

Abstract
As one of the fundamental tasks in text analysis, phrase mining aims at extracting quality phrases from a text corpus and has various downstream applications including information extraction/retrieval, taxonomy construction, and topic modeling. Most existing methods rely on complex, trained linguistic analyzers, and thus likely have unsatisfactory performance on text corpora of new domains and genres without extra but expensive adaption. None of the state-of-the-art models, even data-driven models, is fully automated because they require human experts for designing rules or labeling phrases. In this paper, we propose a novel framework for automated phrase mining, AutoPhrase, which supports any language as long as a general knowledge base (e.g., Wikipedia) in that language is available, while benefiting from, but not requiring, a POS tagger. Compared to the state-of-the-art methods, AutoPhrase has shown significant improvements in both effectiveness and efficiency on five real-world datasets across different domains and languages. Besides, AutoPhrase can be extend to model single-word quality phrases.
Keywords: Automatic Phrase Mining, Phrase Mining, Distant Training, Part-of-Speech tag, Multiple Languages
1. INTRODUCTION
Phrase mining refers to the process of automatic extraction of high-quality phrases (e.g., scientific terms and general entity names) in a given corpus (e.g., research papers and news). Representing the text with quality phrases instead of n-grams can improve computational models for applications such as information extraction/retrieval, taxonomy construction, and topic modeling [21], [10], [19].
Almost all the state-of-the-art methods, however, require human experts at certain levels. Most existing methods [13], [31], [38] rely on complex, trained linguistic analyzers (e.g., dependency parsers) to locate phrase mentions, and thus may have unsatisfactory performance on text corpora of new domains and genres without extra but expensive adaption. Our latest domain-independent method SegPhrase [23] outperforms many other approaches [1], [13], [31], [38], [9], [30], [10], but still needs domain experts to first carefully select hundreds of varying-quality phrases from millions of candidates, and then annotate them with binary labels.
Such reliance on manual efforts by domain and linguistic experts becomes an impediment for timely analysis of massive, emerging text corpora in specific domains. An ideal automated phrase mining method is supposed to be domain-independent, with minimal human effort 1 or reliance on linguistic analyzers. Bearing this in mind, we propose a novel automated phrase mining framework AutoPhrase in this paper, going beyond SegPhrase, to further avoid additional manual labeling effort and enhance the performance, mainly using the following two new techniques.
-
1)
Robust Positive-Only Distant Training. In fact, many high-quality phrases are freely available in general knowledge bases, and they can be easily obtained to a scale that is much larger than that produced by human experts. Domain-specific corpora usually contain some quality phrases also encoded in general knowledge bases, even when there may be no other domain-specific knowledge bases. Therefore, for distant training, we leverage the existing high-quality phrases, as available from general knowledge bases, such as Wikipedia and Freebase, to get rid of additional manual labeling effort. We independently build samples of positive labels from general knowledge bases and negative labels from the given domain corpora, and train a number of base classifiers. We then aggregate the predictions from these classifiers, whose independence helps reduce the noise from negative labels.
-
2)
POS-Guided Phrasal Segmentation. There is a trade-off between the accuracy and domain-independence when incorporating linguistic processors in the phrase mining method.
On the domain independence side, the accuracy might be limited without linguistic knowledge. It is difficult to support multiple languages well, if the method is completely language-blind.
- On the accuracy side, relying on complex, trained linguistic analyzers may hurt the domain-independence of the phrase mining method. For example, it is expensive to adapt dependency parsers to special domains like clinical reports.As a compromise, we propose to incorporate a pre-trained part-of-speech (POS) tagger to further enhance the performance, when it is available for the language of the document collection. The POS-guided phrasal segmentation leverages the shallow syntactic information in POS tags to guide the phrasal segmentation model locating the boundaries of phrases more accurately.
In principle, AutoPhrase can support any language as long as a general knowledge base in that language is available. In fact, at least 58 languages have more than 100,000 articles in Wikipedia as of Feb, 20172. Moreover, since pre-trained part-of-speech (POS) taggers are widely available in many languages (e.g., more than 20 languages in Tree Tagger [35]3), the POS-guided phrasal segmentation can be applied in many scenarios. It is worth mentioning that for domain-specific knowledge bases (e.g., MeSH terms in the biomedical domain) and trained POS taggers, the same paradigm applies. In this study, without loss of generality, we only assume the availability of a general knowledge base together with a pre-trained POS tagger.
As demonstrated in our experiments, AutoPhrase not only works effectively in multiple domains like scientific papers, business reviews, and Wikipedia articles, but also supports multiple languages, such as English, Spanish, and Chinese. In addition, AutoPhrase can be extended to model single-word phrases.
Our main contributions are highlighted as follows:
We study an important problem, automated phrase mining, and analyze its major challenges as above.
We propose a robust positive-only distant training method for phrase quality estimation to minimize the human effort.
We develop a novel phrasal segmentation model to leverage POS tags to achieve further improvement, when a POS tagger is available.
We demonstrate the robustness, accuracy, and efficiency of our method and show improvements over prior methods, with results of experiments conducted on five real-world datasets in different domains (scientific papers, business reviews, and Wikipedia articles) and different languages (English, Spanish, and Chinese).
We successfully extend AutoPhrase to model single-word phrases, which brings about 10% to 30% recall improvements on different datasets.
The rest of the paper is organized as follows. Section 2 positions our work relative to existing works. Section 3 defines basic concepts including four requirements of phrases. The details of our method are covered in Section 4. Extensive experiments and case studies are presented in Section 5. Sections 6 extends AutoPhrase to model the single-word phrases and explores the effectiveness. We conclude the study in Section 7.
2. RELATED WORK
Identifying quality phrases efficiently has become ever more central and critical for effective handling of massively increasing-size text datasets. In contrast to keyphrase extraction [17], [27], [36], [24], [33], this task goes beyond the scope of single documents and utilizes useful cross-document signals. In [4], [14], [29], interesting phrases can be queried efficiently for ad-hoc subsets of a corpus, while the phrases are based on simple frequent pattern mining methods. The natural language processing (NLP) community has conducted extensive studies typically referred to as automatic term recognition [36], [13], [31], [38], [3], for the computational task of extracting terms (such as technical phrases). This topic also attracts attention in the information retrieval (IR) community [11], [30] since selecting appropriate indexing terms is critical to the improvement of search engines where the ideal indexing units represent the main concepts in a corpus, not just literal bag-of-words.
Text indexing algorithms typically filter out stop words and restrict candidate terms to noun phrases. With pre-defined part-of-speech (POS) rules, one can identify noun phrases as term candidates in POS-tagged documents. Supervised noun phrase chunking techniques [32], [37], [6] exploit such tagged documents to automatically learn rules for identifying noun phrase boundaries. Other methods may utilize more sophisticated NLP technologies such as dependency parsing to further enhance the precision [18], [26]. With candidate terms collected, the next step is to leverage certain statistical measures derived from the corpus to estimate phrase quality. Some methods rely on other reference corpora for the calibration of “termhood” [38]. The dependency on these various kinds of linguistic analyzers, domain-dependent language rules, and expensive human labeling, makes it challenging to extend these approaches to emerging, big, and unrestricted corpora, which may include many different domains, topics, and languages.
To overcome this limitation, data-driven approaches opt instead to make use of frequency statistics in the corpus to address both candidate generation and quality estimation [9], [30], [34], [7], [10], [23]. They do not rely on complex linguistic feature generation, domain-specific rules or extensive labeling efforts. Instead, they rely on large corpora containing hundreds of thousands of documents to help deliver superior performance [23]. In [30], several indicators, including frequency and comparison to super/subsequences, were proposed to extract n-grams that reliably indicate frequent, concise concepts. Deane [9] proposed a heuristic metric over frequency distribution based on Zipfian ranks, to measure lexical association for phrase candidates. As a preprocessing step towards topical phrase extraction, El-Kishky et al. [10] proposed to mine significant phrases based on frequency as well as document context following a bottom-up fashion, which only considers a part of quality phrase criteria, popularity and concordance. Our previous work [23] succeeded at integrating phrase quality estimation with phrasal segmentation to further rectify the initial set of statistical features, based on local occurrence context. Unlike previous methods which are purely unsupervised, [23] required a small set of phrase labels to train its phrase quality estimator. [22] follows [23] and further refines the phrasal segmentation. It is worth mentioning that all these approaches still depend on the human effort (e.g., setting domain-sensitive thresholds). Therefore, extending them to work automatically is challenging.
