbations during ongoing movements. In this case it is difficult to distinguish adaptation-related error processing from the recruitment of neural resources for ongoing control, such as suppression of the ongoing planned movement. Cognitive control and response inhibition have been shown to elicit an N200 ERP component, which occurs with the same scalp distribution and timing as the FRN (Folstein and Van Petten 2008). We predicted that the FRN would be elicited by binary reinforcement feedback during motor adaptation in the absence of sensory error signals whereas sensory error feedback that does not disrupt task success or reward outcomes would not elicit an FRN despite producing adaptation. We provided feedback only at movement end point to avoid confounds due to movements themselves or error processing related to ongoing control.
The FRN potential is superimposed on the P300, a well-characterized positive ERP component that peaks later than FRN and with a more posterior scalp distribution. It has been proposed that the P300 reflects the updating of an internal model of stimulus context upon processing of unexpected stimuli to facilitate adaptive responding (Donchin 1981; Donchin and Coles 1988; Krigolson et al. 2008; MacLean et al. 2015; Polich 2007). In line with this interpretation, the P300 is observed ubiquitously in processing task-related feedback, and therefore we expected to detect a P300 in response to both sensory error and reward feedback. However, a supposed model-updating function of the P300 seems especially relevant to accounts of sensory error-based motor adaptation, in which internal models of motor dynamics are updated by sensory error feedback (Synofzik et al. 2008; Wolpert et al. 1995). It is thought that RL, however, can occur in a purely associative way without the use of internal models of motor dynamics (Haith and Krakauer 2013). Furthermore, the P300 is typically localized to parietal regions, which are heavily implicated in visuomotor adaptation (Bledowski et al. 2004; Diedrichsen et al. 2005; Linden 2005; Tanaka et al. 2009). We tested whether the P300 is modulated by sensory error induced by VMR and whether P300 amplitude correlated to behavioral adaptation induced by sensory error feedback.
MATERIALS AND METHODS
Experimental Design and Statistical Analysis
Participants made reaching movements toward a visual target and received visual feedback pertaining to reach angle only at movement end point. Neural responses to feedback were recorded by EEG. Participants were instructed that each reach terminating within the target would be rewarded with a small monetary bonus. Participants first performed a block of 50 practice trials. The subsequent behavioral procedure consisted of four blocks of a reward learning task and four blocks of a VMR task. The order of the blocks alternated between the two task types but was otherwise randomized. Participants took self-paced rests between blocks.
In the VMR task, a cursor appeared at movement end point to represent the position of the hand. In randomly selected trials, cursor feedback indicated a reach angle that was rotated relative to the unperturbed feedback. We tested for behavioral adaptation and modulation of ERPs in response to VMR. The perturbations were small relative to the size of the target, such that participants nearly always landed in the target, fulfilling the goal of the task and earning a monetary reward. Thus reward and task error were constant between perturbed and nonperturbed feedback, and by comparing the two conditions we could isolate the neural correlates of sensory error processing.
In the reward learning task, no cursor appeared to indicate the position of the hand. Instead, binary feedback represented whether or not participants succeeded in hitting the target. This allowed us to assess reward-based learning in isolation from sensory error processing, as visual information revealing the position of the hand was not provided. Reward was delivered probabilistically, with a higher probability of reward for reaches in one direction than the other, relative to participants’ recent history of reach direction. We compared the neural responses to reward and nonreward feedback to assess the neural correlates of reward processing during adaptation.
Linear relationships between behavioral and EEG measures were assessed with robust regression, implemented by the MATLAB fitlm function with robust fitting option. This method uses iteratively reweighted least-squares regression, assigning lower weight to outlier data points (Holland and Welsch 1977). We used robust regression because standard correlation techniques with relatively small sample size are highly sensitive to outlier data and violations of assumptions (Schönbrodt and Perugini 2013; Wilcox 2001; Yarkoni 2009). Student’s t-tests were performed with MATLAB R2016b, and the Lilliefors test was used to test the assumption of normality. In the case of nonnormal data, the Wilcoxon signed-rank test was used to test pairwise differences. Repeated-measures analyses of variance (ANOVAs) were conducted with IBM SPSS Statistics version 25. For all ANOVAs, Mauchly’s test was used to validate the assumption of sphericity.
Participants
A total of n = 20 healthy, right-handed participants were included in our study (23.21 ± 3.09 yr old; 12 women, 8 men). Three participants underwent the experimental procedure but were excluded because of malfunction of the EEG recording equipment. One participant who reported performing movements based on a complex strategy that was unrelated to the experimental task was excluded. Participants provided written informed consent to experimental procedures approved by the Research Ethics Board at Western University.
Apparatus/Behavioral Task
Participants produced reaching movements with their right arm while holding the handle of a robotic arm (InMotion2; Interactive Motion Technologies; Fig. 1). Position of the robot handle was sampled at 600 Hz. A semisilvered mirror obscured vision of the arm and displayed visual information related to the task. An air sled supported each participant’s right arm.
Fig. 1.
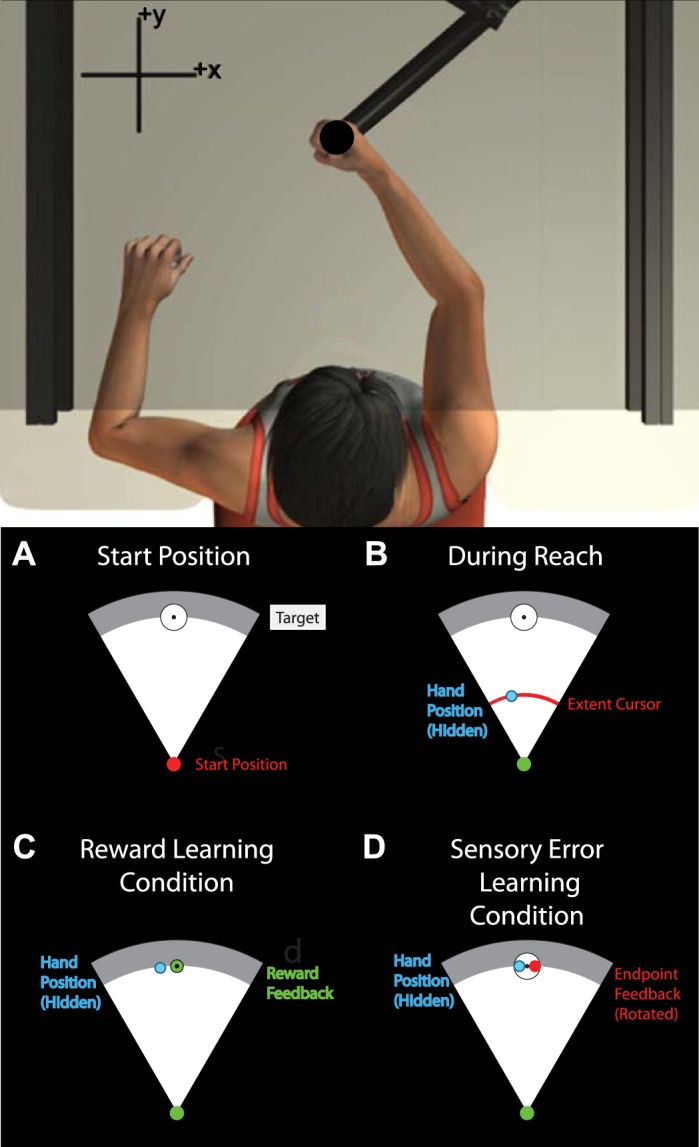
Experimental setup. A: participants (n = 20) reached to visual targets while holding the handle of a robotic arm. Vision of the arm was obscured by a screen that displayed visual information related to the task. B: during reaches, hand position was hidden but an arc-shaped cursor indicated the extent of the reach without revealing reach angle. Feedback was provided at reach end point. C: in the reward learning condition, binary feedback represented whether reaches were successful or unsuccessful in hitting the target by turning green or red, respectively. Reach adaptation was induced by providing reward for movements that did not necessarily correspond to the visual target. D: in the visuomotor rotation condition, feedback represented the end-point position of the hand. Adaptation was induced by rotating the angle of the feedback relative to the actual reach angle.
Participants reached to a white circular target 14 cm away from a circular start position (1-cm diameter) in front of their chest (Fig. 1A). The start position turned from red to green to cue the onset of each reach once the handle had remained inside it continuously for 750 ms. Participants were instructed that they must wait for the cue to begin each reach but that it was not necessary to react quickly upon seeing the cue.
Participants were instructed to make forward reaches and to stop their hand within the target. An arc-shaped cursor indicated reach extent throughout each movement without revealing reach angle. In only the first five baseline trials of each block, an additional circular cursor continuously indicated the position of the hand throughout the reach. A viscous force field assisted participants in braking their hand when the reach extent was >14 cm.
The robot ended each movement by fixing the handle position when the hand velocity decreased below 0.03 m/s. The hand was fixed in place for 700 ms, during which time visual feedback of reach angle was provided. Feedback indicated either reach end point position, a binary reward outcome, or feedback of movement speed (see below). Visual feedback was then removed, and the robot guided the hand back to the start position.
Reach end point was defined as the position at which the reach path intersected the perimeter of a circle (14-cm radius) centered at the start position. Reach angle was calculated as the angle between vectors defined by reach end point and the center of the target, each relative to the start position, such that reaching straight ahead corresponds to 0° and counterclockwise reach angles are positive (Fig. 1A). Feedback about reach angle was provided either in the form of end-point position feedback or binary reward feedback. The type of feedback, as well as various feedback manipulations, varied according to the assigned experimental block type (see Reward Learning Task and Visuomotor Rotation Task). Participants were told that they would earn additional monetary compensation for reaches that ended within the target, up to a maximum of CAD$10.
Movement duration was defined as the time elapsed between the hand leaving the start position and the moment hand velocity dropped below 0.03 m/s. If movement duration was >700 ms or <450 ms, no feedback pertaining to movement angle was provided. Instead, the gray arc behind the target turned blue or yellow to indicate that the reach was too slow or too fast, respectively. Participants were informed that movements with an incorrect speed would be repeated but would not otherwise affect the experiment.
To minimize the impact of eyeblink-related EEG artifacts, participants were asked to fixate their gaze on a black circular target in the center of the reach target and to refrain from blinking throughout each arm movement and subsequent presentation of feedback.
Practice Block
Each participant first completed a block of practice trials that continued until he/she achieved 50 movements within the desired range of movement duration. Continuous position feedback was provided during the first 5 trials, and only end-point position feedback was provided for the following 10 trials. Subsequently, no position feedback was provided outside the start position.
