

Abstract
Purpose:
Masked speech recognition in normal-hearing listeners depends in part on masker type and semantic context of the target. Children and older adults are more susceptible to masking than young adults, particularly when the masker is speech. Semantic context has been shown to facilitate noise-masked sentence recognition in all age groups, but it is not known whether age affects a listener’s ability to use context with a speech masker. The purpose of the present study was to evaluate the effect of masker type and semantic context of the target as a function of listener age.
Method:
Listeners were children (5–16 yrs), young adults (19–30 yrs), and older adults (67–81 yrs), all with normal or near-normal hearing. Maskers were either speech-shaped noise or two-talker speech, and targets were either semantically correct (high context) sentences or semantically anomalous (low context) sentences.
Results:
As predicted, speech reception thresholds were lower for young adults than either children or older adults. Age effects were larger for the two-talker masker than the speech-shaped noise masker, and the effect of masker type was larger in children than older adults. Performance tended to be better for targets with high than low semantic context, but this benefit depended on age group and masker type. In contrast to adults, children benefitted less from context in the two-talker speech masker than the speech-shaped noise masker. Context effects were small compared to differences across age and masker type.
Conclusion:
Different effects of masker type and target context are observed at different points across the lifespan. While the two-talker masker is particularly challenging for children and older adults, the speech masker may limit the use of semantic context in children but not adults.
INTRODUCTION
The ability of normal-hearing listeners to recognize speech in the presence of a competing masker depends in part on their age: performance improves with increasing age in school-age children and deteriorates with increasing age in older adults. These age effects tend to be more pronounced for maskers composed of speech than for noise maskers. The child/adult difference in speech reception thresholds (SRTs) is larger and extends later into childhood when measured with a speech masker than a speech-shaped noise masker (e.g., Buss et al. 2017; Wightman and Kistler 2005). Similarly, the difference between SRTs of young adults and older adults is typically larger for complex maskers like speech than for noise maskers (Goossens et al. 2017; Helfer and Freyman 2014; Rajan and Cainer 2008; Tun et al. 2002). While semantic context tends to improve sentence recognition, this effect also depends on listener age. The benefit associated with sentence context can be more modest for young children than for young adults (Elliott 1979; Nittrouer and Boothroyd 1990), and it has been suggested that young children may be particularly poor at utilizing context information in the presence of a speech masker (Buss, Leibold, et al. 2016). In contrast, older adults benefit from semantic context to a similar or even greater degree than young adults (e.g., Cohen and Faulkner 1983; Pichora-Fuller et al. 1995).
While studies of development and aging are often conducted using different experimental methods and stimuli, many of the same factors have been proposed as possible contributors to the poor masked speech recognition observed for young children and older adults. Working memory abilities are correlated with masked speech recognition scores in both young children (McCreery et al. 2016) and older adults (Gordon-Salant and Cole 2016). Group differences could therefore be related to the finding that young adults perform better than older adults and young children on tests of short term memory, particularly tasks in which subjects are asked to recall the co-occurrence of stimulus features (e.g., the identity of a visually presented letter and its location; Fandakova et al. 2014). Limitations of stream segregation have been implicated in masked speech recognition, particularly in the presence of speech maskers, for both children and older adults (e.g., Buss et al. 2017; Ezzatian et al. 2015). Differences in voice pitch (F0) between the target and masker voice are less beneficial for young children (Flaherty et al. 2017) and older adults (Lee and Humes 2012) compared to young adults. The ability to selectively attend to the target is thought to play a role in the child/adult difference for speech recognition in a speech masker (Leibold et al. 2016; Wightman et al. 2010). Like young children, older adults appear to be less adept at ignoring task-irrelevant auditory stimuli compared to young adults (Alain and Arnott 2000; Alain and Woods 1999; Giard et al. 2000). While young adults benefit from masker envelope fluctuation, this benefit can be more modest in young children (Buss, Leibold, et al. 2016) and older adults (Grose et al. 2009; Larsby et al. 2005; Stuart and Phillips 1996). Failure to benefit from masker fluctuation could be related to greater susceptibility to forward and backward masking in children (Buss et al. 2013) and older adults (Grose et al. 2016) compared to young adults.
Despite the numerous similarities between development and aging, there are some important differences in the factors contributing to masked speech recognition across the lifespan. One important difference between speech recognition in children and older adults is peripheral hearing sensitivity. The incidence of hearing loss increases with increasing age in older adults (Humes et al. 2010; Lin et al. 2011), and that loss is typically evident at high frequencies before low frequencies. As a consequence of the prevalence of hearing loss in older adults, differentiating effects related to age and high-frequency hearing loss is a challenge. While some studies assume that normal hearing up to 4 kHz is sufficient to rule out effects specific to presbycusis, others indicate that this assumption may not be warranted (e.g., Dubno et al. 2000). Hearing loss in older adults could limit performance via reduced audibility or reduced frequency selectivity (Humes 2007; Phillips et al. 2000), which in turn could reduce glimpsing of speech in a complex masker (Best et al. 2017).
In development, detection in quiet tends to be poorer in young children than young adults, but this effect is stronger at low than high frequencies. Thresholds at 10 kHz are adult-like by about 5 years of age, but thresholds at 0.4 – 1 kHz are not adult-like until around 10 years of age (Trehub et al. 1988). Factors proposed to account for these developmental effects include changes in middle ear mechanics, cortical development, and maturation of listening behaviors (Buss, Porter, et al. 2016; Moore and Linthicum 2007; Okabe et al. 1988). Previous studies of the development of masked speech recognition have typically required audiometrically normal hearing at octave frequencies, defined as thresholds ≤ 20 dB HL between 0.25 and 8 kHz (ANSI 2010). In contrast to the case of threshold elevation in older adults, peripheral frequency selectivity of young school-age children is similar to that of young adults (Hall and Grose 1991).
Language ability is another notable difference between children and older adults. While older adults have a lifetime of experience with language, children have a more limited history of exposure. The lexical restructuring hypothesis (Metsala and Walley 1998) provides one framework for thinking about the relationship between linguistic experience and speech recognition in children. According to this hypothesis, the first words that a young child learns are coarsely represented in memory, in part because minimal detail is required to differentiate them. As more words are acquired, more detailed templates are developed in order to differentiate from among the growing set of alternatives. As a consequence of the increasing detail in the phonetic representation of words in memory, fewer acoustic cues are required to recognize words. Support for this view comes from the gating paradigm, where listeners are asked to recognize words that have been gated off before the end, and performance is quantified as the duration of the word segment required for correct identification. Using this paradigm, Metsala (1997) reported that 7-year-olds require 30- to 75-ms longer word segments than young adults in order to correctly identify target words, depending on word frequency and neighborhood density. This effect is reduced but still evident for some types of words in 11-year-olds, the oldest age group tested. Children’s need for more redundant speech cues compared to adults could be an important factor in their greater audibility requirements and susceptibility to masking in traditional masked speech paradigms (Buss et al. 2017; McCreery and Stelmachowicz 2011). The lexical restructuring hypothesis and its possible role in masked speech perception receives support from the observation that masked speech recognition scores are correlated with vocabulary size in young children (McCreery et al. 2016).
