

Supplemental Digital Content is available in the text.
Keywords: Bias analysis, Selection bias, Sensitivity analysis, Target population
Abstract
When epidemiologic studies are conducted in a subset of the population, selection bias can threaten the validity of causal inference. This bias can occur whether or not that selected population is the target population and can occur even in the absence of exposure–outcome confounding. However, it is often difficult to quantify the extent of selection bias, and sensitivity analysis can be challenging to undertake and to understand. In this article, we demonstrate that the magnitude of the bias due to selection can be bounded by simple expressions defined by parameters characterizing the relationships between unmeasured factor(s) responsible for the bias and the measured variables. No functional form assumptions are necessary about those unmeasured factors. Using knowledge about the selection mechanism, researchers can account for the possible extent of selection bias by specifying the size of the parameters in the bounds. We also show that the bounds, which differ depending on the target population, result in summary measures that can be used to calculate the minimum magnitude of the parameters required to shift a risk ratio to the null. The summary measure can be used to determine the overall strength of selection that would be necessary to explain away a result. We then show that the bounds and summary measures can be simplified in certain contexts or with certain assumptions. Using examples with varying selection mechanisms, we also demonstrate how researchers can implement these simple sensitivity analyses. See video abstract at, http://links.lww.com/EDE/B535.
When bias in an epidemiologic study is unavoidable, various methods can be used to assess the robustness of results to factors that limit causal inference, such as unmeasured confounding, measurement error, and selection. While there exist relatively simple sensitivity analysis approaches for measurement error and unmeasured confounding,1–5 those for selection bias are limited by computational or mathematical complexity, the need for strong assumptions or the specification of a large number of parameters, or applicability only to certain selection mechanisms or study designs.6–13
In this article, we show that selection bias can be bounded by straightforward expressions that allow for a simple approach to sensitivity analysis. We use the term selection bias to describe the extent to which a parameter being estimated differs from a causal effect in either the total population or some subset of it, due to the restriction of the study population. This bias is sometimes defined as that resulting from selecting on a collider—that is, a common effect of two variables in the causal structure.14 Such selection may be due to convenience in study design or analysis, a desire to evaluate an exposure–outcome relationship in a subset of the population, an attempt to limit other types of bias, or nonparticipation and loss to follow-up.
For example, in birth defects studies, it is often difficult or impossible to collect data on pregnancies that do not result in a live birth. Analyzing the exposure–outcome relationship in only live births may lead to selection bias when a factor determining the probability of live birth is also related to the exposure of interest. In other types of studies, a question about a particular subpopulation is the motivation for the selection. For example, an exposure (e.g., obesity) may be particularly harmful or protective among people with certain health conditions (e.g., cardiovascular disease). However, even when selection is due to interest in a particular subpopulation, selecting on a factor of interest does not eliminate the potential for bias, if for example that factor itself is related to the exposure.
Solutions to these problems often involve a number of assumptions, particularly when the target of causal inference is the whole population and not just the subpopulation from which the sample was selected. Our simplified approach to assessing selection bias makes clear the target of inference and limits the number of parameters and assumptions that determine the possible magnitude of the bias. We show that the magnitude of the bias in the causal risk ratio can be bounded by simple expressions that relate the variables in the causal structure, which may be known or hypothetical. In the eTable and eAppendix (http://links.lww.com/EDE/B521), we extend the results to the risk difference scale. The bounds differ depending on the target population of interest and the selection procedure but require no assumptions about the type or number of measured or unmeasured variables that cause the bias, or interactions between pairs of variables. We consider several causal structures under which the bounds can be applied and motivate their use in the contexts above and with other examples. Finally, we show that under certain assumptions about the equality of the parameters determining bias, a summary measure can be constructed for each of various scenarios, which can be used as a simple technique for assessing the robustness to selection bias of results from an epidemiologic analysis.
THE SELECTION BIAS BOUNDING FACTOR
The Size and Structure of the Bias
Consider a situation in which a causal population-level risk ratio (RR) comparing two levels of an exposure denoted 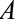 is the parameter of interest. Although our results hold comparing any two values of categorical or continuous
is the parameter of interest. Although our results hold comparing any two values of categorical or continuous 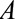 , we will assume binary
, we will assume binary 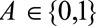 for ease of notation. Let
for ease of notation. Let 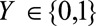 denote the binary outcome and
denote the binary outcome and 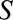 be a binary indicator of selection, where
be a binary indicator of selection, where 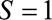 indicates the subset of the population included in the study and
indicates the subset of the population included in the study and 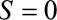 indicates the subset of the population excluded in the study. Let
indicates the subset of the population excluded in the study. Let  denote a set of measured covariates. In case–control studies, the odds ratio (OR) may approximate the RR; we assume that this approximation holds throughout this article. Furthermore, although cases are selected with higher probability than controls in such studies, we can ignore that aspect of the selection mechanism, as it does not bias the OR.
denote a set of measured covariates. In case–control studies, the odds ratio (OR) may approximate the RR; we assume that this approximation holds throughout this article. Furthermore, although cases are selected with higher probability than controls in such studies, we can ignore that aspect of the selection mechanism, as it does not bias the OR.
We will use potential outcome notation wherein 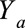 indicates the value of
indicates the value of 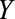 under treatment
under treatment 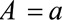 . Let the causal RR conditional on covariates
. Let the causal RR conditional on covariates 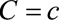 ,
, 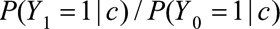 be denoted
be denoted 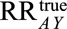 and assume that it is identifiable as
and assume that it is identifiable as 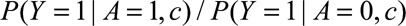 . This requires that certain identifiability conditions hold, including consistency, positivity, and, in particular, exchangeability
. This requires that certain identifiability conditions hold, including consistency, positivity, and, in particular, exchangeability 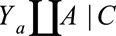 ; that is, that
; that is, that 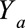 is independent of actual exposure
is independent of actual exposure 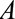 conditional on measured covariates
conditional on measured covariates  .15 For simplicity in the development that follows, we will assume that all analyses are carried out within strata of measured confounders
.15 For simplicity in the development that follows, we will assume that all analyses are carried out within strata of measured confounders  as necessary and exclude reference to those variables, but all subsequent probability expressions can be interpreted as conditional on measured covariates
as necessary and exclude reference to those variables, but all subsequent probability expressions can be interpreted as conditional on measured covariates  .
.