Reward Learning Task
Binary reward feedback was provided to induce adaptation of reach angle. Each participant completed four blocks in the reward learning condition. We manipulated feedback with direction of intended learning and reward frequency as factors, using a 2 × 2 design (direction of learning × reward frequency) across blocks. For each direction of intended learning (clockwise and counterclockwise), each participant experienced a block with high reward frequency and a block with low reward frequency. Reward frequency was manipulated to assess effects related to expectation, under the assumption that outcomes that occurred less frequently would violate expectations more strongly. Each block continued until the participant completed 115 reaches with acceptable movement duration. Participants reached toward a circular target 1.2 cm (4.9°) in diameter. The first 15 reaches were baseline trials during which continuous position feedback was provided during the first 5 trials, followed by 10 trials with only end-point position feedback. After these baseline trials no position feedback was provided, and binary reward feedback was instead provided at the end of the movement. Target hits and misses were indicated by the target turning green and red, respectively.
Unbeknownst to participants, reward feedback was delivered probabilistically. The likelihood of reward depended on the difference between the current reach angle and the median reach angle of the previous 10 reaches. In the high-reward frequency condition, reward was delivered at a probability of 100% if the difference between the current reach angle and the running median was in the direction of intended learning and at a probability of 30% otherwise (Eq. 1). When the running median was at least 6° away from zero in the direction of intended learning, reward was delivered at a fixed probability of 65%. This was intended to minimize conscious awareness of the manipulation by limiting adaptation to ±6°. In the low-reward frequency condition, reward was similarly delivered at a probability of either 70% or 0% (Eq. 2). When the running median was at least 6° away from zero in the direction of intended learning, reward was delivered at a fixed probability of 35%. Reach angle and feedback throughout a representative experimental block are shown in Fig. 2.
Fig. 2.
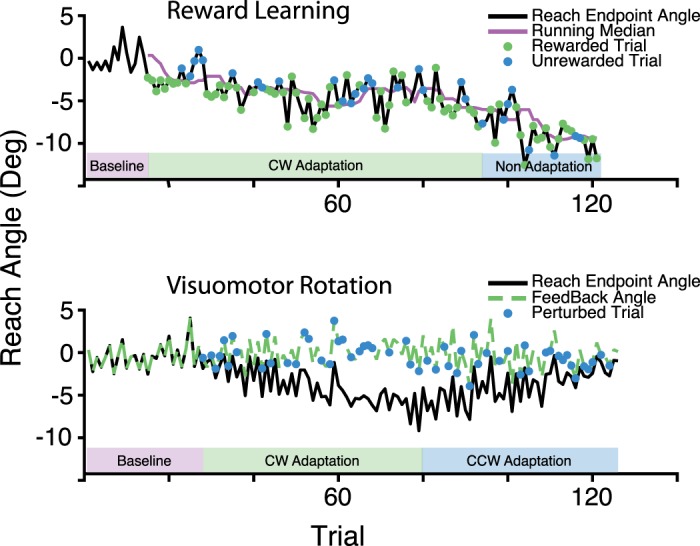
Reach angles of a representative participant (n = 1). Top: the reward learning block assigned to the clockwise (CW) adaptation with the high-reward frequency condition. Reaches were rewarded with 100.0% probability for reach angles less than the median of the previous 10 reaches and with 30.0% probability for reach angles greater than this running median. Reward was delivered at a fixed probability of 65.0% when the running median was less than −6°, indicated by the “Non-Adaptation” portion of the block. Bottom: the visuomotor rotation block assigned to the 1.5° rotation condition. The rotation is imposed randomly in 50% of trials. The rotation is initially counterclockwise (CCW) but reverses when the mean of the previous 5 reach angles becomes less than −6.0°.
We employed this adaptive, closed-loop reward schedule so that the overall frequency of reward was controlled. This allowed us to assess correlations between neural measures and behavior without confounding learning and reward frequency.
| (1) |
| (2) |
where p is probability of reward described separately for the high- and low-reward frequency conditions, θ is the reach angle on trial i, z = 1 for counterclockwise learning blocks, and z = −1 for clockwise learning blocks.
Visuomotor Rotation Task
End-point feedback was rotated relative to the actual reach angle to induce sensory error-based adaptation. Each participant completed four blocks in the VMR condition. We manipulated feedback with initial rotation direction and perturbation size as factors, using a 2 × 2 design across blocks. For each direction of initial rotation (clockwise and counterclockwise) each participant experienced a block with large rotation (1.5°) and a block with small rotation (0.75°). Each block continued until participants completed 125 reaches within acceptable movement duration limits. Participants reached toward a circular target 2.5 cm (10.2°) in diameter. Participants first performed baseline reaches during which cursor feedback reflected veridical reach angle continuously for the first 10 trials and only at movement end point for the subsequent 15 trials. After the baseline reaches the adaptation portion of each block began, unannounced to participants.
During the adaptation trials, end-point position feedback was provided that did not necessarily correspond to the true hand position. Participants were instructed that end-point feedback within the target would earn them bonus compensation, but no explicit reward feedback was provided. To determine the feedback angle in the small- and large-perturbation conditions, we added a rotation of 0.75° or 1.5°, respectively, to the true reach angle in a randomly selected 50% of trials. In addition, on every trial we subtracted an estimate of the current state of reach adaptation (Eq. 3).
| (3) |
X denotes feedback angle, θ denotes reach angle, and q denotes the perturbation. z denotes the direction of the perturbation (z = 1 for counterclockwise perturbations and z = −1 for clockwise perturbations). s denotes the size of the perturbation (0.75° or 1.5° in the small- and large-error conditions, respectively). u is a discrete random variable that is realized as either 1 or 0 with equal probability (50%).
If the state of adaptation is accurately estimated and subtracted from the true reach angle, then a reach that reflects the state of adaptation without movement error will result in either unperturbed feedback at 0° or rotated feedback at the angle of the perturbation. The online estimate of adaptation consisted of a running average of the previous five reach angles and a model of reach adaptation that assumed that participants would adapt to a fixed proportion of the reach errors experienced during the previous three trials. A windowed average centered around the current reach angle could estimate the current state of reach adaptation, but the online running average was necessarily centered behind the current reach angle. Thus an online model was necessary to predict the state of adaptation. An adaptation rate of 0.25 was chosen for the online model on the basis of pilot data.
This design allowed us to compare perturbed and unperturbed feedback in randomly intermixed trials. Previous studies have imposed a fixed perturbation throughout a block of trials and compared early trials to late trials in which the error has been reduced through adaptation (MacLean et al. 2015; Tan et al. 2014). In such designs, differences in neural response might be attributed to changes in the state of adaptation or simply habituation to feedback, as opposed to sensory error per se. Alternatively, rotations can be imposed randomly in either direction, but previous work has demonstrated that neural and behavioral responses are larger for consistent perturbations, presumably because the sensorimotor system attributes variability in feedback to noise processes (Tan et al. 2014).
We sought to limit the magnitude of adaptation to 6° in an attempt to minimize awareness of the manipulation. The direction of the perturbation was reversed whenever the average reach angle in the previous five movements differed from zero by at least 6° in the direction of intended reach adaptation. Reach angle and feedback angle throughout a representative experimental block are shown in Fig. 2.
EEG Data Acquisition
EEG data were acquired from 16 cap-mounted electrodes with an active electrode system (g.GAMMA; g.tec Medical Engineering) and amplifier (g.USBamp; g.tec Medical Engineering). We recorded from electrodes placed according to the 10-20 System at sites Fz, FCz, Cz, CPz, Pz, POz, FP1, FP2, FT9, FT10, FC1, FC2, F3, F4, F7, and F8, referenced to an electrode placed on participants’ left earlobe. Impedances were maintained below 5 kU. Data were sampled at 4,800 Hz and filtered online with band-pass (0.1–1,000 Hz) and notch (60 Hz) filters. A photodiode attached to the display monitor was used to synchronize recordings to stimulus onset.
Behavioral Data Analysis
Reward learning task.
Motor learning scores were calculated for each participant as the difference between the average reach angle in the counterclockwise learning blocks and the average reach angle in the clockwise learning blocks. We assessed reach angle throughout the entire task primarily because reach direction was often unstable and a smaller window was susceptible to drift. Furthermore, this metric of learning reflected the rate of adaptation throughout the block without assuming a particular function for the time course of learning. Finally, this metric was not dependent on the choice of a particular subset of trials.
We excluded baseline trials and trials that did not meet the movement duration criteria, as no feedback related to reach angle was provided on these trials (6.5% of trials in the VMR task, 7.4% of trials in the reward learning task).
Visuomotor rotation task.
To quantify trial-by-trial learning we first calculated the change in reach angle between successive trials, as in Eq. 4:
| (4) |
We then performed a linear regression on Δθi with the rotation imposed on trial i as the predictor variable. The rotation was 0°, ±0.75°, or ±1.5°. This regression was performed on an individual participant basis, separately for each of the four VMR conditions (corresponding to feedback rotations of −1.5°, −0.75°, 0.75°, and 1.5°). For these regressions, we excluded trials that did not meet the duration criteria or that resulted in a visual error of >10° [mean = 2.65 trials per participant (SD 4.3)], as these large errors were thought to reflect execution errors or otherwise atypical movements. We took the average of the resulting slope estimates across blocks, multiplied by −1, as a metric of learning rate for each participant, as it reflects the portion of visual errors that participants corrected with a trial-by-trial adaptive process. Based on simulations of our experimental design using a standard memory updating model (Thoroughman and Shadmehr 2000) (not described here), we found that it was necessary to perform the regression separately for each rotation condition, as collapsing across the different rotation sizes and directions could introduce bias to the estimate of learning rate.
EEG Data Denoising
EEG data were resampled to 480 Hz and filtered off-line between 0.1 and 35 Hz with a second-order Butterworth filter. Continuous data were segmented into 2-s epochs time-locked to feedback stimulus onset at 0 ms (time range: −500 to +1,500 ms). Epochs containing artifacts were removed with a semiautomatic algorithm for artifact rejection in the EEGLAB toolbox [see Delorme and Makeig (2004) for details]. Epochs flagged for containing artifacts as well as any channels with bad recordings were removed after visual inspection. Subsequently, extended infomax independent component analysis was performed on each participant’s data (Delorme and Makeig 2004). Components reflecting eye movements and blink artifacts were identified by visual inspection and subtracted by projection of the remaining components back to the voltage time series.
Event-Related Component Averaging
After artifact removal, we computed ERPs by trial averaging EEG time series epochs for various feedback conditions described in the sections below. ERPs were computed on an individual participant basis separately for recordings from channels FCz and Pz. All ERPs were baseline corrected by subtracting the average voltage in the 75-ms period immediately following stimulus onset. We used a baseline period following stimulus onset because stimuli were presented immediately upon movement termination and the period before stimulus presentation was more likely to be affected by movement-related artifacts. Trials in which reaches did not meet the movement duration criteria were excluded, as feedback relevant to reach adaptation was not provided on these trials (6.5% of trials in the VMR task, 7.4% of trials in the reward learning task.).
Reward learning task.
We computed ERPs separately for feedback conditions corresponding to “frequent reward,” “infrequent reward,” “frequent nonreward,” and “infrequent nonreward.” Reward in the high-reward frequency condition and nonreward in the low-reward frequency condition were deemed frequent, whereas reward in the low-reward frequency condition and nonreward in the high-reward frequency condition were deemed infrequent (Holroyd and Krigolson 2007).
