

Abstract
The use of diagnosis (DX) data is crucial to secondary use of electronic health record (EHR) data, yet accessible structured DX data often lack in accuracy. DX descriptions associated with structured DX codes vary even after recording biopsy results; this may indicate poor data quality. We hypothesized that biopsy reports in cancer care charts do not improve intrinsic DX data quality. We analyzed DX data for a manually well-annotated cohort of patients with brain neoplasms. We built statistical models to predict the number of fully-accurate (i.e., correct neoplasm type and anatomical location) and inaccurate DX (i.e. type or location contradicts cohort data) descriptions. We found some evidence of statistically larger numbers of fully-accurate (RR=3.07, p=0.030) but stronger evidence of much larger numbers of inaccurate DX (RR=12.3, p=0.001 and RR=19.6, p<0.0001) after biopsy result recording. Still, 65.9% of all DX records were neither fully-accurate nor fully-inaccurate. These results suggest EHRs must be modified to support more reliable DX data recording and secondary use of EHR data.
Introduction
The secondary use of Electronic Health Record (EHR) data is a fundamental tool of learning healthcare systems1,2and is essential to research endeavors including comparative effectiveness research3,4and precision medicine.5–7Patient Diagnosis (DX) data is a typical starting point of the cohort selection process for research studies that reuse clinical data.8,9Thus, the accurate assignment of structured and accessible DX data within the EHRs is crucial to ensure reliable research outcomes.10However, DX code recording has well-known limitations due to coding system11–15definition challenges and their implementation in most common EHR systems.16The challenges are compounded by EHR systems providing multiple descriptions for each individual DX code.17Though this seems to facilitate DX code search, the large number of options may complicate selecting the most appropriate textual description. At its core, the problem stems from both unreliable DX recording practices within clinical workflows and ambiguity in the DX coding structures.11,15
Informaticians have studied structured DX data limitations for decades, revealing alarming error rates in DX and procedure code assignment.10,18,19Error rates have improved over time (e.g. ICD code inaccuracy rates went from 20- 70% in the 1970s to 20% in 1980s) but their reliability remains questioned. In response, secondary users of clinical data have sought to work around these DX data limitations20–22by employing methods such as natural language processing for DX extraction from clinical notes and EHR phenotyping.22–27Although these methods improve the precision and recall of particular sets of patients for cohort selection,28they introduce an additional layer of uncertainty to secondary analyses.20,24They also fail to take advantage of knowledge available on the clinical side, where the data is generated. Ensuring accurate input may be a more viable solution to produce reliable clinical data, which can also better support learning healthcare systems in the long run.
Though this is a healthcare-wide issue, the problem is compounded in oncology informatics on both, DX recording practices within clinical workflows and DX coding structures. Typically, cancer care involves a team-based approach, which requires patients to interact with multiple specialties and units (e.g., scheduling, encounters, billing, diagnostic imaging, surgical procedures, radiotherapy, etc.). EHR systems rarely support recording accurate and precise DX codes in a consistent manner across workflows, making DX logging burdensome to oncologists.29–31Moreover, standard DX code descriptions are not designed to support secondary use of clinical data,3leaving useful DX information locked in progress notes, complicating fact retrieval.3For example, ICD-10 codes C71.* correspond to a malignant neoplasm of the brain DX. Though these codes allow encoding of the neoplasm site (e.g., C71.1 represents a malignant neoplasm of the frontal lobe), they are not designed to provide information on neoplasm type (e.g. IDH mutant glioma, IDH wild type glioma, glioblastoma, etc.) that is crucial to treatment selection and patient classification, as opposed to ICD-O-3 codes.12However, customized DX descriptions provided by EHR vendors do include neoplasm type information but present wide-varying levels of precision for a single DX code that complicates structured DX data recording.32Both aspects may be may be partial causes of the structured DX data unreliability.3
Our previous work shows that biopsy (BX) reports in oncology charts do not reduce variability in structured primary encounter DX descriptions, in an EHR with multiple textual DX descriptions per DX.32This variability may be a consequence of variable accuracy in DX data due to no active support for concordant33,34DX recording. We were unable to find other analyses shedding light on the impact of BX recording on DX data quality and accuracy in the literature. Thus, we hypothesized that recording BX reports in oncological EHR charts does not improve intrinsic data quality33,35(i.e., high accuracy, low inaccuracy) in structured DX data. To test our main hypothesis, we assessed the validity of two sub-hypotheses: (I) Recording BX reports does not increase the number of fully-accurate DX codes and (II) Recording BX reports does not decrease the number of inaccurate DX records. In this study, we define full accuracy as the inclusion of a neoplasm type and neoplasm site within a DX description. We tested these hypotheses on EHR data from patients diagnosed with brain neoplasms (i.e., ICD-10 diagnosis code, C71.*). We selected this disease for its large number of textual diagnosis descriptions for a limited list of specific diagnosis codes, the availability of a clinician-generated patient cohort and each patient chart containing a definitive histopathology stating the most precise accurate DX description possible. We present descriptive and summary statistics and then present our results from statistical modelling for hypothesis testing. This analysis contributes to our current understanding of DX logging practices, limitations and pitfalls in EHR systems providing multiple DX description per DX code. This work suggests improvements to the current systems and practices that enhances the clinical data quality and correspondingly more reliable secondary uses of clinical data towards a functioning learning healthcare system.