Suppose now, due to some selection mechanism, we are limited to estimating the RR only within a subpopulation, denoted by 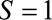 , so that we estimate
, so that we estimate 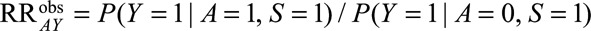 . If we restrict analysis to
. If we restrict analysis to 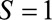 , selection bias occurs if it is not the case that
, selection bias occurs if it is not the case that 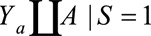 , even though
, even though 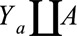 in the population. The bias is not due to the fact that the RRs in the total and selected populations differ but to the fact that
in the population. The bias is not due to the fact that the RRs in the total and selected populations differ but to the fact that 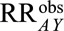 is not a causal effect even in the selected population. (Later in the text, Results 5A and 5B correspond to the situation in which such an effect is of interest.)
is not a causal effect even in the selected population. (Later in the text, Results 5A and 5B correspond to the situation in which such an effect is of interest.)
Several causal structures in which selection bias may occur are shown in the Figure. In each situation, bias is induced by a selection process, which is itself differential with respect to the exposure or outcome and some unmeasured (or possibly measured) factor(s), denoted  . Consider the setting in which conditional on some unmeasured covariate(s)
. Consider the setting in which conditional on some unmeasured covariate(s) 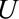 , we have
, we have 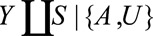 . This independence holds in the causal diagrams in the Figure A, B, and D. For ease of notation, we will consider
. This independence holds in the causal diagrams in the Figure A, B, and D. For ease of notation, we will consider 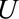 to be a categorical variable, but the results hold for general
to be a categorical variable, but the results hold for general 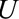 or vector of variables denoted
or vector of variables denoted  . We can rewrite the target parameter in terms of
. We can rewrite the target parameter in terms of  :
:
FIGURE.
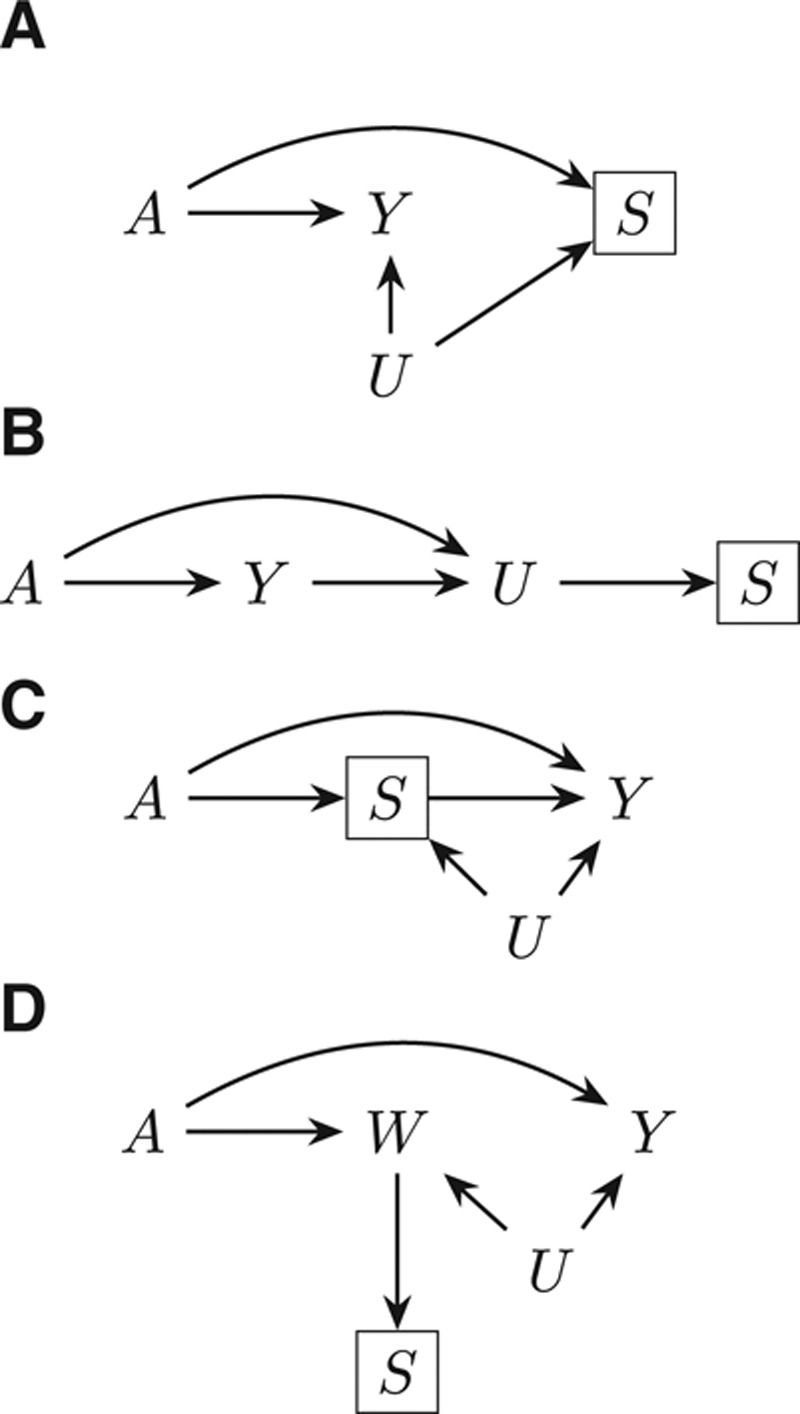
Examples of causal diagrams under which bias for a causal effect of  on
on 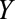 can result due to selection. Selection is shown with the boxed
can result due to selection. Selection is shown with the boxed 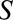 , representing that only a selected population, which may have different distributions of the variables upstream of
, representing that only a selected population, which may have different distributions of the variables upstream of 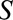 than the total population, is studied. For simplicity, no confounders of the
than the total population, is studied. For simplicity, no confounders of the 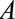 –
–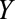 relationship are shown but could certainly be present. A, The birth defects example, where
relationship are shown but could certainly be present. A, The birth defects example, where 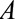 is infection with Zika virus,
is infection with Zika virus, 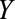 is microcephaly,
is microcephaly, 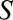 is live birth, and
is live birth, and 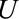 is socioeconomic and behavioral factors. B, The estrogen cancer example, where selection is based on a factor
is socioeconomic and behavioral factors. B, The estrogen cancer example, where selection is based on a factor 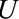 (symptoms that lead to an intraendometrial diagnostic procedure) that is affected by both estrogen use (
(symptoms that lead to an intraendometrial diagnostic procedure) that is affected by both estrogen use (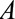 ) and the presence of endometrial cancer (
) and the presence of endometrial cancer (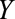 ). C, The obesity paradox example, where
). C, The obesity paradox example, where 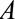 is obesity,
is obesity, 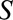 is a disease such as heart failure, and
is a disease such as heart failure, and 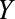 is mortality. D, A study in which only participants who agree to DNA collection (
is mortality. D, A study in which only participants who agree to DNA collection (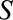 ) are selected to a study of the relationship between (1) a genetic risk score (
) are selected to a study of the relationship between (1) a genetic risk score (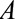 ) for smoking (
) for smoking (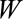 ) and (2) an education outcome (
) and (2) an education outcome (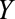 ).31
).31
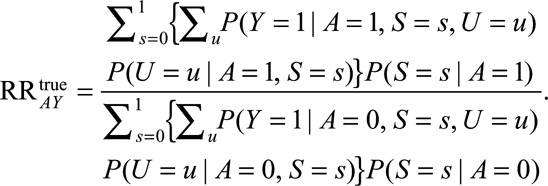 |
Let the relative bias due to selection be defined as 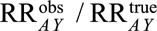 . By bounding this value, we can assess the maximum strength of the bias in terms of parameters that describe relationships between
. By bounding this value, we can assess the maximum strength of the bias in terms of parameters that describe relationships between 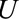 and other variables.
