

Abstract
Numerous publications have now addressed the principles of designing, analyzing, and reporting the results of stepped‐wedge cluster randomized trials. In contrast, there is little research available pertaining to the design and analysis of multiarm stepped‐wedge cluster randomized trials, utilized to evaluate the effectiveness of multiple experimental interventions. In this paper, we address this by explaining how the required sample size in these multiarm trials can be ascertained when data are to be analyzed using a linear mixed model. We then go on to describe how the design of such trials can be optimized to balance between minimizing the cost of the trial and minimizing some function of the covariance matrix of the treatment effect estimates. Using a recently commenced trial that will evaluate the effectiveness of sensor monitoring in an occupational therapy rehabilitation program for older persons after hip fracture as an example, we demonstrate that our designs could reduce the number of observations required for a fixed power level by up to 58%. Consequently, when logistical constraints permit the utilization of any one of a range of possible multiarm stepped‐wedge cluster randomized trial designs, researchers should consider employing our approach to optimize their trials efficiency.
Keywords: admissible design, cluster randomized trial, multiple comparisons, optimal design, stepped‐wedge
1. INTRODUCTION
In a cluster randomized trial (CRT), groups of participants, not individuals, are randomized. The advantages this can bring are today recognized as numerous. For example, CRTs can aid the control of contamination between participants and can bring increased administrative efficiency, helping to overcome the barriers of recruiting large numbers of participants.1 Unfortunately, there are also several well‐noted disadvantages to CRTs.(2, 3) Specifically, double blinding should ideally be present in every trial; however, it is often impossible in CRTs. Moreover, missing data can quickly become a problem if whole clusters are lost to follow‐up.
Nevertheless, there has now been much work conducted on design and analysis procedures for CRTs. One type of CRT that has received considerable attention recently, and which we focus on here, is the stepped‐wedge (SW)‐CRT (see, eg, the work of Hussey and Hughes4). In a SW‐CRT, an intervention is introduced over several time periods, and typically, all clusters receive the intervention by the end of the trial. Numerous potential advantages to this design have been forwarded. Principally, all clusters receiving the intervention is advantageous if it is expected to do more good than harm. The design's sequential implementation can also increase feasibility when there are logistical or practical constraints. However, these alleged advantages have been disputed. Primarily, it has been argued that an intervention should not be implemented in every cluster when it has not yet been proven to be effective. For brevity, we refer the reader elsewhere for further discussion of these points.(5, 6, 7, 8, 9, 10, 11, 12, 13)
Methodological developments in this area include the work of Hussey and Hughes,4 who provided guidance on sample size calculations for cross‐sectional SW‐CRTs analyzed with a particular linear mixed model. Here, cross‐sectional designs refer to a scenario in which measurements are accrued on different participants in each time period. This work was later built upon to establish a design effect for cross‐sectional SW‐CRTs14 and also to allow for transition periods and multiple levels of clustering.15 Recently, similar results for cohort SW‐CRTs, in which repeated measurements are accrued on a single group of patients, have been presented.16 Finally, explanations on determining the sample size required by SW‐CRTs through simulation have also been presented.17
Thus, sample size determination for SW‐CRTs has been well studied. However, the above articles only discuss sample size calculations for a particular design. That is, a design with prescribed rules about how the experimental intervention will be allocated across the clusters. Moreover, with the exception of the work of Baio et al,17 each paper deals only with a specific analysis model. Addressing these limitations, recent research has ascertained optimal treatment allocation rules for several general classes of cross‐sectional SW‐CRT design, analyzed with a highly flexible linear mixed model.(18, 19, 20) A subset of these results has subsequently been extended to cohort SW‐CRTs.21 Nonetheless, there is still a need for guidance on the optimal design of SW‐CRTs with more specialized analysis models.
Furthermore, the above publications relate only to the design of two‐arm SW‐CRTs. Very little research has been conducted on the design of CRTs with multiple experimental treatment arms, and in particular, scenarios in which clusters may switch between interventions. We refer to such designs in this article as multiarm SW‐CRTs (MA‐SWs). Formulae for the variance of the treatment effect estimators of several possible designs with three treatment arms, using a specific linear mixed model for data analysis, are available.22 An additional paper recently proposed, and compared the efficiencies of, several simple variants of the classical SW‐CRT design that could be used to accommodate multiple interventions.23 Finally, utilizing experimental design theory, the performance of several analysis models for the same such MA‐SW designs was recently examined.24 However, these are the only works that we are aware of pertaining to the design of MA‐SWs. This is perhaps surprising since several studies have recently been conducted in such a manner.(25, 26) Furthermore, intuitively, these designs could have numerous advantages that it would be beneficial to highlight. Explicitly, evaluating multiple interventions within the same CRT could bring the same sort of efficiency gains MA trials bring to individually randomized studies.27 That is, the required number of clusters or observations could be reduced relative to conducting several separate trials. Moreover, it could allow for a reduction in required funding as a consequence of reduced administrative costs and may allow for the assessment of intervention interactions. Furthermore, one would anticipate that such designs could on average decrease the time taken for each cluster to receive a particular intervention, which may improve cluster and patient participation. However, the potential of MA‐SWs can only be realized if we design such studies effectively; poorly designed MA‐SW trials would likely result in a poor answer being acquired to numerous important questions.
Therefore, here, we first discuss how one can compute the sample size required by, and optimized treatment sequence allocations for, a MA‐SW design when a linear mixed model is used for data analysis. We then consider one particular analysis model, and utilizing a recently undertaken trial as our principal motivation, discuss how large the efficiency gains made using our methods could be in practice.
2. METHODS
2.1. Notation, hypotheses, and analysis
We designate a MA‐SW as any trial conforming to the following requirements.
The trial is carried out in C ≥ 2 clusters, over T ≥ 2 time periods, with m > 1 measurements made in each cluster in each time period.
In each time period, each cluster receives a combination of a set of D interventions (indexed by d = 0,…,D − 1).
The sequence of intervention allocations for each cluster is specified randomly.
We make no assumptions about whether the m measurements from each time period are on different patients; a cross‐sectional design, or the same patients; a cohort design. We do not require each cluster to begin on, receive, or conclude the trial on any particular intervention. We also do not enforce the usual one‐directional switching associated with conventional SW‐CRTs, so as to allow for transitions between experimental interventions in any order, if this is desired. As a consequence of this, the methodology we describe is applicable to the design of MA cluster randomized crossover trials. We keep in mind, however, that each of the interventions must be received by at least one cluster in some time period for its effect to be estimable.
Throughout, we assume that the accrued data from the trial will be normally distributed, and an identifiable linear mixed model will be utilized for data analysis, denoted as
where
y is the vector of responses;
β=(β 1,…,β p)⊤ is a vector of p fixed effects;
A is the design matrix that links y to β;
u is a vector of random effects, with u∼N(0,G), where G is a specified (assumed known) matrix;
Z is the design matrix that links y to u;
ϵ is a vector of residuals, with ϵ∼N(0,R), where R is a specified (assumed known) matrix.
