

Abstract
The majority of countries in Africa and nearly one-third of all countries require mortality models to infer the complete age schedules of mortality that are required to conduct population estimates, projections/forecasts, and other tasks in demography and epidemiology. Models that relate child mortality to mortality at other ages are important because almost all countries have measures of child mortality. A general, a parameterizable component model of mortality is defined using the singular value decomposition (SVD-Comp) and calibrated to the relationship between child or child/adult mortality and mortality at other ages in the observed mortality schedules of the Human Mortality Database. Cross-validation is used to validate the model, and the predictive performance of the model is compared with that of the log-quadratic (Log-Quad) model, which is designed to do the same thing. Prediction and cross-validation tests indicate that the child mortality–calibrated SVD-Comp is able to accurately represent the observed mortality schedules in the Human Mortality Database, is robust to the selection of mortality schedules used for calibration, and performs better than the Log-Quad model. The child mortality–calibrated SVD-Comp can be used where and when child mortality is available but mortality at other ages is unknown.
Keywords: Mortality, Model, SVD, HMD, SVD-Comp
Introduction
Complete age-specific mortality schedules are necessary inputs to a wide variety of formal demographic and epidemiological methods. A key example is the biennial World Population Prospects (WPP) produced by the United Nations Population Division (United Nations, Department of Economic and Social Affairs, Population Division 2015b). These are generally considered the reference population indicators and are widely used by other domestic and international agencies as inputs to estimation and modeling exercises. The WPP contains estimates of time-, sex-, and age-specific mortality, fertility, and population size from 1950 to the present and forecasts of the same quantities to 2100 for all countries of the world. Consequently, each WPP update must contain full age-specific mortality schedules covering the period 1950–2100.
Some countries in the developing world, particularly in Africa, do not yet have civil registration and vital statistic systems that function well enough to report accurately on either fertility or mortality. Focusing on mortality, Table 1 displays the number of countries or world regions for which no information is available on either child mortality or adult mortality, with Africa broken out. Because of the exhaustive coverage of household surveys investigating fertility and matemal/child health, essentially the whole world has at least some recent information on child mortality (Li 2015). In contrast, 50 countries around the world with a total population of nearly 1 billion people have no information on adult mortality, with the bulk of those in Africa—33 countries with a total population of 666 million people.
Table 1.
Countries or regions with no information on either child or adult mortality
| Child Mortality |
Adult Mortality |
|||||
|---|---|---|---|---|---|---|
| Regions | Population (millions) | Percentage of Population | Regions | Population (millions) | Percentage of Population | |
| World | 1 | 1 | 0.0 | 50 | 973 | 13.2 |
| Africa | 1 | 1 | 0.0 | 33 | 666 | 56.1 |
Note: U.N. countries and regions that do not have information on either child or adult mortality for the 2015 update of the World Population Prospects. The table shows the population and fraction of the total population for which information is missing.
Source: United Nations, Department of Economic and Social Affairs, Population Division (2015c: tables I.1b and I.1c).
Mortality models are used to solve this problem and produce full age schedules of mortality. Table 2 describes the number of countries or world regions for which the U.N. Population Division must use mortality models of some kind to produce either estimates of life expectancy at birth e0 or full age schedules of mortality. Most African countries require mortality models for both, and 38.6 % of countries globally require a model for e0 and 32.6 % for age-specific mortality.
Table 2.
Countries and regions where mortality models are necessary to estimate life expectancy at birth (e0) or age-specific mortality rates
|
e0 |
ASMR |
||||
|---|---|---|---|---|---|
| Countries/Regions | Count | % | Count | % | |
| World | 233 | 90 | 38.6 | 76 | 32.6 |
| Africa | 58 | 50 | 86.2 | 50 | 86.2 |
Note: Counts of the number of U.N. countries and areas where mortality models were used to generate estimates of e0 or age-specific mortality rates for the 2015 update of the World Population Prospects.
The standard approach to generating complete age schedules of mortality for countries and areas with insufficient data is to take advantage of the fact that they do have information on child mortality. Typically, model life tables are used to extrapolate full mortality schedules from 5q0—this is what the U.N. Population Division does (making heavy use of the traditional Coale and Demeny (1966) model life tables), and the Institute for Health Metrics and Evaluation (IHME) uses variations on the modified logit (Mod-Logit) model (Murray et al. 2003) to do the same.
The commonly used model life table systems—regional model life tables and stable populations (Coale and Demeny 1966), life tables for developing countries (United Nations 1982), modified logit life table system (Mod-Logit) (Murray et al. 2003; Wang et al. 2013), and flexible two-dimensional mortality model (Log-Quad) (Wilmoth et al. 2012)—combine a specific model structure and defined variable parameters with a set of fixed parameters that summarize the relationships between mortality at different ages in a set of observed life tables. All are empirical models in the sense that they summarize observed mortality and use that summary to produce predicted mortality schedules that are consistent with observed mortality. They come in both regional and continuous forms. The regional models identify and replicate commonly observed mortality patterns associated with geographic regions (and de facto periods) and allow mortality to vary continuously within each region-specific pattern. In contrast, the continuous models generate mortality patterns that vary smoothly. Both approaches are essentially two-parameter models. The regional models first identify a discrete region and then use effectively continuously varying life expectancy within each region to adjust the level of region-specific mortality. The continuous models have two continuously varying parameters (e.g., life expectancy, child mortality, or adult mortality).
Murray et al. (2003) enumerated three characteristics required of mortality models: (1) simplicity and ease of use; (2) comprehensive representation of the true variability in sex- and age-specific mortality observed in real populations; and (3) validity that is well quantified by comparing age schedules of mortality predicted by the model with corresponding observed life tables. To those I would add (1) generality with respect to the underlying model structure; (2) flexibility in terms of input parameters; and (3) an ability to handle a wide range of age groups, including very narrow, without having to fundamentally alter the structure of the model.
This work defines and describes a new SVD component–based mortality modeling framework that satisfies all of those requirements. The SVD-component framework provides a general, flexible way to model any demographic age schedule as a function of covariates or predictors that are related to age-specific variation in the age schedule. Here, the SVD-component framework is demonstrated by creating a mortality model that predicts single-year-of-age mortality schedules using either 5q0 or both 5q0 and 45q15 as predictors, similar to both the Mod-Logit and Log-Quad models. The resulting model can be used to produce single-year-of-age mortality schedules from 5q0 alone that are consistent with observed mortality schedules, and this could be useful for those like the U.N. Population Division who must manipulate full age schedules of mortality but have observed values only for 5q0. The resulting SVD-component model performs better than the current state-of-the-art two-parameter model (Log-Quad), provides predictions by single year of age, and is easily extensible to include additional predictors beyond child and adult mortality.
Mortality Models
Traditional model life tables (e.g., Coale and Demeny 1966; Ledermann 1969; Murray et al. 2003; United Nations, Department of Economic and Social Affairs, Population Division 1955, 1982; Wang et al. 2013; Wilmoth et al. 2012) take an inductive, empirically driven approach to identify and parsimoniously express the regularity of mortality with age based on observed relationships in large collections of high-quality life tables. Some fertility models (e.g., Coale and Trussell 1974; Lee 1993) do the same. An alternative, sometimes deductive approach, can be found in the wide variety of parametric or functional-form mortality models (e.g., Gompertz 1825; Heligman and Pollard 1980; Li and Anderson 2009; Makeham 1860) that define age-specific measures of mortality in an analytical form, sometimes with interpretable parameters. Brass (1971) developed a new approach with his two-parameter relational model that has been extended and refined in many ways, (for example, Murray et al. 2003; Zaba 1979). More recently, the Log-Quad model of Wilmoth et al. (2012) combines empirical and functional-form approaches to mortality models.
Population forecasting has motivated another important family of related mortality models. Forecasting generates many iterations of age-specific mortality and fertility into the future, and those are usually based on a summary of the corresponding age-specific mortality and fertility in the past. Hence, there is an immediate need to represent full age schedules and their dynamics compactly. This has led to the widespread use of dimension-reduction or data-compression techniques to reduce the dimensionality of the problem so that only a few parameters are necessary to represent age schedules and their dynamics. Ledermann and Breas (1959) appear to have been the first to use principal components analysis (PCA) to summarize age-specific mortality and generate model life tables, and many subsequent investigators refined this approach (e.g., Bourgeois-Pichat 1962,1990; Ledermann 1969; United Nations, Department of Economic and Social Affairs, Population Division 1982). Following the early use of PCA to build model life tables, PCA and related methods, such as the singular value decomposition (SVD) (e.g., Good 1969; Stewart 1993; Strang 2009), have been widely used and refined by forecasters to create time series models of mortality and fertility (e.g., Bozik and Bell 1987; Lee 1993; Lee and Carter 1992). See Bell (1997) for a comprehensive summary of this line of development in various fields, dominated by actuarial science and applications in forecasting.
The Lee-Carter approach (Lee 1993; Lee and Carter 1992) has been widely used in demography. The model as presented in Lee and Carter (1992) is
| (1) |
where x is age, t is time, m is a matrix of age- and time-specific mortality rates, a is the time-constant vector of mean (over columns of m) logged age-specific mortality rates through time, and b is the time-constant first left singular vector from an SVD decomposition of the matrix of residuals generated by subtracting a from each column of m.
Fitting the model requires three separate steps: (1) calculate ax; (2) calculate the residuals rxt = ln(mxt) – ax; and (3) extract the first left singular vector from the SVD of r and calculate a value of kt for each column of m that minimizes the elements εxt (kt, are essentially the elements of the first right singular vector multiplied by the first singular value of this SVD).