and other variables.
The Bounding Factor
We bound the relative bias from above, assuming that the 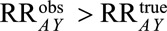 . If not, and the
. If not, and the 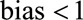 , interest is naturally in a bound from below. We can then reverse the coding of
, interest is naturally in a bound from below. We can then reverse the coding of 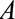 so that
so that 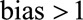 , resulting in an appropriate bound once the coding is reversed.
, resulting in an appropriate bound once the coding is reversed.
We define the following parameters:
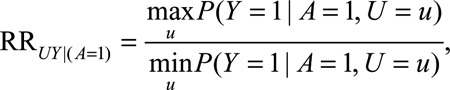 |
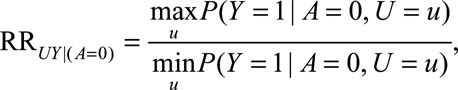 |
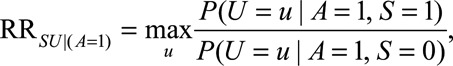 |
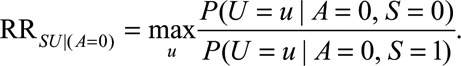 |
The 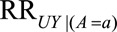 parameters can be interpreted as the maximum relative risks for
parameters can be interpreted as the maximum relative risks for 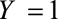 comparing any two values of
comparing any two values of 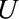 within strata of
within strata of 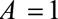 and
and 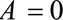 , respectively. It need not be a causal relationship that is described by this risk ratio, as
, respectively. It need not be a causal relationship that is described by this risk ratio, as 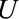 may be downstream of
may be downstream of 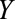 in some situations that are susceptible to selection bias (e.g., Figure B). The
in some situations that are susceptible to selection bias (e.g., Figure B). The 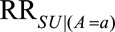 parameters are the maximum factors by which selection is associated with an increased prevalence of some value of
parameters are the maximum factors by which selection is associated with an increased prevalence of some value of 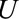 within stratum
within stratum 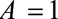 and by which nonselection is associated with an increased prevalence of some value of
and by which nonselection is associated with an increased prevalence of some value of 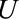 within stratum
within stratum 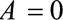 . If
. If 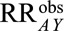 has been estimated within strata of measured confounders
has been estimated within strata of measured confounders  , then these parameters are defined conditional on the same confounders.
, then these parameters are defined conditional on the same confounders.
We now present our first result, a proof of which is given in the eAppendix (http://links.lww.com/EDE/B521).
Result 1A
If 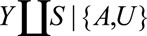 , then:
, then:
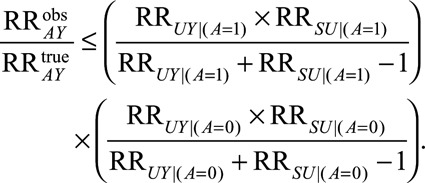 |
Result 1A tells us that the bias is guaranteed to be equal to or smaller in magnitude than the given expression, which we will call in general a bounding factor. A researcher or reader who proposes that some factor 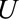 has led to selection bias can propose values that plausibly describe the relationships between that factor and selection and the outcome and calculate the bounding factor from these parameters. That bounding factor (or set of bounding factors constructed from ranges of values) can be divided out of the estimate of
has led to selection bias can propose values that plausibly describe the relationships between that factor and selection and the outcome and calculate the bounding factor from these parameters. That bounding factor (or set of bounding factors constructed from ranges of values) can be divided out of the estimate of 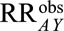 to come up with the smallest possible RR that would be compatible with
to come up with the smallest possible RR that would be compatible with 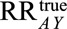 .
.
Example: Zika Virus
After a rise in microcephaly cases in northeast Brazil closely followed an outbreak of Zika virus in that region, evidence from biologic and ecologic data supported a causal link.16 In particular, models using surveillance data showed that the population risk of microcephaly increased after Zika infections in the first semester of pregnancy.17 The relationship was seemingly confirmed with the first case–control study to examine the association, from which de Araújo et al reported an adjusted OR of 73.1 (95% confidence interval [CI] = 13.0, ).18 Both live and still births were recruited as cases; however, pregnancies that resulted in miscarriage or elective abortion would have been missed by this study design, which corresponds to Figure A. The probability of not having a termination (
).18 Both live and still births were recruited as cases; however, pregnancies that resulted in miscarriage or elective abortion would have been missed by this study design, which corresponds to Figure A. The probability of not having a termination (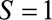 ) may be affected by exposure to the virus (
) may be affected by exposure to the virus (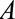 ) and socioeconomic or behavioral conditions such as lack of access to medical care (
) and socioeconomic or behavioral conditions such as lack of access to medical care (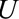 ), which may also affect the probability of microcephaly (
), which may also affect the probability of microcephaly (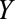 ) (e.g., giving birth in a public hospital, low education, and being unmarried have been associated with microcephaly in Brazil19). Selecting only live and still births in the analysis may therefore lead to selection bias.
) (e.g., giving birth in a public hospital, low education, and being unmarried have been associated with microcephaly in Brazil19). Selecting only live and still births in the analysis may therefore lead to selection bias.
