

Abstract
Background
Word embeddings have been prevalently used in biomedical Natural Language Processing (NLP) applications due to the vector representations of words capturing useful semantic properties and linguistic relationships between words. Different textual resources (e.g., Wikipedia and biomedical literature corpus) have been utilized in biomedical NLP to train word embeddings and these word embeddings have been commonly leveraged as feature input to downstream machine learning models. However, there has been little work on evaluating the word embeddings trained from different textual resources.
Methods
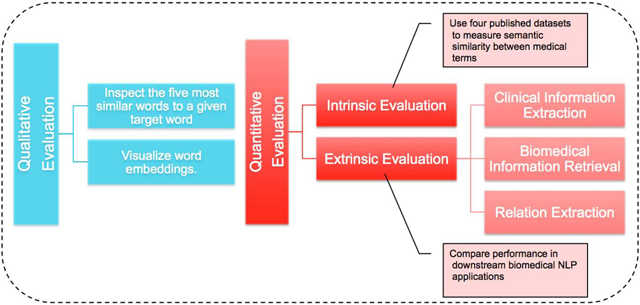
In this study, we empirically evaluated word embeddings trained from four different corpora, namely clinical notes, biomedical publications, Wikipedia, and news. For the former two resources, we trained word embeddings using unstructured electronic health record (EHR) data available at Mayo Clinic and articles (MedLit) from PubMed Central, respectively. For the latter two resources, we used publicly available pre-trained word embeddings, GloVe and Google News. The evaluation was done qualitatively and quantitatively. For the qualitative evaluation, we arbitrarily selected medical terms from three medical categories (i.e., disorder, symptom, and drug), and manually inspected the five most similar words computed by word embeddings for each of them. We also analyzed the word embeddings through a 2-dimensional visualization plot of 377 medical terms. For the quantitative evaluation, we conducted both intrinsic and extrinsic evaluation. For the intrinsic evaluation, we evaluated the medical semantics of word embeddings using four published datasets for measuring semantic similarity between medical terms, i.e., Pedersen’s dataset, Hliaoutakis’s dataset, MayoSRS, and UMNSRS. For the extrinsic evaluation, we applied word embeddings to multiple downstream biomedical NLP applications, including clinical information extraction (IE), biomedical information retrieval (IR), and relation extraction (RE), with data from shared tasks.
Results
The qualitative evaluation shows that the word embeddings trained from EHR and MedLit can find more relevant similar medical terms than those from GloVe and Google News. The intrinsic quantitative evaluation verifies that the semantic similarity captured by the word embeddings trained from EHR is closer to human experts’ judgments on all four tested datasets. The extrinsic quantitative evaluation shows that the word embeddings trained on EHR achieved the best F1 score of 0.900 for the clinical IE task; no word embeddings improved the performance for the biomedical IR task; and the word embeddings trained on Google News had the best overall F1 score of 0.790 for the RE task.
Conclusion
Based on the evaluation results, we can draw the following conclusions. First, the word embeddings trained on EHR and MedLit can capture the semantics of medical terms better and find semantically relevant medical terms closer to human experts’ judgments than those trained on GloVe and Google News. Second, there does not exist a consistent global ranking of word embeddings for all downstream biomedical NLP applications. However, adding word embeddings as extra features will improve results on most downstream tasks. Finally, the word embeddings trained on biomedical domain corpora do not necessarily have better performance than those trained on general domain corpora for any downstream biomedical NLP task.
Keywords: word embeddings, natural language processing, information extraction, information retrieval, machine learning
Graphical Abstract
I. Introduction
Word embeddings have been prevalently used in Natural Language Processing (NLP) applications due to the vector representations of words capturing useful semantic properties and linguistic relationships between words using deep neural networks [1], [2], [3]. Word embeddings are commonly utilized as feature input to machine learning models, which enables machine learning techniques to process rew text data. There has been an increasing number of studies applying word embeddings in common NLP tasks, such as information extraction (IE) [4], [5], [6], information retrieval (IR) [7], sentiment analysis [8], [9], question answering [10], [11], and text summarization [12], [13]. Recently, in the biomedical domain, word embeddings have been remarkably utilized in applications such as biomedical named entity recognition (NER) [14], [15], medical synonym extraction [16], relation extraction (RE) (e.g., chemical-disease relation [17], drug-drug interaction [18], [19] and protein-protein interaction [20]), biomedical IR [21], [22] and medical abbreviation disambiguation [23].
There are two main text resources utilized to train word embeddings for the biomedical NLP applications: internal task corpora (e.g., training data) [21] and external data resources (e.g., Wikipedia) [24]. The use of the former resource is straightforward as the internal corpora capture the nuances of language topic specific to the task [25]. Exploiting external data resources is based on an implicit assumption that the external resources contain knowledge that could be used to enhance domain tasks [26], [27], [28]. In addition, a number of pre-trained word embeddings are publicly available, such as the embeddings of Google News1 and GloVe2. These embeddings could capture the semantics of general English words from a large corpus. However, one question remains unanswered: do we need to train word embeddings for a specific NLP task given a number of public pre-trained word embeddings? This question becomes more significant for domain areas, and particularly more important for the clinical domain. The reason is that little electrical health record (EHR) data is publicly available due to the Health Insurance Portability and Accountability Act (HIPAA) requirements, while biomedical literature is more widely available through resources such as PubMed3. However, to the best of our knowledge, there has been little work done to evaluate word embeddings trained from these textual resources for biomedical NLP applications.
In this study, we empirically evaluated word embeddings trained from four different corpora, namely clinical notes, biomedical publications, Wikipedia, and news. For the former two resources, we utilized clinical notes from the EHR system at Mayo Clinic and articles from PubMed Central (PMC)4 to train word embeddings. For the latter two resources, we used publicly available pre-trained word embeddings, GloVe and Google News. We performed the evaluation qualitatively and quantitatively. For the qualitative evaluation, we adopted the method used in Levy and Goldberg’s study [3], and manually inspected five of the most similar medical words to each of arbitrarily selected medical words from three medical categories (disorder, symptom, and drug). In addition, we analyzed word embeddings through a 2-dimensional visualization plot of 377 medical words. For the quantitative evaluation, we conducted both intrinsic and extrinsic evaluation. The intrinsic evaluation directly tested semantic relationships between medical words using four published datasets for measuring semantic similarity between medical terms, i.e., Pedersen [29], Hliaoutakis [30], MayoSRS [31], and UMNSRS [32], [33]. For the extrinsic evaluation, we applied word embeddings to downstream NLP applications in the biomedical domain including clinical IE, biomedical IR, and RE, and measured the performance of word embeddings.