Methods
We extracted structured DX data and relevant covariates from multiple EHR tables recording multiple clinical workflows from the Wake Forest Baptist Medical Center’s Translational Data Warehouse. We used a clinician- generated manually extracted gold standard to identify the most accurate DX description for a set of 36 patients. We then used these descriptions to identify accurate and inaccurate DX descriptions attached to DX codes in our final dataset. We employed statistical modeling to test our hypotheses. Specifically, we built count regressions to predict the number of accurate and inaccurate DX based on a dichotomous pre/post-BX indicator variable and other covariates such as the number of clinicians logging DX descriptions. We first built both models for primary encounter DX data. We then verified the effect’s robustness by re-building the model with additional data from other clinical workflows such as DX attached to orders. We also included workflow provenance (i.e., primary encounter DX, encounter DX, problem list DX or order DX) as a predictor variable to assess differences across workflows. Lastly, we verified temporal robustness of the effect. Our study was approved by Wake Forest University School of Medicine’s Institutional Review Board (IRB) before any data extraction or analysis.
Our DX accuracy gold standard was distilled from the electronic charts of 36 patients treated for brain neoplasm that were pre-selected during a previous clinician-initiated and led chart review. Comprehensive medical record review was performed of each patient by two independent reviewers. The primary post-operative diagnosis was determined based on a review of pathology report and clinician notes. All treating clinicians were available for consultation when needed. Discrepancies between the two reviewers were resolved by an independent neuro-oncologist. The DX data recorded in our standard represented the most accurate DX depiction at the highest achievable level of precision achievable from structured DX choices. Two features were used to define these DX descriptions: the neoplasm’s type (e.g., astrocytoma, oligodendroglioma, glioblastoma, etc.) and its location (e.g., frontal lobe, temporal lobe, parietal lobe, etc.).
We compared the target DX description from our standard to each DX record for all patients in our dataset. Each DX could be deemed either accurate or inaccurate. To be accurate, a DX entry would have to match the neoplasm type and location attributed to the patient in our standard. An inaccurate DX would contradict the standard’s neoplasm type or location. For example, a DX describing a frontal lesion for a patient with a temporal lesion would be inaccurate; a DX describing an astrocytoma for a patient actually treated for a glioblastoma would also be inaccurate even if the description pointed at the correct anatomical site. Note that partially-accurate or sub-optimal DX descriptions were not classified as accurate or inaccurate, as they would not contradict the true DX and leave a chance for correct logging subsequently. In other words, some DX descriptions could be as generic as “neoplasm of the brain, site not specified”, which is not “fully-accurate” as fails to provide the most accurate description possible from structured DX descriptions available in the EHR but is not inaccurate either, as it does not misinform secondary analyses. We have termed such records “sub-optimal” DX descriptions.
Our final analytical dataset was extracted from our Translational Data Warehouse and contained 1,643 primary encounter DX observations of 31 patients, recorded from January 1st, 2016 to June 1st,2018. This time frame was defined to ensure ICD coding version consistency (i.e., to include DXs after October 2015; ICD-10 implementation date). Four patients from the initial date did not have any neoplasm DX or BX data within the selected time window. One patient was excluded due to a confirmed neurofibromatosis DX, which would make the patient’s neoplasm DX history much more complex and not clinically comparable to other patients in the set. Our dataset also contained 2,075 non-primary encounter DX, 44 problem list DX and 10,052 DX attached to procedure orders for the same 31 patients within the same time frame. Our initial dataset consisted of DX records with their corresponding timestamp and patient identifier. Each DX had a specific DX description and was associated with an ICD-10 code. Each patients’ initial BX result recording date was added to each DX record with the ‘PostBX’ indicator that served at the dichotomous independent variable for our regressions. Dichotomous variables were recorded to encode whether each DX was accurate or inaccurate. We also included the number of days before or after the BX each DX was recorded, the provider recording the DX and the department (i.e., care units involved in patient treatment such as oncology, surgery and neurology) where the DX was recorded. Summary statistics such as mean, median and extreme values were employed to screen the data for outliers, missing values and erroneous input. Dates were also reviewed for potential errors such as values being outside the study’s time window. We verified the normality of continuous variables using histograms.
To test our hypotheses, we built count regressions36to predict the number of accurate and inaccurate DX across patient charts using R’s generalized linear model (GLM).37We tested for zero inflation using Van den Broek’s zero-inflation test38and for overdispersion by comparing means and standard deviations in our main outcome variables (i.e., number of accurate and inaccurate DX) and using the AER package.39We selected negative binomial regressions to best fit our overdispersed, non-zero-inflated datasets. For all our models, the number of accurate and inaccurate DX records was our main outcome variable. We predicted this outcome based on our ‘PostBX’ dichotomous variable that described whether each DX record group was recorded before or after BX results were recorded in the EHR. We explored model improvement by including covariates such as the total number of DX records, the number of district DX records and the maximum number of days from the BX in each DX record group as well as the number of departments and the number of clinicians contributing to the DX group. We tested for variable interactions in all models with more than one variable. We re-ran each regression using a time window of 90 days before and after the BX to confirm the effect’s temporal robustness.40
Multiple software tools were used to carry out this analysis. Data extraction and preprocessing was done using a DataGrip software client (version 2017.2.2, JetBrains s.r.o., Prague, Czech Republic). Visual exploration and analyses were done using Tableau (version 10.2.4, Tableau Software, Inc., Seattle, WA). All statistical analyses and data manipulation such as data scrubbing and reshaping were done in R version 3.4.130and RStudio (version 1.1.383, RStudio, Inc., Boston, MA). Statistical significance was set at p=0.05 for all models.
