

Abstract
Recent attempts to predict refractory epileptic seizures using machine learning algorithms to process electroencephalograms (EEGs) have shown great promise. However, research in this area requires a specialized workstation. Commercial solutions are unsustainably expensive, can be unavailable in most countries, and are not designed specifically for seizure prediction research. On the other hand, building the optimal workstation is a complex task, and system instability can arise from the least obvious sources imaginable. Therefore, the absence of a template for a dedicated seizure prediction workstation in today’s literature is a formidable obstacle to seizure prediction research. To increase the number of researchers working on this problem, a template for a dedicated seizure prediction workstation needs to become available. This paper proposes a novel dedicated system capable of machine learning-based seizure prediction and training for under U.S. $1000, which is significantly less expensive (U.S. $700 or more) than comparable commercial solutions. This powerful workstation will be capable of training sophisticated machine learning algorithms that can be deployed to lightweight wearable devices, which enables the creation of wearable EEG-based seizure early warning systems.
Keywords: EEG analysis, EEG machine learning computer, seizure prediction, seizure prediction workstation
We present the design and methodology of a dedicated seizure prediction workstation which facilitates cost-efficient seizure prediction research. The proposed design could pave the way for the development of wearable and optimized solutions for eHealth applications. The proposed workstation enables research into sophisticated algorithms that can be trained on the workstation and deployed to a wearable system, such as an EEG cap-based seizure prediction system.

I. Introduction
20% to 40% of individuals who suffer from epileptic seizures have refractory epilepsy, which means that their condition is poorly understood and is not currently treatable [1]. Victims of refractory epilepsy live with neither a cure nor knowledge of when a seizure will occur. A 2016 survey arrived at a consensus that the randomness of seizures is the most disruptive part of having refractory epilepsy [2]. A breakthrough in seizure prediction will improve the quality of life of patients suffering from this condition by providing them with the opportunity to take precautions when a seizure is imminent and to have peace of mind the rest of the time.
Machine learning, a field in which learning models use automated learning techniques to learn subspace transformations of input data that reveal insightful information about the data, has proven to be a promising approach towards the problem of seizure prediction. By presenting machine learning models with EEG data taken from EEG caps worn by epileptic patients, the models can learn transformations of the EEG data that are useful for distinguishing between interictal periods of brain activity (when no seizure is imminent) and preictal periods of brain activity (when a seizure is imminent).
There are two classes of machine learning models: shallow learning models and deep learning models. These two classes differ in their reliance on feature engineering, which is the oftentimes difficult extraction of useful features such as frequency content, power spectral density, etc. from the raw input data prior to any learning taking place. Shallow learning models are profoundly reliant on feature engineering, whereas deep learning models are capable of learning from the raw data. Despite this enormous advantage of deep learning models, they can be very computationally expensive (require much computing power) in some cases. Therefore, both shallow learning models and deep learning models have their utility in solving this problem.
Shallow learning-based seizure prediction techniques thus far have yielded sensitivities (the rate at which seizures are forecasted successfully) greater than 90% with low false positive rates [3]. On the other hand, deep learning approaches to seizure prediction have yielded sensitivities of almost 70% [4]. Our research is focused on developing, testing, and validating a machine learning based seizure prediction algorithm with high discriminative capacity (specificity and sensitivity).
To train a machine learning model with high discriminative capacity a powerful and dedicated workstation is needed. A subpar computer will either be intolerably slow or totally incapable of training complex models. Furthermore, neither renting cloud infrastructure nor purchasing a commercially sold machine learning workstation is cost-effective. For the above reasons, it is necessary to build a desktop computer that best suits our specific and dedicated computing needs. In this paper, the conceptual design for a powerful and cost-effective machine learning workstation is proposed. The proposed computing machine can train extremely complex models quickly. A general pipeline for EEG machine learning research is presented in section II, in conjunction with a discussion of the computational obstacles present in each phase of the pipeline. The conceptual design of the proposed system is presented in section III, alternatives are discussed in section IV, and the paper is concluded in section V.
II. Training Pipeline and Computational Obstacles
Machine learning research follows a general pipeline: signal acquisition and storage, to data preprocessing, to training a machine learning model. Understanding this pipeline and the computational obstacles it presents – and does not present – to EEG research enables the construction of a suitable workstation.
A. Signal Acquisition and Storage
The machine learning process begins with the creation of a dataset that machine learning models can learn from. In this step, EEG data are captured from an array of electrodes placed either intracranially or on a patient’s scalp and are stored onto some media. These recordings compose the raw EEG dataset.
The structure of raw EEG datasets is an important consideration when designing a computer to process them. Factors such as storage media size and unforeseen recording issues always result in a dataset that consists of multiple almost-contiguous recording files. This is important since it allows researchers to manipulate raw EEG datasets file-by-file, instead of all at once. This reduces the system’s main memory requirement to as low as 16 GB (see section 3E).