II. Related work
Due to the success of word embeddings in a variety of NLP applications, some existing studies evaluate word embeddings in representing word semantics quantitatively. Most of them focus on evaluating the word embeddings generated by different approaches. Baroni et al. [34] presented the first systematic evaluation of word embeddings generated by four models, i.e., DISSECT5, CBOW [1] using word2vec6, Distributional Memory model7, and 4) Collobert and Weston model8 using a corpus of 2.8 billion tokens in the general English domain. They tested these models on fourteen benchmark datasets in five categories, including semantic relatedness, synonym detection, concept categorization, selectional preferences, and analogy. They found that the word2vec model, CBOW, performed the best for almost all the tasks.
Schnabel et al. [35] trained the CBOW model of word2vec [1], C&W embeddings [36], Hellinger PCA [37], GloVe [38], TSCCA [39], and Sparse Random Projections [40] on a 2008 GloVe dump, and tested on the same fourteen datasets. They found that the CBOW outperformed other embeddings on 10 datasets. They also conducted an extrinsic evaluation by using the embeddings as input features to two downstream tasks, namely noun phrase chunking and sentiment classification. They found the results of CBOW were also among the best.
Ghannay et al. [41] conducted a similar intrinsic evaluation, they additionally evaluated the skip-gram models of word2vec [1], CSLM word embeddings [42], dependency-based word embeddings [3], and combined word embeddings on four NLP tasks, including Part-Of-Speech tagging, chunking, named entity recognition, mention detection, and two linguistic tasks. They trained these word embeddings on the Gigaword corpus composed of 4 billion words and found that the dependency-based word embeddings gave the best performance on the NLP tasks and that the combination of embeddings yielded significant improvement. Nayak et al’s study [43] recommended that the evaluation of word embeddings should test both syntactic and semantic properties, and that the evaluation tasks should be closer to real-word applications. However, few of these studies evaluated word embeddings for tasks in the biomedical domain.
As most of the aforementioned studies evaluate word embeddings in the general (i.e., non-biomedical) NLP domain, only one recent study by Pakhomov et al. [33] evaluates word embeddings in the biomedical domain, to the best of our knowledge. They trained the CBOW model on two biomedical corpora, namely clinical notes and biomedical publications, and one general English corpora, namely GloVe. The word embeddings were evaluated on subsets of UMNSRS dataset, which consisted of pairs of medical terms with the similarity of each pair assessed by medical experts, and on a document retrieval task and a word sense disambiguation task. They found that the semantics captured by the embeddings computed from biomedical publications were on par with that from clinical notes. We extended their evaluation of word embeddings by: 1) utilizing four datasets to evaluate word embeddings on capturing medical term semantics; 2) conducting a qualitative evaluation; and 3) examining word embeddings on more downstream applications with data provided by shared biomedical NLP tasks.
III. Word Embeddings and Parameter Settings
We utilized word2vec in this study as it has been shown that word2vec generates better word embeddings for most general NLP tasks than other approaches [34], [35]. Since no evidence shows that the CBOW architecture outperforms the skip-gram architecture or vice versa, we arbitrarily chose the skip-gram architecture for word2vec.
Word embeddings can be represented as a mapping , which maps a word w from a vocabulary V to a real-valued vector θ in an embedding space with the dimension of D. The skip-gram architecture, proposed by Mikolov et al. [1], uses the focus word as the single input layer, and the target contextual words as the output prediction layer. To avoid expensive computation over every word in V, Mikolov et al. [1] proposed a technique called “negative-sampling” that samples a few output words and updates embeddings for this small sample in each iteration. We formulate the model mathematically in the following. Given a sequence of target word w1, w2,…, wT and its contextual word h1, h2, …, hT, the training objective is to maximize the conditional log probability of observing the actual output contextual word given the input target word, i.e.,
| (1) |
where J is the objective function, and P(h∣w) is the conditional probability in the neural probabilistic language model. P(h∣w) is usually defined by
| (2) |
where θ′ and θ are the input and output word embeddings, respectively. Accordingly, the log probability can be written as:
| (3) |
We can take the derivative of J to obtain the embeddings, updating the equation iteratively. However, the computation is extremely expensive as in each iteration, the algorithm needs to go through the vocabulary V. By using negative-sampling, Mikolov et al. [1] defined an empirical log probability P′(h∣w) to approximate P(h∣w):
| (4) |
where σ(x) = 1/(1 + exp(−x)) is a softmax function that normalizes a real vector into a probability vector, is an empirical distribution that generates k negative samples with f(hi) being the term frequency for term hi. The word embeddings θ can be computed by maximizing the objective function in Equation (1) by replacing P(h∣w) with P′(h∣w).
We tested different vector dimensions of D (i.e., 20, 60, 100) for the vector representation trained on EHR and MedLit and chose 100 for EHR and 60 for MedLit according to the performance in our intrinsic evaluation. Similarly, we chose the dimension of 100 for GloVe, and 300 for Google News since only 300 was publicly available for Google News. The experimental results of using different vector dimensions for the word embeddings are provided in Appendix A. For training word embeddings on the EHR and MedLit, we set the window size to 5, the minimum word frequency to 7 (i.e., the words that occurred less than 7 times in the corpus were ignored), and the negative sampling parameter to 5. These parameters were selected based on previous studies [1], [3], [19].
IV. Data and Text Pre-prosessing
The first corpus, denoted as EHR, contains textual clinical notes for a cohort of 113k patients receiving their primary care at Mayo Clinic, spanning a period of 15 years from 1998 to 2013. The vocabulary size of this corpus is 103k. The second corpus, denoted as MedLit, is obtained from a snapshot of the Open Access Subset9 of PubMed Central (PMC)10 in March 2016, which is an online digital database of freely available full-text biomedical literature. It contains 1.25 million biomedical articles, and 2 million distinct words in the vocabulary. As a comparison, additional public pre-trained word embeddings from two general English resources, i.e., Google News 11 and GloVe 12, were utilized in the evaluation. The Google News embeddings have vector representations for 3 million words from Google News, trained by the word2vec [1]. The GloVe embeddings were trained by the GloVe model [38], and have 400k unique words in the vocabulary from a snapshot of Wikipedia in 2014 and Gigaword Fifth Edition13.
The MedLit and EHR corpora were pre-processed minimally by removing punctuation, lowercasing, and replacing all digits with ”7”. One exception is that we replaced ‘-’ with ‘–’ if two or more words were connected by ‘-’ and treated these words as one. For the MedLit corpus, we additionally removed website urls, email addresses, and twitter handles. For the EHR corpus, the clinical narratives are written by medical practitioners, and thus contain more incomplete sentences than research articles. Therefore, we conducted additional pre-processing on the EHR corpus specific for the clinical notes from Mayo Clinic. Specifically, the section of “Family history” in the corpus was removed if it was semi-structured [44]. As shown by an example in Table I, the semi-structured “Family history” section does not provide much valuable semantic information. The section of “Vital Signs” was totally removed since it did not contain contextual information for training word embeddings. Table II shows an example of the “Vital Signs” section in the EHR corpus. Moreover, we replaced all text contractions with their respective complete text (e.g., “can’t” is replaced with “can not”), and removed all the clinical notes metadata and note section headers, dates, phone numbers, weight and height information, and punctuation.