Visuomotor rotation task.
We created trial-averaged ERP responses for trials with rotated feedback and trials with nonrotated feedback, separately for the 0.75° and 1.5° rotation conditions. The resulting ERPs are identified by the conditions “rotated 0.75°,” “nonrotated 0.75,” “rotated 1.5°,” and “nonrotated 1.5°.”
To test for effects of absolute end-point error, which is determined not only by VMR but also by movement execution errors, we sorted trials in the adaptation portion of the VMR blocks by the absolute value of the angle of visual feedback relative to the center of the target. We created “most accurate” and “least accurate” ERPs for each participant by selecting the 75 trials with the smallest and largest absolute feedback angle, respectively.
We computed ERPs to test a correlation, across participants, between behavioral learning rate and the average neural response to feedback during adaptation to VMR. These ERPs, labeled as belonging to the “adaptation” condition, included all trials in the rotated 0.75°, nonrotated 0.75°, rotated 1.5°, and nonrotated 1.5° conditions.
Feedback-Related Negativity Analysis
The FRN was analyzed with a difference wave approach with ERPs recorded from FCz, where it is typically largest (Holroyd and Krigolson 2007; Miltner et al. 1997; Pfabigan et al. 2011). Although the FRN is classically characterized by a negative voltage peak following nonreward feedback, multiple lines of evidence suggest that a reward-related positivity also contributes to the variance captured by the difference wave approach, despite not producing a distinct peak (Baker and Holroyd 2011; Becker et al. 2014; Carlson et al. 2011; Heydari and Holroyd 2016; Walsh and Anderson 2012). Furthermore, difference waves can be computed separately for frequent and infrequent outcomes, which subtracts effects of pure surprise while preserving any interaction between feedback valence and reward frequency (Holroyd and Krigolson 2007). Difference waves were computed for each participant by subtracting ERPs corresponding to unsuccessful outcomes from those corresponding to successful outcomes. FRN amplitude was determined as the mean value of the difference wave between 200 and 350 ms after feedback presentation. This time window was chosen a priori on the basis of previous reports (Walsh and Anderson 2012). To test for the presence of the FRN for each difference wave, we submitted FRN amplitude to a t-test against zero.
Visuomotor rotation task.
First, we created difference waves to test whether the rotations imposed on randomly selected trials elicited FRN. The rotated 0.75° ERPs were subtracted from the nonrotated 0.75° ERPs to create a “small VMR” difference wave. The rotated 1.5° ERPs were subtracted from the nonrotated 1.5° ERPs to create a “large VMR” difference wave.
Next, we created a difference wave to test whether a FRN was observable by comparing trials where the end-point feedback was furthest from the center of the target to those where feedback was closest to the center of the target. The “least accurate” ERPs were subtracted from the “most accurate” ERPs to create an “end-point error” difference wave.
Reward learning task.
The frequent-nonreward ERP was subtracted from the frequent-reward ERP to create a “frequent” difference wave, and the infrequent-nonreward ERP was subtracted from the infrequent-reward EPR to create an “infrequent” difference wave.
P300 Analysis
To analyze the P300 we used ERPs recorded from channel Pz, where it is typically largest (Fabiani et al. 1987; Hajcak et al. 2005; MacLean et al. 2015; Polich 2007). We calculated P300 amplitude using base-to-peak voltage difference. The temporal regions of interest (ROIs) for the peak and base were determined with grand averages computed across participants and conditions for each task (see Visuomotor rotation task and Reward learning task below). P300 peak was defined as the maximum peak occurring 250–500 ms after stimulus onset, which always corresponded to the largest peak in the analyzed epoch. P300 base was defined as the minimum preceding peak that occurred at least 100 ms after stimulus onset. For each subject, peak and base voltages were calculated separately for each condition ERP as the average voltage within 50-ms windows centered around the temporal ROIs defined at the group level. P300 amplitude was then determined as the difference between peak and base voltage.
Visuomotor rotation task.
P300 amplitude was calculated in four conditions using the rotated 0.75°, nonrotated 0.75°, rotated 1.5°, and nonrotated 1.5° ERPs. Temporal ROIs were determined, as described above, by aggregating all trials across participants and the four conditions into a single set and averaging to produce an “aggregate grand average from trials” waveform. This approach allows for data-driven ROI selection without inflated type I error rate and has been shown to be insensitive to trial number asymmetry across conditions (Brooks et al. 2017). We tested for differences in P300 amplitude related to VMR with two-way repeated-measures ANOVA with factors rotation (levels: nonrotated, rotated) and rotation magnitude (levels: 0.75°, 1.5°).
Reward learning task.
P300 amplitude was calculated in four conditions using the infrequent reward, frequent reward, infrequent nonreward, and frequent nonreward feedback condition ERPs described above. Because the waveform morphology was considerably different for the ERPs elicited by reward feedback and those elicited by nonreward feedback, we defined temporal ROIs separately for the reward conditions (infrequent reward, frequent reward) and the nonreward conditions (infrequent nonreward and frequent nonreward). In both cases, temporal ROIs were determined by aggregating all trials across participants and the corresponding two conditions into a single set and averaging to produce an “aggregate grand average from trials” waveform. This ROI selection method has only been shown to be necessarily unbiased when all conditions display similar waveform morphology and are grouped together (Brooks et al. 2017). For this reason, we repeated our analysis, using a common method of selecting peaks for each individual participant and condition ERP after matching the number of trials across conditions, which produced similar results.
We tested for differences in P300 amplitude between feedback conditions with two-way repeated-measures ANOVA with factors reward (levels: rewarded, nonrewarded) and expectancy (levels: infrequent, frequent).
RESULTS
Behavioral Results
Reward learning task.
In the reward learning task participants adapted their reach angle on the basis of binary reward feedback (Fig. 3). We calculated a reward learning score for each subject by subtracting the average reach angle in the clockwise learning condition from that in the counterclockwise learning condition, excluding the baseline trials, such that the average reward learning score would be approximately zero if participants did not respond to the reward feedback in any way. We observed a mean reward learning score of 5.47 (SD 4.66), which is significantly greater than zero [1-sample t-test; t(19) = 5.25, P < 0.001]. Participants received reward on 67.0% (SD 4.9) of trials in the high-frequency condition and 38.6% (SD 4.3) of trials in the low-frequency condition.
Fig. 3.
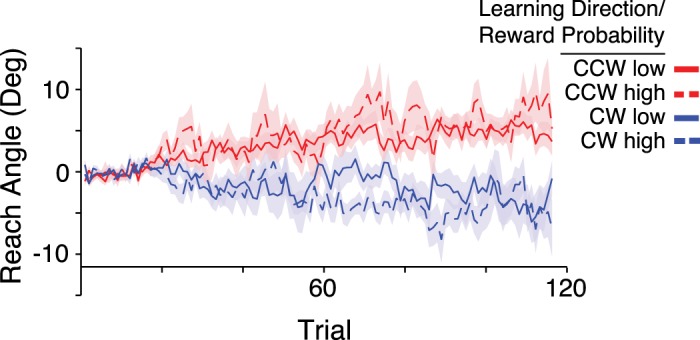
Participants (n = 20) adapted their reach angle in the reward learning condition. Group average reach angles in the reward learning conditions are plotted. Each participant completed 4 blocks. For each direction of intended learning [clockwise (CW) and counterclockwise (CCW)], each participant completed a block in the high-reward frequency (65%) condition and a block in the low-reward frequency (35%) condition. Shaded regions: ±1 SE.
Visuomotor rotation task.
In the VMR task participants received end-point cursor feedback and adapted their reach angles in response to the rotated cursor feedback imposed on randomly selected trials. To estimate trial-by-trial learning rates for individual participants, we quantified the linear relationship between the change in reach angle after each trial with the rotation imposed on the preceding trial as the predictor variable, separately for each rotation condition (−1.5°, −0.75°, 0.75°, and 1.5°). We took the average of the resulting slope estimates and multiplied it by −1 to obtain a measure of learning rate. This metric reflects the proportion of VMR that each participant corrected with a trial-by-trial adaptive process. The mean learning rate was 0.49 (SD 0.46), which was significantly different from zero [1-sample t-test; t(19) = 4.8, P < 0.001]. This indicates that participants corrected for visual errors on a trial-by-trial basis. Figure 4 shows the average change in reach angle for each size and direction of the imposed cursor rotation.
Fig. 4.
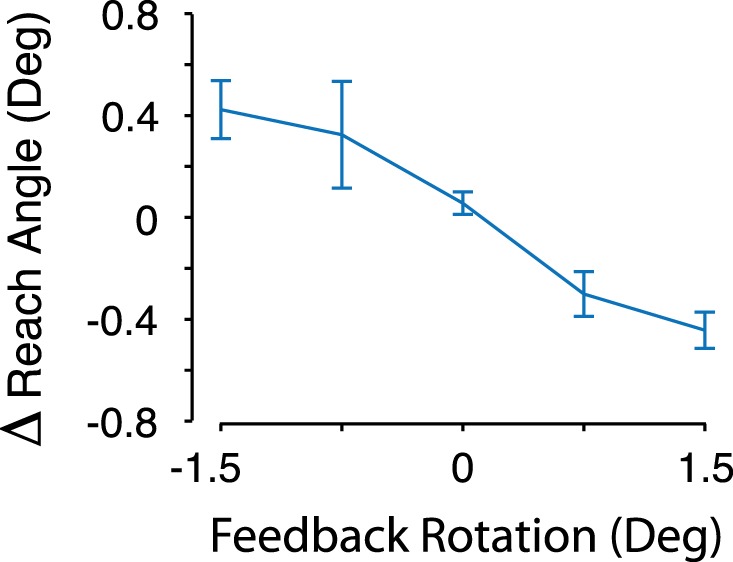
Participants (n = 20) adapted their reach angle on a trial-by-trial basis in the visuomotor rotation condition. The average change (Δ) in reach angle between subsequent pairs of trials is plotted for each size and direction of rotation imposed on the preceding trial. The average change in reach angle is in all cases opposite to the rotation, indicating that participants adapted their reaches to counteract the perturbations.
Feedback-Related Negativity Results
Reward learning task.
Figure 5A shows the ERPs recorded from electrode FCz during the reward learning condition, averaged across participants. The mean value of the “frequent” difference wave recorded from FCz between 200 and 350 ms was significantly different from zero [mean = 5.34 μV (SD 4.11), t(19) = 5.81, P < 0.001, 1-sample t-test], indicating that frequent feedback elicited a FRN in our reward learning task. The mean value of the “infrequent” difference wave was also significantly larger than zero [mean = 7.09 μV (SD 2.76), t(19) = 11.47, P < 0.001, 1-sample t-test], indicating that infrequent feedback also elicited a FRN.
Fig. 5.