Dataset size is another important consideration. EEG datasets can be extremely large, depending on the number of patients involved in the study and the methodology used to capture the patient data. For example, recordings for one patient from the Boston Children’s Hospital – Massachusetts Institute of Technology (CHB-MIT) dataset, which was created using a sample rate of 256 Hz, contain about 14 gigabytes (GB) of data. On the other hand, similar recordings for one patient from the European Epilepsy Database, which were created using a much higher sample rate, contain close to a terabyte (TB) of information. Clearly, a workstation for EEG processing requires a large storage capacity for local storage of EEG datasets. Insufficient storage capacity will preclude the retention of multiple (or extremely large) datasets.
B. Data Preprocessing
Once a raw EEG dataset has been created, the data must undergo a step called “preprocessing.” This step consists of the feature engineering step mentioned in the introduction as well as providing “targets” for the model. These “targets” are what the model will learn to predict correctly from the data. This preprocessed data is stored as a new dataset.
As in the case of raw EEG dataset manipulation, dataset preprocessing does not require a large amount of main memory. This is due to the fact that libraries like PyTables enable the dynamic compression of a dataset as it is created.
The CPU (discussed in section 3C) is exclusively responsible for the speed of this step, which can be incredibly time-consuming. For example, a preprocessing run to generate targets and compute spectrograms from the time-series EEG data of one patient from the CHB-MIT dataset takes us over a day using an NVIDIA Jetson TX2 development board. A slow CPU presents a bottleneck.
C. Training
These new, preprocessed, data will be used for training the model. In this part of the pipeline, the machine learning model learns to correctly classify the EEG data. Intuitively, EEG data can be viewed as datapoints in N-dimensional space, where N is equal to the amount of electrodes used in the recording. Hence, each electrode provides a component of a datapoint’s coordinates in N-dimensional space. The training process can then be described as finding the right subspace transformation such that something useful can be predicted about the data. In the case of seizure prediction, the model’s job is to learn to distinguish between interictal and preictal datapoints by finding a subspace transformation such that the two types of data form groups in distinct regions of space.
The computational obstacles to training depend on whether shallow learning or deep learning techniques are being used. Shallow learning is inherently computationally inexpensive, therefore powerful hardware is unnecessary for it. Conversely, deep learning is highly computationally expensive but is possible with the use of “graphics cards” (see section 3A). Therefore, a researcher’s deep learning options are limited by the graphics card(s) being used.
EEG deep learning research faces a unique challenge in that both perceptual models and non-perceptual models are useful. Essentially, this means that a researcher may find it useful to treat EEG recordings as pictures (via conversions to spectrograms during preprocessing) or as time-series sequences. A researcher in this field needs to be able to train models that are suited to both types of data. This increases the amount of on-board memory a graphics card needs to have.
D. Summary
An analysis of the structure of raw EEG datasets, the generation of preprocessed data, and the computational complexity of training reveals three potential hardware bottlenecks for EEG machine learning: an insufficiently powerful graphics card, low storage capacity, and a slow CPU. In the next section, we apply these findings to present a cost-effective design (less than $1000) that is very powerful for the purpose of EEG machine learning research.
III. Conceptual Design
A dedicated seizure prediction workstation needs to meet several requirements. It needs to have sufficient processing power to rapidly train sophisticated learning models, sufficient storage capacity to facilitate local storage of information, and meet stringent cost-effectiveness criteria. Fig. 1 shows our building blocks which satisfy these requirements, and a detailed explanation of each component ensues. Note that as technology advances, the reader should adhere to our general design methodology to choose newer components, rather than the specific models discussed in this article.
FIGURE 1.

Block diagram of proposed workstation. The model selected for each component is depicted along with an indication of where in the paper it is explained.
A. Graphics Card
A graphics card is a printed circuit board with a Graphics Processing Unit (GPU) and Video Random Access Memory (VRAM) installed on it. A GPU is a collection of as many as several thousand processors that are designed to perform the same operation in parallel, which is useful for performing large matrix operations quickly. VRAM, on the other hand, is used to hold data that the GPU will execute. Whereas a graphics card is unnecessary for training shallow learning models, it is essential for deep learning. Training a deep learning model is inherently computationally expensive, but thankfully it depends heavily on matrix math. Since GPUs perform matrix math very efficiently, a GPU makes deep learning possible for those users who traditionally would not have had access to the computing resources necessary to work in this research area. A graphics card is absolutely necessary for deep learning.
1). Competing Companies
Several graphics card companies exist, however, the best for deep learning purposes is the company NVIDIA. NVIDIA invested earlier than anyone else into developing a programming interface named CUDA, which is exclusively compatible with NVIDIA GPUs. Due to this early investment, people created popular deep learning frameworks such as TensorFlow and PyTorch using CUDA, and consequently these frameworks function effortlessly with CUDA Enabled GPUs but not with other GPUs [5].
Therefore, NVIDIA graphics cards are the best choice.