Results
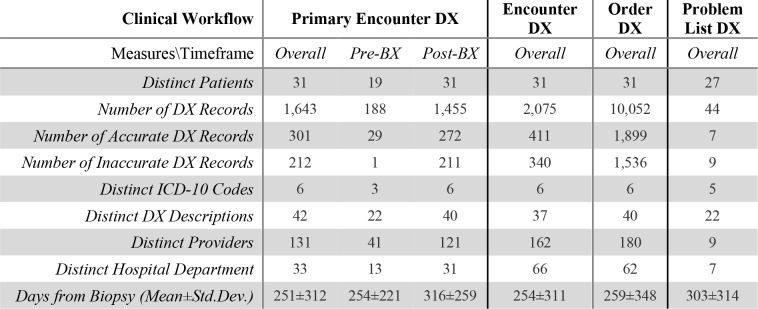
The final analytical dataset contained 1,643 primary encounter DX records for 31 patients (Table 1). Our dataset also contained 2,071 encounter DX marked as non-primary and 10,052 DX entered with clinical orders. We also included 44 distinct DX descriptions from Problem List EHR tables for 27 patients. Only site-specific descriptions corresponding to ICD-10 codes C71.0 through C71.4 appeared in the dataset. However, most DX were associated with C71.9, Malignant neoplasm of brain, unspecified (73.5% overall, 84.6% before BX and 72.0% Post BX). This was also the case for all three other DX sources with non-site-specific DX description rates of 69.6% for non-primary encounter DX and 70.3% for order-related DX and 70.4% for problem list DX descriptions. 42 standardized DX descriptions were associated with these 6 ICD-10 codes overall in the Primary DX data, with only 22 appearing before biopsy and 40 after. This was comparable to the order DX data, which contained 40 distinct DX descriptions for the same number of ICD codes with 20 and 37 distinct descriptions appearing before and after the BX respectively. Encounter and problem list had 37 (19 before and 35 after BX) and 22 (2 before and 21 after BX) descriptions for the same number of ICD codes respectively. The number of distinct providers interacting with a patient’s chart per workflow varied between 9 for the problem list data to 180 providers for order DX data. The number of distinct departments contributing to the patient’s care and charting varied between 7 for problem list DX and 66 for non- primary encounter DX data. The average number of days before and after biopsy varied between 251±312 for primary encounter DX and 303±314 for problem list DX data.
Table 1.
Descriptive statistics divided by data provenance.
|
Fully-accurate and inaccurate DX rates were fairly similar across workflows. Primary DX had an accuracy rate of 18.32% overall, 15.42% pre-BX and 18.69% post-BX. Accuracy rates were comparable for other DX sources with 19 81% (20.68% pre-BX and 19.70% post-BX) for non-primary encounter DX, 18.89% (13.45% pre-BX and 19.77% post-BX) for order DX and 15.91% (0% pre-BX and 16.67% post-BX) for problem list DX overall. Inaccuracy rates for Primary DX were 12.90% overall, 0.53% pre-BX and 14.50% post-BX. Inaccuracy rates were also comparable across DX sources with 16.39% (0.84% pre-BX and 18.38% post-BX) for non-primary encounter DX, 15.28% (0.29% pre-BX and 17.70% post-BX) for order DX and 20.45% (50.00% pre-BX and 19.05% post-BX) for problem list DX overall. It is crucial to note that the largest portion of structured DX recordings was neither fully-accurate nor inaccurate and thus, sub-optimal. For example, 68.78% of Primary Encounter DX were sub-optimal. These rates were similar for other workflows as well with 63.81% for Non-Primary Encounter DX, 65.83% for Order DX and 63.64% for problem list DX.
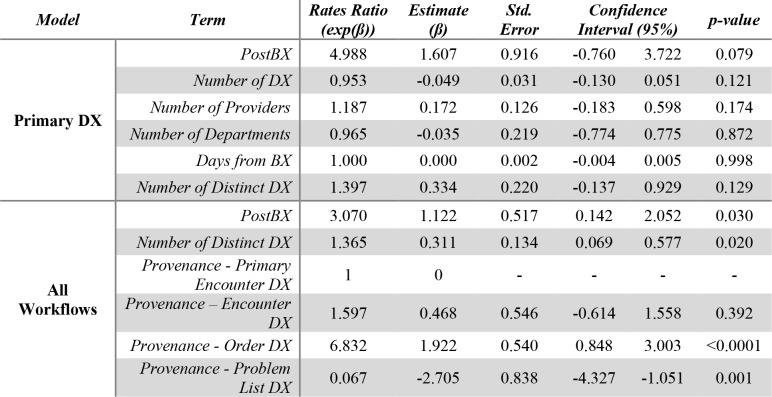
We were only able to find limited evidence of a statistically-significant difference between the number of accurate DX records before and after the BX (Table 2). On one hand, we were not able to find a statistically-significant relationship between our PostBX indicator variable and the number of accurate DX using primary DX records alone (Table 2, Primary DX Model). However, the estimate suggested that DX records after the BX were likely to have close to 5 times the number of accurate DX controlling for the total number of DX with a p-value close to significance (β=1.61, p=0.079). None of the other covariates were clearly associated with the outcome. For this dataset, single and double-variable regression models failed to converge, potentially indicating insufficient data, for which we included DX from other sources (Table 2, All Workflow Model). On the other hand, our model including DX data from all DX data sources did reveal a statistically significant relationship between the number of accurate DX and the PostBX indicator. According to our model, PostBX DX description lists are likely to have close to 3 times the number of accurate DX compared to pre-BX lists (β=1.12, p=0.030). The number of distinct DX and the workflow were also predictive of the number of accurate DX. The number of distinct DX showed a rates ratio (RR) of 1.36 (β=0.331, p=0.020). We also found differences in the predicted number of accurate DX across workflows taking Primary Encounter DX as our reference category except for non-primary encounter DX (β=0.468, p=0.392). Order DX were much more likely to have higher accurate DX data after the BX (RR=6.832, β=1.92, p<0.0001), whereas problem list DX showed a RR indicating that an increase in accuracy after DX was much less likely (RR=0.067, β=-2.71, p=0.001). Interestingly, we found no relationship between the total number of DX, the number of providers, the number of departments and the number of days from the BX, all characteristics of the patient’s treatment and the care team generating the data. We were unable to reproduce these results with a 90-day time window indicating that these results may not be robust. In a simple model linking the number of accurate DX and our PostBX indicator we found a RR of 2.77 (β=1.02, p=0.183). No interactions were found to be significant in any of our accuracy regressions.