In older adults, mature linguistic knowledge is thought to play an important role in supporting speech perception (Pichora-Fuller 2008). Some data indicate that older adults have larger vocabularies than young adults, although sampling and test bias have been argued to affect these estimates (Verhaeghen 2003). Based on the lexical restructuring hypothesis, one might expect that older adults’ large vocabularies would allow them to recognize words based on initial segments that are comparable to or perhaps even shorter than those supporting recognition in younger adults. However, this expectation is not supported. When tested using the gating paradigm, older adults perform worse than younger adults, requiring 32- to 110-ms longer segments to recognize words in isolation, depending in part on older listeners’ hearing status (Lash et al. 2013; Wingfield et al. 1991). Analyzing listener responses with respect to the initial phoneme indicates a robust age effect: whereas young adults are able to identify the initial phoneme 90% of the time based on a 50-ms segment, older adults require a 150-ms segment to perform at this level (Wingfield et al. 1991). This observation has been interpreted as reflecting age-related hearing loss; the detrimental effects of hearing loss are countered by linguistic experience only once the stimulus duration provides sufficient speech cues for that experience to be helpful. This interpretation is consistent with the observation that older adults benefit more from lexical familiarity in a masked word vs non-word recognition task than young adults or children (Nittrouer and Boothroyd 1990).
In addition to lexical familiarity, semantic context appears to provide more benefit for older adults than for young children. When the gated word paradigm is performed using sentence materials, with the target word occurring at the end of the sentence, semantic context can close the gap between young and older adults’ performance (Lash et al. 2013; Wingfield et al. 1991). Older adults appear to derive more benefit from semantic context than young adults under some conditions (Pichora-Fuller et al. 1995; Sommers and Danielson 1999), although it has been argued that this greater benefit is associated with hearing loss rather than age alone (Dubno et al. 2000; Frisina and Frisina 1997). Children also benefit from sentence context (Fallon et al. 2002), although it has been suggested that they benefit less than adults (Elliott 1979; Nittrouer and Boothroyd 1990). Buss, Leibold, et al. (2016) hypothesized that young children’s ability to use context may depend on the masker type. In that study, the foils provided in the four-alternative response context were either phonetically similar or phonetically dissimilar to the target. Both children and adults benefitted from the context associated with phonetically dissimilar response alternatives when target words were presented in a speech-shaped noise masker. In contrast, young children derived substantially less benefit than older children and adults from context when the masker was two-talker speech. Children’s ability to benefit from context in the noise masker but not the two-talker speech masker could be due to the greater cognitive demands associated with segregating the target voice from the masker voices. It is unclear whether the effect of masker type on children’s ability to use context in a forced-choice task generalizes to the use of semantic context in an open-set sentence recognition task.
Despite the sizable literature examining the effects of listener age on masked speech recognition, the vast majority of studies have evaluated either young children or older adults; very few studies have evaluated performance across a broad range of listener ages using consistent stimuli and test procedures (e.g., Nittrouer and Boothroyd 1990). The approach of focusing on either development or aging has been largely successful, uncovering many of the same factors limiting performance in children and older adults. However, evaluating performance in both age groups using the same paradigm and stimuli could clarify the relative contributions of those factors across the lifespan. For example, Buss et al. (2017) proposed that children’s immature speech-in-speech recognition may be due primarily to the combination of two factors: 1) difficulties in perceptually segregating the target from the masker, and 2) a limited ability to recognize speech based on spectro-temporally sparse cues, a process described as glimpsing. By this view, the more modest developmental effects observed with a noise masker than a speech masker could be due to greater ease of perceptual segregation for speech in noise, whereas the lexical restructuring hypothesis predicts that redundant cues would be required to recognize speech in both maskers. While older adults tested in a speech masker would also be expected to struggle with auditory stream segregation, their greater linguistic knowledge would be expected support more efficient use of sparse speech cues, provided that hearing loss did not degrade those cues. Comparing performance across age groups could help to clarify the relative contributions of factors such as perceptual segregation and glimpsing to masked speech recognition.
The present study was designed with two main goals in mind. The first was to characterize speech-in-noise and speech-in-speech recognition across the lifespan using consistent procedures and test materials. Performance with a two-talker masker was of particular interest because using a small number of masker talkers has been argued to maximize perceptual masking (Freyman et al. 2004; Rosen et al. 2013), although this effect varies markedly across particular stimuli (Calandruccio et al. 2010; Freyman et al. 2004). The second goal was to evaluate the hypothesis that the semantic context provided by the target sentence has differential effects on performance in a two-talker masker depending on listener age. Based on the word recognition data of Buss, Leibold, et al. (2016) we hypothesized that young children would derive less benefit from semantic context in the two-talker masker than young adults. In contrast, older adults’ greater linguistic knowledge and life experience was expected to facilitate the use of sentence context even under the higher processing loads associated with listening in a complex masker.
Methods
Listeners
Listeners were recruited in three groups: children (5 – 16 yrs, mean = 10.0 yrs, n = 42, 25 females), young adults (19 – 30 yrs, mean = 24.8 yrs, n = 21, 11 females), and older adults (67 – 81 yrs, mean = 71.2 yrs, n = 13, 10 females). All were native speakers of American English and had normal or near-normal pure-tone thresholds up to at least 4 kHz. Exclusion criteria included known neurological disorders or developmental delays, as well as a history of ear disease. Children had thresholds of 20 dB HL or less at octave frequencies from 250 to 8000 Hz, with the exception of a 25-dB-HL threshold at 500 Hz in the left ear for the youngest listener. Young adults had thresholds of 15 dB HL or less at octave frequencies from 250 to 8000 Hz bilaterally. Older adults had thresholds of 25 dB HL or less in the better-hearing ear from 250 to 4000 Hz, with thresholds in the poorer-hearing ear of 35 dB HL or less; thresholds at 8000 Hz ranged from 15 to 55 dB HL in the better-hearing ear. The laxer inclusion criterion for older adults reflects the fact that strictly normal thresholds become increasingly rare in older adults (Lin et al. 2011). Older adults passed the Montreal Cognitive Assessment-Basic (MoCA-B; Julayanont et al. 2015; Nasreddine et al. 2005), with a score of 26 or higher. Stimuli in this experiment were presented diotically, so audibility was limited by the better threshold in the two ears at each frequency. The distribution of better-ear thresholds is plotted by listener group in Figure 1.
Figure 1.
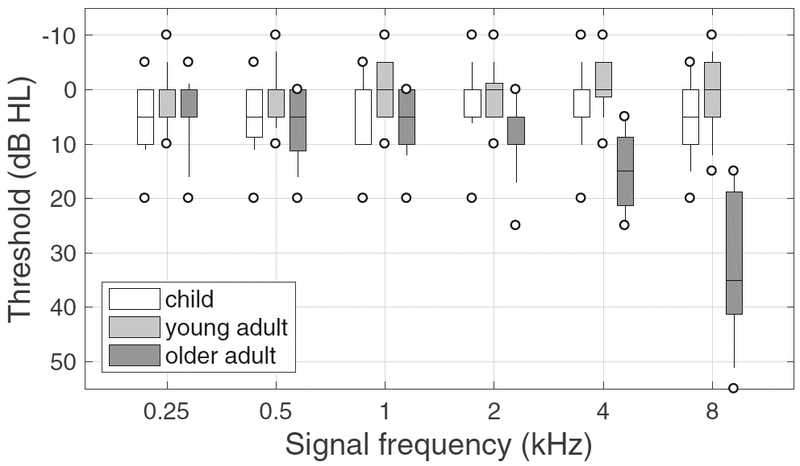
Distribution of pure-tone thresholds as a function of frequency. At each frequency, the better of the two thresholds (one from each ear) was selected for each listener. Horizontal lines indicate the median, boxes span the 25th to 75th percentiles, vertical lines span the 10th to 90th percentiles, and circles indicate the minimum and maximum values. Box fill reflects the listener age group, as defined in the legend.