Suppose that access to medical care affected the probability of microcephaly by up to two-fold among the Zika exposed and unexposed (i.e., 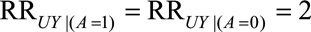 ) and that lack of access to medical care for pregnant women was up to 1.7 times more likely for women without an induced abortion among the Zika exposed (
) and that lack of access to medical care for pregnant women was up to 1.7 times more likely for women without an induced abortion among the Zika exposed (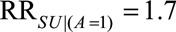 ) and access to medical care up to 1.5 times more likely for women with an induced abortion among the unexposed (
) and access to medical care up to 1.5 times more likely for women with an induced abortion among the unexposed (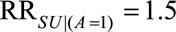 ), the bias factor is then
), the bias factor is then
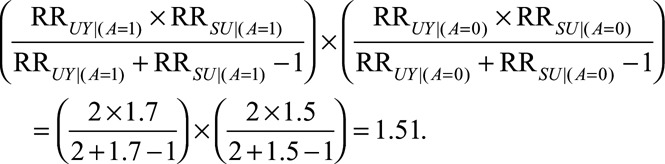 |
The most such selection bias that could alter the estimate can be obtained by dividing the original estimate and confidence interval by this bias factor to obtain an OR of 48.4 (95% CI = 8.6, ), which is of course still a very large effect estimate.
), which is of course still a very large effect estimate.
A Summary Measure
Instead of calculating each of the parameters in the bounding factor individually, we may be interested in assessing the overall susceptibility of a result to selection bias. This can be done with a single value that summarizes the extent to which an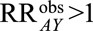 may be a spurious finding entirely due to selection bias.
may be a spurious finding entirely due to selection bias.
Result 1B
If 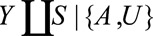 , then the minimum magnitude of each of the four parameters that make up the bounding factor, assuming the four are equal, that would be sufficient to shift a given
, then the minimum magnitude of each of the four parameters that make up the bounding factor, assuming the four are equal, that would be sufficient to shift a given 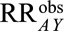 to the null is given by the following equation:
to the null is given by the following equation:
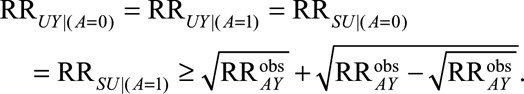 |
For example, if 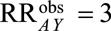 , then all four of the parameters in the bounding factor must be equal to or greater than
, then all four of the parameters in the bounding factor must be equal to or greater than 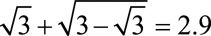 to have generated sufficient selection bias. If one of the four is smaller than 2.9, then one or more of the parameters must be greater than 2.9 to compensate. Because it only depends on
to have generated sufficient selection bias. If one of the four is smaller than 2.9, then one or more of the parameters must be greater than 2.9 to compensate. Because it only depends on 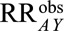 , this summary measure is easy to calculate and compare across studies. However, it is context specific: it is interpreted relative to the selection mechanism in a given study and conditional on whatever confounders have been controlled for in the analysis. Based on content knowledge, investigators and readers can judge whether there exists an
, this summary measure is easy to calculate and compare across studies. However, it is context specific: it is interpreted relative to the selection mechanism in a given study and conditional on whatever confounders have been controlled for in the analysis. Based on content knowledge, investigators and readers can judge whether there exists an 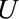 that could be so strongly related both to the outcome and to selection within strata of the exposure and the measured confounders.
that could be so strongly related both to the outcome and to selection within strata of the exposure and the measured confounders.
Such calculations can also be performed using the lower limit of the confidence interval instead of 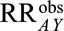 , to see what strength of the selection parameters would be necessary to result in a confidence interval that includes the null value of 1.
, to see what strength of the selection parameters would be necessary to result in a confidence interval that includes the null value of 1.
Example: Zika Virus Revisited
With no assumptions about the exact nature of the unmeasured factors  , we can use Result 1B to assess the plausibility that the Zika–microcephaly association is fully explained by selection bias. By calculating the summary measure
, we can use Result 1B to assess the plausibility that the Zika–microcephaly association is fully explained by selection bias. By calculating the summary measure 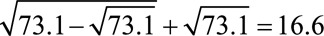 , we come to conclusions about the strength of the relationships with the unmeasured behaviors or socioeconomic conditions (such as lack of access to medical care) that would be necessary to produce an
, we come to conclusions about the strength of the relationships with the unmeasured behaviors or socioeconomic conditions (such as lack of access to medical care) that would be necessary to produce an 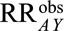 of 73.1 if
of 73.1 if 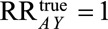 . Selection bias could explain the observed association if there was an unmeasured variable (e.g., lack of access to medical care) that increased the risk of microcephaly by 16.6-fold in both exposed and unexposed women, that was 16.6 times higher among exposed women with live or still births than among those whose pregnancies were terminated, and that was also 16.6 times lower among the unexposed. However, weaker relationships between the unmeasured factor and both selection and microcephaly would not suffice to fully explain the observed exposure–outcome association. Risk ratios of that magnitude are rarely seen in epidemiologic research, particularly in the context of behavioral differences, lending confidence that the increased microcephaly risk is not the result of selection bias. We can repeat the calculation with the lower bound of the confidence interval, 13.0, to assess the magnitude of selection bias necessary to shift the confidence interval to include the null. This gives a summary measure of 6.7; although it is perhaps plausible that one of the parameters is that large, it seems unlikely that all four are. Assuming that confounding was fully accounted for in the study via matching and multivariable control and that all variables were correctly measured, it seems that even in the presence of possible selection bias, the evidence is very strong that Zika infection in pregnant women causes microcephaly.
. Selection bias could explain the observed association if there was an unmeasured variable (e.g., lack of access to medical care) that increased the risk of microcephaly by 16.6-fold in both exposed and unexposed women, that was 16.6 times higher among exposed women with live or still births than among those whose pregnancies were terminated, and that was also 16.6 times lower among the unexposed. However, weaker relationships between the unmeasured factor and both selection and microcephaly would not suffice to fully explain the observed exposure–outcome association. Risk ratios of that magnitude are rarely seen in epidemiologic research, particularly in the context of behavioral differences, lending confidence that the increased microcephaly risk is not the result of selection bias. We can repeat the calculation with the lower bound of the confidence interval, 13.0, to assess the magnitude of selection bias necessary to shift the confidence interval to include the null. This gives a summary measure of 6.7; although it is perhaps plausible that one of the parameters is that large, it seems unlikely that all four are. Assuming that confounding was fully accounted for in the study via matching and multivariable control and that all variables were correctly measured, it seems that even in the presence of possible selection bias, the evidence is very strong that Zika infection in pregnant women causes microcephaly.