2). Optimal Specifications
The ideal NVIDIA graphics card has as much VRAM and streaming multiprocessors (SMs) as possible [5]. An SM is the basic unit of the GPU, and each SM contains a fixed amount of the specialized processors that are responsible for the GPUs efficiency with matrix operations. Therefore, a greater number of SMs indicates a more powerful GPU when comparing similar architectures. A higher amount of VRAM allows for VRAM hungry models such as convolutional neural networks to be trained without the program crashing due to insufficient VRAM. Cards with 11 GB of VRAM are routinely used with success in comparable machine learning competitions, therefore at least 11 GB is ideal for EEG deep learning research (although future readers should verify that new innovations in deep learning research do not require an even larger amount of memory). The card with the optimal combination of these specifications for a given budget, while still being sufficient for the desired application, is the card to buy.
3). Installing Multiple Cards
Multiple graphics cards may be installed in a workstation. Access to multiple graphics cards enables the concurrent training of models and the use of data or model parallelism. Since each model can take a long time to train, the ability to train several models concurrently dramatically increases productivity. Data and model parallelism are useful since cards cooperate to hasten model training and to train models that would be unfeasible with the memory of one of the cards individually. These are nice advantages to have, so many high-end machine learning workstations incorporate multiple graphics cards into their design. However, such an arrangement is expensive and unnecessary for EEG machine learning research thanks to NVIDIA’s new RTX lineup.
NVIDIA’s RTX lineup removes the need for parallelism in a workstation for two reasons: half precision (16-bit accuracy) operation is now a realistic option when training models, and their SMs are augmented by special processors called “tensor cores” in addition to the traditional ”CUDA Cores.” Up to now, GPUs had been operating in single precision mode (32-bit accuracy) by default. However, half precision is sufficient for deep learning research, and it enables twice as many items to be stored in VRAM as when single precision is used [6]. This renders parallelism unnecessary for resolving VRAM shortage issues. “Tensor Cores” are cores that were designed especially for deep learning, and are much more efficient than the traditional “CUDA Cores” that were originally designed for graphics processing (which previous generation consumer-level NVIDIA GPUs are exclusively composed of). These two advances enable us to design a workstation with only one graphics card without sacrificing the ability to quickly train a wide variety of models.
4). Selected Model
Table 1 illustrates a comparison between several RTX cards and previous generation card arrangements that would have been excellent for EEG machine learning research. Clearly, not only do the RTX cards incorporate much more powerful SMs, but also more of them. Furthermore, in half precision mode (which is unrealistic for previous generation cards) even the cheapest RTX card effectively has 16 GB of VRAM compared to premium last generation cards [6]. Although future innovative deep learning models or training methodologies may require more than 16 GB of VRAM, this amount of memory is enough to train most conceivable deep learning models at present.
TABLE 1. Graphics Card Comparison.
| Model | SMs (Architecture) | VRAM (Effective with Half Precision) | Price (USD) |
|---|---|---|---|
| RTX 2070 | 36 (Turing) | 8 GB (16 GB) | 599 |
| RTX 2080 | 46 (Turing) | 8 GB (16 GB) | 799 |
| RTX 2080 Ti | 68 (Turing) | 11 GB (22 GB) | 1199 |
| GTX 1080 Ti | 28 (Pascal) | 11 GB (N/A) | 699 |
| Titan Xp | 30 (Pascal) | 12 GB (N/A) | 1200 |
| 2 GTX 1070 Tis (working in parallel) | 20 each (Pascal) | 8 GB each (N/A) | 996 |
The RTX 2070 is much less expensive than previous generation cards that would have been suitable for this type of research, despite being much more powerful. It is also capable of quickly training more complex models than previously possible on a single card. Therefore, the RTX 2070 is currently the most practical solution to the requirement of rapidly training complex models.
5). Exact Variant
The exact variant of RTX 2070 needs to be selected. NVIDIA allows many manufacturers to produce their own versions of NVIDIA graphics cards. These variations of the reference card differ in factors such as the maximum supported clock speed of the card, its overclocking potential (the ability to force it to run faster than supported by the manufacturer), and the cooling solution used. Maximum supported clock rate only varies slightly between versions, and overclocking potential does not affect EEG machine learning researchers since system stability is more important than pure speed. Therefore, we only consider cost and the type of cooling solution installed on the card.
Graphics cards are sold in one of three configurations: air-cooled, liquid-cooled, or hybrid-cooled. In air cooled systems, the entire card is cooled through an onboard heat sink and fan – heat is transferred from hot components of the card to a heat sink, then to air that is blown over the heat sink. In a liquid cooled system, the card is cooled by cyclically circulating liquid over metal blocks that are in contact with heat generating components and afterwards through a radiator with a fan forcing air through its fins. In a hybrid configuration, the GPU is liquid-cooled and the rest of the card is air-cooled.
Liquid and hybrid-cooling systems offer better performance over air-cooled systems, but they also have a reputation for leaking and causing damage to the workstation. In addition, they are unnecessary since the GPU will automatically decrease its performance slightly (which is called “throttling”) to prevent overheating. The benefit of being able to run a GPU at optimal performance all the time does not outweigh the risk of damaging the system. Therefore, an air-cooled solution is preferable.
Finally, the exact variant can be selected. Of the air-cooled cards available, we want one with an open-air style configuration, since such a configuration results in cooler temperatures. Its alternative, a blower-style configuration, is only needed when placing multiple graphics cards next to each other (blower-style configurations eject hot air out from one end of the card as opposed to on all sides). The most affordable card that we could find, which satisfies all these criteria, is the Zotac RTX 2070.