The Lee-Carter model contains two conceptually separate elements: (1) a one-parameter (i.e., kt) model of the full age-specific mortality or fertility schedule, and (2) a time series model for that parameter. The temporal sequence of values taken by kt is the focus of a stochastic time series model that is responsible for the temporal dynamics of the method, including the forecasts. Development of the time series model is previewed in earlier work by the authors (Carter and Lee 1986).
Putting aside the time series model for kt it becomes clear that the structure of the Lee-Carter model appears to be a simplified version of the more complex age-period-cohort mortality model conceived earlier by Wilmoth and elaborated over a number of years (Wilmoth 1990; Wilmoth and Caselli 1987; Wilmoth et al. 1989).1 Wilmoth’s model is designed to separate and identify age, period, and cohort effects in an age and time matrix of mortality rates. The basic structure is log(mx) = (mean model) + (residual model), with the final form
| (2) |
where i is age, j is period, k = (j – i) indexes cohorts, f is logged age- and period-specific mortality (log(m)), α is an age effect, β is a period effect, the is over a set of ρ rank-1 matrices from the SVD of the residuals remaining after the main effects are subtracted from f and θk is a residual cohort effect remaining after subtracting both the main effects and the SVD approximation of the first residuals from f. This form first appears in Wilmoth et al. (1989).
The model is fit in three steps, effectively explaining ever more nuanced variation in a sequence of residuals: (1) calculate αi, and βj such that they minimize the first residuals rij = fij – (αi + βj); (2) use the first ρ terms from the SVD of the matrix of residuals r to calculate the second residual ; and (3) calculate values for the elements of θk such that they minimize sij – θk = εij. The SVD or multiplicative term took shape over several publications (Wilmoth 1990; Wilmoth and Caselli 1987; Wilmoth et al. 1989) to eventually be the standard SVD form that appears in the final model, with the SVD first appearing in Wilmoth et al. (1989).
An examination of Eqs. (1) and (2) reveals the relationship between the Wilmoth and Lee-Carter models. Moving from Wilmoth to Lee-Carter requires the following steps: (1) remove the main period effect βj and the cohort effect θk, and (2) take only the first term in the SVD approximation of the first residual. The SVD term then becomes ϕ1γi1δj1 or, dropping the m = 1 index, γi(ϕδj). Replacing Wilmoth’s i and j with Lee-Carter’s x and t and letting k = ϕδ makes the equivalence clear. Lee and Carter (1992) acknowledged that their model has much in common with the Wilmoth model. They cited Wilmoth by way of explaining the SVD solution to calculating the elements of b, whereas this is just the simplest rank-1 form of the time-varying term in the model Wilmoth proposed.
Motivated by the U.N. Population Division’s work that sometimes involves predicting full age schedules of mortality from child (and adult) mortality (Li 2015), Wilmoth et al. (2012) presented another adaptation of the original Wilmoth model, this time to generate model life tables as a function of 5q0 or (5q0, 45ql5). Adopting the nomenclature from log-linear models, this log-quadratic (Log-Quad) model has the following form:
| (3) |
where x is age; m is age-specific mortality; a, b, and c are constant age-specific coefficients for the quadratic mean model; h is the input value of log(5q0); v is an age-specific correction factor; and k is a coefficient for v. Correction factor values vx are identified by calculating the SVD of the matrix of residuals that remain after the quadratic portion of the model is subtracted from life tables that are part of the Human Mortality Database (HMD) (University of California, Berkeley and Max Planck Institute for Demographic Research n.d.) and using the resulting first left singular vector as a starting point.2 Thus, the Log-Quad model has the now familiar mean/residual form of the original Wilmoth model, and the structure of the residual model is a one-term version of the SVD form originally proposed by Wilmoth et al. (1989). The Log-Quad’s contribution is an innovative new mean model that takes advantage of the empirically observed curvilinear relationship between child mortality and mortality at other ages. The Log-Quad model is elegant, simple, and parsimonious—one (5q0) or two (5q0 and k)3 parameters—and it performs well, accurately representing a wide range of life tables, including life tables with very low mortality, and generally outperforming all other model life tables (Wilmoth et al. 2012).
Other investigators have worked on a variety of matrix-summary approaches to characterize the variability in mortality rates, but none of their work has been as widely used as the Lee-Carter model. Working independently, Fosdick and Hoff (2012) developed an explicitly statistical separable factor analysis model to summarize mortality in the HMD, and at its core, this is similar to the SVD term in Wilmoth’s model. Also working independently, I developed a component model of mortality inspired by the use of matrix factorization methods and the fast Fourier transform in image compression (Clark 2001). The component model is a simple linear sum of independent, age-varying vectors (components) that, when combined with appropriate weights, can closely approximate age-specific mortality schedules. This model has the simple basic form
| (4) |
where m is a vector of age-specific mortality rates, ui, are a set of c vectors containing age-varying values identified in a set of observed mortality rates, wi are weights, and r is a vector of residuals. This is similar to Ledermann’s original use of factor analysis to build a system of model life tables based on factors resulting from a PCA decomposition of a matrix of age-specific mortality rates (Ledermann 1969; Ledermann and Breas 1959) and the PCA-based model underlying the U.N. model life tables (United Nations, Department of Economic and Social Affairs, Population Division 1982), both of which have the mean/residual structure of the Wilmoth models because they use PCA operating on a centered data cloud. The component model has been used to summarize mortality data from the INDEPTH Network using PCA-derived components (Clark 2001; Clark et al. 2009; INDEPTH Network 2002), similarly for the HMD (Clark and Sharrow 2011a,b), and more recently in work on small-area estimates of mortality (Alexander et al. 2017). This approach combines a simple linear model with PCA, SVD, or similar methods to concentrate information along a few dimensions; see Clark (2015) for a detailed discussion.
The component model is similar to the SVD-inspired first residual model term in Wilmoth’s Eq. (2). However, neither Wilmoth nor subsequent investigators identified or developed the relationship between the SVD decomposition of a matrix of mortality rates and the columnwise weighted-sum model in Eq. (4). A key conceptual difference between the two approaches is that Eq. (4) does not have a mean model. Consequently, the factors identified by the SVD model everything, not just the residual as in all the Wilmoth-inspired models. The first component, u1, is effectively the mean age-specific mortality schedule, and its weight reflects the overall level of mortality. The remaining components, ui for i > 1, define deviations from the average age pattern, independent of level. All this follows directly from the properties of the SVD and a substantive interpretation of both the left and right singular vectors when applied to demographic age schedules (Clark 2015). Additionally, the weights are viewed as continuously varying parameters that can be the object or output of additional models—for example, clustered using objective clustering methods to identify groups of similar age schedules, estimation using either traditional or Bayesian methods, or predicted from covariates that vary systematically with age schedules, as this article demonstrates.
Finally, along with other researchers, I applied the component model to HIV-related mortality in countries with large HIV epidemics (Sharrow et al. 2014). In that article, we demonstrated that the weights in Eq. (4) vary systematically with HIV prevalence. We took advantage of that fact to build a model that predicts three weights as a function of HIV prevalence and then predicts mortality age schedules from the predicted weights using Eq. (4). The resulting HIV-calibrated component model uses the weights as a link between HIV prevalence and full age schedules of mortality.
In this article I describe how the SVD can be used to develop a general modeling framework for demographic age schedules. This framework has the important advantages of being (1) straightforward and easy to understand and use; (2) general and applicable to any demographic age schedule; (3) able to incorporate covariates or predictors in a unified way; and (4) able to handle age groups of any granularity (e.g., one year or five years) in the same way. I demonstrate this framework by creating and validating an accurate one- or two-parameter mortality model based on age-patterns of mortality contained in the HMD.
Data
Human Mortality Database Life Tables
The HMD contains rigorously cleaned, checked, and validated information on deaths and exposure from a number of mainly developed countries “where death registration and census data are virtually complete.” The data are aggregated and presented in a wide variety of formats. The objective of this analysis is to capture and characterize as much variability in age-specific mortality as possible, and consequently I use the 1 × 1 HMD life tables for each sex. Those provide all columns of a standard life table for single calendar years by single year of age from 0 to 110+. Each country provides data for different historical periods, and some countries are subdivided into more specific subpopulations. In the latter situation, a national population life table is typically provided that aggregates across the subgroups. Both the national and subgroup populations are included in this analysis to maximize the variability in age-specific mortality schedules in the overall data set. A few of the 1 × 1 life tables from the HMD contain problems: (1) the life tables for Belgium 1914–1918 for both sexes contain no data; and (2) the female life tables for Iceland in 1852 and the Maori Population of New Zealand in 1949, 1956, and 1959 display implausible mortality at older ages. All those life tables are excluded. Table 3 contains an organized list of the life tables included in this analysis: 4,610 life tables for each sex and 9,220 in total. The HMD data used in this analysis were downloaded on Friday November 2, 2018 from the HMD web site (http://www.mortality.org/hmd/zip/all_hmd/hmd_statistics.zip).
Table 3.