Table 2.
Accurate DX Count Regression Results. The Primary DX model shows a non-significant trend towards a larger number of accurate DX after the BX, whereas the All Workflows model shows a similar statistically- significant effect describing a larger number of accurate DX after the BX with RR close to 3.
|
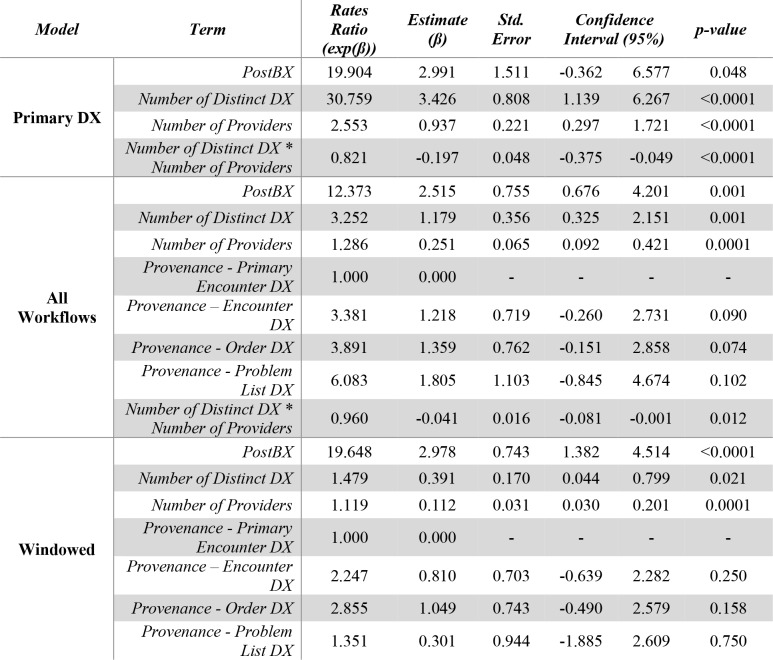
We found much stronger evidence of a statistically-significant difference between the number of inaccurate DX records before and after the BX on three models, showing a seemingly robust effect of a much number of inaccurate DX after the BX (Table 3). First, our Primary DX regression (Table 3, Primary DX Model) revealed that a list of DX descriptions post-BX was likely to have almost 20 more inaccurate DX (RR=19.9, β=2.99, p=0.048). The number of distinct DX and distinct providers were predictive of the number of inaccurate DX with RRs of 30.7 (β=3.43, p<0.001) and 2.55 (β=0.937, p<0.001) respectively. We found an interaction between these two variables (RR=0.821, β=-0.197, p<0.001). Second, our final model and results were quite similar to the previous results for our multi-workflow dataset (Table 3, All Workflows Model). In this dataset, a list of DX descriptions was likely to have over 12 more inaccurate DX than its pre-BX section (RR=12.4, β=2.52, p=0.0001). The number of distinct DX and distinct providers were predictive of the number of inaccurate DX with RRs of 3.25 (β=1.18, p=0.001) and 1.29 (β=0.251, p=0.0001) respectively. We found an interaction between these two variables (RR=0.960, β=-0.041, p=0.012). We found no statistically-significant differences in the predicted number of accurate DX across workflows taking Primary Encounter DX with p-values of 0.090, 0.074 and 0.102 for non-primary encounter, order and problem list DX respectively. The interaction between the number of distinct DX and number of providers was also significant in this model (RR=0.960, β=-0.041, p=0.012). Finally, our model built on our 90-day windowed data also showed very similar results (Table 3, Windowed Model). This model revealed similar RR to our primary encounter DX data suggesting that list of DX descriptions was likely to have over 19 more inaccurate DX than its pre-BX section (RR=19.6, β=2.98, p<0.0001). The number of distinct DX and distinct providers were predictive of the number of inaccurate DX with RRs of 1.48 (β=0.391, p=0.021) and 1.12 (β=0.112, p=0.0001) respectively. We found an interaction between these two variables (RR=0.960, β=-0.041, p=0.0002). We found no statistically-significant differences in the predicted number of accurate DX across workflows taking Primary Encounter DX with p-values of 0.250, 0.158 and 0.750 for non-primary encounter, order and problem list DX respectively. We were unable to account for the interaction as its inclusion would prevent our model estimator to reach convergence; this was likely due to the data reduction caused by dataset windowing. We explored the inclusion of covariates such as number of days from BX, total number of DX and number of departments for each of these models finding no significant relationship to the number of inaccurate DX.
Table 3.
Inaccurate DX Count Regression Results. The Primary DX model shows a statistically-significant effect describing a larger number of inaccurate DX after the BX (RR=19.9, p=0.048). This effect confirmed in the All Workflows model (RR=12.3, p=0.001) and then in the 90-day windowed model (RR=19.6, p<0.0001).
|
Discussion
We used statistical regressions to evaluate the effect of BX recoding on the subsequent number of accurate and inaccurate DX recordings. On one hand, we only found limited evidence that BX reports increase the number of fully- accurate DX records (i.e., correct neoplasm type and correct anatomical location) in oncological charts; the effect seemed to vary across workflows. Hypothesis I was, thus, only partially rejected. On the other hand, we found that the number of inaccuracies was much larger after the BX across clinical workflows, strongly supporting hypothesis II. The results also show an effect dependency on the number of providers involved in DX recording and the number of distinct DX descriptions recorded. However, the largest portion of structured DX records seems to correspond DX descriptions that are neither fully-accurate or inaccurate (i.e., sub-optimal DX records). Our results suggest the validity of our main hypothesis stating that the presence of precise DX information (e.g., an unstructured BX report) alone does not necessarily translate to higher intrinsic quality in a patient’s oncological DX charts.