B. Peripheral Component Interconnect Express (PCIe) Lanes
Peripheral Component Interconnect Express (PCIe) is a communications standard in which peripheral devices, which are computer components that are not critical to computer operation, are allotted a certain amount of “PCIe lanes” to use for extremely fast communication with the CPU cores of the CPU chip, which is the executive center of the computer. This communication happens via one of two intermediaries: special circuitry on the CPU chip called “uncore” (now known as the “system agent” in Intel CPU chips) or the chipset. This is illustrated in Fig. 2:
FIGURE 2.

Block diagram of CPU and peripheral interaction. PCIe lanes are used to connect certain peripherals to the CPU chip, either directly or via the chipset.
1). CPU PCIe Lanes
PCIe lanes dedicated to connecting peripherals to uncore are called CPU PCIe lanes, since uncore is on the CPU chip. Peripherals using CPU PCIe lanes communicate with the CPU cores very quickly, since uncore is the only intermediary between the peripherals and the CPU cores. Therefore, demanding peripherals such as graphics cards use CPU PCIe lanes.
2). Chipset PCIe Lanes
PCIe lanes dedicated to connecting peripherals to the chipset, which is a chip on the motherboard that is used as a communications hub for slower components, are called chipset PCIe lanes. Peripherals using chipset PCIe lanes communicate slower with the CPU cores than those connected to CPU PCIe lanes since the chipset acts as an additional intermediary between the peripherals and the CPU cores (see Fig. 2). Therefore, less demanding peripherals such as network cards use chipset PCIe lanes.
3). PCIe Lane Count
All systems support a finite amount of PCIe lanes, so care must be taken to ensure that each peripheral that is to be installed has access to enough PCIe lanes. Each peripheral has a datasheet that states the amount and type of PCIe lanes needed for the peripheral to function optimally. These amounts should be compared with the amount supported by the CPU chip, (which will support CPU PCIe lanes) and the Motherboard (which will support both CPU and chipset PCIe lanes). If too few PCIe lanes exist, peripherals may still function, although at a reduced bandwidth. Thankfully, so long as the peripherals still function, a drop in PCIe bandwidth would be unnoticeable unless working with a truly large distributed system (e.g. 96 GPUs working together) [6]. Maximizing PCIe lane access for each device is not important – only ensuring that they function is.
With the motherboard and CPU of the proposed design, all peripherals have access to enough PCIe lanes to function: the graphics card has access to 4 lanes (the minimum required), and a Nonvolatile Memory Express Solid-State Drive (NVMe SSD, discussed in section 3G), functions at full bandwidth (2 chipset PCIe lanes).
C. Central Processing Unit (CPU) Chip
A CPU chip is a chip with uncore and one or more CPUs, which are called cores, as shown in Fig. 2. A CPU is a circuit that implements control and arithmetic necessary to the general operation of a computer, and uncore is a set of circuits that are used to facilitate communication between the CPU(s) and other computer components. Importantly, part of the uncore is responsible for supporting the CPU PCIe lanes discussed in section 3B.
An extremely powerful CPU is not necessary for deep learning training, since most of the deep learning training process takes place on the graphics card(s) of a system. On the other hand, shallow learning and data preprocessing take place using the CPU for all facets of program execution, and therefore would ostensibly benefit from a powerful CPU. However, neither of these tasks are computationally intensive to begin with. Therefore, a fast yet low-cost CPU should be chosen for this workstation.
1). Parallelization
In addition to having several CPUs (also called cores) on the same chip, modern technology allows for the creation of CPUs that switch between threads (the smallest executable segments a program can be split into) so quickly that they appear to be two separate CPUs. Therefore, it is possible to place many CPUs on the same chip, where each CPU functions as if it is more than one CPU. These technologies are important for parallelization. Parallelization is the concept that many processors or even computers can be coordinated to work on different parts of a task in order to complete the overall task faster. However, programs need to be intentionally written to take advantage of parallelized hardware for it to provide an advantage in performance, and not all programs are or can be written this way. Clearly then, the advantage of a CPU chip is application specific. If a program is suitable for parallelization, a CPU chip with many available threads will probably be faster than a CPU chip with fewer threads but faster single-core speed. If a program is not written to take advantage of parallelization, parallel processing ability might prove to be less important for faster program execution than single-core speed. In such a situation, a CPU chip with faster single-core speed would be preferable over a chip with more parallel computing capability. To cover all situations, it is wise to buy a CPU chip that will be appropriate for programs that are well suited to parallelization or not. A CPU chip with fast single-core speed as well as many cores (with each preferably acting like more than one core) will satisfy this criterion.
2). CPU PCIe Lane Count
The uncore on the CPU chip needs to support sufficient CPU PCIe lanes for the peripherals that are going to use them to communicate with the CPUs. In this design we propose the use of 1 graphics card, which uses CPU PCIe lanes. To function, the graphics card requires 4 CPU PCIe lanes. 4 more CPU PCIe lanes will be required to facilitate communication between the uncore and the chipset, using the motherboard that we have selected, as shown in Fig. 2. As discussed in section 3B, maximizing the amount of PCIe lanes is not important for a workstation of this level of complexity. Therefore, a CPU chip that supports at least 8 CPU PCIe lanes will be sufficient.