Stimuli
Target stimuli were recordings of a female talker reading sentences with either low or high semantic context, in a conversational style. This corpus, developed by Stelmachowicz et al. (2000), uses words within the vocabulary of children as young as 4 years of age, and it includes 60 semantically correct (high-context) sentences and 60 semantically anomalous (low-context) sentences. An example of a high-context sentence is, “Tough guys sound mean.” An example low-context sentence is, “Quick books look bright.” All sentences are syntactically correct. Recordings of these target sentences were 1.0 – 2.1 sec in duration, with means of 1.6 sec (low-context) and 1.5 sec (high-context). The target talker’s mean F0 was 203 Hz for these recordings. Level tends to drop off over the course of declarative sentences, and an analysis of recordings used in the present experiment showed that trend. Level by word was measured by placing markers at the boundaries between words, using visual and auditory features, and computing the stimulus level between sequential markers using Praat. Level dropped by an average of 1.4 dB between the first and second word, 1.8 dB between the second and third word, and 1.5 dB between the third and fourth word. This trend did not differ for the low- and high-context stimuli (p = 0.453)1.
The masker was either two-talker speech or speech-shaped noise. The two-talker speech masker was created by Calandruccio et al. (2014) based on recordings of two female talkers reading different excerpts from Jack and the Beanstalk (Walker 1999). These recordings were edited to remove pauses longer than 300 ms, normalized to equal power, and summed to create a 2.8-min sample of two-talker speech that repeated without abrupt transition. The two masker talkers had average F0s of 170 and 208 Hz. The speech-shaped noise was 90 sec in duration and had the same long-term average power spectrum as the two-talker masker.
All children, a subset of young adults (n=10), and all older adults were tested using stimuli that were not filtered. A subset of young adults (n=11) was tested with stimuli that were passed through a 128-tap FIR filter which simulated a high-frequency hearing loss, with attenuation of 20 dB at 4 kHz and 50 dB at 8 kHz. The rationale for collecting data with low-pass filtered stimuli was to simulate effects of reduced high-frequency audibility of older adults. Given the wide range of 8-kHz thresholds in the better-hearing ear in the older adult group (15–55 dB HL), no attempt was made to match audibility across individuals. Rather, data collected on young adults with the low-pass filtered stimuli were expected to give a general indication of effects of reduced high-frequency audibility.
Procedures
Testing took place in a double-walled sound-isolated booth. Stimuli were played out of a real-time processor (Tucker-Davis Technologies, RP2) at 24,414 Hz and presented diotically over headphones (Sennheiser HD25). The listener’s task was to repeat back the target sentence. A tester inside the booth scored each word as correct or incorrect. The masker played continuously at 60 dB SPL, and the target level was adjusted adaptively according to two interleaved one-down, one-up adaptive tracks. The track for odd-numbered trials counted a sentence correct if one or more words were repeated back correctly; the track for even-numbered trials counted a sentence correct if no more than one word was repeated back incorrectly. For both tracks the signal level was initially adjusted in steps of 8 dB. This step size was reduced to 4 dB after the second track reversal, and further reduced to 2 dB after the fourth track reversal. Each pair of tracks included 30 trials total (15 per track), with one target sentence presented on each trial. The selection of sentences to be played in each masker and the order of sentences within a threshold estimation track were randomly selected for each listener. Listeners completed four conditions in random order: two masker types (speech-shaped noise, two-talker speech) × two levels of target context (low context, high context). Listeners heard each sentence only once.
The rationale for using two interleaved tracks with different criteria -- one permissive and one strict -- was to ensure a wide range of performance, which is necessary for an accurate psychometric function fit. Data from each pair of tracks, comprising responses to 120 words (30 sentences × 4 words each), were fitted with a logit, defined as,
For this function, α is the midpoint, β is the slope, x is the target level in dB target-to-masker ratio (TMR), and y is the proportion of words correct. Data for all listeners appeared to asymptote at 100%, so no inattention parameter was included. Functions were fitted using a custom MATLAB script by minimizing a quantity resembling Chi-square-error (Dai 1995), which accounts for non-uniform error variance. The SRT was defied as α, the target level associated with 50% correct. While the primary outcome of interest was the SRT, this analysis approach also supports an evaluation of the psychometric function slope.
The relatively limited age range in each group of adults precludes a meaningful evaluation of listener age within young adults or within older adults. Therefore, analyses of child data incorporated age as a continuous variable, and the analyses of adult data evaluated group effects. Linear mixed models included subject as a random factor. Statistics were performed using R (Pinheiro et al. 2016; R Core Team 2016), and a significance criterion of p < 0.05 was adopted. Procedures were approved by the Biomedical IRB at the University of North Carolina at Chapel Hill.
RESULTS
Psychometric function fits to individual listeners’ data were generally quite good, with a median of approximately 85% of variance accounted for in each listener group and stimulus condition. There are only three cases in which fits accounted for less than 50% of the variance. For three listeners (5.8, 6.3, and 68.2 yrs), fits to data for the high-context target in the two-talker masker accounted for 43–45% of variance. The results reported below include all data, except where explicitly noted.
SRTs as a function of child age
Figure 2 shows SRTs in dB TMR, plotted as a function of age. Results obtained in the speech-shaped noise appear in the left panel, and those obtained in the two-talker masker appear in the right panel. Overall there is a trend for SRTs to improve with increasing child age, reaching a group minimum for young adults, and rising again between the young adult and older adult age groups. This age effect is larger for the two-talker speech masker than the speech-shaped noise masker. Semantic context of the target tends to improve performance, but this effect is not consistent across groups and conditions, and it is small compared to variance in thresholds associated with listener age, masker type, and measurement noise.
Figure 2:
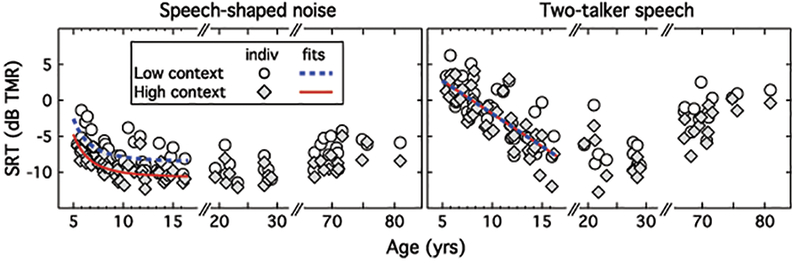
SRTs in dB TMR plotted as a function of listener age. Notice the different abscissa scales for child and adult listeners, and hash marks associated with the age ranges for each of the three listener groups. Open circles show results obtained with low-context sentences, and filled diamonds show results obtained with high-context sentences. Results obtained in the speech-shaped noise masker are shown in the left panel, and those for the two-talker masker are shown in the right panel. Lines indicate fits as a function of child age.
Within the group of child listeners, SRTs tend to improve with increasing age, but the trajectory of that improvement appears to differ for the two maskers. For the speech-shaped noise masker, performance begins to asymptote around 10 years of age; in contrast, for the two-talker speech masker, performance appears to continue improving through 16 years of age. Differential effects of child age for the two masker types were evaluated by fitting mean SRTs for each masker with the function y = m xk + b, where y is the SRT in dB TMR, and x is child age in years. For the speech-shaped noise masker, k was −3.1 (SE = 2.6), consistent with the observation that maturation appears to level off within the age range of children tested. This value of k was compared to k = 1, the value associated with linear improvement with age; this difference approached significance one-tailed (t41 = −1.54, p = 0.066). For the two-talker speech masker, k was 1.2 (SE = 0.8), consistent with the visual impression of a linear data pattern (k = 1). Subsequent analyses of SRT by child age were therefore fitted using age transformed with an exponent of k = −3.1 for the speech-shaped noise masker. No transformation was applied for the two-talker speech masker. A value of k > 1 was rejected as unrealistic given the assumption that performance in older adolescents converges on adult values rather than continuing to improve below adult values.