3. PRELIMINARIES
The goal of this paper is to develop an automated phrase mining method to extract quality phrases from a large collection of documents without human labeling effort, and with only limited, shallow linguistic analysis. The main input to the automated phrase mining task is a corpus and a knowledge base. The input corpus is a textual word sequence in a particular language and a specific domain, of arbitrary length. The output is a ranked list of phrases with decreasing quality.
The AutoPhrase framework is shown in Figure 1. The work flow is completely different from our previous domain-independent phrase mining method requiring human effort [23], although the phrase candidates and the features used during phrase quality (re-)estimation are the same. In this paper, we propose a robust positive-only distant training to minimize the human effort and develop a POS-guided phrasal segmentation model to improve the model performance. In this section, we briefly introduce basic concepts and components as preliminaries.
Fig. 1.
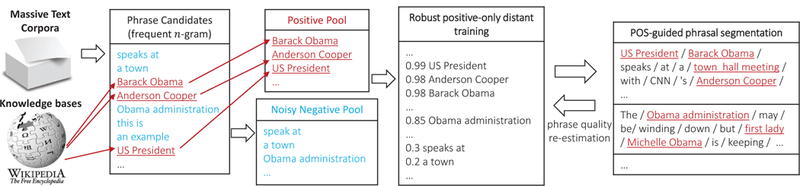
The overview of AutoPhrase. The two novel techniques developed in this paper are highlighted.
A phrase is defined as a sequence of words that appear consecutively in the text, forming a complete semantic unit in certain contexts of the given documents [12]. Compare to the entity, the phrase is a more general concept. Indeed, many high quality phrases are entities, like person names. However, there are also other phrases such as verb phrases. The phrase quality is defined to be the probability of a word sequence being a complete semantic unit, meeting the following criteria [23]:
Popularity: Quality phrases should occur with sufficient frequency in the given document collection.
Concordance: The collocation of tokens in quality phrases occurs with significantly higher probability than expected due to chance [16].
Informativeness: A phrase is informative if it is indicative of a specific topic or concept.
Completeness: Long frequent phrases and their subsequences within those phrases may both satisfy the 3 criteria above. A phrase is deemed complete when it can be interpreted as a complete semantic unit in some given document context. Note that a phrase and a subphrase contained within it, may both be deemed complete, depending on the context in which they appear. For example, “relational database system”, “relational database” and “database system” can all be complete in certain context.
AutoPhrase will estimate the phrase quality based on the positive and negative pools twice, once before and once after the POS-guided phrasal segmentation. That is, the POS-guided phrasal segmentation requires an initial set of phrase quality scores; we estimate the scores based on raw frequencies beforehand; and then once the feature values have been rectified, we re-estimate the scores.
Only the phrases satisfying all above requirements are recognized as quality phrases.
Example 1: Examples are shown in the following table. “strong tea” is a quality phrase while “heavy tea” fails to be due to concordance. “this paper” is a popular and concordant phrase, but is not informative in research publication corpus. “NP-complete in the strong sense” is a quality phrase while “NP-complete in the strong” fails to be due to completeness. □
To automatically mine these quality phrases, the first phase of AutoPhrase (see leftmost box in Figure 1) establishes the set of phrase candidates that contains all n-grams over the minimum support threshold τ (e.g., 30) in the corpus. Here, this threshold refers to raw frequency of the n-grams calculated by string matching. In practice, one can also set a phrase length threshold (e.g., n ≤ 6) to restrict the number of words in any phrase. Given a phrase candidate w1w2 … wn, its phrase quality is:
refers to the event that these words constitute a phrase. Q(.), also known as the phrase quality estimator, is initially learned from data based on statistical features4, such as point-wise mutual information, point-wise KL divergence, and inverse document frequency, designed to model concordance and informativeness mentioned above. Note the phrase quality estimator is computed independent of POS tags. For unigrams, we simply set their phrase quality as 1.
Example 2: A good quality estimator will return Q(this paper) ≈ 0 and Q(relational database system) ≈1 □
Then, to address the completeness criterion, the phrasal segmentation finds the best segmentation for each sentence.
Example 3: Ideal phrasal segmentation results are as follows.
□
During the phrase quality re-estimation, related statistical features will be re-computed based on the rectified frequency of phrases, which means the number of times that a phrase becomes a complete semantic unit in the identified segmentation. After incorporating the rectified frequency, the phrase quality estimator Q(·) also models the completeness in addition to concordance and informativeness.
Example 4: Continuing the previous example, as shown in the following table, the raw frequency of the phrase “great firewall” is 2, but its rectified frequency is 1. Both the raw frequency and the rectified frequency of the phrase “firewall software” are 1. The raw frequency of the phrase “classifier SVM” is 1, but its rectified frequency is 0.□
4. METHODOLOGY
In this section, we focus on introducing our two new techniques. First, a novel robust positive-only distant training method is developed to leverage the quality phrases in public, general knowledge bases. Second, we introduce the part-of-speech tags into the phrasal segmentation process and try to let our model take advantage of these language-dependent information, and thus perform more smoothly in different languages.
4.1. Robust Positive-Only Distant Training
To estimate the phrase quality score for each phrase candidate, our previous work [23] required domain experts to first carefully select hundreds of varying-quality phrases from millions of candidates, and then annotate them with binary labels. For example, for computer science papers, our domain experts provided hundreds of positive labels (e.g., “spanning tree” and “computer science”) and negative labels (e.g., “paper focuses” and “important form of “). However, creating such a label set is expensive, especially in specialized domains like clinical reports and business reviews, because this approach provides no clues for how to identify the phrase candidates to be labeled. In this paper, we introduce a method that only utilizes existing general knowledge bases without any other human effort.
4.1.1. Label Pools
Public knowledge bases (e.g., Wikipedia) usually encode a considerable number of high-quality phrases in the titles, keywords, and internal links of pages. For example, by analyzing the internal links and synonyms5 in English Wikipedia, more than a hundred thousand high-quality phrases were discovered. As a result, we place these phrases in a positive pool.
Knowledge bases, however, rarely, if ever, identify phrases that fail to meet our criteria, what we call inferior phrases. An important observation is that the number of phrase candidates, based on n-grams (recall leftmost box of Figure 1), is huge and the majority of them are actually of inferior quality (e.g., “Francisco opera and”). In practice, based on our experiments, among millions of phrase candidates, usually, only about 10% are in good quality6. Therefore, phrase candidates that are derived from the given corpus but that fail to match any high-quality phrase derived from the given knowledge base, are used to populate a large but noisy negative pool.
4.1.2. Noise Reduction
Directly training a classifier based on the noisy label pools is not a wise choice: some phrases of high quality from the given corpus may have been missed (i.e., inaccurately binned into the negative pool) simply because they were not present in the knowledge base. Instead, we propose to utilize an ensemble classifier that averages the results of T independently trained base classifiers. As shown in Figure 2, for each base classifier, we randomly draw K phrase candidates with replacement from the positive pool and the negative pool respectively (considering a canonical balanced classification scenario). This size-2K subset of the full set of all phrase candidates is called a perturbed training set [5], because the labels of some (δ in the figure) quality phrases are switched from positive to negative. In order for the ensemble classifier to alleviate the effect of such noise, we need to use base classifiers with the lowest possible training errors. We grow an unpruned decision tree to the point of separating all phrases to meet this requirement. In fact, such decision tree will always reach 100% training accuracy when no two positive and negative phrases share identical feature representations in the perturbed training set. In this case, its ideal error is , which approximately equals to the proportion of switched labels among all phrase candidates Therefore, the value of K is not sensitive to the accuracy of the unpruned decision tree and is fixed as 100 in our implementation. Assuming the extracted features are distinguishable between quality and inferior phrases, the empirical error evaluated on all phrase candidates, p, should be relatively small as well.