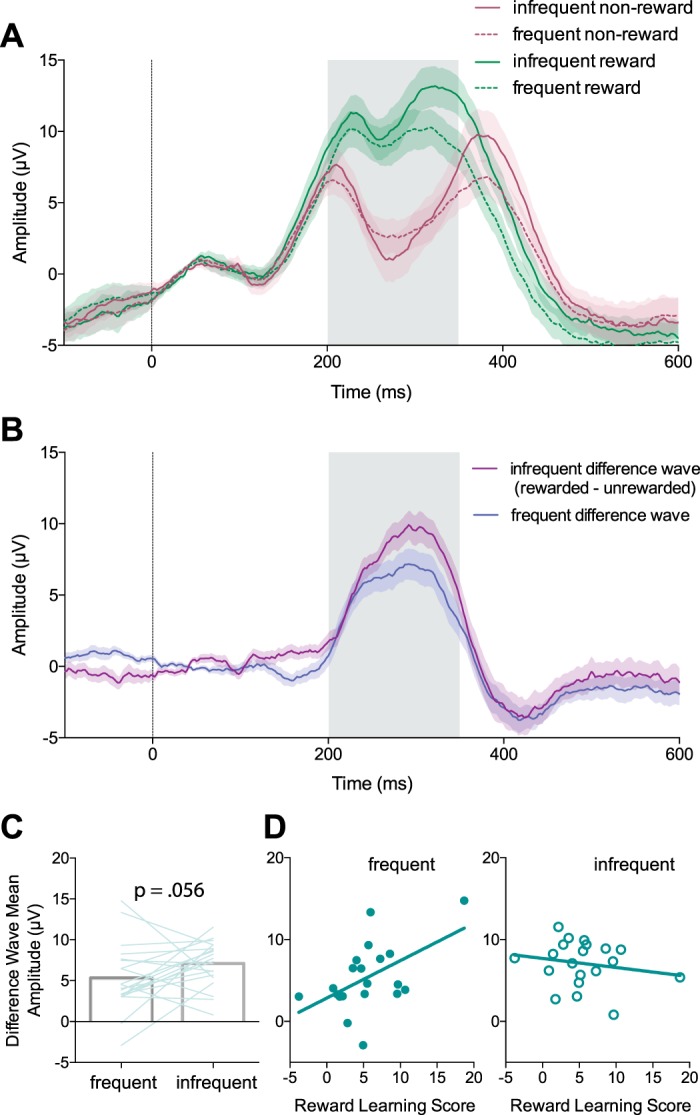
The feedback-related negativity was elicited by reward feedback during the reward learning task. A: trial-averaged event-related potentials (ERPs) recorded from electrode FCz aligned to feedback presentation (0 ms, vertical blue line). Frequent and infrequent reward reflect reward feedback in the high- and low-reward frequency conditions, respectively. Frequent and infrequent nonreward refer to nonreward feedback in the low- and high-reward frequency conditions, respectively. Shaded regions: ±SE (n = 20). The gray shaded box indicates the temporal window of the feedback-related negativity. B: the difference waves (reward ERP − nonreward ERP) for frequent and infrequent feedback aligned to feedback presentation. C: the mean amplitude of the difference wave (reward ERP − nonreward ERP) between 200 and 350 ms for infrequent and frequent feedback. D: the mean amplitudes of the difference waves are predictive of behavioral learning scores across participants for the frequent feedback but not the infrequent feedback.
The mean amplitude of the “infrequent” difference wave was not reliably larger than the mean amplitude of the “frequent” difference wave, although the difference showed a nearly significant trend in this direction [t(19) = 1.66, P = 0.056, paired t-test, 1-tailed; Fig. 5C]. Robust multiple linear regression was used to predict reward learning scores, which we calculated for each subject as the difference in average reach angle between the clockwise and counterclockwise learning conditions, based on the mean values of the “frequent” and “infrequent” difference waves as predictors. The predictors were not correlated (r = 0.11, P = 0.642). The overall multiple regression model was not significant [F(2,17) = 2.72, P = 0.095], with an R2 of 0.242. Participants’ predicted reward learning score, in degrees of reach angle, is equal to 5.243 + 0.525β1 − 0.382β2, where β1 is the mean value of the “frequent” difference wave in microvolts and β2 is the mean value of the “infrequent” difference wave in microvolts. The “frequent” difference wave was a significant predictor of the reward learning score [t(17) = 2.17, P = 0.044], whereas the “infrequent” difference wave was not a significant predictor of the reward learning score [t(17) = −1.06, P = 0.30]. Figure 5D shows the relationships between the “frequent” and “infrequent” FRN amplitudes and the reward learning score.
Visuomotor rotation task.
Figure 6A shows the ERPs recorded from electrode FCz during the VMR condition, averaged across participants. The mean value of the “small VMR” difference wave recorded from FCz between 200 and 350 ms was not significantly different from zero (mean =−0.21 μV (SD 1.29), Z = −0.67, W = 87, P = 0.50, Wilcoxon signed-rank test; Fig. 6C). Similarly, the mean value of the “large VMR” difference wave recorded from FCz between 200 and 350 ms was not significantly different from zero [mean = −0.26 μV (SD 1.22), t(19) = −0.97, P = 0.34, 1-sample t-test; Fig. 6C). These findings indicate that the VMRs imposed in the VMR task did not reliably elicit a FRN.
Fig. 6.
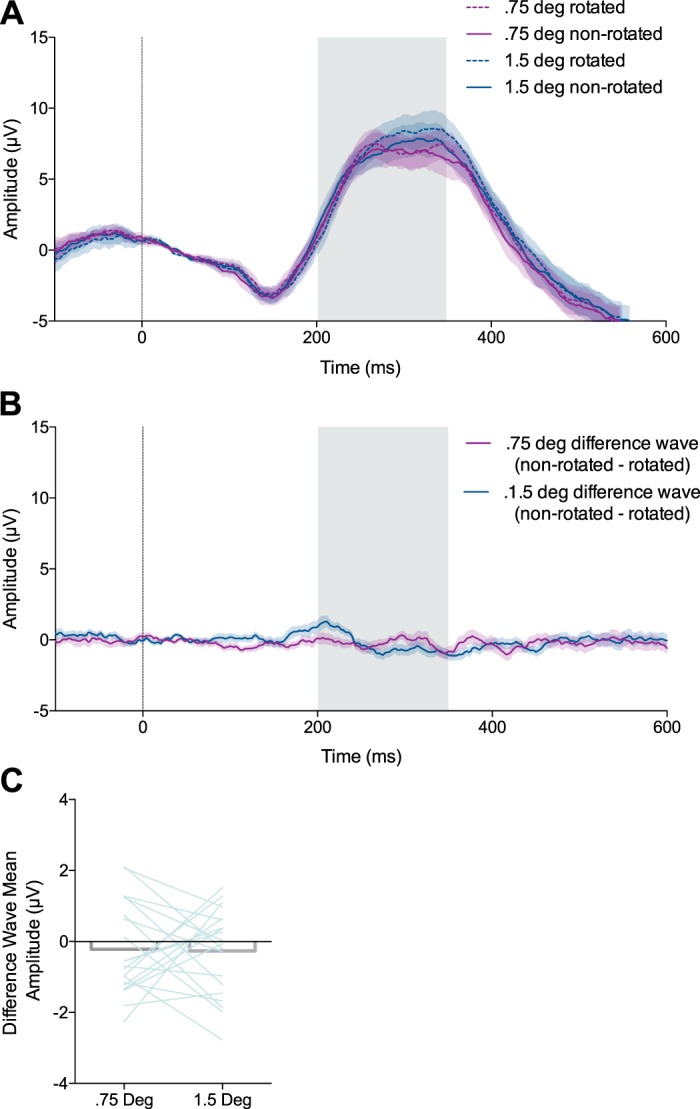
The feedback-related negativity (FRN) was not elicited by sensory error feedback during the visuomotor rotation task. A: trial-averaged event-related potentials (ERPs) recorded from electrode FCz aligned to feedback presentation (0 ms, vertical line). Shaded regions: ±SE (n = 20). The gray shaded box indicates the temporal window of the FRN. B: the difference waves (nonrotated ERP − rotated ERP) for the 0.75° and 1.5° rotation conditions aligned to feedback presentation. C: the mean amplitude of the difference wave (nonrotated ERP − rotated ERP) between 200 and 350 ms for the 0.75° and 1.5° rotation conditions. Error bars show ±SE.
The mean value of the “end-point error” difference wave recorded from FCz between 200 and 350 ms was not significantly different from zero [mean = 0.61 μV (SD 3.28), t(19) = 0.82, P = 0.42, 1-sample t-test], indicating that a FRN did not reliably occur on the basis of end-point error feedback. The fact that we were able to detect a FRN in the reward learning task but not in the VMR task is consistent with the notion that the FRN reflects reward processing but not sensory error processing and that our experimental design successfully dissociated the two.
P300 Results
Reward learning task.
Figure 7A shows ERPs recorded from electrode Pz during the reward learning condition, averaged across participants. We performed a 2 × 2 repeated-measures ANOVA on P300 amplitude with factors expectancy and reward. Figure 7B shows P300 amplitude for each condition, averaged across participants. We found a significant main effect of feedback expectancy [F(1,19) =97.16, P < 0.001], indicating that P300 amplitude was significantly larger in the infrequent feedback conditions. We also found a significant main effect of reward [F(1,19) = 13.18, P = 0.002], indicating that P300 amplitude was larger after rewarded trials compared with unrewarded trials. We found no reliable interaction between reward and expectancy [F(1,19) = 0.992, P = 0.332). P300 amplitude was not significantly correlated to reward learning scores for any of the four feedback conditions: frequent reward [R2 = 0.17, F(1,18) = 0.97, P = 0.34], infrequent reward [R2 = 0.030, F(1,18) = 0.558, P = 0.47], frequent nonreward [R2 = 0.067, F(1,18) = 1.3, P = 0.27], and infrequent nonreward [R2 = 0.06, F(1,18) = 1.15, P = 0.30].
Fig. 7.
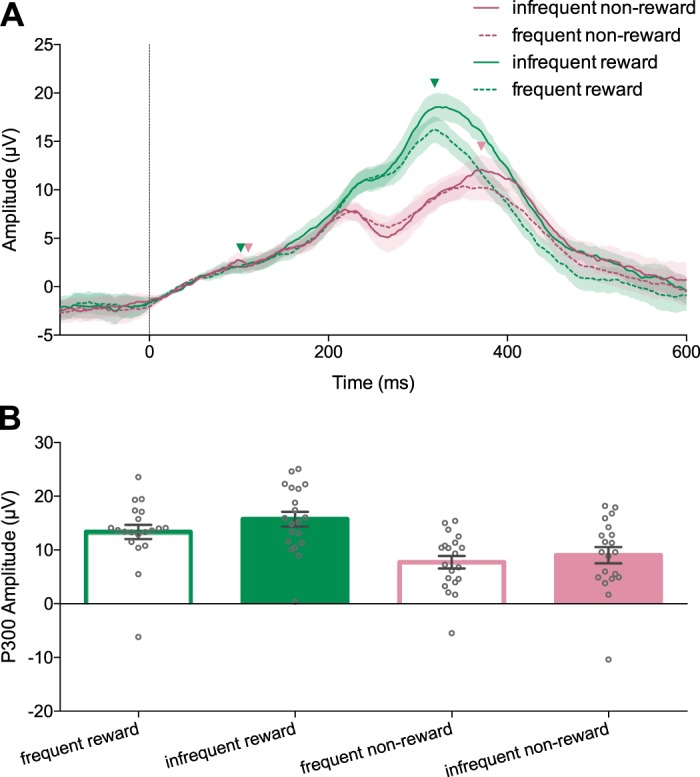
The P300 is modulated by feedback during the reward learning task. A: trial-averaged event-related potentials (ERPs) recorded from electrode Pz aligned to feedback presentation (0 ms, vertical line). Shaded regions: ±SE (n = 20). Arrowheads indicate the time points for the base and peak of the P300. B: P300 amplitude in each feedback condition (error bars: ±SE). P300 amplitude is larger for rewarded feedback relative to unrewarded feedback and for infrequent feedback relative to frequent feedback.