Effects of child age were evaluated using a pair of masker-specific linear mixed models. Results are reported in Table 1. For the speech-shaped noise masker, there were significant effects of age (p<0.001) and semantic context (p<0.001), and no interaction (p = 0.992). For the two-talker speech masker, there was a significant effect of age (p<0.001), but no effect of semantic context (0.935) and no interaction (p = 0.400). Lines fitted to child data in Figure 2 show predictions based on masker-specific models, omitting non-significant factors. This analysis suggests that use of semantic context in children may be limited to the speech-shaped noise maker. One question of interest is whether the differential effect of semantic context in the two maskers is statistically significant. The benefit of context was computed as the difference between SRTs in the low and high context conditions for each masker. That difference was 2.1 dB for the speech-shaped noise masker and 1.0 dB for the two-talker speech masker; in both cases, the benefit of semantic context was significantly greater than zero (speech-shaped noise: t41=8.50, p < 0.001; two-talker speech: t41=2.66, p = 0.011). A paired t-test indicates that the difference in benefit across maskers is significant (t41=2.92, p = 0.006). These results support the conclusion that the benefit of target context is larger for children tested in the speech-shaped noise than in the two-talker speech masker.
Table 1:
Linear mixed models evaluating SRT as a function of child age (yrs). For the model evaluating data obtained in the speech-shaped noise masker, age in years was transformed with an exponent of −3.1; no transformation of age was applied for the model evaluating data obtained in the two-talker speech masker. The semantic context (Con) was either high or low.
| coef | SE | df | t | p | |
| Age | 878.60 | 165.89 | 40 | 5.30 | <0.001 |
| Con(low) | 2.17 | 0.38 | 39 | 5.74 | <0.001 |
| Con(low) × Age | 1.77 | 184.25 | 39 | 0.01 | 0.992 |
| coef | SE | df | t | p | |
| Age | −0.96 | 0.12 | 40 | −8.07 | <0.001 |
| Con(low) | 0.10 | 1.21 | 38 | 0.08 | 0.935 |
| Con(low) × Age | 0.10 | 0.11 | 38 | 0.85 | 0.400 |
SRTs of young adults and older adults
Older adults’ SRTs are higher than those of young adults, particularly for the two-talker masker. Both groups appear to benefit from target context to a comparable degree, however. A linear mixed model comparing SRTs of young adults and older adults, with factors of masker type and semantic context, confirmed the significance of these observations. Results are reported in Table 2. There were significant main effects of age group (p=0.029), masker type (p<0.001), and semantic context (p=0.003). There was a significant interaction between masker type and age group (p < 0.001), reflecting a larger difference between young adults and older adults in the two-talker masker than the speech-shaped noise masker. None of the other interactions approached significance. These results support the conclusion that older adults are more susceptible to masking than young adults, particularly when the masker is two-talker speech, but both groups benefit from semantic context to a similar degree irrespective of masker type.
Table 2:
Linear mixed model evaluating SRT as a function of adult age group (Age), masker type (Msk) and semantic context (Con). Age groups were older adults and young adults (yng). The masker type was either speech-shaped noise or two-talker (tlk). The semantic context was either high or low.
| coef | SE | df | t | p | |
|---|---|---|---|---|---|
| Age(yng) | −2.03 | 0.87 | 21 | −2.34 | 0.029 |
| Msk(tlk) | 5.40 | 0.60 | 63 | 8.96 | <0.001 |
| Con(low) | 1.87 | 0.60 | 63 | 3.11 | 0.003 |
| Msk(tlk) × Age(yng) | −3.46 | 0.91 | 63 | −3.78 | <0.001 |
| Con(low) × Age(yng) | −0.83 | 0.91 | 63 | −0.91 | 0.367 |
| Msk(tlk) × Con(low) | 0.09 | 0.85 | 63 | 0.10 | 0.917 |
| Msk(tlk) × Con(low) × Age(yng) | 0.56 | 1.29 | 63 | 0.43 | 0.667 |
Comparing results for children and adults
One obstacle to directly comparing SRTs for children and adults in a single analysis is the observation of age effects within the child group, which differ for the two maskers. However, the interaction between child age and semantic context was not significant, so the benefit of semantic context can be directly compared across groups. Figure 3 shows the distribution of differences scores between SRTs measured with low- and high-context targets, with age group indicted on the abscissa. Data from young adults and older adults are combined in a single group for this analysis, due to the absence of a significant interaction between age group and context in adult data. Grey boxes indicate the distribution of data for the speech-shaped noise masker, and open boxes indicate data for the two-talker speech masker. Symbols are used to identify results for children, young adults and older adults, as indicated on the abscissa.
Figure 3:
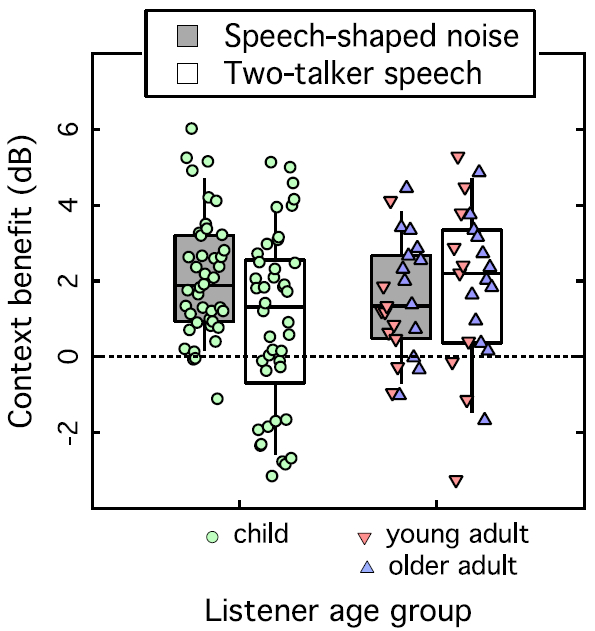
Context benefit in dB computed as the difference in SRTs between low-context and high-context targets. Results are shown separately for children and adults, indicated on the abscissa, and for the two maskers, indicated by box fill. Following the convention of Figure 1, filled boxes indicate results for the speech-shaped noise masker, and open boxes indicate results for the two-talker speech masker. Points superimposed on each box indicate values for individual listeners, ordered by age within each group (youngest on the left). Symbols indicate listener age group, as defined on the abscissa.
The benefit of semantic context was evaluated using a linear mixed model, and the results are reported in Table 3. There was no significant main effect of age group (p = 0.256), but there was an effect of masker type (p = 0.004) and an interaction between masker type and age group (p = 0.027). This interaction confirms the observation that children and adults benefit from context differently it the two maskers, but this effect may not be due solely to children’s limited use of context in the two-talker masker. While there was a trend for less benefit in children than adults for the two-talker masker (t48.8=1.54, p = 0.065 one-tailed), there was also a trend for more benefit in children than adults for the speech-shaped noise masker (t46.8=1.43, p = 0.079 one-tailed). While a smaller benefit for children was predicted for the two-talker masker, no difference was predicted for the speech-shaped noise.