SPECIAL CASES AND THEIR BOUNDING FACTORS AND SUMMARY MEASURES
Here, we consider a number of special cases that result in modified bounding factors and summary measures. The Table summarizes the results, and derivations are provided in the eAppendix (http://links.lww.com/EDE/B521).
TABLE.
Summary of Bounding Factors for Selection Bias on the Risk Ratio Scale and Their Summary Measures Under Different Scenarios

When 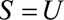 (Results 2A and 2B)
(Results 2A and 2B)
In some situations, 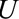 may not be unmeasured and may be common to the entire selected population. This is the case, for example, when some characteristic defines or directly leads to selection into a study. When this is true, the bounding factor is simplified.
may not be unmeasured and may be common to the entire selected population. This is the case, for example, when some characteristic defines or directly leads to selection into a study. When this is true, the bounding factor is simplified.
Result 2A
If 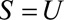 , then
, then
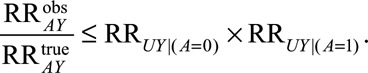 |
We can also construct a summary measure for this situation. It can be used in the same way as that in Result 1B but only describes the minimum magnitude of the two parameters in the modified bounding factor in Result 2A.
Result 2B
If 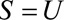 , then the minimum magnitude of each of the two parameters that make up the bounding factor in Result 2A, assuming they are equal, that would be sufficient to shift a given
, then the minimum magnitude of each of the two parameters that make up the bounding factor in Result 2A, assuming they are equal, that would be sufficient to shift a given 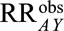 to the null is given by the following equation:
to the null is given by the following equation:
Assumptions About Directionality (Results 3A and 3B)
Although Result 1A requires minimal assumptions, sometimes we can make assumptions that decrease the magnitude of the bounding factor, which can provide us with more confidence that a given result is not due to selection bias. The bounding factor is greatest when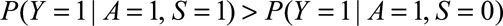 and
and 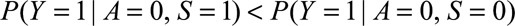 ; that is, when selection is associated with increased risk of the outcome among the exposed and with decreased risk among the unexposed. However, if selection is associated with increased risk among both groups, then we have the following result.
; that is, when selection is associated with increased risk of the outcome among the exposed and with decreased risk among the unexposed. However, if selection is associated with increased risk among both groups, then we have the following result.
Result 3A
If 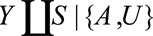 and if
and if 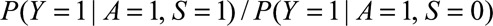 and
and 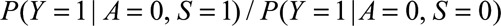 are greater than 1, then
are greater than 1, then
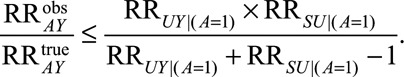 |
Results are analogous with decreased risk for both groups, with 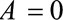 replacing
replacing 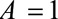 in each of the parameters. (If selection is associated with decreased risk among the exposed and increased risk among the unexposed, the bias
in each of the parameters. (If selection is associated with decreased risk among the exposed and increased risk among the unexposed, the bias 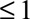 , so
, so 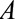 should be recoded to construct a meaningful bound.)
should be recoded to construct a meaningful bound.)
If assumptions about the consistency of the direction of the selection–outcome relationship can be made, then we can also use simpler expressions as the summary measures; for increased risk in both groups, the summary measure is stated in the following result.
Result 3B
If 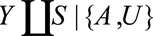 and if
and if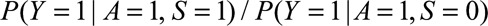 and
and 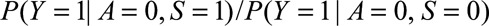 are greater than 1, then the minimum magnitude of each of the two parameters that make up the bounding factor in Result 3A, assuming they are equal, that would be sufficient to shift a given
are greater than 1, then the minimum magnitude of each of the two parameters that make up the bounding factor in Result 3A, assuming they are equal, that would be sufficient to shift a given 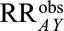 to the null is given by the following equation:
to the null is given by the following equation:
When the outcome risk is decreased with selection in both exposure groups, the summary measure refers to the minimum strength of the parameters 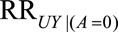 and
and 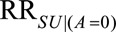 . Results 3A and 3B have the same analytic form of the recently proposed “E-value” calculated to assess robustness to unmeasured confounding.20
. Results 3A and 3B have the same analytic form of the recently proposed “E-value” calculated to assess robustness to unmeasured confounding.20
When 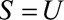 with Directionality Assumptions (Results 4A and 4B)
with Directionality Assumptions (Results 4A and 4B)
When 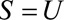 and we can make assumptions about the increase or decrease in risk in both exposure groups with selection, we can combine earlier results. For increased risk in both groups, we have the following result.
and we can make assumptions about the increase or decrease in risk in both exposure groups with selection, we can combine earlier results. For increased risk in both groups, we have the following result.
Result 4A
If 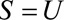 and if
and if 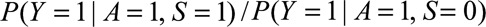 and
and 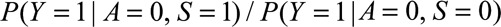 are greater than 1, then
are greater than 1, then
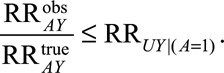 |
The summary measure describing the minimum magnitude of the sole parameter is also simplified.
Result 4B
If 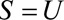 and if
and if 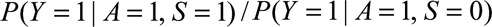 and
and 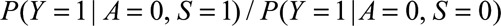 are greater than 1, then the minimum magnitude of
are greater than 1, then the minimum magnitude of 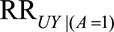 that would be sufficient to shift a given
that would be sufficient to shift a given 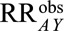 to the null is given by the following equation:
to the null is given by the following equation:
Example: Endometrial Cancer
For many years, the relationship between estrogen replacement therapy and endometrial cancer was clouded by controversy over proper study design to minimize bias. In an attempt to limit differential outcome detection by estrogen exposure, Horwitz and Feinstein21 simultaneously performed a case–control study of exogenous estrogens and endometrial cancer in a population of women who had undergone intraendometrial diagnostic procedures and one with a more “conventional” sampling method. They claimed their estimates of an OR of 2.30 using the “alternative” sampling method and an OR of 11.98 with the conventional method supported their worry about biased cancer detection. However, their selection procedure was shown to induce bias.22 The structure leading to this bias is shown in Figure B, in which 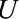 represents a diagnostic procedure; in this case, all of those selected (
represents a diagnostic procedure; in this case, all of those selected (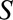 ) have undergone such a procedure. We can use a bounding factor to assess how plausible it is that selection bias could explain the authors’ much reduced OR. In this context, we are curious about whether bias could shift the result to a specific value and not to the null.
) have undergone such a procedure. We can use a bounding factor to assess how plausible it is that selection bias could explain the authors’ much reduced OR. In this context, we are curious about whether bias could shift the result to a specific value and not to the null.