Visuomotor rotation task.
Figure 8A shows ERPs recorded from electrode Pz during the VMR task, averaged across participants. We first tested for an effect of the VMR on P300 amplitude by comparing nonrotated feedback trials and rotated feedback trials. We performed a two-way repeated-measures ANOVA with factors presence of rotation and size of rotation (Fig. 8B). We did not find significant main effects of presence of rotation [F(1,19) = 2.917, P = 0.104]. We also did not find a main effect of size of rotation [F(1,19) = 3.087, P = 0.095]. We did find a significant interaction effect between presence of rotation and rotation magnitude [F(1,19) = 8.728, P = 0.008]. We performed planned pairwise comparisons using Bonferroni corrected t-tests between nonrotated and rotated conditions separately for the small- and large-error conditions. We found that P300 amplitude was significantly greater for rotated compared with nonrotated feedback in the 1.5° rotation condition [t(19) = 2.83, P = 0.021, Bonferroni corrected] but not the 0.75° rotation condition [t(19) = 0.09, P = 0.93].
Fig. 8.
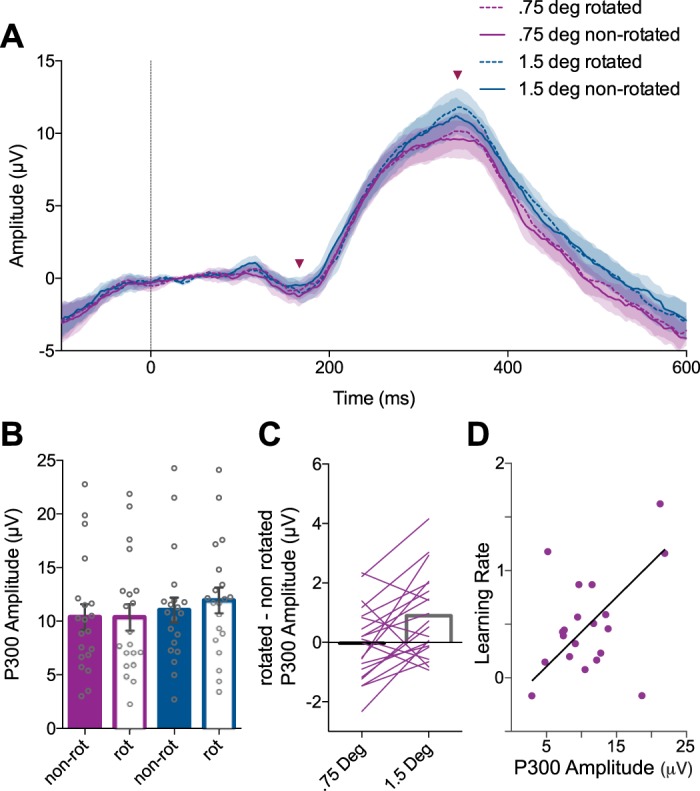
The P300 reflects sensory error processing during the visuomotor rotation task. A: trial-averaged event related potentials (ERPs) recorded from electrode Pz aligned to feedback presentation (0 ms, vertical line). Shaded regions: ±SE (n = 20). Arrowheads indicate the time points for the base and peak of the P300. B: the peak-to-peak amplitude of the P300 during the visuomotor rotation task (error bars: ±SE). C: P300 amplitude was larger for rotated than nonrotated trials in the 1.5° rotation condition but not the 0.75° rotation condition. D: P300 amplitude during adaptation predicted learning rate. Line of best fit corresponds to robust linear regression using iteratively reweighted least squares.
Robust linear regression was used to predict behavioral learning rate in the VMR task based on the amplitude of the P300 measured in the “adaptation” condition ERPs (Fig. 8D). P300 amplitude was a significant predictor of learning rate [F(1,18) = 15.9, P < 0.0001], with an R2 of 0.469. Participants’ predicted learning rate is equal to −0.219 + 0.065β1, where β1 is the P300 amplitude in microvolts.
DISCUSSION
We observed neural correlates of reward and sensory error feedback processing during motor adaptation. We employed reaching tasks that were designed to isolate reward- and sensory error-based learning while producing comparable changes in reach angle. In both tasks, learning occurred in response to temporally discrete feedback shown after each movement. By examining ERPs elicited by feedback delivered at the end of movement we avoided potential confounds caused by neural activity or artifacts related to movement execution, motion of the limb, and online error correction. We observed that the FRN was elicited by binary reward feedback but not by sensory error feedback. This suggests that the process generating the FRN is not necessary for sensory error-based learning and supports the idea that the processes underlying the FRN are specific to reward learning. The P300 occurred in response to both reward and sensory error feedback, and P300 amplitude was modulated by VMR, reward, and surprise. In the VMR task, P300 amplitude depended on the size of the visuomotor perturbation and was correlated to learning rate across participants. This suggests that the P300 might reflect general processing of feedback during motor adaptation that is particularly important for sensory error-based learning.
The FRN Reflects Processing of Reward Feedback but Not Sensory Error Feedback
Although motor adaptation has traditionally focused on sensory error-based learning, recent work suggests that reward-based or RL processes can also contribute to motor adaptation. In the present study, reward-based learning was isolated from sensory error-based learning during the reward learning task by providing only binary reward feedback in the absence of visual information indicating the position of the hand relative to the target. This feedback elicited a well-characterized fronto-central ERP component known as the FRN.
In RL theory, agents estimate the expected value of reward outcomes associated with actions, and actions are selected according to predictions regarding the value of reward outcomes. Reward prediction error (RPE) is the difference between the observed value and the predicted value of a reward outcome. Estimates of expected value are updated proportionally to RPE. The true expected value of a reward outcome is equal to the product of reward magnitude and the probability of reward. In our reward learning task the reward magnitude was fixed and thus can be represented as a binary quantity (0 or 1), and so the expected reward value of a particular action on each trial (e.g., the direction of hand movement) was directly proportional to the probability of reward. Therefore, reward feedback should elicit a positive RPE with increasing magnitude when reward is less probable. Conversely, nonreward should elicit negative RPE with increasing magnitude when reward is more probable.
The FRN was observed in the reward learning task as a difference in voltage between ERPs elicited by nonreward feedback and those elicited by reward feedback. A large body of literature has shown that the FRN is larger for infrequent outcomes than frequent outcomes. Because less frequent outcomes should violate reward predictions more strongly, this finding is taken as support for the theory that the FRN encodes a signed RPE (Cohen et al. 2007; Eppinger et al. 2008; Holroyd et al. 2011; Holroyd and Krigolson 2007; Kreussel et al. 2012; Walsh and Anderson 2012). In the present study, the FRN was larger for improbable feedback than for probable feedback, although the difference was not statistically reliable (P = 0.056). This result is potentially due to the relatively small difference in reward frequency experienced between the low- and high-reward frequency conditions (38.6% and 67.0%, respectively) compared with other studies. We decided to avoid using very low or very high reward frequency as we found it to produce highly variable and strategic behavior in the task. Furthermore, we did not directly assay reward prediction, and as such we reserve conclusions that we measured neural correlates of RPE as opposed to some other potential mechanisms of processing reward or reinforcement outcomes.
A prominent theory proposes that the FRN reflects activity originating in the anterior cingulate cortex driven by phasic dopaminergic signaling related to reward outcomes (Holroyd and Coles 2002; Santesso et al. 2009). This activity is purported to underlie reward-based learning processes by integrating feedback to affect future action selection. We sought to examine the role of the FRN in reward-based learning by testing the correlation between the amplitude of the FRN and the extent of learning as assessed behaviorally.
In typical reward learning paradigms successful learning is correlated with increased reward frequency, and therefore the relationship between the FRN and the magnitude of learning is confounded by any effect of reward frequency on FRN amplitude. In the present study, the reward learning task was adaptive to learning such that the overall reward frequency was largely decoupled from the extent of adaptation. We found that the extent of behavioral learning was predicted by the amplitude of the FRN for the frequent-feedback condition but not the infrequent-feedback condition. One possible explanation for this discrepancy is that participants responded reliably to infrequent feedback outcomes as they were most salient, but the limiting factor for individual differences in learning was a sensitivity to less salient frequent outcomes. Furthermore, frequent outcomes were by definition more numerous and as such could contribute more to the overall extent of learning. Another possibility is that the measurement of FRN amplitude became less reliable in the infrequent-feedback condition because of interference by surprise-related signals that were not directly related to RL, such as the P300. Relationships between the FRN and learning have been observed for tasks such as time estimation and discrete motor sequence learning (Holroyd and Krigolson 2007; van der Helden et al. 2010). Therefore, the present findings support the idea that the same reward feedback processing mechanism can drive learning across both cognitive and motor tasks. However, correlations with limited sample sizes can be unreliable, and the relationship between FRN amplitude and reward learning in the present study was not particularly strong. Future work is needed to further test this relationship, preferably through causal manipulation and behavioral tasks that produce less variable and idiosyncratic learning behavior.
The sensory error-based learning task allowed us to dissociate the neural signatures of reward-based learning and sensory error-based learning. Sensory error often coincides with task error and reward omission, as failure to achieve the expected sensory consequences of a motor command usually entails failure to achieve the subjective goal of the task. Achieving task goals may be inherently rewarding or explicitly rewarded, as in the present study. Our VMR task was designed to elicit learning through sensory error feedback while minimizing task error, as the perturbations were relatively small and rarely resulted in cursor feedback outside of the target. We did not observe the presence of the FRN in response to sensory error feedback, despite reliable observation of behavioral adaptation and the P300 neural response. This suggests that the process that generates the FRN is not necessary for adaptation to sensory errors.