Table 3:
Linear mixed model evaluating context benefit as a function of age group (Grp), masker type (Msk) and semantic context (Con). The age group was either child or adult (adult), and the masker type was either speech-shaped noise or two-talker (tlk).
| coef | SE | df | t | P | |
|---|---|---|---|---|---|
| Grp(adult) | −0.58 | 0.51 | 63 | −1.15 | 0.256 |
| Msk(tlk) | −1.14 | 0.38 | 63 | 2.95 | 0.004 |
| Msk(tlk) × Grp(adult) | 1.47 | 0.65 | 63 | 2.27 | 0.027 |
The linear mixed model fitted to child data as a function of age was used to compare the magnitude of developmental effects to those related to aging. For the speech-shaped noise masker, older adults’ mean SRTs are comparable to those of a 7.2-year-old (low context) or a 6.9-year-old (high context). For the two-talker speech masker, older adults’ mean SRTs are comparable to those of an 8.7-year-old (low context) or a 10.7-year-old (high context). In other words, older adults’ SRTs are comparable to younger children in speech-shaped noise and to somewhat older children for two-talker speech. This pattern of results is consistent with the idea that advanced age is more detrimental relative to immaturity for speech-in-noise recognition, and immaturity is relatively more detrimental for speech-in-speech recognition. This conclusion should be treated as preliminary, however, as no attempt was made to estimate the confidence intervals around these projections of age equivalence.2
Effects of audibility in older adults
Given the elevated high-frequency audiometric thresholds in older adults, the association between pure-tone thresholds and SRTs was evaluated with one-tailed Spearman correlations. There was a trend for a positive correlation between the mean SRT across the four stimulus conditions and the audiometric threshold for octave frequencies above 250 Hz, with values ranging from r = 0.60 (p = 0.016) at 1 kHz to r = 0.38 (p=0.103) at 500 Hz. There was no evidence of a positive correlation between mean SRTs and thresholds at any frequency in data of young adults (p ≥ 0.357). The trend for association between mean SRT and audiometric thresholds in older adults raises the possibility that reduced audibility could have played a role in the greater susceptibility to the two-talker speech masker in older adults compared to young adults. However, this possibility is undermined by the observation that thresholds of older adults were at or below 25 dB HL for audiometric frequencies below 8 kHz.
Data obtained for young adults tested with low-pass filtered stimuli provide an opportunity to evaluate effects of audibility distinct from aging. Figure 4 shows the mean SRTs for the three age groups of adults: young adults and older adults tested in the primary conditions, and young adults tested in the low-pass filtered stimuli. Open circles indicate mean thresholds for the low-context targets, filled diamonds indicate mean thresholds for high-context targets, and error bars indicate one standard deviation. The low-pass filter elevated thresholds by 2.3–4.2 dB relative to young adults tested in the primary conditions with unfiltered stimuli. Relative to older adults, the SRTs for young adults tested with the low-pass filtered stimuli were 0.2–1.2 dB higher in the speech-shaped noise masker and 1.6–2.4 dB lower in the two-talker speech masker. The primary question of interest is whether reduced audibility of high-frequency information can account for older adults’ greater relative susceptibility to masking with the two-talker speech masker compared to young adults. If audibility does account for this masker effect, then a comparison of young adults tested with and without the low-pass filter would be expected to reveal an interaction between age group and masker type. This was not observed (p = 0.377; see Table 4). While reduced high-frequency audibility elevated thresholds, there was no indication that this effect was larger for the two-talker than the speech-shaped noise masker. There was, however, a non-significant trend for greater effects of semantic context for the young adults tested with the low-pass filter compared to young adults tested in the primary conditions (p=0.069; mean benefit of 2.8 vs 1.4 dB, respectively). While this trend did not approach significance in the comparison of young adults and older adults, mean benefit of context was larger for older adults than young adults (1.9 vs 1.4 dB, respectively),
Figure 4:
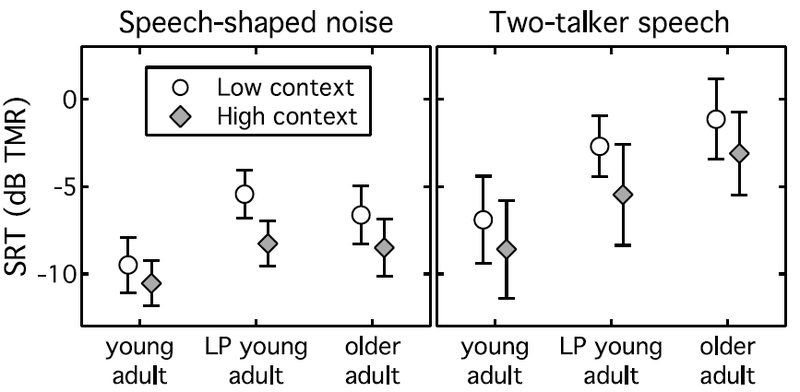
Adults’ SRTs in dB TMR plotted by group. Open circles show results obtained with low-context sentences, and filled diamonds show results obtained with high-context sentences. Results obtained in the speech-shaped noise masker are shown in the left panel, and those for the two-talker masker are shown in the right panel. Error bars show ±1 SD.
Table 4:
Linear mixed model evaluating SRT as a function of stimulus (Stim), masker type (Msk) and semantic context (Con). Stimuli were the standard unfiltered speech or speech that was low-pass filtered (lp). The masker type was either speech-shaped noise or two-talker (tlk). The semantic context was either high or low.
| coef | SE | df | t | p | |
|---|---|---|---|---|---|
| Stim(lp) | 2.28 | 0.89 | 19 | 2.56 | 0.019 |
| Msk(tlk) | 1.94 | 0.70 | 57 | 2.78 | 0.007 |
| Con(low) | 1.04 | 0.70 | 57 | 1.50 | 0.140 |
| Msk(tlk) × Stim(lp) | 0.86 | 0.96 | 57 | 0.89 | 0.377 |
| Con(low) × Stim(lp) | 1.79 | 0.96 | 57 | 1.85 | 0.069 |
| Msk(tlk) × Con(low) | 0.65 | 0.99 | 57 | 0.66 | 0.514 |
| Msk(tlk) × Con(low) × Stim(lp) | −0.71 | 1.36 | 57 | −0.52 | 0.605 |
Psychometric function slope
Estimates of psychometric function slope were quite variable across listeners. However, some systematic differences across groups and conditions were evident. Data from fits accounting for less than 50% of variance were omitted from this analysis, based on the observation of outliers. The psychometric functions fitted to older adult data tended to be steeper than those fitted to young adults. The group difference in fitted values of β was significant in data collected with the two-talker speech masker with both low context targets (4.8 vs 3.6: t20.8 = −3.02, p = 0.007) and high-context targets (4.3 vs 2.8: t20.0 = −3.54, p = 0.002). The group difference did not reach significance for data collected in the speech-shaped noise masker (p ≥ 0.125). In child listeners, there was a non-significant trend for slope to become shallower with increasing age in the two-talker masker (low-context: r = 0.27; p = 0.079; high-context: r = 0.28, p = 0.079). The relationship between child age and psychometric function slope was not significant for the speech-shaped noise masker (p ≥ 0.111).
One consequence of group differences in psychometric function slope is that the differences in SRT across age groups depend on the particular performance criterion used to define threshold. For example, the difference between SRTs for young adults and older adults tested with low-context targets in two-talker speech masker is 5.8 dB when the SRT is evaluated at 50% correct (as reported above); that difference drops to 4.4 dB when the SRT is evaluated at 75% correct.