TABLE I:
An example of the semi-structured “Family history” section from the EHR corpus.
| MOTHER |
| Stroke/TIA |
| BROTHERS |
| 4 brothers alive 1 brother deceased |
| SISTERS |
| 2 sisters alive |
| DAUGHTERS |
| 1 daughter alive |
| Heart disease |
TABLE II:
An example of the “Vital Signs” section from the EHR corpus.
| Height: 149.1 cm. Weight: 44.5 kg. BSA(G): 1.3573 M2. BMI: 20.02 KG/M2. |
V. Qualitative Evaluation
We arbitrarily selected medical words from three medical semantic categories, namely disorder, symptom, and drug. Word embeddings trained from four different corpora were utilized to compute the five most similar words to each selected medical word according to the cosine similarity. Then we adopted the method used in Levy and Goldberg’s study [3] and manually inspected the conceptual similarity between the target word and the most similar words. Suppose w1 and w2 are two words, the similarity between w1 and w2 is defined as
| (5) |
where θ1 and θ2 are vector representations for w1 and w2 in the embedding space, respectively. If the target word is a medical phrase s1 consisting of multiple words, i.e., s1 = w1, w2, …, wn, the similarity function becomes
| (6) |
where is the representation for s1 in the embedding space. This is different from Pakhomov et al’s study [33] where only single word terms were considered. We ranked the words in the vocabulary based on the similarity to the target word and chose the five top ranked words.
Table III lists eight target words from the three medical categories, and the corresponding five most similar words computed by using the word embeddings trained from different resources.
TABLE III:
Selected medical words from three medical semantic categories (i.e., disorder, symptom, and drug) and the corresponding five most similar words induced by the word embeddings trained from different resources.
| Semantic Category |
Target Word | EHR | MedLit | GloVe | Google News |
|---|---|---|---|---|---|
| diabetes | mellitus, | cardiovascular, | hypertension, | diabetics, | |
| Disorder | uncontrolled, | nonalcoholic, | obesity, | hypertension, | |
| cholesterolemia, | obesity, | arthritis, | diabetic, | ||
| dyslipidemia, | mellitus, | cancer, | diabetes_mellitus, | ||
| melitis | polycystic | alzheimer | heart_disease | ||
| peptic ulcer disease | scleroderma, | gastritis, | ulcers, | ichen_planus, | |
| duodenal, | alcoholism, | arthritis, | Candida_infection, | ||
| crohn, | rheumatic, | diseases, | vaginal_yeast_infections, | ||
| gastroduodenal, | ischaemic, | diabetes, | oral_thrush, | ||
| diverticular | nephropathy | stomach | dermopathy | ||
| colon cancer | breast, | breast, | breast, | breast, | |
| ovarian, | mcf, | prostate, | prostate, | ||
| prostate, | cancers, | cancers, | tumor, | ||
| postmenopausally, | tumor_suppressing, | tumor, | pre_cancerous_lesion, | ||
| caner | downregulation | liver | cancerous_polyp | ||
| dyspnea | palpitations, | sweats, | shortness, | dyspnoea, | |
| Symptom | orthopnea, | orthopnea, | breathlessness, | pruritus, | |
| exertional, | breathlessness, | cyanosis, | nasopharyngitis, | ||
| doe, | hypotension, | photophobia, | symptom_severity, | ||
| dyspnoea | rhonchi | faintness | rhinorrhea | ||
| sore throat | scratchy, | runny, | shoulder, | soreness, | |
| thoat, | rhinorrhea, | stomach, | bruised, | ||
| cough, | myalgia, | nose, | inflammed, | ||
| runny, | swab_fecal, | chest, | contusion, | ||
| thraot | nose | neck | sore_triceps | ||
| low blood pressure | readings, | dose, | because, | splattering_tombstones, | |
| pressue, | cardio_ankle, | result, | Zapping_nerves_helps, | ||
| presssure, | ncbav, | high, | pressue, | ||
| bptru, | preload, | enough, | Marblehead_Swampscott_VNA, | ||
| systolically | gr | higher | pill_Norvasc | ||
| Drug | opioid | opiate, | opioids, | analgesic, | opioids, |
| benzodiazepine, | nmda_receptor, | opiate, | opioid_analgesics, | ||
| opioids, | affective_motivational, | opioids, | opioid_painkillers, | ||
| sedative, | naloxone_precipitated, | anti-inflammatory, | antipsychotics, | ||
| polypharmacy | hyperlocomotion | analgesics | tricyclic_antidepressants | ||
| aspirin | ecotrin, | chads, | ibuprofen, | dose_aspirin, | |
| uncoated, | vasc, | tamoxifen, | ibuprofen, | ||
| nonenteric, | newer, | pills, | statins, | ||
| effient, | cha, | statins, | statin, | ||
| onk | angina | medication | calcium_supplements |
For the first target word describing a disorder, diabetes, EHR and MedLit find its synonym, mellitus, in the most similar words while GloVe and Google News fail to find it. EHR finds two terms related to co-morbidities of diabetes, which are cholesterolemia and dyslipidemia, and a common adjective modifier term, uncontrolled. MedLit finds terms relevant to co-existing conditions for diabetes, such as cardiovascular (possibly from cardiovascular disease), nonalcoholic (possibly from nonalcoholic fatty liver disease), obesity, and polycystic (possibly from polycystic ovary syndrome which is a hyperandrogenic disorder that is associated with a high-risk of development of Type 2 diabetes). Most of these terms are related with medical research topics and occur frequently in the biomedical research articles. GloVe finds two related terms, hypertension and obesity, while three other terms, i.e., arthritis, cancer and alzheimer, are less relevant disease names. Google News finds two morphological terms, diabetics and diabetic, relevant to the target words, one synonym, diabetes_mellitus, and one related disease name, heart disease. We can draw similar conclusions for the second and third disorder words.
The dyspnea example in the symptom category demonstrates the advantage of EHR and MedLit. EHR finds palpitations, a common cause of dyspnea, and orthopnea, exertional, and doe (dyspnea on exertion) are synonyms or specific conditions for dyspnea. MedLit finds related symptoms, sweats and orthopnea, a synonym breathlessness, a relevant disorder hypotension, and a term relevant to the symptom rhonchi. GloVe finds synonyms shortness and breathlessness, and less relevant symptoms cyanosis and photophobia. Google News finds less relevant symptoms pruritus and rhinorrhea and less relevant disease nasopharyngitis. Similar observations can be found for sore throat and low blood pressure as well.