Life tables
| Country/Population | Abbreviation | Years Covered | Total Life Tables |
|---|---|---|---|
| Australia | AUS | 1921–2014 | 94 |
| Austria | AUT | 1947–2017 | 71 |
| Belgium | BEL | 1841–1913 | 73 |
| Belgium | BEL | 1919–2015 | 97 |
| Bulgaria | BGR | 1947–2010 | 64 |
| Belarus | BLR | 1959–2016 | 58 |
| Canada | CAN | 1921–2011 | 91 |
| Switzerland | CHE | 1876–2016 | 141 |
| Chile | CHL | 1992–2008 | 17 |
| Czechia | CZE | 1950–2016 | 67 |
| East Germany | DEUTE | 1956–2015 | 60 |
| Germany | DEUTNP | 1990–2015 | 26 |
| West Germany | DEUTW | 1956–2015 | 60 |
| Denmark | DNK | 1835–2016 | 182 |
| Spain | ESP | 1908–2016 | 109 |
| Estonia | EST | 1959–2017 | 59 |
| Finland | FIN | 1878–2015 | 138 |
| France, Civilian Population | FRACNP | 1816–2016 | 201 |
| France, Total Population | FRATNP | 1816–2016 | 201 |
| England and Wales, Civilian National Population | GBRCENW | 1841–2016 | 176 |
| England and Wales, Total Population | GBRTENW | 1841–2016 | 176 |
| Northern Ireland | GBR NIR | 1922–2016 | 95 |
| United Kingdom | GBRNP | 1922–2016 | 95 |
| Scotland | GBR SCO | 1855–2016 | 162 |
| Greece | GRC | 1981–2013 | 33 |
| Croatia | HRV | 2002–2016 | 15 |
| Hungary | HUN | 1950–2017 | 68 |
| Ireland | IRL | 1950–2014 | 65 |
| Iceland | ISL | 1838–1851 | 14 |
| Iceland | ISL | 1853–2016 | 164 |
| Israel | ISR | 1983–2014 | 32 |
| Italy | ITA | 1872–2014 | 143 |
| Japan | JPN | 1947–2016 | 70 |
| Korea | KOR | 2003–2016 | 14 |
| Lithuania | LTU | 1959–2017 | 59 |
| Luxembourg | LUX | 1960–2014 | 55 |
| Latvia | LVA | 1959–2017 | 59 |
| Netherlands | NLD | 1850–2016 | 167 |
| Norway | NOR | 1846–2014 | 169 |
| New Zealand, Maori | NZLMA | 1948–1948 | 1 |
| New Zealand, Maori | NZLMA | 1950–1955 | 6 |
| New Zealand, Maori | NZLMA | 1957–1958 | 2 |
| New Zealand, Maori | NZLMA | 1960–2008 | 49 |
| New Zealand, Non-Maori | NZL NM | 1901–2008 | 108 |
| New Zealand | NZL NP | 1948–2013 | 66 |
| Poland | POL | 1958–2016 | 59 |
| Portugal | PRT | 1940–2015 | 76 |
| Russia | RUS | 1959–2014 | 56 |
| Slovakia | SVK | 1950–2014 | 65 |
| Slovenia | SYN | 1983–2014 | 32 |
| Sweden | SWE | 1751–2016 | 266 |
| Taiwan | TWN | 1970–2014 | 45 |
| Ukraine | UKR | 1959–2013 | 55 |
| United States | USA | 1933–2016 | 84 |
Note: 4,610 consistent 1 × 1 (single-year in both calendar and age) life tables downloaded from the Human Mortality Database on November 2, 2018.
Model Scales
This analysis is conducted on life table probabilities of dying for those who survive to the beginning of each one-year age group. Single-year probabilities, 1qx, are taken directly from the HMD life tables; five-year probabilities, 5qx, are calculated as ; and 45q15 is calculated as Child mortality refers to 5q0, and adult mortality refers to 45q15.
The natural scale of the models is the full real line, so life table probabilities of dying, q, are transformed using the logit function so that their transformed values occupy the full real line. Outputs from the models are transformed back to the probability scale with range [0,1] using the expit function , inverse of the logit.
Methods
Relevant Characteristics of the SVD
This section summarizes from Clark (2015). The SVD (e.g., Good 1969; Stewart 1993; Strang 2009) is a matrix factorization method that decomposes a matrix X into three matrix factors with special properties:
| (5) |
U is a matrix of left singular vectors (LSVs) arranged in columns, V is a matrix of right singular vectors (RSVs) arranged in columns, and S is a diagonal matrix of singular values (SVs). The LSVs and RSVs are independent and have unit length. If one views the columns of X as a set of dimensions, then the rows of X locate points defined along those dimensions—the data cloud. The RSVs define a new set of dimensions that line up with the axes of most variation in the data cloud. The first RSV points from the origin to the data cloud, or if the cloud is around the origin, then it points along the line of maximum variation within the cloud. The remaining RSVs are orthogonal to the first and each other and line up with successively less variable dimensions within the cloud. The elements of the LSVs are values that correspond to the projection of each point along the new dimensions defined by the RSVs. The SVs effectively stretch the new dimensions defined by the RSVs in accordance with the variation in the cloud along each RSV. The numeric value of each SV is the square root of the sum of squared distances from the origin to each point along the corresponding SVD dimension, and their squares sum to the total sum of squared distances from the origin to each point along all of the original dimensions.
The basic form of the SVD in Eq. (5) can be rearranged to yield two new useful expressions:
| (6) |
and
| (7) |
where ui, are LSVs, vi are RSVs, si are SVs, ρ is the rank of X, xℓ are columns of X, and vℓi are the elements of RSV vi. (see the online appendix, section A). Equation (6) says that X can be written as a sum of rank-1 matrices, each created from one of the LSVs by applying weights in the form of the elements of the corresponding RSV. Equivalently, Eq. (7) says that each column xℓ of X can be written as the weighted sum of the LSVs with the weight for each being the ℓth element of the corresponding RSV.4 The LSVs and SVs are constant, so the weights are the variables in these expressions, and their values determine how much of each LSV is added to the mixture to represent the original data. Finally, because the LSVs are independent, ordinary least squares (OLS) regression can be used to estimate models that relate xℓ to the LSVs. If the constant is constrained to be 0, then the coefficients are equal to sivℓi.
Because the RSVs define successively less variable dimensions in the data cloud, the first term in Eqs. (6) and (7) contains the most information and subsequent terms contain less and less (Golub et al. 1987). Including all ρ terms replicates the original data matrix X or any of its columns xℓ exactly, while including only the first few terms provides a good approximation.
SVD Component (SVD-Comp) Model
Given an A × L matrix, Q, of mortality schedules for each sex, calculate the SVD(QZ) = UzSz. Using the resulting factors as in Eq. (7), each A-element mortality schedule, qzℓ, is approximated as the c-term sum,
| (8) |
where A is the number of age groups and rows in Qz; L is the number of life tables and columns in Qz; z ∈, {female, male}; c ≤ ρ the rank of Qz; and ℓ ∈ {1 … L} indexes mortality schedules (Golub et al. 1987). The A-element LSVs, uzi, and the SVs, szi, are constant across all mortality schedules. Because c ≤ ρ, the sum on the right is an approximation of the mortality schedule, as indicated by the ≈. As is clear in the upcoming section on calibration of SVD-Comp, c = 4 is sufficient to make the approximation almost perfect across the entire HMD. If viewed as a data compression technique, all 4,610 sex-specific mortality schedules in the HMD can be very closely approximated with just four age-varying components—a greater than 99.9 % reduction in the volume of data required to represent the HMD. The elements that vary among mortality schedules are the RSVs, vzi, whose elements, vzℓi, are the weights in the sum. This is a continuously varying model, such as Mod-Logit (Murray et al. 2003) and Log-Quad (Wilmoth et al. 2012), rather than a regional model, such as the Coale and Demeny (Coale and Demeny 1966) and U.N. model life tables (United Nations, Department of Economic and Social Affairs, Population Division 1982) model life tables.
Figure 2, presented later in the article, displays the scaled LSVs, sziuzi, obtained from the SVD of the matrix of logit-scale 1qx values contained in the HMD. The SVD-Comp model is simply a weighted sum of those components. The first component represents the average shape and scale of human mortality by age, and the remaining three components add age-specific modifications to that basic shape; that is, all values of the first component are negative (because of the logit transformation), whereas the second through fourth components cross the x-axis.
Fig. 2.
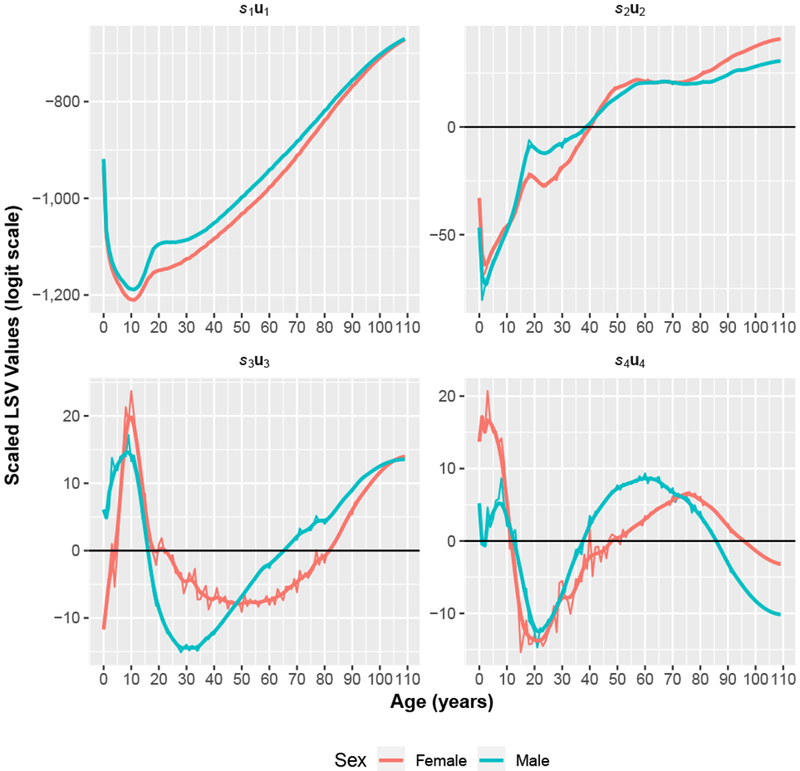
Scaled left singular vectors (LSVs). The first four LSVs are scaled by their corresponding singular values from the SVD of the 4,610 mortality schedules in the HMD. The more variable lines are raw components, and the less variable lines are smoothed with a kernel smoother. The raw values are used throughout this work.