3). Selected Model
Table 2 contains a comparison of the characteristics used in choosing a model. The i3-7100 appears to be the fastest of the CPUs listed. However, since the objective is to build a cost-effective workstation, this chip is inappropriate. Technically, the next best option (performance-wise) is the Ryzen 1200, due to its support for 24 CPU PCIe lanes. However, the extra PCIe lanes do not merit the much higher cost of the chip. The remaining three chips are similarly priced, therefore they will be compared on the basis of performance. Of these 3, the AMD Athlon 200GE is preferable since it provides more threads (which means effective CPUs in this context) than the other two in addition to a higher clock rate. It also supports eight CPU PCIe lanes, which is exactly the minimum amount required for the workstation. This combination of adequate processing power, CPU PCIe lanes, and low price makes the AMD Athlon 200GE the best choice for this computer.
TABLE 2. CPU Comparison.
| Model | Threads | Clock Rate (GHz) | PCIe Lanes | Price (USD) |
|---|---|---|---|---|
| Athlon 200GE | 4 | 3.2 | 8 | 49.99 |
| Ryzen 1200 | 4 | 3.1 | 24 | 94.99 |
| i3-7100 | 4 | 3.8 | 16 | 135.99 |
| Celeron G3900 | 2 | 2.8 | 16 | 41.25 |
| Celeron G4900 | 2 | 3.1 | 16 | 42.99 |
D. CPU Cooling System
The workstation needs to be able to run continuously at high CPU utilization in order to use large amounts of data to train complex models. Therefore, a reliable cooling system is helpful to ensure that the CPU does not throttle its performance during training. As in the case of graphics cards, CPUs can be cooled by liquid or air, and air is preferable for reliability. The Athlon 200GE is bundled with an air cooler, which offers effortless installation and good customer feedback for its silence and performance on this CPU under heavy load. It excels at maintaining the 200GE’s temperatures below 50 degrees Celsius, which is ideal. Therefore, we do not propose an aftermarket cooler.
E. Dynamic Random-Access Memory (DRAM)
Dynamic Random-Access Memory (DRAM), commonly referred to as either RAM or main memory, is a form of primary memory used in computers. There are two forms of memory used by a computer: primary memory and secondary memory. Primary memory is a faster form of memory that cannot preserve data after power loss, whereas secondary memory is a slower form of memory that can preserve data after power loss. Primary memory is necessary since executing programs using instructions and data from secondary memory would be too slow, and secondary memory is necessary since primary memory cannot permanently store information. Therefore, computers are designed to permanently store programs and data in secondary memory, and to simply transfer information to primary memory whenever it is going to be used by the CPU. DRAM forms most of this primary memory, and the rest of the primary memory consists of a small amount of Static Random-Access Memory (SRAM), which is a very fast but very expensive form of memory. For our design, optimizing the amount and type of SRAM is not a concern. However, the DRAM is crucial.
RAM manufacturers advertise many specifications, most of which do not impact workstation performance appreciably. Observe Fig. 3, which is picture of a typical label that can be found on a stick of RAM:
FIGURE 3.

Typical label found on a stick of RAM. A: size and intended architecture. B: DDR generation and fastest supported clock rate. C: timings. D: memory bandwidth. E: operating voltage. F: Intel XMP 2.0 support.
Of the specifications in Fig. 3, the only important one for a machine learning workstation is the kit’s size and intended architecture [6], [7]. Therefore, we present an argument for an affordable RAM kit based on these characteristics.
1). Total Quantity
Specification A of Fig. 3 represents the total quantity of RAM in the kit this stick comes with, as well as how this quantity is reached. In the case of Fig. 3, 4GX4 signifies a kit of 4 RAM sticks with 4 GB each for a total of 16 GB. A workstation that is to be used for deep learning should have at least as much RAM as the VRAM on the graphics card equipped with the most memory [6]. Since we intend to install an RTX 2070 with 8 GB of VRAM and optional half-precision mode, installing 16 GB of RAM is prudent. Furthermore, since raw EEG datasets are manipulated file-by-file during preprocessing, and preprocessed datasets can be compressed as they are created and manipulated subset-by-subset during training, 16 GB will suffice for any experiment an EEG-machine learning researcher wants to run (although installing more RAM would reduce the need to program such memory-saving measures to begin with).
2). Memory Channel Architecture
In addition to the total amount of RAM, how this total amount is reached is important. Motherboards and CPU chips (specifically, a part of uncore called the memory controller) are designed to work with RAM in either single, dual, or quad-channel mode. The higher the channel mode the bigger the gain in memory throughput. This translates into populating the RAM slots of the motherboard in certain minimum increments. For example, if the motherboard and CPU chip support dual-channel mode, then it is expected that some multiple of 2 RAM slots will be filled at the same time. The memory channel architecture supported by the CPU chip and motherboard may be found from a datasheet.