Because our proposed 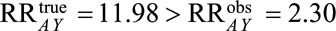 , the
, the 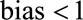 and we recode the exposure for a relative bias of 11.98/2.3 = 5.2. Because everyone in the selected population had symptoms that led to a diagnostic procedure, we will use the bounding factor that assumes
and we recode the exposure for a relative bias of 11.98/2.3 = 5.2. Because everyone in the selected population had symptoms that led to a diagnostic procedure, we will use the bounding factor that assumes 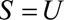 . If we assume that having a hysterectomy is associated with increased cancer prevalence in both estrogen-exposed and unexposed women, we have by Result 4B that
. If we assume that having a hysterectomy is associated with increased cancer prevalence in both estrogen-exposed and unexposed women, we have by Result 4B that 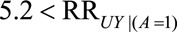 (recalling that
(recalling that 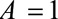 , after recoding, now refers to those unexposed to estrogen). This means that in order for the difference in ORs to be possibly explained by selection bias (that is, for the
, after recoding, now refers to those unexposed to estrogen). This means that in order for the difference in ORs to be possibly explained by selection bias (that is, for the 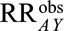 of 2.30 to shift to at least 11.98 after accounting for selection bias), the prevalence of endometrial cancer in nonusers of estrogen who have undergone hysterectomy or other diagnostic procedure must be greater than 5.2 times that in nonusers who have not.
of 2.30 to shift to at least 11.98 after accounting for selection bias), the prevalence of endometrial cancer in nonusers of estrogen who have undergone hysterectomy or other diagnostic procedure must be greater than 5.2 times that in nonusers who have not.
THE SELECTED POPULATION AS THE TARGET POPULATION
In some studies, the causal risk ratio in the selected population, and not in the entire population, may be the target parameter. This may occur, for example, when 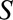 is an indicator of a well-defined population for which an estimated causal effect is desired and not simply the result of poor sampling or selective attrition.
is an indicator of a well-defined population for which an estimated causal effect is desired and not simply the result of poor sampling or selective attrition.
Under the same notation and assumptions as above, we denote 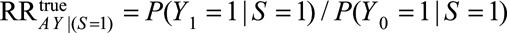 . Again, because it is not true that
. Again, because it is not true that 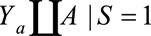 , this is not identifiable as
, this is not identifiable as 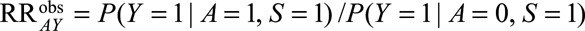 . Instead, if
. Instead, if 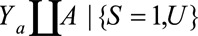 , the RR of interest is identified by marginalizing over the distribution of
, the RR of interest is identified by marginalizing over the distribution of 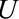 in the selected population, resulting in
in the selected population, resulting in
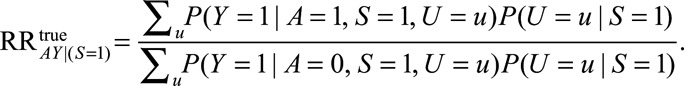 |
Again we are concerned with the relative bias 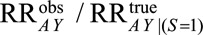 . This bias can be conceptualized as equivalent to that due to unmeasured confounding, which occurs when
. This bias can be conceptualized as equivalent to that due to unmeasured confounding, which occurs when 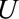 is associated with the exposure
is associated with the exposure 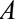 and also affects the outcome
and also affects the outcome 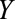 . Although
. Although 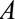 and
and 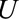 are marginally independent, as in Figure A, C, and D, an association between the two is induced by conditioning on selection into the study, represented by the boxed
are marginally independent, as in Figure A, C, and D, an association between the two is induced by conditioning on selection into the study, represented by the boxed 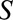 in the diagrams. Then, within stratum
in the diagrams. Then, within stratum 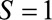 , we have a situation equivalent to confounding by
, we have a situation equivalent to confounding by 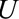 , due to its relationships with the exposure and outcome. Extending previously published bounds for bias due to unmeasured confounding,5 we have a bounding factor for inference in the selected population as follows.
, due to its relationships with the exposure and outcome. Extending previously published bounds for bias due to unmeasured confounding,5 we have a bounding factor for inference in the selected population as follows.
Result 5A
If 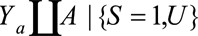 , then
, then
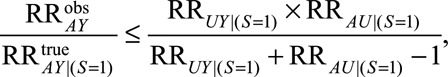 |
where
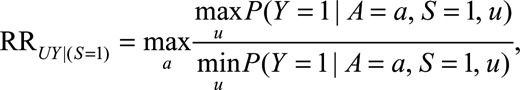 |
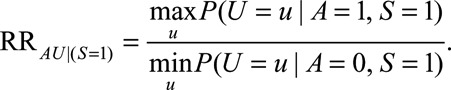 |
The parameter 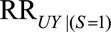 is the maximum risk ratio for the outcome given any two values of
is the maximum risk ratio for the outcome given any two values of 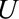 among either the unexposed selected population or the exposed selected population. Because data are available on a sample of this population, this could be approximated using available data on measured confounders.
among either the unexposed selected population or the exposed selected population. Because data are available on a sample of this population, this could be approximated using available data on measured confounders.
Because the second parameter, 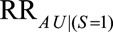 , represents an association induced between two marginally independent variables (i.e., the dependence due to collider stratification), it is not as intuitive to specify. However, it is conceptually similar to one of the two required to define a bound for bias in the natural direct effect,23 where the
, represents an association induced between two marginally independent variables (i.e., the dependence due to collider stratification), it is not as intuitive to specify. However, it is conceptually similar to one of the two required to define a bound for bias in the natural direct effect,23 where the 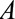 –
–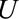 relationship is induced by conditioning on a mediator. In that situation, an approximate bound can be used.24 Similarly, the bound that uses the maximum RR for
relationship is induced by conditioning on a mediator. In that situation, an approximate bound can be used.24 Similarly, the bound that uses the maximum RR for 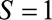 comparing two values of
comparing two values of 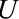 or the maximum risk ratio for
or the maximum risk ratio for 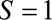 comparing two values of
comparing two values of 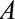 could be used here. Depending on the structure of the selection bias mechanism, one of these two parameters might be more intuitive to quantify and can generally replace
could be used here. Depending on the structure of the selection bias mechanism, one of these two parameters might be more intuitive to quantify and can generally replace 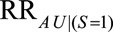 for an approximate bounding factor.
for an approximate bounding factor.
Summary Measure
The summary measure that follows from Result 5A can then be given in the following result.