When the vzℓi are replaced by values that can be related to covariates, as they are just below in Eqs. 9–11, the modeling framework becomes highly flexible: like traditional model life tables, this framework can be used inductively to produce a mortality model that generates age schedules of mortality that are consistent with a collection of observed mortality schedules, or it can be used deductively to generate new age schedules based on a theoretical understanding of how a covariate should affect each component in the model. In general, the age pattern of the scaled LSVs in the sum can be interpreted and manipulated theoretically; see upcoming Fig. 2 and the results discussed in the section “Factors of the SVD.”
Parameterization Using 5q0 and (5q0, 45q15)
Equation (8) describes a relationship between the elements of the RSVs and the age schedule of mortality. Consequently, if a covariate is related to the age schedule of mortality, it will necessarily also have a relationship with the elements of the RSVs, particularly the first few RSVs corresponding to the SVD-defined dimensions that capture the majority of the variability in the data cloud formed by the HMD life tables. It is possible to take advantage of this fact to define and estimate models that relate the elements of the RSVs to child mortality and adult mortality. These take the form
| (9) |
and
| (10) |
where, again, z ∈ {female, male}; i ≤ ρ indexes the RSVs; and ℓ ∈ {1 … L} indexes both the elements of the RSVs and the values of child and adult mortality, one for each sex-specific mortality schedule. Each sex-specific RSV has its own separate model, fzi, that can be used to produce predicted values for the weights in Eq. (8) using new values for 5q0z and 45q15z.
Following my earlier work with others (INDEPTH Network 2002; Sharrow et al. 2014), the final model for any age schedule of mortality probabilities, qz, associated with given values for a set of weights = fzi(5q0) or = fzi(5q0z, 45q15 z,) is
| (11) |
Equation (11) relates either child mortality (5q0) or both child and adult mortality (5q0, 45q15) to full age schedules of mortality according to the patterns of those relationship that exist in the original set of HMD life tables, Q, using a very compact approximation.
This is a fully general approach to predicting mortality or any other demographic age schedules. Equations (9) and (10) can be replaced with models that summarize the relationships between any covariate and elements of the RSVs and weights, and age can be aggregated into any age groups; doing so requires simply recalculating the SVD on the age-aggregated data set.
Calibrating SVD-Comp to the Relationship Between 5q0 and Mortality at Other Ages in the HMD
All computation is carried out using the R statistical programming environment (R Foundation for Statistical Computing 2016).
Calibration SVDs
The life tables of the HMD are arranged into two A × L matrices (Qz) of single-year, age-specific life table probabilities of dying (1qx), one for each sex. A = number of age groups = 110 L = number of life tables = 4,610; and z ∈ {female, male}. The SVD5 of each Qz yields ρ LSVs, uzi; RSVs, vzi; and SVs, sz. To ensure that all age groups have approximately the same influence when calculating the SVDs, each mortality schedule is offset from the origin6 by −10, and the offset is added back to predicted mortality schedules. Four of the new dimensions identified by each SVD are retained—that is, c = 4 in Eq. (11). For females, those account for 0.998328, 0.000936, 0.000071, and 0.000058 of the total sum of squares, respectively, or together 0.999392. Corresponding figures for males are 0.998595, 0.000824, 0.000103, and 0.000052, and together 0.999575. Section C of the online appendix contains additional information on the total sum of squares explained by each component of the SVD.
Models for Predicting Weights.
Based on Eqs. (9) and (10), regression models are defined that relate the RSVs vzi to 5q0z and 45q15z. Scatterplots of the elements of the RSVs versus logit(5q0) in Figs. E1 and E2 in the online appendix make it clear that the relationships are not linear or simple. With no theory to guide the choice of predictors, I tried all combinations of simple transformations of logit(5q0) and logit(45q15) and their interactions. The resulting models explain almost all the variance in the elements of v1 R2 ≈ 97% for both sexes for both sexes), the vast majority of the variance in the elements of v2 (R2 ≈ 87 % for both sexes), and one-third to one-half the variance in the elements of v3 and v4. Additionally, I tried to avoid overfitting or creating odd boundary effects in the predicted values that would have made out-of-sample predictions immediately implausible. These models behave sensibly up to the edges of the sample. The final models are
| (12) |
where i ∈ {1 : 4} indexes the SVD dimensions, and ℓ indexes mortality schedules and elements of vzi. OLS regression is used to estimate coefficients for the eight regression models defined in Eq. (12), and the estimated values are contained in online appendix D, Tables D1 and D2. With new values for both 5q0 and 45q15 as inputs, these models are used to predict values for the weights in Eq. (11)—that is, for prediction, vzℓi on the left-hand side is replaced with .
Models for Adult Mortality
To accommodate a one-parameter model that uses only 5q0 as an input, I define a regression model that relates adult mortality logit(45q15)z to child mortality 5q0Z. The scatterplot of logit(45q15) versus logit(5q0) in Fig. E3 in the online appendix reveals a slightly complicated relationship that is neither linear nor systematically curvilinear. Again, without theory as a guide, I tried a variety of models, including various simple transformations of 5q0. The resulting models explain most of the variance in logit(45q15) (R2 = 93 % for females, and 79 % for males). The final models are
| (13) |
OLS regression is used to estimate coefficients for the two regression models defined by Eq. (13), and the estimated coefficients are contained in Table D3 in the online appendix. This model is used to predict values for 45q15 when only 5q0 is supplied as an input. Then both the input value for 5q0 and the predicted value for 45q15 are used in Eq. (12) to predict the weights in Eq. (11).
Models for Mortality in the First Year of Life
Figure E4 in the online appendix displays the relationship between logit(1q0) and logit(5q0). Mortality falls very rapidly in the first few years of life. Using the child mortality rate (5q0), a five-year summary of mortality between ages 0 and 5, as a predictor of single-year mortality within that same five-year age group is relatively uninformative. Experimentation reveals that 5q0 predicts 1q1 through 1q4 well and 1q0 slightly less well. The prediction of 1q0 can be improved by modeling the relationship between logit(1q0) and logit(5q0) separately as
| (14) |
OLS regression is used to estimate the coefficients of this model, displayed in Table D4 of the online appendix. The model explains essentially all the variance in logit(1q0) (R2 > 99 % for both sexes) and is used to predict values for 1q0 directly from the input value of 5q0.
Using the Model
The full model is used as follows:
Identify input values for 5q0 and optionally 45q15, and transform them to the logit scale. If 45q15 is not available, predict logit(45q15) using the input value for 5q0 and the regression coefficients corresponding to Eq. (13).
Use the input values for logit(5q0) and logit(45q15) obtained in Step 1 and the regression coefficients estimated using Eq. (12) to predict values for the weights defined in Eq. (11).
Insert the weights predicted in Step 2 into Eq. (11) to calculate a predicted age schedule of mortality probabilities, , on the logit scale.
If desired, improve the prediction of logit(1q0) using the regression coefficients corresponding to Eq. (14) to directly predict logit(1q0) from the input value of logit(5q0) from Step 1. Replace the first element of with this predicted value for logit(1q0).
Add 10 to each element of to account for the offset used when calculating the SVDs of the HMD mortality schedules.
Take the expit of to yield single-year age-specific probabilities of dying on the probability scale.
Model Validation
The general sensitivity of the model to exactly which mortality schedules are used for calibration is assessed using a cross-validation approach. Fifty random samples of 50 % of the HMD mortality schedules are drawn, the model is calibrated with each using the previously described calibration process, and all the HMD mortality schedules are predicted. For each of the 50 models, prediction errors are calculated for all mortality schedules as the difference . The error distributions of the in-sample and out-of-sample mortality schedules are summarized and compared.
To investigate the sensitivity of the overall modeling approach to the number of mortality schedules used to calibrate the model, I conduct another cross-validation exercise with varying sample sizes. For each sample fraction from 10 % to 90 % in 20 % increments, 50 random samples are drawn from the HMD life tables. As described just above, I calibrate the model using each sample, and I predict all the HMD mortality schedules, calculate errors, and summarize and compare error distributions for in- and out-of-sample mortality schedules.
Comparing Performance of SVD-Comp and the Log-Quad Model
The Log-Quad model (Wilmoth et al. 2012) is the state-of-the-art mortality model relating child and adult mortality to full age schedules of mortality. I compare prediction errors produced by both the Log-Quad and SVD-Comp models. I use the Log-Quad model as published and the R code provided by Wilmoth et al. (2012) to produce predicted 5qx values for each of the HMD mortality schedules using either 5q0 or both 5q0 and 45<715 as inputs. The Log-Quad model predicts mortality in five-year age groups. To accommodate the one-year age groups (1qx) predicted by the SVD-Comp model, I use standard life table methods to transform predicted single-year to five-year 5qx values. I summarize the distribution of errors, , produced by both models in various ways. Comparisons are made only for predictions using the same inputs for both models, either 5q0 alone or both 5q0 and 45q15.
I also summarize the overall error produced by each model across all the mortality schedules in the HMD. This is done by taking the absolute value of each year-, sex-, and age-specific error and then summing the resulting absolute errors across all ages and years for each sex. This produces a single number—the total absolute error—that indicates the overall difference between the predicted and actual values for all years and ages. In addition to this I present total absolute errors in e0.