Fig. 2.
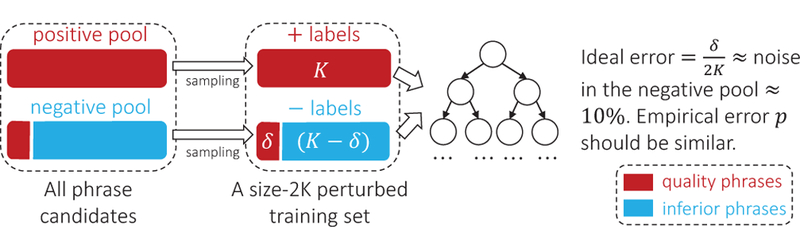
The illustration of each base classifier. In each base classifier, we first randomly sample K positive and negative labels from the pools respectively. There might be δ quality phrases among the K negative labels. An unpruned decision tree is trained based on this perturbed training set.
An interesting property of this sampling procedure is that the random selection of phrase candidates for building perturbed training sets creates classifiers that have statistically independent errors and similar erring probability [5], [25]. Therefore, we naturally adopt random forest [15], which is verified, in the statistics literature, to be robust and efficient. The phrase quality score of a particular phrase is computed as the proportion of all decision trees that predict that phrase is a quality phrase. Suppose there are T trees in the random forest, the ensemble error can be estimated as the probability of having more than half of the classifiers misclassifying a given phrase candidate as follows.
From Figure 3, one can easily observe that the ensemble error is approaching 0 when T grows. In practice, T needs to be set larger due to the additional error brought by model bias. Empirical studies can be found in Figure 8.
Fig. 3.

Ensemble errors of different p’s varying T.
Fig. 8.
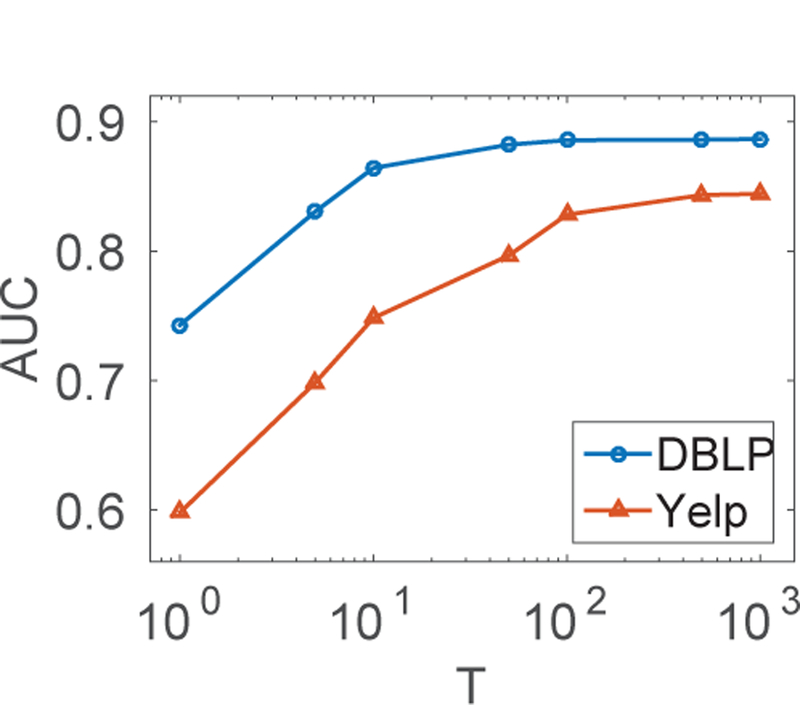
AUC curves of DPDN varying T. The trends of AUC curves are similar as our theoretical analysis in Section 4.1.2. When T is large enough (e.g., 1,000), AUC scores are about 90%, which is very high considering the model error.
4.2. POS-Guided Phrasal Segmentation
Phrasal segmentation addresses the challenge of measuring completeness (our fourth criterion) by locating all phrase mentions in the corpus and rectifying their frequencies obtained originally via string matching.
The corpus is processed as a length-n POS-tagged word sequence Ω = Ω1Ω2 ….Ωn, where Ωi refers to a pair consisting of a word and its POS tag A POS-guided phrasal segmentation is a partition of this sequence into m segments induced by a boundary index sequence The i-th segment refers to
Compared to the phrasal segmentation in our previous work [23], the POS-guided phrasal segmentation addresses the completeness requirement in a context-aware way, instead of equivalently penalizing phrase candidates of the same length. In addition, POS tags provide shallow, language-specific knowledge, which may help boost phrase detection accuracy, especially at syntactic constituent boundaries for that language.
Given the POS tag sequence for the full length-n corpus is t = t1t2 … tn, containing the tag subsequence tl … tr−1 (denote as t[l,r) for clarity), the POS quality score for that tag subsequence is defined to be the conditional probability of its corresponding word sequence being a complete semantic unit. Formally, we have
The POS quality score T(・) is designed to reward the phrases with their correctly identified POS sequences, as follows.
Example 5: Suppose the whole POS tag sequence is “NN NN NN VB DT NN”. A good POS sequence quality estimator might return T(NN NN NN) ≈ 1 and T(NN VB) ≈ 0, where NN refers to singular or mass noun (e.g., database), VB means verb in the base form (e.g., is), and DT is for determiner (e.g., the).□
The particular form of T (·) we have chosen is:
where, δ(tx, ty) is the probability that the POS tag tx is exactly precedes POS tag ty within a phrase in the given document collection. In this formula, the first term indicates the probability that there is a phrase boundary between the words indexed r − 1 and r, while the latter product indicates the probability that all POS tags within t[l,r) are in the same phrase. This POS quality score can naturally counter the bias to longer segments because ∀i > 1, exactly one of δ(ti−1, ti) and (1 − δ(ti−1, ti)) is always multiplied no matter how the corpus is segmented. Note that the length penalty model in our previous work [23] is a special case when all values of δ(tx, ty) are the same.
Mathematically, δ(tx, ty ) is defined as:
As it depends on how documents are segmented into phrases, δ(tx, ty ) is initialized uniformly and will be learned during the phrasal segmentation.
Now, after we have both phrase quality Q(·) and POS quality T (·) ready, we are able to formally define the POS-guided phrasal segmentation model. The joint probability of a POS tagged sequence Ω and a boundary index sequence B = {b1, b2, …, bm+1} is factorized as:
where is the probability of observing a word sequence as the i-th quality segment given the previous boundary index bi and the whole POS tag sequence t.
Since the phrase segments function as a constituent in the syntax of a sentence, they usually have weak dependence on each other [12], [23]. As a result, we assume these segments in the word sequence are generated one by one for the sake of both efficiency and simplicity.
For each segment, given the POS tag sequence t and the start index bi, the generative process is defined as follows.
1) Generate the end index bi+1, according to its POS quality
2) Given the two ends bi and bi+1, generate the word sequence according to a multinomial distribution over all segments of length .
3) Finally, we generate an indicator whether w[bi,bi+1) forms a quality segment according to its quality
We denote for con-venience. Integrating the above three generative steps
together, we have the following probabilistic factorization:
Therefore, there are three subproblems:
-
1)
Learn θu for each word and phrase candidate u;
-
2)
Learn δ(tx, ty ) for every POS tag pair; and
-
3)
Infer B when θu and δ(tx, ty ) are fixed.
We employ the maximum a posterior principle and maximize the joint log likelihood:
| 1 |
Given θu and δ(tx, ty ), to find the best segmentation that maximizes Equation (1), we develop an efficient dynamic programming algorithm for the POS-guided phrasal segmentation as shown in Algorithm 1.
When the segmentation S and the parameter θ are fixed, the closed-form solution of δ(tx, ty ) is:
| 2 |
where 1(·) denotes the identity indicator. δ(tx, ty ) is the unsegmented ratio among all tx, ty pairs in the given corpus.
Similarly, once the segmentation S and the parameter δ are fixed, the closed-form solution of θu can be derived
as:
| 3 |
We can see that θu is the times that u becomes a complete segment normalized by the number of the length-|u| segments.