We suppose that β has been specified such that its first q, q ≤ p, elements, (β 1,…,β q)⊤, are our parameters of interest. Typically, we may have that q = D − 1, with these parameters representing either the direct effects of a set of experimental interventions relative to some control or the direct effect of intervention arm d relative to intervention arm d − 1, for d = 1,…,D − 1. However, we do not require that this be the case. Then, we assume that we will test the following one‐sided hypotheses:
We note though that the determination of MA‐SW designs for alternative hypotheses of interest, eg, two‐sided hypotheses, is also easily achievable by adapting what follows.
To test these hypotheses, following trial completion, we estimate β using the maximum likelihood estimator of a linear mixed model
Then,
We set and denote the covariance matrix of by Λq. That is, .
Our conclusions are then based upon the following Wald test statistics:
Explicitly, we reject H 0f if Z f > e, for critical boundary e. Given e, we can determine for any vector of true fixed effects β q the probability each particular H 0f is rejected, and the probability we reject at least one of H 01,…,H 0q, via the following integrals:
Here,
ϕ(x,μ,Σ) is the probability density function of a multivariate normal distribution with mean μ=(μ 1,…,μ k)⊤ and covariance matrix Σ, dim(Σ) = k × k, evaluated at vector x=(x 1,…,x k)⊤;
(a 1,…,a n)⊤ ∘ (b 1,…,b n)⊤ = (a 1 b 1,…,a n b n)⊤;
is the elementwise square root of the vector of information levels for β q;
diag(v) for a vector v indicates the matrix formed by placing the elements of v along the leading diagonal.
Determining an appropriate value for e depends upon whether a correction for multiple testing is to be utilized. Without such a correction, e can be chosen to control the per‐hypothesis error rate to α by setting e as the solution to
Alternatively, the familywise error rate, the probability of one or more false rejections, can be controlled, for example, using the Bonferroni correction, which sets in this instance e to be the solution of
The choice of whether to utilize a multiple testing correction is not a simple one, with much debate in the literature around when it is necessary. It seems reasonable for MA‐SWs, however, to extrapolate from previous discussions, and note that one should correct in confirmatory settings but should not always feel the need to in exploratory settings.28
2.2. Power considerations
The above fully specifies a hypothesis testing procedure for a MA‐SW. However, at the design stage, it is important to be able to determine values of m, C, and T that provide both the desired per‐hypothesis or familywise error rate and the desired power. Here, we describe two types of power that could be required, since power is not a simple concept in MA trials.
We suppose that power of at least 1 − β is required either to reject each H 0f (individual power) or at least one of H 01,…,H 0q (combined power), when β q=δ=(δ 1,…,δ q)⊤. The element δ f here represents a clinically relevant difference for the effect β f. Using our notation from earlier, these requirements can be written as
The choice between these requirements should be made based on several considerations. The latter will likely require smaller sample sizes; however, it would leave a trial less likely to reject all false null hypotheses. Therefore, trialists must weigh up the cost restrictions and goals of their trial.
2.3. Design specification
We can now return to our considerations on determining appropriate values for m, C, and T. We must also determine as part of the same process a matrix X that indicates the planned allocation of interventions to each cluster across the time periods. Extending the notation commonly utilized for SW‐CRTs, X is a C × T matrix, with X ij indicating which intervention(s) cluster i receives in time period j. If only a single intervention is given to each cluster in each time period, then X ij will be a single number. Otherwise, it may be some combination of values, indicating allocation to multiple interventions. With this, it will now be useful to denote the design utilized by a trial by , and the associated covariance matrix for β q by . Our goal is then to optimize .
Most of the works on sample size determination for SW‐CRTs pre‐supposes that two of the three parameters m, C, and T are fixed (with one usually T) and then looks to identify the third. In addition, the matrix X is usually specified, if not explicitly (in the case where C and T are fixed), then through some rule such as balanced stepping. Here, we take an alternate approach to the determination of the preferred design. We assume that a set of allowed values for T has been specified, . We then suppose that sets of allowed values for C, for each element of , have been specified. We denote these by , with . Furthermore, we suppose that, for each allowed C,T combination, a set of allowed values for m has been provided; . We then take . We allow for such an interrelated specification of the values for m, C, and T to cover many possible design scenarios. For example, increasing the value of T may mean logistical constraints force only lower values of m and C to be possible. In actuality, it is likely a trialist would not need such a complicated structure. For example, the classical case of fixed T and m, searching for the correct value for C, would require only , , and , with , and C max some suitably large value.
Finally, for each C,T combination, we also specify a set of allowed X, which we denote by . Similar to the above, we then take . Shortly, we will describe several possible ways in which could be specified.
Now, with , , , and chosen, formally, our set of all allowed possible designs is
2.4. Admissible design determination
As was discussed, previous research has assessed what is the optimal SW‐CRT design to maximize power in an array of possible design scenarios. This was achieved by developing formulae for the efficiency of designs under particular linear mixed models. Such considerations could, in theory, be extended to MA‐SWs or to alternate analysis models. However, it is not practical to conduct such derivations for every value of D or every analysis model that may need to be utilized. In addition, it is not actually necessary following specification of the set : preferable designs can be determined using exhaustive or stochastic heuristic searches.
Explicitly, for some , modern computing makes an exhaustive search possible using parallelization. Alternatively, in the case where C and T are fixed (either in advance or after some initial design identification), we can employ a different method to determine our final design: a stochastic search. This is sensible when, even with C and T fixed, the design space remains large. Here, we accomplish this optimization using CEoptim in R.29
To perform a search, an optimality criterion is required. Previous research on SW‐CRTs has focused on determining designs that minimize the variance of the treatment effect estimator. Here, we extend this to consider designs that minimize some weighted combination of a trial cost function and some factor formed from the covariance matrix of the treatment effect estimators, .
Specifically, we allocate a function that sets the cost associated with a trial using design . This could be as simple as the required number of observations, or something more complex that factors in the speed the interventions would need to be rolled out according to X, for example.
For , numerous possible optimality criteria have been suggested in the literature. We consider D‐, A‐, and E‐optimal designs, which all have a long history within the field of experimental design. D‐optimality corresponds to minimizing the determinant of , . This can be interpreted as minimizing the volume of the confidence ellipsoid for the β f. For A‐optimality, the average value of the elements along the diagonal of , , is minimized. That is, we minimize the average variance of the β f. Finally, in E‐optimality, we minimize the maximal value of the elements along the diagonal of , , ie, we minimize the most extreme, or largest, of the variances of the β f. We refer the reader elsewhere for greater detail on these criteria.(30, 31)
Then, for example, our admissible design using the D‐optimality criteria will be the , conforming to the trials power requirements, that minimizes
| (1) |
Here, and are rescaled precisely because they exist on different scales. Additionally, 0 ≤ w ≤ 1 is the weight given to minimizing the trials cost relative to the efficiency of . Note that the case w = 1 should often be ignored since many designs will likely share equal values of . Admissible designs using the A‐ or E‐optimality criteria are formed by replacing in the above by or , respectively.