To assess age-specific errors in and life table quantities derived from , I predict with both SVD-Comp and Log-Quad using 5q0 from each HMD life table as input. I construct full life tables from and compared them with the life tables in the HMD.7 I construct age-specific weights from the lx columns of the HMD life tables by summing lx across all HMD life tables in five-year age intervals and then dividing each age-specific sum by the total across all ages. The resulting weights correspond to the proportionate lx age structure of the HMD life tables. I calculate weighted age-specific absolute errors in and by summing absolute errors in and at five-year age intervals across all life tables in the HMD and then multiplying by the corresponding age-specific weight. The weighted age-specific errors in are a refinement on the overall errors in , as described earlier, and reveal how close each model comes to replicating 5qx at each age. The weighted age-specific errors in provide an age-specific summary of the errors at each age in the derived life table columns that are necessary to calculate ex—that is, all the columns.
Application to Mexico and South Africa
SVD-Comp and Log-Quad are used to predict age-specific mortality rates for Mexico in 1983—1985 and South Africa in 2005 using both child and adult mortality as inputs. Data for Mexico come from the Human Life Table Database (Max Planck Institute for Demographic Research et al. n.d.), and data for South Africa from the World Health Organization’s Global Health Observatory data repository (World Health Organization n.d.)—both downloaded on August 21, 2018.
Mexico was chosen because it is a developing country with reasonable data and generally low but otherwise unremarkable mortality. South Africa was chosen because it is a developing country with a unique age-specific mortality schedule during the late 1990s and early 2000s. HIV/AIDS caused many deaths at very young and adult ages, giving rise to a characteristic bulge in mortality at adult ages. Because both Log-Quad and SVD-Comp are calibrated using the HMD, which does not contain life tables with HIV/AIDS-related mortality, both models are expected to perform reasonably well for Mexico, but neither is expected to follow the HIV/AIDS-related mortality bulge in South Africa.
Results
Data and Fits
To provide a sense of the mortality data contained in the HMD and the fits produced by the SVD-Comp model, Fig. 1 displays 1qx on the logit scale for Sweden in 1751 and Austria in 1990, with both data and predicted values produced by SVD-Comp using 5q0 alone as an input.
Fig. 1.
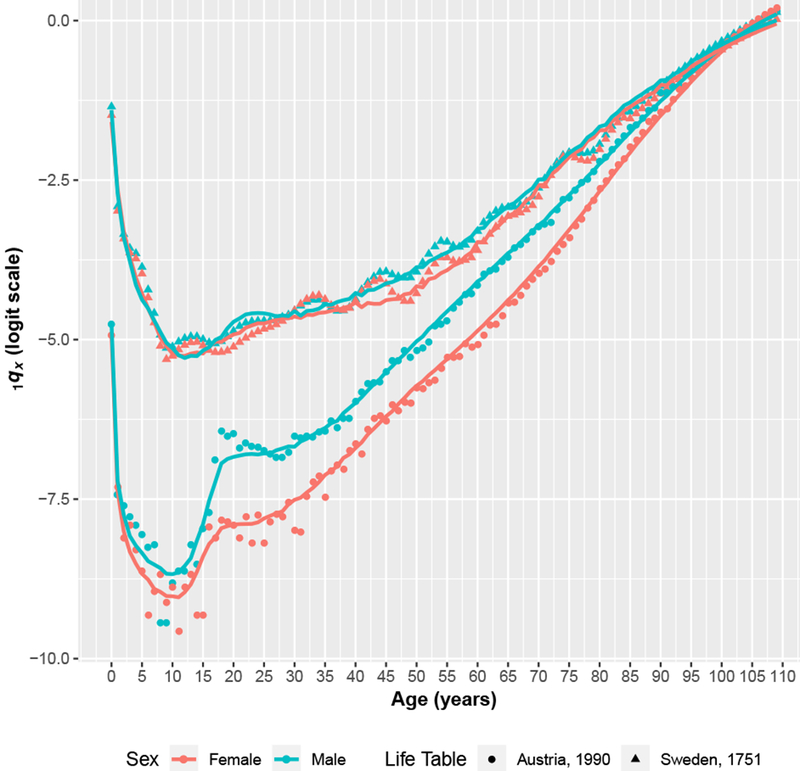
Example data and predictions. 1qx for very high mortality early in Sweden’s time series and low mortality for a more recent year in Austria. Predicted values are produced using 5q0 alone as an input. Data are presented as symbols, and predicted values are presented as lines.
Factors of the SVD
Figure 2 and Table B1 (online appendix) present the sex-specific LSVs from the SVD of the full set of HMD mortality schedules scaled by their corresponding SVs, siui (ignoring the index for sex z). All elements of s1. u1 are negative so that s1 u1 captures the underlying average shape of the mortality profile with age. Weights applied to S1u1 move this underlying mortality profile up and down and hence control the overall level of mortality. The remaining Siui cross the x-axis and therefore represent age-specific deviations from the overall underlying pattern. These scaled LSVs are the components used in the weighted sum in Eq. (11). Figure 2 also displays smoothed8 versions of the scaled LSVs. The smoothed versions can be used to make the predicted mortality schedules smoother.
Calibration Relationships
Figures E1–E4 (online appendix) display the data and predicted values from the models in Eqs. (12), (13), and (14). The corresponding estimated coefficients based on the whole HMD and used to calculate the predicted values in the figures are contained in Tables D1–D4 (online appendix). Figures El and E2 contain scatterplots of the RSV element values versus logit(5q0). The figures display both data and values predicted from Eq. (12) using logit(5q0) and logit(45q15) predicted from the model in Eq. (13) as inputs. There are clear, quasilinear relationships between the elements of the RSVs and logit(5q0). Figure E3 in displays logit(45q15) versus logit(5q0), along with the predicted values from Eq. (13). Finally, Figure E4 displays logit(1q0) versus logit(5q0), along with predicted values from Eq. (14).
Cross-Validation Prediction Errors
Figure 3 displays sex- and age-specific boxplots of the error distribution for one-year age groups from the first cross-validation using 50 samples of 50 % of the HMD to calibrate the SVD-Comp model. The errors are generally very small and centered on 0 through roughly age 60. At older ages, the size of the errors increases, and the median drifts slightly away from 0 in a positive direction, especially at ages older than 90. However, the median error is never much more than 0.01, and as displayed in Fig. 5, median errors are significantly smaller than those produced by the Log-Quad model at the same ages. The error distributions of the in-sample and out-of-sample predictions are indistinguishable at all ages, indicating that the SVD-Comp model is not sensitive to exactly which mortality schedules are used for calibration when half of them are used.
Fig. 3.
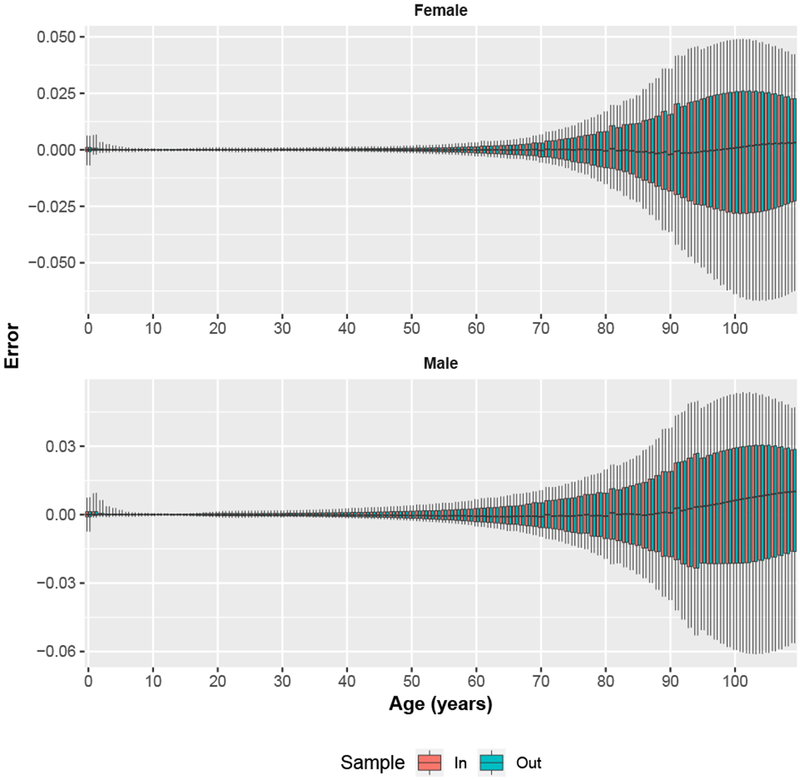
Single-year age group SVD-Comp prediction errors for in-sample and out-of-sample mortality schedules for fifty 50 % samples. Errors are summarized over all in-sample and out-of-sample mortality schedules for the 50 samples. Whiskers extend to 10 % and 90 % quantiles.
Fig. 5.
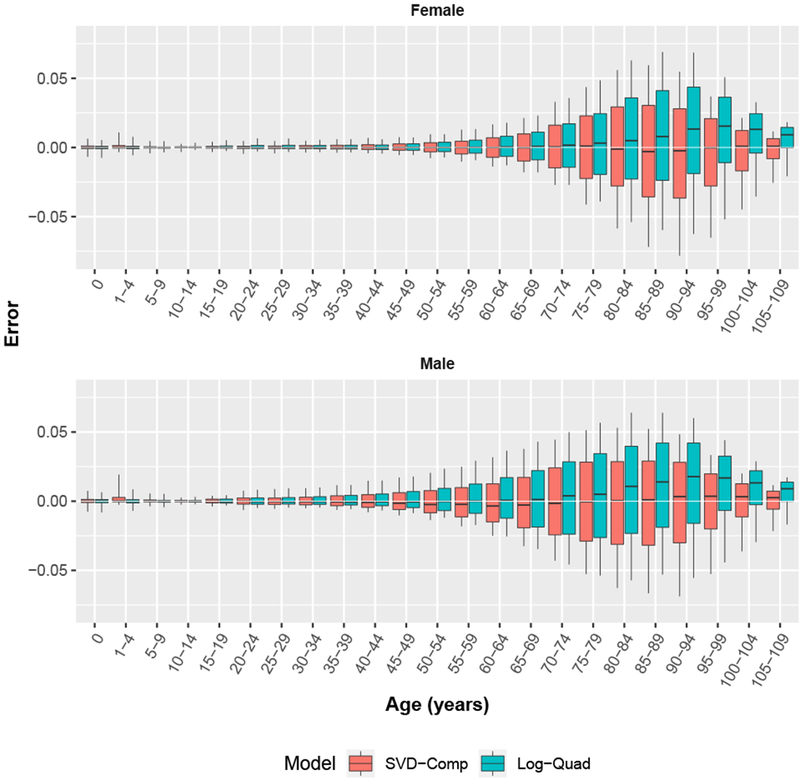
Five-year age group prediction errors for SVD-Comp and Log-Quad models using only child mortality 5q0 as input. Whiskers extend to 10 % and 90 % quantiles.