We can further observe that the semantics captured by the word embeddings trained from different corpora is disparate for the medical terms in the drug category. For opioid, EHR finds opiate, benzodiazepine, sedative, polypharmacy, which are very relevant medications. MedLit finds nmda_receptor, affective_motivational, nalox-one_precipitated, hyperlocomotion, which are related to the mechanism of action of opioid. GloVe finds analgesic and less relevant anti-inflammatory, and Google News finds opioid-related phrases and relevant term antipsychotics. For the target term aspirin, EHR also finds very clinically relevant used terms and MedLit finds relevant terms in research articles while GloVe and Google News only find medication names.
It is obviously shown from these target words and the corresponding similar words that EHR and MedLit can capture the semantics of medical terms better than GloVe and Google News and find more relevant similar medical terms. However, EHR and MedLit find similar medical terms from different perspectives due to their focus difference. EHR contains clinical narratives and thus it is closer to clinical language. It contains terms with different morphologies and even typos, such as melitis, caner and thraot as listed in Table III. Differently, MedLit contains more medical terms used in research articles, and finds similar words mostly from a biomedical research perspective.
In order to show different aspects of medical concepts captured by word embeddings trained from different corpora, we extracted 377 medical terms from the UMNSRS dataset [32], [33] and visualized the word embeddings for these medical terms in a two-dimensional plot using t-distributed stochastic neighbor embedding (t-SNE) [45]. Example clusters of medical terms in the word embeddings are shown in Figure 1. Figure 1a depicts a cluster of symptoms, such as heartburn, vomiting and nausea, from the word embeddings trained on EHR. Figure 1b shows a cluster of antibiotic medications, such as bacitracin, cefoxitin, and chloramphenicol, based on MedLit embeddings. Figures 1c and 1d illustrate clusters of symptoms from the GloVe and Google News embeddings, respectively. Since we did not employ any clustering method, these clusters were intuitively observed from the two-dimensional plot. The visualization of the entire set of 377 medical terms using word embeddings trained from four different corpora is provided in the supplementary file.
Fig. 1:

Examples of word clusters in the visualization of word embeddings trained from four corpora using t-SNE.
VI. Quantitative Evaluation
We conducted both extrinsic and intrinsic quantitative evaluation, where the former used four published datasets for measuring semantic similarity between medical terms and the latter used downstream biomedical NLP tasks to evaluate word embeddings.
A. Intrinsic Evaluation
We tested word embeddings on four published biomedical measurement datasets commonly used to measure semantic similarity between medical terms. The first is Pedersen’s dataset [29] that consists of 30 medical term pairs that were scored by physician experts according to their relatedness. The second is Hliaoutakis’s dataset [30] consisting of 34 medical term pairs with similarity scores obtained by human judgments. The third, the MayoSRS dataset developed by Pakhomov et al. [31], consists of 101 clinical term pairs whose relatedness was determined by nine medical coders and three physicians from Mayo Clinic. The relatedness of each term pair was assessed based on a four point scale: (4.0) practically synonymous, (3.0) related, (2.0) marginally related and (1.0) unrelated. We evaluated the word embeddings using the mean score of the physicians and medical coders. The fourth, UMNSRS similarity dataset developed by Pakhomov et al. [32], consists of 566 medical term pairs whose semantic similarity was determined independently by eight medical residents from the University of Minnesota Medical School. The similarity and relatedness of each term pair was annotated based on a continuous scale by having the resident touch a bar on a touch sensitive computer screen to indicate the degree of similarity or relatedness.
For each pair of medical terms in the testing datasets, we used Equations (5) and (6) to calculate the semantic similarity for each pair. Since some medical terms may not exist in the vocabulary of word embeddings, we used fastText [46] to compute word vectors for these out-of-vocabulary (OOV) medical terms. Specifically, we built character n-gram vectors analogous to fastText’s output by converting each word (e.g., “abcdef”) in the word embeddings to 3-gram (i.e., trigram) format (i.e., “abc”, “bcd”, “cde”, “def”) with vector representation of each trigram the same as that of the original word. After converting all the words, we utilized the averaged vector for the identical trigram extracted from different words (e.g., the vector for “abcdef” is θ1 and that for “defg” is θ2, the final vector for trigram “def” is since “def” is a shared trigram between the two words). Since each word with the number of characters greater than or equal to 3 can be represented as a bag of character trigrams, fastText represents an OOV medical term as the normalized sum of the vector representations of its trigrams [46]. The Pearson correlation coefficient was employed to calculate the correlation between similarity scores from human judgments and those from word embeddings.
Table IV lists the Pearson correlation coefficient results for the four datasets. Overall, the semantic similarity captured by the word embeddings trained on EHR are closer to human experts’ judgments, compared with other word embeddings. MedLit performs worse than EHR but has a comparative result for the UMNSRS dataset. GloVe and Google News are inferior to EHR and MedLit, and perform similarly in representing medical semantics. Note that the four datasets and corresponding semantic similarity scores from both human experts and word embeddings are provided in the supplementary Excel file.
TABLE IV:
Pearson correlation coefficient between similarity scores from human judgments and those from word embeddings on four measurement datasets. The asterisk indicates that difference between word embeddings trained on EHR and those on other resources is statistically significant using t-test (p<0.01).
| Dataset | EHR | MedLit | GloVe | Google News |
|---|---|---|---|---|
| Pedersen’s | 0.632* | 0.569 | 0.403 | 0.357 |
| Hliaoutakis’s | 0.482* | 0.311 | 0.247 | 0.243 |
| MayoSRS | 0.412* | 0.300 | 0.082 | 0.084 |
| UMNSRS | 0.440* | 0.404 | 0.177 | 0.154 |
B. Extrinsic Evaluation
Extrinsic evaluations are used to measure the impact of word embeddings to specific biomedical NLP tasks. In this evaluation, we tested the word embeddings on three biomedical NLP tasks, namely clinical IE, biomedical IR, and RE.
1). Clinical Information Extraction:
Two clinical IE tasks were utilized to evaluate the word embeddings. The first task is an institutional task while the second is a shared task. Using the first task, we would like to examine whether the word embeddings trained on our institutional corpus perform better than external pre-trained word embeddings on a local institutional IE task. We also would like to investigate whether the results are consistent on a global shared task.
In the first experiment, we evaluated the word embeddings on an institutional IE task at Mayo Clinic. In this task, a set of 1000 radiology reports was given to detect whether a hand and figure/wrist fracture could be identified. Reports were drawn from a cohort of residents of Olmsted County, aged 18 or older, who experienced fractures in 2009-2011. Each report was annotated by a medical expert with multiple years of experience abstracting fractures by assigning “1” if a hand and figure/wrist fracture was found, or “0” otherwise.