Note that, if all of the designs in cannot attain the desired power, no admissible design will exist. To counteract this, we can increase the value of β. In an extreme scenario where no design will likely meet any reasonable power requirement, we can set β = 1 and w = 0 and look to determine the design that simply minimizes some function of .
Finally, the rescaling in Equation (1) is only possible in the case of an exhaustive search where minimal and maximal values can be identified. Therefore, in the case of a stochastic search, we consider only meeting the conventional D‐, A‐ and E‐optimality criteria, without rescaling.
2.5. Example trial design scenarios and associated linear mixed model
In what follows, we frame our examples within the context of studies in which there is a nested natural order upon the D interventions. That is, as in the works of Chinbuah et al25 and Pol et al,26 for d = 1,…,D − 1, intervention d consists of intervention d − 1 and some additional factor (eg, intervention d may include additional components of some wider multifaceted intervention over intervention d − 1). We therefore now, in all instances, enforce the restrictions that each cluster receives only a single intervention in each time period and that, if a cluster receives intervention d in time period j, it cannot receive interventions 0,…,d − 1 in time periods j + 1,…,T. Relating this restriction to our matrix X, it implies X ij ≥ X ij − 1 for j = 2,…,T and i = 1…,C.
Our methodology for the determination of admissible MA‐SW designs is now fully specified. Code to implement our methods and replicate our results is available from https://github.com/mjg211/article_code. Next, several example trial design scenarios are considered to demonstrate the efficiency gains our designs could bring. In each, we assume that the goal is to compare the efficacy of intervention 1 to intervention 0, intervention 2 to intervention 1, and so on, giving q = D − 1. Moreover, in all examples, the following linear mixed model, an extension of that used in the works of Girling and Hemming19 and Hooper et al16 to a MA setting, is employed for data analysis
Here,
is the indicator function on event x;
y ijk is the kth response (k = 1,…,m), in the ith cluster (i = 1,…,C), in the jth time period ( j = 1,…,T);
μ is an intercept term;
π j is the fixed effect for the jth time period (with π 1 = 0 for identifiability);
c i is the random effect for cluster i, with ;
θ ij is a random interaction effect for cluster i and period j, with ;
s ik is a random effect for repeated measures in individual k from cluster i, with ;
ϵ ijk is the residual error, with .
Thus, we specify our model to be applicable to a cohort MA‐SW trial. We can then recover a model appropriate for a cross‐sectional design by setting . Note that, by the above, the variance of response y ijk is . In Section 3, we will make reference to the following three correlation parameters:
: the within‐period correlation (the correlation between the responses from two distinct individuals, in the same cluster, in the same time period);
: the interperiod correlation (the correlation between the responses from two distinct individuals, in the same cluster, in distinct time periods);
: the individual autocorrelation (the correlation between the responses from the same individual in distinct time periods).
Finally, note that we also restrict the sets in all instances to those X, which imply the above model is identifiable, which can be verified for any X using the implied design matrix A. However, for brevity, we do not explicitly state this requirement in our forthcoming specifications of the sets .
3. RESULTS
3.1. D = 2: Girling and Hemming (2016) and Thompson et al (2017)
It was previously demonstrated that the efficiency of a conventional SW‐CRT (ie, the case D = 2), analyzed with the above linear mixed model, could be assessed using the cluster mean correlation, given by19
where ρ is the intracluster correlation for the means of the observations at each time‐point, in each cluster. The optimal X matrices to minimize the variance of , when T = 6 and C = 10, were also provided in this paper. We now demonstrate how our exhaustive search procedure can identify such optimal designs.
First, we set and . We place no further restrictions on than those outlined in Section 2.5, and thus,
To minimize , we take w = 0 and β = 1. Since D = 2, the D‐, A‐, and E‐optimality criteria are equivalent, and we do not need to specify a multiple comparison correction. While with β = 1, our choices for α, δ, and desire for individual or combined power are irrelevant. Finally, for simplicity, we reduce our model to that from the work of Hussey and Hughes4 by supposing that . Then, ρ = ρ 0 = ρ 1 = ρ 2 is the conventional intracluster correlation associated with cross‐sectional SW‐CRTs. Accordingly, to find optimal designs for different ranges of E(ρ), as in Girling the work of and Hemming,19 we take as an example σ 2 = 1, , and set ρ as those values that imply E(ρ) ∈ {0.1,0.15,0.3,0.45,0.75,0.9}.
The results of our exhaustive searches are shown in Table 1. In each instance, the optimal design is, as would be expected, identical to that found previously. We have thus confirmed the ability of our search procedure to easily identify optimal designs for a given set of input parameters and chosen linear mixed model. Of course, in this scenario, it would likely, in practice, be easier to utilize the methodology of Girling and Hemming.19
Table 1.
Optimal allocation matrices for cross‐sectional designs with D = 2. The optimal allocation matrices in the case , , , and σ 2 = 1, with w = 0 and β = 1 are shown for a range of possible values of E(ρ). No restrictions are placed on other than the identifiability of Equation (1). Each allocation matrix was identified via our exhaustive search method and matches that identified by previous research
| Factor | Results | ||||||
|---|---|---|---|---|---|---|---|
| E(ρ) | 0.1 | 0.15 | 0.3 | ||||
| X |
|
|
|
||||
| E(ρ) | 0.45 | 0.75 | 0.9 | ||||
| X |
|
|
|
||||
More recently, Thompson et al20 demonstrated that, when , if an equal number of clusters must be allocated to each sequence, then the optimal number of sequences to utilize would be
We now verify their findings by restricting our set as follows:
where a can be any value such that C/a is an integer.
For the design parameters utilized to construct Table 1, we repeated our exhaustive searches but with the modified given above. For E(ρ) ∈ {0.10,0.15,0.30}, we found that the optimal X was
This should not surprise us, as for E(ρ) ∈ {0.10,0.15,0.30}, we have F(ρ) ∈ {1.46,1.63,2.21} to 2 decimal places, and the X listed above is one of the few matrices belonging to the modified that utilizes two sequences.
In contrast, for E(ρ)=0.45, we find F(ρ)=3.04. However, for C=10, the only way equal allocation to sequences can be achieved is to utilize either two or five sequences. It should therefore not surprise us that the optimal X was identified as
which uses five sequences. Finally, for E(ρ) ∈ {0.75,0.9}, we have F(ρ) ∈ {7.46,19.49}, and the optimal X was again one that employs five sequences.