As shown in Algorithm 2, we choose Viterbi Training (or Hard EM in literature [2]) to iteratively optimize parameters, because Viterbi Training converges fast and results in sparse and simple models for Hidden Markov Model-like tasks [2].
4.3. Complexity Analysis
The time complexity of the most time consuming components in our framework, such as frequent n-gram, feature extraction, POS-guided phrasal segmentation, are all O(|Ω|) with the assumption that the maximum number of words in a phrase is a small constant (e.g., n ≤ 6), where |Ω| is the total number of words in the corpus. Therefore, AutoPhrase is linear to the corpus size and thus being very efficient and scalable. Meanwhile, every component can be parallelized in an almost lock-free way grouping by either phrases or sentences.
5. EXPERIMENTS
In this section, we will apply the proposed method to mine quality phrases from five massive text corpora across three domains (scientific papers, business reviews, and Wikipedia articles) and in three languages (English, Spanish, and Chinese). We compare the proposed method with many other methods to demonstrate its high performance. Then we explore the robustness of the proposed positive-only distant training and its performance against expert labeling. The advantage of incorporating POS tags in phrasal segmentation will also be proved. In the end, we present case studies.
5.1. Datasets
To validate that the proposed positive-only distant training can effectively work in different domains and the POS-guided phrasal segmentation can support multiple languages effectively, we have five large collections of text in different domains and languages, as shown in Table 1: Abstracts of English computer science papers from DBLP7, English business reviews from Yelp8, Wikipedia articles9 in English (EN), Spanish (ES), and Chinese (CN). From the existing general knowledge base Wikipedia, we extract popular mentions of entities by analyzing intra-Wiki citations within Wiki content10. On each dataset, the intersection between the extracted popular mentions and the generated phrase candidates forms the positive pool. Therefore, the size of positive pool may vary in different datasets of the same language.
TABLE 1.
Five real-world massive text corpora in different domains and multiple languages. |Ω| is the total number of words. sizep is the size of positive pool. To prove the domain-independence of our model, we will compare the results on the three English datasets, DBLP, Yelp, and EN, as they come from different domains. To demonstrate that our model works smoothly in different languages, we will compare the results on the three Wikipedia article datasets, EN, ES, and CN, as they are of different languages.
| Dataset | Domain | Language | |Ω| | File size | sizep |
|---|---|---|---|---|---|
| DBLP | Scientific Paper | English | 91.6M | 618MB | 29K |
| Yelp | Business Review | English | 145.1M | 749MB | 22K |
| EN | Wikipedia Article | English | 808.0M | 3.94GB | 184K |
| ES | Wikipedia Article | Spanish | 791.2M | 4.06GB | 65K |
| CN | Wikipedia Article | Chinese | 371.9M | 1.56GB | 29K |
5.2. Compared Methods
We compare AutoPhrase with three lines of methods as follows. Every method returns a ranked list of phrases. SegPhrase11/WrapSegPhrae12: In English domain-specific text corpora, our latest work SegPhrase outperformed phrase mining [10], keyphrase extraction [36], [30], and noun phrase chunking methods. WrapSegPhrase extends SegPhrase to different languages by adding an encoding preprocessing to first transform non-English corpus using English characters and punctuation as well as a decoding postprocessing to later translate them back to the original language. Both methods require domain expert labors. For each dataset, we ask domain experts to annotate a representative set of 300 quality/interior phrases.
Parser-based Phrase Extraction:
Using complicated linguistic processors, such as parsers, we can extract minimum phrase units (e.g., NP) from the parsing trees as phrase candidates. Parsers of all three languages are available in Stanford NLP tools [28], [8], [20] Two ranking heuristics are considered: leftmargin=*,noitemsep,nolistsep
TF-IDF ranks the extracted phrases by their term frequency and inverse document frequency in the given documents;
TextRank: An unsupervised graph-based ranking model for keyword extraction [27].
Pre-trained Chinese Segmentation Models:
Different from English and Spanish, phrasal segmentation in Chinese has been intensively studied because there is no space between Chinese words. The most effective and popular segmentation methods are: leftmargin=*,noitemsep,nolistsep
AnsjSeg13 is a popular text segmentation algorithm for Chinese corpus. It ensembles statistical modeling methods of Conditional Random Fields (CRF) and Hidden Markov Models (HMMs) based on the n-gram setting;
JiebaPSeg14 is a Chinese text segmentation method implemented in Python. It builds a directed acyclic graph for all possible phrase combinations based on a prefix dictionary structure to achieve efficient phrase graph scanning. Then it uses dynamic programming to find the most probable combination based on the phrase frequency. For unknown phrases, an HMM-based model is used with the Viterbi algorithm.
Note that all parser-based phrase extraction and Chinese segmentation models are pre-trained based on general corpus.
To introduce a stronger baseline than SegPhrase and WrapSegPhrase, we introduce AutoSegPhrase, which is a hybrid of AutoPhrase and SegPhrase. AutoSegPhrase adopts the length penalty instead of δ(tx, ty ), while other components are the same as AutoPhrase. Meanwhile, the comparison between AutoPhrase and AutoSegPhrase can check the effectiveness of POS-guided phrasal segmentation. In addition, AutoSegPhrase is useful when there is no POS tagger.
5.3. Experimental Settings
Implementation.
The preprocessing includes tokenizers from Lucene and Stanford NLP as well as the POS tagger from TreeTagger. The pre- and post-processing are in Java, while the core functions are all implemented in C++. Experiments were all conducted on a machine with 20 cores of Intel(R) Xeon(R) CPU E5–2680 v2 @ 2.80GHz. Our documented code package has been released and maintained in GitHub15.
Default Parameters.
We set the minimum support threshold σ as 30. The maximum number of words in a phrase is set as 6 according to labels from domain experts. These are two parameters required by all methods. Other parameters required by compared methods were set according to the open-source tools or the original papers.
Human Annotation.
We rely on human evaluators to judge the quality of the phrases which cannot be identified through any knowledge base. More specifically, on each dataset, we randomly sample 500 such phrases from the predicted phrases of each method in the experiments. These selected phrases are shuffled in a shared pool and evaluated by 3 reviewers independently. We allow reviewers to use search engines when unfamiliar phrases encountered. By the rule of majority voting, phrases in this pool received at least two positive annotations are quality phrases. The intra-class correlations (ICCs) are all more than 0.9 on all five datasets, which shows the agreement.
Evaluation Metrics.
For a list of phrases, precision is defined as the number of true quality phrases divided by the number of predicted quality phrases; recall is defined as the number of true quality phrases divided by the total number of quality phrases. We retrieve the ranked list of the pool from the outcome of each method. When a new true quality phrase encountered, we evaluate the precision and recall of this ranked list. In the end, we plot the precision-recall curves. In addition, area under the curve (AUC) is adopted as another quantitative measure. AUC in this paper refers to the area under the precision-recall curve.
5.4. Overall Performance
Figure 4 and Figure 5 present the precision-recall curves of all compared methods evaluated by human annotation on five datasets. Overall, AutoPhrase performs the best, in terms of both precision and recall. Significant advantages can be observed, especially on two non-English datasets ES and CN. For example, on the ES dataset, the recall of AutoPhrase is about 20% higher than the second best method (SegPhrase) in absolute value. Meanwhile, there is a visible precision gap between AutoPhrase and the best baseline. The phrase chunking-based methods TF-IDF and TextRank work poorly, because the extraction and ranking are modeled separately and the pre-trained complex linguistic analyzers fail to extend to domain-specific corpora. TextRank usually starts with a higher precision than TF-IDF, but its recall is very low because of the sparsity of the constructed co-occurrence graph. TF-IDF achieves a reasonable recall but unsatisfactory precision. On the CN dataset, the pre-trained Chinese segmentation models, JiebaSeg and AnsjSeg, are very competitive, because they not only leverage training data for segmentations, but also exhaust the engineering work, including a huge dictionary for popular Chinese entity names and specific rules for certain types of entities. As a consequence, they can easily extract tons of well-known terms and people/location names. Outperforming such a strong baseline further confirms the effectiveness of AutoPhrase.