Failure to adhere to the memory channel architecture of the system will prevent optimum performance and may result in system instability. The selected motherboard and CPU chip support dual-channel mode, therefore a kit with some multiple of 2 sticks is appropriate for this system (since slots will be populated in pairs). The selected motherboard only contains 2 slots, so a kit with exactly two sticks should be purchased. RAM sticks are only made in sizes of 4 GB, 8 GB, 16 GB, and 32 GB. Therefore, a  GB kit for a total of 16 GB is best for this system.
GB kit for a total of 16 GB is best for this system.
3). How to Purchase RAM
It should be noted that all RAM should be installed or replaced at the same time. It is not advisable to try to save money by aggregating RAM sticks from various sources. Instead, it is prudent to purchase the entire quantity of RAM that is needed in the form of one kit. Mixing RAM from different kits might result in system instability due to minute differences in their circuitry that arise during the manufacturing process. RAM sticks that are sold together have been tested by the manufacturer to ensure that they will work together. Therefore, all RAM needs to be purchased at the same time, in one kit.
4). Selected Model
System stability is important. To this end, the CPU chip datasheet and motherboard memory Qualified Vendors List (QVL), which is a list of RAM kits that have been guaranteed by the motherboard manufacturer to work with the motherboard, needs to be consulted. We propose a kit of RAM by simply choosing the least expensive 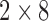 GB kit from the motherboard memory QVL that also complements its black and red color scheme. The Team Dark
GB kit from the motherboard memory QVL that also complements its black and red color scheme. The Team Dark 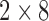 GB DDR4-2666 kit satisfies these criteria.
GB DDR4-2666 kit satisfies these criteria.
F. Motherboard
The Motherboard is essentially a printed circuit board that every other component of the computer is plugged into. For our purposes, it needs to support at least 16 GB of RAM, 8 CPU PCIe lanes, and 2 chipset PCIe lanes (since the selected CPU chip only supports enough PCIe lanes for a graphics card to function) for an NVMe SSD. Table 3 contains a comparison of several motherboards that are compatible with the AMD Athlon 200GE CPU that was selected. This table reveals that the MSI X470 Gaming Plus is overpowered, whereas the other two are suitable. Between the MSI B450M Gaming Plus and the ASRock B450M, the MSI board is much more aesthetically pleasing for only USD 20 more. Therefore, it is proposed here.
TABLE 3. Motherboard Comparison.
| Model | CPU PCIe Lanes for GPUs | PCIe Lanes for NVMe SSD | Max Supported Memory (GB) | Price (USD) |
|---|---|---|---|---|
| MSI B450M Gaming Plus | 16 | 2 | 32 | 84.99 |
| MSI X470 Gaming Plus | 48 | 2 | 64 | 129.58 |
| ASRock B450M | 16 | 4 | 32 | 63.88 |
G. Secondary Memory
Secondary memory is the slower, but permanent, form of memory discussed in section 3E. There are two types of secondary memory to choose from: Solid State Drives (SSDs) and Hard Disk Drives (HDDs). SSDs are more expensive per gigabyte than HDDs, however, they can be dramatically faster. For example, loading every picture from the ImageNet dataset (which is a very popular dataset for training and benchmarking computer vision models) requires over 1.7 hours on a hard drive whereas less than 32 minutes are required using a SATA III based SSD [8]. The proposed design uses a Nonvolatile Memory Express (NVMe) SSD, which is an SSD that uses either CPU or chipset PCIe lanes – with the selected motherboard, it will use chipset PCIe lanes – instead of the SATA specification. Therefore, the proposed SSD would yield an even more impressive improvement over a hard drive.
1). Storage Size
The secondary memory device needs to have sufficient capacity to store EEG cap data from popular epilepsy datasets such as the CHB-MIT dataset, an Ubuntu operating system, and machine learning software. A single patient from the CHB-MIT dataset uses about 14 GB of storage after the recordings are converted to CSV files, which is necessary to use the data. There are recordings for 23 patients in this dataset, therefore around 322 GB are needed to store the raw patient data in a usable format. This dataset was created using a sampling rate of just 256 Hz. Datasets created using higher sample rates, such as those from the European Epilepsy Database, will require much more storage capacity (almost 1 TB for a patient in this case).
This is too much to fit on an affordable SSD. Fortunately, it is possible to combine SSD and HDD technology by placing the operating system and data that is to be immediately used on the SSD while leaving information that is to be used for other experiments on a large and cheap HDD. A 120 GB SSD and 2 TB hard drive combination is cheap and sufficient to accomplish this purpose.
2). Selected Models
Table 4 contains a comparison of several SSD and HDD candidates. We consider only the sequential read speed and interface of these devices since they are the most relevant metrics for machine learning: The utility of fast storage in a machine learning workstation depends on how often data is read from it during training and preprocessing. During preprocessing, raw EEG data is read file-by-file, which does not require a fast storage device. Furthermore, during training, it is normally good practice to load data into RAM in large quantities so that the system does not have to fetch data regularly from the slower (relative to the speed of RAM) storage devices. However, there are a few situations in which reading from secondary storage is easier – for example, when sequentially reading batches of data from a dataset that was compressed using the PyTables library. It takes very little logic to write a Python generator that draws data batch-by-batch from a PyTables dataset. In such a situation, an SSD with fast sequential read speed would be helpful. Under this reasoning, only sequential read speed and the interface used are relevant performance metrics.