3.2. D = 2: sensitivity of the optimal designs to the variance parameter specification
It is important to note that our admissible design determination procedure, like the articles on optimal SW‐CRTs that have come before, is dependent upon the specification of all relevant variance parameters. It is for this reason that Girling and Hemming19 assessed the sensitivity of the performance of their optimized designs to the value of E(ρ), via a simulation study in which E(ρ) was specified using a prior.
Here, we consider an alternative approach to visualizing the performance of optimal designs across possible values of the variance parameters. First, in Figure 1, for w = 0, β = 1, , , , and , we present the locations on an equally spaced grid within at which we identified various designs to be optimal using an exhaustive search (placing no restrictions on ). In total, 11 designs were found to be optimal for at least one combination. We list these in full in the Online Supplementary Material. It would be reasonable to be troubled by this result, as it suggests, a design that we believe to be optimal may not in reality be optimal if the variance parameters are even minorly misspecified.
Figure 1.
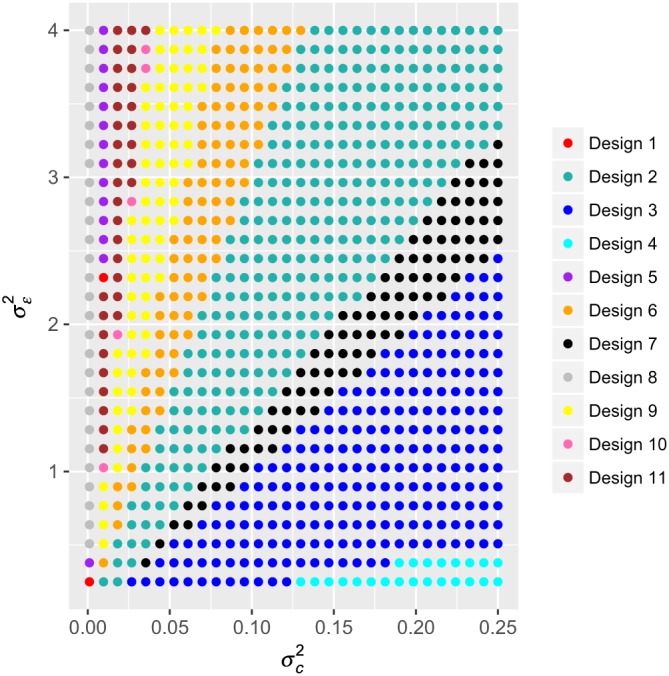
Optimal allocation matrices for cross‐sectional designs with D = 2. The optimal allocation matrices in the case , , , and σ 2 = 1, with w = 0 and β = 1 are shown for a range of possible combinations of . No restrictions are placed on other than the identifiability of Equation (1). Each allocation matrix was identified via our exhaustive search method [Colour figure can be viewed at wileyonlinelibrary.com]
We can, however, inspect how large our concern should be by examining the performance of any of these optimal designs across the possible values of the variance parameters, relative to the performance of the true optimal design at each point. That is, we inspect the ratio of the variance of the intervention effect estimate of a particular design to that of the optimal design at each combination. We present such an evaluation in Figure 2 for the following design matrices:
which are Designs 8 and 3 from Figure 1, respectively. As must obviously be the case, the value of the ratio of the variances is in all instances at least one. We observe that, with the matrix X 1, the variance of the intervention effect estimate is substantially larger than that for the optimal design when the values of and are misspecified, particularly when the value of ρ is in fact large. In contrast, using the matrix X 2 retains efficient performance in many instances. However, if ρ is small then the variance of the intervention effect provided by this design is still more than 40% larger than that of the optimal design.
Figure 2.
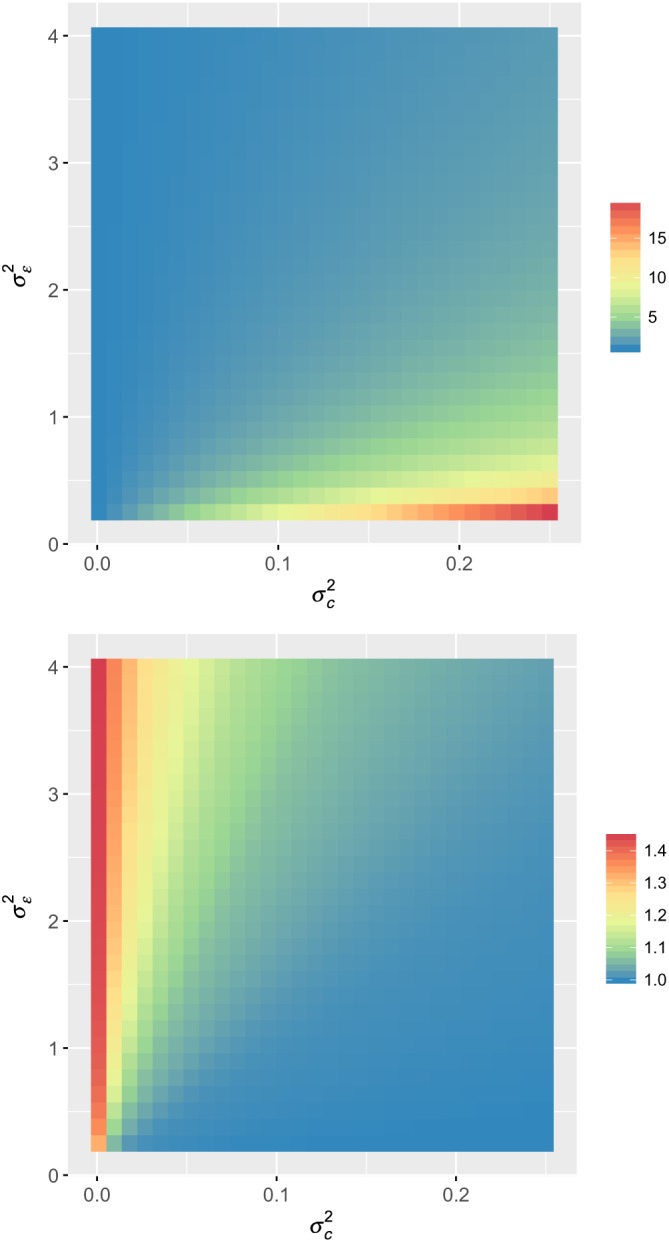
The ratio of the variance of the intervention effect when using design matrices X 1 (top) and X 2 (bottom) relative to the optimal design (given in Figure 1) is shown for a range of possible combinations of [Colour figure can be viewed at wileyonlinelibrary.com]
3.3. D = 2: Li et al (2018)
Li et al21 recently extended the results in the work of Lawrie et al18 to cohort SW‐CRTs. Specifically, they considered a case in which all clusters have to begin in the control condition (intervention 0) and conclude in the experimental (intervention 1). They then demonstrated that the optimal X could be specified by ensuring that the proportion, p t, of clusters allocated to a sequence with t ones preceded by T − t zeros satisfies
where
Here, we explore their findings for several example design scenarios, again via an exhaustive search. As above, we consider the case in which , , and , with σ 2 = 1, w = 0, and β = 1. To follow their restrictions on the allowed X, we enforce that
Then, we denote by p th = (p 1,…,p T − 1)⊤ the vector of the p t for the theoretical optimal designs derived by Li et al,21 and we denote by p emp the vector of the empirical values of the p t for our identified optimal designs. Our findings are presented in Table 2 for (ρ 0,ρ 1,ρ 2) ∈ {0.05,0.1} × {0.001,0.002} × {0.25,0.5}. They illustrate one potential issue with applying the results in the work of Li et al21 in practice that the theoretically optimal values of the p t will likely not be achievable because C is an integer. However, it is clear that the empirical values of the proportions of clusters changing to the experimental intervention in each time period are close to their theoretical values, even in this case where C is small.