Result 5B
If 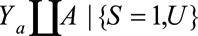 , then the minimum value of
, then the minimum value of 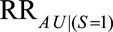 and
and 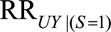 , assuming the two parameters are equal, that would be sufficient to shift a given
, assuming the two parameters are equal, that would be sufficient to shift a given 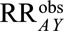 to the null is given by the following equation:
to the null is given by the following equation:
Results 5A and 5B have the same analytic form of the recently proposed E-value calculated to assess robustness to unmeasured confounding.20
Example: Obesity Paradox
The obesity paradox is a well-known phenomenon in chronic disease epidemiology in which overweight and obesity are associated with increased survival compared with normal weight among patients with certain conditions.25 Whether this is a real causal effect (which could result in different weight recommendations for people living with chronic conditions) or due to bias—in particular, bias resulting from selection on a common effect (chronic disease) of both obesity and some unmeasured factor that is also related to death (Figure C)—is the subject of much debate.26–29 Gruberg et al30 investigated the relationship between body mass index and 1-year risk of death among patients who were treated for advanced coronary artery disease (CAD), finding that 10.6% of patients with normal body mass index died, more than double the percentage among the obese patients. Using the OR from their adjusted model, we can calculate that the mortality risk was 1.50 times higher (95% CI = 1.22, 1.86) in patients for whom body mass index was 10 units lower (corresponding approximately to the difference between obesity and normal weight).30 The authors controlled for a number of measured confounders including age and heart function.
Because we are interested in the population of CAD patients, we can use Result 5B to assess the plausibility of such a result being due to some unmeasured common cause of heart failure and death: 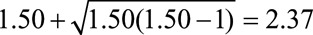 . The unmeasured factor must increase the risk of death among normal weight or obese CAD patients by a factor of 2.37 (independent of the factors already included in the model) and differ between the obesity exposure categories in CAD patients by the same factor, if there were truly no protective effect of obesity on death in that population. Because the latter relationship, between obesity and the unmeasured factor, would be one induced solely by the selection of CAD patients, it may be difficult to specify. It may be more intuitive to consider an unmeasured factor that directly increases the risk of CAD by the same factor of 2.37, which will generally also suffice to bound the selection bias. We can repeat the calculation and interpretation with the lower bound of the confidence interval, which gives us a summary measure of 1.74, to assess the bias necessary for the confidence interval to include the null.
. The unmeasured factor must increase the risk of death among normal weight or obese CAD patients by a factor of 2.37 (independent of the factors already included in the model) and differ between the obesity exposure categories in CAD patients by the same factor, if there were truly no protective effect of obesity on death in that population. Because the latter relationship, between obesity and the unmeasured factor, would be one induced solely by the selection of CAD patients, it may be difficult to specify. It may be more intuitive to consider an unmeasured factor that directly increases the risk of CAD by the same factor of 2.37, which will generally also suffice to bound the selection bias. We can repeat the calculation and interpretation with the lower bound of the confidence interval, which gives us a summary measure of 1.74, to assess the bias necessary for the confidence interval to include the null.
Discussion
Because selection bias can be difficult to quantify, it is often ignored in sensitivity analysis or only explored in complex analyses that must be relegated to appendices. A simple way to characterize the possible extent of selection bias in terms of the relationships in the causal structure that induces it will allow researchers to more easily assess the plausibility of this bias with minimal assumptions.
Thinking about selection bias as described in this article will also force researchers to clearly define the target population of interest, whether that be the total population or those with the characteristics of the selected sample. Making assumptions to simplify the bounding factor can also compel them to think through the mechanisms by which selection bias occurs and the direction of the various effects. However, no such assumptions are required to use our main results. While this article focused on the relative bias of observed RRs, as relative effect measures are common in epidemiology and RRs are often approximated by ORs and hazard ratios under certain assumption, analogous bounds for observed effects on the risk difference scale are presented in the eTable (http://links.lww.com/EDE/B521), and their corresponding derivations in the eAppendix (http://links.lww.com/EDE/B521).
The bounds we presented in this article can be used in several ways. If researchers have quantitative knowledge about factors influencing selection in their study, such as in a situation with loss to follow-up or participation in a sub-study, realistic RRs for unmeasured factors can be used as parameters in the bounds to explore to what extent these could affect  . If only ranges of possible parameters are proposed, the bounds can be varied across those ranges in a table or figure to allow readers to consider the most plausible combinations. Finally, if all that is desired is a summary measure of the extent to which a result could be rendered null by selection bias, or shifted to any other proposed true value, the bounds can be used to describe the magnitude of the parameters that could result in such an observed value.
. If only ranges of possible parameters are proposed, the bounds can be varied across those ranges in a table or figure to allow readers to consider the most plausible combinations. Finally, if all that is desired is a summary measure of the extent to which a result could be rendered null by selection bias, or shifted to any other proposed true value, the bounds can be used to describe the magnitude of the parameters that could result in such an observed value.
There are nonetheless several limitations to these bounds. First, they are only applicable under certain causal structures that lead to selection bias. The results here describe the maximum bias that could result from the parameters; the same parameters could also induce less bias. This conservative approach is useful when less is known about the selection mechanism and a simple exploration of the possible bias is desired. When more information is available, a more complex but precise method may be preferred.7,8,10–12 Next, the  parameter in the bound for the selected population is unintuitive and may be hard to specify even in the presence of solid knowledge about the selection mechanism; however, RRs relating the exposure or selection to the unobserved factor can usually be used in its place.24 Finally, this article only addresses bias due to selection and assumes that other criteria for causal inference, such as control of exposure–outcome confounding and lack of measurement error, have been met. Future work could combine this approach to selection bias with other methods for bias analysis and could take into account the possibility that factors leading to selection bias could be sources of other types of bias.
parameter in the bound for the selected population is unintuitive and may be hard to specify even in the presence of solid knowledge about the selection mechanism; however, RRs relating the exposure or selection to the unobserved factor can usually be used in its place.24 Finally, this article only addresses bias due to selection and assumes that other criteria for causal inference, such as control of exposure–outcome confounding and lack of measurement error, have been met. Future work could combine this approach to selection bias with other methods for bias analysis and could take into account the possibility that factors leading to selection bias could be sources of other types of bias.
Supplementary Material
Footnotes
Editor’s Note: A related commentary appears on p. 517.
Supported by grant R01CA222147 from the NIH (T.V.).
Disclosure: The authors report no conflicts of interest.
Data and computing code: The R package EValue contains functions to implement these methods.
Supplemental digital content is available through direct URL citations in the HTML and PDF versions of this article (www.epidem.com). This content is not peer-reviewed or copy-edited; it is the sole responsibility of the authors.