Fig. 4.

Overall Performance Evaluation in Different Domains: Precision-recall curves of all methods on three English datasets of different domains evaluated by human annotation. Both AutoPhrase and SegPhrase work significantly better than other baselines. AutoPhrase always has better results than SegPhrase on English datasets, even SegPhrase is designed for English.
Fig. 5.

Overall Performance Evaluation in Different Languages: Precision-recall curves of all methods on three Wikipedia article datasets evaluated by human annotation. The advantages of AutoPhrase over SegPhrase are more significant in non-English languages, especially on the Chinese dataset. It is worth noting that on the Chinese dataset, AutoPhrase outperforms than two popular, pre-trained Chinese phrase extraction models. This firmly demonstrates the ability of AutoPhrase to cross the language barrier.
The comparison among the English datasets across three domains (i.e., scientific papers, business reviews, and Wikipedia articles) demonstrates that AutoPhrase is reasonably domain-independent. The performance of parser-based methods TF-IDF and TextRank depends on the rigorous degree of the documents. For example, it works well on the DBLP dataset but poorly on the Yelp dataset. However, without any human effort, AutoPhrase can work effectively on domain-specific datasets, and even outperforms SegPhrase, which is supervised by the domain experts.
The comparison among the Wikipedia article datasets in three languages (i.e., EN, ES, and CN) shows that, first of all, AutoPhrase supports multiple languages. Secondly, the advantage of AutoPhrase over SegPhrase /WrapSegPhrase is more obvious on two non-English datasets ES and CN than the EN dataset, which proves that the helpfulness of introducing the POS tagger
As conclusion, Autopharse is able to support different domains and support multiple languages with minimal human effort.
5.5. Distant Training Exploration
To compare the distant training and domain expert labeling, we experiment with the domain-specific datasets DBLP and Yelp. To be fair, all the configurations in the classifiers are the same except for the label selection process. More specifically, we come up with four training pools:
-
1)
EP means that domain experts give the positive pool.
-
2)
DP means that a sampled subset from existing general knowledge forms the positive pool.
-
3)
EN means that domain experts give the negative pool.
-
4)
DN means that all unlabeled (i.e., not in the positive pool) phrase candidates form the negative pool.
By combining any pair of the positive and negative pools, we have four variants, EPEN (in SegPhrase), DPDN (in AutoPhrase), EPDN, and DPEN.
First of all, we evaluate the performance difference in the two positive pools. Compared to EPEN, DPEN adopts a positive pool compared to EPEN,DPEN adobes a positive pool sampled from knowledge bases instead of the well – designed positive pool given by domain experts. The negative pool EN is shared. As shown in Figure 6, we vary the size of the positive pool and plot their AUC curves. We can find that EPEN outperforms DPEN and the trends of curves on both datasets are similar. Therefore, we conclude that the positive pool generated from knowledge bases has reasonable quality, although its corresponding quality estimator works slightly worse.
Fig. 6.
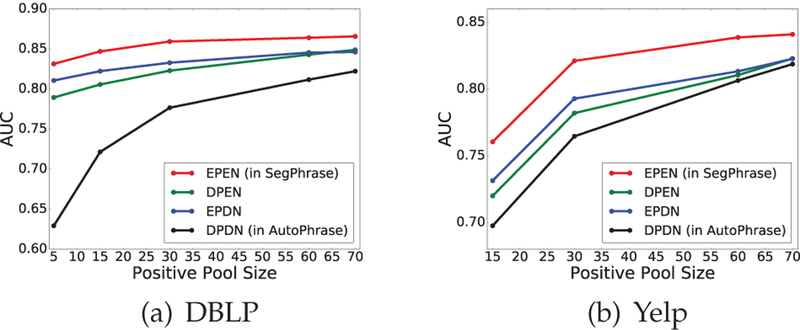
AUC curves of four variants when we have enough positive labels in the positive pool EP. Overall, human annotations lead to better results because they are more clean. However, similar trends between EPEN and DPEN show that the positive pool generated from knowledge bases has reasonable quality; the similar trends between EPEN and EPDN proves that our proposed robust positive-only distant training method works well. DPDN is the worst in this case but it has a great potential to be better as the size of positive pool grows.
Secondly, we verify that whether the proposed noise reduction mechanism works properly. Compared to EPEN, EPDN adopts a negative pool of all unlabeled phrase candidates instead of the well-designed negative pool given by domain experts. Noisy negative pool is slighyly worse than the well designed negative pool, but it still works effectively.
As illustrated in Figure 6, DPDN has the worst performance when the size of positive pools are limited. However, distant training can generate much larger positive pools, which may significantly beyond the ability of domain experts considering the high expense of labeling. Consequently, we are curious whether the distant training can finally beat domain experts when positive pool sizes become large enough. We call the size at this tipping point as the ideal number.
We increase positive pool sizes and plot AUC curves of DPEN and DPDN, while EPEN and EPDN are degenerated as dashed lines due to the limited domain expert abilities. As shown in Figure 7, with a large enough positive pool, distant training is able to beat expert labeling. On the DBLP dataset, the ideal number is about 700, while on the Yelp dataset, it becomes around 1600. Our guess is that the ideal training size is proportional to the number of words (e.g., 91.6M in DBLP and 145.1M in Yelp). We notice that compared to the corpus size, the ideal number is relatively small, which implies the distant training should be effective in many domain-specific corpora as if they overlap with Wikipedia.
Fig. 7.
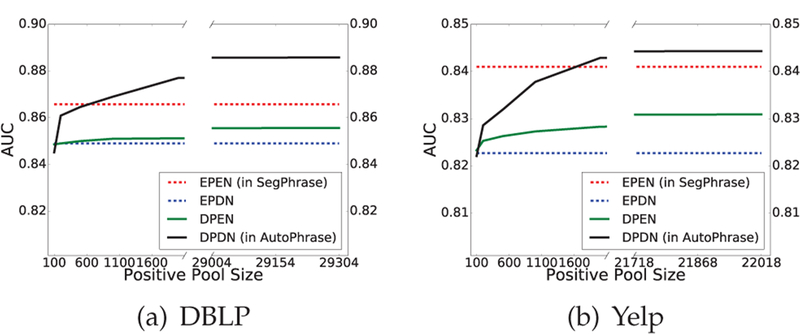
AUC curves of four variants after we exhaust positive labels in the positive pool EP. After leveraging positive pools of enough sizes, DPDN finally becomes the best method. In the real world, the public, general knowledge bases usually have a reasonably large overlap with the domain-specific corpus, which makes DPDN more practically useful
Besides, Figure 7 shows that when the positive pool size continues growing, the AUC score increases but the slope becomes smaller. The performance of distant training will be finally stable when a relatively large number of quality phrases were fed.
We are curious how many trees (i.e., T ) is enough for DPDN. We increase T and plot AUC curves of DPDN. As shown in Figure 8, on both datasets, as T grows, the AUC scores first increase rapidly and later the speed slows down gradually, which is consistent with the theoretical analysis in Section 4.1.2.
5.6. POS-guided Phrasal Segmentation
We are also interested in how much performance gain we can obtain from incorporating POS tags in this segmentation model, especially for different languages. We select Wikipedia article datasets in three different languages: EN, ES, and CN.
Figure 9 compares the results of AutoPhrase and AutoSegPhrase, with the best baseline methods as references. AutoPhrase outperforms AutoSegPhrase even on the English dataset EN, though it has been shown the length penalty works reasonably well in English [23]. The Spanish dataset ES has similar observation. Moreover, the advantage of AutoPhrase becomes more significant on the CN dataset, indicating the poor generality of length penalty.
Fig. 9.

Comparison Between Phrase Mining Methods with/without POS tags (AutoPhrase and AutoSegPhrase) as input. Datasets in different languages are used for the comparison. The best baseline in each dataset is provided as a reference. The results show POS-guided phrasal segmentation works more smoothly in different languages. As the original segmentation method without POS information is designed for English, it works well for English and Spanish but relatively poorly on the Chinese data.