Our study extends the existing literature by exploring aspects beyond DX code assignment accuracy1,15,41such as assessing the impact of DX code descriptions on intrinsic data quality and the effect of unstructured BX data recording on structured data quality. We have evaluated DX descriptions with a focus on full descriptive accuracy and inaccuracy after each patient’s DX is available in the EHR (i.e. the BX report), finding potentially larger accuracy rates, but also a much larger number of inaccurate DX records. These findings extend our initial work32by showing the larger number of inaccuracies after the BX as well as the large proportion of sub-optimal DX recordings. Both findings are congruent with the previously-shown variability rates. Our overall inaccuracy rates are also congruent with our previous findings.10,18,19It is concerning that the largest portion of structured DX seems to be neither fully-accurate or inaccurate (i.e., sub-optimal). However, it is possible that clinicians may be choosing DX codes to facilitate downstream processing rather than documenting care with the highest degree of precision.42Our results also seem to indicate that initial DX records are rarely updated to reflect the conclusive DX resulting from the BX in structured data. We could not find this effect reported quantitatively for structured DX descriptions in other publications. We defined our DX accuracy definitions (i.e., accurate neoplasm type and anatomical site) as a proxy to test intrinsic accuracy dimension of data quality.33,34,43This served as a means to investigate the potential effectiveness of the description-code relationship for semi-structured clinical data entry. Our analysis seems to reveal three pitfalls: variable accuracy rates previously and increased inaccuracies both often cited in the literature15,44but also the large proportion of sub-optimal description, a much less broadly reported side-effect of such system.
Our results demonstrate a core challenge to the reliable secondary use of clinical data and to the extraction of accurate semantically rich structured data. Sub-optimal or inaccurate structured DX descriptions in patient charts are a threat to cohort selection in clinical data warehouses9,22,28and, by proxy, the secondary use of clinical data. Variable rates of accuracy across workflows hint at a major challenge in data logging systems integration. Specifically, accuracy rates did not seem to be related to the number of providers, departments, days and total DX records. This may signify that the system does not propagate fully-accurate DX selection over the patients care process or across workflows. It may be that clinicians are presented with inconsistent DX code selection options for distinct clinical workflows and are not shown previously-recorded data relevant to subsequent DX selection. This is a known threat to data quality but also patient safety.45,46One may argue that the most accurate and precise DX is contained in the clinical progress note and can be used to determine a patient’s true DX, for which improving structured DX data quality is unnecessary. However, accessing such information programmatically or for a large number of patients remains a massive challenge.23,47The literature often cites phenotyping,21,27,28the use of complex algorithms21,48and other technological solutions49–51to address inaccurate DX logging problems but these technologies are still in development.
Much current research aiming to support secondary analysis of clinical data aims at developing methods for data quality assessment and data curation in isolation from clinical practice.4,33,34,43,52–57However, it may also be helpful, in the case of structured DX data, to unobtrusively support entry using real-time analytical methods to recommend potentially-accurate DX candidates automatically. This approach would tap into existing data available in each patient’s chart, but also each clinician’s understanding of patient’s clinical history. This may be a more viable approach to improve the quality of future data, as it takes advantage of the clinical knowledge available in the field that is lost once the data are warehoused.58,59This approach is much more in tune with the ideal of the learning healthcare60and its goal of merging structured and unstructured data to maximize data usefulness and usability.61The main challenges of such endeavor will lie in making recommender systems unobtrusive to help clinicians work more efficient rather than further burdening them with data-entry tasks.29,30In contrast, current DX code logging systems seem to not support consistent or precise DX logging, leaving clinicians the burdensome task of selecting the most accurate DX from a long list of potentially inaccurate codes and descriptions.30In clinical practice, the issue is tightly linked to challenges in EHR interface design and usability usability.29,62,63We believe that future EHR improvements to support fully-accurate and consistent DX could potentially address these problems.
Our analysis presents four limitations mostly related to its preliminary nature. First, our study relied on a limited population of cancer patients (36 subjects). Some of these subjects met the inclusion criteria but returned no data within the study time window, which further reduced the set to 31 patients. However, we had a final dataset with thousands of DX belonging 31 patients has returned adequate statistical results to test some of our hypotheses. Our analysis also had to rely on a hand-curated dataset to ensure a patient population with a very specific clinical condition dictated by a BX report. This would have been very time-consuming and challenging to develop for a larger cohort. A related limitation is that we did not consider comorbidities, yet the preliminary nature of this study required focus rather than comprehensiveness. Hence, further analysis of data from a larger cohort will be pursued in the future to confirm our results. Second, we had a rather simple definition of accuracy that only accounted for neoplasm type and anatomical location. It is known that data quality dimensions such as accuracy and completeness can take multiple forms according to what is needed for secondary analysis.64,65However, our accuracy definition was tuned to the purpose of recording structured DX data from the information available in the patient’s BX report. The information available in such reports that can be encoded in our system are fully described by the neoplasm type and the neoplasm’s location. Third, we only investigated the effects of BX on full DX accuracy and inaccuracy rather than sub-optimal DX recording. Generally, accuracy is evaluated based on non-inaccuracy in DX data reliability analyses.10,18,19However, we found it more useful to evaluate desirable cases (i.e., fully-accurate DX descriptions) and undesirable cases (i.e., DX description inaccuracies). Our descriptive statistics confirm that these cases are not the most prevalent, yet they are the most threatening to the secondary use of clinical data. The causes of sub-optimal DX description selection will be investigated in future work. Finally, we only evaluated the effect of BX recording on DX recording quality for one type of cancer. Given the preliminary nature of this analysis and the lack of other literature in the field covering this topic, we compiled this initial series of statistical analyses showing the increase of inaccuracies after BX and the variability in DX accuracy increase across workflows. Generalizability will be tested with exhaustive analyses of other DX and workflows in future work.