Our results suggest that the ERP responses to reward and sensory error processing can be dissociated in motor adaptation and that the FRN is specific to reward-based learning processes. Although the FRN is classically associated with RL, recent work has identified the FRN or the closely related error-related negativity in various motor learning and execution tasks involving sensory error signals. These studies either concluded that reinforcement- and sensory error-based learning processes share common neural resources or they simply did not distinguish between these two processes (Krigolson et al. 2008; MacLean et al. 2015; Torrecillos et al. 2014). We argue that the brain processes reward and sensory error feedback through distinct mechanisms but the two processes can be confounded when perturbations causing sensory error are also evaluated as an implicit failure to meet task goals. In this case, the brain could process a reward and sensory error independently, although learning might be driven primarily by the sensory error. This is consistent with behavioral studies showing that sensory error-based learning is the primary driver of behavioral change when both reward and sensory feedback are provided (Cashaback et al. 2017; Izawa and Shadmehr 2011).
Recently, Savoie et al. (2018) also examined the effects of sensory error on EEG responses while carefully controlling for reward- or task-related errors. Following Mazzoni and Krakauer (2006), a 45° VMR was imposed on continuous cursor feedback, and participants were instructed to reach to a second target opposite to the rotation. In this paradigm, participants do not experience failure to achieve task goals or reward, as they effectively counteract the rotation through strategic aiming. Nonetheless, participants automatically and implicitly adapt to the sensory error caused by the rotation. This strategic condition was contrasted to a condition with no instructed strategy, in which participants had already adapted fully to a 45° rotation and thus experienced no task or sensory error. Unlike the present study, the authors report a prominent midfrontal negativity resembling the FRN in the strategic condition, despite a lack of task- or reward-related errors. One possible explanation for these conflicting results is that the FRN can be elicited by sensory error but the VMRs used in the present study were simply too small to elicit an observable FRN. Another possible explanation is that the response observed by Savoie et al. (2018) was not an FRN elicited by failure to achieve reward or task goals but another frontal negativity related to implementation of the strategy such as the N200, which can be indistinguishable from the FRN (Holroyd et al. 2008). The N200 is elicited by response conflict and cognitive control, which may have occurred during the strategic aiming condition, as participants were required to inhibit the prepotent response of reaching directly toward the target and instead implement the strategic aiming response (Enriquez-Geppert et al. 2010; Folstein and Van Petten 2008; Nieuwenhuis et al. 2003).
The P300 Is Modulated by Sensory Error, Surprise, and Reward
During the VMR task in the present study, we observed a P300 ERP in response to reach end-point position feedback, and we found that P300 amplitude was sensitive to the magnitude of sensory error. P300 amplitude was increased by the larger but not the smaller VMR. Learning in VMR paradigms is thought to be driven primarily by sensory error-based learning, and therefore our findings suggest that the P300 observed in this task might reflect neural activity that is related to processing of sensory error underlying motor adaptation (Izawa and Shadmehr 2011).
It is important to note that a P300 response is typically elicited by stimulus processing in tasks unrelated to sensory error-based motor adaptation, including the reward learning task in the present study. A prominent and enduring theory proposes that the P300 reflects cortical processing related to the updating of a neural model of stimulus context upon processing of unexpected stimuli (Donchin 1981; Donchin and Coles 1988; Polich 2007). This theory resembles an account of sensory error-based motor adaptation in which the updating of an internal model of motor dynamics occurs when sensory input differs from the predictions of the internal model (Synofzik et al. 2008; Wolpert et al. 1995). It is possible that the P300 reflects a general aspect of feedback processing that is common to both sensorimotor and cognitive function. The P300 is typically localized to parietal regions, which are implicated in processing sensory error during adaptation to VMR (Bledowski et al. 2004; Diedrichsen et al. 2005; Linden 2005; Tanaka et al. 2009). Consistent with the P300 underlying sensory error processing, cerebellar damage impairs sensory error-based adaptation and results in P300 abnormalities (Mannarelli et al. 2015; Martin et al. 1996; Maschke et al. 2004; Paulus et al. 2004; Smith and Shadmehr 2005; Tachibana et al. 1995; Therrien et al. 2016).
Previous studies have examined P300 responses elicited by sensory error feedback. It has been demonstrated that P300 amplitude decreases along with the magnitude of reach errors during the course of prism adaptation (MacLean et al. 2015). This suggests that the P300 is modulated by sensory error, but it does not rule out the possibility that the P300 simply attenuated with time. The P300 has also been reported to occur in response to random shifts in target location (Krigolson et al. 2008), another type of visuospatial error that, however, does not reliably produce learning (Diedrichsen et al. 2005). Both of these studies also reported FRN components occurring in response to task errors. In the present study a P300 response was observed that is correlated to behavioral learning and isolated from the FRN.
In our reward learning task, P300 amplitude was modulated by feedback valence and expectancy but was not correlated to learning. The finding that P300 shows a larger positive amplitude for infrequent feedback regardless of valence is consistent with previous reports and supports the notion that the P300 reflects a general model updating process when the stimulus differs from expectation (Hajcak et al. 2005, 2007; Pfabigan et al. 2011; Wu and Zhou 2009). This is distinct from the interaction between valence and expectancy that is characteristic of encoding RPE, in which surprise has opposite effects on the response to reward and nonreward. We also found that the P300 was larger for reward than nonreward feedback. Some previous studies have shown a similar effect of reward valence on P300 amplitude (Hajcak et al. 2005; Leng and Zhou 2010; Wu and Zhou 2009; Zhou et al. 2010), whereas others have not (Pfabigan et al. 2011; Sato et al. 2005; Yeung and Sanfey 2004). This finding is also consistent with idea that the P300 reflects updating of a model of stimulus context in response to task-relevant feedback, as reward feedback would indicate that the previous action was rewarding while all other possible actions were not rewarding. Nonreward feedback would only indicate that the previous action was not rewarding and thus carries less information for updating of the internal representation of the task.
Outstanding Questions
In VMR paradigms, a dissociation has been drawn between explicit and implicit learning processes that contribute to learning in a largely independent manner (Benson et al. 2011; Heuer and Hegele 2011; Krakauer 2009; Mazzoni and Krakauer 2006; McDougle et al. 2015, 2016; Schween and Hegele 2017; Taylor et al. 2014). The implicit process occurs automatically, without conscious awareness, and constitutes a recalibration of the visuomotor mapping. The explicit process is characterized by conscious and strategic changes in aiming intended to counteract experimental perturbations. The implicit component is known to be dependent on cerebellar processes, whereas explicit learning may rely on prefrontal and premotor cortex (Heuer and Hegele 2011; McDougle et al. 2016; Taylor et al. 2010; Taylor and Ivry 2014).
In the present study, relatively small perturbations of feedback produced gradual changes in reach direction. This gradual form of adaptation is thought to primarily recruit the implicit adaptation process (Klassen et al. 2005; Michel et al. 2007; Saijo and Gomi 2010). Nonetheless, it is possible that a mixture of implicit and strategic learning contributes the observed adaptation, especially considering the finding that visual feedback restricted to movement end point elicits less implicit learning relative to continuous feedback and that strategic aiming is employed to reduce residual error (Taylor et al. 2014). Further work is necessary to determine whether the neural generators of the P300 observed in the VMR task contribute specifically to implicit or strategic learning processes.
Similarly, it is not clear whether adaptation in the reward learning task occurred implicitly or through strategic processes. The extent of learning was variable and idiosyncratic, which may reflect differences in awareness of the manipulation or conscious strategy (Holland et al. 2018). Recent work has shown that when participants learn to produce reach angles directed away from a visual target through binary reward feedback, adaptation is dramatically reduced by instructions to cease any strategic aiming, suggesting a dominant explicit component to reward-based reach adaptation (Codol et al. 2018; Holland et al. 2018). Nonetheless, after learning a 25° rotation through binary feedback and being instructed to cease strategic aiming, small changes in reach angle persist (Holland et al. 2018). It is not clear whether this residual adaptation can be attributed to an implicit form of reward learning or whether it reflects use-dependent plasticity, but it suggests that implicit reward learning may occur for small changes in reach angle, such as those observed in the present study. Future work should determine whether the FRN and P300 are specifically related to strategic or explicit reward-based motor adaptation, especially considering evidence from sequence and cognitive learning domains that the FRN relates more closely to explicit processes (Loonis et al. 2017; Rüsseler et al. 2003).
GRANTS
This work was funded by the Natural Sciences and Engineering Research Council of Canada (P. L. Gribble) and the Canadian Institutes of Health Research (P. L. Gribble).
DISCLOSURES
No conflicts of interest, financial or otherwise, are declared by the authors.
AUTHOR CONTRIBUTIONS
D.J.P., J.G.A.C., and P.L.G. conceived and designed research; D.J.P. performed experiments; D.J.P. analyzed data; D.J.P., J.G.A.C., and P.L.G. interpreted results of experiments; D.J.P. prepared figures; D.J.P. drafted manuscript; D.J.P., J.G.A.C., and P.L.G. edited and revised manuscript; D.J.P. and J.G.A.C. approved final version of manuscript.