TABLE 4. Storage Device Comparison.
| Model | Sequential Read (MB/s) | Interface | Price (USD) |
|---|---|---|---|
| Corsair MP300 (SSD) | 1600 | PCIe 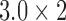
|
39.99 |
| Samsung 850 EVO (SSD) | 540 | SATA III | 148 |
| WD Green (SSD) | 545 | SATA III | 35.99 |
| Barracuda (HDD) | 171 | SATA III | 59.99 |
| Toshiba DT01ACA200 | 152 | SATA III | 64.99 |
Table 4 indicates that the Corsair MP300 120 GB NVMe SSD is the best option since it has a much higher sequential read speed than its competitors. Of the hard drives, the Seagate Barracuda 2 TB 7200 RPM drive has a better sequential read speed. Therefore, the Corsair MP300 120 GB NVMe SSD and a Seagate Barracuda 2 TB 7200 RPM hard drive are proposed for this system. This combination forms a cost-effective solution to the requirement of large, fast, and affordable storage.
H. Power Supply Unit
The Power Supply Unit (PSU) of the computer converts alternating current (AC) from the wall outlet to direct current (DC) for the computer. It needs to have the appropriate electronics to provide sufficient electrical power for every part of the computer. The system we have proposed requires 261 W of electrical power. The EVGA BT 450 W PSU can power this system with slightly under 200 W to spare. This system is proposed due to being the cheapest power supply over 300 W that still had good customer reviews and sleeved cables (which looks better than exposed red and yellow cables).
I. Case
The NZXT H500i mid-tower case offers sufficient size to house the system at a low cost. More expensive cases exist which offer premium features such as separate chambers for the motherboard and for internal storage drives (which ensures that storage drives do not impede airflow through the motherboard area, which contains the hottest components of the computer) or even mesh side panels, but these changes do not affect the cooling capability of the system significantly. The H500i provides the necessary functionality at an affordable cost.
J. Total Cost
The total cost to build our proposed system, using selected vendor pricing information (instead of MSRP information, which hardly ever reflects the actual price of computer components), is USD 963.52. Our design is a truly optimized machine learning workstation, and it can compete with or excel against commercial solutions that are much more expensive.
IV. Alternatives
Researchers who are unable to obtain the parts recommended in this template have alternatives. These options range from alternate brands of graphics cards to cloud computing. The discussion that follows is intended to help educate researchers facing procurement challenges on how they can still contribute to seizure prediction research.
A. Substituting AMD Graphics Cards
If the user is willing to work harder, AMD graphics cards may be substituted into this workstation. Comparing AMD and NVIDIA cards is not totally straightforward. Therefore, in this section we reveal one way to judge the compute power of an AMD GPU and suggest one that is similar to previous generation premium NVIDIA graphics cards.
1). Hardware Considerations
AMD architectures are very different from their NVIDIA counterparts, and consequently their stream processors need to be manufactured onto a card in greater volume for it to be as powerful as an NVIDIA card. Thus, it is difficult to compare NVIDIA and AMD cards by their processor counts. An easier way to compare these cards is to evaluate their compute performance, which is a measure of how many floating-point operations can be computed per second.
AMD cards advertise their Floating-Point Operations Per Second (FLOPS) capability, whereas NVIDIA’s new RTX cards advertise RTX Operations Per Second (RTX-OPS). Therefore, we will recommend an AMD graphics card based on its FLOPS performance compared to trusted previous generation NVIDIA cards for machine learning, which are still excellent and advertise performance in terms of FLOPS. Table 5 contains a comparison of the AMD RX Vega 64 and Radeon Vega Frontier Edition cards with the NVIDIA GTX 1080 Ti and Titan Xp, which were considered state of the art prior to the release of the RTX cards.
TABLE 5. Alternate Graphics Card Comparison.
| Model | Compute Performance (Tera-FLOPS) | VRAM (GB) | Price (USD) |
|---|---|---|---|
| AMD RX Vega 64 | 12.7 | 8 | 499 |
| AMD Radeon Vega Frontier Edition | 13.1 | 16 | 1157 |
| NVIDIA GTX 1080 Ti | 10.8 | 11 | 699 |
| NVIDIA Titan Xp | 11.3 | 12 | 1200 |
The Radeon Vega Frontier edition is a good alternative to the Titan Xp. However, it is expensive. The RX Vega 64 is a much cheaper option, but it is limited by its 8 GB of VRAM and will consequently fall short in some perceptual model training tasks. Therefore, we recommend obtaining a used Radeon Vega Frontier Edition if necessary.
2). Software Considerations
Machine learning with an AMD GPU is possible, but not effortless. Keras should be installed in addition to either the PlaidML deep learning framework or Theano. Of these options Keras with PlaidML is the most likely to be problem-free, since Theano’s website currently states that support for OpenCL (AMD GPUs) is incomplete.