In summary, thanks to the extra context information and syntactic information for the particular language, incorporating POS tags during the phrasal segmentation can work better than equally penalizing phrases of the same length.
5.7. Case Study
We present a case study about the extracted phrases as shown in Table 2. The top ranked phrases are mostly named entities, which makes sense for the Wikipedia article datasets. Even in the long tail part, there are still many high-quality phrases. For example, we have the great spotted woodpecker (a type of birds) and 算机科学技 (i.e., Computer Science and Technology) ranked about 100,000. In fact, we have more than 345K and 116K phrases with a phrase quality higher than 0.5 on the EN and CN datasets respectively.
TABLE 2.
The results of AutoPhrase on the EN and CN datasets, with translations and explanations for Chinese phrases. The whitespaces on the CN dataset are inserted by the Chinese tokenizer. It worths a mention that the general knowledge base only provides about 29K quality phrases in the positive pool and AutoPhrase is able to discover new quality phrases even in the rank of 100K. This implies that AutoPhrase has a power to discover more than 200% new quality phrases than the provided positive pool.
| EN | CN | ||
|---|---|---|---|
| Rank | Phrase | Phrase | Translation (Explanation) |
| 1 | Elf Aquitaine | 江 舜天 | (the name of a soccer team) |
| 2 | Arnold Sommerfeld | 苦艾酒 | Absinthe |
| 3 | Eugene Wigner | 白 魔女 | (the name of a novel/TV-series) |
| 4 | Tarpon Springs | 笔 型电脑 | notebook computer, laptop |
| 5 | Sean Astin | 党委书记 | Secretary of Party Committee |
| . . . | . . . | . . . | . . . |
| 20,001 | ECAC Hockey | 非洲国家 | African countries |
| 20,002 | Sacramento Bee | 左翼党 | The Left (German: Die Linke) |
| 20,003 | Bering Strait | 菲沙河谷 | Fraser Valley |
| 20,004 | Jacknife Lee | 海 体 | Hippocampus |
| 20,005 | WXYZ-TV | 斋 光希 | Mitsuki Saiga (a voice actress) |
| . . . | . . . | . . . | . . . |
| 99,994 | John Gregson | 算机科学技 | Computer Science and Technology |
| 99,995 | white-tailed eagle | 恒天然 | Fonterra (a company) |
| 99,996 | rhombic dodecahedron | 中国作家 会 | The Vice President of Writers |
| 副主席 | Association of China | ||
| 99,997 | great spotted woodpecker | 他命 b | Vitamin B |
| 99,998 | David Manners | 舆论 向 | controlled guidance of the media |
| . . . | . . . | . . . | . . . |
5.8. Efficiency Evaluation
To study both time and memory efficiency, we choose the three largest datasets: EN, ES, and CN.
Figures 10(a) and 10(b) evaluate the running time and the peak memory usage of AutoPhrase using 10 threads on different proportions of three datasets respectively. Both time and memory are linear to the size of text corpora. Moreover, AutoPhrase can also be parallelized in an almost lock-free way and shows a linear speedup in Figure 10(c).
Fig. 10.
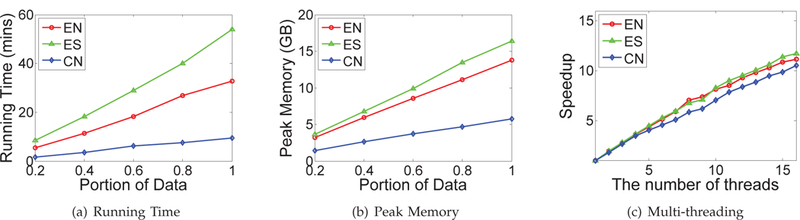
Efficiency evaluation of AutoPhrase on the three largest datasets. Both the running time and the peak memory are linear to the corpus size. Because of an almost lock-free parallelized implementation, the multi-threading speedup is close to linear.
Besides, compared to the previous state-of-the-art phrase mining method SegPhrase and its variants WrapSegPhrase on three datasets, as shown in Table 3, AutoPhrase achieves about 8 to 11 times speedup and about 5 to 7 times memory usage improvement. These improvements are made by a more efficient indexing and a more thorough parallelization.
TABLE 3.
Efficiency comparison between AutoPhrase and SegPhrase /WrapSegPhrase utilizing 10 threads. The difference is mainly caused by a more efficient indexing and a more thorough parallelization.
| EN | ES | CN | ||||
|---|---|---|---|---|---|---|
| Time (mins) |
Memory (GB) |
Time (mins) |
Memory (GB) |
Time (mins) |
Memory (GB) |
|
| AutoPhrase | 32.77 | 13.77 | 54.05 | 16.42 | 9.43 | 5.74 |
| (Wrap)SegPhrase | 369.53 | 97.72 | 452.85 | 92.47 | 108.58 | 35.38 |
| Speedup/Saving | 11.27 | 86% | 8.37 | 82% | 11.50 | 83% |
6. SINGLE-WORD PHRASE EXTENSION
AutoPhrase can be extended to model single-word phrases, which can gain about 10% to 30% recall improvements on different datasets. To study the effect of modeling quality single-word phrases, we choose the three Wikipedia article datasets in different languages: EN, ES, and CN.
6.1. Quality Estimation
In the paper, the definition of quality phrases and the evaluation only focus on multi-word phrases. In linguistic analysis, however, a phrase is not only a group of multiple words, but also possibly a single word, as long as it functions as a constituent in the syntax of a sentence [12]. As a great portion (ranging from 10% to 30% on different datasets based on our experiments) of high-quality phrases, we should take single-word phrases (e.g., UIUC , Illinois , and USA ) into consideration as well as multi-word phrases to achieve a high recall in phrase mining.
Considering the criteria of quality phrases, because single-word phrases cannot be decomposed into two or more parts, the concordance and completeness are no longer definable. Therefore, we revise the requirements for quality single-word phrases as below.
Popularity: Quality phrases should occur with sufficient frequency in the given document collection.
Informativeness: A phrase is informative if it is indicative of a specific topic or concept.
Independence: A quality single-word phrase is more likely a complete semantic unit in the given documents.
Only single-word phrases satisfying all popularity, inde-pendence, and informativeness requirements are recognized as quality single-word phrases.
Example 6: Examples are shown in the following ta-ble. “UIUC” is a quality single-word phrase. “this” is not a quality phrase due to its low informativeness. “united”, usually occurring within other quality multi-word phrases such as “United States”, “United Kingdom”, “United Airlines”, and “United Parcel Service”, is not a quality single-word phrase, because its independence is not enough. □
After the phrasal segmentation, in replacement of concordance features, the independence feature is added for single-word phrases. Formally, it is the ratio of the rectified frequency of a single-word phrase given the phrasal segmentation over its raw frequency. Quality single-word phrases are expected to have large values. For example, “united” is likely to an almost zero ratio.
We use AutoPhrase+ to denote the extended AutoPhrase with quality single-word phrase estimation.
6.2. Experiments
We have a similar human annotation as that in the paper. Differently, we randomly sampled 500 Wiki-uncovered phrases from the returned phrases (both single-word and multi-word phrases) of each method in experiments of the paper. Therefore, we have new pools on the EN, ES, and CN datasets. The intra-class correlations (ICCs) are all more than 0.9, which shows the agreement.
Figure 11 compare all methods based these new pools. Note that all methods except for SegPhrase /WrapSegPhrase extract single-word phrases as well.
Fig. 11.
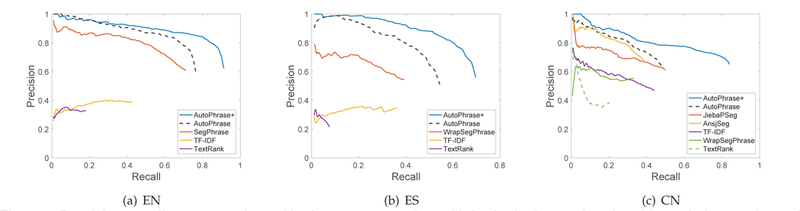
Precision-recall curves evaluated by human annotation with both single-word and multi-word phrases in pools. The most significant recall gap can be observed in the Chinese dataset because the ratio of quality single-word phrases is highest in Chinese.