DISCUSSION
The present study evaluated masked sentence recognition in listeners between the ages of 5 and 81 years of age. Children and young adults had audiometrically normal hearing, while older adults had normal or near-normal hearing through 4 kHz and thresholds up to 55 dB HL at 8 kHz in the better-hearing ear. Although qualitatively similar effects have been observed previously for children and older adults, one goal of the present study was to evaluate effects of development and aging using consistent stimuli and procedures. Of particular interest were the effects of masker type, which included speech-shaped noise and two-talker speech, and the effect of semantic context of the target sentences, which were either semantically meaningful (high context) or semantically anomalous (low context). The prediction was that semantic context of the target would tend to improve performance, but that this effect would be reduced or absent for children tested in the two-talker masker. Such a result would replicate previous results for masked word recognition, where context was manipulated by manipulating the response alternatives (Buss, Leibold, et al. 2016). Older adults were predicted to experience a benefit of context across masker types, due to their greater linguistic knowledge and life experience.
Effects of masker type and target context for children
As expected, masked SRTs improved with age for 5- to 16-year-old children, and the rate of change appeared to depend on masker type. In the noise masker, SRTs for 5-year-olds were 6-dB higher than those of young adults. The child-adult difference was more pronounced for the two-talker speech than the speech-shaped noise masker. For the two-talker masker, SRTs for 5-year-olds were approximately 10-dB higher than those of young adults. These results are broadly consistent with previous reports on the development of masked speech recognition (e.g., Buss et al. 2017; Corbin et al. 2016; Stuart 2008).
While children’s SRTs were on average 2.1-dB better for high-context than low-context targets in the speech-shaped noise maker, that benefit was only 1.0 dB in the two-talker masker. Less benefit in the two-talker masker was predicted based on the results of Buss, Leibold, et al. (2016). In that study, children heard target words presented in either a speech-shaped noise or a two-talker masker. In one set of conditions children responded by selecting from among four illustrations. Those response alternatives were either phonetically similar (e.g., “arm,” “car,” “barn,” and “star”), most often sharing a vowel in common, or phonetically dissimilar (e.g., “arm,” “meat,” “spring,” and “black”). When the response set contains phonetically dissimilar alternatives, the listener can select the correct answer based on a very rudimentary information about the target (e.g., the vowel /a/), whereas additional information is necessary to select the target when the response set contains phonetically similar alternatives. Lower susceptibility to masking for vowels than consonants could be an important consideration in this paradigm (Varnet et al. 2012). Buss, Leibold, et al. (2016) showed that normal-hearing 5- to 13-year-olds and adults benefited from the phonetically dissimilar response context to a comparable degree when the masker was speech-shaped noise, but younger children derived less benefit than older children and adults when the masker was two-talker speech. Results of the present study are broadly consistent with that result. Children benefitted more from semantic context in a sentence recognition task when the masker was speech-shaped noise than when it was two-talker speech; this contrasts with the results of adults, where there was a non-significant trend for more benefit in the two-talker masker than the speech-shaped noise masker. In contrast to the data of Buss et al. (2016), there was no clear evidence of maturation of the ability to use context in a speech masker between 5 and 16 years of age. Children’s limited ability to benefit from semantic context for targets presented in the two-talker masker could reflect their limited cognitive resources; the cognitive demands associated with segregating the speech target from the two-talker masker could leave few resources available for capitalizing on target context. There was a non-significant trend for children to benefit more than adults from context in the speech-shaped noise masker, but this result was not predicted.
Effects of masker type and semantic context for older adults
Like children, older adults were more susceptible to masking than young adults. The magnitude of this age effect was 2.5 dB in the speech-shaped noise, and 5.6 dB in the two-talker masker. The finding of a larger age effect for the speech masker than the noise masker is generally consistent with published data, although the magnitudes of the age and masker effects differ across studies. For example, Rajan and Cainer (2008) reported that older adults (60–69 yrs) had 2-dB higher SRTs than young adults (20–29 yrs) tested in an eight-talker masker, but no effect of age was observed for a speech-shaped noise masker. Goossens et al. (2017) measured sentence recognition in a speech-shaped noise and an unintelligible one-talker masker; SRTs for young adults (20–30 yrs) and older adults (70–80 yrs) differed by 1.8 dB in noise and by 9.2 dB in the speech masker. Older adults in that study had normal thresholds out to 4 kHz.
In contrast to results for child listeners, older adults obtained a similar benefit from semantic context in the speech-shaped noise and two-talker maskers compared to young adults. This result is consistent with previous literature showing that older adults make efficient use of semantic context (e.g., Dubno et al. 2000), provided that their memory capacity is not overly taxed (Gordon-Salant and Cole 2016; Janse and Jesse 2014). We did not observe a larger benefit of semantic context in older adults, an outcome that is sometimes reported (Pichora-Fuller et al. 1995; Sommers and Danielson 1999). Published data indicate that the benefit associated with semantic context increases when the task is more difficult (e.g., via hearing loss or by low-pass filtering the stimuli), although there are large individual differences across listeners in the use of context under these conditions (Grant and Seitz 2000). In the present dataset, young adults tested with low-pass filtered stimuli did not benefit more from semantic context than young adults tested in the primary conditions, although there was a non-significant trend in that direction. Many of the paradigms which show greater reliance on context in older and/or hearing-impaired listeners assess performance in quiet (Grant and Seitz 2000; Lewis et al. 2017; Moradi et al. 2014). Recall that the present experiment evaluated masked speech recognition and adaptively varied the TMR to estimate threshold. It is possible that this approach tends to normalize task difficulty across listeners and reduces effects of context that are related to task difficulty.
While previous reports are relatively consistent with respect to the greater susceptibility to speech maskers in older adults compared to young adults, it is not entirely clear what role peripheral hearing loss might play in speech recognition as a function of masker type. In the present dataset, there was a trend for higher SRTs in older listeners with poorer audiometric thresholds above 250 Hz. Testing young adults with low-pass filtered stimuli elevated high-frequency thresholds, but this effect was not significantly different for the speech-shaped noise masker and the two-talker speech masker. Based on these observations, it seems unlikely that the interaction between adult age group and masker type can be accounted for by differences in high-frequency audibility. Another consideration is the fact that sensorineural hearing loss is sometimes observed to reduce the difference between thresholds in noise and speech maskers (e.g., Arbogast et al. 2005), a finding that has been interpreted as reflecting relatively greater effects of energetic masking in listeners with hearing loss. The association in older adults between SRTs and audiometric thresholds at low and mid frequencies could also reflect a third factor, such as overall neurological health.
Comparing masker effects for children and older adults
Both children and older adults have more difficulty recognizing masked speech than young adults, particularly in the two-talker speech masker. However, this age-by-masker interaction differs at the two ends of the age spectrum. Whereas older adults perform like 7-year-olds when tested with the noise masker, they perform like 9- to 11-year-olds when tested with the two-talker speech masker, depending on target context. These results indicate that the relative susceptibility to masking associated with speech-shaped noise and two-talker speech differs for the children and older adults who participated in this study. The value of this observation lies in the premise that susceptibility to masking depends on multiple factors, such as the listener’s ability to segregate auditory streams, selectively attend to the target, and piece together available cues to recognize the speech target (Bronkhorst 2015). Comparing performance across the lifespan provides an opportunity to assess the relative balance of these factors in development and aging. Differential effects of masker type in children and older adults observed here indicate that these factors do not impact performance in the same way for the two groups. For example, children’s relatively greater susceptibility to the speech masker could indicate that auditory stream segregation plays a relatively larger role in the performance of children than older adults.