Future work will be divided into three segments: confirmatory analyses to verify the robustness of our conclusions, the exploration of root causes and the development of informatics solutions to increase DX data quality in oncological charts. First, we will reproduce this analysis for a different patient cohort to confirm the validity of our conclusions in a larger set of patients and patients diagnosed with a different disease. Then, we will carry out additional secondary analyses of EHR data and qualitative research such as interviews and focus groups to explore the underlying causes DX inaccuracies and sub-optimal DX recording. We will consider implementation, system and human factors such as prescribing habits, DX data entry interfaces, cognitive load, billing considerations and insurance claim transaction requirements. Finally, we will employ informatics methods to develop an intervention to support fully-accurate DX recording by leveraging fragmented data across EHRs.
Conclusion
Our results hint at larger numbers of fully-accurate DX descriptions (i.e., correct neoplasm type and anatomical site) after BX results are recorded in cancer patients’ medical record. However, the number of inaccurate results seems to also be much higher (rates ratios of 12 and 19 versus 3). There also seem to be large differences in accuracy counts across clinical workflows recording DX data. The largest portion of structured DX seems to be made of sub-optimal DX descriptions that are neither fully-accurate nor inaccurate. Interventions must be developed and adopted not only to minimize DX data inaccuracy but also to minimize partially-accurate data recording. This is likely to reduce uncertainty, misinterpretation and challenges threatening the reliability secondary analyses of clinical data. Overcoming such challenges may support the improvement of overall clinical data quality,33–35 reliability of secondary analyses of clinical data1 and the building of the learning system.66,11,67
Acknowledgements
This work was partially supported by the Cancer Center Support Grant from the National Cancer Institute to the Comprehensive Cancer Center of Wake Forest Baptist Medical Center (P30 CA012197), by the National Institute of General Medical Sciences’ Institutional Research and Academic Career Development Award (IRACDA) program (K12-GM102773) and by WakeHealth’s Center for Biomedical Informatics’ first Pilot Award. The authors acknowledge use of the services and facilities, funded by the National Center for Advancing Translational Sciences (NCATS), National Institutes of Health (UL1TR001420).
References
- 1.Safran C. Reuse Of Clinical Data. IMIA Yearbook. 2014;9:52–54. doi: 10.15265/IY-2014-0013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Safran C. Using routinely collected data for clinical research. Statistics in Medicine. 1991;10:559–564. doi: 10.1002/sim.4780100407. [DOI] [PubMed] [Google Scholar]
- 3.Hersh W. R, et al. Caveats for the Use of Operational Electronic Health Record Data in Comparative Effectiveness Research. Medical care. 2013;51:S30–S37. doi: 10.1097/MLR.0b013e31829b1dbd. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Brown J. S, Kahn M, Toh D. Data Quality Assessment for Comparative Effectiveness Research in Distributed Data Networks. Medical Care. 2013;51:S22–S29. doi: 10.1097/MLR.0b013e31829b1e2c. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Beckmann J. S, Lew D. Reconciling evidence-based medicine and precision medicine in the era of big data: challenges and opportunities. Genome Medicine. 2016;8:134. doi: 10.1186/s13073-016-0388-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Chambers D. A, Feero W. G, Khoury M. J. Convergence of Implementation Science, Precision Medicine, and the Learning Health Care System: A New Model for Biomedical Research. JAMA. 2016;315:1941–1942. doi: 10.1001/jama.2016.3867. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Council N. R, Studies D. Toward Precision Medicine: Building a Knowledge Network for Biomedical Research and a New Taxonomy of Disease. National Academies Press; 2011. on E. and L., Sciences, B. on L. & Disease, C. on A. F. for D. a N. T. of. [PubMed] [Google Scholar]
- 8.Köpcke F, Prokosch H.-U. Employing Computers for the Recruitment into Clinical Trials: A Comprehensive Systematic Review. J Med Internet Res. 2014;16 doi: 10.2196/jmir.3446. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Moskowitz A, Chen K. Secondary Analysis of Electronic Health Records. Springer International Publishing; 2016. Defining the Patient Cohort; pp. 93–100. [DOI] [Google Scholar]
- 10.Doremus H. D, Michenzi E. M. Data Quality: An Illustration of Its Potential Impact upon a Diagnosis-Related Group’s Case Mix Index and Reimbursement. Medical Care. 1983;21:1001–1011. [PubMed] [Google Scholar]
- 11.Farzandipour M, Sheikhtaheri A, Sadoughi F. Effective factors on accuracy of principal diagnosis coding based on International Classification of Diseases, the 10th revision (ICD-10) International Journal of Information Management. 2010;30:78–84. [Google Scholar]
- 12.Jack A, et al. International Classification of Diseases for Oncology: ICD-O. World Health Organization; 2000. [Google Scholar]
- 13.McDonald C. J, et al. LOINC, a Universal Standard for Identifying Laboratory Observations: A 5-Year Update. Clinical Chemistry. 2003;49:624–633. doi: 10.1373/49.4.624. [DOI] [PubMed] [Google Scholar]
- 14.Elkin P. L, et al. Evaluation of the Content Coverage of SNOMED CT: Ability of SNOMED Clinical Terms to Represent Clinical Problem Lists. Mayo Clinic Proceedings. 2006;81:741–748. doi: 10.4065/81.6.741. [DOI] [PubMed] [Google Scholar]