REFERENCES
- 1.Rosner B, Willett WC, Spiegelman D. Correction of logistic regression relative risk estimates and confidence intervals for systematic within-Pearson measurement error. Stat Med. 1989;154:1051–1069. [DOI] [PubMed] [Google Scholar]
- 2.Stürmer T, Schneeweiss S, Avorn J, Glynn RJ. Adjusting effect estimates for unmeasured confounding with validation data using propensity score calibration. Am J Epidemiol. 2005;162:279–289. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Cole SR, Chu H, Greenland S. Multiple-imputation for measurement-error correction. Int J Epidemiol. 2006;35:1074–1081. [DOI] [PubMed] [Google Scholar]
- 4.Greenland S. Bayesian perspectives for epidemiologic research: III. Bias analysis via missing-data methods. Int J Epidemiol. 2009;38:1662–1673. [DOI] [PubMed] [Google Scholar]
- 5.Ding P, VanderWeele TJ. Sensitivity analysis without assumptions. Epidemiology. 2016;27:368–377. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Scharfstein DO, Rotnitzky A, Robins JM. Adjusting for nonignorable drop-out using semiparametric nonresponse models. J Am Stat Assoc. 1999;94:1096–1120. [Google Scholar]
- 7.Greenland S. Multiple-bias modelling for analysis of observational data. J R Stat Soc Ser A Stat Soc. 2005;168:267–306. [Google Scholar]
- 8.Geneletti S, Richardson S, Best N. Adjusting for selection bias in retrospective, case–control studies. Biostatistics. 2009;10:17–31. [DOI] [PubMed] [Google Scholar]
- 9.Howe CJ, Cole SR, Chmiel JS, Muñoz A. Limitation of inverse probability-of-censoring weights in estimating survival in the presence of strong selection bias. Am J Epidemiol. 2011;173:569–577. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Törner A, Dickman P, Duberg AS, et al. A method to visualize and adjust for selection bias in prevalent cohort studies. Am J Epidemiol. 2011;174:969–976. [DOI] [PubMed] [Google Scholar]
- 11.Huang TH, Lee WC. Bounding formulas for selection bias. Am J Epidemiol. 2015;182:868–872. [DOI] [PubMed] [Google Scholar]
- 12.McGovern ME, Bärnighausen T, Marra G, Radice R. On the assumption of bivariate normality in selection models: a Copula approach applied to estimating HIV prevalence. Epidemiology. 2015;26:229–237. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Hanley JA. Correction of selection bias in survey data: is the statistical cure worse than the bias? Am J Public Health. 2017;107:503–505. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Hernán MA, Hernández-Díaz S, Robins JM. A structural approach to selection bias. Epidemiology. 2004;15:615–625. [DOI] [PubMed] [Google Scholar]
- 15.Hernán MA, Robins JM. Causal Inference. 2019Boca Raton: Chapman & Hall/CRC. [Google Scholar]
- 16.Rasmussen SA, Jamieson DJ, Honein MA, Petersen LR. Zika virus and birth defects—reviewing the evidence for causality. N Engl J Med. 2016;374:1981–1987. [DOI] [PubMed] [Google Scholar]
- 17.Cauchemez S, Besnard M, Bompard P, et al. Association between Zika virus and microcephaly in French Polynesia, 2013–15: a retrospective study. Lancet. 2016;387:2125–2132. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Araújo TVB de, Ximenes RA de A, Miranda-Filho D de B, et al. Association between microcephaly, Zika virus infection, and other risk factors in Brazil: final report of a case–control study. Lancet Infect Dis. 2018;18:328–336. [DOI] [PubMed] [Google Scholar]
- 19.Silva AA, Barbieri MA, Alves MT, et al. Prevalence and risk factors for microcephaly at birth in Brazil in 2010. Pediatrics. 2018;141:e20170589. [DOI] [PubMed] [Google Scholar]
- 20.VanderWeele TJ, Ding P. Sensitivity analysis in observational research: introducing the E-value. Ann Intern Med. 2017;167:268–274. [DOI] [PubMed] [Google Scholar]
- 21.Horwitz RI, Feinstein AR. Alternative analytic methods for case–control studies of estrogens and endometrial cancer. N Engl J Med. 1978;299:1089–1094. [DOI] [PubMed] [Google Scholar]
- 22.Greenland S, Neutra R. An analysis of detection bias and proposed corrections in the study of estrogens and endometrial cancer. J Chronic Dis. 1981;34:433–438. [DOI] [PubMed] [Google Scholar]
- 23.Ding P, Vanderweele TJ. Sharp sensitivity bounds for mediation under unmeasured mediator–outcome confounding. Biometrika. 2016;103:483–490. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Smith LH, VanderWeele TJ. Mediational E-values: approximate sensitivity analysis for unmeasured mediator–outcome confounding. Epidemiology. 2019: In press. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Lavie CJ, McAuley PA, Church TS, Milani RV, Blair SN. Obesity and cardiovascular diseases: implications regarding fitness, fatness, and severity in the obesity paradox. J Am Coll Cardiol. 2014;63:1345–1354. [DOI] [PubMed] [Google Scholar]
- 26.Banack HR, Kaufman JS. The “obesity paradox” explained. Epidemiology. 2013;24:461–462. [DOI] [PubMed] [Google Scholar]
- 27.Glymour MM, Vittinghoff E. Commentary: selection bias as an explanation for the obesity paradox: just because it’s possible doesn’t mean it’s plausible. Epidemiology. 2014;25:4–6. [DOI] [PubMed] [Google Scholar]
- 28.Banack HR, Kaufman JS. Does selection bias explain the obesity paradox among individuals with cardiovascular disease? Ann Epidemiol. 2015;25:342–349. [DOI] [PubMed] [Google Scholar]
- 29.Sperrin M, Candlish J, Badrick E, Renehan A, Buchan I. Collider bias is only a partial explanation for the obesity paradox. Epidemiology. 2016;27:525–530. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Gruberg L, Weissman NJ, Waksman R, et al. The impact of obesity on the short-term and long-term outcomes after percutaneous coronary intervention: the obesity paradox? J Am Coll Cardiol. 2002;39:578–584. [DOI] [PubMed] [Google Scholar]
- 31.Munafò MR, Tilling K, Taylor AE, Evans DM, Davey Smith G. Collider scope: when selection bias can substantially influence observed associations. Int J Epidemiol. 2018;47:226–235. [DOI] [PMC free article] [PubMed] [Google Scholar]