In our experiment, the word embeddings were employed as features for machine learning models and evaluated by precision, recall, and F1 scores [47]. For a clinical document d = {w1, w2,.., wM} where wi i = 1, 2, …, M is the ith word and M is the total number of words in this document, the feature vector x of document d is defined by
where xi is the embedding vector for word wi from the word embedding matrix. Then x was utilized as input to a conventional machine learning model, which is Support Vector Machine (SVM) in this experiment. We performed 10-fold cross validation on the dataset. The means of precision, recall, and F1 scores from the 10-fold cross validation was reported, which are defined below:
where TP, TN, FP, and FN represent true positives, true negatives, false positives, and false negatives, respectively, and i = 1, 2, …, 10 represents the ith fold cross validation. As a comparison, the baseline method used term frequency features as input.
The experimental results are listed in Table V. The word embeddings trained on EHR are superior to other word embeddings in terms of all metrics (precision: 0.974, recall: 0.972, F1 score: 0.972) with statistical significance using t-test (p<0.01). The fracture dataset in this experiment is curated from the same EHR system as the EHR corpus used to train word embeddings, and thus they have identical sublanguage characteristics. The word embeddings trained on MedLit also have comparable results (precision: 0.946, recall: 0.943, F1 score: 0.942). Since this task is a medical task with specific medical terminologies, the word embeddings trained on Google News have the worst performance. However, the word embeddings trained on GloVe are close to those trained on EHR with 0.02 difference on F1 score without statistical significance (p<0.01). This experiment shows that word embeddings trained on a local corpus have the best performance for a local task but those trained on an external Wikipedia corpus also have comparable performance.
TABLE V:
Results of the institutional fracture extraction task using word embeddings trained from four different corpora. The asterisk indicates that the difference between word embeddings trained on EHR and those on other resources is statistically significant using t-test (p<0.01).
| Metric | baseline | EHR | MedLit | GloVe | Google News |
|---|---|---|---|---|---|
| Precision | 0.612 | 0.974* | 0.946 | 0.951 | 0.809 |
| Recall | 0.612 | 0.972* | 0.943 | 0.950 | 0.856 |
| F1 score | 0.609 | 0.972* | 0.942 | 0.950 | 0.823 |
Secondly, we tested the word embeddings on the 2006 i2b2 (Informatics for Integrating Biology to the Bedside) smoking status extraction shared task [48]. Participants of this task were asked to develop automatic NLP systems to determine the smoking status of patients from their discharge records in Partners HealthCare. For each discharge record, an automatic system should be able to categorize it into five pre-determined smoking status categories: past smoker, current smoker, smoker, non-smoker, and unknown, where a past and a current smoker are distinguished based on temporal expressions in the patient’s medical records. The dataset contains a total of 389 documents, including 35 documents of current smoker, 66 of non-smoker, 36 of past smoker, and 252 of unknown. The settings of this shared task are identical to those of the previous local institutional IE task: SVM was utilized as the machine learning model; 10-fold cross validation was performed; term frequency features were used as input in the baseline; and the means of precision, recall and F1 scores were obtained as metrics.
The experimental results are shown in Table VI. First, it is obvious that the word embedding features perform better than term frequency features due to the semantics embedded in word embeddings, which is consistent with the previous local institutional IE task. The word embeddings trained on EHR produced the best performance with a F1 score of 0.900. The reason might be that the smoking dataset has the similar sublanguage characteristics as the EHR corpus. This result indicates that the effective word embeddings can be shared across institutions for clinical IE tasks. Another interesting observation is that the performance of word embeddings trained on Google News is close to that trained on EHR corpus with a comparable F1 score and a better recall. The performance difference is not statistically significant (p<0.01). This implies that word embeddings trained on a public dataset may not be definitely inferior to these trained on a medically specific dataset for a medical IE task. The likely cause is that the terminology used in the smoking status extraction task also appears frequently in the news, such as medications and advice for smokers.
TABLE VI:
Results of the i2b2 2006 smoking status extraction task using word embeddings trained from four different corpora.
| Metric | baseline | EHR | MedLit | GloVe | Google News |
|---|---|---|---|---|---|
| Precision | 0.692 | 0.919 | 0.878 | 0.893 | 0.910 |
| Recall | 0.486 | 0.903 | 0.871 | 0.889 | 0.905 |
| F1 score | 0.539 | 0.900 | 0.867 | 0.884 | 0.897 |
2). Biomedical Information Retrieval:
To evaluate word embeddings for biomedical IR, we utilized the dataset provided by the Text REtreival Conference 2016 Clinical Decision Support (TREC 2016 CDS) track. The TREC 2016 CDS track focuses on biomedical literature retrieval that helps physicians find the precise literature information and make the best clinical decision at the point of care [49]. The query topics were generated from EHRs in the MIMIC-III dataset [50]. Those topics were categorized into three most common types, Diagnosis, Test and Treatment, according to physicians’ information needs, and 10 topics were provided for each type. Each topic is comprised of a note field (admission note), a description field (jargons and clinical abbreviations are removed) and a summary field (simplified version of the description). The participants were required to use only one of these three fields in their submissions and at least one submission must utilize the note field. Submitted systems should retrieve relevant biomedical articles from a given PMC article collection for each given query topic to answer three corresponding clinical questions: What is the patient’s diagnosis? What tests should the patient receive? How should the patient be treated?. Each IR system can retrieve up to 1000 documents per query.
In order to make the comparison as fair as possible, we first implemented a simple IR system as the baseline system using the original queries following the study in [22], and then employed the simplest query expansion method using the word embeddings. We used the summary field in the query, removed the stop words, and expanded each of the left query terms with five most similar terms from word embeddings. Take the query “A 78 year old male presents with stools and melena” as an example, the term “male” was expanded by “female gentleman lady caucasian man”, “stools” by “stooling liquidy voluminous semiformed tenesmus”, and “melena” by “hematemesis hematochezia melana brbpr hematemasis”. We assigned weight 0.8 to the original query and 0.2 to the expanded query. Indri [51] was utilized as our indexing and retrieval tool. The preprocessing for the corpus included stopword removal and Porter stemming. The stopword list was based on the MedLit stopwords 14. The article-id, title, abstract, and body fields of each document in the corpus were indexed. Language models with two-stage smoothing [52] was used to obtain all the retrieval results. Four official metrics, namely Inferred Normalized Discounted Cumulated Gain (infNDCG)[53], Inferred Average Precision (infAP)[53], Precision at 10 (P@10), and Mean Average Precision (MAP), were utilized to measure the IR performance. infNDCG measures the document ranking quality of an IR system; infAP measures the retrieval effectiveness given incomplete judgments for an IR system; P@10 is the number of relevance documents among the top 10; and MAP is the mean of the average precision scores for each query in a set of queries.
Table VII lists the results of using the word embeddings trained from different resources for query expansion on the TREC 2016 CDS track. It is interesting that the word embeddings based query expansion method failed to improve the retrieval performance, and even worsened the performance when infAP and MAP were metrics. By comparing the retrieval performance, we observe that EHR and MedLit perform slight better than GloVe and Google News without statistical significance (p<0.01). This result implies that applying word embeddings trained from different resources has no significant improvement for the biomedical IR task.