Table 2.
Optimal allocation matrices for cohort designs with D = 2. The optimal allocation matrices in the case , , , and σ 2 = 1, with w = 0 and β = 1 are shown for a range of possible combinations of ρ 0, ρ 1, and ρ 2. Restrictions are placed on such that Equation (1) is identifiable and that each cluster must start in the control intervention (arm 0) and conclude in the experimental intervention (arm 1). Each allocation matrix was identified via our exhaustive search method
| Factor | Results | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| ρ 0 | 0.050 | 0.050 | 0.050 | 0.050 | |||||
| ρ 1 | 0.001 | 0.001 | 0.002 | 0.002 | |||||
| ρ 2 | 0.250 | 0.500 | 0.250 | 0.500 | |||||
| X |
|
|
|
|
|||||
|
|
(0.30,0.08,0.08,0.08,0.30) | (0.24,0.10,0.10,0.10,0.24) | (0.29,0.08,0.08,0.08,0.29) | (0.24,0.10,0.10,0.10,0.24) | |||||
|
|
(0.4,0.1,0.1,0.1,0.3) | (0.3,0.1,0.2,0.1,0.3) | (0.4,0.1,0.1,0.1,0.3) | (0.3,0.1,0.2,0.1,0.3) | |||||
| ρ 0 | 0.100 | 0.100 | 0.100 | 0.100 | |||||
| ρ 1 | 0.001 | 0.001 | 0.002 | 0.002 | |||||
| ρ 2 | 0.250 | 0.500 | 0.250 | 0.500 | |||||
| X |
|
|
|
|
|||||
|
|
(0.32,0.07,0.07,0.07,0.32) | (0.26,0.10,0.10,0.10,0.26) | (0.31,0.07,0.07,0.07,0.31) | (0.26,0.10,0.10,0.10,0.26) | |||||
|
|
(0.4,0.1,0,0.1,0.4) | (0.3,0.1,0.2,0.1,0.3) | (0.4,0.1,0,0.1,0.4) | (0.3,0.1,0.2,0.1,0.3) | |||||
3.4. D = 3: SO‐HIP Study
The SO‐HIP study is a cross‐sectional MA‐SW, with D = 3, to evaluate the effectiveness of sensor monitoring in an occupational therapy rehabilitation program for older people after hip fracture. Specifically, arm 0 corresponds to providing participants with care as usual. Arm 1 then involves the additional use of occupational therapy without sensor monitoring, in contrast to arm 2 that incorporates occupational therapy with cognitive behavioral therapy coaching using sensor monitoring as a coaching tool. Thus, as discussed earlier, intervention d − 1 is nested within intervention d, for d = 1,2.
SO‐HIP plans to enroll six clusters (C = 6) and has six time periods (T = 6), with eight observations made per cluster per period (m = 8), using the following matrix for treatment allocation:
The trial has δ=(1.5σ,0.75σ)⊤ and assumes that and ρ( = ρ 0 = ρ 1 = ρ 2) = 0.05. With this, when σ 2 = 1, using our methods described above, we can identify that the proposed design will have an individual power of 0.88 (β = 0.12) when the familywise error rate is controlled to α = 0.05 using the Bonferroni correction. For further information on this trial, see the published protocol.26
We now consider how much efficiency could be gained by utilizing an alternative design. We presume that, in the trial, any number of time periods two through six could have been employed ( ) and any number of clusters two through six could have actually been utilized ( , with for each ). Finally, we assume that the trials plan to recruit 48 patients in total from each cluster would allow . Here, we enforce that
Taking our cost function to be the total number of observations, , we present several admissible designs in Table 3. Explicitly, in this case, we find that the optimal designs when using the D‐, A‐, and E‐optimality criteria coincide for w = 0 and w = 0.5. Note that we also considered the optimal designs for w = 1 − 10−4, but they were found to be identical to those for w = 0.5.
Table 3.
Optimal allocation matrices for cross‐sectional designs with D = 3. Several optimal allocation matrices in the case , , , , σ 2 = 1, ρ = 0.05, α = 0.05 with the Bonferroni correction, and β = 0.12 for the individual power when δ=(1.5σ,0.75σ)⊤ are shown. Specifically, the optimal design for the optimality criteria is given for w ∈ {0,0.5}. No restrictions are placed on other than the identifiability of Equation (1). Each allocation matrix was identified via our exhaustive search method. The utilized design is also shown for comparison
| Design | ||||||
|---|---|---|---|---|---|---|
| Factor | Proposed | D/A/E‐Optimal: w = 0 | D/A/E‐Optimal: w = 0.5 | |||
| C | 6 | 6 | 6 | |||
| T | 6 | 6 | 5 | |||
| m | 8 | 8 | 4 | |||
| X |
|
|
|
|||
|
|
1.000 | 1.0000 (±0%) | 0.9937 (−0.6%) | |||
|
|
0.8815 | 0.9878 (+12.1%) | 0.8818 (±0%) | |||
|
|
288 | 288 (±0%) | 120 (−58.3%) | |||
|
|
3.090 × 10−3 | 9.990 × 10−4 (−67.7%) | 6.377 × 10−3 (+106.4%) | |||
|
|
5.696 × 10−2 | 3.175 × 10−2 (−44.3%) | 8.508 × 10−2 (+49.4%) | |||
|
|
5.696 × 10−2 | 3.175 × 10−2 (−44.3%) | 1.132 × 10−1 (+98.8%) | |||
We can see that the individual power of the trial could be increased by as much as 12.1%, as a result of reducing the maximum value of the variances of the treatment effect estimators by 44.3% (w = 0). Alternatively, the individual power could be maintained and the required number of observations reduced by up to 58.3% (w = 0.5).