- 15.O'Malley K. J, et al. Measuring Diagnoses: ICD Code Accuracy. Health Services Research. 2005;40:1620–1639. doi: 10.1111/j.1475-6773.2005.00444.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Hsia D. C, Krushat W. M, Fagan A. B, Tebbutt J. A, Kusserow R. P. Accuracy of Diagnostic Coding for Medicare Patients under the Prospective-Payment System. 2010. [DOI] [PubMed]
- 17.Baskaran L. N. G. M, Greco P. J, Kaelber D. C. Case Report Medical Eponyms. Appl Clin Inform. 2012;3:349–355. doi: 10.4338/ACI-2012-05-CR-0019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Lloyd S. S, Rissing J. P. Physician and Coding Errors in Patient Records. JAMA. 1985;254:1330–1336. [PubMed] [Google Scholar]
- 19.Johnson A. N, Appel G. L. DRGs and Hospital Case Records: Implications for Medicare Case Mix Accuracy. Inquiry. 1984;21:128–134. [PubMed] [Google Scholar]
- 20.Conway M, et al. Analyzing the Heterogeneity and Complexity of Electronic Health Record Oriented Phenotyping Algorithms. AMIA Annual Symposium Proceedings. 2011;2011:274–283. [PMC free article] [PubMed] [Google Scholar]
- 21.Wei W.-Q, et al. Combining billing codes, clinical notes, and medications from electronic health records provides superior phenotyping performance. J Am Med Inform Assoc. 2016;23:e20–e27. doi: 10.1093/jamia/ocv130. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Sarmiento R. F, Dernoncourt F. Secondary Analysis of Electronic Health Records. Springer International Publishing; 2016. Improving Patient Cohort Identification Using Natural Language Processing; pp. 405–417. [DOI] [PubMed] [Google Scholar]
- 23.Burger G, Abu-Hanna A, Keizer N. de, Cornet R. Natural language processing in pathology: a scoping review. Journal of Clinical Pathology. 2016;69:949–955. doi: 10.1136/jclinpath-2016-203872. [DOI] [PubMed] [Google Scholar]
- 24.Friedman C, Shagina L, Lussier Y, Hripcsak G. Automated Encoding of Clinical Documents Based on Natural Language Processing. J Am Med Inform Assoc. 2004;11:392–402. doi: 10.1197/jamia.M1552. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Dagliati A, et al. Temporal electronic phenotyping by mining careflows of breast cancer patients. Journal of Biomedical Informatics. 2017;66:136–147. doi: 10.1016/j.jbi.2016.12.012. [DOI] [PubMed] [Google Scholar]
- 26.Halpern Y. Semi-Supervised Learning for Electronic Phenotyping in Support of Precision Medicine. New York University; 2016. [Google Scholar]
- 27.Hripcsak G, Albers D. J. Next-generation phenotyping of electronic health records. Journal of the American Medical Informatics Association. 2013;20:117–121. doi: 10.1136/amiajnl-2012-001145. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Shivade C, et al. A review of approaches to identifying patient phenotype cohorts using electronic health records. J Am Med Inform Assoc. 2014;21:221–230. doi: 10.1136/amiajnl-2013-001935. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Walji M. F, et al. Detection and characterization of usability problems in structured data entry interfaces in dentistry. International Journal of Medical Informatics. 2013;82:128–138. doi: 10.1016/j.ijmedinf.2012.05.018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Howard J, et al. Electronic Health Record Impact on Work Burden in Small, Unaffiliated, Community-Based Primary Care Practices. J GEN INTERN MED. 2013;28:107–113. doi: 10.1007/s11606-012-2192-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Asan O, Nattinger A. B, Gurses A. P, Tyszka J. T, Yen T. W. F. Oncologists’ Views Regarding the Role of Electronic Health Records in Care Coordination. JCO Clinical Cancer Informatics. 2018:1–12. doi: 10.1200/CCI.17.00118. [DOI] [PubMed] [Google Scholar]
- 32.Diaz-Garelli J.-F, Wells B. J, Yelton C, Strowd R, Topaloglu U. Biopsy Records Do Not Reduce Diagnosis Variability in Cancer Patient EHRs: Are We More Uncertain After Knowing? 2018 [PMC free article] [PubMed] [Google Scholar]
- 33.Weiskopf N. G, Weng C. Methods and dimensions of electronic health record data quality assessment: enabling reuse for clinical research. Journal of the American Medical Informatics Association. 2013;20:144–151. doi: 10.1136/amiajnl-2011-000681. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Kahn M. G, et al. A Harmonized Data Quality Assessment Terminology and Framework for the Secondary Use of Electronic Health Record Data. EGEMS (Wash DC) 2016;4 doi: 10.13063/2327-9214.1244. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Wang R. Y, Strong D. M. Beyond Accuracy: What Data Quality Means to Data Consumers. Journal of Management Information Systems. 1996;12:5–33. [Google Scholar]
- 36.Tabachnick B. G, Fidell L. S. Using multivariate statistics, 5th ed. Allyn & Bacon/Pearson Education; 2007. [Google Scholar]
- 37.R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing; 2013. [Google Scholar]
- 38.van den Broek J. A Score Test for Zero Inflation in a Poisson Distribution. Biometrics. 1995;51:738–743. [PubMed] [Google Scholar]
- 39.Kleiber C, Zeileis A. AER: Applied Econometrics with R. 2017 [Google Scholar]
- 40.Diaz-Garelli J.-F, Bernstam E. V, MSE, Rahbar M. H, Johnson T. Rediscovering drug side effects: the impact of analytical assumptions on the detection of associations in EHR data. AMIA Summits on Translational Science Proceedings. 2015;2015:51–55. [PMC free article] [PubMed] [Google Scholar]