Significant recall advantages can be always observed on all EN, ES, and CN datasets. The recall differences between AutoPhrase+ and AutoPhrase, ranging from 10% to 30% sheds light on the importance of modeling single-word phrases. Across two Latin language datasets, EN and ES, AutoPhrase+ and AutoPhrase overlaps in the beginning, but later, the precision of AutoPhrase drops earlier and has a lower recall due to the lack of single-word phrases. On the CN dataset, AutoPhrase+ and AutoPhrase has a clear gap even in the very beginning, which is different from the trends on the EN and ES datasets, which reflects that single-word phrases are more important in Chinese. The major reason behind is that there are a considerable number of high-quality phrases (e.g., person names) in Chinese have only one token after tokenization.
7. CONCLUSIONS
In this paper, we present an automated phrase mining framework with two novel techniques: the robust positive-only distant training and the POS-guided phrasal segmentation incorporating part-of-speech (POS) tags, for the development of an automated phrase mining framework AutoPhrase. Our extensive experiments show that AutoPhrase is domain-independent, outperforms other phrase mining methods, and supports multiple languages (e.g., English, Spanish, and Chinese) effectively, with minimal human effort.
Besides, the inclusion of quality single-word phrases (e.g., ⌈UIUC⌋ and ⌈USA⌋) which leads to about 10% to 30% increased recall and the exploration of better indexing strategies and more thorough parallelization, which leads to about 8 to 11 times running time speedup and about 80% to 86% memory usage saving over SegPhrase. Interested readers may try our released code at GitHub.
For future work, it is interesting to (1) refine quality phrases to entity mentions, (2) apply AutoPhrase to more languages, such as Japanese, and (3) for those languages without general knowledge bases, seek an unsupervised method to generate the positive pool from the corpus, even with some noise.
| Phrase | Quality? | Failure Criteria |
|---|---|---|
| strong tea | ✓ | N/A |
| heavy tea | ✕ | concordance |
| this paper | ✕ | informative |
| NP-complete in the strong sense | ✓ | N/A |
| NP-complete in the strong | ✕ | completeness |
| #1: | ... / the / Great Firewall / is / ... |
| #2: | This / is / a / great / firewall software/ . |
| #3: | The / discriminative classifier / SVM / is / ... |
| Phrase | Raw Freq | Rectified Freq |
|---|---|---|
| great firewall | 2 | 1 |
| firewall software | 1 | 1 |
| classifier SVM | 1 | 0 |
| Single-Word Phrase | Quality? | Failure Reason |
|---|---|---|
| UIUC | ✓ | N/A |
| this | × | informativeness |
| united | × | independence |
ACKNOWLEDGMENT
Research was sponsored in part by the U.S. Army Research Lab. under Cooperative Agreement No.W911NF-09–2-0053 (NSCTA), National Science Foundation IIS-1320617 and IIS 16–18481, grant 1U54GM114838 awarded by NIGMS through funds provided by the trans-NIH Big Data to Knowledge (BD2K) initiative (www.bd2k.nih.gov), and Google PhD Fellowship. The views and conclusions contained in this document are those of the author(s) and should not be interpreted as representing the official policies of the U.S. Army Research Laboratory or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation hereon
Biographies
Jingbo Shang is a Ph.D. student in Department of Computer Science, University of Illinois at Urbana-Champaign. His research focuses on mining and constructing structured knowledge from massive text corpora with minimum human effort. His research has been recognized by many prestigious awards, including Computer Science Excellence Scholarship from CS@Illinois, Grand Prize of Yelp Dataset Challenge in 2015, and Google PhD Fellowship in Structured Data and Database Management in 2017.

Jialu Liu is working at Google Research New York on structured data for knowledge exploration. His primary research interests are scalable information extraction and text mining. He received Ph.D degree from University of Illinois at Urbana Champaign in 2015, supervised by Prof. Jiawei Han.

Meng Jiang received his B.E. degree and Ph.D. degree in 2010 and 2015 at the Department of Computer Science and Technology in Tsinghua University. He is now an assistant professor in the Department of Computer Science and Engineering at the University of Notre Dame. He worked as a postdoctoral research associate at University of Illinois at Urbana-Champaign from 2015 to 2017. He has published over 20 papers on behavior modeling and information extraction in top conferences and journals of the relevant field such as IEEE TKDE, ACM SIGKDD, AAAI, ACM CIKM and IEEE ICDM. He also has delivered six tutorials on the same topics in major conferences. He got the best paper finalist in ACM SIGKDD 2014.

Xiang Ren is a visiting research fellow at Stanford Computer Science and a PhD candidate of Computer Science at University of Illinois at Urbana-Champaign, working with Jiawei Han. Xiang’s research develops data-driven and ma-chine learning methods for turning unstructured text data into machine-actionable structures. More broadly, his research interests span data mining, machine learning, and natural language processing, with a focus on making sense of big text data. His research has been recognized with several prestigious awards including a Google PhD Fellowship, a Yahoo!-DAIS Research Excellence Award, a WWW 2017 Outstanding Reviewer Award, a Yelp Dataset Challenge award and a C. W. Gear Outstanding Graduate Student Award from CS@Illinois. Technologies he developed has been transferred to US Army Research Lab, National Institute of Health, Microsoft, Yelp and TripAdvisor.

Clare R Voss is a senior research computer scientist at the Army Research Laboratory (ARL) in Adelphi, Maryland. She has been actively involved in natural language processing (NLP) for over twenty years, starting with her education (Linguistics B.A., U Michigan; Psychology M.A., U Pennsylvania; Computer Science PhD., U Mary-land) and continuing as a founding member of the multilingual computing group at ARL, where she now leads an interdisciplinary team working on multilingual and multimodal information extraction in support of event analysis for decision makers, as well as joint navigation and exploration using natural language dialog between humans and robots. She is a member of the Advisory Board for the Computational Linguistics Program at the U. of Washington and a past member of the Board of Directors of the Association for Machine Translation in the Americas (AMTA).

Jiawei Han is Abel Bliss Professor in the Department of Computer Science at the University of Illinois. He has been researching into data mining, information network analysis, and database systems, with over 600 publications. He served as the founding Editor-in-Chief of ACM Transactions on Knowledge Discovery from Data (TKDD). Jiawei has received ACM SIGKDD Innovation Award (2004), IEEE Computer Society Technical Achievement Award (2005), IEEE Computer Society W. Wallace McDowell Award (2009), and Daniel C. Drucker Eminent Faculty Award at UIUC (2011). He is a Fellow of ACM and a Fellow of IEEE. He is currently the Director of Information Network Academic Research Center (INARC) supported by the Network Science-Collaborative Technology Alliance (NS-CTA) program of U.S. Army Research Lab. His co-authored textbook “Data Mining: Concepts and Techniques” (Morgan Kaufmann) has been adopted worldwide.

Footnotes
The phrase “minimal human effort” indicates using only existing general knowledge bases without any other human effort.
https://meta.wikimedia.org/wiki/List of Wikipedias
See https://github.com/shangjingbo1226/AutoPhrase for further details.
This percentage is estimated when the used knowledge base is Wikipedia. It may vary when different knowledge bases are used.
https://www.yelp.com/dataset challenge
Contributor Information
Jingbo Shang, Department of Computer Science in University of Illinois at Urbana-Champaign, IL, USA..
Jialu Liu, Google Research, NY, USA..
Meng Jiang, Department of Computer Science in University of Illinois at Urbana-Champaign, IL, USA..
Xiang Ren, Department of Computer Science in University of Illinois at Urbana-Champaign, IL, USA..
Clare R Voss, US Army Research Lab.
Jiawei Han, Department of Computer Science in University of Illinois at Urbana-Champaign, IL, USA..