B. Substituting Outdated Models of NVIDIA Cards
Outdated models of NVIDIA cards may not be compatible with modern deep learning frameworks. Therefore, before using an older card double check that its “compute capability” is sufficient to run the desired deep learning framework. This information can be found from the websites of the desired GPU and deep learning framework.
C. Other Procurement Issues
To help resolve any unique procurement issues that may occur, we have created several alternative workstations for a similar price. These options may be found on our PCPartPicker.com account [9].
D. Cloud Computing
Cloud computing is a term for executing programs on powerful, remotely controlled computational resources. Essentially, users upload their programs and data to a powerful computer or computing instance that is located in a datacenter, and do their work. These resources can be rented on demand.
Amazon Web Services (AWS) rents a wide variety of computing instances. For machine learning purposes, their EC2 p2.xlarge instances are a good option. These instances currently cost $0.90 per hour to rent a single NVIDIA k80 graphics card, which is very powerful. In addition to being relatively affordable, options like AWS have the benefit of being scalable – once a researcher learns to use them, they can rent instances with more graphics cards (for a higher price, of course) as needed. Researchers who are interested in using AWS can read Appendix B of François Chollet’s book Deep Learning with Python to get started [10].
Before paying for a service like AWS, researchers should investigate whether their university has a computing center that is available to researchers who apply for compute time. For example, the University of Texas system has the Texas Advanced Computing Center (TACC), which has a phenomenal selection of instance types available to faculty and staff who complete a minimal application. These principal investigators can add students to their project.
V. Conclusion
Building a dedicated seizure prediction workstation is necessary for carrying out cost-efficient seizure prediction research. A conceptual design for such a workstation was presented here, along with our methodology. The proposed design could pave the way for the development of wearable and optimized solutions for eHealth applications in the future. Machine learning algorithms are computationally intensive to train, but computationally light to deploy. The proposed workstation enables research into sophisticated algorithms that may be trained on the workstation and deployed to a wearable system, such as an EEG cap-based seizure prediction system.
The methodology behind these choices will be applicable for building an EEG machine learning research workstation long after these specific computer components are replaced by newer models. Devices are currently nowhere near being capable of saturating the bandwidth available from PCIe lanes, so PCIe lanes will remain relevant. RAM generations will progress, but capacity and intended motherboard architecture will continue to be the only important characteristics
for a machine learning computer. The processing power of a CPU will remain useful for preprocessing and minimally important for training. Finally, fast secondary memory sequential read speed will continue to be helpful in situations where data is read sequentially from storage during training.
Acknowledgment
This work was not supported by any public, commercial, or not-for-profit funding agencies.
References
- [1].Sirven J., “Evaluation and management of drug-resistant epilepsy,” in UpToDate, Dashe J. F., Ed. Alphen aan den Rijn, The Netherlands: Wolters Kluwer Health, 2018. [Google Scholar]
- [2].2016 Community Survey, Epilepsy Innov. Inst, Landover, MD, USA, 2016, p. 5. [Google Scholar]
- [3].Park Y., Luo L., Parhi K. K., and Netoff T., “Seizure prediction with spectral power of EEG using cost-sensitive support vector machines,” Epilepsia, vol. 52, no. 10, pp. 1761–1770, 2011. [DOI] [PubMed] [Google Scholar]
- [4].Kiral-Kornek I.et al. , “Epileptic seizure prediction using big data and deep learning: Toward a mobile system,” EBioMedicine, vol. 27, pp. 103–111, Dec. 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Ivanov S. (2017). Picking a GPU for Deep Learning—Slav. Accessed: Aug. 19, 2018. [Online]. Available: https://blog.slavv.com/picking-a-gpu-for-deep-learning-3d4795c273b9 [Google Scholar]
- [6].Dettmers T. A Full Hardware Guide to Deep Learning. Accessed: Jan. 3, 2019. [Online]. Available: http://timdettmers.com/2018/12/16/deep-learning-hardware-guide/ [Google Scholar]
- [7].Sebastian L. (2013). Guide to Memory Channels as Fast as Possible, YouTube. Accessed: Dec. 29, 2018. [Online]. Available: https://www.youtube.com/watch?v=-D8fhsXqq4o [Google Scholar]
- [8].Xu B. (2015). Training Deep Net on 14 Million Images by Using a Single Machine, DMLC. [Online]. Available: http://dmlc.ml/mxnet/2015/10/27/training-deep-net-on-14-million-images.html [Google Scholar]
- [9].Teijeiro A., Shokrekhodaei M., and Nazeran H.. PC Part Picker Carts. Accessed: Jan. 7, 2019. [Online]. Available: https://pcpartpicker.com/user/UTEP_EEG_DeepLearning_Group/saved/ [Google Scholar]
- [10].Chollet F., “Appendix B: Running Jupyter Notebooks on an EC2 GPU instance,” in Deep Learning with Python. New York, NY, USA: Manning, 2018, pp. 345–351. [Google Scholar]