Varying Sample Size Cross-Validation Prediction Errors
Figures 4 and E6 (online appendix) contain the second set of cross-validation results investigating the effect of varying the number of mortality schedules used to calibrate the SVD-Comp model. Both figures summarize the overall prediction error distributions (all ages and years combined) for the SVD-Comp model by sample status (i.e., in-sample versus out-of-sample mortality schedules). The sample fraction varies from 10 % to 90 % in increments of 20 %. Figure 4 displays boxplots of the median of medians of overall error. This is very similar comparing in-sample and out-of-sample mortality schedules for both sexes across all sample fractions. In all cases, a slight positive bias results from the positive bias in errors at older ages (see Fig. 3). A similar situation exists for the distributions of the interquartile range of overall errors, (Fig. E6). The only systematic change in these distributions by sample fraction is that the interquartile range of the indicators calculated from the sample decreases as the sample fraction increases, as expected. Inversely, there is a weak trend toward increases in the interquartile range calculated in the out-of-sample group as the sample fraction increases, also as expected. In general the SVD-Comp model appears to be remarkably robust as the number of mortality schedules used for calibration decreases. Performance is satisfactory all the way down to the 10 % sample and is good all the way down to 30 %.
Fig. 4.
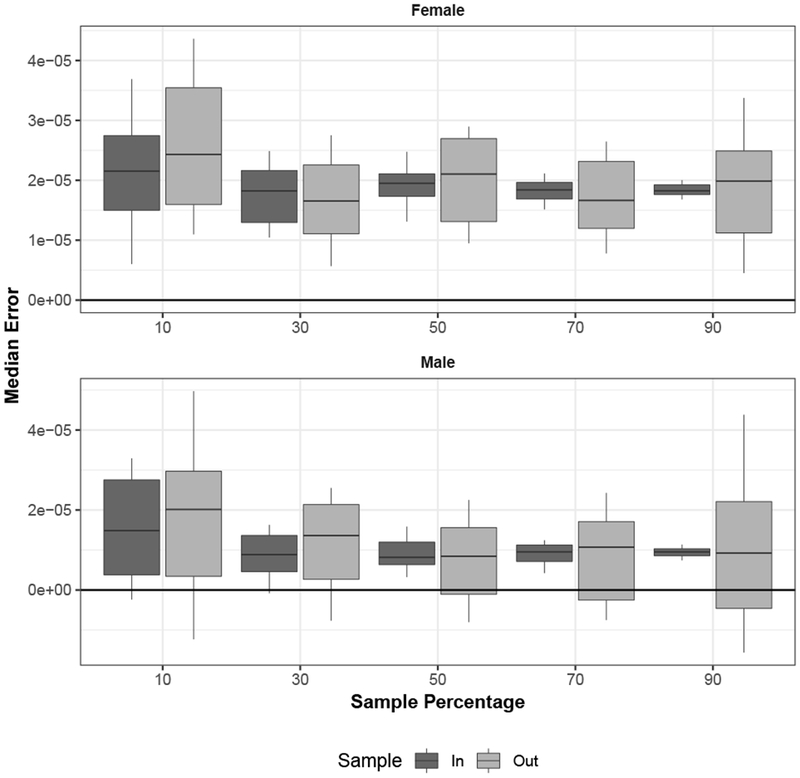
Median prediction error by sample fraction, with 50 samples for each sample fraction. For each sample, the median is calculated across all ages and all mortality schedules in each sample category (in sample and out of sample). Whiskers extend to 10 % and 90 % quantiles.
Comparison Between SVD-Comp and Log-Quad Prediction Errors
Figure 5 displays sex-age-specific boxplots of the distribution of prediction errors for both the SVD-Comp and Log-Quad models. The median error by sex and age is close to 0 for both models through roughly age 70. At ages older than 70 the median error for the Log-Quad model is systematically substantially larger than 0, while for the SVD-Comp model the median error stays at 0. The sex- and age-specific interquartile ranges are similar for both models, very small through roughly age 40, growing slowly between 40 and roughly 85 and then shrinking again through 110. In general, at ages older than 45 the error distribution is biased in a positive direction for the Log-Quad model but is centered on 0 at all ages for the SVD-Comp model.
Table 4 displays the total absolute errors on the natural scale for the SVD-Comp and Log-Quad models for predictions based on either 5q0 alone or both 5q0 and 45q15. The table also presents differences between the total absolute errors for the two models in both additive (Log-Quad - SVD-Comp) and proportional form ((Log-Quad - SVD-Comp) / SVD-Comp). In all cases, the SVD-Comp model predictions are globally closer to the HMD life tables.
Table 4.
Summary of prediction errors for SVD-Como and Lou-Ouad
| Total Absolute Error Predicted by: |
||||
|---|---|---|---|---|
| Model/Summary | C1 5q0 | C2 (5q0, 45q15) | C3 C2 – C1 | |
| Female | ||||
| R1 | SVD-Comp | 1.446 | 1,298 | −148 |
| R2 | Log-Quad | 1,502 | 1,399 | −102 |
| R3 | R2-R1 | 56 | 102 | 46 |
| R4 | R3/R1 (%) | 3.9 | 7.8 | −30.9 |
| Male | ||||
| R1 | SVD-Comp | 1,674 | 1,378 | −296 |
| R2 | Log-Quad | 1,777 | 1,472 | −305 |
| R3 | R2-R1 | 103 | 94 | −9 |
| R4 | R3/R1 (%) | 6.1 | 6.8 | 3.0 |
Notes: Total absolute error and comparisons of total absolute error. Both SVD-Comp models calibrated using all HMD life tables
Tables F1 and F2 (online appendix) display the weighted sum of age-specific absolute errors in and across all 4,610 life tables in the HMD. The last row in each displays the sum across all ages. The unweighted total absolute errors in for SVD-Comp calculated using one through four components are presented in Table F3 i (online appendix). Predicted values for life expectancy at birth, , reflect predictions at all ages so that errors in describe the cumulative effect of prediction errors at all ages. With each additional component, the total absolute errors in are reduced, and four components are required for SVD-Comp to perform better than Log-Quad. This is true in spite of the fact that the models used to predict the weights for the third and fourth components are not as predictive as those used to predict the weights for the first two components (Eq. (12), and Tables D1 and D2 in the online appendix).
Finally, Fig. E5 (online appendix) displays predicted 1qx from the SVD-Comp using 5q0 alone for three different levels of 5q0.
Application to Mexico and South Africa
Figure 6 displays data and predictions from both Log-Quad and SVD-Comp in standard five-year age groups for Mexico in 1983–1985 and South Africa in 2005 using both child and adult mortality as predictors. The two models produce essentially the same predictions for Mexico, and both adequately follow the data given that they are effectively two-parameter models. The situation for South Africa is different. As expected, neither model is able to follow the HIV/AIDS-related bulge at adult ages. Both models thread the predictions through the male age schedule reasonably well, overstating the mortality of adolescents and young adults and understating the mortality of middle-aged adults. For males, both models produce plausible predictions but are unable to reproduce the bulge. SVD-Comp does the same for females, essentially cutting off the bulge; however, Log-Quad produces an implausible age pattern of mortality, with extremely high mortality for older children, adolescents, and young to middle-aged adults. The predictions for South Africa reveal a fundamental limitation of all empirically based mortality models: they cannot represent mortality age profiles that are fundamentally different from those contained in the data used to create them. The solution to this is to identify or create new empirical life tables that represent the age profiles in question and include them in the data used to create the models.
Fig. 6.
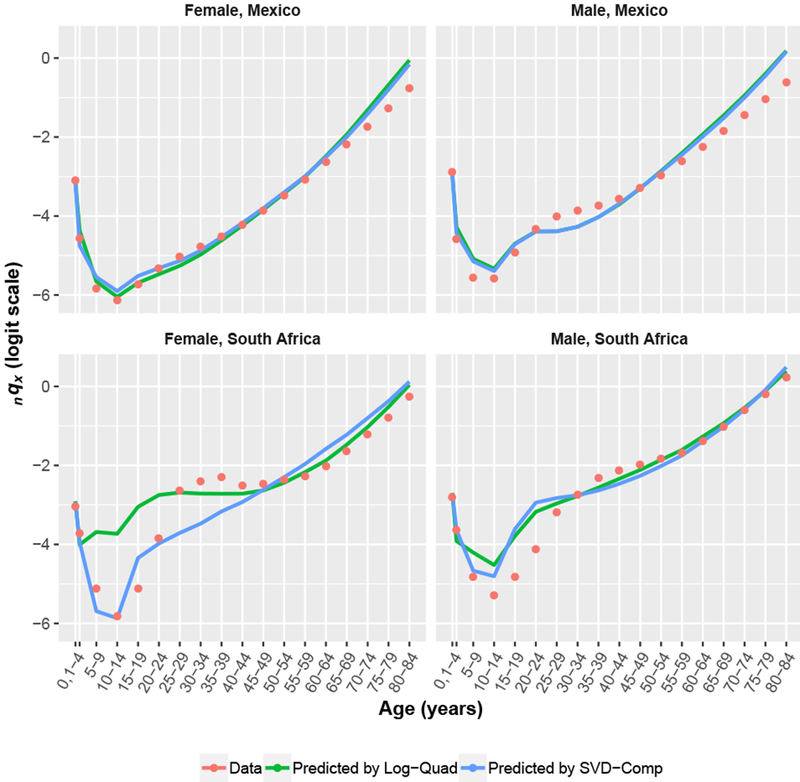
Application to Mexico and South Africa. The figure shows data and predicted values in standard five-year age groups produced by Log-Quad and SVD-Comp models using both child and adult mortality as predictors.