Now, in Table 4, we present corresponding evaluations, but with further restrictions placed on the sets , as follows:
That is, we enforce that each cluster receives interventions 0, 1, and 2. This allows us to perform an assessment of the advantages optimization that can bring in the likely common case in which it is desired that each cluster receive all of the interventions. Note that, in this case, certain combinations of C and T considered above are no longer possible (eg, for T = 2, a cluster cannot receive all three interventions).
Table 4.
Optimal allocation matrices for cross‐sectional designs with D = 3. Several optimal allocation matrices in the case , , , , σ 2 = 1, ρ = 0.05, α = 0.05 with the Bonferroni correction, and β = 0.12 for the individual power when δ=(1.5σ,0.75σ)⊤ are shown. Specifically, the optimal design for the optimality criteria is given for w ∈ {0,0.5}. Restrictions are placed on such that Equation (1) is identifiable and that each cluster must receive each of the interventions. Each allocation matrix was identified via our exhaustive search method. The utilized design is also shown for comparison
| Design | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Factor | Proposed | D‐Optimal: w = 0 | D‐Optimal: w = 0.5 | A/E‐Optimal: w = 0 | A/E‐Optimal: w = 0.5 | |||||
| C | 6 | 6 | 6 | 6 | 6 | |||||
| T | 6 | 6 | 6 | 6 | 6 | |||||
| m | 8 | 8 | 5 | 8 | 5 | |||||
| X |
|
|
|
|
|
|||||
|
|
1.0000 | 1.0000 (±0%) | 1.0000 (±0%) | 1.0000 (±0%) | 1.0000 (±0%) | |||||
|
|
0.8815 | 0.9528 (+8.1%) | 0.8507 (−3.5%) | 0.9570 (+8.6%) | 0.8440 (−4.3%) | |||||
|
|
288 | 288 (±0%) | 180 (−37.5%) | 288 (±0%) | 180 (−37.5%) | |||||
|
|
3.090 × 10−3 | 1.670 × 10−3 (−46.0%) | 3.881 × 10−3 (+25.6%) | 1.712 × 10−3 (−44.6%) | 3.973 × 10−3 (+25.6%) | |||||
|
|
5.696 × 10−2 | 4.264 × 10−2 (−25.1%) | 6.392 × 10−2 (+12.2%) | 4.160 × 10−2 (−27.0%) | 6.373 × 10−2 (+11.9%) | |||||
|
|
5.696 × 10−2 | 4.264 × 10−2 (−25.1%) | 6.531 × 10−2 (+14.7%) | 4.160 × 10−2 (−27.0%) | 6.373 × 10−2 (+11.9%) | |||||
We now find that, while the optimal designs are equivalent when using the A‐ or E‐optimality criteria, the D‐optimal designs are distinct. Overall, while the potential efficiency gains that are possible when restricting to these more classical designs are more modest than those in Table 3, they are still substantial. In particular, the admissible designs with w = 0.5 provide a 37.5% reduction in the required number of observations compared to the utilized design. Moreover, we can still increase the individual power by up to 8.6%.
3.5. D = 3: optimal cross‐sectional designs according to the value of the cluster mean correlation
We have now noted the fact that previous papers have described how the optimal cross‐sectional SW‐CRT design when D = 2 changes according to the value of the cluster mean correlation E(ρ) (where ρ = ρ 0 = ρ 1 = ρ 2 for ). In fact, in Table 1, we provide an example of this for a case with C = 10 and T = 6. In it, we observe that the optimal design as E(ρ) increases changes from one resembling a parallel group CRT, to a more classical SW‐CRT design. Here, we provide a brief assessment of whether such a pattern exists for designs with D = 3, in a setting motivated by the SO‐HIP trial. Thus, we set , , , σ 2 = 1, w = 0, β = 1, and
We then consider which design is optimal according to the D‐, A‐, and E‐optimality criteria for E(ρ) ∈ {0,0.01,…,1}. We present our findings for E‐optimality in Table 5 and for D‐ and A‐optimality in the Online Supplementary Material. Specifically, we can see that, while the pattern to the way in which the optimal X changes is arguably less clear than in the case with D = 2, there is still a trend that the best possible choice shifts from a longitudinal parallel group CRT, to a design resembling an extension of a classical SW‐CRT.
Table 5.
E‐optimal allocation matrices for cross‐sectional designs with D = 3. The E‐optimal allocation matrices in the case , , , and σ 2 = 1, with w = 0 and β = 1 are shown for E(ρ) ∈ {0,0.01,…,1}. No restrictions are placed on other than the identifiability of Equation (1). Each allocation matrix was identified via our exhaustive search method
| Factor | E‐optimal designs | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| E(ρ) | {0,…,0.06} | 0.07 | {0.08,…,0.11} | {0.12,…,0.34} | {0.35,0.36} | {0.37,…,0.65} | |||||||
| X |
|
|
|
|
|
|
|||||||
| E(ρ) | {0.66,…,0.83} | 0.84 | 0.85 | {0.86,…,0.94} | {0.95,…,0.99} | 1.00 | |||||||
| X |
|
|
|
|
|
|
|||||||
3.6. D = 4 : stochastic determination of optimal designs
Finally, we suppose that the SO‐HIP study is to actually be conducted with a fourth intervention arm. This hypothetical trial is to again be conducted in six clusters (C = 6), with eight measurements taken per cluster per period (m = 8), but will now run across eight periods (T = 8). Furthermore, the following natural extension of the design for D = 3 will be used for X:
We assume that the trial will control the familywise error rate to α = 0.05 using the Bonferroni correction. Pre‐trial, the variance parameters have been set as σ 2 = 1 and ρ = 0.05, and we take δ=(1.5σ,0.75σ,0.75σ)⊤.
We then suppose that we desire to determine how much the trials efficiency could be improved if an alternative design was utilized. For this, we employ a stochastic search, as , , and with D = 4 confer a design space too large for an exhaustive comparison.
In Table 6, we present the stochastically identified optimal designs for the D‐, A‐, and E‐optimality criteria. We can see that, in particular, the average variance of our intervention effects could be reduced by up to 49.8% (A‐optimality), or the maximal variance of the intervention effects reduced by up to 48.2% (E‐optimality). It is thus clear that a stochastic search can allow the identification of efficient designs when an exhaustive search would not be feasible.
Table 6.