TABLE VII:
Information retrieval results of using word embeddings trained from four different corpora for query expansion on the TREC 2016 CDS track.
| Metric | baseline | EHR | MedLit | GloVe | Google News |
|---|---|---|---|---|---|
| infNDCG | 0.249 | 0.250 | 0.249 | 0.249 | 0.238 |
| infAP | 0.058 | 0.056 | 0.055 | 0.051 | 0.052 |
| P@10 | 0.247 | 0.243 | 0.248 | 0.233 | 0.243 |
| MAP | 0.067 | 0.063 | 0.065 | 0.063 | 0.059 |
3). Relation Extraction:
For the RE task, we considered drug-drug interaction (DDI) extraction, which is a specific RE task in the biomedical domain. DDI is an unexpected change in a drug’s effect on the human body when the drug and a second drug are co-prescribed and taken together. Automatically extracting DDI information from literature is a challenging and important research topic since the volume of the published literature grows rapidly and greatly. In this experiment, we evaluated the word embeddings on the DDIExtraction 2013 challenge corpus [54]. The dataset for DDIExtraction 2013 was composed of sentences describing DDIs from the DrugBank database and MedLine abstracts. In this dataset, drug entities and DDIs were annotated at the sentence level and each sentence could contain two or more drugs. An RE system should be able to automatically extract DDI drug pairs from a sentence. We exploited the baseline system introduced in [19] where features include words and word bigrams with binary values indicating their presence or absence in a sentence, cosine similarity between centroid vector of each class and the instance, negation (three features indicating negation before the first main drug, between two main drugs, and after the two main drugs). We concatenated the word embeddings to the baseline features and tested the performance. Since Random Forest [55] has the best performance in [19], we utilized it as the classifier with 10-fold cross validation.
Table VIII shows the F1 scores of Random Forest using word embeddings trained from different resourceson the DDIExtraction 2013 challenge. We can see that the overall performance of word embeddings trained on Google News is the best. The reason is that the semantics of general English terms in the context of drug mentions are more important for determining the drug interactions. For example, in the sentence “Acarbose may interact with metformin”, the term “interact” is crucial to classify the relation. Since these crucial terms are generally not medical terminology, word embeddings trained on Google News where the corpus represents general English are able to capture the semantics of these terms. However, Google News outperformed other resources but not conclusive in statistical significance using t-test (p<0.01). Another interesting observation is that word embeddings trained from MedLit have the best performance for the DrugBank corpus while these from Google News perform the best for the MedLine corpus. Though MedLine abstracts are from MedLit articles, this result shows that word embeddings trained from the same corpus are not necessarily superior to other embeddings.
TABLE VIII:
F1 scores of the DDIExtraction 2013 challenge using word embeddings trained from four different corpora.
| Category | baseline | EHR | MedLit | GloVe | Google News |
|---|---|---|---|---|---|
| DrugBank (5265 pairs) | 0.590 | 0.708 | 0.715 | 0.714 | 0.705 |
| MedLine (451 pairs) | 0.690 | 0.696 | 0.690 | 0.699 | 0.708 |
| Total (5716 pairs) | 0.760 | 0.789 | 0.788 | 0.787 | 0.790 |
VII. Conclusion and Discussion
In this study, we provide an empirical evaluation of word embeddings trained from four different corpora, namely clinical notes, biomedical publications, Wikipedia, and news. We performed the evaluation qualitatively and quantitatively. For the qualitative evaluation, we selected a set of medical words and impressionistically evaluated the five most similar medical words. We then analyzed word embeddings through the visualization of those word embeddings. We conducted both extrinsic and intrinsic evaluation for the quantitative evaluation. The intrinsic evaluation directly tested semantic relationships between medical words using four published datasets for measuring semantic similarity between medical terms while the extrinsic evaluation evaluated word embeddings in three downstream biomedical NLP applications, i.e., clinical IE, biomedical IR, and RE.
Based on the evaluation results, we can draw the following conclusions. First, the word embeddings trained on EHR and MedLit can capture the semantics of medical terms better than those trained on GloVe and Google News, and find more relevant similar medical terms. However, EHR finds similar terms vis a vis clinical language while MedLit contains more medical terminology used in medical articles, and finds similar words mostly from a medical research perspective. second, the medical semantic similarity captured by the word embeddings trained on EHR and MedLit are closer to human experts’ judgments, compared to these trained on GloVe and Google News. Third, there does not exist a consistent global ranking of word embeddings for the downstream biomedical NLP applications. However, adding word embeddings as extra features will improve results on most downstream tasks. Finally, word embeddings trained from biomedical domain corpora do not necessarily have better performance than those trained on other general domain corpora. That is, there might be no significant difference when word embeddings trained from an out-domain corpus are employed for a biomedical NLP application. However, the performance of word embeddings trained from a local institutional corpus might perform better for local institutional NLP tasks.
Our experiments implicitly show that applying word embeddings trained from corpora in a general domain, such as Wikipedia and news, is not significantly inferior to applying those obtained from biomedical or clinical domain, which is usually difficult to access due to privacy. This result is consistent with but more general than the conclusion drawn in [33]. Thus, a lack of access to a domain-specific corpus is not necessarily a barrier for the use of word embeddings in practical implementations.
As a future direction, we would like to evaluate word embeddings on more downstream biomedical NLP applications, such as medial named entity recognition and clinical note summarization. We will investigate whether word embeddings trained from different resources represent language characteristics differently for a corpus, such as term frequency and medical concepts. We also want to assess word embeddings across health care institutions using different EHR systems and investigate how sublanguage characteristics affect the portability of word embeddings. Moreover, we want to apply clustering methods on word embeddings and compare the word-level and concept-level difference between clusters of medical terms.
There are a few limitations in this study. First, we only examined the word embeddings trained on the EHR from Mayo Clinic, which might have introduced bias into the conclusion as the EHR quality may vary by institutions. However, it is challenging to obtain word embeddings trained on EHR data from multiple sites. We are currently exploring the use of privacy-preserving techniques for obtaining embeddings from multiple sites leveraging our prior work [56] to have more generalizable embeddings. Second, we tested only two widely used public pre-trained word embeddings. There are a number of word embeddings publicly available15. Third, the generalizability of the results for the biomedical IR and RE tasks may be questionable since we only used one shared task dataset for each task to evaluate the word embeddings.
Supplementary Material
Highlights (for review).
Word embeddings trained from four textual resources, clinical notes, biomedical publications, Wikipedia, and news, were empirically evaluated for the biomedical natural language processing.
The word embeddings trained on clinical notes and biomedical publications can capture the semantics of medical terms better han those trained on Wikipedia and news.
There does not exist a consistent global ranking of word embeddings for all downstream biomedical natural language processing applications.