Conclusions
Masked SRTs improve with age for school-age children, reach a minimum in young adults, and then rise again in older adults. This biphasic age effect is more pronounced for a two-talker masker than a speech-shaped noise masker. Although many of the same factors have been hypothesized to account for this age effect in development and aging literatures, there are some important differences in results obtained with children and older adults. While older adults benefit from semantic context to the same degree as young adults in both maskers, children do not; a larger benefit of semantic context of the targets is observed for children tested with the speech-shaped noise than with the two-talker masker. Children and older adults also differ in their relative susceptibility to masking associated with two-talker and speech-shaped noise. Older adults performed like 7-year-olds in the noise masker, but they performed like 9- to −11-year-olds when tested with a two-talker masker.
ACKNOWLEDGEMENTS
This work was funded by NIH NIDCD R01 DC014460 and T32 DC005360.
Footnotes
This was evaluated using a linear mixed model, with a random intercept, one random effect (sentence number) and two fixed effects (context and word number). The only coefficient that was significant was word number (coef = −1.5, SE = 0.14, p < 0.001).
Estimates of age equivalence depend not only on the distribution of thresholds in both age groups, but also the exponent k, which captures asymptotic maturation in older children.
REFERENCES
- Alain C, Arnott SR (2000). Selectively attending to auditory objects. Front Biosci, 5, D202–212. [DOI] [PubMed] [Google Scholar]
- Alain C, Woods DL (1999). Age-related changes in processing auditory stimuli during visual attention: evidence for deficits in inhibitory control and sensory memory. Psychol Aging, 14, 507–519. [DOI] [PubMed] [Google Scholar]
- ANSI. (2010). ANSI S3.6–2010, American National Standard Specification for Audiometers. New York: American National Standards Institute. [Google Scholar]
- Arbogast TL, Mason CR, Kidd G Jr. (2005). The effect of spatial separation on informational masking of speech in normal-hearing and hearing-impaired listeners. J Acoust Soc Am, 117, 2169–2180. [DOI] [PubMed] [Google Scholar]
- Best V, Mason CR, Swaminathan J, et al. (2017). Use of a glimpsing model to understand the performance of listeners with and without hearing loss in spatialized speech mixtures. J Acoust Soc Am, 141, 81. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bronkhorst AW (2015). The cocktail-party problem revisited: Early processing and selection of multi-talker speech. Atten Percept Psychophys, 77, 1465–1487. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Buss E, He S, Grose JH, et al. (2013). The monaural temporal window based on masking period pattern data in school-aged children and adults. J Acoust Soc Am, 133, 1586–1597. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Buss E, Leibold LJ, Hall JWI (2016). Effect of response context and masker type on word recognition in school-age children and adults. J Acoust Soc Am, 140, 968–977. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Buss E, Leibold LJ, Porter HL, et al. (2017). Speech recognition in one- and two-talker maskers in school-age children and adults: Development of perceptual masking and glimpsing. J Acoust Soc Am, 141, 2650–2660. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Buss E, Porter HL, Leibold LJ, et al. (2016). Effects of self-generated noise on estimates of detection threshold in quiet for school-age children and adults. Ear Hear, 37, 650–659. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Calandruccio L, Dhar S, Bradlow AR (2010). Speech-on-speech masking with variable access to the linguistic content of the masker speech. J Acoust Soc Am, 128, 860–869. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Calandruccio L, Gomez B, Buss E, et al. (2014). Development and preliminary evaluation of a pediatric Spanish-English speech perception task. Am J Audiol, 23, 158–172. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cohen G, Faulkner D (1983). Word recognition: age differences in contextual facilitation effects. Br J Psychol, 74, 239–251. [DOI] [PubMed] [Google Scholar]
- Corbin N, Bonino AY, Buss E, et al. (2016). Development of open-set word recognition in children: Speech-shaped noise and two-talker speech maskers. Ear Hear, 37, 55–63. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dai H (1995). On measuring psychometric functions: A comparison of the constant-stimulus and adaptive up-down methods. J Acoust Soc Am, 98, 3135–3139. [DOI] [PubMed] [Google Scholar]
- Dubno JR, Ahlstrom JB, Horwitz AR (2000). Use of context by young and aged adults with normal hearing. J Acoust Soc Am, 107, 538–546. [DOI] [PubMed] [Google Scholar]
- Elliott LL (1979). Performance of children aged 9 to 17 years on a test of speech intelligibility in noise using sentence material with controlled word predictability. J Acoust Soc Am, 66, 651–653. [DOI] [PubMed] [Google Scholar]
- Ezzatian P, Li L, Pichora-Fuller MK, et al. (2015). Delayed Stream Segregation in Older Adults: More Than Just Informational Masking. Ear Hear, 36, 482–484. [DOI] [PubMed] [Google Scholar]
- Fallon M, Trehub SE, Schneider BA (2002). Children’s use of semantic cues in degraded listening environments. J Acoust Soc Am, 111, 2242–2249. [DOI] [PubMed] [Google Scholar]
- Fandakova Y, Sander MC, Werkle-Bergner M, et al. (2014). Age differences in short-term memory binding are related to working memory performance across the lifespan. Psychol Aging, 29, 140–149. [DOI] [PubMed] [Google Scholar]
- Flaherty MM, Leibold LJ, Buss E (2017). Developmental effects in the ability to benefit from F0 differences between target and masker speech. In The 40th Midwinter Research Meeting of the Association for Research in Otolaryngology Baltimore, MD. [Google Scholar]
- Freyman RL, Balakrishnan U, Helfer KS (2004). Effect of number of masking talkers and auditory priming on informational masking in speech recognition. J Acoust Soc Am, 115, 2246–2256. [DOI] [PubMed] [Google Scholar]
- Frisina DR, Frisina RD (1997). Speech recognition in noise and presbycusis: relations to possible neural mechanisms. Hear Res, 106, 95–104. [DOI] [PubMed] [Google Scholar]
- Giard MH, Fort A, Mouchetant-Rostaing Y, et al. (2000). Neurophysiological mechanisms of auditory selective attention in humans. Front Biosci, 5, D84–94. [DOI] [PubMed] [Google Scholar]
- Goossens T, Vercammen C, Wouters J, et al. (2017). Masked speech perception across the adult lifespan: Impact of age and hearing impairment. Hear Res, 344, 109–124. [DOI] [PubMed] [Google Scholar]
- Gordon-Salant S, Cole SS (2016). Effects of age and working memory capacity on speech recognition performance in noise among listeners with normal hearing. Ear Hear, 37, 593–602. [DOI] [PubMed] [Google Scholar]
- Grant KW, Seitz PF (2000). The recognition of isolated words and words in sentences: individual variability in the use of sentence context. J Acoust Soc Am, 107, 1000–1011. [DOI] [PubMed] [Google Scholar]
- Grose JH, Mamo SK, Hall JW III. (2009). Age effects in temporal envelope processing: Speech unmasking and auditory steady state responses. Ear Hear, 30, 568–575. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Grose JH, Menezes DC, Porter HL, et al. (2016). Masking Period Patterns and Forward Masking for Speech-Shaped Noise: Age-Related Effects. Ear Hear, 37, 48–54. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hall JW III, Grose JH (1991). Notched-noise measures of frequency selectivity in adults and children using fixed-masker-level and fixed-signal-level presentation. J Speech Hear Res, 34, 651–660. [DOI] [PubMed] [Google Scholar]