Optimal allocation matrices for cross‐sectional designs with D = 4. Several optimal allocation matrices in the case , , , σ 2 = 1, ρ = 0.05, α = 0.05 with the Bonferroni correction, w = 0, and β = 0.12 for the individual power when δ=(1.5σ,0.75σ,0.75σ)⊤ are shown. No restrictions are placed on other than the identifiability of Equation (1). Each allocation matrix was identified via our stochastic search method. The proposed design is also shown for comparison
| Design | ||||||||
|---|---|---|---|---|---|---|---|---|
| Factor | Proposed | D‐optimal | A‐optimal | E‐optimal | ||||
| X |
|
|
|
|
||||
|
|
1.000 | 1.000 (±0%) | 1.000 (±0%) | 1.000 (±0%) | ||||
|
|
0.852 | 0.992 (+11.6%) | 0.996 (+11.7%) | 0.989 (+11.6%) | ||||
|
|
0.852 | 0.990 (+11.6%) | 0.984 (+11.6%) | 0.989 (+11.6%) | ||||
|
|
1.559 × 10−4 | 1.985 × 10−5 (−87.3%) | 2.108 × 10−5 (−86.5%) | 2.090 × 10−5 (−86.6%) | ||||
|
|
5.590 × 10−2 | 2.873 × 10−2 (−48.6%) | 2.806 × 10−2 (−49.8%) | 2.886 × 10−2 (−48.4%) | ||||
|
|
5.590 × 10−2 | 3.024 × 10−2 (−45.9%) | 3.085 × 10−2 (−44.8%) | 2.893 × 10−2 (−48.2%) | ||||
4. DISCUSSION
We have presented a method to determine admissible MA‐SW designs. Our work builds on previous results for SW‐CRTs to allow trialists to determine efficient designs when any linear mixed model is to be used for data analysis and when there is any number of treatment arms.
For our primary motivating example, the SO‐HIP study, we demonstrated for the considered parameters that the individual power could have been maintained with the number of required observations reduced by 58%. While for some possible design parameter combinations, this reduction would likely not be so pronounced, it is clear that admissible designs in this context could bring notable efficiency gains.
It is important to note, however, that there are some scenarios in which our approach would likely not be applicable. This includes cases where the design space is extremely large, even after C and T have been specified precisely. A trialist must then either look to extend the approach of Girling and Hemming19 or look to reduce the size of to make an exhaustive or stochastic search possible.
More significantly, our methodology, like all others on optimal SW‐CRT design, assumes that the variance parameters of the analysis model of interest are known. Accordingly, our approach may not be a wise one when substantial uncertainty exists about their values. When confidence does exist around their specification, it remains important to assess the sensitivity of the chosen design to the underlying assumptions, using, for example, an approach like that in Section 3.2.
Our methodology is also limited to linear mixed models. For large sample sizes our methods may still be appropriate for alternate endpoints such as binary or count data, but they would not always be acceptable in these domains. In the Online Supplementary Material, we provide a brief demonstration of how our methods can be applied to binary outcome variables. In addition, for some linear mixed models, allowing the number of time periods T to vary may cause issues if a complex correlation structure is assumed for the accrued responses.
Furthermore, as for any trial, the particular linear mixed model used for data analysis should be chosen carefully. Here, an unwise choice of model could cause problems as the chosen design may not be optimal for an alternative potential model. More importantly though, as discussed recently by Kasza et al,32 an incorrect choice of correlation structure can have a significant impact on the sample size required by, and the power of, SW‐CRTs. It is easy to envisage this problem being exacerbated in MA‐SWs, given that the presence of multiple interventions may necessitate a highly complex correlation structure. Thus, we highlight again that arguably more appropriate linear mixed models for the analysis of SW‐CRT data than that considered here are supported by our methodology, and we advise that, in general, it would be important to consider their utilization.
We made few principal assumptions about the nature of the trial design. Our method is applicable to both cross‐sectional and cohort studies and to cases where either a single or multiple interventions are allocated to each cluster in each time period. Nonetheless, from those MA‐SW trials conducted so far, it appears that a common likelihood will be that there is some natural ordering to the interventions. Lyons et al,23 however, do provide a detailed description of alternative possibilities to this.
In Section 3, we employed several different types of restrictions on the sets . In particular, we demonstrated that our approach can be easily applied to attain classical designs where the clusters receive all interventions and to cases where there must be equal allocation to sequences. In general, not placing restrictions on , beyond those that are absolutely required, will result in the determination of the most efficient design. However, particularly through Table 4, we were able to demonstrate that optimization is still useful when such restrictions are considered necessary.
Finally, it is important to discuss the fact that, in practice, a choice must be made around which optimality criteria to use and what value to use for w. Unfortunately, there is no simple solution to this. Previous authors have highlighted that D‐optimality is an easy quantity to explain to practitioners from many fields.31 However, it is difficult to claim that A‐ and E‐optimality would be more complex to describe. Arguably, A‐optimality is most useful when the parameters of interest are of equal importance. In contrast, D‐ and E‐optimality may favor more specialized considerations. However, note that in certain situations, as in Table 1, we may find that the optimal design for each of these criteria is equivalent. Thus, such a choice may not always be required. Finally, when choosing w, if gathering observations is cheap, we may anticipate that setting w approximately equal to 0 is logical. This would also be the case when we have a fixed number of observations in mind, and simply want to optimize X, as in many of the discussions in Section 3. Most typically though, it is likely we would need to find a balance between cost and efficiency. In this case, larger values of w would seem appealing. But, we would rarely recommend setting w = 1, as even placing a tiny weight on the D‐, A‐, or E‐ optimality criteria can result in the choice of a much more efficient X, for only slightly increased cost.
In conclusion, we have presented methodology to identify highly efficient MA‐SWs. Of course, the most important factor for any real trial is that a design and analysis procedure are chosen that are appropriate for the complexities of the data the trial will likely accrue. However, when logistical, practical, and statistical, constraints permit the possibility to use one of a range of designs, researchers should consider the use of our approach to optimize their trials efficiency. As we have demonstrated, restrictions can readily be placed on the sets to retain the needs of the trial but still allow more efficient designs to be identified.
Supporting information
SIM_8022‐Supp‐0001‐sup_material.pdf
ACKNOWLEDGEMENTS
The authors would like to thank the two anonymous reviewers whose comments helped to substantially improve the quality of this article.
This work was supported by the Medical Research Council (grant MC_UP_1302/2 to APM and MJG) and by the National Institute for Health Research Cambridge Biomedical Research Centre (grant MC_UP_1302/6 to JMSW).