REFERENCES
- [1].Ahmad K, Gillam L, Tostevin L, et al. University of surrey participation in trec8: Weirdness indexing for logical document extrapolation and retrieval (wilder). In TREC, pages 1–8, 1999. [Google Scholar]
- [2].Allahverdyan A and Galstyan A. Comparative analysis of Viterbi training and maximum likelihood estimation for hmms. In NIPS, pages 1674–1682, 2011 [Google Scholar]
- [3].Baldwin T and Kim SN. Multiword expressions. Handbook of Natural Language Processing, second edition. Morgan and Claypool, 2010. [Google Scholar]
- [4].Bedathur S, Berberich K, Dittrich J, Mamoulis N, and Weikum G.Interesting-phrase mining for ad-hoc text analytics. Proc. VLDB Endow, 3(1–2):1348–1357, Sept. 2010. [Google Scholar]
- [5].Breiman L. Randomizing outputs to increase prediction accuracy. Machine Learning, 40(3):229–242, 2000. [Google Scholar]
- [6].Chen K.-h. and Chen H-H. Extracting noun phrases from large-scale texts: A hybrid approach and its automatic evaluation.In Proceedings of the 32Nd Annual Meeting on Association for Computational Linguistics, ACL ‘94, pages 234–241, Stroudsburg, PA, USA, 1994. Association for Computational Linguistics. [Google Scholar]
- [7].Danilevsky M, Wang C, Desai N, Ren X, Guo J, and Han J. Automatic construction and ranking of topical keyphrases on collections of short documents. In SDM, 2014. [Google Scholar]
- [8].De Marneffe M-C, MacCartney B, Manning CD, et al. Generating typed dependency parses from phrase structure parses. In Proceedings of LREC, volume 6, pages 449–454, 2006. [Google Scholar]
- [9].Deane P. A nonparametric method for extraction of candidate phrasal terms. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, ACL ‘05, pages 605– 613, Stroudsburg, PA, USA, 2005. Association for Computational Linguistics. [Google Scholar]
- [10].El-Kishky A, Song Y, Wang C, Voss CR, and Han J. Scalable topical phrase mining from text corpora. Proc. VLDB Endow, 8(3):305–316, Nov. 2014. [Google Scholar]
- [11].Evans DA and Zhai C. Noun-phrase analysis in unrestricted text for information retrieval. In Proceedings of the 34th Annual Meeting on Association for Computational Linguistics, ACL ‘96, pages 17–24, Stroudsburg, PA, USA, 1996. Association for Computational Linguistics. [Google Scholar]
- [12].Finch G. Linguistic terms and concepts Macmillan Press Limited,2000. [Google Scholar]
- [13].Frantzi K, Ananiadou S, and Mima H. Automatic recognition of multi-word terms:. the c-value/nc-value method. JODL, 3(2):115–130, 2000. [Google Scholar]
- [14].Gao C and Michel S. Top-k interesting phrase mining in ad-hoc collections using sequence pattern indexing. In Proceedings of the 15th International Conference on Extending Database Technology, EDBT ‘12, pages 264–275, New York, NY, USA, 2012. ACM. [Google Scholar]
- [15].Geurts P, Ernst D, and Wehenkel L. Extremely randomized trees. Machine learning, 63(1):3–42, 2006. [Google Scholar]
- [16].Halliday MA et al. Lexis as a linguistic level. In memory of JR Firth, 148:162, 1966. [Google Scholar]
- [17].Hasan KS and Ng V. Conundrums in unsupervised keyphrase extraction: making sense of the state-of-the-art. In COLING, 2010. [Google Scholar]
- [18].Koo T, Carreras X, and Collins M. Simple semi-supervised dependency parsing. ACL-HLT, 2008. [Google Scholar]
- [19].Leskovec J, Backstrom L, and Kleinberg J. Meme-tracking and the dynamics of the news cycle. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ‘09, pages 497–506, New York, NY, USA, 2009. ACM. [Google Scholar]
- [20].Levy R and Manning C. Is it harder to parse chinese, or the chinese treebank? In Proceedings of the 41st Annual Meeting on Association for Computational Linguistics - Volume 1, ACL ‘03,pages 439–446, Stroudsburg, PA, USA, 2003. Association for Computational Linguistics. [Google Scholar]
- [21].Li B, Wang B, Zhou R, Yang X, and Liu C. Citpm: A cluster-based iterative topical phrase mining framework. In International Conference on Database Systems for Advanced Applications, pages 197–213. Springer, 2016. [Google Scholar]
- [22].Li B, Yang X, Wang B, and Cui W. Efficiently mining high quality phrases from texts. In AAAI, pages 3474–3481, 2017. [Google Scholar]
- [23].Liu J, Shang J, Wang C, Ren X, and Han J. Mining quality phrases from massive text corpora. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, SIGMOD ‘15, pages 1729–1744, New York, NY, USA, 2015. ACM. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [24].Liu Z, Chen X, Zheng Y, and Sun M. Automatic keyphrase extraction by bridging vocabulary gap. In Proceedings of the Fifteenth Conference on Computational Natural Language Learning, CoNLL ‘11, pages 135–144, Stroudsburg, PA, USA, 2011. Association for Computational Linguistics. [Google Scholar]
- [25].Martíınez-Muñoz G and Suárez A. Switching class labels to generate classification ensembles. Pattern Recognition, 38(10):1483–1494, 2005. [Google Scholar]
- [26].McDonald R, Pereira F, Ribarov K, and Hajič J. Non-projective dependency parsing using spanning tree algorithms. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing, HLT ‘05, pages 523–530, Stroudsburg, PA, USA, 2005. Association for Computational Linguistics. [Google Scholar]
- [27].Mihalcea R and Tarau P. Textrank: Bringing order into texts. In ACL, 2004. [Google Scholar]
- [28].Nivre J, de Marneffe M-C, Ginter F, Goldberg Y, Hajic J, Manning CD, McDonald R, Petrov S, Pyysalo S, Silveira N, et al. Universal dependencies v1: A multilingual treebank collection. In Proceedings of the 10th International Conference on Language Resources and Evaluation (LREC 2016), 2016. [Google Scholar]
- [29].Dey DP,A, and Majumdar D. Fast mining of interesting phrases from subsets of text corpora. In EDBT, 2014. [Google Scholar]
- [30].Parameswaran A, Garcia-Molina H, and Rajaraman A. Towards the web of concepts: Extracting concepts from large datasets. Proc. VLDB Endow, 3(1–2):566–577, Sept. 2010. [Google Scholar]
- [31].Park Y, Byrd RJ, and Boguraev BK. Automatic glossary extraction: Beyond terminology identification. In Proceedings of the 19th International Conference on Computational Linguistics - Volume 1, COLING ‘02, pages 1–7, Stroudsburg, PA, USA, 2002. Association for Computational Linguistics. [Google Scholar]
- [32].Punyakanok V and Roth D. The use of classifiers in sequential inference. In NIPS, 2001. [Google Scholar]
- [33].Rafiei-Asl J and Nickabadi A. Tsake: A topical and structural automatic keyphrase extractor. Applied Soft Computing, 58:620–630, 2017. [Google Scholar]
- [34].Ramisch C, Villavicencio A, and Boitet C. Multiword expressions in the wild? the mwetoolkit comes in handy. In COLING, pages 57–60, 2010. [Google Scholar]
- [35].Schmid H. Treetagger— a language independent part-of-speech tagger Institut für Maschinelle Sprachverarbeitung, Universität Stuttgart, 43:28, 1995. [Google Scholar]
- [36].Witten IH, Paynter GW, Frank E, Gutwin C, and Nevill-Manning CG. Kea: Practical automatic keyphrase extraction. In Proceedings of the Fourth ACM Conference on Digital Libraries, DL ‘99, pages 254–255, New York, NY, USA, 1999. ACM. [Google Scholar]
- [37].Xun E, Huang C, and Zhou M. A unified statistical model for the identification of english basenp. In Proceedings of the 38th Annual Meeting on Association for Computational Linguistics, ACL ‘00, pages 109–116, Stroudsburg, PA, USA, 2000. Association for Computational Linguistics. [Google Scholar]
- [38].Zhang Z, Iria J, Brewster CA, and Ciravegna F. A comparative evaluation of term recognition algorithms. LREC, 2008. [Google Scholar]