- 41.Escudié J.-B, et al. A novel data-driven workflow combining literature and electronic health records to estimate comorbidities burden for a specific disease: a case study on autoimmune comorbidities in patients with celiac disease. BMC Medical Informatics and Decision Making. 2017;17:140. doi: 10.1186/s12911-017-0537-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Richesson R. L, Horvath M. M, Rusincovitch S. A. Clinical Research Informatics and Electronic Health Record Data. Yearb Med Inform. 2014;9:215–223. doi: 10.15265/IY-2014-0009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Kahn M, et al. Transparent Reporting of Data Quality in Distributed Data Networks. eGEMs (Generating Evidence & Methods to improve patient outcomes) 2015;3 doi: 10.13063/2327-9214.1052. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Botsis T, Hartvigsen G, Chen F, Weng C. Secondary Use of EHR: Data Quality Issues and Informatics Opportunities. AMIA Summits on Translational Science Proceedings. 2010;2010:1. [PMC free article] [PubMed] [Google Scholar]
- 45.Donaldson M. S, Corrigan J. M, Kohn L. T, others . To err is human: building a safer health system. Vol. 6. National Academies Press; 2000. [PubMed] [Google Scholar]
- 46.Zhang J, Walji M. Better EHR: usability, workflow and cognitive support in electronic health records. 2014 [Google Scholar]
- 47.Meystre S. M, Savova G. K, Kipper-Schuler K. C, Hurdle J. F. Extracting information from textual documents in the electronic health record: a review of recent research. Yearb Med Inform. 2008:128–144. [PubMed] [Google Scholar]
- 48.Denny J. C, et al. Systematic comparison of phenome-wide association study of electronic medical record data and genome-wide association study data. Nature Biotechnology. 2013;31:1102. doi: 10.1038/nbt.2749. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Murphy S. N, et al. Serving the enterprise and beyond with informatics for integrating biology and the bedside (i2b2) J Am Med Inform Assoc. 2010;17:124–130. doi: 10.1136/jamia.2009.000893. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Natter M. D, et al. An i2b2-based, generalizable, open source, self-scaling chronic disease registry. J Am Med Inform Assoc. 2013;20:172–179. doi: 10.1136/amiajnl-2012-001042. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Segagni D, et al. The ONCO-I2b2 project: integrating biobank information and clinical data to support translational research in oncology. Stud Health Technol Inform. 2011;169:887–891. [PubMed] [Google Scholar]
- 52.Callahan T. J, Barnard J. G, Helmkamp L. J, Maertens J. A, Kahn M. G. Reporting Data Quality Assessment Results: Identifying Individual and Organizational Barriers and Solutions. eGEMs (Generating Evidence & Methods to improve patient outcomes) 2017;5 doi: 10.5334/egems.214. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Hripcsak G, et al. Observational Health Data Sciences and Informatics (OHDSI): opportunities for observational researchers. MEDINFO. 2015;15 [PMC free article] [PubMed] [Google Scholar]
- 54.Kahn M. G, Raebel M. A, Glanz J. M, Riedlinger K, Steiner J. F. A Pragmatic Framework for Single-site and Multisite Data Quality Assessment in Electronic Health Record-based Clinical Research. Medical care. 2012;50 doi: 10.1097/MLR.0b013e318257dd67. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Johnson S. G, Speedie S, Simon G, Kumar V, Westra B. L. AMIA; 2015. A Data Quality Ontology for the Secondary Use of EHR Data. [PMC free article] [PubMed] [Google Scholar]
- 56.Johnson S. G, Speedie S, Simon G, Kumar V, Westra B. L. Application of An Ontology for Characterizing Data Quality For a Secondary Use of EHR Data. Applied Clinical Informatics. 2016;7:69–88. doi: 10.4338/ACI-2015-08-RA-0107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.DQe-v: A Database-Agnostic Framework for Exploring Variability in Electronic Health Record Data Across Time and Site Location. Available at: https://egems.academyhealth.org/articles/10.13063/2327-9214.1277/. (Accessed: 18th June 2018) [DOI] [PMC free article] [PubMed]
- 58.Sahama T. R, Croll P. R. A Data Warehouse Architecture for Clinical Data Warehousing; Proceedings of the Fifth Australasian Symposium on ACSW Frontiers - Volume 68; Australian Computer Society, Inc.; 2007. pp. 227–232. [Google Scholar]
- 59.Singh R, Singh K, others A descriptive classification of causes of data quality problems in data warehousing. International Journal of Computer Science Issues. 2010;7:41–50. [Google Scholar]
- 60.Medicine I. The Learning Healthcare System: Workshop Summary. National Academies Press; 2007. of & Medicine, R. on E.-B. [PubMed] [Google Scholar]
- 61.Care R. Data Quality Challenges and Opportunities in a Learning Health System. National Academies Press (US); 2013. on V. & S.-D. H. & Medicine, I. of. [Google Scholar]
- 62.Zhang J, Walji M. F. TURF: Toward a unified framework of EHR usability. Journal of Biomedical Informatics. 2011;44:1056–1067. doi: 10.1016/j.jbi.2011.08.005. [DOI] [PubMed] [Google Scholar]
- 63.Abran A, Khelifi A, Suryn W, Seffah A. Usability Meanings and Interpretations in ISO Standards. Software Quality Journal. 2003;11:325–338. [Google Scholar]
- 64.Weiskopf N. G, Rusanov A, Weng C. Sick Patients Have More Data: The Non-Random Completeness of Electronic Health Records. AMIA Annual Symposium Proceedings. 2013;2013:1472–1477. [PMC free article] [PubMed] [Google Scholar]
- 65.Weiskopf N, George Hripcsak, Swaminathan S, Weng C. Defining and measuring completeness of electronic health records for secondary use. Journal of Biomedical Informatics. 2013;46:830–836. doi: 10.1016/j.jbi.2013.06.010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Lorence D. Regional variation in medical classification agreement: benchmarking the coding gap. J Med Syst. 2003;27:435–443. doi: 10.1023/a:1025607805588. [DOI] [PubMed] [Google Scholar]
- 67.Burgun A, Botti G, Beux P. L. Issues in the Design of Medical Ontologies Used for Knowledge Sharing. Journal of Medical Systems. 2001;25:95–108. doi: 10.1023/a:1005668530110. [DOI] [PubMed] [Google Scholar]