REFERENCES
- Alexander WH, Brown JW. Medial prefrontal cortex as an action-outcome predictor. Nat Neurosci 14: 1338–1344, 2011. doi: 10.1038/nn.2921. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Baker TE, Holroyd CB. Dissociated roles of the anterior cingulate cortex in reward and conflict processing as revealed by the feedback error-related negativity and N200. Biol Psychol 87: 25–34, 2011. doi: 10.1016/j.biopsycho.2011.01.010. [DOI] [PubMed] [Google Scholar]
- Becker MP, Nitsch AM, Miltner WH, Straube T. A single-trial estimation of the feedback-related negativity and its relation to BOLD responses in a time-estimation task. J Neurosci 34: 3005–3012, 2014. doi: 10.1523/JNEUROSCI.3684-13.2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bédard P, Sanes JN. Brain representations for acquiring and recalling visual-motor adaptations. Neuroimage 101: 225–235, 2014. doi: 10.1016/j.neuroimage.2014.07.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Benson BL, Anguera JA, Seidler RD. A spatial explicit strategy reduces error but interferes with sensorimotor adaptation. J Neurophysiol 105: 2843–2851, 2011. doi: 10.1152/jn.00002.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bledowski C, Prvulovic D, Hoechstetter K, Scherg M, Wibral M, Goebel R, Linden DE. Localizing P300 generators in visual target and distractor processing: a combined event-related potential and functional magnetic resonance imaging study. J Neurosci 24: 9353–9360, 2004. doi: 10.1523/JNEUROSCI.1897-04.2004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brooks JL, Zoumpoulaki A, Bowman H. Data-driven region-of-interest selection without inflating Type I error rate. Psychophysiology 54: 100–113, 2017. doi: 10.1111/psyp.12682. [DOI] [PubMed] [Google Scholar]
- Carlson JM, Foti D, Mujica-Parodi LR, Harmon-Jones E, Hajcak G. Ventral striatal and medial prefrontal BOLD activation is correlated with reward-related electrocortical activity: a combined ERP and fMRI study. Neuroimage 57: 1608–1616, 2011. doi: 10.1016/j.neuroimage.2011.05.037. [DOI] [PubMed] [Google Scholar]
- Cashaback JG, McGregor HR, Mohatarem A, Gribble PL. Dissociating error-based and reinforcement-based loss functions during sensorimotor learning. PLOS Comput Biol 13: e1005623, 2017. doi: 10.1371/journal.pcbi.1005623. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cockburn J, Frank M. Reinforcement learning, conflict monitoring, and cognitive control: an integrative model of cingulate-striatal interactions and the ERN. In: Neural Basis of Motivational and Cognitive Control, edited by Mars RB, Sallet J, Rushworth MF, Yeung N. Cambridge, MA: MIT Press, 2011. [Google Scholar]
- Codol O, Holland PJ, Galea JM. The relationship between reinforcement and explicit control during visuomotor adaptation. Sci Rep 8: 9121, 2018. doi: 10.1038/s41598-018-27378-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cohen MX, Elger CE, Ranganath C. Reward expectation modulates feedback-related negativity and EEG spectra. Neuroimage 35: 968–978, 2007. doi: 10.1016/j.neuroimage.2006.11.056. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Delorme A, Makeig S. EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J Neurosci Methods 134: 9–21, 2004. doi: 10.1016/j.jneumeth.2003.10.009. [DOI] [PubMed] [Google Scholar]
- Diedrichsen J, Hashambhoy Y, Rane T, Shadmehr R. Neural correlates of reach errors. J Neurosci 25: 9919–9931, 2005. doi: 10.1523/JNEUROSCI.1874-05.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Donchin E. Presidential address, 1980. Surprise!...Surprise? Psychophysiology 18: 493–513, 1981. doi: 10.1111/j.1469-8986.1981.tb01815.x. [DOI] [PubMed] [Google Scholar]
- Donchin E, Coles MG. Is the P300 component a manifestation of context updating? Behav Brain Sci 11: 357–374, 1988. doi: 10.1017/S0140525X00058027. [DOI] [Google Scholar]
- Enriquez-Geppert S, Konrad C, Pantev C, Huster RJ. Conflict and inhibition differentially affect the N200/P300 complex in a combined go/nogo and stop-signal task. Neuroimage 51: 877–887, 2010. doi: 10.1016/j.neuroimage.2010.02.043. [DOI] [PubMed] [Google Scholar]
- Eppinger B, Kray J, Mock B, Mecklinger A. Better or worse than expected? Aging, learning, and the ERN. Neuropsychologia 46: 521–539, 2008. doi: 10.1016/j.neuropsychologia.2007.09.001. [DOI] [PubMed] [Google Scholar]
- Fabiani M, Gratton G, Karis D, Donchin E. Definition, identification, and reliability of measurement of the P300 component of the event-related brain potential. Adv Psychophysiol 2: 1–78, 1987. [Google Scholar]
- Folstein JR, Van Petten C. Influence of cognitive control and mismatch on the N2 component of the ERP: a review. Psychophysiology 45: 152–170, 2008. doi: 10.1111/j.1469-8986.2007.00602.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Galea JM, Mallia E, Rothwell J, Diedrichsen J. The dissociable effects of punishment and reward on motor learning. Nat Neurosci 18: 597–602, 2015. doi: 10.1038/nn.3956. [DOI] [PubMed] [Google Scholar]
- Galea JM, Ruge D, Buijink A, Bestmann S, Rothwell JC. Punishment-induced behavioral and neurophysiological variability reveals dopamine-dependent selection of kinematic movement parameters. J Neurosci 33: 3981–3988, 2013. doi: 10.1523/JNEUROSCI.1294-12.2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Glimcher PW. Understanding dopamine and reinforcement learning: the dopamine reward prediction error hypothesis. Proc Natl Acad Sci USA 108, Suppl 3: 15647–15654, 2011. [Erratum at Proc Natl Acad Sci USA 108: 17568–17569, 2011.] doi: 10.1073/pnas.1014269108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Haith AM, Krakauer JW. Model-based and model-free mechanisms of human motor learning. Adv Exp Med Biol 782: 1–21, 2013. doi: 10.1007/978-1-4614-5465-6_1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hajcak G, Holroyd CB, Moser JS, Simons RF. Brain potentials associated with expected and unexpected good and bad outcomes. Psychophysiology 42: 161–170, 2005. doi: 10.1111/j.1469-8986.2005.00278.x. [DOI] [PubMed] [Google Scholar]
- Hajcak G, Moser JS, Holroyd CB, Simons RF. It’s worse than you thought: the feedback negativity and violations of reward prediction in gambling tasks. Psychophysiology 44: 905–912, 2007. doi: 10.1111/j.1469-8986.2007.00567.x. [DOI] [PubMed] [Google Scholar]
- Hauser TU, Iannaccone R, Stämpfli P, Drechsler R, Brandeis D, Walitza S, Brem S. The feedback-related negativity (FRN) revisited: new insights into the localization, meaning and network organization. Neuroimage 84: 159–168, 2014. doi: 10.1016/j.neuroimage.2013.08.028. [DOI] [PubMed] [Google Scholar]
- Heuer H, Hegele M. Generalization of implicit and explicit adjustments to visuomotor rotations across the workspace in younger and older adults. J Neurophysiol 106: 2078–2085, 2011. doi: 10.1152/jn.00043.2011. [DOI] [PubMed] [Google Scholar]
- Heydari S, Holroyd CB. Reward positivity: reward prediction error or salience prediction error? Psychophysiology 53: 1185–1192, 2016. doi: 10.1111/psyp.12673. [DOI] [PubMed] [Google Scholar]
- Holland P, Codol O, Galea JM. Contribution of explicit processes to reinforcement-based motor learning. J Neurophysiol 119: 2241–2255, 2018. doi: 10.1152/jn.00901.2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Holland PW, Welsch RE. Robust regression using iteratively reweighted least-squares. Commun Stat Theory Methods 6: 813–827, 1977. doi: 10.1080/03610927708827533. [DOI] [Google Scholar]
- Holroyd CB, Coles MG. The neural basis of human error processing: reinforcement learning, dopamine, and the error-related negativity. Psychol Rev 109: 679–709, 2002. doi: 10.1037/0033-295X.109.4.679. [DOI] [PubMed] [Google Scholar]
- Holroyd CB, Krigolson OE. Reward prediction error signals associated with a modified time estimation task. Psychophysiology 44: 913–917, 2007. doi: 10.1111/j.1469-8986.2007.00561.x. [DOI] [PubMed] [Google Scholar]
- Holroyd CB, Krigolson OE, Lee S. Reward positivity elicited by predictive cues. Neuroreport 22: 249–252, 2011. doi: 10.1097/WNR.0b013e328345441d. [DOI] [PubMed] [Google Scholar]
- Holroyd CB, Pakzad-Vaezi KL, Krigolson OE. The feedback correct-related positivity: sensitivity of the event-related brain potential to unexpected positive feedback. Psychophysiology 45: 688–697, 2008. doi: 10.1111/j.1469-8986.2008.00668.x. [DOI] [PubMed] [Google Scholar]
- Huang VS, Haith A, Mazzoni P, Krakauer JW. Rethinking motor learning and savings in adaptation paradigms: model-free memory for successful actions combines with internal models. Neuron 70: 787–801, 2011. doi: 10.1016/j.neuron.2011.04.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Inoue K, Kawashima R, Satoh K, Kinomura S, Sugiura M, Goto R, Ito M, Fukuda H. A PET study of visuomotor learning under optical rotation. Neuroimage 11: 505–516, 2000. doi: 10.1006/nimg.2000.0554. [DOI] [PubMed] [Google Scholar]
- Inoue M, Uchimura M, Kitazawa S. Error signals in motor cortices drive adaptation in reaching. Neuron 90: 1114–1126, 2016. doi: 10.1016/j.neuron.2016.04.029. [DOI] [PubMed] [Google Scholar]
- Izawa J, Shadmehr R. Learning from sensory and reward prediction errors during motor adaptation. PLOS Comput Biol 7: e1002012, 2011. doi: 10.1371/journal.pcbi.1002012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Klassen J, Tong C, Flanagan JR. Learning and recall of incremental kinematic and dynamic sensorimotor transformations. Exp Brain Res 164: 250–259, 2005. doi: 10.1007/s00221-005-2247-4. [DOI] [PubMed] [Google Scholar]
- Krakauer JW. Motor learning and consolidation: the case of visuomotor rotation. Adv Exp Med Biol 629: 405–421, 2009. doi: 10.1007/978-0-387-77064-2_21. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krakauer JW, Ghilardi MF, Mentis M, Barnes A, Veytsman M, Eidelberg D, Ghez C. Differential cortical and subcortical activations in learning rotations and gains for reaching: a PET study. J Neurophysiol 91: 924–933, 2004. doi: 10.1152/jn.00675.2003. [DOI] [PubMed] [Google Scholar]
- Kreussel L, Hewig J, Kretschmer N, Hecht H, Coles MG, Miltner WH. The influence of the magnitude, probability, and valence of potential wins and losses on the amplitude of the feedback negativity. Psychophysiology 49: 207–219, 2012. doi: 10.1111/j.1469-8986.2011.01291.x. [DOI] [PubMed] [Google Scholar]
- Krigolson OE, Holroyd CB, Van Gyn G, Heath M. Electroencephalographic correlates of target and outcome errors. Exp Brain Res 190: 401–411, 2008. doi: 10.1007/s00221-008-1482-x. [DOI] [PubMed] [Google Scholar]
- Leng Y, Zhou X. Modulation of the brain activity in outcome evaluation by interpersonal relationship: an ERP study. Neuropsychologia 48: 448–455, 2010. doi: 10.1016/j.neuropsychologia.2009.10.002. [DOI] [PubMed] [Google Scholar]
- Linden DE. The p300: where in the brain is it produced and what does it tell us? Neuroscientist 11: 563–576, 2005. doi: 10.1177/1073858405280524. [DOI] [PubMed] [Google Scholar]
- Loonis RF, Brincat SL, Antzoulatos EG, Miller EK. A meta-analysis suggests different neural correlates for implicit and explicit learning. Neuron 96: 521–534.e7, 2017. doi: 10.1016/j.neuron.2017.09.032. [DOI] [PMC free article] [PubMed] [Google Scholar]