- Helfer KS, Freyman RL (2014). Stimulus and listener factors affecting age-related changes in competing speech perception. J Acoust Soc Am, 136, 748–759. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Humes LE (2007). The contributions of audibility and cognitive factors to the benefit provided by amplified speech to older adults. J Am Acad Audiol, 18, 590–603. [DOI] [PubMed] [Google Scholar]
- Humes LE, Kewley-Port D, Fogerty D, et al. (2010). Measures of hearing threshold and temporal processing across the adult lifespan. Hear Res, 264, 30–40. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Janse E, Jesse A (2014). Working memory affects older adults’ use of context in spoken-word recognition. Q J Exp Psychol (Hove), 67, 1842–1862. [DOI] [PubMed] [Google Scholar]
- Julayanont P, Tangwongchai S, Hemrungrojn S, et al. (2015). The Montreal Cognitive Assessment-Basic: A Screening Tool for Mild Cognitive Impairment in Illiterate and Low-Educated Elderly Adults. J Am Geriatr Soc, 63, 2550–2554. [DOI] [PubMed] [Google Scholar]
- Larsby B, Hallgren M, Lyxell B, et al. (2005). Cognitive performance and perceived effort in speech processing tasks: effects of different noise backgrounds in normal-hearing and hearing-impaired subjects. Int J Audiol, 44, 131–143. [DOI] [PubMed] [Google Scholar]
- Lash A, Rogers CS, Zoller A, et al. (2013). Expectation and entropy in spoken word recognition: effects of age and hearing acuity. Exp Aging Res, 39, 235–253. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee JH, Humes LE (2012). Effect of fundamental-frequency and sentence-onset differences on speech-identification performance of young and older adults in a competing-talker background. J Acoust Soc Am, 132, 1700–1717. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Leibold LJ, Yarnell Bonino A, Buss E (2016). Masked speech perception thresholds in infants, children, and adults. Ear Hear, 37, 345–353. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lewis D, Kopun J, McCreery R, et al. (2017). Effect of context and hearing loss on time-gated word recognition in children. Ear Hear, 38, e180–e192. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lin FR, Niparko JK, Ferrucci L (2011). Hearing loss prevalence in the United States. Arch Intern Med, 171, 1851–1852. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McCreery RW, Spratford M, Kirby B, et al. (2016). Individual differences in language and working memory affect children’s speech recognition in noise. Int J Audiol, 1–10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McCreery RW, Stelmachowicz PG (2011). Audibility-based predictions of speech recognition for children and adults with normal hearing. J Acoust Soc Am, 130, 4070–4081. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Metsala JL (1997). An examination of word frequency and neighborhood density in the development of spoken-word recognition. Mem Cognit, 25, 47–56. [DOI] [PubMed] [Google Scholar]
- Metsala JL, Walley AC (1998). Spoken vocabulary growth and the segmental restructuring of lexical representations: Precursors of phonetic awareness and early reading ability In Word recognition in beginning literacy (pp. 49–62). Mahwah, N.J.: L. Erlbaum Associates. [Google Scholar]
- Moore JK, Linthicum FH Jr. (2007). The human auditory system: A timeline of development. Int J Audiol, 46, 460–478. [DOI] [PubMed] [Google Scholar]
- Moradi S, Lidestam B, Hallgren M, et al. (2014). Gated auditory speech perception in elderly hearing aid users and elderly normal-hearing individuals: effects of hearing impairment and cognitive capacity. Trends Hear, 18. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nasreddine ZS, Phillips NA, Bedirian V, et al. (2005). The Montreal Cognitive Assessment, MoCA: a brief screening tool for mild cognitive impairment. J Am Geriatr Soc, 53, 695–699. [DOI] [PubMed] [Google Scholar]
- Nittrouer S, Boothroyd A (1990). Context effects in phoneme and word recognition by young children and older adults. J Acoust Soc Am, 87, 2705–2715. [DOI] [PubMed] [Google Scholar]
- Okabe K, Tanaka S, Hamada H, et al. (1988). Acoustic impedance measurement on normal ears of children. J Acoust Soc Jap, 9, 287–294. [Google Scholar]
- Phillips SL, Gordon-Salant S, Fitzgibbons PJ, et al. (2000). Frequency and temporal resolution in elderly listeners with good and poor word recognition. J Speech Lang Hear Res, 43, 217–228. [DOI] [PubMed] [Google Scholar]
- Pichora-Fuller MK (2008). Use of supportive context by younger and older adult listeners: Balancing bottom-up and top-down information processing. Int J Audiol, 47, S72–S82. [DOI] [PubMed] [Google Scholar]
- Pichora-Fuller MK, Schneider BA, Daneman M (1995). How young and old adults listen to and remember speech in noise. J Acoust Soc Am, 97, 593–608. [DOI] [PubMed] [Google Scholar]
- Pinheiro J, Bates D, DebRoy S, et al. (2016). nlme: Linear and Nonlinear Mixed Effects Models. In R package version 3.1.-. [Google Scholar]
- R Core Team. (2016). R: A language and environment for statistical computing In R Foundation for Statistical Computing. Vienna, Austria. [Google Scholar]
- Rajan R, Cainer KE (2008). Aging without hearing loss or cognitive impairment causes decrease in speech intelligibility only in informational maskers. Neurosci, 154, 784–795. [DOI] [PubMed] [Google Scholar]
- Rosen S, Souza P, Ekelund C, et al. (2013). Listening to speech in a background of other talkers: Effects of talker number and noise vocoding. J Acoust Soc Am, 133, 2431–2443. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sommers MS, Danielson SM (1999). Inhibitory processes and spoken word recognition in young and older adults: the interaction of lexical competition and semantic context. Psychol Aging, 14, 458–472. [DOI] [PubMed] [Google Scholar]
- Stelmachowicz PG, Hoover BM, Lewis DE, et al. (2000). The relation between stimulus context, speech audibility, and perception far normal-hearing and hearing-impaired children. J Speech Lang Hear Res, 43, 902–914. [DOI] [PubMed] [Google Scholar]
- Stuart A (2008). Reception thresholds for sentences in quiet, continuous noise, and interrupted noise in school-age children. J Am Acad Audiol, 19, 135–146. [DOI] [PubMed] [Google Scholar]
- Stuart A, Phillips DP (1996). Word recognition in continuous and interrupted broadband noise by young normal-hearing, older normal-hearing, and presbyacusic listeners. Ear Hear, 17, 478–489. [DOI] [PubMed] [Google Scholar]
- Trehub SE, Schneider BA, Morrongiello BA, et al. (1988). Auditory sensitivity in school-age children. J Exp Child Psychol, 46, 273–285. [DOI] [PubMed] [Google Scholar]
- Tun PA, O’Kane G, Wingfield A (2002). Distraction by competing speech in young and older adult listeners. Psychol Aging, 17, 453–467. [DOI] [PubMed] [Google Scholar]
- Varnet L, Meyer J, Hoen M, et al. (2012). Phoneme resistence during speech-in-speech comprehension. In 13th Annual Conference of the International Speech Communication Association Portland, Oregan. [Google Scholar]
- Verhaeghen P (2003). Aging and vocabulary scores: a meta-analysis. Psychol Aging, 18, 332–339. [DOI] [PubMed] [Google Scholar]
- Walker R (1999). Jack and the Beanstalk. Cambridge, M.A.: Barefoot Books. [Google Scholar]
- Wightman FL, Kistler DJ (2005). Informational masking of speech in children: Effects of ipsilateral and contralateral distracters. J Acoust Soc Am, 118, 3164–3176. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wightman FL, Kistler DJ, O’Bryan A (2010). Individual differences and age effects in a dichotic informational masking paradigm. J Acoust Soc Am, 128, 270–279. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wingfield A, Aberdeen JS, Stine EA (1991). Word onset gating and linguistic context in spoken word recognition by young and elderly adults. J Gerontol, 46, P127–129. [DOI] [PubMed] [Google Scholar]