The word embeddings trained on biomedical domain corpora do not necessarily have better performance than those trained on general domain corpora for the downstream biomedical natural language processing tasks.
VIII. Acknowledgement
This work has been supported by the National Institute of Health (NIH) grants R01LM011934, R01GM102282, and U01TR002062.
Appendix A. Intrinsic evaluation of word embeddings with different dimensions.
Table IX shows the intrinsic evaluation results of word embeddings using different dimensions.
TABLE IX:
Pearson correlation coefficient between the similarity scores computed by word embeddings using different dimensions (d) and those assigned by human experts on four datasets.
| Dataset | EHR (d=20) |
EHR (d=60) |
EHR (d=100) |
MedLit (d=20) |
MedLit (d=60) |
MedLit (d=100) |
GloVe (d=50) |
GloVe (d=100) |
Google News (d=300) |
|---|---|---|---|---|---|---|---|---|---|
| Pedersen’s | 0.390 | 0.542 | 0.632 | 0.304 | 0.569 | 0.363 | 0.334 | 0.403 | 0.357 |
| Hliaoutakis’s | 0.333 | 0.417 | 0.482 | 0.117 | 0.311 | 0.164 | 0.159 | 0.247 | 0.243 |
| MayoSRS | 0.192 | 0.296 | 0.412 | 0.177 | 0.300 | 0.154 | 0.001 | 0.082 | 0.084 |
| UMNSRS | 0.310 | 0.375 | 0.440 | 0.295 | 0.404 | 0.396 | 0.190 | 0.177 | 0.154 |
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- [1].Mikolov T, Yih W.-t., and Zweig G, “Linguistic regularities in continuous space word representations.” in hlt-Naacl, vol. 13, 2013, pp. 746–751. [Google Scholar]
- [2].Liu F, Chen J, Jagannatha A, and Yu H, “Learning for biomedical information extraction: Methodological review of recent advances,” arXiv preprint arXiv:1606.07993, 2016. [Google Scholar]
- [3].Levy O and Goldberg Y, “Dependency-based word embeddings.” in ACL (2), 2014, pp. 302–308. [Google Scholar]
- [4].Wang Y, Wang L, Rastegar-Mojarad M, Moon S, Shen F, Afzal N, Liu S, Zeng Y, Mehrabi S, Sohn S et al. , “Clinical information extraction applications: A literature review,” Journal of biomedical informatics, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Zeng D, Liu K, Lai S, Zhou G, Zhao J et al. , “Relation classification via convolutional deep neural network.” in COLING, 2014, pp. 2335–2344. [Google Scholar]
- [6].Nguyen TH and Grishman R, “Employing word representations and regularization for domain adaptation of relation extraction.” in ACL (2), 2014, pp. 68–74. [Google Scholar]
- [7].Ganguly D, Roy D, Mitra M, and Jones GJ, “Word embedding based generalized language model for information retrieval,” in Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval ACM, 2015, pp. 795–798. [Google Scholar]
- [8].Tang D, Wei F, Yang N, Zhou M, Liu T, and Qin B, “Learning sentiment-specific word embedding for twitter sentiment classification.” in ACL (1), 2014, pp. 1555–1565. [Google Scholar]
- [9].Maas AL, Daly RE, Pham PT, Huang D, Ng AY, and Potts C, “Learning word vectors for sentiment analysis,” in Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1 Association for Computational Linguistics, 2011, pp. 142–150. [Google Scholar]
- [10].Ren M, Kiros R, and Zemel R, “Exploring models and data for image question answering,” in Advances in neural information processing systems, 2015, pp. 2953–2961. [Google Scholar]
- [11].Dong L, Wei F, Zhou M, and Xu K, “Question answering over freebase with multi-column convolutional neural networks.” in ACL (1), 2015, pp. 260–269. [Google Scholar]
- [12].Yogatama D, Liu F, and Smith NA, “Extractive summarization by maximizing semantic volume.” in EMNLP, 2015, pp. 1961–1966. [Google Scholar]
- [13].Rush AM, Chopra S, and Weston J, “A neural attention model for abstractive sentence summarization,” arXiv preprint arXiv:1509.00685, 2015. [Google Scholar]
- [14].Tang B, Cao H, Wang X, Chen Q, and Xu H, “Evaluating word representation features in biomedical named entity recognition tasks,” BioMed research international, vol. 2014, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].Liu S, Tang B, Chen Q, and Wang X, “Effects of semantic features on machine learning-based drug name recognition systems: word embeddings vs. manually constructed dictionaries,” Information, vol. 6, no. 4, pp. 848–865, 2015. [Google Scholar]
- [16].Jagannatha AN, Chen J, and Yu H, “Mining and ranking biomedical synonym candidates from wikipedia,” in Proceedings of the Sixth International Workshop on Health Text Mining and Information Analysis (Louhi), 2015, pp. 142–151. [Google Scholar]
- [17].Jiang Z, Jin L, Li L, Qin M, Qu C, Zheng J, and Huang D, “A crd-wel system for chemical-disease relations extraction,” in The fifth BioCreative challenge evaluation workshop, 2015, pp. 317–326. [Google Scholar]
- [18].Liu S, Tang B, Chen Q, and Wang X, “Drug-drug interaction extraction via convolutional neural networks,” Computational and mathematical methods in medicine, vol. 2016, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Wang Y, Liu S, Rastegar-Mojarad M, Wang L, Shen F, Liu F, and Liu H, “Dependency embeddings and amr embeddings for drug-drug interaction extraction from biomedical texts,” in Proceedings of the 8th ACM Conference on Bioinformatics, Computational Biology, and Health Informatics ACM, 2017. [Google Scholar]
- [20].Jiang Z, Li L, and Huang D, “A general protein-protein interaction extraction architecture based on word representation and feature selection,” International Journal of Data Mining and Bioinformatics, vol. 14, no. 3, pp. 276–291, 2016. [Google Scholar]
- [21].Jo S-H and Lee K-S, “Cbnu at trec 2016 clinical decision support track,” in Text REtrieval Conference (TREC 2016), 2016. [Google Scholar]
- [22].Wang Y, Rastegar-Mojarad M, Elayavilli RK, Liu S, and Liu H, “An ensemble model of clinical information extraction and information retrieval for clinical decision support.” in TREC, 2016. [Google Scholar]
- [23].Wu Y, Xu J, Zhang Y, and Xu H, “Clinical abbreviation disambiguation using neural word embeddings,” in Proceedings of the 2015 Workshop on Biomedical Natural Language Processing (BioNLP), 2015, pp. 171–176. [Google Scholar]
- [24].Gurulingappa H, Toldo L, Schepers C, Bauer A, and Megaro G, “Semi-supervised information retrieval system for clinical decision support.” in TREC, 2016. [Google Scholar]
- [25].Diaz F, Mitra B, and Craswell N, “Query expansion with locally-trained word embeddings,” arXiv preprint arXiv:1605.07891, 2016. [Google Scholar]