- MacLean SJ, Hassall CD, Ishigami Y, Krigolson OE, Eskes GA. Using brain potentials to understand prism adaptation: the error-related negativity and the P300. Front Hum Neurosci 9: 335, 2015. doi: 10.3389/fnhum.2015.00335. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mannarelli D, Pauletti C, De Lucia MC, Currà A, Fattapposta F. Insights from ERPs into attention during recovery after cerebellar stroke: a case report. Neurocase 21: 721–726, 2015. doi: 10.1080/13554794.2014.977922. [DOI] [PubMed] [Google Scholar]
- Marko MK, Haith AM, Harran MD, Shadmehr R. Sensitivity to prediction error in reach adaptation. J Neurophysiol 108: 1752–1763, 2012. doi: 10.1152/jn.00177.2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Martin TA, Keating JG, Goodkin HP, Bastian AJ, Thach WT. Throwing while looking through prisms. I. Focal olivocerebellar lesions impair adaptation. Brain 119: 1183–1198, 1996. doi: 10.1093/brain/119.4.1183. [DOI] [PubMed] [Google Scholar]
- Maschke M, Gomez CM, Ebner TJ, Konczak J. Hereditary cerebellar ataxia progressively impairs force adaptation during goal-directed arm movements. J Neurophysiol 91: 230–238, 2004. doi: 10.1152/jn.00557.2003. [DOI] [PubMed] [Google Scholar]
- Mazzoni P, Krakauer JW. An implicit plan overrides an explicit strategy during visuomotor adaptation. J Neurosci 26: 3642–3645, 2006. doi: 10.1523/JNEUROSCI.5317-05.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McDougle SD, Bond KM, Taylor JA. Explicit and implicit processes constitute the fast and slow processes of sensorimotor learning. J Neurosci 35: 9568–9579, 2015. doi: 10.1523/JNEUROSCI.5061-14.2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McDougle SD, Ivry RB, Taylor JA. Taking aim at the cognitive side of learning in sensorimotor adaptation tasks. Trends Cogn Sci 20: 535–544, 2016. doi: 10.1016/j.tics.2016.05.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Michel C, Pisella L, Prablanc C, Rode G, Rossetti Y. Enhancing visuomotor adaptation by reducing error signals: single-step (aware) versus multiple-step (unaware) exposure to wedge prisms. J Cogn Neurosci 19: 341–350, 2007. doi: 10.1162/jocn.2007.19.2.341. [DOI] [PubMed] [Google Scholar]
- Miltner WH, Braun CH, Coles MG. Event-related brain potentials following incorrect feedback in a time-estimation task: evidence for a “generic” neural system for error detection. J Cogn Neurosci 9: 788–798, 1997. doi: 10.1162/jocn.1997.9.6.788. [DOI] [PubMed] [Google Scholar]
- Nieuwenhuis S, Holroyd CB, Mol N, Coles MG. Reinforcement-related brain potentials from medial frontal cortex: origins and functional significance. Neurosci Biobehav Rev 28: 441–448, 2004. doi: 10.1016/j.neubiorev.2004.05.003. [DOI] [PubMed] [Google Scholar]
- Nieuwenhuis S, Yeung N, van den Wildenberg W, Ridderinkhof KR. Electrophysiological correlates of anterior cingulate function in a go/no-go task: effects of response conflict and trial type frequency. Cogn Affect Behav Neurosci 3: 17–26, 2003. doi: 10.3758/CABN.3.1.17. [DOI] [PubMed] [Google Scholar]
- Nikooyan AA, Ahmed AA. Reward feedback accelerates motor learning. J Neurophysiol 113: 633–646, 2015. doi: 10.1152/jn.00032.2014. [DOI] [PubMed] [Google Scholar]
- Paulus KS, Magnano I, Conti M, Galistu P, D’Onofrio M, Satta W, Aiello I. Pure post-stroke cerebellar cognitive affective syndrome: a case report. Neurol Sci 25: 220–224, 2004. doi: 10.1007/s10072-004-0325-1. [DOI] [PubMed] [Google Scholar]
- Pekny SE, Izawa J, Shadmehr R. Reward-dependent modulation of movement variability. J Neurosci 35: 4015–4024, 2015. doi: 10.1523/JNEUROSCI.3244-14.2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pfabigan DM, Alexopoulos J, Bauer H, Sailer U. Manipulation of feedback expectancy and valence induces negative and positive reward prediction error signals manifest in event-related brain potentials. Psychophysiology 48: 656–664, 2011. doi: 10.1111/j.1469-8986.2010.01136.x. [DOI] [PubMed] [Google Scholar]
- Polich J. Updating P300: an integrative theory of P3a and P3b. Clin Neurophysiol 118: 2128–2148, 2007. doi: 10.1016/j.clinph.2007.04.019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Reuter EM, Pearcey GE, Carroll TJ. Greater neural responses to trajectory errors are associated with superior force field adaptation in older adults. Exp Gerontol 110: 105–117, 2018. doi: 10.1016/j.exger.2018.05.020. [DOI] [PubMed] [Google Scholar]
- Rüsseler J, Kuhlicke D, Münte TF. Human error monitoring during implicit and explicit learning of a sensorimotor sequence. Neurosci Res 47: 233–240, 2003. doi: 10.1016/S0168-0102(03)00212-8. [DOI] [PubMed] [Google Scholar]
- Saijo N, Gomi H. Multiple motor learning strategies in visuomotor rotation. PLoS One 5: e9399, 2010. doi: 10.1371/journal.pone.0009399. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Santesso DL, Evins AE, Frank MJ, Schetter EC, Bogdan R, Pizzagalli DA. Single dose of a dopamine agonist impairs reinforcement learning in humans: evidence from event-related potentials and computational modeling of striatal-cortical function. Hum Brain Mapp 30: 1963–1976, 2009. doi: 10.1002/hbm.20642. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sato A, Yasuda A, Ohira H, Miyawaki K, Nishikawa M, Kumano H, Kuboki T. Effects of value and reward magnitude on feedback negativity and P300. Neuroreport 16: 407–411, 2005. doi: 10.1097/00001756-200503150-00020. [DOI] [PubMed] [Google Scholar]
- Savoie FA, Thénault F, Whittingstall K, Bernier PM. Visuomotor prediction errors modulate EEG activity over parietal cortex. Sci Rep 8: 12513, 2018. doi: 10.1038/s41598-018-30609-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schönbrodt FD, Perugini M. At what sample size do correlations stabilize? J Res Pers 47: 609–612, 2013. [Erratum at J Res Pers 74: 194, 2018.] doi: 10.1016/j.jrp.2013.05.009. [DOI] [Google Scholar]
- Schween R, Hegele M. Feedback delay attenuates implicit but facilitates explicit adjustments to a visuomotor rotation. Neurobiol Learn Mem 140: 124–133, 2017. doi: 10.1016/j.nlm.2017.02.015. [DOI] [PubMed] [Google Scholar]
- Shmuelof L, Huang VS, Haith AM, Delnicki RJ, Mazzoni P, Krakauer JW. Overcoming motor “forgetting” through reinforcement of learned actions. J Neurosci 32: 14617–14621a, 2012. doi: 10.1523/JNEUROSCI.2184-12.2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith MA, Shadmehr R. Intact ability to learn internal models of arm dynamics in Huntington’s disease but not cerebellar degeneration. J Neurophysiol 93: 2809–2821, 2005. doi: 10.1152/jn.00943.2004. [DOI] [PubMed] [Google Scholar]
- Synofzik M, Lindner A, Thier P. The cerebellum updates predictions about the visual consequences of one’s behavior. Curr Biol 18: 814–818, 2008. doi: 10.1016/j.cub.2008.04.071. [DOI] [PubMed] [Google Scholar]
- Tachibana H, Aragane K, Sugita M. Event-related potentials in patients with cerebellar degeneration: electrophysiological evidence for cognitive impairment. Brain Res Cogn Brain Res 2: 173–180, 1995. doi: 10.1016/0926-6410(95)90006-3. [DOI] [PubMed] [Google Scholar]
- Tan H, Jenkinson N, Brown P. Dynamic neural correlates of motor error monitoring and adaptation during trial-to-trial learning. J Neurosci 34: 5678–5688, 2014. doi: 10.1523/JNEUROSCI.4739-13.2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tanaka H, Sejnowski TJ, Krakauer JW. Adaptation to visuomotor rotation through interaction between posterior parietal and motor cortical areas. J Neurophysiol 102: 2921–2932, 2009. doi: 10.1152/jn.90834.2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Taylor JA, Ivry RB. Cerebellar and prefrontal cortex contributions to adaptation, strategies, and reinforcement learning. Prog Brain Res 210: 217–253, 2014. doi: 10.1016/B978-0-444-63356-9.00009-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Taylor JA, Klemfuss NM, Ivry RB. An explicit strategy prevails when the cerebellum fails to compute movement errors. Cerebellum 9: 580–586, 2010. doi: 10.1007/s12311-010-0201-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Taylor JA, Krakauer JW, Ivry RB. Explicit and implicit contributions to learning in a sensorimotor adaptation task. J Neurosci 34: 3023–3032, 2014. doi: 10.1523/JNEUROSCI.3619-13.2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Therrien AS, Wolpert DM, Bastian AJ. Effective reinforcement learning following cerebellar damage requires a balance between exploration and motor noise. Brain 139: 101–114, 2016. doi: 10.1093/brain/awv329. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thoroughman KA, Shadmehr R. Learning of action through adaptive combination of motor primitives. Nature 407: 742–747, 2000. doi: 10.1038/35037588. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Torrecillos F, Albouy P, Brochier T, Malfait N. Does the processing of sensory and reward-prediction errors involve common neural resources? Evidence from a frontocentral negative potential modulated by movement execution errors. J Neurosci 34: 4845–4856, 2014. doi: 10.1523/JNEUROSCI.4390-13.2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van der Helden J, Boksem MA, Blom JH. The importance of failure: feedback-related negativity predicts motor learning efficiency. Cereb Cortex 20: 1596–1603, 2010. doi: 10.1093/cercor/bhp224. [DOI] [PubMed] [Google Scholar]
- Walsh MM, Anderson JR. Learning from experience: event-related potential correlates of reward processing, neural adaptation, and behavioral choice. Neurosci Biobehav Rev 36: 1870–1884, 2012. doi: 10.1016/j.neubiorev.2012.05.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wilcox RR. Modern insights about Pearson’s correlation and least squares regression. Int J Sel Assess 9: 195–205, 2001. doi: 10.1111/1468-2389.00172. [DOI] [Google Scholar]
- Wolpert DM, Ghahramani Z, Jordan MI. An internal model for sensorimotor integration. Science 269: 1880–1882, 1995. doi: 10.1126/science.7569931. [DOI] [PubMed] [Google Scholar]
- Wu Y, Zhou X. The P300 and reward valence, magnitude, and expectancy in outcome evaluation. Brain Res 1286: 114–122, 2009. doi: 10.1016/j.brainres.2009.06.032. [DOI] [PubMed] [Google Scholar]
- Yarkoni T. Big correlations in little studies: inflated fMRI correlations reflect low statistical power—commentary on Vul et al. (2009). Perspect Psychol Sci 4: 294–298, 2009. doi: 10.1111/j.1745-6924.2009.01127.x. [DOI] [PubMed] [Google Scholar]
- Yeung N, Botvinick MM, Cohen JD. The neural basis of error detection: conflict monitoring and the error-related negativity. Psychol Rev 111: 931–959, 2004. doi: 10.1037/0033-295X.111.4.931. [DOI] [PubMed] [Google Scholar]
- Yeung N, Sanfey AG. Independent coding of reward magnitude and valence in the human brain. J Neurosci 24: 6258–6264, 2004. doi: 10.1523/JNEUROSCI.4537-03.2004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhou Z, Yu R, Zhou X. To do or not to do? Action enlarges the FRN and P300 effects in outcome evaluation. Neuropsychologia 48: 3606–3613, 2010. doi: 10.1016/j.neuropsychologia.2010.08.010. [DOI] [PubMed] [Google Scholar]