Grayling MJ, Mander AP, Wason JMS. Admissible multiarm stepped‐wedge cluster randomized trial designs. Statistics in Medicine. 2019;38:1103–1119. 10.1002/sim.8022
Abbreviations: CRT, cluster randomized trial; SW, stepped‐wedge; MA, multiarm
REFERENCES
- 1. Vickers AJ. Clinical trials in crisis: four simple methodologic fixes. Clin Trials. 2014;11(6):615‐621. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Donner A, Klar N. Pitfalls of and controversies in cluster randomization trials. Am J Public Health. 2004;94(3):416‐422. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3. Edwards SJL, Braunholtz DA, Lilford RJ, Stevens AJ. Ethical issues in the design and conduct of cluster randomised controlled trials. BMJ. 1999;318(7195):1407‐1409. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Hussey MA, Hughes JP. Design and analysis of stepped wedge cluster randomized trials. Contemp Clin Trials. 2007;28(2):182‐191. [DOI] [PubMed] [Google Scholar]
- 5. Mdege ND, Man M‐S, Brown CA, Torgerson DJ. There are some circumstances where the stepped‐wedge cluster randomized trial is preferable to the alternative: no randomized trial at all. Response to the commentary by Kotz and colleagues. J Clin Epidemiol. 2012;65(12):1253‐1254. [DOI] [PubMed] [Google Scholar]
- 6. Hemming K, Girling A, Martin J, Bond SJ. Stepped wedge cluster randomized trials are efficient and provide a method of evaluation without which some interventions would not be evaluated. J Clin Epidemiol. 2013;66(9):1058‐1059. [DOI] [PubMed] [Google Scholar]
- 7. Keriel‐Gascou M, Buchet‐Poyau K, Rabilloud M, Duclos A, Colin C. A stepped wedge cluster randomized trial is preferable for assessing complex health interventions. J Clin Epidemiol. 2014;67(7):831‐833. [DOI] [PubMed] [Google Scholar]
- 8. Kotz D, Spigt M, Arts ICW, Crutzen R, Viechtbauer W. Researchers should convince policy makers to perform a classic cluster randomized controlled trial instead of a stepped wedge design when an intervention is rolled out. J Clin Epidemiol. 2012;65(12):1255‐1256. [DOI] [PubMed] [Google Scholar]
- 9. Kotz D, Spigt M, Arts ICW, Crutzen R, Viechtbauer W. Use of the stepped wedge design cannot be recommended: a critical appraisal and comparison with the classic cluster randomized controlled trial design. J Clin Epidemiol. 2012;65(12):1249‐1252. [DOI] [PubMed] [Google Scholar]
- 10. Kotz D, Spigt M, Arts ICW, Crutzen R, Viechtbauer W. The stepped wedge design does not inherently have more power than a cluster randomized controlled trial. J Clin Epidemiol. 2013;66(9):1059‐1060. [DOI] [PubMed] [Google Scholar]
- 11. Hoop E, Tweel I, Graaf R, et al. The need to balance merits and limitations from different disciplines when considering the stepped wedge cluster randomized trial design. BMC Med Res Methodol. 2015;15:93. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Hargreaves JR, Copas AJ, Beard E, et al. Five questions to consider before conducting a stepped wedge trial. Trials. 2015;16:350. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Prost A, Binik A, Abubakar I, et al. Logistic, ethical, and political dimensions of stepped wedge trials: critical review and case studies. Trials. 2015;16:351. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. Woertman W, Hoop E, Moerbeek M, Zuidema SU, Gerritsen DL, Teerenstra S. Stepped wedge designs could reduce the required sample size in cluster randomized trials. J Clin Epidemiol. 2013;66(7):752‐758. [DOI] [PubMed] [Google Scholar]
- 15. Hemming K, Lilford R, Girling AJ. Stepped‐wedge cluster randomised controlled trials: a generic framework including parallel and multiple‐level designs. Stat Med. 2015;34(2):181‐196. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16. Hooper R, Teerenstra S, Hoop E, Eldridge S. Sample size calculation for stepped wedge and other longitudinal cluster randomised trials. Stat Med. 2016;35(26):4718‐4728. [DOI] [PubMed] [Google Scholar]
- 17. Baio G, Copas A, Ambler G, Hargreaves J, Beard E, Omar RZ. Sample size calculation for a stepped wedge trial. Trials. 2015;16:354. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Lawrie J, Carlin JB, Forbes AB. Optimal stepped wedge designs. Stat Probab Lett. 2015;99:210‐214. [Google Scholar]
- 19. Girling AJ, Hemming K. Statistical efficiency and optimal design for stepped cluster studies under linear mixed effects models. Stat Med. 2016;35(13):2149‐2166. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Thompson JA, Fielding K, Hargreaves J, Copas A. The optimal design of stepped wedge trials with equal allocation to sequences and a comparison to other trial designs. Clin Trials. 2017;14(6):639‐647. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. Li F, Turner EL, Preisser JS. Optimal allocation of clusters in cohort stepped wedge designs. Stat Probab Lett. 2018;137:257‐263. [Google Scholar]
- 22. Teerenstra S, Calsbeek H. Stepped‐wedge like designs to compare active implementation strategies with natural development in absence of active implementation. Paper presented at: The 36th Annual Conference of the International Society for Clinical Biostatistics; 2015; Utrech, The Netherlands. [Google Scholar]
- 23. Lyons VH, Li L, Hughes JP, Rowhani‐Rahbar A. Proposed variations of the stepped‐wedge design can be used to accommodate multiple interventions. J Clin Epidemiol. 2017;86:160‐167. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Matthews JNS, Forbes AB. Stepped wedge designs: insights from a design of experiments perspective. Stat Med. 2017;36(24):3772‐3790. [DOI] [PubMed] [Google Scholar]
- 25. Chinbuah MA, Kager PA, Abbey M, et al. Impact of community management of fever (using antimalarials with or without antibiotics) on childhood mortality: a cluster‐randomized controlled trial in Ghana. Am J Trop Med Hyg. 2012;87(85, suppl 5):11‐20. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. Pol MC, Ter Riet G, Hartingsveldt M, Kröse B, Rooij S, Buurman B. Effectiveness of sensor monitoring in an occupational therapy rehabilitation program for older persons after hip fracture, the SO‐HIP study: study protocol of a three‐arm stepped wedge cluster randomized trial. BMC Health Serv Res. 2017;17:3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27. Parmar MKB, Carpenter J, Sydes MR. More multiarm randomised trials of superiority are needed. Lancet. 2014;384(9940):283‐284. [DOI] [PubMed] [Google Scholar]
- 28. Wason JMS, Stecher L, Mander AP. Correcting for multiple‐testing in multi‐arm trials: is it necessary and is it done? Trials. 2014;15:364. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. Benham T, Duan Q, Kroese DP, Liquet B. CEoptim: cross‐entropy R package for optimization. J Stat Softw. 2017;76. [Google Scholar]
- 30. Atkinson AC, Donev AN. Optimum Experimental Designs. Oxford, UK: Oxford University Press; 1992. [Google Scholar]
- 31. Dmitrienko A, Chuang‐Stein C, D'agostino R. Pharmaceutical Statistics Using SAS: A Practical. Cary, NC: SAS Institute Inc; 2007. [Google Scholar]
- 32. Kasza J, Hemming K, Hooper R, Matthews JNS, Forbes AB. Impact of non‐uniform correlation structure on sample size and power in multiple‐period cluster randomised trials. Stat Meth Med Res. 2017. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
SIM_8022‐Supp‐0001‐sup_material.pdf