- [26].Shen F and Lee Y, “Knowledge discovery from biomedical ontologies in cross domains,” PloS one, vol. 11, no. 8, p. e0160005, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [27].Shen F, Liu H, Sohn S, Larson DW, and Lee Y, “Predicate oriented pattern analysis for biomedical knowledge discovery,” Intelligent Information Management, vol. 8, no. 03, pp. 66–85, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [28].Shen F, Liu H, Sohn S, Larson D, and Lee Y, “Bmqgen: Biomedical query generator for knowledge discovery,” Bioinformatics and Biomedicine (BIBM), 2015 IEEE International Conference on, pp. 1092–1097, 2015. [Google Scholar]
- [29].Pedersen T, Pakhomov SV, Patwardhan S, and Chute CG, “Measures of semantic similarity and relatedness in the biomedical domain,” Journal of biomedical informatics, vol. 40, no. 3, pp. 288–299, 2007. [DOI] [PubMed] [Google Scholar]
- [30].Hliaoutakis A, “Semantic similarity measures in mesh ontology and their application to information retrieval on medline,” Master’s thesis, 2005. [Google Scholar]
- [31].Pakhomov SV, Pedersen T, McInnes B, Melton GB, Ruggieri A, and Chute CG, “Towards a framework for developing semantic relatedness reference standards,” Journal of biomedical informatics, vol. 44, no. 2, pp. 251–265, 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [32].Pakhomov S, McInnes B, Adam T, Liu Y, Pedersen T, and Melton GB, “Semantic similarity and relatedness between clinical terms: an experimental study,” in AMIA annual symposium proceedings, vol. 2010 American Medical Informatics Association, 2010, p. 572. [PMC free article] [PubMed] [Google Scholar]
- [33].Pakhomov SV, Finley G, McEwan R, Wang Y, and Melton GB, “Corpus domain effects on distributional semantic modeling of medical terms,” Bioinformatics, vol. 32, no. 23, pp. 3635–3644, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [34].Baroni M, Dinu G, and Kruszewski G, “Don’t count, predict! a systematic comparison of context-counting vs. context-predicting semantic vectors.” in ACL (1), 2014, pp. 238–247. [Google Scholar]
- [35].Schnabel T, Labutov I, Mimno DM, and Joachims T, “Evaluation methods for unsupervised word embeddings.” in EMNLP, 2015, pp. 298–307. [Google Scholar]
- [36].Collobert R, Weston J, Bottou L, Karlen M, Kavukcuoglu K, and Kuksa P, “Natural language processing (almost) from scratch,” Journal of Machine Learning Research, vol. 12, no. August, pp. 2493–2537, 2011. [Google Scholar]
- [37].Lebret R and Collobert R, “Word emdeddings through hellinger pca,” arXiv preprint arXiv:1312.5542, 2013. [Google Scholar]
- [38].Pennington J, Socher R, and Manning C, “Glove: Global vectors for word representation,” in Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), 2014, pp. 1532–1543. [Google Scholar]
- [39].Dhillon P, Rodu J, Foster D, and Ungar L, “Two step cca: A new spectral method for estimating vector models of words,” arXiv preprint arXiv:1206.6403, 2012. [Google Scholar]
- [40].Li P, Hastie TJ, and Church KW, “Very sparse random projections,” in Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining ACM, 2006, pp. 287–296. [Google Scholar]
- [41].Ghannay S, Favre B, Esteve Y, and Camelin N, “Word embedding evaluation and combination.” in LREC, 2016. [Google Scholar]
- [42].Schwenk H, “Cslm-a modular open-source continuous space language modeling toolkit.” in INTERSPEECH, 2013, pp. 1198–1202. [Google Scholar]
- [43].Nayak N, Angeli G, and Manning CD, “Evaluating word embeddings using a representative suite of practical tasks,” ACL 2016, p. 19, 2016. [Google Scholar]
- [44].Wang Y, Wang L, Rastegar-Mojarad M, Liu S, Shen F, and Liu H, “Systematic analysis of free-text family history in electronic health record,” AMIA Summits on Translational Science Proceedings, vol. 2017, p. 104, 2017. [PMC free article] [PubMed] [Google Scholar]
- [45].Maaten L. v. d. and Hinton G, “Visualizing data using t-sne,” Journal of Machine Learning Research, vol. 9, no. November, pp. 2579–2605, 2008. [Google Scholar]
- [46].Bojanowski P, Grave E, Joulin A, and Mikolov T, “Enriching word vectors with subword information,” arXiv preprint arXiv:1607.04606, 2016. [Google Scholar]
- [47].Wang Y, Atkinson E, Amin S, and Liu H, “A distant supervision paradigm for clinical information extraction,” 2018. [Google Scholar]
- [48].Uzuner Ö, Goldstein I, Luo Y, and Kohane I, “Identifying patient smoking status from medical discharge records,” Journal of the American Medical Informatics Association, vol. 15, no. 1, pp. 14–24, 2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [49].Roberts K, Demner-Fushman D, Voorhees EM, and Hersh WR, “Overview of the trec 2016 clinical decision support track.” in TREC, 2016. [Google Scholar]
- [50].Johnson AE, Pollard TJ, Shen L, Lehman L.-w. H., Feng M, Ghassemi M, Moody B, Szolovits P, Celi LA, and Mark RG, “Mimic-iii, a freely accessible critical care database,” Scientific data, vol. 3, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [51].Strohman T, Metzler D, Turtle H, and Croft WB, “Indri: A language model-based search engine for complex queries,” in Proceedings of the International Conference on Intelligent Analysis, vol. 2, no. 6 Citeseer, 2005, pp. 2–6. [Google Scholar]
- [52].Zhai C and Lafferty J, “Two-stage language models for information retrieval,” in Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval ACM, 2002, pp. 49–56. [Google Scholar]
- [53].Yilmaz E, Kanoulas E, and Aslam JA, “A simple and efficient sampling method for estimating ap and ndcg,” in Proceedings of the 31st annual international ACM SIGIR conference on Research and development in information retrieval ACM, 2008, pp. 603–610. [Google Scholar]
- [54].Segura Bedmar I, Martínez P, and Herrero Zazo M, “Semeval-2013 task 9: Extraction of drug-drug interactions from biomedical texts (ddiextraction 2013).” Association for Computational Linguistics, 2013. [Google Scholar]
- [55].Breiman L, “Random forests,” Machine learning, vol. 45, no. 1, pp. 5–32, 2001. [Google Scholar]
- [56].Huang Y, Lee J, Wang S, Sun J, Liu H, and Jiang X, “Privacy-preserving predictive modeling: Harmonization of contextual embeddings from different sources,” JMIR medical informatics, vol. 6, no. 2, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.