Discussion
The SVD-Comp model is a simple framework for building mortality models. Its key advantages are (1) a simple linear structure that does not need to be changed for the model to be used in a variety of ways; (2) a general interface—that is, the weights in Eq. (11)—through which input parameters can affect the age pattern of mortality (3) an ability to handle arbitrarily defined age groups without having to alter the fundamental structure of the model, such as the one-year age groups used here; and (4) through its structure, an inherent constraint that ensures that mortality at each age is related to mortality at each other age according to the age patterns reflected in each of the components. In addition to these advantages, the model also satisfies the combined list of desired characteristics for a mortality model enumerated in the Introduction.
This approach is general and allows all-age mortality schedules (in arbitrarily fine age groups) to be predicted from any covariates that are related to age-specific mortality. This general relationship is quantified in the models (Eq. (12)) that relate the weights in Eq. (11) to the covariates, given that the relationship of each age to all others is maintained through the constant components derived from the SVD, and those intra-age relationships are affected all together through the weights on the components. This constrains the intra-age relationships and relates them to the covariates in a simple, flexible way.
When the weights are modeled as functions of child mortality and calibrated using the relationship between the empirical weights (vzℓl in Eq. (8)) and child mortality in the HMD, the model serves the same purpose as the Log-Quad model (Wilmoth et al. 2012), and it performs slightly better in a direct comparison while having the advantage of directly producing mortality schedules by single year of age. Note that this comparison is conducted with the Log-Quad as presented in Wilmoth et al. (2012). In that article, the authors explicitly favored an estimation technique that would, they claimed, reduce estimation bias at the cost of having (slightly) larger prediction errors when evaluated against the historical data set—a fact that is apparent in Fig. 5. The published Log-Quad was calibrated to the slightly different and smaller set of HMD life tables that existed at the time and met the authors’ criteria for inclusion. Consequently, the results of the comparison would likely change if the Log-Quad were recalibrated using the same set of HMD life tables described and used here. However, given the robustness of the SVD-Comp to the set of life tables used in calibration (see the sections Cross-Validation Prediction Errors, and Varying Sample Size Cross-Validation Prediction Errors), this potential difference is unlikely to be large.
Concerning calibration and complexity, the cross-validation results clearly demonstrate that the calibration to the HMD is robust with respect to exactly which and how many mortality schedules are used, and SVD-Comp is no more complex than Log-Quad. SVD-Comp requires one SVD calculation and six regression models (four in Eq. (12), one in Eq. (13), and one in Eq. (14)) for each sex to capture the relationship between child mortality and mortality at other ages in the HMD—12 regression models in total. Log-Quad requires one SVD calculation and one log-quadratic model of the general form log(5mx) ~ log(5q0) + log(5q0)2 for each five-year age group and another to refine the prediction of 1q0 for each sex—46 regression models in total. The total number of regression coefficients required by each model (for each sex) is: 44 for SVD-Comp and 70 for Log-Quad. The total number of discrete values required for prediction (for each sex) is 484 (4.4 per age group) for SVD-Comp and 92 (3.8 per age group) for Log-Quad. The models directly predict mortality in SVD-Comp using single-year age groups and in Log-Quad using five-year age groups. Comparing the complexity of the models is not easy and depends on where one focuses, but it is clear that neither is obviously more or less complex than the other. Perhaps the only important difference in this respect is that there is nothing in the overall Log-Quad model to directly constrain the relationship of mortality at one age to another except for the quadratic form of the relationship between mortality at each age and 5q0, whereas SVD-Comp manipulates a linear combination of age-specific vectors, so that the relationships between ages are constrained to fall within the four-dimensional space defined by the four components used by SVD-Comp.
Together with my earlier work with others on an HIV-calibrated version of SVD-Comp (Sharrow et al. 2014), this demonstration suggests that it is reasonable to expect that SVD-Comp could be calibrated in a variety of additional ways to produce useful models that relate age-specific mortality to, for example, life expectancy at birth (or some other age), GDP, geographic region, period, epidemiological indicators (as in Sharrow et al. 2014), a combination of any of these, or something else. Moreover, subtle effects on the age structure of mortality, such as the rotation in age-specific mortality identified by Li and Gerland (2011), could be incorporated by adding the necessary elements to the models for the weights. The same approach could be applied to develop models for the difference between underlying age-specific mortality and age-specific mortality affected by specific shocks, such as natural disasters, conflicts, or epidemic diseases (e.g., HIV). It is even possible to refine the Lee-Carter model in Eq. (1) by adding more components to the SVD-derived bxkt term so that the enhanced model could represent a wide range of age patterns instead of the constant age pattern included in the existing formulation. This would add more parameters to the model, but the payoff might be sufficient to make that worthwhile. Going further, the entire Lee-Carter model could be replaced by the SVD-Comp model, which would give it the ability to model changing levels and age patterns of mortality independently and generally be more flexible.
The general SVD-Comp model in Eq. (11) can be used in another way to interpolate or smooth incomplete or noisy age schedules by simply using OLS regression of the incomplete mortality schedule against the corresponding elements of the first few components, sziuzi, with the constant constrained to be 0, and then predicting the full mortality schedule from all elements of the components and the coefficients estimated by the regression. Bayesian estimation can also be used to estimate the weights and their uncertainty, similar to Sharrow et al. (2013).
The application to Mexico and South Africa confirmed that the HMD-calibrated SVD-Comp works at least as well as Log-Quad when applied to mortality schedules in populations well outside of the HMD. For South Africa, neither model was able to reproduce the HIV/AIDS-related mortality bulge at adult ages. SVD-Comp produced plausible mortality schedules for both sexes that were as close as possible to South Africa’s, given that it could not reproduce the bulge. In contrast, Log-Quad produced a plausible mortality schedule for males but a nonsensical schedule for females. These results reveal an urgent need to increase the diversity of mortality schedules available in freely accessible archives, such as HMD, and in particular, an important need to compile much better mortality data for Africa and other developing world regions, where age schedules of mortality are different from what has been observed in the developed world. Additionally, the application to South Africa suggests that SVD-Comp may provide a stable framework to begin building mortality models that include epidemiological (e.g., HIV prevalence and antiretroviral therapy coverage) and other predictors. Earlier work using modeled data (Sharrow et al. 2014) is a start. However, because building models using modeled data is of limited value, reasonably large, high-quality empirical mortality data sets must be assembled from the places where models such as Log-Quad and SVD-Comp are most useful.
Software and Reproducibility Materials
A GitHub repository contains all the code necessary to reproduce the results presented in this manuscript (https://github.com/sinafala/svd-comp). Both the appendices and a PDF rendered from the R Markdown file (on GitHub) that produces the results are available online
An R package (R Foundation for Statistical Computing 2016) implementing the HMD child or child/adult mortality-calibrated version of SVD-Comp presented above is available as fully open source and free software to download directly from the GitHub repository using the devtools R package and command: install github(repo = “sinafala/svdComp5q0”)
Supplementary Material
Acknowledgments
This work was supported in part by Grant R01 HD054511 from the Eunice Kennedy Shriver National Institute of Child Health and Human Development (NICHD). The funder had no part in the design, execution, or interpretation of the work. Tables of regression coefficients were formatted using the LaTeX package stargazer (Hlavac 2015).
Footnotes
The core ideas underlying the Wilmoth model appear in his doctoral dissertation (Wilmoth 1988), with further refinement in the following years, culminating in the English-language summary (Wilmoth 1990).
The first left singular vector of the HMD residuals are massaged slightly to ensure all elements of v are positive and smooth.
If desired, k is chosen so that the resulting mortality schedule matches an input value 45q15.
This is the expression used to model the first residual in Wilmoth’s age/period/cohort model, shown in Eq. (2).
SVDs are calculated using the svd function in the base package of R.
This ensures that the whole data cloud is separated from the origin by an amount that is substantially greater than the typical value of each logit-transformed mortality rate, and therefore each age group has roughly equivalent leverage in the optimization required to identify the first new dimension of the SVD. The remaining dimensions are effectively identified on a centered data cloud.
The SVD-Comp life tables are constructed using standard procedures in one-year age groups with nax values taken from the HMD life tables. The Log-Quad life tables are constructed using R code provided by Wilmoth et al. (2012) in five-year age groups.
For components i ∈ (2, 3, 4}, kernel smoother with Gaussian kernel and bandwidth = i + 1 for ages i and older.
Publisher's Disclaimer: This Author Accepted Manuscript is a PDF file of a an unedited peer-reviewed manuscript that has been accepted for publication but has not been copyedited or corrected. The official version of record that is published in the journal is kept up to date and so may therefore differ from this version.
References
- Alexander M, Zagheni E, & Barbieri M (2017). A flexible Bayesian model for estimating subnational mortality. Demography, 54, 2025–2041. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bell WR (1997). Comparing and assessing time series methods for forecasting age-specific fertility and mortality rates. Journal of Official Statistics, 13, 279–303. [Google Scholar]
- Bourgeois-Pichat J (1962). Factor analysis and sex-age-specific death rates: A contribution to the study of the dimensions of mortality. United Nations Population Bulletin, 6, 147–201. [Google Scholar]
- Bourgeois-Pichat J (1990). Application de Γ analyse factorielle a Γ etude de la mortalitie [Application of factor analysis to the study of mortality]. Population (French ed.), 45, 773–802. [Google Scholar]
- Bozik JE, & Bell WR (1987). Forecasting age specific fertility using principal components. Proceedings of the American Statistical Association, Social Statistics Section, 396, 401. [Google Scholar]
- Brass W (1971). On the scale of mortality In Brass W (Ed.), Biological aspects of demography (pp. 69–110), London, UK: Taylor and Francis. [Google Scholar]
- Carter LR, & Lee RD (1986). Joint forecasts of U.S. marital fertility, nuptiality, births, and marriages using time series models. Journal of the American Statistical Association, 81, 902–911. [Google Scholar]
- Clark SJ (2001). An investigation into the impact of HIV on population dynamics in Africa (Doctoral dissertation). Philadelphia: University of Pennsylvania; Retrieved from https://repository.upenn.edu/dissertations/AAI3031652 [Google Scholar]
- Clark SJ (2015). A singular value decomposition-basedfactorization and parsimonious component model of demographic quantities correlated by age: Predicting complete demographic age schedules with few parameters. Retrieved from https://arxiv.org/abs/1504.02057
- Clark SJ, Jasseh M, Punpuing S, Zulu E, Bawah A, & Sankoh O (2009, May). INDEPTH model life tables 2.0 Paper presented at the annual meeting of the Population Association of America, Detroit, MI. [Google Scholar]
- Clark SJ & Sharrow DJ (2011a, April). Contemporary model life tables for developed countries: An application of model-based clustering Paper presented at the annual meeting of the Population Association of America, Washington, DC. [Google Scholar]
- Clark SJ & Sharrow DJ (2011b). Contemporary model life tables for developed countries: An application of model-based clustering (Working Paper No. 107). Seattle: University of Washington Center for Statistics and the Social Sciences; Retrieved from http://www.csss.washington.edu/Papers/wp107.pdf [Google Scholar]
- Coale AJ, & Demeny P (1966). Regional model life tables and stable populations. Princeton, NJ: Princeton University Press. [Google Scholar]
- Coale AJ, & Trussell TJ (1974). Model fertility schedules: Variations in the age structure of childbearing in human populations. Population Index, 40, 185–258. [PubMed] [Google Scholar]
- Fosdick BK, & Hoff PD (2012). Separable factor analysis with applications to mortality data. Annals of Applied Statistics, 8, 120–147. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Golub GH, Hoffman A, & Stewart GW (1987). A generalization of the Eckart-Young-Mirsky matrix approximation theorem. Linear Algebra and Its Applications, 88–89, 317–327. [Google Scholar]
- Gompertz B (1825). On the nature of the function expressive of the law of human mortality, and on a new mode of determining the value of life contingencies. Philosophical Transactions of the Royal Society of London, 115, 513–583. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Good IJ (1969). Some applications of the singular decomposition of a matrix. Technometrics, 11, 823–831. [Google Scholar]
- Heligman L, & Pollard JH (1980). The age pattern of mortality. Journal of the Institute of Actuaries, 107, 49–80. [Google Scholar]
- Hlavac M (2015). stargazer: Well-formatted regression and summary statistics tables (r package version 5.2). Cambridge, MA: Harvard University; Retrieved from http://CRAN.R-project.org/package=stargazer [Google Scholar]
- INDEPTH Network. (2002). INDEPTH mortality patterns for Africa. In Population and health in developing countries (vol. 1, pp. 83–128). Ottawa, Canada: International Development Research Centre. [Google Scholar]
- Ledermann S (1969). Nouvelles tables-types de mortality [New standard mortality tables] (Travaux et Documents No. 53, Institut national d’études démographiques). Paris: Presses Universitaires de France. [Google Scholar]
- Ledermann S, & Breas J (1959). Les dimensions de la mortalite [The dimensions of mortality]. Population (FrenchEdition), 14, 637–682. [Google Scholar]
- Lee RD (1993). Modeling and forecasting the time series of U.S. fertility: Age distribution, range, and ultimate level. International Journal of Forecasting, 9, 187–202. [DOI] [PubMed] [Google Scholar]
- Lee RD, & Carter LR (1992). Modeling and forecasting U.S. mortality. Journal of the American Statistical Association, 87, 659–671. [Google Scholar]
- Li N (2015). Estimating life tables for developing countries (Technical Paper No. 2014/4). New York, NY: United Nations, Department of Economic and Social Affairs, Population Division; Retrieved from http://www.un.org/en/development/desa/population/publications/pdf/technical/TP2014-4.pdf [Google Scholar]
- Li N, & Gerland P (2011, April). Modifying the Lee-Carter method to project mortality changes up to 2100 Paper presented at the 2011 annual meeting of the Population Association of America, Washington, DC. [Google Scholar]
- Li T, & Anderson JJ (2009). The vitality model: A way to understand population survival and demographic heterogeneity. Theoretical Population Biology, 76, 118–131. [DOI] [PubMed] [Google Scholar]
- Makeham WM (1860). On the law of mortality and the construction of annuity tables. Assurance Magazine, and Journal of the Institute of Actuaries, 8, 301–310. [Google Scholar]
- Max Planck Institute for Demographic Research, University of California, Berkeley, & Institut d’études demographiques (INED). (n.d.) Human life table database [Data set]. Retrieved from https://www.lifetable.de/data/hld.zip
- Murray CJ, Ferguson BD, Lopez AD, Guillot M, Salomon JA, & Ahmad O (2003). Modified logit life table system: Principles, empirical validation, and application. Population Studies, 57, 165–182. [Google Scholar]
- R Foundation for Statistical Computing. (2016). The R Project for Statistical Computing. Retrieved from http://www.r-project.org
- Sharrow D, Clark SJ, Collinson M, Kahn K, & Tollman S (2013). The age pattern of increases in mortality affected by HIV: Bayesian fit of the Heligman-Pollard model to data from the Agincourt HDSS field site in rural northeast South Africa. Demographic Research, 29, 1039–1096. 10.4054/DemRes.2013.29.39 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sharrow DJ, Clark SJ, & Raftery AE (2014). Modeling age-specific mortality for countries with generalized HIV epidemics. PloS ONE, 9, e96447 10.1371/journal.pone.0096447 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stewart GW (1993). On the early history of the singular value decomposition. SIAM Review, 35, 551–566. [Google Scholar]
- Strang G (2009). Introduction to linear algebra (4th ed.). Wellesley, MA: Wellesley-Cambridge Press. [Google Scholar]
- United Nations, Department of Economic and Social Affairs, Population Division. (1955). Age and sex patterns of mortality: Model life-tables for under-developed countries (Population Studies No. 22). New York, NY: United Nations. [Google Scholar]
- United Nations, Department of Economic and Social Affairs, Population Division. (1982). Model life tables for developing countries. (Population Studies No. 77). New York, NY: United Nations. [Google Scholar]
- United Nations, Department of Economic and Social Affairs, Population Division. (2015a). World Population Prospects: The 2015 Revision, DVD Edition New York, NY: United Nations. [Google Scholar]
- United Nations, Department of Economic and Social Affairs, Population Division. (2015b). World population prospects: The 2015 revision. New York, NY: United Nations. [Google Scholar]
- United Nations, Department of Economic and Social Affairs, Population Division. (2015c). World population prospects: The 2015 revision, methodology of the United Nations population estimates and projections (Working Paper No. ESA/P/WP.242). New York, NY: United Nations. [Google Scholar]
- University of California, Berkeley and Max Planck Institute for Demographic Research, (n.d.) Human Mortality Database [Data set]. Available from http://www.mortality.org
- Wang H, Dwyer-Lindgren L, Lofgren KT, Rajaratnam JK, Marcus JR, Levin-Rector A, . . . Murray CJL (2013). Age-specific and sex-specific mortality in 187 countries, 1970–2010: A systematic analysis for the Global Burden of Disease Study 2010. Lancet, 380, 2071–2094. [DOI] [PubMed] [Google Scholar]
- Wilmoth J, Vallin J, & Caselli G (1989). Quand certaines generations ont une mortalite differente de celle que Ton pourrait attendre [When some generations have different mortality than expected]. Population (French Edition), 44, 335–376. [Google Scholar]
- Wilmoth J, Zureick S, Canudas-Romo V, Inoue M, & Sawyer C (2012). A flexible two-dimensional mortality model for use in indirect estimation. Population Studies, 66, 1–28. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wilmoth JR (1988). On the statistical analysis of large arrays of demographic rates (Doctoral dissertation). Princeton, NJ: Department of Statistics, Princeton University. [Google Scholar]
- Wilmoth JR (1990). Variation in vital rates by age, period, and cohort. Sociological Methodology, 20, 295–335. [PubMed] [Google Scholar]
- Wilmoth JR, & Caselli G (1987). A simple model for the statistical analysis of large arrays of mortality data: Rectangular us diagonal structure (IIASA Working Paper WP-87-058). Laxenburg, Austria: International Institute for Applied Systems Analysis. [Google Scholar]
- World Health Organization, (n.d.) Global Health Observatory data repository [Data set]. Retrieved from http://apps.who.int/gho/data/?theme=main&vid=61540
- Zaba B (1979). The four-parameter logit life table system. Population Studies, 33, 79–100. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.